Báo cáo Bài Tập Lớn Môn Nhập môn trí tuệ nhân tạo | Đại học Bách Khoa Hà Nội
Báo cáo Bài Tập Lớn Môn Nhập môn trí tuệ nhân tạo. Tài liệu được sưu tầm gồm 31 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Nhập môn trí tuệ nhân tạo hust 18 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:












Preview text:
lOMoAR cPSD| 61552889 Đ
Ạ I H Ọ C BÁCH KHOA HÀ N Ộ I Trư
ờ ng Công ngh ệ thông tin và Truy ề n thông BÁO CÁO
BÀI T Ậ P L Ớ N
H ọ c ph ầ n : Nh ậ p môn trí tu ệ nhân t ạ o – IT 3103 Mã l ớ p: 156726
Gi ả ng viên hư ớ ng d ẫ n :
Th ầ y Đ ặ ng Tu ấ n Linh H ọ và tên – MSSV :
Nghiêm Xuân Di ệ n – 20215007 Hà N ộ i, tháng 6/2025 lOMoAR cPSD| 61552889 Mục lục
1. Giới thiệu và mô tả về bài toán ....................................................................................... 3
1.1. Bối cảnh và tầm quan trọng của vấn đề .................................................................... 3
1.2. Mục tiêu nghiên cứu ................................................................................................. 4
1.3. Đóng góp của nghiên cứu ........................................................................................ 4
2. Cơ sở lý thuyết ............................................................................................................... 4
2.1. Convolutional Neural Networks (CNNs) .................................................................. 4
2.2. Transfer Learning.................................................................................................... 5
2.3. MobileNetV2 ............................................................................................................ 6
3. DATASET và tiền xử lý dữ liệu ........................................................................................ 7
3.1. Mô tả Dataset ........................................................................................................... 7
3.2. Chiến lược tiền xử lý dữ liệu.................................................................................... 7
3.2.1. Pipeline1 – cnn1 (15 frames/video) ..................................................................... 7
3.2.2. Pipeline2 – cnn2 (30 frames/video) .................................................................. 8
3.2.3. So sánh hiệu suất và tài nguyên ..................................................................... 10
3.2.4. Chất lượng dữ liệu và hiệu suất model ........................................................... 10
3.2.5. Khuyến nghị .................................................................................................... 11
4. Phân tích thiết kế và triển khai mô hình ...................................................................... 12
4.1. Cấu hình training – file 1 ........................................................................................ 12
4.2. Architecture Design – file 1 ................................................................................... 12
4.3. Optimizer và Loss Configuration – file 1 ............................................................... 13
4.4. Cấu hình training – file 2 ....................................................................................... 14
4.5. Advanced Architecture Strategy – file 2 ............................................................... 14
4.6. Advanced Optimizer Configuration – file 2 ............................................................ 14
4.7. Focal Loss Implementation – file 2 ....................................................................... 15
4.8. Callback Strategy Comparison ............................................................................. 15
5. Kết quả và đánh giá ..................................................................................................... 16
5.1. Model 1 ................................................................................................................... 16
5.2. Model 2.................................................................................................................. 18
6. Triển khai script để sử dụng model ............................................................................. 20
6.1. Tính năng dự đoán thật/giả từ 1 bức ảnh ................................................................ 20 lOMoAR cPSD| 61552889
6.2. Tính toán % dự đoán chính xác của model từ 1 folder ảnh ..................................... 25
6.3. Real-time webcam face detection ..................................................................... 27
7. Kết luận và hướng phát triển ....................................................................................... 29
7.1. Kết luận chính ........................................................................................................ 29
7.2. Hạn chế và thách thức ........................................................................................... 30
7.3. Hướng phát triển ................................................................................................... 30
8. Hướng dẫn cài đặt và sử dụng ..................................................................................... 31
1. Giới thiệu và mô tả về bài toán
1.1. Bối cảnh và tầm quan trọng của vấn đề
Face Anti-Spoofing đã trở thành một trong những thách thức quan trọng nhất trong
lĩnh vực thị giác máy tính và an ninh sinh trắc học. Với sự phát triển mạnh mẽ của các
hệ thống nhận diện khuôn mặt trong nhiều ứng dụng thực tế như kiểm soát ra vào,
thanh toán điện tử, và xác thực danh tính, việc đảm bảo an toàn trước các cuộc tấn
công giả mạo trở nên cực kỳ cấp thiết.
Các hệ thống nhận diện khuôn mặt truyền thống thường dễ bị lừa bởi những phương
thức tấn công đơn giản như sử dụng ảnh in, video phát lại trên thiết bị di động, hoặc các lOMoAR cPSD| 61552889
mô hình 3D. Điều này tạo ra lỗ hổng an ninh nghiêm trọng, có thể dẫn đến những hậu
quả không mong muốn trong các ứng dụng yêu cầu độ bảo mật cao.
1.2. Mục tiêu nghiên cứu
Dự án này nhằm giải quyết vấn đề Face Anti-Spoofing thông qua việc xây dựng một
mô hình học sâu có khả năng: •
Phân biệt chính xác giữa khuôn mặt thật và các hình thức tấn công giả mạo phổ biến •
Hoạt động hiệu quả với tài nguyên tính toán hạn chế nhờ sử dụng kiến trúc MobileNetV2 •
Đạt được độ chính xác cao trong điều kiện thực tế với các biến thể về ánh sáng,
góc nhìn và chất lượng hình ảnh
1.3. Đóng góp của nghiên cứu
Nghiên cứu này đóng góp vào lĩnh vực Face Anti-Spoofing thông qua: •
So sánh hiệu quả của hai phương pháp Transfer Learning khác nhau (Feature
Extraction vs Fine-tuning) trên bài toán Face Anti-Spoofing •
Phân tích tác động của các pipeline tiền xử lý dữ liệu khác nhau đến hiệu suất mô hình •
Triển khai thực tế một hệ thống Face Anti-Spoofing có thể ứng dụng trong các
môi trường có tài nguyên hạn chế
2. Cơ sở lý thuyết
2.1. Convolutional Neural Networks (CNNs)
Convolutional Neural Networks là nền tảng của hầu hết các ứng dụng thị giác máy
tính hiện đại. CNN hoạt động dựa trên nguyên lý mô phỏng cơ chế thị giác của con
người, thay vì xử lý toàn bộ hình ảnh cùng một lúc, CNN sử dụng các bộ lọc (filters)
nhỏ để "quét" qua hình ảnh và trích xuất các đặc trưng cục bộ.
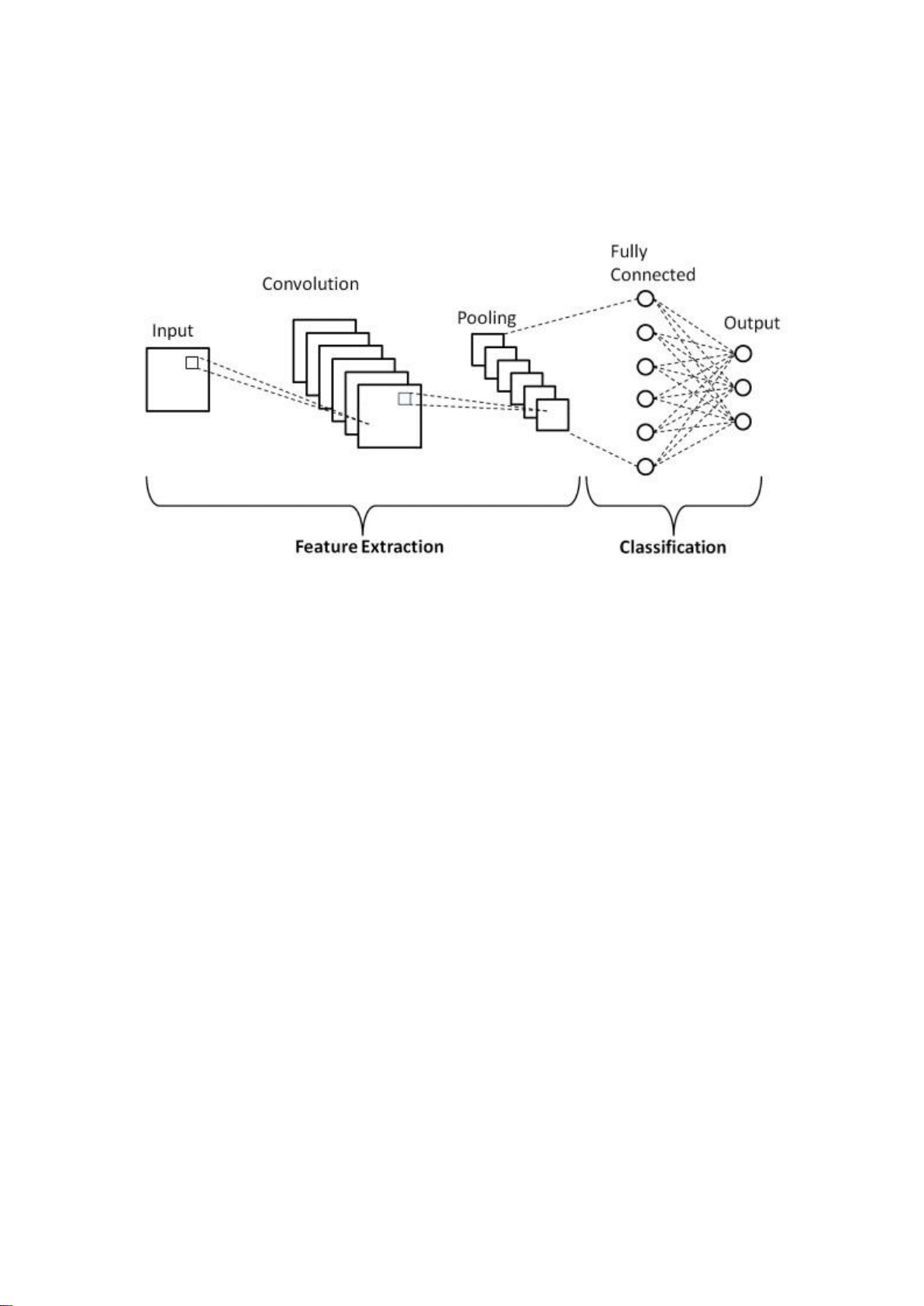
Kiến trúc CNN điển hình bao gồm ba thành phần chính:
Convolution Layer: Đây là lớp cốt lõi của CNN, hoạt động như một "kính lúp di động"
trên hình ảnh. Mỗi bộ lọc trong lớp này chuyên phát hiện một loại đặc trưng cụ thể
như cạnh ngang, cạnh dọc, góc, hoặc các pattern phức tạp hơn. Quá trình convolution
tạo ra các feature map, mỗi map thể hiện mức độ hiện diện của một đặc trưng cụ thể
tại các vị trí khác nhau trong hình ảnh.
Pooling Layer: Lớp này đóng vai trò như một "bộ tóm tắt thông minh", giảm chiều dữ
liệu trong khi vẫn giữ lại những thông tin quan trọng nhất. Max pooling, phương pháp lOMoAR cPSD| 61552889
được sử dụng phổ biến nhất, chọn giá trị cao nhất trong mỗi vùng, giúp mô hình trở nên
bất biến với những thay đổi nhỏ về vị trí của đối tượng.
Fully Connected Layer: Lớp này hoạt động như "bộ não tổng hợp", kết hợp tất cả các đặc
trưng đã được trích xuất để đưa ra quyết định cuối cùng. Mỗi neuron trong lớp này kết
nối với tất cả các neuron của lớp trước, cho phép mô hình học được mối quan hệ phức
tạp giữa các đặc trưng.
Figure 1: Cấu trúc CNN đơn giản 2.2. Transfer Learning
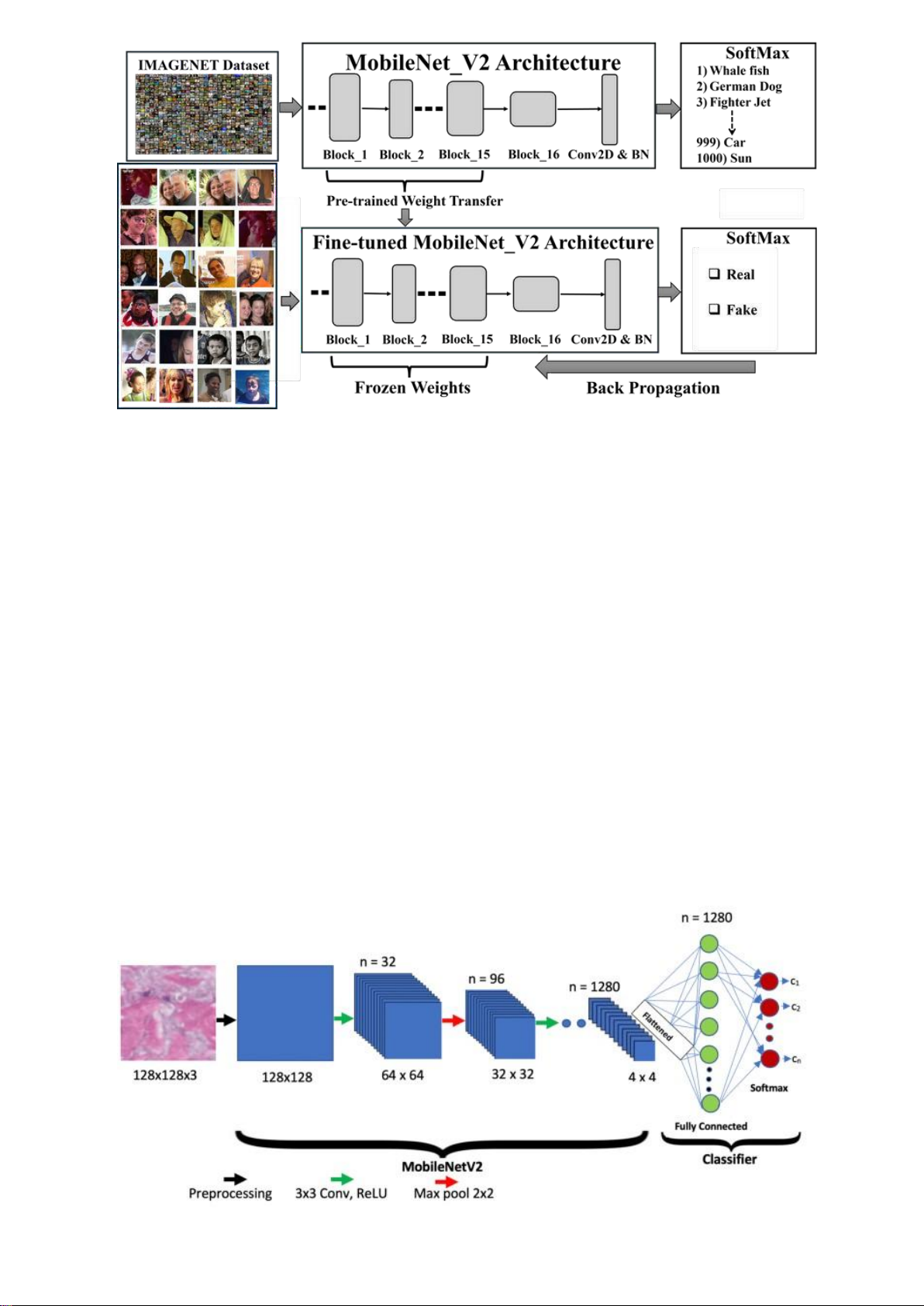
Transfer Learning là một paradigm quan trọng trong học máy, đặc biệt hữu ích khi
làm việc với dữ liệu hạn chế. Thay vì huấn luyện một mô hình từ đầu, Transfer Learning
cho phép chúng ta tận dụng kiến thức đã được học từ các tập dữ liệu lớn để giải quyết bài toán mới.
Trong bối cảnh Face Anti-Spoofing, Transfer Learning mang lại những lợi ích đặc biệt quan trọng:
Tận dụng đặc trưng cơ bản: Các mô hình được huấn luyện trước trên ImageNet đã học
được cách nhận diện các đặc trưng cơ bản như cạnh, texture, gradient màu sắc và
ánh sáng. Những đặc trưng này cực kỳ quan trọng trong việc phân biệt giữa da thật
và ảnh in, vì chúng có thể phát hiện sự khác biệt về chất lượng texture và phản xạ ánh sáng.
Hiệu quả với dữ liệu hạn chế: Face Anti-Spoofing datasets thường có kích thước nhỏ
hơn nhiều so với các tập dữ liệu classification tổng quát. Transfer Learning cho phép
đạt được hiệu suất cao ngay cả khi chỉ có vài nghìn mẫu training.
Thời gian huấn luyện ngắn: Thay vì cần hàng tuần để huấn luyện từ đầu, Transfer
Learning cho phép đạt được kết quả tốt chỉ trong vài giờ hoặc vài ngày. lOMoAR cPSD| 61552889
Figure 2: Transfer Learning với MobileNetV2 2.3. MobileNetV2
MobileNetV2 là một kiến trúc CNN được thiết kế đặc biệt cho các ứng dụng trên thiết
bị di động và môi trường có tài nguyên hạn chế. Kiến trúc này sử dụng Depthwise
Separable Convolutions và Inverted Residuals để giảm đáng kể số lượng tham số và
phép tính trong khi vẫn duy trì hiệu suất cao.
Những đặc điểm nổi bật của MobileNetV2 phù hợp với bài toán Face Anti-Spoofing:
Hiệu quả tính toán: Với chỉ khoảng 3.4 triệu tham số, MobileNetV2 có thể chạy realtime
trên các thiết bị di động, phù hợp cho các ứng dụng Face Anti-Spoofing thực tế.
Khả năng trích xuất đặc trưng tốt: Mặc dù compact, MobileNetV2 vẫn có khả năng học
được các đặc trưng phức tạp cần thiết để phân biệt giữa khuôn mặt thật và giả.
Pre-trained weights chất lượng cao: MobileNetV2 pre-trained trên ImageNet cung cấp
một nền tảng tốt để fine-tune cho bài toán Face Anti-Spoofing.
Figure 3: Kiến trúc của MobileNetV2 lOMoAR cPSD| 61552889
3. DATASET và tiền xử lý dữ liệu 3.1. Mô tả Dataset
Dự án sử dụng "Anti-Spoofing Dataset, 30,000 sets" được tạo bởi tác giả Kucev Roman
và công bố trên Kaggle. Dataset này được thiết kế đặc biệt để nghiên cứu các phương
pháp Face Anti-Spoofing và bao gồm ba loại tấn công chính:
Replay Attack: Sử dụng video được quay trước để phát lại trước camera. Đây là một
trong những phương thức tấn công phổ biến nhất, khi kẻ tấn công sử dụng smartphone
hoặc tablet để phát lại video của nạn nhân.
Printouts Attack: Sử dụng ảnh in trên giấy để lừa hệ thống. Phương thức này dễ thực
hiện và chi phí thấp, nhưng thường để lại các dấu hiệu đặc trưng như độ phân giải
thấp, thiếu chiều sâu, và các artifact từ quá trình in ấn.
Cut-out Printouts Attack: Phiên bản nâng cao của printouts attack, trong đó kẻ tấn
công cắt phần mắt trong ảnh in để tạo cảm giác "sống động" hơn.
Dataset gốc cung cấp khoảng 30,000 mẫu với tỷ lệ cân bằng giữa các lớp, đảm bảo mô
hình không bị bias về một loại tấn công cụ thể. Nhưng trên Kaggle chỉ có 1 bộ dataset
rút gọn khiêm tốn với dung lượng 1,45 GB với 9 video mỗi loại tấn công, 9 video người
dùng thật và 9 ảnh selfie real của từng người.
3.2. Chiến lược tiền xử lý dữ liệu
Dự án triển khai hai pipeline tiền xử lý khác nhau, mỗi pipeline được tối ưu cho một mô hình cụ thể:
3.2.1. Pipeline1 – cnn1 (15 frames/video)
* Xử lý hình ảnh cơ bản
Pipeline1 sử dụng hàm preprocess_image() với các bước xử lý đơn giản: def preprocess_image(image):
# Chuyển đổi không gian màu từ BGR sang RGB
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Chuẩn hóa ảnh image = image / 255.0 return image lOMoAR cPSD| 61552889
Ưu điểm của phương pháp này: •
Đơn giản và dễ hiểu, phù hợp cho người mới bắt đầu •
Tốc độ xử lý nhanh do ít phép biến đổi •
Ít tài nguyên tính toán, phù hợp với máy có cấu hình thấp Nhược điểm: •
Không tận dụng được thông tin quan trọng từ vùng khuôn mặt •
Xử lý toàn bộ frame có thể chứa nhiều thông tin nhiễu •
Thiếu các kỹ thuật tăng cường chất lượng ảnh
* Data Augmentation truyền thống
Pipeline1 sử dụng ImageDataGenerator của Keras:
# Hàm tạo data augmentation def create_data_generator():
return ImageDataGenerator( rotation_range=20,
width_shift_range=0.2, height_shift_range=0.2,
shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode='nearest' )
Đây là phương pháp augmentation cổ điển với các phép biến đổi hình học cơ bản.
Mặc dù hiệu quả, nhưng chưa tận dụng được những kỹ thuật augmentation hiện đại.
3.2.2. Pipeline2 – cnn2 (30 frames/video)
* Phát hiện và crop khuôn mặt
Pipeline2 tích hợp MTCNN (Multi-task Cascaded Convolutional Networks) để phát hiện khuôn mặt: detector = MTCNN()
def preprocess_image(frame): # Phát hiện mặt và crop
faces = detector.detect_faces(frame) if faces: x, y, w, h = faces[0]['box']
face = frame[y:y+h, x:x+w] else: face = frame face =
cv2.cvtColor(face, cv2.COLOR_BGR2RGB) face
= cv2.resize(face, IMAGE_SIZE) face = face / 255.0 return face
Lợi ích vượt trội: •
Tập trung vào vùng quan trọng nhất - khuôn mặt lOMoAR cPSD| 61552889 •
Loại bỏ background noise và thông tin không liên quan •
Chuẩn hóa vị trí khuôn mặt trong ảnh, giúp model học tốt hơn •
Tăng độ robust khi xử lý các video có góc quay khác nhau Thách thức: •
Tăng thời gian xử lý do phải chạy face detection •
Có thể thất bại khi khuôn mặt bị che khuất hoặc góc quay quá nghiêng •
Cần xử lý trường hợp không phát hiện được mặt (fallback mechanism)
* Data pipeline hiệu quả với TensorFlow Dataset
Pipeline2 sử dụng tf.data API để tạo pipeline xử lý dữ liệu tối ưu:
train_ds = tf.data.Dataset.from_tensor_slices((X_train, y_train))\ .shuffle(1024)\
.map(augment, num_parallel_calls=tf.data.AUTOTUNE)\ .batch(BATCH_SIZE)\ .prefetch(tf.data.AUTOTUNE)
Ưu việt của pipeline này: •
Parallel Processing: Sử dụng num_parallel_calls=tf.data.AUTOTUNE để tự động tối ưu số thread •
Prefetching: GPU có thể xử lý batch hiện tại trong khi CPU chuẩn bị batch tiếp theo •
Memory Efficiency: Không cần load toàn bộ dữ liệu vào RAM cùng lúc •
Auto-tuning: TensorFlow tự động điều chỉnh các tham số để đạt hiệu suất tối ưu
* Augmentation Layers tích hợp
Pipeline2 sử dụng Keras preprocessing layers:
augmentation_layers = keras.Sequential([
layers.RandomFlip('horizontal'), layers.RandomRotation(0.1),
layers.RandomZoom(0.1), layers.RandomContrast(0.1),
layers.RandomTranslation(0.1, 0.1) ])
Lợi ích so với ImageDataGenerator: •
Tích hợp trực tiếp vào model graph, chạy trên GPU •
Augmentation được thực hiện real-time trong quá trình training •
Không cần sinh và lưu trữ ảnh augmented lOMoAR cPSD| 61552889 •
Tốc độ nhanh hơn và tiết kiệm bộ nhớ
3.2.3. So sánh hiệu suất và tài nguyên
* Tốc độ xử lý
File 1: Nhanh trong giai đoạn preprocessing nhưng chậm trong training do: •
ImageDataGenerator sinh ảnh augmented offline •
Không tận dụng được GPU cho preprocessing •
Pipeline đơn giản, không có parallelization
File 2: Chậm hơn trong giai đoạn preprocessing (do MTCNN) nhưng nhanh hơn trong training: •
Face detection tốn thời gian nhưng chỉ làm một lần •
tf.data pipeline tối ưu cho GPU •
Augmentation real-time trên GPU
* Sử dụng bộ nhớ File 1: •
Cần lưu trữ tất cả ảnh gốc và ảnh augmented • Memory footprint lớn hơn •
Có thể gặp vấn đề với datasets lớn File 2: •
Chỉ lưu ảnh gốc, augmentation on-the-fly • Memory efficient • Scalable với datasets lớn
3.2.4. Chất lượng dữ liệu và hiệu suất model
* Chất lượng input
File 1: Sử dụng toàn bộ frame, có thể chứa nhiều thông tin không liên quan như
background, lighting conditions, objects khác. Điều này có thể làm model học các pattern không mong muốn.
File 2: Tập trung vào vùng khuôn mặt, giúp model học các đặc trưng quan trọng cho anti-spoofing như: •
Chi tiết da (pores, wrinkles) •
Eye movement và blinking patterns • Facial depth information lOMoAR cPSD| 61552889 • Micro-expressions
* Consistency và Standardization
File 2 vượt trội trong việc chuẩn hóa dữ liệu: •
Khuôn mặt luôn ở vị trí tương đối cố định trong ảnh •
Kích thước khuôn mặt được normalize •
Giảm variance không mong muốn trong dataset 3.2.5. Khuyến nghị
* Khi nào sử dụng file 1 •
Tài nguyên tính toán hạn chế • Cần prototype nhanh •
Dataset nhỏ và đơn giản •
Thời gian development ngắn
* Khi nào sử dụng file 2 • Production environments •
Datasets lớn và phức tạp • Yêu cầu accuracy cao •
Có tài nguyên GPU đầy đủ lOMoAR cPSD| 61552889
4. Phân tích thiết kế và triển khai mô hình
4.1. Cấu hình training – file 1
File 1 sử dụng cấu hình training với các hyperparameters được thiết kế cho stability và tính đơn giản: # Cấu hình IMAGE_SIZE = (224, 224) BATCH_SIZE = 32 EPOCHS = 30
FRAMES_PER_VIDEO = 15 RANDOM_STATE = 42
Phân tích tác động của từng tham số:
IMAGE_SIZE = (224, 224): Kích thước này được chọn có lý do sâu sắc. Đây là input size
chuẩn của hầu hết pre-trained models như MobileNetV2, ResNet, VGG. Việc sử dụng
kích thước này cho phép tận dụng tối đa knowledge từ ImageNet pre-training. Kích
thước 224x224 cũng đủ lớn để capture các chi tiết quan trọng của khuôn mặt như
texture, pores, micro-expressions mà không quá lớn gây ra computational overhead.
BATCH_SIZE = 32: Đây là một lựa chọn cân bằng giữa gradient stability và memory
efficiency. Batch size nhỏ hơn (8-16) sẽ tạo ra gradient noise cao hơn, có thể giúp
model escape local minima nhưng training sẽ không ổn định. Batch size lớn hơn
(64128) sẽ có gradient ổn định hơn nhưng yêu cầu nhiều memory và có thể dẫn đến
overfitting trên small datasets. Batch size 32 là sweet spot cho most cases.
EPOCHS = 30: Số epoch này được thiết kế để work với early stopping callback. Thực
tế model có thể converge sớm hơn nhờ early stopping với patience=5, nghĩa là training
sẽ dừng nếu validation loss không cải thiện trong 5 epochs liên tiếp.
FRAMES_PER_VIDEO = 15: Số lượng frames này đủ để capture temporal information mà
không quá nhiều gây ra computational burden. Với typical video 30fps trong 2-3 giây, 15
frames sẽ cover toàn bộ duration một cách đều đặn.
4.2. Architecture Design – file 1
File 1 thiết kế architecture theo nguyên tắc transfer learning classic:
def create_model(input_shape):
# Sử dụng transfer learning với MobileNetV2
# Lý do chọn MobileNetV2: nhẹ, hiệu quả, phù hợp cho ứng dụng real-time
base_model = applications.MobileNetV2( weights='imagenet', # Sử
dụng pre-trained weights include_top=False, # Bỏ classifier
layers cuối input_shape=input_shape ) lOMoAR cPSD| 61552889
# Đóng băng base model để giữ nguyên feature extraction base_model.trainable = False
Tác động của việc freeze base model: Quyết định này có những implications quan
trọng. Khi freeze base model, chúng ta chỉ training classifier head, điều này có nghĩa
là model sẽ rely hoàn toàn vào ImageNet features. Đây là approach an toàn khi
dataset nhỏ (tránh overfitting) nhưng có thể hạn chế khả năng của mô hình trong việc
học các đặc trưng đặc thù cho tác vụ chống giả mạo.
Classifier head design:
# First dense layer: học các pattern phức tạp
layers.Dense(256, activation='relu', name='dense_256'),
layers.Dropout(0.5), # Ngăn overfitting layers.BatchNormalization(),
# Second dense layer: tinh chỉnh các đặc trưng
layers.Dense(128, activation='relu', name='dense_128'),
layers.Dropout(0.3), # Dropout thấp hơn ở layer gần output layers.BatchNormalization(),
# Output layer: 1 neuron với sigmoid cho binary classification
# Sigmoid output range [0,1]: gần 0 = Real, gần 1 = Fake
layers.Dense(1, activation='sigmoid', name='binary_output')
Kiến trúc này follow pattern giảm dần số neurons (256 → 128 → 1) với dropout rates
cũng giảm dần (0.5 → 0.3 → 0). Điều này tạo ra một funnel effect, từ từ compress
information và reduce overfitting risk ở những layers cuối.
4.3. Optimizer và Loss Configuration – file 1
# Compile với cấu hình tối ưu cho binary classification
optimizer = keras.optimizers.Adam( learning_rate=0.001,
beta_1=0.9, beta_2=0.999, epsilon=1e-07 )
Learning rate 0.001: Đây là default learning rate của Adam, phù hợp cho transfer
learning scenarios. Khi chỉ training classifier head, learning rate này đủ lớn để
converge nhanh nhưng không quá lớn gây instability.
Adam optimizer parameters: Beta_1=0.9 và beta_2=0.999 là default values đã được
chứng minh hiệu quả về mặt thực nghiệm. Beta_1 điều khiển tốc độ suy giảm theo hàm
mũ cho ước lượng mô-men bậc nhất (gradient), còn Beta_2 điều khiển tốc độ suy giảm
cho ước lượng mô-men bậc hai (bình phương gradient). lOMoAR cPSD| 61552889
4.4. Cấu hình training – file 2
File 2 thể hiện một phương pháp tiên tiến hơn với fine-tuning strategy: IMAGE_SIZE = (224, 224) BATCH_SIZE = 32 EPOCHS = 50 FRAMES_PER_VIDEO = 30 RANDOM_STATE = 42
EPOCHS = 50: Số epochs tăng lên đáng kể so với File 1. Điều này cần thiết vì File 2 sử
dụng fine-tuning approach, cần nhiều thời gian hơn để adjust pre-trained weights. Tuy
nhiên, với early stopping patience=3 (ngắt hơn File 1), model sẽ dừng sớm nếu không improve.
FRAMES_PER_VIDEO = 30: Gấp đôi so với File 1, điều này cho phép mô hình có thể nắm
bắt được nhiều thông tin hơn và các thay đổi tinh vi giữa các khung hình. Điều này đặc
biệt quan trọng đối với bài toán chống giả mạo (anti-spoofing), vì các video giả có thể
chứa các hiện tượng giả tạo (artifacts) chỉ xuất hiện ở một số khung hình nhất định.
4.5. Advanced Architecture Strategy – file 2
File 2 sử dụng partial fine-tuning approach:
for layer in base.layers[:-50]: layer.trainable = False for
layer in base.layers[-50:]: layer.trainable = True
Tác động của partial fine-tuning: Phương pháp này cho phép mô hình thích nghi các
đặc trưng đã được huấn luyện sẵn (pre-trained features) với domain chống giả mạo
(anti-spoofing) mà không làm tăng nguy cơ overfitting. Việc chỉ "mở khóa" (unfreeze)
50 lớp cuối có nghĩa là các đặc trưng cấp cao sẽ được tinh chỉnh lại (fine-tuned), trong
khi vẫn giữ nguyên các đặc trưng cấp thấp đã học được từ ImageNet. L2 Regularization:
kernel_regularizer=regularizers.l2(1e-4)
L2 regularization với hệ số 1e−4 được áp dụng lên các lớp dense. Điều này nhằm phạt
những trọng số quá lớn, từ đó khuyến khích mô hình học các mẫu đơn giản hơn và
giảm hiện tượng overfitting. Hệ số 1e−4 được lựa chọn như một điểm cân bằng – đủ
lớn để tạo ra ảnh hưởng, nhưng không quá lớn đến mức làm cho mô hình underfit.
4.6. Advanced Optimizer Configuration – file 2
optimizer = optimizers.Adam(learning_rate=5e-5) lOMoAR cPSD| 61552889
Learning rate 5e-5: Nhỏ hơn đáng kể so với File 1 (0.001). Điều này rất quan trọng
trong fine-tuning. Khi tinh chỉnh các trọng số đã được huấn luyện trước (pre-trained
weights), ta cần sử dụng learning rate nhỏ để tránh làm mất đi các đặc trưng hữu ích
đã học từ ImageNet. Nếu sử dụng learning rate lớn, mô hình có thể gặp phải hiện
tượng quên thảm họa (catastrophic forgetting).
4.7. Focal Loss Implementation – file 2
File 2 implement Focal Loss thay vì standard binary crossentropy:
def focal_loss(gamma=2., alpha=.25): def loss(y_true, y_pred):
y_pred = K.clip(y_pred, K.epsilon(), 1-K.epsilon()) p_t =
tf.where(K.equal(y_true, 1), y_pred, 1-y_pred) alpha_factor =
K.ones_like(y_true) * alpha alpha_t = tf.where(K.equal(y_true, 1),
alpha_factor, 1-alpha_factor) return -K.mean(alpha_t * K.pow((1 -
p_t), gamma) * K.log(p_t)) return loss
Tác động của Focal Loss: Hàm mất mát binary crossentropy truyền thống coi tất cả các
ví dụ đều quan trọng như nhau. Focal Loss giải quyết vấn đề mất cân bằng lớp bằng
cách giảm trọng số của các ví dụ dễ và tập trung việc huấn luyện vào các ví dụ khó.
Tham số gamma = 2.0 điều chỉnh mức độ giảm trọng số — gamma càng cao thì mô
hình càng tập trung nhiều hơn vào các ví dụ khó. Tham số alpha = 0.25 giúp xử lý mất
cân bằng giữa các lớp bằng cách gán trọng số khác nhau cho các lớp dương và âm.
Trong bối cảnh chống giả mạo (anti-spoofing), điều này đặc biệt hữu ích vì một số ví dụ
giả mạo rất dễ phân loại (như ảnh in chất lượng kém), trong khi những ví dụ khác lại rất
khó (như các video phát lại chất lượng cao). Focal Loss giúp đảm bảo mô hình tập trung
huấn luyện nhiều hơn vào các trường hợp khó phân biệt.
4.8. Callback Strategy Comparison File 1 Callbacks: callbacks = [
EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=3, min_lr=1e-6),
ModelCheckpoint(MODEL_PATH, monitor='val_accuracy', save_best_only=True, verbose=1) ] File 2 Callbacks: callbacks = [
EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=3, min_lr=1e-7),
ModelCheckpoint(MODEL_PATH, monitor='val_accuracy', save_best_only=True),
TensorBoard(log_dir='logs/anti_spoofing_v1') ] lOMoAR cPSD| 61552889
Chiến lược Patience: File 2 sử dụng patience = 3 thay vì 5, khiến quá trình huấn luyện
mạnh tay hơn trong việc dừng sớm (early stopping). Điều này hợp lý vì với cách tiếp
cận fine-tuning và learning rate nhỏ, mô hình có thể hội tụ nhanh hơn và dễ bị chững lại (plateau).
Giảm tốc độ học (Learning Rate Reduction): Cả hai file đều áp dụng chiến lược tương
tự, nhưng File 2 sử dụng min_lr nhỏ hơn (1e-7 so với 1e-6). Điều này cho phép điều
chỉnh tốc độ học tinh vi hơn ở giai đoạn cuối của quá trình huấn luyện, giúp mô hình tối ưu hóa tốt hơn.
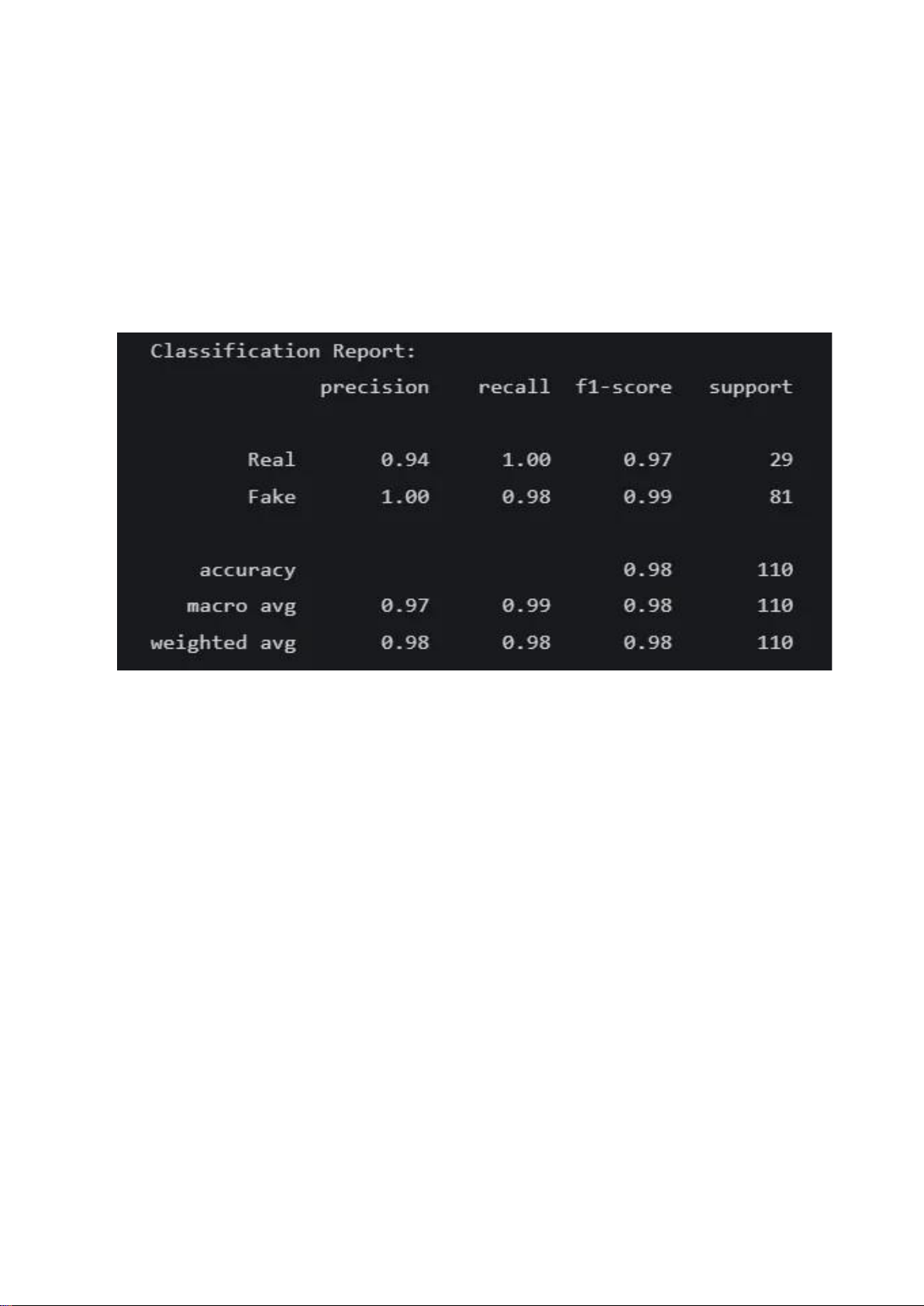
5. Kết quả và đánh giá 5.1. Model 1
Dựa trên quá trình huấn luyện và các số liệu đánh giá, mô hình chống giả mạo khuôn
mặt (face anti-spoofing) đã đạt được hiệu suất cao và ổn định. Dưới đây là phân tích chi
tiết về các khía cạnh của kết quả.
1. Hiệu Suất Tổng Thể của Mô Hình
Mô hình thể hiện khả năng phân biệt xuất sắc giữa khuôn mặt thật (Real) và giả mạo
(Fake) trên tập dữ liệu kiểm tra. •
Classification Report (Báo cáo Phân loại): Báo cáo phân loại trên tập kiểm tra cho
thấy hiệu suất gần như hoàn hảo:
o Độ chính xác (Accuracy): Mô hình đạt độ chính xác tổng thể là 98%, cho
thấy tỷ lệ dự đoán đúng trên toàn bộ tập dữ liệu là rất cao.
o Precision (Độ chuẩn):
▪ Đối với lớp Real, precision là 0.94. Điều này có nghĩa là khi mô
hình dự đoán một khuôn mặt là "Real", nó đúng trong 94% các trường hợp.
▪ Đối với lớp Fake, precision là 1.00, một kết quả xuất sắc. Khi mô
hình xác định một khuôn mặt là "Fake", nó hoàn toàn chắc chắn
và không có trường hợp nào bị nhầm lẫn (không có khuôn mặt
thật nào bị dự đoán sai là giả).
o Recall (Độ phủ):
▪ Đối với lớp Real, recall là 1.00. Mô hình đã xác định chính xác tất
cả các trường hợp khuôn mặt "Real" có trong tập kiểm tra.
▪ Đối với lớp Fake, recall là 0.98. Mô hình đã phát hiện được 98%
trong tổng số các trường hợp giả mạo. lOMoAR cPSD| 61552889 o F1-Score:
▪ F1-score là trung bình điều hòa của precision và recall, cung cấp
một thước đo cân bằng. Với F1-score là 0.97 cho "Real" và 0.99
cho "Fake", mô hình cho thấy sự cân bằng tuyệt vời giữa độ chuẩn và độ phủ.
o Support (Số lượng mẫu): Tập kiểm tra bao gồm 29 mẫu "Real" và 81 mẫu
"Fake". Sự mất cân bằng nhẹ này được xử lý tốt bởi mô hình, như đã thấy
qua chỉ số weighted avg (trung bình có trọng số) đạt 0.98 trên tất cả các chỉ số.
Figure 4: Classification Report Model 1
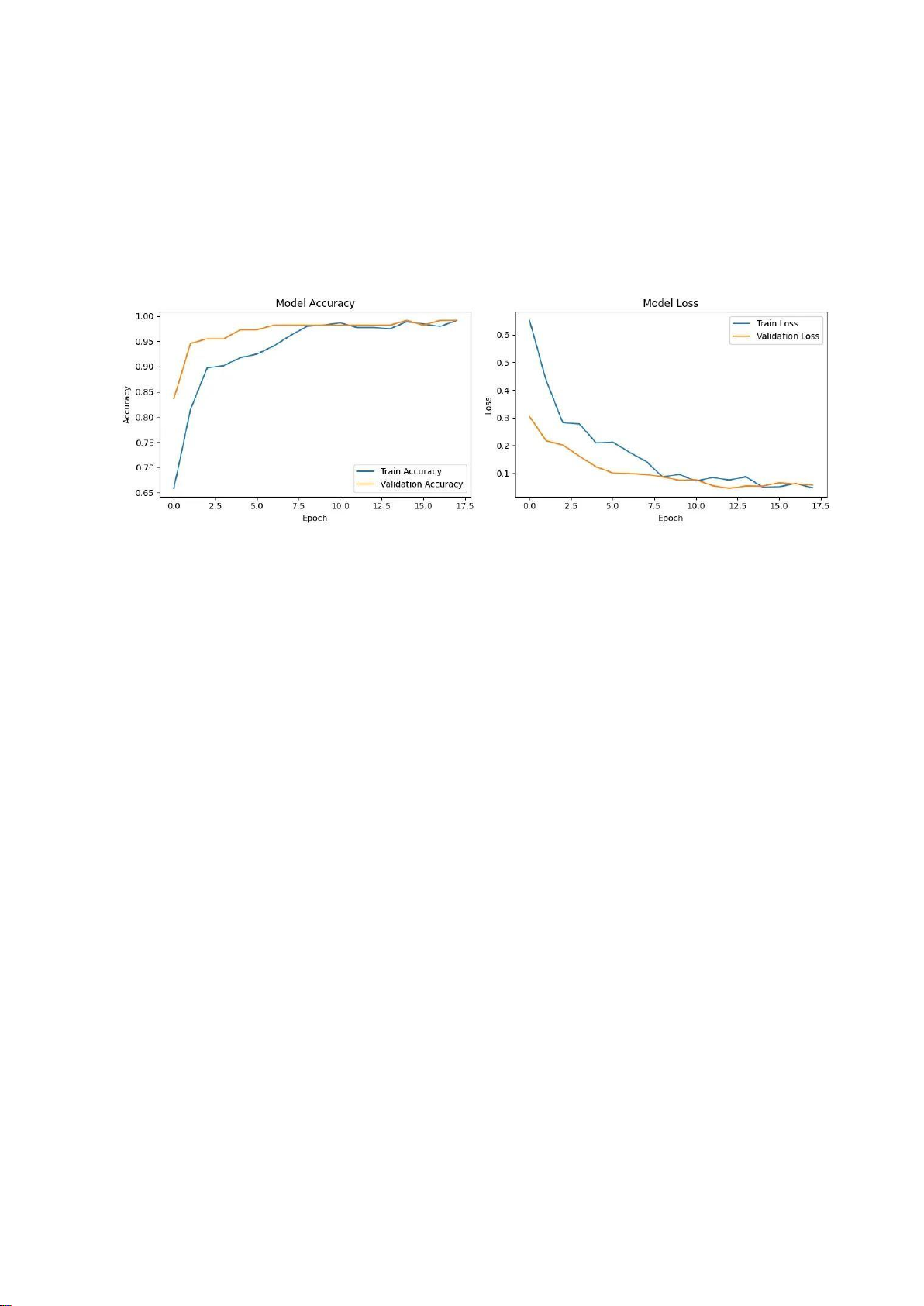
2. Phân Tích Quá Trình Huấn Luyện (Training Dynamics)
Biểu đồ "Model Accuracy" và "Model Loss" cung cấp cái nhìn sâu sắc về quá trình học
của mô hình qua từng epoch. •
Model Accuracy (Độ chính xác của Mô hình):
o Đường Train Accuracy (màu xanh) và Validation Accuracy (màu cam)
đều tăng trưởng đều đặn và nhanh chóng qua các epoch đầu tiên.
o Cả hai đường tiệm cận nhau và cùng đạt đến mức rất cao (gần 1.0), cho
thấy mô hình không chỉ học tốt trên dữ liệu huấn luyện mà còn tổng quát
hóa tốt trên dữ liệu chưa từng thấy (tập validation).
o Không có khoảng cách đáng kể giữa hai đường cong, điều này chứng tỏ
mô hình không bị overfitting (học vẹt). •
Model Loss (Hàm mất mát của Mô hình):
o Cả Train Loss và Validation Loss đều giảm mạnh và hội tụ về giá trị rất thấp. lOMoAR cPSD| 61552889
o Đường Validation Loss giảm một cách mượt mà cùng với Train Loss, một
lần nữa khẳng định rằng mô hình đang học các đặc trưng hữu ích thay
vì chỉ ghi nhớ dữ liệu huấn luyện.
o Quá trình huấn luyện đã dừng lại ở epoch thứ 18, có thể là do cơ chế
EarlyStopping được kích hoạt. Cơ chế này giúp ngăn chặn việc huấn
luyện không cần thiết khi hiệu suất trên tập validation không còn cải
thiện, đồng thời lưu lại trọng số của mô hình tốt nhất (tại epoch 15 với val_accuracy là 0.9909).
Figure 5: Training Dynamics Model 1 5.2. Model 2
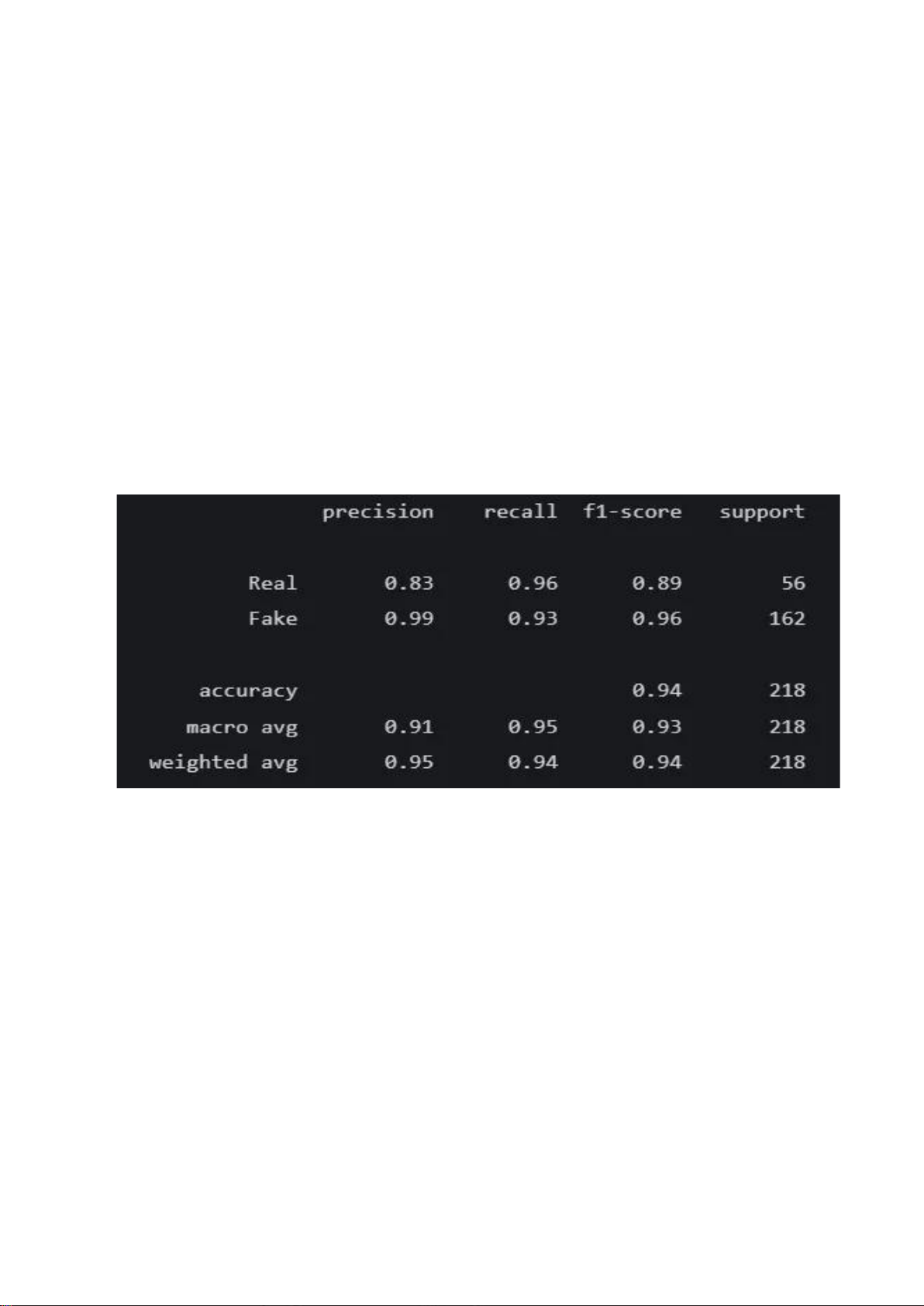
Mô hình thứ hai này là một phiên bản cải tiến, áp dụng các kỹ thuật nâng cao hơn trong
tiền xử lý, kiến trúc và quá trình huấn luyện. Kết quả cho thấy hiệu suất tổng thể tốt,
với những đặc điểm đáng chú ý phản ánh các chiến lược đã được sử dụng.
1. Hiệu Suất Tổng Thể của Mô Hình
Báo cáo phân loại trên tập kiểm tra cho thấy mô hình có khả năng phân biệt tốt, đặc
biệt là trong việc phát hiện các trường hợp giả mạo.
• Classification Report (Báo cáo Phân loại):
o Độ chính xác (Accuracy): Mô hình đạt độ chính xác tổng thể là 94%, một
kết quả rất cao, cho thấy khả năng dự đoán đúng vượt trội trên toàn bộ tập kiểm tra.
o Precision (Độ chuẩn):
▪ Đối với lớp Real, precision là 0.83. Điều này có nghĩa là khi mô
hình dự đoán một khuôn mặt là "Real", có 83% khả năng dự đoán đó là đúng.
▪ Đối với lớp Fake, precision đạt đến 0.99. Đây là một kết quả gần
như hoàn hảo, cho thấy khi mô hình xác định một khuôn mặt là
"Fake", nó cực kỳ chắc chắn và gần như không bao giờ nhầm lẫn
một khuôn mặt thật thành giả.
o Recall (Độ phủ): lOMoAR cPSD| 61552889
▪ Đối với lớp Real, recall là 0.96. Mô hình đã nhận diện thành công
96% trong tổng số các khuôn mặt thật, cho thấy nó ít khi gây phiền
toái cho người dùng thật.
▪ Đối với lớp Fake, recall là 0.93. Mô hình đã phát hiện được 93%
trong tổng số các nỗ lực tấn công giả mạo có trong tập kiểm tra.
o F1-Score: F1-score của lớp "Fake" (0.96) cao hơn so với lớp "Real" (0.89),
phản ánh hiệu suất mạnh mẽ hơn trong việc xử lý các trường hợp giả mạo.
o Nhận xét chung: Mô hình này cực kỳ hiệu quả trong việc chặn các cuộc
tấn công giả mạo (precision lớp Fake rất cao). Tuy nhiên, có một sự đánh
đổi nhỏ: độ chuẩn (precision) của lớp "Real" là 83% cho thấy vẫn còn một
tỷ lệ nhỏ các trường hợp giả mạo có thể "lọt qua" và bị nhận nhầm là
thật. Đây là một yếu tố quan trọng cần cân nhắc khi triển khai trong thực tế.
Figure 6: Classification Report Model 2
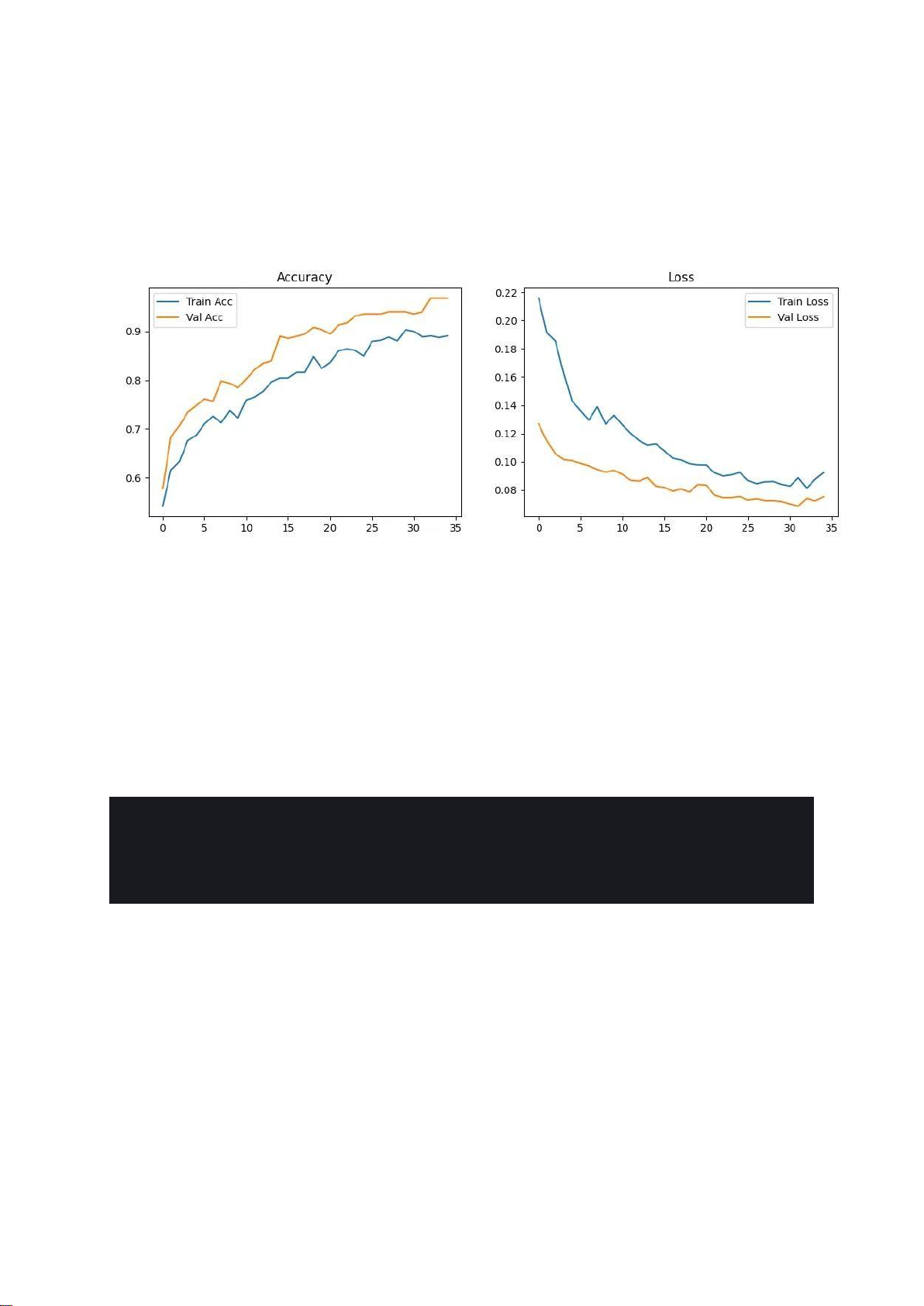
2. Phân Tích Quá Trình Huấn Luyện (Training Dynamics)
Biểu đồ "Accuracy" và "Loss" cho thấy một quá trình huấn luyện rất lành mạnh và được kiểm soát tốt. •
Model Accuracy & Loss:
o Một điểm rất đáng chú ý là đường cong của tập validation (màu cam)
luôn cho kết quả tốt hơn so với tập train (màu xanh): Validation Accuracy
cao hơn Train Accuracy và Validation Loss thấp hơn Train Loss.
o Đây là một hiện tượng tích cực và không phải là dấu hiệu của lỗi. Nó
thường xảy ra khi mô hình sử dụng các kỹ thuật chính quy hóa mạnh mẽ
như Dropout với tỷ lệ cao (ở đây là 0.6 và 0.4). Trong quá trình huấn luyện,
một phần các nơ-ron bị "tắt" ngẫu nhiên (do Dropout), làm giảm hiệu
suất của mô hình trên tập train. Tuy nhiên, khi đánh giá trên tập
validation, tất cả các nơ-ron đều được sử dụng, do đó mô hình phát huy
hết sức mạnh và cho kết quả tốt hơn. lOMoAR cPSD| 61552889
o Điều này khẳng định rằng mô hình được chính quy hóa rất tốt và có khả
năng tổng quát hóa cao, hoàn toàn không bị overfitting. •
Sự hội tụ: Cả hai đường cong loss đều giảm đều đặn và các đường cong
accuracy đều tăng trưởng ổn định, cho thấy mô hình học một cách nhất quán.
Quá trình huấn luyện dừng lại ở epoch thứ 35, do EarlyStopping được kích hoạt
khi val_loss không còn cải thiện đáng kể, giúp tiết kiệm thời gian và giữ lại
phiên bản tốt nhất của mô hình.
Figure 7: Training Dynamics Model 2
6. Triển khai script để sử dụng model
6.1. Tính năng dự đoán thật/giả từ 1 bức ảnh *
Vì cách tiền xử lý của mỗi model là khác nhau nên việc triển khai script cho
tính năng này cũng khác nhau như sau: Script 1:
def preprocess_image(image: np.ndarray) -> np.ndarray: img = cv2.cvtColor(image,
cv2.COLOR_BGR2RGB) img = cv2.resize(img,
IMAGE_SIZE) return img.astype(np.float32) / 255.0
Tài liệu liên quan:
-

Phần mềm tìm đường đi ngắn nhất trên bản đồ dựa trên các thuật toán | Môn Nhập môn trí tuệ nhân tạo - Đại học Bách Khoa Hà Nội
68 34 -

Ứng dụng các thuật toán tìm kiếm để giải bài toán ghép tranh (N-Puzzle) | Môn Nhập môn trí tuệ nhân tạo - Đại học Bách Khoa Hà Nội
58 29 -

Dự báo giá của các công ty logistics trong thị trường kinh tế biến động | Môn Nhập môn trí tuệ nhân tạo - Đại học Bách Khoa Hà Nội
68 34 -

Phần mềm tìm đường đi trên bản đồ phường Phương Mai, quận Đống Đa, Hà Nội | Môn Nhập môn trí tuệ nhân tạo - Đại học Bách Khoa Hà Nội
70 35