Báo cáo bài tập Thực hành cơ sở dữ liệu đề tài "Ứng dụng AI trong phân loại thư rác"
Báo cáo bài tập Thực hành cơ sở dữ liệu đề tài "Ứng dụng AI trong phân loại thư rác" của Học viện Công nghệ Bưu chính Viễn thông với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: Cơ sở dữ liệu (TEL1343) 12 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:











Preview text:
lOMoARcPSD| 37922327
ĐỀ TÀI: ỨNG DỤNG HỌC MÁY TRONG PHÂN LOẠI THƯ RÁC MỤC LỤC
CHƯƠNG I. TỔNG QUAN VỀ THƯ RÁC VÀ HỌC MÁY..............1
1.1 Mục tiêu và phương pháp nghiên cứu..................................2 1.1.1.
Mục tiêu nghiên cứu.........................................................2
1.2 Tổng quan về thư rác.............................................................2 1.2.1
Khái niệm thư rác................................................................2 1.2.2
Tác hại của thư rác..............................................................2 1.2.3
Tầm quan trọng của phân loại thư rác..............................4 1.3.
Tổng quan về học máy........................................................5 1.3.1.
Trí tuệ nhân tạo.................................................................5 1.3.2.
Học máy.............................................................................5 1.3.3.
Các kỹ thuật học máy.......................................................5 1.3.4.
Một số ứng dụng của học máy.........................................5 1.3.5.
Học máy có giám sát.........................................................5 1.4.
Kết luận chương...................................................................5
CHƯƠNG 2 . XÂY DỰNG MÔ HÌNH LỌC THƯ RÁC DỰA
TRÊN NAÏVE BAYES.......................................................................5
2.1. Thuật toán học máy Bayes..........................................................5 LỜI NÓI ĐẦU
Trong xã hội hiện đại ngày nay, trao đổi bằng thư điện tử Trong thực tế, thư rác đã
trở thành một vấn đề đáng lo ngại trong cuộc sống hàng ngày của chúng ta. Hòm thư
điện tử của chúng ta thường xuyên nhận được hàng trăm, thậm chí hàng nghìn email
thư rác mỗi ngày, gây phiền toái và làm mất thời gian. Chưa dừng lại ở đó, thư rác
còn tạo ra nguy cơ bị lừa đảo, tấn công mạng và lây lan mã độc cho những người nhận được thư rác.
Với sự gia tăng về số lượng và sự tinh vi của các hình thức thư rác, việc phân
loại thư rác trở nên cực kỳ quan trọng. Phân loại thư rác là quá trình xác định và tách lOMoARcPSD| 37922327
biệt các email thư rác khỏi email chính thức và quan trọng. Mục tiêu là tìm ra cách
hiệu quả để tự động lọc ra và đưa vào hộp thư chính xác những email quan trọng và
loại bỏ những email không mong muốn.
CHƯƠNG I. TỔNG QUAN VỀ THƯ RÁC VÀ HỌC MÁY
Mục tiêu và phương pháp nghiên cứu
1.1.1. Mục tiêu nghiên cứu
Dựa vào nhu cầu thực tế cần xây dựng một hệ thống lọc thư rác đơn giản và
hiệu quả. Bên cạnh đó, việc tạo ra một hệ thống phân loại thư rác cũng là để chứng
minh được lợi ích khi ứng dụng AI trong phân loại thư rác.
1.1.2. Phương pháp nghiên cứu
Phương pháp luận được sử dụng trong đề tài này bao gồm phương pháp nghiên
cứu và tổng hợp lý thuyết và phương pháp thực nghiệm. Mục lý thuyết được nghiên
cứu và thu thập từ các sách, bài báo tạp chí chuyên ngành. Sau khi có được nền tảng
lý thuyết và mô hình thực nghiệm sẽ tiến hành. Mô hình thực nghiệm được xây dựng,
hỗ trợ bởi một số nền tảng lý thuyết. Các kết quả thực nghiệm sẽ được đối chiếu với
kết quả lý thuyết để chứng minh sự thành công của thực nghiệm. 1.1
Tổng quan về thư rác
1.1.1 Khái niệm thư rác
Thư rác (spam mail) là các thông điệp không mong muốn và không được yêu
cầu gửi đến người nhận. Thư rác thường chứa các thông tin quảng cáo, thông tin
không chính xác, lừa đảo hoặc liên kết độc hại. Nội dung của thư là căn cứ chính
quyết định xem bức thư đó có phải là thư rác hay không. Đây cũng là cơ sở cho
giải pháp phân loại thư rác bằng nội dung thư.
1.1.2 Tác hại của thư rác
Các tác hại mà thư rác gây ra đối với người dùng:
- Phiền toái và quản lý email:
+ Thư rác làm cho hòm thư điện tử trở nên quá tải và khó quản lý.
+ Tìm kiếm email quan trọng trở nên khó khăn.
- Nguy cơ an ninh thông tin: lOMoARcPSD| 37922327
+ Thư rác có thể chứa các liên kết độc hại hoặc phần mềm độc hại. + Virus,
spyware, ransomware và các mối đe dọa khác có thể được lây lan qua email thư rác.
- Lừa đảo và đánh cắp thông tin:
+ Thư rác thường mang tính lừa đảo, cố gắng lừa người nhận để tiết lộ thông
tin cá nhân hoặc tài chính.
+ Người gửi thư rác có thể cố gắng lừa người nhận thực hiện các giao dịch gian lận.
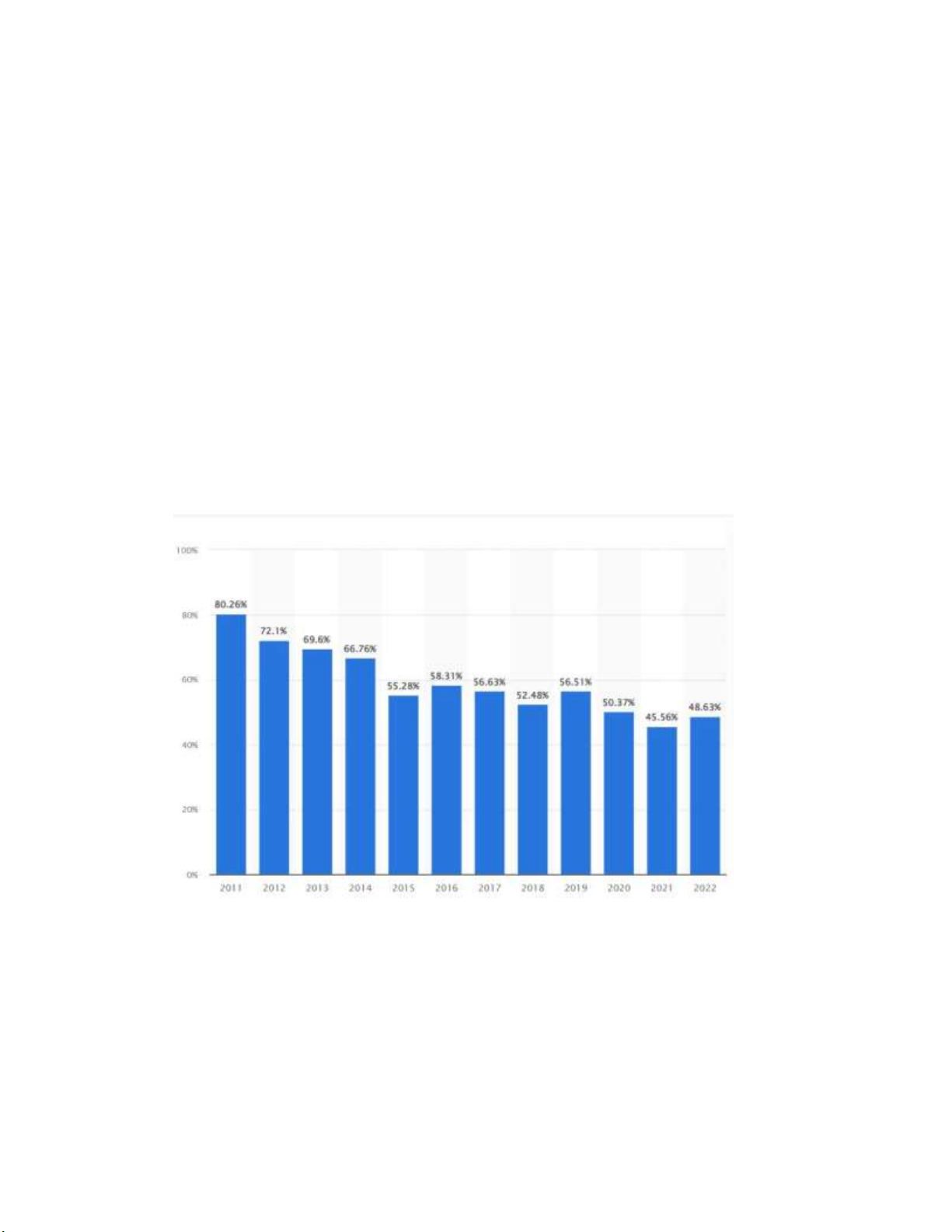
Thư rác chiếm một phần rất lớn của băng thông mạng, theo thống kê của
Statista [3], từ những năm 2012 đến 2018, số lượng thư rác luôn nhiều hơn so
với số lượng thư hợp lệ (ham). Mặc dù số lượng thư rác có giảm xuống so với
những năm trước đây từ 69% giảm xuống 55%, tuy nhiên, có thể thấy thư rác
vẫn chiếm một lượng băng thông mạng lớn.
Hình 1.1. Tỉ lệ thư rác điện tử từ năm 2011 đến 2022 [1 Statista
https://www.statista.com/statistics/420400/spam-email-traffic-share-annual/]
Theo thống kê mới nhất của Statista , thư rác chiếm 48,63% lưu lượng thư
điện tử vào năm 2022. Như vậy, tỷ lệ thư rác e-mail toàn cầu thực sự đang giảm: tỷ
lệ thư rác hàng năm toàn cầu trong năm 2022 là 48,63%, giảm gần một nửa so năm 2011 là 80,26% . lOMoARcPSD| 37922327
Vào năm 2022, có khoảng hơn 300 tỷ email được gửi và nhận hàng ngày trên
khắp thế giới. Phần lớn trong số đó là các e-mail quảng cáo được gửi bởi các nhà
tiếp thị mỗi ngày. Trong khi nhiều người sử dụng cho rằng nội dung đó nằm trong
thư mục thư rác của họ, e-mail tiếp thị nói chung là vô hại, tuy gây khó chịu cho
người dùng. Tuy nhiên, mọi thứ đang được cải thiện đối với các nhà tiếp thị. Và
không phải tất cả các thư rác đều là những email quảng cáo an toàn, mà một phần
không nhỏ các thư rác có tính chất độc hại, nhằm phá hoại hoặc chiếm quyền điều
khiển hệ thống của người dùng.
Thống kê tron năm 2022 về các nguồn của thư rác, 48,63% tổng số email trên
toàn thế giới và 52,78% tổng số email trong phân khúc Internet của Nga là thư rác,
có tới 29,82% tất cả các email spam có nguồn gốc từ Nga
1.1.3 Tầm quan trọng của phân loại thư rác
Phân loại thư rác trong giao tiếp qua email đóng vai trò quan trọng và mang lại
nhiều lợi ích đáng kể. Dưới đây là các ý chính chi tiết về tầm quan trọng của việc phân loại thư rác:
- Giảm thiểu sự phiền toái: Thư rác tạo ra sự phiền toái và làm giảm hiệu
quả trong quản lý email. Bằng cách phân loại thư rác, chúng ta có thể loại
bỏ các email không mong muốn và tập trung vào những email quan trọng.
- Bảo vệ an ninh thông tin: Thư rác thường chứa các liên kết độc hại hoặc
phần mềm độc hại có thể gây nguy hiểm cho an ninh thông tin và sự riêng
tư của người nhận. Phân loại thư rác giúp ngăn chặn sự lây lan của các mối
đe dọa này và bảo vệ hệ thống và dữ liệu cá nhân khỏi các cuộc tấn công.
- Tiết kiệm thời gian và công sức: Với số lượng email ngày càng tăng, việc
phân loại thư rác giúp tiết kiệm thời gian và công sức của người dùng.
Thay vì phải xem xét và loại bỏ thủ công từng email thư rác, họ có thể dễ
dàng xác định và loại bỏ tự động các email không mong muốn. lOMoARcPSD| 37922327
- Tăng cường hiệu quả giao tiếp: Phân loại thư rác giúp người dùng tập trung
vào các email quan trọng và cần thiết, cải thiện hiệu quả trong giao tiếp
qua email. Điều này đồng nghĩa với việc đáp ứng nhanh chóng các email
quan trọng, tránh trì hoãn và đảm bảo không bỏ sót thông tin quan trọng.
- Phát triển công nghệ phân loại thông minh: Sử dụng trí tuệ nhân tạo và các
thuật toán học máy, phân loại thư rác ngày càng trở nên thông minh và linh
hoạt. Các mô hình học máy có thể được huấn luyện để tự động nhận diện
các mẫu thư rác mới và cải thiện độ chính xác của quá trình phân loại.
1.3. Tổng quan về học máy
1.3.1. Trí tuệ nhân tạo
Trong khoa học máy tính, trí tuệ nhân tạo hay AI (tiếng Anh: artificial
intelligence), đôi khi được gọi là trí thông minh nhân tạo, là trí thông minh
được thể hiện bằng máy móc, trái ngược với trí thông minh tự nhiên của con
người. Thông thường, thuật ngữ "trí tuệ nhân tạo" thường được sử dụng để
mô tả các máy móc (hoặc máy tính) có khả năng bắt chước các chức năng
"nhận thức" mà con người thường phải liên kết với tâm trí, như "học tập" và "giải quyết vấn đề"
Trong cuộc Cách mạng công nghiệp 4.0, AI là một trong những yếu tố
then chốt. Từ một khái niệm mơ hồ, AI đang dần thay đổi thế giới một cách toàn diện. 1.3.2. Học máy
Học máy (machine learning) là một lĩnh vực của trí tuệ nhân tạo liên quan đến
việc nghiên cứu và xây dựng các kĩ thuật cho phép các hệ thống “học” tự động từ dữ
liệu để giải quyết những vấn đề cụ thể. Một cách tổng quát, trong cuốn sách Machine
Learning của tác giả Tom Mitchell xuất bản năm 1997, học máy được định nghĩa
như sau: Một chương trình máy tính được cho là học để thực hiện một nhiệm vụ T lOMoARcPSD| 37922327
từ kinh nghiệm E, nếu hiệu suất thực hiện công việc T của nó được đo bởi chỉ số
hiệu suất P và được cải thiện bởi kinh nghiệm E theo thời gian.
Như vậy, học máy nói đến một chương trình giúp cho máy tính có thể giải
một bài toán cụ thể bằng những “kinh nghiệm” mà nó đã được “học” từ dữ liệu.
Chương trình này có sự khác biệt lớn so với các chương trình lập trình truyền thống.
Ở các chương trình lập trình truyền thống, con người sẽ phải viết ra các qui tắc, điều
kiện để máy tính thực hiện nhiệm vụ và đưa ra câu trả lời. Ngược lại, đối với Học
máy, nhiệm vụ của máy tính là phải dựa vào dữ liệu quan sát để tìm ra được các qui tắc này.
1.3.3. Các thuật toán học máy
Hiện nay thuật toán học máy được chia làm 3 loại chính là: Học máy không
giám sát, học máy có giám sát và học bán giám sát .
- Học máy có giám sát là cách học từ những mẫu dữ liệu mà ở đó các kỹ
thuật học máy giúp hệ thống xây dựng cách xác định những lớp dữ liệu.
- Học máy không giám sát là việc học từ quan sát và khám phá một cách tự
động mà không hề được định nghĩa trước.
- Học bán giám sát là các thuật toán học tích hợp từ học giám sát và học không giám sát.
1.3.4. Một số ứng dụng của học máy
Ứng dụng: Học máy có rất nhiều ứng dụng trong thực tế, đặc biệt là những
ngành cần xử lý lượng dữ liệu khổng lồ. Trong đó, một số ứng dụng thường thấy của học máy là:
- Xử lý ngôn ngữ tự nhiên (Natural Language Processing): Xử lý văn bản
giao tiếp giữa người và máy,…
- Nhân dạng: Nhận dạng giọng nói, sinh trắc học, chữ viết tay,… lOMoARcPSD| 37922327
- Chẩn đoán trong ý tế: Phân tích ảnh chụp X-Quang, các chẩn đoán xét nghiệm,…
- Sinh học: Phân tích mã gen, quán trình hình thành gen,…
- Chơi trò chơi: Tự động chơi các môn như cờ vua, cờ vây,…
1.3.5. Học máy có giám sát
Học có giám sát (supervised learning) là một kỹ thuật của ngành học máy
nhằm mục đích xây dựng một hàm f từ dữ tập dữ liệu huấn luyện (Training data).
Dữ liệu huấn luyện bao gồm các cặp đối tượng đầu vào và đầu ra mong muốn. Đầu
ra của hàm f có thể là một giá trị liên tục hoặc có thể là dự đoán một nhãn phân lớp
cho một đối tượng đầu vào.
Nhiệm vụ của chương trình học có giám sát là dự đoán giá trị của hàm f cho
một đối tượng đầu vào hợp lệ bất kì, sau khi đã xét một số mẫu dữ liệu huấn luyện
(nghĩa là các cặp đầu vào và đầu ra tương ứng). Để đạt được điều này, chương trình
học phải tổng quát hóa từ các dữ liệu sẵn có để dự đoán được những tình huống chưa
gặp phải theo một cách hợp lý.
Ứng dụng của học máy có giám sát là phân loại thư rác, phân loại các chuyên
mục trong trang web, xác định giới tính qua khuôn mặt trong ảnh…
1.4. Kết luận chương
Trong chương 1, một số vấn đề như định nghĩa, tác hại, tầm quan trọng của
thư rác đã được trình bày. Qua đó, nêu lên vấn đề cần thiết phải xây dựng một
mô hình phân loại thư rác. Bên cạnh đó, một vài khái niệm cơ bản về học máy
cũng như một số ứng dụng của học máy cũng đã được đề cập trong chương.
CHƯƠNG 2. PHÂN LOẠI THƯ RÁC BẰNG PHƯƠNG PHÁP HỌC MÁY lOMoARcPSD| 37922327
2.1. Thuật toán học máy Bayes
2.1.1. Định lý Naïve Bayes
Định lý Bayes là một quy tắc trong xác suất thống kê, được đặt theo tên nhà
toán học người Anh Thomas Bayes. Định lý Bayes cung cấp phương pháp tính toán
xác suất của một sự kiện dựa trên thông tin trước đó.
Theo định lý Bayes, giả sử có hai sự kiện A và B, xác suất có điều kiện P(A|
B) (xác suất của A khi biết B đã xảy ra) có thể tính được từ xác suất có điều kiện
P(B|A) (xác suất của B khi biết A đã xảy ra), xác suất xảy ra của A (P(A)), và xác
suất xảy ra của B (P(B)). Định lý Bayes được biểu diễn bằng công thức sau: P(A|B)
= (P(B|A) * P(A)) / P(B) Trong đó:
· P(A|B) là xác suất của sự kiện A khi biết B đã xảy ra.
· P(B|A) là xác suất của sự kiện B khi biết A đã xảy ra.
· P(A) là xác suất xảy ra của sự kiện A.
· P(B) là xác suất xảy ra của sự kiện B.
2.1.2. Mô tả thuật toán Naïve Bayes
Thuật toán Naive Bayes là một thuật toán học máy được dựa trên nguyên tắc
định lý Bayes. Thuật toán này được sử dụng trong các bài toán phân loại và dự đoán,
đặc biệt là trong lĩnh vực xử lý ngôn ngữ tự nhiên và khai phá dữ liệu.
Naive Bayes được gọi là "naive" (ngây thơ) vì nó giả định rằng các đặc trưng
(features) của dữ liệu là độc lập và có ảnh hưởng riêng biệt lên kết quả dự đoán. Mặc
dù giả định này thường không chính xác trong thực tế, Naive Bayes vẫn được sử
dụng phổ biến do tính đơn giản và khả năng xử lý hiệu quả với dữ liệu lớn.
Thuật toán Naive Bayes tính toán xác suất của các lớp (classes) dựa trên xác
suất của các đặc trưng. Đầu tiên, dữ liệu huấn luyện được sử dụng để tính toán các
xác suất có điều kiện. Sau đó, khi có một dữ liệu mới, thuật toán sử dụng định lý lOMoARcPSD| 37922327
Bayes để tính toán xác suất xảy ra của các lớp và chọn lớ ớp có xác suất cao nhất là
kết quả dự đoán. Công thức tính xác suất của một lớp trong Naive Bayes được biểu diễn như sau:
P(C|X) = (P(X|C) * P(C)) / P(X) Trong đó:
· P(C|X) là xác suất của lớp C khi biết dữ liệu X.
· P(X|C) là xác suất của dữ liệu X khi biết lớp C.
· P(C) là xác suất xảy ra của lớp C.
· P(X) là xác suất xảy ra của dữ liệu X.
Trong quá trình huấn luyện, Naive Bayes tính toán các xác suất P(X|C) bằng
cách giả định rằng các đặc trưng (features) là độc lập nhau. Điều này có nghĩa là xác
suất của một đặc trưng trong dữ liệu được tính riêng biệt cho từng lớp, và xác suất
tổng hợp của dữ liệu X được tính bằng cách nhân các xác suất này lại với nhau.
Naive Bayes có thể được áp dụng cho nhiều loại dữ liệu, bao gồm cả dữ liệu
dạng văn bản. Trong trường hợp này, các đặc trưng của văn bản có thể là các từ và
xác suất P(X|C) được tính dựa trên tần suất xuất hiện của từng từ trong các văn bản
huấn luyện thuộc cùng một lớp.
Mặc dù Naive Bayes có giả định đơn giản và bỏ qua mối quan hệ giữa các đặc
trưng, nó thường cho kết quả khá tốt trong nhiều bài toán phân loại và dự đoán. Đặc
biệt, với dữ liệu lớn và độc lập tương đối giữa các đặc trưng, Naive Bayes có thể đạt
hiệu suất cao và thời gian tính toán nhanh.
2.1.3. Áp dụng trong phân loại thư rác
Theo thuật toán Naïve Bayes, để quyết định thư E có phải là thư rác (Spam)
hay thư bình thường (Ham), có thể thông qua so sánh 2 xác suất có điều kiện:
P[spam|X] và P[ham|X] (X là tập các đặc tính của thư E). lOMoARcPSD| 37922327
Công thức Bayes được sử dụng để tính xác suất thư rác với giả định rằng tất
cả các đặc tính trong thư là độc lập, không phụ thuộc lẫn nhau. Ví dụ, trong email X
có xuất hiện các từ “sold”, “selloff”, “price”, “free”, “apply”, “exclusive”, “deal”,
“click”, “now”, ... Mỗi từ có thể được coi là một đặc tính, với giả định rằng tất cả
các từ là độc lập. Nhưng thực tế thì không phải vậy, vì “exclusive” thường đi với
“deal” và “click” thường theo sau bởi “now”, ... Do dựa vào giả định là “Naïve”
(ngây thơ) như vậy, nên thuật toán có tên là Naïve Bayes. Tuy nhiên, giả định này
lại mang tới một kết quả bất ngờ về cả độ chính xác lẫn tốc độ trong huấn luyện và
dự đoán, phù hợp cho tập dữ liệu lớn, nhiều chiều và chống nhiễu.
Quá trình xây dựng bộ lọc sử dụng Naïve Bayes gồm 3 giai đoạn [3]:
• Tiền xử lý dữ liệu (pre-processing): Dữ liệu thô thường không đầy đủ, chứagiá
trị nhiễu. Giai đoạn này loại bỏ nhiều từ thừa như các từ liên kết hoặc những
đoạn không cần thiết cho quá trình phân loại;
• Lựa chọn đặc tính (feature selection): Như trong ví dụ nêu trên, một từtrong
thư có thể được coi là một đặc tính. Tuy nhiên, để huấn luyện mô hình thì đặc
tính cần chuyển thành số liệu. Do đó, đặc tính có thể là xác suất xuất hiện của
từ đó trong thư điện tử, số lượng sai chính tả, ... Những đặc tính này có thể
được chọn lựa thủ công hoặc thông qua một số phương pháp tính toán;
• Áp dụng thuật toán Naïve Bayes để thu được kết quả phân loại. Việc đánhgiá
thuật toán này được trích dẫn từ kết quả từ nghiên cứu. Các tác giả sử dụng 2
tập dữ liệu là Spam Data và Spambase (như đã mô tả ở trên) và đánh giá độ
chính xác của thuật toán khi sử dụng chúng. lOMoARcPSD| 37922327
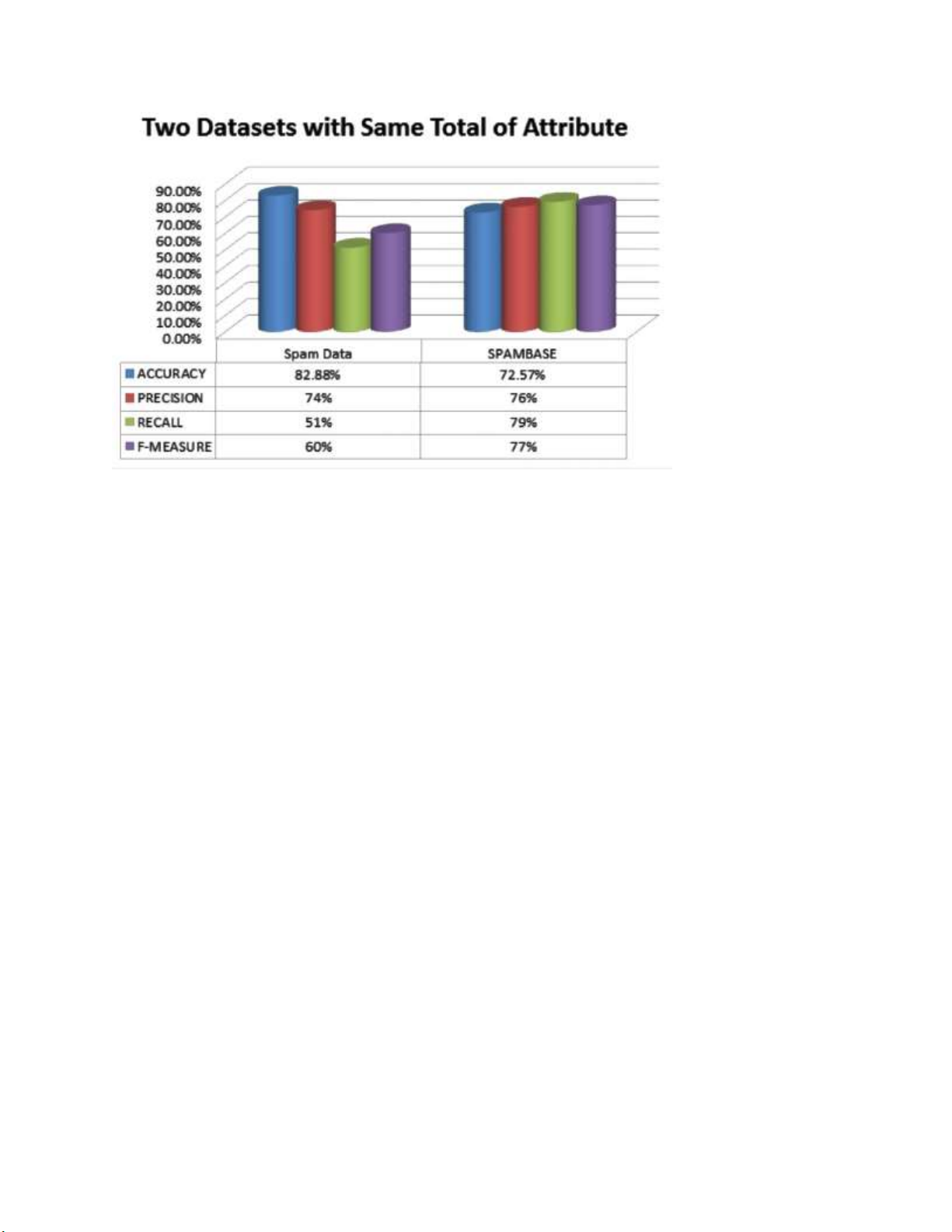
Hình 4. Đánh giá bộ thư rác sử dụng Naïve Bayes với tập dữ liệu Spam Data và Spambase. Trong đó:
- Accuracy: Phần trăm xác định đúng thư rác và thư bình thường
- Recall: Phần trăm thư rác được chặn đúng
- Precision: Tỷ lệ dự đoán thư rác đúng
- F-Measure: Trung bình của Accuracy và Recall có trọng số.
Từ kết quả thu được, nhóm tác giả nhận định rằng, bộ lọc sử dụng Naïve Bayes có
hiệu suất tốt hơn trên tập Spambase so với tập Spam Data, ngay cả khi Spam Data
đạt được chỉ số Accuracy cao hơn. Do bộ lọc có kết quả tốt trên Precision, Recall và
F-measure cũng quan trọng không kém. Spam Data có nhiều đặc tính và mẫu của
thư với tổng cộng 9.324 thư và 500 đặc tính, thu thập từ rất nhiều tài khoản thư điện
tử khác nhau, trong khi Spambase có 4.601 thư và 58 đặc tính với dữ liệu chỉ từ một tài khoản.
Có sự khác biệt về kết quả như vậy là do bộ lọc sử dụng Naïve Bayes không nhất
định cần nhiều số lượng mẫu thư và đặc tính lớn để huấn luyện phân loại cho bộ lọc thư rác. lOMoARcPSD| 37922327
Thuật toán phân loại sử dụng Naïve Bayes có thể thực hiện tốt hơn trên tập dữ liệu
thu thập từ một tài khoản thư điện tử so với nhiều tài khoản. Đó là bởi bộ lọc Naïve
Bayes có thể tập trung huấn luyện với nhiều loại thư rác khác nhau đến từ riêng một tài khoản.
Với những khả năng này, người dùng có thể tự cài đặt bộ lọc trên thiết bị một cách
độc lập, và tiếp tục huấn luyện với dữ liệu riêng để có được bộ lọc hiệu quả hơn, phù
hợp với tài khoản thư điện tử của mình.
Các bộ lọc trên máy chủ như DSPAM, SpamAssassin, SpamBayes, Bogofilter và
ASSP đều sử dụng thuật toán Naïve Bayes và nó có thể được nhúng vào hệ thống
của các nhà cung cấp dịch vụ thư điện tử.
Tuy nhiên, bộ lọc sử dụng Naïve Bayes có thể bị phá vỡ bởi kẻ phát tán thư rác bằng
cách thêm nhiều từ hợp lệ trong thư rác, dẫn đến bộ lọc có thể phân loại nhầm. Tuy
nhiên, vấn đề này có thể được giải quyết bằng biểu đồ Paul Graham chỉ sử dụng
những đặc tính cần thiết, tập trung vào những từ quan trọng trong việc phân loại thư.
Một tình huống khác là kẻ phát tán thư rác có thể thay thế từ ngữ bằng hình ảnh để
vượt qua bộ lọc Naïve Bayes, do vậy cần tích hợp các phương pháp khác theo để giải quyết.
2.2. Học máy theo phương pháp mạng nơron nhân tạo
2.2.1. Giới thiệu mạng nơron nhân tạo
Neural Network đọc tiếng việt là Mạng nơ-ron nhân tạo, đây là một chuỗi những
thuật toán được đưa ra để tìm kiếm các mối quan hệ cơ bản trong tập hợp các dữ
liệu. Thông qua việc bắt bước cách thức hoạt động từ não bộ con người. Nói cách
khác, mạng nơ ron nhân tạo được xem là hệ thống của các tế bào thần kinh nhân tạo.
Đây thường có thể là hữu cơ hoặc nhân tạo về bản chất.
2.2.2. Mô tả thuật toán 2.2.2. Huấn luyện mạng nơ-ron nhân tạo 2.2.3. Ứng
dụng trong phân loại thư rác lOMoARcPSD| 37922327
2.3. Xây dựng mô hình lọc thư rác dựa trên học máy có giám sát
2.3.1. Lựa chọn mô hình và thuật toán 2.3.2. Xây dựng hệ thống 2.4. Kết luận chương
Tài liệu liên quan:
-

Ngân hàng đề thi - 350 câu hỏi trắc nghiệm môn Cơ sở dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
48 24 -

Tiểu luận môn Cơ sở dữ liệu đề tài "Thiết kế cơ sở dữ liệu quản lý Shop thời trang Anjing"
560 280 -

Nội dung bài giảng môn Cơ sở dữ liệu nội dung: Hệ quản trị cơ sở dữ liệu ACCESS
720 360 -

Bài thực hành Cơ sở dữ liệu bài số 01 | Học viện Công nghệ Bưu chính Viễn thông
455 228