Báo Cáo Cuối Kỳ Môn Học Máy INT3405: Phân Tích Cảm Xúc Foody.vn. Môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội.
Tóm tắt
Báo cáo này trình bày nghiên cứu thực nghiệm về hiệu quả của các kỹ thuật học máy trong việc phân loại cảm xúc trên website Foody.vn về trạng thái tiêu cực hay tích cực. Nhóm sử dụng dữ liệu trong đó có 40000 mẫu (bao gồm testset và trainset) có 20000 mẫu positive và 20000 mẫu negative để training (food_train.vcs) đủ 40000 mẫu. Nhóm sử dụng các đánh giá đồ ăn, hạn chế tính từ và trạng từ, xử lý phủ định, giới hạn tần số từ bằng ngưỡng và sử dụng kiến thức từ đồng nghĩa WordNet. Nhóm đánh giá với độ chính xác của 2 phương pháp học máy LSTM và Bi-LSTM .Nhóm kết thúc nghiên cứu với những giải thích và kết luận về tỷ lệ chính xác của công việc.
Báo Cáo Cuối Kỳ Môn Học Máy INT3405: Phân Tích Cảm Xúc Foody.vn. Môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội.
Tài liệu gồm 9 trang giúp bạn tham khảo, củng cố kiến thức và ôn tập đạt kết quả cao trong kỳ thi sắp tới. Mời bạn đọc đón xem!
Môn: Học máy 10 tài liệu
Trường: Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội 824 tài liệu
Tác giả:


Preview text:
lOMoAR cPSD| 59735516
Báo Cáo Cuối Kỳ Môn Học Máy
Sentiment Analysis Problem on Foody.vn
INT3405_20_Team_CHL (Thứ tự hiện tại trên Kaggle
22 - Điểm số : 0.92775)
Nguyễn Văn Cường Phạm Quang Huy Đỗ Văn Linh K64 - R K64-R K64-R 19020512@vnu.edu.vn 19020557@vnu.edu.vn 19020569@vnu.edu.vn Trần Ngọc Kính Tống Văn Hùng K64-K1 K64-K1 19020564@vnu.edu.vn 19020552@vnu.edu.vn Tên Công Việc
Tên các thành viên phụ trách Tìm thêm dữ liệu Phạm Quang Huy Xử lý dữ liệu
Phạm Quang Huy (Bi-LSTM), Đỗ Văn Linh (LSTM)
Đề xuất, xây dựng và huấn luyện Nguyễn Văn Cường (LSTM,Bi-LSTM) mô hình
Tổng hợp kết quả và viết báo
Trần Ngọc Kính, Tống Văn Hùng cáo Tóm tắt
Bi-LSTM, Sentiment Analylis Problem)
Báo cáo này trình bày nghiên cứu thực I. GIỚI THIỆU
nghiệm về hiệu quả của các kỹ thuật học máy
Trong những năm gần đây, một số
trong việc phân loại cảm xúc trên website
lượng lớn các trang web cho phép người
Foody.vn về trạng thái tiêu cực hay tích cực.
dùng đóng góp, sửa đổi và chấm điểm nội
Nhóm sử dụng dữ liệu trong đó có 40000
dung. Người dùng có cơ hội thể hiện quan
mẫu (bao gồm testset và trainset) có 20000
điểm cá nhân về các chủ đề cụ thể. Ví dụ như
mẫu positive và 20000 mẫu negative để
các blog, diễn đàn hay các trang web đánh
training (food_train.vcs) đủ 40000 mẫu.
giá sản phẩm và mạng xã hội.
Nhóm sử dụng các đánh giá đồ ăn, hạn chế
Ý kiến có thể được thể hiện trong nhiều
tính từ và trạng từ, xử lý phủ định, giới hạn
hình thức khác nhau. Ví dụ như các sàn
tần số từ bằng ngưỡng và sử dụng kiến thức
thương mại điện tử như shopee hay lazada
từ đồng nghĩa WordNet. Nhóm đánh giá với
cho phép xếp hạng sản phẩm theo một
độ chính xác của 2 phương pháp học máy
thang điểm cố định cũng như là các ý kiến cá
LSTM và Bi-LSTM .Nhóm kết thúc nghiên cứu
nhân. Những đánh giá này ngày càng có xu
với những giải thích và kết luận về tỷ lệ chính
hướng dài hơn, thường bao gồm một vài xác của công việc.
đoạn văn bản, chúng có xu hướng giống với
các thông điệp trên blog hay các bình luận
(Keywords - Machine learning,LSTM,
ngắn trên mạng xã hội. lOMoAR cPSD| 59735516
Phân loại các cảm xúc của khách hàng
trình đọc data và chỉnh sửa data
trên foody nhằm khám phá thái độ của
(find_more_data.py).Sử dụng thư viện pyvi
khách hàng về các món ăn cụ thể được bán để cắt từ ghép.
từ các cửa hàng. Nó sử dụng kỹ thuật xử lý
2.2 Lựa chọn và sử dụng các tính năng Để
ngôn ngữ tự nhiên và học máy để tìm kiếm
thực hiện việc học, cần phải trích xuất đặc
các mẫu thống kê và ngôn ngữ trong đoạn
điểm từ văn bản để có thể phân loại chính
đánh giá phản hồi các sản phẩm.
xác. Trong hầu hết các phương pháp học máy,
Nhóm mong muốn có các nhận xét
các tính năng trong một vector được coi là
ngắn gọn, thể hiện cô đọng, trực tiếp về các
độc lập về mặt thống kê với nhau. Việc lựa
đánh giá của khách hàng. Nhóm đã tập trung
chọn các tính năng ảnh hưởng mạnh mẽ đến
vào hai thuộc tính chính của văn bản
việc học.Chúng ta nên chọn các đặc điểm
• Chủ quan: cho dù đánh giá là chủ
của văn bản gốc có liên quan cho nhiệm vụ quan hay khách quan.
phân tích cảm xúc. Thuật toán chính xác để
• Phân cực: cho dù đánh giá là tích cực
tìm các tính năng tốt nhất không tồn tại, nên hay tiêu cực.
cần phải dựa vào trực giác, và thử nghiệm để
Nhóm sử dụng phương pháp thống kê cho kết quả tốt nhất.
để nắm bắt các yếu tố và phong cách của câu 2.2.1 LSTM
chủ quan và phân cực. Phân tích thống kê
được thực hiện ở cấp độ câu. Nhóm đã áp
Long short-term memory (LSTM) là
dụng các kỹ thuật học máy để phân loại tập
một kiến trúc artificial recurrent neural tin nhắn.
network (RNN) được sử dụng trong lĩnh vực
Nhóm quan tâm đến các câu hỏi sau:
Deep learning. Nó được đề xuất vào năm •
1997 bởi Sepp Hochreiter và Jurgen
Chúng ta có thể trích xuất tính chủ
schmidhuber. Không giống như các
quan và phân cực từ các đánh giá
feedforward neural networks, LSTM có các ngắn ở mức độ nào? •
kết nối phản hồi. Nó có thể xử lý không chỉ
Những kỹ thuật học máy nào phù hợp
các điểm dữ liệu đơn lẻ (chẳng hạn như hình cho mục đích này
ảnh) mà còn toàn bộ chuỗi dữ liệu (chẳng
• Các thuộc tính của các đánh giá có hạn như speech hoặc video).
quan trọng đối với việc phân tích cảm
LSTM ứng dụng cho các tác vụ như
xúc tương tự như thuộc tính của một
phân dạng chữ viết tay hoặc nhận dạng số ngữ liệu hiện có?
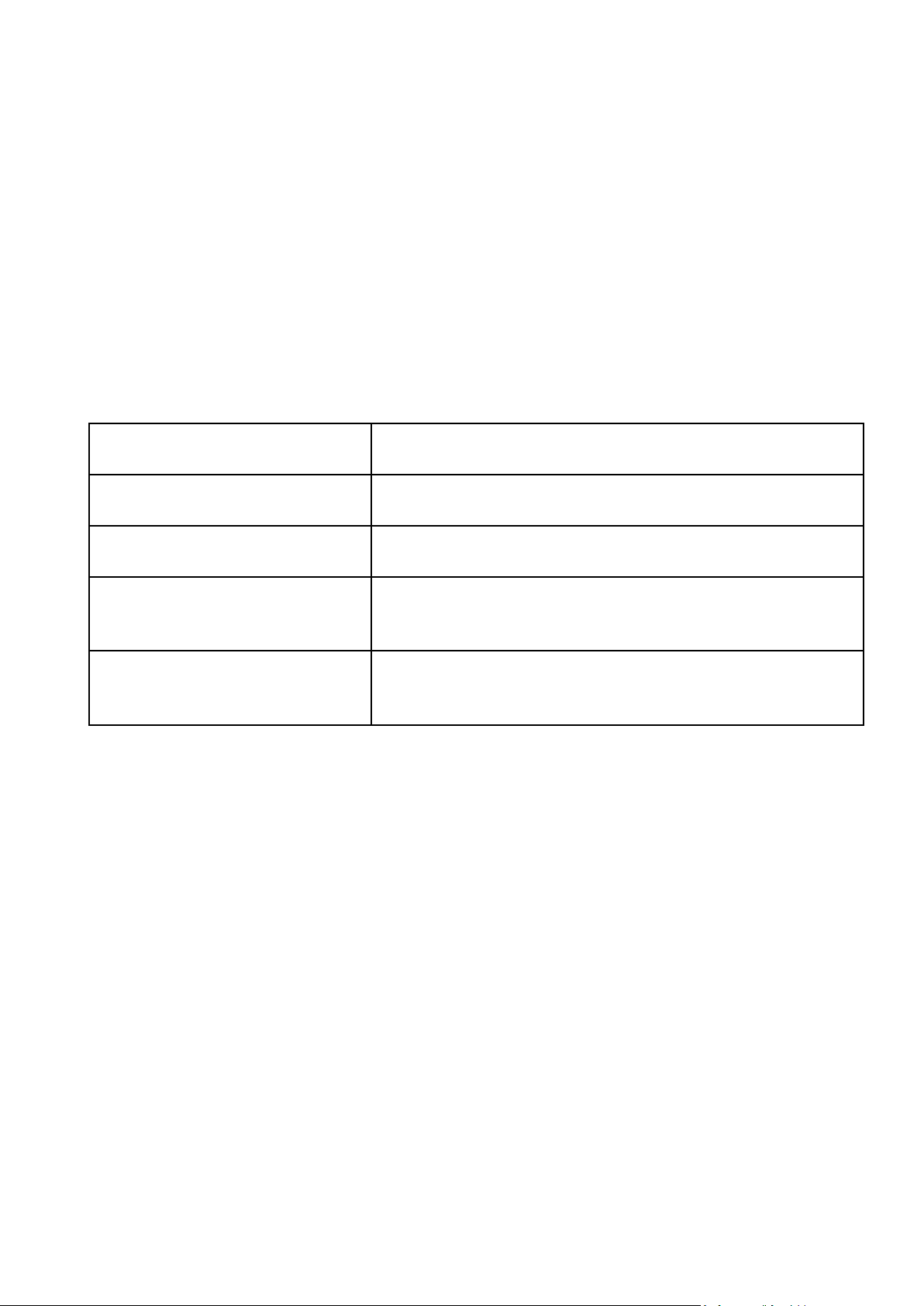
giọng nói một đơn vị bao gồm một cell, input II. PHƯƠNG PHÁP
gate, output gate và forget gate.Cell ghi nhớ
Phương pháp phân tích của nhóm dựa trê
các giá trị trong khoảng thời gian tùy ý và 3
n Học Máy. Nhóm giải thích nguồn dữ liệu
gate điều chỉnh luồng thông tin.
mà nhóm đã sử dụng trong 2.1, Cách sử dụn
g các tính năng trong 2.2 và cách thực hiện p
Hình 2.2.1. Sơ đồ 3 gate của LSTM hân loại trong 2.3.
2.1 Nguồn dữ liệu
Nhóm sử dụng dữ liệu gốc được cung
cấp.Nhưng do dữ liệu gốc bị thiếu quá
nhiều nên nhóm có tìm thêm dữ liệu ở 1 site:
“https://github.com/congnghia0609/ntcscv /tree/master/data”
Nhóm đã dữ liệu ở site trên và lưu
Input gate – Nó phát hiện ra giá trị nào từ
chúng trong các tệp food_train.csv,
đầu vào sẽ được sử dụng để sửa đổi bộ nhớ.
more_food_cmt.csv và test.csv.Nhóm tạo ra
Hàm Sigmoid quyết định giá trị nào sẽ cho lOMoAR cPSD| 59735516
qua 0 hoặc 1. Và hàm tanh đưa ra trọng số
hạn như tính trung bình, tính tổng, nhân
cho các giá trị được truyền, quyết định mức hoặc nối.
độ quan trọng của chúng trong khoảng từ -1
Hình 2.2.2. Mô hình Bi-LSTM đến 1.
it=σ (W j .[ℎt −1,xt ]+bi)
Ct=tanℎ(WC . [ℎt −1, xt]+bc )
Forget gate – Nó khám phá các chi tiết cần
loại bỏ khỏi khối. Một hàm sigmoid quyết
Kiểu kiến trúc này có nhiều lợi thế
định nó. Nó xem xét trạng thái trước đó (ht1)
trong các vấn đề trong thế giới thực, đặc
và đầu vào nội dung (Xt) và xuất ra một số
biệt là trong NLP. Lý do chính là mọi thành
giữa 0 (bỏ qua điều này) và 1 (giữ nguyên
phần của chuỗi đầu vào đều có thông tin từ
điều này) cho mỗi số trong trạng thái ô Ct-1.
cả quá khứ và hiện tại. Vì lý do này, BiLSTM
có thể tạo ra đầu ra có ý nghĩa hơn, kết hợp
các lớp LSTM từ cả hai hướng. Chẳng hạn,
f t=σ .(Wf . [ℎt −1, xt]+bf ) câu: “Apple là thứ mà…”
Output gate – Đầu vào và bộ nhớ của khối
được sử dụng để quyết định đầu ra. Hàm
có thể là về trái táo như trái cây hoặc về
Sigmoid quyết định giá trị nào cho qua 0
công ty Apple. Do đó, LSTM không biết
hoặc 1. Và hàm tanh quyết định giá trị nào
“Apple” nghĩa là gì, vì nó không biết ngữ
cho qua 0, 1. Và hàm tanh đưa ra trọng số cảnh trong tương lai.
cho các giá trị được truyền, quyết định mức
Ngược lại, rất có thể trong cả hai câu
độ quan trọng của chúng trong khoảng từ -1
sau: “Apple là thứ mà các đối thủ cạnh
đến 1 và nhân lên với đầu ra là sigmoid.
tranh không thể sao chép được.” và
“Táo(apple) là thứ tôi thích ăn.” BiLSTM sẽ
có đầu ra khác nhau cho mọi thành phần
Ot=σ (W o[ℎt −1,xt ]+bo) ℎt=ot
(từ) của chuỗi (câu). Do đó , mô hình ∗tanℎ (Ct )
BiLSTM có lợi trong một số tác vụ NLP,
chẳng hạn như phân loại câu, dịch thuật và 2.2.2 Bi-LSTM
nhận dạng thực thể. Ngoài ra, nó còn tìm
thấy các ứng dụng của nó trong nhận dạng
LSTM hai chiều (Bi-LSTM) là mạng
giọng nói, dự đoán cấu trúc protein, nhận
thần kinh hồi quy được sử dụng chủ yếu
dạng chữ viết tay và các lĩnh vực tương tự.
trong xử lý ngôn ngữ tự nhiên. Không giống
như LSTM tiêu chuẩn, đầu vào chảy theo cả
hai hướng và nó có khả năng sử dụng thông
2.3 Cách phân loại
tin từ cả hai phía. Đây cũng là một công cụ
mạnh mẽ để lập mô hình phụ thuộc tuần tự
Thuật toán phân loại dự đoán nhãn
giữa các từ và cụm từ theo cả hai hướng
cho một câu đầu vào đã cho. Nhóm đã sử của chuỗi.
dụng thuật toán LSTM hoặc Bi-LSTM để xử
Tóm lại, Bi-LSTM bổ sung thêm một lý.
Nhận đầu vào là một chuỗi dữ liệu
lớp LSTM, giúp đảo ngược hướng của luồng
được xử lý mã hóa đầu ra có 1 đầu ra là xác
thông tin. Tóm lại, điều đó có nghĩa là chuỗi suất
đầu vào chảy ngược trong lớp LSTM bổ
• Nếu xác suất > 0.5: bình luận đánh
sung. Sau đó, chúng tôi kết hợp các đầu ra
giá trên 5 sao thì sẽ được dán nhãn
từ cả hai lớp LSTM theo một số cách, chẳng tích cực (positive) lOMoAR cPSD| 59735516
• Nếu xác suất < 0.5: bình luận đánh
sklearn.metrics để đánh giá chất lượng dự
giá dưới 5 sao thì sẽ được dán nhãn đoán mô hình. tiêu cực (negative)
Cách xử lý chuỗi thì sử dụng thư viện
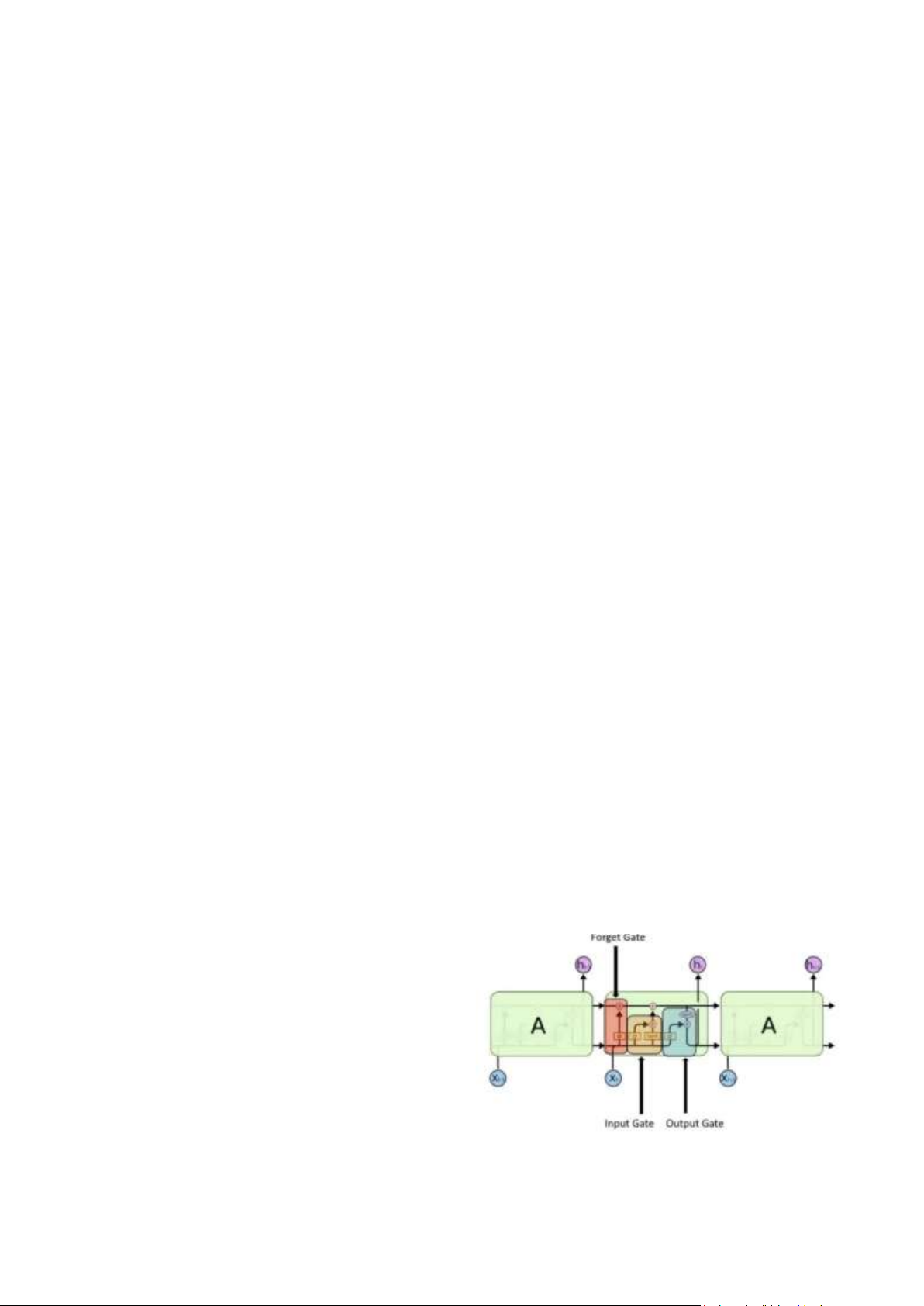
Xây dựng mô hình LSTM với các thông số
pyvi để cắt từ , thư viện sẽ cắt các từ ghép như hình 3.1.2. để mình sử dụng.
Lọc dấu câu do có nhiều bình luận có
Hình 3.1.2. Các thông số của mô hình
ký tự đặc biệt ví dụ như: :)) , :((, -_-, … nên
nhóm chỉ lọc một số dấu sử dụng đa số. LSTM III. ĐÁNH GIÁ
3.1 Thiết lập thí nghiệm 3.1.1 Bi-LSTM
Chương trình sử dụng NLTK 0.9.9 bao
gồm kho văn bản đánh giá cảm xúc của nó,
cơ sở học máy và các ràng buộc WordNet. Cụ
3.2. Chuẩn bị dữ liệu Ta sẽ sử dụng dữ liệu
thể nhóm sử dụng các gói nltk.corpus,
được cung cấp sẵn trên Kaggle và dữ liệu
nltk.stem, bs4 và pyvi để tiền xử lý dữ liệu
crawl thêm ở bên ngoài về
đầu vào. Gói sklearn.model_selection,
keras.models, keras.layers và keras.utils để
xây dựng mô hình. Nhóm cũng đã sử dụng
python numpy và pandas để tính toán và
phân tích lệnh thông số dòng. Ngoài ra,
nhóm đã sử dụng gói matplotlib để vẽ các đồ
thị, gensim.models để tạo ngram và vectơ
hoá dữ liệu đầu vào. Cuối cùng là gói
sklearn.metrics để đánh giá chất lượng dự đoán mô hình.
Xây dựng mạng Bi-LSTM với các thông
python numpy và pandas để tính toán và
phân tích lệnh thông số dòng. Ngoài ra,
nhóm đã sử dụng gói matplotlib để vẽ các đồ
thị, gensim.models để tạo ngram và vectơ
hoá dữ liệu đầu vào. Cuối cùng là gói lOMoAR cPSD| 59735516
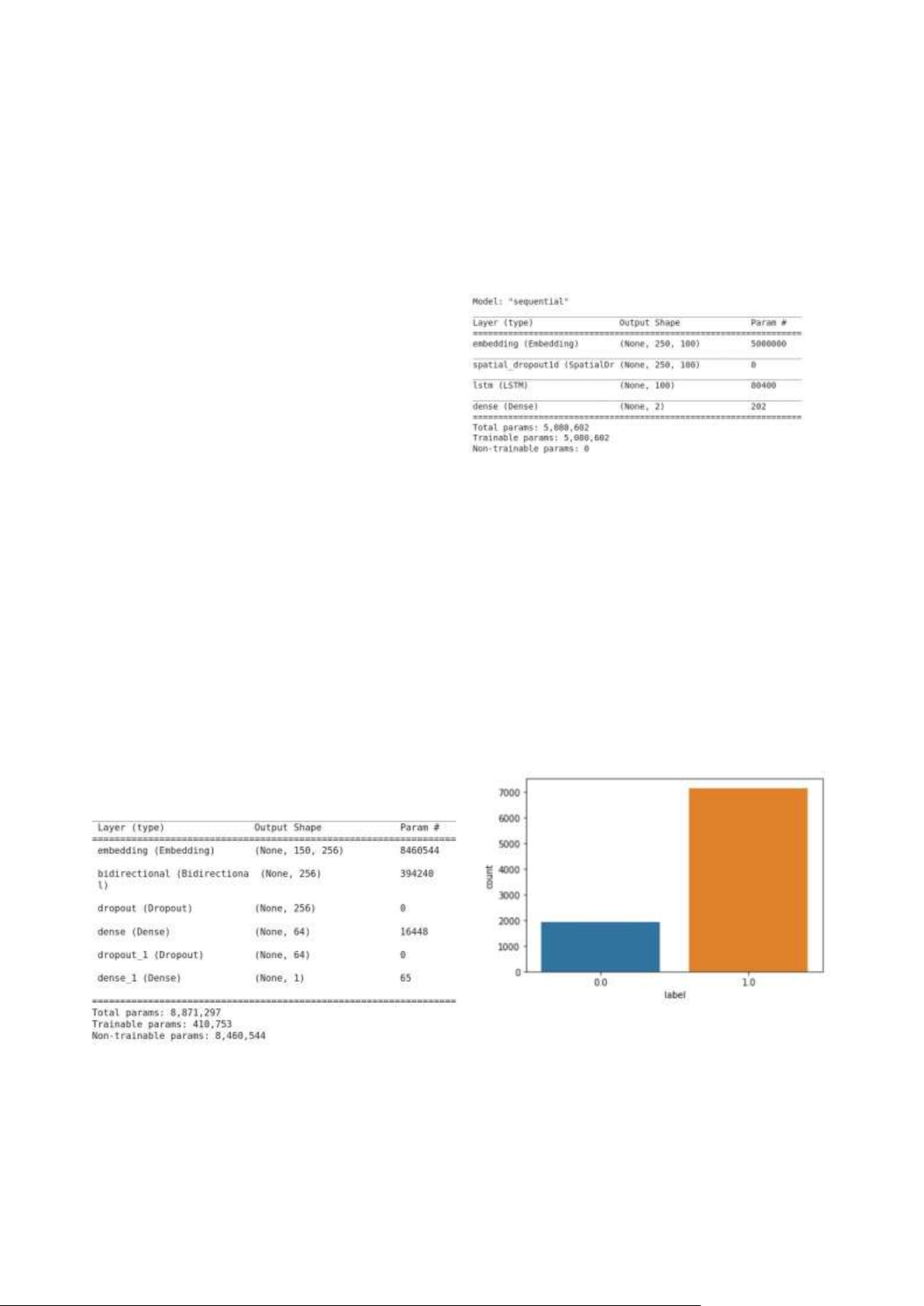
Hình 3.2.1 Dữ liệu được cung cấp sẵn trên
Do dữ liệu cung cấp sẵn hình 3.2.1 phân bố kaggle
không đồng đều nên ta sẽ crawl thêm và
Hình 3.2.2. Dữ liệu sau khi crawl thêm
được được bộ dữ liệu có phân bố như hình số như hình 3.1.1
Hình 3.1.1 Các thông số mạng Bi-LSTM 3.1.2 LSTM
Đối với LSTM thì nhóm đã sử dụng các
gói nltk.stem và pyvi để tiền xử lý dữ liệu đầu
vào. Gói sklearn.model_selection để xây
dựng mô hình. Nhóm cũng đã sử dụng 3.2.2.
3.3. Đánh giá mô hình *LSTM
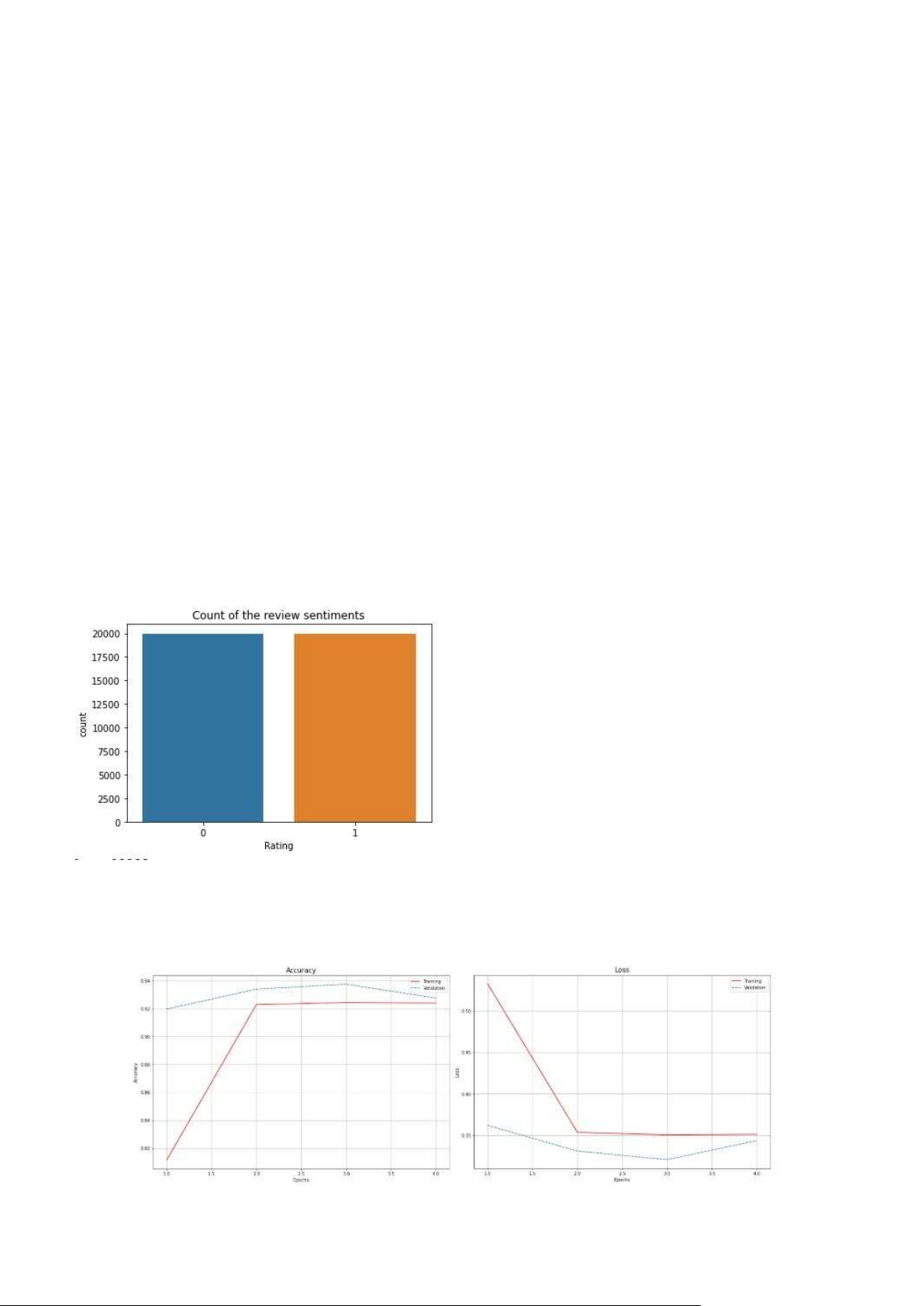
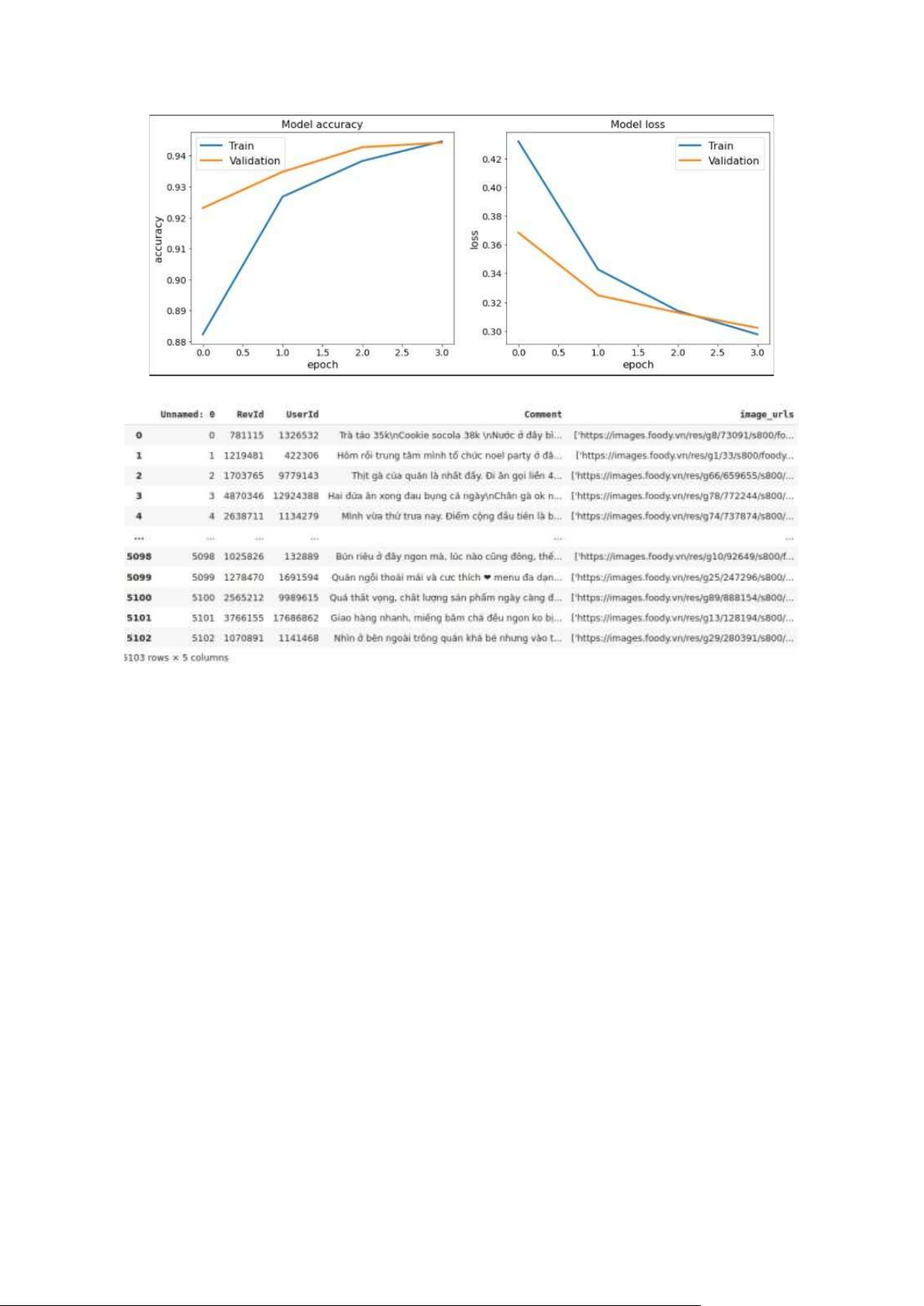
LSTM model : độ chính xác trên tập train
khoảng 94.19% hình 3.2.1 Số liệu sử dụng
điểm AUC-ROC Điểm submission trên Kaggle là 0.90757 sử
dụng tập test như hình 3.3.3 *Bi-LSTM
Bi-LSTM model : độ chính xác trên tập train
khoảng 94.46% hình 3.2.2 Số liệu sử dụng điểm AUC-ROC
Điểm submission trên Kaggle 0.92775
Hình 3.3.1 Kết quả khảo sát mô hình LSTM lOMoAR cPSD| 59735516
Hình 3.3.2 Kết quả khảo sát mô hình Bi-LSTM
Hình 3.3.3. Tập data test được cho sẵn trên Kaggle IV. KẾT LUẬN
sử dụng giải pháp này để tích hợp vào các
Trong báo cáo này, nhóm đã phân tích
ứng dụng với mục đích khảo sát cảm xúc trải
cảm xúc bình luận trên website Foody.vn.
nghiệm khách hàng đối với tất cả sản phẩm
Nhóm sử dụng các bình luận trên Foody.vn dịch vụ khác nhau.
(food_train.vcs) để làm mẫu đầu vào. Nhóm
Trong các nghiên cứu tiếp theo, nhóm
đã sử dụng thuật toán để đánh giá sự phân
sẽ mở rộng bằng cách cài đặt hệ thống để tự
cực của chúng (Khen/ Chê). Kết quả cho thấy
động cập nhật dữ liệu. Dữ liệu sẽ tự trích
mô hình Bi-LSTM có thể thực hiện được xử
xuất dữ liệu từ trên website và loại bỏ dữ
lý đầu vào và đánh giá phân loại tốt hơn mô
liệu trùng lặp trước khi lưu vào cơ sở dữ liệu.
hình LSTM. Giải quyết được bài toán trong
Thu thập dữ liệu nhiều hơn nữa từ nhiều
thời kỳ bùng nổ dữ liệu đó là cung cấp các
nguồn, và phát triển nghiên cứu theo hướng
thông tin trải nghiệm khách hàng. Từ đó phân tích dữ liệu
doanh nghiệp trong lĩnh vực đồ ăn thức
lớn (Bigdata). Ứng dụng triển khai các báo
uống sẽ có chiến lược để phát triển dịch vụ
cáo phân tích ý kiến người dùng trên
sản phẩm tốt hơn nhằm thu hút và giữ chân
website, đặc biệt là trên thiết bị di động,
khách hàng tốt hơn. Ngoài ra nghiên cứu sẽ
giúp doanh nghiệp tiện lợi hơn trong việc
là tiền đề cho các ứng dụng phân tích dữ liệu,
xem báo cáo và ra quyết định tốt hơn. lOMoAR cPSD| 59735516
Link file code báo cáo được nhóm lưu trữ
https://www.baeldung.com/cs/bidirecti trên Drive : o
https://drive.google.com/drive/folders/1mf
nal-vs-unidirectional-lstm
BfrrZa6vwfL35a0W63WD4reFf88b3v? [3] Tài liệu về
fbclid=IwAR3wshZfMpZ_IXSf1iS17GM2
LSTM https://websitehcm.com/long-
PKl42TL30jqcjOIEJy6Js6GZwpyVnKe_R
shortterm-memory-lstm-la-gi/ Ss [4] Dữ liệu crawl thêm
https://github.com/congnghia0609/ntc
Tài Liệu Tham Khảo scv/tree/master/data [1] Trang web của
[5] Mô hình tiền xử lý word2vec
Foody https://www.foody.vn
https://machinelearningcoban.com/ [2] Tài liệu về Bi-
tabml_book/ch_embedding/ LSTM word2vec.html Phụ lục
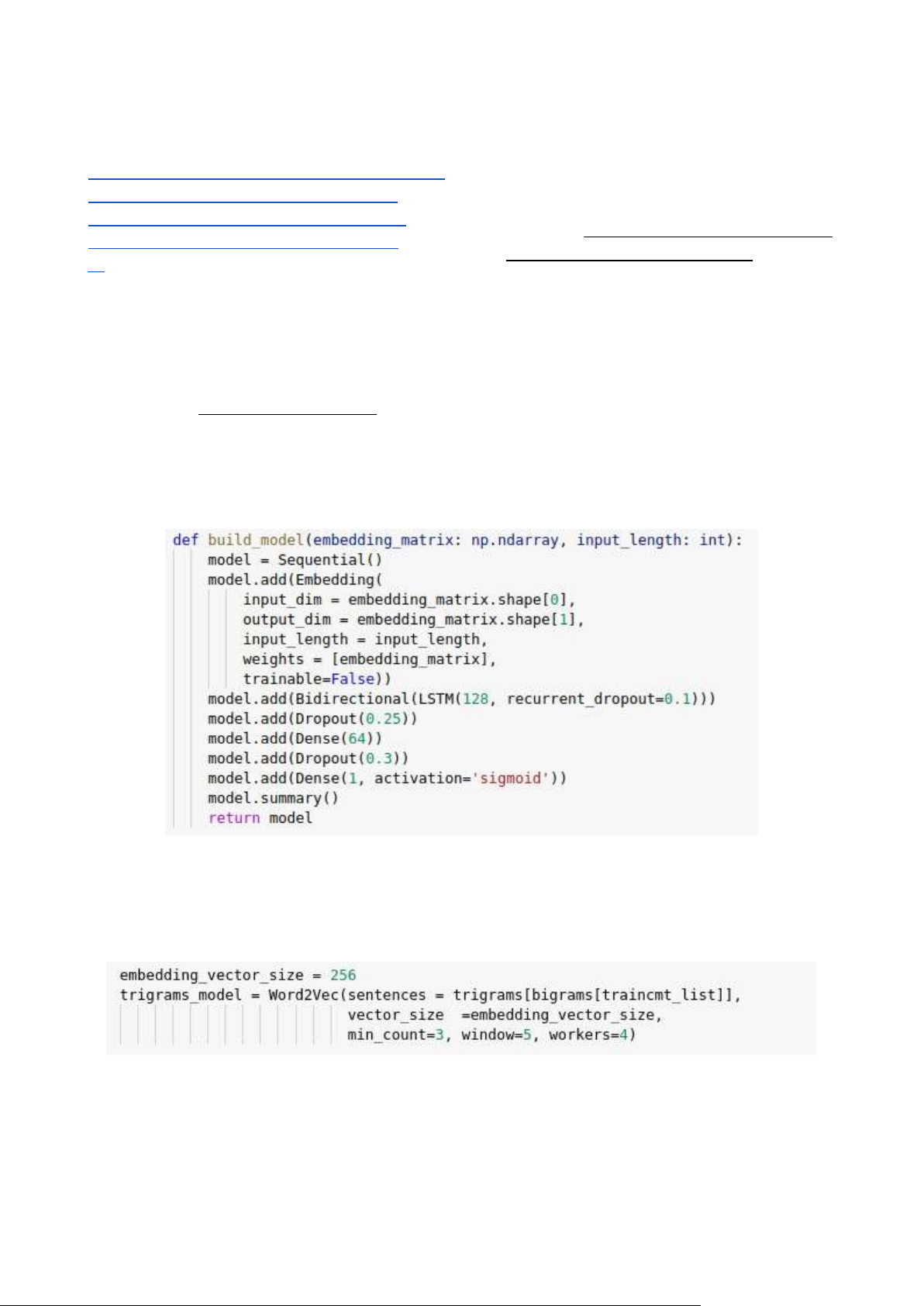
Mô hình Bi-LSTM được sử dụng trong bài
Hàm tiền xử lý để tách các từ ra khỏi câu phục vị cho việc lập từ điển lOMoAR cPSD| 59735516
Ở đây ta sẽ dùng Word2Vec để xử lý chuyển các câu thành các vector embeding với 256 đặc trưng Mô hình LSTM
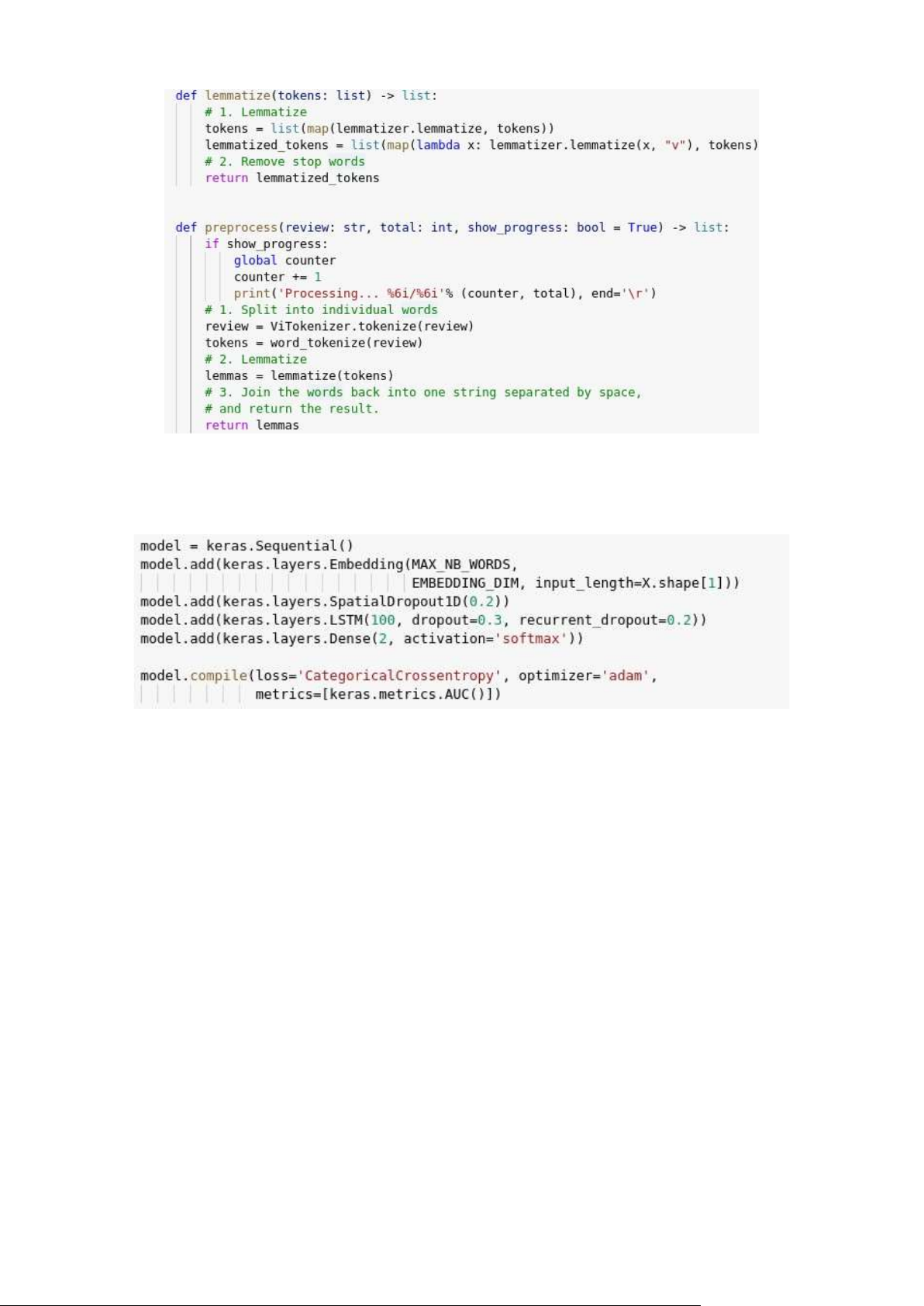
Tiền xử lý của khi dùng LSTM ở đây ta sẽ dùng hàm Tokenizer của keras để
chuyển chuỗi string về vector embeding để có thể sử lý bằng LSTM lOMoAR cPSD| 59735516
Tài liệu liên quan:
-

Bài giảng về Decision Trees and Bias-Variance môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
30 15 -

Bài giảng về Information Theory and Linear Regression | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
30 15 -

Tài liệu học thuật về Deep Learning môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
36 18 -

Ôn tập cuối kỳ: Regularized cost and gradient môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
70 35 -

Ôn tập cuối kỳ: Logistic Regression môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
66 33