Chương 3. Phân tích Luật Kết Hợp | Khai thác dữ liệu và ứng dụng | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
Khai phá luật kết hợp là một kĩ thuật quan trọng của khai phá dữ liệu. Mục tiêu nhằm phát hiện mối quan hệ giữa các mục dữ liệu trong cơ sở dữ liệu. Mục đích : + Công cụ hỗ trợ trong hoạt động sales và marketing, đặc biệt trong lĩnh vực bán lẻ và thương mại điện tử. - Luật kết hợp được sử dụng để tìm ra các mối quan hệ kết hợp giữa các mặt hàng hoặc sản phẩm trong các giao dịch mua sắm. Tài liệu được sưu tầm và soạn thảo dưới dạng file PDF để gửi tới các bạn cùng tham khảo, ôn tập đầy đủ kiến thức, chuẩn bị cho các buổi học thật tốt. Mời bạn đọc đón xem!
Môn: Khai thác dữ liệu và ứng dụng 11 tài liệu
Trường: Trường Đại học Khoa học tự nhiên, Đại học Quốc gia Hà Nội 1.1 K tài liệu
Tác giả:











Preview text:
Bảng đánh giá đóng góp ST Họ và Tên Nội dung Tỷ lệ đóng T góp 1 Nguyễn Đức Thắng
Các chuẩn đo đánh giá sức 20% mạnh luật kết hợp 2 Nguyễn Nhật Hoàng
Các cách lưu trữ dữ liệu giao 20% dịch 3 Nguyễn Cao Huy
Giới thiệu luật kết hợp 20% 4 Nguyễn Văn Quý
Áp dụng phân tích luật kết 20% hợp trên Weka 5 Võ Thành Được Thuật toán Apriori 20%
Chương 3: Phân tích luật kết hợp
3.1 Giới thiệu về luật kết hợp
Khai phá luật kết hợp là một kĩ thuật quan trọng của khai phá dữ
liệu. Mục tiêu nhằm phát hiện mối quan hệ giữa các mục dữ liệu trong cơ sở dữ liệu. Mục đích :
+ Công cụ hỗ trợ trong hoạt động sales và marketing, đặc biệt
trong lĩnh vực bán lẻ và thương mại điện tử.
- Luật kết hợp được sử dụng để tìm ra các mối quan hệ kết hợp
giữa các mặt hàng hoặc sản phẩm trong các giao dịch mua sắm. - Kinh doanh:
Sử dụng luật kết hợp là để hiểu và dự đoán hành vi mua sắm của
khách hàng, từ đó tạo ra các hoạt động marketing và bán hàng hiệu quả hơn. - Y tế:
Association rules trong lĩnh vực y học mục đích hỗ trợ bác sĩ
biết được xác suất xảy ra căn bệnh A bất kỳ khi liên kết đến
hàng loạt các yếu tố, triệu chứng B, C,...Association rules còn
cho phép các nhà nghiên cứu phát hiện ra các triệu chứng mới, căn bệnh mới. - Sinh học - Tài chính,tín dụng
Ví dụ thực tế về kinh doanh:
+ Khi một phụ nữ đến siêu thị mua dầu gội đầu, có khả năng cô ấy
cũng sẽ mua thêm dầu xả, dầu dưỡng tóc, mũ gội đầu hoặc khăn trùm tóc.
+ Dựa trên dữ liệu giao dịch, của mình đã thu thập được từ các lần giao dịch :
- Giao dịch 1: Bánh mì, Sữa, Trứng, Mì gói
- Giao dịch 2: Bánh mì, Sữa, Trứng
- Giao dịch 3: Bánh mì, Mì gói
- Giao dịch 4: Sữa, Trứng
- Giao dịch 5: Bánh mì, Sữa, Mì gói
=> Nếu khách hàng mua Bánh mì và Sữa, thì khả năng cao họ cũng sẽ mua Trứng. Ví dụ về y tế:
+ "Nếu người bị vàng da, mất vàng, thì có thể mắc các bệnh lý về
gan" Ban đầu các nhà y học có thể chưa biết được lý do tại sao
da vàng sẽ mắc bệnh gan, nhưng qua Association rules thấy một
tỷ lệ khá cao trong Confidence: những bệnh nhân vàng da đa
phần mắc bệnh gan sau này.
3.2 Các chuẩn đo đánh giá sức mạnh của luật kết hợp
Để đo lường và lựa chọn một luật kết hợp bất kỳ chúng ta sử dụng Support và Confidence 3.2.1.Khái niệm
Luật kết hợp trong khai phá dữ liệu, "độ hỗ trợ" và "độ tin cậy" là hai
khái niệm quan trọng để đánh giá hiệu suất của các quy tắc kết hợp
được tìm thấy từ dữ liệu. Độ Hỗ Trợ (Support):
+ Độ hỗ trợ đo lường tần suất xuất hiện của một luật trong dữ liệu.
+ Là thước đo quan trọng vì nếu một luật kết hợp có tỷ lệ Support
thấp thì ít xuất hiện hoặc là do tình cờ
+ Càng cao độ hỗ trợ, luật càng phổ biến. Độ Tin Cậy (Confidence):
+ Độ tin cậy đo lường mức độ chắc chắn rằng một quy tắc là đúng,
dựa trên sự xuất hiện của một điều kiện (hoặc tập điều kiện) trong dữ liệu.
+ Càng cao độ tin cậy, càng chắc chắn rằng quy tắc sẽ là đúng khi điều kiện xuất hiện. Kết luận :
Đối với một luật kết hợp, sự cân nhắc giữa độ hỗ trợ và độ tin cậy quan trọng.
Một luật có thể có độ hỗ trợ cao nhưng độ tin cậy thấp, điều này có
thể là do điều kiện xuất hiện thường xuyên, nhưng không nhất thiết
dẫn đến kết quả mong đợi. Ngược lại, một luật có độ tin cậy cao
nhưng độ hỗ trợ thấp có thể là do quy tắc ít khi xuất hiện nhưng khi
xuất hiện thì rất chắc chắn.
Khi xây dựng mô hình khai phá dữ liệu, người ta thường sử dụng các
ngưỡng độ hỗ trợ và độ tin cậy để lọc ra những luật quan trọng và ý nghĩa.
Các giá trị ngưỡng này thường phụ thuộc vào bối cảnh cụ thể của vấn
đề và mức độ yêu cầu chắc chắn của người sử dụng. 3.2.2.Lợi ích
+ Đánh giá độ tin cậy của mô hình giúp xác định mức độ chính xác và
đáng tin cậy của dự đoán. Sử dụng để dự đoán hoặc phân loại dữ liệu mới.
+ Có độ tin cậy và độ hỗ trợ cao tăng cường niềm tin của người sử
dụng vào quá trình khai phá dữ liệu. Sử dụng để đưa ra quyết định
quan trọng trong doanh nghiệp hoặc các lĩnh vực .
+ Đánh giá độ hỗ trợ giúp xác định sức mạnh và yếu điểm của các
nguồn dữ liệu và mô hình. Lựa những phương pháp có độ hỗ trợ cao nhất.
+ Khi có độ tin cậy thấp hoặc độ hỗ trợ không đủ, người thực hiện có
thể xác định lỗi và cải thiện quá trình khai phá dữ liệu 3.2.3.Ví dụ
Ví dụ về việc áp dụng độ hỗ trợ và độ tin cậy trong khai phá dữ liệu,
sử dụng dữ liệu về mua sắm trong một cửa hàng: Dữ liệu:
Bạn có một cơ sở dữ liệu giao dịch mua sắm với thông tin về sản
phẩm được mua và các thông tin khác như giảm giá, ngày, và phương thức thanh toán. Ví dụ Luật:
+ Luật: Nếu ai đó mua bột giặt và nước rửa chén cùng một lúc, thì
họ cũng thường mua nước lọc.
Hỗ trợ: 10% (10% giao dịch có cả bột giặt và nước rửa chén)
Tin cậy: 80% (Khi có bột giặt và nước rửa chén, 80% cũng có nước lọc) Giải thích :
Với luật thứ nhất, độ hỗ trợ là 10%, có nghĩa là 10% trong số tất cả
các giao dịch có cả bột giặt và nước rửa chén.
Độ tin cậy là 80%, có nghĩa là trong 80% các trường hợp có bột giặt
và nước rửa chén, cũng có nước lọc.
Điều này cho thấy rằng mối quan hệ giữa bột giặt và nước rửa chén
với nước lọc là mạnh mẽ.
+ Luật: Nếu ai đó mua thực phẩm đóng gói và bia, thì họ cũng mua thạch.
Hỗ trợ: 5% (5% giao dịch có cả thực phẩm đóng gói và bia)
Tin cậy: 90% (Khi có thực phẩm đóng gói và bia, 90% cũng có thạch) Giải thích :
Với luật thứ hai, độ hỗ trợ là 5%, chỉ 5% trong số tất cả các giao dịch
có cả thực phẩm đóng gói và bia. Tuy nhiên, độ tin cậy là 90%, nghĩa
là khi có thực phẩm đóng gói và bia, 90% trong số này cũng có thạch.
Điều này có thể chỉ ra một mối quan hệ mạnh mẽ hơn giữa thực phẩm
đóng gói và bia với thạch.
→ Các giá trị ngưỡng của độ hỗ trợ và độ tin cậy có thể được điều
chỉnh để lựa chọn các luật quan trọng và có ý nghĩa cho mô hình khai phá dữ liệu của bạn. 3.2.4. Công thức + Độ Hỗ Trợ (Support):
Độ hỗ trợ của một luật được tính bằng tỷ lệ giữa số lần xuất hiện của
tập hợp điều kiện trong dữ liệu và tổng số giao dịch.
Công thức: Support ( A và B) = (Số lần xuất hiện của A VÀ B)/(Tổng số giao dịch )
+ Độ Tin Cậy (Confidence):
Độ tin cậy đo lường mức độ chắc chắn rằng luật là đúng khi điều kiện
xảy ra. Nó được tính bằng tỷ lệ giữa số lần xuất hiện của cả điều kiện
và kết quả (hành vi cần dự đoán).
Công thức : Confidence = (Số lần xuất hiện của A và B)/(P ( A) ) Trong đó:
P( A) : Số lần xuất hiện A
→ Khi xác định ngưỡng cho độ hỗ trợ và độ tin cậy, bạn có thể lọc ra
các luật quan trọng và ý nghĩa. Áp dụng công thức Dữ liệu:
Giả sử bạn có một cơ sở dữ liệu ghi lại các giao dịch mua sắm trong
một cửa hàng và bạn muốn phân tích mối quan hệ giữa việc mua bột
giặt và nước rửa chén. Giao dịch:
Giao dịch 1: Bột giặt, Nước rửa chén, Nước lọc
Giao dịch 2: Bột giặt, Nước rửa chén, Thạch
Giao dịch 3: Bột giặt, Thực phẩm đóng gói, Bia
Giao dịch 4: Nước rửa chén, Thực phẩm đóng gói, Nước lọc Áp dụng công thức :
Tính độ hỗ trợ cho luật “ Nước rửa chén và Bột giặt “
Số lần xuất hiện của X = là 2 Tổng số giao dịch là 4 Support = (2)/4=0,5
Tính độ tin cậy: “ Nước rửa chén và Bột giặt “
Số lần xuất hiện đồng thời của X và Y { Nước rửa chén và bột giặt }là 2 P( Nước rửa chén ) = 3
Confidence = (2)/(3 )=0,66666666
Kết luận : Nếu khách hàng mua Nước rửa chén thì sẽ mua bột giặt với
độ tin cậy là 66,6% và độ ủng hộ là 50 %
3.3 Các cách lưu trữ cơ sở dữ liệu giao dịch
3.4 Thuật toán Apriori
❖ Do Apriori do Rakesh Agrawal, Tomasz Imielinski, Arun Swami đề xuất [1993].
❖ Tìm giao dịch t có độ hỗ trợ và độ tin cậy thỏa mãn lớn hơn một giá trị ngưỡng nào đó.
● Thuật giải được tỉa bớt những tập ứng cử viên có tập con không
phổ biến trước khi tính độ hỗ trợ.
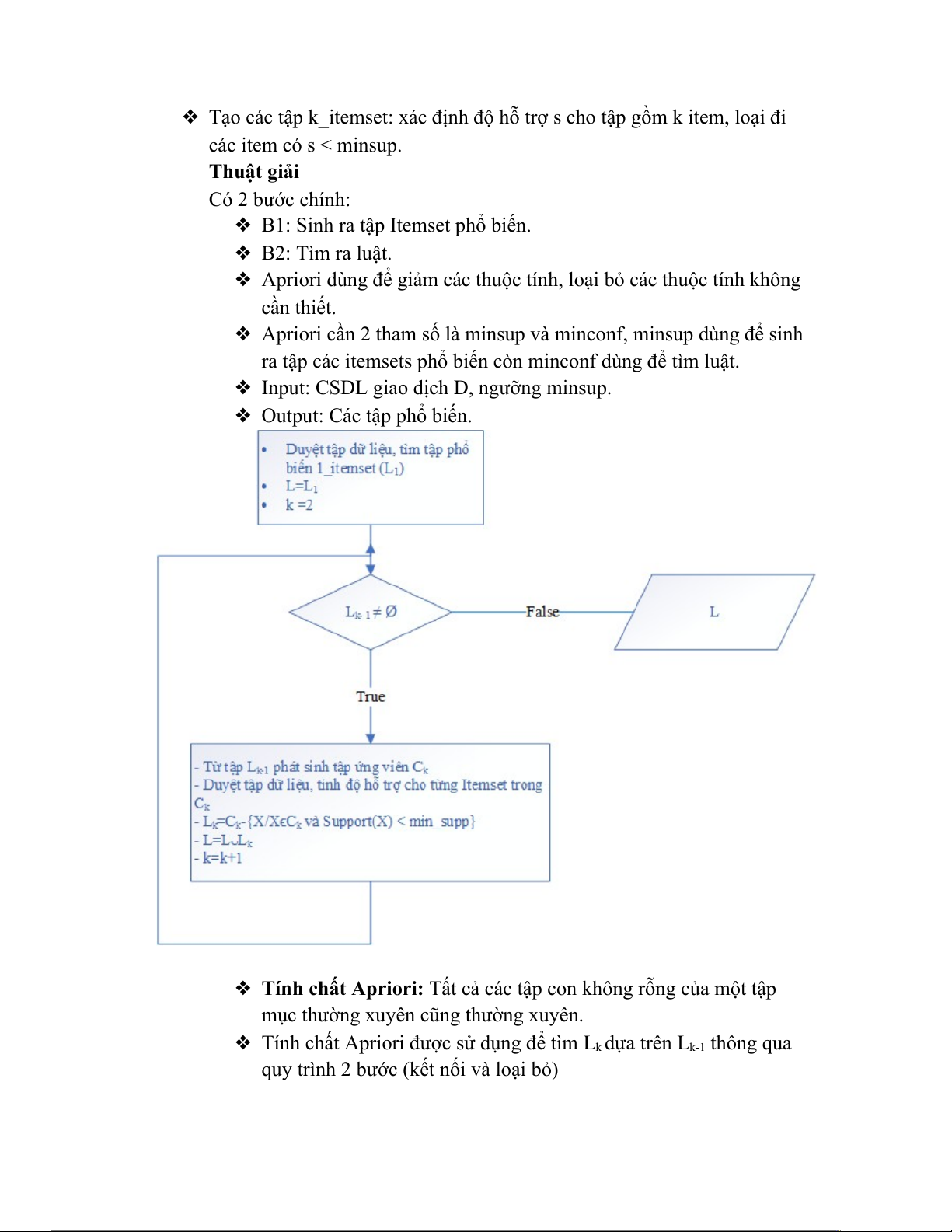
3.4.1. Ý tưởng thuật giải
❖ Tạo các tập 1_itemset: từ các item trên CSDL, ta xác định độ hỗ trợ s cho
từng item dựa vào CSDL đã mã hóa, loại đi các item có s < minsup.
❖ Tạo các tập 2_itemset: xác định độ hỗ trợ s cho tập gồm 2 item, loại đi các item có s < minsup. ❖ …
❖ Tạo các tập k_itemset: xác định độ hỗ trợ s cho tập gồm k item, loại đi các item có s < minsup. Thuật giải Có 2 bước chính:
❖ B1: Sinh ra tập Itemset phổ biến. ❖ B2: Tìm ra luật.
❖ Apriori dùng để giảm các thuộc tính, loại bỏ các thuộc tính không cần thiết.
❖ Apriori cần 2 tham số là minsup và minconf, minsup dùng để sinh
ra tập các itemsets phổ biến còn minconf dùng để tìm luật.
❖ Input: CSDL giao dịch D, ngưỡng minsup.
❖ Output: Các tập phổ biến.
❖ Tính chất Apriori: Tất cả các tập con không rỗng của một tập
mục thường xuyên cũng thường xuyên.
❖ Tính chất Apriori được sử dụng để tìm Lk dựa trên Lk-1 thông qua
quy trình 2 bước (kết nối và loại bỏ)
❖ Thuật giải Apriori_Gen
● Mục đích: tìm Ck - sinh các tập mục ứng cử là ứng cử viên cho các
tập k_itemset và xóa các tập mục không phổ biến theo điều kiện minsup.
● Input: Lk-1, tập mục (k-1)_itemset phổ biến minsup, độ hỗ trợ tối thiểu.
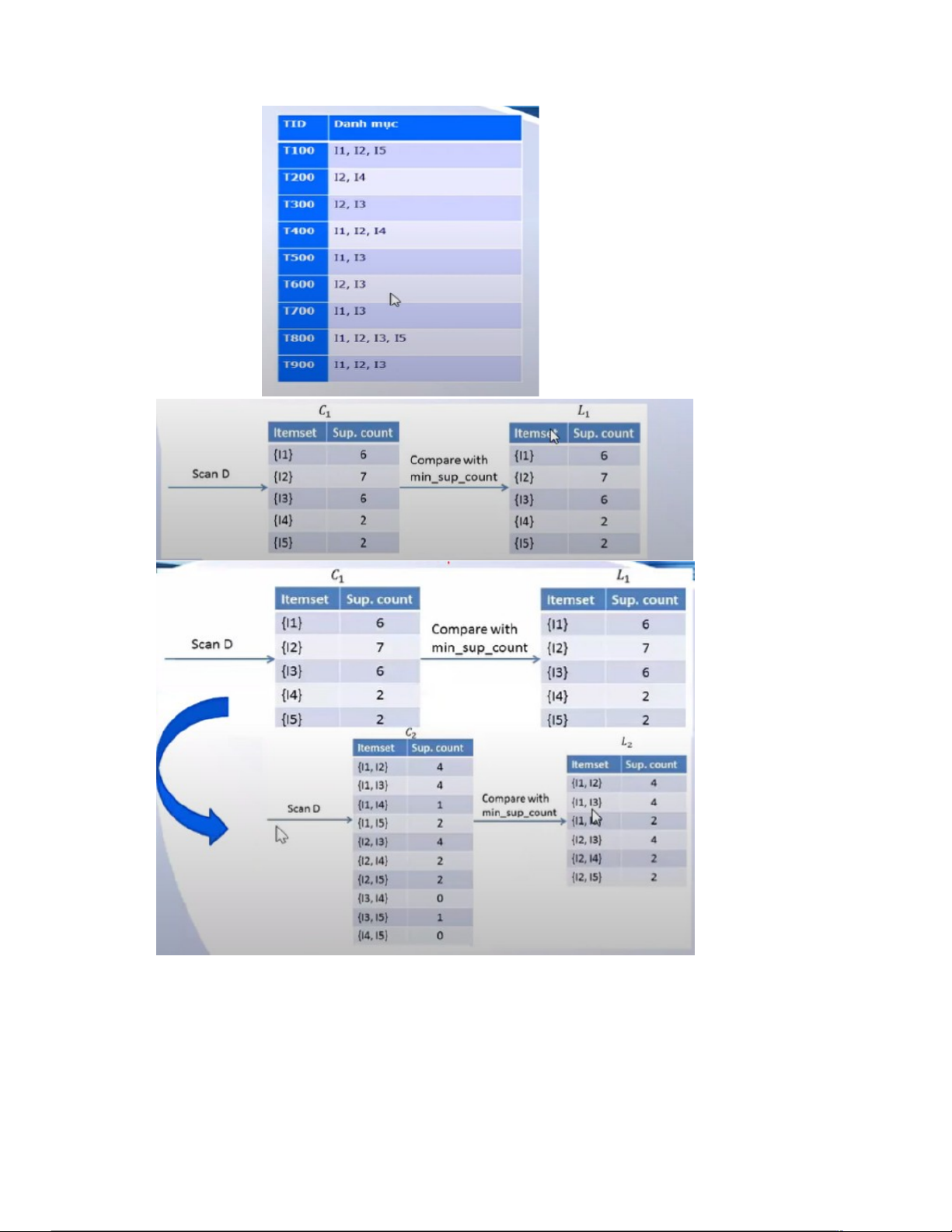
● Output: Ck , tập ứng cử viên k_itemset ❖ Ví dụ:
● Giả sử thiết lập giá trị min_sup_count=2
● Tương ứng với min_sup=2/9=22%
● Tập các 1_itemset L1 xác định bằng cách đếm tần suất xuất hiện
trong cơ sở dữ liệu giao dịch.
L=L1 hợp L2 hợp L3={I1, I2, I3, I4, I5, I1I2, I1I3, I1I5, I2I3, I2I4, I2I5, I1I2I3,I1I2I5} ❖ Ví dụ 2:
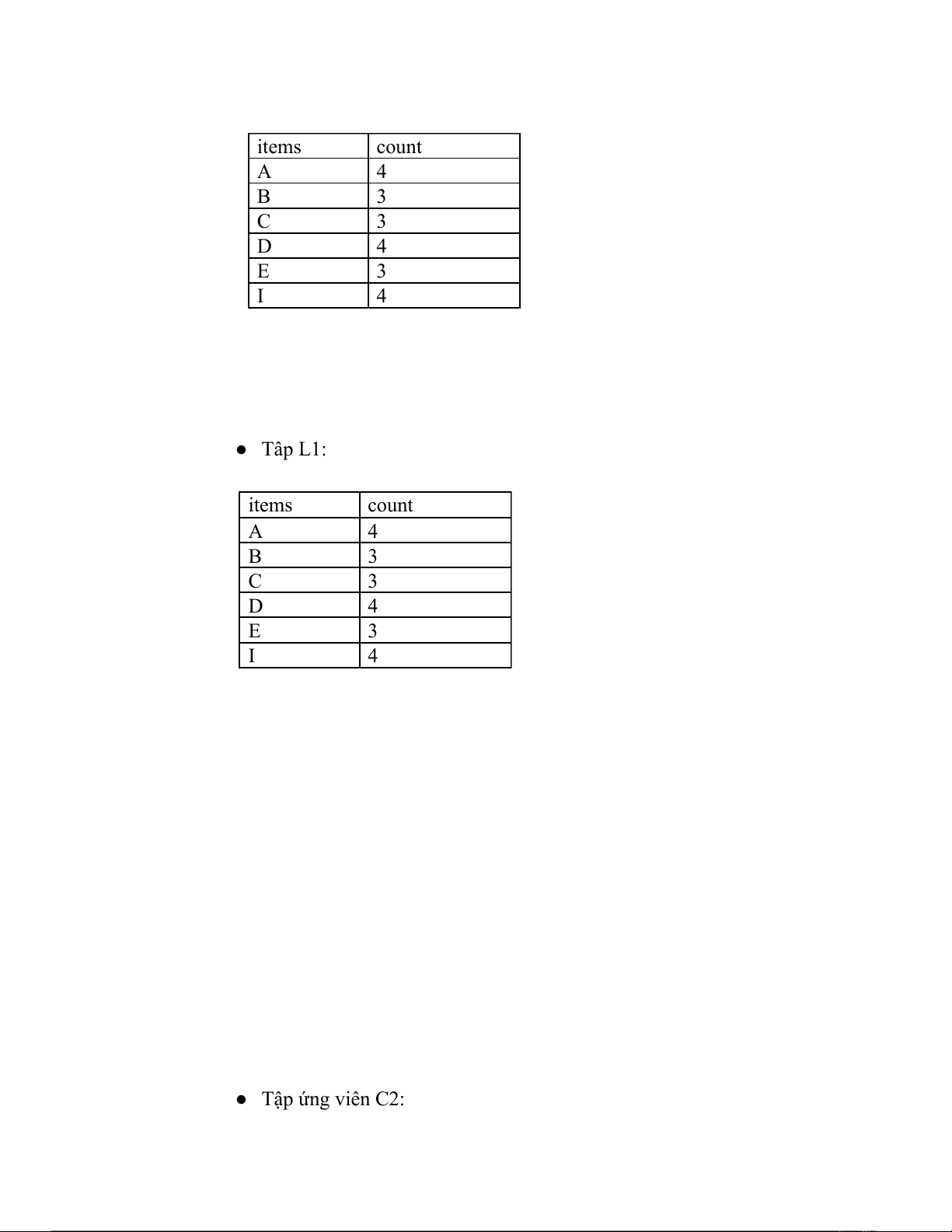
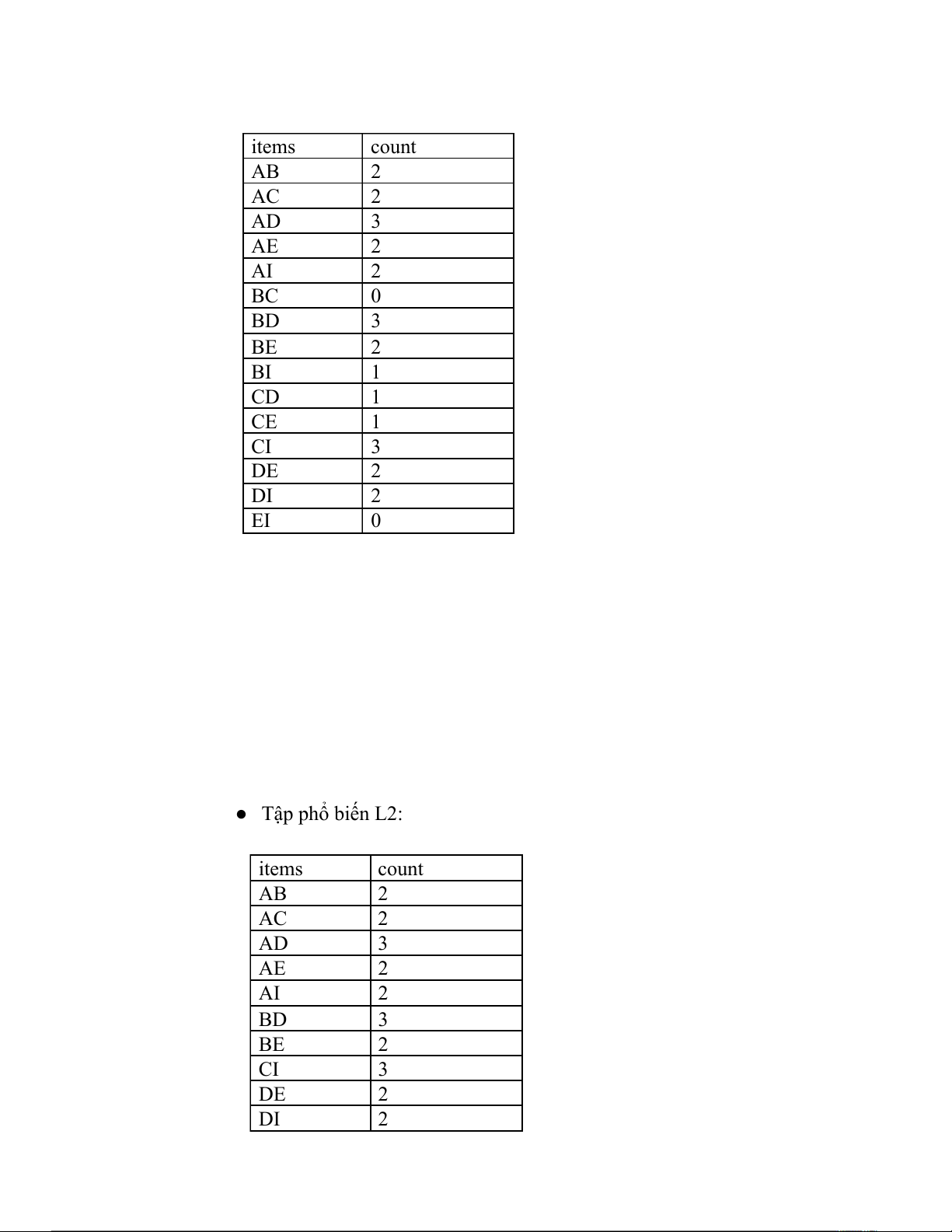
● MINSUP = 0.3 = 0.3 = 2/6 → count: 2 thì tập phổ biế n: ● C1: items count A 4 B 3 C 3 D 4 E 3 I 4 ● Tâp L1: items count A 4 B 3 C 3 D 4 E 3 I 4 ● Tập ứng viên C2: items count AB 2 AC 2 AD 3 AE 2 AI 2 BC 0 BD 3 BE 2 BI 1 CD 1 CE 1 CI 3 DE 2 DI 2 EI 0 ● Tập phổ biến L2: items count AB 2 AC 2 AD 3 AE 2 AI 2 BD 3 BE 2 CI 3 DE 2 DI 2 ● Tập ứng viên C3 items count ABD 2 ABE 2 ACI 2 ADE 2 ADI 1 BDE 2 ● Tập phổ biến L3 items count ABD 2 ABE 2 ACI 2 ADE 2 BDE 2 ● Tập ứng viên C4 items count ABDE 2 ● Tập phổ biến L4 items count ABDE 2 ● Tập ứng viên C5 items count Rỗng
FI={A,B,C,D,E,I,AB,AC,AD,AE,AI,BE,BD,CI,DE,DI,ABD,ABE,ACI,ADE, BDE,ABDE}
3.5 Áp dụng phân tích luật kết hợp trên Weka
Bước 1 : mở weka và chọn explorer
Bước 2 : chọn file cần phân tích
ở đây chúng ta sử dụng file supermarket.arff được tích hợp sẵn trong thư viện data được tích hợp sẵn
trên weka , đây là file dữ liệu hóa đơn của 1 siêu thị được tích hợp trong weka để nghiên cứu ,file ghi
lại thông tin hóa đơn của khách hàng mua những mặt hàng gì và thanh toán ở quầy nào, nếu có thì kí
hiệu “t” không có thì kí hiệu “?”
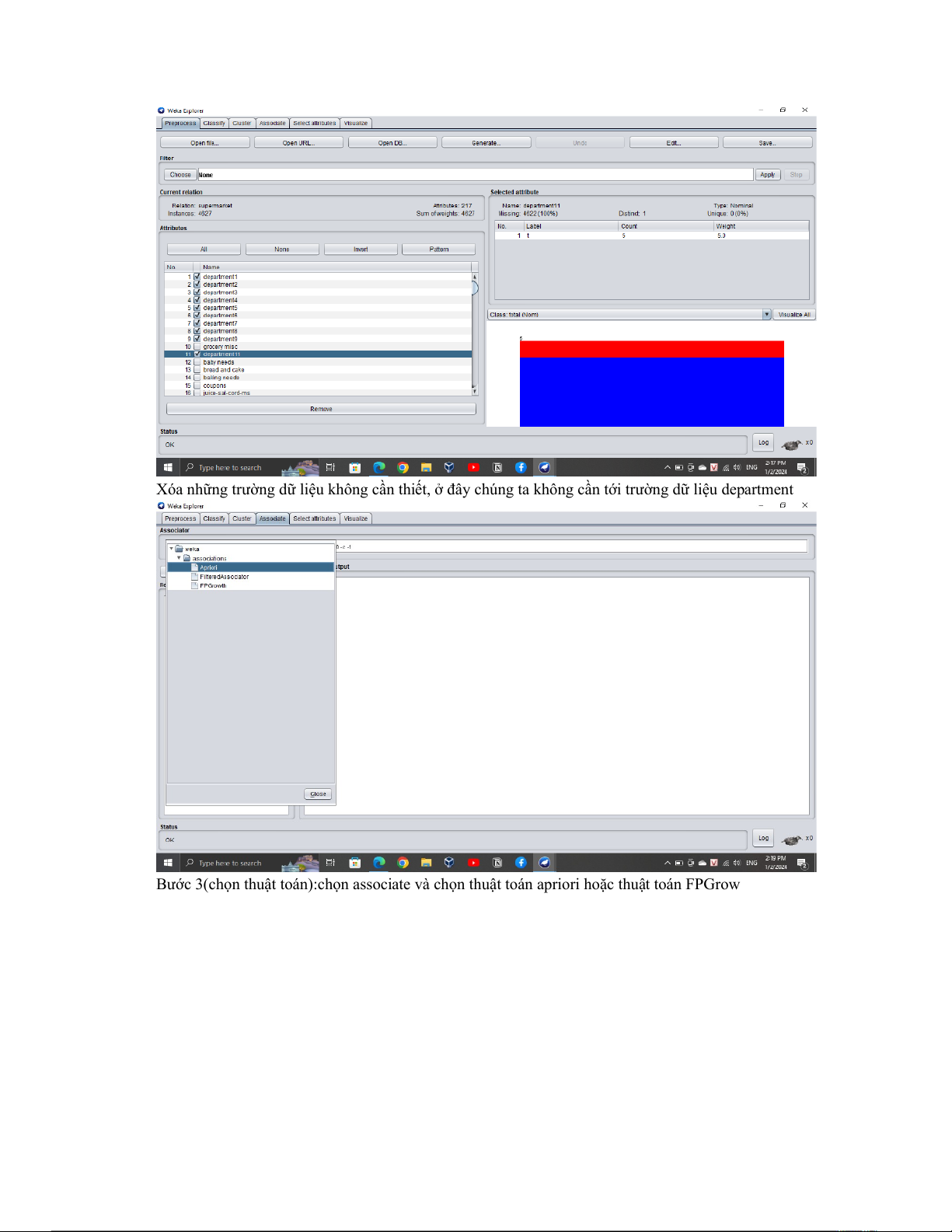
Xóa những trường dữ liệu không cần thiết, ở đây chúng ta không cần tới trường dữ liệu department
Bước 3(chọn thuật toán):chọn associate và chọn thuật toán apriori hoặc thuật toán FPGrow
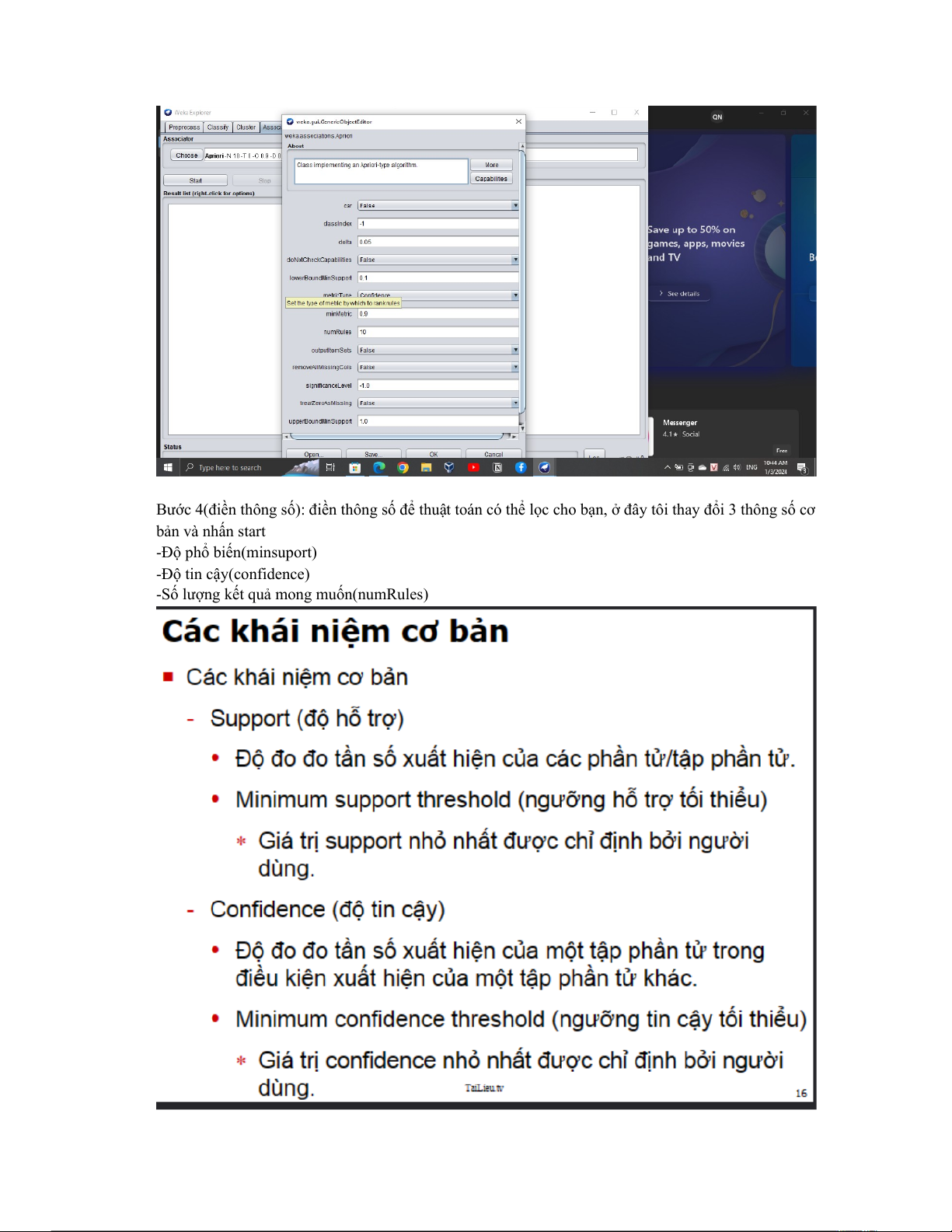
Bước 4(điền thông số): điền thông số để thuật toán có thể lọc cho bạn, ở đây tôi thay đổi 3 thông số cơ bản và nhấn start -Độ phổ biến(minsuport) -Độ tin cậy(confidence)
-Số lượng kết quả mong muốn(numRules) bước 5: nhận kết quả
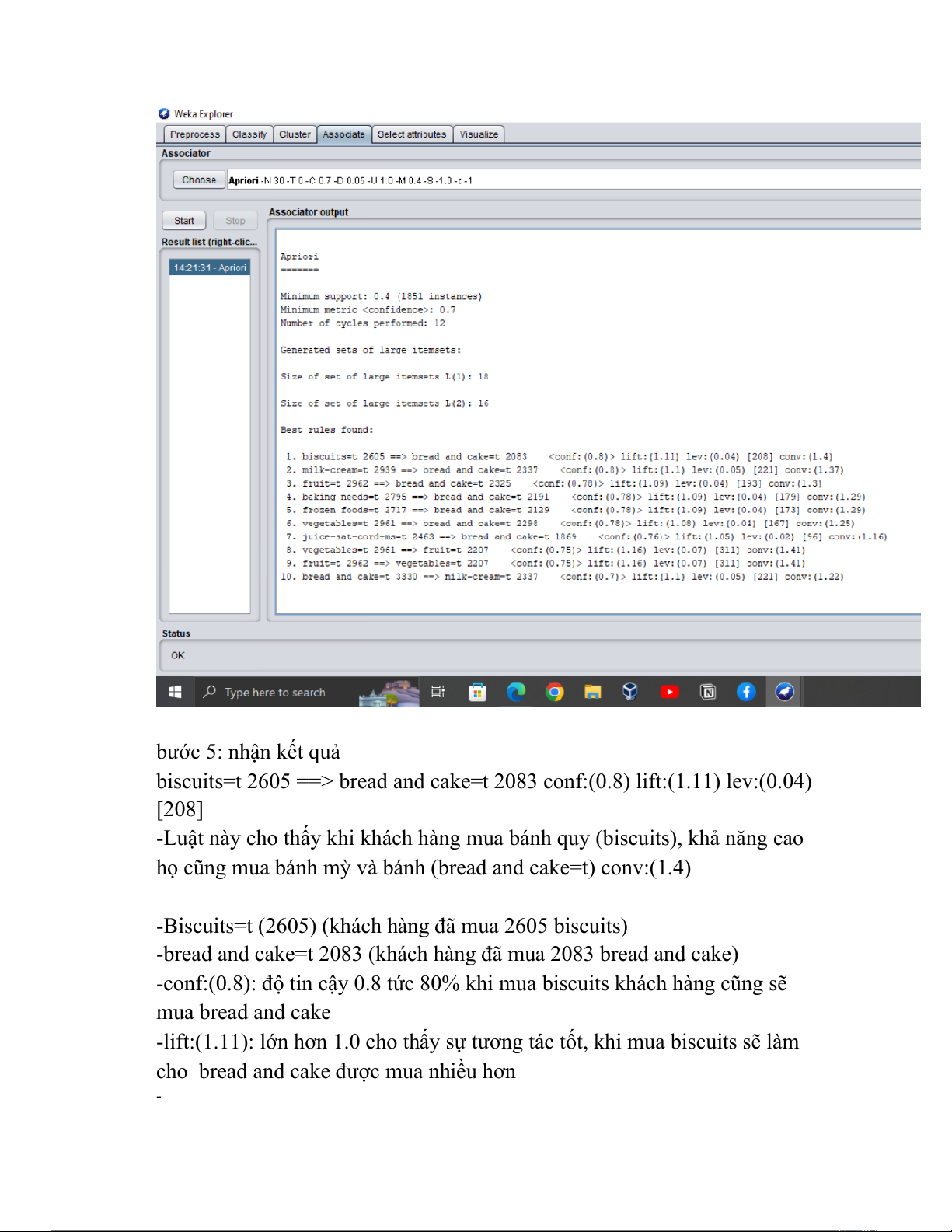
biscuits=t 2605 ==> bread and cake=t 2083 conf:(0.8) lift:(1.11) lev:(0.04) [208]
-Luật này cho thấy khi khách hàng mua bánh quy (biscuits), khả năng cao
họ cũng mua bánh mỳ và bánh (bread and cake=t) conv:(1.4)
-Biscuits=t (2605) (khách hàng đã mua 2605 biscuits)
-bread and cake=t 2083 (khách hàng đã mua 2083 bread and cake)
-conf:(0.8): độ tin cậy 0.8 tức 80% khi mua biscuits khách hàng cũng sẽ mua bread and cake
-lift:(1.11): lớn hơn 1.0 cho thấy sự tương tác tốt, khi mua biscuits sẽ làm
cho bread and cake được mua nhiều hơn -
Tài liệu liên quan:
-

Bài tập Cấu trúc dữ liệu | Trường Đại học Khoa học tự nhiên, Đại học Quốc gia Hà Nội
29 15 -

Chương 7: Khai Thác Dữ Liệu Web và Ứng Dụng | Khai thác dữ liệu và ứng dụng | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
113 57 -

Bài tập ôn tập Khai Thác Dữ Liệu | Khai thác dữ liệu và ứng dụng | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
109 55 -

Các Kỹ Thuật Khai Thác Dữ Liệu và Ứng Dụng | Khai thác dữ liệu và ứng dụng | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
217 109