Chương 7: Khai Thác Dữ Liệu Web và Ứng Dụng | Khai thác dữ liệu và ứng dụng | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
Khai thác dữ liệu web là quá trình tự động hóa việc thu thập thông tin từ các trang web để phân tích và sử dụng. Điều này thường được thực hiện bằng cách sử dụng các công cụ và kỹ thuật để trích xuất dữ liệu từ các trang web và chuyển đổi nó thành định dạng dễ đọc hoặc sử dụng. Tài liệu được sưu tầm và soạn thảo dưới dạng file PDF để gửi tới các bạn cùng tham khảo, ôn tập đầy đủ kiến thức, chuẩn bị cho các buổi học thật tốt. Mời bạn đọc đón xem!
Môn: Khai thác dữ liệu và ứng dụng 11 tài liệu
Trường: Trường Đại học Khoa học tự nhiên, Đại học Quốc gia Hà Nội 1.1 K tài liệu
Tác giả:














Preview text:
CHƯƠNG I. NỘI DUNG BÁO CÁO
1. Giới thiệu về khai thác dữ liệu Web 1.1. Khái niệm
Khai thác dữ liệu web là quá trình tự động hóa việc thu thập thông tin từ
các trang web để phân tích và sử dụng. Điều này thường được thực hiện bằng
cách sử dụng các công cụ và kỹ thuật để trích xuất dữ liệu từ các trang web và
chuyển đổi nó thành định dạng dễ đọc hoặc sử dụng. 1.2. Phương pháp
Các phương pháp khai thác dữ liệu web bao gồm web scraping, API
(Application Programming Interface), và sử dụng các công cụ tự động hóa để
điều khiển trình duyệt và tương tác với trang web.
Web scraping là quá trình tự động lấy dữ liệu từ trang web bằng cách
phân tích cú pháp HTML và CSS của trang. Công cụ như BeautifulSoup,
Scrapy hay Selenium thường được sử dụng trong quá trình này.
API là một cách chính thức và an toàn hơn để lấy dữ liệu từ trang web,
nếu trang web cung cấp API. Điều này giúp tránh được các vấn đề pháp lý
và tăng tính ổn định của quá trình khai thác dữ liệu. 1.3. Mục đích
Khai thác dữ liệu web có thể được sử dụng cho nhiều mục đích, bao gồm
nghiên cứu thị trường, giám sát giá cả, phân tích cảm xúc trên mạng xã hội, hay
đơn giản là thu thập thông tin tự động từ nhiều nguồn khác nhau trên internet.
Tuy nhiên, cần lưu ý rằng việc khai thác dữ liệu cần tuân thủ các quy định pháp
lý và chính sách bảo mật của trang web được khai thác. 2. Khai thác nội dung Web
Khai phá nội dung Web là quá trình tự động hóa việc thu thập thông tin
giá trị trên các trang web. Khác với khai phá cấu trúc và cấu trúc Web,
khai phá nội dung Web tập trung vào nội dung của trang web, bao gồm cả
văn bản và đa phương tiện như âm thanh, hình ảnh, và siêu liên kết.
Trong lĩnh vực khai phá Web, khai phá nội dung Web được coi là kỹ
thuật quan trọng đối với CSDL quan hệ. Nó giúp phát hiện tri thức từ dữ
liệu không cấu trúc trong các tài liệu Web, đặt ra những thách thức do đặc
điểm không cấu trúc của dữ liệu.
Có hai cách tiếp cận chính cho khai phá nội dung Web: Tìm kiếm thông
tin và Khai phá Đa phương tiện trong CSDL lớn.
2.1. Khai phá kết quả tìm kiếm 2
Phân loại tự động tài liệu sử dụng searching engine: Search engine có
thể đánh chỉ số tập trung dữ liệu hỗn hợp trên Web. Ví dụ:
o Trước tiên tải về các trang Web từ các Website.
o Thứ hai, search engine trích ra những thông tin chỉ mục mô tả từ
các trang Web đó để lưu trữ chúng cùng với URL của nó trong search engine.
o Thứ ba sử dụng các phương pháp KPDL để phân lớp tự động và
tạo điều kiện thuận tiện cho hệ thống phân loại trang Web và
được tổ chức bằng cấu trúc siêu liên kết
Trực quan hóa kết quả tìm kiếm: Trong hệ thống phân loại, có nhiều
tài liệu thông tin không liên quan nhau. Nếu ta có thể phân tích và
phân cụm kết quả tìm kiếm, thì hiệu quả tìm kiếm sẽ được cải thiện tốt
hơn, nghĩa là các tài liệu “tương tự” nhau về mặt nội dung thì đưa
chúng vào cùng nhóm, các tài liệu “phi tương tự” thì đưa chúng vào các nhóm khác nhau. 2.2. Khai phá văn bản Web
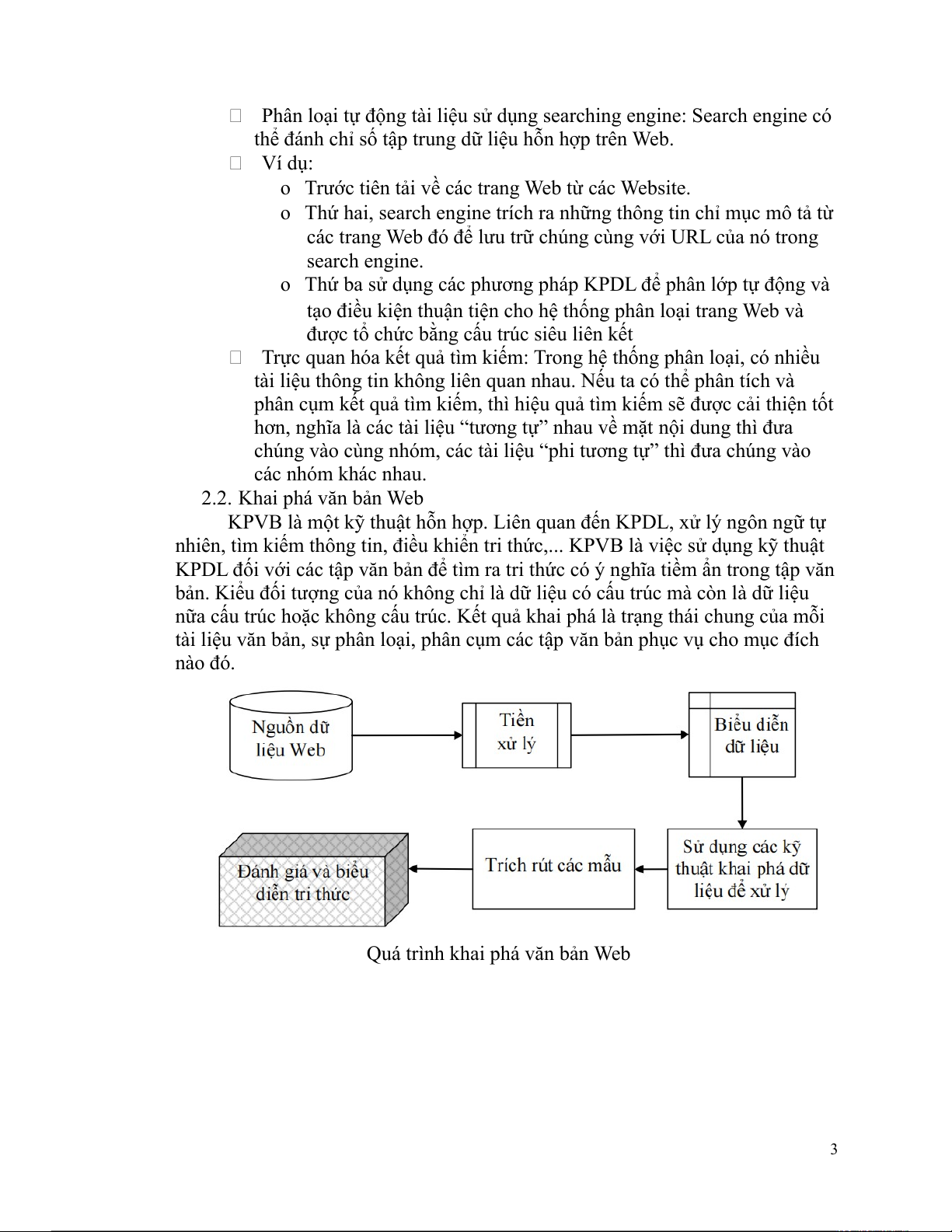
KPVB là một kỹ thuật hỗn hợp. Liên quan đến KPDL, xử lý ngôn ngữ tự
nhiên, tìm kiếm thông tin, điều khiển tri thức,... KPVB là việc sử dụng kỹ thuật
KPDL đối với các tập văn bản để tìm ra tri thức có ý nghĩa tiềm ẩn trong tập văn
bản. Kiểu đối tượng của nó không chỉ là dữ liệu có cấu trúc mà còn là dữ liệu
nữa cấu trúc hoặc không cấu trúc. Kết quả khai phá là trạng thái chung của mỗi
tài liệu văn bản, sự phân loại, phân cụm các tập văn bản phục vụ cho mục đích nào đó.
Quá trình khai phá văn bản Web 3
2.2.1. Lựa chọn dữ liệu
Văn bản cục bộ được định dạng tích hợp thành các tài liệu để khai phá và
phân phối trên nhiều dịch vụ Web, sử dụng kỹ thuật truy xuất thông tin.
2.2.2. Tiền xử lý dữ liệu
Ta thường lấy ra những metadata đặc trưng như là một căn cứ và lưu trữ
các đặc tính văn bản cơ bản bằng việc sử dụng các quy tắc/ phương pháp để làm
rõ dữ liệu. Để có được kết quả khai phá tốt ta cần có dữ liệu rõ ràng, chính xác
và xóa bỏ dữ liệu hỗn độn và dư thừa. Trước hết cần hiểu yêu cầu của người
dùng và lấy ra mối quan hệ giữa nguồn tri thức được lấy ra từ nguồn tài nguyên.
Thứ hai, làm sạch, biến đổi và sắp xếp lại những nguồn tri thức này. Cuối cùng,
tập dữ liệu kết quả cuối cùng là bảng 2 chiều. Sau bước tiền xử lý, tập dữ liệu
đạt được thường có các đặc điểm:
Dữ liệu thống nhất và hỗn hợp cưỡng bức.
Làm sạch dữ liệu không liên quan, nhiễu và dữ liệu rỗng. Dữ liệu không
bị mất mát và không bị lặp.
Giảm bớt số chiều và làm tăng hiệu quả việc phát hiện tri thức bằng việc
chuyển đổi, quy nạp, cưỡng bức dữ liệu,...
Làm sạch các thuộc tính không liên quan để giảm bớt số chiều của dữ liệu.
2.2.3. Biểu diễn văn bản
KPVB Web khai phá tài liệu HTML và yêu cầu biến đổi dữ liệu cho xử
lý. Dữ liệu thường được lưu trữ trong mảng 2 chiều và sử dụng mô hình
TF-IDF để vector hóa, tuy nhiên, việc này có thể dẫn đến số chiều vector
lớn. Lựa chọn đặc trưng quan trọng là quan trọng để tối ưu hiệu suất của KPVB.
Phân lớp và loại bỏ từ gồm các bước như chọn lọc từ mô tả đặc trưng,
quét tập tài liệu để làm sạch từ tần số thấp, và loại bỏ các từ vô nghĩa như
"ah," "eh," "oh," "o," "the," "an," "and," "of," "or."
2.2.4. Trích rút các từ đặc trưng
Rút ra các đặc trưng là một phương pháp, nó có thể giải quyết số chiều
vector đặc trưng lớn được mang lại bởi kỹ thuật KPVB.
Việc rút ra các đặc trưng dựa trên hàm trọng số:
o Mỗi từ đặc trưng nhận một giá trị tin cậy dựa trên hàm trọng số, với
tần số xuất hiện cao và tính chất của từ ảnh hưởng đến giá trị tin
cậy. Các từ đặc trưng quan trọng được lưu trữ và kích thước tập đặc
trưng được xác định sau thực nghiệm. 4
o Rút trích đặc trưng dựa trên phân tích thành phần chính, sử dụng từ
đặc trưng chính để giảm số chiều. Cũng áp dụng phương pháp quy
nạp thuộc tính dữ liệu để tổng hợp dữ liệu. 2.2.5. Khai phá văn bản
Sau khi tập hợp, lựa chọn và trích ra tập văn bản hình thành nên các đặc
trưng cơ bản, nó sẽ là cơ sở để KPDL. Từ đó ta có thể thực hiện trích, phân loại,
phân cụm, phân tích và dự đoán.
2.2.5.1. Trích rút văn bản
Trích rút văn bản giúp tóm tắt ý nghĩa chính của tài liệu, hỗ trợ việc hiểu
nội dung mà không cần đọc toàn bộ. Thực hiện trong searching engine, nó giúp
đưa ra trích dẫn nhanh chóng và tăng hiệu quả tìm kiếm bằng việc sử dụng nhiều
thuật toán khác nhau. Điều này cải thiện trải nghiệm người dùng và tăng cường
độ chính xác của kết quả tìm kiếm.
2.2.5.2. Phân lớp văn bản
Phương pháp phân lớp tự động tài liệu hiệu quả và nhanh chóng, thích
hợp cho việc tìm kiếm và duyệt tài liệu web. Sử dụng Navie Bayesian và "K-
láng giềng gần nhất" để khai phá thông tin văn bản. Quá trình bao gồm phân loại
tài liệu, xác định đặc trưng và tính toán độ tương tự. Các tài liệu có độ tương tự
cao thuộc cùng một phân lớp, đảm bảo hiệu suất đánh giá và lựa chọn chính xác
giữa các phân loại. Trong việc lựa chọn có 2 giai đoạn: Huấn luyện và phân lớp.
Thuật toán phân lớp K-Nearest Neighbor
2.2.5.3. Phân cụm văn bản 5
Phân loại tài liệu vào nhiều cụm mà không cần xác định trước chủ đề.
Trong cùng một cụm, độ tương tự giữa các tài liệu cao, ngoại cụm thì thấp.
Quan hệ giữa các cụm thường được định nghĩa là "gần nhau", giảm trạng thái
hiển thị kết quả. Điều này có thể đáp ứng yêu cầu của người dùng với phạm vi
tìm kiếm nhỏ hơn. Sử dụng phương pháp sắp xếp liên kết và phân cấp trong phân cụm văn bản.
Thuật toán phân cụm phân cấp
Phương pháp sắp xếp liên kết tạo ra một cây phản ánh mối quan hệ tương tự
giữa các tài liệu. Mặc dù chính xác, nhưng tốc độ chậm, đặc biệt với tập tài liệu lớn, là không khả thi.
Thuật toán phân cụm phân hoạch
Phương pháp này có các đặc điểm là kết quả phân cụm ổn định và nhanh
chóng. Nhưng ta phải xác định trước các phần tử khởi đầu và số lượng
của nó, mà chúng sẽ ảnh hưởng trực tiếp đến hiệu quả phân cụm. 6
2.2.5.4. Phân tích và dự đoán xu hướng
Phân tích tài liệu Web giúp định rõ quan hệ phân phối dữ liệu ở từng giai
đoạn và cung cấp cơ sở để dự đoán sự phát triển trong tương lai.
2.3. Đánh giá chất lượng mẫu
KPDL Web tương đương với quá trình machine learning, tạo ra mẫu tri
thức và đánh giá chất lượng thông qua phân lớp tập tài liệu thành tập huấn luyện
và tập kiểm tra. Việc lặp lại học và kiểm thử cuối cùng dùng để đánh giá chất lượng mô hình.
3. Khai khác hoạt động sử dụng Web
Khai thác sử dụng web tập trung vào việc dự đoán hành vi của người
dùng khi họ tương tác trên WWW. Nó nghiên cứu và khám phá mẫu điều
hướng của người dùng trên web, sử dụng dữ liệu thu thập từ tương tác của
họ để tìm thông tin hữu ích. Các dự án và công cụ trong lĩnh vực này
thường phân tích Weblog để hiểu mô hình truy cập của người dùng và có
thể được áp dụng cho mục đích cá nhân hóa, tối ưu hóa hệ thống, điều
chỉnh trang web, kinh doanh thông minh và mô tả đặc điểm sử dụng.
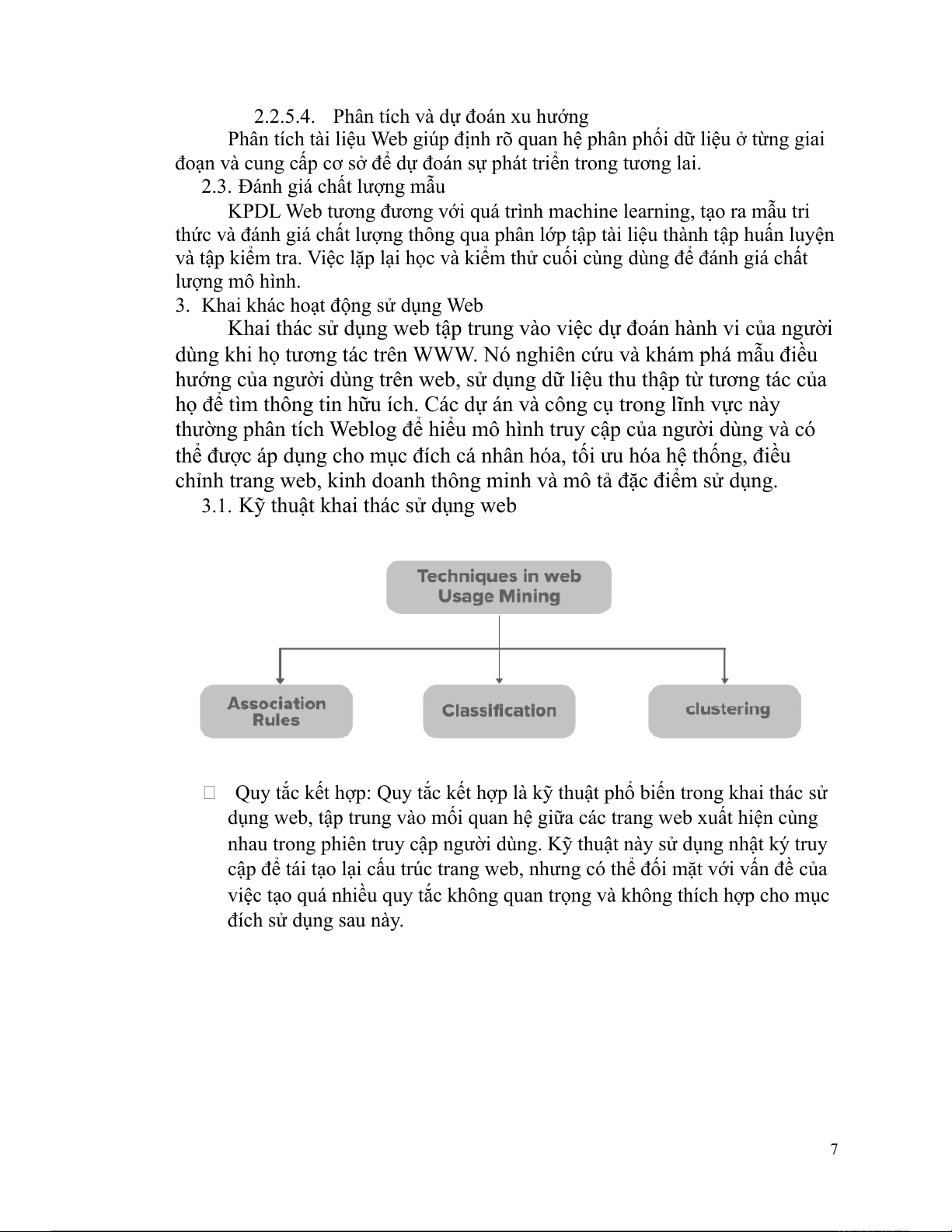
3.1. Kỹ thuật khai thác sử dụng web
Quy tắc kết hợp: Quy tắc kết hợp là kỹ thuật phổ biến trong khai thác sử
dụng web, tập trung vào mối quan hệ giữa các trang web xuất hiện cùng
nhau trong phiên truy cập người dùng. Kỹ thuật này sử dụng nhật ký truy
cập để tái tạo lại cấu trúc trang web, nhưng có thể đối mặt với vấn đề của
việc tạo quá nhiều quy tắc không quan trọng và không thích hợp cho mục đích sử dụng sau này. 7
Phân loại: Phân loại trong khai thác sử dụng web tập trung vào ánh xạ bản
ghi cụ thể thành các lớp được xác định trước, như hồ sơ người
dùng/khách hàng liên quan đến các danh mục cụ thể. Việc này đòi hỏi
trích xuất các tính năng quan trọng nhất cho lớp liên quan, và có thể sử
dụng nhiều thuật toán như Máy vectơ hỗ trợ, Hàng xóm gần nhất K, Hồi
quy logistic, Cây quyết định, và nhiều loại khác. Ví dụ, dựa trên lịch sử
mua hàng, khách hàng có thể được phân loại thành các loại/loại thường
xuyên và không thường xuyên.
Phân cụm: Phân cụm là kỹ thuật nhóm các thứ có đặc điểm tương tự lại
với nhau. Có hai loại chính là phân cụm sử dụng và phân cụm trang. Phân
cụm trang dựa trên dữ liệu sử dụng, tự động nhóm các mục thường được
truy cập/mua cùng nhau. Trong khi phân cụm người dùng tạo các nhóm
người dùng có các kiểu duyệt tương tự nhau. Phân cụm trang cũng nhanh
chóng lấy thông tin trên các trang web. 3.2. Ưu điểm
Các cơ quan chính phủ được hưởng lợi từ công nghệ này để vượt qua khủng bố.
Khả năng dự đoán của các công cụ khai thác đã giúp xác định các
hoạt động tội phạm khác nhau.
Mối quan hệ khách hàng đang được công ty hiểu rõ hơn với sự hỗ trợ
của các công cụ khai thác này. Nó giúp họ đáp ứng nhu cầu của khách
hàng nhanh hơn và hiệu quả hơn. 3.3.Nhược điểm
Quyền riêng tư nổi bật như một vấn đề lớn. Phân tích dữ liệu vì lợi ích
của khách hàng là tốt. Nhưng việc sử dụng cùng một dữ liệu cho mục
đích khác có thể nguy hiểm. Việc sử dụng nó trong phạm vi hiểu biết
của cá nhân có thể gây ra mối đe dọa lớn cho công ty.
Không có tiêu chuẩn đạo đức cao trong một công ty khai thác dữ liệu,
hai hoặc nhiều thuộc tính có thể được kết hợp để lấy một số thông tin
cá nhân của người dùng, điều này một lần nữa là không đáng tôn trọng.
3.4. Các ứng dụng của khai thác sử dụng web
Cá nhân hóa nội dung web: World Wide Web có rất nhiều thông tin và
đang mở rộng rất nhanh chóng từng ngày. Vấn đề lớn là hàng ngày, 8
nhu cầu cụ thể của mọi người ngày càng tăng và họ thường không
nhận được kết quả truy vấn đó. Vì vậy, giải pháp cho vấn đề này là cá
nhân hóa web. Cá nhân hóa web có thể được định nghĩa là phục vụ
nhu cầu của người dùng dựa trên việc theo dõi hành vi điều hướng và
sở thích của họ. Cá nhân hóa web bao gồm hệ thống gợi ý, tùy chỉnh
hộp kiểm, v.v. Hệ thống gợi ý rất phổ biến và được nhiều công ty sử dụng.
Trước khi phục hồi: Tìm nạp trước về cơ bản có nghĩa là tải dữ liệu
trước khi cần để giảm thời gian chờ đợi dữ liệu đó, do đó có thuật ngữ
'tìm nạp trước'. Tất cả các kết quả mà chúng tôi nhận được từ việc khai
thác sử dụng web có thể được sử dụng để tạo ra các chiến lược tìm nạp
trước và lưu vào bộ nhớ đệm, từ đó có thể giảm đáng kể thời gian phản hồi của máy chủ.
Thương mại điện tử: Khai thác sử dụng web đóng một vai trò rất quan
trọng trong các công ty dựa trên web. Vì trọng tâm cuối cùng của họ là
thu hút Khách hàng, giữ chân khách hàng, bán chéo, v.v. Để xây dựng
mối quan hệ bền chặt với khách hàng, công ty dựa trên web phải dựa
vào việc khai thác cách sử dụng web để họ có thể hiểu rõ hơn về quyền
lợi của khách hàng. Ngoài ra, nó còn cho công ty biết về việc cải thiện
thiết kế web của mình ở một số khía cạnh.
3.5. Những vấn đề trong khai khá theo sử dụng Web
Khai phá theo cách dùng Web có 2 việc: Trước tiên, Web log cần được
làm sạch, định nghĩa, tích hợp và biến đổi. Dựa vào đó để phân tích và khai phá.
Những vấn đề tồn tại:
Cấu trúc vật lý các Web site khác nhau từ những mẫu người dùng truy xuất.
Rất khó có thể tìm ra những người dùng, các phiên làm việc, các
giao tác. Vấn đề chứng thực phiên người dùng và truy cập Web:
Các phiên chuyển hướng của người dùng: Nhóm các hành động
được thực hiện bởi người dùng từ lúc họ truy cập vào Website
đến lúc họ rời khỏi Web site đó. Những hành động của người
dùng trong một Web site được ghi và lưu trữ lại trong một file
đăng nhập (log file) (file đăng nhập chứa địa chỉ IP của máy 9
khách, ngày, thời gian từ khi yêu cầu được tiếp nhận, các đối
tượng yêu cầu và nhiều thông tin khác như các giao thức của
yêu cầu, kích thước đối tượng,...).
3.5.1. Chứng thực phiên người dùng
Xác thực người dùng dựa trên địa chỉ IP, coi mỗi người dùng cùng một
Client IP là một người. Xác thực phiên làm việc thông qua việc tạo mới một
phiên khi tìm thấy địa chỉ mới hoặc khi thời gian trên mỗi địa chỉ IP vượt quá
ngưỡng (ví dụ: 30 phút).
3.5.2. Đăng nhập Web và xác định phiên chuyển hướng người dùng
Dịch vụ file đăng nhập Web: Một file đăng nhập Web là một tập các sự
ghi lại những yêu cầu người dùng về các tài liệu trong một Web site, ví dụ:
3.5.3. Các vấn đề đối với việc xử lý Web log
Thông tin cung cấp có thể không đầy đủ và chi tiết.
Thiếu thông tin về nội dung của các trang đã được thăm.
Ghi lại quá nhiều đăng nhập do yêu cầu của các proxy.
Mục đăng nhập không đầy đủ do proxy và các yêu cầu của chương trình gián điệp.
Lọc mục đăng nhập, đặc biệt là các file với các đuôi như gif, jpeg, jpg.
Ước lượng thời gian thăm trang để đánh giá mức quan tâm của người dùng.
Khoảng thời gian giữa hai yêu cầu trang khác nhau. 10
Quy lui: Người dùng rời trang khi họ đã hoàn thành tìm kiếm và
không muốn chờ lâu để chuyển hướng.
3.5.4. Phương pháp chứng thực phiên làm việc và truy cập Web
Chứng thực phiên làm việc dựa trên nhóm các tham chiếu trang,
sử dụng phương pháp heuristics với đánh giá IP và thời gian kết
thúc phiên (ví dụ: 30 phút).
Nội dung của phiên làm việc có thể nhận được dựa trên mô hình
hành vi của người dùng, bao gồm phân loại tham chiếu là "nội
dung" hoặc "chuyển hướng".
Trọng số được gán cho mỗi trang Web dựa trên các độ đo về sự
quan tâm của người dùng, chẳng hạn như thời gian xem một trang
và số lần chuyển hướng.
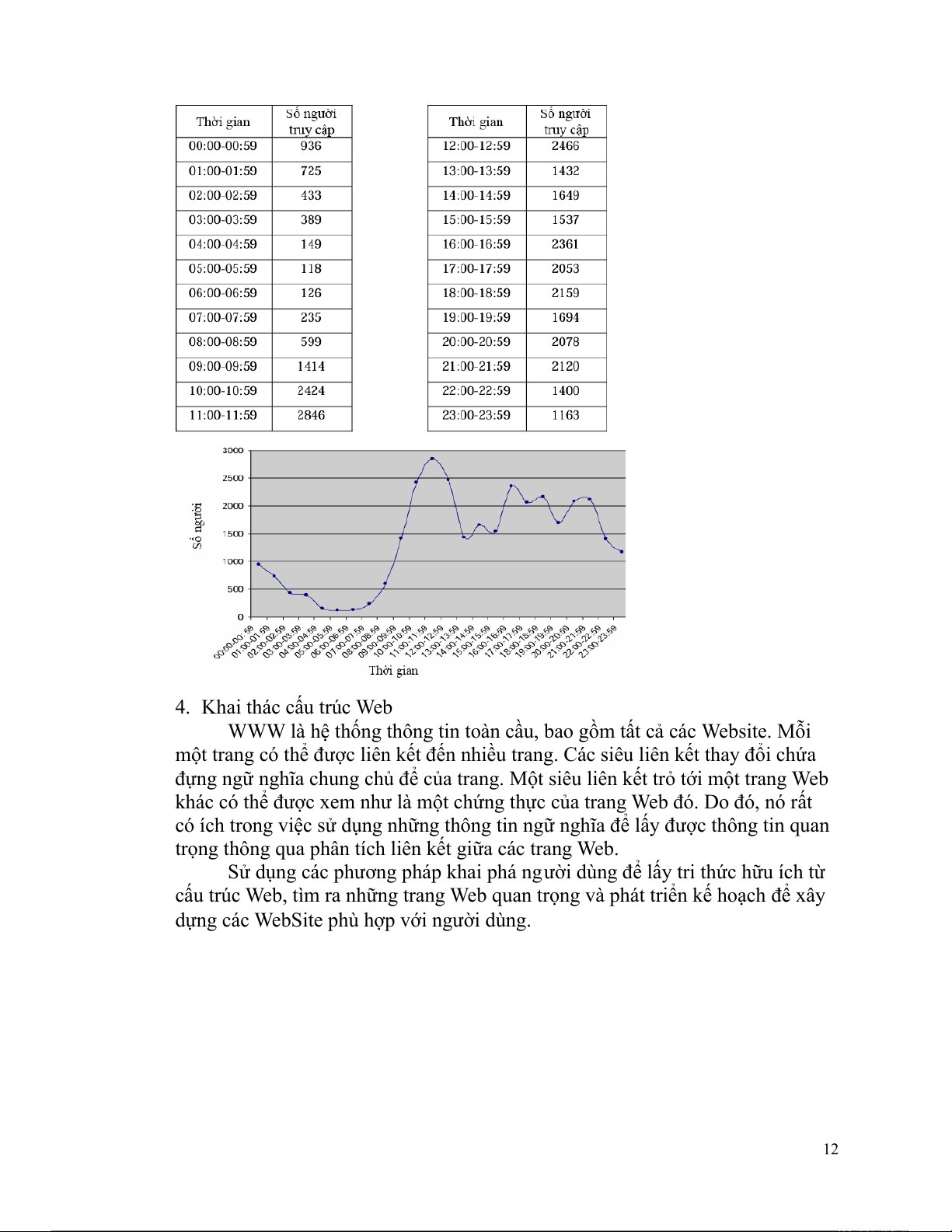
3.6. Ví dụ khai phá theo sử dụng Web
Ví dụ này sử dụng phương pháp khai phá phân lớp và phân cụm, luật kết
hợp có thể được dùng để phân tích số lượng người dùng. Sau đó người thiết kế
Web có thể đưa ra nhiều dịch vụ khác nhau tại các thời điểm khác nhau theo các
quy tắc của người dùng truy cập Website. Chất lượng dịch vụ tốt sẽ thúc đẩy số
lượng người dùng thăm Web site. Quá trình thực hiện như sau:
Chứng thực người dùng khi truy cập vào trang web, phân tích để tìm ra
những người quan trọng dựa trên mức độ truy cập, thời gian ở lại, và sở thích trang web.
Phân tích chủ đề đặc biệt và nội dung sâu của trang web, ví dụ như
hoạt động hàng ngày của một quốc gia, giới thiệu tour, để hiểu quan hệ
tự nhiên giữa người dùng và nội dung web.
Tìm ra các dịch vụ hấp dẫn và tiện lợi cho người dùng. Dựa vào hiệu
quả của hoạt động truy cập và điều kiện duyệt web, có thể dự kiến và
đánh giá nội dung trang web một cách tốt hơn.
Dựa trên dữ liệu kiểm tra, xác định mức độ truy cập của người dùng
thông qua phân tích trang web và yêu cầu phục vụ thay đổi theo giờ và ngày. 11 4. Khai thác cấu trúc Web
WWW là hệ thống thông tin toàn cầu, bao gồm tất cả các Website. Mỗi
một trang có thể được liên kết đến nhiều trang. Các siêu liên kết thay đổi chứa
đựng ngữ nghĩa chung chủ để của trang. Một siêu liên kết trỏ tới một trang Web
khác có thể được xem như là một chứng thực của trang Web đó. Do đó, nó rất
có ích trong việc sử dụng những thông tin ngữ nghĩa để lấy được thông tin quan
trọng thông qua phân tích liên kết giữa các trang Web.
Sử dụng các phương pháp khai phá người dùng để lấy tri thức hữu ích từ
cấu trúc Web, tìm ra những trang Web quan trọng và phát triển kế hoạch để xây
dựng các WebSite phù hợp với người dùng. 12
Mục tiêu của khai phá cấu trúc Web là để phát hiện thông tin cấu trúc về
Web. Nếu như khai phá nội dung Web chủ yếu tập trung vào cấu trúc bên trong
tài liệu thì khai phá cấu trúc Web cố gắng để phát hiện cấu trúc liên kết của các
siêu liên kết ở mức trong của tài liệu. Dựa trên mô hình hình học của các siêu
liên kết, khai phá cấu trúc Web sẽ phân loại các trang Web, tạo ra thông tin như
độ tương tự và mối quan hệ giữa các WebSite khác nhau. Nếu trang Web được
liên kết trực tiếp với trang Web khác thì ta sẽ muốn phát hiện ra mối quan hệ
giữa các trang Web này. Chúng có thể tương tự với nhau về nội dung, có thể
thuộc dịch vụ Web giống nhau do đó nó được tạo ra bởi cùng một người. Những
nhiệm vụ khác của khai phá cấu trúc Web là khám phá sự phân cấp tự nhiên
hoặc mạng lưới của các siêu liên kết trong các Website của một miền đặc biệt.
Điều này có thể giúp tạo ra những luồng thông tin trong Website mà nó có thể
đại diện cho nhiều miền đặc biệt. Vì thế việc xử lý truy vấn sẽ trở nên dễ dàng hơn và hiệu quả hơn.
Việc phân tích liên kết Web được sử dụng cho những mục đích:
Sắp thứ tự tài liệu phù hợp với truy vấn của người sử dụng.
Quyết định Web nào được đưa vào lựa chọn trong truy vấn. Phân trang.
Tìm kiếm những trang liên quan.
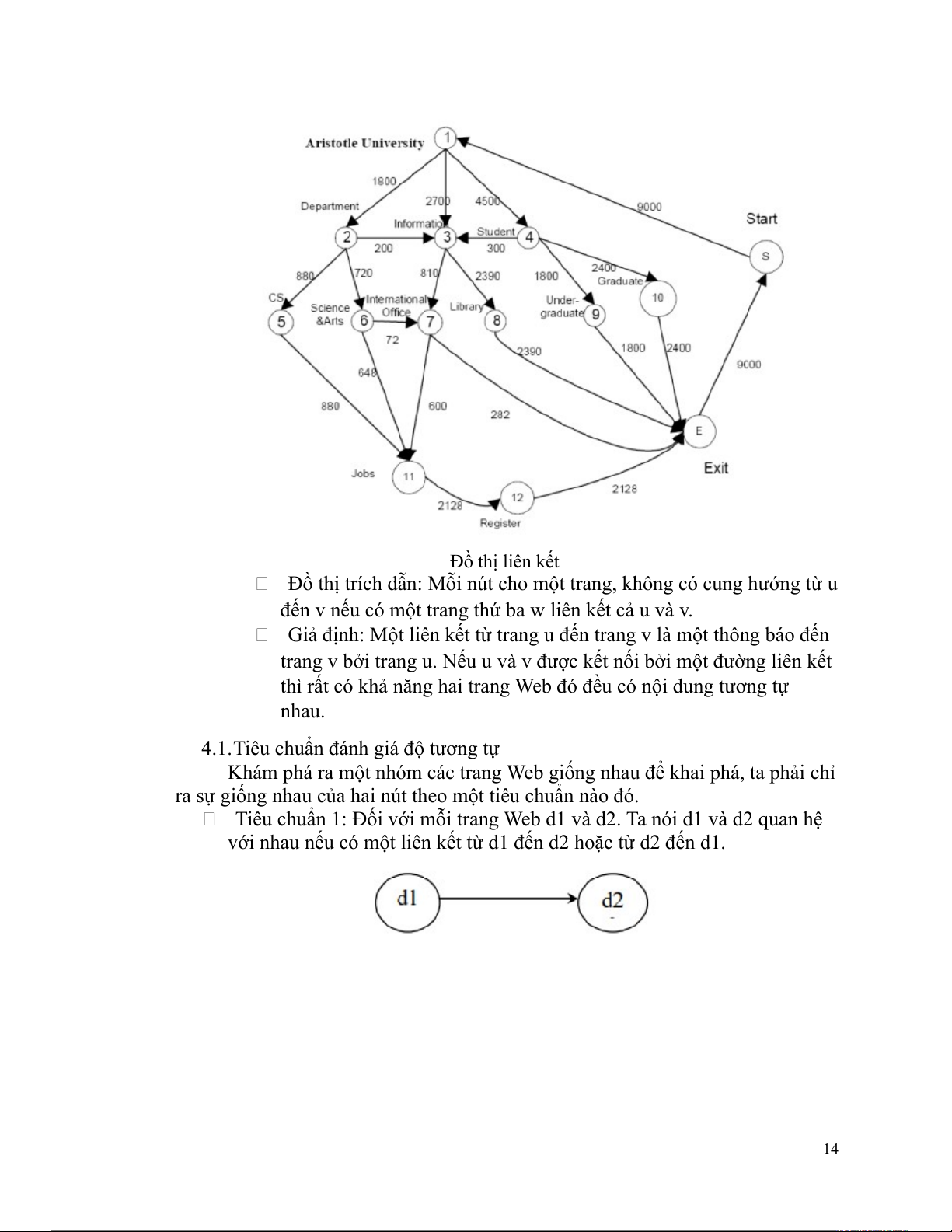
Web được xem như là một đồ thị:
Web được xem như là một đồ thị: 13 Đồ thị liên kết
Đồ thị trích dẫn: Mỗi nút cho một trang, không có cung hướng từ u
đến v nếu có một trang thứ ba w liên kết cả u và v.
Giả định: Một liên kết từ trang u đến trang v là một thông báo đến
trang v bởi trang u. Nếu u và v được kết nối bởi một đường liên kết
thì rất có khả năng hai trang Web đó đều có nội dung tương tự nhau.
4.1.Tiêu chuẩn đánh giá độ tương tự
Khám phá ra một nhóm các trang Web giống nhau để khai phá, ta phải chỉ
ra sự giống nhau của hai nút theo một tiêu chuẩn nào đó.
Tiêu chuẩn 1: Đối với mỗi trang Web d1 và d2. Ta nói d1 và d2 quan hệ
với nhau nếu có một liên kết từ d1 đến d2 hoặc từ d2 đến d1. 14
Quan hệ trực tiếp giữa 2 trang
Tiêu chuẩn 2: Đồng trích dẫn: Độ tương tự giữa d1 và d2 được đo bởi số trang dẫn tới cả d1 và d2.
Độ tương tự đồng trích dẫn
Tương tự chỉ mục: Độ tương tự giữa d1 và d2 được đo bằng số trang mà cả d1 và d2 đều trở tới. Độ tương tự chỉ mục
4.2. Khai phá và quản lý cộng đồng Web
Cộng đồng Web là một nhóm gồm các trang Web chia sẻ chung những
vấn đề mà người dùng quan tâm. Các thành viên của cộng đồng Web có thể
không biết tình trạng tồn tại của mỗi trang (và có thể thậm chí không biết sự tồn
tại của cộng đồng). Nhận biết được các cộng đồng Web, hiểu được sự phát triển
và những đặc trưng của các cộng đồng Web là rất quan trọng. Việc xác định và
hiểu các cộng đồng trên Web có thể được xem như việc khai phá và quản lý Web.
Đặc điểm cộng đồng Web: 15
Các trang Web trong cùng một cộng đồng sẽ “tương tự” với nhau
hơn các trang Web ngoài cộng đồng
Mỗi cộng đồng Web sẽ tạo thành một cụm các trang Web.
Các cộng đồng Web được xác định một cách rõ ràng, tất cả mọi
người đều biết, như các nguồn tài nguyên được liệt kê bởi Yahoo.
Cộng đồng Web được xác định hoàn chỉnh: Chúng là những cộng
đồng bất ngờ xuất hiện.
Cộng đồng Web ngày càng được mọi người quan tâm và có nhiều ứng dụng trong thực
tiễn. Vì vậy, việc nghiên cứu các phương pháp khám phá cộng đồng là rất có ý nghĩa
to lớn trong thực tiễn. Để trích dẫn ra được các cộng đồng ẩn, ta có thể phân tích đồ thị
Web. Có nhiều phương pháp để chứng thực cộng đồng như thuật toán tìm kiếm theo
chủ đề HITS, luồng cực đại và nhát cắt cực tiểu, thuật toán PageRank,... 4.3. Thuật toán PageRank
Google dựa trên thuật toán PageRank , nó lập chỉ mục các liên kết giữa
các Website và thể hiện một liên kết từ A đến B như là xác nhận của B bởi A.
Các liên kết có những giá trị khác nhau. Nếu A có nhiều liên kết tới nó và C có
ít các liên kết tới nó thì một liên kết từ A đến B có giá trị hơn một liên kết từ C
đến B. Giá trị được xác định như thế được gọi là PageRank của một trang và xác
định thứ tự sắp xếp của nó trong các kết quả tìm kiếm (PageRank được sử dụng
trong phép cộng để quy ước chỉ số văn bản để tạo ra các kết quả tìm kiếm chính
xác cao). Các liên kết có thể được phân tích chính xác và hiệu quả hơn đối với
khối lượng chu chuyển hoặc khung nhìn trang và trở thành độ đo của sự thành
công và việc biến đổi thứ hạng của các trang. 16
Kết quả thuật toán PageRank
PageRank không đơn giản chỉ dựa trên tổng số các liên kết đến. Các tiếp
cận cơ bản của PageRank là một tài liệu trong thực tế được xét đến quan trọng
hơn là các tài liệu liên kết tới nó, nhưng những liên kết về (tới nó) không bằng
nhau về số lượng. Một tài liệu xếp thứ hạng cao trong các phần tử của PageRank
nếu như có các tài liệu thứ hạng cao khác liên kết tới nó. Cho nên trong khái
niệm PageRank, thứ hạng của một tài liệu được dựa vào thứ hạng cao của các tài
liệu liên kết tới nó. Thứ hạng ngược lại của chúng được dựa vào thứ hạng thấp
của các tài liệu liên kết tới chúng.
5. Công cụ tìm kiếm hiện đại
Khai thác dữ liệu web là một lĩnh vực con của Data Mining tập trung vào việc trích
xuất thông tin hữu ích từ dữ liệu web. Dữ liệu web là một lượng lớn dữ liệu không
có cấu trúc, đa dạng và liên tục thay đổi, bao gồm văn bản, hình ảnh, video, âm thanh, v.v.
Công cụ tìm kiếm đóng vai trò quan trọng trong việc khai thác dữ liệu web. Chúng
cung cấp khả năng truy cập và thu thập dữ liệu web một cách hiệu quả. Các công cụ
tìm kiếm phổ biến bao gồm Google, Bing, Yahoo, DuckDuckGo, v.v.
Lợi ích của việc sử dụng công cụ tìm kiếm trong khai thác dữ liệu web: 17
● Khả năng truy cập dữ liệu khổng lồ: Công cụ tìm kiếm cho phép truy cập
vào một lượng lớn dữ liệu web, bao gồm cả dữ liệu được cập nhật thường xuyên.
● Hiệu quả: Công cụ tìm kiếm giúp thu thập dữ liệu một cách nhanh chóng và
hiệu quả, tiết kiệm thời gian và nguồn lực.
● Dễ sử dụng: Hầu hết các công cụ tìm kiếm đều có giao diện đơn giản và dễ
sử dụng, giúp người dùng dễ dàng truy cập dữ liệu.
Các kỹ thuật khai thác dữ liệu web với công cụ tìm kiếm:
● Crawling: Thu thập dữ liệu web bằng cách sử dụng các chương trình tự
động gọi là crawler hoặc spider.
● Indexing: Lưu trữ dữ liệu web đã thu thập được trong một cơ sở dữ liệu để truy cập dễ dàng.
● Querying: Truy vấn cơ sở dữ liệu để lấy thông tin mong muốn.
● Extraction: Trích xuất thông tin hữu ích từ dữ liệu web đã thu thập được.
● Analysis: Phân tích dữ liệu web để khám phá các mẫu hình và xu hướng. Ví dụ ứng dụng:
● Phân tích thị trường: Thu thập dữ liệu về giá cả sản phẩm, đối thủ cạnh
tranh, xu hướng thị trường, v.v.
● Phân tích tình cảm: Phân tích ý kiến của khách hàng về sản phẩm, dịch vụ, thương hiệu, v.v.
● Xây dựng mô hình dự đoán: Dự đoán hành vi của khách hàng, xu hướng thị trường, v.v. Công cụ hỗ trợ: ●
Google Search Console: Giúp quản lý trang web và theo dõi hiệu suất tìm kiếm. ●
Bing Webmaster Tools: Cung cấp các công cụ và báo cáo để quản lý trang web và tối ưu hóa cho Bing. ●
Moz Pro: Giúp phân tích SEO và tối ưu hóa trang web. ●
Screaming Frog SEO Spider: Công cụ SEO giúp thu thập dữ liệu và phân tích trang web. 18 19
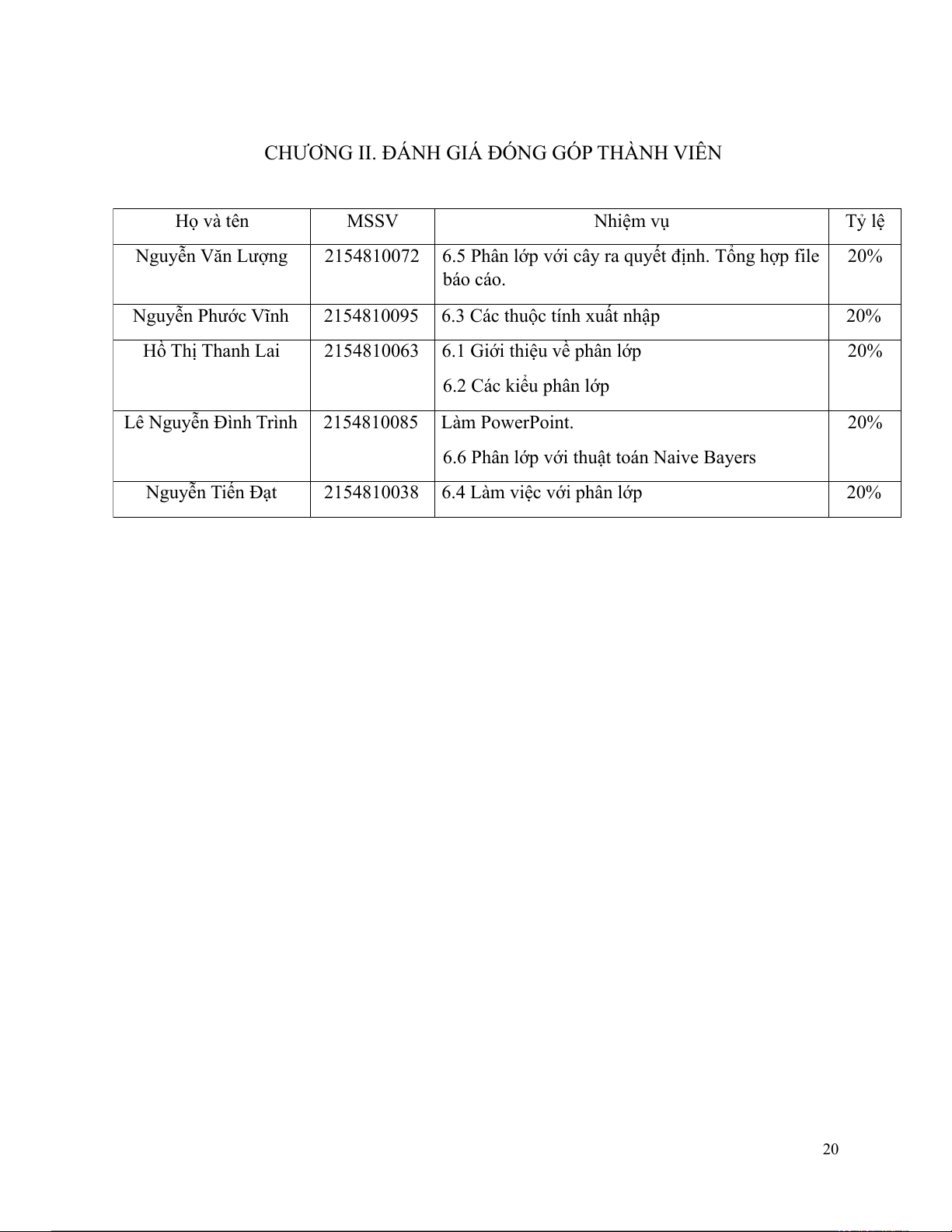
CHƯƠNG II. ĐÁNH GIÁ ĐÓNG GÓP THÀNH VIÊN Họ và tên MSSV Nhiệm vụ Tỷ lệ Nguyễn Văn Lượng 2154810072
6.5 Phân lớp với cây ra quyết định. Tổng hợp file 20% báo cáo. Nguyễn Phước Vĩnh 2154810095
6.3 Các thuộc tính xuất nhập 20% Hồ Thị Thanh Lai 2154810063
6.1 Giới thiệu về phân lớp 20% 6.2 Các kiểu phân lớp Lê Nguyễn Đình Trình 2154810085 Làm PowerPoint. 20%
6.6 Phân lớp với thuật toán Naive Bayers Nguyễn Tiến Đạt 2154810038
6.4 Làm việc với phân lớp 20% 20
Tài liệu liên quan:
-

Bài tập Cấu trúc dữ liệu | Trường Đại học Khoa học tự nhiên, Đại học Quốc gia Hà Nội
28 14 -

Bài tập ôn tập Khai Thác Dữ Liệu | Khai thác dữ liệu và ứng dụng | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
109 55 -

Các Kỹ Thuật Khai Thác Dữ Liệu và Ứng Dụng | Khai thác dữ liệu và ứng dụng | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
216 108 -

Chương 3. Phân tích Luật Kết Hợp | Khai thác dữ liệu và ứng dụng | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
95 48