Chương 5 phân cụm dữ liệu | Bài giảng hệ thống thông tin quản lý
Chương 5 phân cụm dữ liệu | Bài giảng hệ thống thông tin quản lý. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời đọc đón xem!
Môn: Hệ thống thông tin quản lý (HVNN) 117 tài liệu
Trường: Học viện Ngân hàng 2.3 K tài liệu
Tác giả:









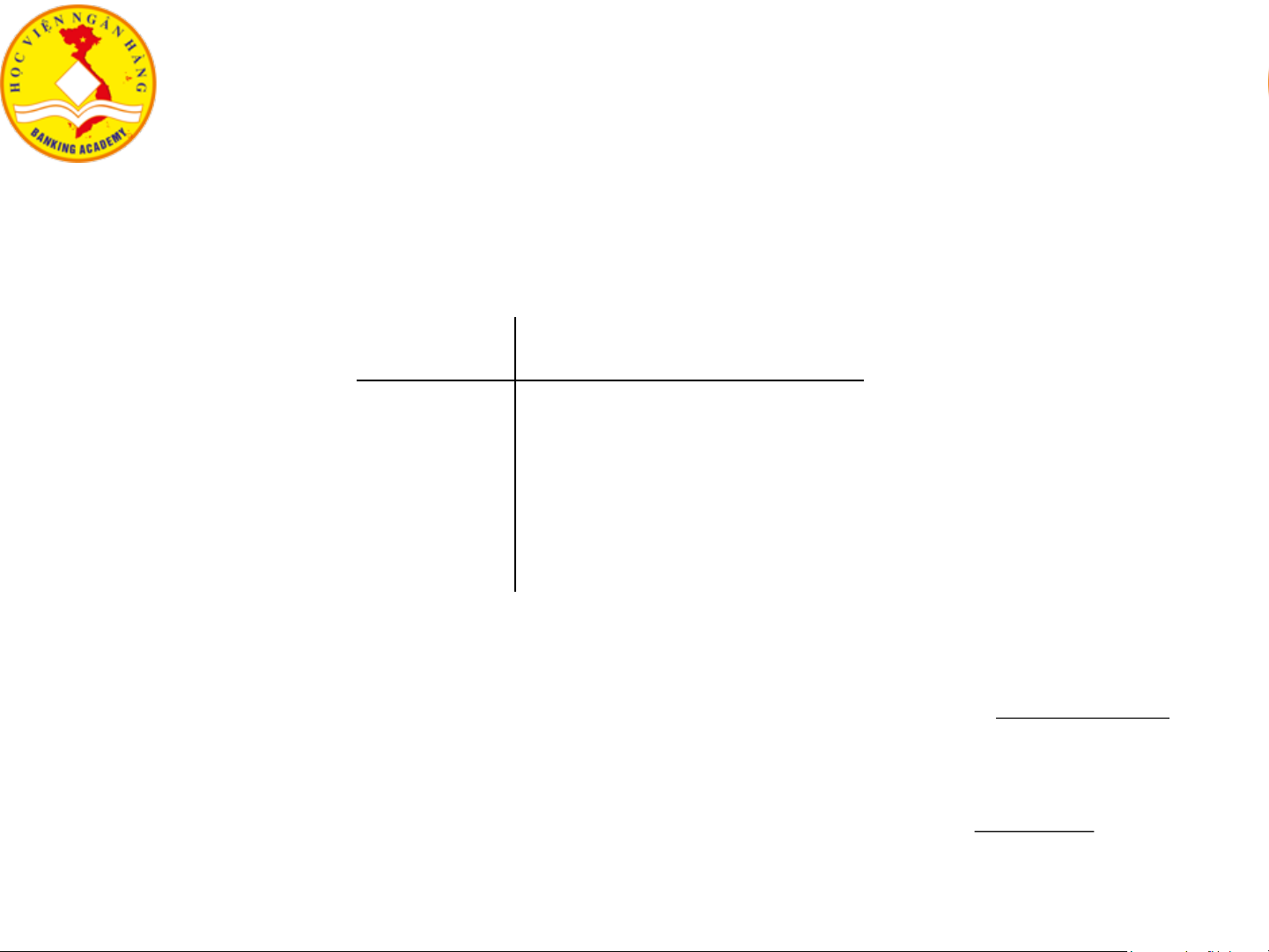

Preview text:
HỌC VIỆN NGÂN HÀNG
KHOA HỆ THỐNG THÔNG TIN QUẢN LÝ
Hà Nội, Monday, September 8, 2025 Nội dung
❖4.1. Tổng quan về gom cụm dữ liệu
❖4.2. Gom cụm dữ liệu bằng phân hoạch
❖4.3. Gom cụm dữ liệu bằng phân cấp
❖4.4. Gom cụm dữ liệu dựa trên mật độ
❖4.5. Gom cụm dữ liệu dựa trên mô hình
❖4.6. Các phương pháp gom cụm dữ liệu khác 2 4.0. Tình huống # 3 4.0. Tình huống # Gom cụm ảnh
Nguồn: http://kdd.ics.uci.edu/databases/CorelFeatures/CorelFeatures.data.html 4 4.0. Tình huống … Gom cụm 5 4.0. Tình huống …
❖ Hỗ trợ giai đoạn tiền xử lý dữ liệu (data preprocessing)
❖ Mô tả sự phân bố dữ liệu/đối tượng (data distribution)
❖ Nhận dạng mẫu (pattern recognition)
❖ Phân tích dữ liệu không gian (spatial data analysis)
❖ Xử lý ảnh (image processing)
❖ Phân mảnh thị trường (market segmentation)
❖ Gom cụm tài liệu ((WWW) document clustering) ❖ … 6
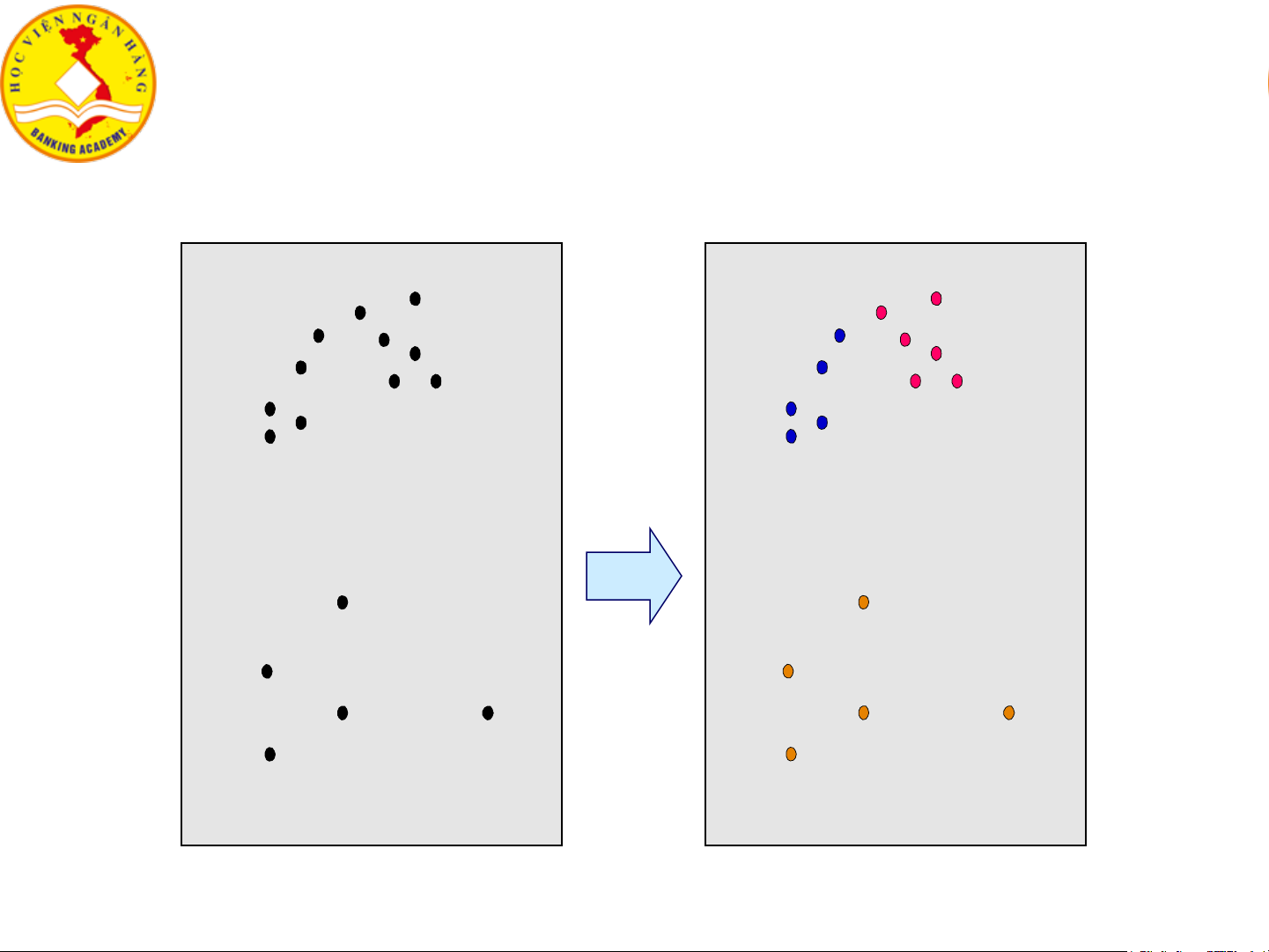
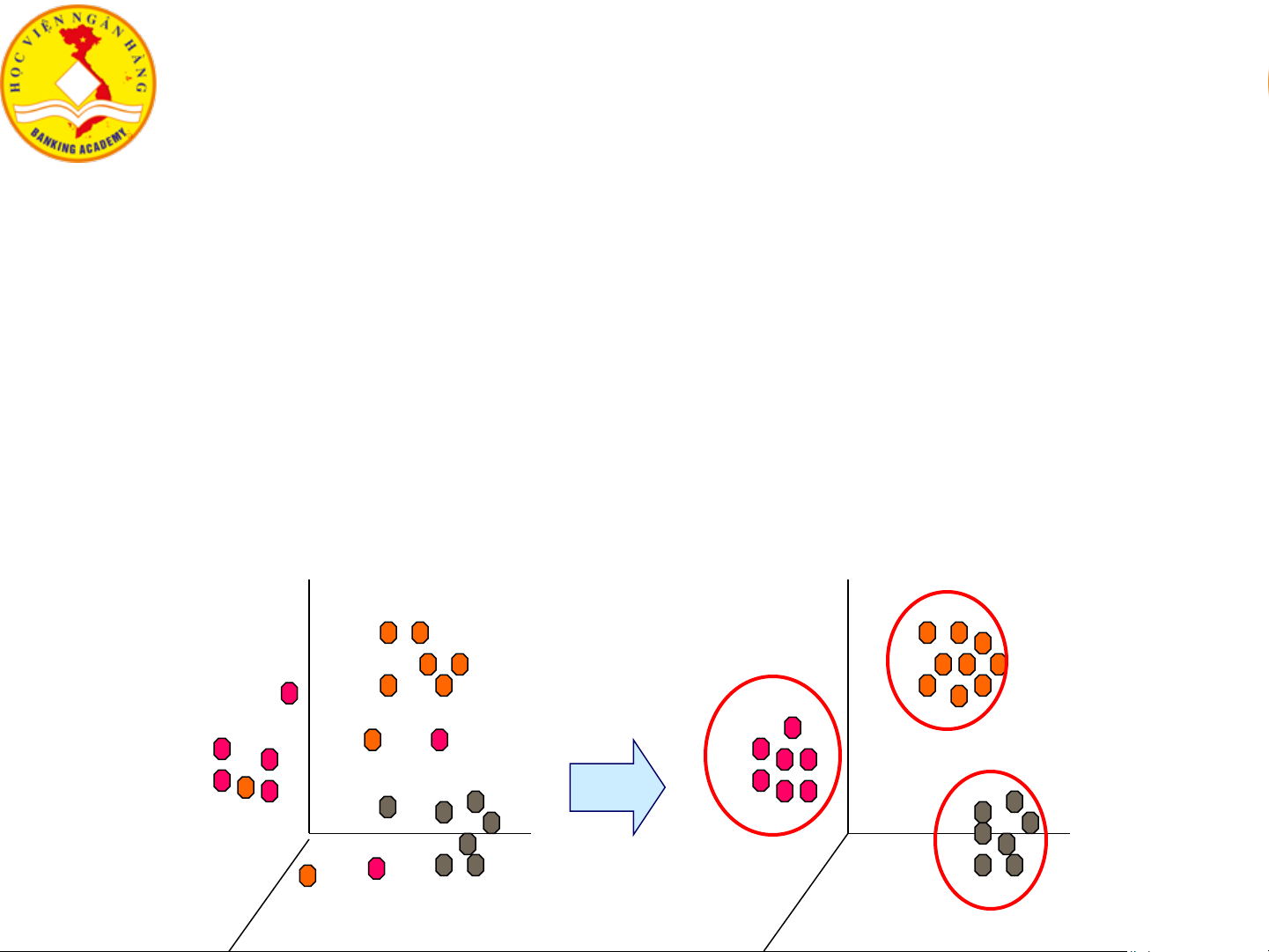
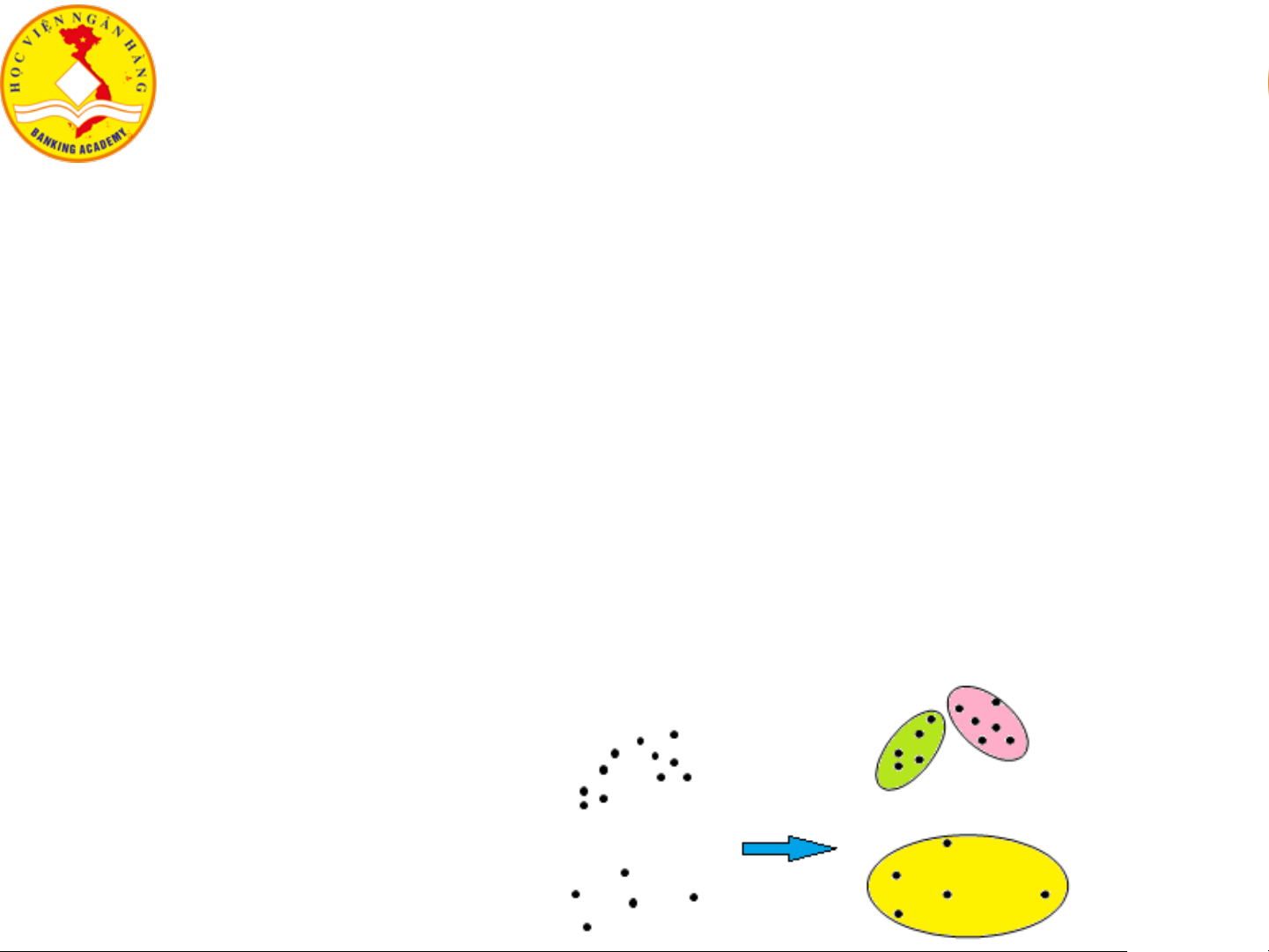
4.1. Tổng quan về gom cụm dữ liệu ❖ Gom cụm
▪ Quá trình gom nhóm/cụm dữ liệu/đối tượng vào các lớp/cụm
▪ Các đối tượng trong cùng một cụm tương tự với nhau hơn so với đối tượng ở các cụm khác.
• Obj1, Obj2 ở cụm C1; Obj3 ở cụm C2 → Obj1 tương tự Obj2 hơn so với tương tự Obj3. Gom cụm 7
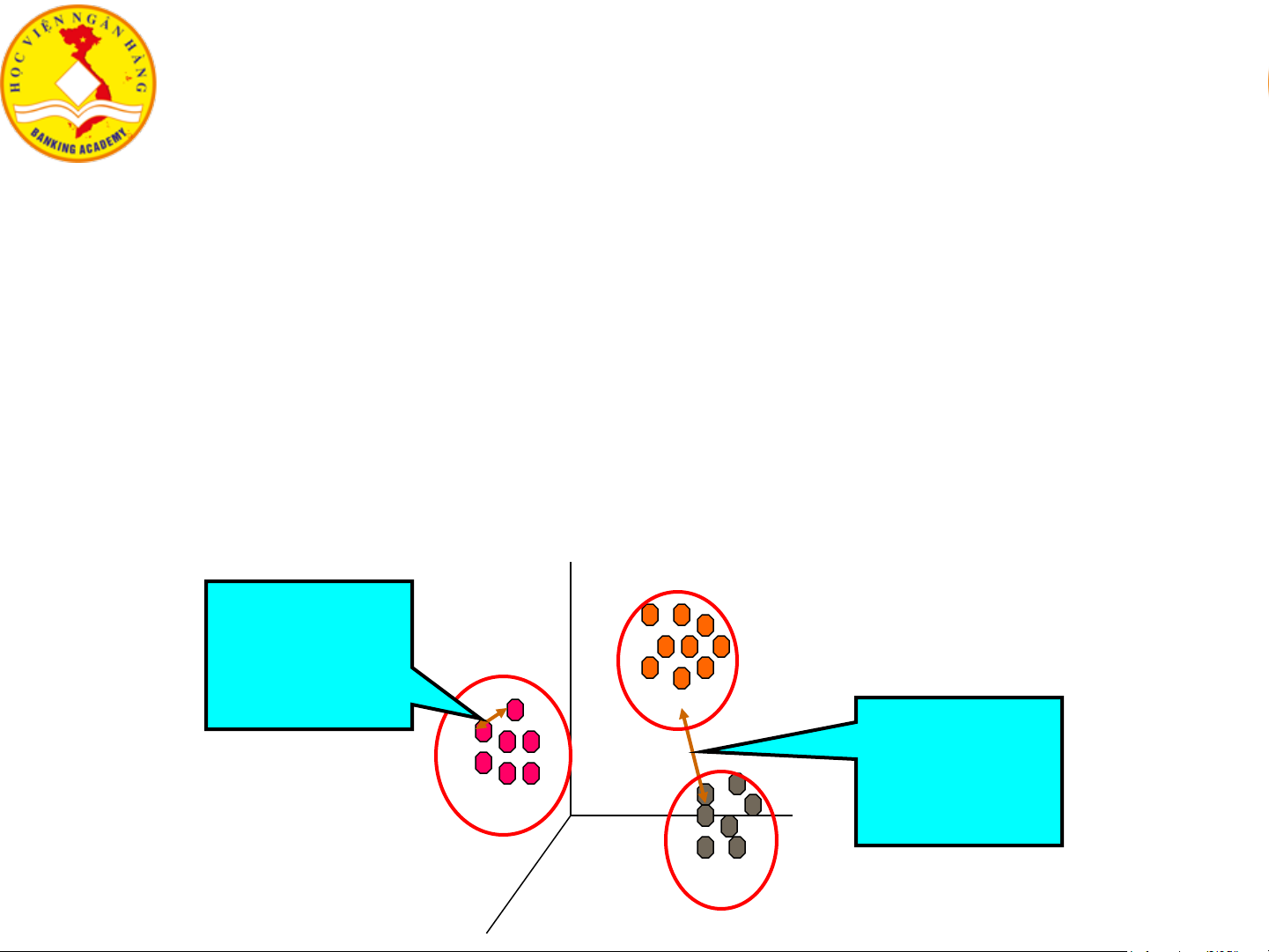
4.1. Tổng quan về gom cụm dữ liệu ❖ Gom cụm
▪ Quá trình gom nhóm/cụm dữ liệu/đối tượng vào các lớp/cụm
▪ Các đối tượng trong cùng một cụm tương tự với nhau hơn so với đối tượng ở các cụm khác.
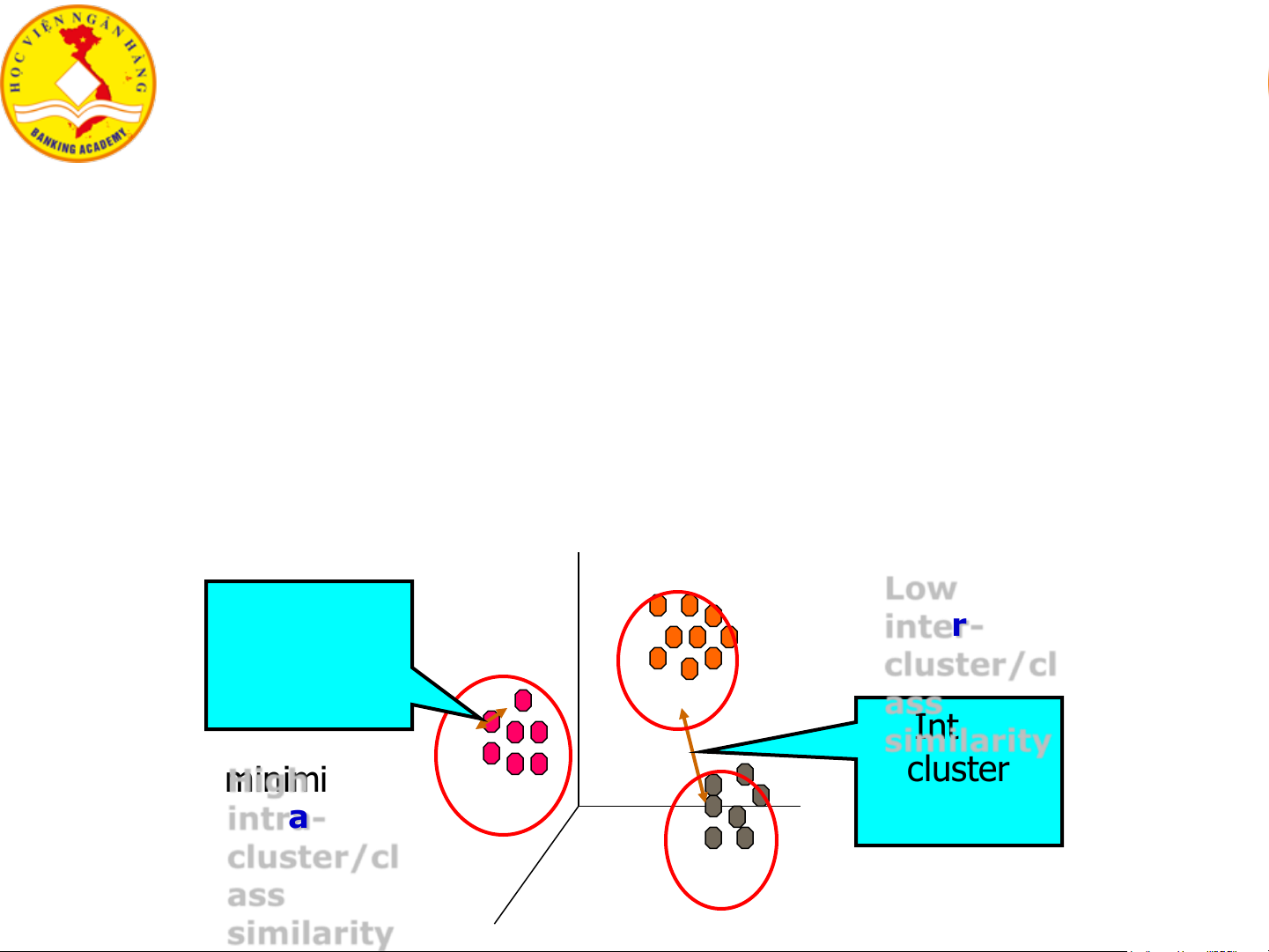
• Obj1, Obj2 ở cụm C1; Obj3 ở cụm C2 → Obj1 tương tự Obj2 hơn so với tương tự Obj3. Intra- cluster distances Inter- are cluster minimized. distances are maximized. 8
4.1. Tổng quan về gom cụm dữ liệu ❖ Gom cụm
▪ Quá trình gom nhóm/cụm dữ liệu/đối tượng vào các lớp/cụm
▪ Các đối tượng trong cùng một cụm tương tự với nhau hơn so với đối tượng ở các cụm khác.
• Obj1, Obj2 ở cụm C1; Obj3 ở cụm C2 → Obj1 tương tự Obj2 hơn so với tương tự Obj3. Low Intra- inter- cluster cluster/cl distances ass Inter- are similarity cluster minim High ized. intra- distances cluster/cl are ass maximized. 9 similarity
4.1. Tổng quan về gom cụm dữ liệu
❖ Vấn đề kiểu dữ liệu/đối tượng được gom cụm
▪ Ma trận dữ liệu (data matrix) x . . x . . x 11 1f 1p
. . . . . . . . . . x . . x . . x i1 if ip
. . . . . . . . . . x . . x . . x n1 nf np -n đối tượng (objects)
-p biến/thuộc tính (variables/attributes) 10
4.1. Tổng quan về gom cụm dữ liệu
❖Vấn đề kiểu dữ liệu/đối tượng được gom cụm
▪ Ma trận sai biệt (dissimilarity matrix) 0 d(2,1) 0 ) d(3,1 d , 3 ( ) 2 0 : : : d(n ) 1 , d( , n ) 2 ... ... 0
d(i, j) là khoảng cách giữa đối tượng i và j; thể hiện sự khác biệt giữa đối
tượng i và j; được tính tuỳ thuộc vào kiểu của các biến/thuộc tính. 11
4.1. Tổng quan về gom cụm dữ liệu
❖Vấn đề kiểu dữ liệu/đối tượng được gom cụm
d(i, j) là khoảng cách giữa đối tượng i và j; thể hiện sự khác biệt giữa
đối tượng i và j; được tính tuỳ thuộc vào kiểu của các biến/thuộc tính. d(i,j) 0 d(i,i) = 0 d(i,j) = d(j,i)
d(i,j) d(i,k) + d(k,j) 12
4.1. Tổng quan về gom cụm dữ liệu
❖ Vấn đề kiểu dữ liệu/đối tượng được gom cụm
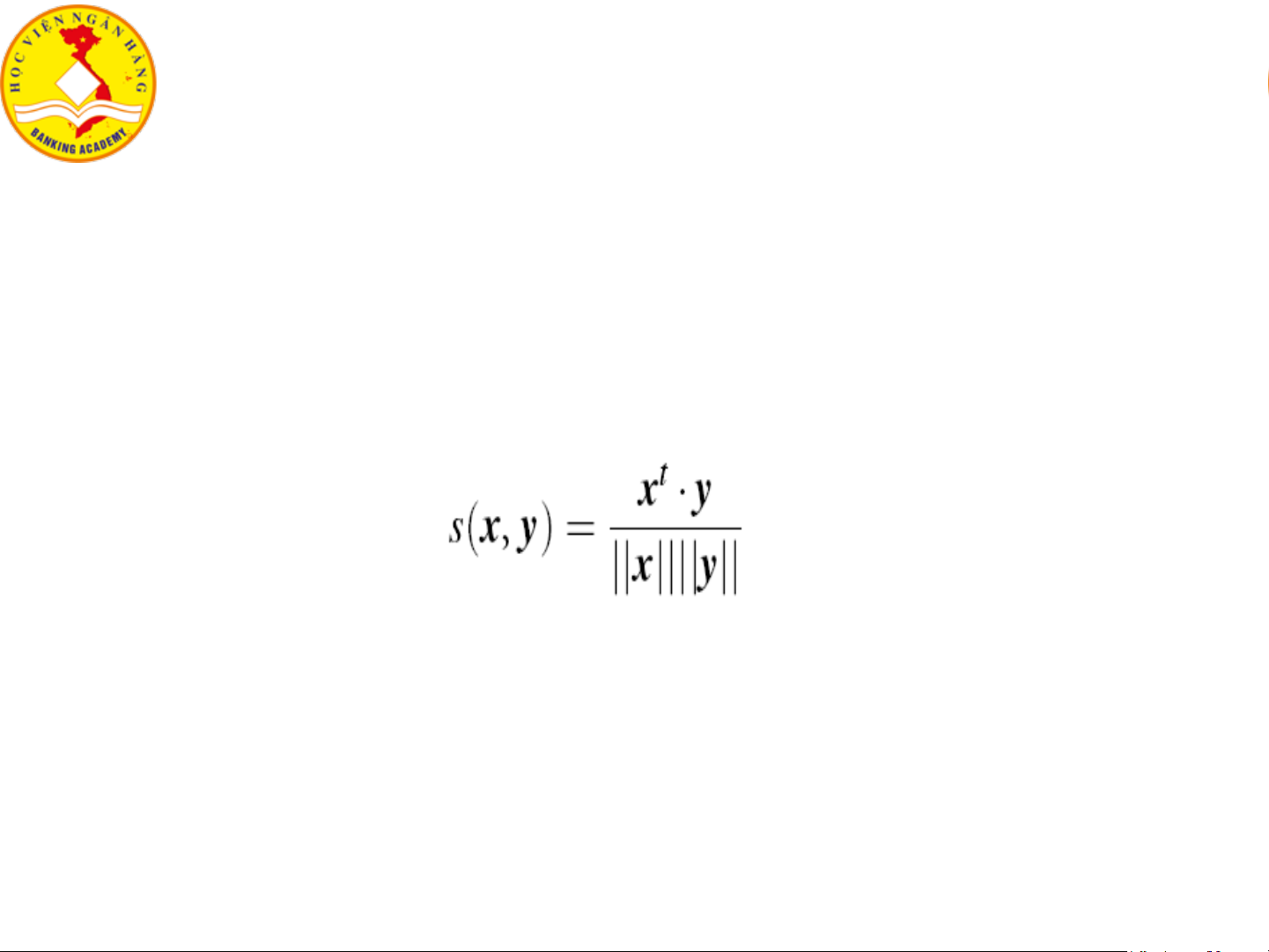
▪ Đối tượng vector (vector objects)
• Đối tượng i và j được biểu diễn tương ứng bởi vector x và y.
• Độ tương tự (similarity) giữa i và j được tính bởi độ đo cosine: x = (x1, …, xp) y = (y1, …, yp)
s(x, y) = (x1*y1 + … + xp*yp)/((x12 + … + xp2)1/2*(y12+ … + yp2)1/2) 13
4.1. Tổng quan về gom cụm dữ liệu
❖ Vấn đề kiểu dữ liệu/đối tượng được gom cụm
▪ Interval-scaled variables/attributes
▪ Binary variables/attributes
▪ Categorical variables/attributes
▪ Ordinal variables/attributes
▪ Ratio-scaled variables/attributes
▪ Variables/attributes of mixed types 14
4.1. Tổng quan về gom cụm dữ liệu
❖ Interval-scaled variables/attributes
Mean absolute deviation: s = 1(| x −m |+| x −m | ... + +| x −m |) f n 1f f 2 f f nf f Mean: 1
m = (x + x + ... + x . ) f n 1 f 2 f nf x −m if f Z-score measurement: z = if s f 15
4.1. Tổng quan về gom cụm dữ liệu
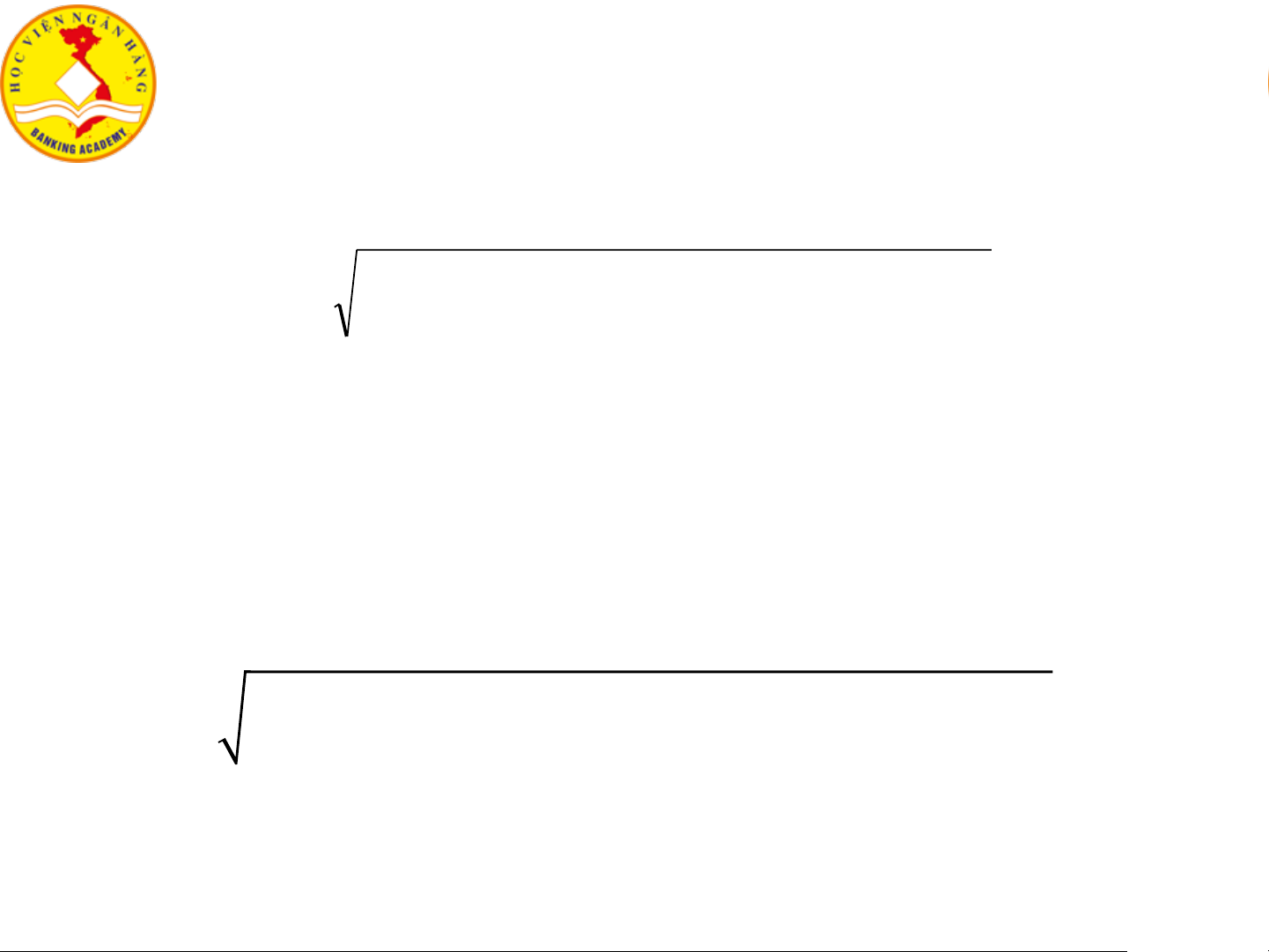
❖ Độ đo khoảng cách Minkowski q q q
d i(, j) = q (| x − x | +| x − x | .
+ .+| x − x | ) i1 j1 i2 j2 p i p j
❖ Độ đo khoảng cách Manhattan d( ,i j) | = − x |+| − x | ... + +| − x | 1 i x 1 i x j 2 2 i x j p jp
❖ Độ đo khoảng cách Euclidean 𝑑(𝑖, 𝑗) =
(|𝑥𝑖1 − 𝑥𝑗1|2 + |𝑥𝑖2 − 𝑥𝑗2|2+. . . +|𝑥𝑖𝑝 − 𝑥𝑗𝑝|2) 16
4.1. Tổng quan về gom cụm dữ liệu
❖ Binary variables/attributes Object j 1 0 sum 1 a b a+b Object i 0 c d c+d
sum a+c b+d p (= a + b + c + d)
Hệ số so trùng đơn giản nếu b+c d i ( , j) = đối xứng (symmetric):
a+b+c+d
Hệ số so trùng Jaccard nếu không đối xứng b+c d i ( , j) = (asymmetric): a+b+c 17
Phát biểu bài toán phân cụm dữ liệu
Phân cụm dữ liệu là quá trình học không giám sát trên
một tập dữ liệu đầu vào nhằm phân chia tập dữ liệu ban
đầu thành các tập dữ liệu con có tính chất tương tự nhau.
• Đầu vào: Tập dữ liệu D gồm n phần tử trong không gian m chiều. – D = {x1, x2,…,xn} –
xi = (x1i, x2i,…, xmi) mô tả m thuộc tính của phần tử thứ i.
• Đầu ra: Phân các dữ liệu thuộc D thành các cụm sao cho: –
Các phần tử trong cùng một cụm có tính chất tương tự nhau (gần nhau). –
Các phần tử ở các cụm khác nhau có tính chất khác nhau (xa nhau). 18
Các phương pháp phân cụm dữ liệu
Phân cụm phân vùng (phân cụm phẳng)
• Nhằm phân một tập dữ liệu có n phần tử cho trước thành k
nhóm dữ liệu sao cho: mỗi phần tử dữ liệu chỉ thuộc về một
nhóm dữ liệu và mỗi nhóm dữ liệu có tối thiểu ít nhất một phần tử dữ liệu.
• Tiếp cận: từ dưới lên (gộp dần), từ trên xuống (chia dần)
• Độ đo tương tự / khoảng cách
• K-mean, k-mediod, CLARANS, … 19
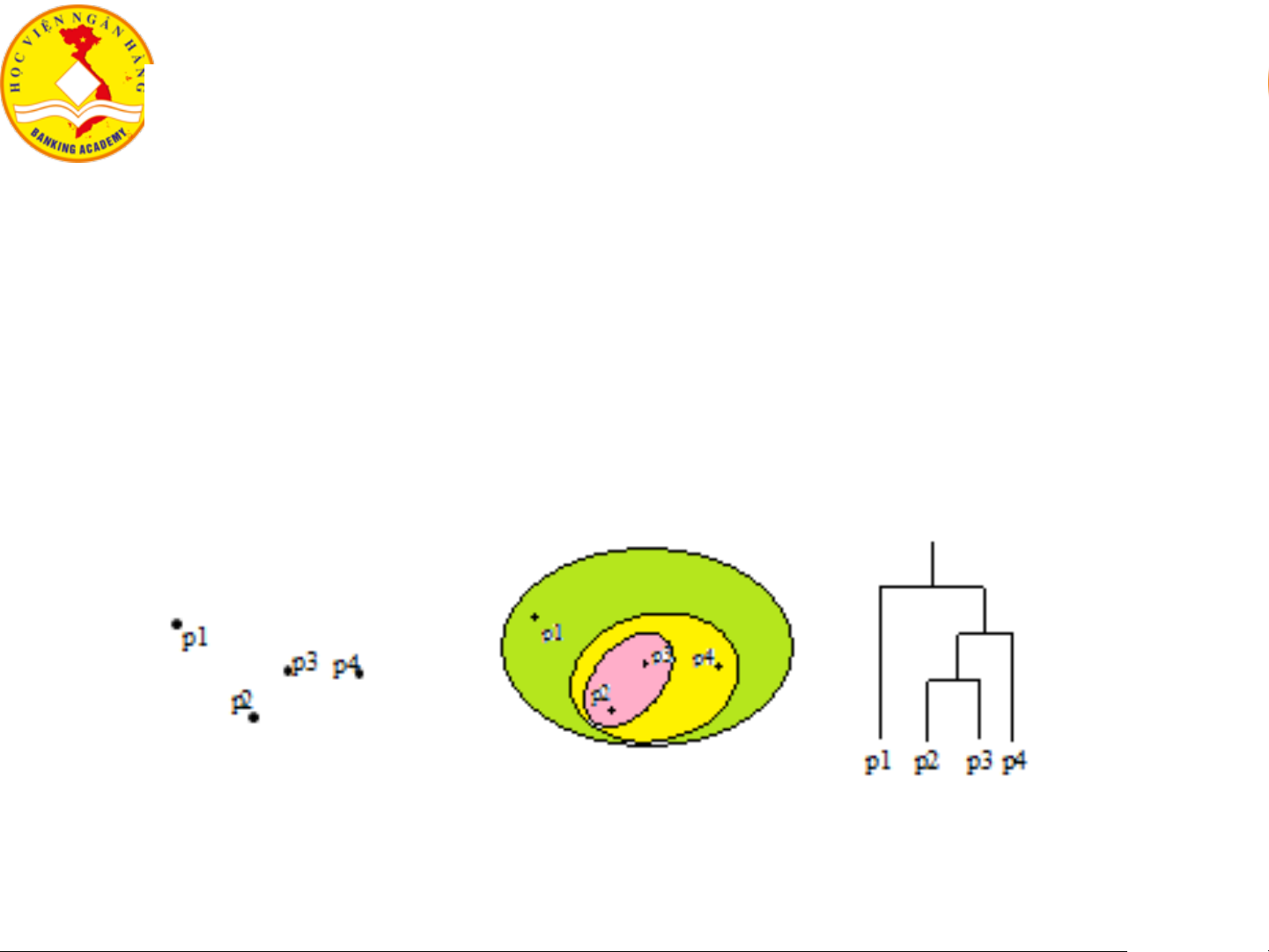
Các phương pháp phân cụm dữ liệu Phân cụm phân cấp
• Nhằm phân một tập dữ liệu có n phần tử cho trước thành một
cấu trúc có một thứ tự phân cấp nhất định (thường có dạng hình cây)
• Độ đo tương tự / khoảng cách
• HAC, CHAMELEON, BIRRCH, CURE… 20
Tài liệu liên quan:
-

Chương 3 kho dữ liệu | Bài giảng hệ thống thông tin quản lý
36 18 -

Chương 2 quản trị dữ liệu | Bài giảng hệ thống thông tin quản lý
35 18 -

Chương 1 tổng quan về hệ hỗ trợ ra quyết định | Bài giảng hệ thống thông tin quản lý
36 18 -

Tìm hiểu về quy trình hoạt động của Công ty Cổ phần sữa Đà Lạt môn Hệ thống thông tin quản lý | Học viện Ngân hàng
48 24