Đề tài: Ứng dụng mô hình học máy trong việc xác định khách hàng tiềm năng thông qua các chiến lược Marketing
Đề tài: Ứng dụng mô hình học máy trong việc xác định khách hàng tiềm năng thông qua các chiến lược Marketing và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng, ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học.
Môn: Corporate Finance (CF2033) 92 tài liệu
Trường: Trường Đại học Hoa Sen 5.3 K tài liệu
Tác giả:

















Preview text:
BỘ GIÁO DỤC VÀ ĐÀO TẠO
TRƯỜNG ĐẠI HỌC KINH TẾ TP.HCM TIỂU LUẬN
MÔN HỌC: KHOA HỌC DỮ LIỆU
Đề tài: Ứng dụng mô hình học máy trong việc xác định khách
hàng tiềm năng thông qua các chiến lược Marketing MỤC LỤC
I. GIỚI THIỆU ĐỀ TÀI..............................................................................................4
1. Lý do chọn đề tài..................................................................................................4
2. Mục đích nghiên cứu...........................................................................................4
3. Phương pháp thực hiện.......................................................................................5
4. Đối tượng nghiên cứu..........................................................................................5
5. Cấu trúc của bài nghiên cứu...............................................................................5
II. CƠ SỞ LÝ LUẬN...................................................................................................5
1. Giới thiệu về khai phá dữ liệu.............................................................................5
1.1. Khai phá dữ liệu là gì?.................................................................................6
1.2. Quy trình khai phá dữ liệu...........................................................................6
1.3. Ứng dụng của khai phá dữ liệu....................................................................7
1.4. Công cụ khai phá dữ liệu được sử dụng trong bài nghiên cứu – Orange. 7
2. Một số thuật toán sử dụng trong bài nghiên cứu...............................................7
2.1. Phương pháp cây ra quyết định (Decision Tree).........................................7
2.2. Phương pháp hồi quy logistic (Logistic Regression)...................................8
2.3. Phương pháp Mạng Nơ ron nhân tạo (Neural Network)...........................9
III. MÔ HÌNH NGHIÊN CỨU ĐỀ XUẤT...............................................................10
1. Mô tả dữ liệu:.....................................................................................................10
2. Xử lý dữ liệu:......................................................................................................13
3. Trực quan hóa dữ liệu:......................................................................................13
3.1. Năm sinh:.....................................................................................................13
3.2. Trình độ học vấn:........................................................................................14
3.3. Tình trạng hôn nhân:..................................................................................14
3.4. Thu nhập hộ gia đình hàng năm:...............................................................15
3.5. Hộ gia đình có con:.....................................................................................16
3.6. Ngày khách hàng gia nhập:........................................................................17
3.7. Lượt truy cập:.............................................................................................18
3.8. Số tiền khách hàng chi tiêu trong 2 năm:..................................................18
3.9. Thói quen mua hàng của khách:................................................................19
3.10. Phản hồi của khách hàng:........................................................................20
IV. KẾT QUẢ THỰC HIỆN.....................................................................................20
1. Phân tích kết quả dựa trên Orange.................................................................20
2. Đánh giá kết quả và mô hình...........................................................................24
V. KẾT LUẬN VÀ NHẬN XÉT..........................................................................24
I. GIỚI THIỆU ĐỀ TÀI
1. Lý do chọn đề tài
Trong thời đại công nghiệp 4.0 bùng nổ, hàng loạt các thiết bị máy móc hiện đại
ra đời, và cùng với đó là sự xuất hiện đa dạng của các ngành nghề mới đang dẫn đầu
trong công nghiệp. Và công nghệ thông tin tại Việt Nam ngày nay cũng dần phát triển
và bùng nổ khiến cho việc thu thập một lượng lớn dữ liệu tăng lên nhanh chóng. Trước
tình hình bùng nổ thông tin đang diễn ra, những người ra quyết định trong các tổ chức
tài chính, thương mại, khoa học,... không muốn bỏ sót bất cứ thông tin nào thu thập
được. Họ muốn lưu trữ tất cả thông tin vì cho rằng trong đó ẩn chứa những giá trị tiềm
ẩn cần được phát hiện.
Những lí do trên đây chính là tiền đề cho sự ra đời kỹ thuật khai phá dữ liệu
(KPDL) (Data Mining) khi nhu cầu phát triển các kỹ thuật thu thập, lưu trữ, phân tích
dữ liệu, … đòi hỏi kỹ thuật xử lý thông minh và hiệu quả hơn ngày một tăng cao. Nhờ
đó, chúng ta có khả năng khai thác những tri thức hữu dụng và thật sự cần thiết từ kho
dữ liệu khổng lồ. Việc chọn lọc đúng đắn không những giúp cải thiện kết quả đầu ra
trong hiện tại mà còn hỗ trợ việc ra quyết định một cách chính xác hơn.
Phân tích tính cách khách hàng là một phân tích chi tiết về những khách hàng lý
tưởng của một doanh nghiệp. Nó giúp doanh nghiệp hiểu rõ hơn về khách hàng của
mình và giúp họ dễ dàng sửa đổi sản phẩm theo nhu cầu, hành vi và mối quan tâm cụ
thể của các loại khách hàng khác nhau. Dựa vào đó, doanh nghiệp có thể sửa đổi sản
phẩm của mình thông qua những mục tiêu của khách hàng ở những phân khúc khác
nhau. Nhằm tiết kiệm chi phí trong việc quảng cáo thông tin sản phẩm cũng như đánh
trọng tâm vào tâm lý người dùng, đem lại hiệu quả cao trong kinh doanh.
Bởi sự quan trọng tất yếu đó, sinh viên nghiên cứu quyết định thực hiện đề tài
về phân tích về phân khúc khách hàng tiềm năng của ngành thực phẩm thông qua biến
tính cách khách hàng, để từ đó đưa ra được những chiến lược kinh doanh tốt nhất.
2. Mục đích nghiên cứu
Với đề tài nghiên cứu “Ứng dụng mô hình máy tính học vào việc xác định khách
hàng tiềm năng trong ngành thực phẩm” tập trung vào hai mục tiêu chính:
- Khai phá được ứng dụng Data Mining, tìm ra được phương pháp chuẩn xác
nhất và phù hợp trong việc sử dụng mô hình máy tính học vào phân tích kinh tế.
- Nghiên cứu về các phương pháp của cụ thể, phương pháp phân lớp dữ liệu
(phương pháp phân lớp đưa ra các dự báo, phân loại và cũng như phân lớp các
đối tượng). Nghiên cứu sẽ đưa các phương pháp phân lớp dữ liệu, và từ đó sẽ
chọn ra một phương pháp tối ưu và đảm bảo nhất cho quá trình dự báo dữ liệu.
Cụ thể là thuật toán phân lớp dữ liệu bằng Neural Network.
- Dự báo các mô hình hoạt động kinh doanh sẽ dựa vào bộ dữ liệu đã được huấn
luyện, từ đó sẽ đưa ra những mô hình hoạt động kinh doanh tốt nhất cho các doanh nghiệp.
3. Phương pháp thực hiện
Sử dụng công cụ khai phá dữ liệu Orange để xử lý dữ liệu, biểu diễn dữ liệu
cũng như so sánh các mô hình. Dùng phần mền Excel để phân tích mô tả chi tiết từng biến dữ liệu.
4. Đối tượng nghiên cứu
Đối tượng nghiên cứu là những khách hàng mua sản phẩm lương thực thiết yếu
của công ty. Bộ dữ liệu cho dự án này được cung cấp bởi Tiến sĩ Omar Romero-
Hernandez, và được tải xuống từ web Kaggle.com. Tập dữ liệu bao gồm thông tin dữ
liệu thô chứa 2240 hàng dữ liệu (khách hàng) và 29 cột (đặc tính).
5. Cấu trúc của bài nghiên cứu Gồm có 4 chương
Chương 1: GIỚI THIỆU
Chương 2: CƠ SỞ LÝ LUẬN
Chương 3: PHÂN TÍCH VÀ DỰ BÁO
Chương 4: KẾT LUẬN VÀ GIẢI PHÁP II. CƠ SỞ LÝ LUẬN
1. Giới thiệu về khai phá dữ liệu
1.1. Khai phá dữ liệu là gì?
Khai phá dữ liệu (Data Mining) là quá trình sắp xếp, phân loại một tập hợp các
dữ liệu lớn để xác định các mẫu và thành lập một mối quan hệ nhằm giải quyết nhiều
vấn đề thông qua việc phân tích dữ liệu. Các MCU khai phá dữ liệu cho phép các công
ty hay các doanh nghiệp có thể dự báo được xu hướng trong tương lai.
Quá trình để khai phá dữ liệu là một quá trình rất phức tạp đòi hỏi dữ liệu cần
phải chuyên sâu và yêu cầu nhiều kỹ năng tính toán khác nhau. Hơn nữa, khai phá dữ
liệu không chỉ giới hạn trong việc trích xuất các dữ liệu mà còn sử dụng để làm sạch,
chuyển đổi, tích hợp dữ liệu và phân tích các mẫu.
1.2. Quy trình khai phá dữ liệu
Quy trình khai phá dữ liệu bao gồm 7 bước như sau:
- Bước 1: Làm sạch dữ liệu. Đây là bước loại bỏ nhiễu và các dữ liệu không cần thiết
và được đánh giá là khá quan trọng vì những dữ liệu bẩn nếu được sử dụng trực tiếp
trong khai phá dữ liệu có thể sẽ gây ra kết quả nhầm lẫn, dự báo và tạo ra các kết quả không được chính xác. - Bước 2: Tích
hợp dữ liệu. Đây là quá trình hợp nhất dữ liệu thành những kho dữ liệu
sau khi đã làm sạch và xử lý. Ở bước này, có thể giúp cho dữ liệu của chúng ta cải
thiện về độ chính xác cũng như tốc độ của quá trình khai phá dữ liệu. - Bước 3: Làm
giảm dữ liệu. Trích chọn dữ liệu từ những kho dữ liệu sau đó chuyển
đổi về dạng thích hợp cho quá trình khai thác tri thức. Quá trình này bao gồm cả việc
xử lý với dữ liệu nhiễu (noisy data), dữ liệu không đầy đủ (incomplete data), .v.v.
Mục đích ở bước này là giúp kích thước của dữ liệu có khối lượng nhỏ hơn nhưng nó
vẫn đảm bảo và vẫn duy trì về tính toàn vẹn. - Bước 4: Chuyển
đổi dữ liệu. Trong bước này, dữ liệu được chuyển thành một dạng
phù hợp với quy trình khai phá dữ liệu. Dữ liệu được hợp nhất để quy trình khai phá
dữ liệu có thể hiệu quả hơn và các mẫu dễ hiểu hơn. - Bước 5: Khai
thác dữ liệu. Đây là một trong các bước quan trọng nhất, trong đó sử
dụng những phương pháp thông minh để chắt lọc ra những mẫu dữ liệu. Ở bước này,
chúng ta đi khai thác dữ liệu là để xác định các mẫu và một lượng lớn dữ liệu từ những suy luận.
- Bước 6: Đánh giá mẫu. Bước này bao gồm việc xác định các mẫu đại diện cho nhiều
kiến thức dựa trên những thước đo, cho biết những kiến thức nào là cần thiết, kiến
thức nào là dư thừa và sẽ bị loại bỏ. Các phương pháp trực quan hóa và tóm tắt dữ liệu
được sử dụng để người dùng có thể hiểu được bộ dữ liệu của mình.
- Bước 7: Trình bày thông tin. Quá trình này sử dụng các kỹ thuật để biểu diễn và thể
hiện trực quan cho người dùng. Dữ liệu sẽ được diễn giải lại dưới các báo cáo, hoặc
các báo cáo dạng bảng,…
1.3. Ứng dụng của khai phá dữ liệu
Khai phá dữ liệu được ứng dụng rất nhiều trong đời sống xã hội tiêu biểu ở một
số những lĩnh vực như sau: phân tích thị trường – chứng khoán, phát hiện gian lận,
quản trị rủi ro doanh nghiệp, bán lẻ, trí tuệ nhân tạo, thương mại điện tử, phòng chống
tội phạm,… và còn rất nhiều các lĩnh vực khác.
Ở lĩnh vực thương mại điện tử nhiều công ty thương mại điện tử đang áp dụng
ứng dụng của Data Mining để bán hàng qua nhiều nước thông qua các trang web của
họ. Một trong những công ty nổi tiếng nhất ứng dụng điều này là Amazon. Họ sử dụng
các kỹ thuật khai phá dữ liệu để lái “những người đã xem sản phẩm đó cũng thích sản
phẩm được giới thiệu này”.
1.4. Công cụ khai phá dữ liệu được sử dụng trong bài nghiên cứu – Orange
Orange là phần mềm dùng để khai thác dữ liệu theo phương diện mã nguồn mở.
Orange giúp cho người dùng có một giao diện lập trình sinh động và trực, dễ theo dõi
chi tiết để phân tích dữ một một cách nhân nhất, chính xác, cụ thể. Orange là gói phần
mềm dựa trên những công cụ dùng để trực quan hóa dữ liệu, khai thác và phân tích dữ
liệu chính xác thông qua ngôn ngữ lập trình. Orange cũng là một phần mềm kết hợp
công cụ khai phá dữ liệu và học máy, và cung cấp những trực quan tương tác, thẩm mỹ
cho người dùng phần mềm, nó được viết bằng Python.
Orange là phần mềm hướng tới mục tiêu tự động hóa. Đây là một trong những
phần mềm khai phá dữ liệu tiện dụng, dễ dàng trong việc sử dụng nhờ giao diện nhỏ
gọn, các toolbox được sắp xếp một cách mạch lạc, hợp lý, bất kỳ ai cũng có thể sử
dụng. Vì vậy, Orange là phần mềm mà nhóm tôi sẽ sử dụng trong bài nghiên cứu.
2. Một số thuật toán sử dụng trong bài nghiên cứu
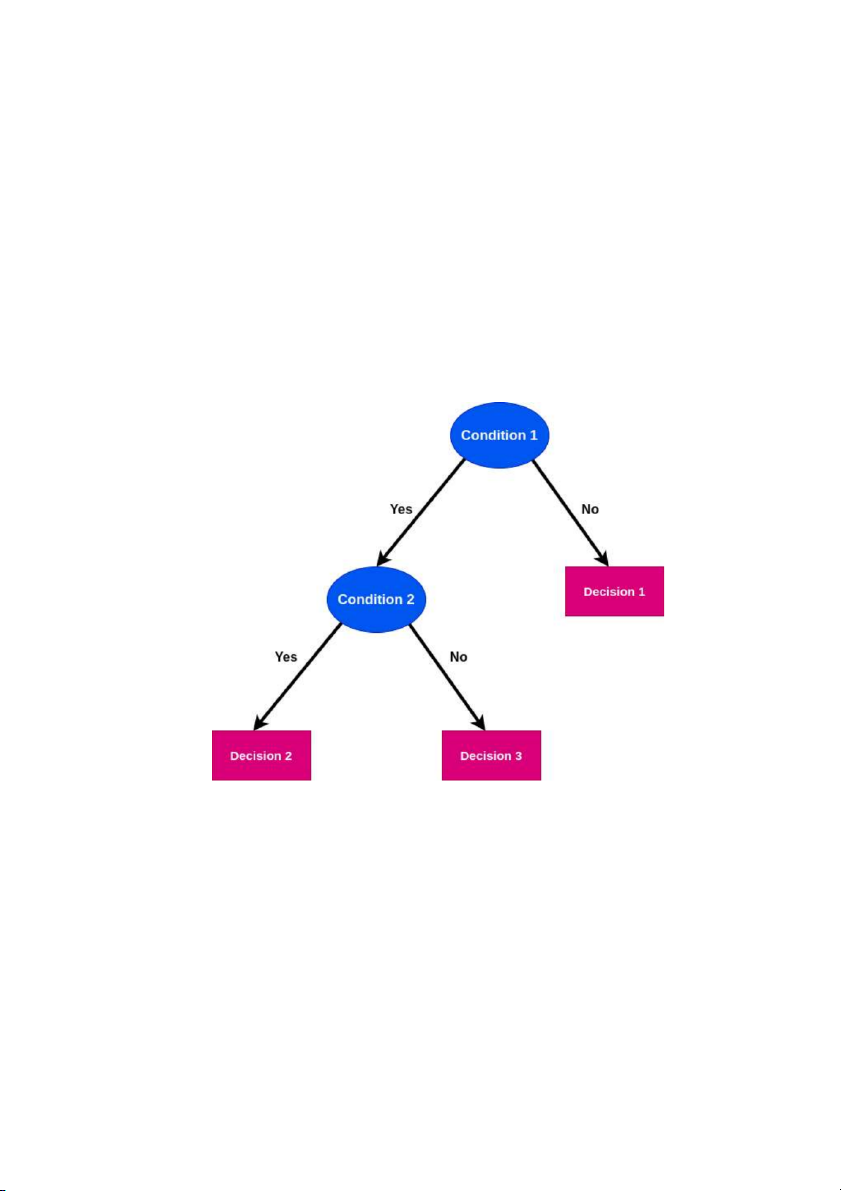
2.1. Phương pháp cây ra quyết định (Decision Tree)
Cây quyết định là một cây phân cấp có cấu trúc được dùng để phân lớp các đối tượng
dựa vào dãy các luật. Các thuộc tính của đối tượng có thể thuộc các kiểu dữ liệu khác
nhau như Nhị phân (Binary), Định danh (Nominal),Thứ tự (Ordinal), Số lượng
(Quantitative) trong khi đó thuộc tính phân lớp phải có kiểu dữ liệu là Binary hoặc Ordinal.
Từ dữ liệu về các đối tượng sẵn có, phương pháp cây quyết định sẽ giúp chúng ta mô
tả, phân loại, tổng quan dữ liệu cho trước này. Cụ thể hơn, cây quyết định sẽ đưa ra các
dự đoán cho từng đối tượng
Hình 2.1: Minh họa thuật toán phân lớp cây quyết định (Decision tree)
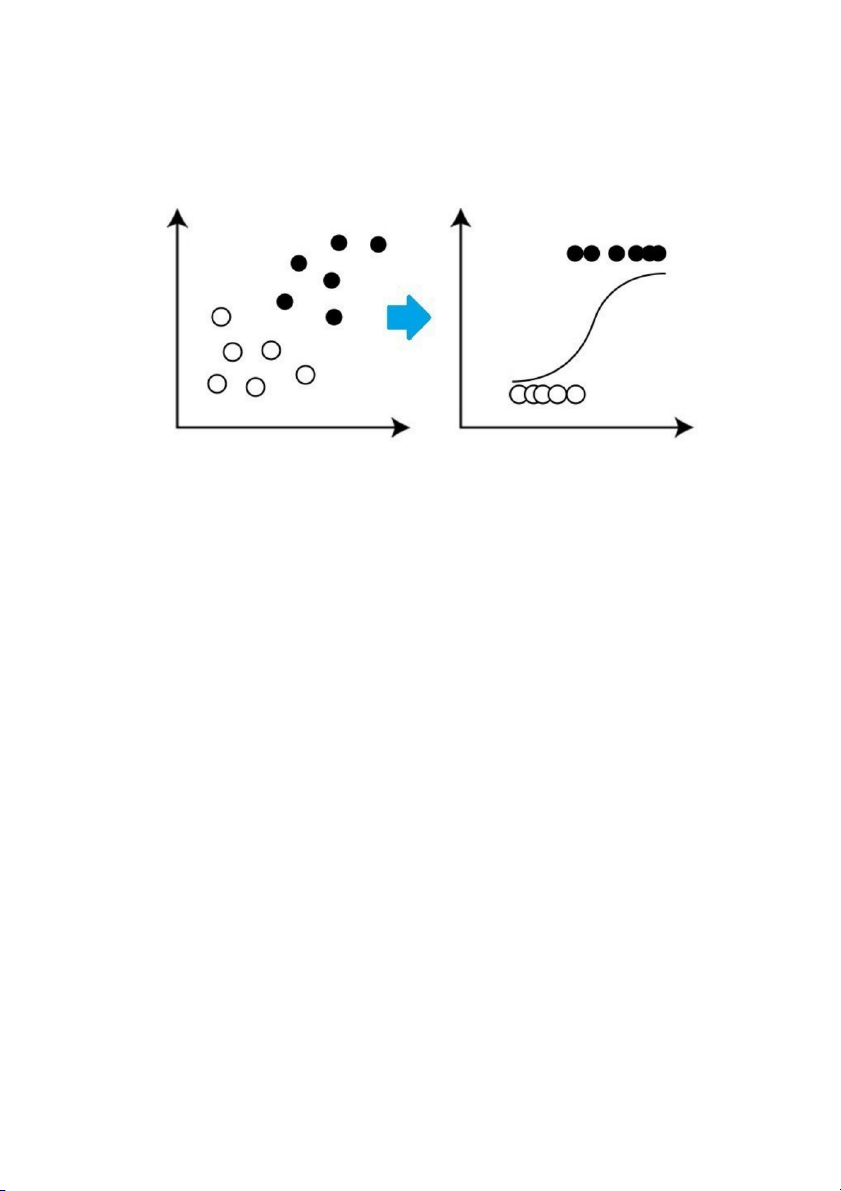
2.2. Phương pháp hồi quy logistic (Logistic Regression)
Hồi quy logistic là một mô hình thống kê ở dạng cơ bản sử dụng một hàm logistic để
lập mô hình một biến phụ thuộc nhị phân, mặc dù tồn tại nhiều phần mở rộng phức tạp
hơn. Trong phân tích hồi quy, hồi quy logistic (hay hồi quy logit) là ước lượng các
tham số của mô hình logistic (một dạng của hồi quy nhị phân). Về mặt toán học, mô
hình logistic nhị phân có một biến phụ thuộc với hai giá trị có thể có, chẳng hạn như
đạt / không đạt được đại diện bởi một biến chỉ báo, trong đó hai giá trị được gắn nhãn "0" và "1".
Hình 2.2: Minh họa thuật toán phân lớp Hồi quy Logistic (Logistic Regression)
Nguồn: ANALYTICS VIDHYA. Understanding Logistic Regression.
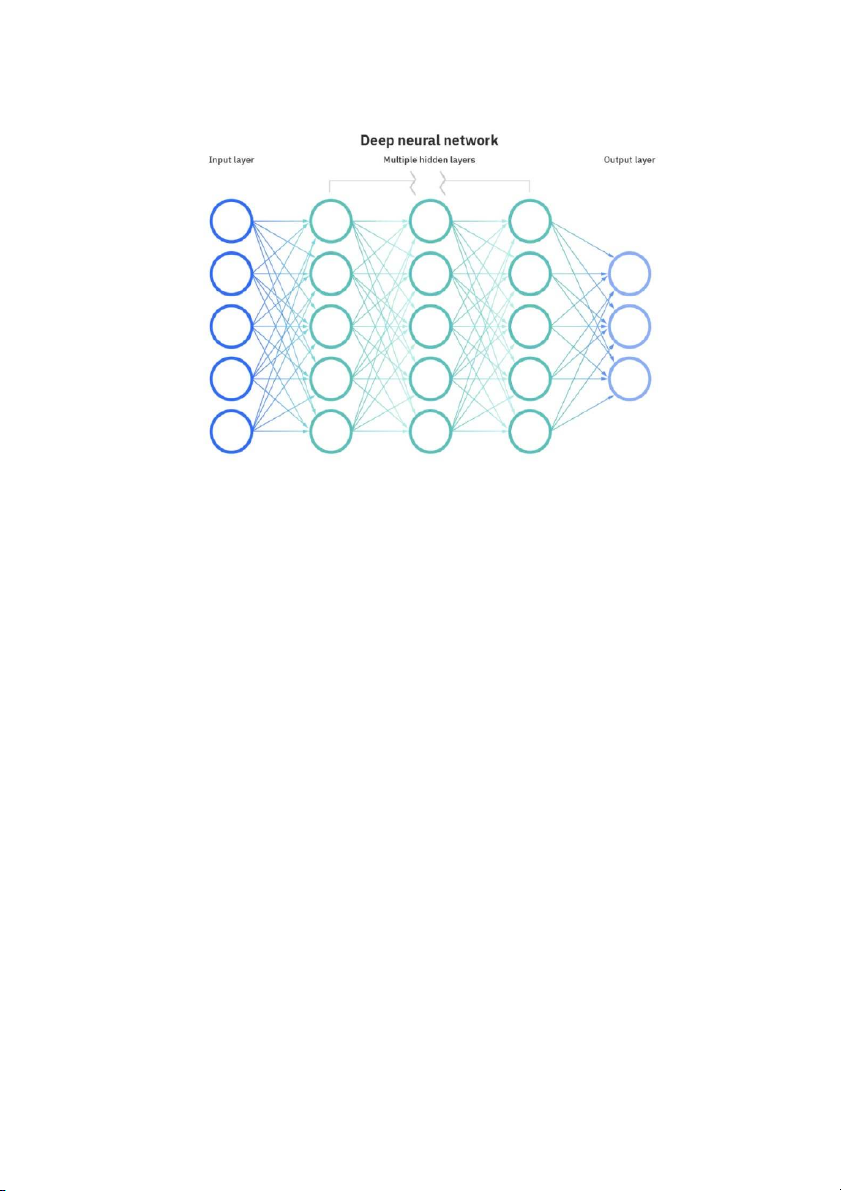
2.3. Phương pháp Mạng Nơ ron nhân tạo (Neural Network)
Mạng Nơ ron nhân tạo (hay Neural Network) là mạng sử dụng một loạt các thuật toán
phức tạp nhằm xác định, xử lý thông tin và tìm ra các mối quan hệ cơ bản tiềm ẩn
trong bộ dữ liệu. Lấy cảm hứng từ mô hình hoạt động của các tế bào thần kinh và khớp
thần kinh trong não của con người, Neural Network là sự kết nối các nút đơn giản, còn
được gọi là tế bào thần kinh. Và một tập hợp các nút như vậy tạo thành một mạng lưới
các nút. Mỗi nút có một cấu trúc tương thích với hàm hồi quy tuyến tính đa biến.
Chúng sẽ được sắp xếp với các lớp liên kết với nhau. Lớp đầu vào sẽ thu nhập các dữ
liệu đầu vào và các lớp đầu ra sẽ nhận các phân loại hoặc tín hiệu đầu ra mà các mẫu
đầu vào có thể phản ánh lại.
Thuật toán này có khả năng thích ứng được với mọi thay đổi từ dữ liệu đầu vào và đưa
ra được mọi kết quả chính xác nhất mà có thể giữ nguyên những tiêu chí đầu ra.
Hình 2.3: Minh họa thuật toán phân lớp Mạng Nơ ron nhân tạo (Neural Network)
III. MÔ HÌNH NGHIÊN CỨU ĐỀ XUẤT
1. Mô tả dữ liệu:
Trong các cột dữ liệu, cột Response là mục tiêu của bài nghiên cứu, cho biết
khách hàng có chấp nhận ưu đãi trong chiến dịch cuối cùng hay không. Sinh viên
sử dụng 80% dữ liệu để huấn luyện và 20% để kiểm tra dữ liệu. Các biến bao gồm: Tên cột Miêu tả đặc tính ID Mã số khách hàng Year Birth Năm sinh khách hàng Education
Trình độ học vấn của khách hàng Marital Status
Tình trạng hôn nhân của khách hàng Income
Thu nhập hộ gia đình hàng năm của khách hàng Kid home
Nhà có con trong độ tuổi trẻ em Teen home
Nhà có con trong độ tuổi thanh thiếu niên Dt Customer Ngày khách hàng gia nhập Recency Lần truy cập gần đây Mnt Wines
Số tiền chi cho rượu vang trong 2 năm qua Mnt Fruits
Số tiền chi cho trái cây trong 2 năm qua Mnt Meat Products
Số tiền chi cho thịt trong 2 năm qua Mnt Fish Products
Số tiền chi cho cá trong 2 năm qua Mnt Sweet Products
Số tiền chi cho đồ ngọt trong 2 năm qua
Tài liệu liên quan:
-

Lý do chọn đề tài báo cáo trong công việc - Tài liệu tham khảo | Đại học Hoa Sen
466 233 -

Models for warehouse management Classification and Project - Tài liệu tham khảo | Đại học Hoa Sen
222 111 -

Project Report Room for rent Group 4 - Tài liệu tham khảo | Đại học Hoa Sen
306 153 -

Brealey Fo CF 8ed Chapter 5 - Tài liệu tham khảo | Đại học Hoa Sen
291 146 -

Top 200 câu hỏi trắc nghiệm phân tích đầu tư và chứng khoán - Tài liệu tham khảo | Đại học Hoa Sen
1 K 481