Experiences with Managing Data Ingestion into a Corporate Datalake| Tài liệu tham khảo môn quản trị dữ liệu và trực quan hóa| Trường Đại học Bách Khoa Hà Nội
INTRODUCTION
The Hadoop Distributed File System (HDFS) [1] is an
inexpensive means of aggregating storage from commodity
machines across a cluster. It has been shown to scale to
petabytes of data [2] allowing organizations to store and
process data at a scale that had not previously been feasible
without very expensive dedicated systems. This has led to the
concept of a Datalake where a company can store their raw
data in such a way that it could be governed by one set of
policies but processed by multiple different teams [3], [4].
Môn: Quản trị dữ liệu và trực quan hóa 51 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.7 K tài liệu
Tác giả:






Preview text:
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/338037501
Experiences with Managing Data Ingestion into a Corporate Datalake
Conference Paper · December 2019
DOI: 10.1109/CIC48465.2019.00021 CITATIONS READS 3 359 5 authors, including: Sean Rooney Luis Garcés-Erice IBM
IBM Research, Zurich, Switzerland
59 PUBLICATIONS 560 CITATIONS
46 PUBLICATIONS 1,031 CITATIONS SEE PROFILE SEE PROFILE Daniel Bauer IBM
54 PUBLICATIONS 551 CITATIONS SEE PROFILE
Some of the authors of this publication are also working on these related projects: IcorpMaker View project Gaming View project
All content following this page was uploaded by Sean Rooney on 19 December 2019.
The user has requested enhancement of the downloaded file.
Experiences with Managing Data Ingestion into a Corporate Datalake
Sean Rooney, Daniel Bauer, Luis Garc´es-Erice, Peter Urbanetz, Florian Froese, Saˇsa Tomi´c
IBM Research, Zurich Laboratory 8803 R¨uschlikon, Switzerland
E-mail: {sro,dnb,lga,urb,ffr,sat}@zurich.ibm.com
Abstract—We explain our experiences in designing, building
if the Datalake is to become a central store for all data in
and running a large corporate Datalake. Our platform has been
the company. In this paper we share our experiences with
running for over two years and makes a wide variety of corporate
ingesting data into a large corporate Datalake built by a global
data assets, such as sales, marketing, customer information, as
company for storing its own data. We describe the challenges
well as data from less conventional sources such as weather, news
and social media available for analytics purposes to many teams
we faced and describe the choices we made. In particular, we
across the company. We focus on describing the management of
describe the overall architecture (and how we came to it) in
data and in particular how it is transferred and ingested into the
Section II, we describe how data is brought into the Datalake platform.
in Section III and look at the implementation aspects of the
ingestion process in Section IV, highlighting features such as I. INTRODUCTION
scalability and recovery from failure.
The Hadoop Distributed File System (HDFS) [1] is an II. ARCHITECTURE
inexpensive means of aggregating storage from commodity
machines across a cluster. It has been shown to scale to
Initially, we didn’t know how much data would be brought
petabytes of data [2] allowing organizations to store and
into the Datalake LandingZone, what kind of data it would be
process data at a scale that had not previously been feasible
or the technical skill of those doing the ingestion. We did know
without very expensive dedicated systems. This has led to the
that a lot of our company data was stored in geographically
concept of a Datalake where a company can store their raw
distributed silos in relational databases (mostly DB2), so we
data in such a way that it could be governed by one set of
decided to privilege this particular ingestion use case while not
policies but processed by multiple different teams [3], [4].
excluding others. We also understood that multiple different
Hadoop introduced the concept of schema-on-read for data
teams would be involved in bringing data into the Datalake
management, whereby data can be stored independently of the
as ownership and responsibility of the data sources were
tools that the teams choose to process it. This greatly increases
distributed across the company.
the flexibility of the platform as data can be ingested without
Our first decision was to introduce the notion of a data asset
consideration of the exact computation engines that are best
as a unit by which data in the Datalake would be managed.
suited to extract information from it.
We tried to make this as general as possible by defining a data
Initially Hadoop proposed Map/Reduce as the preferred asset as having:
way of processing data, but because SQL is the lingua-franca • a unique name;
of many data engineers the community developed tools for
• an access policy with pre-defined roles and their mem-
executing SQL on Hadoop. Although, this has been extended bership;
by both proprietary systems such as Impala [5] and open
• a set of data source systems containing the asset’s data.
source projects like Drill, the central component of SQL
The policy consists of 3 roles: A Consumer role which
on Hadoop remains Hive [6]. Spark [7] emerged to support
grants read access to the data asset; a Producer role which
use-cases where SQL was not sufficient for analytics, e.g.,
grants the user the right to bring data into the Datalake for that
Machine Learning, Graph Processing etc. In our experience,
data asset; an Owner role which identifies who is ultimately
most people manipulating data in the Datalake are using some
responsible for the data made available. Membership of those combination of Spark and SQL.
roles is assigned through groups in a dedicated Datalake
In a corporate environment most data (certainly the most
LDAP. It then becomes the responsibility of the data asset
valuable data) is kept in relational databases. The reference
owner to approve role membership and to actually perform
tool to bring relational data onto HDFS is Sqoop [8], although
the operation of moving the data onto the platform with the
there is no lack of proprietary tools to achieve the same. Sqoop
tools and processes we provide. Our assumption was the data
connects to a large variety of databases using JDBC, and
asset owner could reasonably be expected to understand the
stores tables on HDFS, for example in Parquet [9] format.
technology in which their data was stored, but could not be
Other means to bring data onto Datalakes are Flume, Nifi and
expected to have much (or indeed any) knowledge of the core
Kafka. Many different ingestion tools need to be integrated Datalake systems.
This led us to divide the Datalake into different zones with
Kerberos to interact with the rest of the cluster while imperson-
which consumers and producers interact. In particular:
ating the user that was authenticated, such that access control
can be applied to the user making the request and not the
• A DropZone in which data producers have full control
over the data asset, to copy it, change it etc. and with service itself.
which they interact using the tools they think most
Internal processes such as ingestion, which for performance appropriate.
reasons require direct access to system components (e.g. call-
ing HDFS directly, not through the WebHDFS REST API),
• A LandingZone which is an immutable store of canonical
data assets, that is cataloged, monitored and which can
are given an actual Kerberos identity. This distinction between
only be updated via the well defined ingestion process.
user and processes is somewhat artificial, but:
By canonical we mean a data asset that belongs to the
• makes management of users much simpler as they don’t
authorized data sets available in the Datalake. Projects
need explicit Kerberos identities;
interact with the data assets in the LandingZone via
• forces interaction with the Datalake through well defined
the tools we provide i.e. SQL, Spark and WebHDFS.
interfaces that can be monitored for auditing, as direct
Users request read access to specific data assets via a
Kerberos communication is not possible; governance process.
• allows the Datalake Kerberos domain to be isolated
• An IntegrationZone in which projects using the Datalake
through a firewall from the rest of the company network.
can store enriched forms of data for particular project
The Datalake infrastructure deploys its own LDAP registry
needs. Data produced in this zone can also be ingested
which is synchronized periodically with the corporate enter-
into the LandingZone following the same processes as
prise LDAP service. The corporate registry implements well-
other data assets, whereby it becomes part of the canon-
defined processes for creating and managing LDAP groups, ical set.
assuring ID uniqueness, and automatically removing employ-
ees leaving the company, all of which the Datalake LDAP
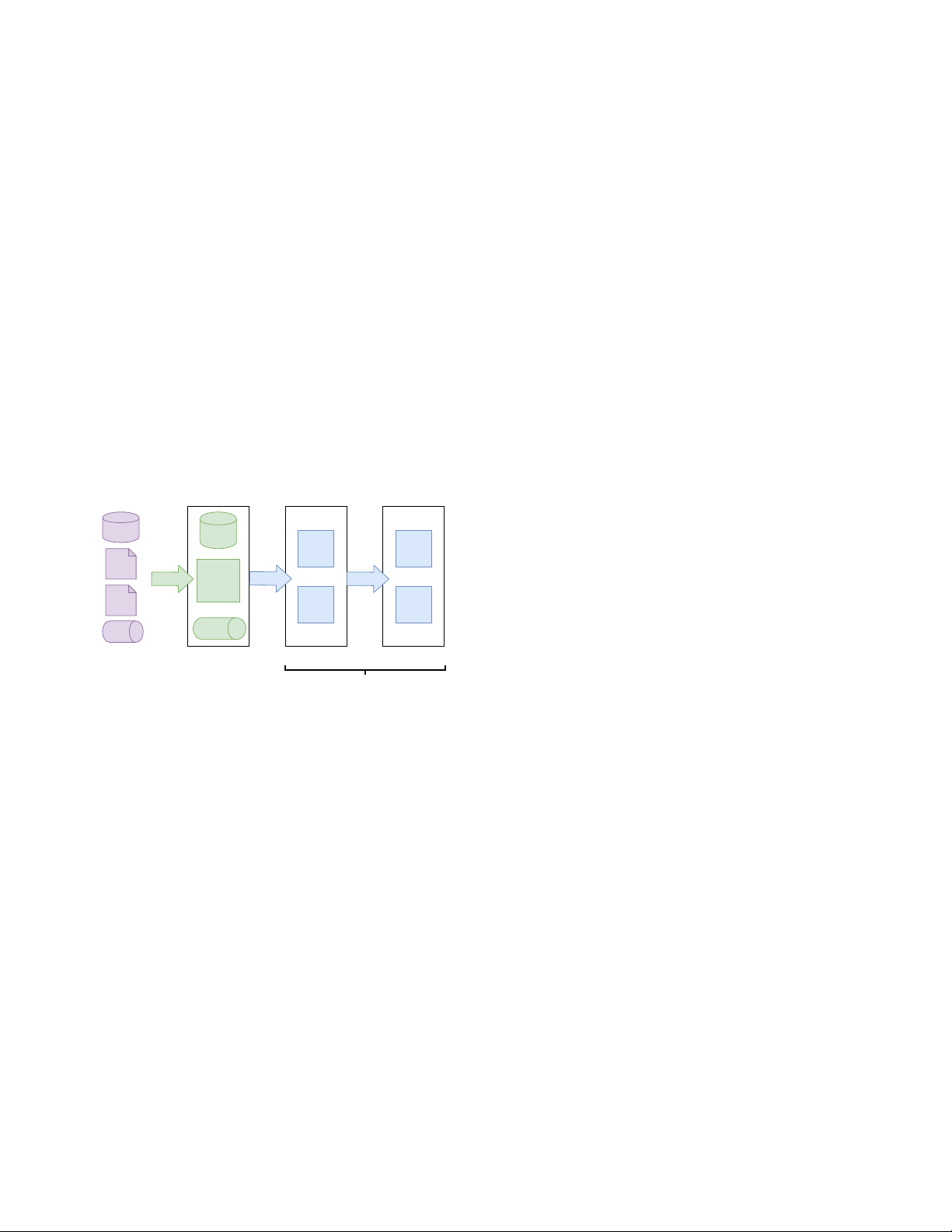
inherits to simplify its own administration. In the Datalake RDBMS DropZone
LDAP we introduce additional information about the users DB Parquet Parquet
to make that available in the Hadoop cluster, such as user CSV Files Files XML
names that conform with the restrictions found across all the JSON HDFS Transfer DropZone Ingest Transform (Files) supported applications. Unstr. Archive Archive Files
In the LandingZone, Ranger rules are used to control access Files Files
to the data on HDFS. Each data asset has an associated direc- Kafka Kafka Topic DropZone
tory with a rule that grants read access to the corresponding Operational DropZone LandingZone IntegrationZone Data Sources
consumer group. On the SQL interface, the SELECT privilege Data Lake Core
is granted to the same group on the tables corresponding to the
data asset. On Kafka (through a custom plugin), read access
is granted to the same group on the corresponding topics and Fig. 1. Datalake Zones
another Ranger rule is put in place to control access to the
location on HDFS where data from those topics is dumped.
Figure 1 show the distinct phases in moving data into the
This is possible because the Datalake LDAP makes the group distinct zones.
information available to all these technologies in a coherent
The zones are not defined by specific technologies (a given manner.
zone may be supported by multiple technologies) but rather
Before data enters the Datalake, an on-boarding process
by the classification of the data that they contain: ungoverned,
captures the source of the data, ownership, data classification canonical, enriched.
and special requirements, among other information. Data clas-
Being a complex, heterogeneous, distributed computing
sification is used in defining the necessary protection policies
environment housing a large array of data assets of varying
as mandated by corporate security standards and regulatory
sensitivity accessed by a diverse user community, numerous
obligations (e.g., GDPR). Access to specific data assets is
security challenges presented themselves. Further, security was
through a governed process resulting in the inclusion of users
added to Hadoop as an afterthought [10]; we follow standard
in LDAP groups aligned to the data asset.
practice and use Kerberos [11] for authentication between sys-
tem components in the Hadoop cluster. This enables internal
III. BRINGING DATA INTO THE DATALAKE
policies and prevents rogue nodes from joining the cluster.
The process of bringing data from the source systems into
As Kerberos is used strictly within the cluster core, most
the Datalake is divided into related but distinct tasks: the
human users do not interact with the Datalake over Kerberos.
creation of a data asset; the transfer of data across typically
Instead, users interact with the cluster through selected entry
geographically separated systems as efficiently as possible; the
points, most notably the Knox gateway and BigSQL, which
ingestion of data into the Datalake such that it is cataloged,
use standard corporate credentials rooted to the enterprise
governed and made available to consumers. We now explain
LDAP registry. These subsystems themselves however use these tasks in detail: 2 A. Data Asset Creation
The notion of a DropZone initially involved some reticence
When a new data asset is to be brought into the Datalake,
from the asset owners as they perceived it as overhead. Why
the asset owner specifies the type of data and a DropZone
move data into a DropZone and then have to move it into the
is created. Different types of data are supported by different
LandingZone, why not do it directly? As they used the system,
technologies within the DropZone. For example, when a new
however, the fact that they could use the same tools they were
relational database is to be made available on the Datalake,
accustomed to and the minimal overhead introduced by the
a database is created in the DropZone. An LDAP group is
highly parallelizable task of copying from the DropZone to
associated with the producer role for the data asset granting
LandingZone over multiple 10 Gb Ethernet links, convinced
members administrative access to that database. The data asset
them. Note that owing to the nature of HDFS in-place updates
owner can then add whoever they think is appropriate to this
of data on the filesystem cannot be done. Consequently, each
LDAP group via a governed process. Once the data is copied
time new data is ingested into the LandingZone, the existing
into the corresponding database in the DropZone producers
data is over written or appended. Ingestors can however move
can then trigger the transfer of data into the LandingZone by
data incrementally to the Relational Database in the DropZone
invoking the ingestion REST API.
and from there do a full overwrite into HDFS.
The main advantage of the DropZone from an operational B. Data Transfer
point of view is that it removes the need of the Datalake
We didn’t specify any particular tools to copy the data into
to interact with an arbitrary set of source systems (Netezza,
the DropZone, but had assumed that system administrators
MySQL, MSSQL), with different drivers and versions. It also
would write scripts using low level tools to actually move
removes operational dependencies imposed on the ingestion
the data. We find in practice that the teams bringing the data
process by the production source system, e.g. having a par-
tend to prefer commercial ETL tools to actually coordinate
ticular table inaccessible because it was being updated and
the data transfer, despite the fact that these are sub-optimal
thus locked for reading operations. Furthermore, it allows us
for the simple moving of bytes from one location to another.
to delegate the actual movement of data to many different
The advantage of having a standard graphical user interface
teams, each of which understands the nature of their data sets
and the ability of even inexperienced employees to coordinate and systems.
the data movement trumps the disadvantages for most asset
We initially configured the DropZone database system as a
owners. This observation led us to two refinements:
High Availability (HA) scalable cluster, so that it could sustain
DropZone User Defined Function The ingestion REST
a large number of simultaneous connections. We found that
interface was not easy to integrate into the ETL tools so we
this actually caused more problems than it solved, confus-
developed a User Defined Function (UDF) on the DropZone
ing producer teams and making operations and maintenance
database that invokes the ingestion REST service. This UDF
unnecessarily complex. In the end we found that using large
is designed to be executed by a standard SQL operation
stand-alone database systems for the DropZone was sufficient.
i.e. SELECT, which can conveniently be made part of an
This can be scaled by simply creating a new independent
ETL pipeline defined using tools such as Data-Stage [12]. The
database system when the load on the existing ones exceeds
description of which data is to be ingested and the method of a threshold.
ingestion are defined as parameters to this SELECT statement.
The concept of a DropZone maps naturally onto other forms
The UDF signals to the Datalake via a convenient notification
of data. For data available as files we create a DropZone area
that this data should be ingested. This ingestion request is
on HDFS where we grant data asset producers the ability
scheduled and performed at a later time. As a database object,
to write data. Each data asset is assigned a directory, and
the UDF is protected using the permission mechanisms of
access control is performed through a Ranger [13] rule in
the database to grant the only LDAP producer group the
HDFS allowing the producer group in LDAP to write to that
EXECUTE privilege on the UDF for the given data asset.
location. The ingestion of different files follows a different
The insertion of the UDF is performed during the creation of
process depending on how data needs to be transformed to
a DropZone database. As only users that are allowed to ingest
be stored on the LandingZone, but the moving of the raw
data into the Datalake for that data asset can connect to the
data follows the same process. The producers of the data
corresponding DropZone database, access control is essentially
asset interact with HDFS, typically by uploading files via the
delegated to the DropZone. The ability to read the tables of
WebHDFS REST API to the DropZone. For cases where it
the database for transfer into the LandingZone is enabled by
is more convenient to pull data from the source, the team
inserting a special system identity with appropriate rights into
developed YARN applications that did this for specific storage
every DropZone database when it is created.
system e.g. sFTP. There are two forms of file data: data that
User Interface As the compelling argument for the use of
is structured or semi-structured in nature, but available in file
the ETL tooling was the User Interface, we wrote a UI for
formats (e.g. JSON, CSV, XML, etc.), and data in unstructured
database system administration operations like federate and
format (e.g. PDFs, log, or media files). Ingestors of CSV files
load which hides their complexity by concentrating on the
are required to supply a description of the metadata in an
most common use case. This was radically faster than using
appropriate form in a dedicated file. Schema inference was
ETL tooling and was adopted by many of the asset owners.
used for file types like XML and JSON. In addition, JSON 3
and XML data sets containing nested structures are flattened
in the Datalake. Governance distinguishes between different
(normalized) and stored in multiple tables. The appropriate
forms of metadata, business metadata, technical metadata etc.
foreign key relations are put in place such that the original
For example, business metadata would involve tagging data
nested structures can easily be reconstructed.
items with terms such as CLIENTDATA to indicate what
For streaming data we define a data asset as a collection
aspect of a business the data pertains to. These typically
of related Kafka [14] topics. We require data asset owners to
require domain experts to do the labeling. Technical metadata
publish messages into topics on a Kafka DropZone cluster,
is simply a description of the data itself, for examples the
controlling access through LDAP groups. Consumers of the
types of table columns. When data is relational in nature,
data asset are then allowed to read from the corresponding top-
technical metadata is automatically extracted from the tables
ics. For permanent storage, data from the topics is periodically
in the LandingZone during the ingestion process. As stated
written into the LandingZone in an asset-specific directory
previously when the data is unstructured, the producer is
using a Confluent Kafka Connect HDFS adapter [15], where
required to supply a file containing metadata as a set of
it can be used by analytics batch processes.
key/value pairs. This is then used to update the technical
Note that a single data asset may be associated with multiple
metadata. As part of the ingestion process,the audit log that
DropZone types if the sources for the data are heterogeneous:
records the status of each ingestion on a database is updated,
for example, some tables in a data asset may be copied from a
as well as who requested it and when. Finally, a notification
source database while other parts of the same data asset may
is sent to an event queue to signal that the ingestion has
be available only as CSV files.
completed. In the next section, we highlight some of the
implementation details of the ingestion process. C. Data Ingestion
Data ingestion is not primarily about copying data, but
IV. BATCH-INGESTION PROCESS IMPLEMENTATION
rather about ensuring that the process of ingesting data into
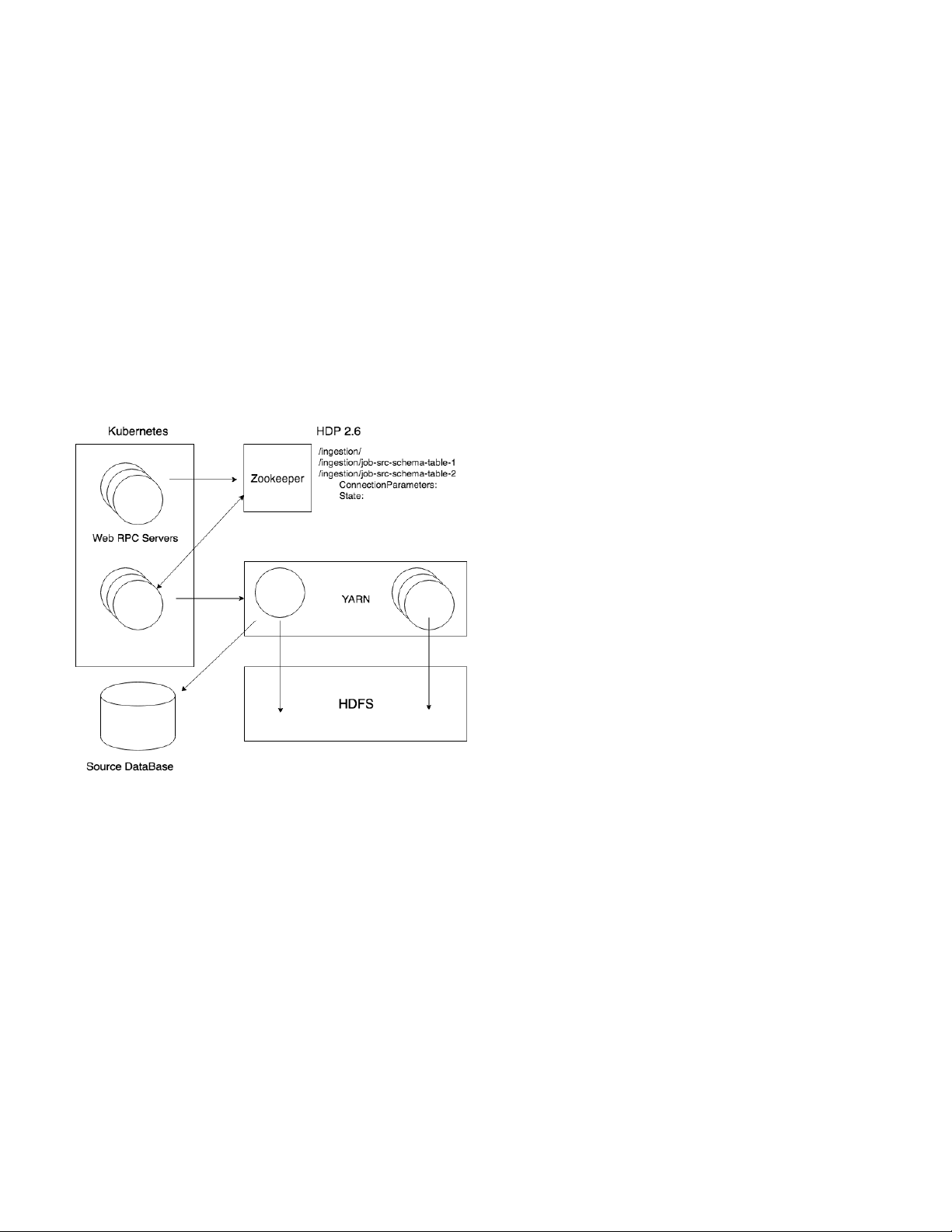
We use the Hortonworks Data Platform (Version 2.6) [16]
the lake is a governed and auditable process. For compliance
for data storage and processing, while control and management
reasons it is necessary to record who brought the data into the
processes are run on Kubernetes [17] on a separate cluster.
Datalake, when this occurred, the nature of the data, who can
We chose HDP for its integration with BigSQL [18] which access it etc.
from the client’s view point is almost fully equivalent to DB2.
For a data asset to be ingested, data clearly needs to be
Docker is a convenient way of packaging software and an
copied into a dedicated location, but it also needs to be
orchestration platform like Kubernetes allows for automatic
made part of a catalog of data available in the Datalake. The
restart, scaling etc, Currently, the control and management en-
Governance Catalog is where data assets are listed, classified,
tities directly interact with the following Hadoop components:
and policies describing the acceptable usage of the data can
Zookeeper, Yarn, Oozie, Ranger, Spark and HDFS. be published.
Zookeeper [19] is used to store the description of the
For the actual data copy, relational and file data ingestion
ingestion jobs. Each node in the dedicated path in Zookeeper
is requested via the ingestion REST API, either directly or
contains the description and the state of the job to be per-
indirectly via the UDF described previously. Normally this
formed containing all the parameters that the actual ingestion
is the final step of the data transfer into the Datalake as far
work-flow requires to complete. This is populated when users
as the ingestors are concerned. The use of the UDF remains
trigger the ingestion REST interface. Zookeeper gives us
the most common way of triggering data ingestion into the
useful features such as atomicity and high availability. Storing LandingZone.
the job state in Zookeeper allows us to make the processes
The direct invocation of the REST API is required when
running the ingestion jobs entirely stateless. This simplifies the
ingesting file data, as directories on HDFS have no equivalent
recovery from failure when arbitrary system components fail,
of a database UDF. In this case users need to explicitly authen-
as a restarted or auxiliary process can pick up the ingestion
ticate themselves via user name and password as part of the process from where it left of.
REST call. The ability to read the contents of every directory
The control component that starts ingestions is called an
in the HDFS DropZone space is given to the functional user
IngestionController (IC). The responsibility of the IC is to
which runs the ingestion process.
monitor a branch in the Zookeeper directory structure. It wakes
The ability to write to the DropZone enables the capability
up when a new entity is added by a producer through the
to load/update the data of that asset in the LandingZone.
Ingestion REST service. The IC reads the configuration and
The process that actually performs the ingestion however is
uses it to schedule the ingestion job. Multiple ICs are run so
automated and outside the control of the data asset owner,
they compete to determine which one actually gets to start
allowing it to be standard across all data assets.
and monitor the job. The job is implemented as an Oozie [20]
From a functional point of view, the ingestion process
work-flow. Oozie describes a work-flow as a directed acyclic
connects to the DropZone and copies the requested data to the
graph of actions, using YARN [21] to run each action on the
canonical location on the HDFS LandingZone, converting re-
Hadoop cluster. As such, Oozie hides all the details of running
lational data to Parquet [9] format. In addition, the Governance
applications in a distributed environment, and orchestrates the
Catalog is updated to register the fact that data is now available
execution of complex jobs, for example handling partial failure 4
in the job execution, restarting not from the beginning but from place.
the action which failed. However, integrating Oozie with more
We use a simple naming schema such that the data
recent technologies such as Spark is not very well documented,
from table TABLE from a schema SCHEMA from a
especially in a “Kerberized” environment which relies heavily
data asset ASSET is placed in a HDFS directory called on impersonation of users.
ASSET/SCHEMA/TABLE and the table TABLE created in
Although initially we assumed we would have com-
BigSQL is in the corresponding schema, ASSET_SCHEMA.
plex work-flows involving specific types of processing
We initially tried to use the SPLITBY feature of Sqoop
(e.g. anonymization of data) which would allow teams to
to parallelize the ingestions. SPLITBY partitions the Sqoop
augment the ETL capabilities of the Datalake ingestion, we
job among different mappers in a Map/Reduce job using
found this involved too tight coupling in the development,
the provided SPLITBY key on the original table. It is very
administration and maintenance of the work-flows. Instead,
difficult to determine a good SPLITBY key as the partitioning
we use Oozie for ingestion into the LandingZone and send
algorithm simply looks at the range for that column and
a notification of an ingestion event on a dedicated Kafka
splits it into N mappers. In practice, we found that most
topic. This allows other teams to trigger their own post-
tables actually do not have a suitable column to SPLITBY.
ingestion work-flows upon receipt of the notification using
For example, for a table with a million rows with a col-
their preferred technology. We now detail some features of
umn that represents an integer where almost all the values the implementation.
are close to 100 and one is zero, 10 mappers would get
assigned the ranges [0. . . 9],[10. . . 19],. . . ,[90. . . 100]; the first
mapper reads one row, the next eight nothing and the last
one processes almost all the rows. The result is that there
is no real parallelization and resources are wasted, as CPU
and memory get assigned for each mapper running. This is
compounded by the fact that values at the end of the range
of a given type are often used by the data owner to have
special meaning, i.e. “0” means undefined. We tried to address
this by dynamically creating views of tables with a special
monotonically increasing ROWNUMBER field, such that the
table could be SPLITBY in uniform blocks, but we found that
this was problematic in practice as it was difficult to ensure
that the virtual ROWNUMBER was consistent when accessed
by processes in parallel. Currently we advise ingestors to use
the SPLITBY feature if there is a column in the actual table
with a more or less uniform distribution.
b) Creating the Relational Representation: We explicitly
connect to the database from which the table is ingested in
order to extract its technical metadata. We create the table
after the data had been transferred to HDFS, using the repre-
sentation closest to the original, given the constraints imposed Fig. 2. Batch Ingestion
by Hive. We found that some table constraints from the
source database could be used by the BigSQL query planner
Figure 2 summarizes the components involved in batch
to create a better query plan, even though the constraints ingestion.
were informational only, i.e. they were not enforced by the
a) Copying Data into the LandingZone: When the source
database system. For example, registering that a column is
data is in a relational database table we use Sqoop to actually
a primary key in the source table allows the query planner
move the data. BigSQL, the SQL/Hadoop system we use,
to assume uniqueness of that column and thereby optimize
offers a wrapper around Sqoop via a SQL statement LOAD
certain queries, even though the notion of an index does not
HADOOP which loads the data into a table in Hive. Through exist in BigSQL.
benchmarking we determined that the Parquet format was
Creating a database table involves accessing the system
faster for most use cases than the alternatives. As a result, we
tables of BigSQL, which can block if users have a lock on
use Parquet for storing all relational data within the canonical
those tables; we therefore adopted the approach of checking
data set in the LandingZone. ORC [22] was not available at
whether the table with the same schema already exists on the
the time for BigSQL; since then we have tested it and found
system and executing the CREATE TABLE only when the
ORC performs approximately the same as Parquet for our most
table doesn’t already exist or when its schema has changed.
common use cases. We explicitly state a location on HDFS
This helps to reduce the crosstalk between users.
rather than use the default Hive location so that we can manage
c) Ensure Access Control is Applied to the Data: At the
access to the raw files without interfering with Hive ACLs in
SQL level the SELECT, i.e. READ, privilege is granted on 5
the tables of an asset to the LDAP groups that grant the
are already hosted on a platform that allows processing and
consumer role, i.e. all the tables brought when data asset
combination with other data at scale.
ASSET is ingested are automatically accessible to members V. INGESTION OF STREAMING DATA
of the ASSET_CONSUMER LDAP group. The actual parquet
files are created at the corresponding location on HDFS as
Data from streaming data sources are also stored in the
explained before. Some users require file level access to the
HDFS LandingZone. However, there are a few key differences
data either to run analytics Spark jobs or simple to copy the
between batch and streaming data ingestions:
data from the Hadoop cluster into other systems. Logically,
• batch data ingestions are performed on demand or peri-
only the users that can read the data via SQL, should also
odically while streaming data ingestions are performed
be able to read the data on HDFS. Within the Hadoop continuously,
cluster we use Ranger to impose access control rules on
• data producers can set different requirements in each
the systems for which Ranger plugins are available. Ranger
batch ingestion (e.g. update the metadata or not), while
supports an HDFS plugin, which is implemented as a distinct
this is much harder to do in a streaming data ingestion;
authorization layer within the HDFS stack. This layer has the
• batch data ingestions are a traditional way to ingest re-
same API as the standard HDFS authorization layer and is
lational data, and the tool-chains for batch data ingestion
completely transparent to applications. It gets the rules from are much more mature.
the centralized Ranger policy engine. So, for example, one can
In addition to these general observations, since the principal
configure that only members of a specific LDAP group can
technology for managing relational data in our Datalake is
read a specific location on HDFS. The Ranger plugin caches
BigSQL, which stores data in immutable Parquet files on
the state of the rules, refreshing them periodically, such that
HDFS, it is impossible to perform individual updates or inserts
the impact on I/O throughput is minimal. Upon creation of the
to the existing data. Therefore, for the streaming data inges-
data asset in the Datalake, the Ranger rule which defines the
tions we provide different levels of support for the two use
policy enforcement is also created.
cases: unstructured (or semi-structured) data and structured
d) Update the Governance Catalog: Once the data trans- data.
fer is complete, the Oozie work-flow described in Section IV
a) Streaming Ingestion of Unstructured Data: The in-
contacts the Governance Catalog to update the technical
gestion framework of choice for streaming data ingestion is
metadata about the asset. This is an optional step that can be
Apache Kafka, extended with our custom libraries for LDAP-
disabled when the data producers know that the table structure
based authentication and authorization. Access to Kafka
is unchanged and therefore the update to the metadata is not
topics is controlled using Kafka ACL rules and LDAP required.
groups, such that a certain group (e.g. ASSET_PRODUCER)
The metadata update is performed by invoking an applica-
has write access to a topic, and another LDAP group
tion that gathers technical metadata for the type of asset. The
(e.g. ASSET_CONSUMER) has read access to a topic.
Catalog is provided with credentials which in turn can access
Data producers are provided with a set of topics to which
the different systems to extract the required information.
they can push data in either text or binary format. The
For example, upon ingestion of a table from the DropZone
majority of data producers selected JSON formatting for data,
into the LandingZone, the Catalog can access the relational
which is textual and semi-structured. The data is stored in
representation of the table in BigSQL to extract the column
the Kafka topics for a limited time, and then deleted. For names and their types.
persistent storage, we have set up Confluent Kafka HDFS sink
e) Update the Logs: As the Ingestion Controller moni-
connectors, which write data from Kafka topics into predefined
tors the progress of a particular ingestion job, it updates the
HDFS folders, in a compressed format to reduce the impact
status in a log kept in a database. The purpose of the log is
of the JSON file format verbosity. The data on HDFS is twofold:
partitioned by year/month/day, such that data analytics can
• It allows producers to monitor the state of the ingestion
easily target a subset of data, if desired.
jobs requested for their assets.
Data consumers can connect directly to the topics, if they
• It provides an audit log about what data was ingested on
need real-time access to the most recent data, and run data
which date, where it originated from and who requested
exploration or analytics jobs over the recent data using tools
the ingestion. This is essential to verify the chain of
such as Apache Spark, Flink, etc. Alternatively, in the case data
approvals leading to the data being made available in the
consumers need access to historical data, they can connect to
Datalake, and to estimate how recent or up to date data
the HDFS storage and run analytics over the partitioned and is. archived historical data.
Although we initially started offering logs in a stand-alone
b) Streaming Ingestion of Structured Data: Some users
database, we revisited this decision to finally have all logs
need to ingest structured data, e.g. relational database table
hosted on the SQL/Hadoop system itself. This removes one
rows, into the Datalake in a streaming fashion. The functional
extra component that needs dedicated maintenance and config-
requirements of such users stem typically from either: 1)
uration, and consolidates all data on the Datalake, improving
having a streaming data source (e.g. performance metrics, logs,
its availability. Analysis of the logs is also easier as they
events) but no strong need for real time visibility of new data, 6
or 2) requiring a real time view of the updates, for example to
time, i.e. a weekend’s backlog can be handled in an hour. As
ensure consistency across different data assets. In the former
the offered load increases we can scale the CPU and memory
case, the data updates can be aggregated and batch-updated allocated to YARN accordingly.
on HDFS such that BigSQL and other data analytics systems
can get regular updates without a significant performance or
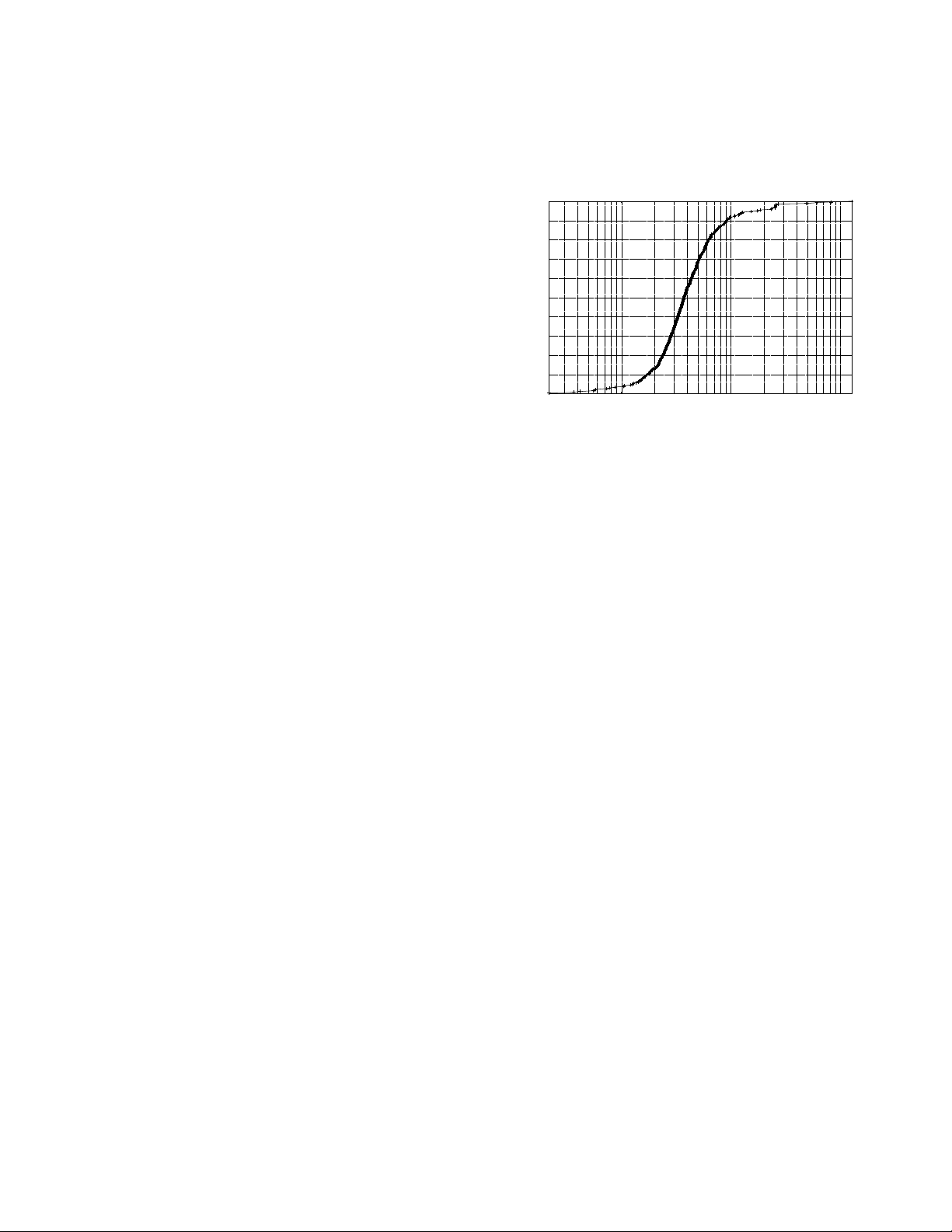
CDF of the ingestion times into the Data Lake
resource impact. In the latter case, however, real-time updates 100
directly in BigSQL are not an option and such users can 90
use another DBMS storage system suitable for small real- 80
time updates, such as DB2 Warehouse or DB2 Event Store. If
necessary, data from these alternative DBMS storage systems 70
can be periodically ingested into the central BigSQL store. 60 50 VI. SCALING CDF (%) 40
More than a hundred teams bring data to the Datalake, 30
and more are currently on-boarding. It was therefore critical 20
to architect the system in a horizontally scalable way. The 10
Ingestion Controller and REST API can be scaled out easily, 0
as the only state they require is kept in Zookeeper. ICs and 1 10 100
REST APIs run in Kubernetes [17]. The number of replicas for Time (minutes)
a given container can be increased or decreased on-demand,
and in the presence of errors are restarted automatically. Fig. 3.
Distribution of the data ingestion times into the Data Lake.
The Oozie work-flow performing the ingestion runs in
YARN in the Hadoop cluster. As new ingestion requests arrive
The largest tables have billions of rows, but the vast majority
and the jobs are submitted to Oozie, they get queued in the
are much smaller. 94% of ingestions finish in less than 15
YARN resource manager. YARN allocates resources to queues.
minutes and 99% in less than 2.5 hours (see the cumulative
Applications get assigned to queues where they can claim
distribution function of ingestion times in Figure 3) meaning
resources to run. Half of YARN’s capacity is reserved for the
that from the point of view of ingestion most tables can be
queue where the ingestion jobs run, ensuring that new data
ingested many times a day. This does not include the data
coming in is never starved because of resources being used
transfer from the source to our site, but this is outside of
for data exploration. The Hadoop cluster can be scaled almost
our control and is typically limited by the network bandwidth
indefinitely by registering new servers with YARN. When we
or by rate control mechanisms at the source. For very large
get bursts of requests for assets to be ingested, the ingestion
tables we are currently exploring [23], [24] the use of Change
jobs not getting resources immediately are queued by YARN
Data Capture (CDC) [25] to send only modifications. A huge
and executed when resources are released by completed jobs.
amount of tooling exists for CDC between relational databases,
At the time of writing the HDP cluster contains 20 worker
but having been designed for use by database administrators
nodes each with 256 GB of RAM and 28 cores. In addition
it is surprisingly difficult to make them work in the automated
there are 7 master nodes with 8 cores and 64 GB of RAM.
self-service model that we use. This is the subject of on-going
We divide the management function amongst the management research.
nodes in the way recommended by [10]. All the nodes run as VII. HANDLING FAILURE
VMs on an OpenStack instance. Half the worker nodes are
dedicated to the BigSQL and the other half to YARN. The
The expectation is that the Datalake runs 24/7 and it is used
HDFS file systems has 1 Petabyte of storage.
by teams in different time zones. Support teams are available
Measured over the year to date, we handle roughly 3,000
to answer basic questions around the clock, but problems they
table ingestions per day (consisting of about 4 billion rows of
can not resolve are handled by the Datalake engineering team.
data). This represents roughly 400 GB of data in compressed
Broadly we can classify failures as belonging to three varieties:
Parquet updated each day. The amount of resource allocated to
• failure of components in the platform
YARN allow roughly 100 tables to be ingested in parallel. We • user errors
rate-control on a per data asset basis such that no data asset can • data type mismatches
consume more than 50% of the available resources. We found
that some ingesting data producers would occasionally grab A. Component Failure
all the resources leading to starvation of other teams – giving
Typically components fail because of a problem during
the perception that the system had failed. More sophisticated
maintenance, or a user error by a system administrator, e.g.
scheduling algorithms were considered but in the end we
adding the wrong firewall rule. Due to the highly integrated
simply provision enough resources to ensure that: 1) in normal
nature of the system, failure cascades. For example, if the
operations no ingesting job is ever queued and 2) if there is an
Kerberos server is down, every component in the Hadoop
outage, the backlog can be handled in a reasonable amount of
system starts failing. Although we tried to make the system 7
highly available, most of the High-Availability (HA) com-
has been fixed. Requiring the producer teams themselves to
ponents do not fail independently in the failure modes we
explicitly retry is a very rare event and has more to do with
observe, limiting the benefits of HA in our environment. For
misconfiguration of their process. Errors caused by other user
example, if the storage system backing the HDFS disks has
behavior on the SQL interface with the LandingZone are
a problem, both the Active and Standby YARN Resource
also transient as their query is eventually killed allowing the
manager fail at the same time. Actual software errors from
ingestions they are blocking to succeed.
the Hadoop components or from our own code are remarkably
Failures that are due to incorrect parameters to the ingestion
rare. Typically it is sufficient for a system administrator to
API or problems with the types of the data can not be fixed
undo a change and/or restart a component. From the user’s
by retrying automatically. As an ingestion is identified by a
point of view the errors are transient, i.e. trying again to
name derived from the source, we allow producers to overwrite
perform a failed operation resolves the problem.
a job when they ingest from the same source, i.e. when
they fix the problem, the new ingestion job overwrites the B. User Error
description of the failed one causing it to be removed. As
User errors involve providing incorrect parameters in REST
we cannot count on ingestors always fixing their jobs, failing
calls, or trying to access data assets with incorrect credentials.
jobs are automatically removed after some time. Retrying
The use of the UDF in the DropZone databases minimizes
them periodically consumes resources and without some type
the degree of freedom for ingestion from DB2, but some
of garbage collection the system would end-up constantly
teams need to directly call the REST API, for example when
rerunning jobs that will never succeed.
an external database is used as the DropZone. We spent
significant time documenting the processes and ensured that VIII. C
the user interfaces of all our tools link to the corresponding ONCLUSION documentation.
Our corporate datalake was started with the spirit of “build
Many user errors are caused by other users misusing the
it and they will come”. Some came willingly, some more re-
SQL interface offered by the platform, for example locking a
luctantly, but in the end when projects came and stayed on the
system table, such that a schema definition can not be updated.
lake it was because that’s where the data was. Projects would
In a more tightly controlled system, every query would be
accept the drawback of a shared environment, the inefficiencies
reviewed for correctness and an estimation made of its priority
of SQL on Hadoop, lack of indexes, etc., if they could easily
and the resources that should be allocated to it. By design, in
get access to the data they needed. Consequently, the utility
the Datalake teams are free to use the platform as they see fit.
of the lake increases each time a new data asset is added.
Abuse can be mitigated by certain policies in place such as
The challenge was how to allow diverse data assets belonging
killing a query if it holds a lock longer than a certain time,
to different divisions in the company to bring data into the
but ultimately users need to be made aware that it is a shared
lake autonomously and independently, without compromising
platform and that demands certain obligations and imposes
security, consistency or governance. We have described how
constraints on what it can be used for. User education provided
we arrived at a solution to this problem by trying to make
better results than trying to implement draconian technical
the data asset owner’s job as simple as possible, allowing limits on the platform tools.
them to use well understood tools to trigger standard ingestion C. Type Mismatching
processes, while attempting to mask the inherent complexity of
the system. We changed and refined our solution by observing
Data in Hadoop is processed following schema-on-read, so
the behaviour of users both from the problem tickets raised and
there should not be type mismatches, as an application can
from the detailed logs we gather. We designed our work-flows
decide the type of the data on the fly. In practice SQL users
to be scalable as we didn’t and don’t know the exact load that
expect the relational types of the data types in the lake to
will be placed on the lake. We try to make failure recovery
be identical to those of the source database, e.g. that the
as automated as possible and put enough information at our
precision for TIMSTAMP is respected. BigSQL is based on
user’s disposal to self diagnose problems in order make their
Hive, which imposes certain restrictions on the data types that (and our) lives simpler.
can be offered. Type mismatches then occur when types in the
original database table cannot be mapped to those available in
Hive. We found that giving the producers a simplified view of REFERENCES
the error logs via a REST service and providing them with the
means to recover a detailed description of the errors, allowed
[1] K. Shvachko, H. Kuang, S. Radia, and R. Chansler, “The hadoop
the data ingestors to self diagnose most problems. Typically
distributed file system,” in Proceedings of the 2010 IEEE 26th
Symposium on Mass Storage Systems and Technologies (MSST), ser.
producers would adjust their ETL processes and tables in the MSST ’10.
Washington, DC, USA: IEEE Computer Society, 2010,
DropZone to ensure compatibility with the LandingZone.
pp. 1–10. [Online]. Available: http://dx.doi.org/10.1109/MSST.2010.
When an ingestion job fails, it automatically retries three 5496972
[2] I. Polato, R. R´e, A. Goldman, and F. Kon, “A comprehensive view of
times and then continues to retry at periodic intervals. Doing
hadoop research a systematic literature review,” Journal of Network and
so allows ingestions to succeed soon after a component failure
Computer Applications, vol. 46, p. 1–25, 11 2014. 8 [3] R. Ramakrishnan, B. Sridharan, J. R. Douceur, P. Kasturi,
[12] “IBM Infosphere DataStage.” [Online]. Available: https://www.ibm.
B. Krishnamachari-Sampath, K. Krishnamoorthy, P. Li, M. Manu, com/marketplace/datastage
S. Michaylov, R. Ramos, N. Sharman, Z. Xu, Y. Barakat, C. Douglas,
[13] “How Ranger works.” [Online]. Available: https://hortonworks.com/
R. Draves, S. S. Naidu, S. Shastry, A. Sikaria, S. Sun, and apache/ranger/#section 2
R. Venkatesan, “Azure data lake store: A hyperscale distributed file
[14] J. Kreps, N. Narkhede, and J. Rao, “Kafka: a distributed messaging
service for Big Data analytics,” in Proceedings of the 2017 ACM
system for log processing. netdb’11,” in NetDB’11, 2011.
International Conference on Management of Data, ser. SIGMOD ’17.
[15] Confluent, “Connect the kafka confluent platform.” [Online]. Available:
New York, NY, USA: ACM, 2017, pp. 51–63. [Online]. Available:
https://docs.confluent.io/current/connect/index.html
http://doi.acm.org/10.1145/3035918.3056100 [16] Hortonworks, “Hdp 2.6.5 release notes.” [Online].
[4] C. Mathis, “Data lakes,” Datenbank-Spektrum, vol. 17, no. 3,
Available: https://docs.hortonworks.com/HDPDocuments/HDPforCloud/ pp. 289–293, 2017. [Online]. Available: https://doi.org/10.1007/
HDPforCloud-2.6.5/hdp-release-notes/content/hdp relnotes.html s13222-017-0272-7
[17] B. Burns, B. Grant, D. Oppenheimer, E. Brewer, and J. Wilkes, “Borg,
[5] M. Kornacker, A. Behm, V. Bittorf, T. Bobrovytsky, A. Choi, J. Erickson,
omega, and kubernetes,” Queue, vol. 14, no. 1, pp. 10:70–10:93, Jan.
M. Grund, D. Hecht, M. Jacobs, I. Joshi, L. Kuff, D. Kumar, A. Leblang,
2016. [Online]. Available: http://doi.acm.org/10.1145/2898442.2898444
N. Li, H. Robinson, D. Rorke, S. Rus, J. Russell, D. Tsirogiannis, [18] S. Harris and N. Bissoon, “Big SQL vs Spark SQL at
S. Wanderman-milne, and M. Yoder, “Impala: A modern, open-source
100TB: How do they stack up?” IBM, Tech. Rep., February
SQL engine for Hadoop,” in In Proc. CIDR’15, 2015.
2017. [Online]. Available: https://developer.ibm.com/hadoop/2017/02/
[6] A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka, S. Anthony,
07/experiences-comparing-big-sql-and-spark-sql-at-100tb/ H. Liu, P. Wyckoff, and R. Murthy, “Hive: A warehousing
[19] “ZooKeeper.” [Online]. Available: https://zookeeper.apache.org
solution over a map-reduce framework,” Proc. VLDB Endow.,
[20] “Oozie - Apache Oozie Workflow Scheduler for Hadoop.” [Online].
vol. 2, no. 2, pp. 1626–1629, Aug. 2009. [Online]. Available:
Available: https://oozie.apache.org/
https://doi.org/10.14778/1687553.1687609
[21] “Hadoop YARN.” [Online]. Available: https://hadoop.apache.org/docs/
[7] M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica,
current/hadoop-yarn/hadoop-yarn-site/YARN.html
“Spark: Cluster computing with working sets,” in Proceedings of the
[22] ORC v1 format specification, Apache Foundation. [Online]. Available:
2Nd USENIX Conference on Hot Topics in Cloud Computing, ser.
https://orc.apache.org/specification/ORCv1/ HotCloud’10.
Berkeley, CA, USA: USENIX Association, 2010, pp.
[23] D. Bauer, F. Froese, L. Garc´es-Erice, S. Rooney, and P. Urbanetz,
10–10. [Online]. Available: http://dl.acm.org/citation.cfm?id=1863103.
“Recurrent movement of relational data within a hybrid cloud,” in In 1863113
proceedings of the IEEE International Conference on Big Data (Big
[8] “Sqoop.” [Online]. Available: http://sqoop.apache.org
Data), SCDM Workshop, 2018, pp. 3359–3363. [9] Parquet format, Apache Foundation. [Online]. Available: https:
[24] Red Hat Inc., “Debezium.” [Online]. Available: https://debezium.io/
//parquet.apache.org/documentation/latest/ [25] I. Bralgin, “Change data capture (CDC) methods.”
[10] B. Spivey and J. Echeverria, Hadoop Security: Protecting Your Big Data [Online]. Available:
https://www.dwh-club.com/dwh-bi-articles/ Platform, 1st ed. O’Reilly Media, Inc., 2015.
change-data-capture-methods.html
[11] J. G. Steiner, C. Neuman, and J. I. Schiller, “Kerberos: An authentication
service for open network systems,” in IN USENIX CONFERENCE
PROCEEDINGS, 1988, pp. 191–202. 9 View publication stats
Tài liệu liên quan:
-

Bài giảng Bài 01: Các dịch vụ mạng Windows 2000 môn Quản trị mạng Window | Đai học Bách Khoa Hà Nội
10 5 -

Perception in Visualization| Tài liệu tham khảo môn quản trị dữ liệu và trực quan hóa| Trường Đại học Bách Khoa Hà Nội
335 168 -

39 studies about human perception in 30 minutes| Tài liệu tham khảo môn quản trị dữ liệu và trực quan hóa| Trường Đại học Bách Khoa Hà Nội
293 147 -

My steps to learn about Apache NiFi| Tài liệu tham khảo môn quản trị dữ liệu và trực quan hóa| Trường Đại học Bách Khoa Hà Nội
460 230 -

Text Visualization Browser| Tài liệu tham khảo môn quản trị dữ liệu và trực quan hóa| Trường Đại học Bách Khoa Hà Nội
316 158