Nhóm 5 - sáng thứ 3 - Tài liệu tham khảo | Đại học Hoa Sen
Nhóm 5 - sáng thứ 3 - Tài liệu tham khảo | Đại học Hoa Senà thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng, ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học.
Môn: Dẫn nhập phương pháp nghiên cứu 9 tài liệu
Trường: Trường Đại học Hoa Sen 5.3 K tài liệu
Tác giả:







Preview text:
Nhóm 5 - sáng thứ 3 Nguyễn Tấn Đạt Từ Duy Khanh Nguyễn Hữu Trường Hoàng Võ Hải Nam Nguyễn Quang Cầu
Nhóm chúng em sử dụng bộ dữ liệu Bank Marketing để nghiên cứu các thuộc tính của
khách hàng như độ tuổi, nghề nghiệp, trình độ học vấn và nhiều thông tin khác. Mục
tiêu của chúng em là xác định những thông tin quan trọng nhất và áp dụng phân tích
dữ liệu để phân loại và nhóm các khách hàng lại với nhau. Qua đó, chúng em hy vọng
sẽ tạo ra các nhóm khách hàng khác nhau để phục vụ họ một cách tốt nhất và đáp ứng
nhu cầu đặc thù của từng nhóm. 1.1 PHÂN CỤM DỮ LIỆU
1.1.1 Một số phương pháp phân cụm
Sử dụng một số phương pháp phân cụm: • Thuật toán K-means • Hieracical Clustering
1.1.2 Kết quả xây dự mô hình
✔ Bước 1: Xây dựng mô hình
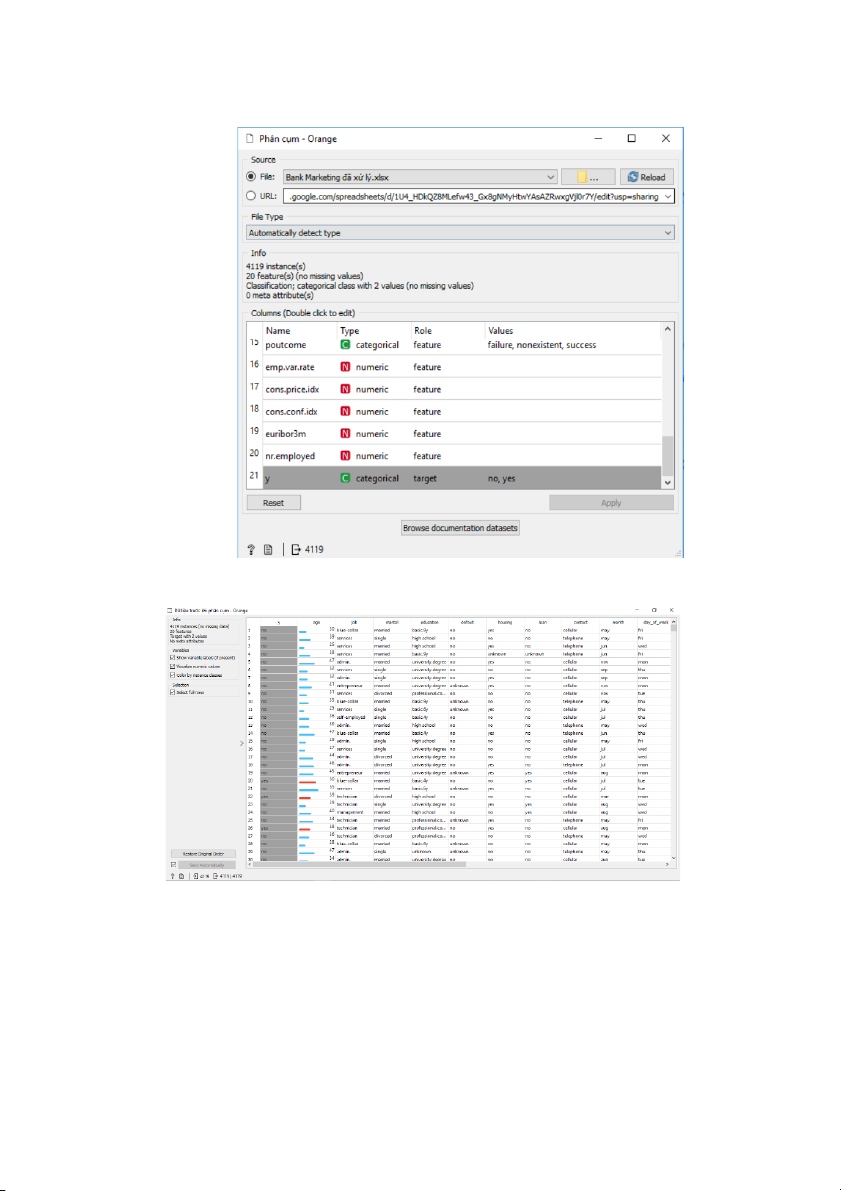
-Sau khi tiền xử lý dữ liệu, ta bắt đầu phân cụm. Chọn file BankMarketing đã xử
lý.xlxx để đưa dữ liệu vào.
- Vì dữ liệu là bộ dữ liệu đã có nhãn (phân lớp). Vậy nên khi thực hiện phân cụm ta
xem như bộ dữ liệu này chưa có lớp bằng cách skip thuộc tính “Y”. 1
Hình 1: Đưa dữ liệu vào để phân cụm
Khi đó ta có bảng dữ liệu trước phân cụm:
Hình 2: Dữ liệu trước phân cụm
Tập dữ liệu có 4119 dữ liệu, 20 biến và không có dữ liệu bị lỗi
✔ Bước 2: Sử dụng mô hình
- Sử dụng K-Means và Hieracical Clustering để phân cụm dữ liệu. Sau đó dựa
vào điểm tương đồng các cụm cao hay thấp để lựa chọn thuật toán phân cụm 2
- Sử dụng Bank Marketing đã xử lý.xlxx để tiến hành phân cụm, chọn biến Y là biến phụ thuộc (target)
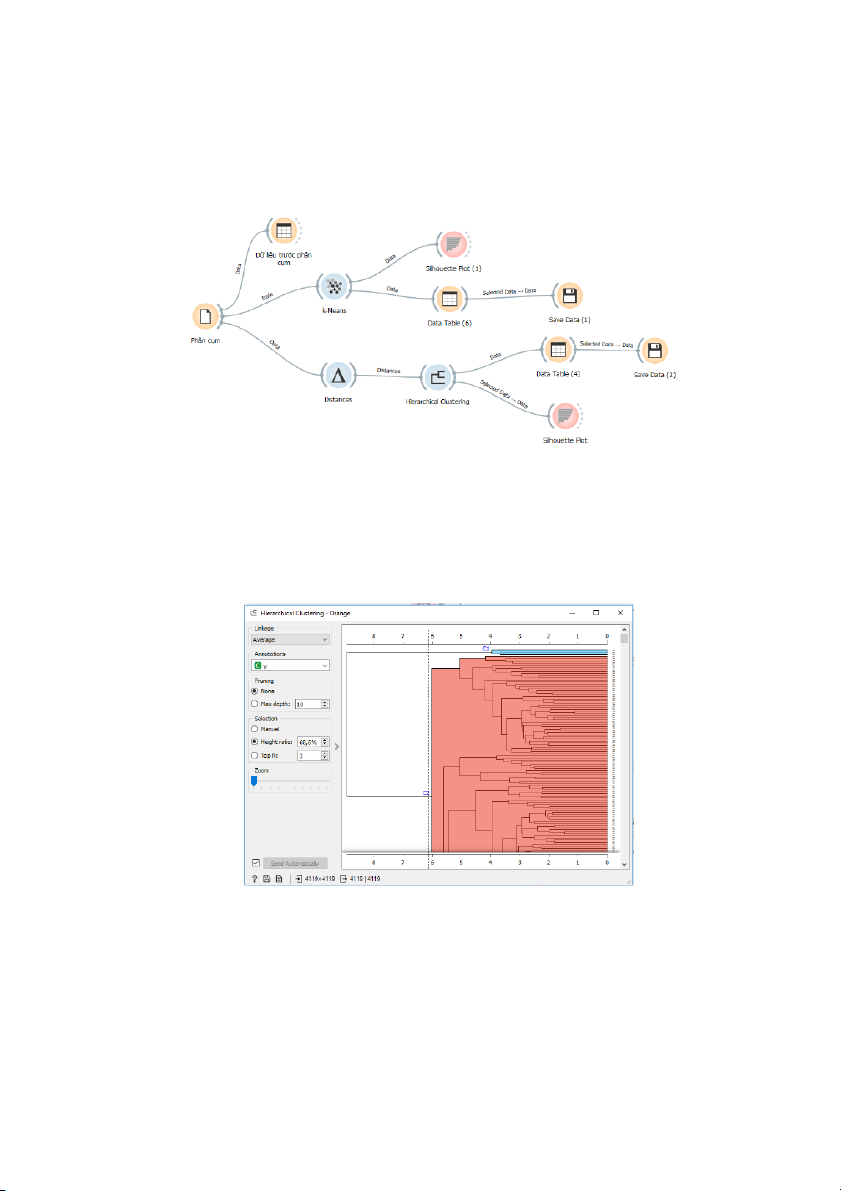
Mô hình phân cụm dữ liệu:
Hình 3: Mô hình phân cụm dữ liệu
Phân cụm dữ liệu bằng phương pháp Hieracical Clustering
- Kéo thả chọn Distance để tính khoảng cách giữa các dữ liệu trong file. Sau đó chọn
Hieracical Clustering để tiến hành phân chia số cụm. Kéo đường thẳng trong hộp thoại
Hieracical Clustering để tiến hành phân chia dữ liệu thành 2,3,4 và 5 cụm theo thứ tự các hình dưới đây.
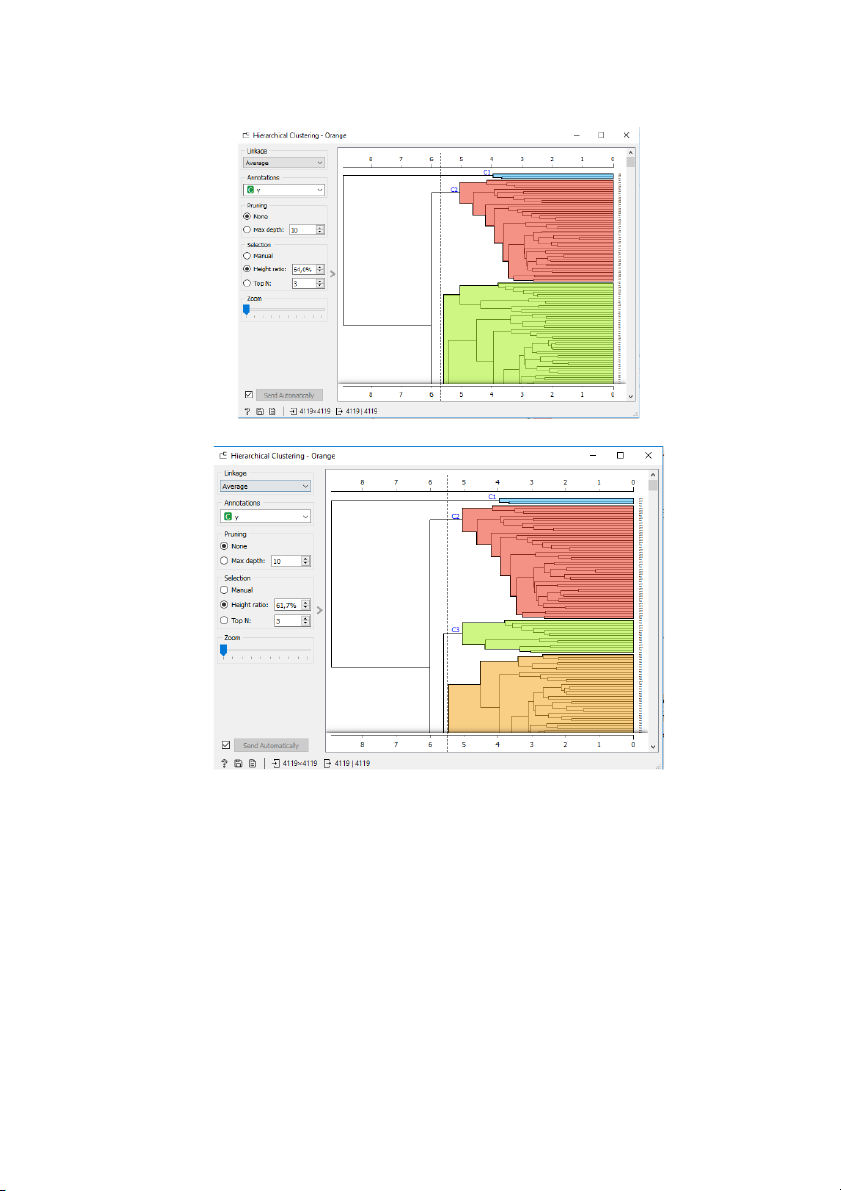
Hình 3: Hộp thoại Hieracical Clustering khi chia dữ liệu thành 2 cụm 3
Hình 4: Hộp thoại Hieracical Clustering khi chia dữ liệu thành 3 cụm
Hình 5: Hộp thoại Hieracical Clustering khi chia dữ liệu thành 4 cụm 4
Hình 6: Hộp thoại Hieracical Clustering khi chia dữ liệu thành 5 cụm
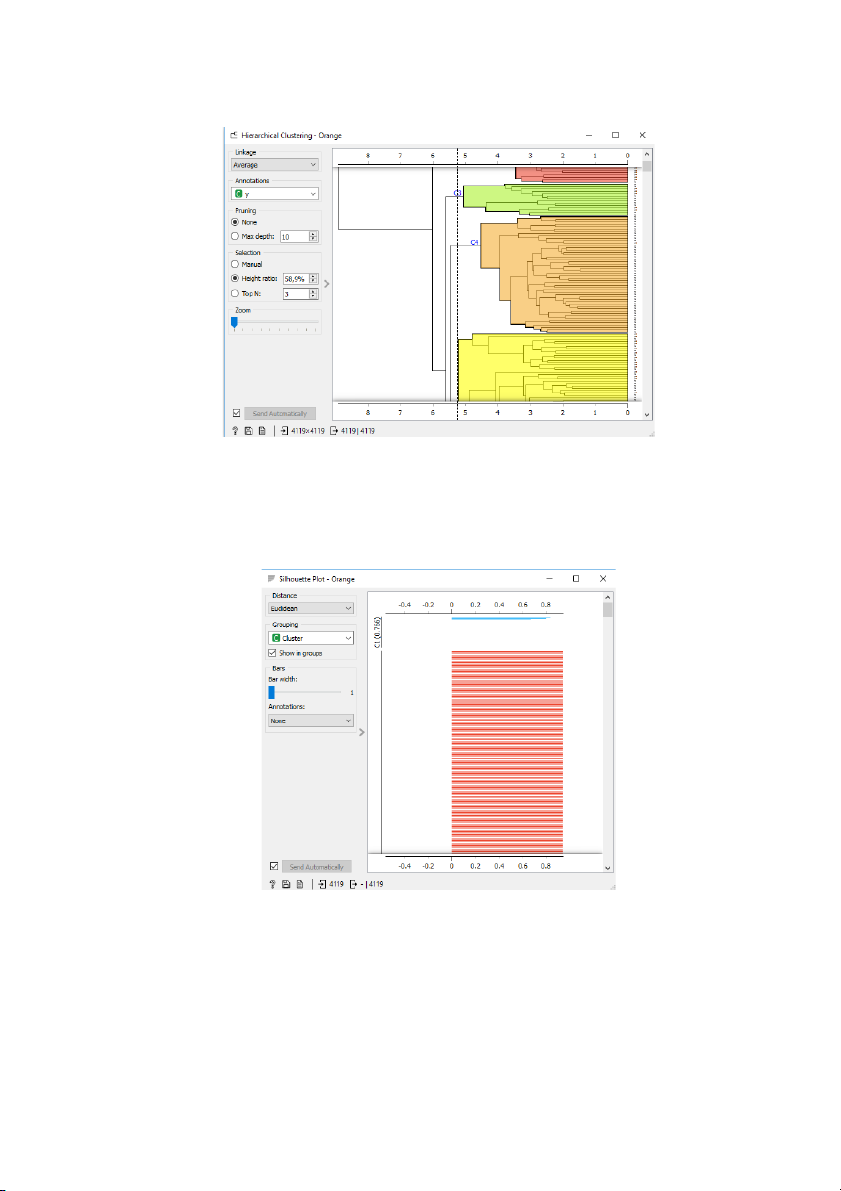
Sau khi chia dữ liệu lần lượt thành 2,3,4,5 cụm thì ta dùng Silhouette Plot để
xem kết quả phân cụm, từ đó lựa chọn phương án tối ưu
Khi đó, Silhouette Plot sẽ được tính khoảng cách theo công thức Euclidean, group chọn
Cluster. Ta có kết quả phân cụm lần lượt như sau:
Hình 7: Kết quả khi chia dữ liệu thành 2 cụm 5
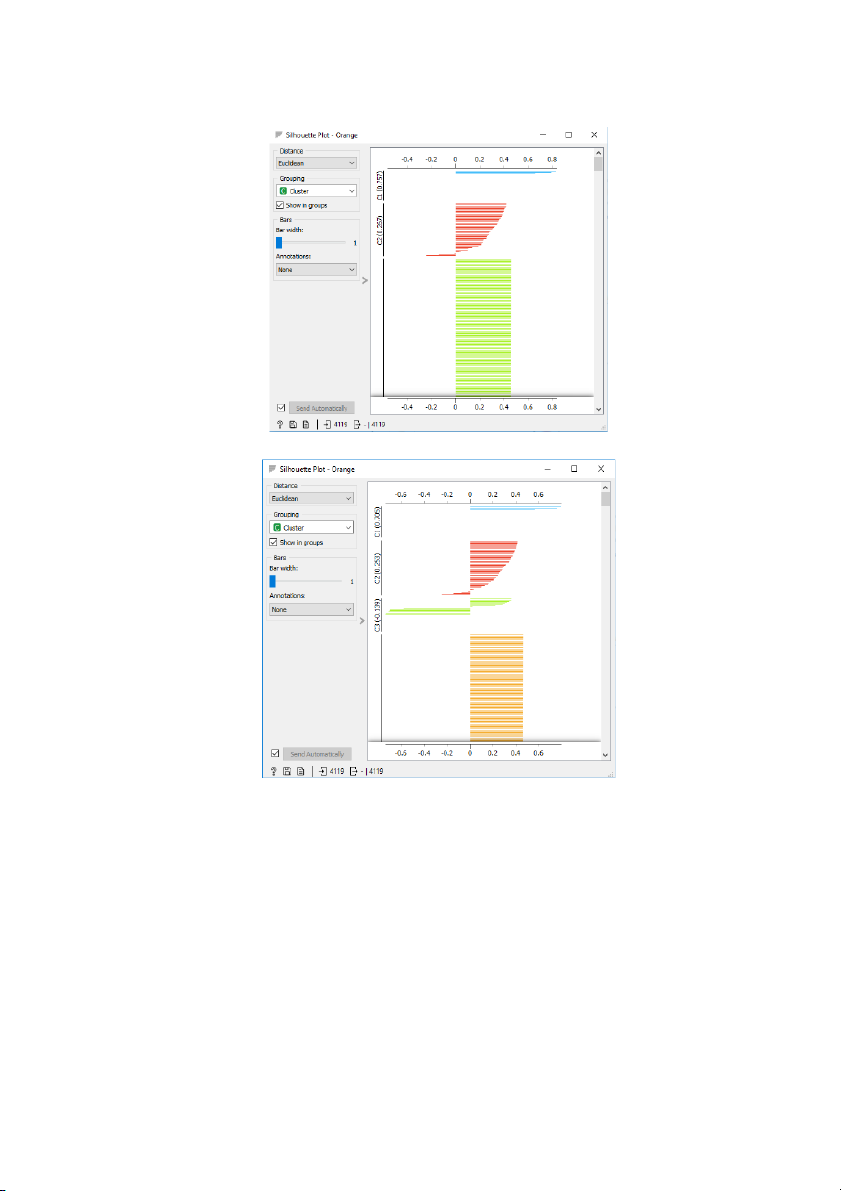
Hình 8: Kết quả khi chia dữ liệu thành 3 cụm
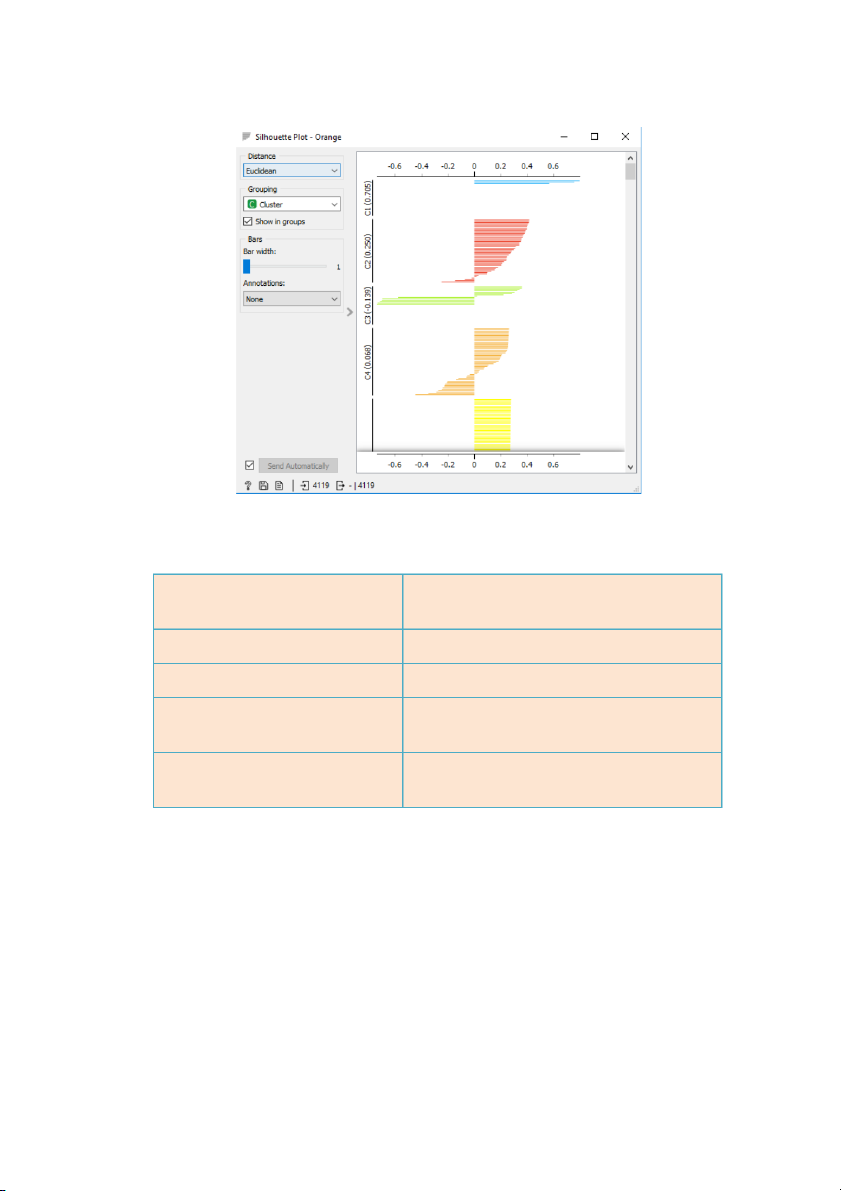
Hình 9: Kết quả khi chia dữ liệu thành 4 cụm 6
Hình 10: Kết quả khi chia dữ liệu thành 5 cụm
-Sau khi dùng Silhouette Plot ta có bảng sau
Phương pháp chia dữ liệu
Mức độ tương đồng từng cụm khi ở từng phương pháp 2 cụm C1 (0,766); C2 (0,904) 3 cụm
C1(0,757) ; C2(0,267); C3 (0,212) 4 cụm C1(0,705) ; C2(0,253); C3 (-0,139); C4( 0,211) 5 cụm
C1(0,705) ; C2(0,250); C3 (-0,139); C4(0,068); C5(-0,006) Nhận xét:
✔ Silhouette Scores là một phép đo quan trọng để đánh giá độ tương đồng và sự
phân tách giữa các cụm. Giá trị Silhouette Scores càng lớn thì độ tương đồng
của từng điểm trong cụm càng cao, và kết quả phân cụm càng tốt.
✔ Sau khi thử phân cụm bộ dữ liệu thành 2, 3, 4 và 5 cụm, kết quả cho thấy rằng
phân thành 2 cụm là tối ưu nhất. Điều này đồng nghĩa với việc chia dữ liệu
thành hai nhóm đạt được mức độ tương đồng cao nhất giữa các điểm dữ liệu.
✔ Mức độ tương đồng giữa các cụm có giá trị Silhouette Scores cao hơn so với các
trường hợp khác. Cụ thể, giá trị là 0,766 ở cụm 1 và 0,904 ở cụm 2, cho thấy sự 7
phân chia giữa hai cụm này là tốt và các điểm dữ liệu trong từng cụm tương đồng với nhau.
✔ Khi thử phân thành 3 cụm, 4 cụm và 5 cụm, mức độ tương đồng giữa các cụm
giảm xuống và thậm chí xuống dưới mức âm. Mức độ tương đồng âm cho thấy
rằng các phân cụm này không hiệu quả và không phù hợp với dữ liệu. Kết luận:
Dựa trên kết quả Silhouette Scores, phân cụm bộ dữ liệu bằng phương pháp
Hierarchical Clustering cho ra kết quả tốt nhất khi chia thành 2 cụm.
Phân cụm dữ liệu bằng phương pháp K-mean
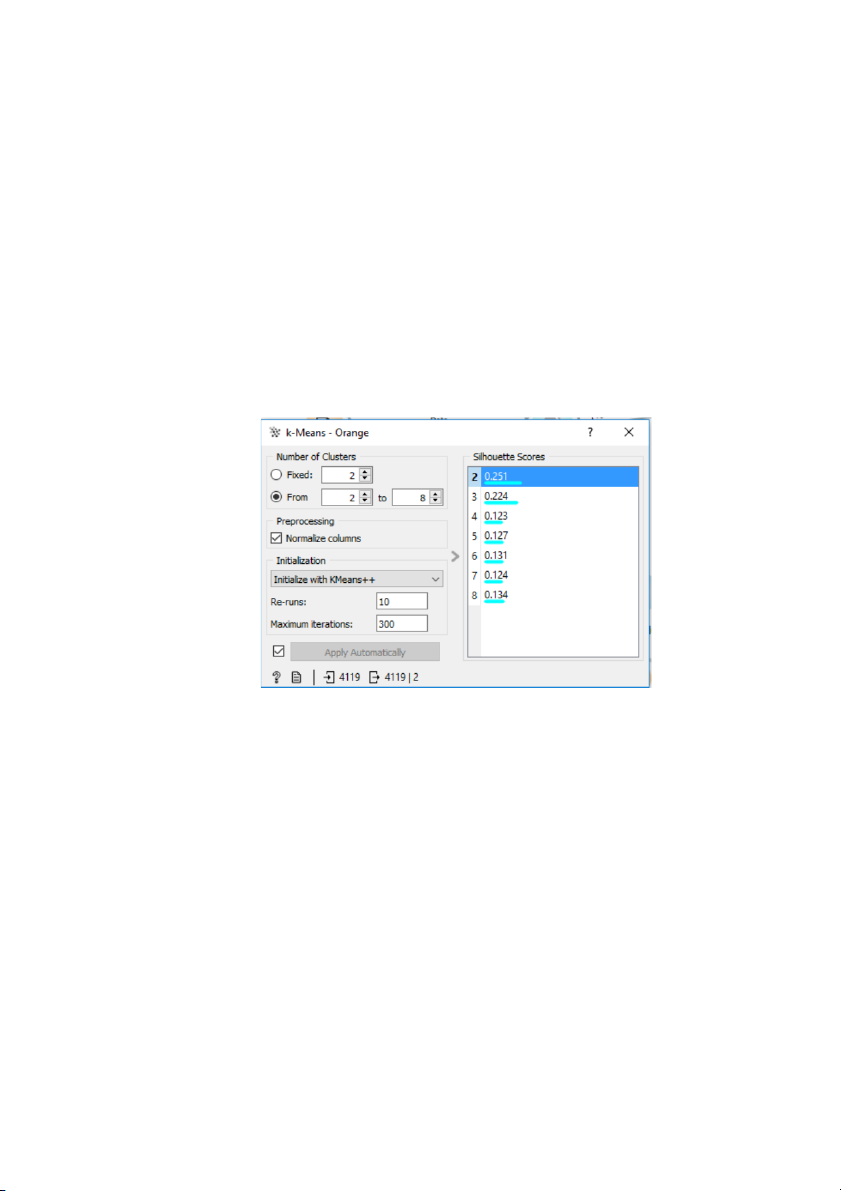
Từ bộ dữ liệu, kéo thả và chọn K-Mean để tiến hành phân cụm. Sau đó nhấn đúp chuột
vào biểu tượng K-mean để xuất hiện hộp thoại K-mean . Number of Clusters chọn
From 2 to 8 để ra kết quả của Silhouette Scores từng trường hợp, cụ thể ở đây là khi phân thành 2,3,…8 cụm
Hình 11: Hộp thoại K-mean Nhận xét:
✔ Silhouette Scores vẫn là một phép đo quan trọng để đánh giá chất lượng phân
cụm, và kết quả phân cụm càng tốt khi giá trị này càng lớn, đồng thời mức độ
tương đồng ở từng cụm cũng càng cao.
✔ Dựa vào hộp thoại K-means, bạn đã tìm ra rằng khi chia dữ liệu thành 2 cụm,
điểm Silhouette Scores là lớn nhất, cụ thể là 0,251. Điều này cho thấy rằng sự
phân chia thành 2 cụm đạt được mức độ tương đồng cao nhất giữa các điểm dữ liệu.
✔ Khi thử chia thành 3, 4 hoặc nhiều hơn các cụm, bạn đã nhận thấy mức độ tương
đồng giữa các cụm giảm xuống. Điều này là dấu hiệu cho thấy phân chia thành 2
cụm là lựa chọn tốt nhất. Kết luận:
Dựa trên kết quả Silhouette Scores và hộp thoại K-means, phân cụm dữ liệu bằng
phương pháp K-means cho ra kết quả tốt nhất khi chia thành 2 cụm. Sự tương đồng và 8
phân tách giữa các cụm đạt được mức độ tốt nhất trong trường hợp này, và phân chia
này có thể hữu ích để nhận biết và phân loại các nhóm dữ liệu trong tập dữ liệu của bạn.
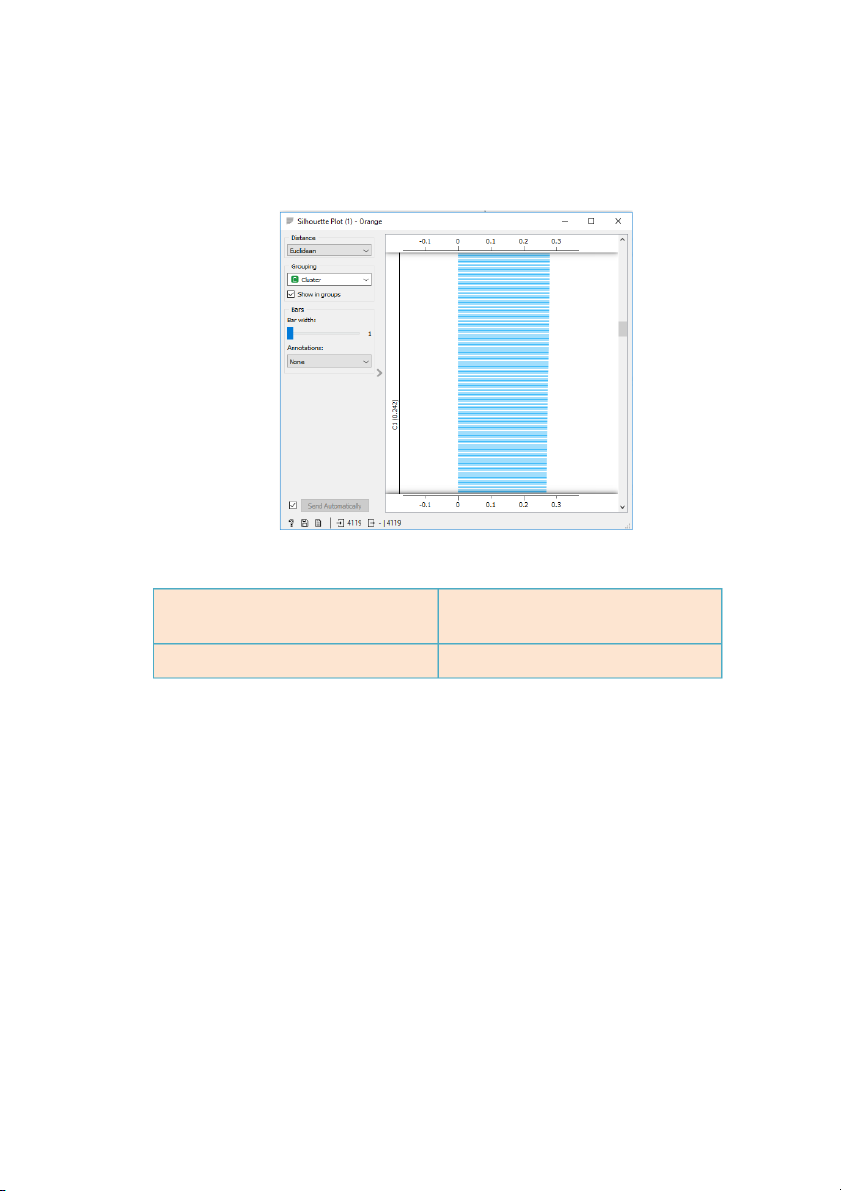
Ta có bảng Silhouette Plot của K-mean khi chia thành 2 cụm như sau:
Hình 12: Silhouette Plot khi phân cụm bằng K-mean
Phương pháp chia dữ liệu
Mức độ tương đồng từng cụm khi ở từng phương pháp 2 cụm C1 (0,242); C2 (0,188)
Lưu bảng dữ liệu với tên là Kmean.xlxx
1.1.3 Trích xuất dữ liệu và So sánh với nhãn hiện có:
Sau khi tiến hành phân cụm dữ liệu, nhóm bắt đầu trích xuất dữ liệu ra dạng bảng dưới
dạng excel để tiến hành so sánh với nhãn hiện có. 9
Hình 13: Bảng dữ liệu excel khi đã phân cụm theo phương pháp Hierarchical clustering.
Hình 14: Bảng dữ liệu excel khi đã phân cụm theo phương pháp k-Means
Sau đó bắt đầu thực hiện đếm các kết quả của thuộc tính “Y” trong dữ liệu có nhãn ban
đầu. Qua kết quả tổng hợp Pivot Table ta thấy bộ dữ liệu ban đầu có 451 kết quả của
thuộc tính “Y” có giá trị “Yes” và 3668 kết quả còn lại có giá trị “No” 10
Tài liệu liên quan:
-

Nghiên cứu Bệnh Trầm Cảm Ảnh Hưởng Đến Sinh Viên | Báo cáo Dẫn nhập phương pháp nghiên cứu
72 36 -

Hien phap nam 2013 - Tài liệu tham khảo | Đại học Hoa Sen
319 160 -

Hợp đồng mua bán ngoại thương - Tài liệu tham khảo | Đại học Hoa Sen
217 109 -

Đề tài : Thực trạng và xu hướng căn cứ anh hưởng đến giá trị con người - Tài liệu tham khảo | Đại học Hoa Sen
216 108 -

Phương pháp nghiên cứu khoa học - Tài liệu tham khảo | Đại học Hoa Sen
441 221