Ôn thi BigData| Môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
1. How big is big data?
(Hadoop và Spark)
Big Data 5V
Velocity (speed of generating data) – Variety (types and forms of data) – Value(potential for ...) – Veracity (level of quality, accuracy and uncertainty) – Volume (vast amouns of data, how large can scale?)
Môn: Lưu trữ và xử lý dữ liệu lớn 27 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.4 K tài liệu
Tác giả:







Preview text:
Introduction to Big Data Storage & Processing Hệ số: Lec1: 1. How big is big data? (Hadoop và Spark) Big Data 5V
Velocity (speed of generating data) – Variety (types and forms of data) –
Value(potential for …) – Veracity (level of quality, accuracy and uncertainty) –
Volume (vast amouns of data, how large can scale?)
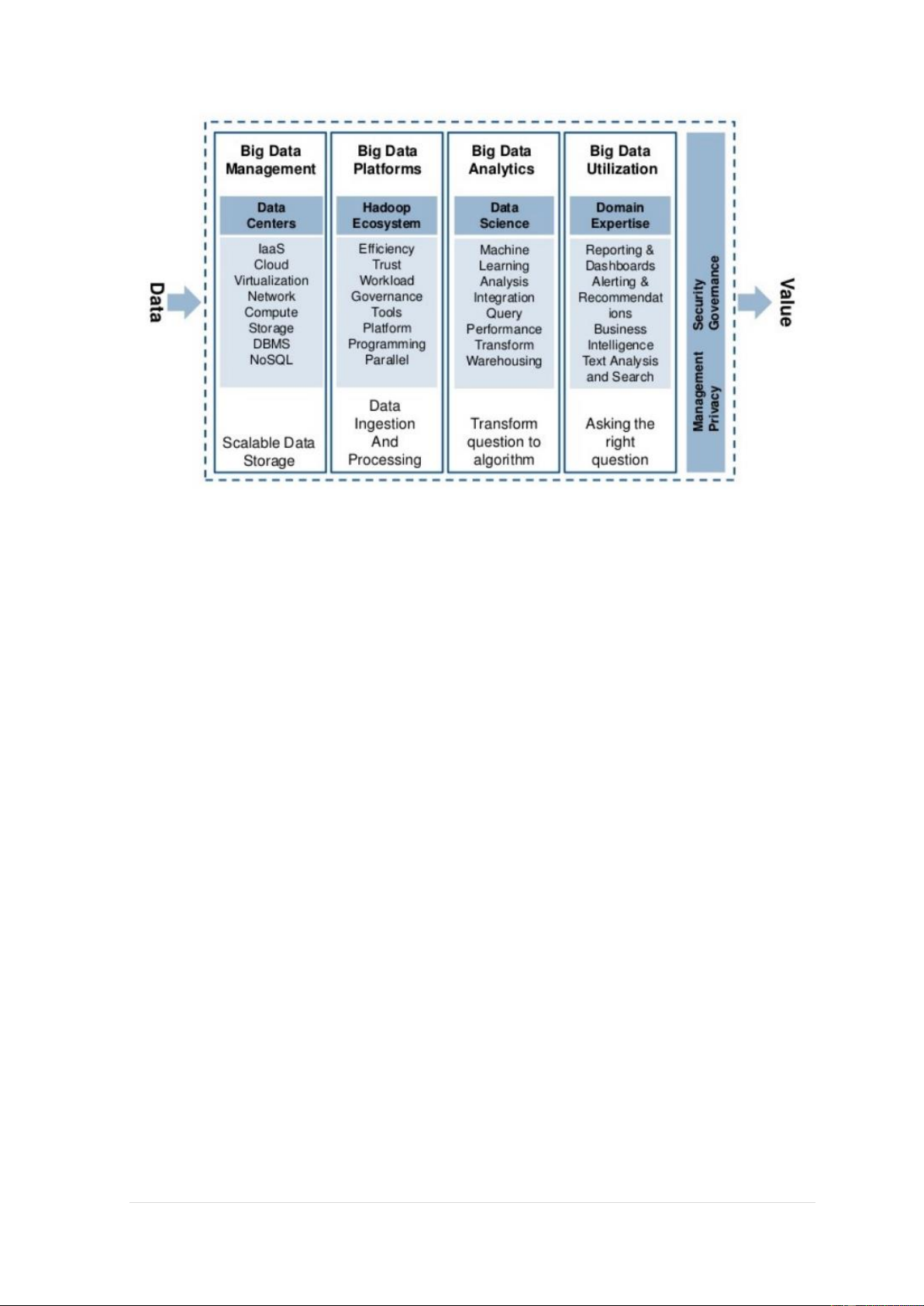
inadequate to deal with: không đủ để đối phó - Big data technology stack
Data => Scalable Data Storage => Data Ingestion and Processing =>
Transform question to algorithm => Asking the right question => (Management,
Seciruty, Privacy, Governmance) Value. 1 | P a g e - Scalable data management Scalability (khả mở)
Accessibility (khả năng truy cập) Transparency (trong suốt)
Availability (sẵn sàng): Fault tolerance
- Scalable data ingestion and processing
Data ingestion (nhập dữ liệu)
Data processing (xử lý dữ liệu)
- Scalable analytic algorithms Challenges Big volume Big dimensionality Realtime processing Scaling-up ML algorithms
Adapting the algorithm to handle Big Data in a single machine
Scaling-up algorithms by parallelism 2 | P a g e
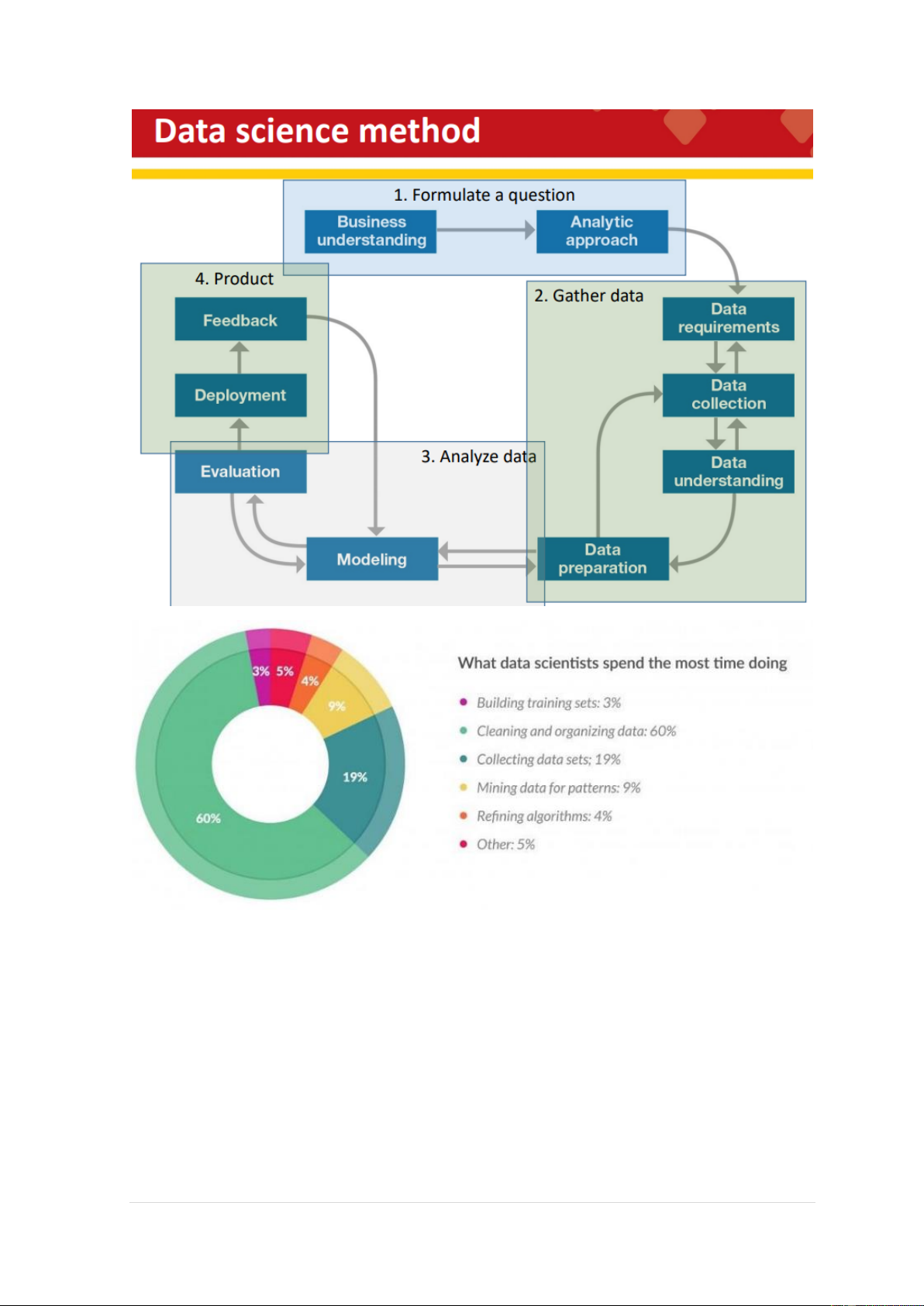
- Data engineers (làm việc backend nhiều hơn, infrastructure) vs. Data scientists
(làm việc nhiều hơn với khách hàng). 3 | P a g e 4 | P a g e - Lec2: Hadoop Ecosystem
1. BTVN (HDFS, chạy Ví dụ về Hadoop)
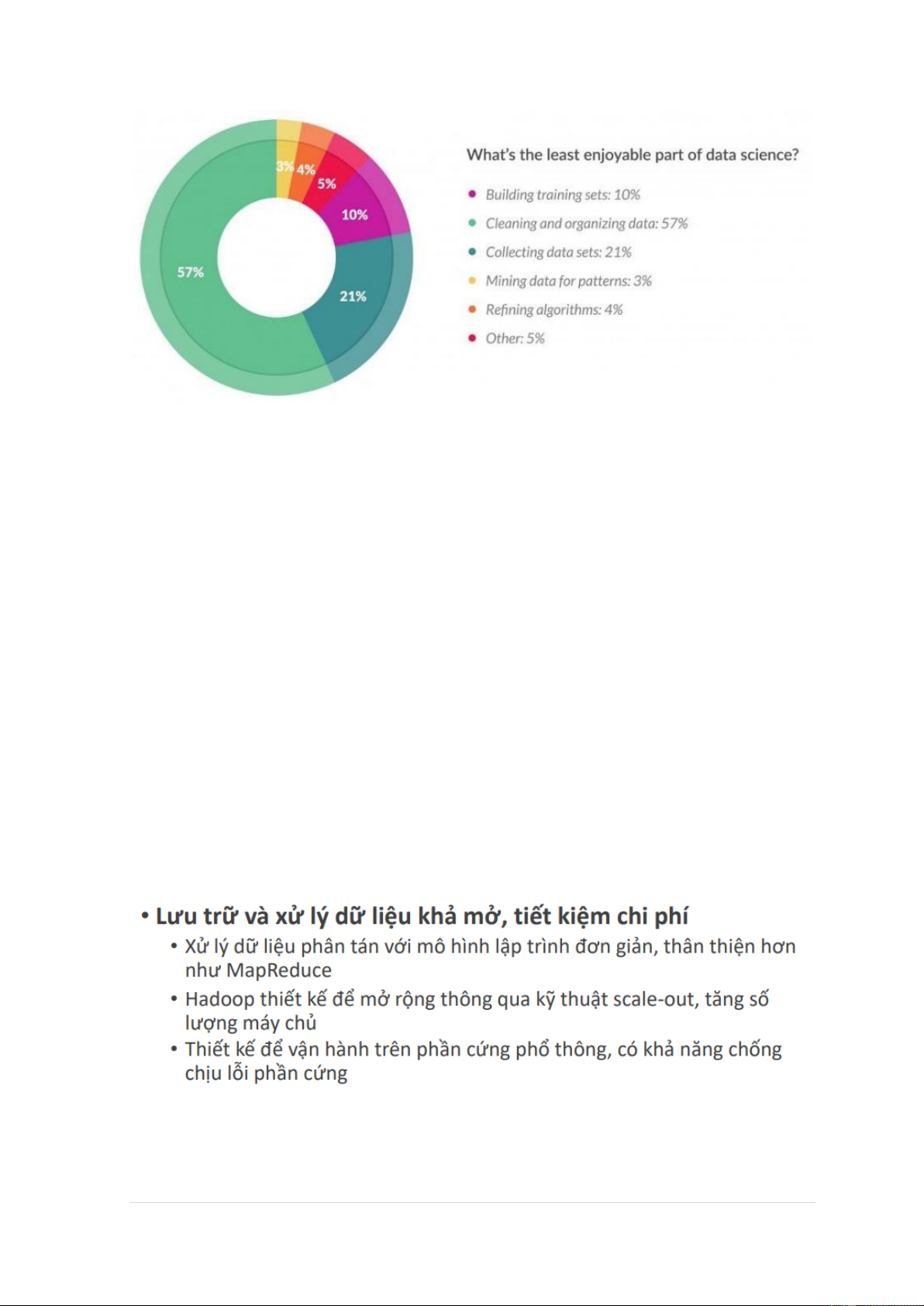
Hadoop hình thành từ 2008 do Yahoo phát triển
Apache Hadoop thân thiện hơn MapReduce (của Google)
MapReduce là mô thức xử lý dữ liệu mặc định trong Hadoop - Mục tiêu chính
Lưu trữ dự liệu khả mở (scalability), tin cậy (reliability) Powerfull data processing (Efficient visualization)
- Thách thức: Thiết bị lưu trữ tốc độ chậm, máy tính thiếu tin cậy, lập trình song
song phân tán không dễ dàng.
- Hadoop lấy cảm hứng từ Bài báo Page Rank của Google (Map Reduce). 5 | P a g e (IMR of Amazon)
*Hadoop mở rộng bằng kỹ thuật scale-out
- Có một máy master (nhiều máy master phụ)
- Giải quyết bài toán chịu lỗi thông qua kỹ thuật “dư thừa”
=> Hadoop thiết kế sao cho các lỗi xảy ra trong hệ thống được xử lý tự động,
không ảnh hưởng tới các ứng dụng phía trên.
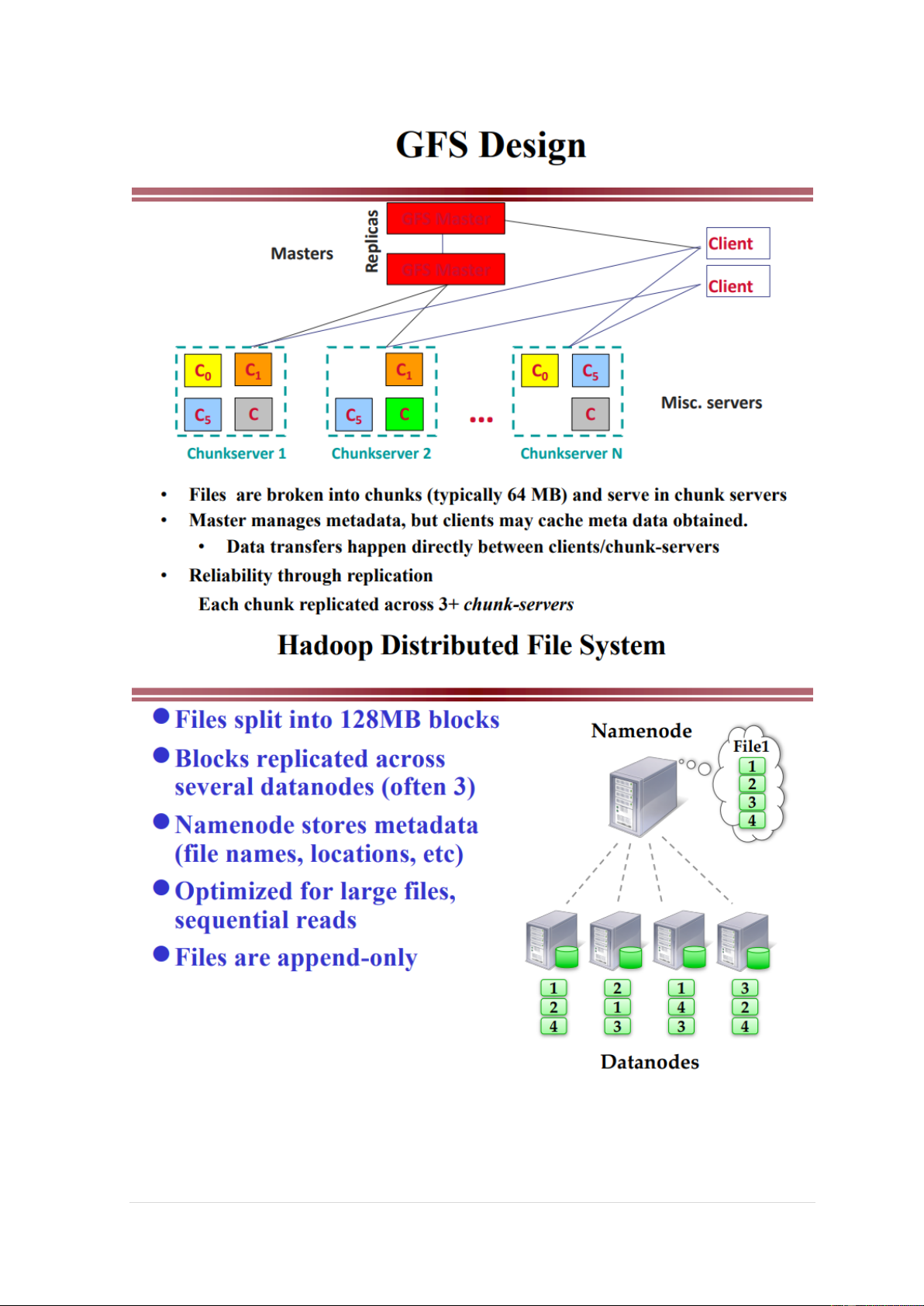
2. HDFS: Hadoop Distributed File System
Các chunk là các tập tin hệ thống trong tập tin cục bộ của máy chủ datanode 3. MapReduce 6 | P a g e
Hardware failure is the norm rather than the exception.
Detection of faults and quick, automatic recovery from them is a core architectural goal of HDFS.
The emphasis is on high throughput of data access rather than low latency of data access
It should provide high aggregate data bandwidth and scale to hundreds of nodes in a single cluster
This assumption simplifies data coherency issues and enables high throughput data access.
Moving Computation is cheaper than moving data
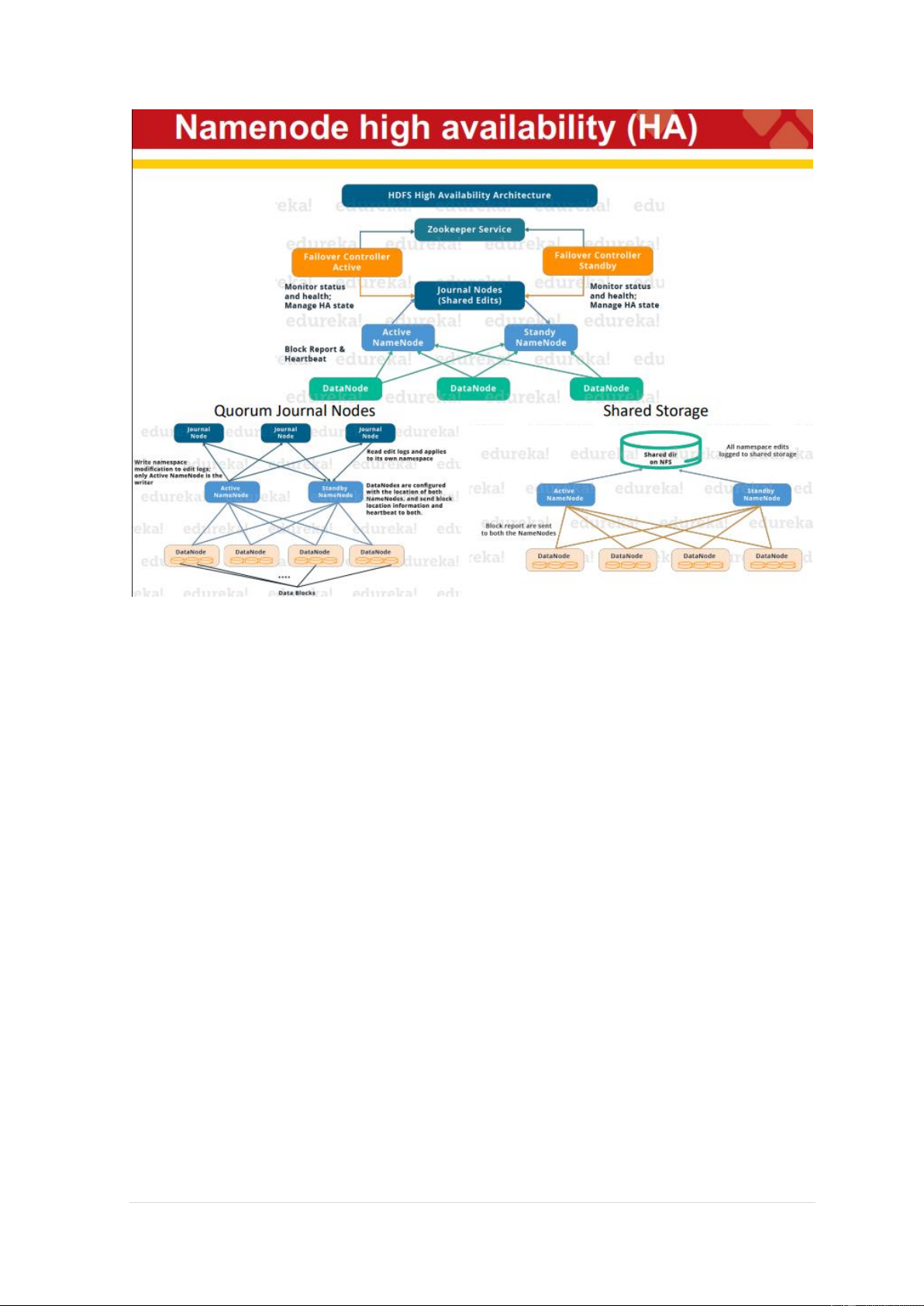
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server
The architecture does not preclude running multiple DataNodes on the same
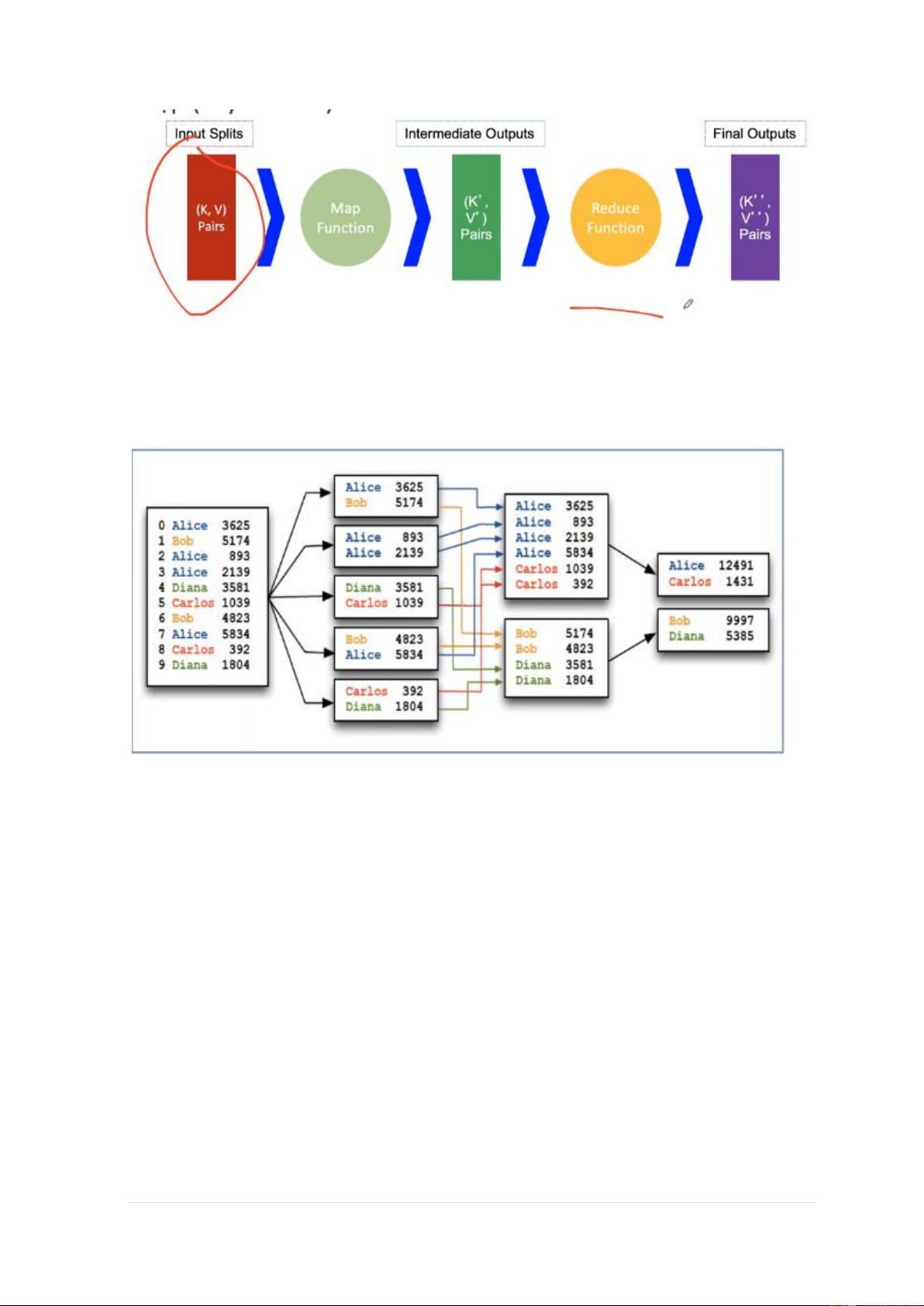
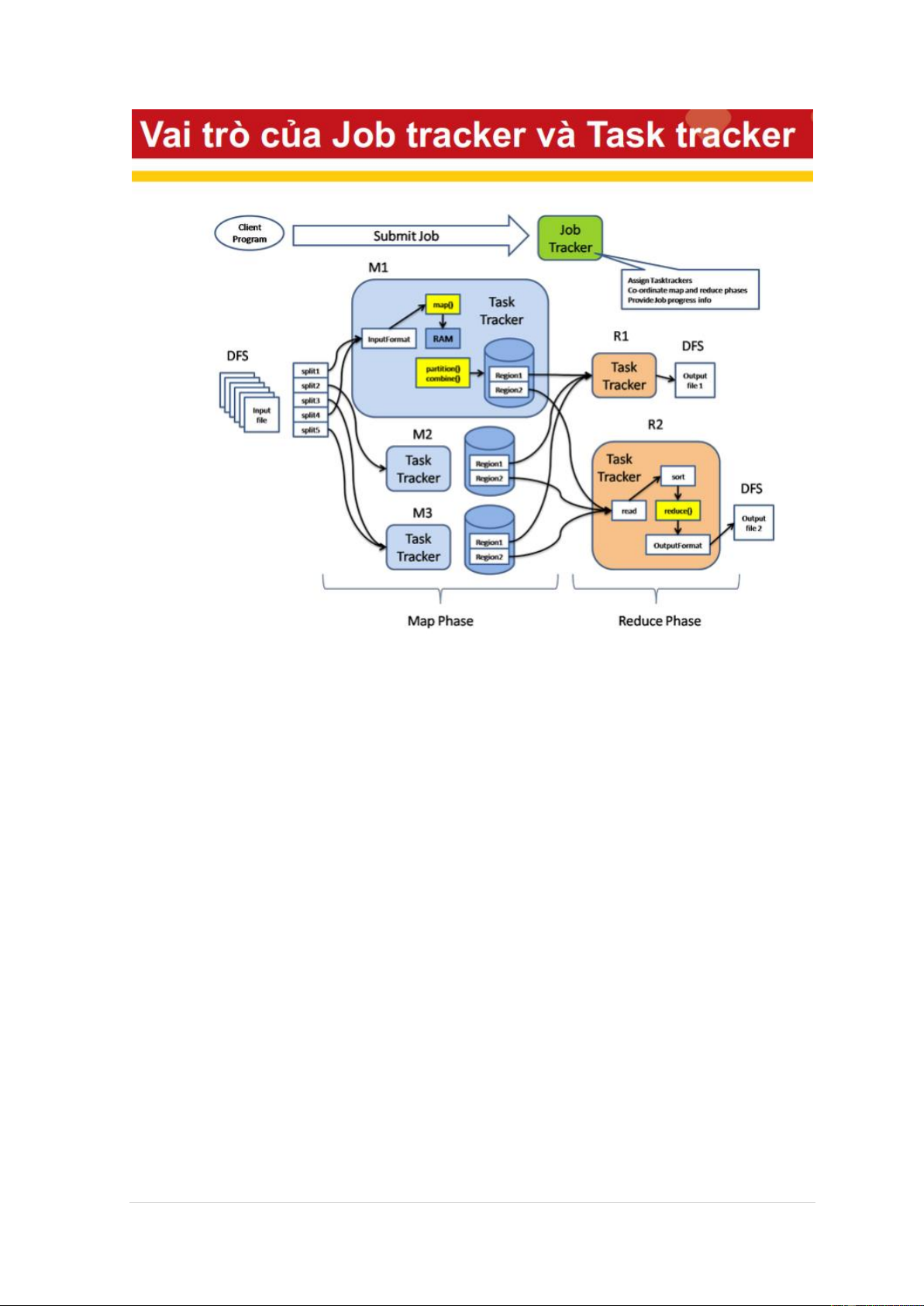
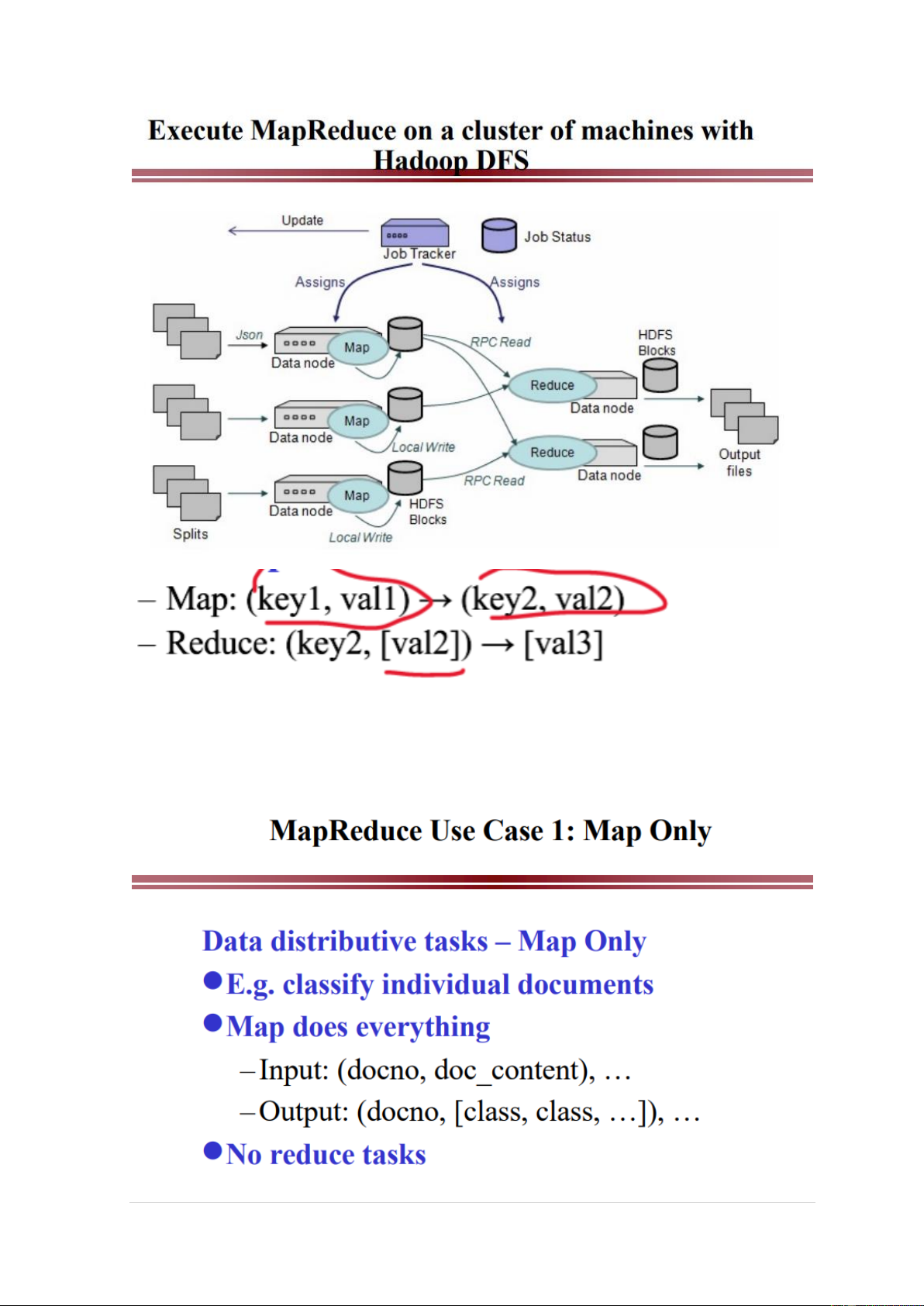
machine but in a real deployment that is rarely the case. 7 | P a g e - MapReduce:
Simplicity – Flexbiltity – Scalability
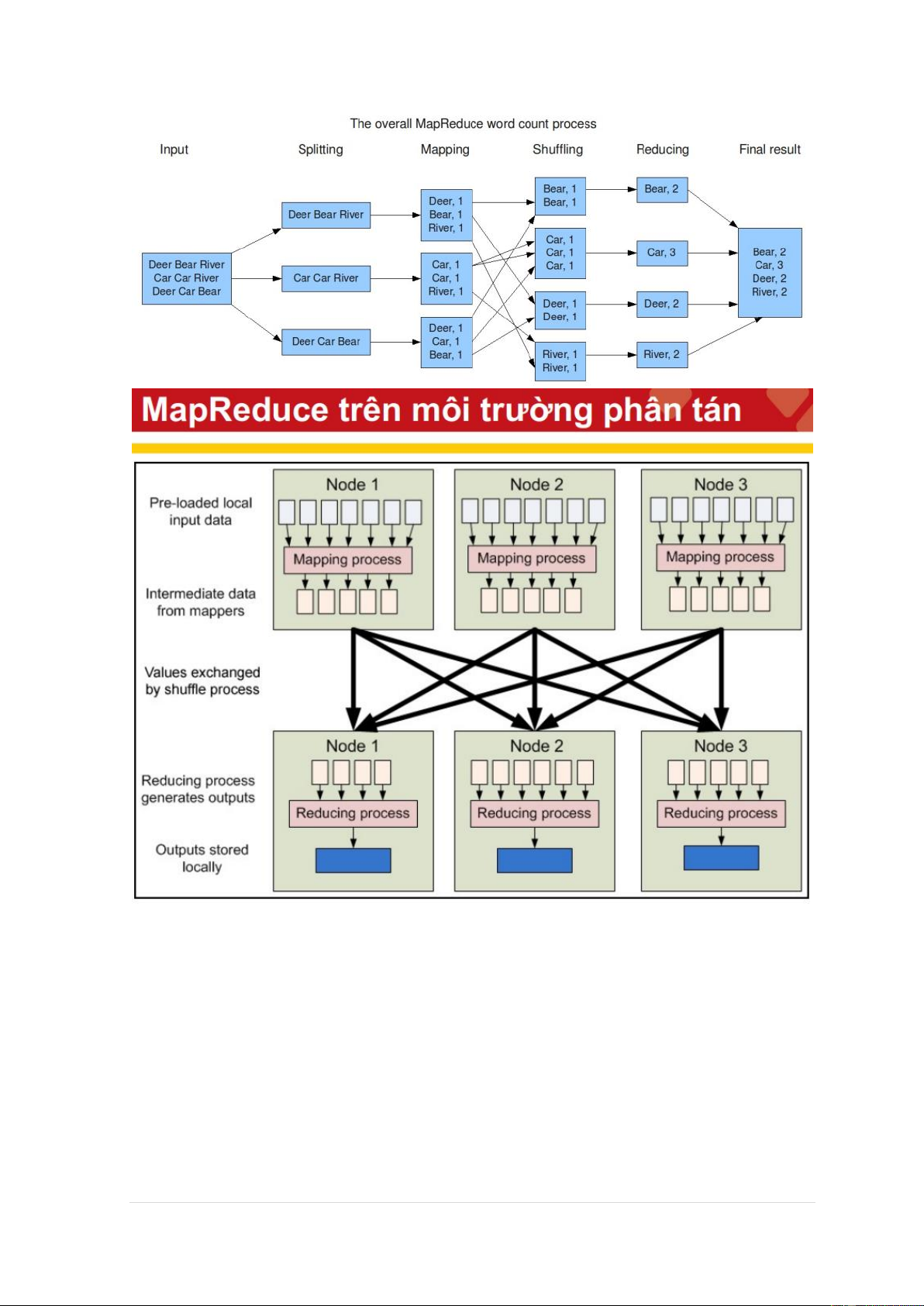
A MapReduce job = {Isolated Tasks} n 8 | P a g e 9 | P a g e
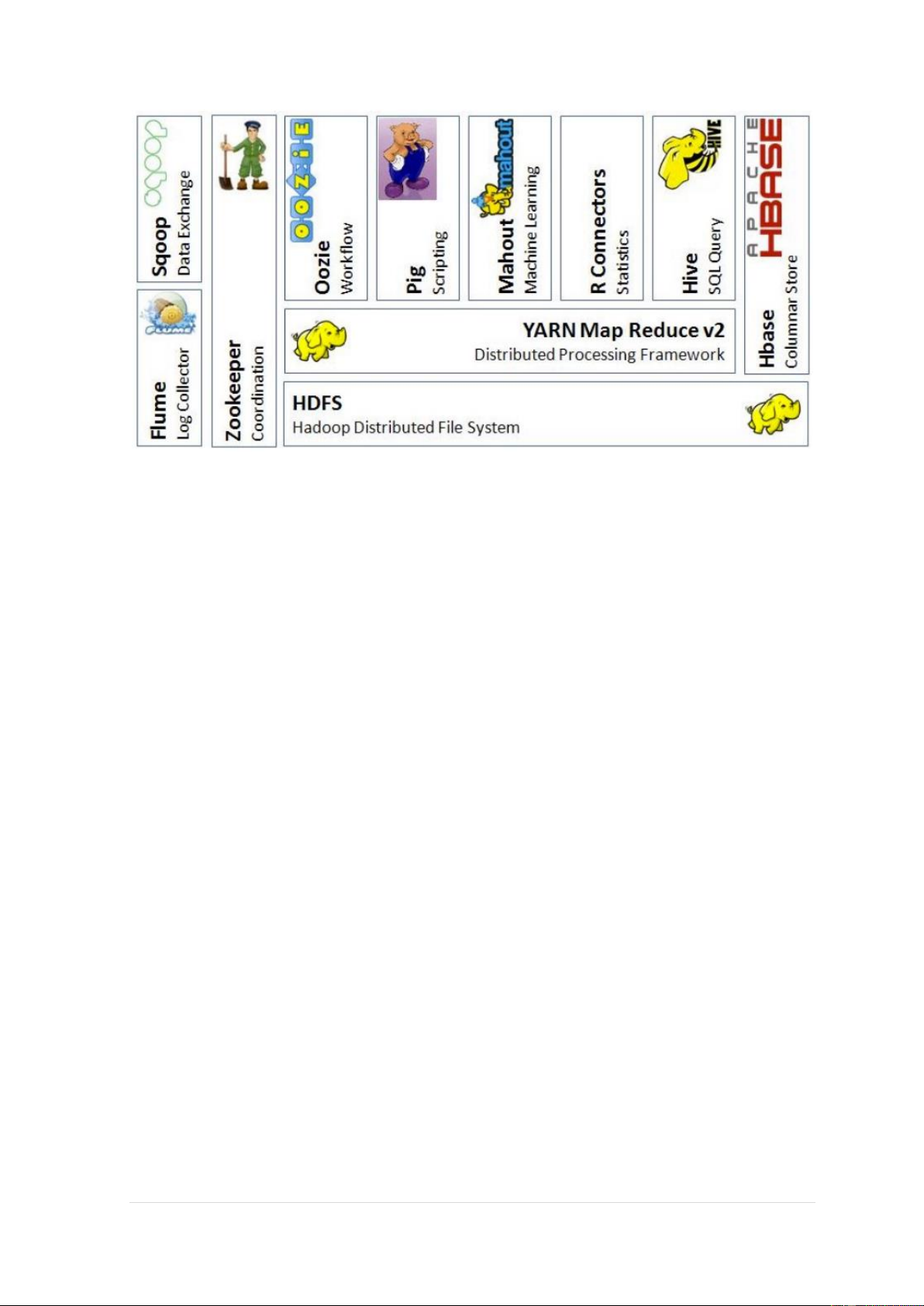
*) Nằm trong hệ sinh thái Hadoop nhưng không phải “core Hadoop”
Apache Pig (giao diện xử lý mức cao)
Apache Hive (Lớp trừu tượng mức cao cảu MapReduce)
Apache Hbase (CSDL cột mở rộng phân tán)
Apache Sqoop (công cụ chuyển khối dữ liệu từ ApacheHadoop sang CSDL quan hệ)
Apache Kafka (phân tách mạch lạc các thành phần tham gia vào luồng dữ liệu)
Apache Oozie (hệ thống lập lịch luồng công việc) (work-flow)
Apache Zookeeper (dịch vụ cung cấp các chức năng phối hợp phân tán độ tin cậy
cao) – service lõi, tối quan trọng tỏng các hệ thống phân tán
Thuật toán PAXOS: thuật toán đồng thuận để xác định failure
- Proposer (leader) đề xuất, các acceptors chấp nhận, nếu đa số chọn chấp nhận đề
xuất này thì leader thông báo giá trì đề xuất cho các learners.
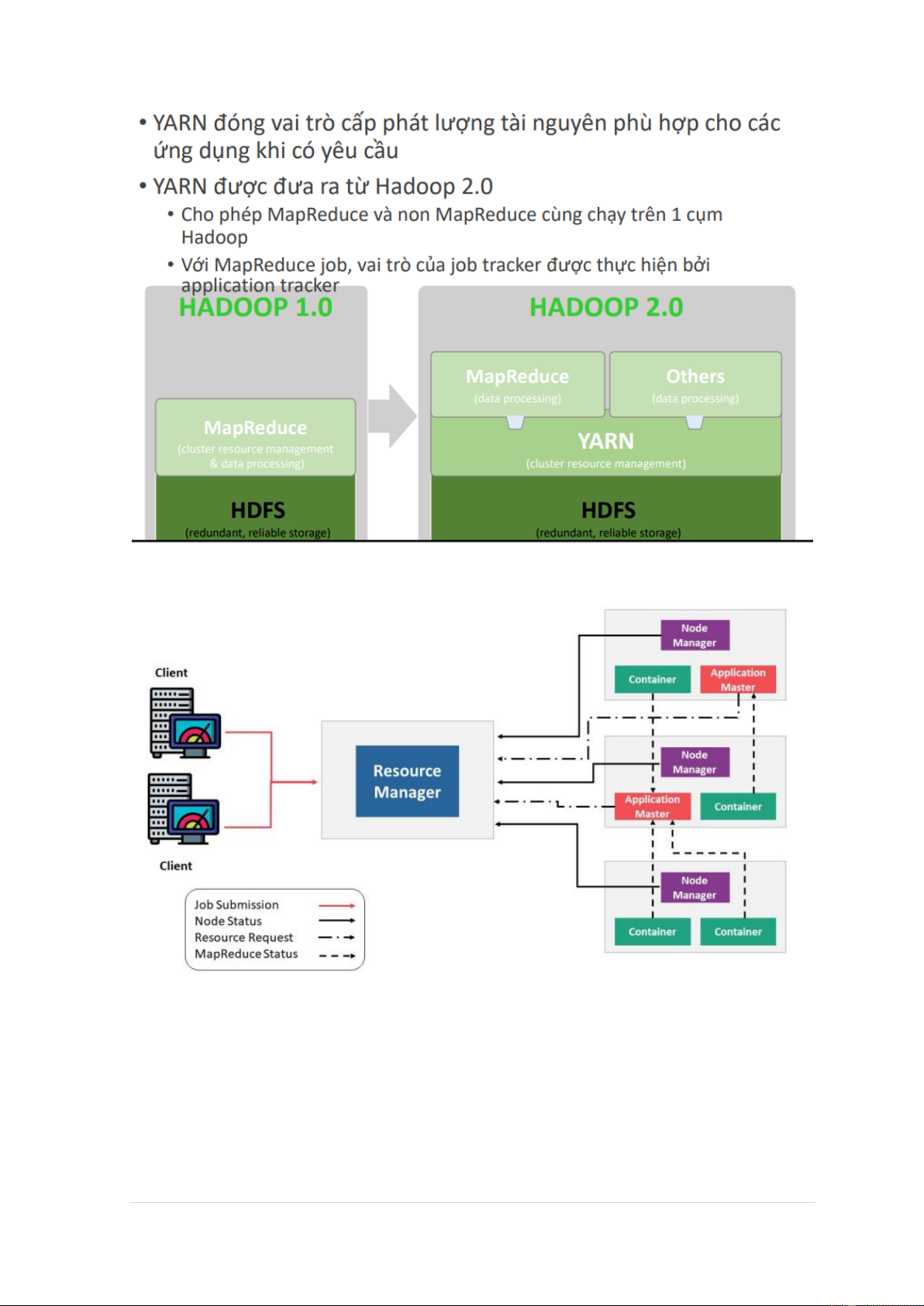
YARN – Yet Another Resorce Negotiator 10 | P a g e - Cấp phát trên Yarn - Hệ sinh thái Hadoop 11 | P a g e
Lec3: HDFS (Hadoop Distributed File System) 1. Overview 2. Kiến trúc HDFS
- Metadata in memory: gồm các list, thuộc tính cơ bản như thời gian khởi tạo - Transaction Log
Rack gồm nhiều Node, Node chứa nhiều Board (Block), đơn vị nhỏ nhất là chunk
Không nên để 2 Board cùng 1 Rack 12 | P a g e *) HDFS data format 1. Text (CSV, TSV, Json)
2. Sequence file (Binary Key-value)
3. Avro (row based) (Flexible data scheme – JSON)
4. Parquet (column-oriented binary file format) 13 | P a g e
Lec4: (MapReduce - Parallel Programming with Hadoop) 14 | P a g e 15 | P a g e
1. Số Mapper bằng số chunk đầu vào
Không cấu hình được số Mapper (do lượng dữ liệu đầu vào)
Cho những Mapper chạy trên đúng nốt chứa dữ liệu (Locality) 16 | P a g e
2. Số lượng Reducer bằng số lượng máy 2.
Map Input: (StudentName, ClassID)
Map Output: ((ClassA, 1),(ClassA, 1),..(ClassF, 1),(ClassF, 1),..)
Reduce input: ((ClassA,[1, 1,..]], ... (ClassF,[1, 1,..]),..)
Reduce output: ((ClassA, num_stu_A),..(ClassF, num_stu_F),..) 2.
Map Input: (StudentName, classID) Map output: (class_code, 1)
Reduce input: (class_code, [1,1,...])
Reduce output: (classID, numberOfStudent) 3.
Master Server chia M nhiệm vụ map cho các máy và giám sát các tiến trình.
Nhiệm vụ map đọc dữ liệu cục bộ, lưu trữ kết quả map lưu trên cục bộ
(không lưu vào HDFS để ko nhân bản nên, sử dụng sẽ bỏ đi).
Pha Shuffle giao cho Reducers những buffers, những cái đọc và xử lý từ xa bởi Reducers.
Reducers cho ra kết quả trên bộ lưu trữ ổn định (HDFS). 17 | P a g e 3.
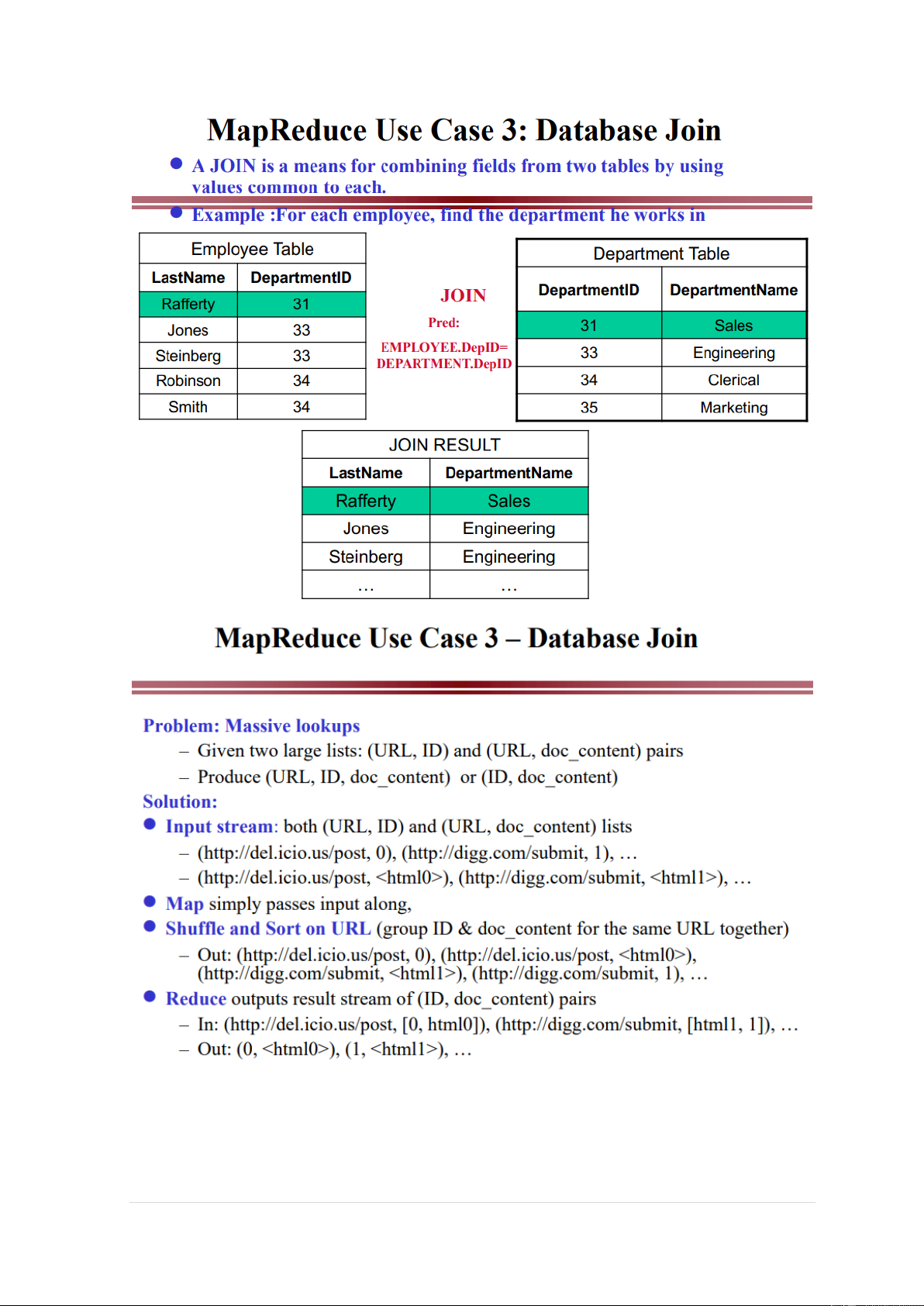
Map Input: (LastName, departmentID), (departmentID, departmentName);
Map output: (departmentID, Lastname), (departmentID, departmentName);
Reduce Input: (departmentID, [Lastname, departmentName]); 18 | P a g e
Reduce Output: (Lastname, departmentName) 4. Fault Tolerance 4.
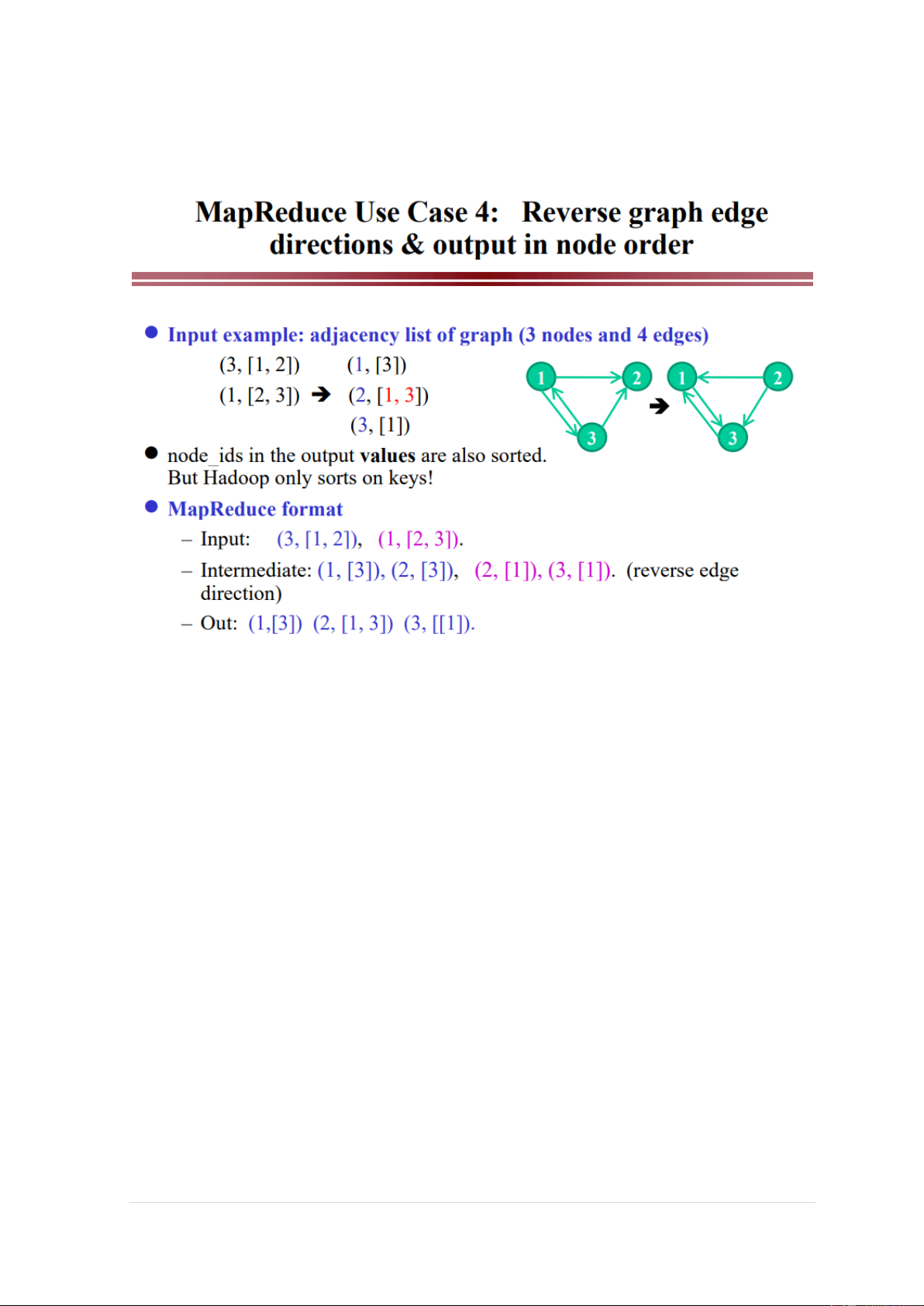
Map Input: (node, [adjacents]) Map Output: (adjacent, node)
Reduce input: (adjacent, [nodes])
Reduce output: (adjacent, [nodes])
Map Input: (3, [1, 2]), (1, [2, 3]).
Map Output: (1, [3]), (2, [3]), (2, [1]), (3, [1])
Reduce Input: (1, [3]), (2, [1]), (2, [3]), (3, [1])
Reduce Output: (1,[3]) (2, [1, 3]) (3, [[1])
5. Inverted Indexing Preliminaries 6. Page Rank 5.
Map Input: (S1, [S2,S3]), (S2, [S1]), (S3, [S1,S2]) (S1, W1), (S2, W2), (S3, W3) (S1, n1), (S2, n2), (S3, n3) 19 | P a g e
Map output: (S2, W1/n1), (S3, W1/n1), (S1, W2/n2), (S1, W3/n3), (S2, W3/n3)
Reduce input: (S1, [W2/n2, W3/n3]), (S2, [W1/n1, W3/n3]), (S3, [W1/n1])
Reduce output: (S1, W11=W2/n2+W3/n3), (S2, W22=W1/n1+W3/n3), (S3, W33=W1/n1)
Lec4: No SQL (Mongose DB) 1. Key-Value 20 | P a g e
Tài liệu liên quan:
-

Báo cáo Bài Tập Lớn: Phân Tích Dữ Liệu Thời Tiết | Lưu trữ và xử lý dữ liệu | Trường Đại học Bách Khoa
10 5 -

Xây dựng luồng dữ liệu lưu trữ, xử lý và phân tích giá bất động sản tại Anh từ 1995 | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
47 24 -

TOP câu hỏi trắc nghiệm Môn Lưu trữ và xử lý dữ liệu lớn | Đại học Bách Khoa Hà Nội
56 28 -

Lưu trữ và xử lý, phân tích dữ liệu phim | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
40 20 -

Đề trắc nghiệm BigData và đáp án| Môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
520 260