Tiểu luận giữa kỳ Phân tích dữ liệu | Trường Đại học Kinh Tế - Luật, Đại học Quốc gia Thành phố Hồ Chí Minh
Tiểu luận giữa kỳ Phân tích dữ liệu | Trường Đại học Kinh Tế - Luật, Đại học Quốc gia Thành phố Hồ Chí Minh. Tài liệu được sưu tầm giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem.
Môn: Thống kê ứng dụng (TK) 133 tài liệu
Trường: Trường Đại học Kinh Tế - Luật, Đại học Quốc gia Thành phố Hồ Chí Minh 1.5 K tài liệu
Tác giả:






Preview text:
ĐẠI HỌC QUỐC GIA THÀNH PHỐ HỒ CHÍ MINH
TRƯỜNG ĐẠI HỌC KINH TẾ - LUẬT 🙞🕮🙜 BÀI PHÂN TÍCH
Học kỳ 3/ 2024 - 2025
HỌC PHẦN: PHÂN TÍCH DỮ LIỆU
MÃ LỚP HỌC PHẦN: 243BMA202502
GVHD: TS. PHẠM VĂN CHỮNG
NHÓM SINH VIÊN THỰC HIỆN Họ và tên MSSV
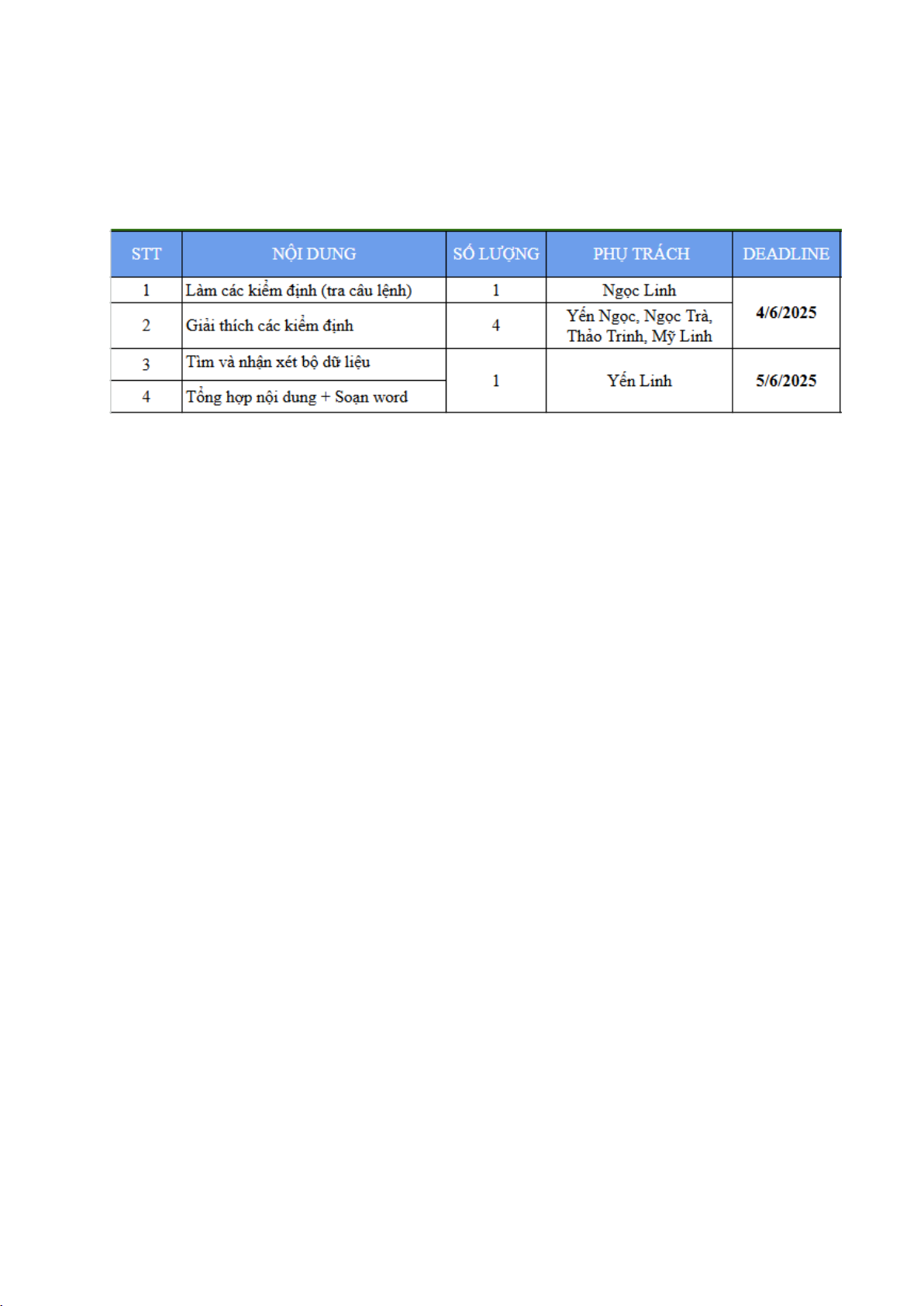
Mức độ hoàn thành Bùi Yến Linh K234050535 100% Trần Phạm Yến Ngọc K234050552 100% Lê Thị Mỹ Linh K234050536 100% Bùi Ngọc Linh K234060704 100% Ngô Nguyễn Thảo Trinh K234010123 100% Nguyễn Thị Ngọc Trà K234010119 100% 1
BẢNG PHÂN CÔNG CÔNG VIỆC 1 LỜI CẢM ƠN
Trước tiên, chúng em xin gửi lời cảm ơn chân thành và sâu sắc đến thầy Phạm
Văn Chững vì đã tận tình giảng dạy và hướng dẫn chúng em trong suốt quá trình học
tập môn Phân tích dữ liệu. Những kiến thức quý báu được truyền đạt trong học phần
này chính là nền tảng vững chắc để chúng em hoàn thành bài nghiên cứu này.
Chúng em cũng xin gửi lời cảm ơn đến các anh/chị và bạn bè đã hỗ trợ, chia
sẻ tài liệu, kinh nghiệm và góp ý trong suốt quá trình thực hiện báo cáo. Nhờ có sự
giúp đỡ và đồng hành đó, chúng em đã có thêm động lực và định hướng rõ ràng hơn
khi nghiên cứu và phân tích số liệu của doanh nghiệp.
Mặc dù đã cố gắng hết sức trong việc thu thập, xử lý thông tin và trình bày
nội dung, nhưng do kinh nghiệm và kiến thức thực tiễn còn hạn chế, bài báo cáo khó
tránh khỏi những thiếu sót. Chúng em rất mong nhận được sự góp ý từ thầy để có thể
hoàn thiện tốt hơn trong các nghiên cứu sau này.
TP Hồ Chí Minh, ngày 07 tháng 06 năm 2025. 2 MỤC LỤC
BẢNG PHÂN CÔNG CÔNG VIỆC ......................................................................................................... 1
LỜI CẢM ƠN ........................................................................................................................................... 2
I. GIỚI THIỆU VÀ NHẬN XÉT CHUNG VỀ BỘ DỮ LIỆU ................................................................. 4
I.1. Giới thiệu bộ dữ liệu ....................................................................................................................... 4
I.1. Biến định tính ............................................................................................................................. 4
I.2. Biến định lượng .......................................................................................................................... 7
I.2. Nhận xét chung về bộ dữ liệu ....................................................................................................... 13
II. CÁC PHƯƠNG PHÁP KIỂM ĐỊNH THỐNG KÊ ........................................................................... 13
II.1. Kiểm định phân phối chuẩn ........................................................................................................ 13
II.1.1. Kiểm định cho biến charges ................................................................................................. 14
II.1.2. Kiểm định cho biến bmi ....................................................................................................... 15
II.1.3. Kiểm định cho biến age ....................................................................................................... 17
II.1.4. Kiểm định cho biến children ................................................................................................ 19
II.1.5. Tổng kết kiểm định phân phối chuẩn ................................................................................... 21
II.2. Các kiểm định phi tham số (không phân phối chuẩn) ................................................................. 21
II.2.1. Kiểm định Spearman ............................................................................................................ 21
II.2.2. Kiểm định Dấu (Sign Test) .................................................................................................. 22
II.2.3. Kiểm định Hạng dấu (Wilcoxon signed-rank test) .............................................................. 24
II.2.4. Kiểm định Tổng hạng Wilcoxon (Mann–Whitney U test) .................................................. 26
II.2.5. Kiểm định Kruskal Wallis (K-W) ........................................................................................ 28
II.2.6. Kiểm định dunntest .............................................................................................................. 31
II.2.7. Kiểm định Chi bình phương ................................................................................................ 36
II.3. Các kiểm định tham số ................................................................................................................ 38
II.3.1. Kiểm định độ lệch chuẩn (sdtest) ......................................................................................... 38
II.3.2. Kiểm định t-test (1 mẫu) ...................................................................................................... 39
II.3.3. Kiểm định phương sai giữa các nhóm (Levene) .................................................................. 41
II.3.4. Kiểm định t-test (2 mẫu độc lập) ......................................................................................... 42
II.3.5. Kiểm định ANOVA (Phân tích phương sai nhiều yếu tố) ................................................... 44
II.3.6. Kiểm định Tukey (Phân tích sâu ANOVA) ......................................................................... 46
II.2.7. Kiểm định hệ số tương quan (Pearson) ................................................................................ 48
KẾT LUẬN ............................................................................................................................................. 50 3
I. GIỚI THIỆU VÀ NHẬN XÉT CHUNG VỀ BỘ DỮ LIỆU
I.1. Giới thiệu bộ dữ liệu
Bộ dữ liệu “Medical Cost Personal Datasets” được đăng tải trên nền tảng
Kaggle là một tập dữ liệu thực tế phản ánh chi phí y tế cá nhân dựa trên các đặc điểm
nhân khẩu học và lối sống.
(Nguồn: https://www.kaggle.com/datasets/mirichoi0218/insurance).
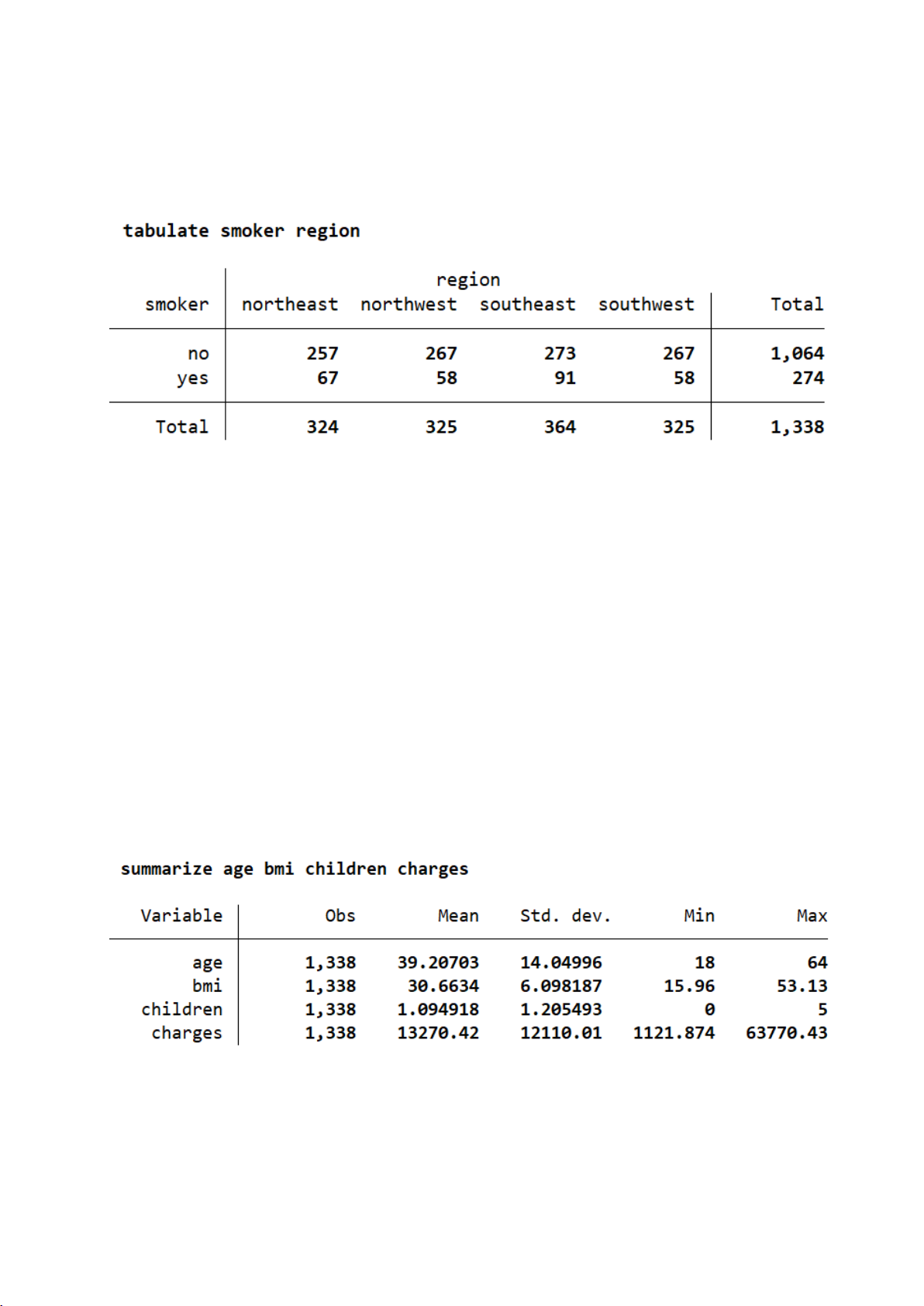
Tập dữ liệu bao gồm 1.338 quan sát với 7 biến, bao gồm: tuổi (age), giới tính
(sex), chỉ số khối cơ thể (BMI), số con cái phụ thuộc (children), tình trạng hút thuốc
(smoker), khu vực sinh sống (region), và chi phí y tế (charges). Đây là một bộ dữ liệu
có cấu trúc đơn giản, phù hợp để áp dụng các phương pháp phân tích dữ liệu cơ bản
đến nâng cao, đặc biệt là trong lĩnh vực thống kê ứng dụng và học máy.
Chất lượng dữ liệu được đánh giá ở mức rất tốt, với đầy đủ thông tin và không
có giá trị thiếu (missing values). Các biến định tính như giới tính, tình trạng hút thuốc
hay khu vực được mã hóa rõ ràng bằng các nhãn cụ thể, trong khi các biến định lượng
như tuổi, BMI và chi phí được thể hiện bằng số thực. Việc không có dữ liệu bị thiếu
hoặc sai định dạng giúp giảm thiểu thời gian tiền xử lý và tăng độ tin cậy cho các phân tích sau này.
I.1. Biến định tính
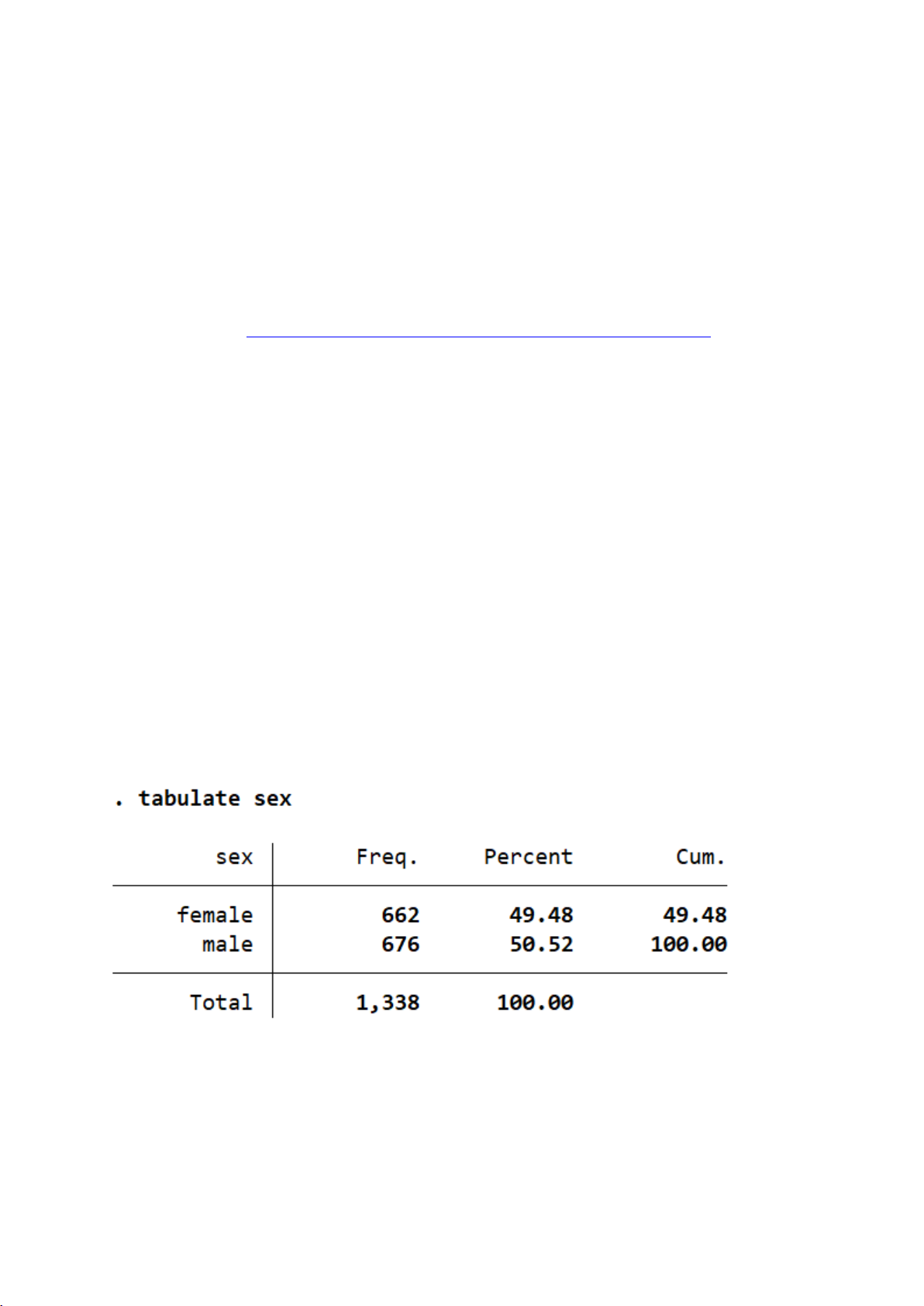
Bộ dữ liệu bao gồm tổng cộng 1.338 cá nhân, được phân chia gần như đồng
đều theo giới tính: Nam giới chiếm 676 người, tương ứng 50,52% tổng số quan sát;
Nữ giới chiếm 662 người, tương ứng 49,48%. 4
=> Tỷ lệ giới tính giữa nam và nữ gần bằng nhau, giúp đảm bảo tính cân đối
và đại diện khi phân tích theo giới.
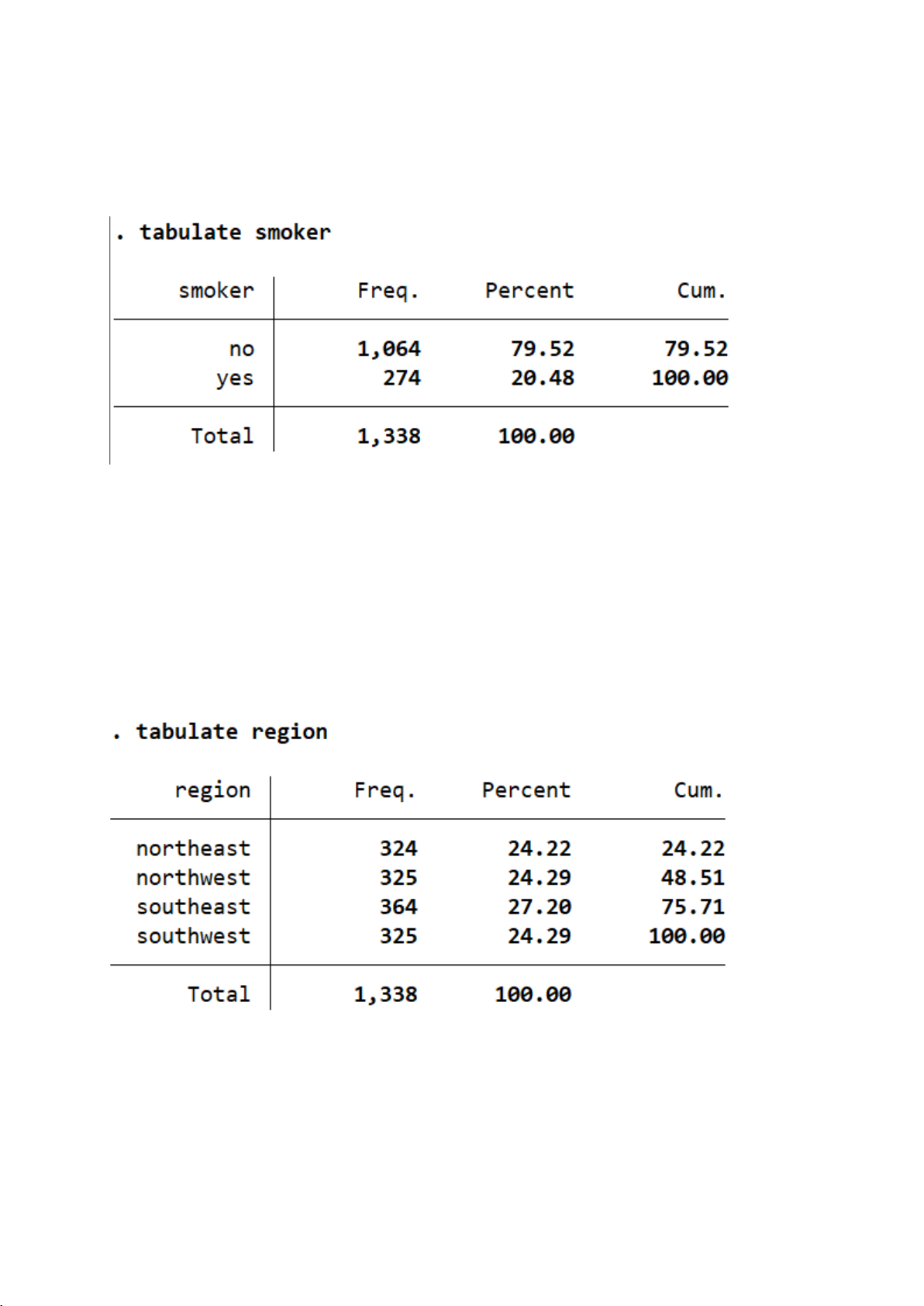
Bộ dữ liệu bao gồm 1.338 cá nhân, trong đó: 1.064 người không hút thuốc,
chiếm 79,52%; 274 người hút thuốc, chiếm 20,48%. Phần lớn người trong bộ dữ liệu
là không hút thuốc. Tỷ lệ hút thuốc chiếm khoảng 1/5 dân số trong mẫu
=> Đây là một hành vi tương đối ít phổ biến trong nhóm người được khảo sát.
Bộ dữ liệu gồm 1.338 cá nhân, được phân bổ theo 4 vùng địa lý như sau:
● Southeast (Đông Nam): 364 người (27,20%) – là vùng có số lượng quan sát cao nhất. 5
● Southwest (Tây Nam): 325 người (24,29%).
● Northwest (Tây Bắc): 325 người (24,29%).
● Northeast (Đông Bắc): 324 người (24,22%) – là vùng có số lượng quan sát
thấp nhất, nhưng không chênh lệch nhiều.
⇒ Tổng thể, các vùng có số quan sát khá đồng đều, dao động trong khoảng 24% – 27%.
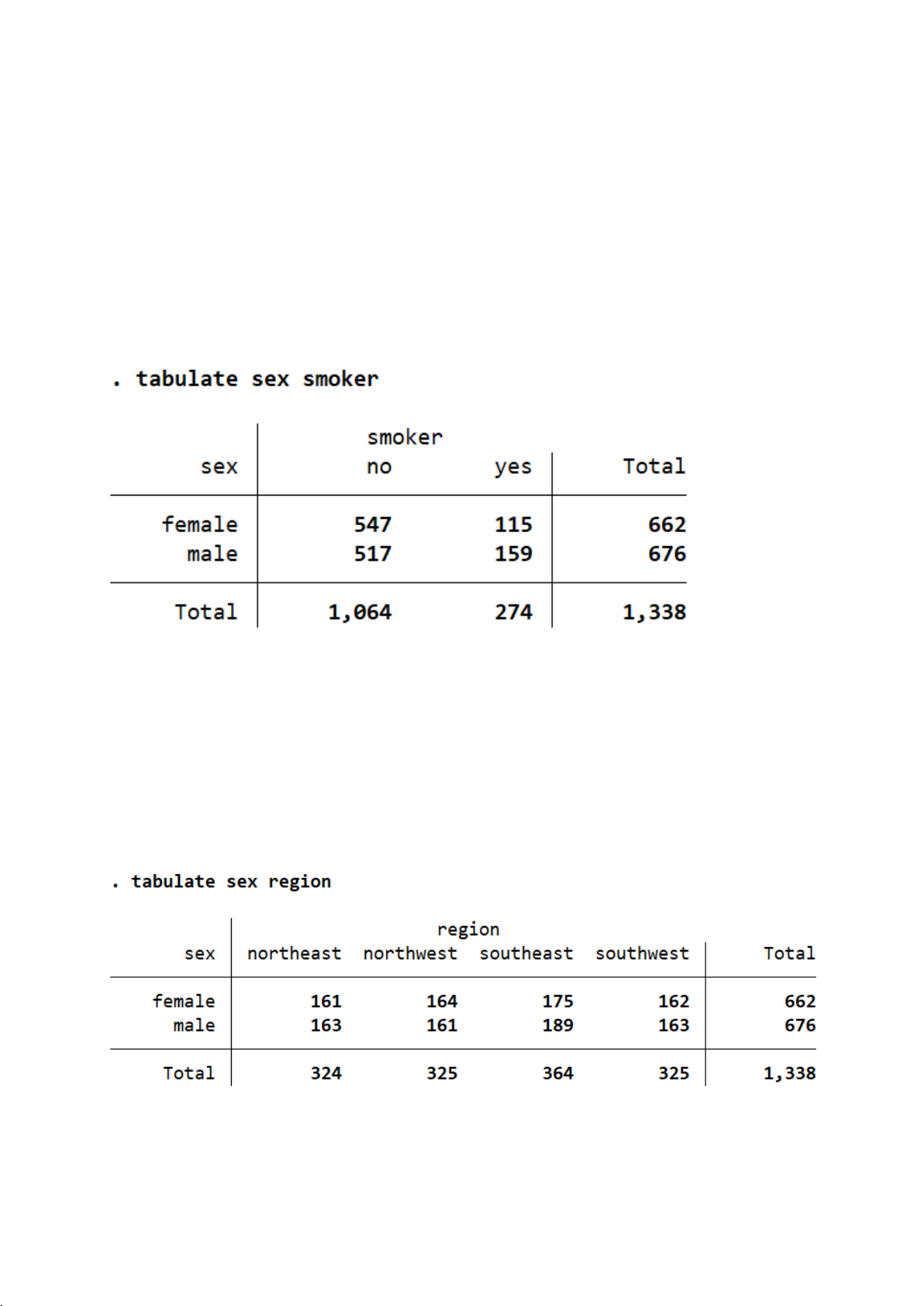
Trong bộ dữ liệu, 20,5% cá nhân là người hút thuốc. Tỷ lệ hút thuốc ở nam
cao hơn nữ: 23,5% nam giới hút thuốc so với 17,4% nữ giới.
⇒ Điều này cho thấy giới tính có thể là yếu tố ảnh hưởng đến hành vi hút thuốc.
Tỷ lệ nam và nữ được phân bố khá đồng đều giữa các vùng. Mỗi vùng có
khoảng 160 – 190 người thuộc mỗi giới (nam/nữ). 6
⇒ Không có sự mất cân đối đáng kể nào về giới tính giữa các khu vực địa lý trong bộ dữ liệu.
Tình trạng hút thuốc có sự khác biệt giữa các vùng. Vùng Southeast ghi nhận
tỷ lệ hút thuốc cao nhất (25%), trong khi các vùng Northwest và Southwest có tỷ lệ thấp hơn (khoảng 17,8%).
⇒ Yếu tố vùng địa lý có thể liên quan đến hành vi hút thuốc.
I.2. Biến định lượng
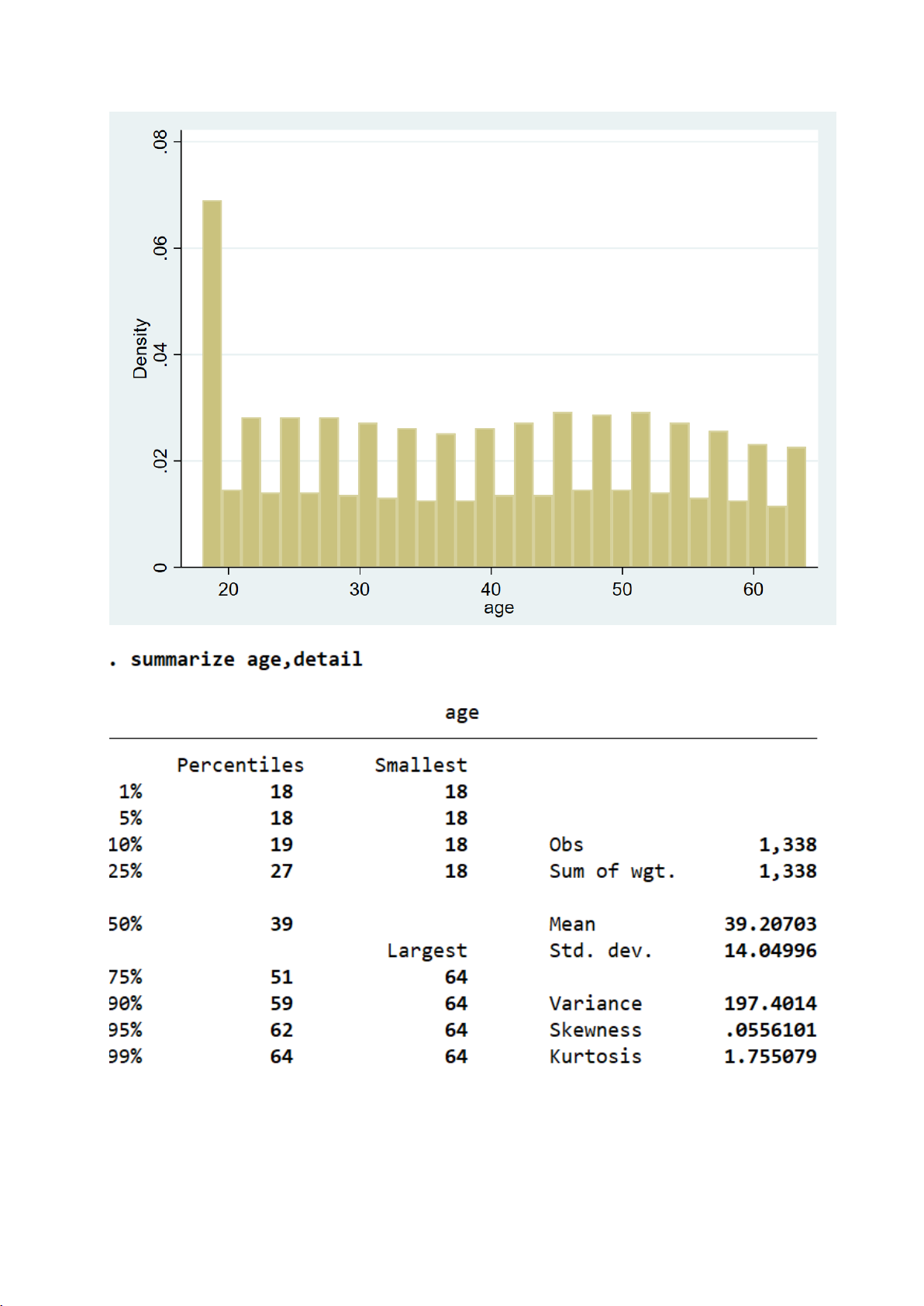
Nhìn chung, bộ dữ liệu gồm 1.338 quan sát, bao gồm thông tin về tuổi, chỉ số
BMI, số con và chi phí y tế. Trung bình người tham gia tầm 39 tuổi, chỉ số BMI
khoảng 30.7, và có 1 người con. Chi phí y tế trung bình khoảng 13.270 (đơn vị tiền),
với sự dao động lớn giữa các cá nhân. 7
Người tham gia có độ tuổi từ 18 đến 64 tuổi, với tuổi trung bình là khoảng
39,2 và độ lệch chuẩn khoảng 14,05 tuổi. 8
⇒ Điều này cho thấy độ tuổi phân bố khá rộng trong mẫu khảo sát. 9
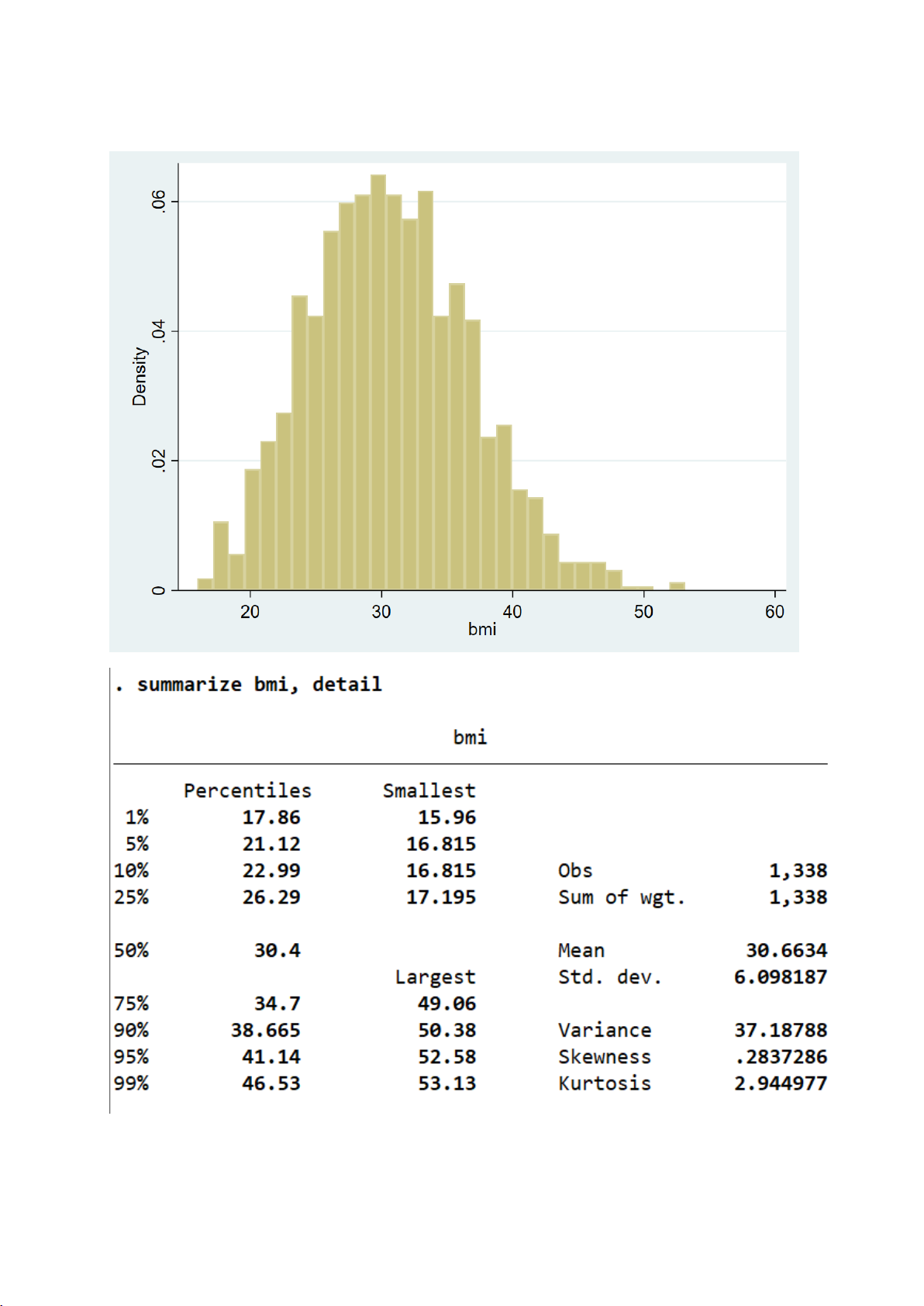
Chỉ số BMI trung bình là 30,66, nằm trong ngưỡng thừa cân hoặc béo phì
nhẹ, với giá trị thấp nhất là 15,96 và cao nhất là 53,13. Độ lệch chuẩn khoảng 6,10
⇒ Thể hiện sự đa dạng nhất định về thể trạng. 10
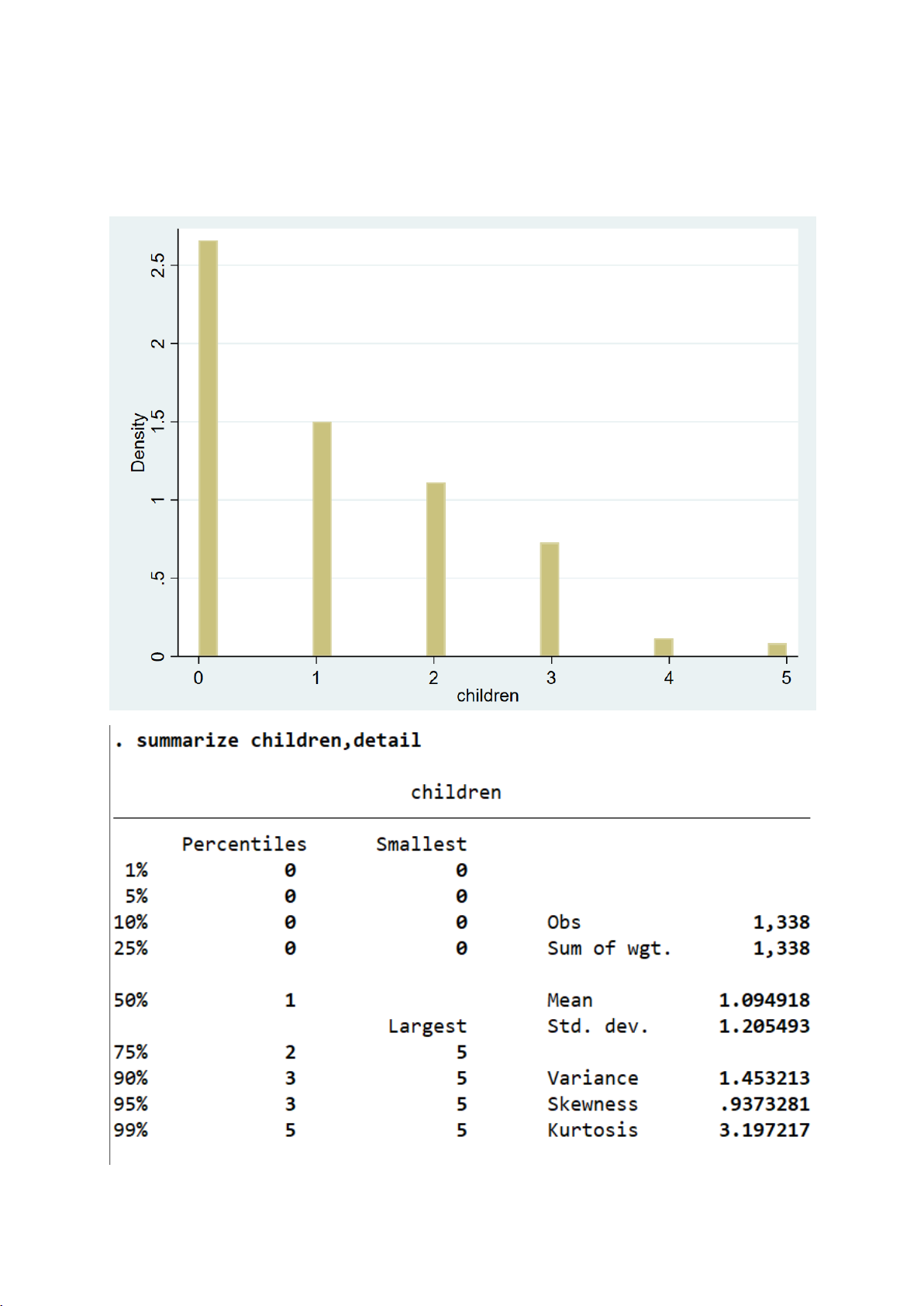
Trung bình mỗi người có khoảng 1,1 người con, với giá trị từ 0 đến 5 con.
Độ lệch chuẩn khoảng 1,21
⇒ Cho thấy số con dao động đáng kể giữa các cá nhân. 11
Biến này thể hiện chi phí y tế hoặc bảo hiểm, dao động từ 1.121,87 đến
63.770,43 (đơn vị tiền không được ghi rõ, có thể là đô la Mỹ nếu theo chuẩn thường
dùng). Chi phí trung bình là 13.270,42, với độ lệch chuẩn khá lớn (12.110,01) 12
⇒ Cho thấy sự phân hóa cao về mức chi tiêu y tế trong dân số.
I.2. Nhận xét chung về bộ dữ liệu
Xét về phân phối dữ liệu, có thể thấy chi phí y tế (charges) phân bố lệch phải
rõ rệt, với một số trường hợp có chi phí rất cao. Điều này cho thấy sự tồn tại của các
cá nhân có mức chi tiêu y tế đột biến, thường là do hút thuốc hoặc mắc các bệnh lý
phức tạp. Trong khi đó, các biến như chỉ số BMI và tuổi có phân phối gần chuẩn hơn,
giúp dễ dàng áp dụng các kiểm định thống kê thông thường.
Phân tích mối quan hệ giữa các biến cho thấy nhiều kết quả đáng chú ý. Chẳng
hạn, tình trạng hút thuốc có ảnh hưởng mạnh mẽ đến chi phí y tế, khi người hút thuốc
thường có mức chi phí trung bình cao hơn rất nhiều so với người không hút. Tuổi tác
và BMI cũng có mối tương quan thuận với chi phí y tế, phản ánh xu hướng người lớn
tuổi hoặc người thừa cân béo phì sẽ phải chi trả nhiều hơn cho các dịch vụ chăm sóc
sức khỏe. Bên cạnh đó, sự khác biệt giữa các khu vực địa lý về mức chi phí cũng đáng
lưu tâm, có thể là do sự chênh lệch về chi phí y tế hoặc thói quen sinh hoạt theo vùng miền.
Tổng thể, đây là một bộ dữ liệu có giá trị thực tiễn cao, mang lại nhiều tiềm
năng cho các bài toán phân tích dữ liệu, đặc biệt là trong việc xây dựng mô hình dự
đoán chi phí y tế. Nó không chỉ giúp người học làm quen với các kỹ thuật thống kê
và trực quan hóa dữ liệu, mà còn khuyến khích tư duy phân tích và tìm kiếm mối liên
hệ giữa các yếu tố ảnh hưởng đến sức khỏe con người.
II. CÁC PHƯƠNG PHÁP KIỂM ĐỊNH THỐNG KÊ
II.1. Kiểm định phân phối chuẩn
Để xác định xem có thể áp dụng các kiểm định tham số cho các biến nghiên
cứu hay không, ta tiến hành kiểm định phân phối chuẩn (Shapiro-Wilk và kiểm định
độ lệch/độ nhọn Skewness/Kurtosis).
- Giả thuyết kiểm định:
H₀: Biến có phân phối chuẩn.
H₁: Biến không có phân phối chuẩn. 13
- Nếu p-value < 0.05 → bác bỏ giả thuyết H₀ → biến không phân phối chuẩn →
cân nhắc sử dụng kiểm định phi tham số hoặc biến đổi dữ liệu.
- Nếu p-value > 0.05 → không có đủ bằng chứng để bác bỏ giả thuyết H₀ →
biến có thể tuân theo phân phối chuẩn
=> Việc kiểm định được áp dụng cho các biến: age, bmi, charges, children.
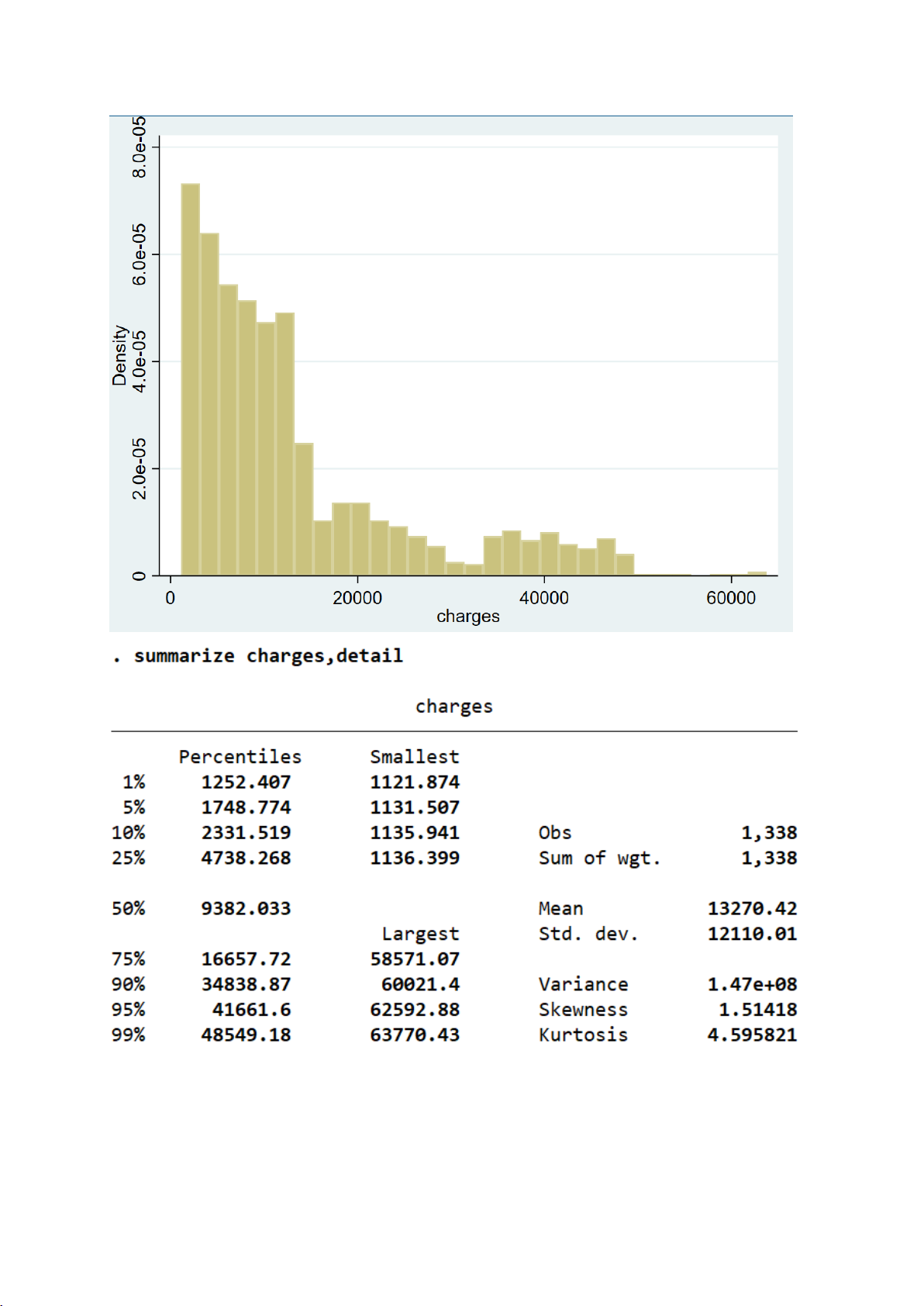
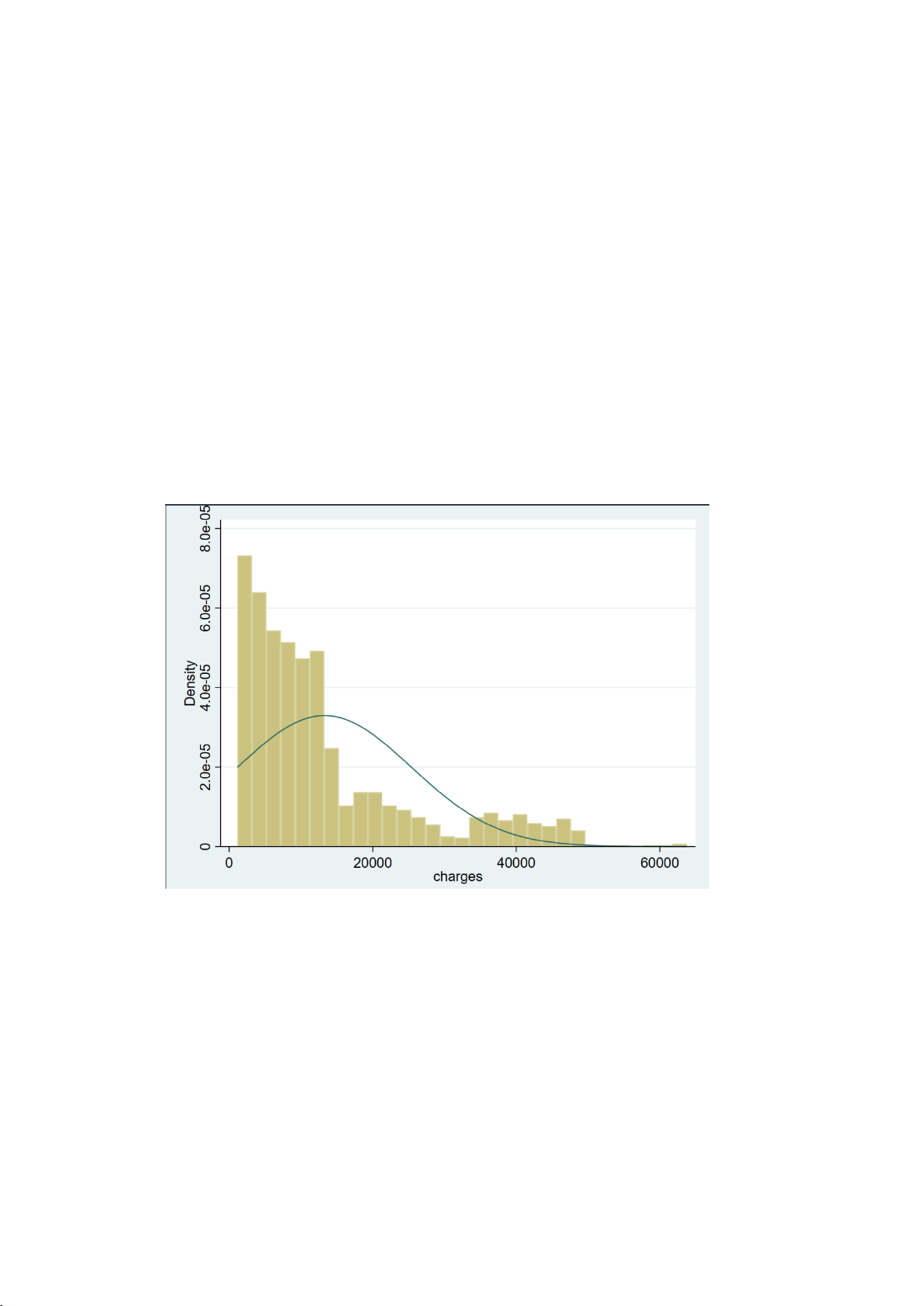
II.1.1. Kiểm định cho biến charges
- Biểu đồ histogram để kiểm tra trực quan phân phối so với đường chuẩn:
Biểu đồ histogram cho thấy:
- Biến charges lệch phải mạnh (right-skewed)
- Không có hình dạng "chuông" của phân phối chuẩn
- Xuất hiện nhiều giá trị cao, có thể là outliers
⇒ Dự đoán sơ bộ: Biến charges không tuân theo phân phối chuẩn 14 -
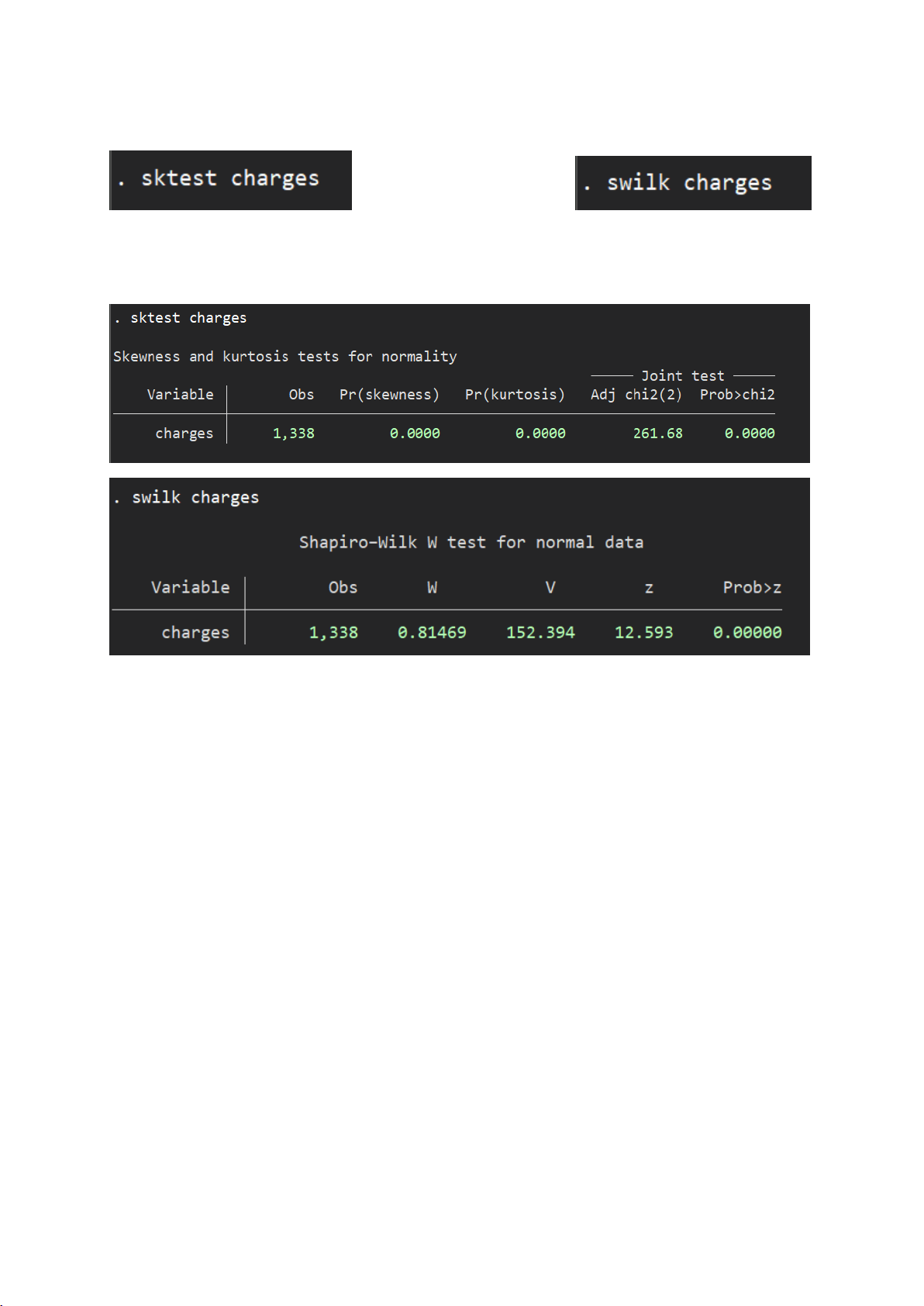
Câu lệnh kiểm định: -
Kết quả stata:
Cả hai kiểm định Skewness-Kurtosis (sktest) và Shapiro-Wilk (swilk) đều cho p-value = 0.0000.
=> Vì p-value < 0.05 → Bác bỏ H₀ → Biến charges không tuân theo phân phối chuẩn.
⇒ Ý nghĩa kiểm định: Không nên áp dụng các kiểm định giả định phân phối chuẩn
cho biến charges (ví dụ: t-test, ANOVA,...), cần cân nhắc sử dụng kiểm định phi tham
số, hoặc chuyển đổi biến để tiệm cận chuẩn nếu cần thiết.
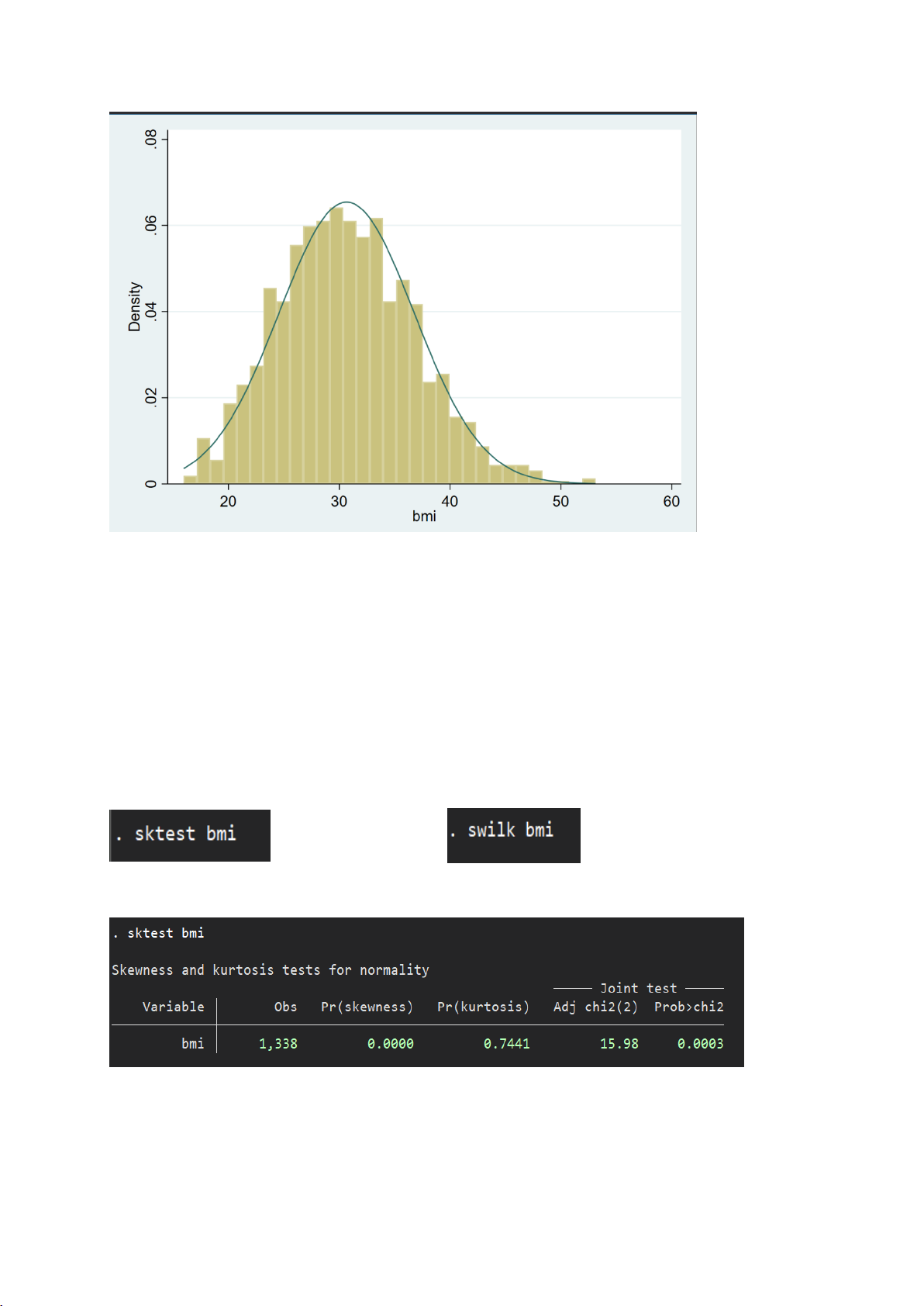
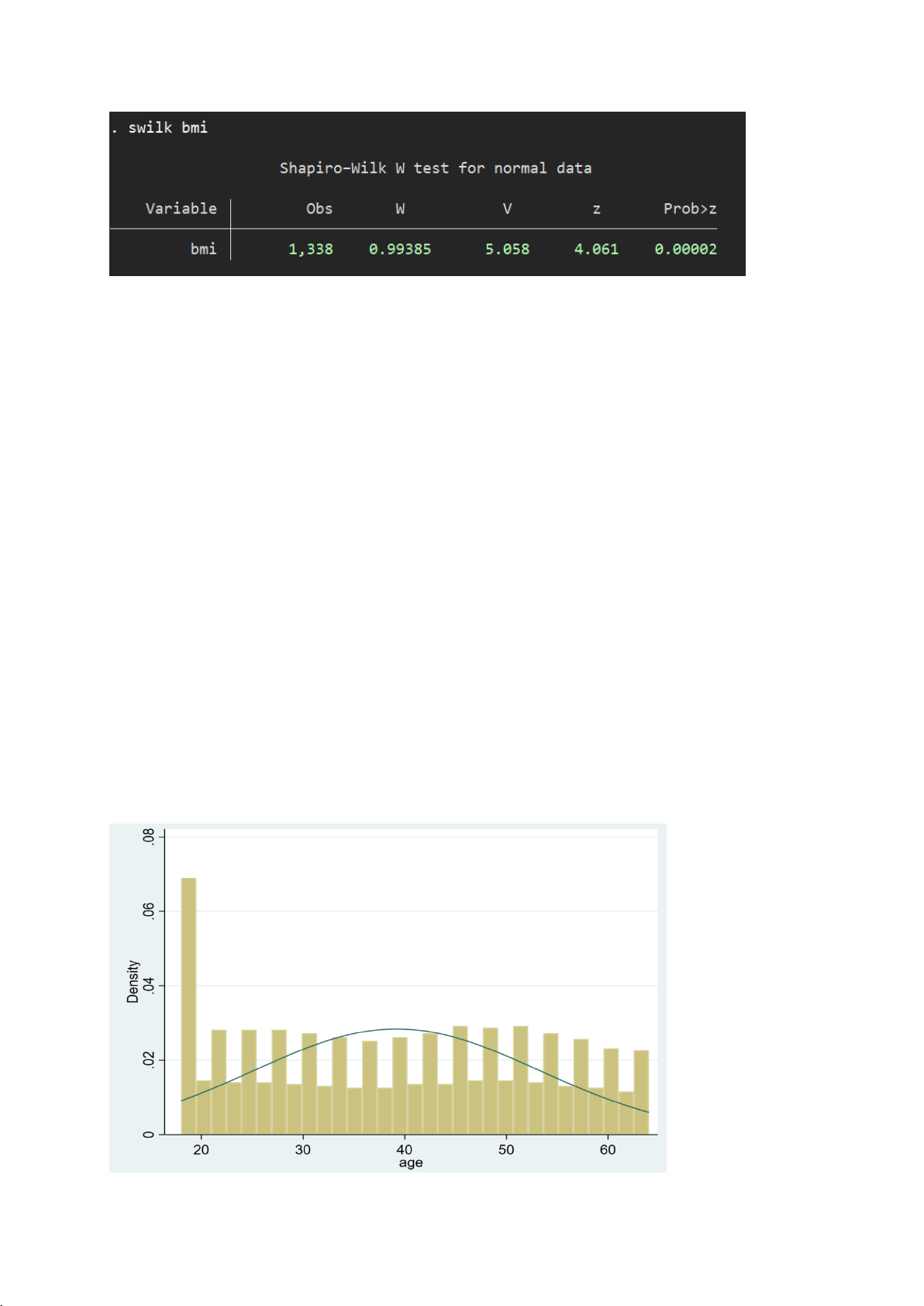
II.1.2. Kiểm định cho biến bmi
- Biểu đồ histogram để kiểm tra trực quan phân phối so với đường chuẩn: 15
Biểu đồ histogram cho thấy:
● Biến bmi có hình chuông tương đối rõ, lệch phải nhẹ.
● Đường mật độ phủ khá khớp với đường chuẩn → có dấu hiệu tiệm cận phân phối chuẩn.
- Câu lệnh kiểm định:
- Kết quả stata: 16
Cả hai kiểm định Skewness-Kurtosis (sktest) và Shapiro-Wilk (swilk) đều cho p-value = 0.0000.
=> Vì p-value < 0.05 → Bác bỏ H₀ → Biến bmi không tuân theo phân phối chuẩn.
⇒ Ý nghĩa kiểm định: Biến bmi không tuân theo phân phối chuẩn, dù quan sát
histogram có thể cho thấy hơi tiệm cận chuẩn. Sự sai lệch nhỏ cũng khiến kiểm định
thống kê phát hiện lệch chuẩn. Không nên áp dụng các kiểm định giả định phân phối
chuẩn cho biến charges (ví dụ: t-test, ANOVA,...), cần cân nhắc sử dụng kiểm định
phi tham số, hoặc chuyển đổi biến để tiệm cận chuẩn nếu cần thiết.
II.1.3. Kiểm định cho biến age
- Biểu đồ histogram để kiểm tra trực quan phân phối so với đường chuẩn: 17
Biểu đồ histogram cho thấy:
● Phân phối không đối xứng — có một đỉnh lớn ở tuổi khoảng 18–20, sau đó dàn trải.
● Không có dạng chuông đặc trưng của phân phối chuẩn
=> Kết luận sơ bộ: Biến age không tuân theo phân phối chuẩn
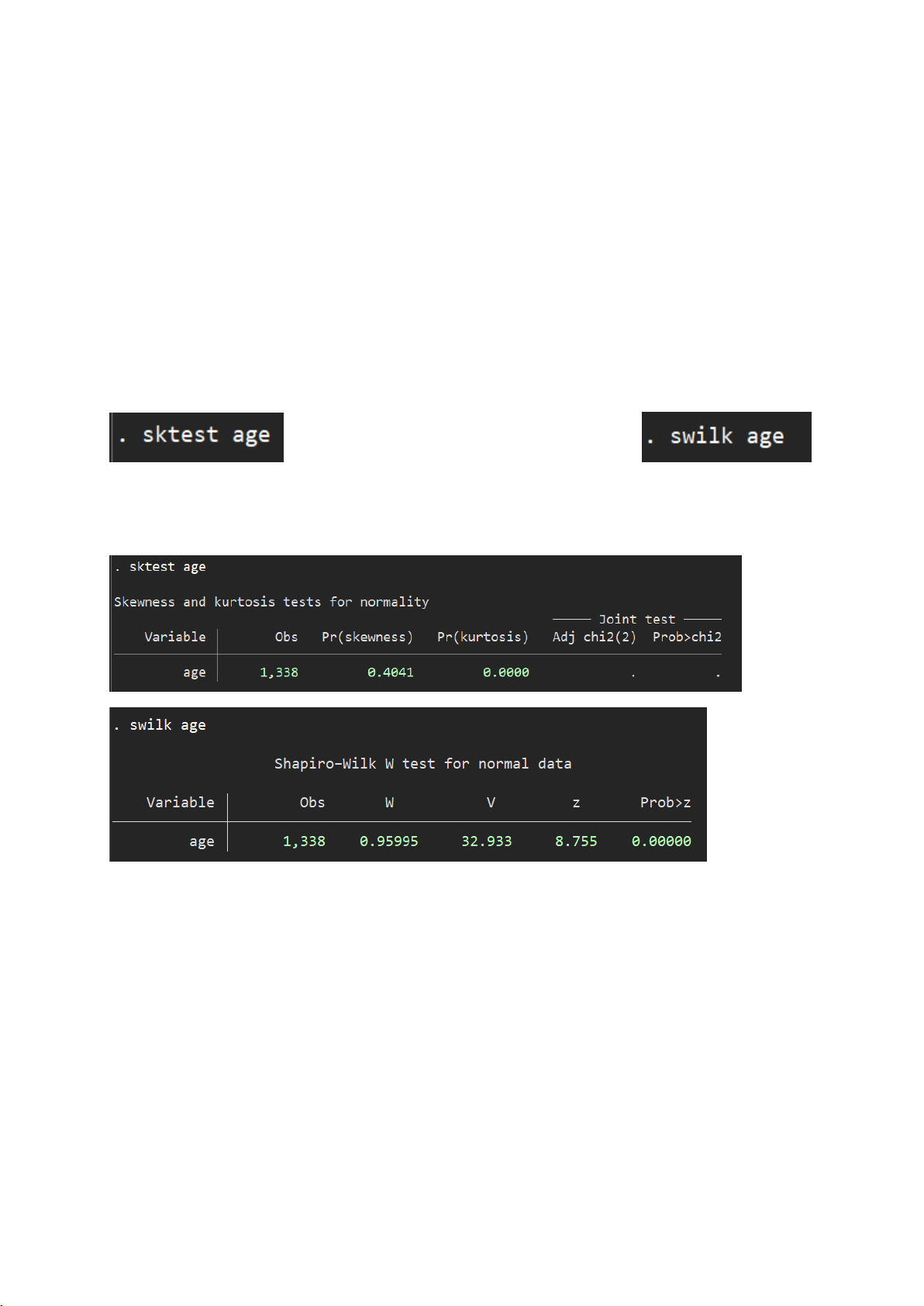
- Câu lệnh kiểm định:
- Kết quả stata:
* Kiểm định bằng sktest:
Do kết quả kiểm định không hiển thị giá trị prob>chi2 của kiểm định hợp nhất
(joint test), ta sẽ xem xét riêng hai thành phần:
● Giả thuyết kiểm định độ lệch (skewness):
H₀: Dữ liệu không lệch (skewness = 0)
H₁: Dữ liệu có độ lệch
● Giả thuyết kiểm định độ nhọn (kurtosis):
H₀: Dữ liệu có độ nhọn chuẩn (kurtosis = 3) 18
H₁: Dữ liệu có độ nhọn khác chuẩn
Kết quả kiểm định:
● Pr(skewness) = 0.4041 ⇒ Không có bằng chứng để bác bỏ H₀ ⇒ Dữ liệu không lệch.
● Pr(kurtosis) = 0.0000 ⇒ Bác bỏ H₀ ⇒ Dữ liệu có độ nhọn khác chuẩn.
⇒ Kết luận từ sktest: Dữ liệu không tuân theo phân phối chuẩn do có vấn đề về độ nhọn.
*Kiểm định bằng swilk:
● Giả thuyết H₀: Dữ liệu có phân phối chuẩn
● Kết quả: p-value = 0.00000 < 0.05 ⇒ Bác bỏ H₀
⇒ Biến age không tuân theo phân phối chuẩn.
⇒ Cả hai kiểm định sktest và swilk đều chỉ ra rằng biến age không có phân phối chuẩn.
⇒ Ý nghĩa kiểm định:
● Dù kiểm định sktest cho thấy Pr(skewness) > 0.05, tức là dữ liệu không có vấn
đề về độ lệch, nhưng Pr(kurtosis) = 0.0000 lại cho thấy có vấn đề về độ nhọn
phân phối. Nếu không xem xét kỹ cả hai thành phần, ta có thể dễ dàng kết luận
sai rằng dữ liệu có phân phối chuẩn.
● Nhìn chung, không nên áp dụng các kiểm định thống kê yêu cầu giả định phân
phối chuẩn (như t-test, ANOVA,...) cho biến age. Thay vào đó, nên xem xét
sử dụng kiểm định phi tham số hoặc biến đổi dữ liệu (log, căn bậc hai...) để
tiệm cận phân phối chuẩn nếu cần thiết.
II.1.4. Kiểm định cho biến children -
Biểu đồ histogram để kiểm tra trực quan phân phối so với đường chuẩn: 19
Tài liệu liên quan:
-

Giáo trình Nền tảng công nghệ cho Hệ thống thông tin | Trường Đại học Kinh tế – Luật, Đại học Quốc gia Thành phố Hồ Chí Minh
40 20 -

Đề thi Thống kê ứng dụng | Trường Đại học Kinh tế – Luật, Đại học Quốc gia Thành phố Hồ Chí Minh
429 215 -

Bài tập thống kê ứng dụng | Trường Đại học Kinh tế – Luật, Đại học Quốc gia Thành phố Hồ Chí Minh
469 235 -

Tài liệu luyện thi thống kê ứng dụng | Trường Đại học Kinh tế – Luật, Đại học Quốc gia Thành phố Hồ Chí Minh
481 241