Tìm hiểu OpenStack 3.1: Tổng quan và giao thức AMQP môn Điện toán đám mây | Trường Đại học Bách Khoa Hà Nội
OpenStack là một hệ điều hành đám mây mã nguồn mở bao gồm nhiều dự án con hoặc dịch vụ mã nguồn mở. Các dịch vụ này điều khiển một lượng lớn tài nguyên tính toán (compute), lưu trữ (storage) và mạng (networking) trong toàn bộ trung tâm dữ liệu. Tài liệu được sưu tầm gồm 68 trang, giúp các bạn nắm vững kiến thức, rèn luyện kỹ năng và đạt được kết quả tốt trong học tập. Mời các bạn đón xem!
Môn: Điện toán đám mây HUST 12 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:











Preview text:
OpenStack 3.1 Overview 3.1.1 Introduction
OpenStack là một hệ điều hành đám mây mã nguồn mở bao gồm nhiều dự án con hoặc dịch vụ
mã nguồn mở. Các dịch vụ này điều khiển một lượng lớn tài nguyên tính toán (compute), lưu trữ
(storage) và mạng (networking) trong toàn bộ trung tâm dữ liệu. Tất cả được quản lý thông qua
một bảng điều khiển (dashboard) cho phép quản trị viên kiểm soát và giúp người dùng triển khai
tài nguyên thông qua giao diện web. Những dịch vụ này được cung cấp nhằm tạo ra một môi
trường hạ tầng như một dịch vụ (Infrastructure as a Service – IaaS).
Tất cả các dịch vụ của OpenStack đều cung cấp API RESTful để giao tiếp với nhau và sử dụng
giao thức HTTP cho việc trao đổi dữ liệu. Nhờ sử dụng loại API này, hệ thống có thể mở rộng dễ
dàng và có khả năng chịu lỗi cao.
Tuy nhiên, giao tiếp thực sự giữa các dịch vụ được thực hiện bởi các worker – tức các tiến trình
riêng biệt, chuyên thực thi các tác vụ cụ thể. Các tiến trình này có thể chạy trên các máy khác
nhau và giao tiếp qua AMQP (Advanced Message Queuing Protocol), sử dụng RabbitMQ làm hệ thống bus mặc định.
Về lưu trữ dữ liệu dịch vụ, mỗi dịch vụ OpenStack đều có cơ sở dữ liệu SQL riêng để lưu thông
tin trạng thái. Để đảm bảo độ bền dữ liệu và hiệu suất xử lý, hệ thống có thể triển khai các mô
hình cơ sở dữ liệu đa chủ (multi-master replicated databases).
Để cung cấp đầy đủ các tài nguyên cần thiết để tạo ra một đám mây dịch vụ hạ tầng, hệ thống
OpenStack cung cấp các dịch vụ sau đây:
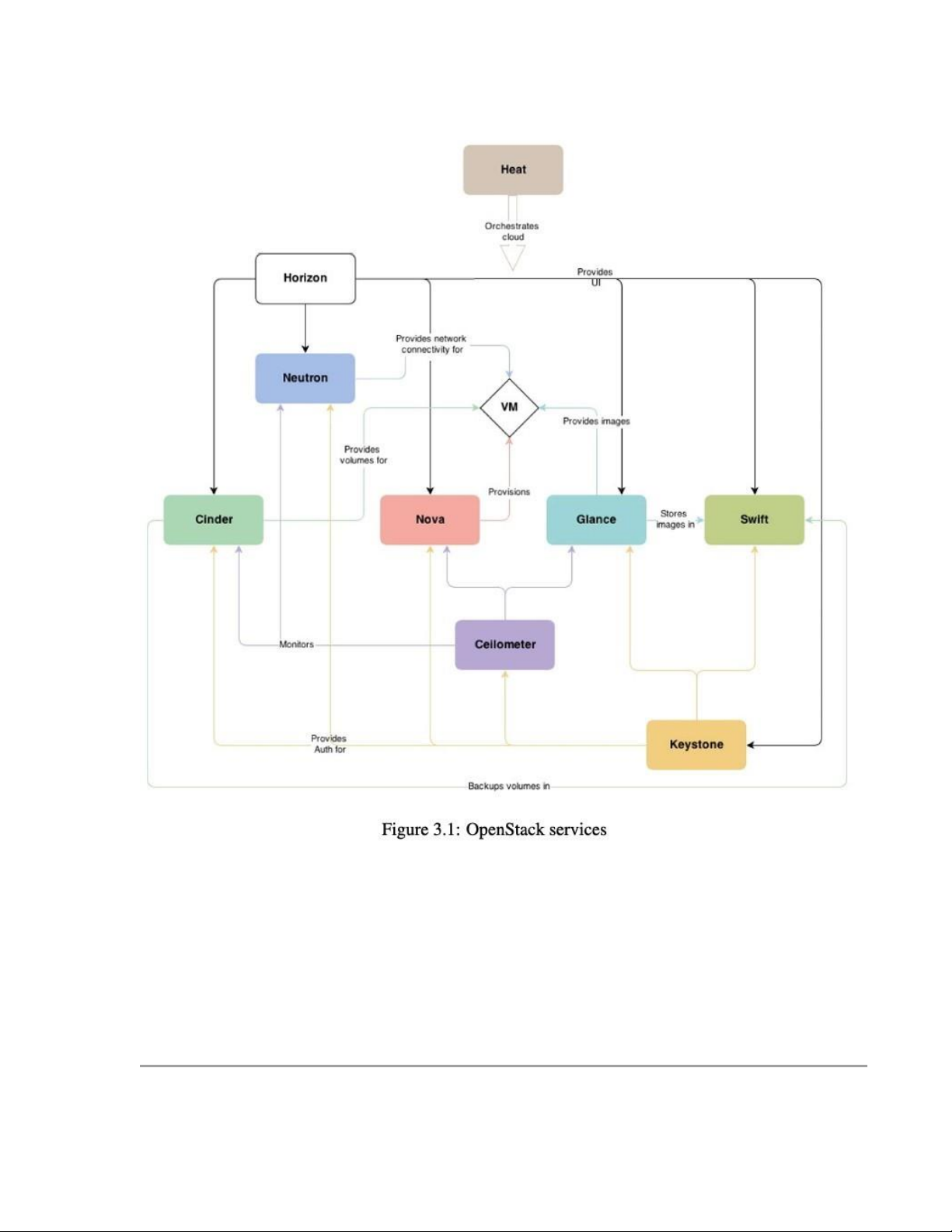
• Keystone: Identity service (quản lý danh tính và xác thực – cổng ra vào của cả hệ thống),
xác thực người dùng, cấp token truy cập, quản lý vai trò, nhóm và quyền trong hệ thống
cloud, mọi dịch vụ đều dựa vào nó để xác thực
• Nova: Compute service( tính toán – xử lý và chạy máy ảo (VMs)), cung cấp computing
resources: CPU, RAM,… Nova đóng vai trò cốt lõi trong việc chạy và điều khiển các máy ảo (instance)
• Neutron: Networking service( kết nối mạng giữa các máy ảo, giữa máy ảo vs Internet
hoặc mạng nội bộ, IP, router, switch ảo, firewall)
• Glance: Image service (ảnh hệ thống), quản lý và phân phối các bản image của máy ảo(
gồm hệ điều hành và cấu hình cài sẵn), cho phép upload, share, use các images: Ubuntu, CentOS, Windows,…
• Swift: Object Storage service(lưu trữ đối tượng – hình ảnh, tệp lớn, video, backup,…)
• Cinder: Block Storage service (lưu trữ khối): cung cấp thiết bị lưu trữ dạng block (như ổ
cứng) cho các máy ảo, gắn vào, tháo ra , dùng như ổ thật
• Heat: Orchestration(điều phối tài nguyên hạ tầng) service, quản lý sắp xếp và tự động hóa
quy trình triển khai, quản lý tài nguyên.
• Trove: Database service, triển khai, quản lý và vận hành các cơ sở dữ liệu (MySQL,
PostgreSQL, MongoDB,…) trên nền tảng cloud, users ko cần tự cài
• Ironic: Bare Metal service(dịch vụ triển khai trên máy chủ vật lý), cung cấp truy cập trực
tiếp đến phần cứng vật lý thay vì qua máy ảo
• Sahara: Data processing service, triển khai, quản lý các framework xử lý dữ liệu lớn như
Hadoop, Spark, thực hiện tác vụ phân tích, xử lý dữ liệu phân tán
• Zaqar: Message service (truyền thông điệp), các components trong hệ thống giao tiếp với
nhay bằng cách gửi và nhận thông điệp (messages) thông qua hàng đợi (queue), đảm bảo
tính phi đồng bộ và mở rộng hệ thống, trong Openstack, Zaqar cung cấp hàng đợi tin
nhắn giống như RabbitMQ hoặc Amazon SQS
• Barbican: Key management service (quản lý Khóa mã hóa), tạo, lưu trữ phân phối và xóa
các khóa mã hóa(encryption keys), bảo mật thông tin : mật khẩu, khóa API, chứng chỉ số
• Designate: DNS service (phân giải tên miền), giúp chuyển đổi tên miền (như
openstack.org) thành địa chỉ IP mà máy tính có thể hiểu và kết nối được
• Manila: Shared Filesystems service (hệ thống tệp dùng chung), nhiều máy ảo hoặc người
dùng truy cập và sử dụng chung 1 hệ thống tệp - ổ đĩa mạng, cung cấp khả năng tạo, gán
và quản lý các file share dùng chung giữa các instance
• Magnum: Containers service (quản lý Containers), containers-môi trường đóng gói ứng dụng nhẹ hơn máy ảo
• Murano: Application catalog (danh mục ứng dụng triển khai sẵn), chứa các app, config,
templates mà ng dùng có thể dễ dàng chọn và triển khai trong môi trường cloud
• Congress: Governance service (dịch vụ quản trị), thường gẵn với Keystone, quản lý
chính sách, vai trò, quyền truy cập và các quy định vận hành trong cloud
• Mistral: Workflow service (quản lý quy trình tự động), tư động hóa các tác vụ phức tạp
theo trình tự định sẵn – tạo luồng công việc để phối hợp nhiều bước (tạo VM, cấu hình mạng, gán quyền)
• MagnetoDB: Key-value store as a service( dịch vụ lưu trữ khóa giá trị), cung cấp cơ sở
dữ liệu kiểu khóa-giá trị, dữ liệu được lưu dưới dạng cặp key : value, nhanh và đơn giản để truy xuất
• Horizon: Dashboard (giao diện quản trị web), là UI giúp người dùng tương tác vơi các
dịch vụ như Nova, Neutron, Glance,… thông qua giao diện đồ họa thay vì dòng lệnh
• Celiometer: Telemetry service (dịch vụ theo dõi và phân tích số liệu hệ thống), thu thập
và giám sát số liệu từ các dịch vụ khác như Nova, Neutron, Cinder,… để theo dõi tình
trạng hoạt động và đảm bảo hệ thống luôn hoạt động hiệu quả
Những services cơ bản cần có trong Openstack: Keystone, Nova, Neutron, Heat, Glance,
Cinder, Horizon và Celiometer
3.1.2 Architecture (Kiến trúc)
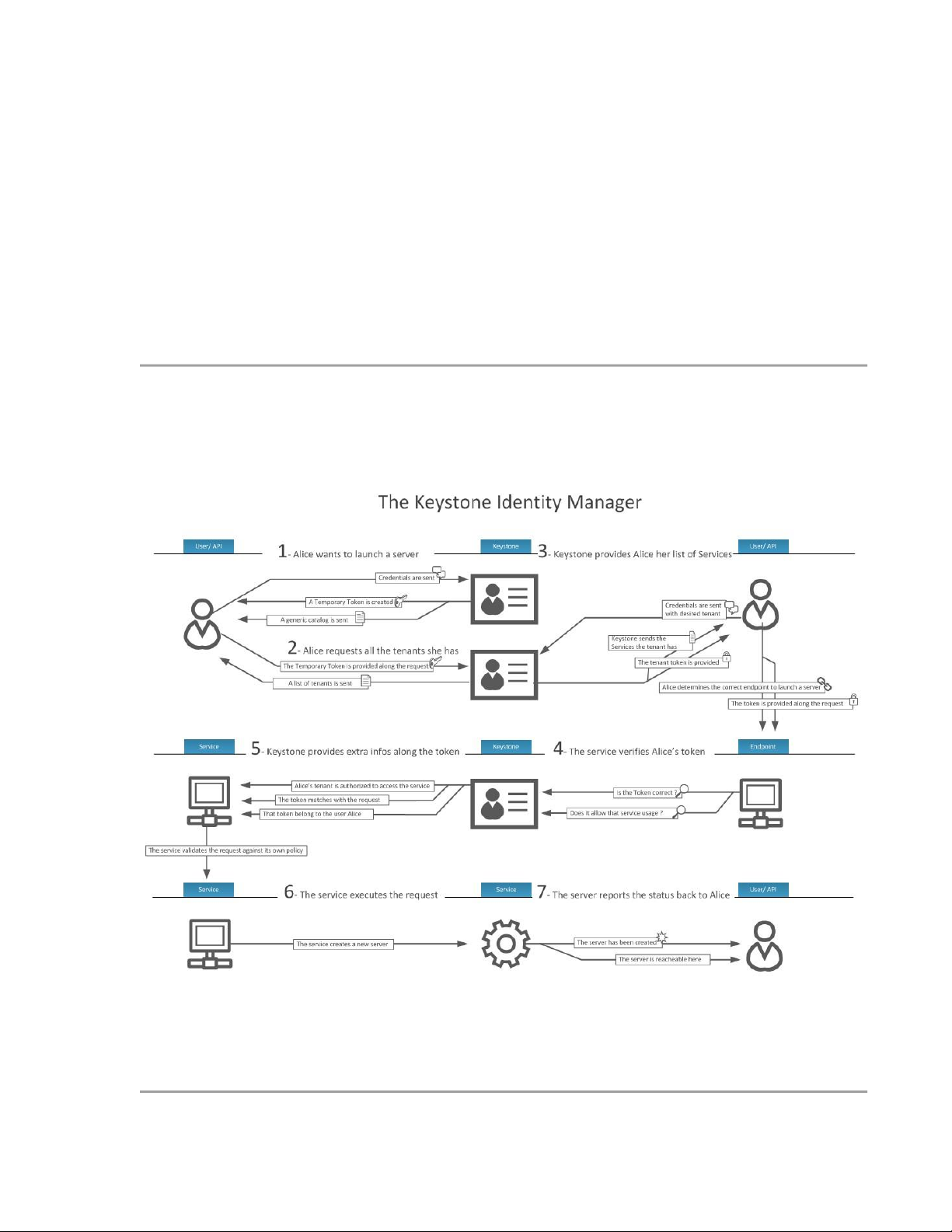
Hệ thống OpenStack tuân theo một quy trình đơn giản khi người dùng cố gắng truy cập vào một dịch vụ:
1. Người dùng gửi thông tin xác thực (credentials) đến Keystone khi muốn thực hiện một
hành động đối với một dịch vụ.
2. Nếu xác thực thành công, Keystone gửi lại cho người dùng một token tạm thời và danh
sách các tenant mà người dùng có quyền truy cập.
3. Người dùng gửi lại token tạm thơì và tenant mong muốn đến Keystone.
4. Nếu thông tin xác thực và tenant mong muốn là hợp lệ, Keystone sẽ gửi lại một tenant
token và danh sách các dịch vụ khả dụng dành cho tenant đó.
5. Người dùng xác định endpoint phù hợp với hành động cần thực hiện và gửi yêu cầu tới
endpoint, kèm theo tenant token để xác thực.
6. Để ngăn chặn kết nối từ các thực thể không được phép, dịch vụ sẽ yêu cầu Keystone kiểm
tra token, xác thực tính hợp lệ và quyền truy cập.
7. Nếu Keystone xác thực token và quyền sử dụng dịch vụ thành công, dịch vụ sẽ kiểm tra
theo chính sách riêng (policy) xem người dùng có được phép thực hiện hành động đó không.
8. Nếu quá trình kiểm tra chính sách thành công, yêu cầu sẽ được thực thi.
Hình 3.2 (không hiển thị ở đây) minh họa quy trình trên, đảm bảo người dùng chỉ có thể truy
cập tài nguyên một cách bảo mật và được kiểm soát chặt chẽ.
3.1.3 Giao thức AMQP và triển khai RabbitMQ Giao thức AMQP
AMQP (Advanced Message Queuing Protocol) là một tiêu chuẩn mở dùng để truyền các
thông điệp nghiệp vụ giữa các ứng dụng hoặc tổ chức. •
Nó kết nối hệ thống với nhau, cung cấp dữ liệu cho các tiến trình nghiệp vụ và đảm bảo
truyền tải chính xác các chỉ thị cần thiết để hoàn thành tác vụ.
AMQP là một giao thức nhị phân ở tầng ứng dụng, được thiết kế để hỗ trợ hiệu quả cho
nhiều kiểu ứng dụng nhắn tin và mô hình giao tiếp.
Nó cung cấp cơ chế giao tiếp theo hướng message (message-oriented), kiểm soát luồng
truyền với các cam kết về mức độ bảo đảm giao hàng: • at-most-once:
→ Mỗi tin nhắn chỉ được giao một lần hoặc không giao (giao 0 hoặc 1 lần). • at-least-once:
→ Mỗi tin nhắn chắc chắn được giao, nhưng có thể giao nhiều lần. • exactly-once:
→ Mỗi tin nhắn luôn được giao chính xác một lần.
Xác thực và mã hóa trong AMQP dựa trên SASL và TLS, và nó giả định sử dụng một giao
thức vận chuyển đáng tin cậy ở tầng dưới, chẳng hạn như TCP (Transmission Control Protocol).
Figure 3.2: OpenStack Architecture
Đặc tả AMQP được định nghĩa theo nhiều lớp (layers):
• Hệ thống kiểu dữ liệu (Type system):
Được dùng để định nghĩa định dạng của thông điệp, cho phép thể hiện siêu dữ liệu
(metadata) chuẩn hoặc mở rộng để các thực thể xử lý có thể hiểu và phân tích được. Nó
cũng được sử dụng để xác định các nguyên thủy giao tiếp (communication primitives)
được dùng để trao đổi thông điệp giữa các thực thể.
• Giao thức liên kết (Link protocol):
Đơn vị cơ bản trong AMQP là frame (khung dữ liệu). Có 9 loại frame chính trong AMQP
để quản lý việc thiết lập, kiểm soát và kết thúc quá trình truyền thông điệp giữa hai điểm đầu cuối (peers): •
open: Dùng để thiết lập kết nối, cho phép nhiều phiên (multiplexed sessions). •
begin: Dùng để bắt đầu phiên làm việc, là nhóm các liên kết (links). •
attach: Dùng để thiết lập một liên kết một chiều (unidirectional link) mới. •
transfer: Dùng để gửi thông điệp. •
flow: Quản lý dòng dữ liệu và điều khiển luồng (flow control). •
disposition: Dùng để xác định trạng thái (state) của một lần truyền dữ liệu. •
detach: Dùng để ngắt liên kết. •
end: Dùng để kết thúc phiên. •
close: Dùng để đóng kết nối.
• Định dạng thông điệp (Message format):
Định dạng thông điệp được chia thành 2 phần chính: 1. Bare message:
Là nội dung chính do ứng dụng gửi tạo ra. Phần này không bị thay đổi khi được truyền
qua các tiến trình hoặc hệ thống. 2. Header:
Là phần tiêu đề, gồm tập hợp các trường chuẩn liên quan đến việc giao hàng (delivery), chẳng hạn như:
o Thời gian sống (TTL - time to live)
o Độ bền (durability) o Độ ưu tiên (priority)
• Khả năng của thông điệp (Message capabilities):
AMQP giả định rằng các node giao tiếp ngang hàng (peer nodes) có các hành vi chung nhất định: •
Một số kết quả tiêu chuẩn cho các lần truyền thông điệp. •
Cơ chế chỉ định hoặc yêu cầu giữa hai mô hình truyền tin chính:
o consumer cạnh tranh và o
consumer không cạnh tranh,
thông qua các chế độ phân phối. •
Khả năng tạo các node theo yêu cầu. •
Khả năng lọc các loại thông điệp mà receiver quan tâm nhận.
RabbitMQ – Trình môi giới thông điệp (message broker)
RabbitMQ là triển khai mặc định của giao thức AMQP trong OpenStack.
RabbitMQ đóng vai trò là một nền tảng chung cho các ứng dụng gửi và nhận thông điệp, cho phép: •
Các ứng dụng kết nối với nhau như các thành phần của một hệ thống lớn hơn. •
Giao tiếp không đồng bộ (asynchronous) – tách biệt giữa gửi và nhận dữ liệu.
RabbitMQ cung cấp một "nơi an toàn" để lưu trữ thông điệp cho đến khi nó được tiêu thụ.
Trong OpenStack, RabbitMQ mang lại các tính năng nổi bật: •
✅ Độ tin cậy (Reliability): Hỗ trợ các tính năng như:
o Lưu trữ bền vững (persistence) o Gửi xác nhận
(acknowledgement) o Xác nhận của publisher
o Khả năng sẵn sàng cao (high availability) •
🔄 Định tuyến linh hoạt (Flexible Routing):
Hỗ trợ nhiều loại exchange để phục vụ các mô hình định tuyến khác nhau. •
🖧 Cụm hóa (Clustering):
Các RabbitMQ server có thể cụm lại trong mạng nội bộ để tạo thành một broker logic duy nhất. •
🔁 Hàng đợi sẵn sàng cao (Highly Available Queues):
Các hàng đợi có thể được nhân bản (mirror) trên nhiều máy chủ để đảm bảo dữ liệu
không mất nếu một máy hỏng. •
🧩 Hỗ trợ nhiều client (Many Clients):
Hỗ trợ đa số ngôn ngữ lập trình thông dụng. •
🕵️ Theo dõi (Tracing):
Hỗ trợ debug, truy vết message. •
🔌 Hệ thống plugin:
RabbitMQ có nhiều plugin để mở rộng khả năng sử dụng theo nhiều cách.
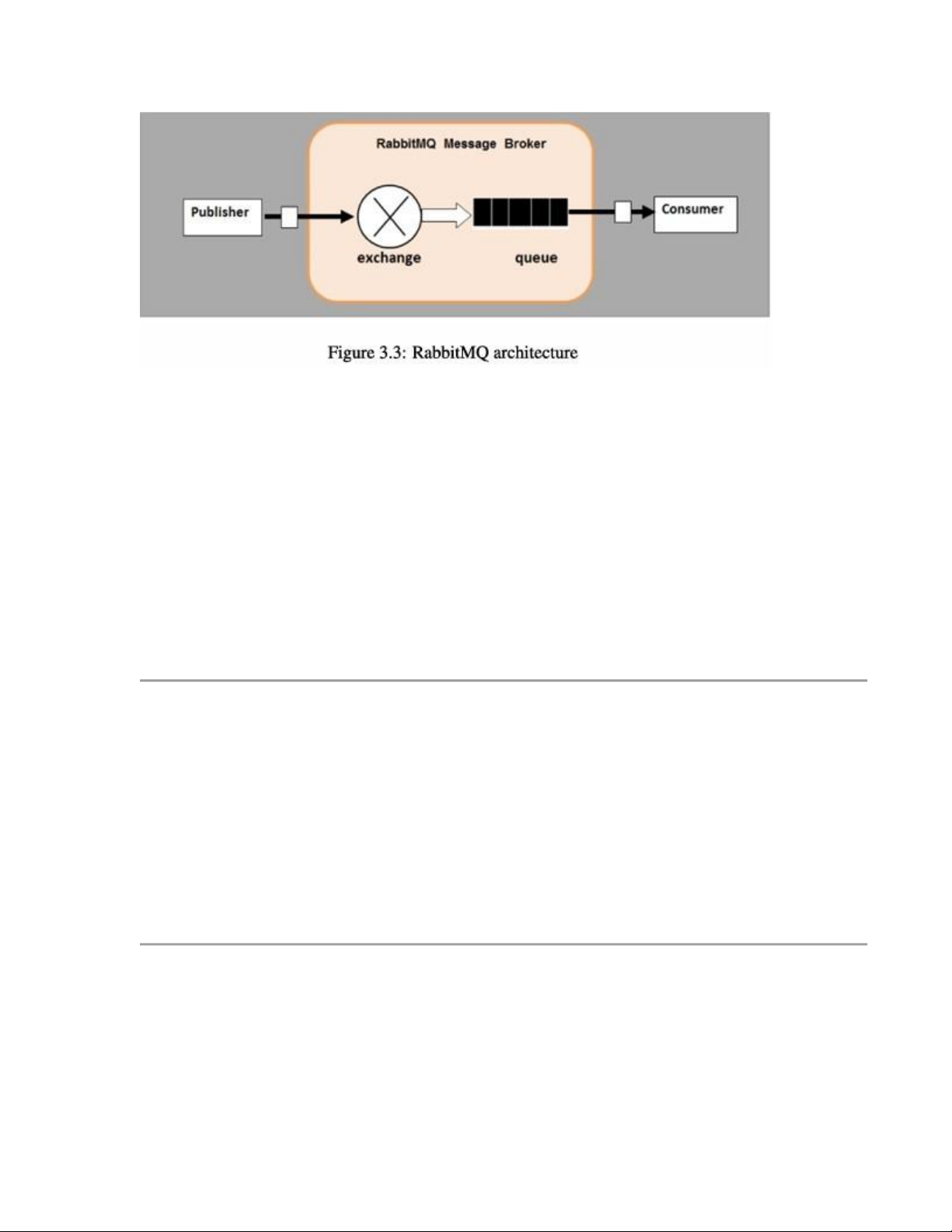
📌 RabbitMQ xử lý việc truyền nhận giữa publisher (gửi) và consumer (nhận), thông qua các thành phần chính: •
Exchange (cơ chế định tuyến), • Queue (hàng đợi), • Binding (liên kết).
Hình 3.3 sẽ minh họa rõ hơn về quá trình kết nối publisher và consumer trong RabbitMQ. Queue (Hàng đợi)
Một queue là một kiểu "hộp thư" chứa các thông điệp (messages) bên trong RabbitMQ.
Mặc dù thông điệp được truyền qua các ứng dụng hoặc message broker, nhưng chúng chỉ
được lưu trữ bên trong hàng đợi (queue) — nơi hoạt động như một bộ đệm vô hạn. Điều này có nghĩa là: •
Không có giới hạn cứng về số lượng message, •
Queue có thể lưu trữ nhiều thông điệp nếu cần.
📌 Nhiều publisher (trình xuất bản) có thể gửi message đến cùng một hàng đợi, và nhiều
consumer (trình nhận) có thể cố gắng đọc từ cùng một queue.
🔑 Ý tưởng cốt lõi trong mô hình nhắn tin của RabbitMQ: •
Producer (nhà sản xuất) không bao giờ gửi trực tiếp đến queue. •
Thay vào đó, producer chỉ gửi message đến một exchange. •
Exchange sẽ quyết định message đó sẽ được gửi đến queue nào (nếu có) tùy theo loại
exchange và quy tắc liên kết.
💡 Thực tế, producer có thể không biết message có đến được queue nào hay không.
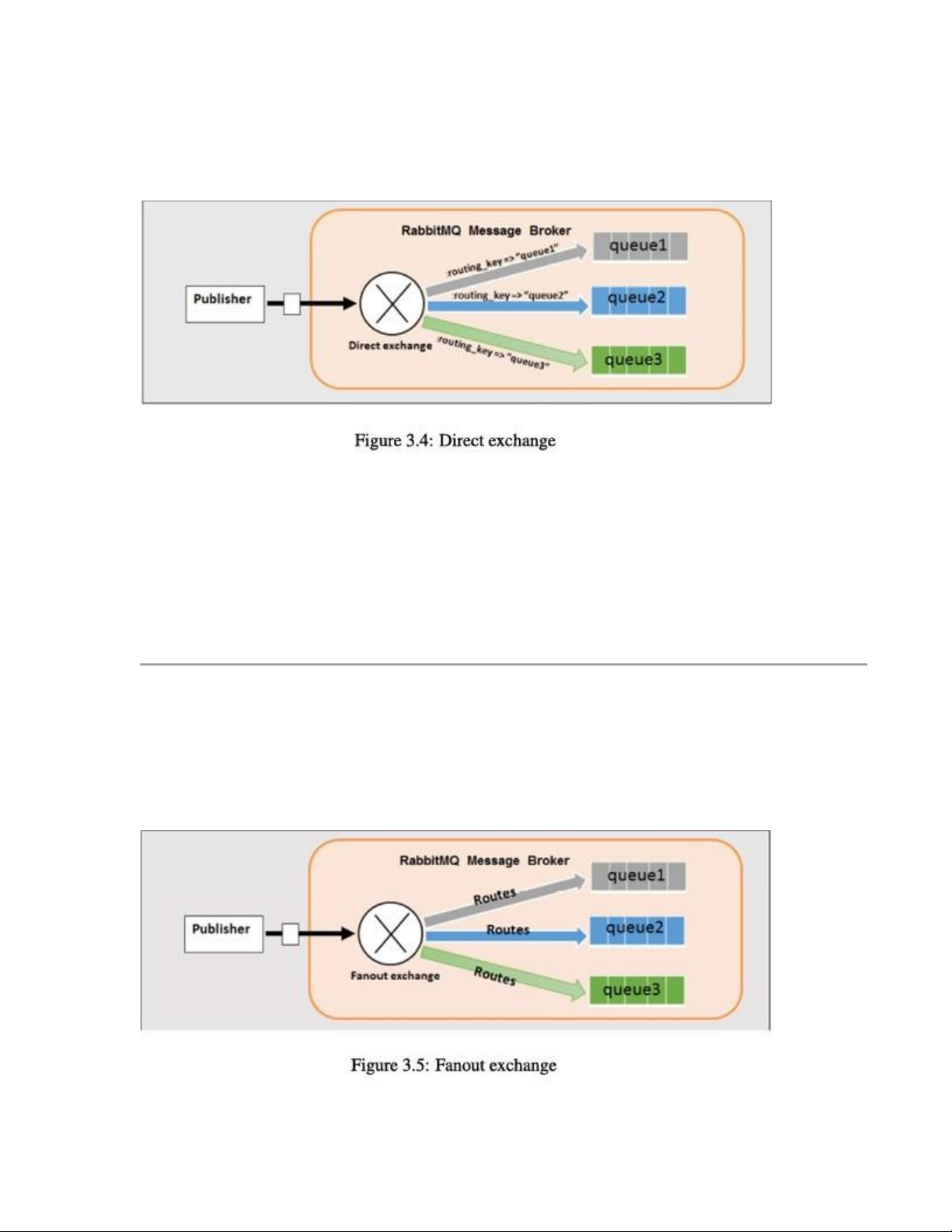
Direct Exchange – Trao đổi trực tiếp •
Direct exchange gửi thông điệp tới các hàng đợi dựa trên khóa định tuyến (routing key). •
Đây là hình thức phù hợp cho mô hình unicast – tức là message chỉ được gửi đến một hàng đợi cụ thể.
📌 Hình 3.4 minh họa cách hoạt động của direct exchange.
Fanout Exchange – Trao đổi quảng bá •
Fanout exchange (được minh họa trong hình 3.5) sẽ gửi thông điệp đến tất cả các hàng
đợi (queues) đã được liên kết với nó, bỏ qua hoàn toàn khóa định tuyến (routing key). 📌 Nói cách khác:
Nếu có N hàng đợi được liên kết (bound) với một fanout exchange, thì khi một message mới
được gửi đến exchange đó, tất cả N hàng đợi sẽ nhận được bản sao của message.
🎯 Fanout exchange phù hợp cho các trường hợp phát tán (broadcast) thông điệp, chẳng hạn: •
Gửi log đến nhiều hệ thống giám sát. •
Gửi cùng một thông điệp đến nhiều dịch vụ xử lý song song.
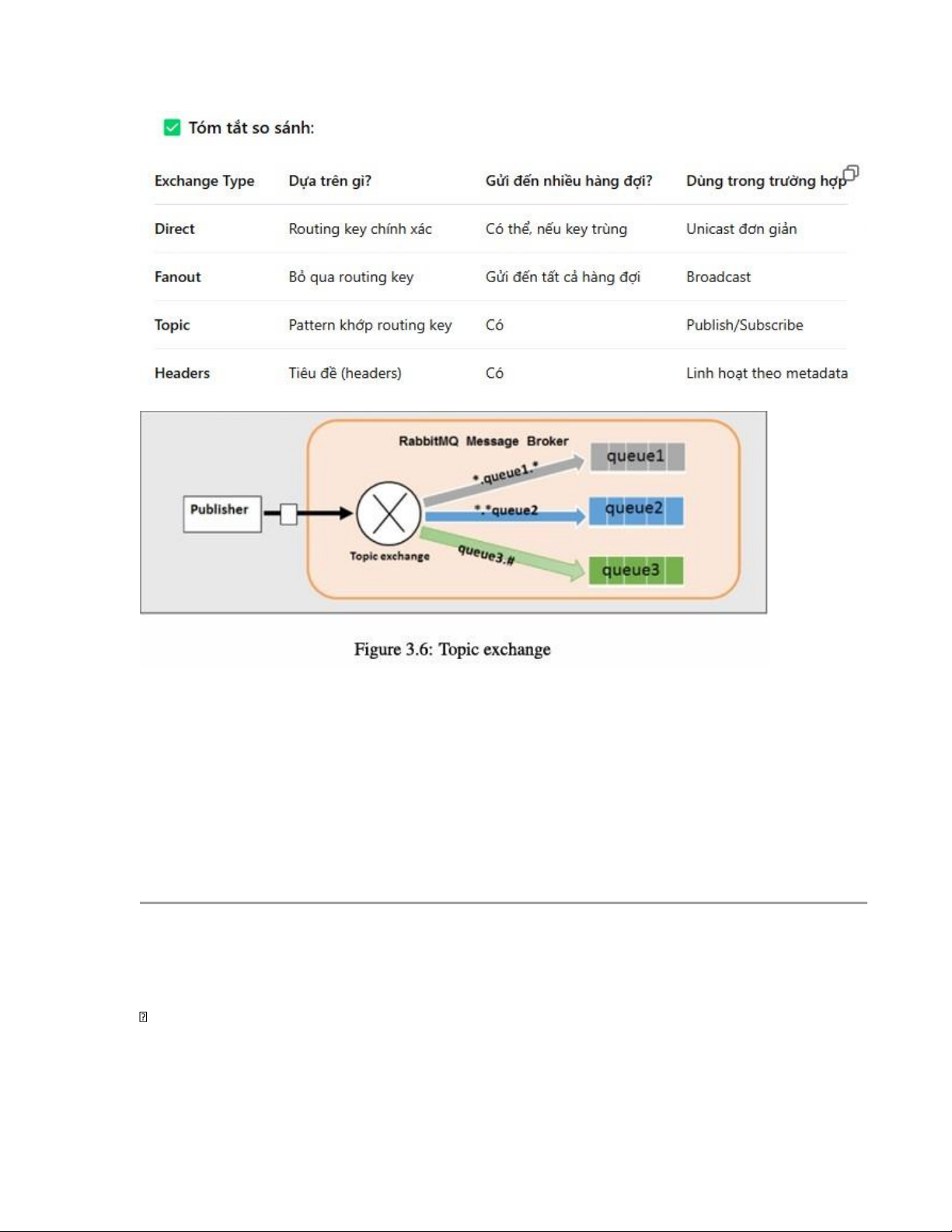
Topic Exchange – Trao đổi theo chủ đề •
Topic exchange (được minh họa trong hình 3.6) định tuyến thông điệp đến một hoặc
nhiều hàng đợi dựa trên sự khớp giữa khóa định tuyến (routing key) của thông điệp và
mẫu (pattern) đã được sử dụng khi liên kết hàng đợi với exchange. •
Loại exchange này thường dùng trong các mô hình publish/subscribe (xuất bản/đăng
ký), nơi nhiều hàng đợi có thể quan tâm đến các chủ đề (topics) khác nhau.
📌 Ứng dụng phổ biến: dùng để multicast (gửi cho nhiều đối tượng) trong các hệ thống
xử lý sự kiện hoặc ghi log theo từng module.
Headers Exchange – Trao đổi theo tiêu đề •
Headers exchange được thiết kế để định tuyến dựa trên nhiều thuộc tính (attributes)
mà dễ biểu diễn bằng các tiêu đề (headers) của thông điệp hơn là routing key. •
Headers exchange bỏ qua hoàn toàn routing key. •
Thay vào đó, nó dùng các giá trị trong phần headers của message để xác định nơi cần gửi.
📌 Một thông điệp sẽ được coi là khớp (matching) nếu giá trị của các headers phù hợp
với điều kiện được khai báo khi liên kết hàng đợi.
3.2 Giao tiếp thông điệp trong OpenStack (OpenStack messaging)
AMQP là công nghệ nhắn tin được OpenStack lựa chọn, nơi các dịch vụ nội bộ giao tiếp với
nhau qua AMQP và với bên ngoài thông qua các REST-call.
Broker AMQP – RabbitMQ – hoạt động như cầu nối giữa hai dịch vụ nội bộ trong
OpenStack. Nó cho phép các dịch vụ giao tiếp với nhau bằng cách sử dụng Remote
Procedure Call (RPC), kết hợp với các kiểu trao đổi thông điệp như direct, fanout, và topic-based.
3.2.1 Nút môi giới thông điệp RabbitMQ (RabbitMQ message broker node)
Trong các thành phần của OpenStack, một số thành phần đóng vai trò là invoker (người gửi),
chịu trách nhiệm gửi thông điệp vào hệ thống hàng đợi qua hai thao tác: rpc.call và rpc.cast.
Các thành phần khác đóng vai trò là worker (người nhận), có nhiệm vụ nhận thông điệp từ
hàng đợi và xử lý phản hồi (đặc biệt trong các thao tác rpc.call).
Dưới đây là các thành phần chính của nút môi giới RabbitMQ:
• Topic Publisher (Trình xuất bản theo chủ đề)
– Sử dụng trong rpc.call hoặc rpc.cast để đẩy thông điệp vào hệ thống hàng đợi.
– Mỗi publisher luôn kết nối tới topic-based exchange giống nhau trong suốt vòng đời của thông điệp.
• Direct Consumer (Người tiêu dùng trực tiếp)
– Chỉ được sử dụng trong rpc.call, dùng để nhận phản hồi từ hàng đợi.
– Mỗi consumer kết nối đến direct-based exchange qua một hàng đợi độc quyền (exclusive queue).
• Topic Consumer (Người tiêu dùng theo chủ đề)
– Được kích hoạt khi một Worker được khởi tạo và tồn tại trong suốt vòng đời của nó.
– Nhận thông điệp từ hàng đợi và thực hiện hành động phù hợp theo quy tắc của Worker.
– Có thể kết nối qua shared queue hoặc exclusive queue, tùy theo thiết lập. – Mỗi Worker có hai topic consumers: • Một dùng trong rpc.cast. • Một dùng trong rpc.call.
• Direct Publisher (Trình xuất bản trực tiếp)
– Chỉ được sử dụng trong rpc.call, dùng để gửi phản hồi kết quả trở lại cho thành phần yêu cầu.
– Kết nối đến direct-based exchange, định danh bởi thông tin định tuyến của thông điệp nhận được.
3.2.2 OpenStack RPC modes
RPC in OpenStack Messaging sử dụng 2 kiểu: •
rpc.cast: Thông điệp gửi đi không chờ kết quả phản hồi •
rpc.call: Thông điệp sẽ chờ kết quả khi có giá trị trả về
Một số dịch vụ trong OpenStack như Nova và Cinder cung cấp một lớp trình điều hợp
(adapter) để xử lý việc tuần tự hóa (marshaling) và giải tuần tự hóa (unmarshaling) các thông
điệp thành các lời gọi hàm. Mỗi dịch vụ thường tạo hai hàng đợi khi khởi tạo: •
Một hàng đợi nhận các thông điệp với khóa định tuyến (routing key) dạng NODETYPE.NODE-ID •
Và một hàng đợi khác nhận thông điệp với khóa định tuyến dạng tổng quát hơn là NODE-TYPE.
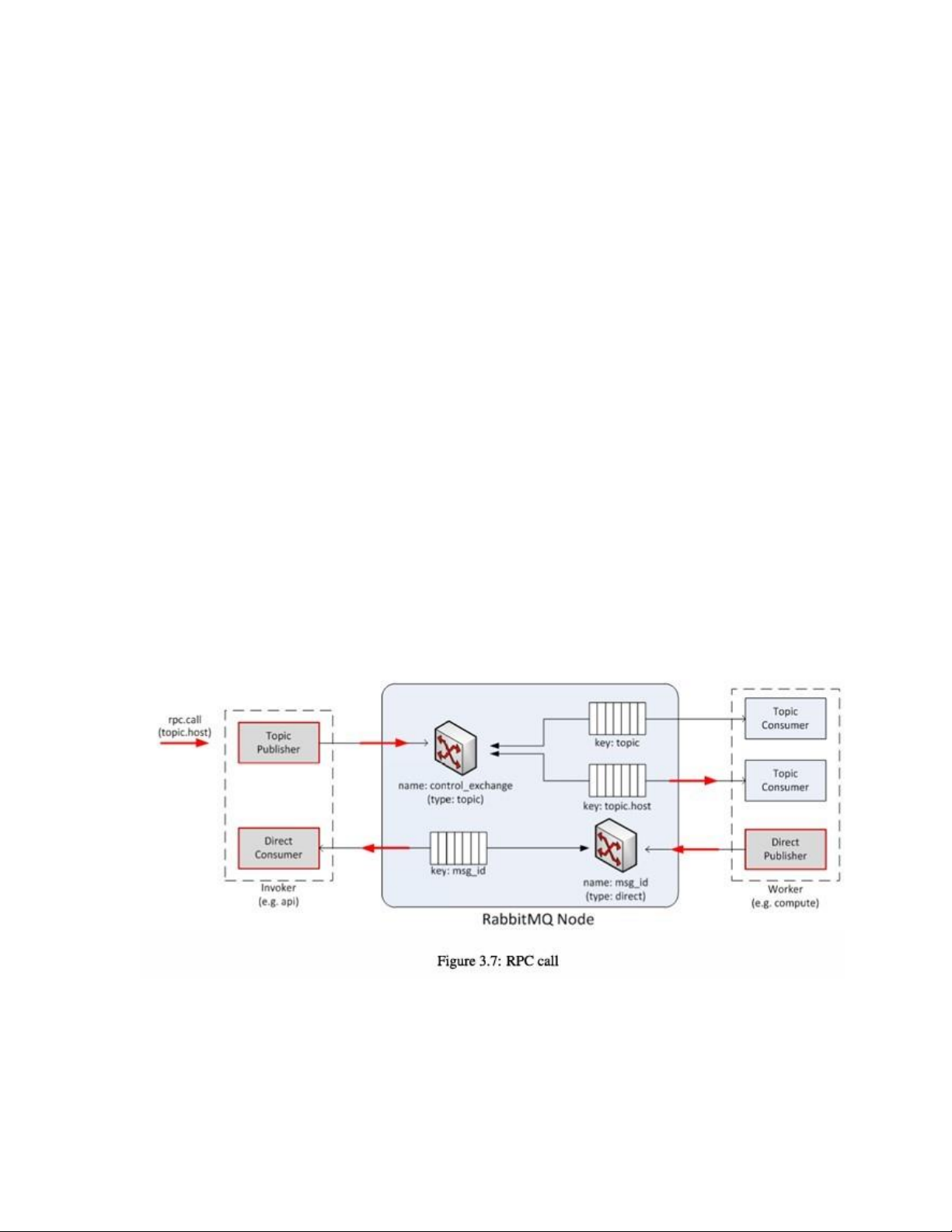
Lời gọi RPC (RPC calls)
Hoạt động rpc.call, được minh họa trong hình 3.7, thực hiện theo các bước sau:
1. Khởi tạo Topic Publisher để gửi yêu cầu thông điệp đến hệ thống hàng đợi. Ngay trước
khi thực hiện việc gửi, một Direct Consumer cũng được khởi tạo để chờ nhận thông điệp phản hồi.
2. Khi thông điệp được phân phối qua exchange, nó sẽ được lấy bởi Topic Consumer,
dựa vào khóa định tuyến (như topic.host), và chuyển cho Worker phụ trách xử lý tác vụ.
3. Sau khi tác vụ được hoàn thành, một Direct Publisher sẽ được sử dụng để gửi thông
điệp phản hồi về hệ thống hàng đợi.
4. Khi thông điệp phản hồi được phân phối qua exchange, nó sẽ được lấy bởi Direct
Consumer, dựa vào khóa định tuyến (như msg.id), và chuyển đến Invoker. RPC cast
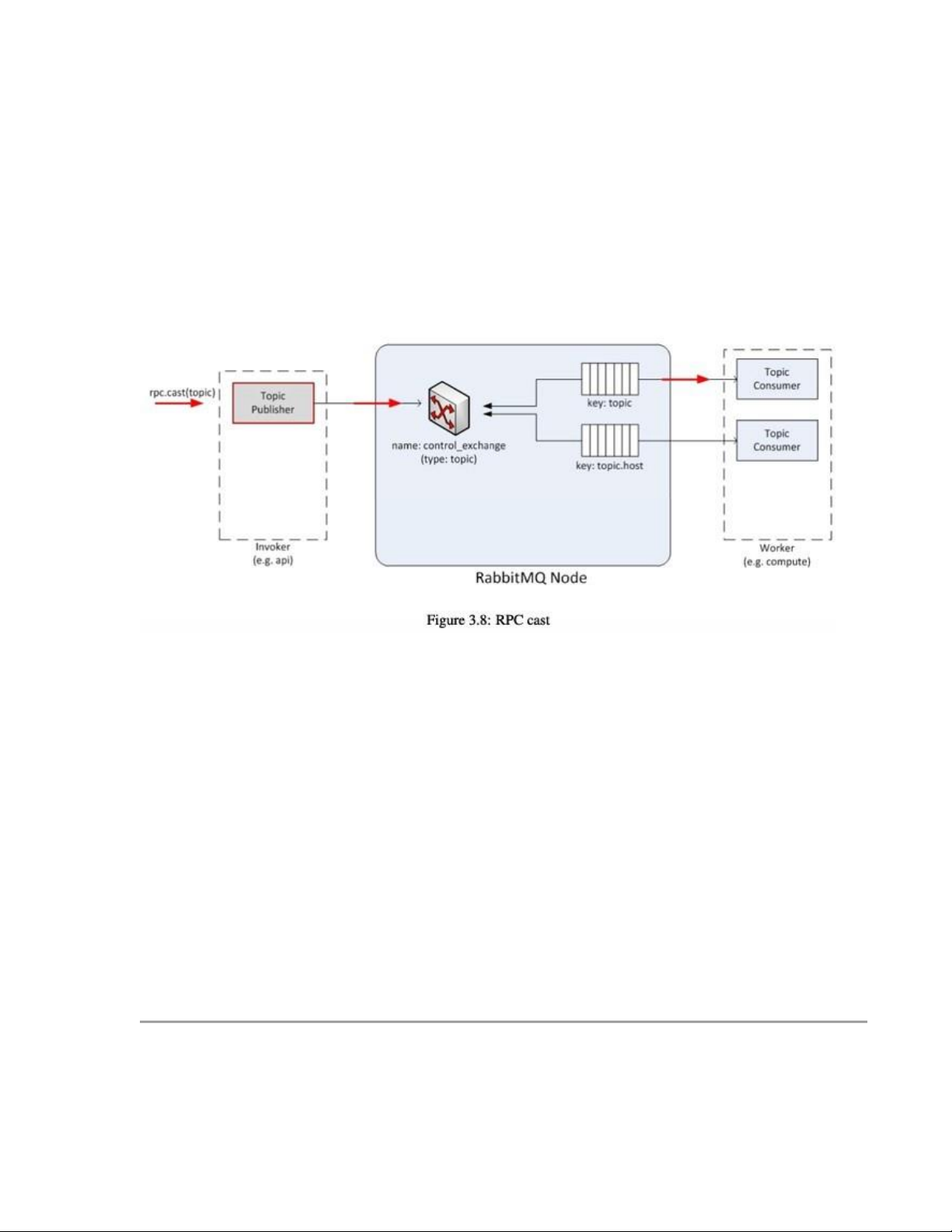
Hoạt động rpc.cast, được minh họa trong hình 3.8, thực hiện theo các bước sau:
1. Một Topic Publisher được khởi tạo để gửi yêu cầu thông điệp đến hệ thống hàng đợi.
2. Khi thông điệp được phân phối qua exchange, nó sẽ được nhận bởi Topic Consumer
dựa trên khóa định tuyến (như là topic) và chuyển đến Worker chịu trách nhiệm xử lý tác vụ.
Publisher sẽ gửi thông điệp đến một topic exchange, và một consumer sẽ nhận thông điệp từ hàng đợi.
Không có phản hồi nào được mong đợi, vì đây là một hành động cast (gửi đơn) chứ không
phải call (gọi có phản hồi). 3.3 Keystone
Dịch vụ Keystone cung cấp một hệ thống xác thực (authentication) và phân quyền
(authorization) dùng chung cho các dịch vụ OpenStack. Keystone chịu trách nhiệm quản lý
người dùng, vai trò (roles), và dự án (project/tenant) mà họ thuộc về. Ngoài ra, Keystone còn
cung cấp danh mục (catalog) các dịch vụ OpenStack khác để xác minh yêu cầu của người dùng thông qua Keystone.
Về cơ bản, Keystone có hai chức năng chính để kiểm soát quá trình xác thực và phân quyền của người dùng: •
Quản lý người dùng (User management): Keystone theo dõi người dùng và những gì
họ được phép thực hiện. Nhiệm vụ này được thực hiện bằng cách kiểm tra và quản trị mối
liên kết giữa người dùng, vai trò và tenant. •
Danh mục dịch vụ (Service catalog): Keystone cung cấp một danh sách các dịch vụ
hiện có và vị trí các điểm cuối API (API endpoints) của chúng.
3.3.1 Thành phần (Components)
Các thành phần Keystone cần có để thực hiện chức năng của nó bao gồm: •
User (Người dùng): Là biểu diễn số hóa của một cá nhân, hệ thống, hoặc dịch vụ sử
dụng dịch vụ đám mây OpenStack. Keystone đảm bảo rằng các yêu cầu đến đều xuất phát
từ một người dùng hợp lệ, thuộc một tenant cụ thể và được gán role phù hợp để nhận
token truy cập tài nguyên. •
Tenant (Dự án/nhóm tài nguyên): Là một nhóm được sử dụng để cô lập tài nguyên
và/hoặc người dùng. Có thể ánh xạ các nhóm này tới khách hàng, dự án hoặc tổ chức. •
Role (Vai trò): Một role bao gồm tập hợp quyền và đặc quyền được gán cho việc thực
hiện một nhóm tác vụ cụ thể. Token do Keystone phát hành sẽ bao gồm danh sách các
role của người dùng. Các dịch vụ sẽ diễn giải các role này theo chính sách nội bộ định
nghĩa trong tệp policy.json. •
Credentials (Thông tin xác thực): Là dữ liệu mà chỉ người dùng cụ thể biết, được dùng
để chứng minh danh tính. •
Token: Là một chuỗi ký tự đại diện cho quyền truy cập tài nguyên. Mỗi token chứa mô tả
về các tài nguyên có thể truy cập. Token có thể bị thu hồi bất kỳ lúc nào và có thời hạn sử dụng xác định. •
Endpoint (Điểm cuối): Là một địa chỉ truy cập mạng (URL) mà tại đó các dịch vụ có thể
được truy cập bởi người dùng. 3.3.2 Kiến trúc
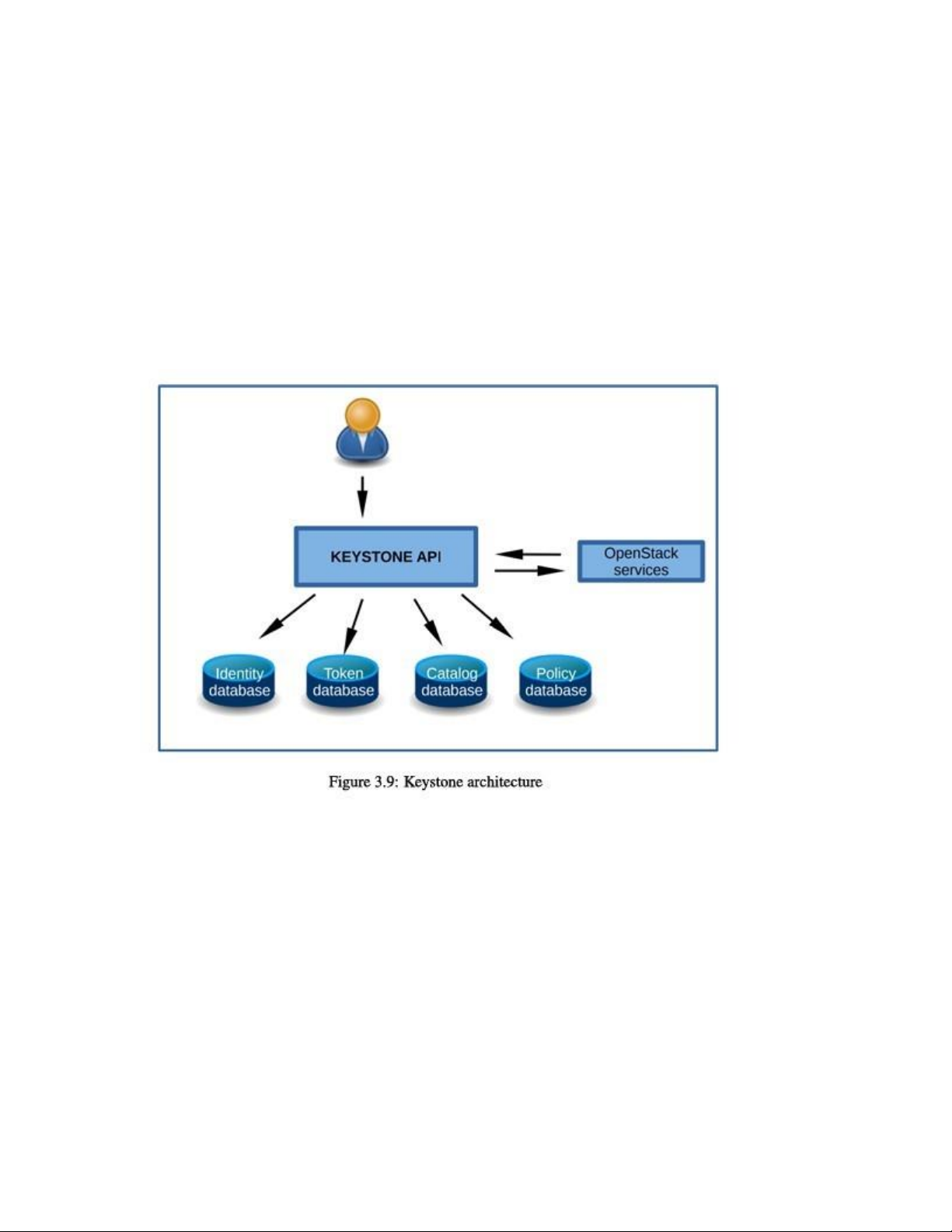
Kiến trúc của Keystone được tổ chức thành một nhóm các dịch vụ nội bộ, được cung cấp
thông qua một hoặc nhiều endpoint, như minh họa trong hình 3.9: •
Identity (Dịch vụ nhận dạng): Cung cấp khả năng xác thực thông tin định danh và dữ
liệu liên quan đến Người dùng, Tenant và Role, cũng như các metadata liên quan. •
Token (Dịch vụ mã thông báo): Xác minh và quản lý các token được sử dụng để xác
thực yêu cầu, sau khi thông tin xác thực của người dùng/tenant đã được kiểm tra. •
Catalog (Danh mục): Cung cấp danh sách các endpoint (điểm cuối API) dùng để khám phá dịch vụ. •
Policy (Chính sách): Cung cấp cơ chế phân quyền dựa trên luật (rule-based authorization engine).
Mỗi dịch vụ trong số này có thể sử dụng nhiều loại backend khác nhau, giúp Keystone linh
hoạt phù hợp với nhiều môi trường và nhu cầu. Các backend khả dụng bao gồm: •
KVS Backend: Giao diện backend đơn giản, có thể được sử dụng phía sau bất kỳ hệ
thống nào hỗ trợ tra cứu khóa chính. •
SQL Backend: Backend dùng cơ sở dữ liệu SQL để lưu trữ dữ liệu vĩnh viễn. •
PAM Backend: Backend đơn giản bổ sung, sử dụng dịch vụ PAM của hệ thống hiện tại
để xác thực. Cung cấp mối quan hệ một-một giữa người dùng và tenant. •
LDAP Backend: Sử dụng hệ thống LDAP để lưu trữ người dùng và tenant trong các
nhánh (subtree) riêng biệt. •
Templated Backend: Sử dụng một mẫu cấu hình đơn giản để định nghĩa Keystone. 3.4 Nova
Nova chịu trách nhiệm quản lý và triển khai các hệ thống điện toán đám mây, là thành phần
chính của hệ thống hạ tầng như một dịch vụ (Infrastructure-as-a-Service - IaaS) trong
OpenStack. Đây cũng là dịch vụ phức tạp và phân tán nhất của OpenStack.
Nova làm việc với Keystone để xác thực (authentication), và Glance để truy xuất các ảnh đĩa
và máy ảo (server images), vốn chỉ có thể truy cập bởi tenant hoặc người dùng được cấp quyền.
Các mô-đun chính của Nova được viết bằng Python và được cấu hình như một tập hợp các
tiến trình hoạt động phối hợp để chuyển các yêu cầu API thành việc khởi tạo các máy ảo (VMs).
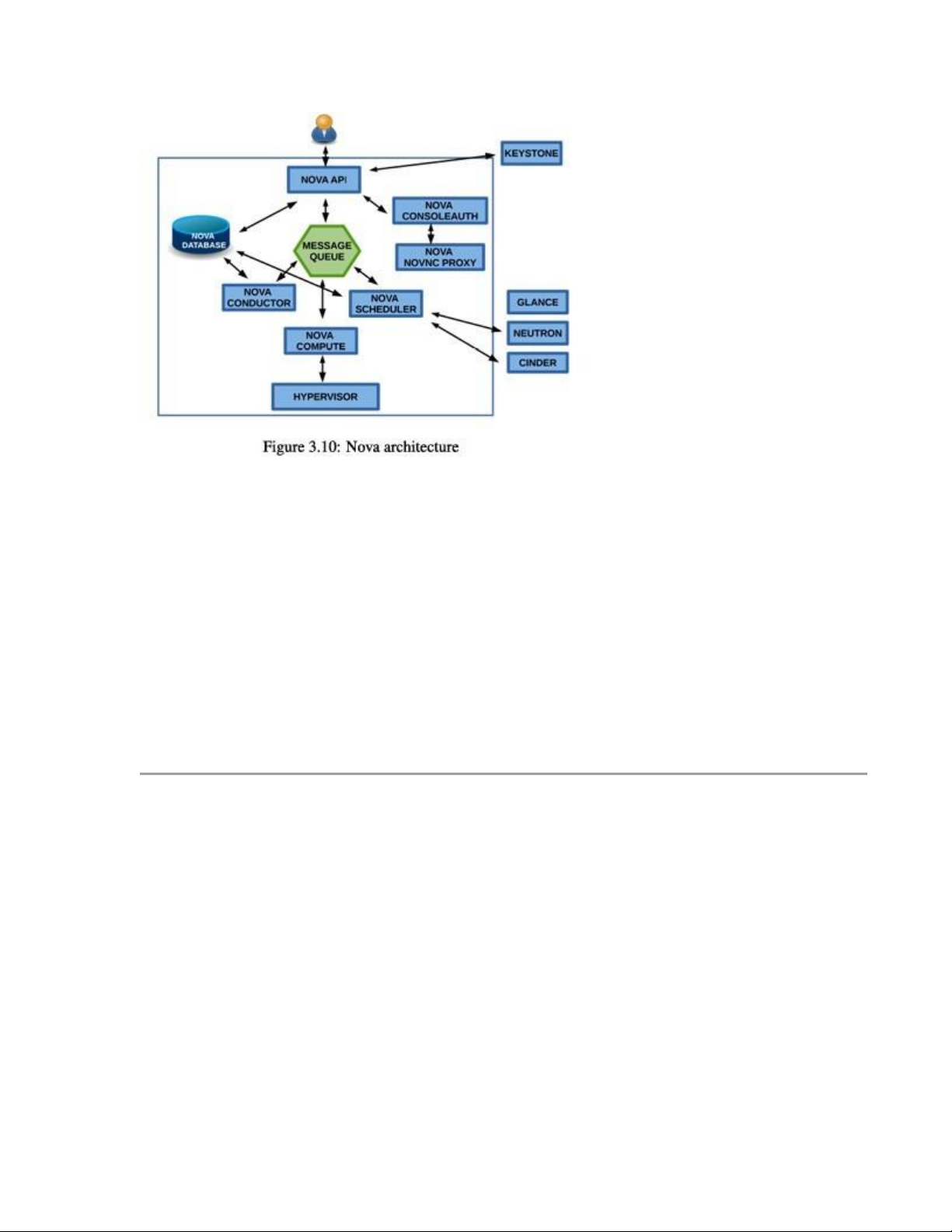
3.4.1 Kiến trúc (Architecture)
Nova được xây dựng dựa trên kiến trúc phân tán (shared-nothing) và dựa trên giao tiếp
qua hàng đợi tin nhắn (messaging-based). Các thành phần chính của Nova có thể chạy trên
nhiều máy chủ khác nhau, do đó mọi giao tiếp giữa các thành phần đều thông qua hàng đợi tin nhắn.
Để tránh làm nghẽn tiến trình khi phải chờ phản hồi, Nova sử dụng các đối tượng trì hoãn
(deferred objects) với callback để kích hoạt xử lý khi phản hồi được nhận.
Nova sử dụng một cơ sở dữ liệu SQL dùng chung cho tất cả các thành phần. Đối với hệ
thống nhỏ, đây là giải pháp hợp lý. Nhưng với các hệ thống lớn hoặc yêu cầu cao về bảo mật,
người ta có thể triển khai nhiều kho dữ liệu với hệ thống tổng hợp.
Kiến trúc Nova (trong hình 3.10) được chia thành các khu vực chức năng: • API:
Phụ trách nhận các yêu cầu HTTP, chuyển đổi lệnh, và giao tiếp với các thành phần khác
thông qua hàng đợi oslo.messaging hoặc HTTP. Các thành phần:
- nova-api service: Tiếp nhận và xử lý các lệnh API từ người dùng để thao tác trên máy ảo.
- nova-api-metadata service: Xử lý các yêu cầu metadata từ máy ảo. • Compute:
Phụ trách giao tiếp với hypervisor và quản lý máy ảo. Các thành phần:
- nova-compute service: Daemon chịu trách nhiệm tạo/hủy máy ảo thông qua các API
hypervisor như XenAPI, libvirt (KVM, QEMU), VMwareAPI...
- nova-scheduler service: Chọn máy chủ phù hợp để chạy máy ảo, dựa trên yêu cầu từ hàng đợi.
- nova-conductor module: Trung gian giữa nova-compute và cơ sở dữ liệu để hạn chế
truy cập trực tiếp từ nova-compute tới DB. • Networking:
Quản lý IP forwarding, bridges, VLANs... Thành phần:
- nova-network worker daemon: Xử lý các yêu cầu liên quan đến mạng, như tạo cầu
nối (bridge), gán IP, hoặc thiết lập luật iptables. • Console:
Cung cấp quyền truy cập từ xa tới console máy ảo. Các thành phần:
- nova-consoleauth daemon: Xác thực người dùng muốn truy cập console.
- nova-novncproxy daemon: Cho phép truy cập console qua VNC (giao diện đồ họa trên web).
- nova-cert daemon: Cấp chứng chỉ x509 cho console.
• Image: Nova tương tác với Glance để lấy image đĩa khi khởi tạo máy ảo.
- nova-objectstore daemon: Là một giao diện tương thích với S3 để đăng ký các
image với dịch vụ lưu trữ ảnh (Image Service) của OpenStack.
- euca2ools client: Là một tập hợp các lệnh dòng lệnh dùng để quản lý tài nguyên đám mây.
• Cơ sở dữ liệu (Database):
Thành phần này chịu trách nhiệm lưu trữ hầu hết trạng thái của hạ tầng đám mây trong quá
trình xây dựng (build-time) và khi vận hành (run-time), bao gồm: •
Các loại máy ảo khả dụng • Các instance đang chạy •
Mạng và dự án đang hoạt động
3.4.2 Tài nguyên Nova (Nova resources)
Nova hỗ trợ nhiều kiểu triển khai compute khác nhau thông qua plugin hoặc driver: •
Máy chủ ảo (Virtual servers): Trong hầu hết các trường hợp, Nova chỉ cung cấp quyền
truy cập vào máy chủ ảo từ một hypervisor duy nhất. Tuy nhiên, một triển khai Nova có
thể bao gồm nhiều loại hypervisor khác nhau. •
Container: Nova cho phép sử dụng các container dựa trên LXC hoặc Docker theo cách
tương tự như cách sử dụng máy ảo theo nhu cầu. •
Máy chủ vật lý (Bare Metal servers): Nova cho phép sử dụng máy chủ vật lý theo cách
tương tự như máy ảo theo yêu cầu.
3.4.3 Bộ lập lịch theo bộ lọc (Filter scheduler)
Filter Scheduler hỗ trợ lọc (filtering) và tính trọng số (weighting) để đưa ra quyết định hợp
lý về nơi khởi tạo một instance mới. Bộ lập lịch này chỉ hoạt động với các nút Compute (Compute Nodes). Lọc (Filtering)
Trong quá trình hoạt động, Filter Scheduler đầu tiên tạo một danh sách (dictionary) các host
chưa lọc, sau đó tiến hành lọc chúng bằng các thuộc tính bộ lọc. Sau khi lọc, bộ lập lịch chọn
các host phù hợp nhất cho số lượng instance yêu cầu (mỗi lần chọn host có trọng số cao nhất
và thêm vào danh sách host được chọn).
Tài liệu liên quan:
-

Bài tập môn Điện toán đám mây | Đại học Bách Khoa Hà Nội
66 33 -

Bài tập môn Điện toán đám mây | Đại học Bách Khoa Hà Nội
56 28 -

Tài liệu Tổng quan về điện toán đám mây | Trường Đại học Bách Khoa Hà Nội
287 144 -

Tài liệu học tập Các vấn đề và giải pháp bảo mật môn Điện toán đám mây | Trường Đại học Bách Khoa Hà Nội
95 48 -

Đề cương chi tiết học phần môn Điện toán đám mây | Trường Đại học Bách Khoa Hà Nội
115 58