Tổng hợp bài giảng môn Lưu trữ và xử lý dữ liệu lớn_Thầy Đào Thanh Chung| Bài giảng môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
Tổng hợp bài giảng môn Lưu trữ và xử lý dữ liệu lớn_Thầy Đào Thanh Chung| Bài giảng môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội. Tài liệu gồm 214 trang giúp bạn ôn tập và đạt kết quả cao trong kỳ thi sắp tới. Mời bạn đọc đón xem.
Môn: Lưu trữ và xử lý dữ liệu lớn 27 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.4 K tài liệu
Tác giả:












Preview text:
Lecture 1: Introduction to Apache Spark 1 IT4931
Lưu trữ và phân tích dữ liệu lớn 11/2021 IT4931 Thanh-Chung Dao Ph.D. Lecture Agenda
¨ W1: Spark introduction + Lab ¨ W2: Spark RDD + Lab
¨ W3: Spark Machine Learning + Lab
¨ W4: Spark on Blockchain Storage + Lab 2 Today’s Agenda • History of Spark • Introduction • Components of Stack
• Resilient Distributed Dataset – RDD 3 HISTORY OF SPARK 4 History of Spark 2004 2010 MapReduce paper Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 2008 2014 MapReduce @ Google Hadoop Summit Apache Spark top-level 2006 Hadoop @Yahoo! History of Spark
circa 1979 – Stanford, MIT, CMU, etc.
set/list operations in LISP, Prolog, etc., for paral el processing
www-formal.stanford.edu/ jmc/ history / lisp/ lisp.htm circa 2004 – Google
MapReduce: Simplified Data Processing on Large
Clusters Jeffrey Dean and Sanjay Ghemawat
research.google.com/ archive/ mapreduce.html circa 2006 – Apache
Hadoop, originating from the Nutch Project Doug Cutting
research.yahoo.com/ files/ cutting.pdf circa 2008 – Yahoo
web scale search indexing Hadoop Submit, HUG, etc.
developer.yahoo.com/hadoop/
circa 2009 – Amazon AWS Elastic MapReduce
Hadoop modified for EC2/S3, plus support for Hive, Pig, Cascading, etc.
aws.amazon.com/ elasticmapreduce/ MapReduce
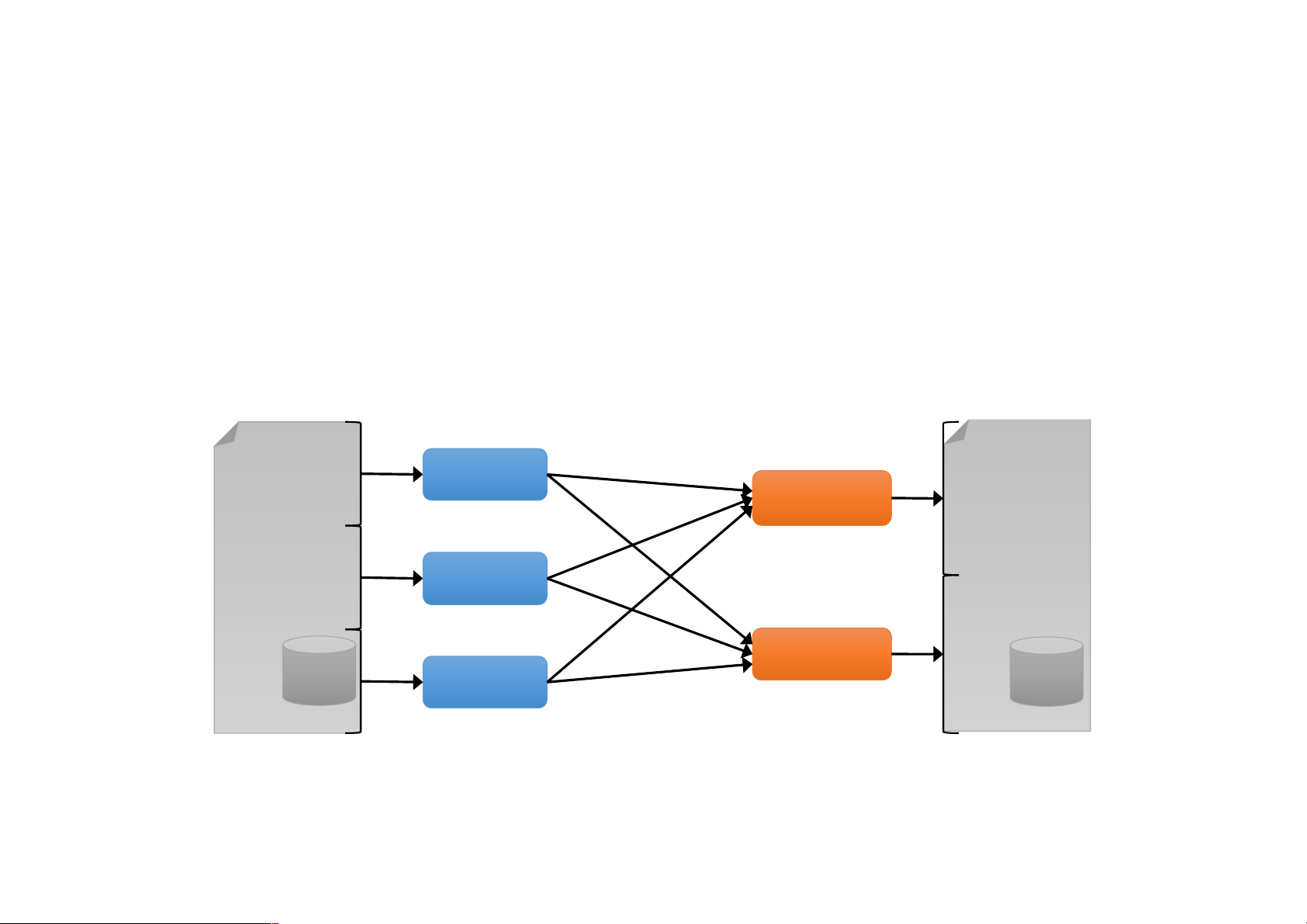
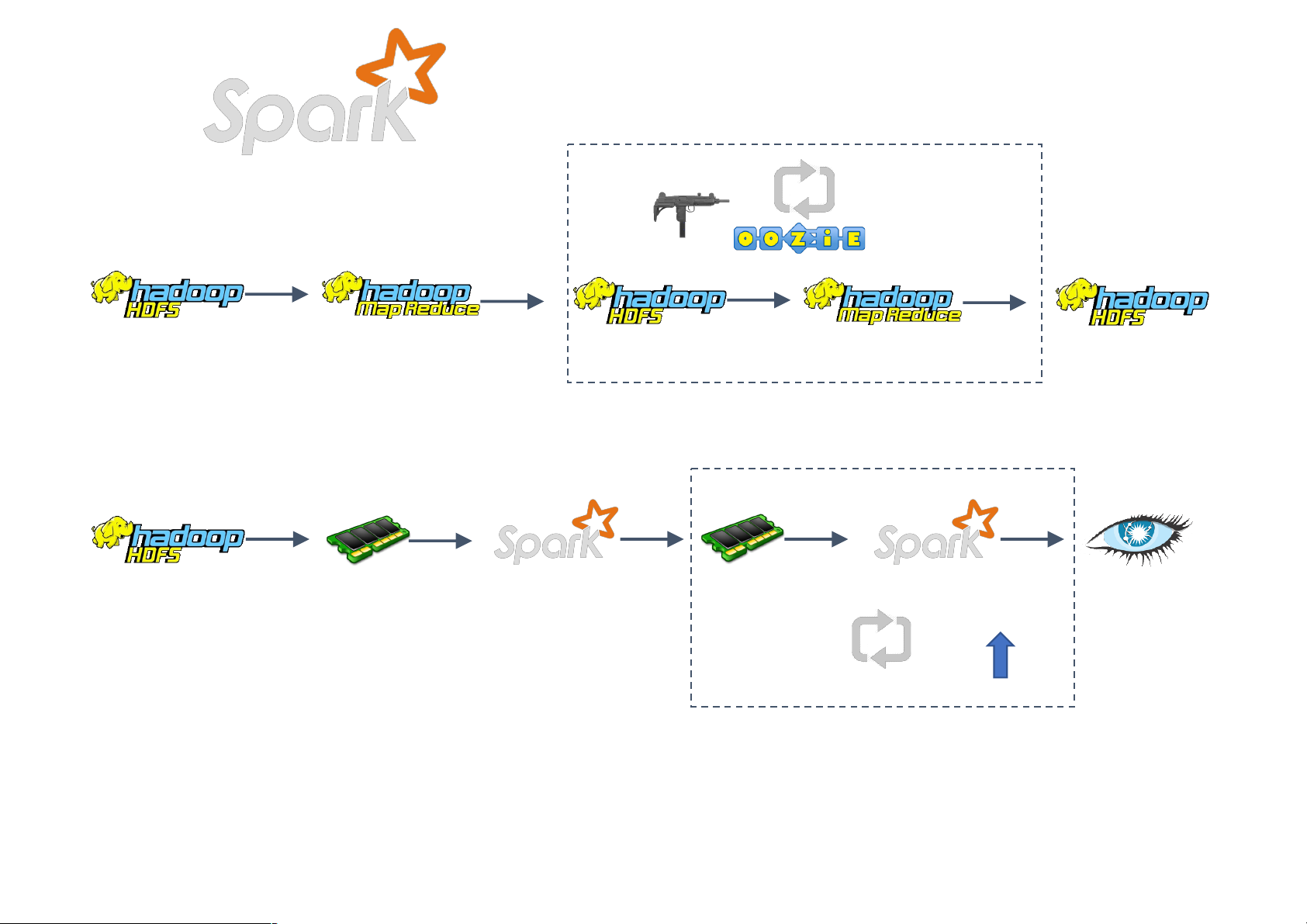
Most current cluster programming models are
based on acyclic data flow from stable storage to stable storage Map Reduce Input Map Output Reduce Map MapReduce
• Acyclic data flow is inefficient for applications
that repeatedly reuse a working set of data:
• Iterative algorithms (machine learning, graphs)
• Interactive data mining tools (R, Excel, Python) Data Processing Goals •
Low latency (interactive) queries on historical
data: enable faster decisions •
E.g., identify why a site is slow and fix it •
Low latency queries on live data (streaming):
enable decisions on real-time data •
E.g., detect & block worms in real-time (a worm
may infect 1mil hosts in 1.3sec) •
Sophisticated data processing: enable “better” decisions •
E.g., anomaly detection, trend analysis
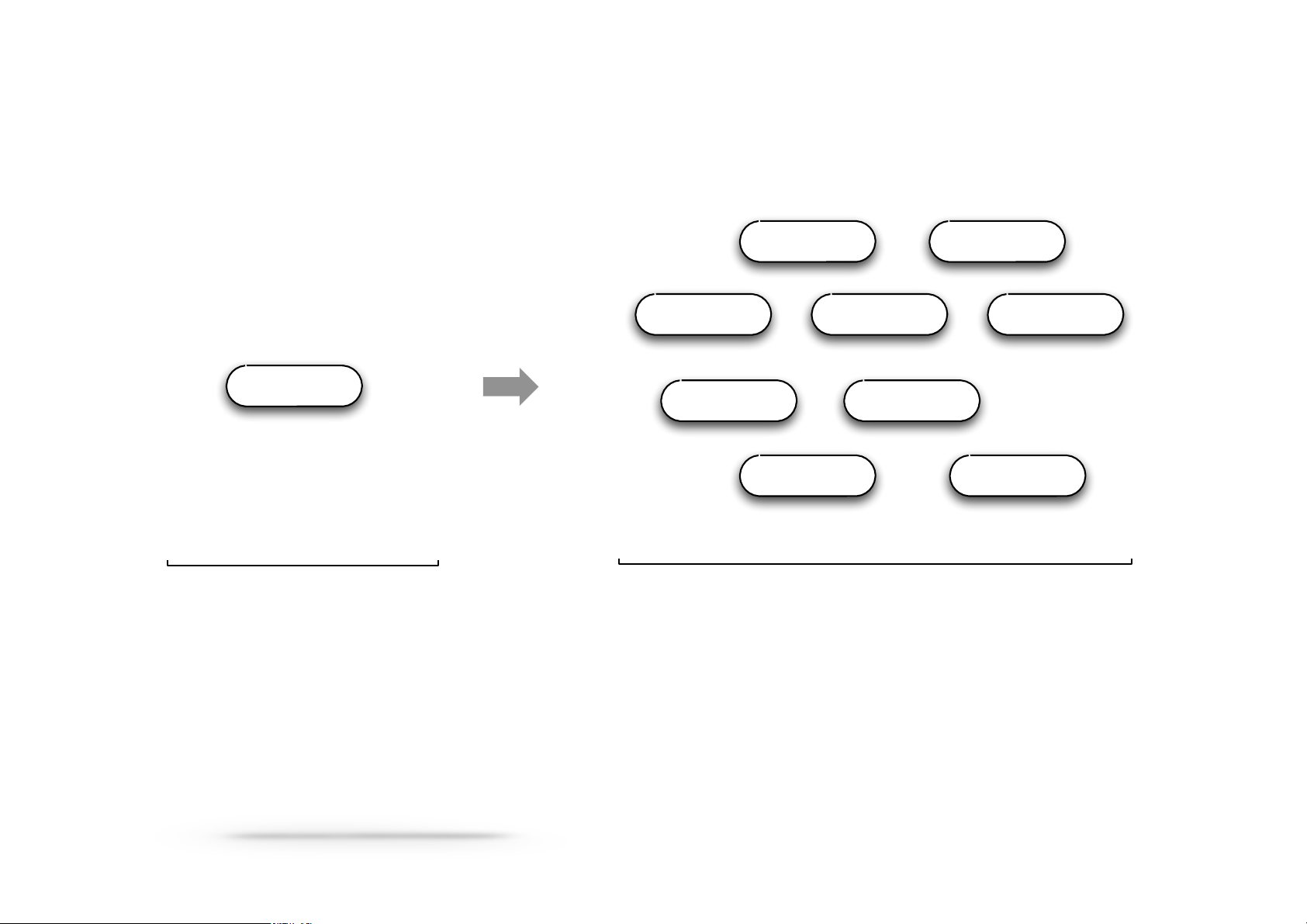
Therefore, people built specialized systems as workarounds… Specialized Systems Pregel Giraph Dremel Dril Tez MapReduce Impala GraphLab Storm S4
General Batch Processing Specialized Systems:
iterative,interactive,streaming,graph,etc.
The State of Spark,andWhereWe're Going Next Matei Zaharia Spark Summit (2013) youtu.be/ nU6vO2EJAb4
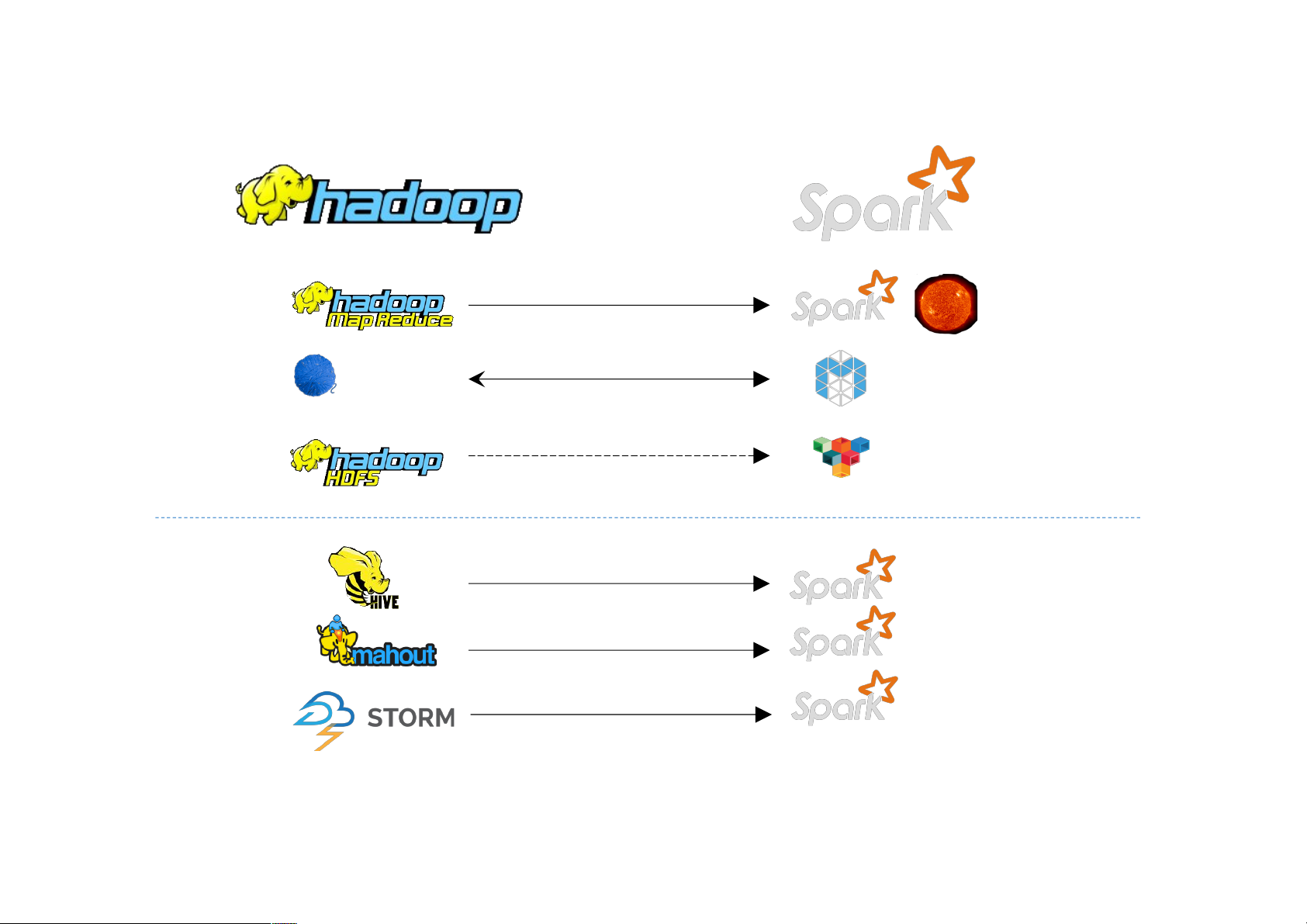
Storage vs Processing Wars NoSQL battles Compute battles MapReduce Re vs l ational vs NoSQ Sp L ark HBase vs Spark Streaming vs Storm Cassanrdra Redis vs Memcache Ri d Hi a vs k ve vs Spark SQL vs Im pala
MongoDB vs CouchDB vs Couchbase Neo4j Mahout vs MLlib vs H20 vs Titan vs Giraph vs OrientDB Solr vs Elasticsearch
Storage vs Processing Wars NoSQL battles Compute battles MapReduce Re vs l ational vs NoSQ Sp L ark HBase vs Spark Streaming vs Storm Cassanrdra Redis vs Memcache Ri d Hi a vs k ve vs Spark SQL vs Im pala
MongoDB vs CouchDB vs Couchbase Neo4j vs Titan Mahout vs MLlib vs H20 vs Giraph vs OrientDB Solr vs Elasticsearch Specialized Systems (2007 – 2015?) Giraph Pregel (2014 – ?) (2004 – 2013) Tez Dril Dremel Mahout Storm S4 Impala GraphLab Specialized Systems
General Batch Processing
(iterative, interactive, ML, streaming, graph, SQL, etc) General Unified Engine vs YARN Mesos Tachyon SQL MLlib Streaming 10x – 100x
Support Interactive and Streaming Comp. •
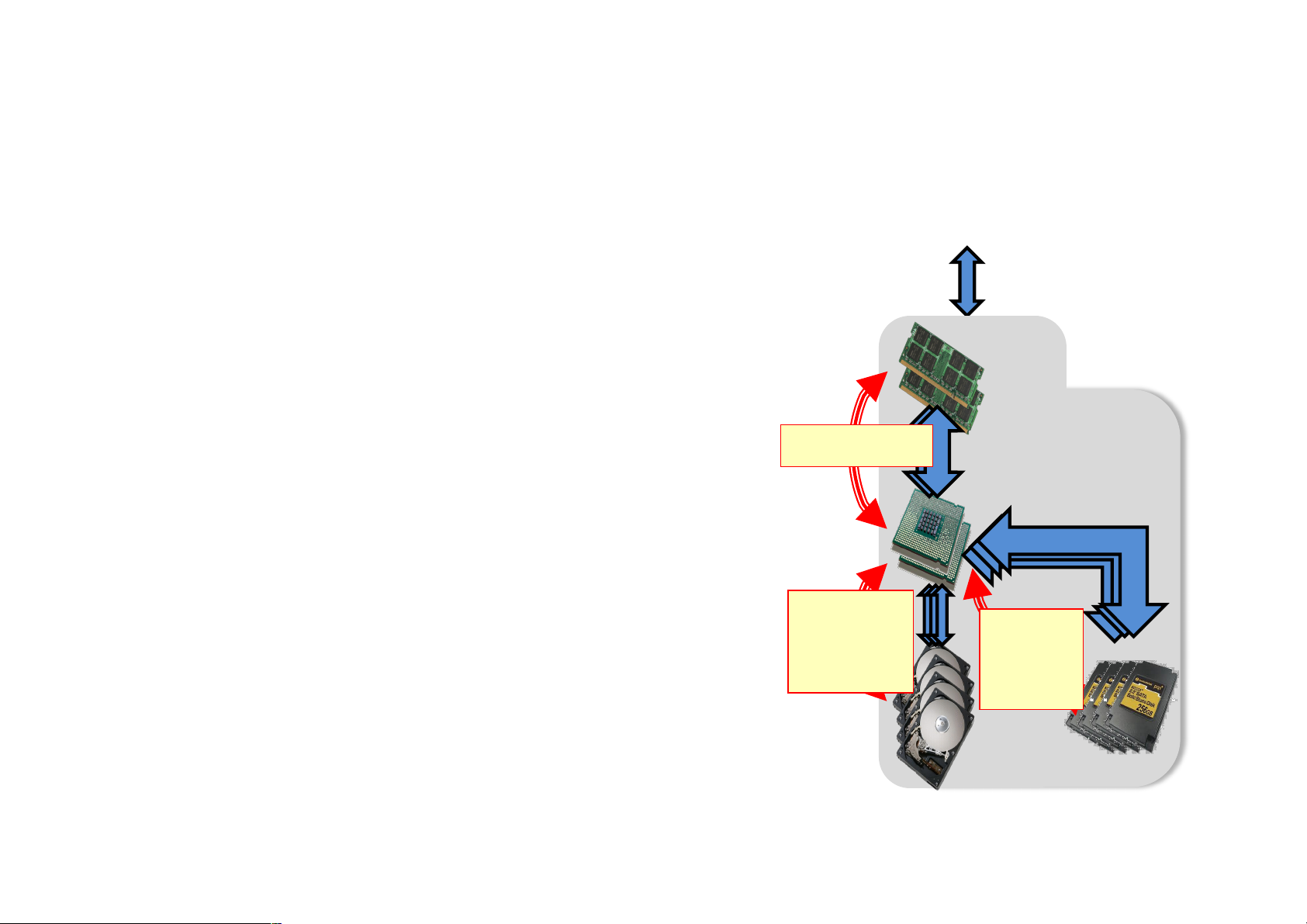
Aggressive use of memory • Why? 10Gbps
1. Memory transfer rates >> disk or SSDs 128-512GB
2. Many datasets already fit into memory 40-60GB/s • Inputs of over 90% of jobs in Facebook, Yahoo!, and Bing clusters fit into memory 16 cores • e.g., 1TB = 1 bil ion records @ 1KB each 0.2- 1-
3. Memory density (stil ) grows with 1GB/s (x10 disks) 4GB/s Moore’s law (x4 disks) 10-30TB • RAM/SSD hybrid memories at 1-4TB horizon High end datacenter node
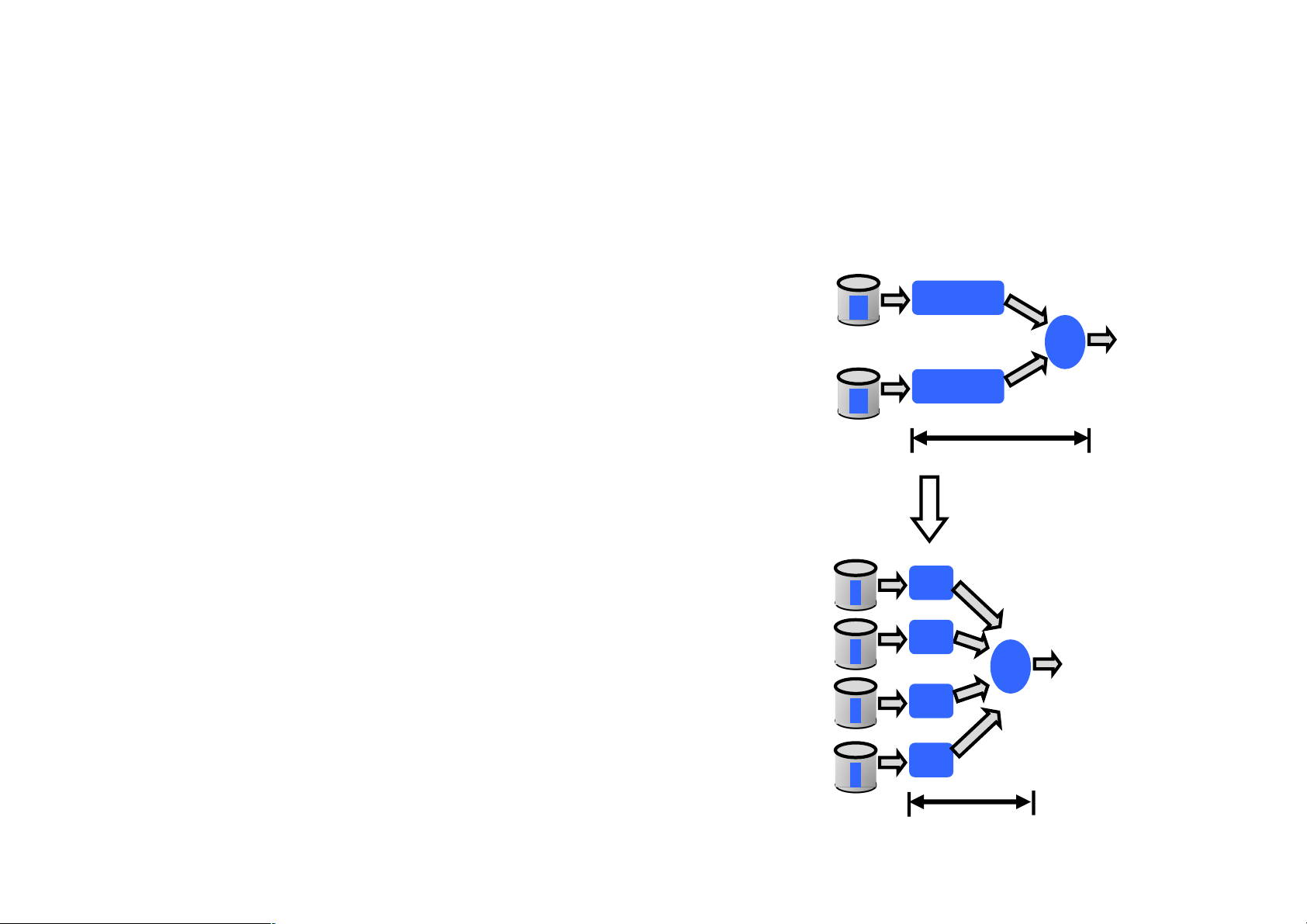
Support Interactive and Streaming Comp. • Increase parallelism • Why?
• Reduce work per node à improve latency result • Techniques: •
Low latency paral el scheduler that achieve high locality T •
Optimized paral el communication
patterns (e.g., shuffle, broadcast) •
Efficient recovery from failures and straggler mitigation result Tnew (< T) Berkeley AMPLab
§ “Launched” January 2011: 6 Year Plan • 8 CS Faculty • ~40 students • 3 software engineers
• Organized for col aboration: Berkeley AMPLab • Funding: • XData, CISE Expedition Grant • Industrial, founding sponsors • 18 other sponsors, including
Goal: Next Generation of Analytics Data Stack for Industry & Research:
• Berkeley Data Analytics Stack (BDAS) • Release as Open Source Databricks making big data simple • Founded in late 2013
• by the creators of Apache Spark
• Original team from UC Berkeley AMPLab
• Raised $47 Mil ion in 2 rounds Databricks Cloud:
“A unified platform for building Big Data pipelines – from
ETL to Exploration and Dashboards, to Advanced Analytics and Data Products.”
Tài liệu liên quan:
-

Báo cáo Bài Tập Lớn: Phân Tích Dữ Liệu Thời Tiết | Lưu trữ và xử lý dữ liệu | Trường Đại học Bách Khoa
10 5 -

Xây dựng luồng dữ liệu lưu trữ, xử lý và phân tích giá bất động sản tại Anh từ 1995 | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
47 24 -

TOP câu hỏi trắc nghiệm Môn Lưu trữ và xử lý dữ liệu lớn | Đại học Bách Khoa Hà Nội
56 28 -

Lưu trữ và xử lý, phân tích dữ liệu phim | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
40 20 -

Đề trắc nghiệm BigData và đáp án| Môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
520 260