Tổng hợp tài liệu môn Điện toán đám mây | Trường Đại học Bách Khoa Hà Nội
Công ty VNXX điều hành 10.000 chỗ làm việc máy tính. Tình huống 1: Máy khách béo (PC) Công suất tiêu thụ trên mỗi máy tính để bàn: 400 watt. Công suất tiêu thụ trên mỗi màn hình: 100 watt. Tài liệu được sưu tầm gồm 20 trang, giúp các bạn nắm vững kiến thức, rèn luyện kỹ năng và đạt được kết quả tốt trong học tập. Mời các bạn đón xem!
Môn: Điện toán đám mây HUST 12 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:














Preview text:
Chương 1: 1.
Công ty VNXX điều hành 10.000 chỗ làm việc máy tính. •
Tình huống 1: Máy khách béo (PC) Công suất tiêu thụ trên mỗi máy tính để
bàn: 400watt Công suất tiêu thụ trên mỗi màn hình: 100 watt •
Tình huống 2: Máy khách mỏng Tiêu thụ điện trên máy khách mỏng: 30 watt
Côngsuất tiêu thụ trên mỗi màn hình: 100 watt
Công suất tiêu thụ trên mỗi phiến máy chủ: 400 watt. Mỗi phiến máy chủ có đủ tài
nguyên để chạy 40 máy ảo.
Chi phí điện mỗi năm cho hoạt động 24/7 khi giá điện là 0,24 $ / kWh là bao nhiêu? Tình huống 1:
0.24*10,000*(400+100)*24*365/1000 = 10,512,000 $ Tình huống 2:
0.24*10,000*(100+30)*24*365/1000 = 2,733,120 $
0.24*(10,000/40)*400*24*365/1000 =
210,240 $ => 2,733,120 + 210,240 = 2,943,360 $ 2.
Hãy tưởng tượng bạn đã huấn luyện một con chim bồ câu mang một ổ USB có dung
lượng lưu trữ là 32 GB. Chim bồ câu có thể bay với tốc độ trung bình 72 km / h.
1. Đối với khoảng cách nào thì chim bồ câu có tốc độ dữ liệu cao hơn so với mạng
máytính có tốc độ dữ liệu là 100 Mbps? Đổi 72 km/h = 20 m/s 100Mb/s = 12.5 MB/s Truyền 32GB
=> thời gian mạng máy tính truyền: 32*1024/12.5
=> thời gian chim bồ câu truyền: S/20 (với S là quãng đường cần tìm)
Để tốc độ dữ liệu của chim bồ câu cao hơn mạng máy tính truyền
⇔ t chim bồ câu < t mạng máy tính => S/20 < 32*1024/12.5 => S < 52428.8(m)
2. Câu trả lời của bạn thay đổi như thế nào, nếu tốc độ trung bình của chim bồ câu là108 km / h? Đổi 108 km/h = 30 m/s
=> thời gian chim bồ câu truyền: S/30
=> S/30 < 32*1024/12.5 => S < 78643.2 (m)
3. Câu trả lời của bạn thay đổi như thế nào, nếu dung lượng của ổ USB tăng gấp đôi?
Truyền 64GB => thời gian mạng máy tính truyền: 64*1024/12.5
=> S/20 < 64*1024/12.5 => S < 104857.6 (m)
4. Câu trả lời của bạn thay đổi như thế nào, nếu tốc độ dữ liệu của mạng máy tính tănggấp đôi?
Tốc độ mạng tăng gấp đôi => thời gian mạng máy tính truyền:
32*1024/25 => S/20 < 32*1024/25 => S < 26214.4 (m) 3.
1. Khách hàng có thể chạy các phiên bản máy chủ ảo và thậm chí lập ra các trung
tâmdữ liệu ảo thuộc loại dịch vụ đám mây nào? iaaS vì khách hàng có thể cài đặt lại cấu hình
2. PaaS là gì và khách hàng có thể làm gì với nó?
Nền tảng là một dịch vụ (PaaS) là mô hình điện toán đám mây trong đó nhà cung
cấp bên thứ ba cung cấp các công cụ phần cứng và phần mềm – thường là những
công cụ cần thiết để phát triển ứng dụng – cho người dùng qua internet.
3. Khách hàng sử dụng dịch vụ phần mềm cần những gì?
Có kết nối Internet, trình duyệt web, đăng ký dịch vụ
4. Sự khác biệt chính giữa dịch vụ Public và Private Cloud là gì? 5. Đám mây lai là gì?
Đám mây lai là sự kết hợp giữa các nền tảng điện toán đám mây, bao gồm một hay
nhiều nhà cung cấp dịch vụ đám mây công cộng (ví dự như Amazon hay Google)
với một nền tảng đám mây nội bộ được thiết kế riêng cho một tổ chức hoặc một cơ
sở hạ tầng IT của tư nhân. Đám mây công cộng và đám mây nội bộ hoạt động độc
lập với nhau và giao tiếp thông qua kết nối được mã hóa để truyền tải dữ liệu và ứng dụng. 4.
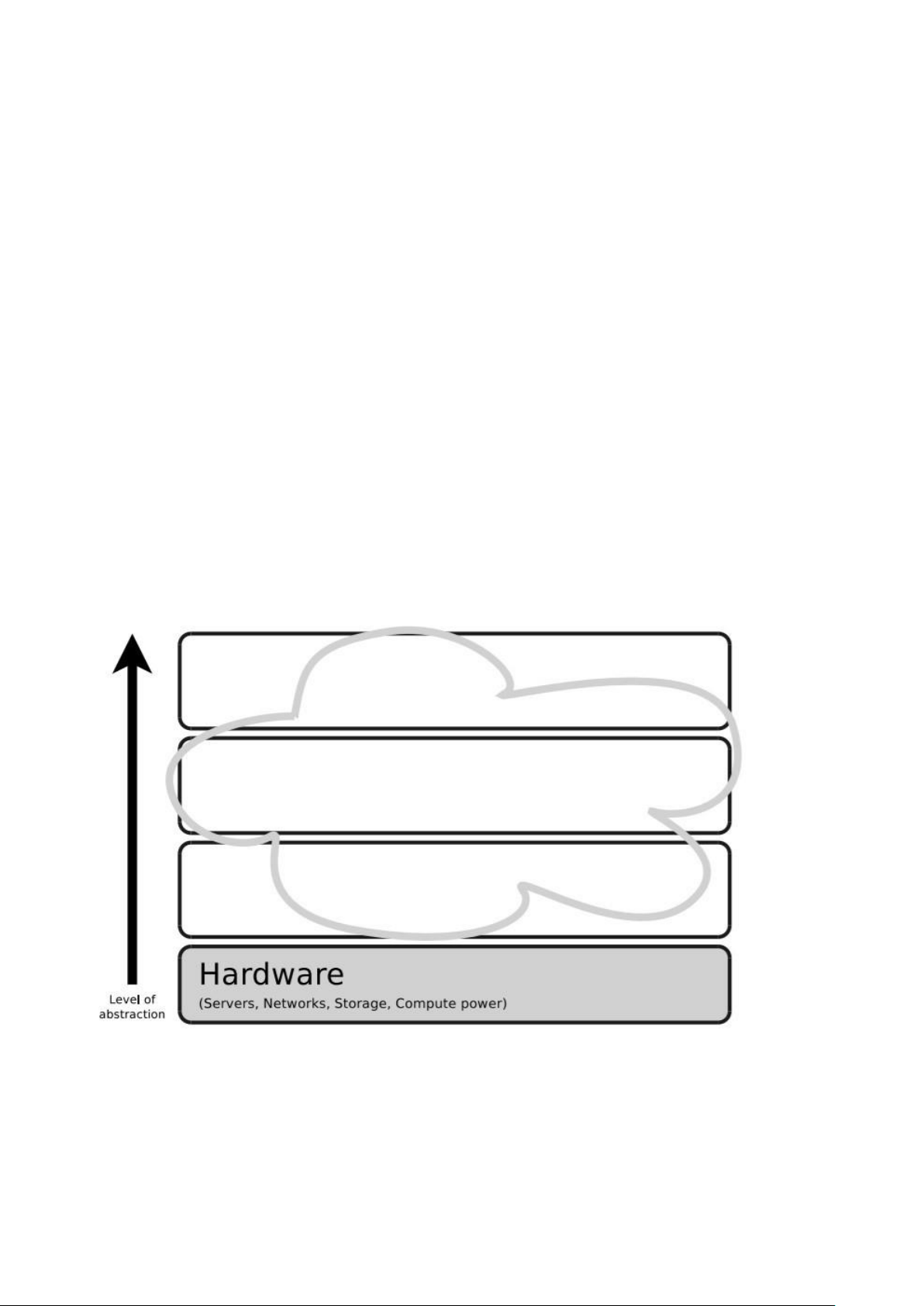
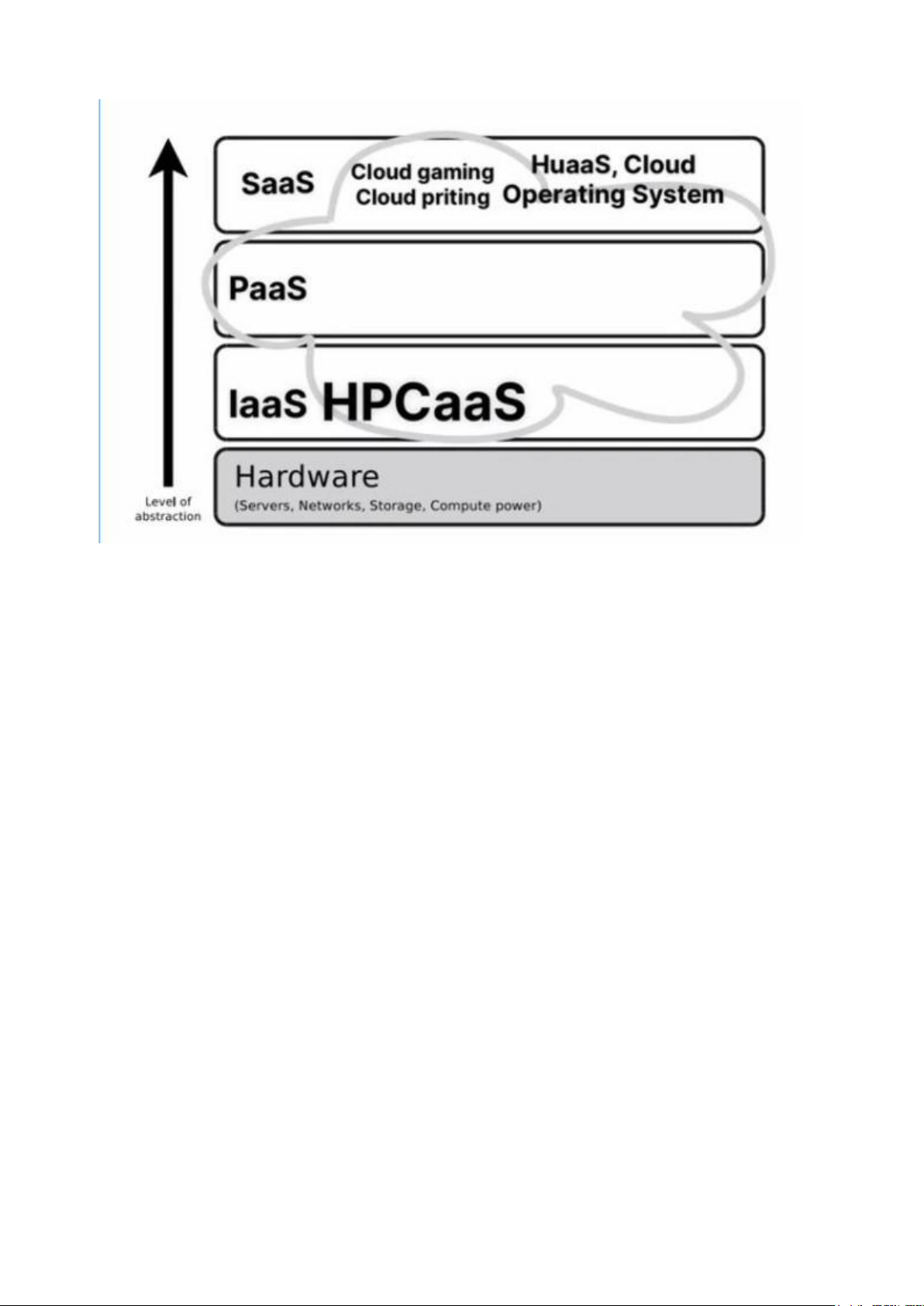
1. Gán các danh mục dịch vụ đám mây này cho các lớp trong hình • PaaS • Cloud Gaming • Cloud Printing • IaaS • HPCaaS • HuaaS • Cloud Operating System • SaaS
2. Assign these cloud service offerings to the layers in the figure
• Google App Engine → PaaS
• Google Cloud Print → SaaS
• Amazon Elastic Compute Cloud → IaaS
• Amazon Mechanical Turk → SaaS • eyeOS → PaaS
• EC2 Cluster Compute Instances → IaaS • Google Apps → SaaS • OnLive → SaaS
Cloud OS nên ném xuống PaaS nhé !
NGUỒN CHỖ NÀY KO UY TÍN ĐÂU NHA
Một số ví dụ về dịch vụ PaaS: Đám mây SAP, Microsoft Azure,
Heroku, AWS Lambda, Công cụ ứng dụng của Google, Dokku, Nền tảng
đám mây Apprenda, Pivotal Cloud Foundry, Tia chớp Salesforce, IBM
Cloud Foundry, Red Hat OpenShift, Nền tảng đám mây Oracle, Zoho Creator, Wasabi,Cloudways
Một số ví dụ về dịch vụ IaaS: Máy chủ Cherry, Microsoft Azure,
Dịch vụ web của Amazon,InMotionHosting Flex Metal Cloud, Cơ sở hạ
tầng đám mây của Google, Đám mây của IBM, Vultr, Cơ sở hạ tầng đám
mây Oracle, Digital Ocean, ServerCentral, Dây buộc, Đám mây Alibaba,
Rackspace Open Cloud, Hewlett Packard Enterprise, Công nghệ đám
mây xanh, Đám mây CenturyLink, Đám mây doanh nghiệp của Hitachi
Một số ví dụ về dịch vụ SaaS: ● Salesforce
● Google Workspace apps ● Microsoft 365 ● HubSpot ● Trello ● Netflix ● Zoom ● Zendesk ● DocuSign ● Slack
● Adobe Creative Cloud ● Shopify ● Mailchimp Chương 2: 1.
Nêu các đặc điểm cơ bản của Hadoop?
Hadoop có một bộ xử lý gọi là hệ thống xử lý dữ liệu phân tán, có 1 máy chính gọi
là Master và nhiều máy nhỏ hơn gọi là Node. Khi yêu cầu một tác vụ như lưu trữ
dữ liệu, xử lý hoặc đọc dữ liệu thì máy Master sẽ đưa yêu cầu đến các Node nhỏ
hơn, tách yêu cầu thành nhiều phần để xử lý. Và sau đó kết quả sẽ được trả về cho
Master và đưa về người dùng. Hadoop có 2 lớp chính:
Lớp xử lý/tính toán (MapReduce)
MapReduce là một mô hình lập trình để thể hiện các phép tính phân tán qua hàng
trăm hoặc hàng ngàn máy chủ trong một cụm Hadoop.
Lớp lưu trữ (HDFS)
HDFS cho phép dữ liệu có thể phân tán: -
Điều này có thể hiểu như sau: Nếu như có
một cụm Hadoop mà trong đó bao
gồm 20 máy tính thì bạn chỉ cần đưa một file dữ liệu vào HDFS. Khi đó, thì file sẽ
tự động được chia nhỏ thành nhiều phần rồi được lưu trữ ở 20 máy tính đó. -
HDFS cho phép tính toán và phân tán
song song: Thay vì chỉ sử dụng một
máy để xử lý công việc, thì với HDFS
thì bạn có thể để các máy hoạt động
song song để xử lý chung một công
việc để tiết kiệm thời gian. -
HDFS cho phép nhân bản các file:
Đặc điểm này sẽ giúp bạn đề phòng
được các trường hợp một máy tính
trong cụm Hadoop phát sinh sự cố thì
dữ liệu sẽ được backup lại mà không bị mất. -
HDFS có thể mở rộng theo chiều dọc:
Lúc này, bạn sẽ có nhiệm vụ nâng cấp
cho các hệ thống bằng cách tăng cấu
hình cho máy tính lên. Tính năng này
còn được gọi là Scale Up hay Vertical scaling. -
HDFS sở hữu khả năng mở rộng hệ
thống theo chiều ngang: Đặc điểm này
có nghĩa rằng, bạn không cần phải
nâng cấp cho phần cứng mà chỉ cần
mua thêm một chiếc máy tính mới để
chia sẻ với chiếc máy hiện tại là được. 2. Trong HDFS, data node là gì
Data node lưu trữ và truy xuất các khối khi chúng được yêu cầu (bởi Client hoặc
Name node). Trong nội bộ, một tệp được chia thành một hoặc nhiều khối và các khối
này được lưu trữ trong một tập hợp các nút dữ liệu.
Datanode sẽ là nơi lưu trữ các file dữ liệu mà bạn đưa vào. 3.
Tại sao trong HDFS, kích thước block thường rất lớn?
Big data là những tập dữ liệu rất lớn, đơn vị thuộc tầm Terabytes hay Petabytes. Vậy
nếu kích thước của block mà nhỏ tầm 4KB thì một file dữ liệu đưa vào HDFS sẽ bị
chia thành rất nhiều các block, điều này cũng là cho các file metadata ở namenode
phình to hơn. Và đương nhiên điều này khiến việc quản lý metadata khó khăn hơn. 4.
Một hệ thống HDFS có hệ số sao chép (replication factor) là 4, kích thước
block là 128MB. Client ghi 1 file có kích thước 1.2GB vào hệ thống HDFS. a.
Tính số block để chứa file đó 1.2 GB = 1228.8 MB
Số block để chứa 1.2 GB là: 1228.8/128= 10 (block)
Vì hệ số sao chép là 4 nên số block để chứa file là: 10 * 4 = 40 block b.
Tính kích thước không gian lưu trữ HDFS dùng để chứa file đó
Kích thước: 40 * 128 = 5120 MB = 5 GB c.
Tính lượng dữ liệu truyền trên mạng khi thực hiện ghi file đó.
Khi client ghi file vào datanode 1,2 GB sẽ được truyền vào. Có 4 bản sao có datanode nên sẽ có 4 lần ghi.
Khi đó lượng dữ liệu truyền trên mạng khi thực hiện khi file trên là: 1,2 * 1024 * 4 = 4915.2 MB
5. Một hệ thống HDFS có hệ số sao chép (replication factor) là 3, kích thước block
là 128MB. 1 file test.txt kích thước 640MB được lưu như sau
Các datanode và client được nối với nhau qua switch 1Gbps. Tốc độ đọc/ghi đĩa
cứng của Datanode là 40MB/s. Hãy tính thời gian nhỏ nhất có thể để client đọc file
test.txt từ hệ thống này.
Kích thước file 640 MB = 5 block 128 MB. Có 4 datanode tốc độ đọc file khi đọc
song song là 160 MB/s. Tốc độ mạng là 1 Gbps = 128 MB/s.
- Giai đoạn 1: Đọc song song 4 block 1, 2, 4, 5 trên node 1, 2, 3, 4
Block 1, 2, 4 đọc xong và truyền xong trong: 128/40 = 3.2 s
- Giai đoạn 2: Đọc song song block 3 và phần còn lại của block 5 trên 2
node khác nhau: 128/40 = 3.2 s Tổng là 6.4 s Chương 3: 1.
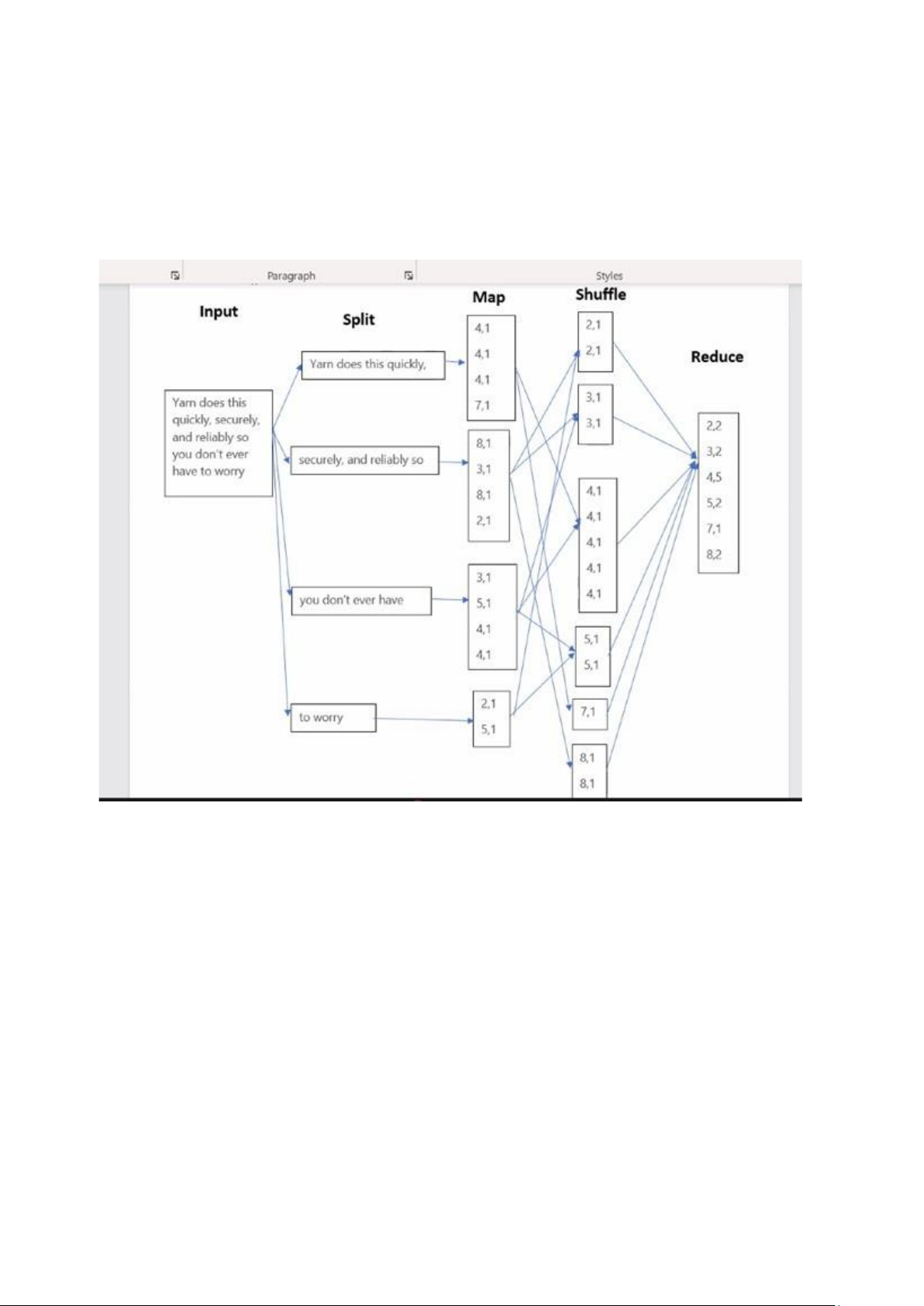
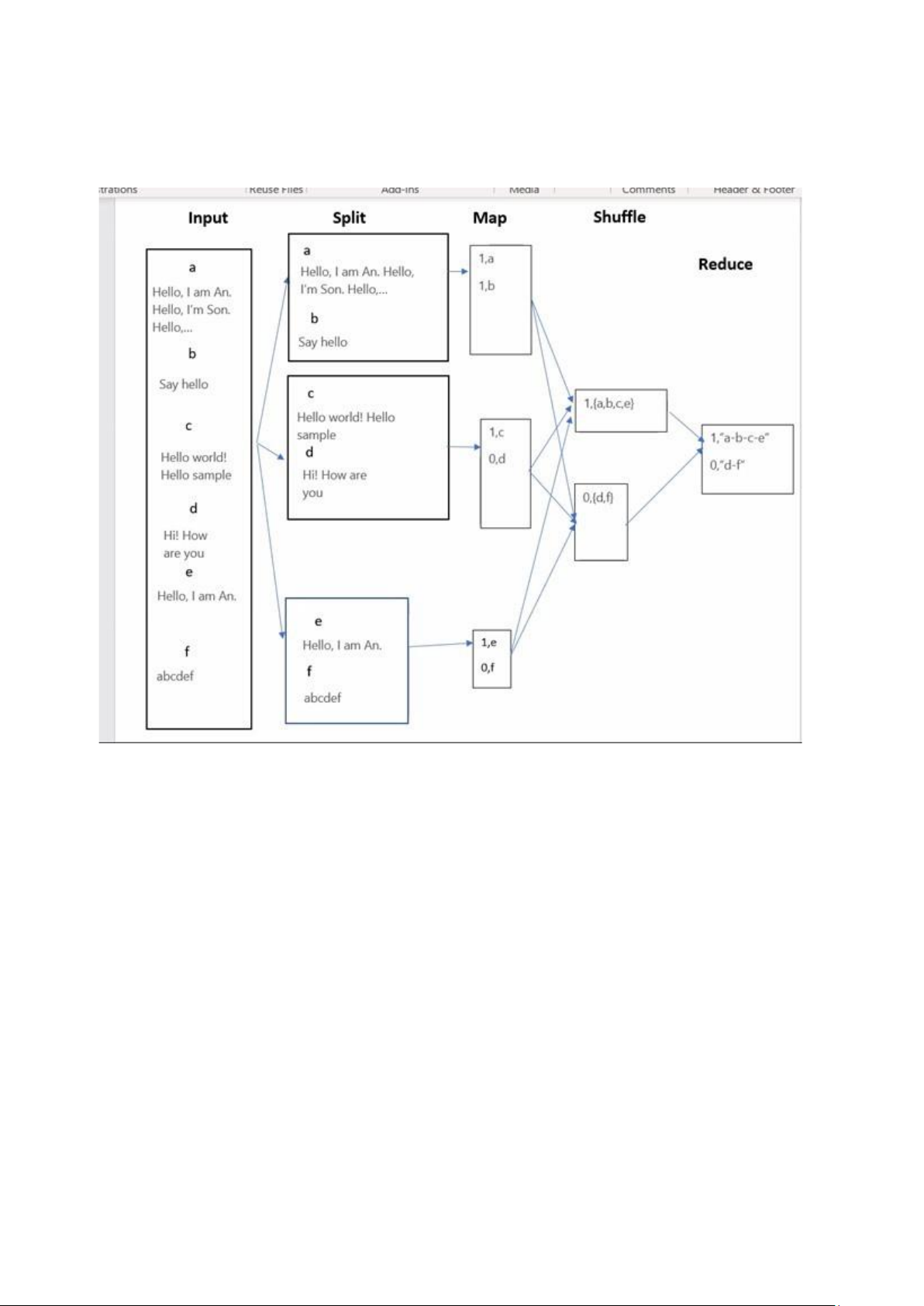
Nêu các thành phần cơ bản của thuật toán MapReduce.
Thành phần cơ bản của thuật toán MapReduce:
- Map: nhận đầu vào một đối tương có khoá (k,v) và trả về một loạt các
cặpkhoá-giá trị: (k1,v1), (k2,v2),…., (kn,vn)
- Khung chức năng tập hợp tất cả các cặp có cùng khoá k và liên kết với
tất cảcác giá trị của k: (k, [v1,….,vn]
- Reduce: nhận đầu vào là khoá và danh sách các giá trị (k, [v1,…,vn])
và kếthợp chúng bằng cách nào đó. 2.
Thiết kế thuật toán MapReduce đếm xem có bao nhiêu từ có độ dài nhất định
tồn tại trong một tập các file text.
Map: key = độ dài của từ, value = 1
Reduce: key không đổi, value = tổng của các value 3.
Thiết kế thuật toán MapReduce để tìm trong một tập các file text danh sách
các file chứa từ “Hello”.
Map: file có chữ “Hello” thì key = 1 và value = tên file.
Reduce: key không đổi, value = nối chuỗi các value và ngăn cách bởi dấu “-”. Chương 4: 1.
Nêu các thành phần cơ bản của định lý CAP.
Định lý CAP: Một hệ thống phân tán chỉ có thể có được hai trong 3 đặc
tính mong muốn: tính nhất quán (Consistency), tính khả dụng
(Availability), Chịu lỗi phân vùng ( Partition tolerance) Các thành phần cơ bản:
- Tính nhất quán (Consistency):
+ Tất cả các bản sao đều chứa cùng một phiên bản dữ liệu
+ Khách hàng luôn có cùng cái nhìn về dữ liệu (bất kể nút
nào) - Khả dụng (Availability):
+ Hệ thống vẫn hoạt động khi bị lỗi giao điểm
+ Tất cả các khách hàng luôn có thể đọc và viết
- Chịu lỗi phân vùng (Partition tolerance) + nhiều điểm truy cập
+ Hệ thống vẫn hoạt động trên hệ thống bị phân chia (sự cố về truyền thông)
+ Hệ thống hoạt động tốt trên toàn bộ vật lý phân vùng mạng 2. So sánh NoSQL và SQL So sánh SQL và NoSQL Tham số SQL NoSQL
Định nghĩa Cơ sở dữ liệu SQL chủ yếu
Cơ sở dữ liệu NoSQL chủ yếu
được gọi là RDBMS hoặc Cơ được gọi là cơ sở dữ liệu không sở dữ liệu quan hệ liên quan hoặc phân tán Design for
RDBMS truyền thống sử dụng Hệ thống cơ sở dữ liệu NoSQL
cú pháp và truy vấn SQL để
bao gồm nhiều loại công nghệ cơ
phân tích và lấy dữ liệu để có sở dữ liệu khác nhau. Các cơ sở
thêm thông tin chi tiết. Chúng dữ liệu này được phát triển để
được sử dụng cho các hệ
đáp ứng nhu cầu trình bày cho sự thống OLAP.
phát triển của ứng dụng hiện đại. Ngôn ngữ Structured query language Không có ngôn ngữ query Query (SQL) Type
SQL databases là cơ sở dữ
NoSQL databases có thể dựa liệu dựa trên bảng
trên tài liệu, cặp khóa-giá trị, cơ sở dữ liệu biểu đồ Schema
SQL databases có lược đồ
NoSQL databases sử dụng lược
được xác định trước
đồ động cho dữ liệu phi cấu trúc. Khả năng
SQL databases có thể mở rộng NoSQL databases có thể mở mở rộng theo chiều dọc rộng theo chiều ngang Ví dụ Oracle, Postgres, and MongoDB, Redis, , Neo4j, MSSQL. Cassandra, Hbase. Phù hợp
Đây là 1 lựa chọn lý tưởng
Không phù hợp với truy vấn cho
cho môi trường truy vấn phức phức tạp tạp Tham số SQL NoSQL
Lưu trữ dữ SQL databases không thích
Phù hợp hơn cho kho lưu trữ dữ liệu phân
hợp cho việc lưu trữ dữ liệu
liệu phân cấp vì nó hỗ trợ cấp phân cấp.
phương thức cặp khóa-giá trị. Variations
Một loại có biến thể nhỏ
Nhiều loại khác nhau bao gồm
các kho khóa-giá trị, cơ sở dữ
liệu tài liệu và cơ sở dữ liệu đồ thị. Tính nhất
Nó phải được cấu hình cho sự Nó phụ thuộc vào DBMS như quán nhất quán chặt chẽ.
một số cung cấp tính nhất quán
mạnh mẽ như MongoDB, trong
khi những người khác cung cấp
chỉ cung cấp sự nhất quán cuối cùng, như Cassandra. Được sử
RDBMS database là tùy chọn NoSQL được sử dụng tốt nhất để dụng tốt
thích hợp để giải quyết các
giải quyết các vấn đề về tính khả nhất cho vấn đề về ACID. dụng của dữ liệu Tầm quan
Nó nên được sử dụng khi hiệu Sử dụng khi nó quan trọng hơn trọng
lực dữ liệu là siêu quan trọng
để có dữ liệu nhanh hơn dữ liệu chính xác Lựa chọn
Khi bạn cần hỗ trợ truy vấn
Sử dụng khi bạn cần mở rộng tốt nhất động
quy mô dựa trên yêu cầu thay đổi Hardware Specialized DB hardware Commodity hardware (Oracle Exadata, etc.) Network Highly available network Commodity network (Ethernet,
(Infiniband, Fabric Path, etc.) etc.)
Loại lưu trữ Highly Available Storage Commodity drives storage (SAN, RAID, etc.) (standard HDDs, JBOD) Tính năng
Hỗ trợ đa nền tảng, Bảo mật
Dễ sử dụng, hiệu suất cao và Tham số SQL NoSQL tốt nhất và miễn phí công cụ linh hoạt. Mô hình
ACID (Atomicity, nhất quán, Cơ bản (Về cơ bản có sẵn, trạng ACID và
cách ly và độ bền) là một
thái mềm, phù hợp cuối cùng) là BASE chuẩn cho RDBMS
một mô hình của nhiều hệ thống NoSQL
Performanc SQL hoạt động tốt và nhanh Nhanh hơn SQL NoSQL thì e
thì việc design tốt là cực kì
denormalized cho phép bạn lấy
quan trọng và ngược lại.
được tất cả thông tin về một item
cụ thể với các condition mà
không cần JOIN liên quan hoặc truy vấn SQL phức tạp. Kết luận
Dự án đã có yêu cầu dữ liệu rõ Phù hợp với những dự án yêu
ràng xác định quan hệ logic có cầu dữ liệu không liên quan, khó
thể được xác định trước.
xác định, đơn giản mềm dẻo khi đang phát triển
Ngắn gọn: NoSQL so với SQL:
- Giản đồ định nghĩa dữ liệu lỏng lẻo
- Các ứng dụng được viết để xử lý các tài liệu/dữ liệu cụ thể-
Được thiết kế để xử lý các cơ sở dữ liệu lớn, phân tán - Đánh đổi:
+ Không hỗ trợ mạnh mẽ cho các truy vấn đặc biệt nhưng được thiết kế
cho tốc độ và sự phát triển của cơ sở dữ liệu.
🡪 Ngôn ngữ truy vấn thông qua API
+ Các đặc tính ACID được nới lỏng
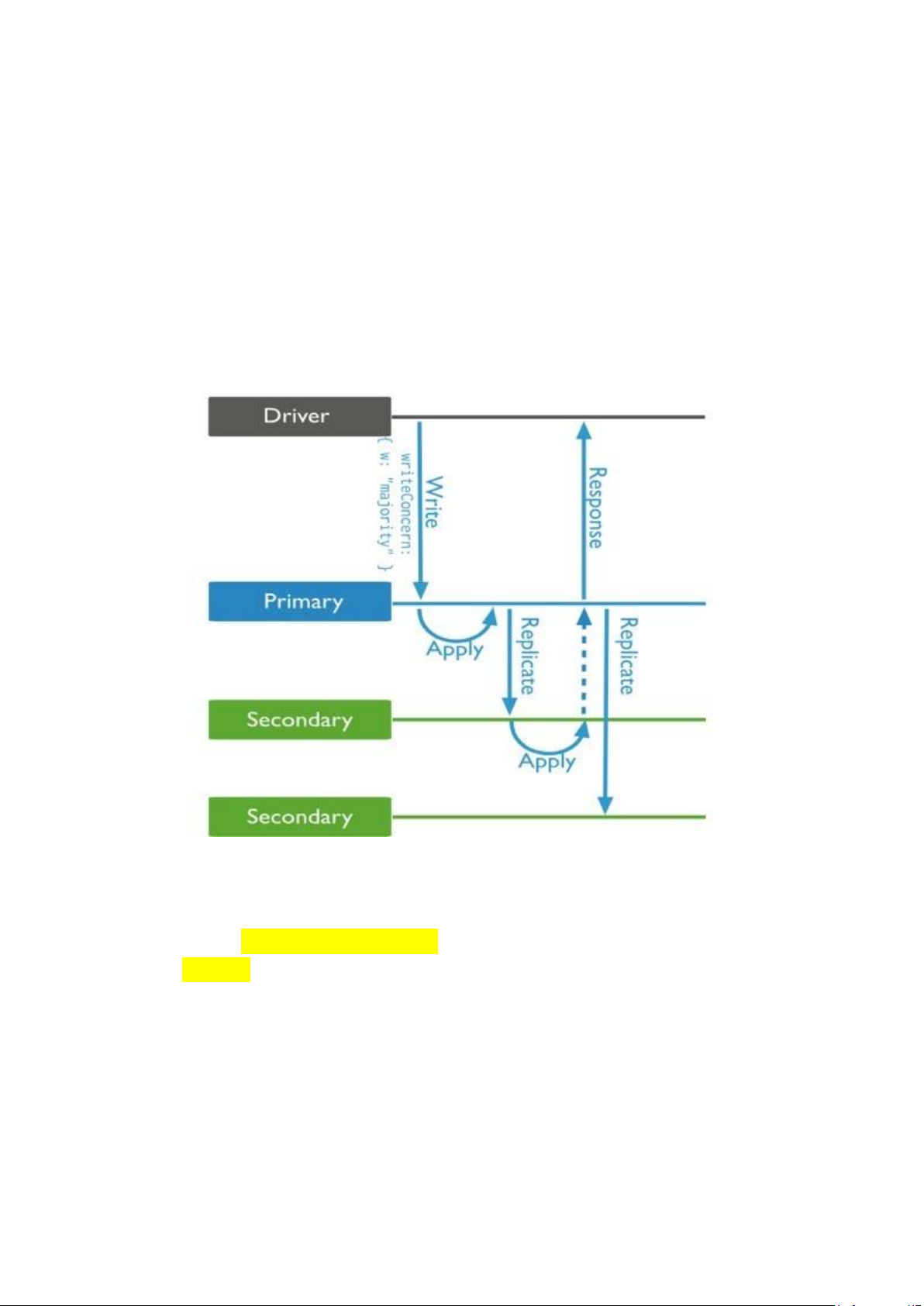
3. 1 tập hợp sao chép trong mongodb có 7 phần tử: 1 chính, 6 phụ. Người dung
cần ghi 1 file dữ liệu 2GB vào tập hợp theo chế độ w:majority. Tốc độ
truyền dữ liệu mạng là 1Gbps. Tốc độ ghi của đĩa cứng là 50MB/s. Hãy
tính thời gian ngắn nhất để ghi thành công file trên.
Thời gian truyền dữ liệu đến primary 2GB = 2*8 Gb/ (1Gbs)
= 16 s //xoá nhớ đính kèm lý do nhá. Thời gian ghi vào primary:
2GB = 2 .2^10 (MB)/ 50MB = 40.96 s
Vì quá trình truyền và ghi diễn ra song song nên thời gian truyền và ghi
dữ liệu vào các phần tử sẽ là 40.96 s.
Theo chế độ w:majority nên chỉ cần phần lớn phần tử xác nhận ghi thành
công (4/7) nên thời gian ngắn nhất: 40.96*4 = 163.84 s Chương 5: 1.
Cân bằng tải là gì?
Cân bằng tải hay còn gọi là Load Balancing, là một phương pháp phân
phối khối lượng tải trên nhiều máy tính hoặc một cụm máy tính để có thể
sử dụng tối ưu các nguồn lực, tối đa hóa thông lượng, giảm thời gian đáp
ứng và tránh tình trạng quá tải trên máy chủ. 2.
Round-robin có trọng số
Trọng số được chỉ định cho mỗi máy chủ dựa trên các tiêu chí do quản trị viên trang
web chọn; tiêu chí được sử dụng phổ biến nhất là khả năng xử lý lưu lượng truy cập
của máy chủ. Trọng số càng cao, tỷ lệ yêu cầu máy khách mà máy chủ nhận được
càng lớn. Ví dụ: nếu máy chủ A được chỉ định trọng số là 3 và máy chủ B có trọng
số là 1, bộ cân bằng tải sẽ chuyển tiếp 3 yêu cầu đến máy chủ A cho mỗi yêu cầu mà
nó gửi đến máy chủ B.
Một cluster có 3 máy chủ A, B, C với trọng số tương ứng la 4, 3, 2. Có 180 request
đến bộ cân bằng tải. Hãy tính số request phân phối cho các máy chủ dùng thuật toán Roundrobin có trọng số.
Số request/1 đơn vị trọng số là: 180/(4+3+2)= 20 (request/1 đơn vị trọng
số) Số request phân phối cho các máy chủ là: A: 4*20 = 80 request B: 3*20 = 60 request C: 2*20 = 40 request
3. Một cluster có 3 máy chủ A, B, C với số connection đang xử lý tương ứng là 433,
413, 403. Có 180 request đến bộ cân bằng tải. Hãy tính số request phân phối cho các
máy chủ dùng thuật toán least connection.
Trung bình request nhận được của mỗi máy là:
(433 + 413 + 403 + 180)/3 = 476 (dư 1 request)
Số request phân phối về các máy chủ dùng thuật toán least connection là: A: 476 – 433 = 43 (request) B: 476 – 413 = 63 (request)
C: 476 – 403 = 73 (request) 🡪 bổ sung thêm 1 request dư 🡪 74 request
4. Trọng số được chỉ định cho mỗi máy chủ dựa trên các tiêu chí do quản trị viên
trang web chọn; tiêu chí được sử dụng phổ biến nhất là khả năng xử lý lưu lượng
truy cập của máy chủ. Trọng số càng cao, tỷ lệ yêu cầu máy khách mà máy chủ nhận
được càng lớn. Ví dụ: nếu máy chủ A được chỉ định trọng số là 3 và máy chủ B có
trọng số là 1, bộ cân bằng tải sẽ chuyển tiếp 3 yêu cầu đến máy chủ A cho mỗi yêu
cầu mà nó gửi đến máy chủ B.
Một cluster có 3 lop máy chủ A, B, C với trọng số tương ứng la 4, 3, 2.
Lớp A: 3 máy; Lớp B: 4 máy; Lớp C: 2 máy
Số request cho mỗi đợt phân tải: 10, 15, 20, 14, 17, 30, 22, 13.
Đề xuất một thuật toán phân tải sao cho cuối cùng thì tải cân bằng Chương 6:
1. Nguy cơ mất kiểm soát là gì?
● Người tiêu dùng mất kiểm soát
- Dữ liệu, ứng dụng, tài nguyên được định vị với nhà cung cấp
- Quản lý danh tính người dùng do đám mây xử lý
- Các quy tắc kiểm soát quyền truy cập của người dùng, chính sách bảo
mật và việc thực thi được quản lý bởi nhà cung cấp đám mây
- Người tiêu dùng tin tưởng vào nhà cung cấp để đảm bảo
+ Bảo mật dữ liệu và quyền riêng tư + Nguồn lực sẵn có
+ Giám sát và sửa chữa các dịch vụ / tài nguyên
1. Nêu các giải pháp giải quyết sự thiếu tin tưởng. ● Ngôn ngữ chính sách
○ Người tiêu dùng có nhu cầu bảo mật cụ thể nhưng không có ý nghĩa về cách họ được xử lý
■ Nhà cung cấp đang làm cái quái gì cho tôi vậy?
■ Hiện tại, người tiêu dùng không thể đưa ra các yêu cầu của họ cho
nhà cung cấp (SLA là một phía)
○ Ngôn ngữ chuẩn để truyền đạt các chính sách và kỳ vọng của một người
■ Được sự đồng ý và ủng hộ của cả hai bên
■ Ngôn ngữ tiêu chuẩn để trình bày SLA
■ Có thể được sử dụng trong môi trường nội bộ đám mây để thực
hiện tư thế bảo mật bao trùm
○ Tạo ngôn ngữ chính sách với các đặc điểm sau:
■ Máy có thể hiểu được (hoặc ít nhất là có thể xử lý),
■ Dễ dàng kết hợp / hợp nhất và so sánh
■ Ví dụ về các tuyên bố chính sách là, “yêu cầu cách ly giữa các
máy ảo”, “yêu cầu cách ly địa lý giữa các máy ảo”, “yêu cầu tách
biệt thực tế giữa các cộng đồng / người thuê khác trong cùng ngành,” v.v.
■ Cần một công cụ xác thực để kiểm tra xem chính sách được tạo
bằng ngôn ngữ chuẩn có phản ánh chính xác ý định của người
tạo chính sách hay không (nghĩa là ngôn ngữ chính sách tương
đương về mặt ngữ nghĩa với ý định của người dùng). ● Chứng nhận ○ Chứng nhận
■ Một số hình thức đánh giá và mô tả có uy tín, độc lập, có thể so
sánh được và các tính năng bảo mật và đảm bảo
■ Sarbanes-Oxley, DIACAP, DISTCAP, v.v. (chúng có đủ cho môi trường đám mây không?) ○ Đánh giá rủi ro
■ Thực hiện bởi các bên thứ ba được chứng nhận
■ Cung cấp cho người tiêu dùng sự đảm bảo bổ sung 3.
1 ví nhận diện người dùng có các thông tin sau:
Tên, ngày-tháng-năm sinh, username, password, email, tel, address, tax code, credit
card, job, office, marital status.
Xác định các thông tin cần thiết cho các dịch vụ sau: - Web mail : email - Google meet: tên , email -
Shopee customer: address, tel, tên - Shopee seller: tên, tax code - Facebook: email Bài thi giữa kì:
Tài liệu liên quan:
-

Bài tập môn Điện toán đám mây | Đại học Bách Khoa Hà Nội
66 33 -

Bài tập môn Điện toán đám mây | Đại học Bách Khoa Hà Nội
56 28 -

Tài liệu Tổng quan về điện toán đám mây | Trường Đại học Bách Khoa Hà Nội
288 144 -

Tài liệu học tập Các vấn đề và giải pháp bảo mật môn Điện toán đám mây | Trường Đại học Bách Khoa Hà Nội
95 48 -

Đề cương chi tiết học phần môn Điện toán đám mây | Trường Đại học Bách Khoa Hà Nội
116 58