BÀI GIẢNG VÀ BÀI TẬP THỐNG KÊ ỨNG DỤNG-1 TRONG KINH TẾ VÀ KINH DOANH
BÀI GIẢNG VÀ BÀI TẬP THỐNG KÊ ỨNG DỤNG-1 TRONG KINH TẾ VÀ KINH DOANH
Môn: Thống kê và xác suất 6 tài liệu
Trường: Đại học Thái Nguyên 386 tài liệu
Tác giả:


















Preview text:
1
TRƯỜNG ĐẠI HỌC NHA TRANG KHOA KINH TẾ BỘ MÔN KINH TẾ HỌC
BÀI GIẢNG VÀ BÀI TẬP THỐNG KÊ ỨNG DỤNG
TRONG KINH TẾ VÀ KINH DOANH
Các tác giả:ThSVõHảiThuỷ TS Nguyễn Thu Thuỷ ThS Lê Văn Tháp
ThS Trần Thị Thu Hòa
CHƯƠNG I. GIỚI THIỆU MÔN HỌC
I.KHÁI NIỆM VỀ MÔN HỌC :
1-Thống kê (Statistics) :
Thống kê là hệ thống các phương pháp dùng để thu thập và xử lý dữ liệu nhằm phục vụ cho quá trình nghiên cứu và
ra quyết định khi dữ liệu được thu thập trong điều kiện không chắc chắn.
Cơ sở lý thuyết cho thống kê là lý thuyết xác suất và thống kê toán. Hiện nay thống kê đã được ứng dụng rộng rãi
trong rất nhiều lĩnh vực như: thống kê dân số, thống kê xã hội, thống kê trong kinh doanh, thống kê bảo hiểm, thống kê
trong giáo dục, thống kê trong sinh học, thống kê trong y học,…Trong lĩnh vực kinh tế và kinh doanh, thống kê đóng vai trò
là công cụ cơ bản để phân tích thực trạng tình hình thông qua dữ liệu thu thập và xử lý nhằm tìm hiểu bản chất và tính quy
luật của hiện tượng trong những điều kiện không gian và thời gian cụ thể.
2-Chức năng của thống kê: Thống kê có 2 chức năng cơ bản sau :
-Thống kê mô tả (Descriptive Statistics) : bao gồm các phương pháp dùng để mô tả các đặc trưng cơ bản của khối
dữ liệu về tổng thể chung hay tổng thể mẫu. Đó là các phương pháp : thu thập dữ liệu, sắp xếp dữ liệu, trình bày tóm tắt dữ
liệu, phân tích dữ liệu …
-Thống kê suy luận (Inferential Statistics) : bao gồm các phương pháp dùng để suy rộng các đặc trưng của tổng thể
chung dựa trên kết quả nghiên cứu trên tổng thể mẫu. Đó là các phương pháp : ước lượng thống kê, kiểm định giả thuyết
thống kê, phân tích phương sai, hồi quy và tương quan, dự báo thống kê…
II. MỘT SỐ KHÁI NIỆM THƯỜNG DÙNG TRONG THỐNG KÊ :
1-Tổng thể chung (population) :
Tổng thể chung (gọi tắt là tổng thể) là một tập hợp các đơn vị cá biệt mà ta đang quan tâm nghiên cứu về 1 hiện
tượng nào đó trên chúng. Từng đơn vị cá biệt tạo thành tổng thể chung được gọi là đơn vị tổng thể.
*Phân loại: Có nhiều cách phân loại tổng thể tuỳ theo đặc điểm của đối tượng nghiên cứu :
-Tổng thể hữu hạn (khi ta xác định được số đơn vị của tổng thể, ) và tổng thể vô hạn (khi ta không thể hoặc khó
xác định được số đơn vị của tổng thể, như: tổng thể sản phẩm sản xuất của 1 cái máy, tổng thể ngày sản xuất của một nhà
máy) -Tổng thể bộc lộ (khi ta có thể trực tiếp quan sát hay nhận biết các đơn vị của tổng thể, như tổng thể sinh viên của
một trường đại học, tổng thể các doanh nghiệp nhà nước,…) và tổng thể tiềm ẩn (khi ta không thể trực tiếp quan sát hay
nhận biết các đơn vị của tổng thể, như tổng thể những người nghiện thuốc lá…)
-Tổng thể đồng chất (khi các đơn vị của tổng thể giống nhau về đặc điểm liên quan đến mục đích nghiên cứu) và
tổng thể không đồng chất (khi các đơn vị của tổng thể không giống nhau về đặc điểm liên quan đến mục đích nghiên cứu).
Việc phân loại này phụ thuộc vào mục đích nghiên cứu cụ thể. Các nghiên cứu thống kê thường dựa trên tổng thể đồng chất.
2-Tổng thể mẫu (sample): 2
Tổng thể mẫu (gọi tắt là mẫu) là một tập hợp con của tổng thể chung, bao gồm các đơn vị cá biệt được ta chọn ra từ
tổng thể chung theo một phương pháp lấy mẫu nào đó.
3-Quan sát (observation):
Quan sát là đơn vị cơ sở để thu thập dữ liệu về hiện tượng nghiên cứu. Người ta gọi 1 đơn vị của mẫu là 1 quan sát
bởi vì trên từng đơn vị này ta sẽ tiến hành thu thập dữ liệu về nó.
4-Tiêu thức thống kê: Tiêu thức thống kê là các đặc điểm của các đơn vị tổng thể được ta chọn ra để nghiên cứu.
Chẳng hạn khi nghiên cứu đặc điểm dân số, thường chọn các tiêu thức là : tên, tuổi, giới tính, dân tộc, tôn giáo, nghề
nghiệp, trình độ văn hoá, tình trạng hôn nhân,… Có 2 loại tiêu thức:
-Tiêu thức định tính (tiêu thức thuộc tính): Là tiêu thức không thể biểu hiện trực tiếp bằng con số.
-Tiêu thức định lượng (tiêu thức số lượng): Là tiêu thức có thể biểu hiện trực tiếp bằng con số. Các con số này được
gọi là các lượng biến. Lượng biến được chia ra 2 loại:
+Lượng biến rời rạc : Là lượng biến mà các giá trị có thể có của nó là những số hữu hạn hay vô hạn, và có thể đếm
được. Ví dụ: số sinh viên trong 1 trường đại học, số nhân khẩu trong 1 hộ gia đình, số thành phẩm nhập kho trong 1 ngày tại một phân xưởng…
+Lượng biến liên tục : Là lượng biến mà các giá trị có thể có của nó có thể lấp kín một khoảng trên trục số. Ví dụ:
trọng lượng chiều cao của 1 học sinh, năng suất lao động của một công nhân…
5-Chỉ tiêu thống kê : Chỉ tiêu thống kê là biểu hiện khái quát đặc điểm về mặt lượng của toàn bộ tổng thể trong điều
kiện không gian và thời gian nhất định. Có thể chia ra 2 loại chỉ tiêu :
-Chỉ tiêu khối lượng: phản ánh khái quát đặc điểm về quy mô của tổng thể. Ví dụ: Tổng dân số của một quốc gia,
tổng quỹ lương của một công ty, khối lượng sản phẩm nhập kho, số lao động của một doanh nghiệp…
-Chỉ tiêu chất lượng: phản ánh khái quát đặc điểm về tính chất, trình độ phổ biến, quan hệ so sánh trong tổng thể.
Chỉ tiêu chất lượng thường mang ý nghĩa phân tích và là kết quả so sánh giữa các chỉ tiêu khối lượng. Ví dụ: năng suất lao
động trung bình của một công nhân, năng suất thu hoạch một loại cây trồng, tỷ lệ hộ nghèo tại một địa phương,…
6-Các loại thang đo :
Để lượng hoá các đặc trưng của các quan sát trên tổng thể nghiên cứu nhằm thuận tiện trong việc xử lý dữ liệu bằng
các phương pháp thống kê, người ta tiến hành xây dựng thang đo khi thu thập dữ liệu. Vậy thang đo là công cụ dùng để mã
hóa các biểu hiện khác nhau của tiêu thức nghiên cứu. Để có thể xử lý dữ liệu trên máy vi tính người ta thường mã hóa
thang đo bằng các con số. Có thể chia ra 4 loại thang đo (xếp theo sự tăng dần khả năng diễn đạt thông tin của thang đo) là :
-Thang đo định danh (Nominal scale) :
Là loại thang đo dùng để biểu hiện sự khác nhau về tên gọi, màu sắc, tính chất, đặc điểm,… giữa các đơn vị của 1
tiêu thức định tính. Người ta thường quy ước dùng các con số 1,2,3,… hay dùng các ký tự A,B,C,…để biểu hiện thang đo
định danh.Các con số của thang đo không nói lên quan hệ hơn kém, không thể tính toán trên những con số này.
Ví dụ: Tên nhãn hiệu bột giặt mà gia đình bạn đang dùng: Tide □ Omo □ Viso □ Tên khác □
-Thang đo thứ bậc (Ordinal scale): Là loại thang đo dùng để biểu hiện sự khác nhau về mặt thứ bậc… giữa các đơn
vị của 1 tiêu thức định tính hay 1 tiêu thức định lượng.
Người ta thường quy ước dùng các con số 1,2,3,… để biểu thị thứ bậc từ cao xuống thấp hay từ thấp lên cao. Như
vậy, các con số của thang đo nói lên quan hệ thứ bậc hơn kém, nhưng không nói lên được khoảng cách giữa các thứ bậc. Có
thể tính toán trên những con số này để biểu hiện đặc trưng chung của tổng thể một cách tương đối.
Ví dụ: Bạn đánh giá năng lực quan trọng nhất mà người thầy cần có là gì ? (bạn hãy xếp thứ tự 1,2,3 cho năng lực từ
quan trọng nhất trở xuống) :
-Có kiến thức uyên bác về môn học : là năng lực quan trọng số □
-Có năng lực sư phạm tốt, giảng dạy rõ ràng, dễ hiểu : số □
-Có khả năng tạo cảm hứng cho SV trong học tập (sự dí dỏm, sự tinh tế trong nhận định, óc sáng tạo, năng khiếu diễn thuyết…) : số □
-Thang đo khoảng (Interval scale) : Là dạng đặc biệt của thang đo thứ bậc, trong đó mỗi thứ bậc sẽ có khoảng cách
đều nhau.Thường sử dụng thang đo khoảng cho tiêu thức định lượng hay tiêu thức định tính.Người ta thường dùng 1 dãy
các con số liên tục và đều đặn từ 1 đến 5, hay từ 1 đến 7, hay từ 1 đến 10 để biểu hiện các khoảng cách đều nhau giữa các
thứ bậc; 2 con số ở 2 đầu dãy số biểu hiện 2 trạng thái đối nghịch nhau. Các con số của thang đo khoảng vừa nói lên quan
hệ thứ bậc hơn kém, vừa nói lên khoảng cách giữa các thứ bậc. Có thể tính toán (cộng, trừ) trên những con số này, tuy nhiên
không thể thực hiện được phép chia tỷ lệ giữa chúng bởi vì “giá trị 0” của thang đo không phải là 1 con số có ý nghĩa thật.
Ví dụ: Bạn có hài lòng với mức lương hiện tại của mình không ? (hãy chọn một con số cho câu trả lời của bạn : 1: rất
hài lòng, 2: khá hài lòng, 3:hài lòng, 4:khá không hài lòng, 5:rất không hài lòng)
-Thang đo tỷ lệ (Ratio scale) : Là một dạng đặc biệt của thang đo khoảng, trong đó trị số 0 của thang đo là 1 con số
có ý nghĩa thật. Chỉ sử dụng thang đo này cho tiêu thức định lượng. Người ta thường biểu thị thang đo tỷ lệ bằng 1 dãy các
con số thực của chính tiêu thức. Các con số của thang đo tỷ lệ vừa nói lên quan hệ thứ bậc hơn kém, vừa nói lên khoảng
cách giữa các thứ bậc; vừa nói lên quan hệ so sánh về mặt tỷ lệ giữa chúng. Thang đo tỷ lệ biểu hiện được nhiều thông tin
nhất trong hệ thống thang đo thống kê.
Ví dụ: Doanh số bán hàng ngày của 1 đại lý, tiền lương tháng của một công nhân, mức chi tiêu của 1 hộ gia đình,…
III- QUÁ TRÌNH NGHIÊN CỨU THỐNG KÊ:
Quá trình nghiên cứu thống kê bất cứ một hiện tượng nào đó, thường trải qua các bước cơ bản sau: 3
-Xác định mục đích nghiên cứu, nội dung và đối tượng nghiên cứu
-Xây dựng hệ thống các khái niệm và các chỉ tiêu thống kê
-Thu thập dữ liệu thống kê
-Xử lý dữ liệu thống kê
-Phân tích và diễn giải kết quả thu được
-Trình bày và báo cáo kết quả nghiên cứu CHƯƠNG II
THU THẬP DỮ LIỆU THỐNG KÊ
I-DỮ LIỆU CẦN THU THẬP:
1- Khái niệm:Dữ liệu cần thu thập là toàn bộ dữ liệu có liên quan đến hiện tượng nghiên cứu. Việc thu thập dữ liệu
thường tốn nhiều thời gian, công sức và chi phí, do đó cần phải xác định rõ mục đích nghiên cứu để xác định cụ thể những
dữ liệu cần thu thập, để không tốn thời gian và chi phí cho việc thu thập những dữ liệu ít quan trọng hoặc ít liên quan trực
tiếp đến hiện tượng nghiên cứu
Ví dụ: Để nghiên cứu vấn đề ăn ở của sinh viên học xa nhà, có thể thu thập các dữ liệu sau:
-Bạn đang sống ở đâu ?
-Nơi ở cách trường bao xa ?
-Bạn đánh giá như thế nào về nơi ở của mình: sự yên tĩnh, mức độ an ninh, sự tiện nghi, mức độ thuận lợi cho việc học,chi phí thuê, …
-Hàng ngày bạn ăn ở đâu ?
-Nếu ăn tại quán, bạn đánh giá như thế nào về bữa ăn của mình: độ ngon, độ dinh dưỡng, độ an toàn về mặt vệ sinh,
mức độ phục vụ, chi phí bữa ăn,… 2- Phân loại:
*Căn cứ vào tính chất dữ liệu: Có thể chia ra 2 loại dữ liệu :
- Dữ liệu định tính: Là dữ liệu thu thập bằng thang đo định danh hay thang đo thứ bậc; phản ánh các tính chất khác
nhau hoặc các thứ bậc khác nhau của các đơn vị.
- Dữ liệu định lượng: Là dữ liệu thu thập bằng thang đo khoảng hay thang đo tỷ lệ; phản ánh các mức độ khác nhau của các đơn vị
Nhận xét: Ta có thể chuyển từ dữ liệu định lượng sang dữ liệu định tính, nhưng ta không thể chuyển theo chiều ngược
lại. Việc thu thập dữ liệu định tính đơn giản hơn dữ liệu định lượng, nhưng dữ liệu định lượng chứa đựng nhiều thông tin
hơn và dễ áp dụng các phương pháp phân tích hơn.
*Căn cứ vào nguồn cung cấp dữ liệu: Có thể chia ra 2 loại dữ liệu:
- Dữ liệu sơ cấp (dữ liệu ban đầu) : Là những dữ liệu chưa qua xử lý, được thu thập lần đầu, và thu thập trực tiếp từ
các đơn vị của tổng thể nghiên cứu, thông qua các cuộc điều tra thống kê. Dữ liệu sơ cấp đáp ứng tốt yêu cầu nghiên cứu,
tuy nhiên việc thu thập dữ liệu ban đầu thường phức tạp, tốn nhiều thời gian, công sức và chi phí. Để khắc phục nhược điểm
này, người ta không tiến hành điều tra hết toàn bộ các đơn vị của tổng thể, mà chỉ điều tra trên 1 số đơn vị gọi là điều tra
chọn mẫu, nhưng vấn đề quan trọng nhất là đảm bảo cho tổng thể mẫu phải có khả năng đại diện được cho tổng thể chung.
- Dữ liệu thứ cấp: Đây là những dữ liệu đã được tổng hợp, xử lý; và được thu thập từ những nguồn có sẵn như : từ
nội bộ doanh nghiệp; từ các cơ quan thống kê (Tổng cục thống kê, Chi cục thống kê các tỉnh thành phố,…); từ các cơ quan
chính phủ (Bộ, cơ quan ngang Bộ, Ủy ban nhân dân các cấp,…); từ các tổ chức, hiệp hội nghề nghiệp (Viện nghiên cứu
kinh tế, Phòng công nghiệp và thương mại,…); từ các báo, tạp chí… Hiện nay có khá nhiều dữ liệu thứ cấp đã được đưa lên
mạng internet qua các trang web của các đơn vị cung cấp thông tin. Việc thu thập dữ liệu thứ cấp thường ít tốn thời gian và
chi phí; nhưng dữ liệu thường không đầy đủ, ít chi tiết, không đáp ứng tốt yêu cầu nghiên cứu
II- CÁC LOẠI ĐIỀU TRA THỐNG KÊ :
Để có nguồn dữ liệu có chất lượng cao, đáp ứng được mục tiêu của cuộc nghiên cứu, nhất thiết phải tổ chức việc thu
thập dữ liệu sơ cấp thông qua việc tổ chức điều tra thống kê.
1- Căn cứ vào thời gian thu thập dữ liệu: Có thể chia ra 2 loại điều tra :
- Điều tra thường xuyên: là thu thập dữ liệu về hiện tượng nghiên cứu một cách liên tục, theo sát với quá trình phát
sinh và phát triển của hiện tượng. Dữ liệu thu thập từ điều tra thường xuyên có thể phản ánh sự phát triển của hiện tượng
trong 1 thời kỳ nhất định.
Ví dụ: Trong doanh nghiệp, điều tra hàng ngày về số công nhân đi làm, số sản phẩm sản xuất, số sản phẩm tiêu thụ,
số vật tư sử dụng vào sản xuất…
- Điều tra không thường xuyên: là thu thập dữ liệu về hiện tượng nghiên cứu một cách không liên tục, không gắn
liền với quá trình phát sinh và phát triển của hiện tượng; chỉ khi nào có nhu cầu nghiên cứu thì mới tiến hành thu thập dữ
liệu. Dữ liệu thu thập từ điều tra không thường xuyên chỉ phản ánh trạng thái của hiện tượng tại 1 thời điểm nhất định.
Ví dụ: Điều tra dân số, điều tra tình hình tai nạn giao thông, điều tra tình hình an toàn vệ sinh thực phẩm…
2-Căn cứ vào phạm vi thu thập dữ liệu: Có thể chia ra 2 loại điều tra :
- Điều tra toàn bộ: là thu thập dữ liệu về tất cả các đơn vị thuộc tổng thể nghiên cứu, không bỏ sót bất kỳ một đơn vị
nào. Đây là nguồn dữ liệu đầy đủ nhất về hiện tượng nghiên cứu; tuy nhiên chỉ có thể nghiên cứu hiện tượng một cách bao
quát; mặt khác, rất tốn kém thời gian, nhân lực và chi phí cho điều tra. 4
Ví dụ: Tổng điều tra dân số, tổng kiểm kê đất đai,tổng kiểm kê hàng hoá tồn kho…
- Điều tra không toàn bộ: là thu thập dữ liệu về một số đơn vị thuộc tổng thể nghiên cứu. Điều tra không toàn bộ được chia thành 3 loại:
+Điều tra chọn mẫu : Có nghĩa là chọn ra một mẫu từ tổng thể chung để thu thập dữ liệu; trên cơ sở dữ liệu thu thập
được trên mẫu, ta sẽ tìm ra các đặc trưng của mẫu và từ đó suy rộng ra đặc trưng chung của toàn bộ tổng thể. Để chọn mẫu,
ta có thể dùng phương pháp chọn mẫu ngẫu nhiên hay chọn mẫu phi ngẫu nhiên. Đây là loại điều tra được sử dụng nhiều
nhất trong nghiên cứu thống kê vì tiết kiệm được thời gian, chi phí, và kết quả đáng tin cậy.
Ví dụ: Điều tra chọn mẫu để nghiên cứu chất lượng sản phẩm trên các dây chuyền sản xuất hàng loạt, điều tra sự hài
lòng của công nhân sau khi công ty áp dụng hình thức trả lương mới,…
+Điều tra trọng điểm: Có nghĩa là chỉ thu thập dữ liệu của những bộ phận chủ yếu nhất, quan trọng nhất của tổng
thể nghiên cứu. Trên cơ sở dữ liệu thu thập được, ta sẽ nhận định nhanh về tình hình cơ bản của hiện tượng, chứ không suy
rộng thành đặc trưng chung của toàn bộ tổng thể.
Ví dụ: Điều tra giá bán hàng ở các trung tâm thương mại để nắm nhanh tình hình biến động giá cả hàng tiêu dùng
trên thị trường, điều tra năng suất cây trồng ở những vùng trồng chuyên canh…
+Điều tra chuyên đề: Có nghĩa là chỉ thu thập dữ liệu trên 1 hay 1 số rất ít đơn vị của tổng thể nhưng lại đi sâu
nghiên cứu nhiều khía cạnh khác nhau của đơn vị đó. Trên cơ sở dữ liệu thu thập được, ta chỉ có thể nhận định về bản thân
đơn vị được điều tra; chứ không thể nhận định về tình hình cơ bản của hiện tượng, cũng như không thể suy rộng thành đặc
trưng chung của toàn bộ tổng thể. Đơn vị được chọn để điều tra chuyên đề thường là đơn vị đặc biệt yếu kém hay đặc biệt
xuất sắc; nhằm tìm ra những nhân tố ảnh hưởng đến các đơn vị này, từ đó có biện pháp ngăn chặn các tiêu cực hay nhân rộng các điển hình.
Ví dụ: Điều tra chuyên đề đối với một số ít sinh viên có năng lực vượt trội về học tập và nghiên cứu khoa học hoặc
đối với một số sinh viên quá yếu kém trong học tập…
III. SAI SỐ TRONG ĐIỀU TRA THỐNG KÊ: 1-Khái niệm:
Sai số trong điều tra thống kê là chênh lệch giữa giá trị thu thập trong điều tra với giá trị thực tế của đơn vị điều tra.
Rất khó xác định và khó loại bỏ được sai số trong điều tra; nhưng nếu ta nắm được các nguyên nhân phát sinh sai số thì có
thể chủ động làm hạn chế sai số.
2-Phân loại: Căn cứ vào nguyên nhân phát sinh, có thể chia làm 2 loại sai số sau:
2.1-Sai số do đăng ký:
Đây là loại sai số phát sinh do ghi chép số liệu không chính xác như:
-Do lập kế hoạch điều tra không tốt, không sát với thực tế hiện tượng.
-Do nhân viên điều tra thiếu ý thức và tinh thần trách nhiệm (ghi sai, cân đong đo đếm sai…), do trình độ nhân viên
điều tra yếu kém không hiểu được chính xác nội dung các câu hỏi, do nhân viên điều tra không trung thực nên cố tình ghi chép sai,…
-Do đơn vị được điều tra trả lời sai vì không hiểu rõ câu hỏi, hoặc do họ không được tuyên truyền vận động tốt nên
trả lời qua loa chiếu lệ hay cố tình trả lời sai,…
-Do dụng cụ đo lường không chính xác
-Do lỗi trong in ấn phiếu điều tra, bảng hướng dẫn ghi chép…
2.2-Sai số do tính chất đại biểu:
Đây là loại sai số thường phát sinh trong các cuộc điều tra chọn mẫu. Do các đơn vị được chọn vào mẫu để tiến hành
điều tra không có khả năng đại diện cho toàn bộ tổng thể, nên khi suy rộng kết quả trên mẫu cho tổng thể sẽ phát sinh sai số
có tính chất đại biểu.
3-Biện pháp nhằm hạn chế sai số trong điều tra thống kê:
-Làm tốt công tác chuẩn bị điều tra : tuyến chọn và huấn luyện nhân viên điều tra, làm tốt công tác tuyên truyền phổ
biến mục tiêu ý nghĩa của cuộc điều tra, in ấn chính xác phiếu điều tra và tài liệu hướng dẫn, tạo điều kiện làm việc tốt cho
nhân viên điều tra với thời gian, thù lao, chế độ thưởng phạt hợp lý nhằm để nâng cao tinh thần trách nhiệm của họ…
-Cần phải chọn phương pháp lấy mẫu phù hợp với đối tượng nghiên cứu, nên dùng bảng câu hỏi đơn giản và giới hạn
ở những câu hỏi cần thiết cho những vấn đề chính của cuộc điều tra nhằm để tạo ra sự tập trung và tránh gây mệt mỏi cho cả
người hỏi và người trả lời.
-Sau khi điều tra xong, tiến hành kiểm tra một cách hệ thống toàn bộ cuộc điều tra, bằng cách chọn ra 20% hay 30%
số phiếu để kiểm tra có đúng đối tượng cần nghiên cứu không, có đảm bảo mặt logic của dữ liệu không, kiểm tra việc tính
toán trong dữ liệu, kiểm tra khả năng đại diện của mẫu,…
IV- PHƯƠNG PHÁP THU THẬP DỮ LIỆU SƠ CẤP:
Có nhiều phương pháp để thu thập dữ liệu sơ cấp tuỳ theo đặc điểm của hiện tượng nghiên cứu và nguồn kinh phí có
được. Sau đây là các phương pháp thường dùng:
1-Phương pháp phỏng vấn bằng thư (mail interview):
*Nội dung phương pháp: Gởi bảng câu hỏi đã soạn sẵn, kèm phong bì đã dán tem đến người muốn điều tra qua
đường bưu điện. Nếu mọi việc trôi chảy, đối tượng điều tra sẽ trả lời và gởi lại bảng câu hỏi cho cơ quan điều tra cũng qua đường bưu điện. 5
*Ưu nhược điểm: Có thể điều tra với số lượng lớn đơn vị, có thể đề cập đến nhiều vấn đề riêng tư tế nhị, chi phí điều
tra thấp…Tuy nhiên tỷ lệ trả lời thường thấp, mất nhiều thời gian chờ đợi thư đi và thư hồi âm, không kiểm soát được người
trả lời , người trả lời thư có thể không đúng đối tượng mà ta nhắm tới…
*Trường hợp áp dụng: Khi người mà ta cần hỏi rất khó đối mặt, do họ ở quá xa, hay họ sống quá phân tán, hay họ
sống ở khu dành riêng rất khó vào, hay họ thuộc giới kinh doanh muốn gặp phải qua bảo vệ thư ký…; khi vấn đề cần điều
tra thuộc loại khó nói, riêng tư (chẳng hạn: kế hoạch hoá gia đình, thu nhập, chi tiêu,…); khi vấn đề cần điều tra cực kỳ hấp
dẫn đối với người được phỏng vấn. (chẳng hạn: phụ nữ với vấn đề mỹ phẩm, nhà quản trị với vấn đề quản lý,…); khi vấn đề
cần điều tra cần thiết phải có sự tham khảo tra cứu nhất định nào đó…
2-Phương pháp phỏng vấn bằng điện thoại (telephone interview):
*Nội dung phương pháp: Nhân viên điều tra tiến hành việc phỏng vấn đối tượng được điều tra bằng điện thoại theo
một bảng câu hỏi được soạn sẵn.
*Ưu nhược điểm: Thu thập dữ liệu nhanh chóng, tiết kiệm chi phí, tỷ lệ trả lời cao…Tuy nhiên thời gian phỏng vấn
bị hạn chế vì người trả lời thường không sẵn lòng nói chuyện lâu qua điện thoại, nhiều khi người cần hỏi từ chối trả lời hay không có ở nhà…
*Trường hợp áp dụng: Khi mẫu nghiên cứu gồm nhiều đối tượng, phân bố phân tán trên nhiều địa bàn thì phỏng vấn
bằng điện thoại có chi phí thấp hơn phỏng vấn bằng thư. Nên sử dụng kết hợp phỏng vấn bằng điện thoại với phương pháp
thu thập dữ liệu khác để tăng thêm hiệu quả của phương pháp.
3-Phương pháp phỏng vấn cá nhân trực tiếp (personal interviews):
*Nội dung phương pháp: Nhân viên điều tra đến gặp trực tiếp đối tượng được điều tra để phỏng vấn theo một bảng câu hỏi đã soạn sẵn.
*Ưu nhược điểm: Do gặp mặt trực tiếp nên nhân viên điều tra có thể thuyết phục đối tượng trả lời, có thể giải thích rõ
cho đối tượng về các câu hỏi, có thể dùng hình ảnh kết hợp với lời nói để giải thích, có thể kiểm tra dữ liệu tại chỗ trước khi
ghi vào phiếu điều tra. Tuy nhiên phương pháp này đòi hỏi chi phí cao, mất nhiều thời gian và công sức.
*Trường hợp áp dụng: Khi hiện tượng nghiên cứu phức tạp, cần phải thu thập nhiều dữ liệu; khi muốn thăm dò ý kiến
đối tượng qua các câu hỏi ngắn gọn và có thể trả lời nhanh được,…
4-Phương pháp nhóm chuyên đề: (forcus groups)
*Nội dung phương pháp: Nhân viên điều tra tiến hành đặt câu hỏi phỏng vấn từng nhóm, thường từ 7 đến 12 người
có am hiểu và kinh nghiệm về một vấn đề nào đó, để thông qua thảo luận tự do trong nhóm nhằm làm bật lên vấn đề ở nhiều
khía cạnh sâu sắc, từ đó giúp cho nhà nghiên cứu có thể nhìn nhận vấn đề một cách thấu đáo và toàn diện.
*Ưu nhược điểm: Thu thập dữ liệu đa dạng, khách quan và khoa học. Tuy nhiên kết quả thu được không có tính đại
diện cho tổng thể chung, chất lượng dữ liệu thu được hoàn toàn phụ thuộc vào kỹ năng của người điều khiển thảo luận, các
câu hỏi thường không theo một cấu trúc có sẵn nên khó phân tích xử lý.
*Trường hợp áp dụng: Phương pháp này có ý nghĩa trong việc xây dựng hay triển khai một bảng câu hỏi để sử dụng
trong nghiên cứu định lượng về sau; làm cơ sở để tạo ra những giả thiết cần kiểm định trong nghiên cứu. Chẳng hạn: Trắc
nghiệm phản ứng của người tiêu dùng đối với các mẫu quảng cáo, đối với sản phẩm mới, tìm ra các nguyên nhân làm giảm doanh số…
V- PHƯƠNG PHÁP CHỌN MẪU: Có 2 phương pháp chọn mẫu cơ bản :
1-Phương pháp chọn mẫu ngẫu nhiên (probability sampling methods):
*Khái niệm : Chọn mẫu ngẫu nhiên (hay chọn mẫu xác suất) là phương pháp chọn mẫu mà khả năng được chọn vào
tổng thể mẫu của tất cả các đơn vị của tổng thể đều như nhau. Đây là phương pháp tốt nhất để ta có thể chọn ra một mẫu có
khả năng đại biểu cho tổng thể. Vì có thể tính được sai số do chọn mẫu, nhờ đó ta có thể áp dụng được các phương pháp
ước lượng thống kê, kiểm định giả thuyết thống kê trong xử lý dữ liệu để suy rộng kết quả trên mẫu cho tổng thể chung
Tuy nhiên ta khó áp dụng phương pháp này khi không xác định được danh sách cụ thể của tổng thể chung (ví dụ
nghiên cứu trên tổng thể tiềm ẩn); tốn kém nhiều thời gian, chi phí, nhân lực cho việc thu thập dữ liệu khi đối tượng phân
tán trên nhiều địa bàn cách xa nhau,…
*Các phương pháp chọn mẫu ngẫu nhiên:
-Chọn mẫu ngẫu nhiên đơn giản (simple random sampling):
Trước tiên lập danh sách các đơn vị của tổng thể chung theo một trật tự nào đó : lập theo vần của tên, hoặc theo quy
mô, hoặc theo địa chỉ…, sau đó đánh số thứ tự các đơn vị trong danh sách; rồi rút thăm, quay số, dùng bảng số ngẫu nhiên,
hoặc dùng máy tính để chọn ra từng đơn vị trong tổng thể chung vào mẫu.
Thường vận dụng khi các đơn vị của tổng thể chung không phân bố quá rộng về mặt địa lý, các đơn vị khá đồng đều
nhau về đặc điểm đang nghiên cứu. Thường áp dụng trong kiểm tra chất lượng sản phẩm trong các dây chuyền sản xuất hàng loạt.
-Chọn mẫu ngẫu nhiên hệ thống(systematic sampling):
Trước tiên lập danh sách các đơn vị của tổng thể chung theo một trật tự quy ước nào đó, sau đó đánh số thứ tự các
đơn vị trong danh sách. Đầu tiên chọn ngẫu nhiên 1 đơn vị trong danh sách ; sau đó cứ cách đều k đơn vị lại chọn ra 1 đơn
vị vào mẫu,…cứ như thế cho đến khi chọn đủ số đơn vị của mẫu.
Ví dụ : Dựa vào danh sách bầu cử tại 1 thành phố, ta có danh sách theo thứ tự vần của tên chủ hộ, bao gồm 240.000
hộ. Ta muốn chọn ra một mẫu có 2000 hộ. Vậy khoảng cách chọn là : k= 240000/2000 = 120, có nghĩa là cứ cách 120 hộ thì
ta chọn một hộ vào mẫu.
-Phương pháp chọn mẫu cả khối (cluster sampling): 6
Trước tiên lập danh sách tổng thể chung theo từng khối (như làng, xã, phường, lượng sản phẩm sản xuất trong 1
khoảng thời gian…). Sau đó, ta chọn ngẫu nhiên một số khối và điều tra tất cả các đơn vị trong khối đã chọn. Thường dùng
phương pháp này khi không có sẵn danh sách đầy đủ của các đơn vị trong tổng thể cần nghiên cứu.
Ví dụ : Tổng thể chung là sinh viên của một trường đại học. Khi đó ta sẽ lập danh sách các lớp chứ không lập danh
sách sinh viên, sau đó chọn ra các lớp để điều tra.
-Phương pháp chọn mẫu phân tầng (stratified sampling):
Trước tiên phân chia tổng thể thành các tổ theo 1 tiêu thức hay nhiều tiêu thức có liên quan đến mục đích nghiên cứu
(như phân tổ các DN theo vùng, theo khu vực, theo loại hình, theo quy mô,…). Sau đó trong từng tổ, dùng cách chọn mẫu
ngẫu nhiên đơn giản hay chọn mẫu hệ thống để chọn ra các đơn vị của mẫu.
Đối với chọn mẫu phân tầng, số đơn vị chọn ra ở mỗi tổ có thể tuân theo tỷ lệ số đơn vị tổ đó chiếm trong tổng thể,
hoặc có thể không tuân theo tỷ lệ.
Ví dụ : Ta muốn chọn ra một mẫu phân tầng theo giới tính và thu nhập. Giả sử quy mô mẫu là
500 người, được chọn từ một địa bàn có nam chiếm 45%, nữ chiếm 55% ; người dân có thu nhập cao
chiếm 20%, thu nhập trung bình chiếm 30% và thu nhập thấp chiếm 50%. Dựa vào các tỷ lệ trên ta có
thể bố trí mẫu như sau : Giới tính Thu nhập thấp Thu nhập trung bình Thu nhập cao cộng Nam 112 68 45 225 Nữ 138 82 55 275 cộng 250 150 100 500
Ví dụ : Một toà soạn báo muốn tiến hành nghiên cứu trên một mẫu 1000 doanh nghiệp trên cả nước về sự quan tâm
của họ đối với tờ báo nhằm tiếp thị việc đưa thông tin quảng cáo trên báo.
Toà soạn có thể căn cứ vào các tiêu thức : vùng địa lý (miền Bắc, miền Trung, miền Nam) ; hình thức sở hữu (quốc
doanh, ngoài quốc doanh, công ty 100% vốn nước ngoài,…) để quyết định cơ cấu của mẫu nghiên cứu.
-Chọn mẫu nhiều giai đoạn (multi-stage sampling):
Phương pháp này thường áp dụng đối với tổng thể chung có quy mô quá lớn và địa bàn nghiên cứu quá rộng. Việc
chọn mẫu phải trải qua nhiều giai đoạn (nhiều cấp). Trước tiên phân chia tổng thể chung thành các đơn vị cấp I, rồi chọn các
đơn vị mẫu cấp I. Tiếp đến phân chia mỗi đơn vị mẫu cấp I thành các đơn vị cấp II, rồi chọn các đơn vị mẫu cấp II…Trong
mỗi cấp có thể áp dụng các cách chọn mẫu ngẫu nhiên đơn giản, chọn mẫu hệ thống, chọn mẫu phân tầng, chọn mẫu cả khối
để chọn ra các đơn vị mẫu.
Ví dụ :Muốn chọn ngẫu nhiên 50 hộ từ một thành phố có 10 khu phố, mỗi khu phố có 50 hộ. Cách tiến hành như
sau : Trước tiên đánh số thứ tự các khu phố từ 1 đến 10, chọn ngẫu nhiên trong đó 5 khu phố. Đánh số thứ tự các hộ trong
từng khu phố được chọn. Chọn ngẫu nhiên ra 10 hộ trong mỗi khu phố ta sẽ có đủ mẫu cần thiết.
2-Phuơng pháp chọn mẫu phi ngẫu nhiên (non-probability sampling methods):
*Khái niệm : Chọn mẫu phi ngẫu nhiên (hay chọn mẫu phi xác suất) là phương pháp chọn mẫu mà các đơn vị trong
tổng thể chung không có khả năng ngang nhau để được chọn vào mẫu nghiên cứu. Chẳng hạn : Ta tiến hành phỏng vấn các
bà nội trợ tới mua hàng tại siêu thị tại một thời điểm nào đó ; như vậy sẽ có rất nhiều bà nội trợ do không tới mua hàng tại
thời điểm đó nên sẽ không có khả năng được chọn
Việc chọn mẫu phi ngẫu nhiên hoàn toàn phụ thuộc vào kinh nghiệm và sự hiểu biết về tổng thể của người nghiên
cứu nên kết quả điều tra thường mang tính chủ quan của người nghiên cứu. Mặt khác, ta không thể tính được sai số do chọn
mẫu, do đó không thể áp dụng phương pháp ước lượng thống kê để suy rộng kết quả trên mẫu cho tổng thể chung
*Các phương pháp chọn mẫu phi ngẫu nhiên:
-Chọn mẫu thuận tiện (convenience sampling):
Có nghĩa là lấy mẫu dựa trên sự thuận lợi hay dựa trên tính dễ tiếp cận của đối tượng, ở những nơi mà nhân viên điều
tra có nhiều khả năng gặp được đối tượng. Chẳng hạn nhân viên điều tra có thể chặn bất cứ người nào mà họ gặp ở trung
tâm thương mại, đường phố, cửa hàng,. để xin thực hiện cuộc phỏng vấn. Nếu người được phỏng vấn không đồng ý thì họ
chuyển sang đối tượng khác. Lấy mẫu thuận tiện thường được dùng trong nghiên cứu khám phá, để xác định ý nghĩa thực
tiễn của vấn đề nghiên cứu; hoặc để kiểm tra trước bảng câu hỏi nhằm hoàn chỉnh bảng; hoặc khi muốn ước lượng sơ bộ về
vấn đề đang quan tâm mà không muốn mất nhiều thời gian và chi phí.
-Chọn mẫu phán đoán (judgement sampling):
Là phương pháp mà phỏng vấn viên là người tự đưa ra phán đoán về đối tượng cần chọn vào mẫu. Như vậy tính đại
diện của mẫu phụ thuộc nhiều vào kinh nghiệm và sự hiểu biết của người tổ chức việc điều tra và cả người đi thu thập dữ
liệu. Chẳng hạn, nhân viên phỏng vấn được yêu cầu đến các trung tâm thương mại chọn các phụ nữ ăn mặc sang trọng để
phỏng vấn. Như vậy không có tiêu chuẩn cụ thể “thế nào là sang trọng” mà hoàn toàn dựa vào phán đoán để chọn ra người cần phỏng vấn.
-Chọn mẫu định ngạch (quota sampling):
Đối với phương pháp chọn mẫu này, trước tiên ta tiến hành phân tổ tổng thể theo một tiêu thức nào đó mà ta đang
quan tâm, cũng giống như chọn mẫu ngẫu nhiên phân tầng, tuy nhiên sau đó ta lại dùng phương pháp chọn mẫu thuận tiện
hay chọn mẫu phán đoán để chọn các đơn vị trong từng tổ để tiến hành điều tra. Sự phân bổ số đơn vị cần điều tra cho từng
tổ được chia hoàn toàn theo kinh nghiệm chủ quan của người nghiên cứu. Chẳng hạn nhà nghiên cứu yêu cầu các vấn viên
đi phỏng vấn 800 người có tuổi trên 18 tại 1 thành phố. Nếu áp dụng phương pháp chọn mẫu định ngạch, ta có thể phân tổ 7
theo giới tính và tuổi như sau:chọn 400 người (200 nam và 200 nữ) có tuổi từ 18 đến 40, chọn 400 người (200 nam và 200
nữ) có tuổi từ 40 trở lên. Sau đó nhân viên điều tra có thể chọn những người gần nhà hay thuận lợi cho việc điều tra của họ
để dễ nhanh chóng hoàn thành công việc.
VI- PHƯƠNG PHÁP THIẾT KẾ BẢNG CÂU HỎI:
Bảng câu hỏi là một công cụ dùng để thu thập dữ liệu. Bảng câu hỏi bao gồm một tập hợp các câu hỏi và các câu trả
lời được sắp xếp theo logic nhất định. Bảng câu hỏi là phương tiện dùng để giao tiếp giữa người nghiên cứu và người trả lời
trong tất cả các phương pháp phỏng vấn. Thông thường có 8 bước cơ bản sau đây để thiết kế một bảng câu hỏi:
1- Xác định các dữ liệu cần tìm:
Dựa vào mục tiêu và nội dung nghiên cứu, để xác định cụ thể tổng thể nghiên cứu và nội dung các dữ liệu cần phải
thu thập trên tổng thể đó.
2-Xác định phương pháp phỏng vấn :
Tuỳ theo phương pháp phỏng vấn (gởi thư, gọi điện thoại, phỏng vấn trực tiếp, phỏng vấn bằng thư điện tử…) sẽ
thiết kế bảng câu hỏi khác nhau.
-Phỏng vấn bằng thư: phải đặt câu hỏi hết sức đơn giản và có những chỉ dẫn về cách trả lời thật rõ ràng chi tiết.
-Phỏng vấn qua điện thoại: vấn viên phải giải thích cặn kẽ rõ ràng để người trả lời hiểu rõ câu hỏi và trả lời chính xác;
bởi vì người trả lời không thấy được bảng câu hỏi và các hình ảnh minh hoạ
-Phỏng vấn trực tiếp: có thể dùng câu hỏi dài và phức tạp vì vấn viên có điều kiện để giải thích rõ câu hỏi, kèm theo
có thể dùng hình ảnh minh hoạ.
-Phỏng vấn bằng thư điện tử: có thể dùng các câu hỏi phức tạp và có thể gửi kèm hình ảnh minh hoạ.
3-Phác thảo nội dung bảng câu hỏi:
Tương ứng với từng nội dung cần nghiên cứu, phác thảo các câu hỏi cần đặt ra. Cần sắp xếp các câu hỏi theo từng
chủ điểm một cách hợp lý
4-Chọn dạng cho câu hỏi: Có 2 dạng câu hỏi: câu hỏi đóng và câu hỏi mở
*Câu hỏi mở: Là dạng câu hỏi không cấu trúc sẵn phương án trả lời, do đó người trả lời có thể trả lời hoàn toàn theo
ý họ, và nhân viên điều tra có nhiệm vụ phải ghi chép lại đầy đủ các câu trả lời.
*Câu hỏi đóng: Là dạng câu hỏi mà ta đã cấu trúc sẵn phương án trả lời. Bao gồm 4 dạng sau :
-Câu hỏi phản đối: Là dạng câu hỏi mà câu trả lời có dạng: “ có hoặc không”.
-Câu hỏi xếp hạng thứ tự: Là dạng câu hỏi mà ta đưa ra sẵn các phương án trả lời, và để cho người trả lời lựa chọn,
so sánh và xếp hạng chúng theo thứ tự.
Ví dụ: Nhân tố tác động đến quyết định ghi danh học ngành quản trị kinh doanh của bạn là gì ? (Xếp hạng từ 1 đến 5
theo thứ tự từ nhân tố có tác động lớn nhất đến nhân tố có tác động ít nhất :
Do ý thích của bản thân □, Do hướng dẫn, gợi ý của người thân □, Do ảnh hưởng của bạn bè □, Do ảnh hưởng của
sinh viên các khoá trước □, Do uy tín của giảng viên □
-Câu hỏi đánh dấu tình huống trong danh sách: Là dạng câu hỏi mà ta đưa ra sẵn danh sách các phương án trả lời, và
người trả lời sẽ đánh dấu vào những đề mục phù hợp với họ.
Ví dụ: Bạn hãy đánh dấu vào nhãn hiệu kem đánh răng mà bạn sử dụng nhiều nhất trong danh sách các nhãn hiệu liệt
kê dưới đây (chỉ chọn 1 phương án trả lời):
Nhãn P/S □ , nhãn Colgate □, nhãn Close-up□, nhãn Fresh □, nhãn khác□ (ghi rõ tên)
-Câu hỏi dạng bậc thang: Là dạng câu hỏi dùng thang đo thứ tự hoặc thang đo khoảng để hỏi về mức độ đồng ý hay
phản đối, mức độ thích hay ghét…của người trả lời về một vấn đề nào đó .
Ví dụ: Đối với công dụng tạo mùi thơm cho quần áo của sản phẩm bột giặt OMO, mức độ hài lòng của bạn về sản
phẩm như thế nào (chỉ được chọn một trong những phương án trả lời sau):
rất thích □, thích vừa phải □, không thích không ghét □, ghét vừa phải □, rất ghét □
5. Xác định từ ngữ thích hợp cho bảng câu hỏi:
Nên tuân theo nguyên tắc chung sau đây khi xác định từ ngữ cho bảng câu hỏi:
-Nên dùng từ ngữ quen thuộc, tránh dùng tiếng lóng hoặc từ chuyên môn
-Nên dùng từ ngữ dễ hiểu, để mọi người ở bất cứ trình độ nào cũng có thể hiểu được.
-Tránh đưa ra câu hỏi dài quá
-Tránh đặt câu hỏi mơ hồ, không rõ ràng. Ví dụ: Không nên hỏi : Bạn có thường xuyên đi mua sắm tại siêu thị
không? (người trả lời sẽ không biết “thường xuyên” là bao nhiêu lần?)
-Tránh đưa ra câu hỏi quá cụ thể. Ví dụ: Không nên hỏi: Khi đến một viện bảo tàng, bạn đã đọc bao nhiêu lần các
bảng ghi hướng dẫn về hiện vật được trưng bày (người trả lời khó nhớ cụ thể số lần đọc của mình)
-Tránh hỏi trực tiếp những vấn đề riêng tư cá nhân. Ví dụ: Không nên hỏi con số cụ thể về thu nhập của một người,
mà chỉ nên hỏi theo từng nhóm : chẳng hạn dưới 1 triệu đ/tháng, từ 1 đến 3 triệu đ, từ 3 đến 5 triệu,…
-Tránh đưa ra câu hỏi quá cường điệu hay quá nhấn mạnh vào một khía cạnh nào đó. Ví dụ: Bạn có ủng hộ việc tăng
giá điện để đầu tư phát triển ngành điện trong điều kiện lạm phát giá cả hiện nay không ?
-Tránh đặt câu hỏi đã gợi ý sẵn câu trả lời. Ví dụ: Bạn có tán thành việc không cho học sinh sử dụng xe máy đến
trường nhằm làm giảm bớt tai nạn giao thông không?
-Tránh đặt câu hỏi dựa theo giá trị xã hội đã xác nhận. Ví dụ: ông có kiếm nhiều tiền hơn vợ không? (thông thường sẽ
nhận được câu trả lời là “có” vì theo quan niệm xã hội thì chồng phải hơn vợ) 8
-Tránh dùng ngôn từ đã có sẵn sự đánh giá thiên kiến. Ví dụ: Không nên dùng những từ như : sản phẩm hàng đầu,
sản phẩm đại hạ giá,…
6. Xác định cấu trúc bảng câu hỏi:
*Yêu cầu : Nên sắp xếp các câu hỏi theo trình tự hợp lý. Câu hỏi này phải dẫn đến câu hỏi kế tiếp theo một trình tự
hợp lý, theo một dòng tư tưởng liên tục. Một vấn đề lớn nên phân ra nhiều vấn đề nhỏ. Trong các câu trả lời lại tiếp tục đặt
ra câu hỏi phân nhánh để tiếp tục sàng lọc thông tin.
Nên tuân theo trình tự về tâm lý: Sau khi đã thiết lập mối quan hệ thân thiện tốt đẹp thì mới hỏi các câu hỏi riêng tư.
Nên theo trình tự là hỏi cái chung rồi mới đến cái riêng; những câu hỏi ít gây hứng thú nên hỏi cuối cùng, nên theo trình tự
để khơi gợi trí nhớ về các sự việc đã qua.
*Cấu trúc bảng câu hỏi :thường bao gồm 5 phần :
-Phần mở đầu: Có tác dụng gây thiện cảm để tạo nên sự hợp tác của người trả lời lúc bắt đầu buổi phỏng vấn.
-Câu hỏi định tính: Có tác dụng xác định rõ đối tượng được phỏng vấn
-Câu hỏi hâm nóng: Có tác dụng gợi nhớ để tập trung vào chủ đề mà bảng câu hỏi đang hướng tới.
-Câu hỏi đặc thù: Có tác dụng làm rõ nội dung cần nghiên cứu
-Câu hỏi phụ: Có tác dụng thu thập thêm thông tin về đặc điểm nhân khẩu người trả lời (giới tính, tuổi tác, nghề nghiệp,. )
7- Thiết kế việc trình bày bảng câu hỏi:
Cần quan tâm đến việc in ấn trình bày bảng câu hỏi để tạo thiện cảm và lôi cuốn người trả lời tham gia vào cuộc
phỏng vấn. Dùng giấy màu có tác dụng kích thích trả lời hơn. In bảng câu hỏi thành tập có tác dụng hấp dẫn hơn so với trang rời.
8-Điều tra thử để trắc nghiệm bảng câu hỏi:
Về nguyên tắc, một bảng câu hỏi cần phải được điều tra thử để trắc nghiệm trước khi phỏng vấn chính thức. Việc
điều tra được tiến hành trên một mẫu nhỏ được chọn ra từ tổng thể mẫu cần nghiên cứu, để xem người trả lời có hiểu và trả
lời đúng không, để xem người phỏng vấn có làm tốt nhiệm vụ không, để xem thông tin được thu thập như thế nào, và xác
định thời gian cho thực hiện phỏng vấn một người. Sau khi điều tra thử sẽ xử lý và phân tích dữ liệu để qua đó chỉnh sửa,
loại bỏ, bổ sung thêm câu hỏi… CHƯƠNG III
SẮP XẾP VÀ TRÌNH BÀY DỮ LIỆU THỐNG KÊ
I-SẮP XẾP DỮ LIỆU THỐNG KÊ :
Sau khi thu thập dữ liệu, nếu khối dữ liệu nhỏ ta có thể sắp xếp dữ liệu theo thứ tự tăng dần hay giảm dần đối với dữ
liệu định lượng hay theo một trật tự quy định nào đó đối với dữ liệu định tính; nếu khối dữ liệu lớn ta có thể sắp xếp dữ liệu
theo phương pháp phân tổ.
1. Khái niệm phân tổ thống kê :
Phân tổ thống kê có nghĩa là căn cứ vào 1 hay 1 số tiêu thức nào đó để sắp xếp các đơn vị của tổng thể vào các tổ có tính chất khác nhau.
Nguyên tắc phân tổ là : các đơn vị được xếp vào 1 tổ thì phải có tính chất giống nhau (hoặc gần giống nhau); các đơn
vị thuộc các tổ khác nhau thì phải có tính chất khác nhau một cách rõ rệt.
2.Nội dung chủ yếu của phân tổ: Để thực hiện sắp xếp dữ liệu theo phương pháp phân tổ, ta cần thực hiện các công việc chủ yếu sau :
2.1-Xác định mục đích phân tổ : Làm rõ thông tin cần tìm sau khi sắp xếp dữ liệu bằng phương pháp phân tổ.
2.2-Xác định tiêu thức phân tổ: Tiêu thức phân tổ là căn cứ để tiến hành phân tổ. Cần phải chọn tiêu thức bản chất
nhất, đáp ứng cao nhất mục đích nghiên cứu làm tiêu thức phân tổ.
2.3-Xác định số tổ cần chia: Xét 2 trường hợp
*Nếu tiêu thức phân tổ là tiêu thức định tính: có 2 trường hợp:
-Tiêu thức có ít biểu hiện : cứ mỗi biểu hiện ta lập 1 tổ. Ví dụ : Phân tổ sinh viên theo giới tính : chia ra 2 tổ : nam và nữ
-Tiêu thức có nhiều biểu hiện: ta sẽ ghép nhiều biểu hiện khác nhau vào 1 tổ. Ví dụ : Phân tổ doanh nghiệp theo
ngành kinh tế : có thể chia ra : doanh nghiệp công nghiệp, doanh nghiệp nông nghiệp, doanh nghiệp thuỷ sản, doanh nghiệp
xây dựng, doanh nghiệp thương mại,…
*Nếu tiêu thức phân tổ là tiêu thức định lượng : có 2 trường hợp:
-Tiêu thức có ít lượng biến: cứ mỗi lượng biến ta lập 1 tổ . Ví dụ : Phân tổ hộ gia đình theo số nhân khẩu, phân tổ bài
thi theo điểm thi, phân tổ nhân khẩu theo tuổi, phân tổ công nhân theo bậc thợ…
-Tiêu thức có nhiều lượng biến : ta sẽ ghép nhiều lượng biến vào 1 tổ, tạo nên khoảng cách tổ, trong đó giới hạn dưới
là lượng biến nhỏ nhất và giới hạn trên là lượng biến lớn nhất của mỗi tổ.
+Nếu sự khác nhau về chất giữa các lượng biến không đều nhau, ta dùng khoảng cách tổ không đều. Ví dụ : Phân
tổ nhân khẩu theo tuổi có khả năng lao động
+Nếu sự khác nhau về chất giữa các lượng biến tương đối đều nhau, ta dùng khoảng cách tổ đều . Có 2 trường hợp : 9 X
> Đối với lượng biến liên tục: Công thức khoảng cách tổ : h = max - X min k
Giới hạn trên và giới hạn dưới của 2 tổ kề nhau sẽ trùng nhau. Nếu lượng biến trùng với giới hạn trên của tổ
đứng trước, và trùng với giới hạn dưới của tổ đứng sau, thì ta xếp nó vào tổ đứng sau. (X
> Đối với lượng biến rời rạc: Công thức khoảng cách tổ : h =
max - X min ) - (k - 1) k
Giới hạn trên và giới hạn dưới của 2 tổ kề nhau sẽ cách nhau 1 đơn vị
k là số tổ,có thể tính theo công thức thống kê kinh nghiệm sau: k =(2n)1/3 =(2n)0,3333
h là khoảng cách tổ (h và k được làm tròn số); n : số đơn vị của tổng thể
Xmax, Xmin là lượng biến lớn nhất và nhỏ nhất của tiêu thức phân tổ
2.4-Xác định tần số của mỗi tổ:Sau khi sắp xếp các đơn vị vào các tổ, ta xác định đặc trưng phân phối các đơn vị
của tổng thể vào mỗi tổ thông qua các chỉ tiêu : tần số, tần số tích lũy; tần suất, tần suất tích lũy.
-Tần số (hay tần số tuyệt đối) : Là số đơn vị tổng thể được sắp xếp vào 1 tổ. Tần số càng lớn biểu hiện số lần xuất
hiện của các giá trị lượng biến thuộc tổ đó trong tổng thể càng lớn và ngược lại.
-Tần số tích lũy (hay tần số cộng dồn): Tần số tích lũy của 1 tổ là số cộng dồn tần số của tổ đó với các tần số của các
tổ đứng trước tổ đó. Như vậy tần số tích lũy của tổ thứ 1 là tần số của tổ đó; tần số tích lũy của tổ thứ 2 bao gồm tần số của
tổ thứ 2 và tần số của tổ thứ 1
-Tần suất (hay tần số tương đối) : Là tỷ lệ số đơn vị của từng tổ chiếm trong tổng thể.
-Tần suất tích lũy (hay tần suất cộng dồn) : Tần suất tích lũy của 1 tổ là số cộng dồn tần suất của tổ đó với các tần
suất của các tổ đứng trước tổ đó.
2.5-Trình bày tài liệu sau khi phân tổ : Thường dùng hình thức bảng tần số hay biểu đồ phân phối. (xem mục II)
II. TRÌNH BÀY DỮ LIỆU THỐNG KÊ: Thường trình bày dữ liệu dưới các dạng sau:
1-Trình bày dữ liệu dưới dạng biểu đồ nhánh và lá (stem and leaf):
*Khái niệm: Biểu đồ nhánh và lá là một hình thức trình bày dữ liệu bằng cách tách mỗi con số trong dữ liệu ra làm 2
phần: phần lá tương ứng với các chữ số ở bên phải, phần nhánh tương ứng với các chữ số bên trái. Việc phân chia ra 2
phần nhánh và lá chỉ có tính quy ước và có thể thay đổi linh hoạt theo đặc điểm của dữ liệu. Nếu phần lá quá dài, ta có thể
tách phần nhánh ra làm 2 phần : nhánh trên và nhánh dưới để biểu đồ được cân đối hơn.
Ví dụ: Với dữ liệu về mẫu là :
52,53,54,54,55,55,56,59,60,60,60,60,60,60,61,61,62,62,64,65,65,66,66,66,67,68,68,71,71,72,74,7
5, 77,78. Ta có thể trình bày dưới dạng biểu đồ nhánh và lá như sau: Nhánh Lá 5 2 3 4 4 5 5 6 9 6 0 0 0 0 0 0 1 1 2 2 5 6 6 6 7 8 8 7 1 1 2 4 5 7 8
Hoặc trình bày dưới dạng nhánh trên và nhánh dưới như sau: Nhánh Lá 5 2 3 4 4 5 5 5 6 9 6 0 0 0 0 0 0 1 1 2 2 4 6 5 6 6 6 7 8 8 7 1 1 2 4 7 5 7 8
*Đặc điểm: Là hình thức trình bày dữ liệu thích hợp đối với khối dữ liệu nhỏ. Biểu đồ nhánh và lá có dạng giống như
biểu đồ phân phối tần số khi ta quay biểu đồ ngược chiều kim đồng hồ lên trên 1 góc 90 độ. Biểu đồ giúp ta quan sát chi tiết
từng dữ liệu thu thập được trên từng đơn vị; giúp ta hình dung được đặc điểm phân phối của dữ liệu trên các đơn vị của tổng
thể. 2-Trìnhbàydữliệudướidạngbảng: 2.1-Bảng thống kê:
*Khái niệm: Bảng thống kê là 1 hình thức trình bày các tài liệu thống kê một cách hệ thống, hợp lý và rõ ràng, nhằm
nêu lên các đặc trưng về mặt lượng của hiện tượng nghiên cứu.
*Cấu thành của bảng thống kê:
Tên bảng: nói lên nội dung chủ yếu của cả bảng, thời gian và địa điểm nghiên cứu.
Phần chủ đề (biểu hiện qua tên các hàng) : dùng để giới thiệu về tổng thể nghiên cứu. Chẳng hạn cho biết tổng thể
bao gồm những đơn vị nào, hay tổng thể được hợp thành từ những bộ phận nào, hay tổng thể được nghiên cứu ở những địa
điểm nào, ở những thời gian nào ?
Phần giải thích (biểu hiện qua tên các cột) : dùng để nêu lên các đặc trưng của tổng thể nghiên cứu. Có 2 cách trình bày phần giải thích: 10
+Cách trình bày giản đơn: bố trí các chỉ tiêu giải thích theo kiểu song song với nhau, độc lập nhau.
+Cách trình bày kết hợp: bố trí các chỉ tiêu giải thích theo kiểu phối hợp với nhau, đan xen vào nhau.
*1 số quy tắc khi lập bảng:
-Có thể làm tròn số khi chỉ cần nêu lên bản chất chung nhất của hiện tượng; bằng cách nâng đơn vị tính lên: Từ kg
làm tròn thành tạ, tấn, nghìn tấn, triệu tấn; từ đồng làm tròn thành nghìn đ, triệu đ, tỷ đ, nghìn tỷ đ; từ mét làm tròn thành nghìn m, triệu m…
-Nếu cả bảng có chung một đơn vị tính thì ghi đơn vị tính chung đó trên đầu bảng, ngay dưới tên bảng, bằng nét chữ
nhỏ và để trong ngoặc đơn
-Nếu mỗi cột có đơn vị tính riêng thì ghi đơn vị tính ngay dưới tên cột và để trong ngoặc đơn.
-Nếu mỗi hàng có đơn vị tính riêng thì lập thêm 1 cột ghi đơn vị tính sát ngay cột ghi tên hàng.
Có thể biểu hiện khái quát bảng thống kê như sau: Tên bảng Phần giải thích Các chỉ tiêu giải thích Tên cột Phần chủ đề Tên hàng Cộng 2.2-Bảng tần số:
*Khái niệm : Bảng tần số là 1 loại bảng thống kê biểu hiện tình hình phân phối các đơn vị của tổng thể theo 1 hay 1 số tiêu thức nào đó.
Trong bảng tần số, người ta thường dùng 2 chỉ tiêu cơ bản là tần số và tần suất. Tùy theo yêu cầu nghiên cứu ta có thể
tính thêm tần số tích lũy và tần suất tích lũy.
*Các dạng bảng tần số thường gặp:
-Bảng tần số giản đơn: Phản ánh tình hình phân phối các đơn vị của tổng thể theo 1 tiêu thức.
Ví dụ: Bảng phân tổ công nhân một xí nghiệp theo mức thu nhập
Mức thu nhập (triệu đ/tháng) tần số tần số tích luỹ tần suất (%) tần suất tích luỹ (%) dưới 1 từ 1 đến dưới 2 từ 2 đến dưới 3 từ 3 đến dưới 4 từ 4 đến dưới 5 từ 5 trở lên cộng
-Bảng tần số kết hợp : Phản ánh tình hình phân phối các đơn vị của tổng thể theo 2 hay 3 tiêu thức kết hợp với nhau.
Chẳng hạn: Kết hợp giữa 2 tiêu thức định tính, kết hợp giữa 2 tiêu thức định lượng, kết hợp giữa 1 tiêu thức định tính và 1
tiêu thức định lượng, kết hợp giữa 3 tiêu thức định tính, kết hợp giữa 3 tiêu thức định lượng, kết hợp giữa 1 tiêu thức đinh
tính và 2 tiêu thức định lượng, kết hợp giữa 2 tiêu thức định tính và 1 tiêu thức định lượng,…
Ví dụ: Bảng phân tổ công nhân một xí nghiệp theo mức thu nhập và tuổi nghề Mức thu nhập Số công Tuổi nghề (năm) (triệu đ/tháng) nhân dưới 5 từ 5 đến dưới 10 từ 10 đến dưới 15 từ 15 trở lên dưới 1 từ 1 đến dưới 2 từ 2 đến dưới 3 từ 3 đến dưới 4 từ 4 đến dưới 5 từ 5 trở lên cộng
Ví dụ: Bảng phân tổ công nhân một xí nghiệp theo mức thu nhập, giới tính và tuổi nghề Giới tính Mức thu nhập Số công Tuổi nghề (năm) (triệu đ/tháng) nhân dưới 5 từ 5 đến dưới 10 từ 10 đến dưới 15 từ 15 trở lên dưới 1 NAM từ 1 đến 2 từ 2 đến 3 từ 3 đến 4 từ 4 đến 5 từ 5 trở lêncộng dưới 1 NỮ từ 1 đến 2 từ 2 đến 3 từ 3 đến 4 từ 4 đến 5 từ 5 trở lêncộng cộng 11
2-Trình bày dữ liệu dưới dạng biểu đồ:
2.1- Biểu đồ thống kê :
* Khái niệm : Biểu đồ thống kê là các hình vẽ hoặc các đường nét hình học dùng để trình bày các dữ liệu thống kê.
* Các dạng biểu đồ thường dùng :
-Dạng biểu đồ hình thanh (Bar chart): Có 2 dạng : thanh dọc và thanh ngang. Thường dùng để biểu hiện : quy mô
của hiện tượng và sự phát triển quy mô theo thời gian; sự phân phối các đơn vị theo 1 tiêu thức số lượng nào đó; kết cấu của
tổng thể và sự biến động của kết cấu theo thời gian,…
-Dạng biểu đồ hình tròn (Pie chart): Có dạng 1 hình tròn chia thành nhiều hình quạt : hình tròn biểu hiện cho tổng
thể, hình quạt biểu hiện cho từng bộ phận trong tổng thể. Dạng biểu đồ này thường dùng để biểu hiện kết cấu của tổng thể trong từng năm.
-Dạng biểu đồ hình gấp khúc (Line chart): Thường dùng để biểu hiện quy mô của hiện tượng, sự phân phối các đơn
vị theo 1 tiêu thức số lượng nào đó, mối liên hệ giữa 2 tiêu thức số lượng,…
2.2- Biểu đồ phân phối :
* Khái niệm: Biểu đồ phân phối (histogram) là dạng biểu đồ phản ánh tình hình phân phối các đơn vị tổng thể theo 1
hay 1 số tiêu thức nào đó.
*Các dạng biểu đồ thường dùng:
-Biểu đồ phân phối tần số (hoặc tần suất): Trên hệ trục toạ độ, trục hoành biểu thị tiêu thức nghiên cứu (nhóm tuổi,
năng suất lao động, tiền lương,…), trục tung biểu thị tần số (hoặc tần suất) của các tổ.
-Biểu đồ phân phối tần số và tần số tích lũy (hoặc tần suất và tần suất tích lũy): Trên hệ trục toạ độ, trục hoành biểu
thị tiêu thức nghiên cứu, trục tung biểu thị tần số và tần số tích lũy của các tổ
-Biểu đồ phân phối tần số và tần suất tích lũy: Trên hệ trục toạ độ, trục hoành biểu thị tiêu thức nghiên cứu, trục tung
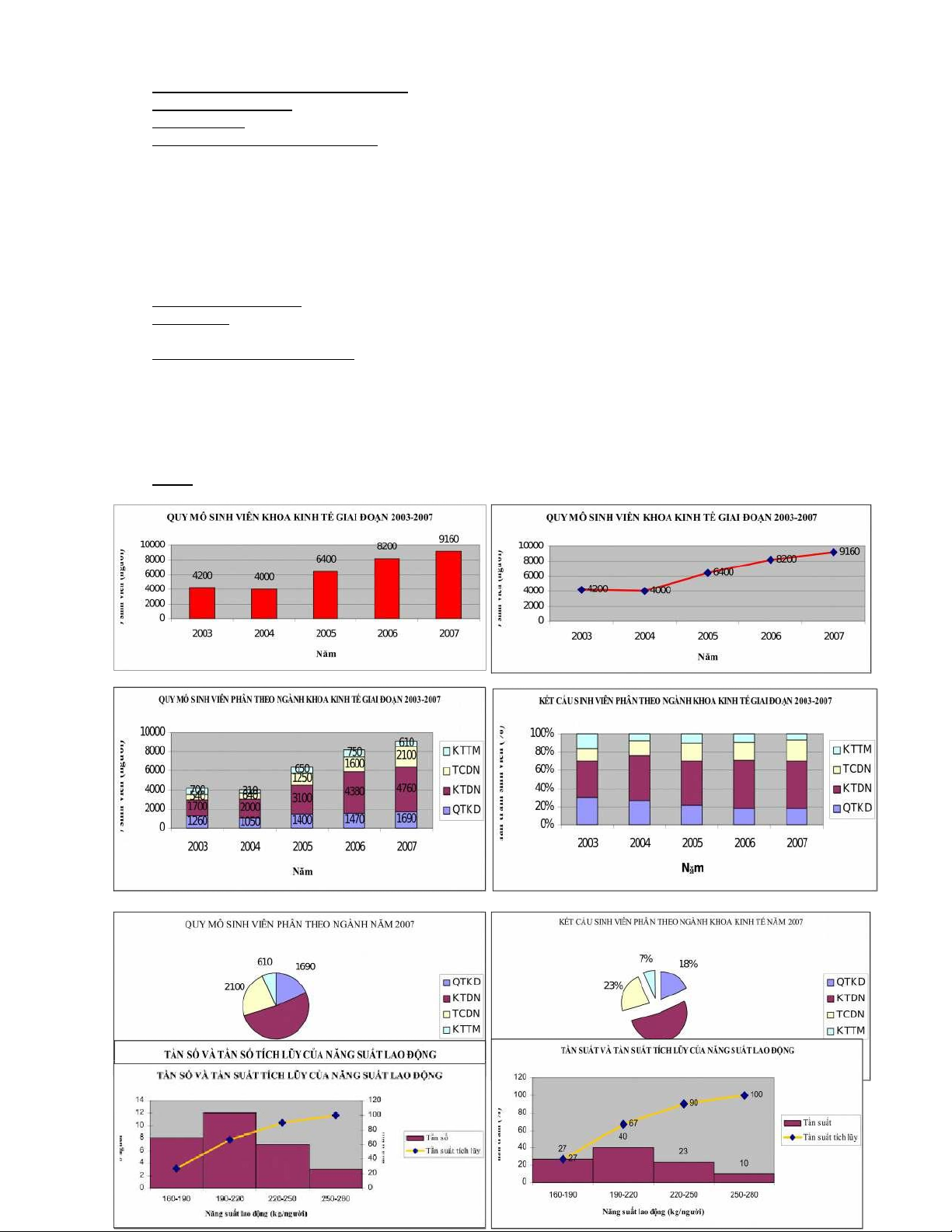
thứ nhất biểu thị tần số, trục tung thứ hai biểu thị tần suất tích lũy Ví dụ:
Downloaded by Nguyen Linh (vjt33@gmail.com) 12
CHƯƠNG IV. PHÂN TÍCH DỮ LIỆU THỐNG KÊ
Để phân tích đặc trưng cơ bản của một khối dữ liệu, người ta thường phân tích dữ liệu theo 2 mặt : độ tập trung và độ phân tán của dữ liệu.
I. PHÂN TÍCH ĐỘ TẬP TRUNG CỦA DỮ LIỆU (measure of central tendency):
Để đo lường khuynh hướng tập trung của dữ liệu; người ta thường sử dụng các tham số : số trung bình, số trung vị, số yếu vị.
1-Số trung bình (mean, average):
*Khái niệm: Số trung bình là con số đại diện cho tổng thể về 1 tiêu thức định lượng nào đó.
*Cách tính : Có 2 trường hợp:
1.1. Đối với dữ liệu không phân tổ : N n x x Trung bình tổng thể : i Trung bình mẫu: i μ = i=1 x = i=1 N n
Trong đó: xi là lượng biến thứ i ; N là số đơn vị của tổng thể, n là số đơn vị của mẫu
1.2. Đối với dữ liệu có phân tổ : k k x fii x fii
Trung bình tổng thể : μ = i=1 Trung bình mẫu: k x = i=k1 f f i i i=1 i=1
Trong đó: fi là tần số của tổ thứ i (i =1,2,…, k)
*Ưu nhược điểm: Cách tính đơn giản, dễ hiểu. Tuy nhiên tính đại diện của số trung bình cho toàn bộ khối dữ liệu sẽ
không cao khi biểu đồ phân phối của tổng thể bị lệch về 1 bên quá lớn; hoặc khi khối dữ liệu có những lượng biến quá lớn
hay quá nhỏ một cách bất thường so với các lượng biến khác.
2- Số yếu vị (Mode):
* Khái niệm: Cho khối dữ liệu được phân tổ, số yếu vị – ký hiệu Mo - là lượng biến có tần số lớn nhất trong khối dữ liệu đó.
Nói cách khác: Mo là lượng biến xuất hiện nhiều lần nhất trong khối dữ liệu
*Cách tính: Xét 2 trường hợp:
2.1. Nếu dữ liệu không có khoảng cách tổ
Mo là lượng biến có tần số lớn nhất, có nghĩa là có số lần xuất hiện nhiều nhất trong khối dữ liệu.
2.2. Nếu dữ liệu có khoảng cách tổ:
-Trước tiên ta tìm tổ có chứa Mo (tổ có tần số lớn nhất)
-Sau đó ta tính trị số gần đúng của M theo công thức: M =x + h fMo - fMo-1 o o Mo(min) Mo ( f f ) ) Mo +( f - Mo- 1 Mo - f Mo+1 Trong đó:
hM : khoảng cách tổ của tổ có chứa M0 , x 0 M
: giới hạn dưới của tổ có chứa M 0 0(min)
fM : tần số của tổ có chứa M0 , f 0
M 0- 1 : tần số của tổ đứng trước tổ có chứa M 0
fM0+1: tần số của tổ đứng sau tổ có chứa M0
*Ưu nhược điểm : Cách tính Mo rất đơn giản, dễ hiểu. Trong thực tế, người ta thường dùng Mo trong việc nghiên
cứu kích cỡ để sản xuất quần áo, giày dép, nón mũ… để sản phẩm vừa cỡ với nhiều khách hàng nhất. Tuy nhiên phạm vi
ứng dụng của Mo rất hạn chế bởi vì có khi có đến 2 hay 3 Mo , hoặc có khi không có Mo ; mặt khác, Mo không quan tâm
đến toàn bộ lượng biến của khối dữ liệu.
Downloaded by Nguyen Linh (vjt33@gmail.com) 13
3-Số trung vị: (Median)
*Khái niệm: Cho khối dữ liệu được sắp xếp theo thứ tự tăng dần, số trung vị - ký hiệu Me - là lượng biến đứng ở vị
trí giữa của khối dữ liệu đó. Như vậy, số trung vị sẽ chia dãy số lượng biến ra làm 2 phần có tần số bằng nhau. Nói cách
khác, có 50% số quan sát có giá trị lớn hơn số trung vị và có 50% số quan sát có giá trị nhỏ hơn số trung vị. *Cách tính :
3.1-Nếu dữ liệu không phân tổ : Có 2 trường hợp: n+1
-Nếu cỡ mẫu n là số lẻ: Me là lượng biến đứng ở vị trí thứ 2 n n + 2
-Nếu cỡ mẫu n là số chẵn: Me là số trung bình của 2 lượng biến đứng ở vị trí thứ và vị trí thứ 2 2
3.2-Nếu dữ liệu có phân tổ: Có 2 trường hợp:
-Nếu không có khoảng cách tổ : Me là lượng biến có tần số tích lũy bằng fi +1 2 f +1 i
-Nếu có khoảng cách tổ: Trước tiên ta tìm tổ có chứa Me ,đó là tổ tương ứng với tần số tích lũy bằng ; sau đó ta f 2 i - S
tính Me theo công thức: Me- 1 M =x 2 e Me(min) + hMe f Me
Trong đó: xMe(min) : giới hạn dưới của tổ có chứa Me , hMe : khoảng cách tổ của tổ có chứa Me
fMe : tần số của tổ có chứa Me , SMe-1 : tần số tích lũy của tổ đứng trước tổ có chứa Me
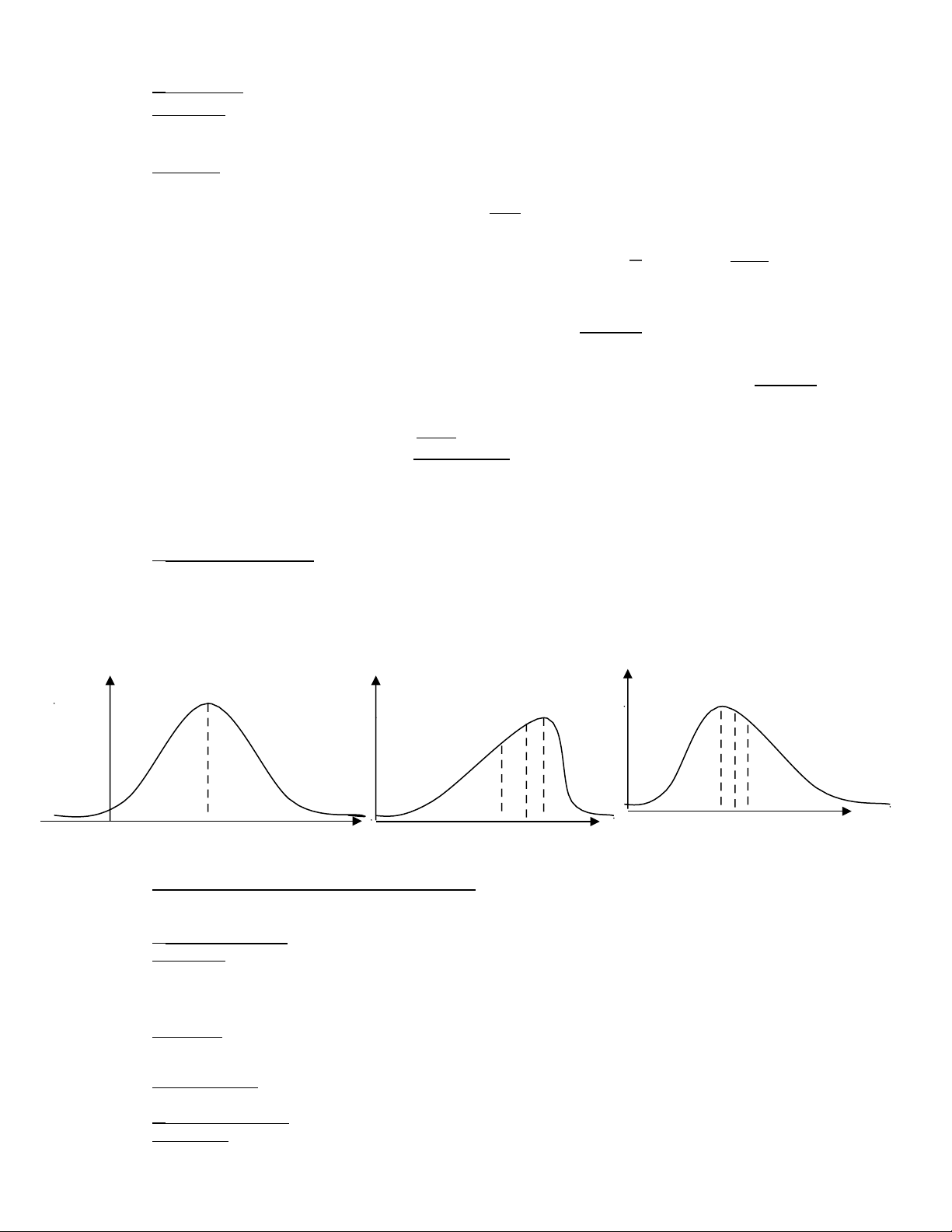
4-Hình dạng phân phối :
Dựa vào các tham số đo lường khuynh hướng tập trung của khối dữ liệu, ta có thể biết được hình dáng phân phối của
dãy số lượng biến như sau:
-Khi số trung bình = số trung vị = số yếu vị, ta có dạng phân phối là đối xứng.
-Khi số trung bình < số trung vị < số yếu vị, ta có dạng phân phối là lệch trái.
-Khi số yếu vị < số trung vị < số trung bình, ta có dạng phân phối là lệch phải
μ =μe =μo
μ ∈ μe ∈ μo
μo ∈ μe ∈ μ Phân phối đối xứng Phân phối lệch trái Phân phối lệch phải
II. PHÂN TÍCH ĐỘ PHÂN TÁN CỦA DỮ LIỆU (measure of dispersion):
Để đo lường độ phân tán nhằm phản ánh khuynh hướng biến động của khối dữ liệu, người ta thường sử dụng các
tham số : Khoảng biến thiên; khoảng tứ phân vị; độ lệch tuyệt đối trung bình, phương sai, độ lệch tiêu chuẩn,…
1-Khoảng biến thiên (Range)
*Khái niệm: Khoảng biến thiên – ký hiệu R - là hiệu số giữa lượng biến lớn nhất và lượng biến nhỏ nhất của khối dữ
liệu. Rcàng lớn, độphân táncủa khối dữliệu càng cao,tổng thểcàng ít đồng đều, tính đại diện của sốtrung bình cho toàn
bộ khối dữ liệu càng thấp và ngược lại.
*Cách tính: R =X max - X min
Trong đó : X max là lượng biến lớn nhất, X min là lượng biến nhỏ nhất
*Ưu nhược điểm: Cách tính đơn giản, đo lường được một cách khái quát đặc trưng về độ phân tán của khối dữ liệu .
Tuy nhiên không đo lường được độ phân tán của các đơn vị bên trong tổng thể; do đó phạm vi ứng dụng của R rất hạn chế.
2-Khoảng tứ phân vị (hay Khoảng trải giữa): *Khái niệm:
Downloaded by Nguyen Linh (vjt33@gmail.com) 14
Tứ phân vị (quartiles) : Là các lượng biến lần lượt chia khối dữ liệu đã được sắp xếp theo thứ tự tăng dần thành 4
phần có tần số bằng nhau. Như vậy tứ phân vị sẽ bao gồm 3 lượng biến ở các vị trí sau trong dãy số lượng biến: Tứ phân vị n +1 2(n +1)
thứ nhất (ký hiệu Q1) ở vị trí thứ
. Tứ phân vị thứ hai (ký hiệu Q2) ở vị trí thứ
, tức là số trung vị . Tứ phân 4 4 3(n +1)
vị thứ ba (ký hiệu Q3) ở vị trí thứ , 4
Khoảng tứ phân vị (interquartile range) (ký hiệu ∆Q) : Là hiệu số giữa tứ phân vị thứ ba và tứ phân vị thứ nhất. ∆Q = Q3 – Q1
*Ưu nhược điểm: Việc tính toán đơn giản, cho ta hình dung được độ phân tán của khối dữ liệu. Không chịu ảnh
hưởng của sự biến động của các lượng biến trong khối dữ liệu vì nó chỉ xét tới vị trí tương đối của các lượng biến khi chúng
được sắp xếp theo thứ tự tăng dần. Tuy nhiên có nhược điểm là không xét tới toàn bộ các lượng biến của khối dữ liệu.
3-Độ lệch tuyệt đối trung bình (mean absolute deviation) :
*Khái niệm: Độ lệch tuyệt đối trung bình – ký hiệu d - là số trung bình của các độ lệch tuyệt đối giữa các lượng biến
và số trung bình của các lượng biến đó. *Cách tính:
3.1. Nếu dữ liệu không phân tổ: n N Tính cho tổng thể mẫu:
xi - x ; tính cho tổng thể chung: xi - μ d = i=1 n d = i=1 N
3.3.Nếu dữ liệu có phân tổ k k xi - x f i xi - μ f i
Tính cho tổng thể mẫu: d = i=1
; tính cho tổng thể chung: d = i=1 k k f f i i i=1 i=1
*Ưu nhược điểm: Xét tới toàn bộ các lượng biến để đo độ biến thiên của chúng trong khối dữ liệu, tuy nhiên sự ràng
buộc trong dấu tuyệt đối làm hạn chế khả năng ứng dụng của tham số này.
4-Phương sai (Variance):
*Khái niệm: Phương sai là số trung bình của bình phương các độ lệch giữa các lượng biến và số trung bình của các lượng biến đó.
*Cách tính: Xét 2 trường hợp:
4.1. Nếu dữ liệu không phân tổ N 2 Phương sai tổng thể: (xi - μ)
ơ 2 = i=1 N n n 2 2 Phương sai mẫu :
(xi - x) ; phương sai mẫu hiệu chỉnh: (xi - x)
sˆ2 = i=1 n
s2 = i=1 n- 1
4.2. Nếu dữ liệu có phân tổ: k 2
(xi - μ) . fi
Phương sai tổng thể : ơ 2 = i=1 k fi i=1 k k
(xi - x)2. fi
(xi - x)2. fi
Phương sai mẫu : sˆ2 = i=1
; phương sai mẫu hiệu chỉnh: s2 = i=1 k k fi fi - 1 i=1 i=1
Chú ý: Để phân tích độ phân tán của dữ liệu mẫu chỉ cần dùng phương sai mẫu hiệu chỉnh
*Ưu nhược điểm: Phương sai đo lường được sự biến thiên của tất cả các quan sát quanh giá trị trung bình; khắc phục
được sự bù trừ nhau về dấu giữa các lượng biến. Tuy nhiên có nhược điểm là không có đơn vị tính, nên khó hình dung được
ý nghĩa thực tiễn của nó.
Downloaded by Nguyen Linh (vjt33@gmail.com) 15
5-Độ lệch tiêu chuẩn (Standard deviation):
*Khái niệm: Độ lệch tiêu chuẩn (gọi tắt là độ lệch chuẩn) là căn bậc 2 của phương sai.
*Cách tính: Độ lệch chuẩn của tổng thể : ơ = ơ 2 Độ lệch chuẩn của mẫu: s = s2
*Ưu điểm: Độ lệch tiêu chuẩn có cùng đơn vị tính với các lượng biến, giúp ta hình dung rõ hơn ý nghĩa thực tiễn của
nó là phản ánh độ sai lệch trung bình giữa từng lượng biến so với số trung bình của chúng; là cơ sở để tìm ra quy luật phân
phối xác suất của khối dữ liệu. Có thể nói đây là tham số tốt nhất để đo lường độ phân tán của tất cả các quan sát trong khối
dữ liệu.6-Hệsốbiếnthiên (Coefficient of variation -CV):
*Khái niệm: Hệ số biến thiên là tỷ lệ giữa độ lệch chuẩn và số trung bình của khối dữ liệu. *Cách tính: ơ s
Hệ số biến thiên của tổng thể : CV =
X100% Hệ số biến thiên của mẫu: CV = X100% μ x
*Ý nghĩa: Hệ số biến thiên là tham số đo lường mức độ biến thiên tương đối giữa các khối dữ liệu có giá trị trung
bình khác nhau. Hệ số biến thiên càng lớn nói lên sự biến thiên càng lớn.
Ví dụ: Cho dữ liệu về lương (nghìn đ/người) của 2 nhóm công nhân. Nhóm thứ 1 có lương trung bình là 4500 và độ
lệch chuẩn là 600, nhóm thứ 2 có lương trung bình là 3800 và độ lệch chuẩn là 550. So sánh sự biến thiên về lương giữa 2 nhóm ? 600 550 nhóm 1: CV =
X100% = 13,33%, nhóm 2: CV = X100% = 14,47% 4500 3800
Nhận xét: Độ lệch chuẩn về lương ở nhóm 2 nhỏ hơn nhóm 1 dễ cho ta có cảm nhận là lương của công nhân nhóm 2
ít biến thiên hơn so với nhóm 1, tuy nhiên khi phân tích bằng hệ số biến thiên thì kết quả hoàn toàn ngược lại.
Chú ý: Hệ số biến thiên còn có tác dụng so sánh mức độ biến thiên giữa 2 khối dữ liệu có đơn vị tính khác nhau. Ví
dụ: Một công ty dịch vụ vận tải muốn chọn lựa một trong hai phương án tính cước : tính theo trọng lượng hay tính theo thể
tích các kiện hàng. Công ty chọn ngẫu nhiên ra 100 kiện hàng và thu thập dữ liệu về trọng lượng và thể tích của chúng. Kết qủa như sau:
-Trọng lượng: số trung bình là 25,84 kg và độ lệch chuẩn là 2,34 kg
-Thể tích: số trung bình là 9510 cm3 và độ lệch chuẩn là 578 cm3 2,34
Hệ số biến thiên theo trọng lượng: CV = X100% 25,84 = 9,06% 578
Hệ số biến thiên theo thể tích: CV = X100% = 6,08% 9510
Nhận xét: Trọng lượng của các kiện hàng trong mẫu thì biến thiên nhiều hơn so với thể tích của chúng, do đó công ty
sẽ chọn cách tính cước theo trọng lượng.
III- QUY LUẬT PHÂN PHỐI CỦA DỮ LIỆU
Dựa trên 2 tham số tối ưu đo lường độ tập trung và độ phân tán của khối dữ liệu là số trung bình và độ lệch chuẩn, ta
có thể tìm ra tính quy luật phân phối của chúng dựa trên 2 quy tắc sau:
1- Quy tắc Tchebyshev: 1
Cho 1 tổng thể bất kỳ với số trung bình là μ và độ lệch chuẩn là ơ , thì luôn luôn có ít nhất 100. (1- )% m2 quan
sát có giá trị rơi trong khoảng μ + m.ơ , với m>1
Ví dụ: Nếu m=1,5 thì sẽ có ít nhất 55,56% quan sát có giá trị rơi vào khoảng ( μ + 1,5ơ )
Nếu m=2 thì sẽ có ít nhất 75% quan sát có giá trị rơi vào khoảng ( μ + 2ơ )
Nếu m=3 thì sẽ có ít nhất 88,89 % quan sát có giá trị rơi vào khoảng ( μ + 3ơ )
Nhận xét: Quy tắc Tchebychev có khả năng ứng dụng cho bất kỳ một tổng thể nào để đưa ra nhận định về tính quy
luật trong phân phối của chúng, tuy nhiên độ sai lệch so với thực tế còn khá lớn
2- Quy tắc thực nghiệm:
Cho 1 tổng thể chung hay tổng thê mẫu có phân phối đối xứng hình chuông (phân phối chuẩn) thì :
Có khoảng 68,3% quan sát có giá trị tập trung trong phạm vi 1 lần độ lệch chuẩn so với số trung bình (Quy tắc 1 ơ )
Có khoảng 95,4% quan sát có giá trị tập trung trong phạm vi 2 lần độ lệch chuẩn so với số trung bình (Quy tắc 2 ơ )
Có khoảng 99,7% quan sát có giá trị tập trung trong phạm vi 3 lần độ lệch chuẩn so với số trung bình (Quy tắc 3ơ )
Nhận xét: Vì các quan sát của tổng thể có khuynh hướng tập trung nhiều xung quanh khu vực trung tâm nên tạo nên
hình dáng phân phối là đối xứng hình chuông. Quy tắc thực nghiệm phản ánh quy luật phân phối sát với thực tế hơn tuy
nhiên nó chỉ đúng với tổng thể có phân phối đối xứng.
Downloaded by Nguyen Linh (vjt33@gmail.com) 16
CHƯƠNG V. XÁC SUẤT THỐNG KÊ I. CÁC KHÁI NIỆM :
1- Phép thử ngẫu nhiên : Việc thực hiện các điều kiện nhất định để quan sát 1 hiện tượng nào đó có xảy ra hay
không được gọi là thực hiện 1 phép thử ngẫu nhiên.
Đặc điểm của phép thử ngẫu nhiên là có thể biết được các kết cục có thể xảy ra, nhưng không thể biết được kết cục
nào sẽ xảy ra trong lần thử này.
Ví dụ: Các phép thử ngẫu nhiên là : Tung một đồng xu và quan sát sự xuất hiện của mặt sấp; hoặc tung một con xúc
xắc và quan sát sự xuất hiện của mặt có số chấm là 4…
2-Không gian mẫu: Là tập hợp các kết cục sơ đẳng nhất có thể xảy ra trong một phép thử ngẫu nhiên.
Ví dụ: Không gian mẫu của phép thử tung đồng xu là : {sấp, ngửa}
Không gian mẫu của phép thử tung con xúc xắc là: {1,2,3,4,5,6}
3-Biến cố sơ cấp: Là 1 kết cục sơ đẳng nhất có thể xảy ra trong một phép thử. Biến cố sơ cấp là một tập hợp chỉ chứa một phần tử duy nhất.
Ví dụ: Các biến cố sơ cấp của phép thử tung con xúc xắc là : {1}, {2}, {3}, {4}, {5}, {6}
4-Biến cố ngẫu nhiên: Biến cố ngẫu nhiên là các kết cục có thể xảy ra, hoặc có thể không xảy ra trong 1 phép thử
ngẫu nhiên. Biến cố ngẫu nhiên là một tập hợp các biến cố sơ cấp có chung một đặc tính. Người ta thường ký hiệu biến cố
ngẫu nhiên bằng các chữ cái in hoa : A,B,C,.
Ví dụ: Trong phép thử tung con xúc xắc, ta có thể gọi các biến cố sau là biến cố ngẫu nhiên :
gọi A là biến cố “xuất hiện mặt có số chấm là 4”, ta có: A = {4}
gọi B là biến cố “xuất hiện mặt có số chấm chẵn”, ta có: B = {2,4,6}
*Phân biệt biến cố ngẫu nhiên với các biến cố sau:
- Biến cố chắc chắn : Là biến cố chắc chắn xảy ra trong 1 phép thử.
- Biến cố không thể có: Là biến cố chắc chắn không xảy ra trong 1 phép thử.
5-Quan hệ giữa các biến cố:
Biến cố là một tập hợp, do đó dựa trên nền tảng các phép tính về tập hợp ta có thể xây dựng mối quan hệ giữa các biến cố như sau:
-Biến cố đối lập : Cho biến cố A, khi đó biến cố “A không xảy ra” – ký hiệu là A - được gọi là biến cố đối lập của biến cố A.
-Biến cố xung khắc :
+2 biến cố xung khắc : là 2 biến cố không đồng thời xảy ra trong 1 phép thử.
+ n biến cố xung khắc từng đôi: có nghĩa là tất cả các cặp biến cố được tạo nên từ n biến cố này đều xung khắc với
nhau. Các biến cố tạo nên hệ đầy đủ các biến cố thì đều xung khắc từng đôi.
-Biến cố độc lập:
+2 biến cố độc lập: là hai biến cố mà sự xuất hiện của biến cố này không ảnh hưởng đến sự xuất hiện của biến cố kia.
+ n biến cố độc lập trong toàn bộ: có nghĩa là mỗi biến cố trong n biến cố này đều độc lập với tổ hợp bất kỳ các biến cố còn lại.
-Biến cố phụ thuộc: 2 biến cố được gọi là phụ thuộc nếu như sự xuất hiện của biến cố này sẽ có ảnh hưởng đến sự
xuất hiện của biến cố kia. -Biến cố tổng:
+Tổng của 2 biến cố A và B - ký hiệu là A+B - là biến cố xảy ra khi có ít nhất biến cố A hoặc biến cố B xảy ra.
+Tổng của n biến cố Ai, (i =1,n) - ký hiệu là A1 + A2 +. . + An – là biến cố xảy ra khi có ít nhất 1 biến cố Ai xảy ra. -Biến cố tích:
+Tích của 2 biến cố A và B - ký hiệu là AB - là biến cố xảy ra khi cả hai biến cố A và B cùng xảy ra.
+Tích của n biến cố Ai, (i =1,n) - ký hiệu là A1.A2. .An – là biến cố xảy ra khi tất cả các biến cố Ai cùng xảy ra.
-Biến cố đồng khả năng: Hai biến cố được gọi là đồng khả năng khi khả năng xuất hiện biến cố này hay biến cố kia
là như nhau trong một phép thử.
-Hệ đầy đủ các biến cố: Các biến cố A1, A2 ,. ., An được gọi là hệ đầy đủ các biến cố khi kết cục xảy ra của phép
thử là một và chỉ một biến cố nào đó trong số các biến cố trên. Ví dụ: Trong phép thử tung con xúc xắc, gọi Ai là biến cố
xuất hiện mặt có số chấm là i, (i =1,6) , ta nói các Ai là các biến cố tạo nên hệ đầy đủ các biến cố.
II. LÝ THUYẾT CƠ BẢN VỀ XÁC SUẤT (probability)
1.Các khái niệm về xác suất:
1.1. Xác suất theo quan niệm cổ điển
*Khái niệm: Cho một phép thử có n biến cố xung khắc và đồng khả năng xảy ra, khi đó xác suất xuất hiện biến cố A
– ký hiệu P(A) - là con số biểu hiện khả năng xuất hiện biến cố A trong 1 phép thử.
Downloaded by Nguyen Linh (vjt33@gmail.com) 17
*Cách tính: P(A) = Số khả năng cho biến cố A xảy ra / Tổng số khả năng có thể xảy ra
*Ưu nhược điểm: Ta không cần thực hiện phép thử mà vẫn tính được xác suất xuất hiện biến cố A. Tuy nhiên ta
không thể áp dụng được cách tính này khi ta không biết được tổng số khả năng có thể xảy ra, hoặc khi các biến cố không có
cùng khả năng xuất hiện như nhau trong 1 phép thử.
1.2. Xác suất theo quan niệm thống kê:
*Khái niệm: Thực hiện lặp lại n phép thử ngẫu nhiên và quan sát thấy biến cố A xuất hiện f lần trong n phép thử đó;
với điều kiện n đủ lớn thì tần suất f/n sẽ được gọi là xác suất xuất hiện biến cố A.
*Cách tính : P( A) =lim f Suy ra : Nếu n đủ lớn: P(A) ≈ f/n n⟶∞ n
Trong đó: n là số phép thử; f là số lần xuất hiện biến cố A trong n phép thử
*Ưu nhược điểm : Cách tính xác suất này không đòi hỏi phép thử phải có hữu hạn biến cố và mỗi biến cố phải có
đồng khả năng xảy ra trong 1 phép thử. Tuy nhiên nó đòi hỏi phải lặp lại các phép thử rất nhiều lần, nghĩa là phải tiến hành
thực nghiệm, trong khi đó thực tế không cho phép do tốn kém chi phí, hoặc cũng có thể do không thể lặp lại nhiều lần phép
thử. Để khắc phục nhược điểm này, người ta chỉ thực hiện lặp lại phép thử với n đủ lớn để tiết kiệm chi phí.
2-Các tính chất của xác suất:
-Xác suất xuất hiện 1 biến cố A bất kỳ là 1 số không âm và không vượt quá 1: 0 P(A) 1
-Xác suất xuất hiện 1 biến cố chắc chắn thì bằng 1, xác suất xuất hiện 1 biến cố không thể có thì bằng 0
-Nếu xác suất xuất hiện 1 biến cố gần bằng 1 thì có thể cho rằng nó chắc chắn xảy ra; nếu xác suất xuất hiện 1 biến
cố gần bằng 0 thì có thể cho rằng nó chắc chắn không xảy ra trong thực tế.
3-Các công thức tính xác suất:
3.1. Công thức tính xác suất có điều kiện :
*Khái niệm: Cho 2 biến cố bất kỳ A và B. Xác suất để xuất hiện biến cố A với điều kiện biến cố B đã xảy ra được gọi
là xác suất có điều kiện của A với điều kiện B, ký hiệu P(A|B) P(A.B)
*Cách tính: P(A|B) = P(B)
*Ý nghĩa: Trong thực tế, khả năng xảy ra nhiều hay ít của 1 biến cố nào đó chịu sự tác động rất lớn của sự xuất hiện
của 1 biến cố khác. Xác suất có điều kiện cho phép ta dựa vào khả năng xuất hiện của biến cố này để dự báo khả năng xuất
hiện của biến cố khác .
3.2. Công thức tính xác suất của biến cố tổng :
*Khái niệm: Xác suất xảy ra biến cố tổng (A+B) là xác suất để cho có ít nhất biến cố A hoặc biến cố B xảy ra. *Cách tính:
Xác suất của tổng 2 biến cố bất kỳ : P(A+B) = P(A) + P(B) - P(A.B)
Xác suất của tổng 2 biến cố đối lập : P(A+ A ) = 1
Xác suất của tổng 2 biến cố xung khắc : P(A+B) = P(A) + P(B) n
Xác suất của tổng n biến cố xung khắc từng đôi Ai,(i =1,n): P ( A1 + A2 +. .+ An) = P(Ai) i =1
3.3. Công thức tính xác suất của biến cố tích:
*Khái niệm: Xác suất xảy ra biến cố tích (AB) là xác suất để cho biến cố A và biến cố B cùng xảy ra. *Cách tính:
Xác suất của tích 2 biến cố bất kỳ :P(AB) = P(A) . P(B|A) = P(B) . P(A|B)
Xác suất của tích 2 biến cố xung khắc: P(AB) = 0
Xác suất của tích 2 biến cố độc lập : P(AB) = P(A) . P(B)
Xác suất của tích n biến cố độc lập trong toàn bộ: P( A1A2. .An ) =P(A1).P(A2)…P(An)
3.4. Công thức tính xác suất toàn phần :
*Khái niệm: Cho biến cố A và cho B1, B2,. ., Bn là n biến cố xung khắc từng đôi, lập thành 1 hệ đầy đủ các biến cố;
khi đó xác suất để xuất hiện biến cố A với điều kiện các biến cố Bi đã xảy ra được gọi là xác suất toàn phần. n
*Cách tính : P(A) = P(A|B1).P(B1) + P(A|B2).P(B2) + … + P(A|Bn).P(Bn) = P(A|Bi). P(Bi) i=1
3.5. Công thức tính xác suất các giả thiết (công thức Bayes)
*Khái niệm: Cho biến cố A và cho B1, B2 ,. ., Bn là n biến cố xung khắc từng đôi, lập thành 1 hệ đầy đủ các biến cố;
khi đó xác suất để xuất hiện 1 biến cố Bi nào đó với điều kiện biến cố A đã xảy ra, được gọi là xác suất các giả thiết – ký hiệu là P(Bi/A)
Downloaded by Nguyen Linh (vjt33@gmail.com) 18
P(B / A) P(A/ B =
i ).P(Bi ) = P(A/ Bi ).P(Bi) *Cách tính : i P(A) n
P(A / Bi ).P(Bi ) i=1
3.6. Công thức tính xác suất nhị thức (công thức Bernoulli) :
*Khái niệm: Nếu tiến hành n phép thử độc lập, trong mỗi phép thử xác suất xuất hiện biến cố A đều bằng nhau và
bằng p; thì khi đó xác suất để biến cố A xuất hiện đúng k lần trong n phép thử đó được gọi là xác suất nhị thức – ký hiệu là
Pn(k)*Cáchtính : P (k) =Ckpkqn-kvớik=0,1,2,…,nvàq=1-p n n
Trong đó: p : xác suất xuất hiện biến cố A trong 1 phép thử.
q : xác suất không xuất hiện biến cố A trong 1 phép thử
Ckn : tổ hợp chập k của n phần tử C k n!
n(n - 1). .(n - k +1) n(n - 1). .(n - k +1) = = = n
k!(n - k)! k! 1.2. .k CHƯƠNG VI
QUY LUẬT PHÂN PHỐI XÁC SUẤT CỦA BIẾN NGẪU NHIÊN I. CÁC KHÁI NIỆM :
1-Biến ngẫu nhiên :
*Khái niệm :Biến ngẫu nhiên là 1 đại lượng có thể nhận giá trị này hay giá trị khác một cách ngẫu nhiên.
Biến ngẫu nhiên được ký hiệu bằng chữ in hoa : X,Y,Z…; các giá trị của biến ngẫu nhiên được ký hiệu bằng chữ
thường : x, y, z…Biến ngẫu nhiên có 2 đặc điểm :
-Có thể biết được các giá trị có thể có của biến ngẫu nhiên.
-Biến ngẫu nhiên sẽ nhận 1 giá trị nào đó trong tất cả các giá trị có thể có của nó tương ứng với một xác suất nào đó. Ví dụ:
-Tiến hành phép thử tung đồng xu, nếu mặt trên đồng xu là mặt sấp thì sẽ được 1 điểm, còn nếu là mặt ngửa thì sẽ
được 2 điểm. Gọi X là số điểm thu được trong 1 lần tung đồng xu. Ta biết được các giá trị có thể có của X là : 1, 2; tuy
nhiên ta không biết được trong lần tung đồng xu X nhận được bao nhiêu điểm. Ta nói: X là biến ngẫu nhiên.
-Tiến hành chọn ngẫu nhiên 10 sản phẩm từ 1 lô sản phẩm để điều tra về chất lượng của chúng. Gọi số phế phẩm
xuất hiện trong 10 sản phẩm là X. Ta biết được các giá trị có thể có của X là 0,1,2,3,4,5,6,7,8,9,10; tuy nhiên ta không thể
biết được X nhận được giá trị nào trong lần điều tra này. Ta nói: X là một biến ngẫu nhiên. *Phân loại: Có 2 loại :
-Biến ngẫu nhiên rời rạc: các giá trị có thể có của nó là những con số có thể đếm được. Ví dụ: Số nhân khẩu trong 1
hộ gia đình, số tai nạn giao thông trong 1 năm, số khách hàng đến mua sắm tại 1 cửa hàng trong 1 ngày,…
-Biến ngẫu nhiên liên tục: các giá trị có thể có của nó là những con số có thể lấp kín một khoảng trên trục số. Ví dụ:
Thu nhập của 1 hộ gia đình, năng suất của 1 loại cây trồng, năng suất lao động của 1 công nhân, giá thành của 1 sản phẩm,
trọng lượng của 1 sản phẩm…
2-Quy luật phân phối xác suất của biến ngẫu nhiên: *Khái niệm :
-Quy luật phân phối xác suất của biến ngẫu nhiên rời rạc là quy luật biểu diễn mối quan hệ giữa các giá trị có thể có
của biến ngẫu nhiên và các xác suất tương ứng với các giá trị đó.
-Quy luật phân phối xác suất của biến ngẫu nhiên liên tục là quy luật biểu diễn mối quan hệ giữa các khoảng giá trị
có thể có của biến ngẫu nhiên và các xác suất tương ứng với các khoảng giá trị đó.
II. QUY LUẬT PHÂN PHỐI XÁC SUẤT CỦA BIẾN NGẪU NHIÊN RỜI RẠC:
1-Biểu diễn quy luật phân phối xác suất của biến ngẫu nhiên rời rạc:
Đối với biến ngẫu nhiên rời rạc, quy luật phân phối xác suất được biểu diễn thông qua bảng phân phối xác suất và hàm phân phối xác suất.
1.1. Bảng phân phối xác suất :
*Khái niệm: Bảng phân phối xác suất của biến ngẫu nhiên rời rạc X là bảng phản ánh xác suất để cho X nhận 1 giá trị
nào đó trong những giá trị có thể có của nó. Bảng phân phối xác suất có dạng: X P(X= x ) x1 p1 x2 p2 … …
Downloaded by Nguyen Linh (vjt33@gmail.com) 19 xi pi … … Cộng 1
Biến ngẫu nhiên X (ký hiệu bằng chữ in hoa)
x1, x2 , xi … là các giá trị của BNN X (ký hiệu bằng chữ thường)
pi = P(X= xi ): xác suất để biến ngẫu nhiên X nhận giá trị xi
Ví dụ: Trong phép thử tung đồng xu, giả sử nếu nhận được mặt sấp thì được 1 điểm, nếu nhận được mặt ngửa thì được 2
điểm. Ta có bảng phân phối xác suất của biến ngẫu nhiên X (số điểm thu được trong 1 lần tung đồng xu) như sau: X P(X= x ) 1 0,5 2 0,5 cộng 1,0
1.2. Hàm phân phối xác suất (hay hàm xác suất tích lũy):
*Khái niệm: Hàm phân phối xác suất của biến ngẫu nhiên rời rạc X – ký hiệu F(x) - là hàm biểu diễn xác suất để cho
biến ngẫu nhiên X nhận các giá trị không vượt qua giá trị x nào đó F(x)= P(X x) = P(X =xi) xi x
* Biểu đồ : Biểu đồ hàm phân phối xác suất (còn gọi là biểu đồ tần suất tích lũy) có dạng bậc thang, bắt đầu từ 0 và tận cùng bằng 1
2-Một số quy luật phân phối thông dụng của biến ngẫu nhiên rời rạc:
2.1- Quy luật phân phối nhị thức (Binomial Distribution):
Quy luật phân phối nhị thức (còn gọi là phân phối xác suất nhị thức hay phân phối nhị thức) là 1 quy luật phân phối
có nhiều ứng dụng trong thực tế. Nó được áp dụng khi biến ngẫu nhiên rời rạc là “số lần thành công (hay thất bại) trong n
phép thử độc lập”. Khi đó ở mỗi phép thử độc lập chỉ xuất hiện 2 biến cố đối lập là “thành công” và “thất bại”, xác suất để
xuất hiện biến cố “thành công” trong mỗi phép thử phải đều bằng nhau và bằng p và xác suất để xuất hiện biến cố “thất bại” sẽ là q = 1-p.
Ví dụ: Số phế phẩm trong một lô hàng, số khách hàng chấp nhận mua hàng trong n lần chào hàng của một nhân viên
tiếp thị… là các biến ngẫu nhiên có phân phối nhị thức
*Khái niệm:Quy luật phân phối nhị thức là quy luật phân phối xác suất của biến ngẫu nhiên rời rạc X, trong đó X sẽ
nhận các giá trị 0,1,2,…, n với các xác suất tương ứng được tính theo công thức xác suất nhị thức như sau:
P( X =x) =Cx. px.qn- x n!
.px (1- p)n- x với x =0,1,2,…,n; 0
= n
x!(n - x)!
Biến ngẫu nhiên rời rạc X có phân phối nhị thức đuợc ký hiệu : X ~ B(n,p)
* Các đặc trưng cơ bản của biến ngẫu nhiên có phân phối nhị thức:
Số trung bình : μ =n.p
Phương sai :ơ 2 =np(1- p) =npq
Độ lệch chuẩn :ơ = npq
2.2-Quy luật phân phối Poisson (Poisson Distribution):
Quy luật phân phối Poisson được áp dụng khi biến ngẫu nhiên rời rạc là “số lần xảy ra một biến cố nào đó trong một
đơn vị thời gian hoặc trong một đơn vị không gian xác định”. Chẳng hạn: số ca cấp cứu đến bệnh viện vào thời gian 15 phút
đổi ca trực, số khách hàng đến giao dịch tại bưu điện vào thời gian 30 phút ăn trưa của nhân viên, số lần máy bị hỏng trong
1 tuần, số tai nạn giao thông xảy ra trong 1 tháng trên 1 con đường bị hư hỏng nặng, số lỗi trên một trang đánh máy…Khi
đó sự xuất hiện của biến cố mà ta quan tâm có thể xem như là biến cố “thành công” (mặc dù có thể trên thực tế ta không
trông đợi xảy ra kết cục này). Các giá trị có thể có của biến ngẫu nhiên là những con số nguyên dương 0,1,2,…
*Khái niệm:Quy luật phân phối Poisson là quy luật phân phối xác suất của biến ngẫu nhiên rời rạc X, trong đó X sẽ
nhận các giá trị 0,1,2,…, n,… với các xác suất tương ứng được tính theo công thức : e- λ.λx
P(X =x) = x!
với e= 2,71828 (hằng số Nêpe);
x = 0,1,2,…(số lần thành công trong 1 đơn vị thời gian hay trong 1 đơn vị không gian
λ là trung bình của số lần thành công trong 1 đơn vị thời gian hay 1 đơn vị không gian được chọn
p là xác suất thành công (khả năng để biến cố mà ta quan tâm xảy ra)
Biến ngẫu nhiên rời rạc X có phân phối Poisson đuợc ký hiệu : X ~P( λ )
* Các đặc trưng cơ bản của biến ngẫu nhiên có phân phối Poisson:
Số trung bình : μ =λ , phương sai: ơ 2 =λ , độ lệch chuẩn :ơ = λ
III. QUY LUẬT PHÂN PHỐI XÁC SUẤT CỦA BIẾN NGẪU NHIÊN LIÊN TỤC:
Downloaded by Nguyen Linh (vjt33@gmail.com) 20
1-Biểu diễn quy luật phân phối xác suất của biến ngẫu nhiên liên tục:
Đối với biến ngẫu nhiên liên tục, quy luật phân phối xác suất được biểu diễn thông qua hàm mật độ xác suất và hàm phân phối xác suất.
1.1. Hàm mật độ xác suất:
*Khái niệm: Hàm mật độ xác suất của biến ngẫu nhiên liên tục X – ký hiệu f(x) - là hàm biểu diễn xác suất để cho
biến ngẫu nhiên X nhận giá trị trong 1 đoạn [a,b] nào đó. b
P(a ≤ X≤ b) = ∫f (x)dx a
Nhận xét: Đối với biến ngẫu nhiên liên tục, xác suất để biến ngẫu nhiên nhận 1 giá trị cụ thể nào đó thì bằng 0, do đó
ta chỉ có thể xác định xác suất để biến ngẫu nhiên nhận giá trị trong một khoảng giá trị nào đó mà thôi.
Ví dụ: Ta không thể tính xác suất để một em bé có trọng lượng khi sinh ra đúng bằng 3,1 kg, vì kết quả là bằng 0.
Tuy nhiên ta có thể tính xác suất để trọng lượng 1 em bé khi sinh ra nằm trong khoảng từ 3,0 kg đến 3,2 kg bằng cách tính
phần diện tích nằm dưới hàm mật độ xác suất.
1.2. Hàm phân phối xác suất:
*Khái niệm: Hàm phân phối xác suất của biến ngẫu nhiên liên tục X – ký hiệu F(x) - là hàm biểu diễn xác suất để
cho biến ngẫu nhiên X nhận các giá trị không vượt qua giá trị x nào đó. x
F(x) = P(X≤x) = ∫f (x)dx - ∞
2-Một số quy luật phân phối thông dụng của biến ngẫu nhiên liên tục:
2.1- Quy luật phân phối chuẩn (Normal Distribution) :
* Ý nghĩa:Quy luật phân phối chuẩn (gọi tắt là phân phối chuẩn) là quy luật đóng vai trò chủ đạo trong lý thuyết
thống kê suy luận, bởi vì hầu hết các hiện tượng trong cuộc sống đều tuân theo quy luật phân phối chuẩn; mặt khác quy luật
phân phối chuẩn còn được dùng để xấp xỉ các quy luật phân phối của biến ngẫu nhiên rời rạc, hoặc được dùng để xấp xỉ các
quy luật phân phối khác của biến ngẫu nhiên liên tục
*Khái niệm : Quy luận phân phối chuẩn là quy luật phân phối xác suất của biến ngẫu nhiên liên tục X, trong đó X sẽ
nhận các giá trị từ -∞ đến +∞ với hàm mật độ xác suất f (x) có dạng : f (x) 1 - ( x- μ )2 = e 2ơ2 ơ 2u
Biến ngẫu nhiên X có phân phối chuẩn được ký hiệu : X ~ N( μ ,ơ 2 )
Trong đó: e ≈ 2,71828 ; u ≈ 3,14159
x là các giá trị của biến ngẫu nhiên X, - ∞< x <+∞; f (x) >0
μ là số trung bình của biến ngẫu nhiên, phản ánh độ tập trung xác suất quanh số trung bình.
ơ là độ lệch chuẩn của biến ngẫu nhiên, phản ánh độ phân tán xác suất quanh số trung bình.
* Biểu đồ: Phân phối chuẩn có dạng đối xứng hình chuông, có trục đối xứng là đường thẳng x = μ , có trục hoành 1
làm đường tiệm cận ngang, đạt cực đại tại điểm M( μ ; ) ơ . 2u
Xác suất để cho BNN X nhận giá trị trong đoạn [a,b] là diện tích nằm dưới đường cong chuẩn f (x) , bị chặn dưới
bởi trục hoành, và chặn giữa bởi 2 đường thẳng x =a và x =b f(x) f(z) 1 1 ơ 2u 2u f(x) a b μ x μ =0 z z Phân phối chuẩn Phân phối chuẩn tắc
Downloaded by Nguyen Linh (vjt33@gmail.com)



