Báo cáo bài tập lớn môn Xác suất thống kê | Đại học Bách khoa Thành phố Hồ Chí Minh
Báo cáo bài tập lớn môn Xác suất thống kê của Đại học Bách khoa Thành phố Hồ Chí Minh với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: Xác suất thống kê (MT2013) 9 tài liệu
Trường: Trường Đại học Bách khoa - Đại học Quốc gia Thành phố Hồ Chí Minh 721 tài liệu
Tác giả:






Preview text:
lOMoARcPSD| 36991220
các phép thử hóa lý bao gồm pH, axit citric, SO2 tự do, độ cồn (phần trăm rượu
trong dung dịch) và một số yếu tố khác. Dữ liệu gốc được cung cấp tại:
https://archive.ics.uci.edu/ml/datasets/Wine+Quality
Dựa vào lý thuyết và đồ thị tương quan các yếu tố ảnh hưởng chất lượng
rượu, các biến cần xem xét chính là:
+ volatile.acidity: Nồng độ axit dễ bay hơi (gCH3COOH/ dm3)
+ density: tỷ trọng của rượu (g/cm3) V rượunguyênchất
+ alcohol: Độ cồn (C% theo thể tích: Độ cồn =
V hỗnhợp ×100%)
+ chlorides: Nồng độ muối chloride (sodium chlorides) (g/dm3)
+ quality: Chất lượng rượu ( điểm từ 3 đến 8) 2.
Giải quyết bài toán bằng phần mềm RStudio
2.1. Đọc dữ liệu:
Thực hiện đọc dữ liệu CSDL đã Downloads từ web: Wine_data.csv
> install.packages("dplyr")
> install.packages("ggplot2")
> install.packages("corrplot")
> install.packages("psych") > rm(list=ls()) > options(warn=-1) > library(dplyr) > library(ggplot2) > library(corrplot)
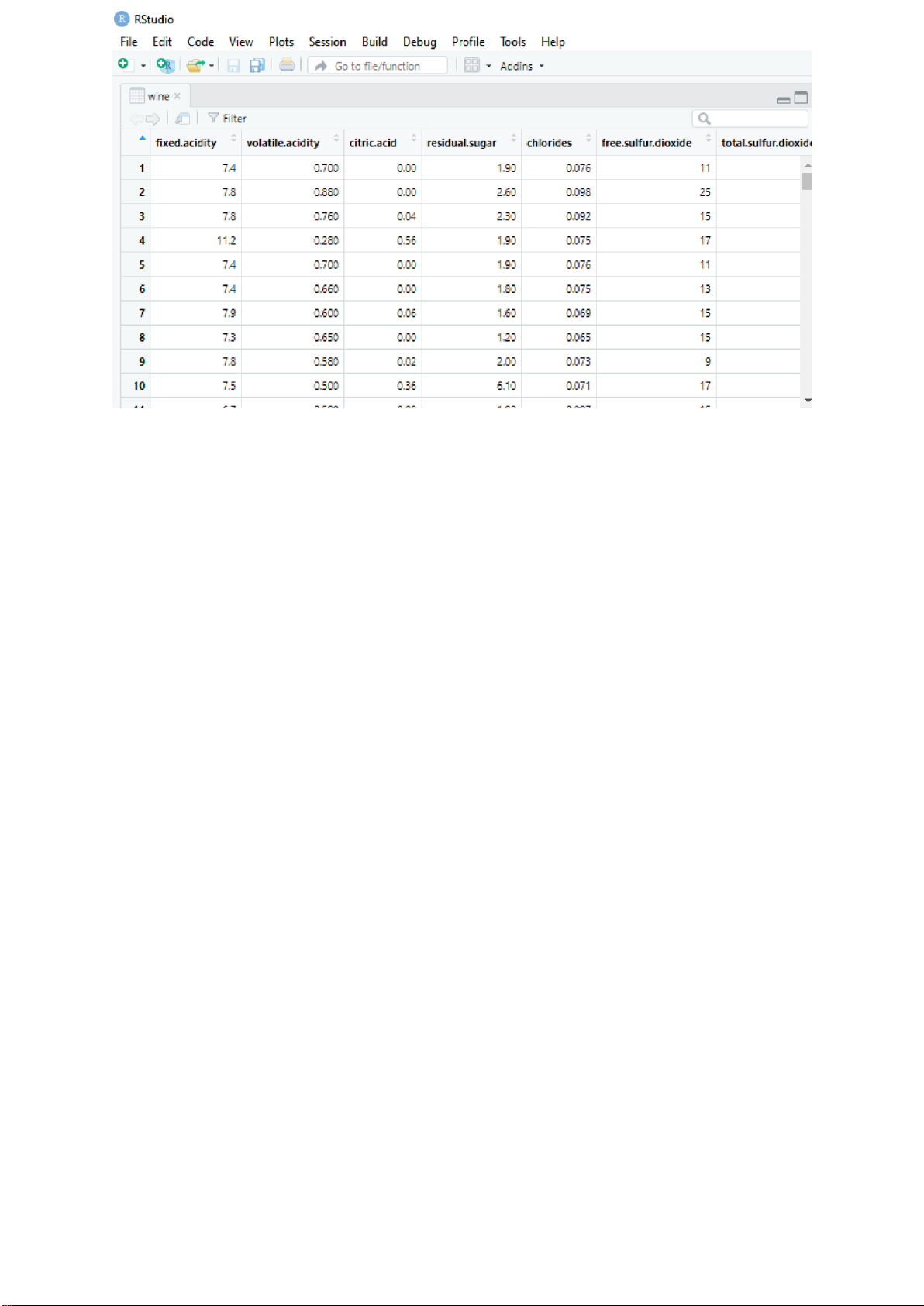
> wine=read.csv("C:/Users/USER/Desktop/XSTK Total/Wine_data.csv", header=TRUE) > View(wine)
Ta được bảng dữ liệu sau: lOMoARcPSD| 36991220
Bởi vì dữ liệu từ files csv chưa được chuyển về dạng bảng nên không thể thực
hiện việc đọc file như ở phần chung, trong header=TRUE dùng để xác định
dòng đầu tiên dùng làm tiêu đề cho các cột dữ liệu.
2.2. Làm sạch dữ liệu
Bài toán này gồm các biến như sau: fixed.acidity, volatile.acidity, citric.acid,
residual.sugar, chlorides, free.sulfur.dioxide, total.sulfur.dioxide, density, pH,
sulphates, alcohol. Với dữ liệu đầu ra là quality (điểm từ 0 đến 10)
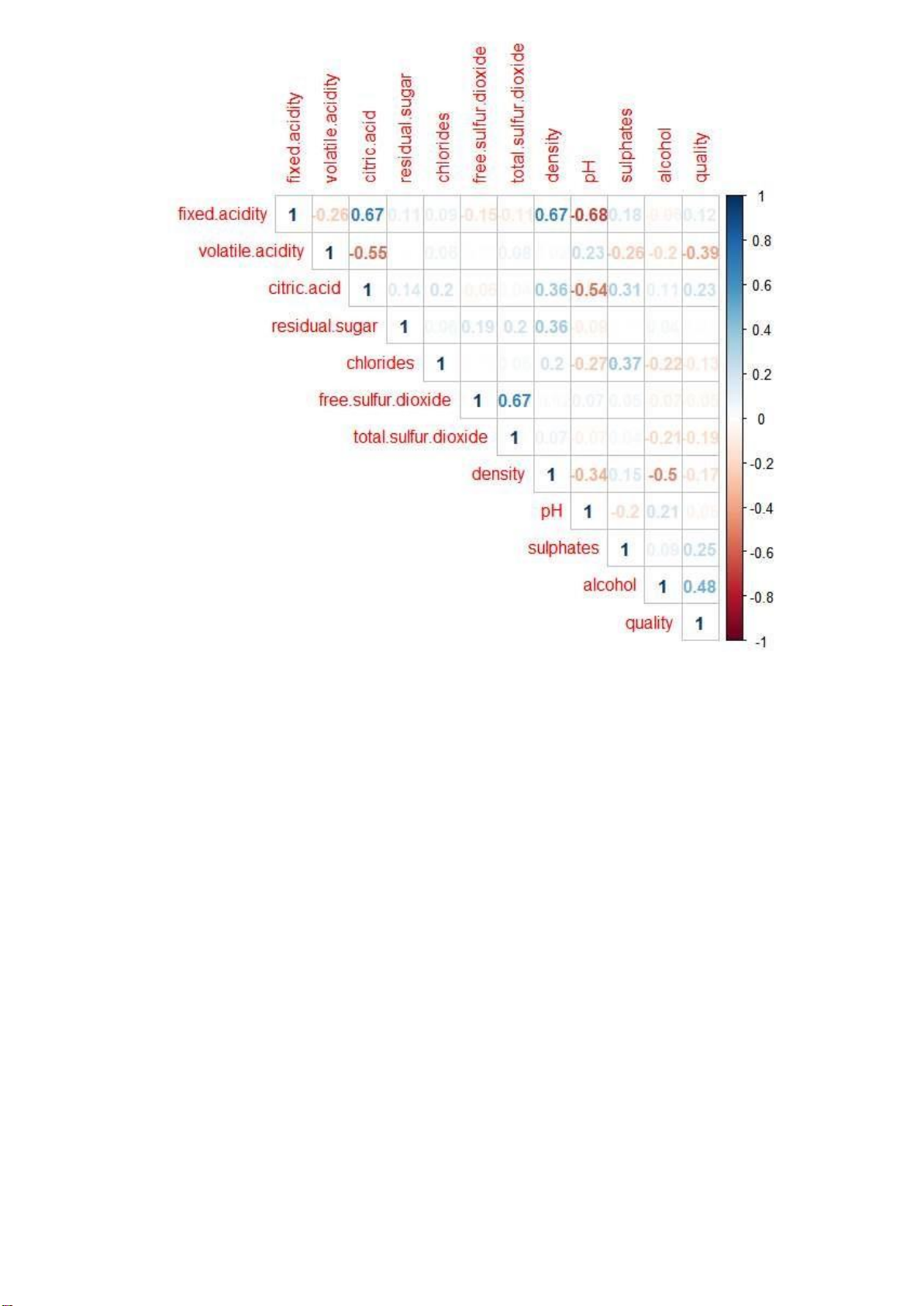
Ta tiến hành vẽ biểu đồ thể hiện hệ số tương quan giữa từng biến trên đối với biến quality: < attach(wine) < winecor= cor(wine)
< corrplot(winecor, type = "upper", method= "number")
Kết quả cho ra biểu đồ hệ số tương quan giữa các biến như sau: lOMoARcPSD| 36991220
Qua biểu đồ trên, ta thấy rằng các biến volatitle acidity, chlorides, density
và alcohol có độ tương quan khá cao với quality lần lượt với hệ số tương quan r
lần lượt là: -0.39, 0,13, -0.17, 0.48
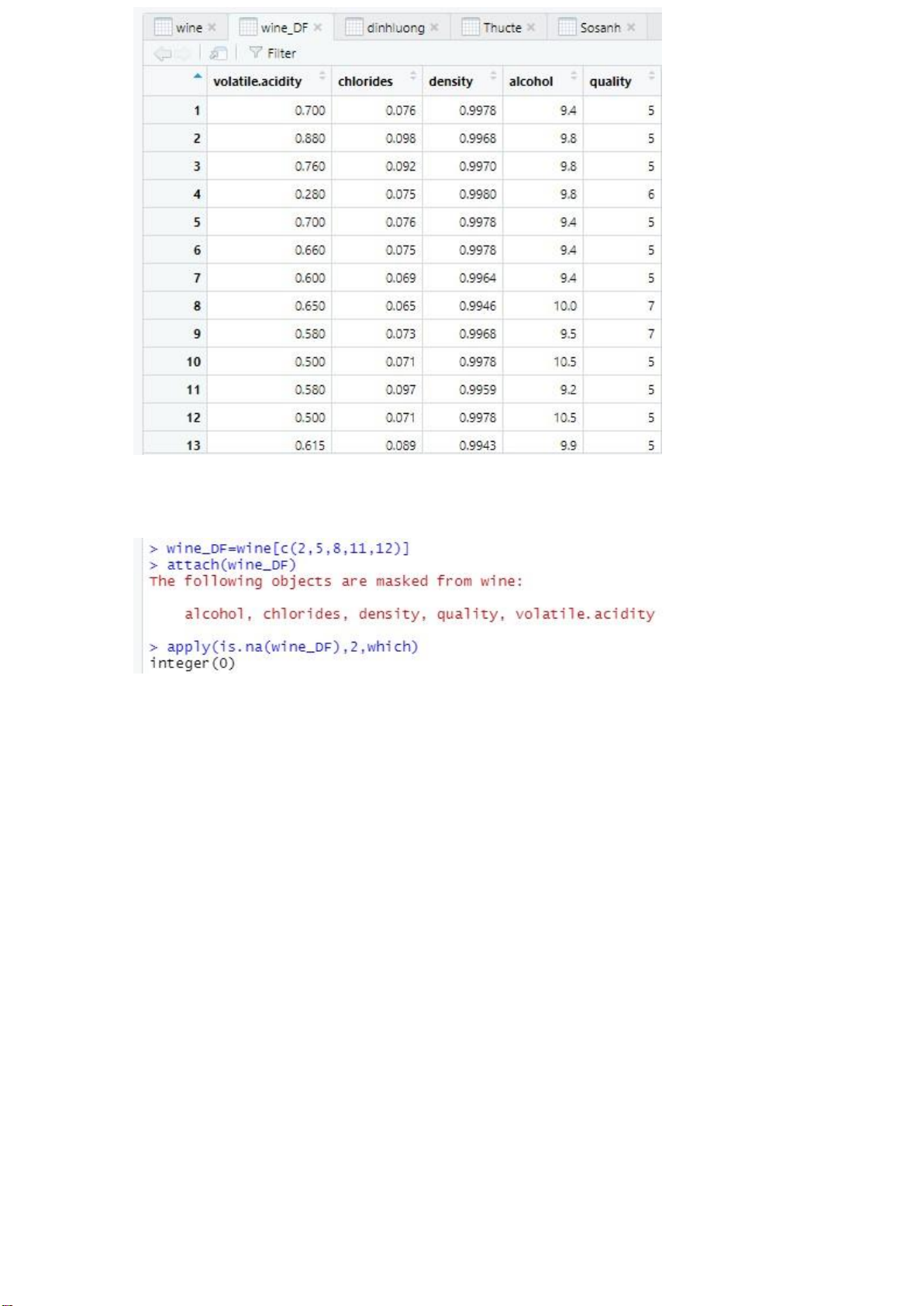
Sau khi chọn biến xong, ta tiến hành tạo một tập dữ liệu con có tên là
wine_DF, với các cột là các dữ liệu đã chọn và tiến hành kiểm tra dữ liệu khuyết:
< wine_DF=wine[c(2,5,8,11,12)] < attach(wine_DF)
< apply(is.na(wine_DF),2,which)
Ta được bảng dữ liệu con wine_DF sau: lOMoARcPSD| 36991220
Vì không có dữ liệu khác nên kết quả trả lại Integer(0)
2.3. Làm rõ dữ liệu (Data visualization):
Các biến liên tục trong bộ dữ liệu wine_DF là các biến sau: volatile.acidity,
citric.acid, residual.sugar, chlorides, free.sulfur.dioxide,
total.sulfur.dioxide, density, pH, sulphates, alcohol tương ứng với các cột từ
1 đến 11 trong dữ liệu.
a. Tính các giá trị thống kê mô tả bao gồm:
Trung bình: mean(), Trung vị: median(), Độ lệch chuẩn: sd(), Giá trị lớn
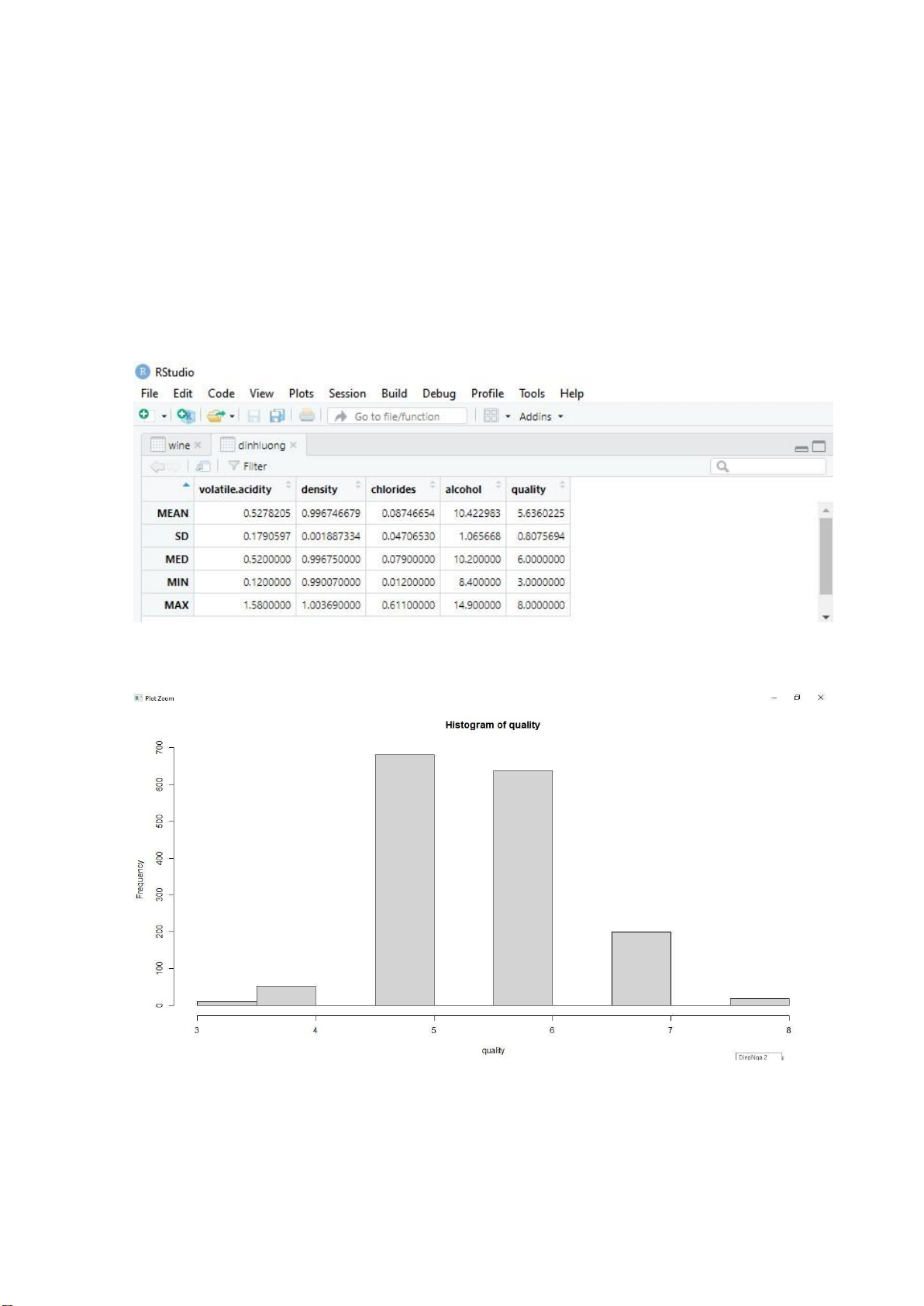
nhất : max(), Giá trị nhỏ nhất: min() < thongke = function(x) + {av = mean(x) + med = median(x) + sd = sd(x) + min = min(x) + max = max(x)
+ c(MEAN = av, SD = sd, MED = med, MIN = min, MAX = max)} lOMoARcPSD| 36991220
> a = thongke(volatile.acidity) > b = thongke(density) > c = thongke(chlorides) > d = thongke(alcohol) > e = thongke(quality)
> dinhluong = data.frame(a,b,c,d,e) > colnames(dinhluong) =
c("volatile.acidity","density","chlorides","alcohol","quality") > View(dinhluong)
Ta được bảng định lượng như sau:
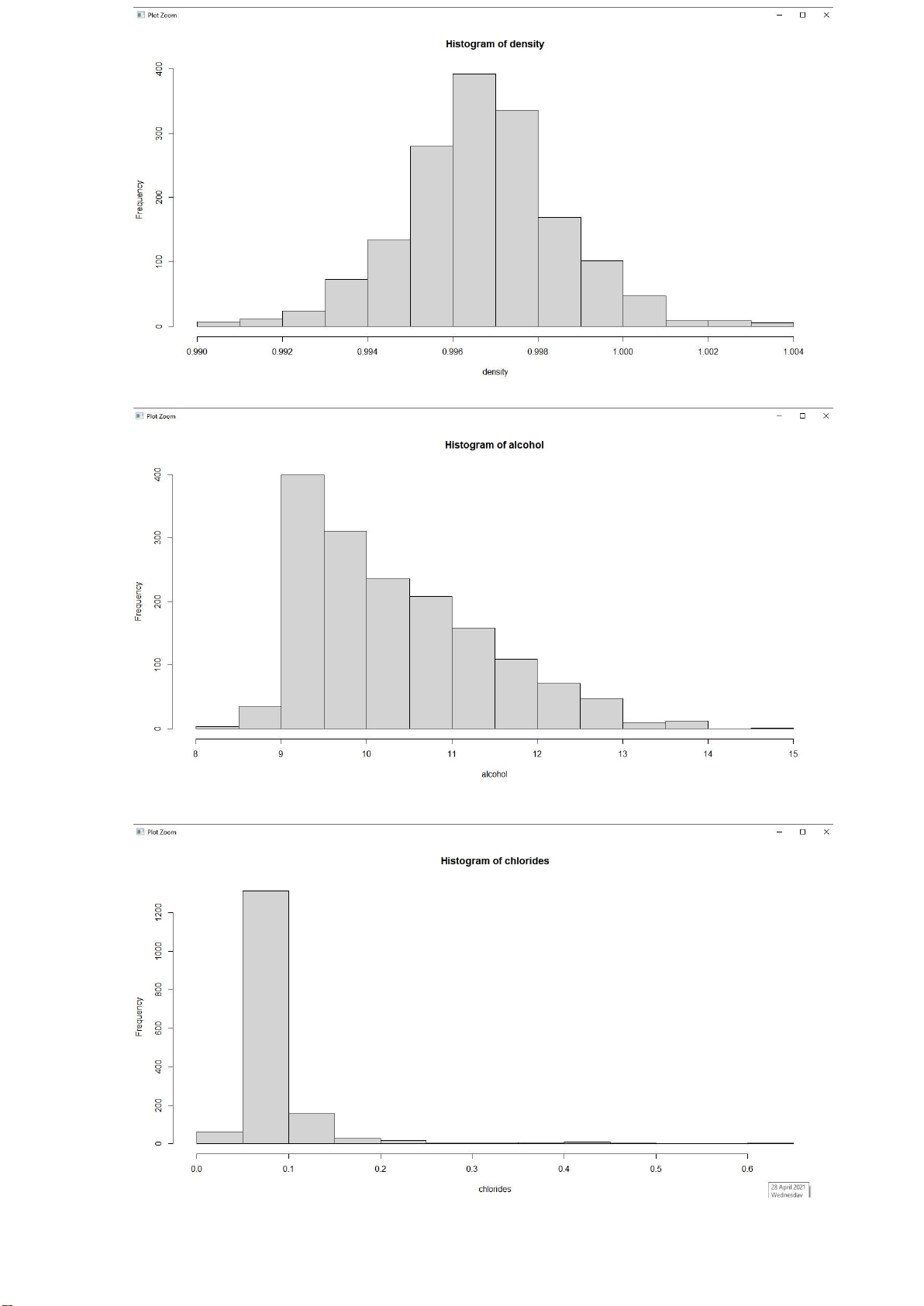
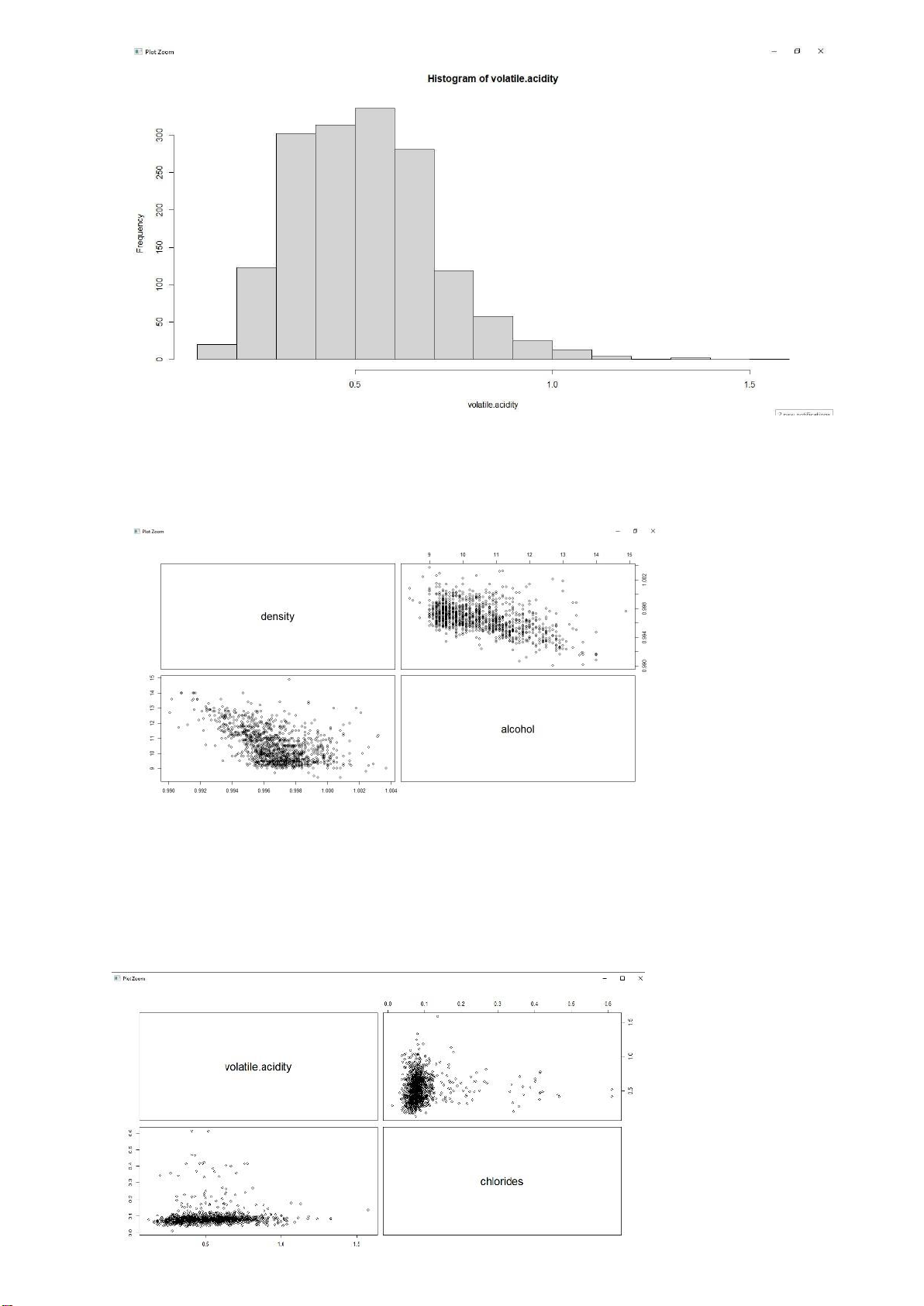
b. Vẽ biểu đồ phân phối của các biến: > hist(quality) > hist(density) lOMoARcPSD| 36991220 > hist(alcohol) > hist(chlorides) lOMoARcPSD| 36991220 > hist(volatile.acidity)
Nhận xét: Ta thấy các đồ thị Histogram có hình dáng khá giống phân phối
chuẩn, nên ở các phần model fitting có thể sử dụng anova(). < pairs(density~alcohol)
Tức là lượng alcohol càng tăng thì lượng density giảm. Hệ số tương quan là
0.05 có nghĩa là tỉ lệ nghịch giữa 2 biến này.
Hoặc xét ô nằm ở hàng 2 cột 1 biểu diễn mối quan hệ giữa Violatile Acidity
và Chlorides gần như là đường thẳng
< pairs(volatile.acidity~chlorides) lOMoARcPSD| 36991220
Tức là khi lượng Volatile acidity tăng thì lượng Chloride gần như không đổi.
Hệ số tương quan là 0.06 nghĩa là có sự tỉ lệ, nhưng ít, khó quan sát thấy.
Do các biến đang khảo sát đều là biến liên tục, ta sử dụng pairs() để vẽ phân
phối của quality theo các biến khảo sát.
Đánh giá quan hệ của quality với các biến còn lại
< pairs(volatile.acidity~quality, legend("top", "Moi quan he Volatile acidity va Quality"))
< pairs(volatile.acidity~quality, main= "Moi quan he Volatile acidity va Quality")
< pairs(chlorides~quality, main= "Moi quan he Chloride va Quality")
< pairs(density~quality, main= "Moi quan he Density va Quality") lOMoARcPSD| 36991220
< pairs(alcohol~quality, main= "Moi quan he Alcohol va Quality")
2.4. Xây dựng các mô hình hồi quy tuyến tính (Fitting linear regression models):
a) Xét mô hình hồi quy tuyến tính bao gồm biến quality là một biến phụ
thuộc, và tất cả các biến còn lại đều là biến độc lập. Dùng lệnh lm() để thực thi
mô hình hồi quy tuyến tính bội: Input:
< m1=lm(quality~volatile.acidity+chlorides+density+alcohol) < summary(m1) Output:
b) Dựa vào kết quả của mô hình hồi quy tuyến tính, loại những biến với các
mức tin cậy 5% khỏi mô hình tương ứng.
Giả thiết kiểm định H : các hệ số hồi quy không có ý nghĩa thống kê. Dựa vào 0
kết quả mô hình tuyến tính, vì biến "chlorides" có Pr(>|t|)= 0.2483 > 0.05 nên
các hệ số hồi quy tương ứng với biến này không có ý nghĩa thống kê. Do đó ta
loại biến "chlorides" ra khỏi mô hình.
c) Dùng Anova để đề xuất mô hình hợp lýInput:
m2=lm(quality~volatile.acidity+density+alcohol) anova(m1,m2) lOMoARcPSD| 36991220
Giải thích: mô hình m2 là mô hình đã loại bỏ biến “chlorides” Output:
Đặt H : hai mô hình giống nhau 0 H1: hai mô hình khác nhau
Ta có Pr >(F) là P -value của kiểm định này. Vì P -value = 0,2483> 0.05
Nên không bác bỏ H , nghĩa là hai mô hình giống nhau 0
d) Từ mô hình hồi quy hợp lý nhất ở câu ( c ) hãy suy luận tác động của các
biến đến chất lượng rượu.
Từ mô hình 1, ta xây dựng được phương trình quy hồi tuyến tính sau:
Y ( quality ) = -19.63746 - 1.36221X1 ( volatile.acidity ) - 0.42248 X2
(chlorides) + 22.66016X3 (density) + 0.33033X4 ( alcohol )
Nghĩa là: Khi axit bay hơi tăng thì chất lượng giảm 1.36221, clorua tăng thì
chất lượng giảm 0.42248, mật độ tăng thì chất lượng tăng 22.66016, cồn tăng thì
chất lượng tăng 0.33033 ( sự thay đổi tăng hay giảm trên một đơn vị đo lường)
e) Từ mô hình hợp lý nhất ở câu c) hãy dùng lệnh plot() để vẽ đồ thị biểu thị
sai số hồi quy và dự báo. Nêu ý nghĩa và nhận xét.
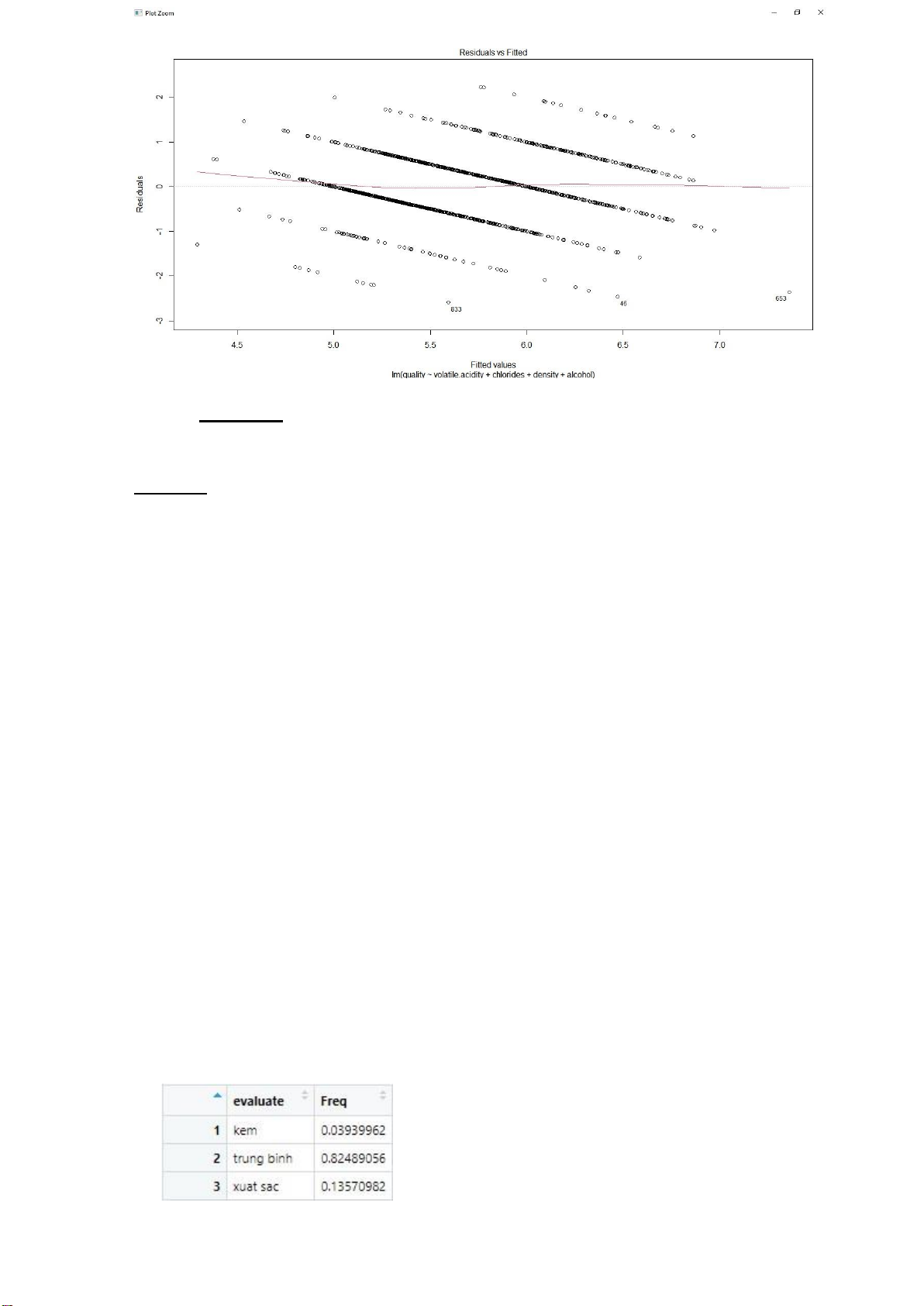
Vẽ biểu đồ biểu thị quan hệ giữa giá trị dự báo và sai số hồi quy của mô hình M1:
< plot(fitted(m1),resid(m1)) < plot(m1,which=1) lOMoARcPSD| 36991220
Nhận xét: đường hồi quy(đường màu đỏ) gần trùng với đường
Residuals=0(đường nét đứt)
Ý nghĩa: Chứng tỏ sự sai số ở mô hình M1 là thấp nhất và việc chọn mô hình
M1 là mô hình hợp lý nhất ở câu c) hoàn toàn hợp lý.
2.5. Dự báo về tỷ lệ chất lượng của rượu
Thống kê về tỷ lệ các mức chất lượng rượu trong CSDL về rượu vang trắng với:
1. Điểm bé hơn 5 là chất lượng kém (kí hiệu là “kem”)
2. Điểm từ 5 đến 6 là chất lượng trung bình (kí hiệu là “trung binh”)
3. Điểm lớn hơn 6 là chất lượng xuất sắc (kí hiệu là “xuat sac”) < evaluate <- quality
< evaluate[quality<5] <-"kem"
< evaluate[quality >=5 & quality <=6] <-"trung binh"
< evaluate[quality>6]<- "xuat sac"
< evaluate<-data.frame(evaluate)
< wine_DF<-cbind(wine_DF, evaluate)
< Thucte<-prop.table(table(evaluate)) < View(Thucte)
Ta được kết quả như sau: Dự báo về tỉ lệ lOMoARcPSD| 36991220
< Mohinh<- lm(quality~volatile.acidity+chlorides+density+alcohol)
< quality_PD<-predict(Mohinh,wine)
< evaluate_PD<-quality_PD
< evaluate_PD[quality_PD<5] <-"kem"
< evaluate_PD[quality_PD >=5 & quality_PD <=6] <-"trung binh"
< evaluate_PD[quality_PD>6]<- "xuat sac"
< evaluate_PD<-data.frame(evaluate_PD)
< wine_PF<-cbind(wine_DF,quality_PD,evaluate_PD)
< Dubao<-prop.table(table(evaluate_PD)) < View(Dubao)
Ta được kết quả như sau:
So sánh thực tế và dự báo < Bang=rbind(Thucte,Dubao) < Sosanh=data.frame(Bang) < View(Sosanh) Ta được bảng sau: Nhận xét:
Nhận thấy giá trị dự báo tỷ lệ về chất lượng rượu ở mức kém và mức xuất sắc
tăng, chất lượng rượu ở mức trung bình giảm.
Nhìn chung thì chất lượng rượu ở mức trung bình vẫn chiếm tỷ lệ cao trong mẫu.
Tài liệu tham khảo
1. Nguyễn Kiều Dung, Bài giảng Xác suất Thống kê
2. Nguyễn Tiến Dũng (chủ biên), Nguyễn Đình Huy, Xác suất – Thống kê & Phân tích số liệu, 2019
3. Nguyễn Đình Huy (chủ biên), Nguyễn Bá Thi, Giáo trình Xác suất và Thống kê, 2018
4. Introductory Statistics with R, J Jambers – D.Hand – W.Hardle
5. Applied Statistics with R, 2020
6. Bài giảng môn học Kinh tế Lượng, TS. Nguyễn Cảnh Huy lOMoARcPSD| 36991220
7. Ví dụ mẫu về hồi quy bội, Hoàng Văn Hà
8. Dữ liệu: https://data.mendeley.com/datasets/z36mjhkr5n/1
Tài liệu liên quan:
-

Tổng hợp đề thi & lời giải chi tiết môn Xác suất thống kê | Trường Đại học Bách khoa - Đại học Quốc gia Thành phố Hồ Chí Minh
51 26 -

Bài tập lớn môn Xác suất thống kê đề tài số 5 về Bộ dữ liệu “Appliances energy prediction Data Set”
450 225 -

Báo cáo bài tập lớn môn Xác suất thống kê "Stats Project 2" nội dung bằng tiếng Anh
503 252 -

Báo cáo bài tập lớn môn Xác suất thống kê đề tài "Xử lý ảnh xám áp dụng mã hóa Huffman để nén dữ liệu ảnh xám"
444 222 -

Báo cáo bài tập lớn môn Xác suất thống kê với yêu cầu "Thống kê mô tả dành cho việc chơi game thường ngày của sinh viên Bách khoa" | Đại học Bách khoa Thành phố Hồ Chí Minh
500 250