Báo cáo bài tập lớn - Nghiên cứu về Name Service | Học viện Nông nghiệp Việt Nam
Bài báo cáo tập trung vào nghiên cứu về dịch vụ tên và dịch vụ thư mục trong hệ thống phân tán. Nó cung cấp cái nhìn tổng quan về các vấn đề thiết kế cơ bản và các phương pháp tiếp cận được sử dụng trong triển khai các dịch vụ này.
Môn: Công nghệ phần mềm (HVNN) 35 tài liệu
Trường: Học viện Nông nghiệp Việt Nam 2.4 K tài liệu
Tác giả:










































Preview text:
KHOA CÔNG NGHỆ THÔNG TIN
BỘ MÔN CÔNG NGHỆ PHẦN MỀM
BÁO CÁO BÀI TẬP LỚN
HỌC PHẦN PHÁT TRIỂN PHẦN MỀM PHÂN TÁN
TÊN ĐỀ TÀI: CHỦ ĐỀ I – NGHIÊN CỨU VỀ NAME SERVICE
Nhóm sinh viên thực hiện: STT Họ tên Mã SV Mã lớp Điểm 1
Bùi Văn Hùng 665022 8 2
Vũ Hoài Nam 6656204 3 Nghiêm Ngọc 6668091 Nga
Hà Nội, tháng 06/2023 1
NHẬN XÉT CỦA GIẢNG VIÊN 2
BẢNG PHÂN CÔNG NHIỆM VỤ
Sinh viên thực hiện STT Nhiệm vụ Họ tên MSV
Phát hiện và nghiên cứu đề 1 Cả nhóm tài
Nghiên cứu phần 13.1, 13.3 Nghiêm Ngọc 2 6668091 Nga 3 Nghiên cứu phần 13.2
Vũ Hoài Nam 6656204
Nghiên cứu phần 13.4, 13.5 665022 4
Bùi Văn Hùng 8 3 Mục lục
13.1 Giới thiệu .................................................................. 6
13.1.1 Tên, Địa Chỉ Và Các Thuộc Tính Khác ............................... 6
13.2 Dịch Vụ Tên Và Hệ Thống Tên Miền ...................... 10
13.2.1 Không Gian Tên .................................................................... 11
13.2.2 Phân Giải Tên ......................................................................... 14
13.2.3 Hệ Thống Tên Miền ............................................................... 17
13.3 Dịch Vụ Thư Mục ..................................................... 25
13.4 Nghiên Cứu Điển Hình: Dịch Vụ Tên Toàn Cầu ..... 26
13.5 Nghiên Cứu Điển Hình: Dịch Vụ Thư Mục X.500 .. 30
13.6 Tóm Tắt..................................................................... 36
13.7 Tài Liệu Tham Khảo ................................................ 36 4
Chương này giới thiệu dịch vụ tên như một dịch vụ riêng biệt được sử dụng
bởi các quy trình máy khách để lấy các thuộc tính như địa chỉ của tài
nguyên hoặc đối tượng khi được đặt tên của chúng. Các thực thể được đặt
tên có thể có nhiều loại và chúng có thể được quản lý bởi các dịch vụ khác nhau.
Ví dụ: dịch vụ tên thường được sử dụng để giữ địa chỉ và các chi tiết khác
của người dùng, máy tính, miền mạng, dịch vụ và các đối tượng từ xa.
Cũng như các dịch vụ tên, chúng tôi mô tả các dịch vụ thư mục, tra cứu các
dịch vụ khi được cung cấp một số thuộc tính của chúng.
Các vấn đề thiết kế cơ bản cho các dịch vụ tên, chẳng hạn như cấu
trúc và quản lý không gian tên được dịch vụ công nhận và các hoạt
động mà dịch vụ tên hỗ trợ, được phác thảo và minh họa trong bối
cảnh Hệ thống tên miền Internet (DNS).
Chúng tôi cũng kiểm tra cách các dịch vụ định danh được triển
khai, bao gồm các khía cạnh như điều hướng thông qua một tập
hợp các máy chủ định danh khi phân giải tên, lưu vào bộ nhớ đệm
dữ liệu đặt tên và sao chép dữ liệu đặt tên để tăng hiệu suất và
tính khả dụng.Hai nghiên cứu điển hình khác được bao gồm: Dịch
vụ tên toàn cầu (GNS) và Dịch vụ thư mục X.500, bao gồm LDAP. 5
13.1 Giới thiệu
Trong một hệ thống phân tán, tên được sử dụng để chỉ nhiều
loại tài nguyên như máy tính, dịch vụ, đối tượng và tệp từ xa, cũng
như cho người dùng. Đặt tên là một vấn đề dễ bị bỏ qua nhưng dù
sao cũng là cơ bản trong thiết kế hệ thống phân tán. Tên tạo điều
kiện giao tiếp và chia sẻ tài nguyên.
Một cái tên là cần thiết để yêu cầu một hệ thống máy tính hành động
dựa trên một tài nguyên cụ thể được chọn trong số nhiều tài nguyên;
ví dụ: tên ở dạng URL là cần thiết để truy cập một trang web cụ
thể. Các quy trình không thể chia sẻ các tài nguyên cụ thể được
quản lý bởi một hệ thống máy tính trừ khi chúng có thể đặt tên cho
chúng một cách nhất quán.
Người dùng không thể liên lạc với nhau thông qua một hệ thống phân
tán trừ khi họ có thể đặt tên cho nhau, ví dụ, bằng địa chỉ email.
Tên không phải là phương tiện nhận dạng hữu ích duy nhất: các
thuộc tính mô tả là một phương tiện khác. Đôi khi khách hàng không
biết tên của thực thể cụ thể mà họ tìm kiếm, nhưng họ có một số
thông tin mô tả nó. Hoặc họ có thể yêu cầu một dịch vụ và biết một
số đặc điểm của nó nhưng không biết thực thể nào thực hiện nó.
Chương này giới thiệu các dịch vụ tên, cung cấp cho khách hàng dữ
liệu về các đối tượng được đặt tên trong các hệ thống phân tán và
khái niệm liên quan về dịch vụ thư mục, cung cấp dữ liệu về các đối
tượng thỏa mãn một mô tả nhất định. Chúng tôi mô tả các phương
pháp tiếp cận được thực hiện trong thiết kế và triển khai các dịch vụ
này, sử dụng Dịch vụ tên miền (DNS), Dịch vụ tên toàn cầu (GNS) và X500 làm 6
nghiên cứu điển hình. Chúng tôi bắt đầu bằng cách kiểm tra các khái
niệm cơ bản về tên và thuộc tính. 13.1.1
Tên, Địa Chỉ Và Các Thuộc Tính Khác
Bất kỳ quá trình nào yêu cầu quyền truy cập vào một tài nguyên
cụ thể phải có tên hoặc số nhận dạng cho tài nguyên đó. Ví dụ về tên
con người có thể đọc được là các tên tệp như
/etc/passwd, URL như http://www.cdk5.net/ và tên miền Internet như
www.cdk5.net. Thuật ngữ định danh đôi khi được sử dụng để chỉ
các tên chỉ được giải thích bởi các chương trình. Tham chiếu đối
tượng từ xa và xử lý tệp NFS là ví dụ về mã định danh. Số nhận
dạng được chọn cho hiệu quả mà chúng có thể được tra cứu và lưu trữ bằng phần mềm.
Needham [1993] phân biệt giữa một cái tên thuần túy và các tên khác.
Tên thuần túy chỉ đơn giản là các mẫu bit không được giải thích. Tên
không thuần túy chứa thông tin về đối tượng mà chúng đặt tên; Đặc
biệt, chúng có thể chứa thông tin về vị trí của đối tượng. Tên thuần
túy luôn phải được tra cứu trước khi chúng có thể được sử dụng. Ở
thái cực khác từ một tên thuần túy là địa chỉ của một đối tượng:
một giá trị xác định vị trí của đối tượng chứ không phải chính đối
tượng. Địa chỉ có hiệu quả để truy cập các đối tượng, nhưng các đối
tượng đôi khi có thể được di chuyển, vì vậy địa chỉ không đủ làm
phương tiện nhận dạng. Ví dụ: địa chỉ email của người dùng thường
phải thay đổi khi họ di chuyển giữa các tổ chức hoặc nhà cung cấp
dịch vụ Internet; Bản thân họ không được đảm bảo để đề cập đến
một cá nhân cụ thể theo thời gian.
Chúng tôi nói rằng một tên được giải quyết khi nó được dịch
thành dữ liệu về tài nguyên hoặc đối tượng được đặt tên, thường là
để gọi một hành động trên nó. Sự liên kết giữa một tên và một đối
tượng được gọi là ràng buộc. Nói chung, tên bị ràng buộc với các
thuộc tính của các đối tượng được đặt tên, thay vì thực hiện chính
các đối tượng. Một thuộc tính là
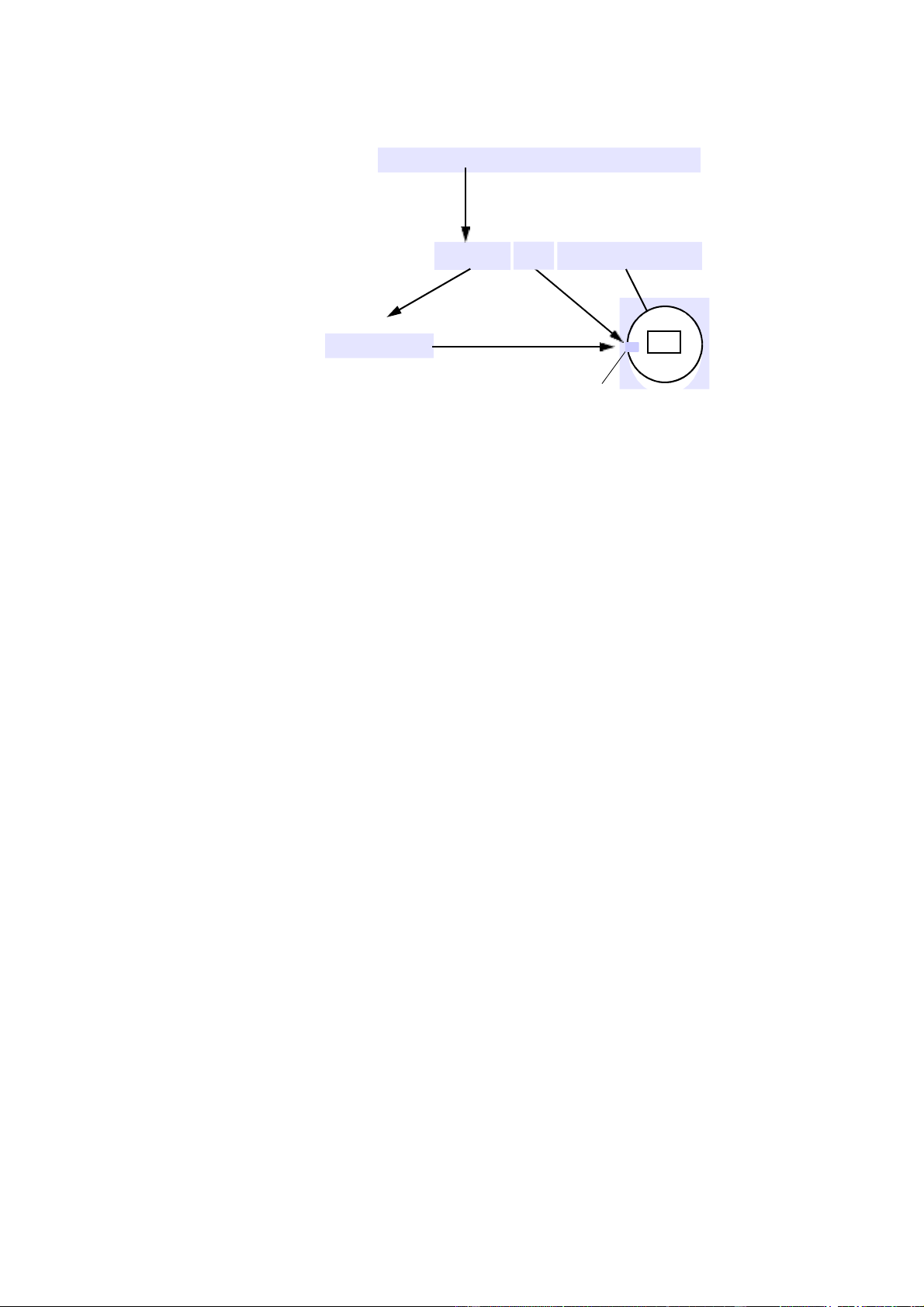
Hình 13.1: Tên miền đặt tên đã soạn được sử dụng để truy cập
tài nguyên từ URL 7 Địa chỉ Tra cứu DNS
ID tài nguyên (số IP, số cổng, tên đường dẫn)
55.55.55.55 8888 WebExamples/earth.ht ml Máy chủ web Địa chỉ mạng 2:60:8C:2:B0m : tệp 5 ộ t Socket
giá trị của một thuộc tính được liên kết với một đối tượng. Một thuộc
tính chính của một thực thể thường có liên quan trong một hệ thống
phân tán là địa chỉ của nó. Chẳng hạn:
• DNS ánh xạ tên miền đến các thuộc tính của máy chủ:
địa chỉ IP của nó, loại mục nhập (ví dụ: tham chiếu đến
máy chủ thư hoặc máy chủ khác) và, ví dụ, khoảng thời
gian mục nhập của máy chủ sẽ vẫn hợp lệ.
• Dịch vụ thư mục X500 có thể được sử dụng để ánh
xạ tên của một người vào các thuộc tính bao gồm địa chỉ
email và số điện thoại của họ.
• Dịch vụ đặt tên và dịch vụ thương mại CORBA đã được
trình bày trong Chương 8. Dịch vụ Đặt tên ánh xạ tên
của một đối tượng từ xa lên tham chiếu đối tượng từ
xa của nó, trong khi Dịch vụ Thương mại ánh xạ tên của
một đối tượng từ xa lên tham chiếu đối tượng từ xa của
nó, cùng với một số thuộc tính tùy ý mô tả đối tượng
theo thuật ngữ mà người dùng có thể hiểu được.
Lưu ý rằng một 'địa chỉ' có thể được coi là một tên khác phải được tra
cứu hoặc nó có thể chứa một tên như vậy. Địa chỉ IP phải được tra
cứu để có được địa chỉ mạng như địa chỉ Ethernet. Tương tự, các
trình duyệt web và ứng dụng email sử dụng DNS để diễn giải tên miền
trong URL và địa chỉ email. Hình 13.1 cho thấy phần tên miền của URL
được giải quyết đầu tiên thông qua DNS thành địa chỉ IP và sau đó, ở
bước nhảy cuối cùng của định tuyến Internet, thông qua ARP đến địa
chỉ Ethernet cho máy chủ web. Phần cuối cùng của URL 8
được giải quyết bởi hệ thống tệp trên máy chủ web để định vị tệp có liên quan.
Tên và dịch vụ: Nhiều tên được sử dụng trong một hệ thống phân
tán dành riêng cho một số dịch vụ cụ thể. Ví dụ: người dùng của
trang web mạng xã hội twitter.com, có tên như @magmapoetry mà
không có dịch vụ nào khác giải quyết. Ngoài ra, khách hàng có thể
sử dụng tên dịch vụ cụ thể khi yêu cầu dịch vụ thực hiện thao tác
trên một đối tượng hoặc tài nguyên được đặt tên mà nó quản lý. Ví
dụ: tên tệp được cung cấp cho dịch vụ tệp khi yêu cầu xóa tệp và
mã định danh quy trình được trình bày cho dịch vụ quản lý quy trình
khi yêu cầu gửi tín hiệu.
Các tên này chỉ được sử dụng trong ngữ cảnh của dịch vụ quản lý
các đối tượng được đặt tên, ngoại trừ khi máy khách giao tiếp về các
đối tượng được chia sẻ.
Tên đôi khi cũng cần thiết để chỉ các thực thể trong một hệ thống phân
tán nằm ngoài phạm vi của bất kỳ dịch vụ đơn lẻ nào. Các ví dụ chính
của các thực thể này là người dùng (với tên riêng và địa chỉ email),
máy tính (với tên máy chủ như www.cdk5.net) và chính các dịch vụ
(như dịch vụ tệp hoặc dịch vụ máy in). Trong phần mềm trung gian
dựa trên đối tượng, tên đề cập đến các đối tượng từ xa cung cấp dịch
vụ hoặc ứng dụng. Lưu ý rằng nhiều tên trong số này phải có thể đọc
được và có ý nghĩa đối với con người, vì người dùng và quản trị viên
hệ thống cần tham khảo các thành phần chính và cấu hình của các
hệ thống phân tán, lập trình viên cần tham khảo các dịch vụ trong
chương trình và người dùng cần giao tiếp với nhau thông qua hệ thống
phân tán và thảo luận về những dịch vụ nào có sẵn trong các phần
khác nhau của nó. Với kết nối được cung cấp bởi Internet, các yêu
cầu đặt tên này có khả năng phạm vi trên toàn thế giới.
Mã định danh tài nguyên thống nhất: Số nhận dạng tài
nguyên thống nhất (URI) [Berners-Lee et al. 2005] xuất phát từ nhu
cầu xác định tài nguyên trên Web và các tài nguyên Internet khác như
hộp thư điện tử. Một mục tiêu quan trọng là xác định các tài nguyên
một cách mạch lạc, để tất cả chúng có thể được xử lý bởi các phần
mềm phổ biến như trình duyệt. URI 'thống nhất' ở chỗ cú pháp của
chúng kết hợp vô thời hạn nhiều loại định danh tài nguyên riêng lẻ
(nghĩa là lược đồ URI) và có các quy trình quản lý không gian tên toàn 9
cầu của lược đồ. Ưu điểm của tính đồng nhất là nó giảm bớt quá trình
giới thiệu các loại định danh mới, cũng như sử dụng các loại định danh
hiện có trong bối cảnh mới, mà không làm gián đoạn việc sử dụng hiện có.
Ví dụ: nếu ai đó phát minh ra một loại URI 'widget' mới, thì URI bắt
đầu widget: sẽ phải tuân theo cú pháp URI toàn cục, cũng như bất kỳ
quy tắc cục bộ nào được xác định cho lược đồ nhận dạng widget.
Các URI này sẽ xác định tài nguyên widget theo cách được xác định
rõ. Nhưng ngay cả phần mềm hiện có không truy cập tài nguyên
widget vẫn có thể xử lý URI widget - ví dụ: bằng cách quản lý các
thư mục chứa chúng. Chuyển sang một ví dụ về việc kết hợp các số
nhận dạng hiện có, điều đó đã được thực hiện cho các số điện thoại
bằng cách tiền tố chúng với tên lược đồ tel và chuẩn hóa đại diện của
chúng, như trong điện thoại: + 1-816-555-1212. Các URI điện thoại
này được thiết kế để sử dụng như liên kết web khiến các cuộc gọi điện
thoại được thực hiện khi được gọi.
Bộ định vị tài nguyên thống nhất: Một số URI chứa thông tin có
thể được sử dụng để định vị và truy cập tài nguyên; một số khác là tên
tài nguyên thuần túy. Thuật ngữ quen thuộc Bộ định vị tài nguyên
thống nhất (URL) thường được sử dụng cho các URI cung cấp thông
tin vị trí và chỉ định phương pháp truy cập tài nguyên, bao gồm các
URL 'http' được giới thiệu trong Phần 1.6. Ví dụ: http://www.cdk5.net/
xác định một trang web tại đường dẫn đã cho ('/') trên www.cdk5.net
máy chủ lưu trữ và chỉ định rằng giao thức HTTP được sử dụng để
truy cập nó. Một ví dụ khác là URL 'mailto', chẳng hạn như
mailto:fred@flintstone.org, xác định hộp thư tại địa chỉ đã cho.
URL là số nhận dạng hiệu quả để truy cập tài nguyên. Nhưng họ phải
chịu bất lợi là nếu một tài nguyên bị xóa hoặc nếu nó di chuyển, giả
sử từ trang web này sang trang web khác, có thể có các liên kết treo
lủng lẳng đến tài nguyên chứa URL cũ. Nếu người dùng nhấp vào
một liên kết lủng lẳng đến tài nguyên web, thì máy chủ web sẽ phản
hồi rằng tài nguyên không được tìm thấy hoặc - tệ hơn, có lẽ - cung
cấp một tài nguyên khác hiện chiếm cùng một vị trí.
Tên tài nguyên thống nhất: Tên tài nguyên thống nhất (URN) là
URI được sử dụng làm tên tài nguyên thuần túy thay vì bộ định vị. Ví dụ: URI: 10
mid:0E4FC272-5C02-11D9-B115-
000A95B55BC8@hpl.hp.com
là một URN xác định email có chứa nó trong trường 'Message- Id' của
nó. URI phân biệt thư đó với bất kỳ thư email nào khác. Nhưng nó
không cung cấp địa chỉ của tin nhắn trong bất kỳ cửa hàng nào, vì
vậy cần phải có thao tác tra cứu để tìm thấy nó.
Một cây con đặc biệt của URI bắt đầu bằng urn: đã được dành
riêng cho URN - mặc dù, như ví dụ giữa: cho thấy, không phải tất
cả các URN đều là urn: URI. Các URI urnprefix sau này đều có dạng
urn:nameSpace:nameSpace- specificName. Ví dụ: urn:ISBN:0-201-
62433-8 xác định sách mang tên 0-201-62433-8 trong lược đồ đặt tên
ISBN tiêu chuẩn. Một ví dụ khác, tên (được phát minh)
urn:doi:10.555/music-pop-1234 đề cập đến ấn phẩm được gọi là
music-pop-1234 trong sơ đồ đặt tên của nhà xuất bản được gọi là
10.555 trong lược đồ Mã định danh đối tượng kỹ thuật số (DOI)
[www.doi.org].
Có các dịch vụ phân giải (dịch vụ tên, theo thuật ngữ của chương này)
như Hệ thống xử lý [www.handle.net] để phân giải các URN như DOI
thành các thuộc tính tài nguyên, nhưng không có dịch vụ nào được
sử dụng rộng rãi. Thật vậy, vẫn tiếp tục có cuộc tranh luận trong
cộng đồng nghiên cứu Web và Internet về mức độ cần thiết của một
loại URN riêng biệt. Một trường phái tư tưởng là 'URL thú vị không
thay đổi' - nói cách khác, mọi người nên gán URL cho các tài nguyên
với sự đảm bảo về tính liên tục tham chiếu của chúng. Chống lại quan
điểm đó là quan sát rằng không phải ai cũng có thể đưa ra những
đảm bảo như vậy, điều này đòi hỏi phải duy trì quyền kiểm soát
tên miền và quản lý tài nguyên một cách cẩn thận. 11 13.2
Dịch Vụ Tên Và Hệ Thống Tên Miền
Dịch vụ tên lưu trữ thông tin về một tập hợp các tên văn
bản, dưới dạng ràng buộc giữa tên và các thuộc tính của các thực thể
mà chúng biểu thị, chẳng hạn như người dùng, máy tính, dịch vụ và
đối tượng. Bộ sưu tập thường được chia thành một hoặc nhiều bối
cảnh đặt tên: các tập hợp con riêng lẻ của các ràng buộc được quản lý
như một đơn vị. Hoạt động chính mà dịch vụ tên hỗ trợ là giải quyết
tên - nghĩa là tra cứu các thuộc tính từ một tên nhất định. Chúng tôi
mô tả việc thực hiện giải pháp tên trong Mục 13.2.2. Các thao tác
cũng được yêu cầu để tạo các ràng buộc mới, xóa ràng buộc và liệt kê
các tên bị ràng buộc, cũng như thêm và xóa ngữ cảnh.
Quản lý tên được tách ra khỏi các dịch vụ khác phần lớn là do tính mở
của các hệ thống phân tán, mang lại các động lực sau:
Thống nhất: Thường thuận tiện cho các tài nguyên được quản lý
bởi các dịch vụ khác nhau sử dụng cùng một sơ đồ đặt tên. URI là
một ví dụ điển hình về điều này.
Tích hợp: Không phải lúc nào cũng có thể dự đoán phạm vi chia sẻ
trong một hệ thống phân tán. Nó có thể trở nên cần thiết để chia sẻ
và do đó đặt tên cho các tài nguyên được tạo trong các miền
quản trị khác nhau. Nếu không có dịch vụ tên chung, các miền
quản trị có thể sử dụng các quy ước đặt tên hoàn toàn khác nhau.
Yêu cầu dịch vụ tên chung: Dịch vụ định danh ban đầu khá đơn
giản, vì chúng được thiết kế chỉ để đáp ứng nhu cầu liên kết tên với
các địa chỉ trong một miền quản lý duy nhất, tương ứng với một mạng
LAN hoặc mạng WAN duy nhất. Sự kết nối của các mạng và quy mô
ngày càng tăng của các hệ thống phân tán đã tạo ra một vấn đề lập
bản đồ tên lớn hơn nhiều.
Grapevine [Birrell et al. 1982] là một trong những dịch vụ tên miền đa
miền, có thể mở rộng sớm nhất. Nó được thiết kế để có thể mở rộng
về số lượng tên và tải các yêu cầu mà nó có thể xử lý. 12
Dịch vụ Tên Toàn cầu, được phát triển tại Trung tâm Nghiên cứu Hệ
thống Tập đoàn Thiết bị Kỹ thuật số [Lampson 1986], là hậu duệ của
Grapevine với các mục tiêu đầy tham vọng, bao gồm:
Để xử lý một số lượng tên về cơ bản tùy ý và để phục vụ một số
lượng tùy ý của các tổ chức hành chính: Ví dụ, hệ thống phải có
khả năng xử lý tên của tất cả các tài liệu trên thế giới.
Tuổi thọ dài: Nhiều thay đổi sẽ xảy ra trong việc tổ chức tập hợp tên
và trong các thành phần triển khai dịch vụ trong suốt vòng đời của nó.
Tính sẵn sàng cao: Hầu hết các hệ thống khác phụ thuộc vào
dịch vụ tên; chúng không thể hoạt động khi nó bị hỏng.
Cách ly lỗi: Lỗi cục bộ không được khiến toàn bộ dịch vụ bị lỗi.
Khả năng chịu đựng sự ngờ vực: Một hệ thống mở lớn không thể
có bất kỳ thành phần nào được tin cậy bởi tất cả các khách hàng trong hệ thống.
Hai ví dụ về dịch vụ tên đã tập trung vào mục tiêu khả năng mở rộng
cho số lượng lớn các đối tượng như tài liệu là dịch vụ tên Globe [van
Steen et al. 1998] và Hệ thống xử lý [www.handle.net]. Quen thuộc
hơn nhiều là Hệ thống tên miền Internet (DNS), được giới thiệu trong
Chương 3, đặt tên cho các máy tính (và các thực thể khác) trên Internet.
Trong phần này, chúng tôi thảo luận về các vấn đề thiết kế chính cho
các dịch vụ tên, đưa ra các ví dụ từ DNS. Chúng tôi theo dõi điều này
với một nghiên cứu điển hình chi tiết hơn về DNS. 13.2.1
Không Gian Tên
Không gian tên là tập hợp tất cả các tên hợp lệ được công nhận
bởi một dịch vụ cụ thể. Dịch vụ sẽ cố gắng tra cứu một tên hợp lệ,
mặc dù tên đó có thể chứng minh không tương ứng với bất kỳ đối
tượng nào - tức là không bị ràng buộc. Không gian tên yêu cầu định
nghĩa cú pháp để tách tên hợp lệ khỏi tên không hợp lệ. Ví dụ: '...'
không được chấp nhận là tên DNS của máy tính, trong khi
www.cdk99.net là hợp lệ (mặc dù nó không bị ràng buộc). 13
Tên có thể có cấu trúc bên trong đại diện cho vị trí của chúng trong
không gian tên phân cấp như tên đường dẫn trong hệ thống tệp hoặc
trong hệ thống phân cấp tổ chức như tên miền Internet; hoặc chúng
có thể được chọn từ một bộ định danh số hoặc tượng trưng phẳng.
Một lợi thế quan trọng của hệ thống phân cấp là nó làm cho không
gian tên lớn dễ quản lý hơn. Mỗi phần của tên phân cấp được giải
quyết liên quan đến một ngữ cảnh riêng biệt có kích thước tương đối
nhỏ và cùng một tên có thể được sử dụng với ý nghĩa khác nhau
trong các ngữ cảnh khác nhau, để phù hợp với các tình huống sử dụng
khác nhau. Trong trường hợp hệ thống tệp, mỗi thư mục đại diện cho
một ngữ cảnh. Do đó, /etc/passwd là một tên phân cấp với hai
thành phần. Phần đầu tiên, 'etc', được giải quyết liên quan đến ngữ
cảnh '/', hoặc root, và phần thứ hai, 'passwd', liên quan đến
ngữ cảnh '/etc'. Tên /oldetc/passwd có thể có ý nghĩa khác vì
thành phần thứ hai của nó được giải quyết trong một ngữ cảnh
khác. Tương tự, cùng một tên /etc/passwd có thể phân giải các tệp
khác nhau trong ngữ cảnh của hai máy tính khác nhau.
Không gian tên phân cấp có khả năng vô hạn, vì vậy chúng cho phép
một hệ thống phát triển vô thời hạn. Ngược lại, không gian tên phẳng
thường là hữu hạn; Kích thước của chúng được xác định bằng cách
cố định độ dài tối đa cho phép cho tên. Một lợi thế tiềm năng khác
của không gian tên phân cấp là các ngữ cảnh khác nhau có thể được
quản lý bởi những người hoặc tổ chức khác nhau.
Cấu trúc của URL 'http' đã được giới thiệu trong Chương 1. Không
gian tên URL cũng bao gồm các tên tương đối như .. /hình
ảnh/hình1.jpg. Khi một trình duyệt hoặc máy khách web khác gặp phải
một tên tương đối như vậy, nó sử dụng tài nguyên trong đó tên tương
đối được nhúng để xác định tên máy chủ lưu trữ và thư mục mà
tên đường dẫn này đề cập đến.
Tên DNS là chuỗi được gọi là tên miền. Một số ví dụ là www.cdk5.net
(máy tính), net, com và ac.uk (ba ví dụ sau là tên miền).
Không gian tên DNS có cấu trúc phân cấp: tên miền bao gồm một
hoặc nhiều chuỗi được gọi là thành phần tên hoặc nhãn, được phân
tách bằng dấu phân cách '.'. Không có dấu phân cách ở đầu hoặc
cuối tên miền, mặc dù thư mục gốc của 14
không gian tên DNS đôi khi được gọi là '.' cho mục đích quản trị. Các
thành phần tên là các chuỗi không thể in rỗng không chứa '.'. Nói
chung, tiền tố của tên là một phần ban đầu của tên chỉ chứa 0 hoặc
nhiều thành phần toàn bộ. Ví dụ: trong DNS www và www.cdk5 đều
là tiền tố của www.cdk5.net. Tên DNS không phân biệt chữ hoa chữ
thường, vì vậy www.cdk5.net và WWW.CDK5.NET có cùng ý nghĩa.
Máy chủ DNS không nhận ra tên tương đối: tất cả các tên được
gọi đến thư mục gốc toàn cục. Tuy nhiên, trong triển khai thực tế,
phần mềm máy khách giữ một danh sách các tên miền được gắn
tự động vào bất kỳ tên thành phần đơn nào trước khi giải quyết. Ví
dụ: tên www được trình bày trong miền cdk5.net có thể đề cập đến
www.cdk5.net; Phần mềm máy khách sẽ nối thêm cdk5.net miền mặc
định và cố gắng giải quyết tên này. Nếu điều này không thành
công, thì các tên miền mặc định khác có thể được thêm vào; Cuối
cùng, tên (tuyệt đối) www sẽ được trình bày cho thư mục gốc để
giải quyết (một thao tác tất nhiên sẽ thất bại trong trường hợp này).
Tuy nhiên, các tên có nhiều hơn một thành phần thường được trình
bày nguyên vẹn cho DNS, dưới dạng tên tuyệt đối.
Bí danh: Bí danh là tên được xác định để biểu thị thông tin giống
như tên khác, tương tự như liên kết tượng trưng giữa tên đường dẫn
tệp. Bí danh cho phép các tên thuận tiện hơn được thay thế cho các
tên tương đối phức tạp và cho phép các tên thay thế được sử
dụng bởi những người khác nhau cho cùng một thực thể. Một ví
dụ là việc sử dụng phổ biến các công cụ rút ngắn URL, thường được
sử dụng trong các bài đăng trên Twitter và các tình huống khác trong
đó không gian ở mức cao.
Ví dụ: sử dụng chuyển hướng web, http://bit.ly/ctqjvH đề cập đến
http://cdk5.net/additional/rmi/programCode/ShapeListClient.j ava. Một
ví dụ khác, DNS cho phép các bí danh trong đó một tên miền được
xác định là viết tắt của một tên miền khác. Bí danh thường được sử
dụng để chỉ định tên của các máy chạy máy chủ web hoặc máy chủ
FTP. Ví dụ: tên www.cdk5.net là bí danh của cdk5.net. Điều này có
lợi thế là khách hàng có thể sử dụng một trong hai tên cho máy
chủ web và nếu máy chủ web được di chuyển sang máy tính
khác, chỉ cần cập nhật mục nhập cho cdk5.net trong cơ sở dữ liệu DNS. 15
Đặt tên miền: Tên miền đặt tên là một không gian tên tồn tại một
cơ quan quản trị tổng thể duy nhất chịu trách nhiệm gán tên trong đó.
Cơ quan này kiểm soát tổng thể tên nào có thể bị ràng buộc trong
miền, nhưng có thể tự do ủy thác nhiệm vụ này.
Tên miền trong DNS là tập hợp các tên miền; về mặt cú pháp, tên
miền là hậu tố chung của các tên miền trong đó, nhưng nếu không thì
không thể phân biệt được, ví dụ, tên máy tính. Ví dụ: net là một tên
miền chứa cdk5.net. Lưu ý rằng thuật ngữ 'tên miền' có khả năng
gây nhầm lẫn, vì chỉ một số tên miền xác định tên miền (những tên
miền khác xác định máy tính).
Việc quản lý tên miền có thể được phân cấp thành tên miền phụ. Tên
miền dcs.qmul.ac.uk - Khoa Khoa học Máy tính tại Queen Mary, Đại
học London ở Anh - có thể chứa bất kỳ tên nào mà khoa muốn.
Nhưng bản thân tên miền dcs.qmul.ac.uk phải được thỏa thuận với
chính quyền trường đại học, những người quản lý tên miền
qmul.ac.uk. Tương tự, qmul.ac.uk phải được thỏa thuận với cơ quan đăng ký ac.uk, v.v.
Trách nhiệm đối với tên miền đặt tên thường đi đôi với trách nhiệm
quản lý và cập nhật phần tương ứng của cơ sở dữ liệu được lưu trữ
trong máy chủ tên có thẩm quyền và được sử dụng bởi dịch vụ định
danh. Dữ liệu đặt tên thuộc các miền đặt tên khác nhau nói chung
được lưu trữ bởi các máy chủ tên riêng biệt do các cơ quan tương ứng quản lý.
Kết hợp và tùy chỉnh không gian tên: DNS cung cấp một không
gian tên toàn cục và đồng nhất, trong đó một tên nhất định đề cập đến
cùng một thực thể, bất kể quy trình nào trên máy tính nào tra cứu tên.
Ngược lại, một số dịch vụ tên cho phép các không gian tên riêng biệt -
đôi khi là không gian tên không đồng nhất - được nhúng vào chúng; Và
một số dịch vụ tên cho phép không gian tên được tùy chỉnh để phù
hợp với nhu cầu của từng nhóm, người dùng hoặc thậm chí các quy trình.
Hợp nhất: Thực tiễn gắn các hệ thống tệp trong UNIX và NFS
(xem Phần 12.3) cung cấp một ví dụ trong đó một phần của không
gian tên này được nhúng thuận tiện vào một không gian tên khác.
Nhưng hãy xem xét cách hợp nhất toàn bộ hệ thống tệp UNIX của
hai (hoặc nhiều) máy tính được gọi 16
là đỏ và xanh. Mỗi máy tính có gốc riêng, với các tên tệp chồng
chéo. Ví dụ: /etc/passwd đề cập đến một tệp có màu đỏ và một tệp
khác có màu xanh lam. Cách rõ ràng để hợp nhất các hệ thống tệp là
thay thế gốc của mỗi máy tính bằng 'siêu root' và gắn kết hệ thống
tệp của mỗi máy tính trong siêu root này, giả sử là / đỏ và / xanh.
Người dùng và chương trình sau đó có thể tham khảo / red / etc /
passwd và / blue / etc / passwd. Nhưng quy ước đặt tên mới tự nó sẽ
khiến các chương trình trên hai máy tính vẫn sử dụng
tên cũ /etc/passwd gặp trục trặc. Một giải pháp là để lại nội dung gốc
cũ trên mỗi máy tính và nhúng các hệ thống tệp được gắn / đỏ và /
xanh của cả hai máy tính (giả sử rằng điều này không tạo ra xung đột
tên với nội dung gốc cũ).
Đạo đức là chúng ta luôn có thể hợp nhất các không gian tên bằng
cách tạo ra một ngữ cảnh gốc cấp cao hơn, nhưng điều này có thể
gây ra vấn đề về khả năng tương thích ngược. Khắc phục sự cố
tương thích, lần lượt, để lại cho chúng tôi không gian tên lai và sự bất
tiện khi phải dịch tên cũ giữa những người dùng của hai máy tính.
Không đồng nhất: Không gian tên Môi trường điện toán phân
tán (DCE) [OSF 1997] cho phép các không gian tên không đồng nhất
được nhúng vào trong đó. Tên DCE có thể chứa các điểm nối, tương
tự như các điểm gắn trong NFS và UNIX (xem Phần 12.3), ngoại trừ
việc chúng cho phép gắn các khoảng trắng tên không đồng nhất. Ví dụ: hãy xem xét tên DCE đầy đủ
/.../dcs.qmul.ac.uk/principals/Jean.Dollimore. Phần đầu tiên của tên
này, /.../dcs.qmul.ac.uk, biểu thị một ngữ cảnh được gọi là ô. Thành
phần tiếp theo là một ngã ba. Ví dụ, các hiệu trưởng nối là một ngữ
cảnh chứa các nguyên tắc bảo mật trong đó thành phần cuối cùng,
Jean.Dollimore, có thể được tra cứu và trong đó các tên chính này có cú pháp riêng. Tương tự, trong
/.../dcs.qmul.ac.uk/files/pub/reports/TR2000-99, các tệp nối là một
ngữ cảnh tương ứng với thư mục hệ thống tệp, trong đó thành phần
cuối cùng pub / reports / TR2000-99 được tra cứu và trong đó không
gian tên tệp có cú pháp riêng biệt. Hai điểm nối chính và tệp là gốc
rễ của không gian tên không đồng nhất, được thực hiện bởi các dịch
vụ tên không đồng nhất. 17
Tùy chỉnh: Chúng tôi đã thấy trong ví dụ về việc nhúng các hệ
thống tệp được gắn NFS ở trên rằng đôi khi người dùng thích xây
dựng không gian tên của họ một cách độc lập hơn là chia sẻ một
không gian tên duy nhất. Việc gắn kết hệ thống tệp cho phép
người dùng nhập các tệp được lưu trữ trên máy chủ và được chia
sẻ, trong khi các tên khác tiếp tục đề cập đến các tệp cục bộ, không
được chia sẻ và có thể được quản lý tự động. Nhưng các tệp giống
nhau được truy cập từ hai máy tính khác nhau có thể được gắn tại các
điểm khác nhau và do đó có tên khác nhau. Không chia sẻ toàn bộ
không gian tên có nghĩa là người dùng phải dịch tên giữa các máy tính.
Dịch vụ đặt tên mùa xuân [Radia et al. 1993] cung cấp khả năng xây
dựng không gian tên một cách linh hoạt và chia sẻ ngữ cảnh đặt tên
riêng lẻ một cách có chọn lọc. Ngay cả hai quy trình khác nhau trên
cùng một máy tính cũng có thể có ngữ cảnh đặt tên khác nhau. Ngữ
cảnh đặt tên mùa xuân là các đối tượng hạng nhất có thể được chia
sẻ xung quanh một hệ thống phân tán. Ví dụ: giả sử người dùng
trên máy tính màu đỏ muốn chạy một chương trình màu xanh lam
đưa ra các tên đường dẫn tệp như /etc/passwd, nhưng những tên này
là để phân giải các tệp trên hệ thống tệp của màu đỏ, không phải màu
xanh lam. Điều này có thể đạt được trong Spring bằng cách chuyển
một tham chiếu đến ngữ cảnh đặt tên cục bộ của màu đỏ sang màu
xanh lam và sử dụng nó làm ngữ cảnh đặt tên của chương trình. Kế
hoạch 9 [Pike et al. 1993] cũng cho phép các quy trình có không gian
tên hệ thống tệp của riêng chúng. Một tính năng mới của Plan 9 (cũng
có thể được thực hiện trong Spring) là các thư mục vật lý có thể
được sắp xếp và hợp nhất thành một thư mục logic duy nhất. Hiệu quả
là một tên được tra cứu trong thư mục logic duy nhất được tra cứu
trong liên tiếp các thư mục vật lý cho đến khi có kết quả khớp, khi các
thuộc tính được trả về. Điều này giúp loại bỏ sự cần thiết phải cung
cấp danh sách các đường dẫn khi tìm kiếm các tệp chương trình hoặc thư viện. 18 13.2.2
Phân Giải Tên
Đối với trường hợp phổ biến của không gian tên phân cấp, phân
giải tên là một quá trình lặp đi lặp lại hoặc đệ quy, theo đó một tên
được trình bày nhiều lần cho ngữ cảnh đặt tên để tra cứu các thuộc
tính mà nó đề cập đến. Ngữ cảnh đặt tên hoặc ánh xạ trực tiếp một tên
nhất định vào một tập hợp các thuộc tính nguyên thủy (chẳng hạn như
của người dùng) hoặc ánh xạ nó vào ngữ cảnh đặt tên tiếp theo và tên
dẫn xuất để trình bày cho ngữ cảnh đó. Để giải quyết một cái tên,
trước tiên nó được trình bày cho một số ngữ cảnh đặt tên ban đầu;
Độ phân giải lặp lại miễn là các ngữ cảnh và tên dẫn xuất khác
được xuất ra. Chúng tôi đã minh họa điều này ở đầu Phần 13.2.1
với ví dụ về /etc/passwd, trong đó 'etc' được trình bày theo ngữ
cảnh '/', và sau đó 'passwd' được trình bày cho ngữ cảnh '/etc'.
Một ví dụ khác về bản chất lặp đi lặp lại của độ phân giải là việc sử
dụng bí danh. Ví dụ: bất cứ khi nào máy chủ DNS được yêu cầu
phân giải bí danh như www.dcs.qmul.ac.uk, trước tiên máy chủ sẽ
phân giải bí danh thành một tên miền khác (trong trường hợp này là
traffic.dcs.qmul.ac.uk), phải được giải quyết thêm để tạo địa chỉ IP.
Nói chung, việc sử dụng bí danh làm cho các chu kỳ có thể có mặt
trong không gian tên, trong trường hợp đó độ phân giải có thể
không bao giờ chấm dứt. Hai giải pháp khả thi là, từ bỏ quy trình giải
quyết nếu nó vượt qua ngưỡng số lượng nghị quyết hoặc để quản trị
viên phủ quyết bất kỳ bí danh nào sẽ giới thiệu chu kỳ.
Máy chủ định danh và điều hướng: Bất kỳ dịch vụ tên nào,
chẳng hạn như DNS, lưu trữ cơ sở dữ liệu rất lớn và được sử dụng
bởi một dân số lớn sẽ không lưu trữ tất cả thông tin đặt tên của nó
trên một máy tính máy chủ duy nhất. Một máy chủ như vậy sẽ là một
nút cổ chai và một điểm thất bại quan trọng. Bất kỳ dịch vụ tên nào
được sử dụng nhiều nên sử dụng sao chép để đạt được tính sẵn
sàng cao. Chúng ta sẽ thấy rằng DNS chỉ định rằng mỗi tập hợp
con của cơ sở dữ liệu của nó được sao chép trong ít nhất hai máy
chủ độc lập với lỗi.
Chúng tôi đã đề cập ở trên rằng dữ liệu thuộc về miền đặt tên thường
được lưu trữ bởi một máy chủ định danh cục bộ được quản lý bởi cơ
quan chịu trách nhiệm về tên miền đó. Mặc dù, 19
trong một số trường hợp, một máy chủ định danh có thể lưu trữ dữ
liệu cho nhiều miền, nhưng nhìn chung đúng khi nói rằng dữ liệu được
phân vùng thành các máy chủ theo miền của nó. Chúng ta sẽ thấy
rằng trong DNS, hầu hết các mục nhập đều dành cho máy tính cục bộ.
Nhưng cũng có các máy chủ định danh cho các tên miền cao hơn,
chẳng hạn như yahoo.com và ac.uk, và cho thư mục gốc.
Việc phân vùng dữ liệu ngụ ý rằng máy chủ tên cục bộ không thể trả
lời tất cả các câu hỏi mà không có sự trợ giúp của các máy chủ tên
khác. Ví dụ: máy chủ định danh trong miền dcs.qmul.ac.uk sẽ không
thể cung cấp địa chỉ IP của máy tính trong miền cs.purdue.edu trừ khi
nó được lưu trong bộ nhớ cache - chắc chắn không phải là lần đầu
tiên nó được yêu cầu.
Quá trình định vị dữ liệu đặt tên từ nhiều máy chủ tên để phân giải
tên được gọi là điều hướng. Phần mềm phân giải tên máy khách
thực hiện điều hướng thay mặt cho khách hàng. Nó giao tiếp với các
máy chủ định danh khi cần thiết để phân giải tên. Nó có thể được
cung cấp dưới dạng mã thư viện và được liên kết với các máy khách,
ví dụ như trong việc triển khai BIND cho DNS (xem Phần 13.2.3) hoặc
trong Grapevine [Birrell et al. 1982]. Giải pháp thay thế, được sử dụng
với X500, là cung cấp độ phân giải tên trong một quy trình riêng biệt
được chia sẻ bởi tất cả các quy trình máy khách trên máy tính đó.
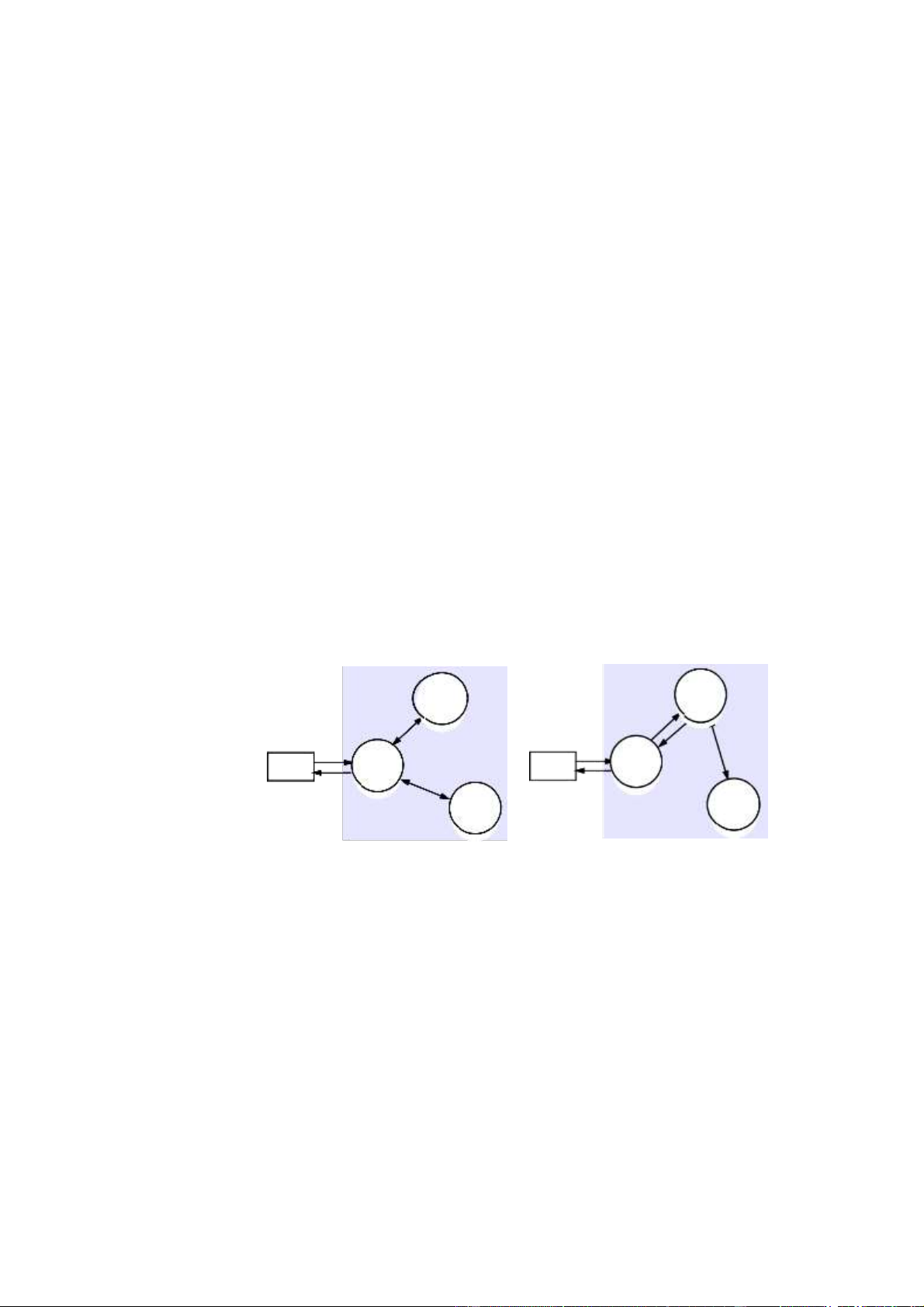
Một mô hình điều hướng mà DNS hỗ trợ được gọi là điều hướng
lặp lại (xem Hình 13.2). Để giải quyết tên, máy khách trình bày tên cho
máy chủ tên cục bộ, máy chủ này cố gắng giải quyết nó. Nếu máy
chủ tên cục bộ có tên, nó sẽ trả về kết quả ngay lập tức. Nếu không,
nó sẽ đề xuất một máy chủ khác có thể trợ giúp. Việc giải quyết tiến
hành tại máy chủ mới, với điều hướng tiếp theo khi cần thiết cho đến
khi tên được định vị hoặc được phát hiện là không bị ràng buộc.
Vì DNS được thiết kế để chứa các mục nhập cho hàng triệu tên
miền và được truy cập bởi số lượng lớn khách hàng, nên sẽ không
khả thi khi có tất cả các truy vấn bắt đầu từ máy chủ gốc, ngay cả
khi nó được sao chép nhiều. Cơ sở dữ liệu DNS được phân vùng giữa
các máy chủ theo cách cho phép nhiều truy vấn được thỏa mãn cục bộ
và các truy vấn khác được thỏa mãn mà không cần phải giải quyết từng phần của 20
tên riêng biệt. Sơ đồ phân giải tên trong DNS được mô tả chi tiết hơn trong Phần 13.2.3.
Hình 13.2: Điều hướng lặp lại NS2 2 Tên 1 Máy chủ Khách NS1 hàng 3 NS3
Một máy khách lặp đi lặp lại liên hệ với máy chủ tên
NS1–NS3 để phân giải tên
NFS cũng sử dụng điều hướng lặp lại trong độ phân giải của tên tệp,
trên cơ sở từng thành phần (xem Chương 12). Điều này là do dịch vụ
tệp có thể gặp liên kết tượng trưng khi phân giải tên. Một liên kết
tượng trưng phải được diễn giải trong không gian tên hệ thống tệp của
máy khách vì nó có thể trỏ đến một tệp trong thư mục được lưu trữ
tại một máy chủ khác. Máy khách phải xác định đây là máy chủ nào,
bởi vì chỉ có máy khách biết các điểm gắn kết của nó.
Trong điều hướng đa hướng, một máy khách multicast tên cần giải
quyết và loại đối tượng cần thiết cho nhóm máy chủ tên. Chỉ máy chủ
chứa các thuộc tính được đặt tên mới phản hồi yêu cầu. Tuy nhiên,
thật không may, nếu tên được chứng minh là không bị ràng buộc,
yêu cầu sẽ được chào đón bằng sự im lặng. Cheriton và Mann
[1989] mô tả một sơ đồ điều hướng dựa trên đa hướng trong đó một
máy chủ riêng biệt được bao gồm trong nhóm để phản hồi khi tên yêu
cầu không bị ràng buộc.
Một giải pháp thay thế khác cho mô hình điều hướng lặp lại là mô hình
trong đó máy chủ tên điều phối độ phân giải của tên và chuyển kết
quả trở lại tác nhân người dùng. Ma [1992] phân biệt điều hướng
điều khiển máy chủ không đệ quy và đệ quy (Hình 13.3). Trong điều
hướng điều khiển máy chủ không đệ quy, bất kỳ máy chủ tên nào cũng
có thể được chọn bởi máy khách. Máy chủ này giao tiếp bằng
multicast hoặc lặp đi lặp lại với các đồng nghiệp của nó theo phong cách 21
được mô tả ở trên, như thể nó là một máy khách. Trong điều hướng
điều khiển máy chủ đệ quy, máy khách một lần nữa liên hệ với một
máy chủ duy nhất. Nếu máy chủ này không lưu trữ tên, máy chủ
sẽ liên hệ với một đồng nghiệp lưu trữ tiền tố (lớn hơn) của tên, từ
đó cố gắng giải quyết nó. Quy trình này tiếp tục đệ quy cho đến khi tên được giải quyết.
Nếu một dịch vụ tên trải rộng trên các miền quản trị riêng biệt, thì
các máy khách thực thi trong một miền quản trị có thể bị cấm truy
cập vào các máy chủ định danh thuộc về một miền khác như vậy. Hơn
nữa, ngay cả các máy chủ định danh cũng có thể bị cấm phát hiện ra
việc đặt tên dữ liệu trên các máy chủ định danh trong một miền quản trị
khác. Sau đó, cả điều hướng do máy chủ điều khiển và không đệ
quy đều không phù hợp và điều hướng do máy chủ điều khiển đệ quy
phải được sử dụng. Máy chủ định danh được ủy quyền yêu cầu dữ
liệu dịch vụ tên từ các máy chủ tên được chỉ định do các cơ quan
quản trị khác nhau quản lý, trả về các thuộc tính mà không tiết lộ nơi
lưu trữ các phần khác nhau của cơ sở dữ liệu đặt tên.
Hình 13.3: Điều hướng không đệ quy và đệ quy do máy chủ điều khiển NS2 NS2 2 2 4 1 3 1 khách NS1 khách NS1 hàng 4 3 hàng 5 NS3 NS3 Không đệ quy Đệ quy Điều khiển máy chủ Điều khiển máy chủ
Máy chủ định danh NS1 giao tiếp với các máy chủ tên khác thay mặt cho máy khách
Bộ nhớ đệm: Trong DNS và các dịch vụ tên khác, phần mềm và
máy chủ phân giải tên máy khách duy trì bộ nhớ cache của kết quả
phân giải tên trước đó. Khi khách hàng yêu cầu tra cứu tên, phần
mềm phân giải tên sẽ tham khảo bộ nhớ cache của nó. Nếu nó giữ
một kết quả gần đây từ một tra cứu trước đó cho tên, nó sẽ trả về cho khách hàng; nếu 22
không, nó thiết lập về việc tìm kiếm nó từ một máy chủ. Máy chủ đó,
lần lượt, có thể trả về dữ liệu được lưu trong bộ nhớ cache từ các máy chủ khác.
Bộ nhớ đệm là chìa khóa cho hiệu suất của dịch vụ định danh và hỗ
trợ duy trì tính khả dụng của cả dịch vụ định danh và các dịch vụ
khác bất chấp sự cố máy chủ định danh. Vai trò của nó trong việc
tăng cường thời gian phản hồi bằng cách lưu thông tin liên lạc với
các máy chủ định danh là rõ ràng. Bộ nhớ đệm có thể được sử dụng
để loại bỏ các máy chủ định danh cấp cao – đặc biệt là máy chủ
gốc – khỏi đường dẫn điều hướng, cho phép giải quyết tiến hành
mặc dù có một số lỗi máy chủ.
Bộ nhớ đệm theo trình phân giải tên máy khách được áp dụng rộng rãi
trong các dịch vụ tên và đặc biệt thành công vì dữ liệu đặt tên
được thay đổi tương đối hiếm. Ví dụ: thông tin như địa chỉ máy tính
hoặc dịch vụ có thể không thay đổi trong nhiều tháng hoặc nhiều năm.
Tuy nhiên, khả năng tồn tại của một dịch vụ tên trả về các thuộc tính lỗi
thời - ví dụ: địa chỉ lỗi thời - trong quá trình giải quyết. 13.2.3
Hệ Thống Tên Miền
Hệ thống tên miền là một thiết kế dịch vụ tên có cơ sở dữ liệu đặt
tên chính được sử dụng trên Internet. Nó được nghĩ ra chủ yếu bởi
Mockapetris và được chỉ định trong RFC 1034 [Mockapetris 1987] và
RFC 1035. DNS đã thay thế sơ đồ đặt tên Internet ban đầu, trong đó
tất cả các tên và địa chỉ máy chủ được giữ trong một tệp chính trung
tâm duy nhất và được FTP tải xuống cho tất cả các máy tính yêu cầu
chúng [Harrenstien et al. 1985]. Đề án ban đầu này đã sớm được
nhìn thấy có ba thiếu sót lớn:
• Nó không mở rộng quy mô cho số lượng lớn máy tính.
• Các tổ chức địa phương muốn quản lý hệ thống đặt tên của riêng họ.
• Một dịch vụ tên chung là cần thiết - không phải là một dịch vụ
chỉ phục vụ cho việc tra cứu địa chỉ máy tính.
Các đối tượng được đặt tên bởi DNS chủ yếu là máy tính - chủ yếu là
địa chỉ IP được lưu trữ dưới dạng thuộc tính - và những gì chúng tôi
đã đề cập trong chương này là tên miền đặt tên 23
được gọi đơn giản là tên miền trong DNS. Tuy nhiên, về nguyên tắc,
bất kỳ loại đối tượng nào cũng có thể được đặt tên và kiến trúc của
nó cung cấp phạm vi cho nhiều triển khai khác nhau. Các tổ chức và
phòng ban trong đó có thể quản lý dữ liệu đặt tên của riêng họ. Hàng
triệu tên bị ràng buộc bởi DNS Internet và các tra cứu được thực hiện
chống lại nó từ khắp nơi trên thế giới. Bất kỳ tên nào cũng có thể được
giải quyết bởi bất kỳ khách hàng nào. Điều này đạt được bằng cách
phân vùng phân cấp cơ sở dữ liệu tên, bằng cách sao chép dữ liệu
đặt tên và bằng bộ nhớ đệm.
Tên miền: DNS được thiết kế để sử dụng trong nhiều triển khai,
mỗi triển khai có thể có không gian tên riêng. Tuy nhiên, trên thực tế,
chỉ có một cái được sử dụng rộng rãi và đó là cái được sử dụng
để đặt tên trên Internet. Không gian tên DNS Internet được phân
vùng cả về mặt tổ chức và theo địa lý. Các tên được viết với tên
miền cấp cao nhất ở bên phải. Các tên miền tổ chức cấp cao nhất
ban đầu (còn được gọi là tên miền chung) được sử dụng trên Internet là: .
– Tổ chức thương mại co m
giá – Các trường đại học và các o tổ chức giáo dục khác dụ c – Cơ quan chính phủ Hoa Ch Kỳ ính ph ủ Mil
– Tổ chức quân sự Hoa Kỳ m
– Các trung tâm hỗ trợ ạn mạng lớn g Or – Các tổ chức không g
được đề cập ở trên Int – Tổ chức quốc tế
Các tên miền cấp cao mới như biz và mobi đã được thêm vào từ đầu
những năm 2000. Danh sách đầy đủ các tên miền 24
chung hiện tại có sẵn từ Internet Assigned Numbers Authority [www.iana.org I].
Ngoài ra, mỗi quốc gia đều có tên miền riêng: chú – Hoa Kỳ ng tôi Vư – Vương ơn quốc g qu Anh ốc An h Fr – Pháp ... – ...
Các quốc gia, đặc biệt là những quốc gia khác ngoài Hoa Kỳ thường
sử dụng tên miền phụ của riêng họ để phân biệt tổ chức của họ. Ví
dụ, Vương quốc Anh có các tên miền co.uk và ac.uk, tương ứng với
com và edu tương ứng (ac là viết tắt của 'cộng đồng học thuật').
Lưu ý rằng, mặc dù hậu tố Vương quốc Anh nghe có vẻ địa lý,
một tên miền như doit.co.uk có thể có dữ liệu đề cập đến máy tính
trong văn phòng Tây Ban Nha của Doit Ltd., một công ty danh nghĩa
của Anh. Nói cách khác, ngay cả các tên miền nghe có vẻ địa lý cũng
thông thường và hoàn toàn độc lập với vị trí thực tế của chúng.
Truy vấn DNS: Internet DNS chủ yếu được sử dụng để phân
giải tên máy chủ đơn giản và để tra cứu máy chủ thư điện tử, như sau:
Độ phân giải tên máy chủ: Nói chung, các ứng dụng sử dụng DNS để
phân giải tên máy chủ thành địa chỉ IP. Ví dụ: khi trình duyệt web được
cung cấp URL chứa tên miền www.dcs.qmul.ac.uk, nó sẽ thực hiện
yêu cầu DNS và lấy địa chỉ IP tương ứng. Như đã được chỉ ra trong
Chương 4, các trình duyệt sau đó sử dụng HTTP để giao tiếp với
máy chủ web tại địa chỉ IP đã cho, sử dụng số cổng dành riêng nếu
không có cổng nào được chỉ định trong URL. Các dịch vụ FTP và
SMTP hoạt động theo cách tương tự; ví dụ: một chương trình FTP có
thể được cung cấp tên miền ftp.dcs.qmul.ac.uk và có thể thực hiện
một cuộc điều tra DNS để lấy địa chỉ IP 25
của nó và sau đó sử dụng TCP để giao tiếp với nó tại số cổng dành riêng.
Vị trí máy chủ thư: Phần mềm thư điện tử sử dụng DNS để phân giải
tên miền thành địa chỉ IP của máy chủ thư - tức là máy tính sẽ chấp
nhận thư cho các miền đó. Ví dụ: khi địa chỉ tom@dcs.rnx.ac.uk
được giải quyết, DNS được truy vấn với địa chỉ dcs.rnx.ac.uk và ký
hiệu loại 'mail'. Nó trả về một danh sách các tên miền của các máy chủ
lưu trữ có thể chấp nhận thư cho dcs.rnx.ac.uk, nếu điều đó tồn tại (và,
tùy chọn, các địa chỉ IP tương ứng). DNS có thể trả về nhiều tên
miền để phần mềm thư có thể thử các lựa chọn thay thế nếu máy chủ
thư chính không thể truy cập được vì một số lý do. DNS trả về giá
trị tùy chọn số nguyên cho mỗi máy chủ thư, cho biết thứ tự thử máy chủ thư.
Một số loại truy vấn khác được triển khai trong một số cài đặt nhưng ít
được sử dụng hơn so với các loại truy vấn vừa đưa ra là:
Độ phân giải ngược: Một số phần mềm yêu cầu trả về tên miền với
địa chỉ IP. Đây chỉ là sự đảo ngược của truy vấn tên máy chủ thông
thường, nhưng máy chủ tên nhận truy vấn chỉ trả lời nếu địa chỉ IP
nằm trong miền riêng của nó.
Thông tin máy chủ: DNS có thể lưu trữ kiểu kiến trúc máy và hệ điều
hành với tên miền của máy chủ. Có ý kiến cho rằng tùy chọn này
không nên được sử dụng ở nơi công cộng, vì nó cung cấp thông tin
hữu ích cho những người cố gắng truy cập trái phép vào máy tính.
Về nguyên tắc, DNS có thể được sử dụng để lưu trữ các thuộc tính
tùy ý. Một truy vấn được chỉ định bởi một tên miền, lớp và loại. Đối
với tên miền trên Internet, lớp là IN. Loại truy vấn chỉ định xem địa chỉ
IP, máy chủ thư, máy chủ định danh hoặc một số loại thông tin khác là
bắt buộc. Một tên miền đặc biệt, in-addr.arpa, tồn tại để giữ địa chỉ IP
để tra cứu ngược. Thuộc tính class được sử dụng để phân biệt, ví dụ,
cơ sở dữ liệu đặt tên Internet với các cơ sở dữ liệu đặt tên DNS (thử
nghiệm) khác. Một tập hợp các kiểu được định nghĩa cho một cơ sở
dữ liệu nhất định; những người cho cơ sở dữ liệu Internet được đưa ra trong Hình 13.5.
Máy chủ định danh DNS: Các vấn đề về quy mô được xử lý
bằng cách kết hợp phân vùng cơ sở dữ liệu đặt tên và sao chép
và lưu vào bộ nhớ đệm các phần của nó gần với các 26
điểm cần thiết. Cơ sở dữ liệu DNS được phân phối trên một mạng lưới
máy chủ logic. Mỗi máy chủ nắm giữ một phần của cơ sở dữ liệu đặt
tên - chủ yếu là dữ liệu cho miền cục bộ. Các truy vấn liên quan đến
máy tính trong miền cục bộ được thỏa mãn bởi các máy chủ trong
miền đó. Tuy nhiên, mỗi máy chủ ghi lại tên miền và địa chỉ của các
máy chủ tên khác, để các truy vấn liên quan đến các đối tượng bên
ngoài miền có thể được thỏa mãn.
Dữ liệu đặt tên DNS được chia thành các vùng. Một vùng chứa dữ liệu sau:
• Dữ liệu thuộc tính cho các tên trong một miền, trừ bất kỳ miền phụ
nào do các cơ quan cấp thấp hơn quản lý. Ví dụ: một vùng có thể
chứa dữ liệu cho Queen Mary, Đại học London - qmul.ac.uk - ít
hơn dữ liệu do các phòng ban nắm giữ (ví dụ: Khoa Khoa học Máy
tính - dcs.qmul.ac.uk).
• Tên và địa chỉ của ít nhất hai máy chủ định danh cung cấp dữ liệu
có thẩm quyền cho khu vực. Đây là những phiên bản dữ liệu vùng
có thể được dựa vào là cập nhật hợp lý.
• Tên của máy chủ định danh chứa dữ liệu có thẩm quyền cho các
tên miền phụ được ủy quyền; và 'dán' dữ liệu cung cấp địa chỉ
IP của các máy chủ này.
• Các tham số quản lý vùng, chẳng hạn như các tham số chi phối bộ
nhớ đệm và sao chép dữ liệu vùng.
Một máy chủ có thể giữ dữ liệu có thẩm quyền cho không hoặc
nhiều vùng. Vì vậy, dữ liệu đặt tên có sẵn ngay cả khi một máy chủ
duy nhất bị lỗi, kiến trúc DNS chỉ định rằng mỗi vùng phải được sao
chép có thẩm quyền trong ít nhất hai máy chủ.
Quản trị viên hệ thống nhập dữ liệu cho một vùng vào tệp chính, đây là
nguồn dữ liệu có thẩm quyền cho vùng. Có hai loại máy chủ được coi
là cung cấp dữ liệu có thẩm quyền. Máy chủ chính hoặc máy chủ
chính đọc dữ liệu vùng trực tiếp từ tệp chính cục bộ. Máy chủ thứ
cấp tải xuống dữ liệu vùng từ máy chủ chính. Họ liên lạc định kỳ với
máy chủ chính để kiểm tra xem phiên bản được lưu trữ của họ có
khớp với phiên bản được lưu trữ bởi máy chủ chính hay không.
Nếu bản sao của trường trung học đã lỗi thời, bản chính sẽ gửi cho
bản sao đó phiên bản mới nhất. Tần suất kiểm tra thứ cấp 27
được quản trị viên đặt làm tham số vùng và giá trị của nó thường là
một hoặc hai lần một ngày.
Bất kỳ máy chủ nào cũng có thể tự do lưu trữ dữ liệu từ các máy chủ
khác để tránh phải liên hệ với họ khi độ phân giải tên yêu cầu lại
cùng một dữ liệu; Nó thực hiện điều này với điều kiện là khách hàng
được thông báo rằng dữ liệu đó là không có thẩm quyền như được
cung cấp. Mỗi mục nhập trong một vùng có giá trị thời gian tồn tại.
Khi một máy chủ không có thẩm quyền lưu trữ dữ liệu từ một máy chủ
có thẩm quyền, nó sẽ ghi lại thời gian tồn tại. Nó sẽ chỉ cung cấp
dữ liệu được lưu trong bộ nhớ cache cho khách hàng cho đến thời
điểm này; Khi được truy vấn sau khi hết khoảng thời gian, nó sẽ
liên hệ lại với máy chủ có thẩm quyền để kiểm tra dữ liệu của nó. Đây
là một tính năng hữu ích giúp giảm thiểu lượng lưu lượng mạng trong
khi vẫn giữ được sự linh hoạt cho quản trị viên hệ thống. Khi các thuộc
tính dự kiến sẽ hiếm khi thay đổi, chúng có thể được cung cấp một
thời gian lớn tương ứng để sống. Nếu quản trị viên biết rằng các
thuộc tính có thể sẽ sớm thay đổi, họ có thể giảm thời gian tồn tại tương ứng.
Hình 13.4 cho thấy sự sắp xếp của một số cơ sở dữ liệu DNS như nó
đứng trong năm 2001. Ví dụ này cũng có giá trị như nhau ngày nay
ngay cả khi một số dữ liệu đã thay đổi khi hệ thống đã được cấu hình
lại theo thời gian. Lưu ý rằng, trong thực tế, các máy chủ gốc như
a.root-servers.net giữ các mục nhập cho một số cấp độ tên miền,
cũng như các mục nhập cho tên miền cấp một. Điều này là để
giảm số bước điều hướng cần thiết để giải quyết tên miền. Máy chủ
tên gốc giữ các mục nhập có thẩm quyền cho các máy chủ định danh
cho các tên miền cấp cao nhất. Chúng cũng là máy chủ tên có thẩm
quyền cho các tên miền cấp cao nhất chung, chẳng hạn như com và
edu. Tuy nhiên, máy chủ tên gốc không phải là máy chủ định danh
cho các miền quốc gia. Ví dụ: tên miền uk có một tập hợp các máy
chủ định danh, một trong số đó được gọi là ns1.nic.net. Các máy chủ
định danh này biết các máy chủ định danh cho các tên miền cấp hai ở
Vương quốc Anh như ac.uk và co.uk. Các máy chủ định danh cho
tên miền ac.uk biết các máy chủ định danh cho tất cả các tên miền đại
học trong nước, chẳng hạn như qmul.ac.uk hoặc ic.ac.uk. Trong một
số trường hợp, một tên miền đại học ủy 28
thác một số trách nhiệm của mình cho một tên miền phụ, chẳng hạn như dcs.qmul.ac.uk.
Thông tin miền gốc được máy chủ chính sao chép sang một tập hợp
các máy chủ phụ, như được mô tả ở trên. Mặc dù vậy, các máy chủ
gốc phục vụ hàng nghìn hoặc:
Hình 13.4: Máy chủ định danh DNS a.root-servers.net (rễ ) V ns1.nic.uk pưurdue.edu (V ) yơanhoo.com ư g ns.purdue.edu ơn qu (purdue.ed)u gco.uk ốc ns0.ja.net quac.uk An (ac.uk) ốc h *.purdue.edu An h ic.ac.uk qmul.ac.uk dcs.qmul.ac.uk *.dcs.qmul.ac.uk *.ic.ac.uk *.qmul.ac.uk alpha.qmul.ac.uk dns0.dcs.qmul.ac.uk dns0-doc.ic.ac.uk (qmul.ac.u)k (dcs.qmul.ac.u)k (ic.ac.uk)
Tên máy chủ tên được in nghiêng và các miền tương ứng nằm
trong ngoặc đơn. Mũi tên biểu thị các mục nhập máy chủ tên. Nhiều
truy vấn hơn mỗi giây. Tất cả các máy chủ DNS lưu trữ địa chỉ của
một hoặc nhiều máy chủ tên gốc, không thay đổi thường xuyên.
Họ cũng thường lưu trữ địa chỉ của một máy chủ có thẩm quyền
cho tên miền mẹ. Một truy vấn liên quan đến tên miền ba thành phần
như www.berkeley.edu có thể được thỏa mãn bằng cách sử dụng
hai bước điều hướng tồi tệ nhất: một đến máy chủ gốc lưu trữ mục
nhập máy chủ tên thích hợp và bước thứ hai đến máy chủ có tên được trả về.
Tham khảo Hình 13.4, jeans-pc.dcs.qmul.ac.uk tên miền có thể
được tra cứu từ bên trong dcs.qmul.ac.uk bằng cách sử dụng
dns0.dcs.qmul.ac.uk máy chủ cục bộ. Máy chủ này không lưu trữ
mục nhập cho www.ic.ac.uk máy chủ web, nhưng nó giữ một mục
nhập được lưu trong bộ nhớ cache 29
cho ic.ac.uk (mà nó lấy được từ máy chủ được ủy quyền ns0.ja.net).
Có thể liên hệ với dns0doc.ic.ac.uk máy chủ để giải quyết tên đầy đủ.
Điều hướng và xử lý truy vấn: Máy khách DNS được gọi là trình
phân giải. Nó thường được triển khai như phần mềm thư viện. Nó
chấp nhận các truy vấn, định dạng chúng thành các tin nhắn ở dạng
dự kiến theo giao thức DNS và giao tiếp với một hoặc nhiều máy
chủ tên để đáp ứng các truy vấn. Một giao thức yêu cầu-trả lời đơn
giản được sử dụng, thường sử dụng các gói UDP trên Internet (máy
chủ DNS sử dụng số cổng nổi tiếng). Trình phân giải hết thời gian
chờ và gửi lại truy vấn của nó nếu cần. Trình phân giải có thể được
cấu hình để liên hệ với danh sách các máy chủ định danh ban đầu
theo thứ tự ưu tiên trong trường hợp một hoặc nhiều máy chủ không khả dụng.
Hình 13.5: Bản ghi tài nguyên DNS Loại Ý nghĩa
Nội dung chính bản ghi Một Địa chỉ máy tính Số IPv4 (IPv4) AAAA Địa chỉ máy tính Số IPv6 (IPv6) NS Máy chủ tên có thẩm Tên miền cho máy chủ quyền Tên miền cho bí danh
CNAME Tên chuẩn cho bí Các thông số chi phối danh vùng SOA
Đánh dấu sự bắt đầu của dữ liệu cho một Tên miền vùng Con trỏ tên miền (tra Kiến trúc máy và hệ PTR cứu ngược) điều hành Thông tin máy chủ HINFO lưu trữ MX Trao đổi thư Danh sách các cặp <ưu tiên, chủ nhà> 30
.TXT Chuỗi văn bản Văn bản tùy ý
Kiến trúc DNS cho phép điều hướng đệ quy cũng như điều hướng
lặp lại. Trình phân giải chỉ định loại điều hướng nào là bắt buộc khi liên
hệ với máy chủ định danh. Tuy nhiên, máy chủ định danh không bị
ràng buộc để thực hiện điều hướng đệ quy. Như đã chỉ ra ở trên,
điều hướng đệ quy có thể buộc các luồng máy chủ, có nghĩa là các
yêu cầu khác có thể bị trì hoãn.
Để tiết kiệm giao tiếp mạng, giao thức DNS cho phép nhiều truy vấn
được đóng gói vào cùng một thông báo yêu cầu và cho các máy chủ
định danh tương ứng để gửi nhiều câu trả lời trong tin nhắn phản hồi của chúng.
Bản ghi tài nguyên: Dữ liệu vùng được lưu trữ bởi máy chủ định
danh trong các tệp thuộc một trong một số loại bản ghi tài nguyên cố
định. Đối với cơ sở dữ liệu Internet, chúng bao gồm các loại được đưa
ra trong Hình 13.5. Mỗi bản ghi đề cập đến một tên miền, không được
hiển thị. Các mục trong bảng đề cập đến các mục đã được đề cập,
ngoại trừ các bản ghi AAAA lưu trữ địa chỉ IPv6 trong khi bản ghi
A lưu trữ địa chỉ IPv4 và các mục TXT được bao gồm để cho phép
lưu trữ thông tin khác tùy ý cùng với tên miền.
Dữ liệu cho một vùng bắt đầu với bản ghi kiểu SOA, chứa các tham số
vùng xác định, ví dụ, số phiên bản và tần suất thứ cấp sẽ làm mới
bản sao của chúng. Tiếp theo là danh sách các bản ghi loại NS chỉ
định máy chủ tên cho miền và danh sách các bản ghi loại MX cung cấp
tên miền của máy chủ thư, mỗi tiền tố là một số thể hiện sở thích
của nó. Ví dụ, một phần của cơ sở dữ liệu cho dcs.qmul.ac.uk tên
miền tại một thời điểm được thể hiện trong Hình 13.6, trong đó thời
gian sống 1D có nghĩa là 1 ngày. Các bản ghi khác của loại A sau này
trong cơ sở dữ liệu cung cấp địa chỉ IP cho hai máy chủ tên dns0
và dns1. Địa chỉ IP của máy chủ thư và máy chủ tên thứ ba được
cung cấp trong cơ sở dữ liệu tương ứng với miền của chúng.
Hình 13.6: Bản ghi dữ liệu vùng DNS tên miền Thời . ki giá trị 31 gian class ểu để sống dcs.qmul.a 1D TRO NS DNS0 c.uk NG dcs.qmul.a 1D TRO NS DNS1 c.uk NG dcs.qmul.a 1D TRO M 1 c.uk NG X mail1.qmul.a c.uk dcs.qmul.a 1D TRO M 2 c.uk NG X mail2.qmul.a c.uk
Phần lớn các bản ghi còn lại trong khu vực cấp thấp hơn như
dcs.qmul.ac.uk sẽ thuộc loại A và ánh xạ tên miền của máy tính vào
địa chỉ IP của nó. Chúng có thể chứa một số bí danh cho các dịch vụ nổi tiếng, ví dụ: tên miền
Thời gian . kiểu giá trị
để sống class www 1D TRO CNAM giao thông NG E giao 1D TRO Một 138.37.95 thông NG .150
Nếu tên miền có bất kỳ tên miền phụ nào, sẽ có thêm các
bản ghi loại NS chỉ định máy chủ tên của chúng, cũng sẽ có các mục
A riêng lẻ . Ví dụ: tại một thời điểm, cơ sở dữ liệu cho qmul.ac.uk chứa
các bản ghi sau cho các máy chủ tên trong tên miền phụ dcs.qmul.ac.uk của nó: tên
Thời gian . kiểu giá trị miền để sống class Dcs 1D TRO NS dns0.dcs NG dns0.dc 1D TRO Một 138.37.88.2 s NG 49 Dcs 1D TRO NS DNS1.DCS 32 NG DNS1.D 1D TRO Một 138.37.94.2 CS NG 48
Chia sẻ tải theo máy chủ định danh: Tại một số trang web,
các dịch vụ được sử dụng nhiều như Web và FTP được hỗ trợ bởi một
nhóm các máy tính trên cùng một mạng. Trong trường hợp này, cùng
một tên miền được sử dụng cho mỗi thành viên của nhóm. Khi một tên
miền được chia sẻ bởi nhiều máy tính, có một bản ghi cho mỗi máy
tính trong nhóm, cung cấp địa chỉ IP của nó. Theo mặc định, máy
chủ định danh trả lời các truy vấn mà nhiều bản ghi khớp với tên được
yêu cầu bằng cách trả về các địa chỉ IP theo lịch trình vòng tròn. Các
máy khách kế tiếp được cấp quyền truy cập vào các máy chủ khác
nhau để các máy chủ có thể chia sẻ khối lượng công việc. Bộ nhớ đệm
có khả năng làm hỏng lược đồ này, vì một khi máy chủ tên không có
thẩm quyền hoặc máy khách có địa chỉ của máy chủ trong bộ nhớ
cache của nó, nó sẽ tiếp tục sử dụng nó. Để chống lại hiệu ứng này,
các hồ sơ được đưa ra một thời gian ngắn để sống.
Việc triển khai BIND của DNS: Berkeley Internet Name Domain
(BIND) là một triển khai DNS cho các máy tính chạy UNIX. Các
chương trình máy khách liên kết trong phần mềm thư viện dưới dạng
trình phân giải. Máy chủ định danh DNS chạy daemon có tên.
BIND cho phép ba loại máy chủ định danh: máy chủ chính, máy chủ
phụ và máy chủ chỉ bộ nhớ đệm. Chương trình được đặt tên chỉ thực
hiện một trong các loại này, theo nội dung của tệp cấu hình. Hai loại
đầu tiên như được mô tả ở trên. Các máy chủ chỉ lưu vào bộ nhớ
đệm đọc từ tệp cấu hình đủ tên và địa chỉ của các máy chủ có
thẩm quyền để phân giải bất kỳ tên nào. Sau đó, họ chỉ lưu trữ dữ
liệu và dữ liệu này mà họ tìm hiểu bằng cách phân giải tên cho khách hàng.
Một tổ chức điển hình có một máy chủ chính, với một hoặc nhiều máy
chủ phụ cung cấp tên phục vụ trên các mạng cục bộ khác nhau tại
trang web. Ngoài ra, các máy tính cá nhân thường chạy máy chủ chỉ
có bộ nhớ đệm của riêng chúng, để giảm lưu lượng mạng và tăng tốc
thời gian phản hồi hơn nữa.
Thảo luận về DNS: Việc triển khai DNS Internet đạt được thời
gian phản hồi trung bình tương đối ngắn cho các tra cứu, 33
xem xét lượng dữ liệu đặt tên và quy mô của các mạng liên quan.
Chúng tôi đã thấy rằng nó đạt được điều này bằng cách kết hợp phân
vùng, sao chép và lưu vào bộ nhớ đệm dữ liệu đặt tên. Các đối tượng
được đặt tên chủ yếu là máy tính, máy chủ định danh và máy chủ thư.
Ánh xạ tên-địa chỉ IP của máy tính (máy chủ) thay đổi tương đối hiếm,
cũng như danh tính của máy chủ định danh và máy chủ thư, do đó bộ
nhớ đệm và sao chép xảy ra trong một môi trường tương đối khoan dung.
DNS cho phép đặt tên dữ liệu trở nên không nhất quán. Đó là, nếu dữ
liệu đặt tên được thay đổi, thì các máy chủ khác có thể cung cấp
cho khách hàng dữ liệu cũ trong các khoảng thời gian theo thứ tự
ngày. Không có kỹ thuật sao chép nào được khám phá trong Chương
18 được áp dụng. Tuy nhiên, sự không nhất quán không có hậu quả
cho đến khi khách hàng cố gắng sử dụng dữ liệu cũ. DNS không tự
giải quyết mức độ cứng của địa chỉ được phát hiện.
Ngoài máy tính, DNS cũng đặt tên cho một loại dịch vụ cụ thể
- dịch vụ thư - trên cơ sở mỗi miền. DNS giả định chỉ có một dịch vụ
thư cho mỗi miền được địa chỉ, vì vậy người dùng không phải bao
gồm tên của dịch vụ này một cách rõ ràng trong tên. Các ứng dụng
thư điện tử chọn dịch vụ này một cách minh bạch bằng cách sử dụng
loại truy vấn thích hợp khi liên hệ với máy chủ DNS.
Tóm lại, DNS lưu trữ nhiều loại dữ liệu đặt tên hạn chế, nhưng điều
này là đủ cho đến khi các ứng dụng như thư điện tử áp đặt sơ đồ
đặt tên riêng của chúng lên trên tên miền. Có thể lập luận rằng cơ
sở dữ liệu DNS đại diện cho mẫu số chung thấp nhất của những gì sẽ
được coi là hữu ích bởi nhiều cộng đồng người dùng trên Internet.
DNS không được thiết kế để trở thành dịch vụ tên duy nhất trên
Internet; nó cùng tồn tại với các dịch vụ thư mục và tên cục bộ lưu trữ
dữ liệu phù hợp nhất với nhu cầu địa phương (chẳng hạn như Dịch
vụ thông tin mạng của Sun, lưu trữ mật khẩu được mã hóa, ví dụ,
hoặc Dịch vụ Active Directory của Microsoft [www.microsoft.com I], lưu
trữ thông tin chi tiết về tất cả các tài nguyên trong một miền).
Điều còn lại như một vấn đề tiềm ẩn đối với thiết kế DNS là độ
cứng của nó đối với những thay đổi trong cấu trúc của không gian tên
và thiếu khả năng tùy chỉnh không gian tên cho phù hợp với nhu cầu
địa phương. Những khía cạnh này của thiết kế đặt tên được đưa ra
bởi nghiên cứu điển hình của 34
Dịch vụ tên toàn cầu trong Phần 13.4. Nhưng trước đó, chúng tôi xem
xét các dịch vụ thư mục.
13.3 Dịch Vụ Thư Mục
Chúng tôi đã mô tả cách dịch vụ định danh lưu trữ các bộ sưu
tập cặp và cách các thuộc tính được tra cứu từ tên.
Điều tự nhiên là phải xem xét kép của sự sắp xếp này, trong đó các
thuộc tính được sử dụng làm giá trị cần tra cứu. Trong các dịch vụ
này, tên văn bản có thể được coi là một thuộc tính khác. Đôi khi
người dùng muốn tìm một người hoặc tài nguyên cụ thể, nhưng họ
không biết tên của nó, chỉ biết một số thuộc tính khác của nó. Ví dụ:
người dùng có thể hỏi: 'Tên của người dùng có số điện thoại 020-555
9980 là gì?' Tương tự như vậy, đôi khi người dùng yêu cầu một dịch
vụ, nhưng họ không quan tâm đến thực thể hệ thống nào cung cấp
dịch vụ đó, miễn là dịch vụ có thể truy cập thuận tiện. Ví dụ: người
dùng có thể hỏi, 'Máy tính nào trong tòa nhà này là Macintosh chạy hệ
điều hành Mac OS X?' hoặc 'Tôi có thể in hình ảnh màu có độ phân giải cao ở đâu?'
Dịch vụ lưu trữ các tập hợp các ràng buộc giữa tên và thuộc tính và tra
cứu các mục nhập khớp với thông số kỹ thuật dựa trên thuộc tính
được gọi là dịch vụ thư mục.
Ví dụ như Active Directory Services của Microsoft, X.500 và người anh
em họ LDAP (được mô tả trong Phần 13.5), Univers [Bowman et al.
1990] và Hồ sơ [Peterson 1988]. Dịch vụ thư mục đôi khi được gọi là
dịch vụ trang vàng và các dịch vụ tên thông thường được gọi tương
ứng là dịch vụ trang trắng, tương tự như các loại danh bạ điện thoại
truyền thống. Dịch vụ thư mục đôi khi còn được gọi là dịch vụ tên dựa
trên thuộc tính.
Dịch vụ thư mục trả về tập hợp các thuộc tính của bất kỳ đối tượng
nào được tìm thấy để khớp với một số thuộc tính được chỉ định. Vì
vậy, ví dụ: yêu cầu 'TelephoneNumber = 020 555 9980' có thể trả về
{'Name = John Smith', 'TelephoneNumber = 020 555 9980', 'emailAddress =
john@dcs.gormenghast.ac.uk', ...}. Khách hàng có thể chỉ 35
định rằng chỉ một tập hợp con của các thuộc tính được quan tâm - ví
dụ: chỉ địa chỉ email của các đối tượng phù hợp.
X.500 và một số dịch vụ thư mục khác cũng cho phép các đối tượng
được tra cứu bằng các tên văn bản phân cấp thông thường. Dịch vụ
Khám phá và Thư mục Phổ quát (UDDI), được trình bày trong Phần
9.4, cung cấp cả dịch vụ trang trắng và trang vàng để cung cấp thông
tin về các tổ chức và dịch vụ web mà họ cung cấp.
UDDI sang một bên, thuật ngữ dịch vụ khám phá thường biểu thị
trường hợp đặc biệt của dịch vụ thư mục cho các dịch vụ được cung
cấp bởi các thiết bị trong môi trường mạng tự phát. Như Mục 1.3.2 đã
mô tả, các thiết bị trong mạng tự phát có khả năng kết nối và ngắt
kết nối không thể đoán trước. Một sự khác biệt cốt lõi giữa dịch vụ
khám phá và các dịch vụ thư mục khác là địa chỉ của dịch vụ thư mục
thường được biết đến và được cấu hình sẵn trong các máy khách,
trong khi một thiết bị vào môi trường mạng tự phát phải dùng đến điều
hướng đa hướng, ít nhất là lần đầu tiên nó truy cập dịch vụ khám phá
cục bộ. Mục 19.2.1 mô tả chi tiết các dịch vụ khám phá. Các thuộc
tính rõ ràng mạnh hơn tên gọi của các đối tượng:
Các chương trình có thể được viết để chọn các đối tượng theo thông
số kỹ thuật thuộc tính chính xác nơi tên có thể không được biết đến.
Một ưu điểm khác của các thuộc tính là chúng không để lộ cấu trúc
của các tổ chức với thế giới bên ngoài, cũng như các tên được phân
vùng theo tổ chức. Tuy nhiên, sự đơn giản tương đối của việc sử dụng
tên văn bản khiến chúng khó có thể được thay thế bằng đặt tên dựa
trên thuộc tính trong nhiều ứng dụng.
13.4 Nghiên Cứu Điển Hình: Dịch Vụ Tên Toàn Cầu
Dịch vụ tên toàn cầu (GNS) được thiết kế và triển khai bởi
Lampson và các đồng nghiệp tại Trung tâm nghiên cứu hệ thống DEC
[Lampson 1986] để cung cấp các cơ sở cho vị trí tài nguyên, địa chỉ thư
và xác thực. Các mục tiêu thiết kế của GNS đã được liệt kê ở cuối Phần
13.1; Chúng phản ánh thực tế rằng một dịch vụ tên để sử dụng trong
internetwork phải hỗ trợ cơ sở dữ liệu đặt tên có thể mở rộng để bao
gồm tên của hàng triệu 36
máy tính và (cuối cùng) địa chỉ email cho hàng tỷ người dùng. Các nhà
thiết kế của GNS cũng nhận ra rằng cơ sở dữ liệu đặt tên có khả năng tồn
tại lâu dài và nó phải tiếp tục hoạt động hiệu quả trong khi nó phát triển
từ quy mô nhỏ đến quy mô lớn và trong khi mạng lưới mà nó dựa trên
phát triển. Cấu trúc của không gian tên có thể thay đổi trong thời gian đó
để phản ánh những thay đổi trong cấu trúc tổ chức. Dịch vụ phải phù hợp
với những thay đổi về tên của các cá nhân, tổ chức và nhóm mà nó nắm
giữ và những thay đổi trong cấu trúc đặt tên như những thay đổi xảy ra khi
một công ty được tiếp quản bởi một công ty khác.
Trong mô tả này, chúng tôi tập trung vào những tính năng của thiết kế
cho phép nó phù hợp với những thay đổi như vậy.
Cơ sở dữ liệu đặt tên lớn tiềm năng và quy mô của môi trường phân tán
trong đó GNS được dự định hoạt động làm cho việc sử dụng bộ nhớ đệm
trở nên cần thiết và khiến việc duy trì tính nhất quán hoàn toàn giữa tất
cả các bản sao của mục nhập cơ sở dữ liệu trở nên cực kỳ khó khăn.
Chiến lược nhất quán bộ nhớ cache được áp dụng dựa trên giả định
rằng các bản cập nhật cho cơ sở dữ liệu sẽ không thường xuyên và
việc phổ biến chậm các bản cập nhật là chấp nhận được, vì khách hàng
có thể phát hiện và khôi phục từ việc sử dụng dữ liệu đặt tên lỗi thời.
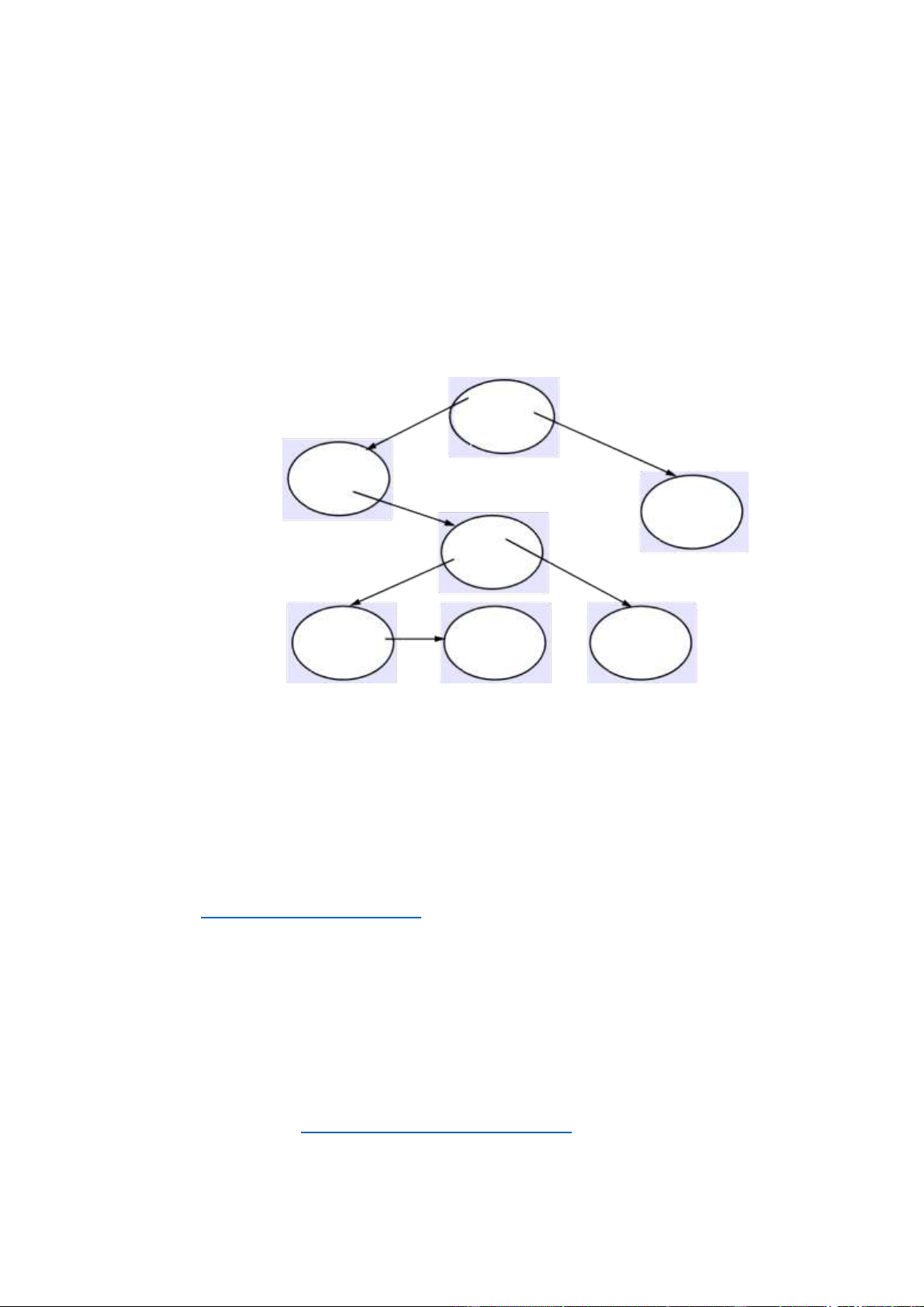
GNS quản lý một cơ sở dữ liệu đặt tên bao gồm một cây các thư mục
chứa tên và giá trị. Các thư mục được đặt tên theo tên đường dẫn
nhiều phần được gọi là thư mục gốc hoặc liên quan đến thư mục làm
việc, giống như tên tệp trong hệ thống tệp UNIX. Mỗi thư mục cũng
được gán một số nguyên, đóng vai trò là mã định danh thư mục duy nhất
(DI). Trong phần này, chúng tôi sử dụng tên in nghiêng khi đề cập đến
DI của một thư mục, để EC là định danh của thư mục EC. Một thư mục
chứa một danh sách các tên và tài liệu tham khảo. Các giá trị được lưu
trữ ở lá của cây thư mục được tổ chức thành cây giá trị, để các thuộc
tính được liên kết với tên có thể là các giá trị có cấu trúc.
Tên trong GNS có hai phần: tên giá trị>. Phần đầu tiên xác
định một thư mục; Thứ hai đề cập đến một cây giá trị, hoặc một số phần
của cây giá trị. Ví dụ, xem Hình 13.7, trong đó các DI được minh họa dưới
dạng các số nguyên nhỏ (mặc dù chúng thực sự được chọn từ một loạt
các số nguyên để đảm bảo 37
tính duy nhất). Các thuộc tính của người dùng Peter.Smith trong thư mục
QMUL sẽ được lưu trữ trong cây giá trị có tên
UK/AC/QMUL, Peter.Smith>. Cây giá trị bao gồm một mật khẩu, có
thể được tham chiếu là
và một số địa chỉ thư, mỗi địa chỉ sẽ được liệt kê trong cây giá trị dưới
dạng một nút duy nhất với tên .
Cây thư mục được phân vùng và lưu trữ trong nhiều máy chủ, với mỗi
phân vùng được sao chép trong một số máy chủ. Tính nhất quán của cây
được duy trì khi đối mặt với hai hoặc nhiều bản cập nhật đồng thời - ví
dụ: hai người dùng có thể đồng thời cố gắng tạo các mục có cùng tên và
chỉ một người thành công. Các thư mục được sao chép trình bày một
vấn đề nhất quán thứ hai; Điều này được giải quyết bằng thuật toán phân
phối cập nhật không đồng bộ đảm bảo tính nhất quán cuối cùng, nhưng
không đảm bảo rằng tất cả các bản sao luôn cập nhật.
Hình 13.7: Cây thư mục GNS và cây giá trị cho người dùng Peter.Smith DI: 599(EC) Vư DI: 543 FR DI: 574 ơn g qu DI: 437 AC ốc An DI: 322 QMUL h Peter.Smith hộp thư mật khẩu Alpha Bêta Gamma
Thích ứng với sự thay đổi: Bây giờ chúng ta chuyển sang các
khía cạnh của thiết kế có liên quan đến việc hỗ trợ tăng trưởng và
thay đổi cấu trúc của cơ sở dữ liệu đặt tên. Ở cấp độ khách hàng và
quản trị viên, sự tăng trưởng được cung cấp thông qua việc mở rộng
cây thư mục theo cách thông thường. Nhưng chúng tôi có thể muốn tích hợp các cây đặt 38
tên của hai dịch vụ GNS riêng biệt trước đây. Ví dụ, làm thế nào
chúng ta có thể tích hợp cơ sở dữ liệu bắt nguồn từ thư mục EC
được hiển thị trong Hình 13.7 với một cơ sở dữ liệu khác cho BẮC
MỸ? Hình 13.8 cho thấy một gốc mới, WORLD, được giới thiệu phía
trên rễ hiện có của hai cây sẽ được hợp nhất. Đây là một kỹ thuật
đơn giản, nhưng nó ảnh hưởng như thế nào đến các khách hàng tiếp
tục sử dụng các tên được gọi là 'gốc' trước khi tích hợp diễn ra? Ví
dụ: < / UK / AC / QMUL, Peter.Smith> là tên được khách hàng sử
dụng trước khi tích hợp. Nó là một tên tuyệt đối (vì nó bắt đầu bằng
ký hiệu cho gốc, '/'), nhưng gốc mà nó đề cập đến là EC, không phải
WORLD. EC và BẮC MỸ là nguồn gốc hoạt động - bối cảnh ban
đầu dựa trên những tên bắt đầu bằng gốc '/' sẽ được tra cứu.
Hình 13.8: Hợp nhất cây dưới một gốc mới DI: 633 (THẾ GIỚI) Thư mục nổi tiếng: #599 = #633/EC #642 = #633/BẮC MỸ EC BẮC MỸ DI: 599 DI: 642 DI: 543 Vư FR DI: 574 DI: 732 Ch CANADADI: 457 ơn ún g g qu tôi ốc An h
Hình 13.9: Tái cấu trúc thư mục DI: 633 (THẾ GIỚI) Thư mục nổi tiếng: #599 = #633/EC #642 = #633/BẮC MỸ EC BẮC MỸ DI: 599 DI: 642 Vư FR Ch Ch CANADA DI: 543 DI: 574 : 732 DI: 457 ơn ún DI ún g g g qu tôi #633t/ôEiC/US ốc An h 39
Sự tồn tại của các định danh thư mục duy nhất có thể được sử
dụng để giải quyết vấn đề này. Gốc làm việc cho mỗi chương trình
phải được xác định là một phần của môi trường thực thi của nó
(giống như được thực hiện cho thư mục làm việc của chương trình).
Khi một khách hàng trong Cộng đồng Châu Âu sử dụng tên của biểu
mẫu < / UK / AC / QMUL, Peter.Smith>, tác nhân người dùng cục bộ
của nó, nhận thức được gốc làm việc, tiền tố mã định danh thư mục
EC(#599), do đó tạo ra tên < # 599 / UK / AC / QMUL, Peter.Smith>.
Tác nhân người dùng chuyển tên dẫn xuất này trong yêu cầu tra cứu
đến máy chủ GNS. Tác nhân người dùng có thể xử lý tương tự với
các tên tương đối được đề cập đến các thư mục làm việc. Khách
hàng nhận thức được cấu hình mới cũng có thể cung cấp tên tuyệt
đối cho máy chủ GNS, được tham chiếu đến thư mục siêu gốc khái
niệm chứa tất cả các định danh thư mục - ví dụ: / AC / QMUL, Peter.Smith> - nhưng thiết kế không thể giả định rằng
tất cả các máy khách sẽ được cập nhật để tính đến thay đổi đó.
Kỹ thuật được mô tả ở trên giải quyết vấn đề logic, cho phép người
dùng và chương trình máy khách tiếp tục sử dụng các tên được xác
định liên quan đến gốc cũ ngay cả khi một gốc thực mới được chèn
vào, nhưng nó để lại một vấn đề thực hiện: trong cơ sở dữ liệu đặt
tên phân tán có thể chứa hàng triệu thư mục, làm thế nào dịch vụ
GNS có thể xác định vị trí một thư mục chỉ được cung cấp định danh
của nó, Chẳng hạn như # 599? Giải pháp được GNS áp dụng là
liệt kê các thư mục được sử dụng làm gốc hoạt động, chẳng hạn như
EC, trong một bảng 'thư mục nổi tiếng' được giữ trong thư mục gốc
thực hiện tại của cơ sở dữ liệu đặt tên. Bất cứ khi nào gốc thực của
cơ sở dữ liệu đặt tên thay đổi, như trong Hình 13.8, tất cả các máy
chủ GNS đều được thông báo về vị trí mới của gốc thực. Sau đó, họ
có thể giải thích tên của dạng WORLD / EC / UK / AC / QMUL (được
gọi là gốc thực) theo cách thông thường và họ có thể giải thích tên
của mẫu # 599 / UK / AC / QMUL bằng cách sử dụng bảng 'thư mục
nổi tiếng' để dịch chúng thành tên đường dẫn đầy đủ bắt đầu từ gốc thực. 40
GNS cũng hỗ trợ tái cấu trúc cơ sở dữ liệu để phù hợp với sự thay đổi
của tổ chức. Giả sử rằng Hoa Kỳ trở thành một phần của Cộng đồng
châu Âu (!). Hình 13.9 cho thấy cây thư mục mới. Nhưng nếu cây con
của Hoa Kỳ chỉ đơn giản được chuyển đến thư mục EC, các tên bắt
đầu WORLD / NORTH AMERICA / US sẽ không còn hoạt động nữa.
Giải pháp được GNS thông qua là chèn một 'liên kết tượng trưng'
thay cho mục nhập ban đầu của Hoa Kỳ (được in đậm trong Hình
13.9). Quy trình tra cứu thư mục GNS diễn giải liên kết như một
chuyển hướng đến thư mục Hoa Kỳ ở vị trí mới của nó.
Thảo luận về GNS: GNS có nguồn gốc từ Grapevine [Birrell et
al. 1982] và Clearinghouse [Oppen và Dalal 1983], hai hệ thống đặt
tên thành công được phát triển chủ yếu cho mục đích gửi thư của Tập
đoàn Xerox. GNS giải quyết thành công nhu cầu về khả năng mở
rộng và cấu hình lại, nhưng giải pháp được áp dụng để hợp nhất
và di chuyển cây thư mục dẫn đến yêu cầu về cơ sở dữ liệu (bảng
các thư mục nổi tiếng) phải được sao chép ở mọi nút. Trong một mạng
quy mô lớn, việc cấu hình lại có thể xảy ra ở bất kỳ cấp độ nào và
bảng này có thể phát triển đến kích thước lớn, mâu thuẫn với mục tiêu khả năng mở rộng.
13.5 Nghiên Cứu Điển Hình: Dịch Vụ Thư Mục X.500
X.500 là một dịch vụ thư mục theo nghĩa được định nghĩa
trong Phần 13.3. Nó có thể được sử dụng theo cách tương tự như một
dịch vụ tên thông thường, nhưng nó chủ yếu được sử dụng để đáp ứng
các truy vấn mô tả và được thiết kế để khám phá tên và thuộc tính của
người dùng hoặc tài nguyên hệ thống khác. Người dùng có thể có nhiều
yêu cầu khác nhau để tìm kiếm và duyệt trong một thư mục người dùng
mạng, tổ chức và tài nguyên hệ thống để có được thông tin về các thực
thể mà thư mục chứa. Việc sử dụng cho một dịch vụ như vậy có thể khá
đa dạng. Chúng bao gồm từ các yêu cầu tương tự trực tiếp với việc sử
dụng danh bạ điện thoại, chẳng hạn như truy cập 'trang trắng' đơn giản để
lấy địa chỉ thư điện tử của người dùng hoặc truy vấn 41
'trang vàng' nhằm mục đích, ví dụ, lấy tên và số điện thoại của nhà để xe
chuyên sửa chữa một loại xe cụ thể, đến việc sử dụng thư mục để truy
cập các chi tiết cá nhân như vai trò công việc, thói quen ăn kiêng hoặc
thậm chí hình ảnh chụp ảnh của các cá nhân.
Các truy vấn như vậy có thể bắt nguồn từ người dùng, trong ví dụ 'trang
vàng' được đề cập ở trên hoặc từ các quy trình, khi chúng có thể được
sử dụng để xác định các dịch vụ nhằm đáp ứng yêu cầu chức năng.
Các cá nhân và tổ chức có thể sử dụng dịch vụ thư mục để cung cấp một
loạt các thông tin về bản thân và các tài nguyên mà họ muốn cung cấp
để sử dụng trong mạng. Người dùng có thể tìm kiếm thư mục cho thông
tin cụ thể chỉ với một phần kiến thức về tên, cấu trúc hoặc nội dung của nó.
Các tổ chức tiêu chuẩn ITU và ISO đã xác định Dịch vụ Thư mục
X.500 [ITU / ISO 1997] là một dịch vụ mạng nhằm đáp ứng các yêu cầu
này. Tiêu chuẩn đề cập đến nó như một dịch vụ để truy cập thông tin về
'các thực thể trong thế giới thực', nhưng nó cũng có khả năng được sử
dụng để truy cập thông tin về các dịch vụ và thiết bị phần cứng và phần
mềm. X.500 được chỉ định là một dịch vụ cấp ứng dụng trong bộ tiêu
chuẩn Kết nối Hệ thống Mở (OSI), nhưng thiết kế của nó không phụ thuộc
đáng kể vào các tiêu chuẩn OSI khác và nó có thể được xem như một
thiết kế cho dịch vụ thư mục mục đích chung. Chúng tôi phác thảo thiết
kế của dịch vụ thư mục X.500 và việc triển khai nó ở đây. Độc giả quan
tâm đến mô tả chi tiết hơn về X.500 và các phương pháp thực hiện nó
nên nghiên cứu cuốn sách của Rose về chủ đề này [Rose 1992]. X.500
cũng là cơ sở cho LDAP (được thảo luận dưới đây) và nó được sử dụng
trong dịch vụ thư mục DCE [OSF 1997]. 42
Hình 13.10: Kiến trúc dịch vụ X.500 DUA DSA DSA DUA DSA DSA DSA DUA DSA
Dữ liệu được lưu trữ trong các máy chủ X.500 được tổ chức
theo cấu trúc cây với các nút được đặt tên, như trong trường hợp các
máy chủ tên khác được thảo luận trong chương này, nhưng trong
X.500, một loạt các thuộc tính được lưu trữ tại mỗi nút trong cây và
có thể truy cập không chỉ bằng tên mà còn bằng cách tìm kiếm các
mục nhập với bất kỳ sự kết hợp bắt buộc nào của các thuộc tính.
Cây tên X.500 được gọi là Cây thông tin thư mục (DIT) và toàn bộ
cấu trúc thư mục bao gồm dữ liệu được liên kết với các nút, được
gọi là Cơ sở thông tin thư mục (DIB). Dự định có một DIB tích hợp
duy nhất chứa thông tin được cung cấp bởi các tổ chức trên toàn thế
giới, với các phần của DIB nằm trong các máy chủ X.500 riêng lẻ.
Thông thường, một tổ chức cỡ trung bình hoặc lớn sẽ cung cấp ít nhất một máy chủ.
Khách hàng truy cập thư mục bằng cách thiết lập kết nối với máy
chủ và đưa ra yêu cầu truy cập. Khách hàng có thể liên hệ với bất kỳ
máy chủ nào với một yêu cầu. Nếu dữ liệu cần thiết không nằm
trong phân đoạn DIB do máy chủ được liên hệ nắm giữ, nó sẽ gọi
các máy chủ khác để giải quyết truy vấn hoặc chuyển hướng máy
khách đến một máy chủ khác.
Trong thuật ngữ của tiêu chuẩn X.500, các máy chủ là Directory
Service Agents (DSA) và các máy khách của chúng được gọi là
Directory User Agents (DUA). Hình 13.10 cho thấy kiến trúc phần mềm
và một trong một số mô hình điều hướng có thể, với mỗi quy trình
máy khách DUA tương tác với một 43
quy trình DSA duy nhất, truy cập các DSA khác khi cần thiết để đáp ứng các yêu cầu.
Mỗi mục trong DIB bao gồm một tên và một tập hợp các thuộc tính.
Như trong các máy chủ tên khác, tên đầy đủ của một mục nhập tương
ứng với một đường dẫn qua DIT từ gốc của cây đến mục nhập.
Ngoài tên đầy đủ hoặc tuyệt đối, DUA có thể thiết lập ngữ cảnh,
bao gồm nút cơ sở và sau đó sử dụng tên tương đối ngắn hơn
cung cấp đường dẫn từ nút cơ sở đến mục nhập được đặt tên.
Hình 13.11 cho thấy một phần của Cây thông tin thư mục bao gồm Đại
học Gormenghast ở Anh và Hình 13.12 là một trong những mục DIB
liên quan. Cấu trúc dữ liệu cho các mục trong DIB và DIT rất linh hoạt.
Mục nhập DIB bao gồm một tập hợp các thuộc tính, trong đó một thuộc
tính có một loại và một hoặc nhiều giá trị. Loại của mỗi thuộc tính
được biểu thị bằng tên loại (ví dụ: countryName, organizationName,
commonName, telephoneNumber, hộp thư ,objectClass). Bạn có thể
xác định các loại thuộc tính mới nếu bắt buộc. Đối với mỗi khác biệt.
Hình 13.11: Một phần của cây thông tin thư mục X.500 Dịch vụ X.500 (root)
... Pháp (quốc gia)Vương quốc Anh (quốc gia)Hy Lạp (quốc gia)... ...
... BT Plc (tổ chức)Đại học Gormenghast (tổ chức)
... Dịch vụ máy tính (organizationalUnit)
Khoa Khoa học Máy tính (organizationalUnit)
Phòng Kỹ thuật (organizationalUnit) ...
... Nhân viên phòng ban (organizationalUnit) ely (applicationProcess)
Sinh viên nghiên cứu (organizationa..l.Unit)
... Alice Flintstone (ngườ.i.). Pat King (người)
James Healey (ngườiJ)anet Papworth (ngườ.i.). 44
tên kiểu Có một định nghĩa kiểu tương ứng, bao gồm mô tả kiểu
và định nghĩa cú pháp trong ký hiệu ASN.1 (ký hiệu chuẩn cho định
nghĩa cú pháp) xác định biểu diễn cho tất cả các giá trị cho phép của kiểu.
Các mục DIB được phân loại theo cách tương tự như các cấu trúc lớp
đối tượng được tìm thấy trong các ngôn ngữ lập trình hướng đối
tượng. Mỗi mục nhập bao gồm một thuộc tính objectClass, xác định
lớp (hoặc lớp) của đối tượng mà một mục nhập đề cập đến.
Organization, organizationalPerson và document là tất cả các ví dụ về
giá trị objectClass. Các lớp tiếp theo có thể được định nghĩa khi
chúng được yêu cầu. Định nghĩa của một lớp xác định thuộc tính
nào là bắt buộc và thuộc tính nào là tùy chọn cho các mục nhập của
lớp nhất định. Các định nghĩa của các lớp được tổ chức trong một hệ
thống phân cấp kế thừa trong đó tất cả các lớp ngoại trừ một (được
gọi là topClass) phải chứa thuộc tính objectClass và giá trị của
thuộc tính objectClass phải là tên của một hoặc nhiều lớp. Nếu có
một số giá trị objectClass, đối tượng kế thừa các thuộc tính bắt
buộc và tùy chọn của mỗi lớp.
Tên của một mục nhập DIB (tên xác định vị trí của nó trong DIT) được
xác định bằng cách chọn một hoặc nhiều thuộc tính của nó làm thuộc
tính phân biệt. Các thuộc tính được chọn cho mục đích này được
gọi là Tên phân biệt (DN) của mục nhập.
Hình 13.12: Mục nhập X.500 DIB Thông tin
Alice Flintstone, Nhân viên bộ phận, Khoa Khoa học Máy tính, Đại học Gormenghast, GB 45 Tên chung Uid Alice.L.Flint Alf stone alf@dcs.gormenghas Alice.Flintst t.ac.uk thư one Alice.Flintstone@dcs.go Alice rmenghast.ac.uk phòngSố Flintstone phòng A. Họ Z42 Flintstone
lớp người dùng Đá lửa Nghiên cứu viên
số điện thoại +44 986 33 4604
Bây giờ chúng ta có thể xem xét các phương thức mà thư mục
được truy cập. Có hai loại yêu cầu truy cập chính: đọc: Một tên tuyệt
đối hoặc tương đối (một tên miền trong thuật ngữ X.500) cho một
mục nhập được đưa ra, cùng với một danh sách các thuộc tính cần
đọc (hoặc một dấu hiệu cho thấy tất cả các thuộc tính là bắt buộc).
DSA định vị mục nhập được đặt tên bằng cách điều hướng trong DIT,
chuyển các yêu cầu đến các máy chủ DSA khác nơi nó không giữ các
phần có liên quan của cây. Nó truy xuất các thuộc tính cần thiết và trả
lại chúng cho máy khách. search: Đây là yêu cầu truy cập dựa trên
thuộc tính. Tên cơ sở và biểu thức bộ lọc được cung cấp dưới dạng
đối số. Tên cơ sở chỉ định nút trong DIT mà từ đó tìm kiếm sẽ bắt
đầu; Biểu thức bộ lọc là một biểu thức boolean sẽ được đánh giá cho
mọi nút bên dưới nút cơ sở. Bộ lọc chỉ định một tiêu chí tìm kiếm: một
sự kết hợp hợp lý của các bài kiểm tra về các giá trị của bất kỳ thuộc
tính nào trong một mục nhập. Lệnh tìm kiếm trả về danh sách tên (tên
miền) cho tất cả các mục bên dưới nút cơ sở mà bộ lọc đánh giá là
TRUE. Ví dụ, một bộ lọc có thể được xây dựng và áp dụng để tìm tên
chung của các thành viên của nhân viên chiếm phòng Z42 trong Khoa
Khoa học Máy tính tại Đại học Gormenghast (Hình 13.12). Một yêu
cầu đọc sau đó có thể được sử dụng để có được bất kỳ hoặc tất cả
các thuộc tính của các mục DIB đó. 46
Tìm kiếm có thể khá tốn kém khi nó được áp dụng cho các phần lớn
của cây thư mục (có thể nằm trong một số máy chủ). Các đối số bổ
sung có thể được cung cấp để tìm kiếm để hạn chế phạm vi, thời
gian cho phép tìm kiếm tiếp tục và kích thước của danh sách các
mục nhập được trả về.
Quản trị và cập nhật DIB: Giao diện DSA bao gồm các hoạt
động để thêm, xóa và sửa đổi các mục. Kiểm soát truy cập được cung
cấp cho cả truy vấn và hoạt động cập nhật, vì vậy quyền truy cập vào
các phần của DIT có thể bị hạn chế đối với một số người dùng hoặc
lớp người dùng nhất định.
DIB được phân vùng, với kỳ vọng rằng mỗi tổ chức sẽ cung cấp ít
nhất một máy chủ nắm giữ các chi tiết của các thực thể trong tổ chức
đó. Các phần của DIB có thể được sao chép trong một số máy chủ.
Là một tiêu chuẩn (hoặc 'khuyến nghị' trong thuật ngữ CCITT),
X.500 không giải quyết các vấn đề thực hiện. Tuy nhiên, khá rõ ràng
rằng bất kỳ triển khai nào liên quan đến nhiều máy chủ trong một
mạng diện rộng phải dựa vào việc sử dụng rộng rãi các kỹ thuật
sao chép và lưu vào bộ nhớ đệm để tránh chuyển hướng quá nhiều truy vấn.
Một triển khai, được mô tả bởi Rose [1992], là một hệ thống được phát
triển tại Đại học College, London, được gọi là QUIPU [Kille 1991].
Trong việc triển khai này, cả bộ nhớ đệm và sao chép đều được thực
hiện ở cấp độ của các mục nhập DIB riêng lẻ và ở cấp độ bộ sưu tập
các mục nhập có nguồn gốc từ cùng một nút. Giả định rằng các giá trị
có thể trở nên không nhất quán sau khi cập nhật và khoảng thời
gian mà tính nhất quán được khôi phục có thể là vài phút. Hình thức
phổ biến cập nhật này thường được coi là chấp nhận được đối với các
ứng dụng dịch vụ thư mục.
Giao thức truy cập thư mục nhẹ: Giả định của X.500 rằng các
tổ chức sẽ cung cấp thông tin về bản thân họ trong các thư mục công
cộng trong một hệ thống chung đã được chứng minh phần lớn là
không có cơ sở. Tương tự, tính tương thích của nó có nghĩa là sự hấp
thụ của nó tương đối khiêm tốn. 47
Một nhóm tại Đại học Michigan đã đề xuất một cách tiếp cận nhẹ hơn
được gọi là Giao thức truy cập thư mục nhẹ (LDAP), trong đó DUA
truy cập các dịch vụ thư mục X.500 trực tiếp qua TCP / IP thay vì
các lớp trên của ngăn xếp giao thức ISO. Điều này được mô tả trong
RFC 2251 [Wahl et al. 1997]. LDAP cũng đơn giản hóa giao diện
thành X.500 theo những cách khác: ví dụ: nó cung cấp một API tương
đối đơn giản và nó thay thế mã hóa ASN.1 bằng mã hóa văn bản.
Mặc dù thông số kỹ thuật LDAP dựa trên X.500, LDAP không yêu cầu
nó. Việc triển khai có thể sử dụng bất kỳ máy chủ thư mục nào khác
tuân theo đặc tả LDAP đơn giản hơn, trái ngược với đặc tả X.500. Ví
dụ: Dịch vụ Active Directory của Microsoft cung cấp giao diện LDAP.
Không giống như X.500, LDAP đã được áp dụng rộng rãi, đặc biệt là
cho các dịch vụ thư mục mạng nội bộ. Nó cung cấp quyền truy cập an
toàn vào dữ liệu thư mục thông qua xác thực. 13.6 Tóm Tắt
Chương này đã mô tả việc thiết kế và thực hiện các dịch vụ tên
trong các hệ thống phân tán. Dịch vụ định danh lưu trữ các thuộc tính
của các đối tượng trong một hệ thống phân tán - đặc biệt là địa chỉ của
chúng - và trả về các thuộc tính này khi tên văn bản được cung cấp để
tra cứu. Các yêu cầu chính đối với dịch vụ tên là khả năng xử lý số lượng
tên tùy ý, tuổi thọ cao, tính sẵn sàng cao, cách ly các lỗi và khả năng
chịu đựng sự ngờ vực.
Vấn đề thiết kế chính là cấu trúc của không gian tên - các quy tắc cú
pháp chi phối tên. Một vấn đề liên quan là mô hình độ phân giải, đưa ra
các quy tắc theo đó tên đa thành phần được phân giải thành một tập
hợp các thuộc tính. Tập hợp các tên bị ràng buộc phải được quản lý. Hầu
hết các thiết kế xem xét không gian tên được chia thành các miền.
Các phần rời rạc của không gian tên, mỗi phần được liên kết với một cơ
quan duy nhất kiểm soát sự ràng buộc của các tên trong đó. Việc triển
khai dịch vụ tên có thể mở rộng các tổ chức và 48
cộng đồng người dùng khác nhau. Nói cách khác, tập hợp các ràng buộc
giữa tên và thuộc tính được lưu trữ tại nhiều máy chủ định danh, mỗi
máy chủ lưu trữ ít nhất một phần của tập hợp tên trong miền đặt tên. Do
đó, câu hỏi về điều hướng được đặt ra - tên có thể được giải quyết
theo thủ tục nào khi thông tin cần thiết được lưu trữ tại một số địa
điểm? Các loại điều hướng được hỗ trợ là lặp lại, đa hướng, đệ quy do
máy chủ điều khiển và điều khiển máy chủ không đệ quy. Một khía cạnh
quan trọng khác của việc triển khai dịch vụ tên là sử dụng sao chép và
lưu vào bộ nhớ đệm. Cả hai đều hỗ trợ làm cho dịch vụ có tính khả dụng
cao và cả hai cũng giảm thời gian giải quyết tên.
Chương này đã xem xét hai trường hợp chính của thiết kế và thực hiện
dịch vụ tên. Hệ thống tên miền được sử dụng rộng rãi để đặt tên máy tính
và giải quyết thư điện tử trên Internet; Nó đạt được thời gian phản hồi tốt
thông qua sao chép và lưu vào bộ nhớ đệm. Dịch vụ tên toàn cầu là
một thiết kế đã giải quyết vấn đề cấu hình lại không gian tên khi thay đổi tổ chức xảy ra.
Chương này cũng xem xét các dịch vụ thư mục, cung cấp dữ liệu về các
đối tượng và dịch vụ phù hợp khi khách hàng cung cấp mô tả dựa trên
thuộc tính. X.500 là một mô hình cho các dịch vụ thư mục có thể nằm
trong phạm vi từ các tổ chức cá nhân đến các thư mục toàn cầu. Nó đã
được sử dụng rộng rãi hơn trong mạng nội bộ kể từ khi phần mềm LDAP xuất hiện.
13.7 Tài Liệu Tham Khảo
1. Ebook Distributed System: Concepts and Design 49
Tài liệu liên quan:
-

Thông tin tổng hợp quản lý sinh viên | Học viện Nông nghiệp Việt Nam
329 165 -

App quản lý quán caffe - giả thiết | Học viện Nông nghiệp Việt Nam
253 127 -

Đề cương thực tập chuyển ngành - Xây dựng phần mềm quản lý quán Cafe | Học viện Nông nghiệp Việt Nam
340 170 -

Thuyết minh đề tài - Đồ án môn học Xây dựng và phát triển phần mềm | Học viện Nông nghiệp Việt Nam
332 166 -

Báo cáo thực tập chuyển ngành - Xây dựng Website bán phụ kiện điện thoại | Học viện Nông nghiệp Việt Nam
423 212