Big Data, ZooKeeper | Tài liệu môn An toàn thông tin Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
+ Big data là một số lượng lớn thông tin đa dạng đến trong việc tăng khối lượng và với vận tốc trị giá hơn bao giờ hết. + Big data có thể được cấu trúc (thường là số, dễ dàng định dạng và lưu trữ) hoặc không cấu trúc (dạng tự do hơn, ít định lượng hơn). Gần như mọi bộ phận trong một công ty có thể sử dụng những phát hiện từ phân tích big data, nhưng những vấn đề từ sự lộn xộn và noise gây ra nhiều vấn đề. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem!
Môn: An toàn thông tin (INSE330380) 147 tài liệu
Trường: Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh 4.4 K tài liệu
Tác giả:






Preview text:
1. Big data
- Định nghĩa: What is big data?
+ Big data là một số lượng lớn thông tin đa dạng đến trong việc tăng khối lượng
và với vận tốc trị giá hơn bao giờ hết.
+ Big data có thể được cấu trúc (thường là số, dễ dàng định dạng và lưu trữ)
hoặc không cấu trúc (dạng tự do hơn, ít định lượng hơn). Gần như mọi bộ phận
trong một công ty có thể sử dụng những phát hiện từ phân tích big data, nhưng
những vấn đề từ sự lộn xộn và noise gây ra nhiều vấn đề.
+ Big data có thể được thu thập từ các nguồn chia sẻ công khai trên các mạng
xã hội và trang web, thu thập từ các ứng dụng và điện tử cá nhân, đặc biệt là từ
các loại log, nhật ký ghi lại hành trình từ xe cộ, camera, …
+ Big data thường được lưu trữ trong cơ sở dữ liệu máy tính và được phân tích
bằng phần mềm được thiết kế đặc biệt để xử lý các bộ big data, phức tạp. - The three Vs of big data:
+ Volume: Với big data, bạn sẽ phải xử lý khối lượng cao của mật độ thấp (phi
tập trung - bao nhiêu thông tin có thể được lưu trữ trong một lượng không gian
lưu trữ cụ thể), dữ liệu không cấu trúc. Đây có thể là dữ liệu của giá trị không
xác định, chẳng hạn như nguồn cấp dữ liệu Twitter, click Streams trên trang
web hoặc ứng dụng di động hoặc thiết bị hỗ trợ cảm biến. Đối với một số tổ
chức, đây có thể là hàng chục Terabyte dữ liệu hoặc hàng trăm petabyte.
+ Velocity: là tốc độ mà dữ liệu được ghi. Thông thường, vận tốc cao nhất của
các data stream vào bộ nhớ (RAM) so với được ghi vào đĩa. Một số sản phẩm
thông minh hỗ trợ Internet hoạt động trong thời gian thực hoặc gần thời gian
thực và sẽ yêu cầu đánh giá và hành động thời gian thực.
+ Variety: đề cập đến nhiều loại dữ liệu có sẵn. Các kiểu dữ liệu truyền thống
được cấu trúc và phù hợp gọn gàng trong cơ sở dữ liệu quan hệ. Với sự gia tăng
của big data, dữ liệu đi kèm trong các loại dữ liệu phi cấu trúc mới. Các loại dữ
liệu phi cấu trúc và bán kết, như văn bản, âm thanh và video, yêu cầu tiền xử lý
bổ sung để lấy ý nghĩa và hỗ trợ siêu dữ liệu.
- What are the requirements for Big Data?
+ File Storage: Mất bao lâu (Velocity) để business user truy xuất data từ các
data center lưu trữ dữ liệu. Các yếu tố ảnh hưởng đến Velocity không chỉ từ
phần cứng mà còn là phần mềm tối ưu như thế nào để đảm bảo độ trễ thấp nhất.
+ Database System: Quá trình bảo quản và lưu trữ dữ liệu cần được đảm bảo để
tránh mất mát và hư hỏng dữ liệu.
+ Data processing tools: Dữ liệu có cấu trúc và phi cấu trúc đòi hỏi mức độ xử
lý khác nhau. Các tính năng xử lý dữ liệu liên quan đến việc thu thập và tổ chức
dữ liệu thô để cung cấp ý nghĩa nhất định. Mô hình hóa dữ liệu sẽ thực hiện các
tập dữ liệu phức tạp và hiển thị chúng trong một sơ đồ trực quan hoặc biểu đồ.
Điều này làm cho nó dễ hiểu và dễ diễn giải cho người dùng đang cố gắng sử
dụng dữ liệu đó để phục vụ cho mục đích công việc.
+ Analytics: Các công cụ phân tích Dữ liệu lớn cung cấp nhiều gói và mô-đun
phân tích để cung cấp cho người dùng các tùy chọn. Ví dụ, phân tích rủi ro là
nghiên cứu về sự không chắc chắn xung quanh bất kỳ hành động nào. Nó có thể
được sử dụng kết hợp với dự báo để giảm thiểu các tác động tiêu cực của các sự
kiện trong tương lai. Phân tích rủi ro cho phép người dùng giảm thiểu những rủi
ro này bằng cách xác định rõ ràng và hiểu được khả năng chịu đựng và tiếp xúc
với rủi ro của tổ chức. 2. ZooKeeper - What is ZooKeeper? + SaaS + Cluster-database + Open source
+ ZooKeeper là một dịch vụ cho các hệ thống phân tán cung cấp giá trị khóa
phân cấp, được sử dụng để cung cấp dịch vụ cấu hình phân tán, dịch vụ đồng
bộ hóa và đăng ký đặt tên cho các hệ thống phân tán lớn. ZooKeeper là một
tiểu dự án của Hadoop nhưng bây giờ là một dự án Apache cấp cao nhất. - How does ZooKeeper work?
+ Nếu bạn đã có một cụm Hadoop nhiều máy chủ thương mại trở lên, bạn sẽ
cần quản lý tập trung toàn bộ cụm về tên, dịch vụ nhóm và đồng bộ hóa, quản
lý cấu hình và hơn thế nữa. Các dự án nguồn mở khác sử dụng cụm Hadoop yêu
cầu các dịch vụ chéo. Sử dụng ZooKeeper có nghĩa là bạn không phải xây dựng
các dịch vụ đồng bộ hóa từ đầu. Tương tác với Zookeeper bằng Java hoặc C.
+ Đối với các ứng dụng, ZooKeeper cung cấp cơ sở hạ tầng để đồng bộ hóa
node chéo bằng cách duy trì thông tin trạng thái trong bộ nhớ trên máy chủ
ZooKeeper. Một máy chủ Zookeeper giữ một bản sao của trạng thái của toàn bộ
hệ thống và vẫn tồn tại thông tin này trong các tệp local log. Các cụm Hadoop
lớn được hỗ trợ bởi nhiều máy chủ Zookeeper, với máy chủ chính đồng bộ hóa
các máy chủ cấp cao nhất.
+ Trong ZooKeeper, một ứng dụng có thể tạo ra cái gọi là znode, là một tệp vẫn
tồn tại trong bộ nhớ trên các máy chủ ZooKeeper. Znode có thể được cập nhật
bởi bất kỳ nút nào trong cụm và bất kỳ nút nào trong cụm đều có thể đăng ký để
được thông báo về những thay đổi đối với znode đó.
+ Nói một cách đơn giản, các ứng dụng có thể đồng bộ hóa các tác vụ của
chúng trên cụm phân tán bằng cách cập nhật trạng thái của chúng trong một
znode ZooKeeper. Znode sau đó thông báo cho phần còn lại của cụm thay đổi
trạng thái của một nút cụ thể. Dịch vụ tập trung trạng thái toàn cụm này rất
quan trọng đối với các tác vụ quản lý và nối tiếp trên một bộ máy chủ phân tán lớn.
- Các project sử dụng ZooKeeper + Apache Hadoop + Apache Accumulo + Apache HBase + Apache Hive + Apache Kafka + Apache Spark + Yahoo
- Apache Zookeeper Architecture
+ ZooKeeper rất đơn giản: ZooKeeper cho phép các quy trình phân tán phối
hợp với nhau thông qua một namespace phân cấp được chia sẻ được tổ chức
tương tự như một hệ thống tệp tiêu chuẩn. Namespace bao gồm các data
register - được gọi là ZNodes, và chúng tương tự như các tệp và thư mục.
Không giống như một hệ thống tệp thông thường, được thiết kế để lưu trữ, dữ
liệu ZooKeeper được lưu trữ trong bộ nhớ, có nghĩa là ZooKeeper có thể đạt
được thông lượng cao và số độ trễ thấp.
+ Có khả năng nhân bản: Giống như các quy trình phân tán mà nó phối hợp,
bản thân ZooKeeper sẽ được nhân rộng trên một bộ máy chủ được gọi là một quần thể.
+ Zookeeper theo cấp bậc. Zookeeper đóng dấu mỗi bản cập nhật với một số
phản ánh thứ tự của tất cả các giao dịch của Zookeeper. Các hoạt động tiếp theo
có thể sử dụng thứ tự để thực hiện các bản tóm tắt cấp cao hơn, chẳng hạn như
các nguyên tắc đồng bộ hóa.
Các máy chủ tạo nên dịch vụ ZooKeeper tương tác với nhau. Họ duy trì một
image trong bộ nhớ trong, cùng với một nhật ký giao dịch và snapshot trong
một persistent store. Miễn là phần lớn các máy chủ có sẵn, dịch vụ ZooKeeper
sẽ có sẵn. Client kết nối với một máy chủ ZooKeeper duy nhất, duy trì kết nối
TCP thông qua đó gửi yêu cầu, nhận phản hồi, nhận các sự kiện theo dõi và gửi
heartbeat. Nếu kết nối TCP với máy chủ bị hỏng, máy khách sẽ kết nối với một máy chủ khác.
+ ZooKeeper rất nhanh. Nó đặc biệt nhanh chóng trong khối lượng công việc
'đọc chiếm ưu thế'. Các ứng dụng ZooKeeper chạy trên hàng ngàn máy, và nó
hoạt động tốt nhất khi đọc phổ biến hơn viết, với tỷ lệ khoảng 10:1.
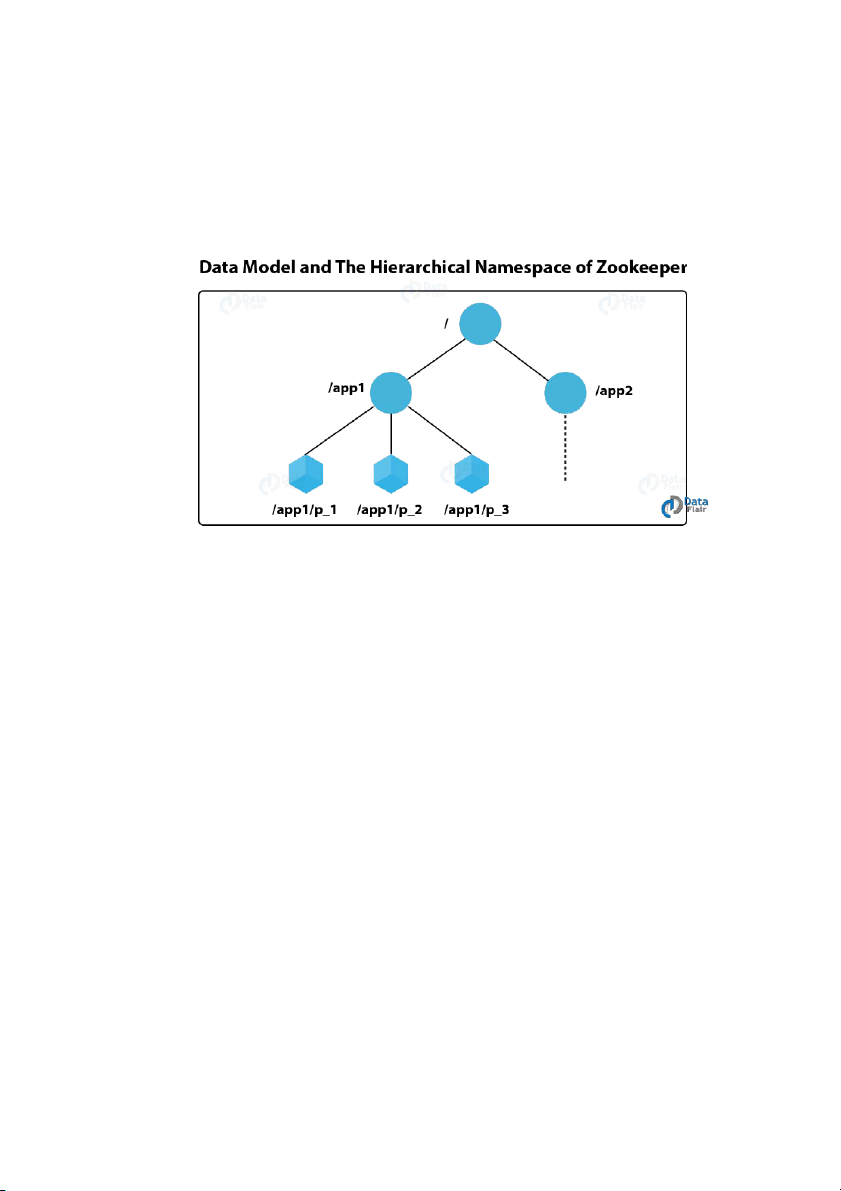
- Data Model and Hierarchical Namespace
+ Giống như một hệ thống tệp tiêu chuẩn, namespace được cung cấp bởi
ZooKeeper. Về cơ bản, một chuỗi các yếu tố đường dẫn phân tách bằng dấu
gạch chéo (/). Trong namespace của ZooKeeper, một đường dẫn xác định mọi
nút. Hơn nữa, trong namespace ZooKeeper, mỗi nút có thể có dữ liệu liên quan
đến nó và con cái của nó.
+ Việc đọc ghi trên các ZNode được diễn ra hoàn toàn tự động, dữ liệu được lưu
trữ tại mỗi Znode trong một không gian tên được đọc và viết nguyên tử. Đọc tất
cả các byte dữ liệu được liên kết với một Znode và một ghi thay thế tất cả dữ
liệu. Ngoài ra, có một Danh sách kiểm soát truy cập (ACL) với mỗi nút hạn chế truy cập.
+ Ngoài ra, trong mỗi máy chủ ZooKeeper, hệ thống phân cấp ZNode được lưu
trữ trong bộ nhớ. Về cơ bản, điều đó giúp phản hồi nhanh chóng để phản hồi
đọc từ khách hàng. Khách hàng có thể đặt các watches để giám sát các Znode
để phản hồi khi Znode thay đổi
- Các API mà ZooKeeper cung cấp
+ create: creates a node at a location in the tree + delete: deletes a node
+ exists: tests if a node exists at a location
+ get data: reads the data from a node
+ set data: writes data to a node
+ get children: retrieves a list of children of a node
+ sync: waits for data to be propagated a. Lợi ích:
+ Đơn giản và nhanh chóng
+ Tính nhất quán tuần tự - Cập nhật từ khách hàng sẽ được áp dụng theo thứ tự họ đã gửi.
Tính nguyên tử - cập nhật hoặc thành công hoặc thất bại. Không có kết quả một phần.
Giao diện đơn giản - Khách hàng sẽ thấy cùng một khung nhìn về dịch vụ bất
kể máy chủ mà nó kết nối.
Độ tin cậy - Khi một bản cập nhật đã được áp dụng, nó sẽ tồn tại từ thời điểm
đó về phía trước cho đến khi khách hàng ghi đè lên bản cập nhật.
Tính kịp thời - Chế độ xem của khách hàng về hệ thống được đảm bảo được cập
nhật trong một thời gian nhất định. b. H n chếế ạ
- Việc thêm ZooKeeper server có thể gây mất mát data
- Rack-Aware Replication Hiện tại, nó không hỗ trợ vị trí và rack-aware.
- Mở rộng trong dịch vụ không hỗ trợ giảm số lượng vỏ, để ngăn ngừa mất dữ liệu ngẫu nhiên.
- Số lượng node trên một node khác chỉ từ 3-5
- Virtual network: không cho phép thay đổi khối lượng đã khởi tạo
- Kerberos trên các mạng ảo, nó không hỗ trợ cho phép Kerberos.
- Hỗ trợ hạn chế: Có sự hỗ trợ hạn chế như vậy đối với các kịch bản cụm chéo. 3. Example of ZooKeeper a. Standalone - Create Znodes
Tạo node bằng cách thêm các path. The flag argument nhằm để quy định znode
thuộc loại ephemeral, persistent, hay sequential. Mặc định, tất cả znodes là persistent.
+ Ephemeral znodes (flag: e) tự động xoá các znode khi hết hạn hoặc bị ngắt
kết lỗi khi gặp sự cố
+ Sequential znodes đảm bảo các znode path là unique.
ZooKeeper Ensemble sẽ thêm số thứ tự cùng với phần đệm 10 chữ số vào
đường dẫn Znode. Ví dụ: đường dẫn Znode / MyApp sẽ được chuyển đổi thành /
MyApp0000001 và số thứ tự tiếp theo sẽ là / MyApp0000000002. Nếu không có
cờ được chỉ định, thì Znode được coi là persistent. Syntax create -flag /path /data - Get data Syntax get /path
Tài liệu liên quan:
-

Quy định xử phạt vi phạm hành chính trong lĩnh vực an ninh mạng | Lý thuyết môn an toàn thông tin mạng Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
533 267 -

Chương 2: thực trạng và những phương pháp trong công tác đấu tranh phòng chống tội phạm mạng | Tài liệu môn An toàn thông tin
350 175 -

LAB 2: Quét mạng (scanning networks) | Báo cáo bài thực hành môn An toàn thông tin Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
555 278 -

LAB 2: Buffer Overflows - Bùi Đức Thắng | Báo cáo bài thực hành môn An toàn thông tin Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
662 331 -

Lab 5. SQL Injection | Tài liệu Môn an toàn thông tin Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
410 205