Chương 12 - Môn Thị trường và các định chế tài chính - Đại Học Kinh Tế - Đại học Đà Nẵng
A distributed database management system (DDBMS) governs the storage and processing of logically related data over interconnected computer systems in which both data and processing are distributed among several sites. Tài liệu giúp bạn tham khảo ôn tập và đạt kết quả cao. Mời bạn đọc đón xem!
Môn: Thị trường và các định chế tài chính 199 tài liệu
Trường: Trường Đại học Kinh tế - Đại học Đà Nẵng 1.4 K tài liệu
Tác giả:











Preview text:
lOMoARcPSD| 50032646 Downloaded by Huyen Thu (hth11@gmail.com) MoARcPSD| 50032646
12-1 T he Evolution of Distributed Database Management Systems
A distributed database management system (DDBMS) governs the storage and
processing of logically related data over interconnected computer systems in which
both data and processing are distributed among several sites. To understand how and
why the DDBMS is di erent from the DBMS, it is useful to brie y examine the changes
in the business environment that set the stage for the development of the DDBMS.
During the 1970s, corporations implemented centralized database management
systems to meet their structured information needs. e use of a centralized database
required that corporate data be stored in a single central site, usually a mainframe c
omputer. Data access was provided through dumb terminals. e centralized approach,
illustrated in Figure 12.1, worked well to ll the structured information needs of
corporations, but it fell short when quickly moving events required faster response
times and equally quick access to information. e slow progression from information
request to approval to specialist to user simply did not serve decision makers well in a
dynamic environment. What was needed was quick, unstructured access to databases,
using ad hoc queries to generate on-the-spot information.
e last two decades gave birth to a series of crucial social and technological changes
that a ected the nature of the systems and the data they use: lOMoARcPSD| 50032646
Business operations became global; with this change, competition expanded from the distributed database
shop on the next corner to the web store in cyberspace. management system (DDBMS)
Customer demands and market needs favored an on-demand transaction style, A DBMS that supports
mostly based on web-based services. a database distributed across several di erent
Rapid social and technological changes fueled by low-cost, smart mobile devices sites; a DDBMS
increased the demand for complex and fast networks to interconnect them. As a governs the storage
consequence, corporations have increasingly adopted advanced network and processing of
technologies as the platform for their computerized solutions. See Chapter 15, logically related data
Database Connectivity and Web Technologies, for a discussion of cloud-based over interconnected services. computer systems in which both data and
Data realms are converging in the digital world more frequently. As a result, processing functions
applications must manage multiple types of data, such as voice, video, music, and are distributed among
images. Such data tends to be geographically distributed and remotely accessed from several sites.
diverse locations via location-aware mobile devices.
e advent of social media as a way to reach new customers and
open new markets has fueled the need to store large amounts of
digital data and created a revolution in the way data is managed
and mined for knowledge. Businesses are looking for new ways to gain business
intelligence through the analysis of vast stores of structured and unstructured data.
ese factors created a dynamic business environment in which companies had to
respond quickly to competitive and technological pressures. As large business units
restructured to form leaner, quickly reacting, dispersed operations, two database requirements became obvious:
Rapid ad hoc data access became crucial in the quick-response decision-making environment.
Distributed data access was needed to support geographically dispersed business units.
During recent years, these factors became even more rmly entrenched. However, the
way they were addressed was strongly in uenced by the following factors:
e growing acceptance of the Internet as the platform for data access and
distribution. e web is e ectively the repository for distributed data.
e mobile wireless revolution. e widespread use of mobile wireless digital devices
includes smartphones and tablets. ese devices have created high demand for data
access. ey access data from geographically dispersed locations and require varied data
exchanges in multiple formats, such as data, voice, video, music, and pictures.
Although distributed data access does not necessarily imply distributed databases,
performance and failure tolerance requirements o en lead to the use of data
replication techniques similar to those in distributed databases.
e accelerated growth of companies using “applications as a service.” is new type of
service provides remote applications to companies that want to outsource their
application development, maintenance, and operations. e company data is
generally stored on central servers and is not necessarily distributed. Just as with
mobile data access, this type of service may not require fully distributed data
functionality; however, other factors such as performance and failure tolerance o
en require the use of data replication techniques similar to those in distributed databases.
e increased focus on mobile business intelligence. More and more companies are
embracing mobile technologies within their business plans. As companies use social
networks to get closer to customers, the need for on-the-spot decision making
increases. Although a data warehouse is not usually a distributed database, it does MoARcPSD| 50032646
rely on techniques such as data replication and distributed queries that facilitate
data extraction and integration. (You will learn more about this topic in Chapter 13,
Business Intelligence and Data Warehouses.)
Emphasis on Big Data analytics. e era of mobile communications unraveled an
avalanche of data from many sources and of many types. Today’s customers have
signi cant in uence on the spending habits of communities, and organizations are
investing in ways to harvest such data to “discover” new ways to e ectively and e ciently reach customers.
At this point, the long-term impact of the Internet and the mobile revolution on
distributed database design and management is just starting to be felt. Perhaps the
success of the Internet and mobile technologies will foster the use of distributed
databases as bandwidth becomes a less troublesome bottleneck. Perhaps the resolution
of bandwidth problems will simply con rm the centralized database standard. In any case,
distributed database concepts and components are likely to nd a place in future database development,
particularly for specialized mobile and location-aware applications.
e distributed database is especially desirable because centralized database manage-
ment is subject to problems such as:
Performance degradation because of a growing number of remote locations over greater distances.
High costs associated with maintaining and operating large central (mainframe)
database systems and physical infrastructure.
Reliability problems created by dependence on a central site (single point of failure
syndrome) and the need for data replication.
Scalability problems associated with the physical limits imposed by a single location,
such as physical space, temperature conditioning, and power consumption.
Organizational rigidity imposed by the database, which means it might not support
the exibility and agility required by modern global organizations.
e dynamic business environment and the centralized database’s shortcomings
spawned a demand for applications based on accessing data from di erent sources at
multiple locations. Such a multiple-source/multiple-location database environment is best managed by a DDBMS.
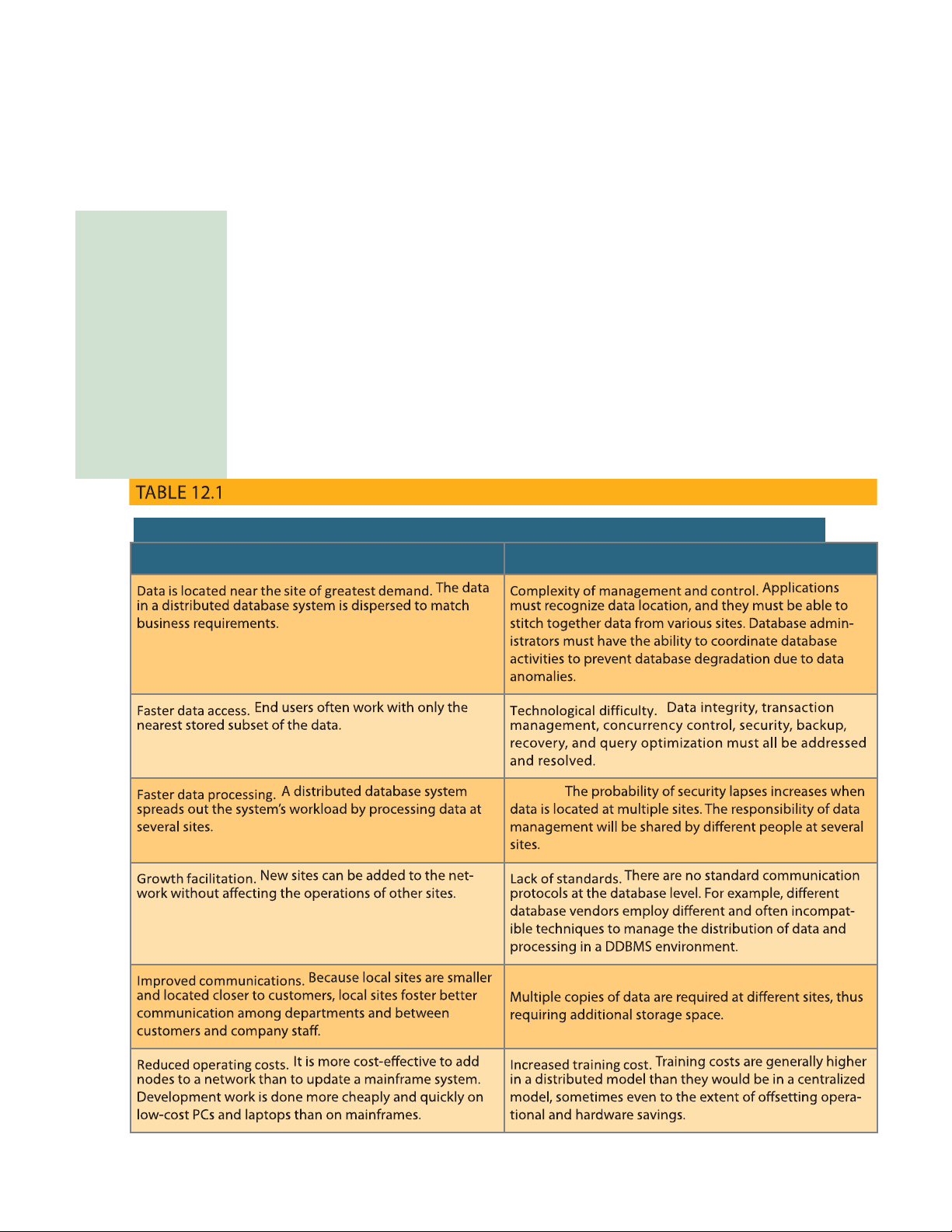
12-2 DDBMS Advantages and Disadvantages
Distributed database management systems deliver several advantages over traditional
systems. At the same time, they are subject to some problems. Table 12.1 summarizes
the advantages and disadvantages associated with a DDBMS.
Distributed databases are being used successfully in many web staples such as
Google and Amazon, but they still have a long way to go before they yield the full
exibility and power they theoretically possess.
e remainder of this chapter explores the basic components and concepts of the
distributed database. Because the distributed database is usually based on the
relational database model, relational terminology is used to explain the basic concepts
and components. Even though some of the most widely used distributed databases are
part of the NoSQL movement (see Chapter 2, Data Models), the basic concepts and
fundamentals of distributed data still apply to them. lOMoARcPSD| 50032646
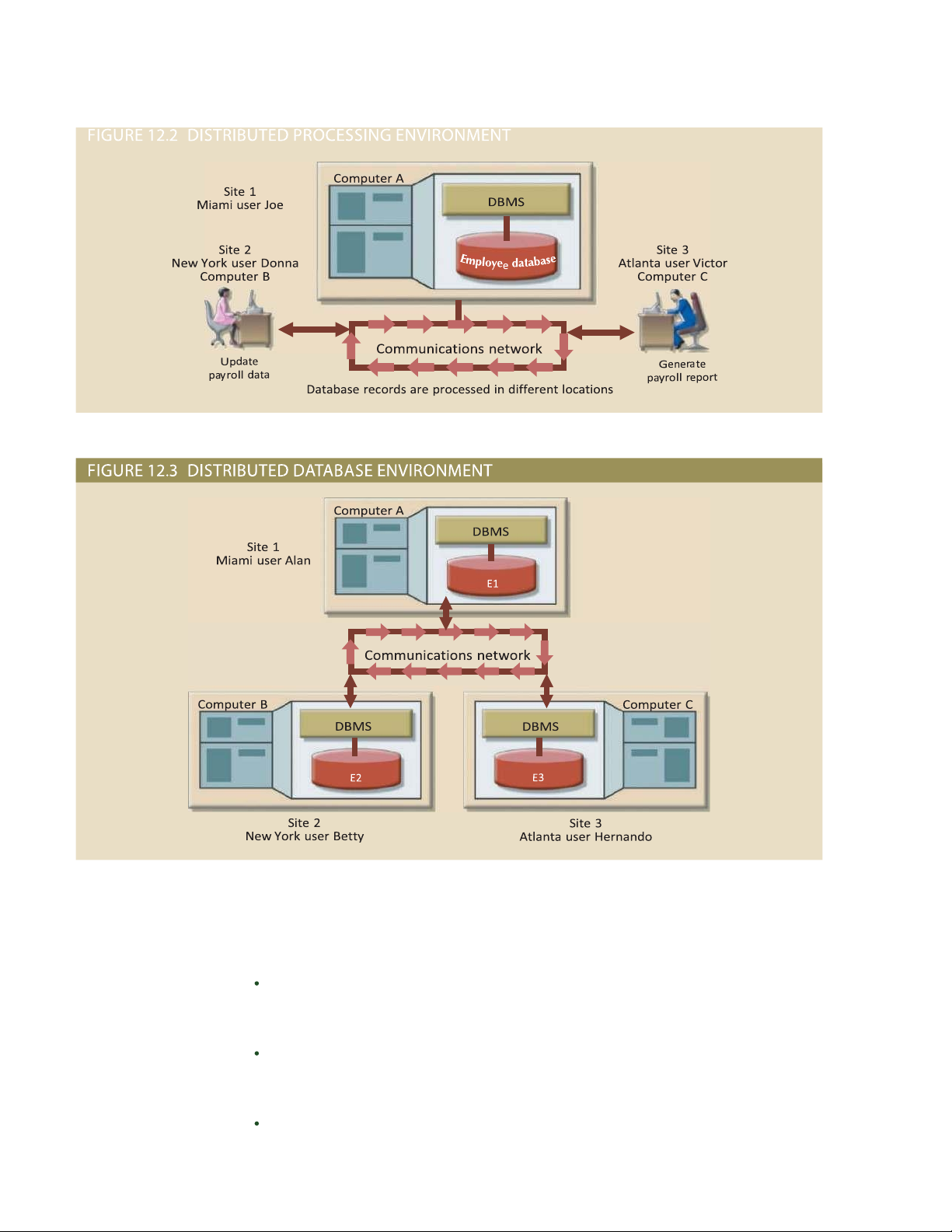
12-3 Distributed Processing and Distributed Databases
In distributed processing, a database’s logical processing is shared among two or more physically
independent sites that are connected through a network. For example, the data
distributed processing input/output (I/O), data selection, and data validation might be performed on one Sharing the logical
processing of a database computer, and a report based on that data might be created on another computer. over two or more sites
A basic distributed processing environment is illustrated in Figure 12.2, which shows
connected by a network. that a distributed processing system shares the database processing chores among three distributed database
sites connected through a communications network. Although the database resides at only A logically
related one site (Miami), each site can access the data and update the database. e database is database that is stored in
two or more physically located on Computer A, a network computer known as the database server. independent sites.
A distributed database, on the other hand, stores a logically related database over two
or more physically independent sites. e sites are connected via a computer
DISTRIBUTED DBMS ADVANTAGES AND DISADVANTAGES ADVANTAGES DISADVANTAGES Security.
Increased storage and infrastructure requirements. MoARcPSD| 50032646 database fragment A subset of a distributed database. Although the fragments may be stored at di erent sites within a computer network, the set of all fragments is treated as a single database. See also horizontal fragmentation and vertical fragmentation. Processor independence.
network. In contrast, the distributed processing system uses only a single-site database but shares the
processing chores among several sites. In a distributed database system, a database is composed of
several parts known as database fragments. e database fragments are located at di erent sites and can be
replicated among various sites. Each database fragment is, in turn, managed by its local database process.
An example of a distributed database environment is shown in Figure 12.3.
e database in Figure 12.3 is divided into three database fragments (E1, E2, and E3)
located at di erent sites. e computers are connected through a network system. In a fully distributed
database, the users Alan, Betty, and Hernando do not need to know the name or location of each database
fragment in order to access the database. Also, the lOMoARcPSD| 50032646
users might be at sites other than Miami, New York, or Atlanta and still be able to
access the database as a single logical unit.
As you examine Figures 12.2 and 12.3, keep the following points in mind:
Distributed processing does not require a distributed database, but a distributed
database requires distributed processing. (Each database fragment is managed by
its own local database process.)
Distributed processing may be based on a single database located on a single
computer. For the management of distributed data to occur, copies or parts of the
database processing functions must be distributed to all data storage sites.
Both distributed processing and distributed databases require a network of interconnected components.
12-4 Characteristics of Distributed Database Management Systems
A DDBMS governs the storage and processing of logically related data over
interconnected computer systems in which both data and processing functions are
distributed among several sites. A DBMS must have at least the following functions to be classi ed as distributed:
Application interface to interact with the end user, application programs, and other
DBMSs within the distributed database
Validation to analyze data requests for syntax correctness
Transformation to decompose complex requests into atomic data request components
Query optimization to nd the best access strategy (which database fragments must be
accessed by the query, and how must data updates, if any, be synchronized?)
Mapping to determine the data location of local and remote fragments
I/O interface to read or write data from or to permanent local storage
Formatting to prepare the data for presentation to the end user or to an application program
Security to provide data privacy at both local and remote databases
Backup and recovery to ensure the availability and recoverability of the database in case of a failure
DB administration features for the database administrator
Concurrency control to manage simultaneous data access and to ensure data consistency
across database fragments in the DDBMS
Transaction management to ensure that the data moves from one consistent state
to another; this activity includes the synchronization of local and remote
transactions as well as transactions across multiple distributed segments
A fully distributed database management system must perform all of the functions of
a centralized DBMS, as follows:
1. Receive the request of an application or end user.
2. Validate, analyze, and decompose the request. e request might include m athematical and logical
operations such as the following: Select all customers with a balance greater than $1,000. e request
might require data from only a single table, or it might require access to several tables.
3. Map the request’s logical-to-physical data components.
4. Decompose the request into several disk I/O operations.
5. Search for, locate, read, and validate the data.
6. Ensure database consistency, security, and integrity.
7. Validate the data for the conditions, if any, speci ed by the request.
8. Present the selected data in the required format.
In addition, a distributed DBMS must handle all necessary functions imposed by the
distribution of data and processing, and it must perform those additional functions
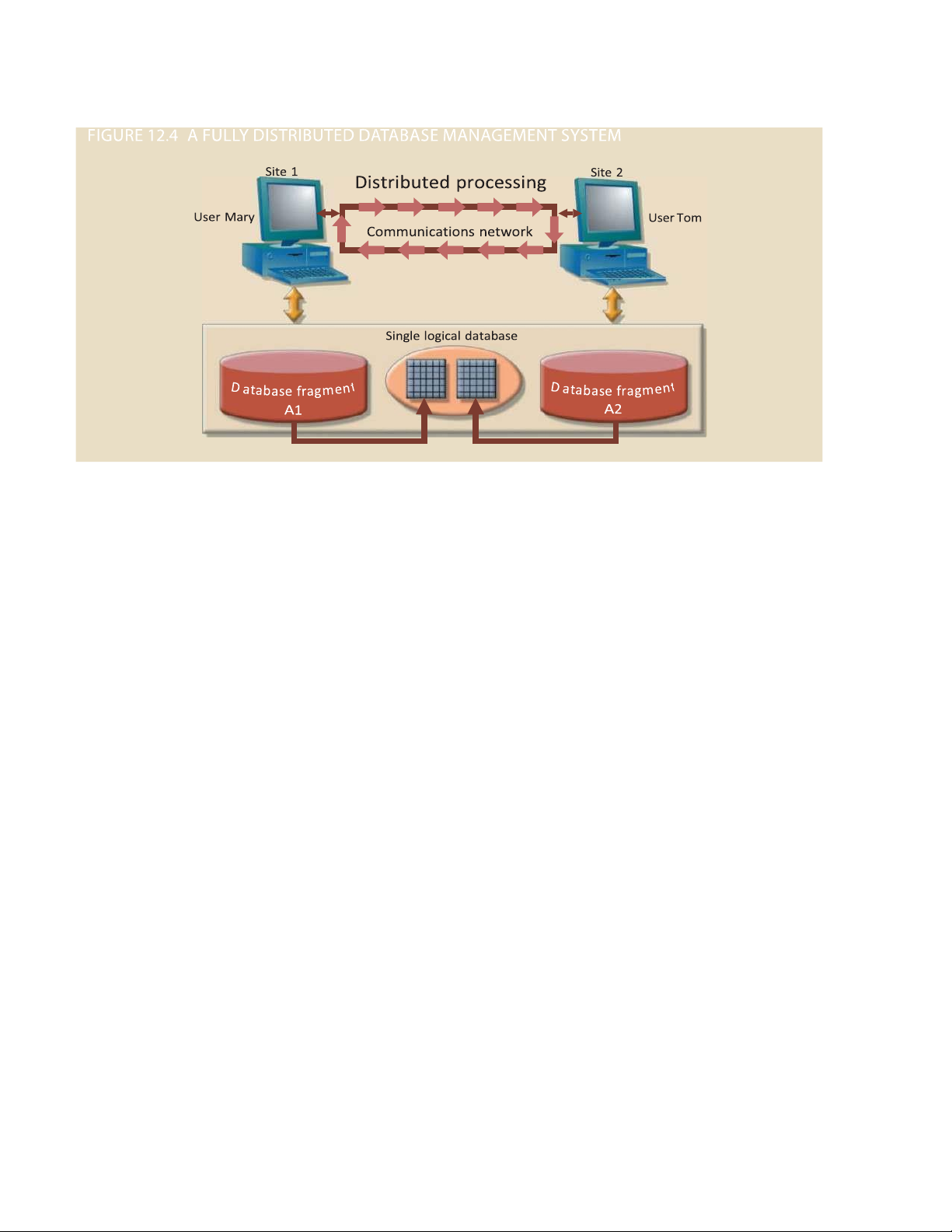
transparently to the end user. e DDBMS’s transparent data access features are illustrated in Figure 12.4. lOMoARcPSD| 50032646
e single logical database in Figure 12.4 consists of two database fragments, A1 and A2, located at
Sites 1 and 2, respectively. Mary can query the database as if it were a local database; so
transaction processor can Tom. Both users “see” only one logical database and do not need to know the names (TP)
of the fragments. In fact, the end users do not even need to know that the d atabase is In a DDBMS, the
divided into fragments, nor do they need to know where the fragments are located. software component on each computer that
To better understand the di erent types of distributed database scenarios, rst consider requests data. The TP is
the components of the distributed database system. responsible for the execution and coordination of all
database requests issued 12-5 DDBMS Components by a local application
e DDBMS must include at least the following components: that accesses data on any DP. Also called
Computer workstations or remote devices (sites or nodes) that form the network system. transaction manager
e distributed database system must be independent of the computer system hardware. (TM) or application processor (AP).
Network hardware and so ware components that reside in each workstation or device. e
application processor network components allow all sites to interact and exchange data. Because the (AP) See transaction
components—computers, operating systems, network hardware, and so on—are likely to processor (TP).
be supplied by di erent vendors, it is best to ensure that distributed database functions transaction manager
can be run on multiple platforms. (TM)
Communications media that carry the data from one node to another. e DDBMS must be See transaction processor (TP).
communications media-independent; that is, it must be able to support several types of data processor (DP) communications media. The resident software
e transaction processor (TP) is the so ware component found in each computer or device component that stores and retrieves data
that requests data. e transaction processor receives and processes the application’s through a DDBMS. The
remote and local data requests. e TP is also known as the application processor (AP) or the DP is responsible for transaction manager (TM). managing the local data in the computer and
e data processor (DP) is the so ware component residing on each computer or device that coordinating access to
stores and retrieves data located at the site. e DP is also known as the data manager (DM). that data. Also known as data manager (DM).
A data processor may even be a centralized DBMS. data manager (DM)
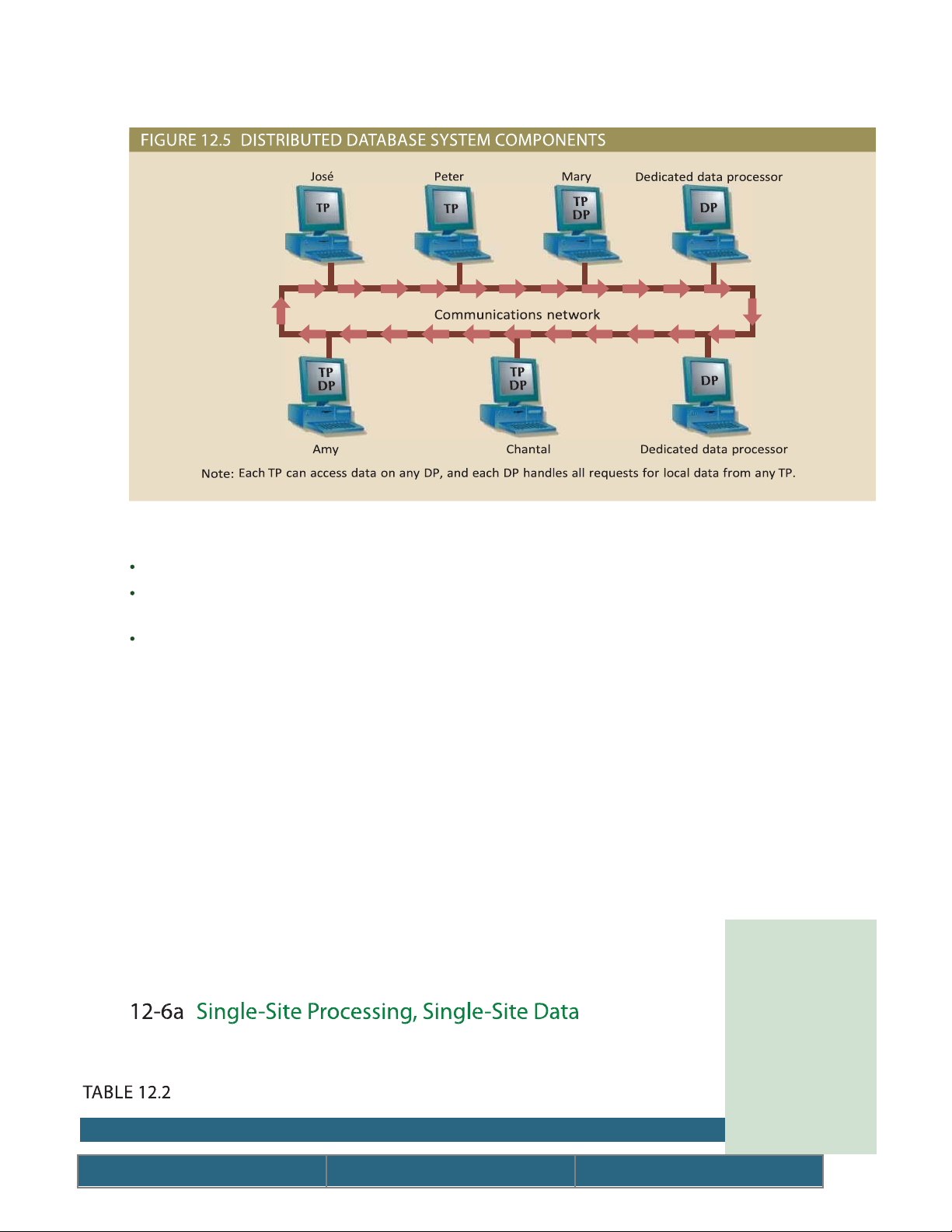
Figure 12.5 illustrates the placement of the components and the
See data processor (DP). interaction among them. e communication among TPs and DPs is made
possible through a speci c set of rules, or protocols, used by the DDBMS. lOMoARcPSD| 50032646
e protocols determine how the distributed database system will:
Interface with the network to transport data and commands between DPs and TPs.
Synchronize all data received from DPs (TP side) and route retrieved data to the appropriate TPs (DP side).
Ensure common database functions in a distributed system. Such functions include
data security, transaction management and concurrency control, data partitioning and
synchronization, and data backup and recovery.
DPs and TPs should be added to the system transparently without a ecting its
operation. A TP and a DP can reside on the same computer, allowing the end user to
access both local and remote data transparently. In theory, a DP can be an
independent centralized DBMS with proper interfaces to support remote access from
other independent DBMSs in the network.
12-6 Levels of Data and Process Distribution
Current database systems can be classi ed on the basis of how process distribution and data distribution
are supported. For example, a DBMS may store data in a single site (using a centralized DB) or in multiple
sites (using a distributed DB), and it may support data processing at one or more sites.
Table 12.2 uses a simple matrix to classify database systems according to data and process single-site processing,
distribution. ese types of processes are discussed in the sections that follow. s ingle-site data (SPSD)
In the single-site A scenario in which all processing is done on a
processing, single- single host computer
site data (SPSD) scenario, all processing is done on a single host computer, and all data is and all data is stored
stored on the host computer’s local disk system. on the host computer’s local disk.
DATABASE SYSTEMS: LEVELS OF DATA AND PROCESS DISTRIBUTION ADVANTAGES SINGLE SITE DATA MULTIPLE SITE DATA e DBMS is on the host
Using Figure 12.6 as an example, you can see that the functions of the TP and DP
are embedded within the DBMS on the host computer. e DBMS usually runs under a
time-sharing, multitasking operating system, which allows several processes to run
concurrently on a host computer accessing a single DP. All data storage and data
processing are handled by a single host computer.
Under the multiple-site processing, single-site data (MPSD) scenario, multiple processes run on di erent
computers that share a single data repository. Typically, the MPSD scenario requires a network le server
running conventional applications that are accessed through a network. Many multiuser accounting
applications running under a personal computer network t such a description (see Figure 12.7). As you
examine Figure 12.7, note that: multiple-site processing, single-
e TP on each workstation acts only as a redirector to route all network data requests site data (MPSD) to the le server. A scenario in which
e end user sees the le server as just another hard disk. Because only the data multiple processes run
storage input/output (I/O) is handled by the le server’s computer, the MPSD o ers on di erent computers sharing a single data
limited capabilities for distributed processing. repository. lOMoARcPSD| 50032646 client/server architecture A hardware and software system composed of clients, servers, and middleware. Features a user of resources communication costs. (client) and a provider of resources (server).
e ine ciency of the last condition can be illustrated easily. For example, suppose that multiple-site p
the le server computer stores a CUSTOMER table containing 100,000 data rows, 50 of rocessing, multiple-
which have balances greater than $1,000. Suppose that Site A issues the following SQL site data (MPMD) query: A scenario describing a fully distributed SELECT * database management FROM CUSTOMER
All 100,000 CUSTOMER rows must travel system WHERE CUS_BALANCE > 1000; with support for multiple data processors and transaction processors at multiple sites. homogeneous DDBMS A system that integrates only one type of centralized database management system over a network. heterogeneous DDBMS A system that integrates di erent types of centralized database management systems over a network. fully h eterogeneous distributed d atabase system (fully h eterogeneous DDBMS)
through the network to be evaluated at Site A. A variation of the multiple-site processing, A system that integrates di erent types of
single-site data approach is known as client/server architecture. Client/server architecture database
is similar to that of the network le server except that all database processing is done at the management systems
server site, thus reducing network tra c. Although both the network le server and the (hierarchical,
client/server systems perform multiple-site processing, the client/server system’s network, and relational) over a
processing is distributed. Note that the network le server approach requires the database network. It supports di
to be located at a single site. In contrast, the client/server architecture is capable of erent database
supporting data at multiple sites. management systems that may even support
e multiple-site processing, multiple-site data (MPMD) scenario describes a fully distributed di erent data models
DBMS with support for multiple data processors and transaction processors at multiple running under di erent computer systems.
sites. Depending on the level of support for various types of databases, DDBMSs are classi
ed as either homogeneous or heterogeneous.
Homogeneous DDBMSs integrate multiple instances of the same DBMS over a network—for example,
multiple instances of Oracle 11g running on di erent platforms. In contrast, heterogeneous DDBMSs
integrate di erent types of DBMSs over a network, but all support the same data model. For example,
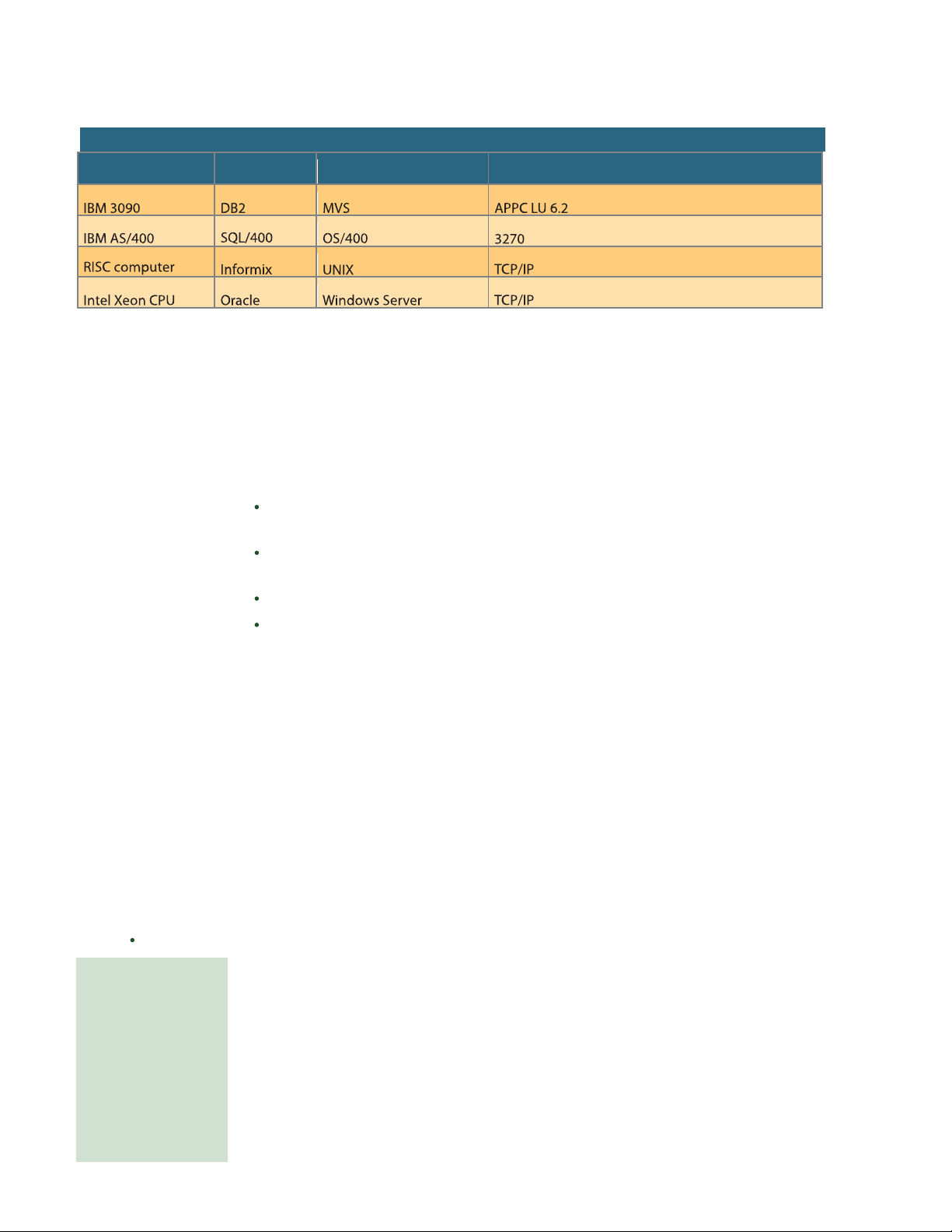
Table 12.3 lists several relational database systems that could be integrated within a DDBMS. A fully
heterogeneous DDBMS will support di erent DBMSs, each one supporting a di erent data model, r unning
under di erent computer systems.
DATABASE SYSTEMS: LEVELS OF DATA AND PROCESS DISTRIBUTION PLATFORM DBMS OPERATING SYSTEM
NETWORK COMMUNICATIONS PROTOCOL
Distributed database implementations are better understood as an abstraction
layer on top of a DBMS. is abstraction layer provides additional functionality that
enables support for distributed database features, including straightforward data
links, replication, advanced data fragmentation, synchronization, and integration. In
fact, most database vendors provide for increasing levels of data fragmentation,
replication, and integration. erefore, the support for distributed databases can be
better seen as a continuous spectrum that goes from homogeneous to fully
heterogeneous distributed data management. Consequently, at any point on this
spectrum, a DDBMS is subject to certain restrictions. For example:
Remote access is provided on a read-only basis and does not support write privileges.
Restrictions are placed on the number of remote tables that may be accessed in a single transaction.
Restrictions are placed on the number of distinct databases that may be accessed.
Restrictions are placed on the database model that may be accessed. us, access
may be provided to relational databases but not to network or hierarchical databases.
e preceding list of restrictions is by no means exhaustive. e DDBMS t echnology
continues to change rapidly, and new features are added frequently. Managing data at
multiple sites leads to a number of issues that must be addressed and understood. e
next section examines several key features of distributed database management systems.
12-7 Distributed Database Transparency Features
A distributed database system should provide some desirable transparency features
that make all the system’s complexities hidden to the end user. In other words, the
end user should have the sense of working with a centralized DBMS. For this reason,
the minimum desirable DDBMS transparency features are:
Distribution transparency allows a distributed database to be treated as a single logical database. If a
DDBMS exhibits distribution transparency, the user does not need to know: distribution
– e data is partitioned—meaning the table’s rows and columns are split vertically or transparency
horizontally and stored among multiple sites. A DDBMS feature that allows a distributed
– e data is geographically dispersed among multiple sites. database to look like a
– e data is replicated among multiple sites. single logical database to an end user. lOMoARcPSD| 50032646
Transaction transparency allows a transaction to update data at more than one network transaction
site. Transaction transparency ensures that the transaction will be either entirely transparency
completed or aborted, thus maintaining database integrity. A DDBMS property that ensures database
Failure transparency ensures that the system will continue to operate in the event of a transactions will
node or network failure. Functions that were lost because of the failure will be picked maintain the distributed
up by another network node. is is a very important feature, particularly in organizations database’s integrity and consistency, and that a
that depend on web presence as the backbone for maintaining trust in their business. transaction will be completed only when all
Performance transparency allows the system to perform as if it were a centralized DBMS. database sites involved
e system will not su er any performance degradation due to its use on a network or complete their part of
because of the network’s platform di erences. Performance transparency also ensures the transaction.
that the system will nd the most cost-e ective path to access remote data. e system failure transparency
should be able to “scale out” in a transparent manner or increase performance capacity A feature that allows
by adding more transaction or data-processing nodes, without a ecting the overall continuous operation of a DDBMS, even if a performance of the system. network node fails.
Heterogeneity transparency allows the integration of several di erent local DBMSs performance
(relational, network, and hierarchical) under a common, or global, schema. e DDBMS is transparency A DDBMS feature that
responsible for translating the data requests from the global schema to the local DBMS allows a system to
schema. e following sections discuss each of these transparency features in greater perform as though it detail. were a centralized DBMS. heterogeneity
12-8 Distribution Transparency transparency A feature that allows a
Distribution transparency allows a physically dispersed database to be managed as though system to integrate
it were a centralized database. e level of transparency supported by the DDBMS varies several centralized DBMSs into one logical
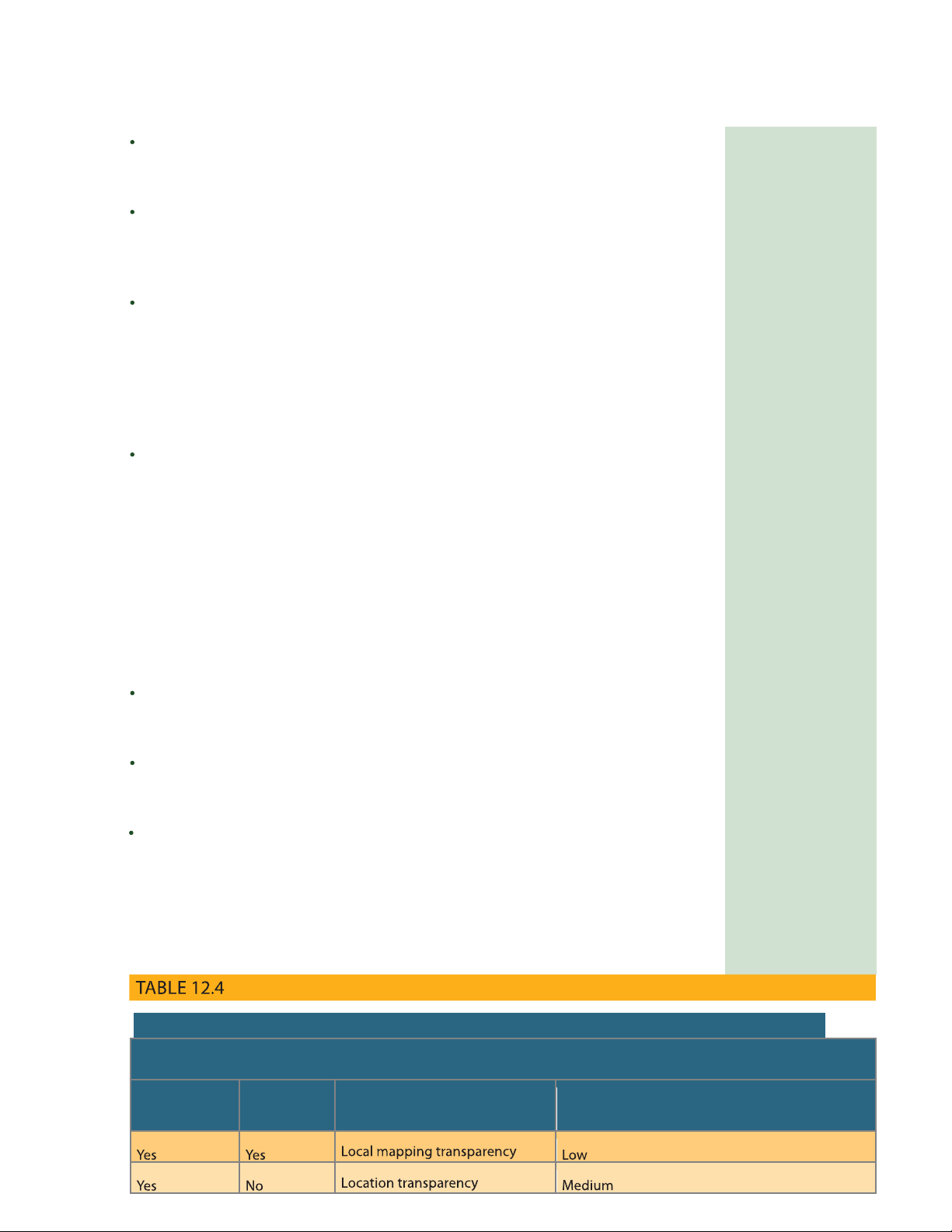
from system to system. ree levels of distribution transparency are recognized: DDBMS.
Fragmentation transparency is the highest level of distribution transparency. e end user fragmentation
or programmer does not need to know that a database is partitioned. erefore, neither transparency
fragment names nor fragment locations are speci ed prior to data access. A DDBMS feature that allows a system to treat
Location transparency exists when the end user or programmer must specify the a distributed database
database fragment names but does not need to specify where those fragments are as a single database even though it is divided located. into two or more
Local mapping transparency exists when the end user or programmer must specify fragments. location
both the fragment names and their locations. Transparency features are summarized transparency A property of a DDBMS in Table 12.4. in which database access requires the user to know only the name of the database fragments. (Fragment locations need not be known.)
SUMMARY OF TRANSPARENCY FEATURES
IF THE SQL STATEMENT REQUIRES: FRAGMENT LOCATION THEN THE DBMS SUPPORTS
LEVEL OF DISTRIBUTON TRANSPARENCY NAME? NAME? lOMoARcPSD| 50032646
To illustrate the use of various transparency levels, suppose you have an EMPLOYEE
table that contains the attributes EMP_NAME, EMP_DOB, EMP_ADDRESS, EMP_
DEPARTMENT, and EMP_SALARY. e EMPLOYEE data is distributed over three di erent
locations: New York, Atlanta, and Miami. e table is divided by location; that is, New
York employee data is stored in fragment E1, Atlanta employee data is stored in
fragment E2, and Miami employee data is stored in fragment E3 (see Figure 12.8).
Now suppose that the end user wants to list all employees born before January 1,
1960. To focus on the transparency issues, also suppose that the EMPLOYEE table is
fragmented and each fragment is unique. e unique fragment condition indicates that
each row is unique, regardless of the fragment in which it is located. Finally, assume
that no portion of the database is replicated at any other site on the network.
Depending on the level of distribution transparency support, you may examine three query cases.
e query conforms to a nondistributed database query format; that is, it does not s pecify local mapping
fragment names or locations. e query reads: transparency A property of a DDBMS SELECT * in which database FROM EMPLOYEE access requires the user to know both the name WHERE EMP_DOB < '01-JAN-1979'; and location of the fragments. Fragment names must unique fragment
be speci ed in the query, but the fragment’s location is not speci ed. e query reads: In a DDBMS, a condition in which each row is SELECT * unique, regardless of FROM E1 which fragment it is located in.
WHERE UNION EMP_DOB < '01-JAN-1979' SELECT * FROM E2 lOMoARcPSD| 50032646
WHERE UNION EMP_DOB < '01-JAN-1979' SELECT * FROM E3 WHERE EMP_DOB < '01-JAN-1979'
Both the fragment name and its location must be speci ed in the query. Using pseudo-SQL: SELECT * FROM El NODE NY
WHERE UNION EMP_DOB < '01-JAN-1979'; SELECT * FROM E2 NODE ATL
WHERE UNION EMP_DOB < '01-JAN-1979'; SELECT * FROM E3 NODE MIA distributed data d WHERE EMP_DOB < '01-JAN-1979'; ictionary (DDD)
As you examine the preceding query formats, you can see how distribution See distributed data
transparency a ects the way end users and programmers interact with the database. catalog.
Distribution transparency is supported by a distributed data dictionary (DDD) or a distributed data c
distributed data catalog (DDC). The DDC contains the description of the entire database as atalog (DDC) A data dictionary that
seen by the database administrator. The database description, known as the distributed contains the
global schema, is the common database schema used by local TPs to translate user description (fragment
requests into subqueries (remote requests) that will be processed by different DPs. The names and locations) of
DDC is itself distributed, and it is replicated at the network nodes. Therefore, the DDC must a distributed database.
maintain consistency through updating at all sites. distributed global schema
Keep in mind that some of the current DDBMS implementations impose limitations on The database schema
the level of transparency support. For instance, you might be able to distribute a database, description of a
but not a table, across multiple sites. Such a condition indicates that the DDBMS supports distributed database
location transparency but not fragmentation transparency. as seen by the database 12-9 Transaction Transparency administrator.
Transaction transparency is a DDBMS property that ensures database
transactions will maintain the distributed database’s integrity and
consistency. Remember that a DDBMS database transaction can update
data stored in many di erent computers connected in a network.
Transaction transparency ensures that the transaction will be
completed only when all database sites involved in the transaction complete their part of the transaction.
Distributed database systems require complex mechanisms to manage transactions
and ensure the database’s consistency and integrity. To understand how the
transactions are managed, you should know the basic concepts governing remote
requests, remote transactions, distributed transactions, and distributed requests. lOMoARcPSD| 50032646
Whether or not a transaction is distributed, it is formed by one or more database
requests. e basic di erence between a nondistributed transaction and a distributed
transaction is that the distributed transaction can update or request data from several
di erent remote sites on a network. To better understand distributed transactions,
begin by learning the di erence between remote and distributed transactions, using
the BEGIN WORK and COMMIT WORK transaction format. Assume the existence of
location transparency to avoid having to specify the data location.
A remote request, illustrated in Figure 12.9, lets a single SQL statement access the
data that are to be processed by a single remote database processor. In other words,
the SQL statement (or request) can reference data at only one remote site. remote request
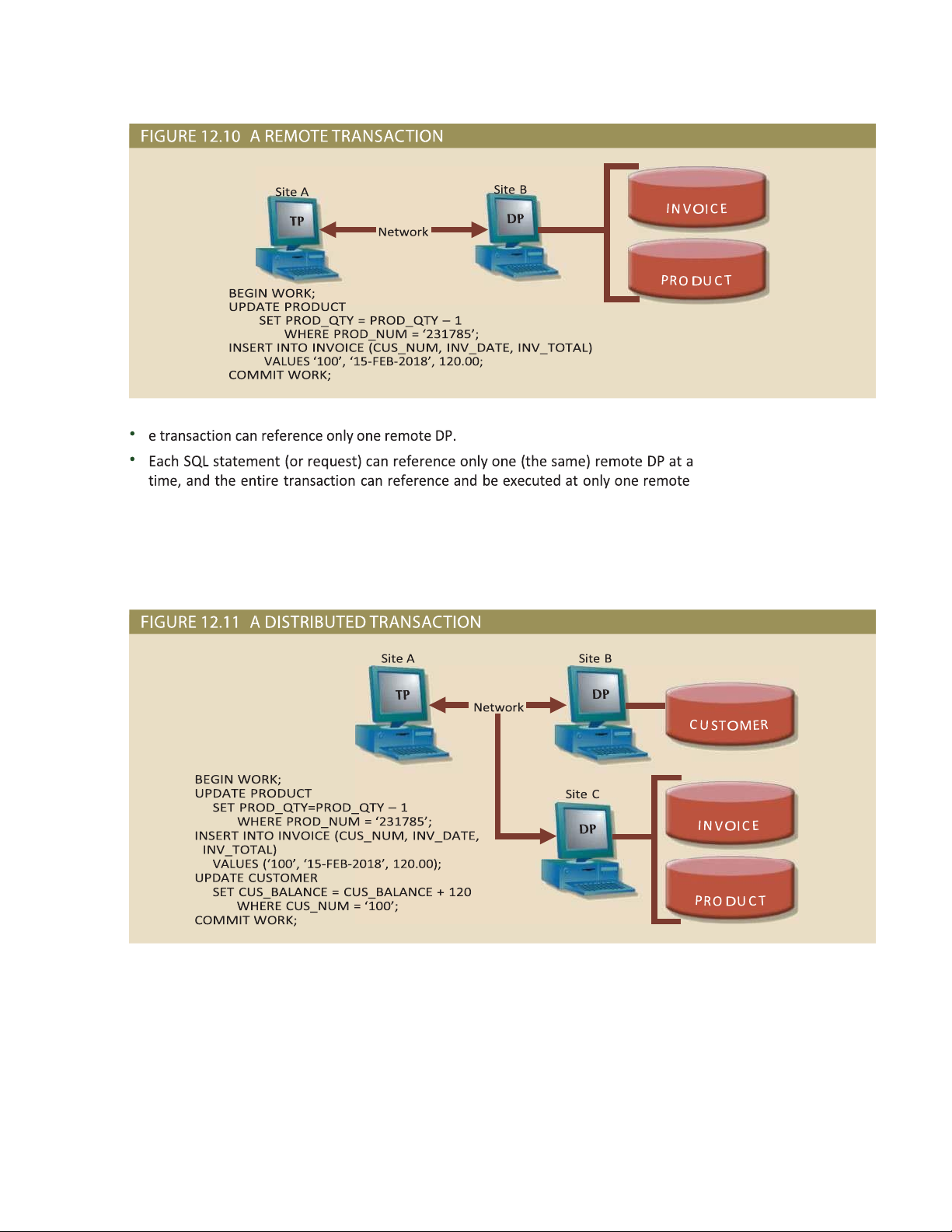
Similarly, a remote transaction, composed of several requests, accesses data at a single A DDBMS feature that
remote site. A remote transaction is illustrated in Figure 12.10. As you examine Figure allows a single SQL
12.10, note the following remote transaction features: e transaction updates the PRODUCT statement to access data in a single remote DP.
and INVOICE tables (located at Site B). e remote transaction is sent to the remote Site B and executed there. remote transaction A DDBMS feature that allows a transaction
1 e details of distributed requests and transactions were originally described by David McGoveran and (formed by several
Colin White, “Clarifying client/server,” DBMS 3(12), November 1990, pp. 78–89. requests) to access data in a single remote DP. lOMoARcPSD| 50032646 DP.
A distributed transaction can reference several di erent local or remote DP sites.
Although each single request can reference only one local or remote DP site, the
transaction as a whole can reference multiple DP sites because each request can
reference a di erent site. e distributed transaction process is illustrated in Figure 12.11.
Note the following features in Figure 12.11:
Tài liệu liên quan:
-

Tóm tắt lý thuyết - Môn Thị trường và các định chế tài chính - Đại Học Kinh Tế - Đại học Đà Nẵng
0.9 K 467 -

Bài tập - Môn Thị trường và các định chế tài chính - Đại Học Kinh Tế - Đại học Đà Nẵng
380 190 -

Top 95 câu trắc nghiệm - Môn Thị trường và các định chế tài chính - Đại Học Kinh Tế - Đại học Đà Nẵng
462 231 -

Top 110 câu trắc nghiệm - Môn Thị trường và các định chế tài chính - Đại Học Kinh Tế - Đại học Đà Nẵng
447 224 -
Đề số 8 - Môn Thị trường và các định chế tài chính - Đại Học Kinh Tế - Đại học Đà Nẵng
327 164