Giải pháp và Mô hình Đề xuất cho Hệ thống RiskSim môn Nghiên cứu về Marketing | Trường Đại Học Tây Nguyên
Mô phỏng Monte Carlo là phương pháp sử dụng các biến ngẫu nhiên và phân phối xácsuất để ước lượng tác động của rủi ro trong các hệ thống phức tạp.
Môn: Nghiên cứu về Marketing 13 tài liệu
Trường: Trường Đại học Tây Nguyên 331 tài liệu
Tác giả:
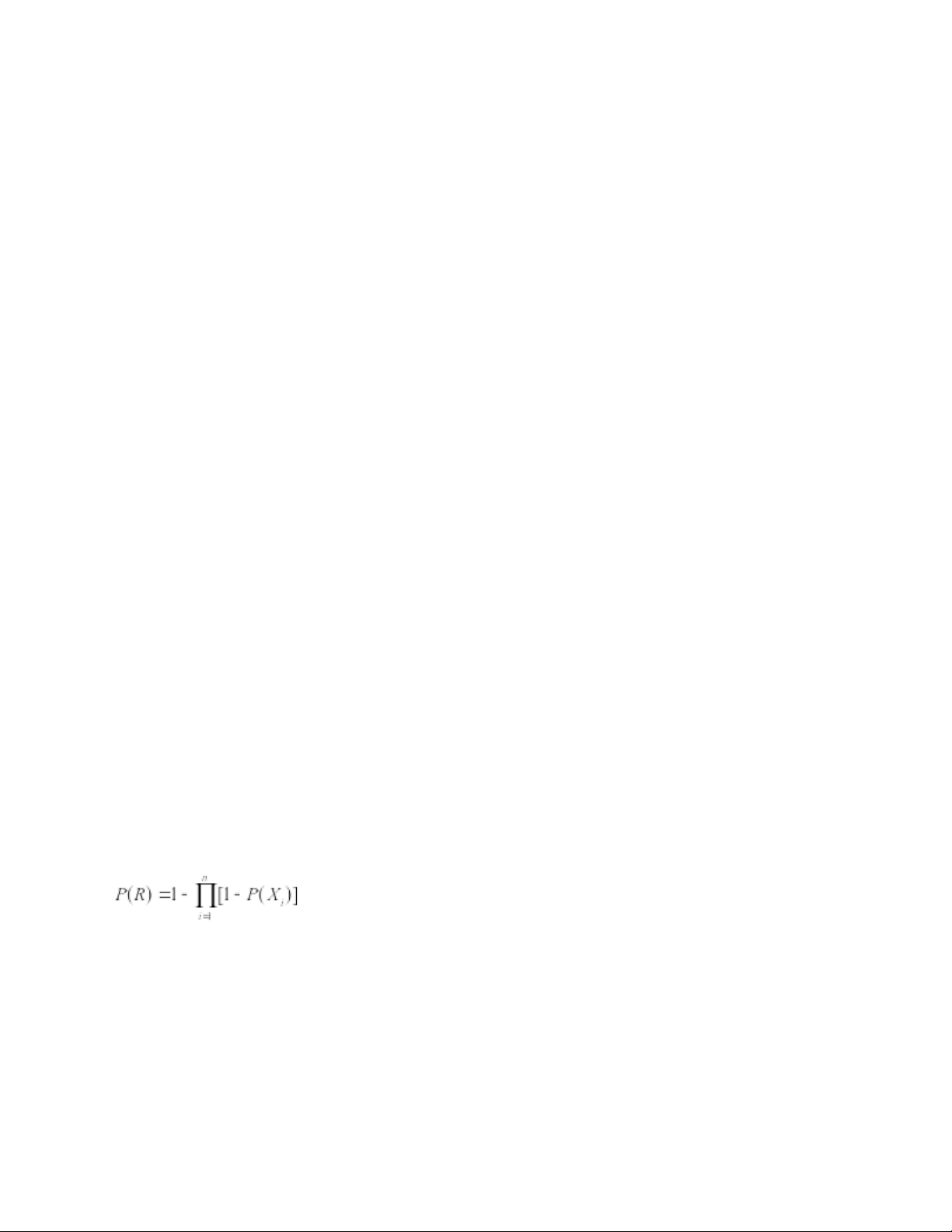









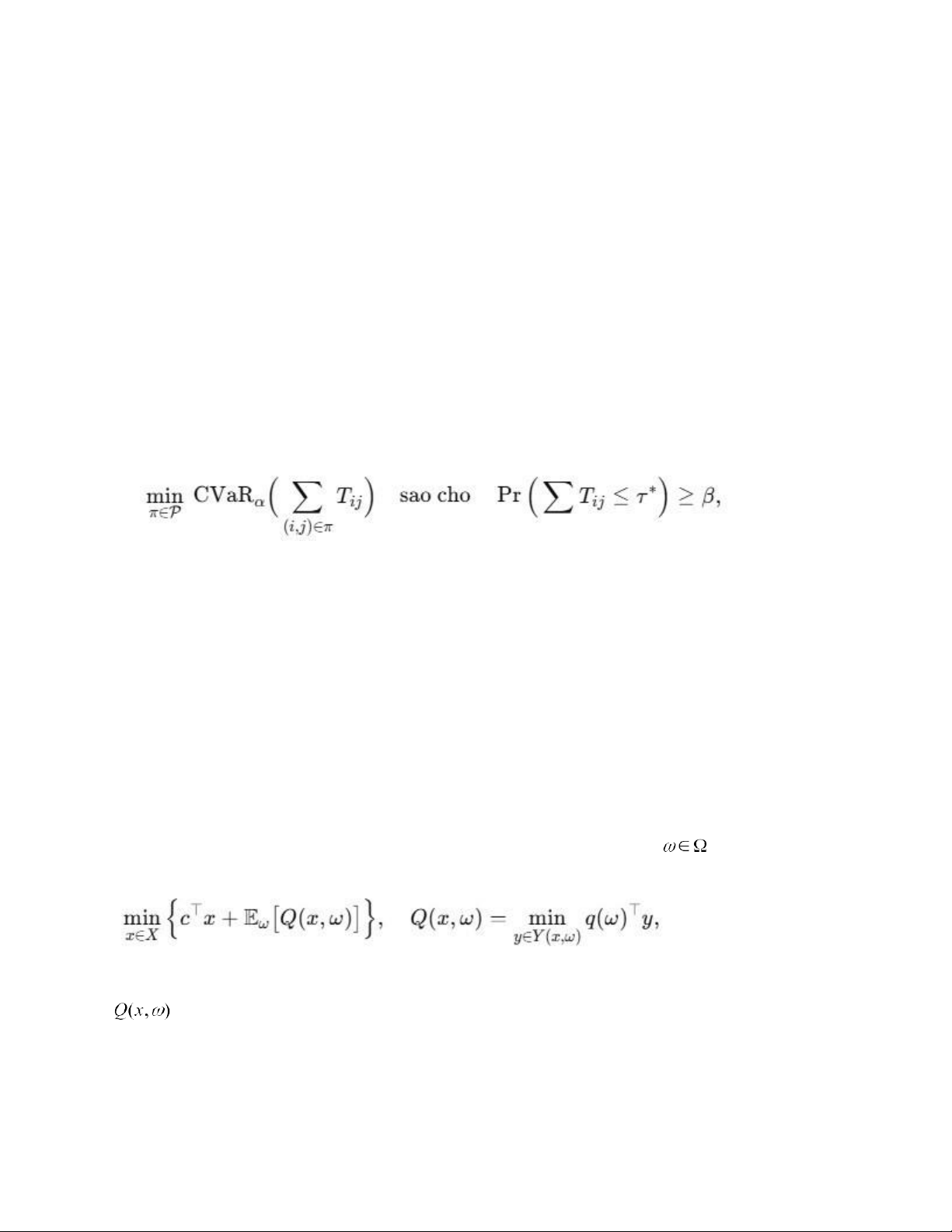









Preview text:
lOMoAR cPSD| 22014077
Chương 3. Giải pháp và mô hình đề xuất
3.1. Mục tiêu Thiết kế Hệ thống
Vi-Chain RiskSim được định vị như một nền tảng tiên phong trong việc mô phỏng rủi ro
logistics theo thời gian thực tại Việt Nam, với khả năng xử lý các kịch bản gián đoạn chuỗi
cung ứng do nhiều tác nhân, bao gồm biến động khí tượng thủy văn, thiên tai, ùn tắc tại
cảng, cũng như các sự kiện địa chính trị có tác động tức thời và lan tỏa. Mục tiêu thiết kế
không chỉ giới hạn ở việc nhận diện và lượng hóa rủi ro mà còn bao gồm khả năng định
lượng phát thải khí nhà kính theo các tiêu chuẩn quốc tế được công nhận rộng rãi, cụ thể
là ISO 14083:2023 và GLEC Framework phiên bản 3. Trên nền tảng đó, hệ thống hướng
tới tối ưu hóa đa mục tiêu, cân bằng đồng thời giữa các yếu tố rủi ro, chi phí, phát thải và
chất lượng dịch vụ. Các thuật toán tối ưu hóa được lựa chọn dựa trên nguyên tắc Pareto
efficiency, cho phép gợi ý các phương án thay thế về tuyến vận tải, cơ sở lưu trữ hàng hóa
và phương thức vận chuyển, bảo đảm hiệu quả vận hành trong bối cảnh bất định. Đồng
thời, việc tuân thủ các chuẩn mực báo cáo ESG (Environmental, Social, Governance) giúp
các doanh nghiệp tham gia hệ thống vừa nâng cao khả năng cạnh tranh, vừa đáp ứng các
yêu cầu minh bạch của thị trường quốc tế.
3.2 Cơ sở lý thuyết và phương pháp tiếp cận
3.2.1 Mô hình hóa rủi ro logistics bằng Monte Carlo
Mô phỏng Monte Carlo là phương pháp sử dụng các biến ngẫu nhiên và phân phối xác suất
để ước lượng tác động của rủi ro trong các hệ thống phức tạp (Metropolis & Ulam, 1949).
Trong lĩnh vực logistics, phương pháp này cho phép đánh giá các kịch bản gián đoạn chuỗi
cung ứng bằng cách chạy hàng nghìn hoặc hàng triệu lần mô phỏng, với mỗi lần sử dụng
một bộ giá trị đầu vào khác nhau, như thời gian vận chuyển, tần suất sự cố cảng, biến động chi phí nhiên liệu.
Giả sử biến ngẫu nhiên Xi đại diện cho một yếu tố rủi ro (ví dụ: thời gian trễ tại cảng), có
phân phối xác suất f (x). Xác suất tổng hợp của sự kiện gián đoạn RRR được tính: i
Phương pháp Monte Carlo cho phép tính giá trị kỳ vọng của các biến đầu ra như chi phí
tăng thêm (ΔC), phát thải tăng thêm (ΔE) do các kịch bản rủi ro gây ra. lOMoAR cPSD| 22014077
3.2.2 Phân tích phát thải khí nhà kính trong logistics
Phát thải khí nhà kính (GHG) từ hoạt động logistics được tính toán dựa trên các chuẩn mực
quốc tế như GLEC Framework (Global Logistics Emissions Council, 2019) và tiêu chuẩn
ISO 14083:2023. Công thức cơ bản để tính phát thải CO e cho từng chặng vận tải:₂ Trong đó: •
d = quãng đường vận chuyển (km) •
EFm = hệ số phát thải cho phương thức vận tải mmm (kgCO e/tấn-km)₂
Ví dụ, theo GLEC (2019), vận tải đường biển container có
tùy loại tàu; đường bộ bằng xe tải hạng nặng ở Việt Nam trung bình (Nguyễn et al., 2023).
3.2.3 Ứng dụng GIS trong tối ưu hóa mạng lưới vận tải
GIS (Geographic Information System) cho phép tích hợp dữ liệu bản đồ, hạ tầng, và trạng
thái giao thông thời gian thực vào mô hình tối ưu hóa tuyến đường. Các thuật toán tối ưu
như Dijkstra hoặc A* được sử dụng để tìm tuyến đường ngắn nhất theo tiêu chí thời gian,
chi phí, hoặc phát thải tối thiểu.
Mô hình đa mục tiêu (Multi-objective Optimization) được áp dụng: Với: •
C(T): tổng chi phí phương án T •
E(T): tổng phát thải phương án T •
R(T): rủi ro gián đoạn của phương án T
3.3. Kiến trúc kỹ thuật tổng thể
Kiến trúc hệ thống Vi-Chain RiskSim được tổ chức theo năm lớp chức năng, tạo thành một
chuỗi xử lý khép kín từ khâu thu thập dữ liệu đa nguồn, chuẩn hóa và phân tích rủi ro, cho
đến tối ưu hóa quyết định và trực quan hóa kết quả. Cấu trúc phân tầng này đảm bảo khả
năng mở rộng, tính tương thích với các chuẩn quốc tế, và khả năng tích hợp linh hoạt với
hạ tầng công nghệ thông tin của doanh nghiệp. lOMoAR cPSD| 22014077
Lớp Thu thập dữ liệu (Data Ingestion Layer) đóng vai trò cửa ngõ của hệ thống, thu
nhận dữ liệu từ cả nguồn nội bộ và bên ngoài. Nguồn nội bộ bao gồm lịch trình vận tải, số
liệu kho bãi, tình trạng đội phương tiện và mức tồn kho từ các hệ thống ERP, TMS, WMS
của doanh nghiệp. Nguồn bên ngoài bao gồm dữ liệu thời tiết và cảnh báo thiên tai từ Trung
tâm Khí tượng Thủy văn Việt Nam và NOAA; dữ liệu tắc nghẽn cảng thu thập từ hệ thống
AIS (Automatic Identification System) và ảnh vệ tinh; chỉ số rủi ro địa chính trị
(Geopolitical Risk Index – GPR), giá nhiên liệu và thông tin chính sách thương mại toàn
cầu. Hệ thống cũng khai thác cơ sở dữ liệu hệ số phát thải CO cho từng loại phương₂ tiện
vận tải, dựa trên các tiêu chuẩn IPCC, IMO và GLEC Framework. Các luồng dữ liệu này
được truyền tải theo thời gian thực thông qua API và mạng lưới cảm biến IoT, bao gồm
GPS, RFID, cảm biến tải trọng và cảm biến nhiên liệu, nhằm đảm bảo tính cập nhật và
chính xác của thông tin đầu vào.
Lớp Xử lý và Chuẩn hóa dữ liệu (Data Processing Layer) chịu trách nhiệm làm sạch dữ
liệu (data cleaning) và chuẩn hóa đơn vị đo lường theo các tiêu chuẩn ISO 80000 và
UN/LOCODE. Tầng này đồng thời thực hiện việc tích hợp dữ liệu thành mô hình dữ liệu
bảng thời gian thực (real-time panel data), cho phép vừa duy trì tính liên tục, vừa lưu giữ
toàn bộ lịch sử diễn biến để phục vụ phân tích xu hướng và tái dựng sự kiện trong quá khứ.
Lớp Phân tích rủi ro và Mô phỏng (Risk & Simulation Layer) là trung tâm phân tích
của hệ thống, nơi áp dụng các phương pháp định lượng tiên tiến để đánh giá tác động tiềm
ẩn của rủi ro. Mô phỏng Monte Carlo đa kịch bản được triển khai với đầu vào là xác suất
xảy ra từng loại rủi ro P(Ei)P(E_i)P(Ei), bao gồm thiên tai, tắc nghẽn, biến động giá nhiên
liệu và xung đột chính trị. Quá trình mô phỏng chạy số vòng lặp lớn (ví dụ 10.000
simulations) nhằm ước lượng phân phối của các chỉ tiêu như chi phí tổn thất, thời gian giao
hàng và lượng phát thải CO . Đối với các rủi ro đột biến, hệ thống tích hợp mô hình₂ Jump-
Diffusion, mô tả các cú sốc rời rạc (như chiến tranh, lệnh cấm xuất khẩu) chồng lên các
biến động liên tục. Song song, phân tích rủi ro mạng lưới (Network Risk Analysis) được
thực hiện bằng cách mô hình hóa chuỗi cung ứng dưới dạng đồ thị (graph network), trong
đó các nút biểu diễn kho, cảng, nhà máy và các cạnh là tuyến vận tải. Các chỉ số như
Betweenness Centrality và Vulnerability Index được tính toán để xác định các “điểm nghẽn
chiến lược” trong mạng lưới.
Lớp Tối ưu hóa quyết định (Optimization Layer) đảm nhiệm giải các bài toán tối ưu
hóa đa mục tiêu (Multi-objective Optimization) nhằm đồng thời giảm thiểu chi phí
logistics, giảm thiểu phát thải CO và tối đa hóa khả năng chống chịu của chuỗi cung₂ ứng.
Thuật toán NSGA-II (Non-dominated Sorting Genetic Algorithm II) được lựa chọn để tìm
ra tập hợp phương án tối ưu Pareto, cung cấp cho nhà quản trị nhiều lựa chọn cân bằng
giữa các mục tiêu. Các phương án có thể bao gồm thay đổi tuyến vận tải giữa các phương lOMoAR cPSD| 22014077
thức đường bộ, đường thủy và đường sắt; điều chỉnh vị trí kho trung chuyển nhằm giảm
quãng đường vận chuyển; hoặc triển khai các phương tiện vận tải phát thải thấp như xe
điện, tàu sử dụng LNG hoặc hệ thống lai hybrid.
Lớp Giao diện và Trực quan hóa (Visualization & Decision Support Layer) là cầu nối
giữa kết quả phân tích và người sử dụng. Lớp này cung cấp bản đồ GIS tương tác hiển thị
tình trạng tuyến vận tải với mã màu rủi ro (xanh cho mức thấp, vàng cho mức trung bình,
đỏ cho mức cao), cùng với vùng ảnh hưởng của thiên tai, tắc nghẽn và xung đột. Người
dùng có thể so sánh trực tiếp các phương án vận hành theo tiêu chí chi phí, thời gian và
phát thải. Dashboard ESG & KPI cung cấp các chỉ số then chốt như tỷ lệ phát thải trên mỗi
tấn-km, tỷ lệ đơn hàng bị ảnh hưởng bởi rủi ro, và mức tiết kiệm CO₂ so với giá trị baseline,
giúp doanh nghiệp theo dõi hiệu quả cải thiện hiệu suất môi trường và vận hành.
Nhờ kiến trúc phân tầng này, Vi-Chain RiskSim không chỉ đóng vai trò như một công cụ
phân tích rủi ro mà còn là một nền tảng hỗ trợ ra quyết định toàn diện, hướng tới mục tiêu
vận hành logistics bền vững và chống chịu cao trong bối cảnh biến động toàn cầu.
3.3. Mô hình dữ liệu & chuẩn hoá phát thải
Mô hình dữ liệu của Vi-Chain RiskSim được thiết kế dựa trên nguyên tắc ánh xạ chuỗi vận
tải thành các phần tử chuỗi vận tải (Transport Chain Elements – TCEs) theo tiêu chuẩn ISO
14083. Mỗi TCE được gắn với một danh mục vận hành vận tải (Transport Operation
Category – TOC) tương ứng với các phương thức như đường bộ, đường sắt, đường biển
hoặc hàng không, hoặc danh mục vận hành trung chuyển (Hub Operation Category – HOC)
áp dụng cho các cảng, kho và bãi. Hệ thống sử dụng các chỉ số đo lường chuẩn mực, bao
gồm phát thải tính theo khối lượng CO e trên mỗi tấn-km (tkm)₂ đối với vận tải, và CO e
trên mỗi tấn hàng hóa thông qua đối với hoạt động tại các điểm₂ trung chuyển.
Khi dữ liệu sơ cấp không sẵn có, hệ thống chủ động áp dụng các hệ số phát thải mặc định
được khuyến nghị trong GLEC Framework phiên bản 3, DEFRA hoặc EcoTransIT, đảm
bảo tính nhất quán và tuân thủ tiêu chuẩn quốc tế. Về phạm vi tính toán, hệ thống mặc định
áp dụng phương pháp Well-to-Wheel (WTW), bao gồm cả giai đoạn Tank-to-Wheel
(TTW) và Well-to-Tank (WTT), nhằm phản ánh đầy đủ phát thải trong toàn bộ vòng đời
nhiên liệu. Tuy nhiên, hệ thống vẫn cung cấp khả năng chuyển đổi sang phạm vi TTW khi
doanh nghiệp có yêu cầu hoặc khi phù hợp với mục tiêu báo cáo. Cách tiếp cận này không
chỉ bảo đảm tính khoa học và minh bạch của dữ liệu phát thải, mà còn cho phép so sánh,
đối chiếu kết quả giữa các phương án vận hành, tạo cơ sở vững chắc cho việc ra quyết định
chiến lược trong bối cảnh quản trị chuỗi cung ứng bền vững. lOMoAR cPSD| 22014077
3.4. Mô hình rủi ro và mô phỏng Monte Carlo
3.4.1. Biến trạng thái, yếu tố rủi ro và đầu ra
Chuỗi cung ứng – logistics quốc gia được biểu diễn dưới dạng một mạng có hướng
G=(V,E), trong đó tập nút V bao gồm các cảng biển, cảng cạn (ICD), kho trung chuyển,
trung tâm phân phối và nhà máy sản xuất. Tập cung E đại diện cho các tuyến vận tải liên
kết giữa các nút, bao gồm các phương thức vận tải đa dạng như đường bộ, đường thủy nội
địa, đường sắt và đường biển.. Tại thời điểm t, vectơ trạng thái
lần lượt gồm tồn kho, thời gian chờ tại nút (xếp dỡ/gate), chi phí vận chuyển đơn vị, thời gian hành trình,
khả dụng tuyến (nhị phân), và
năng lực tuyến. Vectơ yếu tố rủi ro ngoại sinh: Z ={thời tiết, sự cố hạ tầng, sự kiện địa t
chính trị, tắc nghẽn, đứt gãy vận tải }.
Mỗi kịch bản rủi ro ω được mô phỏng sẽ cho ra bộ chỉ tiêu đầu ra:
, trong đó tổng thời gian giao hàng , chi phí , dịch vụ và phát thải
. Mô hình mạng này cho phép phân
tích ảnh hưởng của các biến động rủi ro tới hiệu suất logistics quốc gia, và là nền tảng để
tích hợp vào các kỹ thuật mô phỏng rủi ro như Monte Carlo hoặc phân tích kịch bản.
Việc mô hình hóa dưới dạng mạng có hướng tương tự các nghiên cứu trong lĩnh vực
logistics resilience (Christopher & Peck, 2004; Ivanov & Dolgui, 2021), đồng thời cho
phép áp dụng các thuật toán tối ưu mạng và phân tích độ tin cậy hệ thống.
3.4.2. Mô hình ngẫu nhiên cho các cơ chế rủi ro
Trong bối cảnh chuỗi cung ứng–logistics quốc gia hoạt động trên một hệ thống mạng có
hướng, các yếu tố rủi ro gây gián đoạn hoặc làm suy giảm hiệu suất vận hành có thể được
đặc trưng thông qua một tập hợp các cơ chế ngẫu nhiên. Các cơ chế này phản ánh các
nguồn bất định từ thời gian vận chuyển, tắc nghẽn cục bộ, sự kiện đứt gãy hạ tầng, cho tới
các cú sốc cực đoan và mối phụ thuộc đa tuyến. Việc mô hình hóa chính xác các cơ chế
này là nền tảng để triển khai mô phỏng Monte Carlo và phân tích rủi ro tổng thể. (a)
Thời gian vận chuyển và tắc nghẽn cục bộ. Thời gian hành trình tuyến (i,j) tại
thời điểm t được tách thành ba thành phần lOMoAR cPSD| 22014077
trong đó là hàm theo thời điểm khởi hành h(t) phản ánh hiện tượng tắc nghẽn theo giờ cao
điểm; hiệu chỉnh theo loại phương tiện vận tải m (đường bộ, đường thủy, đường sắt, đường biển), còn
là thành phần trễ do khâu xếp dỡ hoặc chờ cổng (gate delay).
Để mô hình hóa thành phần Q (t), các mô hình hàng đợi được áp dụng tùy đặc điểm hạ ij
tầng. Cụ thể, M/M/1 được sử dụng cho cổng đơn, M/M/s cho nhiều cổng song song, hoặc
M/E /s cho các hệ thống có phân phối phục vụ Erlang–k đặc trưng (ví dụ xếp dỡ container k
tại cảng). Tham số λ (tốc độ đến) và μ (tốc độ phục vụ) được ước lượng từ dữ liệu vận hành
(manifest, biên nhận). Các nghiên cứu trước đây đã chứng minh tính phù hợp của cách tiếp
cận này, điển hình là phân tích tắc nghẽn tại cảng Manila (Philippines), cảng Alexandria
(Ai Cập) và cảng Lagos (Nigeria) UNCTAD,2018; DOT,2015 (b)
Sự kiện đứt gãy (thiên tai, phong tỏa, sự cố). Các sự kiện như thiên tai, phong
tỏa, hoặc sự cố kỹ thuật được mô hình hóa dưới dạng quá trình điểm ngẫu nhiên. Khi có
hiện tượng lan truyền (aftershock), như một sự cố cầu cảng dẫn đến ùn tắc tại các tuyến
kết nối, mô hình Hawkes tự–kích thích được sử dụng để đặc tả cường độ xảy ra sự kiện:
trong đó μ là cường độ nền, α và β đặc trưng cho tác động và tốc độ suy giảm của hiệu ứng
lan truyền. Hawkes process vốn được áp dụng thành công trong mô hình hóa chuỗi sự kiện
phụ thuộc theo thời gian trong lĩnh vực tài chính và viễn thông Hawkes,1971; Bacryetal.,
và gần đây đã được mở rộng cho phân tích gián đoạn logistics Zhouetal.,2022. (c)
Cú sốc lớn hiếm gặp. Những sự kiện như bão nhiệt đới, lũ lụt kéo dài, hoặc phong
tỏa toàn tuyến thường tạo ra phân phối “đuôi dày” cho trễ hoặc chi phí, vượt xa giả định
Gaussian. Để đặc trưng hiện tượng này, Lý thuyết Giá trị Cực trị (Extreme Value Theory
– EVT) được sử dụng. Với ngưỡng uuu đủ cao, phần vượt ngưỡng được mô hình hóa bằng
phân phối Pareto tổng quát (Generalized Pareto Distribution – GPD):
trong đó ξ là tham số hình dạng (tail index) và β là tham
số tỉ lệ. Các tham số này được ước lượng qua phương pháp cực đại hợp lý (MLE) hoặc
Moment có trọng số (PWM), và được kiểm định bằng QQ–plot hoặc kiểm định Anderson– Darling Coles,2001. (d)
Phụ thuộc liên thị trường/đa tuyến. Sự phụ thuộc giữa các tuyến và nút (ví dụ,
việc bế tắc tại cảng A làm tăng trễ ở cảng B) được mô hình hóa bằng copula, cho phép tách
riêng phân phối biên và cấu trúc phụ thuộc. Sau khi hiệu chỉnh phân phối biên theo dữ liệu,
các họ copula như Archimedean (Clayton – nhạy với đuôi thấp, Gumbel – nhạy với đuôi lOMoAR cPSD| 22014077
cao, Frank – đối xứng) hoặc Gaussian copula được lựa chọn dựa trên đặc điểm tail–
dependence và tiêu chí thông tin (AIC, BIC). Với hệ thống phức hợp cảng–kho–tuyến,
Hierarchical Archimedean Copula (HAC) được sử dụng để đặc tả cấu trúc phụ thuộc phân
cấp Nelsen,2006; Genestetal.,2013.
3.4.3. Chuẩn hóa phát thải trong kịch bản
Đối với mỗi kịch bản mô phỏng ω∈Ω, lượng phát thải khí nhà kính (GHG) tổng cộng
CO (ω được tính bằng tổng phát thải trên tất cả các hành trình 2e
trong mạng vận tải của
chuỗi cung ứng. Cụ thể: với
cung đường (arc) từ nút i đến nút j trong mạng vận tải; loại
phương tiện hoặc mode vận tải (đường bộ, đường sắt, đường biển, hàng
không); hệ số phát thải của phương tiện m, phụ thuộc vào tốc độ vận hành
thực tế v và mức tải L (tấn). Hệ số này có thể được lấy từ các bộ dữ liệu chuẩn quốc tế
như DEFRA (UK Department for Environment, Food & Rural Affairs) hoặc IMO
(International Maritime Organization), và hiệu chỉnh dựa trên dữ liệu tiêu thụ nhiên liệu
thực tế của doanh nghiệp.; d (ω) là quãng đường vận tải thực tế trong kịch bản ω, bao gồm ij
cả các tuyến vòng tránh do rủi ro hoặc sự cố. Hệ số có thể lấy từ bộ hệ số quốc tế/địa
phương (như DEFRA/IMO) và hiệu chỉnh bằng dữ liệu nhiên liệu doanh nghiệp. Q (ω) ij
(tấn): khối lượng hàng hóa vận chuyển trên cung đường (i,j) trong kịch bản ω.
Hệ số phát thải EFm phản ánh ảnh hưởng của điều kiện vận hành (ví dụ: tốc độ thấp trong
ùn tắc đô thị làm tăng tiêu hao nhiên liệu của xe tải; hoặc tốc độ tàu biển tối ưu giúp giảm
suất tiêu hao năng lượng). Việc phụ thuộc vào tải L giúp mô hình hóa chính xác hơn mối
quan hệ giữa hệ số phát thải và hệ số tải trọng (load factor), vốn là yếu tố quan trọng
trong đánh giá hiệu quả năng lượng.
Để chuẩn hóa và so sánh giữa các kịch bản, phát thải được quy đổi về biên phát thải
(Marginal Emission Factor – MEF):
với đơn vị kg CO2e/tkm, cho phép so sánh cường độ phát
thải giữa các phương án vận tải, kịch bản rủi ro, hoặc chiến lược tối ưu hóa mạng lưới.
Việc sử dụng bộ hệ số phát thải tiêu chuẩn (DEFRA, 2023; IMO, 2022) đảm bảo tính nhất
quán và khả năng đối sánh quốc tế, trong khi việc hiệu chỉnh bằng dữ liệu nhiên liệu
doanh nghiệp giúp nâng cao độ chính xác và tính đặc thù của mô hình. Cách tiếp cận này
phù hợp với hướng dẫn kiểm kê khí nhà kính của IPCC (2006 Guidelines for National
Greenhouse Gas Inventories) và các tiêu chuẩn đánh giá vòng đời sản phẩm (ISO lOMoAR cPSD| 22014077
14083:2023 – Quantification and reporting of greenhouse gas emissions arising from
transport chain operations).
3.4.4. Mô phỏng Monte Carlo: lấy mẫu, ghép phụ thuộc và lan truyền
Việc đánh giá rủi ro trong chuỗi cung ứng–logistics quốc gia đòi hỏi phải xét đến nhiều
yếu tố ngẫu nhiên và tương quan phức tạp giữa các tuyến và nút. Mô phỏng Monte Carlo
(MC) là công cụ phù hợp để ước lượng phân phối của các biến đầu ra (thời gian giao hàng,
chi phí, dịch vụ, phát thải) dưới tác động của rủi ro ngoại sinh Zt. Tuy nhiên, để đạt độ
chính xác và hiệu quả tính toán cao, nghiên cứu này áp dụng các biến thể nâng cao của
MC, gồm Latin Hypercube Sampling (LHS), Quasi–Monte Carlo (QMC), mô hình
phụ thuộc bằng copula, và hiệu chỉnh đuôi phân phối bằng lý thuyết cực trị (EVT).
(i) Sinh mẫu hiệu quả
Khi số chiều của vectơ rủi ro Zt lớn (tương ứng nhiều tuyến, nhiều loại rủi ro), Monte Carlo
thuần thường cần số lượng mẫu rất lớn để hội tụ, dẫn đến chi phí tính toán cao (Glasserman, 2004).
Do đó, nghiên cứu này sử dụng:
- Latin Hypercube Sampling (LHS): phương pháp phân tầng mẫu trên từng biến
ngẫu nhiên biên, đảm bảo mỗi khoảng xác suất được lấy mẫu ít nhất một lần. Điều
này làm giảm phương sai ước lượng và cải thiện tốc độ hội tụ (McKay et al., 1979).
- Quasi–Monte Carlo (QMC) với dãy Sobol: cải thiện độ đồng đều của các điểm
mẫu trong siêu lập phương đơn vị, đặc biệt hiệu quả khi hàm đầu ra trơn (Joe & Kuo, 2008).
Quy trình: với mỗi biến Zk, chia khoảng [0,1] thành N phân đoạn, lấy mẫu theo thứ tự
Sobol/LHS, sau đó biến đổi ngược theo phân phối biên đã ước lượng.
(ii) Ghép phụ thuộc bằng copula
Các rủi ro ngoại sinh (thời tiết, trễ do hạ tầng, biến động nhu cầu…) thường có tương quan
phức tạp, đặc biệt ở phần đuôi phân phối (tail dependence). Mô hình copula cho phép tách
mô hình hóa biên và cấu trúc phụ thuộc (Nelsen, 2006). Quy trình ước lượng:
1. Ước lượng phân phối biên của từng biến Zk bằng MLE hoặc kernel density.
2. Tính hệ số Kendall’s τ hoặc Spearman’s ρs giữa các cặp biến.
3. Lựa chọn họ copula (Clayton cho phụ thuộc đuôi dưới, Gumbel cho phụ thuộc đuôi
trên, Frank cho đối xứng) dựa trên tail dependence index và tiêu chí AIC/BIC. lOMoAR cPSD| 22014077 4. Sinh vectơ đồng nhất
từ copula đã ước lượng.
5. Biến đổi ngược U qua các hàm phân phối biên để thu vectơ Zt.
(iii) Lan truyền rủi ro qua mạng
Với mỗi kịch bản ω, vectơ trạng thái X (ω) được cập nhật theo bước thời gian rời rạc Δt: t
1. Sinh sự kiện gián đoạn: dùng quá trình Poisson (hoặc Hawkes để xét tự kích hoạt)
cho biến nhị phân khả dụng tuyến Aij(t).
2. Cập nhật thời gian hành trình: trong đó là thời gian nền, là trễ do xếp hàng, là nhiễu ngẫu nhiên.
3. Giải bài toán chọn tuyến có rủi ro (Risk-aware Shortest Path), kết hợp yếu tố thời
gian–chi phí–OTIF–CO e.₂
4. Cập nhật tồn kho, tính OTIF, chi phí, và phát thải cho toàn mạng.
(iv) Hiệu chỉnh đuôi phân phối bằng EVT
Một số sự kiện cực đoan (bão lớn, sự cố hạ tầng nghiêm trọng) tạo ra các giá trị cực trị về
trễ hoặc chi phí. Để mô phỏng chính xác hơn các kịch bản này, áp dụng mô hình peaks–
over–threshold (POT) trong lý thuyết cực trị:
1. Xác định ngưỡng uuu và lấy các giá trị vượt ngưỡng.
2. Ước lượng tham số phân phối GPD (ξ,β) bằng MLE hoặc phương pháp moment có trọng số (PWM).
3. Kiểm định độ phù hợp bằng QQ–plot hoặc Anderson–Darling.
4. Thay thế phần đuôi của phân phối gốc trong quá trình sinh mẫu.
3.4.5. Thước đo rủi ro và thống kê
Trong bối cảnh đánh giá hiệu năng chuỗi cung ứng–logistics dưới tác động của các yếu tố
rủi ro ngoại sinh ZtZ_tZt, việc áp dụng các thước đo rủi ro “coherent” (theo định nghĩa
của Artzner et al., 1999) là cần thiết nhằm đảm bảo tính hợp lý toán học và khả năng tích
hợp vào mô hình tối ưu hóa. Một thước đo rủi ro ρ(⋅) được gọi là coherent nếu thỏa mãn bốn tiên đề: lOMoAR cPSD| 22014077 (i)
Đơn điệu (Monotonicity): Nếu thì (ii)
Dịch chuyển tịnh tiến (Translation Invariance): với a là hằng số (iii)
Đồng nhất dương (Positive Homogeneity): , với (iv)
Cộng tính con (Subadditivity): thể hiện lợi ích của đa dạng hóa rủi ro.
Đối với các đại lượng đầu ra
thu được từ mô phỏng kịch bản ω∈Ω, ta đặc biệt quan tâm đến hai thước đo rủi ro phổ
biến và phù hợp với tính chất “coherent”: (i)
Value-at-Risk (VaR) tại mức tin cậy α∈(0,1): (ii)
Conditional Value-at-Risk (CVaR) hay Expected Shortfall (ES): kỳ vọng của đuôi vượt VaRα,
được ưa chuộng trong thực
tiễn do tính lồi (convexity) và thuận tiện khi giải bài toán tối ưu hóa rủi ro
(Rockafellar & Uryasev, 2000). Ngoài ra, để có cái nhìn sâu hơn về cấu trúc rủi ro, ta còn tính:
• Expected Shortfall Gap: phản ánh độ dày của đuôi phân phối và mức
độ “nghiêm trọng” trung bình của các sự kiện vượt ngưỡng VaR.
• Tỷ lệ không đạt dịch vụ:
thể hiện phần trăm lô hàng
không đáp ứng tiêu chí “đúng hạn–đúng đủ” theo SLA (Service Level Agreement).
• Biên phát thải:
với tkm là tổng tấn–km của luồng hàng,
cho phép đánh giá cường độ phát thải (kg CO2e/tấn–km) và so sánh
giữa các phương án vận tải hoặc kịch bản rủi ro.
Việc kết hợp các thước đo rủi ro này giúp định lượng không chỉ xác suất mà cả mức độ
nghiêm trọng của các tổn thất liên quan đến thời gian giao hàng, chi phí, chất lượng dịch
vụ và tác động môi trường. Đây là cơ sở cho việc ra quyết định tối ưu hóa trong điều kiện lOMoAR cPSD| 22014077
bất định và có thể tích hợp trực tiếp vào các mô hình tối ưu hóa rủi ro–lợi ích dựa trên CVaR.
3.4.6. Tối ưu hóa trên kịch bản: đường đi tin cậy và quy hoạch ngẫu nhiên
Khi đã có tập kịch bản mô phỏng phản ánh tác động của các yếu tố rủi ro ngoại sinh Zt và
các thước đo rủi ro tương ứng, bước tiếp theo là tối ưu hóa quyết định trong điều kiện bất
định. Hai cách tiếp cận chính được áp dụng ở các cấp độ tác nghiệp và chiến thuật: (a)
Đường đi tin cậy (reliable path). Trong mạng cung ứng–logistics có trọng số cạnh
ngẫu nhiên phụ thuộc thời gian T (t), (thời gian vận chuyển từ nút i đến nút j khi khởi hàn ij h
tại thời điểm t), bài toán tìm tuyến vận tải tối ưu nhằm: Tối thiểu hóa thời gian hành
trình kỳ vọng LETT (least expected travel time) hoặc Cực tiểu hóa rủi ro đuôi thông
qua CVaR của tổng thời gian giao hàng, đảm bảo mức tin cậy dịch vụ β:
trong đó π là đường đi; β là mức tin cậy dịch vụ; ρ(⋅) là thước đo rủi ro (LETT hoặc CVaRα).
Các thuật toán shortest path trong mạng ngẫu nhiên và mạng phụ thuộc thời gian (time-
dependent stochastic shortest path) đã được nghiên cứu rộng rãi, có thể triển khai như
heuristic hoặc kernel trong nền tảng tối ưu hóa. (b)
Quy hoạch hai giai đoạn theo kịch bản. Ở cấp độ chiến thuật, khi quyết định liên
quan đến cấu trúc mạng (mở/kết hợp kho, phân bổ năng lực tuyến, bố trí tồn kho), ta áp
dụng khung stochastic programming hai giai đoạn: •
Giai đoạn 1: Quyết định cấu hình ban đầu trước khi biết kịch bản rủi ro xảy ra (ví
dụ: vị trí kho, dung lượng cảng, phân bổ đội xe). •
Giai đoạn 2 (recourse): Điều chỉnh vận hành khi kịch bản được hiện thực
(tái định tuyến, điều phối lại phương tiện, thuê ngoài khẩn cấp).:
có thể thêm ràng buộc rủi ro CVaRα(Q) ≤ κ. Trong đó x là biến quyết định giai đoạn 1,
là chi phí hoặc tổn thất giai đoạn 2 dưới kịch bản ω; κ là ngưỡng rủi ro chấp nhận
được. Ràng buộc CVaR đảm bảo quyết định tối ưu không chỉ hiệu quả về kỳ vọng mà còn
kiểm soát rủi ro đuôi trong các tình huống bất lợi nhất. Đây là khung tiêu chuẩn cho ra lOMoAR cPSD| 22014077
quyết định chiến lược trong môi trường biến động cao, cho phép tích hợp trực tiếp các kết
quả mô phỏng rủi ro từ các phần 3.4.2–3.4.5.
3.4.7. Hiệu chỉnh và kiểm định mô phỏng
Để đảm bảo mô phỏng kịch bản rủi ro trong mạng cung ứng–logistics đạt độ tin cậy và độ
chính xác cao, cần thực hiện ba nhóm kỹ thuật chính:
(a) Kiểm soát phương sai (Variance Reduction)
Mục tiêu: giảm sai số thống kê của các ước lượng (như CVaR, OTIF) mà không cần tăng
số lần chạy mô phỏng. Các kỹ thuật áp dụng: •
Antithetic variates: sử dụng cặp mẫu đối xứng để triệt tiêu một phần biến thiên ngẫu nhiên. •
Control variates: dùng tuyến chuẩn hoặc chỉ số đã biết kỳ vọng để điều chỉnh kết quả. •
Stratification: phân tầng theo khu vực địa lý, loại phương tiện hoặc nhóm tuyến
vận tải để đảm bảo mẫu đại diện. •
LHS (Latin Hypercube Sampling) và QMC (Quasi–Monte Carlo): như mô tả tại
mục 3.4.4, giúp phân bố đều các điểm mẫu trong không gian tham số.
(b) Tiêu chí hội tụ (Convergence Criteria) Mô phỏng dừng khi:
SE[⋅] là sai số chuẩn của ước
lượng, là ngưỡng chấp nhận. ϵ Batch–means: chia chuỗi kết quả thành các nhóm (batch)
độc lập để ước lượng sai số chuẩn và đánh giá hội tụ. c) Hiệu chuẩn tham số (Parameter Calibration) •
Ước lượng tham số hàng đợi: từ dữ liệu thực tế tại cổng/cảng, suy ra λ(tốc độ đến)
và μ (tốc độ phục vụ). •
Kiểm định phân phối biên: dùng kiểm định Kolmogorov–Smirnov (KS) hoặc
Anderson–Darling (AD) để đánh giá mức phù hợp của phân phối thời gian hành trình Tij. •
Lựa chọn cấu trúc phụ thuộc: thử nhiều loại copula, so sánh bằng tiêu chí
AIC/BIC và kiểm tra đặc tính phụ thuộc đuôi (tail–dependence) để chọn mô hình
phù hợp cho các tuyến có rủi ro liên thông. lOMoAR cPSD| 22014077
3.5. Mô hình tính phát thải theo ISO 14083/GLEC
3.5.1. Công thức tổng quát
Với một TCE vận tải k:
Trong đó EFk là hệ số phát thải Well-to-Wheel (WTW) theo mode/phương tiện; tkmk=
Khối lượng(t) x Quảng đường (km); Δadj là hiệu chỉnh ngoài tuyến (detour), tải rỗng
(Empty running), điều hoà nhiệt độ (Auxiliary loads), bốc xếp hub (HOC).
3.5.2. Hệ số phát thải
Hệ số phát thải được tham chiếu từ GLEC Framework v3 và các nguồn chuẩn quốc tế
(ISO 14083:2023, DEFRA, World Bank), tùy theo phương thức vận tải:
Đường bộ (HGV): GLEC v3 cung cấp bảng hệ số mặc định theo tải/“% km rỗng”; cỡ giá
trị từ ~80 đến >170 gCO e/tkm tuỳ tải và rỗng. Nhiều ví dụ thực tế ở châu Âu cho thấy₂
55–85 gCO e/tkm khi tải nặng và kiểm soát tốt “km rỗng”. Trong bối cảnh Việt Nam,₂
World Bank ước tính cường độ phát thải trung bình ~143 gCO /tkm₂ cho vận tải đường
bộ do đội xe già, tải rỗng cao và tắc nghẽn.
Đường sắt: hệ số thường trong khoảng 16–30 gCO e/tkm tuỳ điện hóa/đầu máy diesel,₂ theo các nguồn GLEC/DEFRA.
Đường biển/ven biển (container): điển hình 8–16 gCO e/tkm (thay đổi lớn theo cỡ tàu,₂
tốc độ, tuyến, tải). Phương pháp học thuật/điện toán như EcoTransIT nêu rõ công thức
chuyển đổi từ g/km sang g/tkm theo tải & hệ số sử dụng.
3.5.3. Tiêu chuẩn và phương pháp luận
ISO 14083:2023: Tiêu chuẩn toàn cầu về tính toán và báo cáo phát thải GHG trong vận tải và logistics.
GLEC Framework (Smart Freight Centre): Khung phương pháp được công nhận toàn
cầu, đồng bộ với ISO 14083.
Nguyên tắc ưu tiên: (i)
Dữ liệu sơ cấp (primary data) từ phương tiện, nhiên liệu, GPS. (ii)
Khi không đủ dữ liệu sơ cấp, áp dụng hệ số mặc định từ GLEC/DEFRA và điều
chỉnh theo điều kiện địa phương. lOMoAR cPSD| 22014077 (iii)
Kết quả đầu ra báo cáo theo đơn vị gCO e/tkm₂
, kèm phạm vi và giả định tính toán.
3.6. Bài toán tối ưu đa mục tiêu (rủi ro–chi phí–phát thải–dịch vụ)
Bài toán được xây dựng trên đồ thị vận tải đa phương thức (multi-modal transport network)
với các ràng buộc về năng lực và điều kiện vận hành. Biến quyết định xxx đại diện cho cấu
hình tuyến đường – phương thức vận tải – trung tâm logistics (hub) – loại phương tiện.
Mục tiêu là đồng thời tối thiểu hoá chi phí kỳ vọng, rủi ro thời gian giao hàng, và lượng
phát thải khí nhà kính, đồng thời tối đa hoá hiệu suất dịch vụ (OTIF – On Time In Full).
Mô hình tổng quát được biểu diễn như sau: Trong đó: •
E[C(x)] Chi phí vận hành kỳ vọng (bao gồm vận tải, lưu kho, xử lý hàng, bảo hiểm,…). •
CVaRα[T(x)] Conditional Value-at-Risk ở mức tin cậy α\alphaα đối với thời gian
giao hàng, phản ánh rủi ro ở vùng đuôi phân phối (các trường hợp trễ nặng). •
E[E(x)] Lượng phát thải khí nhà kính kỳ vọng, quy đổi về CO e theo phương pháp₂ ISO 14083/GLEC. •
OTIF(x) Tỷ lệ đơn hàng được giao đúng hạn và đầy đủ, chỉ tiêu phản ánh chất lượng dịch vụ.
Do các mục tiêu có tính xung đột (trade-off) và không thể tối ưu đồng thời về tuyệt đối, bài
toán được giải bằng thuật toán tiến hóa đa mục tiêu NSGA-II để xác định tập Pareto các
phương án tối ưu. Sau khi thu được tập Pareto, ta áp dụng phân tích thoả hiệp
(compromise analysis) như: •
Khoảng chấp nhận (Acceptable Trade-off Region) – xác định dải giá trị chấp
nhận được cho từng chỉ tiêu; •
Điểm lý tưởng (Ideal Point Method) – lựa chọn phương án gần nhất với cấu hình
lý tưởng về tất cả các tiêu chí.
Ràng buộc của bài toán bao gồm: (i)
Năng lực cung ứng: công suất phương tiện, số chuyến, kho bãi, thiết bị bốc xếp. (ii)
Lịch trình vận hành: giờ tàu, giờ xe, slot tại cảng và kho. lOMoAR cPSD| 22014077 (iii)
Cửa sổ thời gian (Time Windows): quy định về thời điểm nhận/giao hàng tại điểm đích. (iv)
SLA (Service Level Agreement) của khách hàng: yêu cầu tối thiểu về
thời gian, tần suất, tỷ lệ giao hàng. (v)
Quy định vận hành & an toàn: tiêu chuẩn ADR (vận chuyển hàng nguy
hiểm), giới hạn trọng tải cầu đường, hành lang an toàn. (vi)
Điều kiện rủi ro khu vực: vùng cấm tàu, khu vực chiến sự, thời tiết cực
đoan hoặc đóng cửa cảng.
3.7. Lộ trình triển khai và kiểm định
Lộ trình triển khai Vi-Chain RiskSim được thiết kế theo ba pha liên tiếp nhằm giảm thiểu
rủi ro triển khai, tối ưu hóa độ tin cậy của mô hình và đảm bảo khả năng mở rộng kỹ thuật
cũng như chấp nhận nghiệp vụ. Pha đầu tiên là giai đoạn thí điểm kéo dài ba đến sáu tháng,
tập trung triển khai trên một đến hai hành lang vận tải trọng điểm, ví dụ kết nối vùng Đông
Nam Bộ với Hà Nội hoặc Hải Phòng. Mục tiêu của giai đoạn này là thiết lập đường ống dữ
liệu (data pipeline) từ các nguồn nội bộ và bên ngoài, hiệu chỉnh mô-đun mô phỏng rủi ro
và mô-đun tính phát thải theo ISO 14083/GLEC, đồng thời thực hiện đối sánh kết quả mô
phỏng với dữ liệu quan sát thực tế để hiệu chuẩn tham số. Các hoạt động kiểm định trong
pha thí điểm bao gồm kiểm tra tính toàn vẹn dữ liệu, đánh giá khả năng thu thập dữ liệu sơ
cấp, phân tích sai số mô hình và khảo sát ban đầu về độ nhạy (sensitivity analysis) đối với
các giả định then chốt như tỷ lệ km rỗng, tốc độ trung bình và xác suất xảy ra sự kiện nhảy.
Sau khi hoàn tất hiệu chỉnh và chứng minh tính tương thích với dữ liệu thực ở quy mô hạn
chế, giai đoạn mở rộng được tiến hành trong khoảng sáu đến mười hai tháng với mục tiêu
nhân rộng mô hình trên toàn mạng lưới logistics. Trong pha này hệ thống sẽ tích hợp tự
động các lịch tàu và xe thương mại, bản đồ số hóa các tuyến và cơ sở hạ tầng, cũng như
các luồng cảnh báo thời tiết theo thời gian thực. Đồng thời, sẽ tiến hành chuẩn hóa đầu ra
báo cáo theo ISO 14083 để đảm bảo khả năng so sánh và tuân thủ báo cáo ESG của doanh
nghiệp. Kiểm định ở giai đoạn mở rộng tập trung vào đánh giá hiệu năng hệ thống khi xử
lý khối lượng dữ liệu lớn, kiểm thử khả năng mở rộng (scalability) của các mô-đun mô
phỏng và tối ưu hóa, đánh giá độ ổn định API tích hợp với hệ thống ERP/TMS/WMS, và
rà soát các kịch bản rủi ro thực nghiệm nhằm chứng minh tính bền vững của các khuyến
nghị tối ưu đối với nhiều điều kiện vận hành khác nhau.
Giai đoạn vận hành đầy đủ, dự kiến bắt đầu sau 12 tháng và kéo dài liên tục, hướng tới tối
ưu hóa quyết định trong thời gian thực và đánh giá lợi ích biện chứng của hệ thống trên
tiêu chí vận hành và môi trường. Các chỉ số đánh giá hiệu quả vận hành sẽ được đo lường
liên tục bao gồm giảm P95 của thời gian trễ giao hàng, giảm ton-km đi bằng đường bộ, và lOMoAR cPSD| 22014077
giảm kilogram CO e trên mỗi đơn vị hàng hóa so với baseline đã xác định trước₂ khi triển
khai. Trong giai đoạn này cần tổ chức kiểm toán độc lập bởi bên thứ ba để xác nhận tính
chính xác của dữ liệu phát thải, thủ tục tính toán và tuân thủ tiêu chuẩn ISO/GLEC; kết quả
kiểm toán sẽ là căn cứ cho báo cáo ESG và cho các quyết định đầu tư mở rộng.
Quá trình kiểm định xuyên suốt các pha triển khai phải được quản trị bởi một khung kiểm
soát chất lượng dữ liệu và kiểm chứng mô hình. Khung này bao gồm các thủ tục xác thực
dữ liệu đầu vào, bản ghi audit trail cho các bước xử lý, bộ thử nghiệm benchmark với các
kịch bản chuẩn, đánh giá độ nhạy và phân tích bất định (uncertainty quantification), cùng
quy trình tái huấn luyện mô hình (re-training) dựa trên dữ liệu sơ cấp mới. Về mặt quản trị,
cần thiết lập ban chỉ đạo liên chức năng gồm đại diện vận hành, CNTT, quản lý rủi ro và
bền vững để đảm bảo rằng mục tiêu kỹ thuật và mục tiêu nghiệp vụ được đồng bộ, đồng
thời áp dụng cơ chế kiểm soát truy cập và mã hóa để bảo vệ dữ liệu nhạy cảm.
Thành công của lộ trình được đánh giá dựa trên bộ chỉ số KPI đo lường cả khía cạnh kỹ
thuật và nghiệp vụ. Về mặt kỹ thuật, các KPI then chốt bao gồm tỉ lệ lỗi dữ liệu sau làm
sạch, thời gian trễ trung bình của pipeline dữ liệu, thời gian phản hồi của API khuyến nghị
và hiệu năng của thuật toán tối ưu hóa (thời gian hội tụ, độ ổn định Pareto). Về nghiệp vụ,
KPI sẽ bao gồm mức giảm chi phí logistics, tỉ lệ cải thiện OTIF, mức giảm phát thải/tkm
và kết quả kiểm toán độc lập. Nếu các KPI không đạt ngưỡng mong muốn ở bất kỳ pha
nào, cần kích hoạt quy trình khắc phục gồm điều chỉnh tham số mô hình, nâng cấp hạ tầng
hoặc tái cấu trúc luồng dữ liệu.
Cuối cùng, lộ trình triển khai cần kèm theo kế hoạch truyền thông và đào tạo nhằm đảm
bảo sự chấp nhận của người dùng cuối. Chương trình này nên bao gồm tài liệu hướng dẫn
vận hành, bộ bài tập tình huống thực tế, cùng workshop cho các nhóm vận hành và quản
lý để họ thấu hiểu cách đọc dashboard, diễn giải tập Pareto và ra quyết định dựa trên phân
tích thoả hiệp. Việc kết hợp kiểm định kỹ thuật chặt chẽ, kiểm toán độc lập và công tác
chuyển giao kiến thức sẽ đảm bảo Vi-Chain RiskSim không chỉ đạt được mục tiêu khoa
học mà còn mang lại giá trị thực tiễn bền vững cho doanh nghiệp.
3.8. Chỉ số đánh giá hiệu quả
Hiệu quả hoạt động của Vi-Chain RiskSim được đánh giá thông qua một bộ chỉ số đa chiều
phản ánh đồng thời khía cạnh rủi ro — dịch vụ, kinh tế, môi trường và tuân thủ — nhằm
đảm bảo rằng các khuyến nghị tối ưu vừa cải thiện tính chống chịu của chuỗi cung ứng,
vừa tối ưu chi phí và giảm phát thải theo các chuẩn quốc tế. Về khía cạnh rủi ro và dịch vụ,
các chỉ số then chốt gồm các chỉ số phần trăm bậc cao của thời gian giao hàng như P95 và
P99, cùng với Conditional Value-at-Risk (CVaR) cho biến trễ. Những chỉ số này đo lường lOMoAR cPSD| 22014077
không chỉ mức trung vị mà còn các rủi ro đuôi, giúp nhận diện các kịch bản trễ nặng mà
tác động đến chuỗi cung ứng là nghiêm trọng. Chỉ số OTIF (On-Time InFull) được sử dụng
để đánh giá chất lượng dịch vụ từ góc độ khách hàng; việc kết hợp P95/P99, CVaR và
OTIF cho phép cân bằng giữa mục tiêu tối ưu hóa chi phí và đảm bảo cam kết dịch vụ trong
điều kiện biến động.
Về khía cạnh kinh tế, hiệu quả được theo dõi thông qua tổng chi phí logistics hợp nhất, bao
gồm chi phí vận tải, chi phí lưu bãi và các khoản phạt liên quan như demurrage và detention,
cùng chi phí nhiên liệu thực tế. Các phép đo này phải được tính toán ở cả mức giản đơn
(tổng chi phí cho một lô hàng) và mức chỉ tiêu bình quân hóa (chi phí trên mỗi tấn, mỗi
đơn hàng hoặc mỗi tkm) để phục vụ so sánh theo thời gian và giữa các phương án. Phân
tích chi tiết các thành phần chi phí cho phép xác định nguồn gốc tăng chi phí khi đối mặt
với rủi ro và đánh giá hiệu quả kinh tế của các biện pháp giảm phát thải hay thay đổi modal.
Khía cạnh môi trường được đo bằng các chỉ số lượng hóa phát thải tiêu chuẩn như kilogram
CO e trên mỗi đơn hàng, gam CO e trên mỗi tkm, tỷ lệ đóng góp của phạm vi₂ ₂ WTW so
với TTW, và tỷ lệ phần trăm tkm được chuyển từ đường bộ sang đường sắt hoặc đường
biển (modal shift). Những chỉ số này phải được tính theo phương pháp ISO 14083/GLEC,
với báo cáo rõ ràng về giả định, phạm vi vòng đời nhiên liệu và nguồn hệ số phát thải sử
dụng. Việc theo dõi tỷ lệ WTW/TTW cung cấp thông tin về mức độ bao phủ vòng đời
nhiên liệu trong báo cáo, trong khi chỉ số modal shift phản ánh sự thay đổi cấu trúc vận tải
góp phần giảm cường độ phát thải. Đối với mục tiêu quản trị môi trường dài hạn, khuyến
nghị thiết lập ngưỡng mục tiêu (targets) giai đoạn theo năm và so sánh với baseline lịch sử
để đánh giá tiến triển.
Với khía cạnh tuân thủ và minh bạch, hệ thống cần báo cáo các chỉ tiêu về tỷ lệ sử dụng dữ
liệu sơ cấp so với hệ số mặc định, cùng tỷ lệ các tuyến và kỳ báo cáo đạt chuẩn ISO 14083
/ EN ISO 14083 như được thúc đẩy bởi các hướng dẫn CEN-CENELEC. Tỷ lệ sử dụng dữ
liệu sơ cấp là một chỉ số quan trọng của độ tin cậy; mức độ cao của dữ liệu sơ cấp giảm bất
định và tăng tính tin cậy của báo cáo phát thải. Minh bạch về nguồn dữ liệu, giả định tính
toán và audit trail có thể được biểu diễn thông qua chỉ số tuân thủ báo cáo, từ đó tạo thuận
lợi cho kiểm toán bên thứ ba và công bố ESG.
Tất cả các chỉ số nêu trên cần được tích hợp trong khung KPI tổng thể, được cập nhật theo
chu kỳ phù hợp (hàng tháng cho vận hành, hàng quý cho đánh giá chiến lược, hàng năm
cho báo cáo ESG). Trong thực thi, mỗi chỉ số nên đi kèm phương pháp tính cụ thể, nguồn
dữ liệu, ngưỡng mục tiêu và biện pháp khắc phục khi lệch so với mục tiêu. Việc kết hợp
các chỉ số rủi ro, kinh tế, môi trường và tuân thủ trong một hệ thống đo lường thống nhất lOMoAR cPSD| 22014077
sẽ giúp nhà quản trị ra quyết định dựa trên bằng chứng, tối ưu hoá trade-off giữa các mục
tiêu và chứng minh lợi ích bền vững của Vi-Chain RiskSim trước các bên liên quan.
3.9. Phân tích kịch bản thực tế minh họa
Phần này trình bày ba kịch bản vận hành thực tế được định lượng hóa nhằm minh họa năng
lực của Vi-Chain RiskSim trong việc so sánh đồng thời các chỉ tiêu phát thải, chi phí và
rủi ro thời gian. Mỗi kịch bản dựa trên sự kiện có nguồn gốc thực tế và được thiết lập mô
phỏng với các giả định minh bạch để đảm bảo khả năng tái tạo và đối chiếu với dữ liệu tham chiếu.
Kịch bản A — Ùn tắc cảng Cát Lái (TP.HCM, 2021). Bối cảnh thực nghiệm xuất phát
từ sự kiện thiếu hụt năng lực xếp dỡ tại Cát Lái trong năm 2021, khi tồn đọng container
vượt 100 000 TEU và dẫn đến kéo dài thời gian lưu bãi, gia tăng chi phí demurrage và làm
gián đoạn chuỗi cung ứng khu vực (World Bank, 2021). Thiết lập mô phỏng xét một lô
hàng khối lượng 20 tấn hướng về miền Bắc với hai lựa chọn vận chuyển. Phương án 1 là
vận chuyển đường bộ trực tiếp từ TP.HCM đến Hà Nội khoảng 1 700 km. Phương án 2
là phương án chuyển tải sang vận tải ven biển: vận chuyển ven bờ từ TP.HCM tới cảng Hải
Phòng giả định 1 200 km, sau đó hành lang đường bộ ngắn Hải Phòng–Hà Nội 120 km. Áp
dụng hệ số phát thải WTW tham chiếu cho Việt Nam là 143 gCO e/tkm cho vận₂ tải đường
bộ (World Bank) và 12 gCO e/tkm cho vận tải ven biển (GLEC/DEFRA cho₂ tuyến nội
vùng). Kết quả ước tính phát thải cho phương án 1 là
Đối với phương án 2, phát thải từ chặng biển là
và chặng đường bộ ngắn là ,
tổng cộng ≈ 631 kg CO e, tương ứng mức giảm khoảng 87% so với phương án thuần₂
đường bộ. Về rủi ro thời gian, mô-đun Monte Carlo bổ sung phân phối trễ do ùn tắc cổng
bãi (xác suất và phân bố thời gian bốc dỡ/hạ bãi), cho phép ước tính CVaR cho thời gian
giao hàng. Phân tích cho thấy phương án ven biển thường vượt trội về phát thải và chi phí
nhiên liệu; thời gian giao có thể tương đương hoặc chậm hơn trong ngưỡng 0–2 ngày nếu
tắc nghẽn tại cảng gốc kéo dài, phụ thuộc vào xác suất tắc cổng và lịch tàu thực tế.
Kịch bản B — Khủng hoảng Biển Đỏ (2024–2025) tác động tới tuyến Á–Âu. Sự gia
tăng rủi ro an ninh trên tuyến Biển Đỏ trong giai đoạn 2024–2025 buộc nhiều hãng tàu
tránh Kênh Suez và lựa chọn hành trình vòng qua Mũi Hảo Vọng, dẫn tới tăng đáng kể độ
dài hành trình, chi phí nhiên liệu và tổng “ton-miles” (UNCTAD; GOV.UK). Ứng dụng
cho hàng xuất khẩu từ Cái Mép–Thị Vải đi EU, mô-đun rủi ro của Vi-Chain RiskSim gán lOMoAR cPSD| 22014077
xác suất chuyển hướng tuyến theo tuần và mô hình hóa biên độ trễ nhảy J khi sự kiện an
ninh kích hoạt. Khi J xuất hiện, hệ thống đề xuất các chiến lược thích ứng bao gồm chia lô
sang hành lang West Coast US kết hợp rail/air hậu cần, chuyển cảng trung chuyển sang các
cảng có slot sẵn như Singapore hoặc Port Klang, hoặc đẩy sớm lịch tàu kết hợp kho đệm
tại hub EU. Mỗi phương án được lượng hóa đầy đủ về chi phí, phát thải và rủi ro thời gian
theo chuẩn ISO 14083/GLEC, tạo cơ sở so sánh có trọng số giữa giảm rủi ro trễ và gia tăng
chi phí/phát thải do chuyển hướng.
Kịch bản C — Bão Noru (9/2022) và hành lang miền Trung. Bão Noru vào tháng 9/2022
đã gây ảnh hưởng nghiêm trọng tới nhiều sân bay miền Trung, kèm theo lệnh sơ tán và
gián đoạn giao thông đường bộ, đường sắt (Quant Next, 2022). Thiết lập mô phỏng minh
họa cho hàng hóa lạnh khối lượng 15 tấn vận chuyển Đà Nẵng → TP.HCM. Phương án
mặc định là vận chuyển đường bộ dài 960 km; phương án thay thế trong điều kiện bão là
vận tải ven biển Đà Nẵng → Cát Lái giả định 900 km kết hợp một quãng đường bộ ngắn
nội vùng 70 km. Sử dụng hệ số 143 gCO e/tkm cho đường bộ và 12₂ gCO e/tkm cho ven
biển, phát thải ước tính cho phương án đường bộ là ₂
; cho phương án ven biển cộng đường bộ ngắn là và
, tổng ≈ 312 kg CO e, tương₂
ứng giảm khoảng 85%. Về rủi ro, trong giai đoạn bão, phân phối thời gian trễ đường bộ
biểu hiện đuôi dày do khả năng đóng đường hoặc sạt lở; mô-đun “nhảy”
(closure/routeblock jump) làm gia tăng đáng kể CVaR thời gian. Nếu luồng biển còn hoạt
động, phương án ven biển thường cho P95 thời gian tốt hơn hoặc tương đương do tránh
được các sự kiện nhảy trên hành lang đường bộ.
Ghi chú phương pháp. Các khoảng cách ven biển nêu trên là ước lượng minh họa; trong
triển khai thực tế, Vi-Chain RiskSim sẽ lấy quãng đường và lịch tàu thực từ các nguồn AIS
và lịch tuyến hãng tàu/đường thủy nội địa để tính tkm và đối chiếu thời gian. Hệ số phát
thải ưu tiên sử dụng dữ liệu sơ cấp khi doanh nghiệp hoặc hãng vận tải cung cấp; khi dữ
liệu sơ cấp không có, hệ thống áp dụng hệ số mặc định tham chiếu từ GLEC v3, DEFRA
và EcoTransIT, đồng thời ghi rõ phạm vi (WTW hoặc TTW) và các giả định liên quan theo
ISO 14083. Việc mô hình hóa rủi ro sử dụng kết hợp phân phối liên tục cho biến động vận
hành và quá trình compound Poisson / jump-diffusion cho các sự kiện đứt gãy hiếm gặp,
trong khi tương quan không gian-thời gian giữa các cung được bắt giữ bằng copula hoặc
ma trận tương quan theo cụm rủi ro để phản ánh ảnh hưởng đồng thời của một sự kiện trên nhiều nút mạng. lOMoAR cPSD| 22014077
Phần kịch bản minh họa trên cho thấy Vi-Chain RiskSim không chỉ cho phép định lượng
tiết kiệm phát thải khi chuyển đổi modal mà còn cung cấp phân tích rủi ro thời gian sắc
bén giúp ra quyết định cân bằng giữa mục tiêu giảm phát thải, tối ưu chi phí và đảm bảo
chất lượng dịch vụ trong bối cảnh các rủi ro phi tuyến và có tính không chắc chắn cao.
Tài liệu liên quan:
-

Phân Tích Hoạt Động Marketing Ngân Hàng OCB tại Đắk Lắk môn Nghiên cứu về Marketing | Trường Đại Học Tây Nguyên
63 32 -

Thực Trạng Hoạt Động Ngân Hàng Thương Mại KH Ở VN & Thế Giới môn Nghiên cứu về Marketing | Trường Đại Học Tây Nguyên
87 44 -

Chiến Lược Digital Marketing Yến Sào Thiên Việt môn Nghiên cứu về Marketing | Trường Đại Học Tây Nguyên
60 30 -

Chiến Lược Digital Marketing cho Coca Cola Dịp Tết môn Nghiên cứu về Marketing | Trường Đại Học Tây Nguyên
58 29 -

Các giải pháp Marketing cho Công ty TNHH Dịch vụ Vận tải Trung Việt môn Nghiên cứu về Marketing | Trường Đại Học Tây Nguyên
92 46