Lưu trữ và xử lý, phân tích dữ liệu phim | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
Apache Kafka là một kho dữ liệu phân tán được tối ưu hóa để thu nạp và xử lý dữ liệu truyền phát theo thời gian thực. Dữ liệu truyền phát là dữ liệu được tạo ra liên tục từ hàng nghìn nguồn dữ liệu khác nhau, các nguồn này thường gửi các bản ghi dữ liệu đồng thời. Tài liệu được sưu tầm gồm 28 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Lưu trữ và xử lý dữ liệu lớn 27 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:












Preview text:
lOMoAR cPSD| 61548706
TRƯỜNG ĐẠI HỌC BÁCH KHOA HÀ NỘI TRƯỜNG CÔNG
NGHỆ THÔNG TIN VÀ TRUYỀN THÔNG
BÁO CÁO BÀI TẬP LỚN
Đề tài: Lưu trữ và xử lý, phân tích dữ liệu phim Lớp: 144943 Học phần:
Lưu trữ và xử lý dữ liệu lớn Mã học phần: IT4931
Giảng viên hướng dẫn: TS. Trần Việt Trung
Danh sách thành viên nhóm: Họ và tên Mã số sinh viên Nguyễn Quốc Nhật Minh 20200408 Bùi Lâm Thanh 20204606 Trần Nhật Hoàng 20204559 Nguyễn Mạnh Dũng 20204730 Trần Quốc Anh 20204652 lOMoAR cPSD| 61548706 Hà Nội, 01/2024 Mục lục
LỜI NÓI ĐẦU ................................................................................................... 3
I. Khái quát công nghệ sử dụng ......................................................................... 4
1.1. Apache Kafka ........................................................................................... 4
1.2. Apache Spark ........................................................................................... 5 a) Giới thiệu
................................................................................................. 5
b) Những ưu điểm nổi bật của Spark .......................................................... 6
1.3. Elasticsearch ............................................................................................ 7 a) Giới thiệu
................................................................................................. 7
b) Ưu điểm của Elasticsearch ...................................................................... 8
1.4. Kibana ...................................................................................................... 8 1.5. MongoDB Cluster
.................................................................................... 9 a) Sơ lược về
MongoDB ............................................................................. 9
b) MongoDB Shard Cluster? ..................................................................... 11
1.6. Docker ....................................................................................................
12 a) Docker là gì ? ........................................................................................ 12
b) Ưu điểm của Docker? ........................................................................... 12
II. Xây dựng chương trình và hệ thống ............................................................ 14
2.1 Luồng dữ liệu của hệ thống .................................................................... 14
2.2 Quá trình thực hiện ................................................................................. 14
2.2.1 Khởi động Docker-compose ............................................................. 14
2.2.2 Crawl dữ liệu .................................................................................... 16
2.2.3 Tạo topic kafka ................................................................................. 16 lOMoAR cPSD| 61548706
2.2.4 Thiết lập MongoDB cluster .............................................................. 16
2.2.5 Triển khai hệ thống với spark ........................................................... 20
2.2.5 Biểu diễn dữ liệu bằng Kibana ......................................................... 25
III. Nhận xét , đánh giá và hướng phát triển .................................................... 28
Tài liệu tham khảo ............................................................................................ 29 LỜI NÓI ĐẦU
Trước đây, khi mạng Internet còn chưa phát triển, lượng dữ liệu con người sinh
ra khá nhỏ giọt và thưa thớt, nhìn chung, lượng dữ liệu này vẫn nằm trong khả năng
xử lý của con người dù bằng tay hay bằng máy tính. Tuy nhiên trong kỷ nguyên số,
khi mà sự bùng nổ công nghệ truyền thông đã dẫn tới sự bùng nổ dữ liệu người dùng,
lượng dữ liệu được tạo ra vô cùng lớn và đa dạng, đòi hỏi một hệ thống đủ mạnh để
phân tích và xử lý những dữ liệu đó.
Khái niệm Big Data đề cập tới dữ liệu lớn theo 3 khía canh khác nhau, thứ nhất
là tốc độ sinh dữ liệu (velocity), thứ hai là lượng dữ liệu (volumn) và thứ ba là độ đa
dạng (variety). Lượng dữ liệu này có thể đến từ nhiều nguồn khác nhau như các nền
tảng truyền thông Google, Facebook, Twitter, … hay thông số thu thập từ các cảm
biến, thiết bị IoT trong đời sống, … Và một sự thật rằng doanh nghiệp nào có thể
kiểm soát và tạo ra tri thức từ những dữ liệu này sẽ tạo ra một tiềm lực rất lớn để cạnh
tranh với những doanh nghiệp khác.
Trong phạm vi của Bài tập lớn này, nhóm chúng em thực hiện tạo một hệ thống
thu thập dữ liệu về các bộ phim từ trang web The Movie Database, sau đó vận dụng
các kiến thức về lưu trữ và dữ liệu lớn để khai thác.
Bài tập lớn của nhóm chúng em bao gồm 3 nội dung chính:
- Tổng quan xây dựng hệ thống
- Xây dựng chương trình và hệ thống
- Nhận xét, đánh giá và hướng phát triển
Mặc dù đã cố gắng hoàn thiện sản phẩm nhưng không thể tránh khỏi những
thiếu hụt về kiến thức và sai sót trong kiểm thử. Chúng em rất mong nhận được những
nhận xét thẳng thắn, chi tiết đến từ thầy để tiếp tục hoàn thiện hơn nữa. Cuối cùng,
nhóm chúng em xin được gửi lời cảm ơn đến thầy TS. Trần Việt Trung dẫn chúng em
trong suốt quá trình hoàn thiện bài tập lớn. Nhóm chúng em xin chân thành cảm ơn thầy. lOMoAR cPSD| 61548706
I. Khái quát công nghệ sử dụng
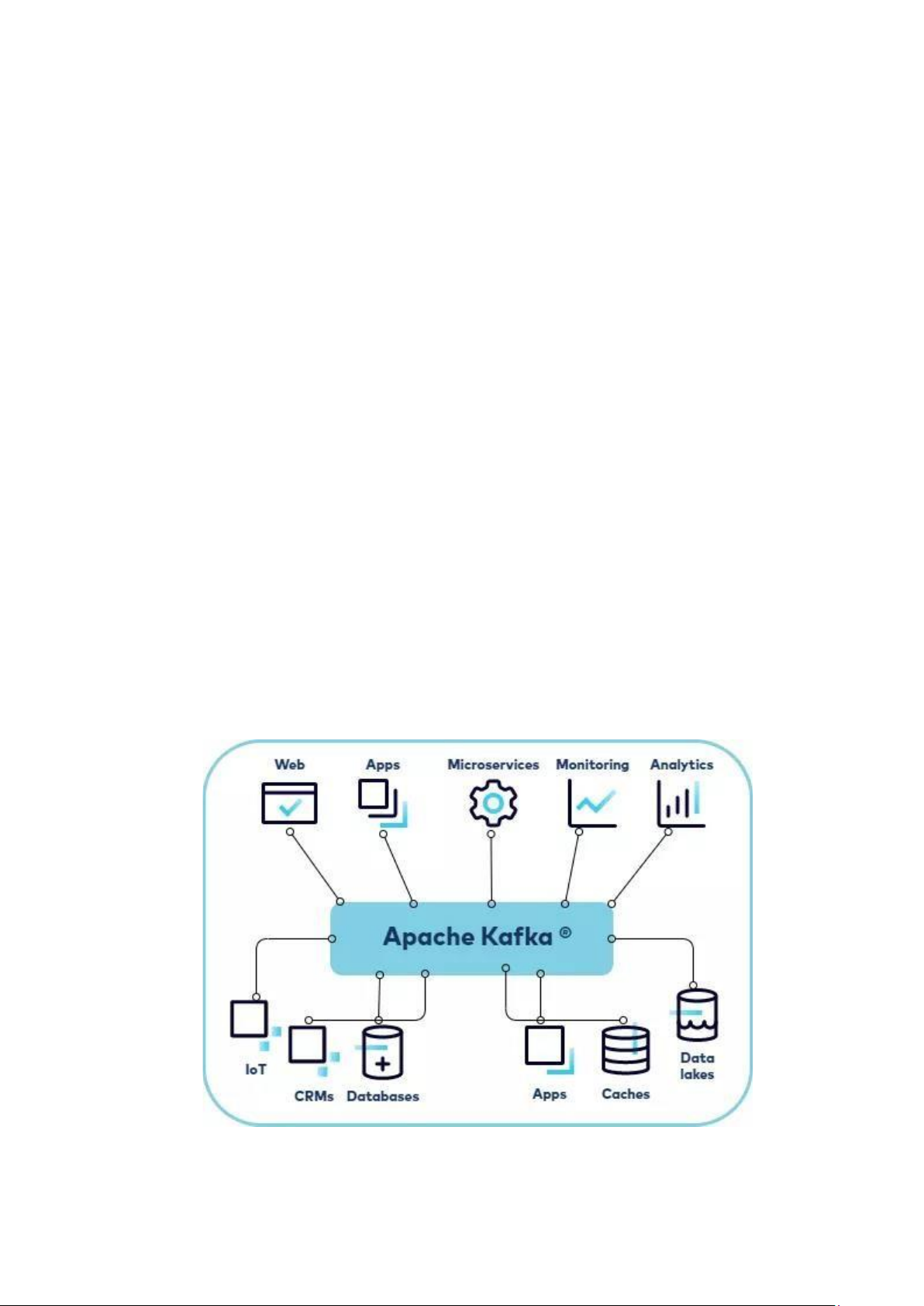
1.1. Apache Kafka
Apache Kafka là một kho dữ liệu phân tán được tối ưu hóa để thu nạp và xử lý
dữ liệu truyền phát theo thời gian thực. Dữ liệu truyền phát là dữ liệu được tạo ra liên
tục từ hàng nghìn nguồn dữ liệu khác nhau, các nguồn này thường gửi các bản ghi dữ
liệu đồng thời. Nền tảng truyền phát cần phải xử lý luồng dữ liệu liên tục này và xử
lý dữ liệu theo trình tự và tăng dần.
Kafka cung cấp ba chức năng chính cho người dùng:
• Xuất bản và đăng ký các luồng bản ghi
• Lưu trữ hiệu quả các luồng bản ghi theo thứ tự tạo bản ghi
• Xử lý các luồng bản ghi trong thời gian thực
Kafka chủ yếu được dùng để xây dựng các quy trình dữ liệu truyền phát trong
thời gian thực và các ứng dụng thích ứng với luồng dữ liệu đó. Kafka kết hợp nhắn
tin, lưu trữ và xử lý luồng nhằm hỗ trợ hoạt động lưu trữ, phân tích cả dữ liệu lịch sử
lẫn dữ liệu trong thời gian thực.
Cấu trúc của kafka bao gồm các thành phần chính sau: lOMoAR cPSD| 61548706
• Producer: Một producer có thể là bất kì ứng dụng nào có chức năng publish message vào một topic.
• Messages: Messages đơn thuần là byte array và developer có thể sử dụng
chúng để lưu bất kì object với bất kì format nào - thông thường là String, JSON và Avro.
• Topic: Một topic là một category hoặc feed name nơi mà record được publish.
• Partitions: Các topic được chia nhỏ vào các đoạn khác nhau, các đoạn này được gọi là partition
• Consumer: Một consumer có thể là bất kì ứng dụng nào có chức năng
subscribe vào một topic và tiêu thụ các tin nhắn.
• Broker: Kafka cluster là một set các server, mỗi một set này được gọi là 1 broker.
• Zookeeper: được dùng để quản lý và bố trí các broker. 1.2. Apache Spark a) Giới thiệu
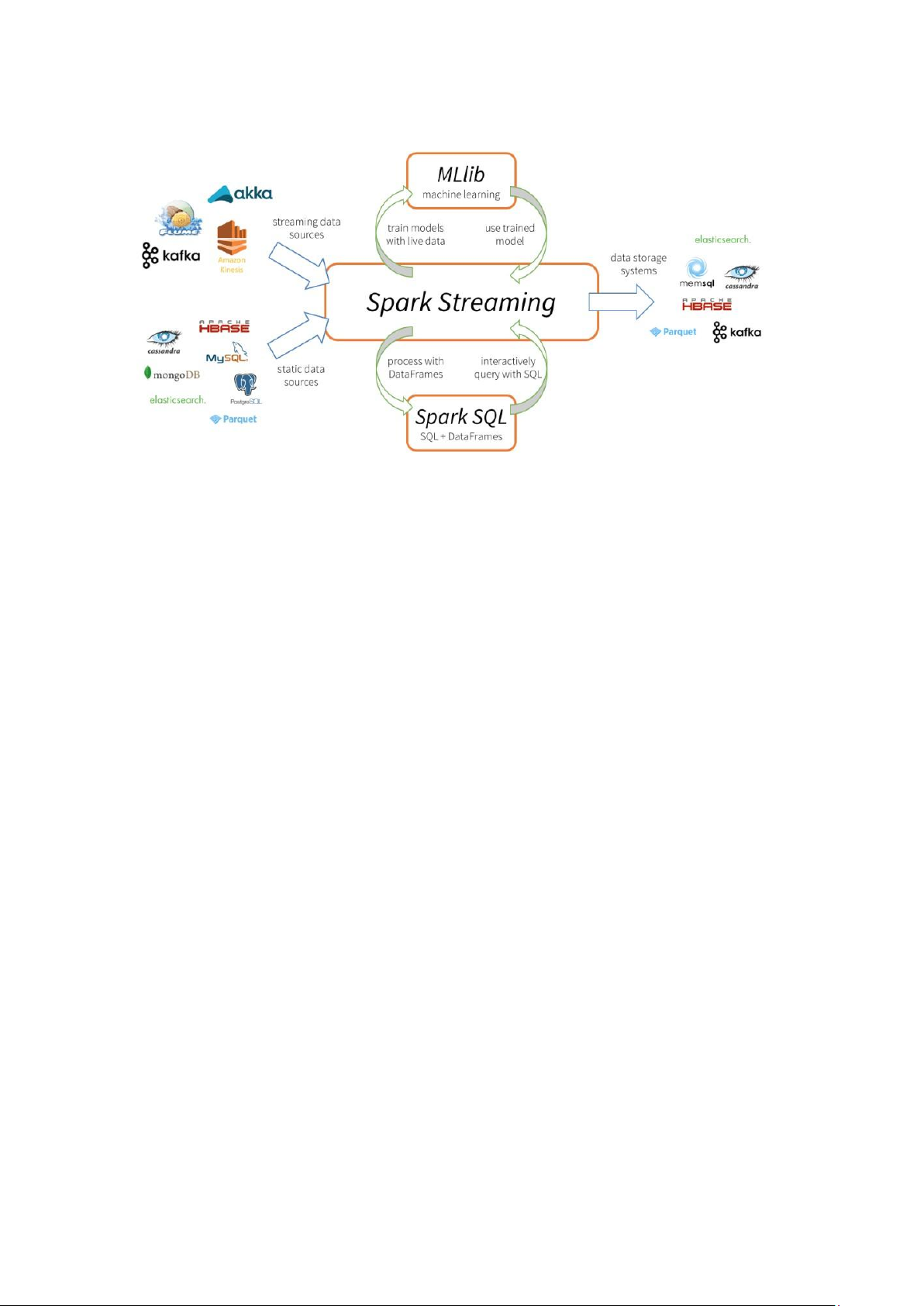
Apache Spark là một framework mã nguồn mở được sử dụng để xử lý dữ liệu
trên quy mô lớn. Nó cung cấp một giao diện cho việc lập trình tính toán đồng thời
trên các cụm máy tính với khả năng chịu lỗi. Khả năng tính toán phân tán của Apache
Spark làm cho nó trở thành một công cụ phù hợp cho việc làm việc với dữ liệu lớn và
Machine Learning. Spark giúp giải quyết những vấn đề liên quan đến việc tính toán
trên các tập dữ liệu khổng lồ bằng cách loại bỏ một số khó khăn lập trình thông qua
một API dễ sử dụng. Điều này giúp cho các nhà phát triển tập trung vào các công việc
quan trọng hơn trong việc xử lý và tính toán trên dữ liệu phân tán. lOMoAR cPSD| 61548706
Apache Spark bao gồm 5 thành phần chính: Spark Core, Spark Streaming, Spark SQL, MLlib và GraphX.
1. Spark Core là thành phần cốt lõi của Spark, thực hiện tính toán và xử lý dữ liệu
trong bộ nhớ, đồng thời tham chiếu đến dữ liệu lưu trữ bên ngoài.
2. Spark SQL tập trung vào xử lý dữ liệu có cấu trúc và cung cấp giao diện SQL để truy vấn dữ liệu.
3. Spark Streaming cho phép xử lý dữ liệu theo thời gian thực hoặc gần thời gian
thực, bằng cách chia nhỏ dữ liệu thành các microbatch và sử dụng API Spark.
4. MLlib là nền tảng học máy phân tán trên Spark, với kiến trúc dựa trên bộ nhớ
và tốc độ nhanh hơn so với thư viện tương đương trên Hadoop.
5. GraphX cung cấp thuật toán xử lý đồ thị phân tán, sử dụng RDD của Spark
Core và hỗ trợ xử lý đồ thị trên khung dữ liệu thông qua gói GraphFrames.
b) Những ưu điểm nổi bật của Spark
Được thiết kế từ dưới lên để tăng hiệu suất, Spark có thể nhanh hơn 100 lần so
với Hadoop khi xử lý dữ liệu quy mô lớn bằng cách khai thác tính toán trên bộ nhớ
và các tối ưu hóa khác. Spark cũng nhanh khi dữ liệu được lưu trữ trên đĩa và hiện
đang giữ kỷ lục thế giới về phân loại trên đĩa quy mô lớn.
Spark có các API dễ sử dụng để làm việc trên các tập dữ liệu lớn, bao gồm hơn
100 toán tử để chuyển đổi dữ liệu và các API dataframe quen thuộc để xử lý dữ liệu bán cấu trúc. lOMoAR cPSD| 61548706
Spark được đóng gói với các thư viện cấp cao, bao gồm hỗ trợ truy vấn SQL,
truyền dữ liệu trực tuyến, học máy và xử lý đồ thị. Các thư viện tiêu chuẩn này làm
tăng năng suất của nhà phát triển và có thể được kết hợp liền mạch để tạo ra các quy
trình làm việc phức tạp. 1.3. Elasticsearch a) Giới thiệu
Elasticsearch là một hệ thống tìm kiếm và phân tích dữ liệu phân tán mã nguồn
mở, được xây dựng trên nền tảng Apache Lucene. Nó cung cấp một cách mạnh mẽ
và linh hoạt để lưu trữ, tìm kiếm và phân tích dữ liệu trong quy mô lớn và thời gian thực.
Elasticsearch hoạt động bằng cách lưu trữ dữ liệu vào các "nút" phân tán, tạo
thành một cụm Elasticsearch. Mỗi nút chứa một phần của dữ liệu và có khả năng xử
lý và tìm kiếm dữ liệu độc lập. Khi dữ liệu được thêm hoặc cập nhật, Elasticsearch tự
động phân bổ và phân tán dữ liệu trên các nút, đảm bảo hiệu suất cao và khả năng mở rộng.
Một trong những điểm mạnh chính của Elasticsearch là khả năng tìm kiếm
nhanh chóng và chính xác. Nó sử dụng cơ chế tìm kiếm ngược (inverted index) dựa
trên Apache Lucene, cho phép tìm kiếm dựa trên từ khóa, văn bản, phạm vi thời gian
và nhiều tiêu chí khác. Elasticsearch cung cấp một API RESTful dễ sử dụng để truy
vấn dữ liệu và trả về kết quả trong thời gian thực.
Ngoài tìm kiếm, Elasticsearch còn cung cấp các tính năng phân tích và khám
phá dữ liệu mạnh mẽ. Với Elasticsearch, ta có thể thực hiện các tác vụ như tạo đồ thị,
tạo bảng điều khiển, thống kê, phân loại, và phân tích các xu hướng dữ liệu. Nó hỗ lOMoAR cPSD| 61548706
trợ các công cụ và thư viện phổ biến như Kibana và Logstash, để tạo ra một giải pháp
đầy đủ cho việc thu thập, xử lý và trực quan hóa dữ liệu.
b) Ưu điểm của Elasticsearch
- Hiệu suất tìm kiếm và truy vấn nhanh chóng: Elasticsearch sử dụng cơ chế tìm
kiếm ngược và phân tán dữ liệu để đảm bảo tìm kiếm và truy vấn dữ liệu nhanh
chóng, kể cả với dữ liệu lớn.
- Khả năng mở rộng: Elasticsearch có thể mở rộng dễ dàng bằng cách thêm nút
vào cụm, giúp xử lý tải cao và mở rộng dữ liệu theo nhu cầu.
- Phân tích và khám phá dữ liệu linh hoạt: Elasticsearch cung cấp các tính năng
phân tích mạnh mẽ để tìm hiểu và khám phá dữ liệu, từ việc tạo biểu đồ đến
phân loại và phân tích xu hướng.
- Dễ dàng tích hợp: Elasticsearch có giao diện API RESTful dễ sử dụng, cho phép
tích hợp dễ dàng với các ứng dụng và công cụ khác.
- Cộng đồng rộng lớn: Elasticsearch là một dự án mã nguồn mở phát triển bởi
một cộng đồng đông đảo, điều này đảm bảo có sự hỗ trợ, cải thiện và phát triển
liên tục từ cộng đồng người dùng.
Tóm lại, Elasticsearch là một hệ thống tìm kiếm và phân tích dữ liệu phân tán
mạnh mẽ, cung cấp tốc độ tìm kiếm nhanh chóng, khả năng mở rộng, tính linh hoạt
trong phân tích dữ liệu và tích hợp dễ dàng. Điều này làm cho Elasticsearch trở thành
một công cụ quan trọng trong việc xử lý và tìm kiếm dữ liệu trong các ứng dụng từ
việc giám sát hệ thống, phân tích log, tìm kiếm sản phẩm đến khám phá dữ liệu và nhiều ứng dụng khác. 1.4. Kibana
Kibana là một công cụ trực quan hóa và phân tích dữ liệu mã nguồn mở, được
thiết kế để làm việc cùng với Elasticsearch. Nó cung cấp một giao diện người dùng
đơn giản và mạnh mẽ để khám phá, trực quan hóa và chia sẻ thông tin từ dữ liệu được
lưu trữ trong Elasticsearch. Nó cho phép ta tạo các biểu đồ, đồ thị, bảng điều khiển
và báo cáo tùy chỉnh để hiểu rõ hơn về dữ liệu của mình. Bằng cách tương tác với dữ
liệu trong Elasticsearch, ta có thể thực hiện các truy vấn, lọc dữ liệu, phân tích xu
hướng và tìm ra thông tin quan trọng từ dữ liệu của mình. Ta có thể coi Kibana như
là màn hình hiển thị dữ liệu từ Elasticsearch. lOMoAR cPSD| 61548706
Kibana là một công cụ trực quan hóa và phân tích dữ liệu mạnh mẽ, làm việc
cùng với Elasticsearch để cung cấp khả năng truy xuất thông tin và phân tích dữ liệu
một cách dễ dàng và hiệu quả. 1.5. MongoDB Cluster
a) Sơ lược về MongoDB
MongoDB là một database hướng tài liệu (document), một dạng NoSQL
database. Vì thế, MongoDB sẽ tránh cấu trúc table-based của relational database để
thích ứng với các tài liệu như JSON có một schema rất linh hoạt gọi là BSON.
MongoDB sử dụng lưu trữ dữ liệu dưới dạng Document JSON nên mỗi một collection
sẽ các các kích cỡ và các document khác nhau. Các dữ liệu được lưu trữ trong
document kiểu JSON nên truy vấn sẽ rất nhanh. lOMoAR cPSD| 61548706
MongoDB lần đầu ra đời bởi MongoDB Inc., tại thời điểm đó là thế hệ 10, vào
tháng Mười năm 2007, nó là một phần của sản phẩm PaaS (Platform as a Service)
tương tự như Windows Azure và Google App Engine. Sau đó nó đã được chuyển
thành nguồn mở từ năm 2009.
MongoDB đã trở thành một trong những NoSQL database nổi trội nhất bấy giờ,
được dùng làm backend cho rất nhiều website như eBay, SourceForge và The New York Times.
Các feature của MongoDB gồm có:
- Query: hỗ trợ search bằng field, các phép search thông thường, regular
expression searches, và range queries.
- Indexing: bất kì field nào trong BSON document cũng có thể được index.
- Replication: có ý nghĩa là “nhân bản”, là có một phiên bản giống hệt phiên
bản đang tồn tại, đang sử dụng. Với cơ sở dữ liệu, nhu cầu lưu trữ lớn, đòi
hỏi cơ sở dữ liệu toàn vẹn, không bị mất mát trước những sự cố ngoài dự
đoán là rất cao. Vì vậy, người ta nghĩ ra khái niệm “nhân bản”, tạo một phiên
bản cơ sở dữ liệu giống hệt cơ sở dữ liệu đang tồn tại, và lưu trữ ở một nơi
khác, đề phòng có sự cố.
- Aggregation: Các Aggregation operation xử lý các bản ghi dữ liệu và trả về
kết quả đã được tính toán. Các phép toán tập hợp nhóm các giá trị từ nhiều
Document lại với nhau, và có thể thực hiện nhiều phép toán đa dạng trên dữ
liệu đã được nhóm đó để trả về một kết quả duy nhất. Trong SQL, count(*)
và GROUP BY là tương đương với Aggregation trong MongoDB.
- Lưu trữ file: MongoDB được dùng như một hệ thống file tận dụng những
function trên và hoạt động như một cách phân phối qua sharding.
b) MongoDB Shard Cluster?
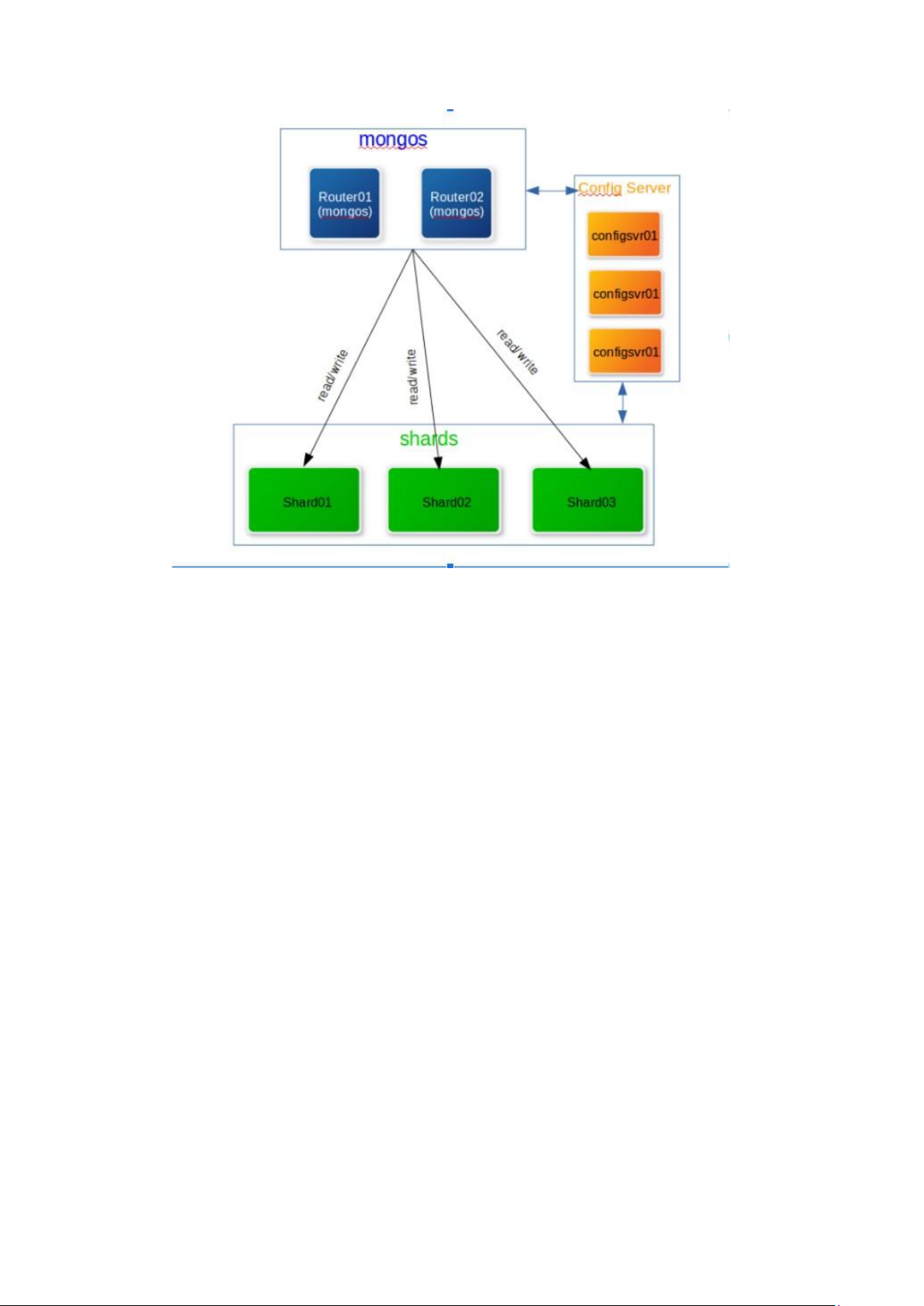
MongoDB Shard Cluster là một kiểu triển khai MongoDB được thiết kế để mở
rộng khả năng chịu tải của hệ thống cơ sở dữ liệu MongoDB bằng cách phân chia dữ
liệu và phân phối chúng trên nhiều máy chủ (shard). Cụ thể, mục tiêu của MongoDB
Shard Cluster là tăng cường khả năng mở rộng ngang của hệ thống, cho phép xử lý
lượng dữ liệu lớn và cung cấp hiệu suất cao. lOMoAR cPSD| 61548706
Dưới đây là một số thành phần của MongoDB Shard Cluster:
- Mongos: Đây thực ra là một query router, cung cấp một giao diện tương
tác giữa ứng dụng và các sharded cluster.
- Mongod: Nó xử lý các yêu cầu dữ liệu, quản lý quyền truy cập dữ liệu và
thực hiện các hoạt động quản lý nền
- Shard: Mỗi shard chứa đựng một tập nhỏ các data đã sharded, từ phiên bản
3.6 trở lên, shards phải được cấu hình chạy replicaset nếu muốn trở thành một phần của cluster.
- Config server: Config server chứa đựng metadata và cấu hình cho cluster,
từ phiên bản 3.4 trở lên config server phải deploy dưới dạng replicaset.
- Replicaset (Primary, secondary): Một replica set trong MongoDB là một
nhóm các tiến trình của mongodb duy trì cùng một bộ dữ liệu. Các replica
set cung cấp tính dự phòng và tính sẵn sàng cao và là cơ sở để triển khai
nhập xuất dữ liệu khi cần thiết. 1.6. Docker a) Docker là gì ? lOMoAR cPSD| 61548706
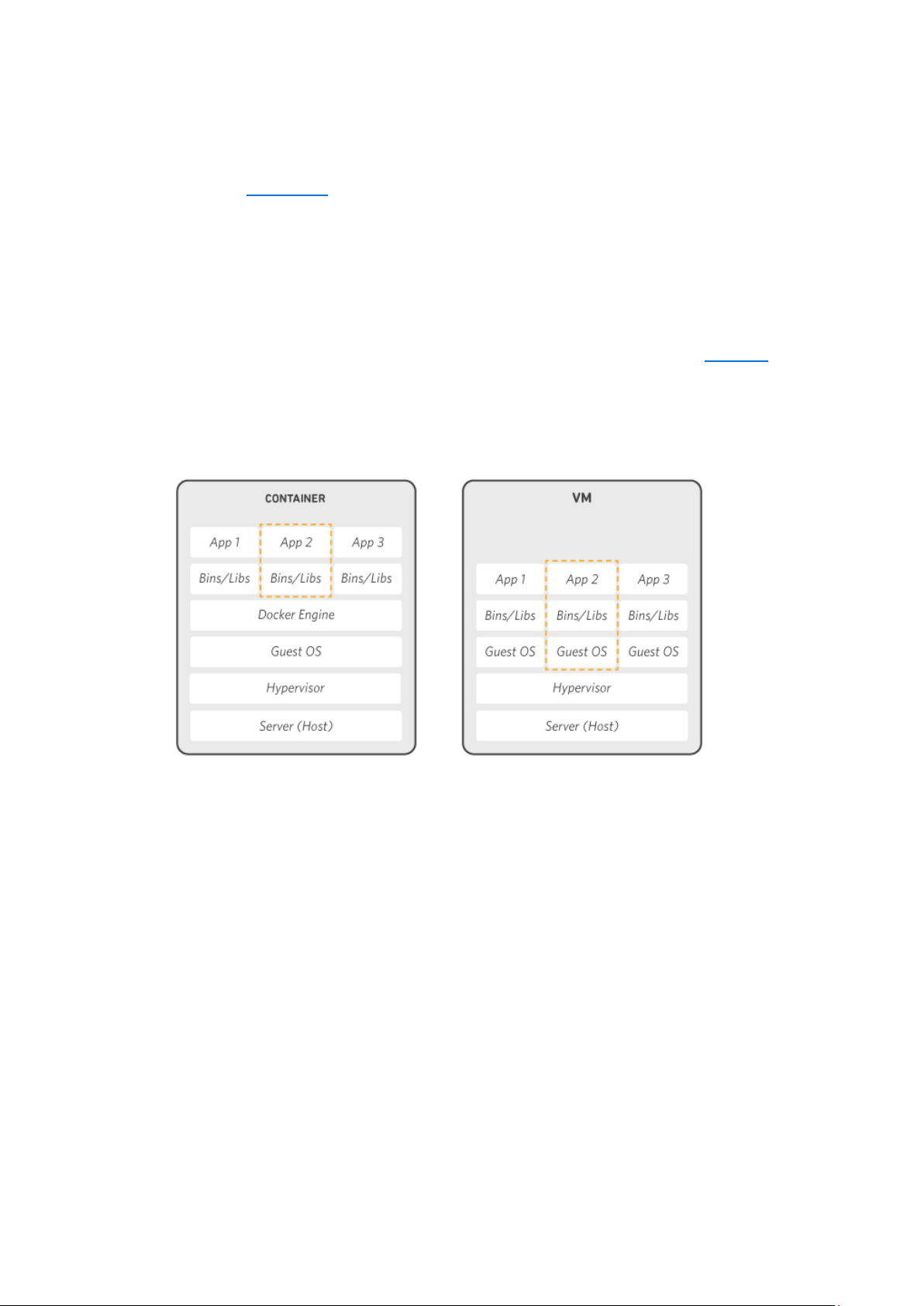
Docker là nền tảng phần mềm cho phép bạn dựng, kiểm thử và triển khai ứng
dụng một cách nhanh chóng. Docker đóng gói phần mềm vào các đơn vị tiêu chuẩn
hóa được gọi là container có mọi thứ mà phần mềm cần để chạy, trong đó có thư
viện, công cụ hệ thống, mã và thời gian chạy. Bằng cách sử dụng Docker, bạn có thể
nhanh chóng triển khai và thay đổi quy mô ứng dụng vào bất kỳ môi trường nào và
biết chắc rằng mã của bạn sẽ chạy được.
Docker hoạt động bằng cách cung cấp phương thức tiêu chuẩn để chạy mã của
bạn. Docker là hệ điều hành dành cho container. Cũng tương tự như cách máy ảo ảo
hóa (loại bỏ nhu cầu quản lý trực tiếp) phần cứng máy chủ, các container sẽ ảo hóa
hệ điều hành của máy chủ. Docker được cài đặt trên từng máy chủ và cung cấp các
lệnh đơn giản mà bạn có thể sử dụng để dựng, khởi động hoặc dừng container.
b) Ưu điểm của Docker?
- Tính dễ ứng dụng: Docker rất dễ cho mọi người sử dụng từ lập trình viên, sys
admin… nó tận dụng lợi thế của container để build, test nhanh chóng. Có thể
đóng gói ứng dụng trên laptop của họ và chạy trên public cloud, private cloud…
- Tốc độ: Docker container rất nhẹ và nhanh, bạn có thể tạo và chạy docker container trong vài giây.
- Môi trường chạy và khả năng mở rộng: Bạn có thể chia nhỏ những chức
năng của ứng dụng thành các container riêng lẻ. Ví dụng Database chạy trên
một container và Redis cache có thể chạy trên một container khác trong khi
ứng dụng Node.js lại chạy trên một cái khác nữa. Với Docker, rất dễ để liên lOMoAR cPSD| 61548706
kết các container với nhau để tạo thành một ứng dụng, làm cho nó dễ dàng
scale, update các thành phần độc lập với nhau. lOMoAR cPSD| 61548706
II. Xây dựng chương trình và hệ thống
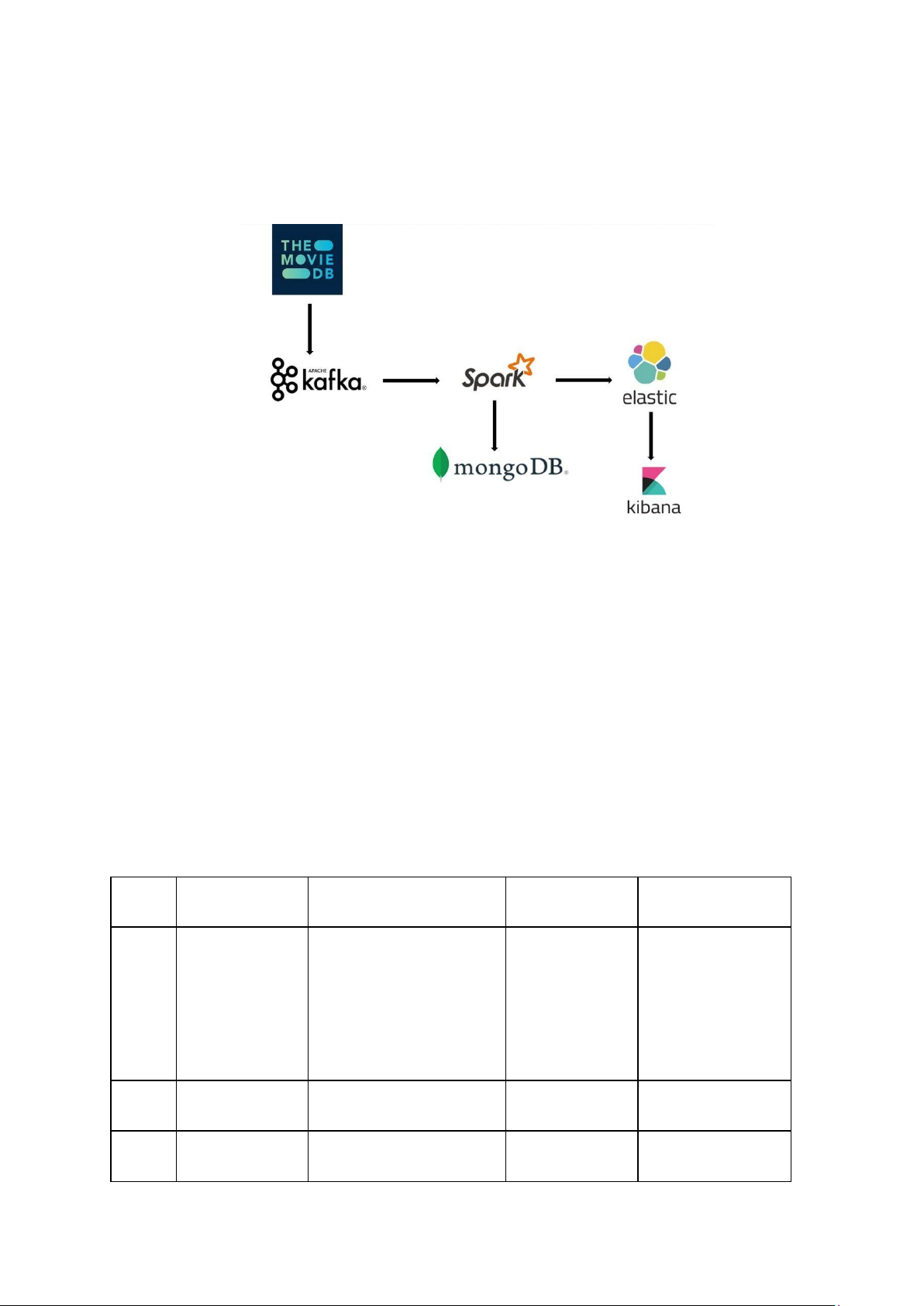
2.1 Luồng dữ liệu của hệ thống
Luồng dữ liệu của hệ thống chúng em xây dựng gồm 4 quá trình:
- Thu thập dữ liệu trên website The Movie Database.
- Lưu dữ liệu vào Kafka.
- Lọc, làm sạch dữ liệu trên Kafka bằng Spark. Sau đó lưu thành 2 bản: 1 bản
lưu trên MongoDB, 1 bản lưu gửi vào Elasticsearch.
- Biểu diễn dữ liệu trên Elasticsearch dưới dạng biểu đồ, đồ thị, danh sách bảng sử dụng Kibana.
2.2 Quá trình thực hiện
2.2.1 Khởi động Docker-compose STT Tên container Image Ports Ghi chú Mã nguồn chương trình được mount 4040:4040 vào bên trong 6066:6066 1 spark-master bitnami/spark:3.2.3 spark-master để 7077:7077 submit do lỗi gặp 8080:8080 phải khi submit job từ local machine. 2 spark-worker-1 bitnami/spark:3.2.3 8081:8081 3 spark-worker-2 bitnami/spark:3.2.3 8082:8081 lOMoAR cPSD| 61548706 4 zookeeper bitnami/zookeeper:3.9 2181:2181 5 kafka1 bitnami/kafka:3.5 9093:9093 6 kafka2 bitnami/kafka:3.5 9094:9094 7 elasticsearch docker.elastic.co/elasticse arch/elasticsearch:7.17.16 9200:9200 docker.elastic.co/kibana/ki 8 kibana bana:7.17.16 5601:5601 9 cfgsvr1 mongo:6.0.12 40001:27017 10 router_mongos mongo:6.0.12 60000:27017 11 shard1svr1 mongo:6.0.12 50001:27017 12 shard1svr2 mongo:6.0.12 50002:27017 13 shard1svr3 mongo:6.0.12 50003:27017 14 shard2svr1 mongo:6.0.12 50004:27017 15 shard2svr2 mongo:6.0.12 50005:27017 16 shard2svr3 mongo:6.0.12 50006:27017
- Spark master: Đây là nút quản lý trong một cụm Spark, nó phân phối công
việc và quản lý các tác vụ trên các nút worker.
- Spark-worker-1, Spark-worker-2: Đây là các nút con trong một cụm Spark,
chúng thực hiện các tác vụ được giao bởi Spark master.
- Zookeeper: Đây là một dịch vụ phối hợp phân tán, mã nguồn mở được sử
dụng để quản lý và đồng bộ hóa các tác vụ trong một hệ thống phân tán.
- Kafka1, Kafka2: Hai nút kafka, sử dụng để xây dựng luồng dữ liệu thời gian thực và ứng dụng.
- Elasticsearch: Đây là một công cụ tìm kiếm và phân tích dữ liệu mạnh mẽ,
cho phép lưu trữ, tìm kiếm và phân tích khối lượng dữ liệu lớn một cách nhanh
chóng và theo thời gian thực. lOMoAR cPSD| 61548706
- Kibana: Đây là một công cụ giao diện người dùng phổ biến được sử dụng để
trực quan hóa dữ liệu và tạo bảng điều khiển báo cáo chi tiết.
- Cfgsvr1: Config server chứa đựng metadata và cấu hình cho cluster.
- Router_mongos: Query router, chịu trách nhiệm định tuyến tới các shard phù hợp. - Shard1svr1, shard1svr2, shard1svr3, shard2svr1, shard2svr2,
shard2svr3: Các shard server dùng để lưu trữ dữ liệu.
2.2.2 Crawl dữ liệu
Chúng em sử dụng API của trang web The Movie Database để crawl dữ liệu về
các bộ phim. Đây là một dự án cộng đồng lớn được phát triển bởi cộng đồng người
hâm mộ phim, cung cấp thông tin chi tiết về phim, bao gồm các bộ phim truyền hình,
bộ phim ngắn, và nhiều loại nội dung khác.
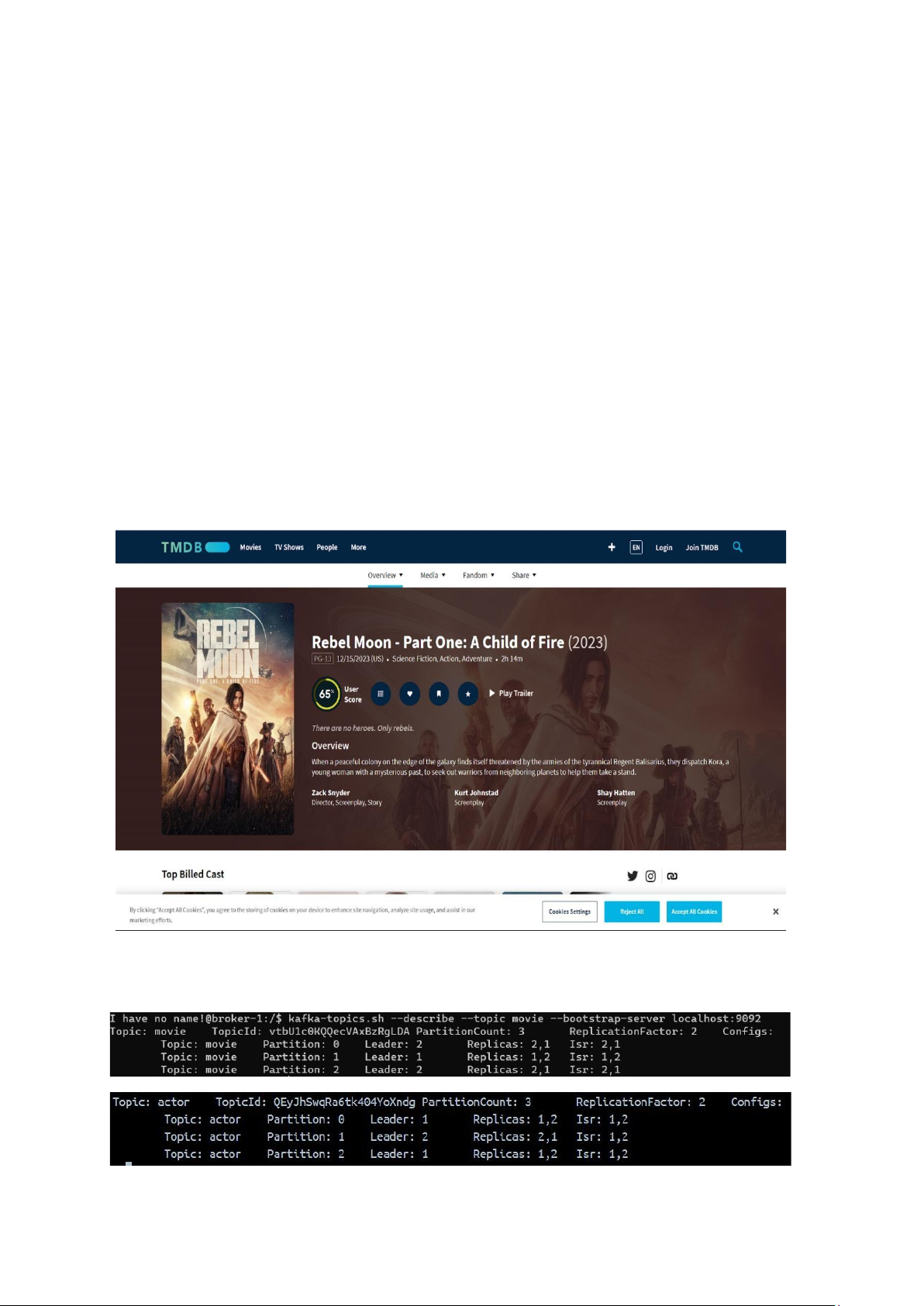
2.2.3 Tạo topic kafka
Tiến hành tạo 2 topic “movie” và “actor” có 3 partition và 2 replication factor: lOMoAR cPSD| 61548706
2.2.4 Thiết lập MongoDB cluster
Tạo các ReplicaSet cfgsvr, shard1, shard2: Thêm các shard vào cluster
Tạo schema và shard collection lOMoAR cPSD| 61548706 Thông tin về database: lOMoAR cPSD| 61548706 Dữ liệu trong database: lOMoAR cPSD| 61548706 Explain query:
2.2.5 Triển khai hệ thống với spark
Hệ thống bao gồm 2 producer và 2 consumer cho dữ liệu movie và actor.
Producer sẽ crawl liên tục và đẩy các message vào 2 topic movie và actor của kafka.
Các consumer sẽ liên tục lắng nghe, nhận dữ liệu và xử lý chúng.
Spark cluster gồm 2 worker như hình dưới:
Tài liệu liên quan:
-

Báo cáo Bài Tập Lớn: Phân Tích Dữ Liệu Thời Tiết | Lưu trữ và xử lý dữ liệu | Trường Đại học Bách Khoa
82 41 -

Xây dựng luồng dữ liệu lưu trữ, xử lý và phân tích giá bất động sản tại Anh từ 1995 | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
78 39 -

TOP câu hỏi trắc nghiệm Môn Lưu trữ và xử lý dữ liệu lớn | Đại học Bách Khoa Hà Nội
82 41 -

Đề trắc nghiệm BigData và đáp án| Môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
543 272