Xây dựng luồng dữ liệu lưu trữ, xử lý và phân tích giá bất động sản tại Anh từ 1995 | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
Đề tài “Xây dựng hệ thống lưu trữ, xử lý và phân tích dữ liệu bất động sản” tập trung vào hệ thống xử lý và phân tích theo lô dữ liệu bất động sản được cung cấp từ các nền tảng trực tuyến hoặc cơ sở dữ liệu bất động sản. Tài liệu được sưu tầm gồm 23 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Lưu trữ và xử lý dữ liệu lớn 27 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:














Preview text:
lOMoAR cPSD| 61548706
ĐẠI HỌC BÁCH KHOA HÀ NỘI
TRƯỜNG CÔNG NGHỆ THÔNG TIN VÀ TRUYỀN THÔNG
BÁO CÁO BÀI TẬP LỚN
Môn học: Lưu trữ và xử lý dữ liệu lớn Đề tài: Xây
dựng luồng dữ liệu lưu trữ, xử lý và phân tích giá bất
động sản tại Anh từ 1995
Giảng viên hướng dẫn: TS. Trần Thế Hùng Mã lớp: 154055 Nhóm: 1 Họ và tên MSSV Nguyễn Hoàng Vĩnh Phong 20210669 Nguyễn Đức Khoa 20210487 Nguyễn Huy Hoàng 20215581 Hà Thế Hiển 20215575 Hà Hữu Thắng 20194837 Nguyễn Tiến Lâm 20194313 Hà Nội, 12 – 2024 lOMoAR cPSD| 61548706 MỤC LỤC
MỤC LỤC ...................................................................................................................... 1
DANH MỤC HÌNH ẢNH .............................................................................................. 3
DANH MỤC BẢNG BIỂU ............................................................................................ 3
LỜI NÓI ĐẦU................................................................................................................ 4
Chương 1 – Giới thiệu đề tài .......................................................................................... 4
1.1 – Tổng quan đề tài ................................................................................................ 4
1.2 – Mô hình kiến trúc hệ thống ............................................................................... 5
1.3 – Các công nghệ sử dụng trong hệ thống ............................................................. 6
Chương 2 – Giới thiệu các công nghệ ............................................................................ 7
2.1 – Apache Hadoop ................................................................................................. 7
2.1.1 – Kiến trúc tổng quan .................................................................................... 7
2.2.2 – Kiến trúc HDFS .......................................................................................... 8
2.2 – Apache Spark ..................................................................................................... 9
2.3 – Apache Kafka .................................................................................................. 10
2.4 – Elasticseaarch và Kibana ................................................................................. 11
Chương 3 – Triển khai hệ thống ................................................................................... 13
3.1 – Triển khai cụm Hadoop Spark sử dụng Docker .............................................. 13
3.1.1 – Kiến trúc cụm HDFS ................................................................................ 13
3.1.2 – Kiến trúc cụm Spark ................................................................................. 13
3.2 – Thu thập và tiền xử lý dữ liệu ......................................................................... 14
3.2.1 – Thu thập dữ liệu từ Kaggle và API........................................................... 14
3.1.2 – Đưa dữ liệu lên HDFS .............................................................................. 15
3.3 – Xử lý dữ liệu theo từng năm và lưu trữ vào kho dữ liệu ................................. 17
3.3.1 – Quy trình xử lý và lưu trữ kho dữ liệu theo từng năm ............................. 17
3.4 – Phân tích dữ liệu và huấn luyện mô hình học máy ......................................... 18
3.4.1 – Phân tích dữ liệu ....................................................................................... 18
3.4.2 – Huấn luyện mô hình học máy .................................................................. 18
3.5 – Trực quan hóa kết quả ..................................................................................... 19 lOMoAR cPSD| 61548706
Chương 4 – Kết luận và hướng phát triển .................................................................... 22
4.1 – Kết luận ........................................................................................................... 22
4.2 – Hướng phát triển.................................................................................................. 22 lOMoAR cPSD| 61548706 DANH MỤC HÌNH ẢNH
Hình 1. Mô hình kiến trúc hệ thống..............................................................................7
Hình 2. Các công nghệ sử dụng....................................................................................8
Hình 3. Apache Hadoop................................................................................................9
Hình 4. Kiến trúc tổng quan của Hadoop......................................................................9
Hình 5. Kiến trúc tổng quan của Spark.......................................................................12
Hình 6. Kiến trúc cum HDFS......................................................................................15
Hình 7: Bảng so sánh thời gian giữa 1, 2 và 3 spark worker.......................................16
Hình 8: Lấy dữ liệu từ UK property............................................................................16
Hình 9: Data sau tiền xử lý..........................................................................................17
Hình 10: Dữ liệu thô lưu trữ trên HDFS......................................................................18
Hình 11: Đọc dữ liệu từ HDFS....................................................................................18
Hình 12: Xử lý các data đầu vào.................................................................................19
Hình 13: So sánh các model với nhau.........................................................................20
Hình 14: Giá trị trung bình theo năm..........................................................................21
Hình 15: Thống kê số giao dịch theo năm...................................................................21
Hình 16: Phân bố BĐS................................................................................................22
Hình 17: Phân tích loại hình BĐS...............................................................................22
DANH MỤC BẢNG BIỂU
Bảng 1. Danh sách trường dữ liệu...............................................................................15 lOMoAR cPSD| 61548706 LỜI NÓI ĐẦU
Trong thời đại số hóa, Big Data đang dẫn dắt cuộc cách mạng dữ liệu trên mọi lĩnh
vực, và giao thông công cộng không nằm ngoài xu hướng đó. Những khối lượng dữ liệu
khổng lồ từ thông tin hành khách, hành trình di chuyển, đến dữ liệu về tài xế và phương
tiện đang mang lại cơ hội to lớn cho các hãng xe công nghệ. Việc khai thác hiệu quả
nguồn dữ liệu này không chỉ giúp nâng cao trải nghiệm người dùng mà còn tối ưu hóa
vận hành, ra quyết định chiến lược, và hướng tới phát triển bền vững.
Bằng cách phân tích hành vi người dùng, lịch sử di chuyển, và phản hồi từ hành
khách, các hãng xe công nghệ có thể thiết kế những trải nghiệm dịch vụ vượt trội. Đồng
thời, việc tối ưu hóa lịch trình và quản lý tài nguyên sẽ không chỉ cải thiện hiệu suất vận
hành mà còn giảm thiểu tác động tiêu cực đến môi trường.
Trước bối cảnh đó, đề tài này tập trung vào việc xây dựng một hệ thống Big Data
tiên tiến, tận dụng các công nghệ hiện đại để phân tích dữ liệu giao thông công cộng
một cách sâu sắc và toàn diện. Hệ thống này không chỉ giải quyết các thách thức liên
quan đến xử lý dữ liệu lớn mà còn đảm bảo tính bảo mật và quyền riêng tư cho người dùng.
Báo cáo trình bày chi tiết các bước thiết kế và triển khai hệ thống, từ việc lựa chọn
công cụ, xây dựng kiến trúc hệ thống, đến các giải pháp khắc phục khó khăn trong quá
trình thực hiện. Mục tiêu của dự án là xây dựng một hệ thống tự động cập nhật, mang
tính thực tiễn cao, hỗ trợ các doanh nghiệp giao thông công cộng khai thác tối đa sức
mạnh của dữ liệu để phát triển bền vững và thông minh hơn.
Chương 1 – Giới thiệu đề tài
1.1 – Tổng quan đề tài
Đề tài “Xây dựng hệ thống lưu trữ, xử lý và phân tích dữ liệu bất động sản” tập trung
vào hệ thống xử lý và phân tích theo lô dữ liệu bất động sản được cung cấp từ các nền
tảng trực tuyến hoặc cơ sở dữ liệu bất động sản. Bằng cách tận dụng khả năng vượt trội
của các công nghệ Big Data, hệ thống sẽ sử dụng Hadoop Local và Docker để tối ưu
hóa việc lưu trữ và xử lý dữ liệu, giúp phân tích chi tiết các yếu tố ảnh hưởng đến giá
trị bất động sản, cung cấp cái nhìn sâu sắc về xu hướng giá trị bất động sản, nhu cầu và
cung cầu thị trường. Mục tiêu chính của dự án:
Nâng cao hiệu quả hoạt động: Phân tích dữ liệu giúp tối ưu hóa việc phân
phối bất động sản, dự đoán các xu hướng giá trị và nhu cầu, cải thiện hiệu suất
tổng thể của hệ thống thị trường bất động sản. lOMoAR cPSD| 61548706
Cải thiện trải nghiệm người dùng: Dự đoán nhu cầu và điều chỉnh các dịch
vụ bất động sản để đáp ứng tốt hơn nhu cầu của khách hàng, cá nhân hóa trải
nghiệm và tăng sự hài lòng.
Quy hoạch phát triển đô thị: Cung cấp thông tin chi tiết về mô hình phát triển
khu vực, các điểm nóng bất động sản và các vấn đề tiềm ẩn, hỗ trợ việc lập kế
hoạch và phát triển thị trường bất động sản hiệu quả.
Nghiên cứu phát triển dịch vụ mới: Xác định các cơ hội kinh doanh mới dựa
trên dữ liệu và xu hướng thị trường, tạo ra các dịch vụ bất động sản sáng tạo và
đáp ứng nhu cầu của người dùng.
1.2 – Mô hình kiến trúc hệ thống
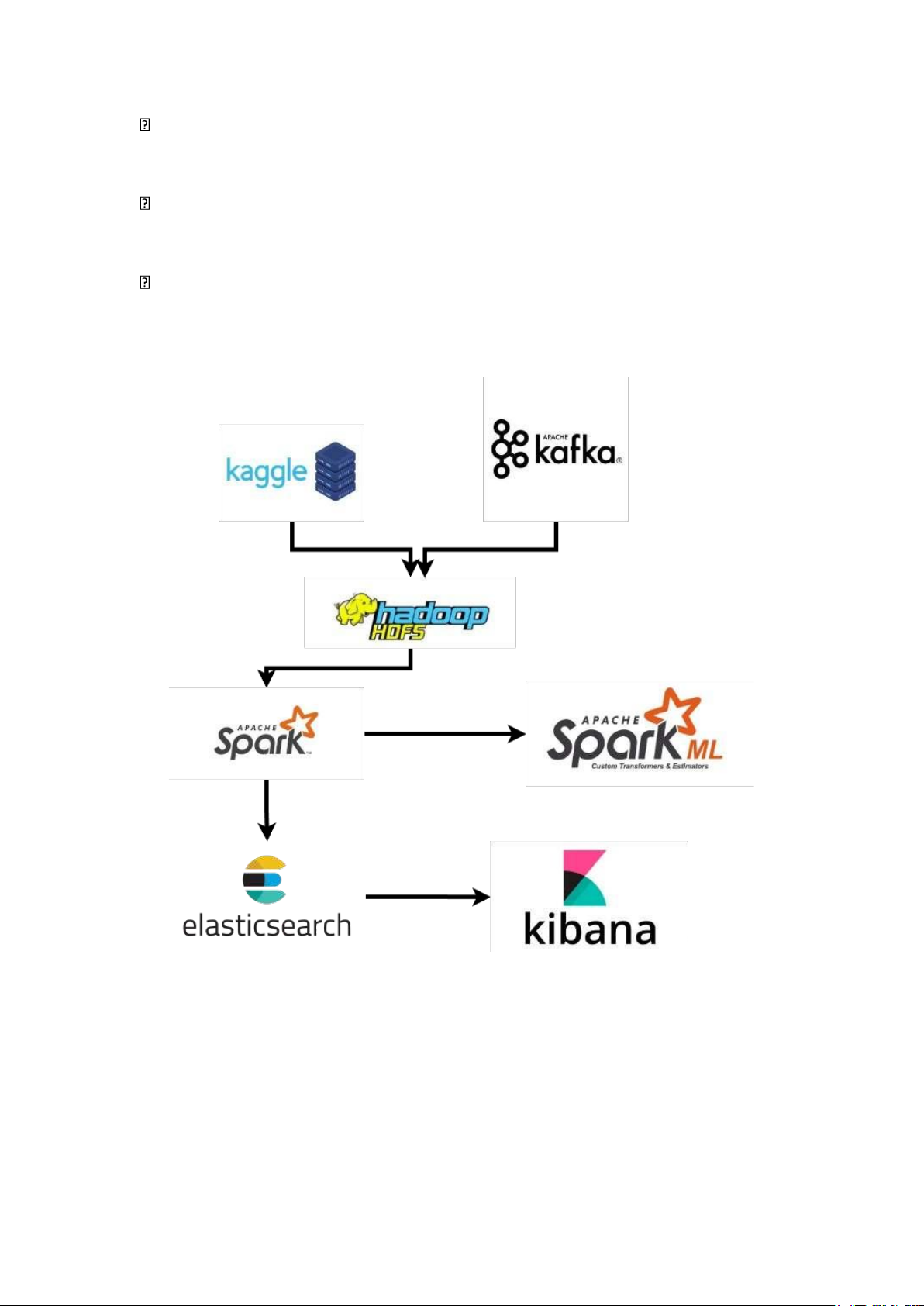
Hình 1. Mô hình kiến trúc hệ thống
Luồng hoạt động của hệ thống gồm các quy trình như sau:
- Thu thập và tiền xử lý dữ liệu: Hệ thống thu thập dữ liệu từ Kaggle, ngoài ra
còn sử dụng Kafka để lấy dữ liệu từ API. Dữ liệu sau đó được tiền xử lý và đẩy lên Hadoop HDFS. lOMoAR cPSD| 61548706
- Xử lý và lưu trữ vào kho dữ liệu: Cụm Hadoop sẽ thực hiện chạy các PySpark
Job để xử lý dữ liệu và lưu trữ vào Hadoop HDFS và elasticsearch.
- Phân tích dữ liệu và huấn luyện mô hình: Kho dữ liệu sau đó được sử dụng
nhằm phân tích và huấn luyện mô hình học máy sử dụng Spark và Spark
MLlib. Kết quả thu được được lưu vào HDFS.
- Trực quan hóa kết quả: Sử dụng Spark để xử lý và truy vấn dữ liệu, xong lưu
dữ liệu đã truy vấn và thực hiện trực quan hoá bằng Dash.
1.3 – Các công nghệ sử dụng trong hệ thống
Hình 2. Các công nghệ sử dụng
• HDFS (Hadoop Distributed File System): Là hệ thống lưu trữ phân tán mạnh
mẽ, HDFS giúp lưu trữ lượng dữ liệu lớn từ các nguồn bất động sản như danh
sách nhà đất, thông tin giao dịch, và các mô hình dự đoán giá trị. HDFS đảm
bảo tính mở rộng và khả năng chịu lỗi khi xử lý dữ liệu lớn.
• Kafka: Kafka là hệ thống quản lý luồng dữ liệu phân tán, giúp truyền tải dữ
liệu theo thời gian thực giữa các thành phần trong hệ thống. Với khả năng xử lý
dữ liệu liên tục, Kafka sẽ đóng vai trò quan trọng trong việc thu thập và phân
phối dữ liệu về các giao dịch bất động sản, cung cấp cái nhìn tức thời về biến động thị trường.
• Spark: Apache Spark là một framework xử lý dữ liệu lớn với khả năng tính
toán nhanh chóng và phân tán. Spark sẽ được sử dụng để xử lý và phân tích các
tập dữ liệu lớn trong hệ thống, từ việc xử lý các batch job đến việc phân tích dữ
liệu theo thời gian thực, đồng thời hỗ trợ các mô hình học máy để dự đoán giá trị bất động sản.
• Elasticsearch: Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu
mạnh mẽ, có khả năng xử lý các truy vấn phức tạp và phân tích dữ liệu theo
thời gian thực. Elasticsearch sẽ được sử dụng để xây dựng chỉ mục và truy vấn
dữ liệu bất động sản, giúp người dùng dễ dàng tìm kiếm các thông tin như giá
trị, vị trí, và đặc điểm của các bất động sản.
• Kibana: Kibana là một công cụ trực quan hóa dữ liệu được tích hợp với
Elasticsearch, giúp tạo các bảng điều khiển và báo cáo dễ hiểu về thị trường bất
động sản. Kibana sẽ cung cấp giao diện người dùng để trực quan hóa các thông
tin về xu hướng giá trị, các điểm nóng giao dịch, và các yếu tố ảnh hưởng đến
giá trị bất động sản, hỗ trợ các nhà quản lý và nhà đầu tư trong việc đưa ra quyết định. lOMoAR cPSD| 61548706
Chương 2 – Giới thiệu các công nghệ 2.1 – Apache Hadoop Hình 3. Apache Hadoop
Apache Hadoop là một framework mã nguồn mở được thiết kế với mục đích lưu trữ
và xử lý dữ liệu lớn trên các cụm máy tính phân tán. Hadoop cung cấp khả năng xử lý
dữ liệu song song, linh hoạt và hiệu quả, thường được sử dụng trong các ứng dụng Big Data.
Hadoop được phát triển bởi Apache Software Foundation và được xây dựng với mục
tiêu mở rộng quy mô từ một máy chủ duy nhất lên đến hàng nghìn máy chủ, mỗi máy
đều có khả năng xử lý và lưu trữ dữ liệu độc lập.
2.1.1 – Kiến trúc tổng quan
HDFS sử dụng kiến trúc Master/Slave – là một mô hình giao tiếp bất đối xứng
trong đó một hoặc một vài thiết bị hoặc tiến trình (Master) đóng vai trò là trung tâm
giao tiếp, điều khiển một hoặc nhiều thiết bị hoặc tiến trình khác (Slave).
Hình 4. Kiến trúc tổng quan của Hadoop
Các thành phần chính của Apache Hadoop:
- Hadoop HDFS: Thành phần lưu trữ file phân tán cung cấp khả năng lưu trữ dữ
liệu khổng lồ và tính năng tối ưu hóa việc sử dụng băng thông giữa các node. lOMoAR cPSD| 61548706
HDFS có thể được sử dụng để chạy trên một cluster lớn với hàng chục ngàn node.
- Hadoop YARN: Thành phần đóng vai trò quản lý và giám sát các node trong cụm
Hadoop với 2 chức năng cơ bản là quản lý tài nguyên và theo dõi, lập lịch công
việc cho từng node trong cụm. YARN cho phép các công cụ xử lý dữ liệu khác
nhau như xử lý tương tác, xử lý đồ thị, xử lý hàng loạt và xử lý luồng chạy và
xử lý dữ liệu được lưu trữ trong HDFS. Khi có các tác vụ hoặc chương trình khác
nhau chạy trên cụm, YARN sẽ quyết định lượng tài nguyên của cụm (như CPU
và bộ nhớ) mà mỗi tác vụ có thể sử dụng nhằm đảm bảo rằng tất cả các tác vụ
chạy trơn tru mà không tranh giành tài nguyên.
- Hadoop MapReduce & Other Application: Thuộc tầng xử lý dữ liệu trong hệ
thống Hadoop, dựa trên YARN để xử lý song song các tập dữ liệu lớn.
o MapReduce: hoạt động bằng cách chia dữ liệu đầu vào thành các đoạn và
phân phối chúng trên các máy khác nhau . Các đoạn đầu vào bao gồm các
cặp khóa-giá trị. Các tác vụ ánh xạ song song xử lý dữ liệu được chia nhỏ
trên các máy trong một cụm. Đầu ra ánh xạ sau đó đóng vai trò là đầu vào
cho giai đoạn giảm. Tác vụ giảm kết hợp kết quả thành một cặp khóa-giá
trị đầu ra cụ thể và ghi dữ liệu vào HDFS.
2.2.2 – Kiến trúc HDFS
HDFS sử dụng kiến trúc Master/Slave, bao gồm NameNode (đóng vai trò Master) và các DataNode (Slave).
- NameNode: Quản lý không gian tên của hệ thống tệp. Nó có vai trò duy trì cấu
trúc cây của hệ thống tệp và metadata của tất cả các tệp, thư mục (thông tin này
được lưu trữ trên ổ đĩa cục bộ dưới dạng namespace image và các edit log).
- DataNode: Là các node thực hiện công việc và lưu trữ chính của hệ thống. Các
node này lưu trữ và truy xuất block mỗi khi có yêu cầu từ NameNode đồng thời
định kỳ báo cáo cho NameNode về danh sách các block đang lưu trữ.
- Secondary NameNode: Hỗ trợ NameNode bằng cách hợp nhất namespace
image và edit logs định kỳ, giúp giảm tải và hỗ trợ khôi phục trạng thái khi cần.
HDFS lưu trữ dữ liệu theo các block với kích thước mặc định là 128MB. Không
giống như hệ thống tệp trên ổ đĩa đơn, một tệp trong HDFS nhỏ hơn một block không
chiếm toàn bộ dung lượng lưu trữ tương ứng của block. Việc sử dụng block trong hệ
thống tệp phân tán mang lại nhiều lợi ích:
- Một tệp có thể lớn hơn bất kỳ ổ đĩa nào trong cụm.
- Việc sử dụng block làm đơn vị trừu tượng thay vì tệp giúp đơn giản hóa hệ thống lưu trữ. lOMoAR cPSD| 61548706
- Block rất phù hợp với việc sao chép để cung cấp khả năng chịu lỗi và đảm bảo
tính sẵn sàng. Để tránh rủi ro do block gặp lỗi, mỗi block được sao chép sang
một số lượng các máy tách biệt trong cụm (thông thường là 3 máy).
- Một bản trên cùng node, một trên node khác cùng rack, và bản thứ ba trên node
thuộc rack khác để tối ưu hóa băng thông và giảm nguy cơ mất dữ liệu.
- Heartbeat và Block Report: DataNode gửi heartbeat để NameNode xác nhận
trạng thái hoạt động; block report cung cấp thông tin về block lưu trữ.
- Rack Awareness: Tận dụng thông tin vị trí rack để sao chép và lưu trữ dữ liệu
hiệu quả, giảm độ trễ và tăng thông lượng.
- High Availability (HA): NameNode kép (Active và Standby) đồng bộ qua
journal node, đảm bảo tính liên tục khi xảy ra lỗi.
- Data Integrity: Sử dụng checksum để phát hiện và xử lý lỗi dữ liệu.
- Scalability: Dễ dàng mở rộng bằng cách thêm DataNode mà không cần dừng hệ thống. 2.2 – Apache Spark
Apache Spark là một công cụ phân tích phân tán mã nguồn mở để xử lý dữ liệu với
khối lượng lớn, được phát triển sơ khởi vào năm 2009 bởi AMPLab. Sau này, Spark đã
được trao cho Apache Software Foundation vào năm 2013 và được phát triển cho đến
nay. Tốc độ xử lý Apache Spark là một hệ thống xử lý dữ liệu phân tán mã nguồn mở,
nổi bật với khả năng xử lý dữ liệu nhanh chóng và hiệu quả nhờ vào cơ chế tính toán
phân tán và sử dụng bộ nhớ (in-memory computing). Spark được thiết kế để xử lý dữ
liệu lớn, giúp giảm thời gian tính toán so với các công nghệ truyền thống như Hadoop
MapReduce. Ngoài ra, Spark hỗ trợ cả xử lý dữ liệu theo lô (batch processing) và dữ
liệu theo thời gian thực thông qua Spark Streaming, mang lại sự linh hoạt cho các ứng
dụng yêu cầu phân tích dữ liệu ngay lập tức.
Spark cung cấp các API mạnh mẽ cho nhiều ngôn ngữ lập trình như Scala, Python,
Java và R, giúp các nhà phát triển xây dựng và triển khai các ứng dụng phân tích dữ liệu
phức tạp. Với khả năng tương thích cao, Spark dễ dàng tích hợp với các công nghệ Big
Data khác như Hadoop HDFS, Hive, và Cassandra, tạo ra một hệ sinh thái linh hoạt và
mạnh mẽ cho việc xử lý và phân tích dữ liệu lớn. lOMoAR cPSD| 61548706
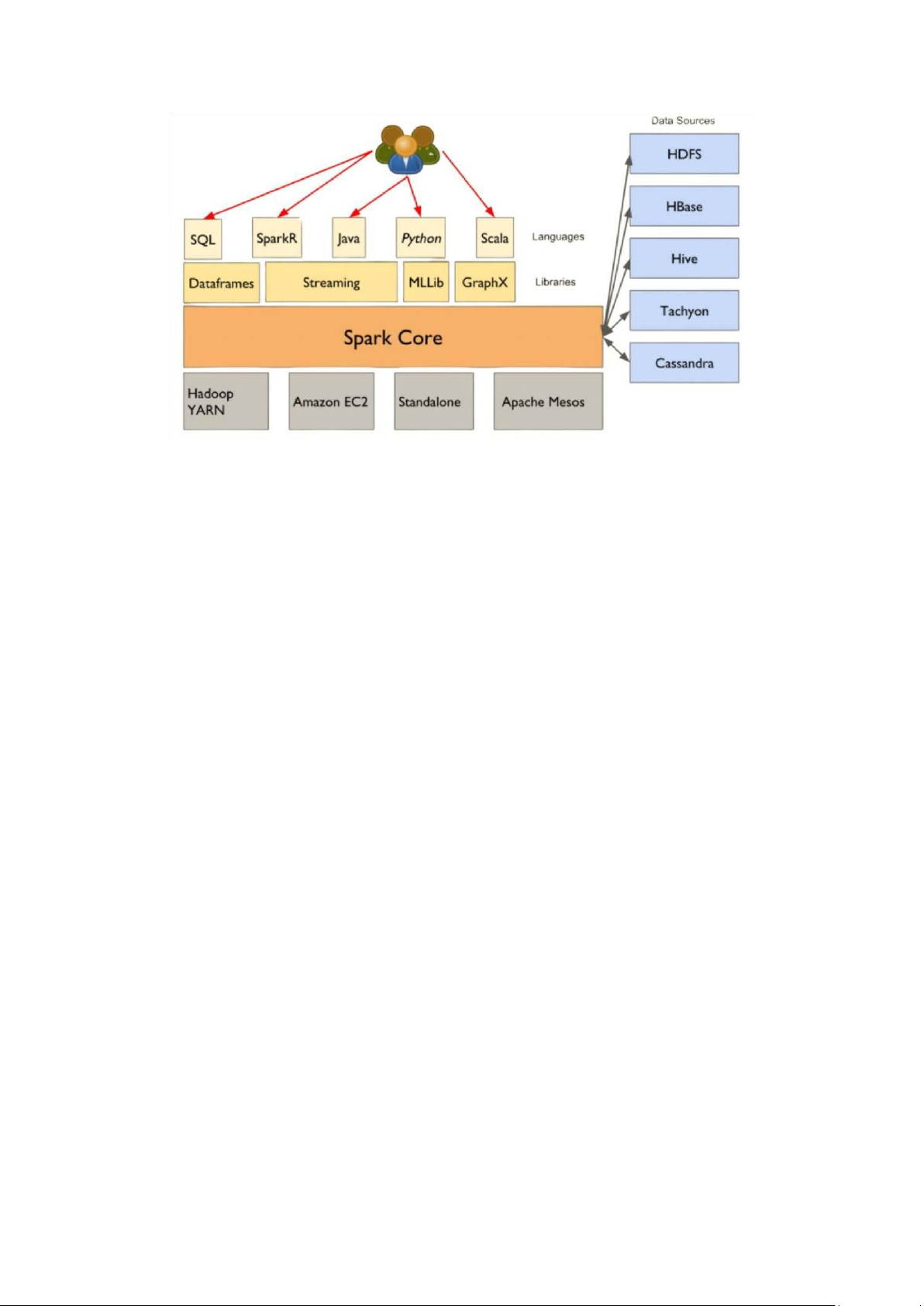
Hình 5. Kiến trúc tổng quan của Spark
Ngoài các tính năng xử lý dữ liệu thông thường, Spark còn hỗ trợ các thư viện cho
học máy (MLlib) và xử lý đồ thị (GraphX), giúp các nhà khoa học dữ liệu xây dựng và
triển khai các mô hình học máy phức tạp. Với khả năng mở rộng từ một máy tính đơn
lẻ đến hàng nghìn máy trong một cluster, Apache Spark là công cụ lý tưởng cho các ứng
dụng yêu cầu xử lý và phân tích dữ liệu lớn, từ phân tích web logs, dự đoán thị trường
đến phân tích cảm biến trong các hệ thống IoT. 2.3 – Apache Kafka
Apache Kafka là một nền tảng xử lý luồng sự kiện phân tán, được thiết kế để xử
lý dữ liệu theo thời gian thực với khả năng mở rộng cao và độ tin cậy. Kafka ban đầu
được phát triển bởi LinkedIn và hiện tại là một dự án mã nguồn mở được quản lý bởi
Apache Software Foundation. Kafka hoạt động như một hệ thống trung gian, cho phép
các ứng dụng sản xuất (producer) gửi dữ liệu và các ứng dụng tiêu thụ (consumer)
nhận dữ liệu một cách hiệu quả.
Kafka tổ chức dữ liệu thành các topic, trong đó mỗi topic là một luồng dữ liệu
được chia nhỏ thành các partition để hỗ trợ xử lý song song. Các producer gửi dữ liệu
đến topic, và dữ liệu này được lưu trữ trên các broker trong cụm Kafka. Các consumer
có thể đăng ký để nhận dữ liệu từ các topic theo cơ chế pub-sub (publish-subscribe)
hoặc qua các nhóm tiêu thụ (consumer groups). Cơ chế lưu trữ theo partition và khả
năng sao chép dữ liệu giúp Kafka đảm bảo hiệu năng cao và tính sẵn sàng ngay cả khi
một node trong cụm bị lỗi.
Kafka nổi bật với khả năng lưu trữ lâu dài nhờ sử dụng cơ chế log. Dữ liệu trong
Kafka được lưu trữ theo thời gian cấu hình, cho phép các consumer xử lý lại từ bất kỳ
thời điểm nào. Điều này làm cho Kafka không chỉ phù hợp với các hệ thống xử lý dữ lOMoAR cPSD| 61548706
liệu theo thời gian thực mà còn là một lựa chọn tốt cho các ứng dụng xử lý dữ liệu phân
tán, như ETL, truyền tải dữ liệu giữa các hệ thống, hoặc lưu trữ tạm trước khi gửi đến kho dữ liệu.
Với kiến trúc linh hoạt và mạnh mẽ, Kafka được sử dụng rộng rãi trong nhiều lĩnh
vực, từ các hệ thống giám sát, phân tích log, xử lý dữ liệu IoT đến các ứng dụng tài
chính yêu cầu xử lý dữ liệu theo thời gian thực. Hệ sinh thái Kafka bao gồm các thành
phần như Kafka Connect (kết nối với các nguồn dữ liệu bên ngoài) và Kafka
Streams (xử lý luồng dữ liệu ngay trong Kafka), mở rộng khả năng tích hợp và xử lý
dữ liệu trong toàn bộ hệ thống.
2.4 – Elasticseaarch và Kibana
Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu mạnh mẽ, được thiết
kế để xử lý các truy vấn phức tạp và phân tích dữ liệu theo thời gian thực.
Elasticsearch sử dụng một cấu trúc dữ liệu gọi là inverted index để cho phép tìm kiếm
nhanh chóng trên các dữ liệu văn bản, làm cho nó trở thành công cụ lý tưởng cho các
ứng dụng yêu cầu tìm kiếm và phân tích trên lượng dữ liệu lớn. Elasticsearch có thể
xử lý và phân tích các loại dữ liệu khác nhau, bao gồm văn bản, log, số liệu thống kê
và dữ liệu cấu trúc, đồng thời hỗ trợ các tính năng như full-text search, phân tích truy
vấn, và tính toán các chỉ số thống kê.
Elasticsearch được xây dựng trên nền tảng phân tán, cho phép mở rộng dễ dàng và
có khả năng chịu lỗi cao, giúp người dùng có thể triển khai một cluster
Elasticsearch để xử lý dữ liệu lớn một cách hiệu quả. Bằng cách tạo chỉ mục cho dữ
liệu, Elasticsearch giúp cải thiện tốc độ truy vấn và tìm kiếm, đồng thời hỗ trợ các tính
năng phân tích nâng cao như lọc, nhóm, và thống kê. Elasticsearch rất hữu ích trong
các trường hợp như phân tích log, giám sát hệ thống, và tìm kiếm trên các ứng dụng dữ liệu lớn.
Kibana, công cụ trực quan hóa dữ liệu được phát triển cùng với Elasticsearch,
cho phép người dùng trực quan hóa và phân tích dữ liệu được lưu trữ trong
Elasticsearch một cách dễ dàng. Kibana cung cấp giao diện người dùng trực quan, cho
phép tạo các dashboard tương tác, biểu đồ, và báo cáo từ dữ liệu Elasticsearch, giúp
người dùng dễ dàng theo dõi các chỉ số quan trọng và xu hướng trong thời gian thực.
Kibana hỗ trợ nhiều loại biểu đồ khác nhau như biểu đồ cột, đường, pie chart, và bản
đồ nhiệt, giúp người dùng nhìn thấy dữ liệu dưới các góc độ khác nhau và đưa ra các quyết định kịp thời.
Cùng với Elasticsearch, Kibana tạo thành một hệ sinh thái mạnh mẽ cho việc tìm
kiếm, phân tích, và trực quan hóa dữ liệu. Kibana giúp khai thác tối đa sức mạnh của
Elasticsearch, cung cấp các công cụ trực quan và dễ sử dụng cho các nhà phân tích dữ
liệu, giúp họ nhanh chóng phát hiện ra các vấn đề tiềm ẩn và tối ưu hóa các quy trình lOMoAR cPSD| 61548706
kinh doanh. Cặp đôi này được sử dụng rộng rãi trong các ứng dụng như phân tích log,
giám sát hệ thống, và phân tích dữ liệu lớn. lOMoAR cPSD| 61548706
Chương 3 – Triển khai hệ thống
3.1 – Triển khai cụm Hadoop Spark sử dụng Docker
3.1.1 – Kiến trúc cụm HDFS
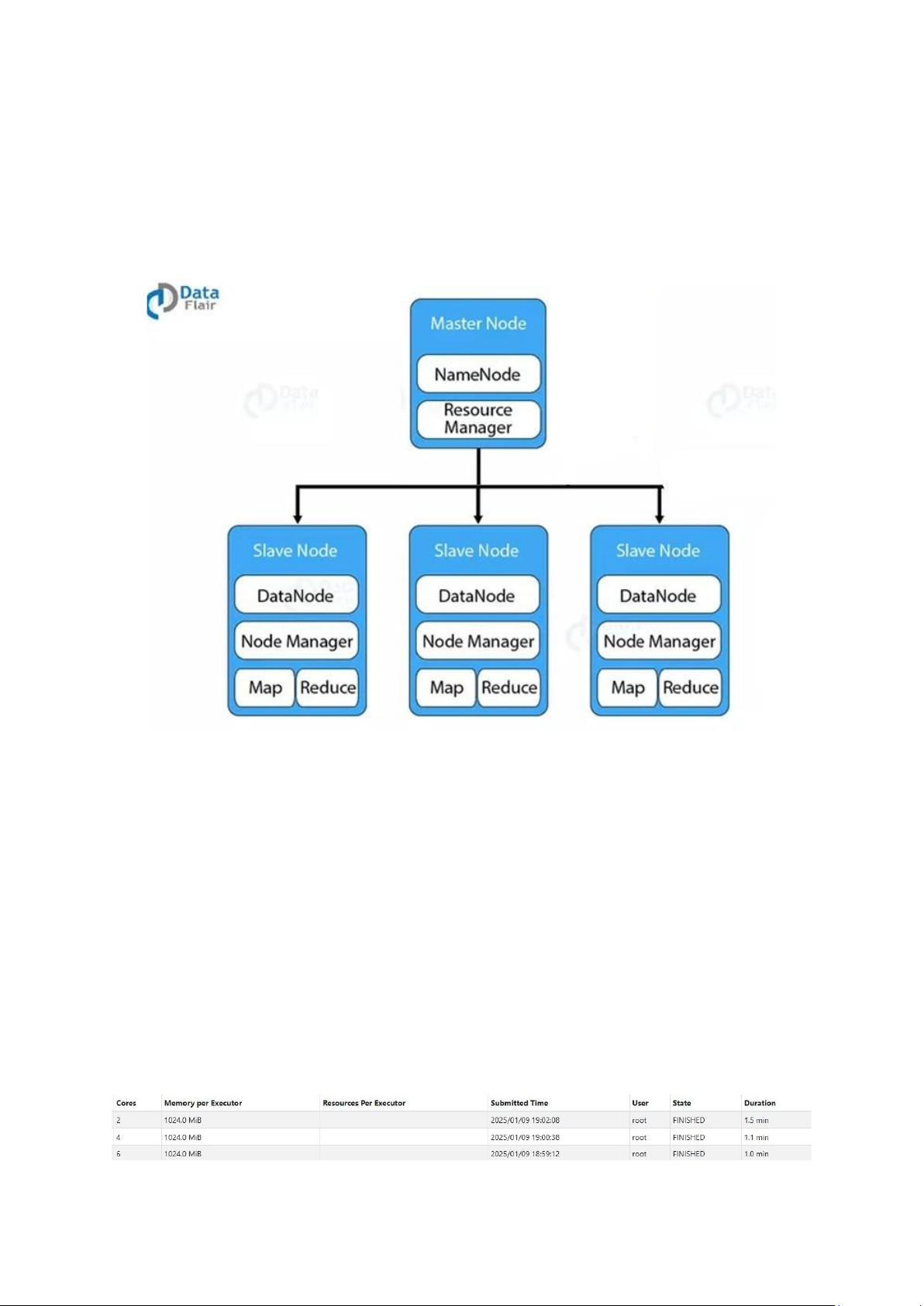
Hình 6. Kiến trúc cum HDFS
Cụm HDFS triển khai bằng Docker sử dụng 1 container đóng vai trò NameNode và
3 container đóng vai trò DataNode. Mỗi container được cấu hình như một node trong
hệ thống, giao tiếp với nhau thông qua mạng Docker, trong đó:
• . NameNode: Container NameNode chịu trách nhiệm quản lý không gian tên
(namespace) của hệ thống tệp, duy trì metadata về tệp và thư mục trong HDFS. Nó
lưu trữ thông tin như cấu trúc thư mục, các block thuộc về tệp nào và vị trí của
block trên DataNode. Container trên được sử dụng ở port 8020.
• DataNode: Ba container DataNode chịu trách nhiệm lưu trữ dữ liệu thực tế dưới
dạng các block. Chúng định kỳ gửi heartbeat và báo cáo danh sách block về
NameNode để đảm bảo NameNode có thông tin cập nhật về trạng thái cụm. Ba
container trên lần lượt được sử dụng ở port 9864, 9865 và 9866.
3.1.2 – Kiến trúc cụm Spark
Hình 7: Bảng so sánh thời gian giữa 1, 2 và 3 spark worker lOMoAR cPSD| 61548706
Trong kiến trúc trên, Spark với 3 worker node là một hệ thống bao gồm master
node chịu trách nhiệm quản lý tài nguyên và điều phối công việc, cùng ba worker node
thực hiện xử lý dữ liệu thực tế. Worker node nhận các nhiệm vụ từ master, chia nhỏ dữ
liệu thành các phần (partition) và xử lý chúng song song trên các tài nguyên tính toán sẵn có.
3.2 – Thu thập và tiền xử lý dữ liệu
3.2.1 – Thu thập dữ liệu từ Kaggle và API
Hình 8: Lấy dữ liệu từ UK property
Dữ liệu về UK Property Price official data 1995-202304 được lấy từ website
Kaggle, ngoài ra còn sử dụng API để lấy dữ liệu và lưu trữ dưới dạng các file csv.
Để đảm bảo dữ liệu thỏa mãn cho việc xử lý và phân tích về sau, mỗi file tải xuống
sẽ được tiền xử lý loại bỏ các hàng chứa giá trị không phù hợp và đưa các trường dữ
liệu về đúng kiểu dữ liệu. Danh sách các trường dữ liệu sau quá trình tiền xử lý: Trường Mô tả
Transaction_unique_identifier Mã của dữ liệu trao đổi price Giá bất động sản Date Thời gian tạo bản ghi postcode
Postcode của thành phố/ county Property_Type Loại tài sản Old/New Tài sản cũ/mới Duration Thời hạn sở hữu PAON Thông tin chính SAON Thông tin phụ Locality Địa phương County
Đơn vị tương tự bé hơn thành phố PPDCategory_Type Loại giao dịch
Bảng 1. Danh sách trường dữ liệu
Dưới đây là mô tả chi tiết các trường dữ liệu:
• Transaction_unique_identifier: Mã định danh duy nhất cho mỗi giao dịch. lOMoAR cPSD| 61548706
Đây là một mã duy nhất giúp phân biệt từng giao dịch trong dataset.
• price: Giá trị giao dịch (thường là giá mua bán bất động sản), đơn vị có thể là
tiền tệ như GBP (Bảng Anh) hoặc một loại tiền tệ khác.
• Date_of_Transfer: Ngày thực hiện giao dịch mua bán bất động sản.
• postcode: Mã bưu điện của khu vực nơi bất động sản được giao dịch.
• Property_Type: Loại hình bất động sản, ví dụ: o D: Detached (Nhà riêng
lẻ). o S: Semi-detached (Nhà liền kề một bên).
o T: Terraced (Nhà phố). o F: Flats/Maisonettes (Căn hộ/chung cư). o O: Other (Khác).
• Old/New: Trạng thái bất động sản: o Y: New (Bất động sản mới xây).
o N: Old (Bất động sản cũ).
• Duration: Loại hình sở hữu bất động sản: o F: Freehold (Quyền sở hữu lâu
dài). o L: Leasehold (Quyền thuê dài hạn).
• PAON (Primary Addressable Object Name): Phần chính của địa chỉ, thường
là số nhà hoặc tên công trình (ví dụ: "10" hoặc "Sunset Villa").
• SAON (Secondary Addressable Object Name): Phần phụ của địa chỉ, ví dụ:
số tầng hoặc tên căn hộ (nếu có).
• Street: Tên đường nơi bất động sản tọa lạc.
• Locality: Tên khu vực hoặc làng/xóm (nếu có).
• Town/City: Tên thị trấn hoặc thành phố.
• District: Tên quận hoặc khu vực hành chính nhỏ hơn cấp tỉnh.
• County: Tên hạt hoặc tỉnh (trong bối cảnh Vương quốc Anh).
• PPDCategory_Type (Price Paid Data Category Type): Phân loại giao dịch: o
A: Giao dịch trong đó có chi tiết giá mua bán đầy đủ.
o B: Giao dịch mà giá không được tiết lộ công khai (ví dụ: tài sản thừa
kế, quyền sở hữu chung).
• Record_Status - monthly_file_only: Trạng thái bản ghi (chỉ có trong file hàng tháng):
o A: Bản ghi thêm mới. o C: Bản ghi bị chỉnh sửa. o D: Bản ghi bị xóa.
3.1.3 – Đưa dữ liệu lên HDFS
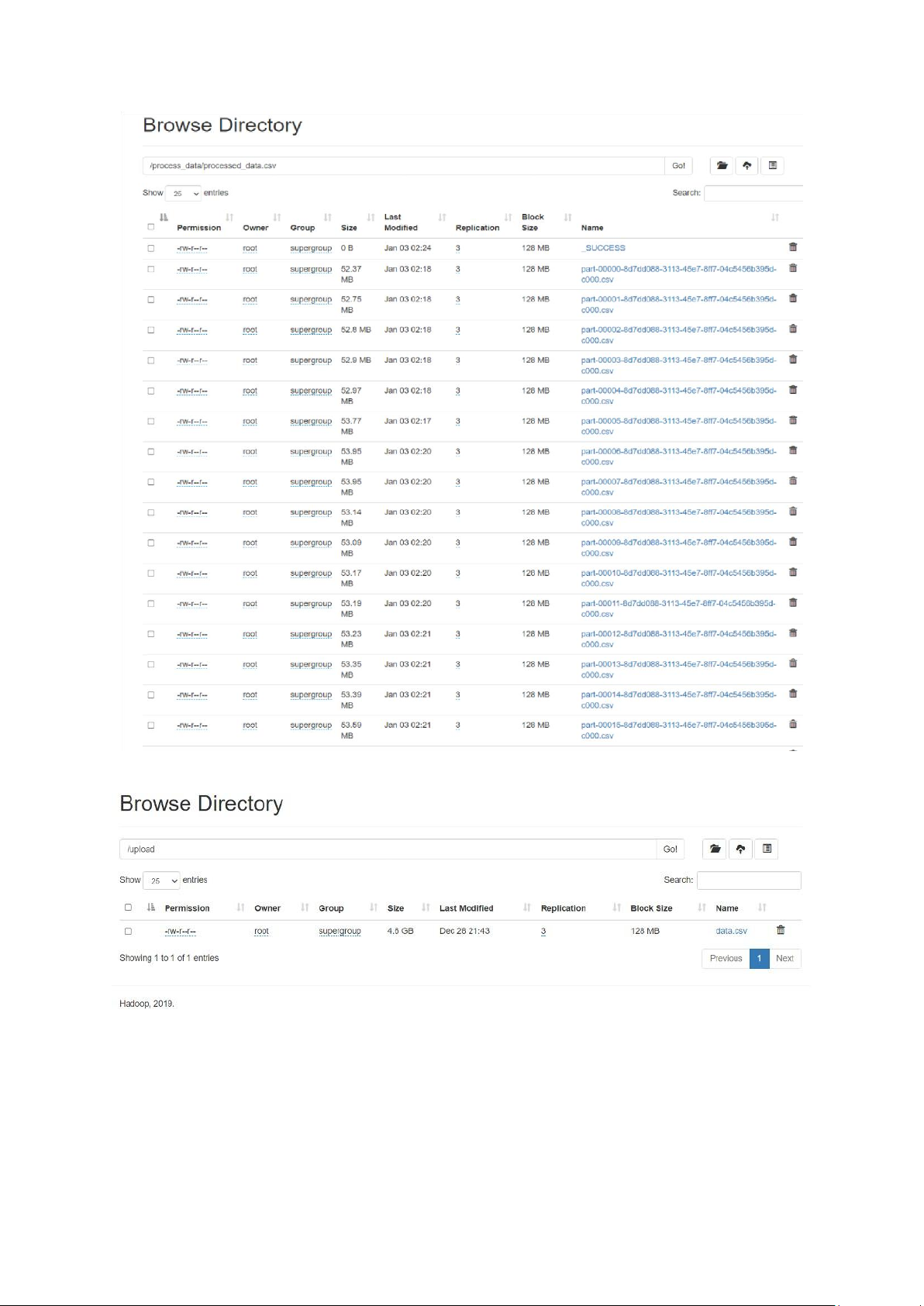
Sau khi tiền xử lý, các file parquet được tải lên HDFS thông qua các script python
được cài sẵn. Các file sau khi xử lý sẽ chia thành các block và lưu qua các datanode
của hdfs để được xử lý sau này. lOMoAR cPSD| 61548706
Hình 9: Data sau tiền xử lý
Hình 10: Dữ liệu thô lưu trữ trên HDFS lOMoAR cPSD| 61548706
3.3 – Xử lý dữ liệu theo từng năm và lưu trữ vào kho dữ liệu
3.3.1 – Quy trình xử lý và lưu trữ kho dữ liệu theo từng năm
Với việc lưu trữ trước dữ liệu thô theo từng năm, để lấy dữ liệu ra xử lý ta sẽ chỉ
cần sử dụng hàm spark.read() với format(“csv”) và load vào đường dẫn của thư mục
với năm tương ứng. Để phục vụ cho tổng hợp dữ liệu (sử dụng SUM, …), bảng fact sẽ
có thêm trường trip_id có tác dụng phân biệt giữa các hàng:
Hình 11: Đọc dữ liệu từ HDFS
Hình 12: Xử lý các data đầu vào
Rút gọn các data bằng cách thay đổi các dữ liệu từ xâu sang số, loại bỏ một số cột
không cần thiết cũng như là xử lý các thông tin bị thiếu. Ngoài ra, cần phải map các dữ
liệu từ dạng xâu sang số để có thể giảm thiểu dung lượng lưu trữ và xử lý dữ liệu sau này. lOMoAR cPSD| 61548706
Sau khi xử lý, dữ liệu sẽ được lưu vào HDFS với thư mục tương ứng để dễ dàng truy
cập khi cần thiết. Ngoài ra, dữ liệu sau xử lý còn được lưu trữ trong elasticsearch để về
sau có thể sử dụng để có thể truy vấn các dữ liệu một cách dễ dàng hơn, phù hợp cho
việc trực quan hoá và phân tích dữ liệu.
3.4 – Phân tích dữ liệu và huấn luyện mô hình học máy
3.4.1 – Phân tích dữ liệu
Nhằm phục vụ phân tích hành vi người dùng, xu hướng sử dụng dịch vụ bất động
sản, ta thực hiện tổng hợp phân tích các dữ liệu sau sử dụng Spark:
Số liệu tổng hợp trong 10 năm:
o Trung bình giá bất động sản qua các năm
o Xu hướng gia tang bất động sản theo loại bất động sản, thời hạn sở hữu, … Số liệu chi tiết:
o Tổng số bản ghi, tổng giá bất động sản
o Thống kê số bất động sản theo địa điểm qua bản đồ nhiệt.
3.4.2 – Huấn luyện mô hình học máy
Feature Selection: Với số lượng trường dữ liệu lớn của kho dữ liệu, đầu tiên ta cần
chạy chọn các feature để từ đó chọn ra các trường có ảnh hưởng đến giá trị bất
động sản (price). Ngoài ra còn có thể sử dụng thuật toán PCA (Principal
Component Analysis) để xác định được tầm ảnh hưởng của từng feature so với giá
trị trên. Sau khi chạy các thuật toán để đánh giá sự ảnh hưởng của các feature đến
Price, nhóm đã chọn được 4 feature có ảnh hưởng lớn nhất để đưa vào mô hình
học máy, đó là 'Property_Type', 'Old/New', 'Duration', 'PPDCategory_Type'
Huấn luyện mô hình học máy dự đoán tổng số tiền: Để có cái nhìn toàn diện để
đánh giá và lựa chọn mô hình phù hợp để sử dụng, ta sẽ thực hiện huấn luyện mô
hình Linear Regression, Random Forest cũng như là thuật toán Decision Tree.
Trong bài tập này, nhóm sẽ sử dụng các tiêu chuẩn đánh giá khá phổ biến cho bài
toán hồi quy (regression) như là MSE (Mean Square Error), MAE (Mean Absolute
Error) cũng như là Accuracy và F1 Score.
Hình 13: So sánh các model với nhau lOMoAR cPSD| 61548706
Như vậy, trong bảng trên, thuật toán Random Forest sẽ đưa ra kết quả tốt nhất với độ
chính xác gần 84% còn Linear Regression sẽ cho ra kết quả tệ nhất. Các tham số MAE
và MSE cũng có đưa ra được cái nhìn chuẩn về độ chính xác của các mô hình nói trên.
3.5 – Trực quan hóa kết quả
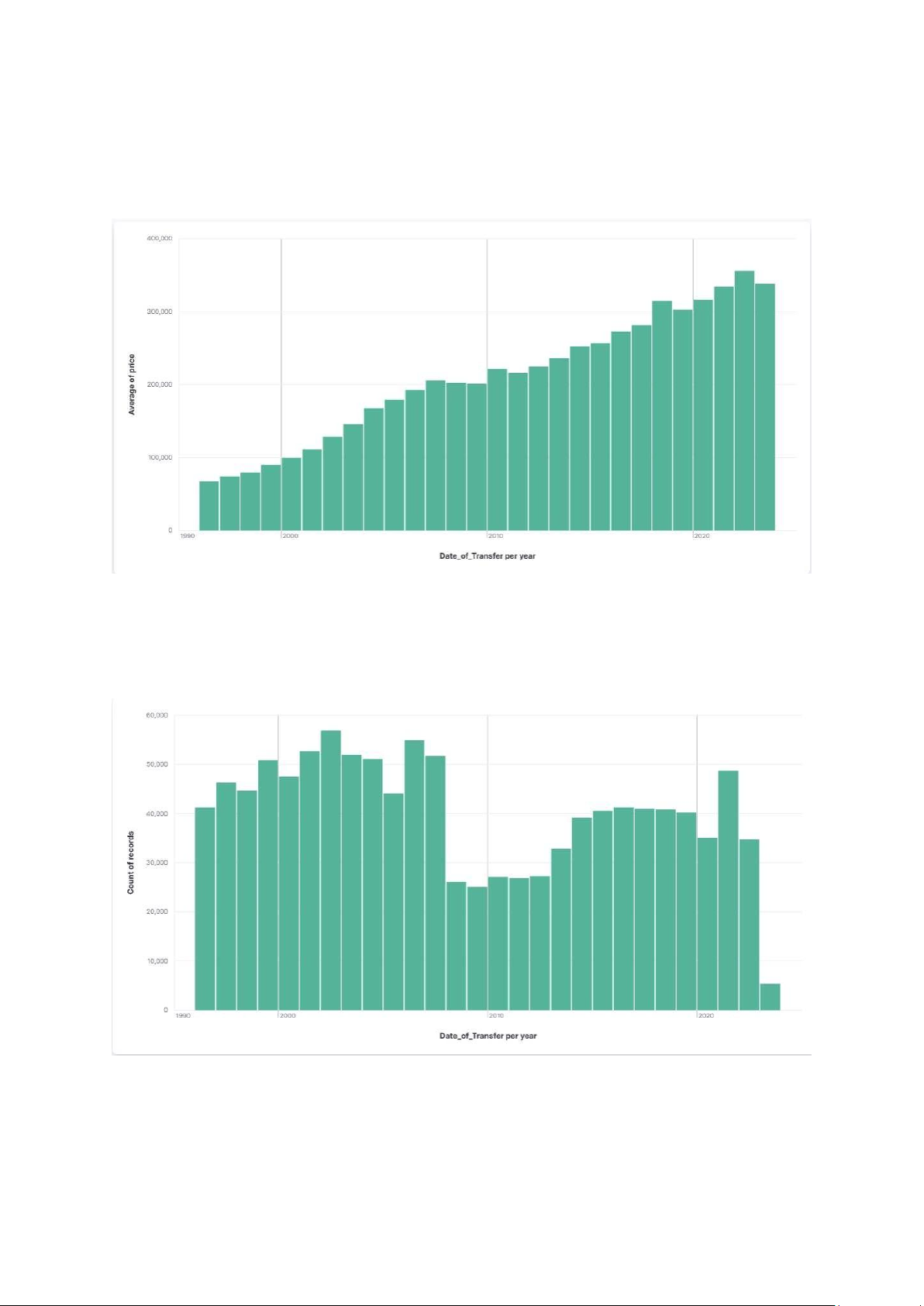
Hình 14: Giá trị trung bình theo năm
• Giá trị trung bình bất động sản đã tăng đều đặn qua các năm từ 1996 đến 2004.
• Xu hướng tăng giá này có thể được lý giải bởi nhu cầu tăng trưởng về nhà ở và
sự tăng trưởng kinh tế trong giai đoạn này.
Hình 15: Thống kê số giao dịch theo năm
• Số lượng giao dịch cũng tăng lên từ 1996 đến 2002, sau đó giữ ổn định ở mức
cao trong hai năm 2003 và 2004.
Tài liệu liên quan:
-

Báo cáo Bài Tập Lớn: Phân Tích Dữ Liệu Thời Tiết | Lưu trữ và xử lý dữ liệu | Trường Đại học Bách Khoa
82 41 -

TOP câu hỏi trắc nghiệm Môn Lưu trữ và xử lý dữ liệu lớn | Đại học Bách Khoa Hà Nội
83 42 -

Lưu trữ và xử lý, phân tích dữ liệu phim | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
70 35 -

Đề trắc nghiệm BigData và đáp án| Môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
543 272