Phân Loại Hoa Iris Bằng Thuật Toán Cây Quyết Định | Bài thảo luận Lập trình Python
Những năm gần đây, AI nổi lên như một bằng chứng của cuộc cách mạng công nghiệp lần thứ tư. Trí tuệ nhân tạo có thể được định nghĩa như một nghành của khoa học máy tính liên quan đến việc tự động hóa các hành vi thông minh. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời đọc đón xem!
Môn: Lập trình Python 29 tài liệu
Trường: Trường Đại học Thương Mại 3 K tài liệu
Tác giả:
















Preview text:
lOMoAR cPSD| 45470368
BỘ GIÁO DỤC VÀ ĐÀO TẠO
TRƯỜNG ĐẠI HỌC THƯƠNG MẠI
KHOA HỆ THỐNG THÔNG TIN KINH TẾ VÀ THƯƠNG MẠI ĐIỆN TỬ
BÁO CÁO THẢO LUẬN
HỌC PHẦN: LẬP TRÌNH VỚI PYTHON ĐỀ TÀI :
BÀI TOÁN PHÂN LOẠI HOA IRIS
DỰA VÀO THUẬT TOÁN CÂY QUYẾT ĐỊNH
Giảng viên hướng dẫn: ThS. Đỗ Thị Thanh Tâm
Nhóm thực hiện: Nhóm 5
Lớp học phần: 231_INFO4511_01
Hà Nội, ngày 28 tháng 11 năm 2023 lOMoAR cPSD| 45470368
DANH SÁCH THÀNH VIÊN NHÓM 5 STT Họ và tên MSV Nhiệm vụ Đánh giá Điểm
Nguyễn Thị Nhung Huyền 23D190020 Lý thuyết Hoàn thành tốt (Nhóm trưởng) nhiệm vụ. Tích cây quyết cực tham gia xây dịnh dựng bài thảo 1 Viết code, luận. mô tả bài toán Triệu Phúc Hương 23D190021 Lý thuyết Hoàn thành tốt Machine nhiệm vụ. Tích Learning cực tham gia xây 2 và thuyết dựng bài thảo trình luận. Nguyễn Trung Kiên Mô tả dữ Hoàn thành tốt
liệu Iris và nhiệm vụ. Tích thuyết cực tham gia xây 3 23D190022 trình dựng bài thảo luận. Lê Thị Lan 23D190023 Làm file Hoàn thành tốt báo cáo nhiệm vụ. Tích word cực tham gia xây 4 dựng bài thảo luận. Đinh Thị Mai Linh 23D190024 Làm Hoàn thành tốt
powerpoint nhiệm vụ. Tích cực tham gia xây 5 dựng bài thảo luận. 2 lOMoAR cPSD| 45470368
CỘNG HÒA XÃ HỘI CHỦ NGHĨA VIỆT NAM
Độc lập-Tự do-Hạnh phúc
Hà Nội, ngày 18 tháng 11 năm 2023
BIÊN BẢN HỌP NHÓM (LẦN 1) I. THỜI GIAN-ĐỊA ĐIỂM
1. Thời gian: 21h, ngày 18/11/2023
2. Địa điểm: Cuộc họp online trên Google Meet
II. THÀNH PHẦN THAM DỰ (5/5)
Nguyễn Thị Nhung Huyền (Nhóm trưởng), Triệu Phúc Hương, Nguyễn
Trung Kiên, Lê Thị Lan, Đinh Thị Mai Linh. III. NỘI DUNG CUỘC HỌP 1.
Nhóm trưởng đề xuất phương án phân chia công việc theo nguyện
vọng, các thành viên đều tán thành. 2.
Các ý kiến được thống nhất theo yêu cầu của đề bài thảo luận, chốt
được nhiệm vụ cụ thể của từng thành viên. 3.
Cả nhóm thảo luận về những vấn đề trong từng câu hỏi mà mỗi thành viên phụ trách. 4.
Nhóm trưởng thống nhất thời gian làm bài và đặt hạn làm bài lần 1.
IV. KẾT LUẬN CUỘC HỌP 1.
Các thành viên tham gia đầy đủ và tích cực thảo luận bàn bạc vấn đề được giao. 2.
Cuộc họp diễn ra suôn sẻ và kết thúc vào 23 giờ ngày 18 tháng 11 năm 2023. Thư ký Nhóm trưởng
(Ký, ghi rõ họ tên)
(Ký, ghi rõ họ tên) Lan Huyền Lê Thị Lan Nguyễn Thị Nhung Huyền
CỘNG HÒA XÃ HỘI CHỦ NGHĨA VIỆT NAM
Độc lập-Tự do-Hạnh phúc
Hà Nội, ngày 30 tháng 11 năm 2023 3 lOMoAR cPSD| 45470368
BIÊN BẢN HỌP NHÓM (LẦN 2) I. THỜI GIAN-ĐỊA ĐIỂM
1. Thời gian: 14h30, ngày 30/11/2023
2. Địa điểm: Thư viện tòa P trường Đại học Thương Mại
II. THÀNH PHẦN THAM DỰ (5/5)
Nguyễn Thị Nhung Huyền (Nhóm trưởng), Triệu Phúc Hương, Nguyễn
Trung Kiên, Lê Thị Lan, Đinh Thị Mai Linh. III. NỘI DUNG CUỘC HỌP 1.
Nhóm trưởng chỉ ra những thiếu sót của bài thảo luận, đưa ra
hướng giải quyết vấn đề. 2.
Các thành viên cho ý kiến và tiến hành hoàn thiện bài thảo luận. 3.
Thuyết trình thử và chuẩn bị quay video thuyết trình chính thức
IV. KẾT LUẬN CUỘC HỌP
1. Các thành viên tham gia đầy đủ, tích cực đóng góp ý kiến cho bài thảo luận nhóm.
2. Cuộc họp diễn ra suôn sẻ và kết thúc vào 23h30 ngày 30 tháng 11 năm 2023. Thư ký Nhóm trưởng
(Ký, ghi rõ họ tên)
(Ký, ghi rõ họ tên) Lan Huyền Lê Thị Lan Nguyễn Thị Nhung Huyền 4 lOMoAR cPSD| 45470368 MỤC LỤC
MỞ ĐẦU..............................................................................................................6
CHƯƠNG 1. CƠ SỞ LÝ THUYẾT...................................................................9
1.1. Machine Learning.......................................................................................9
1.1.1. Định nghĩa............................................................................................9
1.1.2. Một số phương thức của Machine Learning.........................................9
1.2. Bài toán phân lớp dữ liệu..........................................................................11
CHƯƠNG 2. THUẬT TOÁN CÂY QUYẾT ĐỊNH.......................................13
2.1. Giới thiệu chung.......................................................................................13
2.2. Khái niệm cây quyết định........................................................................13
2.3. Các kiểu cây quyết định............................................................................14
2.4. Ví dụ kinh điển.........................................................................................14
2.5. Các tiêu chí phân tách...............................................................................17
Gini impurity................................................................................................17
Entropy.........................................................................................................17
2.6. Các bước dựng cây....................................................................................18
2.7. Một số thuật toán dựng cây.......................................................................18
2.8. Ưu, nhược điểm của thuật toán.................................................................18
CHƯƠNG 3: BỘ DỮ LIỆU IRIS VÀ MÔ TẢ BÀI TOÁN...........................20
3.1. Bộ dữ liệu Iris flower dataset....................................................................20 5 lOMoAR cPSD| 45470368
3.1.1. Giới thiệu............................................................................................20
3.1.2. Sử dụng tập dữ liệu.............................................................................21
3.1.3. Tập dữ liệu..........................................................................................22
3.2. Mô tả bài toán...........................................................................................30
KẾT LUẬN........................................................................................................38
TÀI LIỆU THAM KHẢO................................................................................39 MỞ ĐẦU
1. Đặt vấn đề
Những năm gần đây, AI nổi lên như một bằng chứng của cuộc cách mạng
công nghiệp lần thứ tư. Trí tuệ nhân tạo có thể được định nghĩa như một nghành
của khoa học máy tính liên quan đến việc tự động hóa các hành vi thông minh.
Trí tuệ nhân tạo là một bộ phận của khoa học máy tính và do đó nó phải được
đặt trên những nguyên lý lý thuyết vững chắc, có khả năng ứng dụng được của
lĩnh vực này. Ở thời điểm hiện tại, thuật ngữ này thường dùng để nói đến các
máy tính có mục đích không nhất định và ngành khoa học nghiên cứu về các lý
thuyết và các ứng dụng của trí tuệ nhân tạo.
Theo đà phát triển của công nghệ, ứng dụng trí tuệ nhân tạo luôn là xu
hướng công nghệ tương lai mà các hãng công nghệ trên toàn thế giới đua nhau
sáng tạo, nó là nền tảng cốt lõi của cuốc cách mạng công nghệ 4.0.
ML (Machine Learning) là một lĩnh vực của trí tuệ nhân tạo, được sinh ra
từ khả năng nhận diện mẫu và từ lý thuyết các máy tính có thể học mà không cần
phải lập trình để xử lý các nhiệm vụ cụ thể nào đó.
Hầu hết mọi nghành công nghiệp đang làm việc với hàm lượng lớn dữ liệu
đều nhận ra tầm quan trọng của công nghệ ML. Những cái nhìn sáng suốt từ
nguồn dữ liệu này – chủ yếu dạng thời gian thực – sẽ giúp các tổ chức vận hành
hiệu quả hơn hoặc tạo lợi thế cạnh tranh so với các đối thủ.
Các ứng dụng của ML đã quá quen thuộc với con người: xe tự hành của
Google và Tesla, hệ thống tự tag khuôn mặt trên Facebook, hệ thống gợi ý sản 6 lOMoAR cPSD| 45470368
phẩm của Amazon, hệ thống gợi ý phim của Netflix…, chỉ là một vài trong vô
vàn những ứng dụng của trí tuệ nhân tạo và cụ thể là ML.
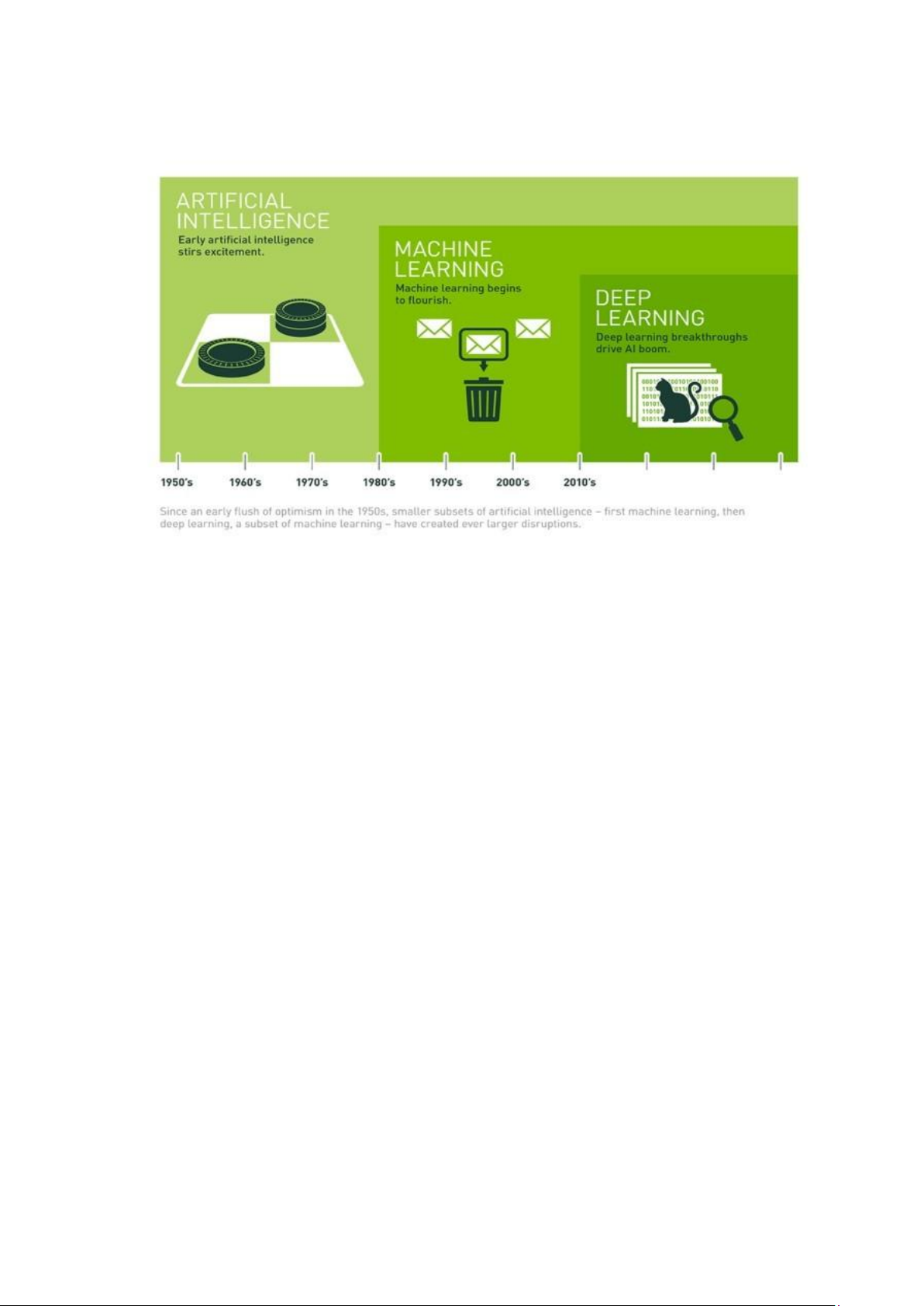
Hình 1. Mối quan hệ giữa AI.Machine Learning và Deep Learning
Xu hướng phát triển công nghệ thông tin ngày càng tăng, song song với nó
lượng dữ liệu được sinh ra cũng ngày một lớn. Vì vậy nhu cầu để xử lý dữ liệu
cũng lớn hơn, ML đang góp phần giải quyết vấn đề này. Một trong những thuật
toán thường dùng trong ML đó là thuật toán Cây quyết định (Decision Tree)
Ứng dụng của thuật toán này thường được sử dụng trong nghiên cứu hoạt
động , đặc biệt là trong phân tích quyết định , để giúp xác định chiến lược có
nhiều khả năng đạt được mục tiêu nhất
2. Mục đích nghiên cứu
• Nghiên cứu, tìm hiểu lý thuyết thuật toán Cây quyết định (Decision Tree).
• Đánh giá thuật toán.
3. Phạm vi và đối tượng nghiên cứu
• Phạm vi nghiên cứu: Thử nghiệm trên Iris flower dataset.
• Đối tượng nghiên cứu: Thuật toán Cây quyết định và bộ Iris flower dataset. 7 lOMoAR cPSD| 45470368
4. Nội dung thực hiện
• Tìm hiểu thuật toán Cây quyết định (Decision Tree)
• Tìm hiểu bộ dữ liệu Iris
• Sử dụng bộ dữ liệu và đánh giá
5. Cấu trúc bài báo cáo • Mở đầu
• Chương 1: Cơ sở lý thuyết
• Chương 2: Thuật toán Cây quyết định (Decision Tree)
• Chương 3: Bộ dữ liệu Iris và Mô tả bài toán • Chương 4: Kết luận 8 lOMoAR cPSD| 45470368
CHƯƠNG 1. CƠ SỞ LÝ THUYẾT
1.1. Machine Learning 1.1.1. Định nghĩa •
Là một lĩnh vực của trí tuệ nhân tạo liên qua đến việc nghiên cứu và
xây dựng các kĩ thuật cho phép các hệ thống học tự động từ dữ liệu để giải quyết
các vấn đề cụ thể. Ví dụ các máy có thể học cách phân loại thư điện tử có phải
thư rác hay không và tự động sắp xếp vào các thư mục tương ứng. •
Machine Learning có liên quan đến thống kê vì cả hai lĩnh vực đều
nghiên cứu việc phân tích dữ liệu, nhưng khác với thống kê, học máy tập trung
vào sự phức tạp của các giải thuật trong việc thực thi tính toán •
Machine Learning có hiện nay được áp dụng rộng rãi bao gồm máy
truy tìm dữ liệu, máy phân tích thị trường chứng khoán, nhận dạng tiếng nói và chữ viết…
1.1.2. Một số phương thức của Machine Learning
Học có giám sát: Thuật toán dự đoán đầu ra của một dữ liệu mới (new
input) dựa trên các cặp (input, outcome) đã biết từ trước. Cặp dữ liệu này còn
được gọi là (data, label), tức (dữ liệu, nhãn). Supervised learning là nhóm phổ
biến nhất trong các thuật toán Machine Learning.
- Học có giám sát được chia thành hai loại chính:
+ Classification (phân lớp): Là quá trình phân lớp một đối tượng dữ liệu
vào một hay nhiều lớp đã cho trước nhờ một mô hình phân lớp (model). Mô hình
này được xây dựng dựa trên một tập dữ liệu được xây dựng trước đó có gán
nhãn (hay còn gọi là tập huấn luyện). Quá trình phân lớp là quá trình gán nhãn
cho đối tượng dữ liệu. 9 lOMoAR cPSD| 45470368
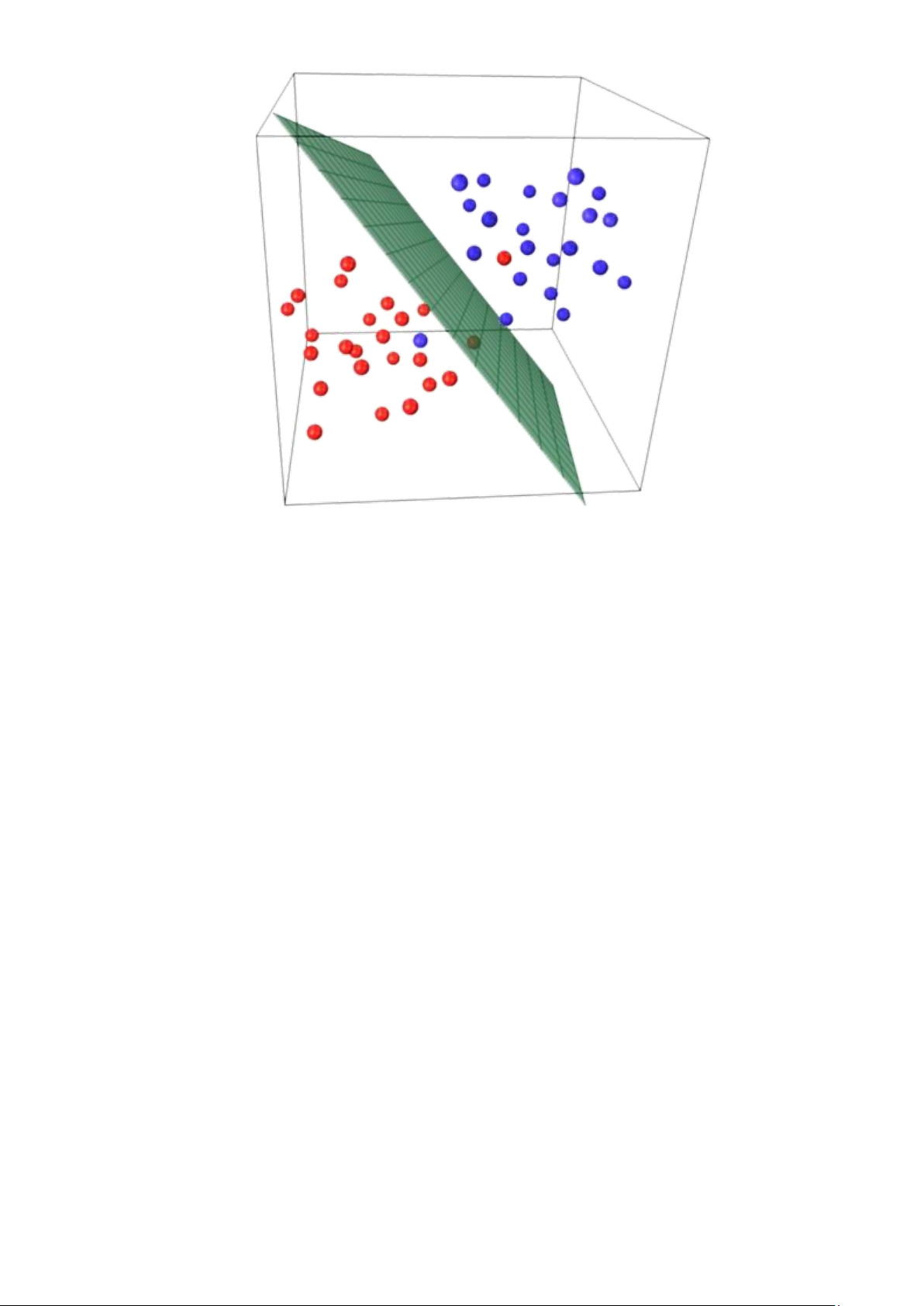
Hình 1.1.2. Ví dụ về mô hình phân lớp
Có nhiều bài toán phân lớp như phân lớp nhị phân, phân lớp đa lớp, phân
lớp đa trị. Trong đó phân lớp nhị phân là một loại phân lớp đặc biệt của phân lớp
đa lớp. 11 Ứng dụng của bài toán phân lớp được sử dụng rất nhiều và rộng rãi
như nhận dạng khuôn mặt, nhận dạng chữ viết, nhận dạng giọng nói, phát hiện thư rác…
+ Regression (hồi quy): Nếu không được chia thành các nhóm mà là một
giá trị thực cụ thể. Đầu ra của một điểm dữ liệu sẽ bằng chính đầu ra của điểm dữ liệu đã biết. •
Học không giám sát: là một kĩ thuật của máy học nhằm tìm ra một mô
hình hay cấu trúc bị ẩn bơi tập dữ liệu không được gán nhãn cho trước. UL khác
với SL là không thể xác định trước output từ tập dữ liệu huấn luyện được. Tùy
thuộc vào tập huấn luyện kết quả output sẽ khác nhau. Trái ngược với SL, tập dữ
liệu huấn luyện của UL không do con người gán nhãn, máy tính sẽ phải tự học
hoàn toàn. Có thể nói, học không giám sát thì giá trị đầu ra sẽ phụ thuộc vào
thuật toán UL. Ứng dụng lớn phổ biến của học không giám sát là bài toán phân cụm. 10 lOMoAR cPSD| 45470368 •
Học bán giám sát: Các bài toán khi có một số lượng lớn dữ liệu nhưng
chỉ một phần trong chúng được dán nhãn. Những bài toán này nằm giữa phương
thưc học giám sát và học không giám sát.
1.2. Bài toán phân lớp dữ liệu
Quá trình phân lớp dữ liệu
Để xây dựng được mô hình phân lớp và đánh giá hiệu quả của mô hình cần
phải thực hiện quá trình sau đây:
Bước 1: Chuẩn bị tập dữ liệu huấn luyện và rút trích đặc trưng. Công đoạn
này được xem là công đoạn quan trọng trong các bài toán về ML. vì đây là input
cho việc học đẻ tìm ra mô hình của bài toán. Chúng ta phải biết cần chọn ra
những đặc trưng tốt của dữ liệu, lược bỏ những đặc trưng không tốt của dữ liệu,
gây nhiễu. Ước lượng số chiều của dữ liệu bao nhiêu là tốt hay nói cách khác là
chọn bao nhiêu feature. Nếu số nhiều quá lớn gây khó khăn cho việc tính 12 toán
thì phải giảm số chiều của dữ liệu nhưng vẫn giữ được độ chính xác của dữ liệu.
Ở bước này chúng ta cũng chuẩn bị bộ dữ liệu để test trên mô hình. Thông
thường sẽ sử dụng crossvalidation (kiểm tra chéo) để chia tập dataset thành hai
phàn, một phần phục vụ cho training và phần còn lại phục vụ cho mục đích
testing trên mô hình. Có hai cách thường sử dụng trong crossvalidation là splitting và kfold.
Bước 2: Xây dựng mô hình phân lớp Mục đích của mô hình huấn luyện là
tìm ra hàm F(x) và thông qua hàm f tìm được để chúng ta gán nhãn cho dữ liệu.
Bước này thường được gọi là học hay training. F(x)= y
Trong đó: x là các feature hay input đầu vào của dữ liệu
y là nhãn dán lớp hay output đầu ra
Thông thường để xây dựng mô hình phân lớp cho bài toán này chúng ta sử
dụng các thuật toán học giám sát như KNN, NN, SVM, Decision tree, Navie Bayers. 11 lOMoAR cPSD| 45470368
Bước 3: Kiểm tra dữ liệu với mô hình Sau khi tìm được mô hình phân lớp ở
bước hai, thì bước này chúng ta sẽ đưa vào các dữ liệu mới đẻ kiểm tra trên mô hình phân lớp.
Bước 4: Đánh giá mô hình phân lớp và chọn ra mô hình tốt nhất
Bước cuối cùng chúng ta sẽ đánh giá mô hình bằng cách đánh giá mức độ
lỗi của dữ liệu testing và dữ liệu training thông qua mô hình tìm được. Nếu
không đạt được kết quả mong muốn của chúng ta thì phải thay đổi các tham số
của thuật toán học để tìm ra các mô hình tốt hơn và kiểm tra, đánh giá lại mô
hình phân lớp. và cuối cùng chọn ra mô hình phân lớp tốt nhất cho bài toán của chúng ta. 12 lOMoAR cPSD| 45470368
CHƯƠNG 2. THUẬT TOÁN CÂY QUYẾT ĐỊNH (DECISION TREE)
2.1. Giới thiệu chung •
Bạn có biết rằng trong cuộc sống hàng ngày, bạn vẫn đang sử dụng
phương pháp Decision Tree (Cây quyết định). Chẳng hạn, bạn đến siêu thị mua
sữa cho cả gia đình. Câu đầu tiên trong đầu bạn sẽ là: Bạn cần mua bao nhiêu sữa? •
Bạn sẽ xác định: Nếu là ngày thường thì gia đình bạn sẽ sử dụng hết 1
lítsữa, còn cuối tuần thì sẽ là 1,5 lít. Như vậy, dựa theo ngày, bạn sẽ quyết định
lượng thực phẩm cần mua cho gia đình bạn. •
Đó chính là một dạng của cây quyết định nhị phân. •
Trong lý thuyết quyết định (chẳng hạn quản lý rủi ro), một cây quyết
định (tiếng Anh: decision tree) là một đồ thị của các quyết định và các hậu quả
có thể của nó (bao gồm rủi ro và hao phí tài nguyên). Cây quyết định được sử
dụng để xây dựng một kế hoạch nhằm đạt được mục tiêu mong muốn. Các cây
quyết định được dùng để hỗ trợ quá trình ra quyết định. Cây quyết định là một
dạng đặc biệt của cấu trúc cây.
2.2. Khái niệm cây quyết định •
Cây quyết định (Decision Tree) là một cây phân cấp có cấu trúc được
dùng để phân lớp các đối tượng dựa vào dãy các luật. Các thuộc tính của đối
tượngncó thể thuộc các kiểu dữ liệu khác nhau như Nhị phân (Binary) , Định
danh (Nominal), Thứ tự (Ordinal), Số lượng (Quantitative) trong khi đó thuộc
tính phân lớp phải có kiểu dữ liệu là Binary hoặc Ordinal. •
Tóm lại, cho dữ liệu về các đối tượng gồm các thuộc tính cùng với lớp
(classes) của nó, cây quyết định sẽ sinh ra các luật để dự đoán lớp của các dữ liệu chưa biết. •
Học bằng cây quyết định cũng là một phương pháp thông dụng trong
khai phá dữ liệu. Khi đó, cây quyết định mô tả một cấu trúc cây, trong đó, các lá
đại diện cho các phân loại còn cành đại diện cho các kết hợp của các thuộc tính
dẫn tới phân loại đó. Một cây quyết định có thể được học bằng cách chia tập hợp 13 lOMoAR cPSD| 45470368
nguồn thành các tập con dựa theo một kiểm tra giá trị thuộc tính. Quá trình này
được lặp lại một cách đệ quy cho mỗi tập con dẫn xuất. Quá trình đệ quy hoàn
thành khi không thể tiếp tục thực hiện việc chia tách được nữa, hay khi một phân
loại đơn có thể áp dụng cho từng phần tử của tập con dẫn xuất. Một bộ phân loại
rừng ngẫu nhiên (random forest) sử dụng một số cây quyết định để có thể cải
thiện tỉ lệ phân loại. •
Cây quyết định cũng là một phương tiện có tính mô tả dành cho việc
tínhtoán các xác suất có điều kiện. •
Cây quyết định có thể được mô tả như là sự kết hợp của các kỹ thuật
toán học và tính toán nhằm hỗ trợ việc mô tả, phân loại và tổng quát hóa một tập dữ liệu cho trước. •
Dữ liệu được cho dưới dạng các bản ghi có dạng:
(x, y) = (x1, x2, x3..., xk, y)
Biến phụ thuộc (dependant variable) y là biến mà chúng ta cần tìm hiểu,
phân loại hay tổng quát hóa. x1, x2, x3... là các biến sẽ giúp ta thực hiện công việc đó. •
Bản chất của cây quyết định là SỰ LỰA CHỌN
2.3. Các kiểu cây quyết định •
Cây hồi quy (Regression tree) ước lượng các hàm giá có giá trị là số
thực thay vì được sử dụng cho các nhiệm vụ phân loại. (ví dụ: ước tính giá một
ngôi nhà hoặc khoảng thời gian một bệnh nhân nằm viện). •
Cây phân loại (Classification tree), nếu y là một biến phân loại như:
giới tính (nam hay nữ), kết quả của một trận đấu (thắng hay thua).
2.4. Ví dụ kinh điển Ví dụ 1: •
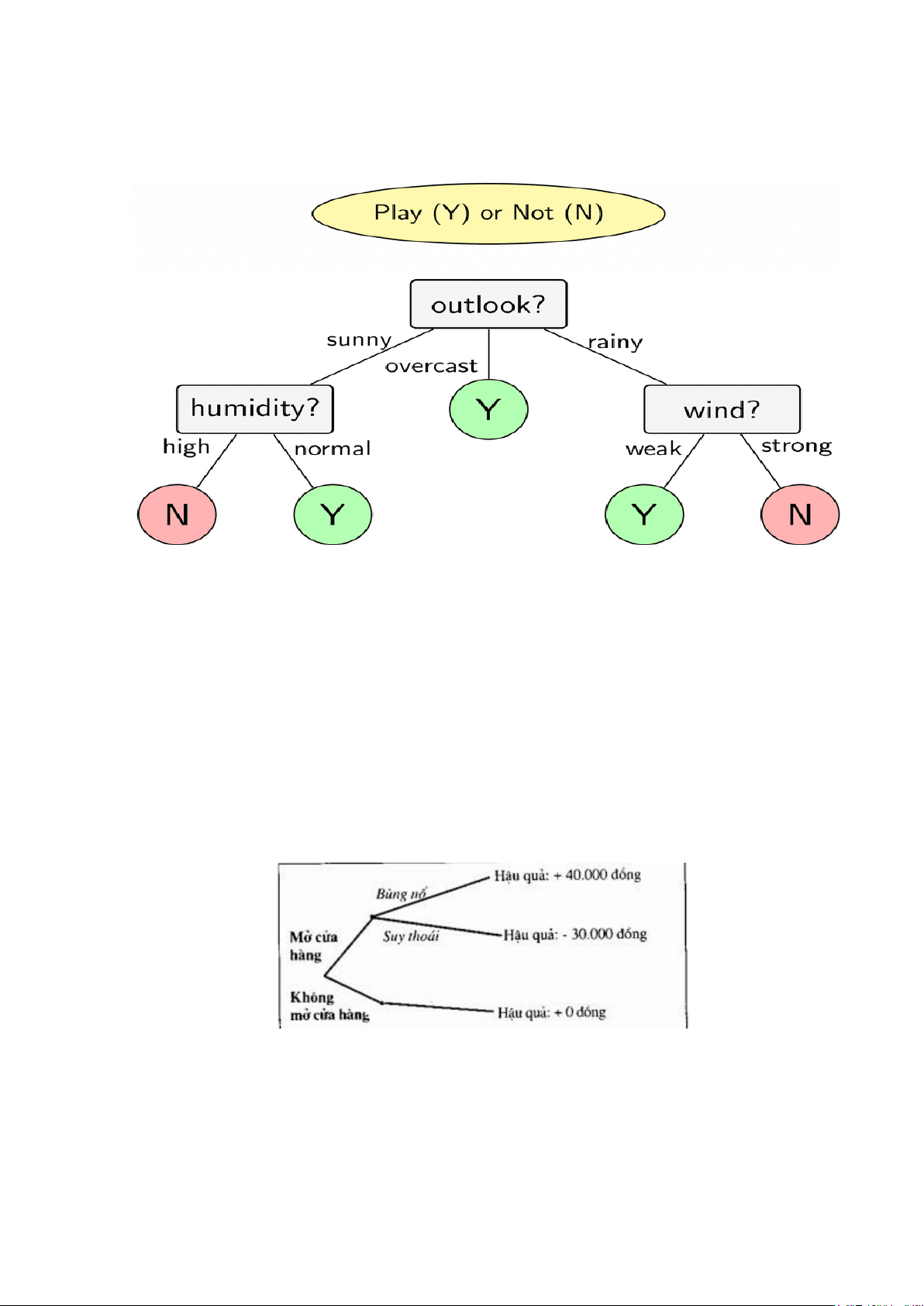
Giả sử dựa theo thời tiết mà các bạn nam sẽ quyết định đi đá bóng hay không? •
Những đặc điểm ban đầu là: Thời tiết Độ ẩm 14 lOMoAR cPSD| 45470368 Gió •
Dựa vào những thông tin trên, bạn có thể xây dựng được mô hình như sau:
Hình 2.4.1. Mô hình cây quyết định •
Dựa theo mô hình trên, ta thấy: Nếu trời nắng, độ ẩm bình thường thì
khả năng các bạn nam đi chơi bóng sẽ cao. Còn nếu trời nắng, độ ẩm cao thì khả
năng các bạn nam sẽ không đi chơi bóng. Ví dụ 2: •
Một người nghĩ đến việc mở một cửa hàng bán lẻ (mà thành công của
nóphụ thuộc vào chi tiêu của người tiêu dùng và bởi vậy phụ thuộc vào thực
trạng của nền kinh tế) sẽ có cây quyết định như hình dưới đây: 15 lOMoAR cPSD| 45470368
Hình 2.4.2. Ví dụ minh họa •
Căn cứ vào Cây quyết định trên, người bán lẻ có hai phương án hành
động là mở cửa hàng và không mở cửa hàng. Anh ta phải cân nhắc hai trạng thái
tự nhiên, tức hai sự kiện có thể xảy ra: nền kinh tế phát triển mạnh hoặc suy thoái. •
Người bán lẻ phải đánh giá khả năng xuất hiện mỗi sự kiện và trong
tìnhhuống này, anh ta dựa trên kinh nghiệm và hiểu biết để nhận định rằng khả
năng xuất hiện mỗi sự kiện bằng 50%. Cuối cùng, người bán lẻ ước tính hậu quả
tài chính là nếu mở cửa hàng sẽ có lãi 40.000 đồng khi kinh tế phát triển mạnh và
lỗ 30.000 đồng nếu có suy thoái. •
Để ra quyết định, người bán lẻ cần một tiêu chuẩn ra quyết định chophép
anh ta lựa chọn phương án hành động tốt nhất trong các phương án có thể có. Vì
sự lựa chọn này gắn với yếu tố rủi ro, nên chúng ta cần biết thái độ của người bán lẻ đối với rủi ro. •
Nếu người bán lẻ không chú ý đến rủi ro, chúng ta có thể tính toán
tínhxác định tương đương với hành vi "mở cửa hàng" bằng cách căn cứ vào hậu
quả tài chính của mỗi kết cục và gia quyền nó theo xác suất xuất hiện của nó. Ví dụ:
Hình 2.4.3. Ví dụ bài toán •
Kết cục này chắc chắn lớn hơn 0 trong trường hợp không mở cửa
hàngvà nó biện minh cho việc tiếp tục thực hiện dự án này. 16 lOMoAR cPSD| 45470368 •
Song nếu người bán lẻ là người ghét rủi ro, tiêu chuẩn giá trị bằng
tiềncó thể không phải là tiêu chuẩn thích hợp, vì anh ta cần nhận được phần
thưởng cho sự rủi ro để chấp nhận hành động. Việc tận dụng tiêu chuẩn cẩn thận
hơn tiêu chuẩn tương đương với tính xác định sẽ làm giảm tiêu chuẩn tương
đương với tính xác định của nhánh "mở cửa hàng" và điều này cũng dẫn đến
quyết định tiếp tục mở cửa hàng.
2.5. Các tiêu chí phân tách Gini impurity
Dùng trong thuật toán CART (Classification and Regression Trees). Nó
dựa vào việc bình phương các xác suất thành viên cho mỗi thể loại đích trong
nút. Giá trị của nó tiến đến cực tiểu (bằng 0) khi mọi trường hợp trong nút rơi
vào một thể loại đích duy nhất.
Giả sử y nhận các giá trị trong {1, 2,..., m} và gọi f(i,j) là tần suất của giá trị j
trong nút i. Nghĩa là f(i,j) là tỷ lệ các bản ghi với y=j được xếp vào nhóm i. Entropy
Dùng trong các thuật toán sinh cây ID3, C4.5 và C5.0. Số đo này dựa trên
khái niệm entropy trong lý thuyết thông tin (information theory).
2.6. Các bước dựng cây
Bước 1. Phân vùng đệ quy dữ liệu thành nhiều tập con.
Bước 2. Tại mỗi nút, xác định biến và quy tắc liên kết với biến để phân tách tốt nhất.
Bước 3. Áp dụng phép tách tại nút đó bằng cách sử dụng biến tốt nhất bằng
cách sử dụng quy tắc được xác định cho biến. 17 lOMoAR cPSD| 45470368
Bước 4. Lặp lại bước 2 và bước 3 trên các nút con.
Bước 5. Lặp lại quá trình này cho đến khi chúng ta đạt được điều kiện dừng.
Bước 6. Gán các quyết định tại các nút lá dựa trên nhãn lớp đa số có mặt tại
nút đó nếu thực hiện nhiệm vụ phân loại hoặc xem xét giá trị trung bình của các
giá trị biến mục tiêu có tại nút lá đó nếu thực hiện nhiệm vụ hồi quy.
2.7. Một số thuật toán dựng cây
Tồn tại các thuật toán tạo cây khác nhau như CART, CHAID, ID3, C4.5, C5.0,
v.v. Trong mỗi thuật toán xây dựng, các tiêu chí được xem xét để chọn tính năng
tốt nhất cung cấp phân tách tốt nhất có thể khác nhau như thuật toán CART sử
dụng thước đo tạp chất Gini Index để xác định tính năng tốt nhất cung cấp độ phân
tách tốt nhất. Tương tự như vậy, ID3 sử dụng Tăng thông tin, C4.5 cũng sử dụng
Tỷ lệ tăng tương tự cho các thuật toán khác. Nhưng thuật toán xây dựng cây tổng
thể vẫn giống như đã đề cập ở trên.
2.8. Ưu, nhược điểm của thuật toán Ưu điểm: •
Cây quyết định là một thuật toán đơn giản và phổ biến. Thuật
toán này được sử dụng rộng rãi bới những lợi ích của nó: •
Mô hình sinh ra các quy tắc dễ hiểu cho người đọc, tạo ra bộ
luật với mỗi nhánh lá là một luật của cây. •
Dữ liệu đầu vào có thể là là dữ liệu missing, không cần chuẩn
hóa hoặc tạo biến giả •
Có thể làm việc với cả dữ liệu số và dữ liệu phân loại •
Có thể xác thực mô hình bằng cách sử dụng các kiểm tra thống kê •
Có khả năng là việc với dữ liệu lớnNhược điểm: •
Kèm với đó, cây quyết định cũng có những nhược điểm cụ thể: •
Mô hình cây quyết định phụ thuộc rất lớn vào dữ liệu của bạn.
Thạm chí,với một sự thay đổi nhỏ trong bộ dữ liệu, cấu trúc mô hình cây
quyết định có thể thay đổi hoàn toàn. 18 lOMoAR cPSD| 45470368 •
Cây quyết định hay gặp vấn đề overfitting
CHƯƠNG 3: BỘ DỮ LIỆU IRIS VÀ MÔ TẢ BÀI TOÁN
3.1. Bộ dữ liệu Iris flower dataset 3.1.1. Giới thiệu
Tập dữ liệu hoa Iris hoặc tập dữ liệu Iris của Fisher là tập dữ liệu đa biến
được giới thiệu bởi nhà thống kê và nhà sinh vật học người Anh Ronald Fisher
trong bài báo năm 1936 Việc sử dụng nhiều phép đo trong các vấn đề phân loại
như một ví dụ về phân tích phân biệt tuyến tính. Đôi khi nó được gọi là tập dữ liệu
Iris của Anderson vì Edgar Anderson đã thu thập dữ liệu để định lượng sự biến
đổi hình thái của hoa Iris của ba loài liên quan. Hai trong số ba loài được thu thập
ở Bán đảo Gaspé "tất cả từ cùng một đồng cỏ, và được chọn vào cùng một ngày
và được đo cùng lúc bởi cùng một người với cùng một bộ máy".
Bộ dữ liệu bao gồm 50 mẫu từ mỗi ba loài Iris (Iris setosa, Iris virginica và
Iris Verscolor). Bốn đặc điểm được đo từ mỗi mẫu: chiều dài và chiều rộng của
đài hoa, chiều dài và chiều rộng cánh hoa, tính bằng centimet. Dựa trên sự kết hợp
của bốn tính năng này, Fisher đã phát triển một mô hình phân biệt tuyến tính để
phân biệt các loài với nhau.
Iris setosa Iris versicolor Iris virginica
Hình 3.1.1. Hình ảnh minh họa về Iris flower dataset
3.1.2. Sử dụng tập dữ liệu
Dựa trên mô hình phân biệt tuyến tính của Fisher, bộ dữ liệu này đã trở thành
trường hợp thử nghiệm điển hình cho nhiều kỹ thuật phân loại thống kê trong học
máy như máy vector hỗ trợ. 19 lOMoAR cPSD| 45470368
Tuy nhiên, việc sử dụng tập dữ liệu này trong phân tích cụm không phổ biến,
vì tập dữ liệu chỉ chứa hai cụm có sự phân tách khá rõ ràng. Một trong những cụm
chứa Iris setosa, trong khi cụm còn lại chứa cả Iris virginica và Iris Versolor và
không thể tách rời nếu không có thông tin về loài mà Fisher sử dụng. Điều này
làm cho dữ liệu trở thành một ví dụ tốt để giải thích sự khác biệt giữa các kỹ thuật
được giám sát và không giám sát trong khai thác dữ liệu: Mô hình phân biệt tuyến
tính của Fisher chỉ có thể thu được khi biết các loài đối tượng: nhãn lớp và cụm
không nhất thiết giống nhau.
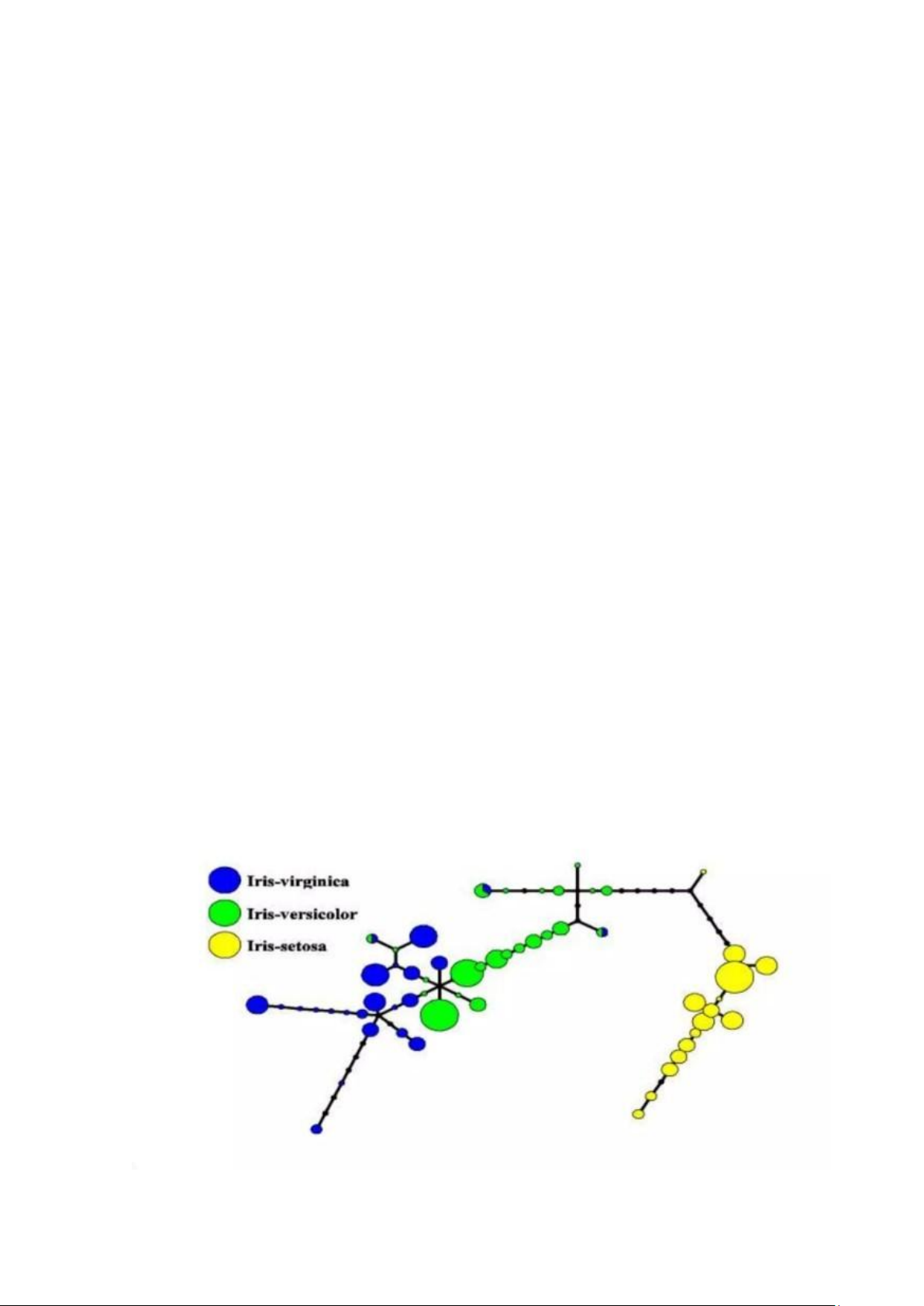
Tuy nhiên, cả ba loài Iris đều có thể tách rời trong hình chiếu trên thành phần
chính phân nhánh phi tuyến. Tập dữ liệu được xấp xỉ bởi cây gần nhất với một số
hình phạt cho số lượng nút, uốn cong và kéo dài quá mức. Các điểm dữ liệu được
chiếu vào nút gần nhất. Đối với mỗi nút, sơ đồ hình tròn của các điểm được chiếu
được chuẩn bị. Diện tích của chiếc bánh tỷ lệ thuận với số lượng điểm được chiếu.
Rõ ràng từ sơ đồ (bên dưới) rằng phần lớn tuyệt đối các mẫu của các loài Iris khác
nhau thuộc về các nút khác nhau. Chỉ một phần nhỏ Iris virginica được trộn với
IrisVersolor (các nút màu xanh lam hỗn hợp trong sơ đồ). Do đó, ba loài Iris (Iris
setosa, Iris virginica và Iris Verscolor) có thể được phân tách bằng các thủ tục
không giám sát trong phân tích thành phần chính phi tuyến. Để phân biệt chúng,
chỉ cần chọn các nút tương ứng trên cây chính. 20
Tài liệu liên quan:
-

Quản lý dịch vụ Vietin Bank | Bài tập lớn môn Lập trình với Python
55 28 -

Xây dựng chương trình quản lý kho hàng các sản phẩm của công ty cổ phần Vinacafé Biên Hòa | Bài thảo luận Lập trình python
65 33 -

Xây dựng chương trình Quản Lý Học Viên trung tâm anh ngữ Oxford | Bài Tập Lớn Cuối Kỳ Lập trình Python
69 35 -

Xây dựng Chương Trình Quản Lý Khách Hàng cho BKAV | Bài tập lập trình python
66 33 -

Xây Dựng Chương Trình Quản Lý Dự Án của công ty phát triển phần mềm Bravo | Bài tập lập trình python
73 37