Tài liệu học tập môn Nhập môn học máy và khai phá dữ liệu | Trường Đại học Bách Khoa Hà Nội
Machine Learning (ML – học máy): to build computer systems that can improve themselves by learning from data (xây dựng những hệ thống mà có khả năng tự cải thiện bản thân bằng cách học từ dữ liệu). Tài liệu được sưu tầm gồm 76 trang, giúp các bạn ôn luyện và phục vụ cho việc học tập, đạt kết quả tốt. Mời các bạn đón xem!
Môn: Nhập môn học máy và khai phá dữ liệu 15 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.4 K tài liệu
Tác giả:














Preview text:
NHẬP MÔN HỌC MÁY VÀ KHAI PHÁ DỮ LIỆU Mục lục
Chương 1: Các khái niệm cơ bản................................................................................................................................................2
1. Machine Learning (ML) vs Data mining (DM)...............................................................................................................2
2. Bài toán học....................................................................................................................................................................2
Chương 2: Tiền xử lý dữ liệu......................................................................................................................................................4
1. Data collection (Thu thập dữ liệu)..................................................................................................................................5
2. Data preprocessing (Tiền xử lý dữ liệu)..........................................................................................................................5
Chương 3: Bài toán hồi quy tuyến tính (Linear Regression).......................................................................................................6
1. Các khái niệm cơ bản về hồi quy tuyến tính...................................................................................................................6
2. Method: ordinary least squares (OLS) – Phương pháp bình phương tối thiểu.................................................................8
3. Method: Ridge regression (Phương pháp hồi quy Ridge)...............................................................................................9
4. Methods: LASSO regression (phương pháp hồi quy LASSO)......................................................................................12
Chương 4: Bài toán phân cụm (Phân cụm với K-means)..........................................................................................................13
1. Clustering (Phân cụm)..................................................................................................................................................14
2. K-means for clustering..................................................................................................................................................14
3. Các vấn đề trong thuật toán K-means...........................................................................................................................16
4. Online K-means (dành cho dữ liệu lớn)........................................................................................................................18
Chương 5: Học dựa trên láng giềng ( K-nearest neighbors – KNN).........................................................................................19
Chương 7: Cây quyết định và rừng ngẫu nhiên.........................................................................................................................23
A. Cây quyết định..............................................................................................................................................................23
1. Biểu diễn cây quyết định.....................................................................................................................................23
2. Learning a decision tree by ID3...........................................................................................................................24
B. Random forests (Rừng ngẫu nhiên)...............................................................................................................................27
Chương 8: Phân loại bằng SVM (Support Vector Machine).....................................................................................................28
1. SVM: the linearly separable case (Trường hợp có thể phân tách tuyến tính được).......................................................29
2. Soft – margin SVM (SVM lề mềm)..............................................................................................................................36
3. Non-linear SVM (Bài toán SVM phi tuyến).................................................................................................................39
Chương 9: Đánh giá kết quả thực nghiệm.................................................................................................................................42
1. Assessing performance (Đánh giá hiệu năng hoạt động)...............................................................................................42
2. Some evaluation techniques (Một số kỹ thuật đánh giá)...............................................................................................42
3. Model selection.............................................................................................................................................................44
4. Model assessment and selection (Lựa chọn và đánh giá mô hình)................................................................................46
5. Performance measures (Đo lường hiệu năng)...............................................................................................................46
Chương 10: Artificial neural network (Mạng noron nhân tạo)..................................................................................................49
Chương 11: Probabilistic modeling (Mô hình xác suất)............................................................................................................63
1. Basics of Probability Theory (Lý thuyết xác suất cơ bản).............................................................................................64
2. Probabilistic models (Mô hình xác suất).......................................................................................................................65
3. Inference and Learning.................................................................................................................................................68
Chương 1: Các khái niệm cơ bản
1. Machine Learning (ML) vs Data mining (DM)
Machine Learning (ML – học máy): to build computer systems that can improve themselves by learning
from data (xây dựng những hệ thống mà có khả năng tự cải thiện bản thân bằng cách học từ dữ liệu)
Data mining (DM – khai phá dữ liệu): to find new and useful knowledge from datasets (tìm kiếm/ khai phá
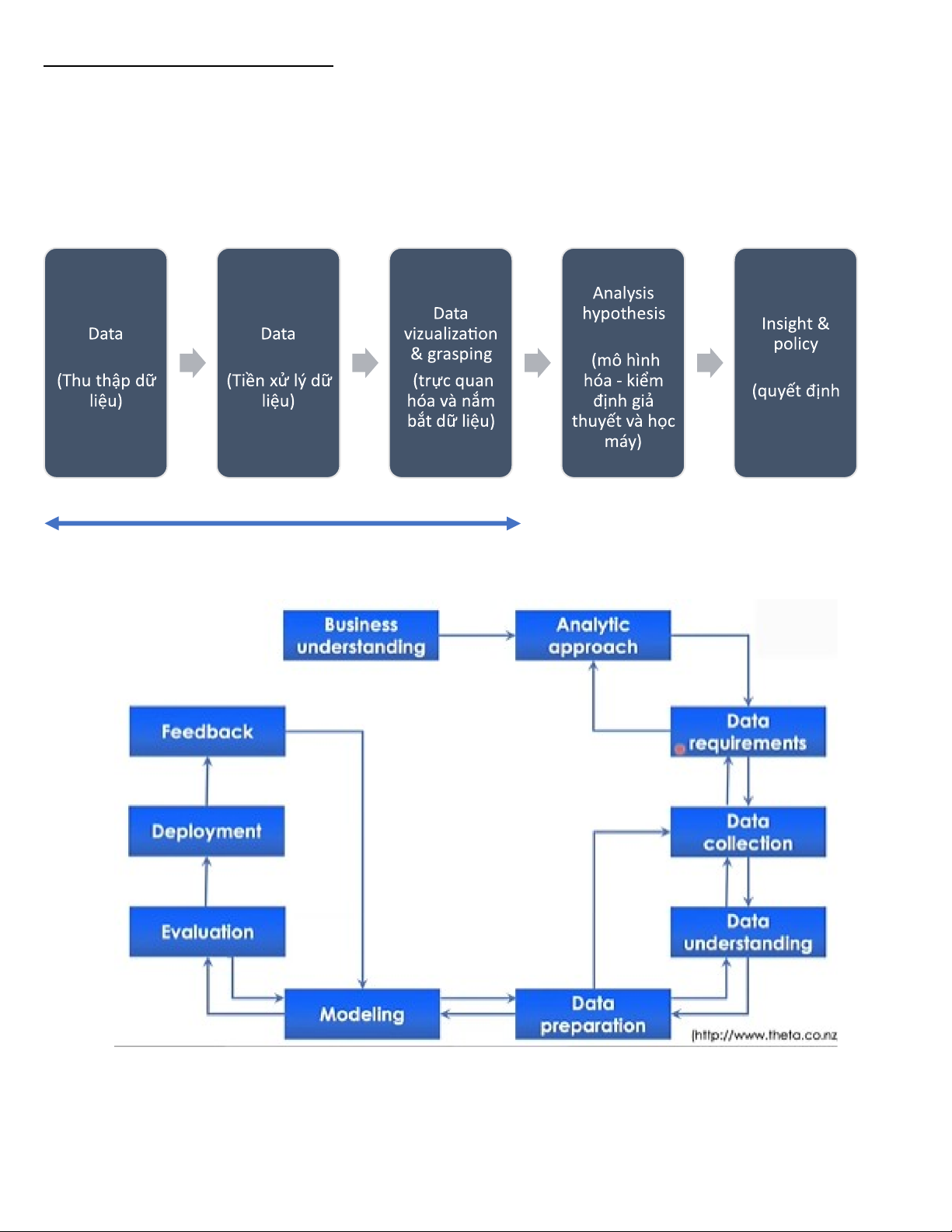
những tri thức mới và hữu dung từ dữ liệu lớn) testing & ML collection processing decision chính sách) 70-90% process
Methodology: product-driven (Phương pháp: định hướng sản phẩm) 2. Bài toán học
What is Machine Learning?
Machine Learning (ML) is an active subfield of Artificial Intelligence (học máy là 1 nhánh của AI). ML seeks to
answer the question “How can we build computer systems that automatically improve with experience, and what are
the fundamental laws that govern all learning processes “ – Học máy tìm câu trả lời cho câu hỏi “Làm thế nào có
thể xây dựng một hệ thống máy tính tự động cải tiến với kinh nghiệm và đâu là những quy luật cơ bản chi phối mọi quá trình học tập “ A learning machine
We say that a machine learns if the system reliably improves its performance (hiệu năng) P at task (nhiệm
vụ) T, folloing experience (kinh nghiệm) E => Alearning problem can be described as a triple (P,T,E)
Ex: Spam filtering for emails (lọc email spam)
T: filter/predict all emails that are spam (phán đoán một email là thườmg hay là rác)
P: the accuracy of prediction, that is the percentage of emails that are correctly classified into normal/spam (độ chính xác – tỷ lệ)
E: set of old emails, each with a label of spam/normal (tập các email cũ, đã được gán nhãn trước là thường hay spam)
– đây chính là tập dữ liệu huấn luyện What does a machine learn? • A mapping (function) f : x → y
x : observations (data), past experience…. (quan sát (dữ liệu), kinh nghiệm quá khứ) y :
prediction, new knowledge, new experience.. (dự đoán, kiến thức mới, trải nghiệm mới) • A model (mô hình)
Data are often supposed(được cho là) to follow or be generated(tạo ra) from an unknomn model
Learning a model means learning the parameters (các tham số) of that model Where does a machine learn from?
• Learn from a set of training examples (training set, tập học, tập huấn luyện)
{x1,x2,…,xn} = observation (quan sát, mẫu, điểm dữ liệu) of x in the past
{y1,y2,…,yn} = observation of y in the past, often called label (nhãn)/ response / output
• After learning we obtain a model, new knowledge or new experience (f) and we can use that
model/function to do prediction (dự đoán) or inference (suy luận) for future observation
Two basic learning problems
• Supervised learning (học có giám sát): learn a function y = f(x) from a given training set {xi , yi } so
that yi ≅f (xi) for every i.
o Classification (categorization, phân loại, phân lớp): if y only belongs to a discrete set (một tập
rời rạc), for example {spam, normal}
o Regression (hồi quy): if y is a real number. Ex prediction of stock indices (chứng khoán)
• Unsupervised learning (học ko giám sát): learn a function y = f(x) from a given training set {xi } o
y can be a data cluster o y can be a hidden structure o y can be a trend
Ví dụ bài toán phân cụm dữ liệu, tìm kiếm mạng người dùng, hay xu hướng ngời tiêu dùng
Design a learning system
Some issues (vấn đề) should be carefully considered (quan tam) when designing a learning system
• Select a training set o Plays (giữ) the key role in the efectiveness of the system o Do the observations have any label?
o The training observations should characterize the whole data space => good for future
predictions (các quan sát huấn luyện phải mô tả toàn bộ không gian dữ liệu)
• Select a representation for the function (model): Linear/ A neural network/ A decision tree
• Select a good algorithm to learn the function
• Định luật No-free-lunch theorem: No algorithm cam beat another on all domains
(không có giải thuật nào luôn hiệu quả nhất trên mọi miền ứng dụng)
Learnability (khả năng học)
• The goodness / limit of the learning algorithm (mức độ tốt/giới hạn của thuật toán học tập) What
is the generalization (tổng quát hóa) of the system?
o Predict well new observations, not only the training data o
Avoid overfitting (tránh trang bị quá nhiều) Overfitting
Function h is called overfitting [Mitchell, 1997] if there exists another function g such that:
g might be worse than h for the training data, but g is better than h for future data.
A learning algorithm is said to overfit relative to another one if it is more accurate in fitting known data, but
less accurate in predicting unseen data. (phù hợp hơn với dữ liệu đã biết nhưng kém chính xác trong việc
dự đoán dữ liệu không nhìn thấy) Overfitting is caused by many factors:
o The trained function/model is too complex (phức tạp) or have too much parameters.
o Noises or errors are present in the training data. o The training size is too small, not
characterizing the whole data space.
Xử lý overfitting => Regularization (hiệu chỉnh)
Chương 2: Tiền xử lý dữ liệu
Tại sao cần phải tiền xửu lý dữ liệu?
• Thuận tiện trong lưu trữ, truy vấn
• Các mô hình học máy thường làm việc với dữ liệu có cấu trúc: ma trận. vecto, chuỗi ….
• Học máy thường làm việc hiệu quả nếu có biểu diễn dữ liệu phù hợp
1. Data collection (Thu thập dữ liệu) Sampling (lấy mẫu)
• What: lấy tập mẫu nhỏ, phổ biến để đại diện cho lĩnh vực cần học
• Why: không thể học toàn bộ. Giới hạn về thời gian và khả năng tính toán
• How: thu thập các mẫu từ thựuc tế hoặc các nguồn chứa dữ liệu như web, database… o Variety (đa
dạng): tập mẫu thu được đủ đa dạng (chứa đầy đủ các đặc trưng của dữ liệu) để phủ hết các ngữ cảnh của lĩnh vực
o Bias (tổng quát): dữ liệu cần tổng quát, không bị sai lệch, thiên vị về một bộ phận nhỏ nào đó
của lĩnh vực Techniques (kỹ thuật)
• Crowd-sourcing: Survey – thực hiện các khảo sát
• Logging: lưu lại lịch sử tương tác của người dùng, truy cập sản phẩm
• Scrapping: tìm kiếm nguồn dữ liệu trên các website, tải về, bóc tách, lọc…
2. Data preprocessing (Tiền xử lý dữ liệu)
Chuyển từ dữ liệu thô sơ (data “rawness”) về dữ liệu có cấu trúc (structures) có thể sử dụng về sau:
• Completeness (đầy đủ): từng mẫu thu thập nên chứa đầy đủ các trường thông tin cần thiết
• Integrity (trung thực): Nguồn thu thập chính thống, đảm bảo mẫu thu được chứa giá trị chính xác trên thực tế
• Homogeneity (đồng nhất): ví dụ như khi xếp số tầng hay xếp hạng người ta có thể dùng “1,2,3..”
hay là “A,B,C..” thì dữ liệu như vậy sẽ chưa đồng nhất, vì vậy cần phải chuârn hóa
• Structures (cấu trúc): tất cả sau khi tiền xử lý dữ liệu phải có cùng định dạng cấu trúc cụ thể chẳng
hạn như vecto hay là một tập các hình ảnh có cùng kích thước định dạng ….
Techniques (kỹ thuật)
a. Cleaning (làm sạch)
Tính đầy đủ + trung thực
• Mẫu dữ liệu cần được thu thập từ các nguồn đáng tin cậy. Phản ánh vấn đề cần giải quyết
• Loại bỏ nhiễu (ngoại lai): bỏ vài mẫu dữ liệu mà có khác biệt lớn với các mẫu khác
• Một mẫu dữ liệu có thể bị trống (theiesu, chưa đầy đủ) cần có chiến lược phù hợp: Bỏ qua, không
đưa và phân tích? Hoặc là bổ sung các trường còn thiếu cho mẫu
Điền các giá trị thiếu có thể dùng:
o Điền lại gái trị bằng tay dựa vào kinh nghiệm, kiến thức (nhiều khi ko thể vì khá khó) o Gán
cho giá trị nhãn đặc biệt hay ngàoi khảong biểu diễn o Gián giá trị trung bình cho nó
o Gián giá trị trung bình của các mẫu khác thuộc cùng lớp đó
o Tìm giá trị có xác suất lớn nhất điền vào chô bị mất ( hồi quy, suy diễn Bayes …)
Tính đồng nhất: các dữ liệu cần có tính đồng nhất về cách biểu diễn, ký hiệu
b. Integrating (tích hợp)
Khi thu thập dữ liệu có rất nhiều nguồn và nhiều kiểu dữ liệu khác nhau như dữ liệu văn bản, dữ liệu hình
ảnh, dữ liệu sóng radio.., muốn sử dụng tất cả các nguồn dữ liệu đó thì chúng ta phải biến đổi chúng thành
các dakng có cấu trúc cụ thể rồi tích hợp các kiểu dữ liệu đó thành một cấu trúc có thể sử dụng c.
Transforming (biến đổi)
• Feature discretization (rời rạc hóa): một sô thuộc tính tỏ ra hiệu quả hơn khi được gom nhóm các giá trị.
• Feature normalization (chuẩn hóa): chuẩn hóa giá trị thuộc tính về cùng một miền giá trị, dễ dàng
cho tính toán. Chẳng hạn như một thuộc tính lấy tất cả chia cho giá trị max thì khi đó tất cả các giá
trị của thuộc tính đó nằm trong miền giá trị [0 ; 1]
• Giảm kích cỡ dữ liệu: giúp giảm kích thước của dữ liệu và đồng thời giữ được ngữ nghĩa cốt lõi
của dữ liệu, giúp tăng tốc quá trình học và khai phá dữ liệu Có một vài chiến lược giảm kích thước dữ liệu:
o Lựa chọn đặc trưng (feature selection): các thuộc tính không liên quan, dư thừa haowjc các
chiều cũng có thể xóa hay loại bỏ
o Giảm chiều (dimension reduction): dùng một số thuật toán (ví dụ như PCA, ICA, LDA…) để
biến đổi dữ liệu ban đầu về không gian có ít chiều hơn o Trừu tượng hóa: các giá trị dữ liệu
thô đươc thay thế bằng các khái niệm trừu tượng
Chương 3: Bài toán hồi quy tuyến tính (Linear Regression)
1. Các khái niệm cơ bản về hồi quy tuyến tính
Regression problem (bài toán hồi quy): learn a function y=f ( x ) from a given training data
D={(x1, y1), (x2, y2),….,(xM , yM )}such that yi ≅f (xi) for every i o Each obseration of x is represented (biểu diễn)
by a vector in an n-dimensional space (không gian n chiều) , xi=(xi1,xi2,…,x¿)T. Each dimension represents an attribute/feature/variate.
Linear model (mô hình tuyến tính): if f(x) is assumed (coi là) to be of linear form
f ( x )=w
0+w1x1+…+wn xn o w
are the regression coefficients/weights (hệ số/trọng số hồi quy),
0,w1,…..,wn w0 sometimes
is called “bias” (độ lệch)
o Learning a linear model is equivalent to learning the coefficient vector w=(w0,w1,…,wn)T
For each observation x=(x1, x2,…, xn)T o The true output: cx (but unknown for future data) o
Prediction (dự đoán) by our model: y=w0+w1x1+…+wn xn and we often except yi ≅cx
→ prediction for a future observation z=(z1, z,…, zn)T, use f ( z)=w0+w1z1+…+wn zn Learning a
regression function (học một hàm hồi quy)
• Learning goal: learn a function f* such that its prediction in the future
is the best or its generalization (sự khái quát) is the best
• Difficulty: infinite (vô hạn) number of functions => How can we learn? Is function f better than g?
→ Use a measure (đo lường):
Loss function (hàm lỗi) is often used to guide learning
Loss function (hàm lỗi)
Empirical loss (lỗi thực nghiệm – RSS)
2. Method: ordinary least squares (OLS) – Phương pháp bình phương tối thiểu Method OLS
Limitations of OLS (giới hạn của phương pháp OLS – dẫn tới thực tế thông thường ít được sử dụng trực tiếp)
3. Method: Ridge regression (Phương pháp hồi quy Ridge)
(để tránh một số tác động tiêu cực của độ lớn của y lên các biến số x, ta nên loại bỏ w0 khỏi the penalty
term trong (*). Tring trường hợp này, nghiệm của w* nên được sửa đổi một chút.)
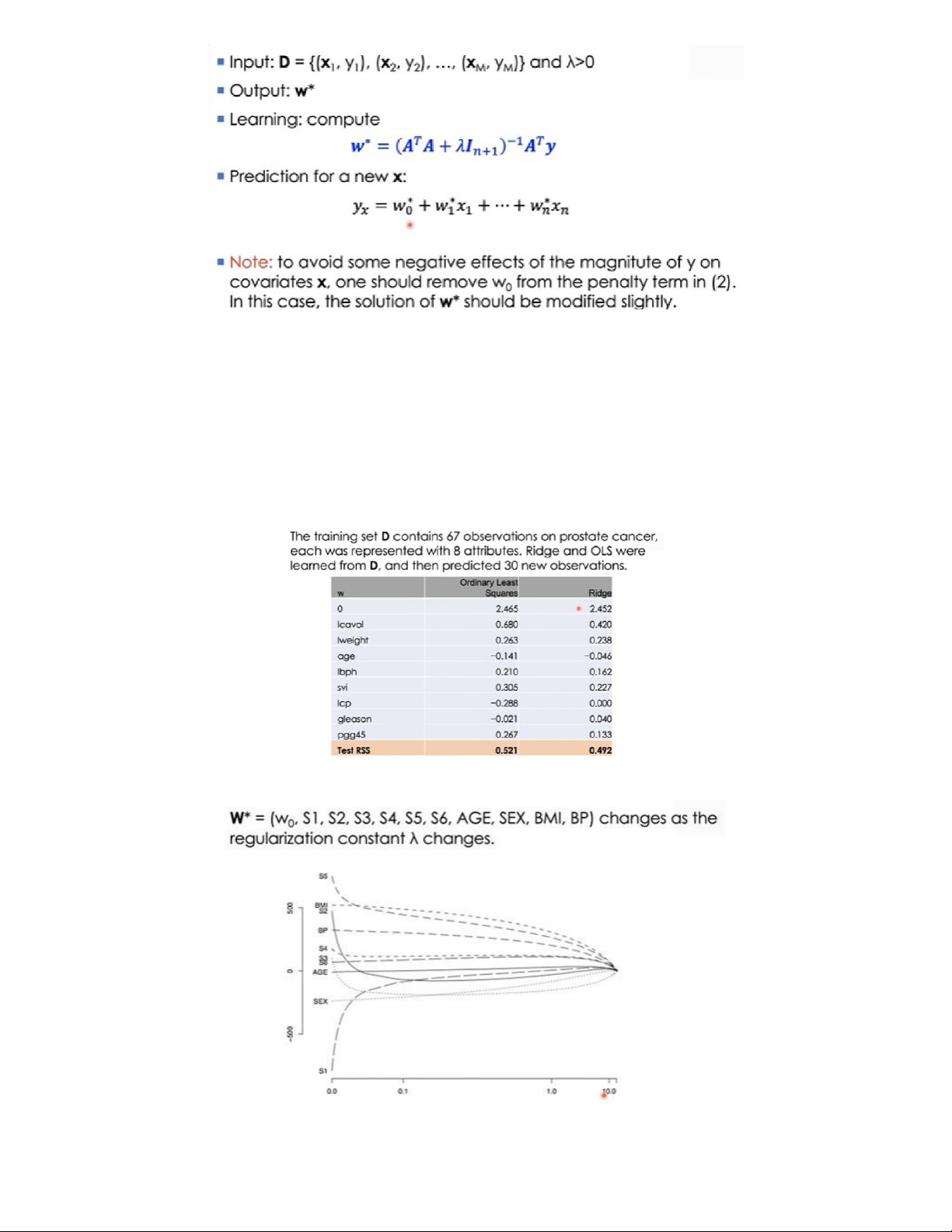
Một ví dụ về việc sử dụng Hồi quy Ridge và OLS
Tập huấn luyện D chứa 67 quan sát về bệnh ung thư tuyến tiền liệt, mỗi quan sát được biểu diễn bằng 8
thuộc tính. Ridge và OLS được học từ D và sau đó dự đoán 30 quan sát nhỏ. Bảng dưới mô tả 9 thành phần
của w (từ w0→w9¿ thu được bằng 2 phương pháp. Test RSS là lỗi thực nghiệm thì nhận thấy hệ số w của hai
phương pháp có sự sai lệch tương đối và kết quả Test RSS của Ridge tốt hơn.
Effect of λ in Ridge regression
Trục ngang là dải giá trị của λ tăng từ 0 đến 10(lớn). Trục dọc là dải giá trị của hệ số w, khi λ càng tăng thì
dải giá trị các hệ số w càng thu hẹp lại và tiến dần tới 0 khi λ lớn.
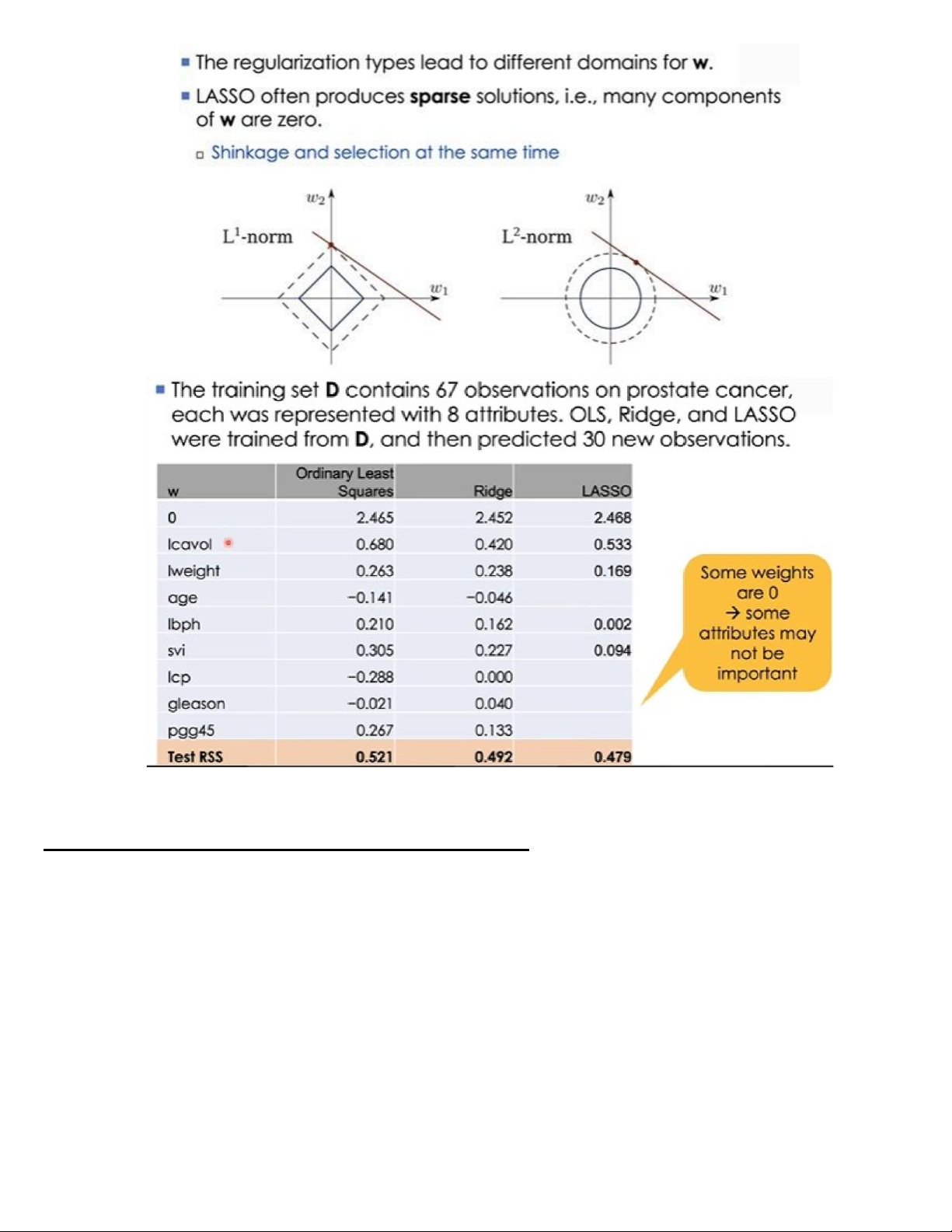
4. Methods: LASSO regression (phương pháp hồi quy LASSO)
Vai trò của phương pháp hồi quy LASSO
Phương pháp Lasso thường tạo ra các nghiệm thưa thớt (sparse solutions) tức là các nghiệm có thành phần trong w bằng 0.
Nếu như đối với phương pháp Ridge sử dụng L2−norm thì miền cho w có dạng là một hình cầu, không
gian nghiệm sẽ có thể rất lớn (là toàn bộ bề mặt ngòai), xác suất tìm được nghiệm thưa (nằm trên trục tọa độ) là rất khó.
Còn phương pháp Lasso sử dụng L1−norm thì miền cho w có dạng là một hình đa diện, kết quả phương
pháp thường cho ra các nghiệm nằm trên các trục tọa độ ( mà đối với không gian n-chiều thì có 2n điểm nằm
trên các trục tọa độ ).
Vì vậy mà phương pháp Lasso này cho phép thu gọn không gian nghiệm và cả số nghiệm đồng thời cho
phép lựa chọn thuộc tính bằng 0.
Một số thành phần của w bằng 0 dẫn đến có thể biểu diễn hàm f chỉ thông qua các thành phần khác 0
của w thôi thì sẽ rút gọn được độ phức tạp của hàm f đi rất nhiều.
Chương 4: Bài toán phân cụm (Phân cụm với K-means)
Nhắc lại một số kiến thức:
Two basic learning problems
• Supervised learning (học có giám sát): learn a function y = f(x) from a given training set {xi , yi } so
that yi ≅f (xi) for every i. → each training instance has a label/response o Classification (categorization,
phân loại, phân lớp): if y only belongs to a discrete set (một tập rời rạc), for example {spam, normal}
o Regression (hồi quy): if y is a real number. Ex prediction of stock indices (chứng khoán)
• Unsupervised learning (học ko giám sát): learn a function y = f(x) from a given training set {xi }
→ no response is available and our target (mục tiêu) is the hidden structure in data
o y can be a data cluster o y can be a hidden structure o y can be a trend
Ví dụ bài toán phân cụm dữ liệu, tìm kiếm mạng người dùng MXH , hay xu hướng người tiêu dùng
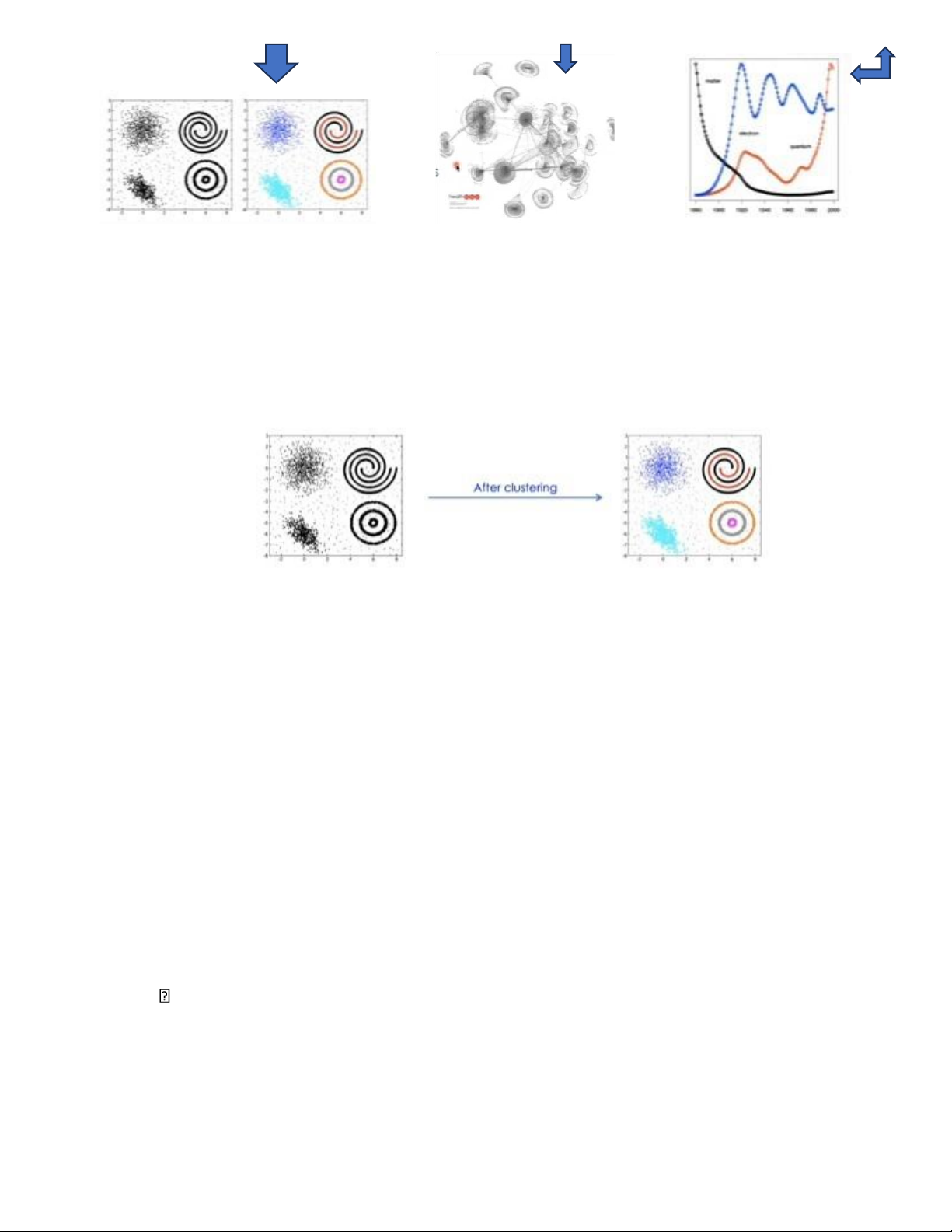
1. Clustering (Phân cụm)
• Clustering problem: o
Input: a training set without any label (một tậo huấn luyện không có
nhãn hay giá trị y) o Output: clusters of the training instances • A cluster o
Consists of similar instances in some senses o Two clusters should be different from each other
• Approaches to clustering (các phương pháp phân cụm) o Partiton-based
clustering (phân cụm dựa trên phân vùng) o Hierarchinal clustering (phân cụm theo cấp bậc)
o Mixture models (mô hình hỗn hợp)
o Deep clustering (phân cụm sâu) o …..
• Evaluation of clustering quality (Đánh giá chất lượng phân cụm) o
Distance/difference between any two clusters should be large (inter-cluster distance)
(khoảng cách/sự khác biệt giữua hai cụm bất kỳ phải lớn) o
Difference between instances inside a cluster should be small
(sự khác biệt giữa các thành phần trong một cụm phải nhỏ) 2. K-means for clustering
• K-means is the most popular method for clustering, which is the partition-based (dựa trên phân
hoạch) Data respresentation: D={x
is avector in the n-dimensional Euclidean space.
1, x2,….,xr } each xi
• K-means partitons D into K clusters (chia D quan sát vào K vùng):
o Each cluster has a central point (một điểm trung tâm) which is called centroid o
K is a pre-specified constrant (hằng số được xác định trước). Main steps of K-means:
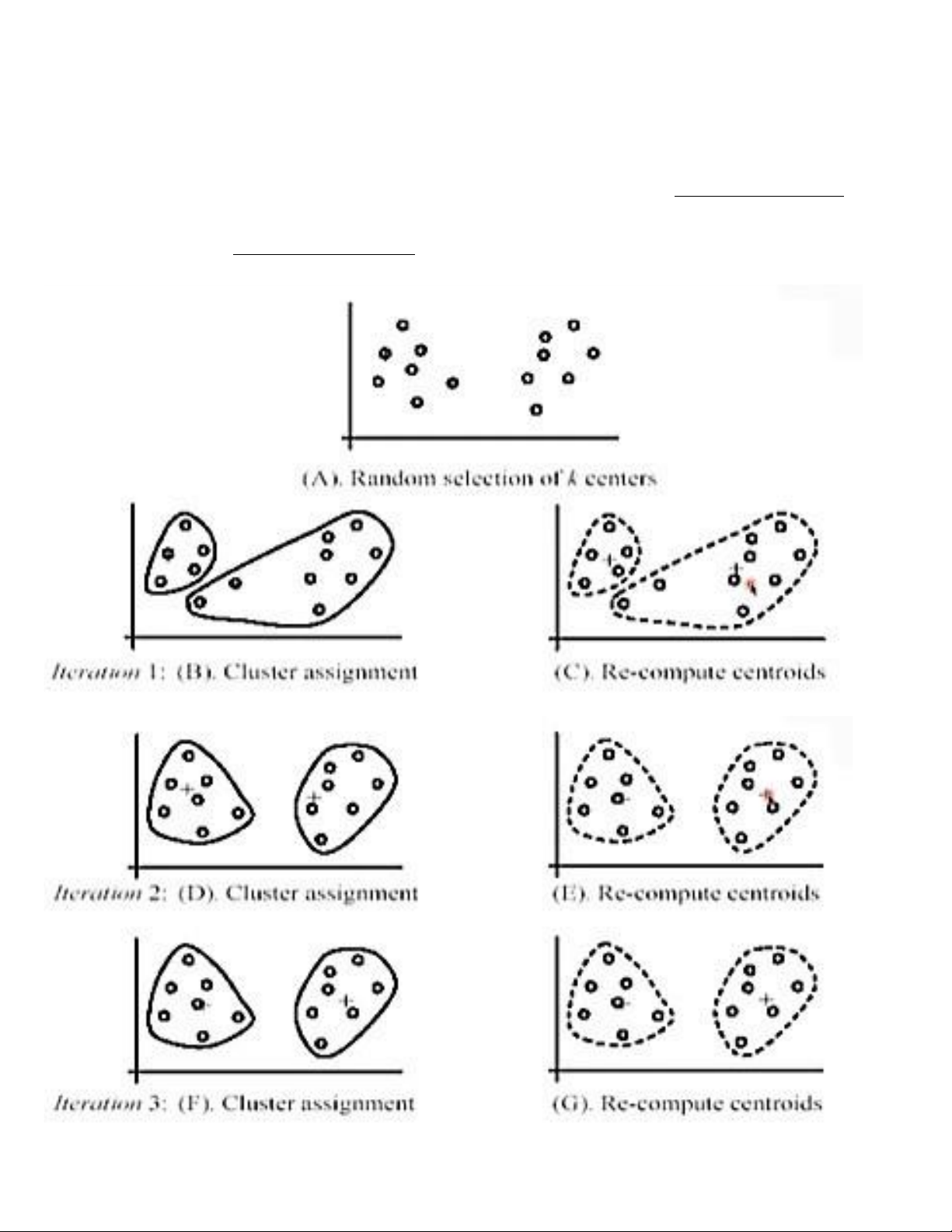
• Input: training data D (tập dữ liệu huấn luyện), number K of clusters (số lượng vùng K) , and distance
measure d(x,y) (đo lường khảong cách giữua hai điểm x, y)
• Initialization: select randomly K instances in D as the initial centroid (lựa chọn ngẫu nhiên K quan
sát trong D làm điểm trung tâm cho K vùng)
• Repeat the following two steps until covergence (lặp lại hai bước đến khi hội tụ - kết quả trùng lặp
xảy ra thì dừng lại) o Step 1: for each instance, assign it to the cluster with nearest centroid
(Bước 1: với mỗi quan sát, đưa nó vào cluster mà gần điểm trung tâm nhất) o Step 2: for
each cluster, recompute its controid from all the instances assigned to that cluster (Bước 2: với
mỗi cluster, tính toán lại điểm trung tâm từ tất cả các quan sát của cluster đó)
Ở ví dụ trên, ta chia tập dữ liệu huấn luyên D thành 2 cụm (K=2). Sau lượt thứ nhất thì D chia thành 2 cụm
như hình vẽ và ta cần tính toán lại controid mới. Với hai controid mới ta thựuc hiện lượt thứ hai, tiếo tục
chia D vào hai cụm, tiếp tục vậy ta có lượt thứ 3. Đến đây nhận thấy kết quả của lượt thứ 2 và thứ 3 là giống
nhau thì ta sẽ dừng lại và thu được kết quả phân cụm.
K-means: covergence (sựu hội tụ của K-means)
• The algorithm converges if (thậut toán hội tụ nếu) o Very few instances are reassigned to new
clusters (rất ít quan sát được ghi vào các cluster mới)
o The centroids do not change significantly (điểm trung tâm ko thay đổi quá nhiều), or o
The following sum does not change significantly K
Error=∑∑ d(x ,mi)2 i=1 x∈C where C is the i i
ithcluster; m is the centroid of cluster i Ci
K-means: centroid, distance
3. Các vấn đề trong thuật toán K-means a. K-means: distance
Distance measure (đo lường khoảng cách)
• Each measure provodes a view on data (mỗi một các đo cung cấp một cái
nhìn về dữ liệu, chẳng hạn như với các đo trong không gian Euclid ở trên
thì ta đã giả thiết là luôn có một đường thẳng nối hai điểm, nhưng chẳng
hạn với khôg gian ohi Eclid (mà chúng ta đang sống) như hình bên thì lại
cần có một thước đo khoảng cách khác được sử dụng ) There are infinite
numbers of distance measures Which distance is goods?
Similarity measures can be used (có thể sử dụng các thước đo tương tự): Similarity between two objects
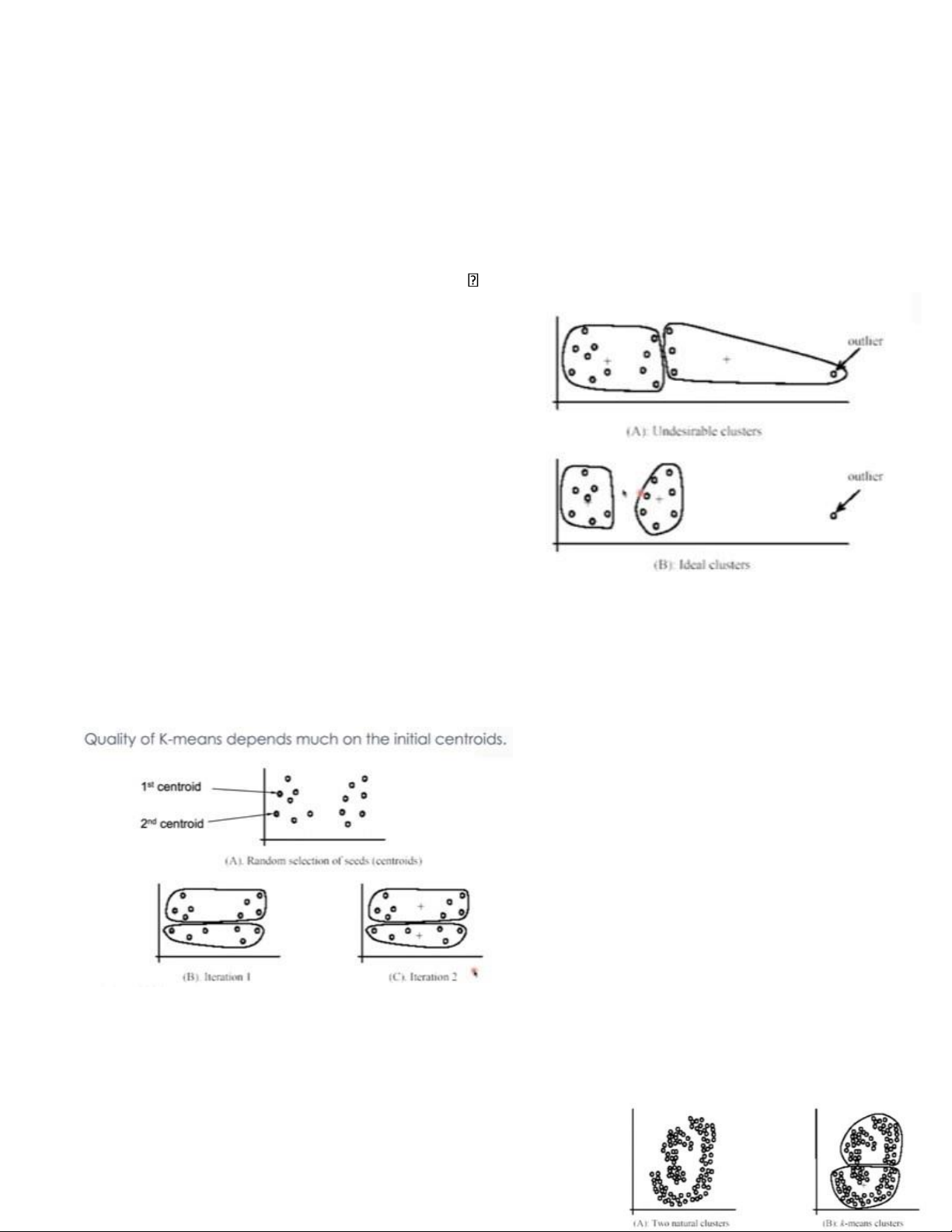
b. K-means: outlier (điểm ngoại lai)
• K-means is sensitive with outliers, i.e., outliers might affect significantly on clustering results. (K-
means khá nhạy cảm với các điểm ngạoi lai, tức là các gt ngoại lai có thể ảnh hưởng đáng kể đến kết
quả phân cụm) o Outliers are instances that significantly differ from the normal instances. (ngoại
lai là quan sát mà có sự khac biệt đáng kể đối với các quan sát thông thường)
o The attribute distributions of outliers are very different from those of normal points. (sự phân bố
thuộc tính của các điểm ngoại lai rất khác so với các điểm bình thường)
o Noises or errors in data can result in outliers. Outlier solutions:
Outlier removal (loại bỏ ngạoi lệ) : we may remove some
instances that are significantly far from the centroids,
compared with other instances (rất xa điểm trung tâm so với
các điểm khác). Removal can be done a priori or when learning clusters.
Random sampling (lấy mẫu ngẫu nhiên): instead of
clustering all data, we take a random sample S from the
whole training data (lấy một mẫu S bất kỳ từ toàn bộ dl).
o S will be used to learn K clusters. Note that S often
contains fewer noises/outliers than the original training data.
o After learning, the remaining data will be assigned to the learned clusters. (dữ liệu còn lại sẽ được
gán cho các cụm đã học)
c. K-means: initialization (sự khởi tạo trong K-means)
Chất lượng của thuật toán K-means phụ thuộc
nhiều vào việc chọn điểm trung tâm, trong ví
dụnhư hình vẽ, việc chọn hai điểm trung tấm đó
làm cho kết quả tạo thành hai cụm ko tốt, các
thành phần có sự cách xa nhau
K-means ++: initialization solution
K-means++: to obtain a good clustering, we can initialize the centroids from D in sequence as follows (để
có được một phân cụm tốt, chúng ta có thể khưởi tạo các controid từ
D theo trình tự như sau:) o Select randomly the first centroid m . 1 o
Select the second centroid which are farthest to m . (xa nhất so với 1 m1¿
o Select ith centroid which are farthest from {m
}. (khoảng cách từ một điểm đến một tập 1,m2,….,mi−1
chính là khoáng cách từ điểm đó đến điểm gần nhất trong tập đó) o …..
By using this initialization scheme, K-means can converge to a near optimal solution. (Bằng cáh sử dụng
sơ đồ khởi tạo này, K-means có thể hội tụ đến một giải pháp gần tối ưu)
d. K-means: curved cluster (cụm cong)
When using Euclidean distance, K-means cannot detect non-spherical clusters (ko thể phát hiện các cụm khổng phải hình cầu)
→gỉaiquyết :sử dụngđộđo khoảngcáchkhác
4. Online K-means (dành cho dữ liệu lớn)
With K-means: we need all training data for each iteration, therefore it cannot work with big datasets and
cannot work with stream data where data come in sequence (dữ liệu tới theo thứ tự)
Online K-means helps us to cluster big/stream data.It is an online version of K-means. It follows the
methodology from online learning and stochastic gradient (nó tuân theo phương pháp học trực tuyến và
gradient ngẫu nhiên) . At each iteration, one instance will be exploited to update the available clusters. (tại
mỗi bước, một quan sát sẽ được khai thác đê cập nhật các cụm có sẵn)
Note that K-means finds K clusters from the training instamces {x1,x2,…,x M } by minimizing the following loss function: Q 1 M K−means
¿ where w (xi) is the nearest centroid to xi
Using its gradient, we can minimize Q by repeating the following update until convergence (lặp lại quá M
trình cập nhật cho đến khi hội tụ) :wt+1=wt+γt ∑[¿ xi−wt (xi)]¿ i=1
Where γ is a small constant, often called learning rate (tốc độ học) t
Tuy nhiên, cách áp dụng trực tiếp gradient vào hàm Q này cần phải tính toán với rất nhiều dữ liệu gây ra sự
tốn kém vì vậy ta ko thể tính toán toàn bộ gradient của hàm Q mà ta chỉ tính một phần thôi (cực tiểu ngãu nhiên)
Online K-means minizises Q stochastically (Online K-means tối thiểu hóa Q một cách ngẫu nhiên): o
At each iteration, we just use a little information from the whole gardient Q’
o Those information comes from the training instances at iteration t (những thôn tin ấy đến từ quan sát
đưojc đào tạo tại lần lặp t) : xt−wt (xt)
Online K-means: algorithm (thuật toán Online K-means)
• Initialize K centroids randomly. (khởi tạo K centroid một cách ngẫu nhiên)
• Update the centroids as an instance comes (cập nhật các centroid khi có một quan sát xuất hiện)
o At iteration t, take an instance x . (tại lần lặp thứ t, lấy một quan sát ) t xt o Find the nearest
centroid w to , and then update (cập nhật) as follows: t xt wt
wt+1=wt+γt(xt−wt)
Note: the learning rates {γ , ,...} are positive constants, which should satisfy (tốc độ học là hằng số dương 1 γ2
thỏa mãn điều kiện (giúp đảm bảo cho thuật toán hội tụ: ) i =1
A popular choice of learning rate:
γt=(t+τ)−κ
• τ ,κ are possitive constants (hằng số dương)
• κ ϵ¿ is called forgetting rate (toc do quen). Large κ means that the algorithm remembers the past
longer, and that new observations play less and less important role as t grows (κ có nghĩa thuật toán
ghi nhớ quá khứ lâu hơn, và các qsát mới ngày càng đóng vai trò ít quan trọng hơn khi t phát triển,
còn khi κ nhỏ thì nó cập nhật các tri thức mới nhanh hơn do κcàng lớn thì γt càng nhỏ nên theo công thức w
ít sai lệch hơn so với )
t+1=wt+γt(xt−wt) thì wt+1 wt
Chương 5: Học dựa trên láng giềng ( K-nearest neighbors – KNN) Main ideas:
• There is no specific assumption on the function to be learned. (ko có 1 giả định cụ thể về hàm cần học)
• Learning phase just stores all the training data. (Giai đoạn học tập chỉ lưu trữ tất cả dữ liệu đào tạo)
• Prediction for a new instance is based on its nearest neighbors in the training data. (dự đoán một phiên
bản mới dựa vào hàng xóm gần nhất trong tập dữ liệu huấn luyện) Thus KNN is called a non-parametric
method (phương pháp phi tham số) Two main ingredients:
• The similarity measure (distance) between instances/objects. (sự đo lường giống nhau giữa 2 qs)
• The neighbors to be taken in prediction. (hàng xóm được chọn để phán đoán)
→Under some conditions, KNN can achieve the Bayes-optimal error which is the performance limit of
any methods. (trong một số điều kiện, KNN có thể đạt được lỗi tối ưu Bayes là giới hạn hiệu suất của bất
kỳ phương pháp nào) “Gyuader and Hengartner, JMLR 2013” o Even 1-NN (with some simple
modifications) can reach thisperformance. (Ngay cả 1-NN (với một số sửa đổi đơn giản) cũng có thể đạt được hiệu suất này)
KNN is close to Manifold learning (KNN gần với phương pháp học Đa dạng – Manifold learning)
KNN for classification ( KNN cho bài toán phân loại)
Ở pha học tập: đơn giản chỉ lưu tất cả dữ hiệu huấn luyện
D, cùng với nhãn của chúng Dự đoán cho một quan sát mới z:
o Với mỗi quan sát x trong D, tính khoảng cách/sự
tương đồng giữa x và z o Xác định tập NB(z) các
lân cận gần nhất của z
o Sử dụng nhãn có số lượng lớn nhất trong NB(z) để dự đoán nhãn cho z
KNN for regresion (KNN cho bài toán hồi quy)
The distance/similarity measure (Thước đo khoảng cách/sự tương đồng)
Each measure implies a view on data (mỗi một thước đo có cách nhìn khác nhau về dữ liệu) and have infinite
Tài liệu liên quan:
-

Báo cáo kỹ thuật Đề tài: dự đoán nguồn gốc tổ tiên địa lý-sinh học (bga) sử dụng dữ liệu dna - Học phần Nhập môn học máy và khai phá dữ liệu | Đại học Bách Khoa Hà Nội
18 9 -

Dự đoán nguồn gốc tổ tiên Địa lý-Sinh học (bga) sử dụng dữ liệu dna môn Nhập môn học máy và khai phá dữ liệu | Đại học Bách Khoa Hà Nội
16 8 -

California eda visualization - Bài tập môn Nhập môn học máy và khai phá dữ liệu | Đại học Bách Khoa Hà Nội
16 8 -

BGA Systematic analyses of AISNPs - môn Nhập môn học máy và khai phá dữ liệu | Đại học Bách Khoa Hà Nội
16 8 -

Tài liệu hướng dẫn thực hiện đồ án môn Khai phá dữ liệu | Đại học Bách Khoa Hà Nội
28 14