Bài giảng Data crawling preprocessing môn Nhập môn học máy và khai phá dữ liệu | Trường Đại học Bách Khoa Hà Nội
Tiền xử lý để làm gì? Thuận tiện trong lưu trữ, truy vấn. Các mô hình học máy thường làm việc với dữ liệu có cấu trúc: ma trận, vectơ, chuỗi,… Học máy thường làm việc hiệu quả nếu có biểu diễn dữ liệu phù hợp. Tài liệu được sưu tầm gồm 30 trang, giúp các bạn ôn luyện và phục vụ cho việc học tập, đạt kết quả tốt. Mời các bạn đón xem!
Môn: Nhập môn học máy và khai phá dữ liệu 15 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:





Preview text:
Introduction to
Machine Learning and Data Mining
(Học máy và Khai phá dữ liệu ) Khoat Than Le Minh Hoa, Nguyen Van Son
School of Information and Communication Technology
Hanoi University of Science and Technology 2021 2 Content
Introduction to Machine Learning & Data Mining
Data crawling and pre-processing Supervised learning Unsupervised learning Practical advice 3 Quỹ thời gian
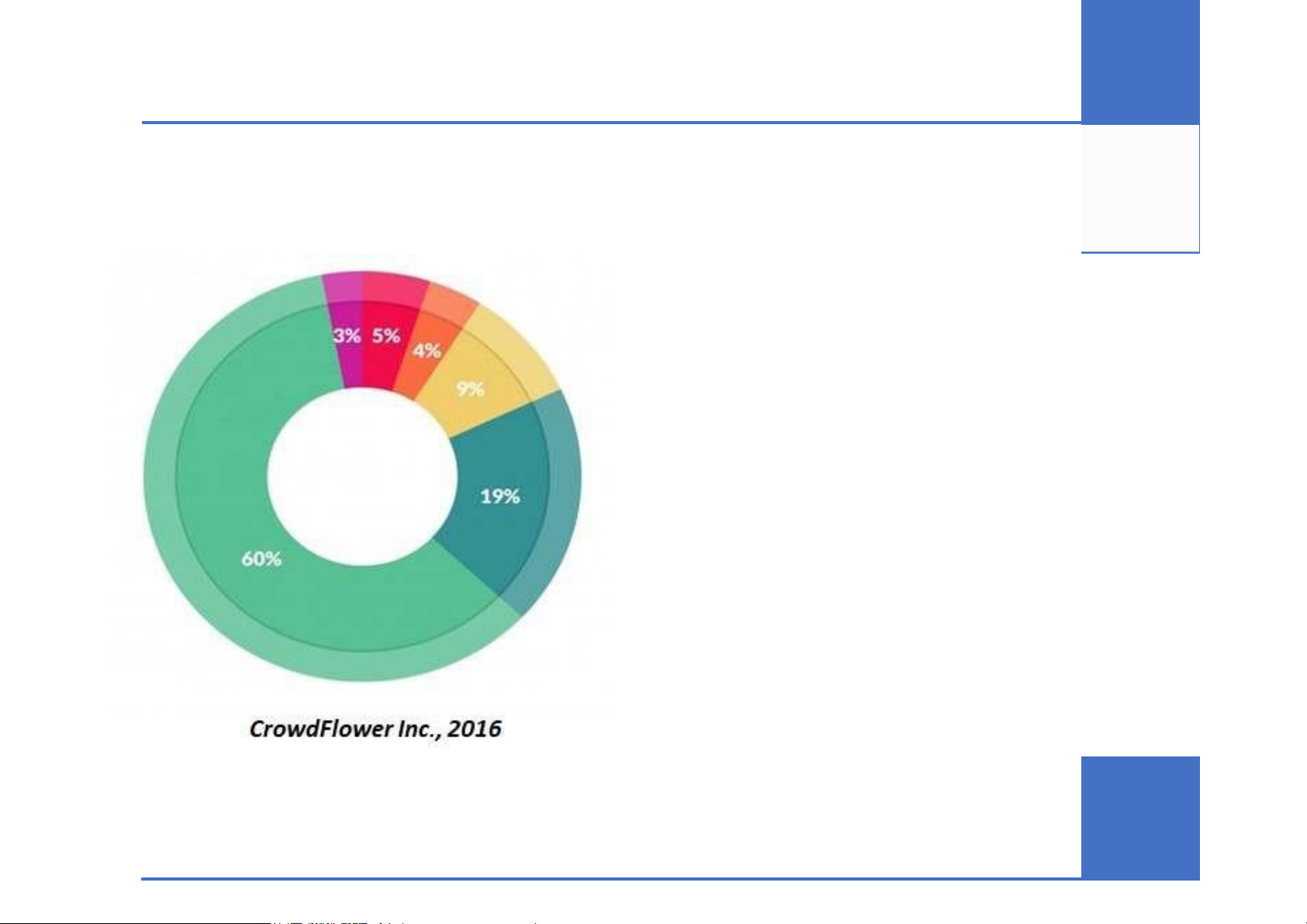
▪ Thời gian dành cho phân tích dữ liệu ra sao?
• Thu thập dữ liệu: 19%
• Thu xếp và làm sạch dữ liệu: 60%
• Tạo tập dữ liệu huấn luyện: 3% • Khai phá: 9%
• Cải thiện thuật toán: 4% • Khác: 5% 4 Why?
Tiền xử lý để làm gì
• Thuận tiện trong lưu trữ, truy vấn
• Các mô hình học máy thường làm việc với dữ liệu có cấu
trúc: ma trận, vectơ, chuỗi,…
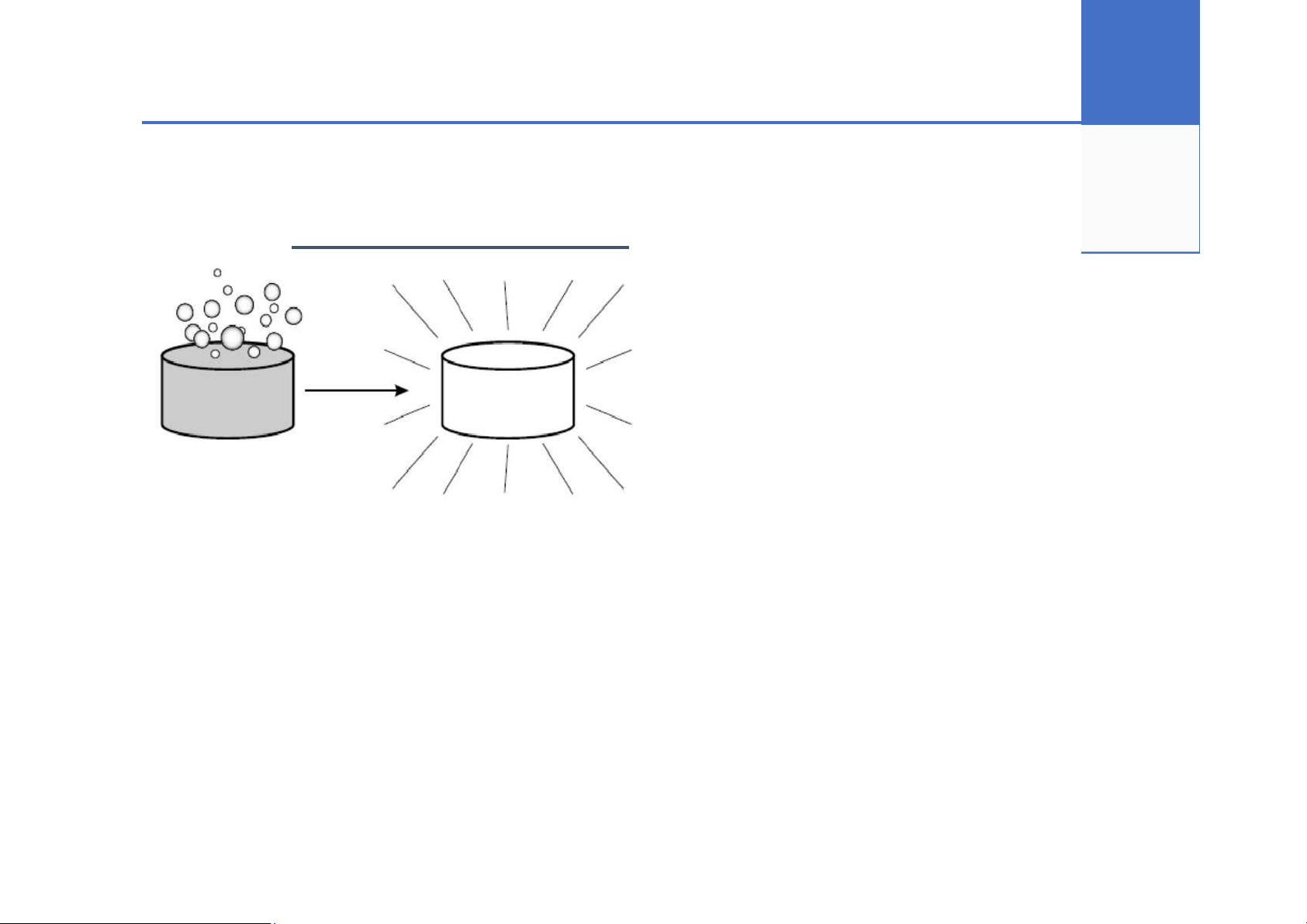
• Học máy thường làm việc hiệu quả nếu có biểu diễn dữ liệu phù hợp Input Output
Vấn đề cần giải quyết của Dữ liệu lĩnh vực số - ma trận vector -0.0920 ! " 3.4931 # -1.8493 ! $ ! ! " ... #" ... -0.2010 ! ! -1.3079 5 How? ▪ Thu thập dữ liệu • Lấy mẫu (sampling)
• Kỹ thuật: crawling, logging, scraping ▪ Xử lý dữ liệu
• Lọc nhiễu, làm sạch, số hoá,… Business Analytic understanding approach Data Feedback requirements Data Deployment collection Data Evaluation understanding Data Modeling preparation 6 Data collection Input Output
Vấn đề cần giải quyết Mẫu dữ liệu 7 Fundamentals :: Sampling
WHAT – lấy tập mẫu the
“One or more small spoon(s) can be enough to assess whether
soup is good or not.”
nhỏ, phổ biến để đại diện cho lĩnh vực cần học.
WHY – không thể học toàn
bộ. Giới hạn về thời gian và khả năng tính toán
HOW – thu thập các
mẫu từ thực tế, hoặc
https://www.coursera.org/learn/inferential-statistics-intro
các nguồn chứa dữ liệu web, database,… 8
Fundamentals :: Sampling :: How Variety – tập mẫu soup is
“One or more small spoon(s) can be enough to assess whether the thu good or not.” được đủ đa
Remember to stir to avoid tasting biases.
dạng để phủ hết các ngữ cảnh của lĩnh vực.
Bias – dữ liệu cần tổng
quát, không bị sai lệch,
thiên vị về 1 bộ phận nhỏ nào đó của lĩnh vực.
https://www.coursera.org/learn/inferential-statistics-intro 9
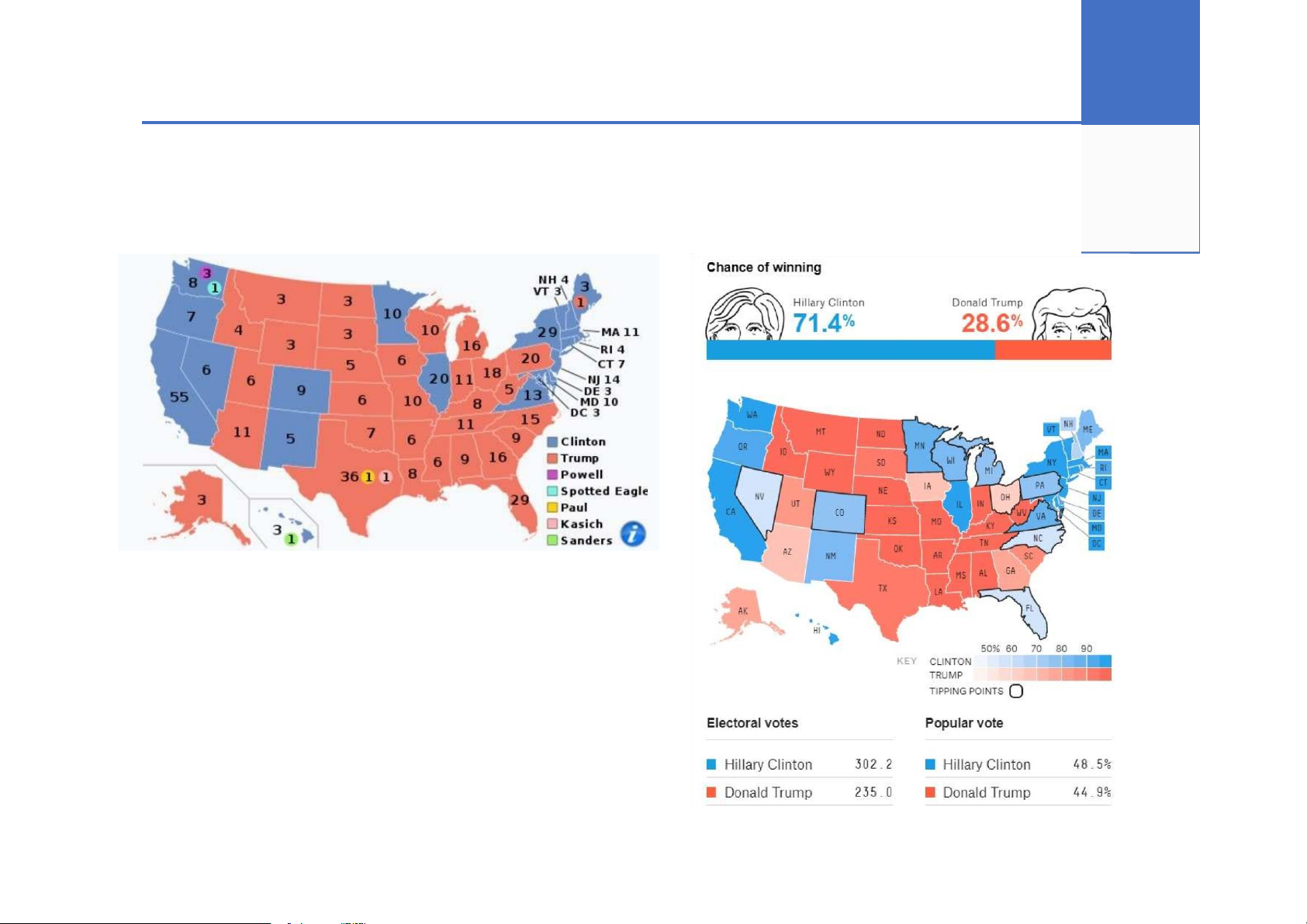
Fundamentals :: Sampling :: How
Variety – các mẫu đủ đa
dạng để phản ánh khách quan? Actual results
https://projects.fivethirtyeight.com/2016-election-forecast/
http://edition.cnn.com/election/results/president Image credit:
Wikipedia, FiveThirtyEight
https://www.coursera.org/learn/inferential-statistics-intro 10 Techniques
▪ Crowd-sourcing: Survey – thực hiện các khảo sát
▪ Logging: lưu lại lịch sử tương tác của người dùng, truy cập sản phẩm,…
▪ Scrapping: tìm kiếm nguồn dữ liệu trên các website, tải về, bóc tách, lọc,… 11
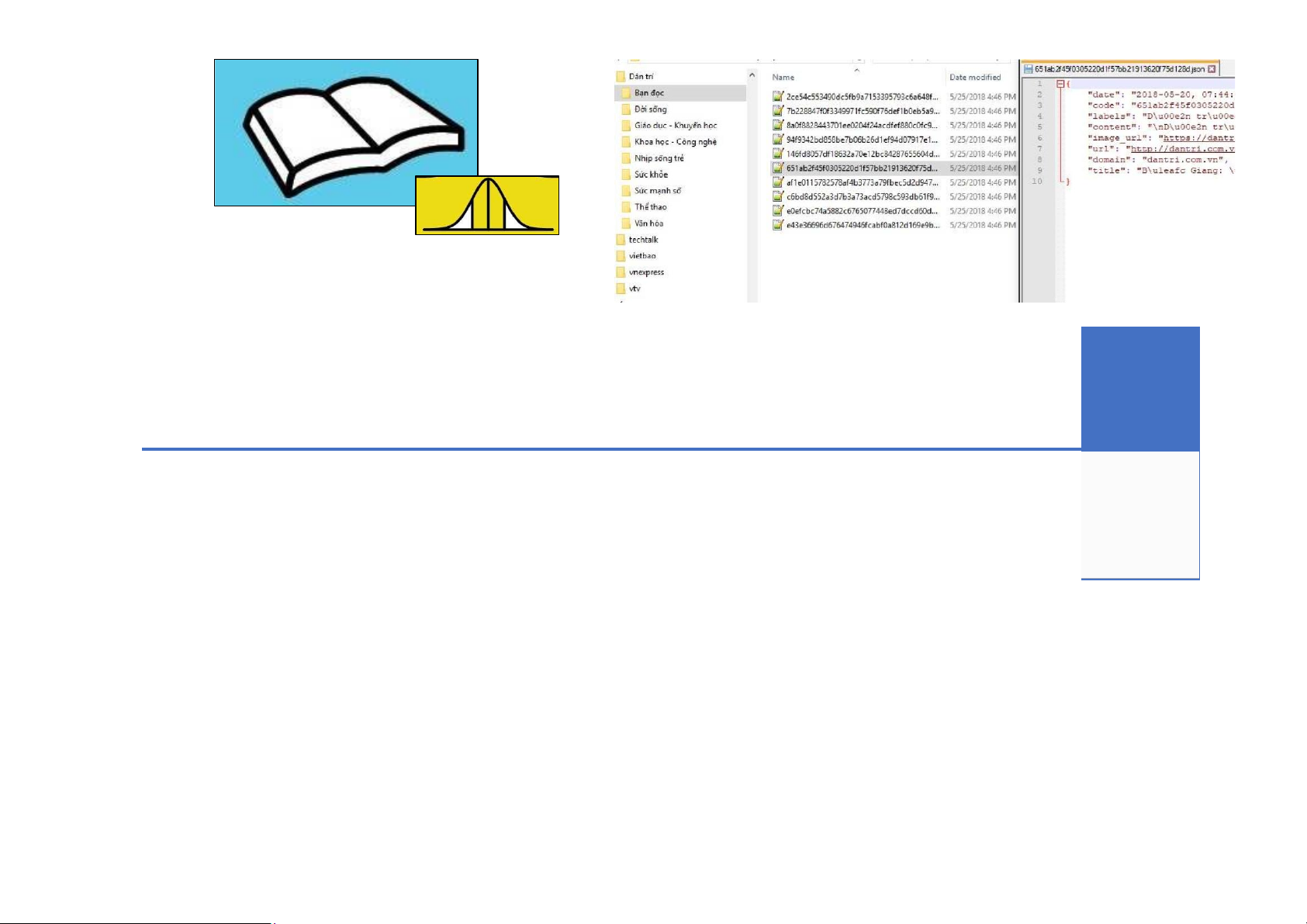
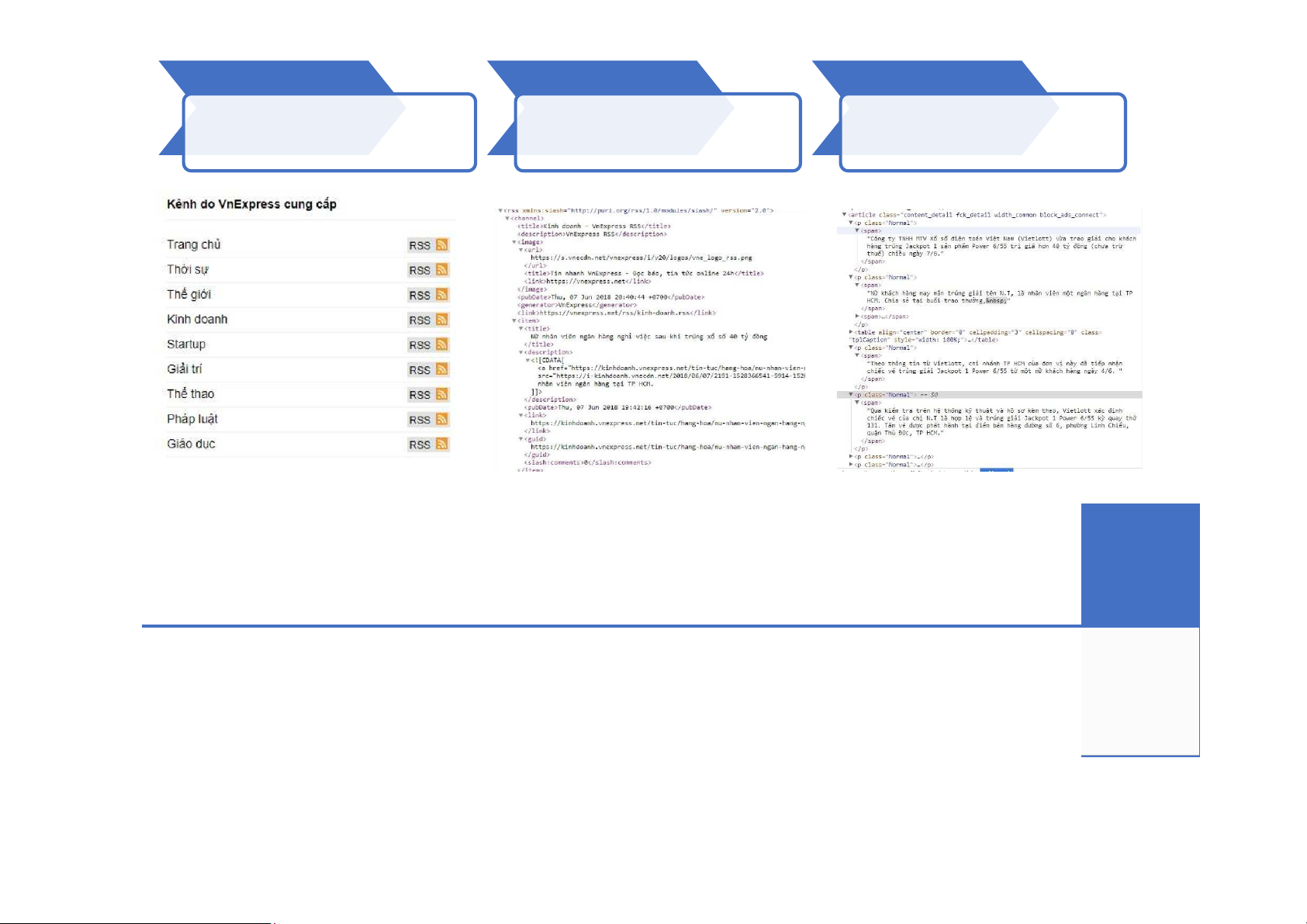
Techniques :: Scrapping :: DEMO
▪ Mục tiêu: Dữ liệu cho bài toán phân loại văn bản – miền báo chí.
▪ DEMO: Hệ thống crawl dữ liệu báo 12 DEMO Input Output
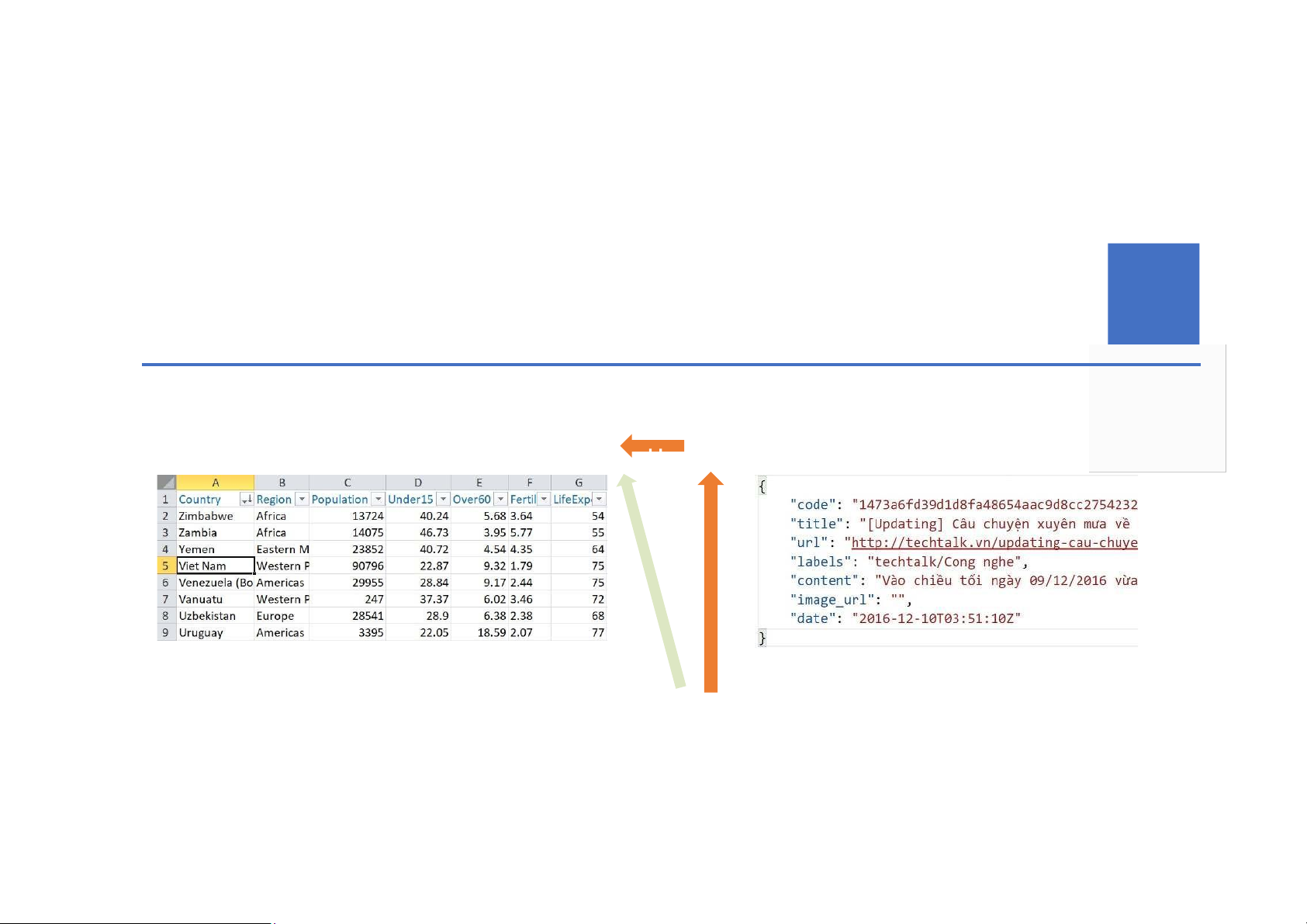
Vấn đề: phân loại văn bản Mẫu dữ liệu: báo chí và báo chí nhãn tương ứng 13 DEMO :: Steps Rss Item Content 14 DEMO :: Sample 15 Data preprocessing Input Output Mẫu dữ liệu thô
Dữ liệu số theo từng ML/AI (text, ảnh, audio, …) model(s) -0.0920 ! " 3.4931 -1.8493 # ! $ ! ! " ... #" ... ! ! -0.2010 -1.3079 16 Fundamentals :: Data rawness Completeness Integrity (đầy đủ) (trung thực)
▪ Nguồn thu thập chính thống, đảm
Từng mẫu thu thập nên đầy đủ thông bảo mẫu thu được
chứa giá trị tin các trường thuộc tính cần thiết chính xác trên thực tế.
▪ Jan. 1 as everyone’s birthday? –
intentional (systematic) noises Homogeneity Structures (đồng nhất) (cấu trúc)
▪ Rating “1, 2, 3” & “A, B, C”; or Age
= “42” & Birthday = “03/07/2010” (inconsistency)
▪ Heterogenous data sources / schemas 17 Techniques Cleaning Integrating Transforming 18 Techniques :: Cleaning
Tính đầy đủ + trung thực
• Mẫu dữ liệu cần được thu
thập từ các nguồn đáng tin cậy.
Phản ánh vấn đề cần giải quyết.
• Loại bỏ nhiễu (ngoại lai): bỏ
vài mẫu dữ liệu mà có khác biệt lớn với các mẫu khác.
• Một mẫu dữ liệu có thể bị trống (thiếu, chưa đầy đủ), cần có chiến lược phù hợp:
• Bỏ qua, không đưa vào phân tích?
• Bổ sung các trường còn thiếu cho mẫu? 19 Techniques :: Cleaning
Điền giá trị thiếu
Điền lại giá trị bằng tay
Gán cho giá trị nhãn đặc biệt hay ngoài khoảng biểu diễn
Gán giá trị trung bình cho nó.
Gán giá trị trung bình của các
mẫu khác thuộc cùng lớp đó.
Tìm giá trị có xác suất lớn nhất
điền vào chỗ bị mất (hồi quy, suy diễn Bayes,…) A1 A2 A3 A4 A5
A6 A7 A8 y ? 3.683 ? -0.634 1 0.409 7 30 5 ? ? 60 1.573 0 0.639 7 30 5 ? 3.096 67 0.249 0 0.089 ? 80 3 2.887 3.870 68 -1.347 ? 1.276 ? 60 5 2.731 3.945 79 1.967 1 2.487 ? 100 4 Techniques :: Cleaning 20 (cont.)
Tính đồng nhất
Các mẫu dữ liệu cần có tính đồng nhất về cách biểu diễn, ký hiệu.
Ví dụ không đồng nhất:
Rating “1, 2, 3” & “A, B, C”;
Age = 42 & Birthday = 03/08/2020 21
Techniques :: Integrating w/ some Transforming Un-structured
texts in websites, emails, articles, tweets 2D/3D images, videos + meta spectrograms, DNAs, …
Tài liệu liên quan:
-

Báo cáo kỹ thuật Đề tài: dự đoán nguồn gốc tổ tiên địa lý-sinh học (bga) sử dụng dữ liệu dna - Học phần Nhập môn học máy và khai phá dữ liệu | Đại học Bách Khoa Hà Nội
38 19 -

Dự đoán nguồn gốc tổ tiên Địa lý-Sinh học (bga) sử dụng dữ liệu dna môn Nhập môn học máy và khai phá dữ liệu | Đại học Bách Khoa Hà Nội
36 18 -

California eda visualization - Bài tập môn Nhập môn học máy và khai phá dữ liệu | Đại học Bách Khoa Hà Nội
35 18 -

BGA Systematic analyses of AISNPs - môn Nhập môn học máy và khai phá dữ liệu | Đại học Bách Khoa Hà Nội
38 19 -

Tài liệu hướng dẫn thực hiện đồ án môn Khai phá dữ liệu | Đại học Bách Khoa Hà Nội
45 23