Tổng quan về phần mềm Orange trong khai phá dữ liệu - Môn Quản trị Học - Đại Học Kinh Tế - Đại học Đà Nẵng
Khai phá dữ liệu (Data Mining) và học máy (Machine Learning) là những lĩnh vực khá khó để khám phá và nghiên cứu. Do đó, nhiều phần mềm đã ra đời với mục tiêu là giúp cho người dùng có thể dễ dàng nghiên cứu các bài toán trong những lĩnh vực khó nhằn này. Một trong những phần mềm đó có thể kể đến là Orange. Tài liệu giúp bạn tham khảo ôn tập và đạt kết quả cao. Mời bạn đọc đón xem!
Môn: Quản trị học (QTH 11) 459 tài liệu
Trường: Trường Đại học Kinh tế - Đại học Đà Nẵng 1.4 K tài liệu
Tác giả:



Preview text:
lOMoARcPSD| 49221369
Tổng quan về phần mềm Orange: KHAI THÁC DỮ LIỆU
HIỆU QUẢ VÀ VUI VẺ
Máy học mã nguồn mở và trực quan hóa dữ liệu.
Xây dựng quy trình phân tích dữ liệu một cách trực quan
với các công cụ đa dạng.
Khai phá dữ liệu (Data Mining) và học máy (Machine Learning) là những lĩnh vực khá
khó để khám phá và nghiên cứu. Do đó, nhiều phần mềm đã ra đời với mục tiêu là giúp
cho người dùng có thể dễ dàng nghiên cứu các bài toán trong những lĩnh vực khó nhằn
này. Một trong những phần mềm đó có thể kể đến là Orange.
Phần mềm Orange biết đến bởi việc tích hợp các công cụ khai phá dữ liệu mã nguồn mở
và học máy thông minh, đơn giản, được lập trình bằng Python với giao diện trực quan và
tương tác dễ dàng. Với nhiều chức năng, phần mềm này có thể phân tích được những dữ
liệu từ đơn giản đến phức tạp, tạo ra những đồ họa đẹp mắt và thú vị và còn giúp việc
khai thác dữ liệu và học máy trở nên dễ dàng hơn cho cả người dùng mới và chuyên gia.
Các công cụ (widgets) cung cấp các chức năng cơ bản như đọc dữ liệu, hiển thị dữ liệu
dạng bảng , lựa chọn thuộc tính đặc điểm của dữ liệu, huấn luyện dữ liệu để dự đoán, so
sánh các thuật toán máy học , trực quan hóa các phần tử dữ liệu, …
Data: Dùng để rút trích, biến đổi, và nạp dữ liệu (ETL process). lOMoARcPSD| 49221369
Visualize: dùng để biểu diễn biểu đồ (chart) giúp quan sát dữ liệu được tốt hơn lOMoARcPSD| 49221369
Model: gồm các hàm máy học (machine learning) phân lớp dữ liệu với Tree, Logictis Regression, SVM,.. .
Evaluate: Là các phương pháp đánh giá mô hình như : Test& Score, Prediction, Confusion.. lOMoARcPSD| 49221369
Unsupervised: Gồm các hàm máy học (machine learing) gom nhóm dữ liệu như: Distance, K-means,...
Add ons: Giúp mở rộng các chức năng nâng cao như xử lý dữ liệu lớn (Big Data) với
Spark, xử lý ảnh với Deep learing, xử lý văn bản, phân tích mạng xã hội,.. Đây có lẽ là
điểm cộng của Orange so với các phần mềm khai phá dữ liệu khác. lOMoARcPSD| 49221369
Phân lớp dữ liệu:
1. Định nghĩa phân lớp dữ liệu:
Là quá trình phân một đối tượng dữ liệu vào một hay nhiều lớp (loại) đã cho trước nhờ
một mô hình phân lớp. Mô hình này được xây dựng dựa trên một tập dữ liệu đã được
gán nhãn trước đó ( thuộc về lớp nào ). Quá trình gán nhãn( thuộc lớp nào) cho đối
tượng dữ liệu chính là quá trình phân lớp dữ liệu.
2. Quá trình phân lớp dữ liệu:
Bước 1: Xây dựng mô hình ( hay còn gọi là giai đoạn “ học” hoặc “ huấn luyện”)
Bước 2: Sử dụng mô hình chia thành 2 bước nhỏ :
• Bước 2.1:Đánh giá mô hình ( kiểm tra tính đúng đắn của mô hình )
• Bước 2.2: Phân lớp dữ liệu mới
3. Một số phương pháp phân lớp: lOMoARcPSD| 49221369
Hồi quy Logistic ( Logistic Regression)
Định nghĩa: Là một mô hình xác suất dự đoán giá trị
đầu ra rời rạc từ một tập các giá trị đầu vào ( biểu diễn dưới dạng vector)
Cây quyết định (Decision Tree) Định nghĩa :
• Trong lý thuyết quản trị, cây quyết định là đồ thị các quyết định cùng các kết quả
khả dĩ đi kèm nhằm hỗ trợ quá trình ra quyết định.
• Trong lĩnh vực khai phá dữ liệu, cây quyết định là phương pháp nhằm mô tả, phân
loại và tổng quát hóa tập dữ liệu cho trước
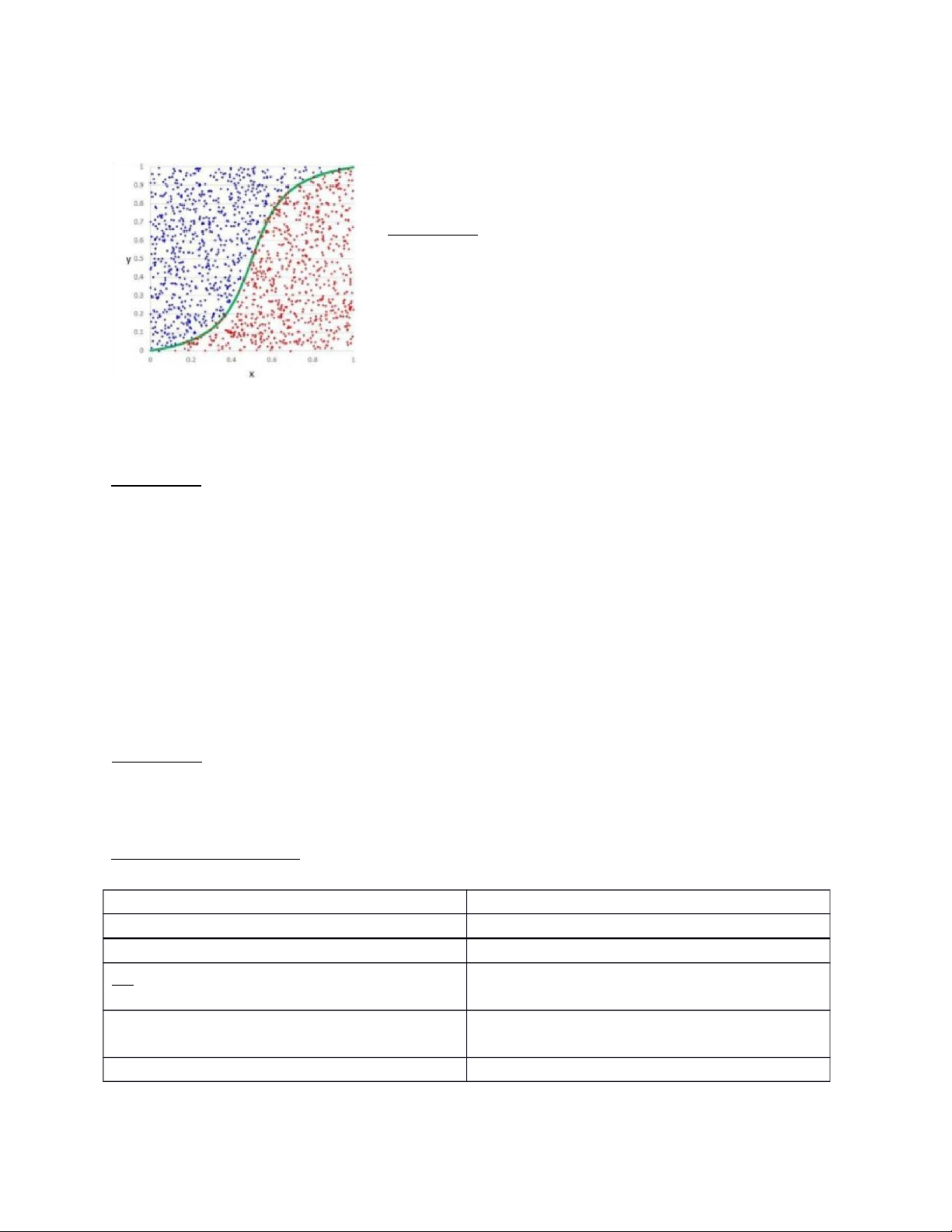
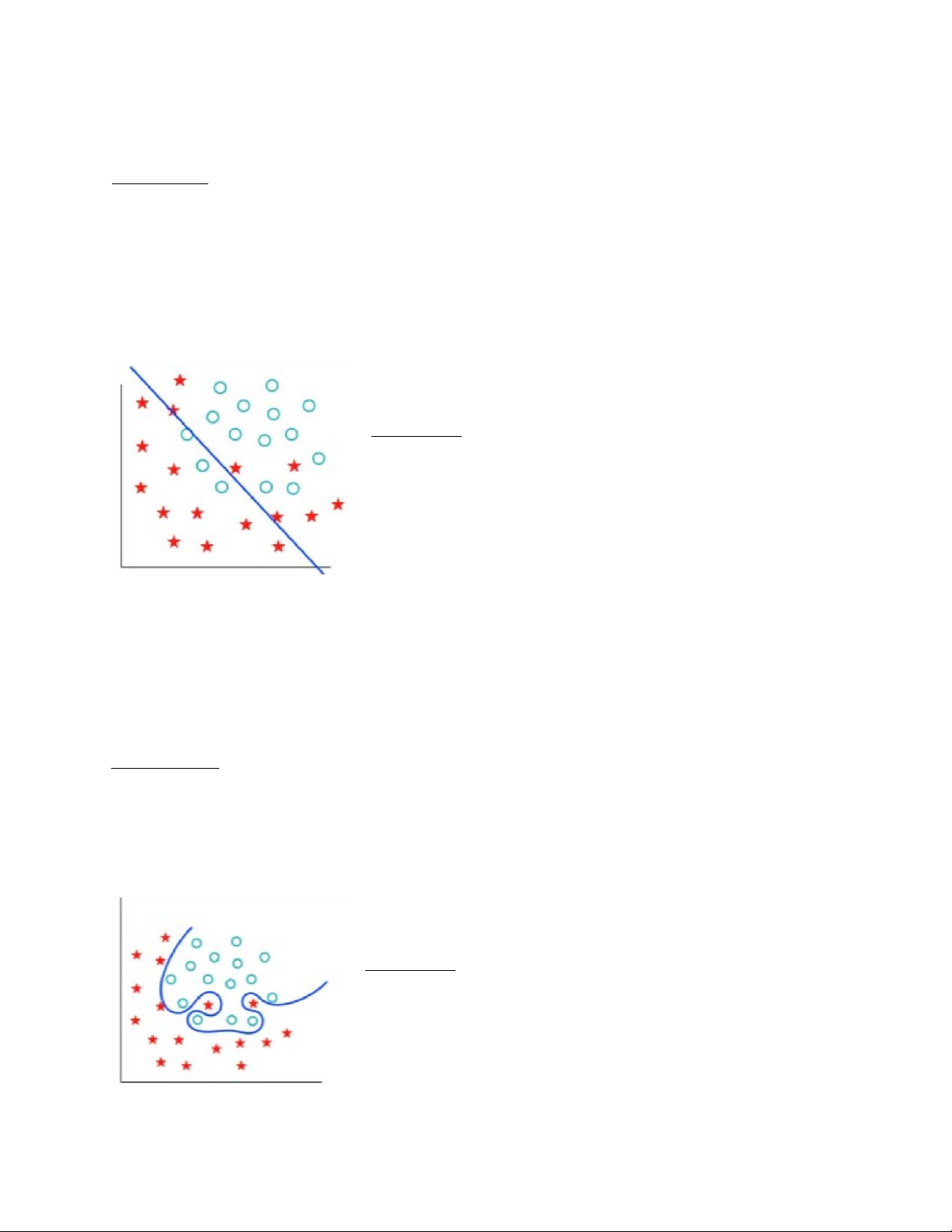
SVM (Support Vector Machine)
Định nghĩa : Là một thuật toán có giám sát, SVM nhận dữ liệu vào, xem chúng như
những vector trong không gian và phân loại chúng vào các lớp khác nhau bằng cách xây
dựng một siêu phẳng trong không gian nhiều chiều làm mặt phân cách các lớp dữ liệu. Các biến thể của SVM: Loại SVM
Hard Margin SVM Hai lớp cần phân lớp là có thể phân chia tuyến tính ( linearly seperable) Soft Margin SVM
Hai lớp cần phân lớp là “gần” phân chia
tuyến tính (almost linear seperable) Multi-class SVM
Phân lớp đa lớp ( biên giữa các lớp là tuyến tính Kernel SVM Dữ liệu là phi tuyến lOMoARcPSD| 49221369
4. Các phương pháp đánh giá mô hình phân lớp:
Định nghĩa: Là các phương pháp nhằm kiểm tra tính hiệu quả của mô hình phân lớp trên
dữ liệu có đặc thù cụ thể, từ đó quyết định có sử dụng mô hình đó hay không.
Một mô hình lý tưởng là một mô hình không quá đơn giản, không quá phức tạp và không
quá nhạy cảm với nhiễu ( tránh underfitting và overfitting ).
Underfitting ( chưa khớp)
Định nghĩa: Là chưa khớp nếu nó chưa được phù hợp với
tập dữ liệu huấn luyện và cả các mẫu mới khi dự đoán. Nguyên nhân:
• Có thể là do mo hình chưa đủ độ phức tạp cần thiết để bao quát được tập dữ liệu.
• Tồn tại nhiều điểm dữ liệu mà mô hình không phân loại được đúng dẫn đến đọ chính xác mô hình thấp.
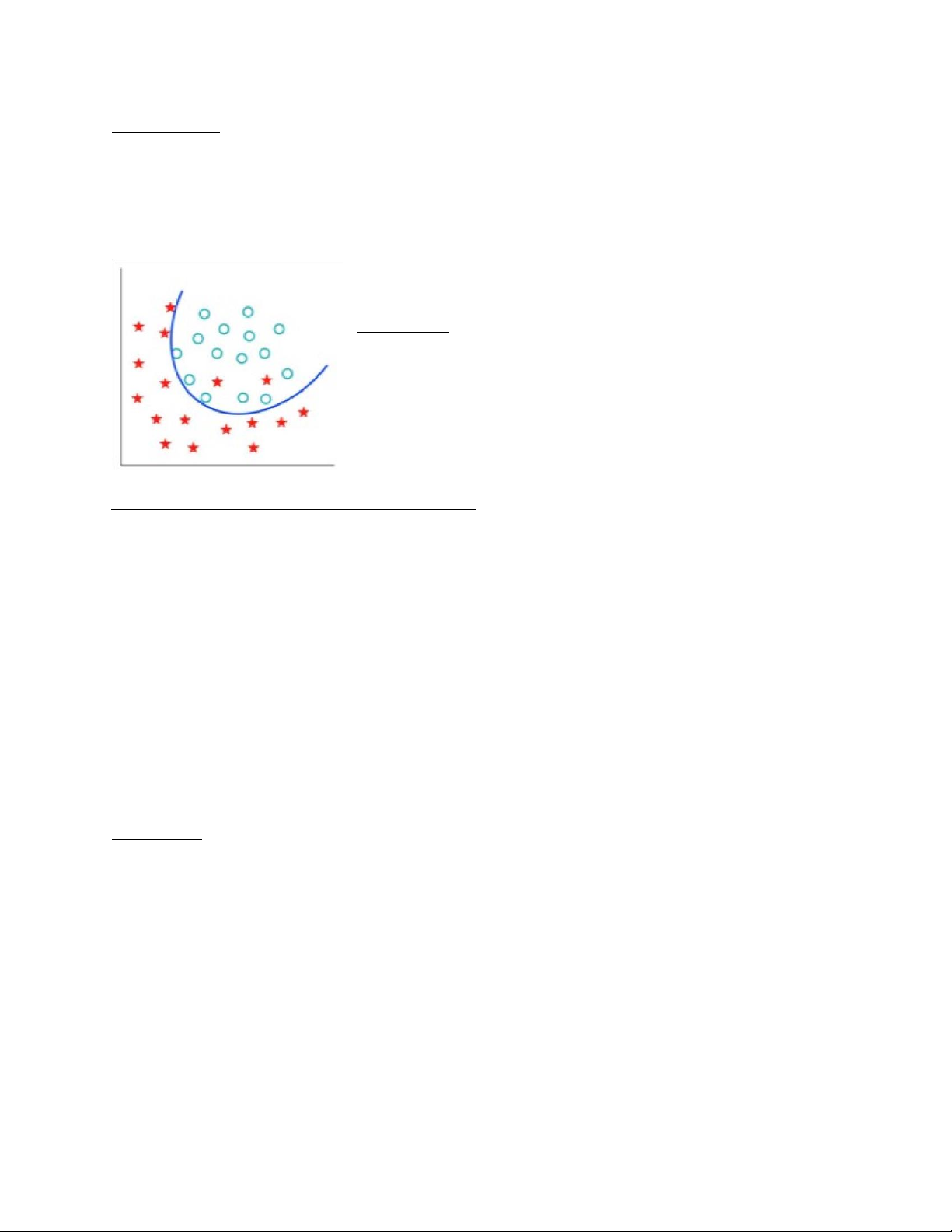
Overfitting ( quá khớp)
Định nghĩa : là hiện tượng mô hình tìm được quá khớp
với dữ liệu huấn luyện. Điều này dẫn đến việc dự đoán cả
nhiễu nên mô hình không còn tốt khi phân lớp trên dữ liệu mới. lOMoARcPSD| 49221369
Nguyên nhân: Lượng dữ liệu huấn luyện quá nhỏ trong khi độ phức tạp của mô hình quá
cao nên mặc dù độ chính xác cao nhưng không thể mô tả được su hướng tổng quát của dữ liệu mới.
Good fitting (Phù hợp)
Định nghĩa: Là trường hợp mô hình cho ra kết quả hợp lý
với cả tập dữ liệu huấn luyện và các giá trị mới.
Các phương pháp đánh giá mô hình phân lớp:
Ma trận nhầm lẫn (Confusion Ma trix)
Định nghĩa: Là ma trận chỉ ra có bao nhiêu điểm dữ liệu thực sự thuộc vào một lớp cụ thể
và được dự đoán là rơi vào lớp nào.
Tính chính xác ( Accuracy )
Định nghĩa: Là tỷ số mẫu được phân lớp đúng trong toàn bộ tập dữ liệu. ROC và AUC
Định nghĩa: Là một đồ thị được sử dụng khá phổ biến trong đánh giá các mô hình phân
loại nhị phân. Đường cong này được tạo ra bằng cách biểu diễn tỷ lệ dự báo true positive
rate (TPR) dựa trên tỷ lệ dự báo false positive rate tại các ngưỡng khác nhau.
Cross Validation: Holdout và K-fold cross validation
• Phương pháp holdout là phân chia tập dự liệu ban đầu thành 2 tập độc lập theo tỷ lệ nhát định.
• Phương pháp k- fold cross validation phân chia dữ liệu thành k tập con có cùng kích thước
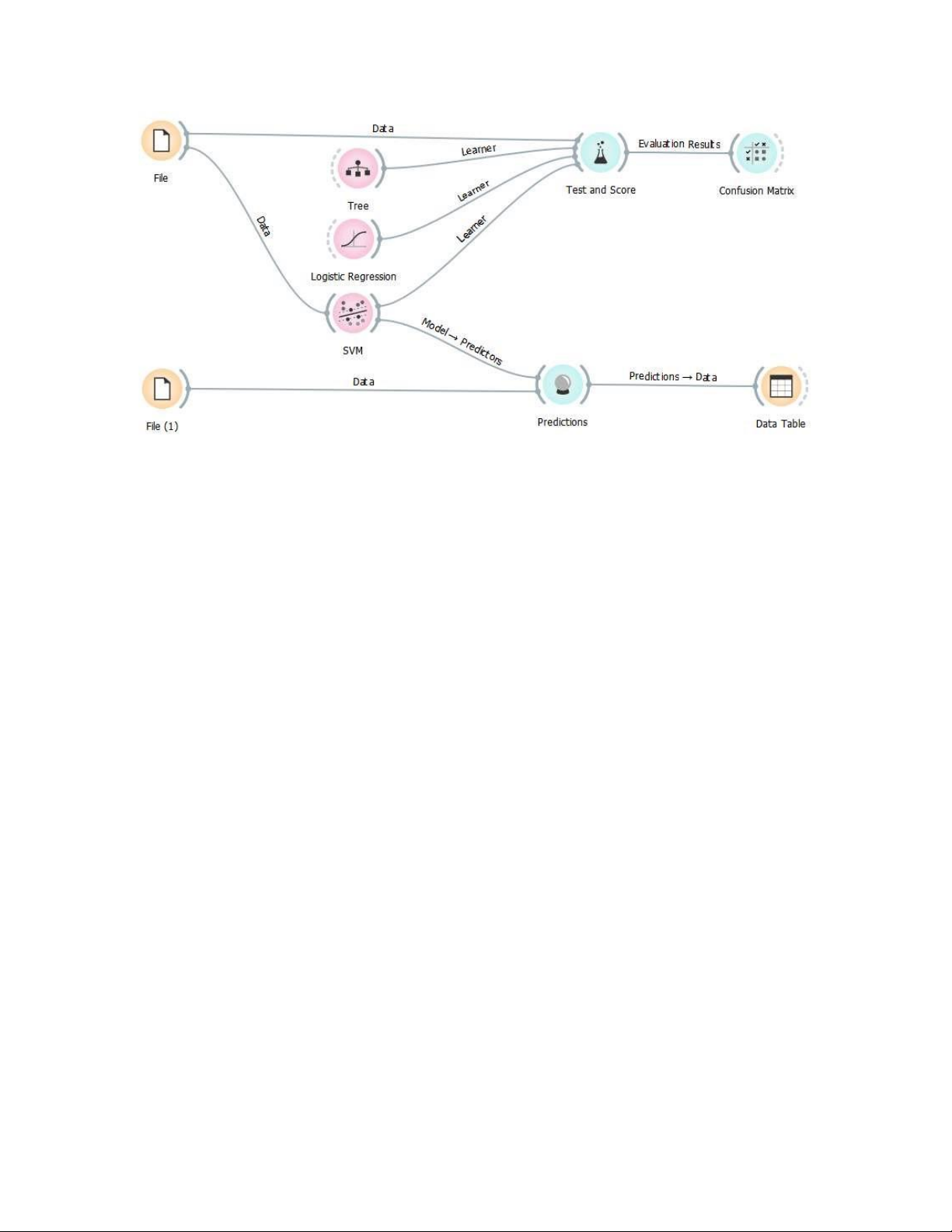
Mô hình phân lớp trên phần mềm Orange: lOMoARcPSD| 49221369 File
Chức năng: đọc dữ liệu từ 1tệp đầu vào
Công cụ File đọc tệp dữ liệu đầu vào (bảng dữ liệu với các trường hợp dữ liệu) và gửi tập
dữ liệu đến kênh đầu ra. Lịch sử của các tệp được mở gần đây nhất được duy trì trong
công cụ. Công cụ File cũng bao gồm một thư mục với các bộ dữ liệu mẫu được cài đặt sẵn với Orange.
Công cụ File đọc dữ liệu từ Excel (.xlsx), được phân tách bằng tab đơn giản (.txt), tệp
được phân tách bằng dấu phẩy (.csv) hoặc URL. Đối với các định dạng khác, xem phần Định dạng khác. lOMoARcPSD| 49221369
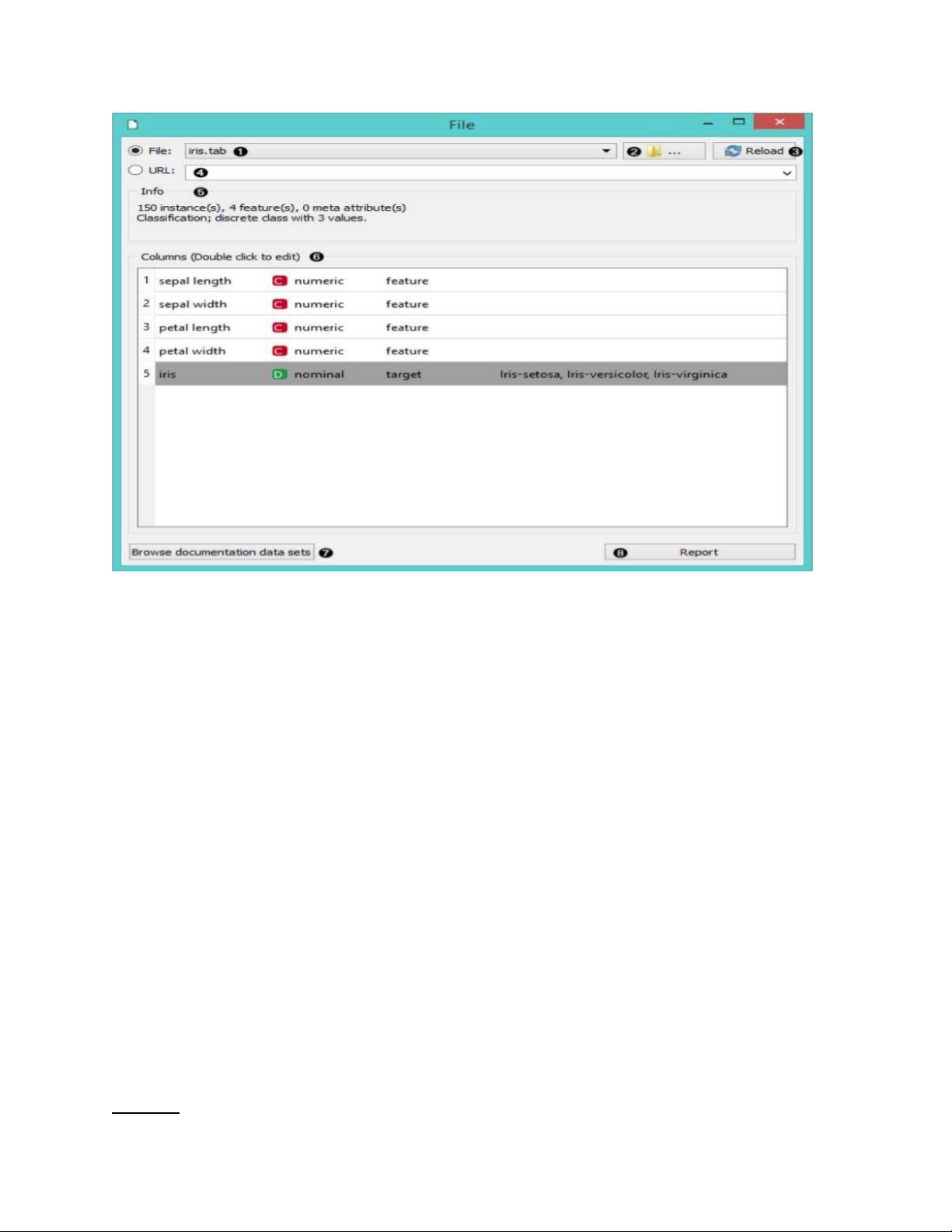
1. Duyệt qua các tệp dữ liệu đã mở trước đó hoặc tải bất kỳ tệp mẫu nào.
2. Duyệt tìm một tệp dữ liệu.
3. Tải lại tập tin dữ liệu hiện được chọn.
4. Chèn dữ liệu từ các địa chỉ URL, bao gồm dữ liệu từ Google Sheets.
5. Tin về tập dữ liệu được tải: kích thước tập dữ liệu, số lượng và loại tính năng dữ liệu.
6. Thông tin bổ sung về các tính năng trong bộ dữ liệu. Các tính năng có thể được chỉnh
sửa bằng cách nhấp đúp vào chúng. Người dùng có thể thay đổi tên thuộc tính, chọn loại
biến cho mỗi thuộc tính (Liên tục, Danh nghĩa, Chuỗi, Thời gian) và chọn cách xác định
thêm các thuộc tính (như Tính năng, Mục tiêu hoặc Meta). Người dùng cũng có thể quyết
định bỏ qua một thuộc tính.
7. Duyệt dữ liệu tài liệu. 8. Tạo một báo cáo. Data Table
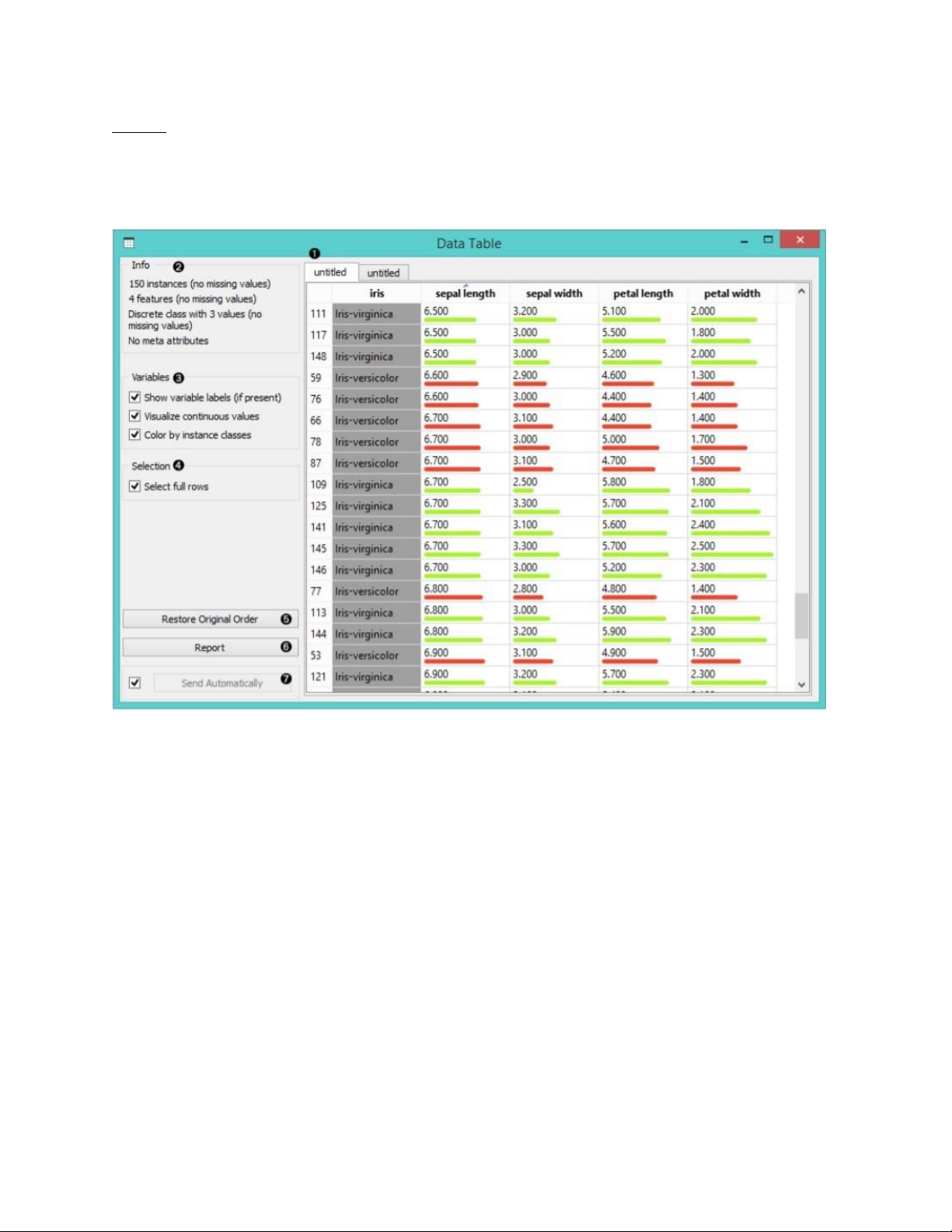
Chức năng : Hiển thị dữ liệu thành một bảng tính
Đầu vào : dữ liệu từ dataset lOMoARcPSD| 49221369
Đầu ra : dữ liệu thể hiện trong bảng tính
Công cụ Data Table nhận đầu vào là một hoặc nhiều bộ dữ liệu và hiện thị chúng trên bảng
tính. Công cụ cũng cho phép sắp xếp các dữ liệu theo thuộc tính hay cũng trợ giúp chúng ta lựa chọn dữ liệu 1. Tên của tệp dữ liệu. 2.
Tên của các biến nằm ở các hàng và giá trị các biến nằm ở các cột. 3.
Thông tin về kích thước tập dữ liệu hiện tại và số lượng và loại biến. Giá trị của
biếnliên tục có thể biểu hiện bằng các thanh với màu sắc được quy về các mức độ khác nhau. 4.
Các biến ( ở hàng) có thể được chọn và đưa vào đầu ra của công cụ. 5.
Sử dụng công cụ Restrore Original Order để khôi phục lại thứ tự ban đầu sau khi
sắpxếp dựa trênthuộc tính. 6. Tạo bản báo cáo. 7.
Trong khi Auto-send được chọn, tất cả thay đổi đều được liên kết với các công cụ
khác.Trong trường hợp không để tất cả thay đổi đều liên quan đến công cụ khác, hãy nhấn Send Select Rows. lOMoARcPSD| 49221369 Tree Đầu vào
Dữ liệu: dữ liệu đầu vào
Tiền xử lý: phương pháp tiền xử lý Đầu ra
Learner: thuật toán quyết định Tree
Mô hình: mô hình được đào tạo
Tree là một thuật toán đơn giản phân chia dữ liệu thành các nút bởi các lớp dữ liệu. Nó là
tiền thân của Random Forest. Tree trong phần mềm Orange được thiết kế bên trong và có
thể xử lý cả bộ dữ liệu rời rạc và liên tục. Nó cũng có thể được sử dụng cho cả nhiệm vụ phân loại và hồi quy.
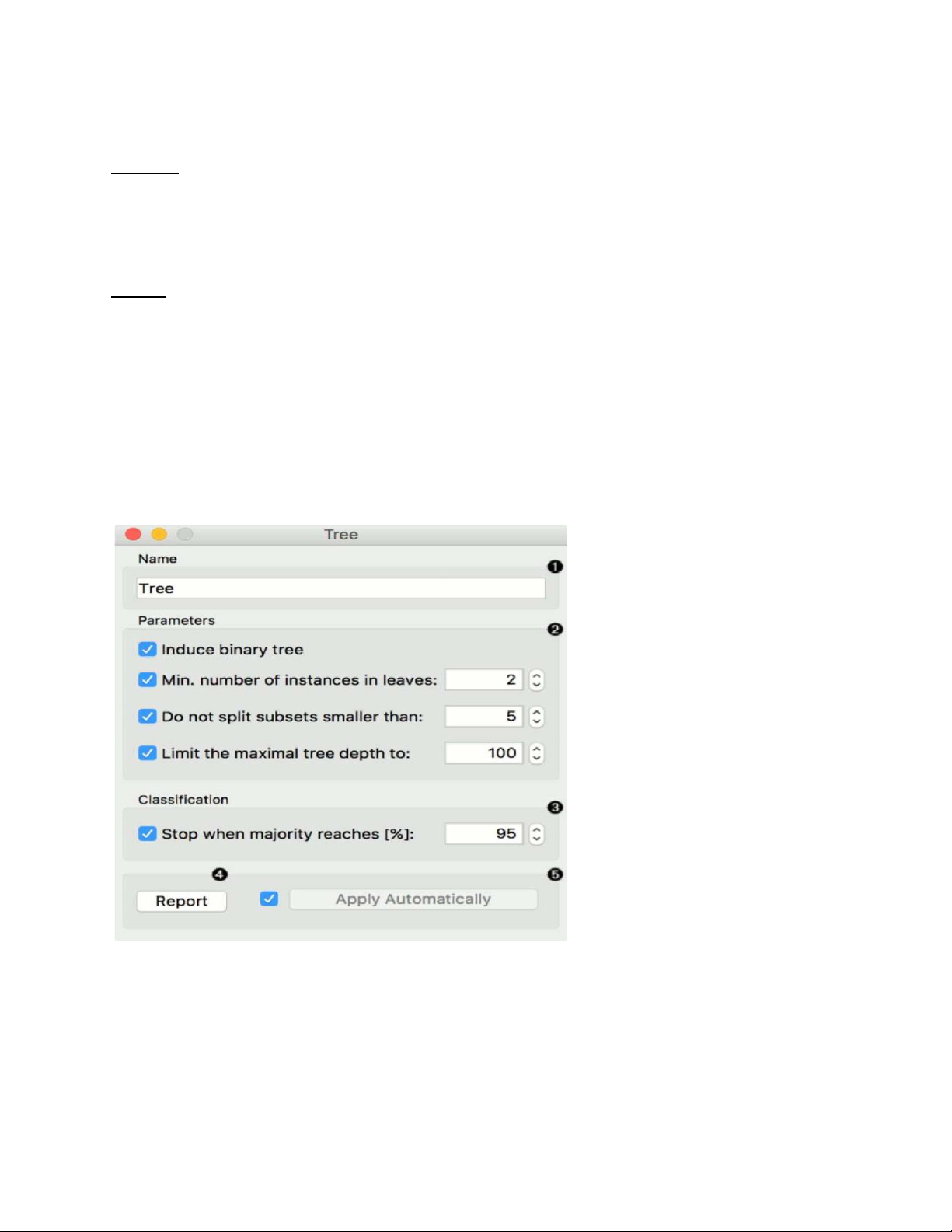
1. Name: Người học có thể được đặt tên theo ý muốn. Tên mặc định là Tree. 2. Thông số:
1. Induce binary tree: xây dựng cây nhị phân (chia thành hai nút con)
2. Min. number of instances in leaves (số tối thiểu các ví dụ lá): nếu được chọn,
thuậttoán sẽ không bao giờ đặt số nút ít hơn số dữ liệu tham khảo lOMoARcPSD| 49221369
3. Do not split subsets smaller than (Không phân chia các tập hợp nhỏ hơn): cấmthuật
toán phân chia các nút có ít hơn số lượng ví dụ đã cho.
4. Limit the maximal tree depth (Giới hạn độ sâu cây tối đa): giới hạn độ sâu của
câyphân loại ở số cấp nút được chỉ định. 4.Tạo một báo cáo.
5.Nhấp vào Apply sau khi thay đổi. Nếu bạn đánh dấu vào ô bên trái nút Apply , các thay
đổi sẽ được tự động. SVM
Support Vector Machines đưa vào không gian chiều có đặc trưng cao cấp hơn Đầu vào
Dữ liệu: dữ liệu đầu vào
Tiền xử lý: phương pháp tiền xử lý Đầu ra
Learner: thuật toán học hồi quy tuyến tính
Mô hình: mô hình được đào tạo
Vectơ hỗ trợ: thể hiện được sử dụng làm vectơ hỗ trợ
Máy vectơ hỗ trợ (SVM) là một kỹ thuật máy học phân tách không gian thuộc tính với một
siêu phẳng, do đó tối đa hóa các điểm dữ liệu của tất cả các lớp. Kỹ thuật này thường mang
lại kết quả dự đoán tối cao.
Đối với hồi quy, SVM thực hiện hồi quy tuyến tính trong không gian tính năng với kích
thước cao bằng cách sử dụng ε-insensitive. Độ chính xác ước tính của nó phụ thuộc tốt vào
các tham số C, ε và kernel.
Hoạt động cho cả nhiệm vụ phân loại và hồi quy. lOMoARcPSD| 49221369 1.
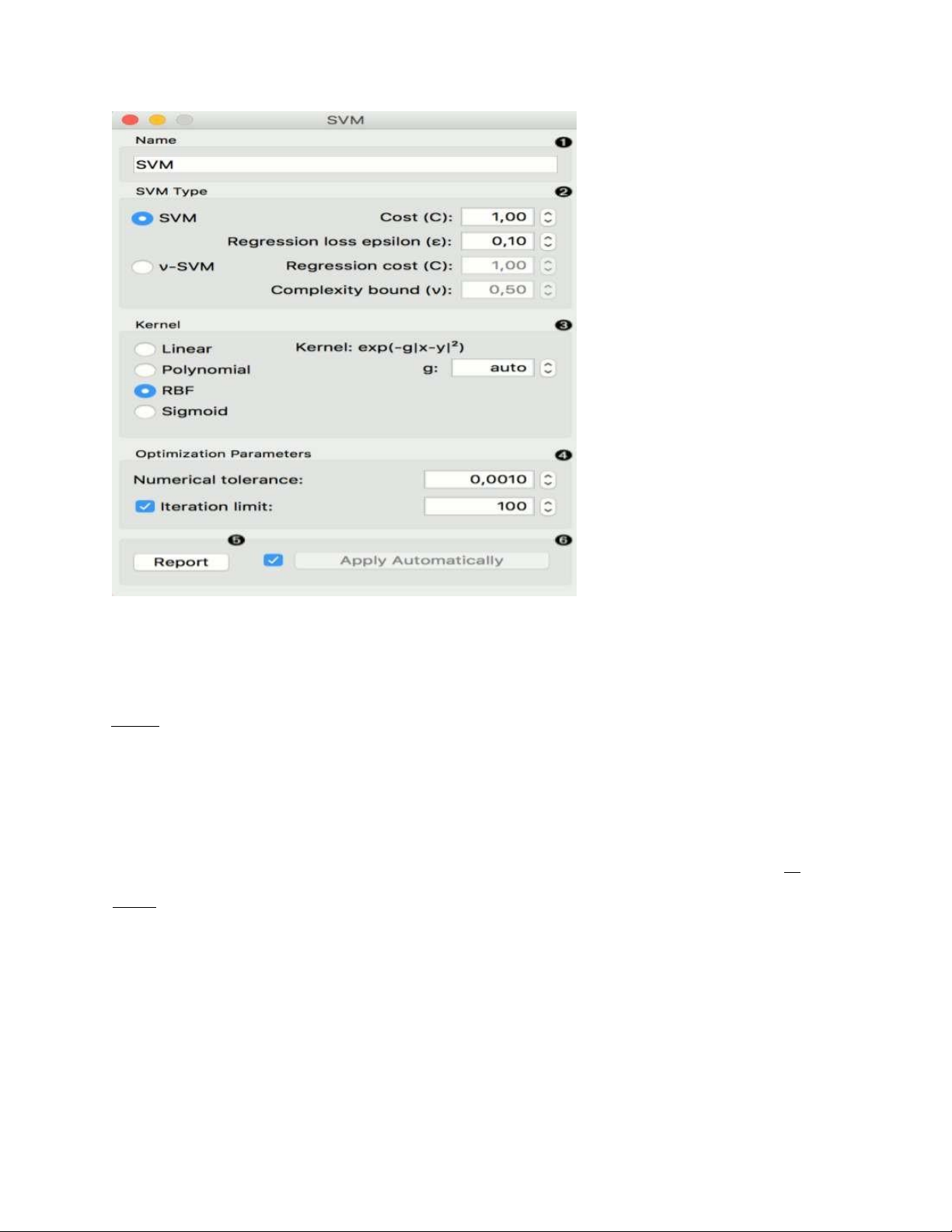
Name: đặt tên bất kì cho mô hình. Tên mặc định là phiên bản SV SVM. 2.
SVM Type với cài đặt kiểm tra lỗi. SVM và ν-SVM dựa trên sự giảm thiểu khác
nhau của hàm lỗi. Ở bên phải, bạn có thể đặt giới hạn lỗi kiểm tra: SVM :
Cost ( C ): giới hạn bất lợi cho sự thiệt hại và áp dụng cho các nhiệm vụ phân loại và hồi quy.
ε: một tham số cho mô hình epsilon-SVR, áp dụng cho hồi quy. Xác định khoảng cách từ
các giá trị thực trong đó không có bất lợi nào được liên kết với các giá trị dự đoán. ν- SVM :
Cost: giới hạn bất lợi cho sự thiệt hại và chỉ áp dụng cho các nhiệm vụ hồi quy ν: một tham
số cho mô hình ν-SVR, áp dụng cho việc phân loại và hồi quy. Giới hạn trên của phần
training error và giới hạn dưới của phần vectơ hỗ trợ. 3.
Kernel là một hàm biến đổi không gian thuộc tính thành không gian tính năng mới
để phù hợp với siêu phẳng có biên độ tối đa, do đó cho phép thuật toán tạo mô hình lOMoARcPSD| 49221369
với tuyến tính , đa thức , RBF và Sigmoid kernel. Các hàm chỉ định kernel được
trình bày khi chọn chúng và các hằng số liên quan là:
g: hằng số gamma trong hàm kernel (giá trị được đề xuất là 1 / k, trong đó k là số lượng
thuộc tính, nhưng vì có thể không có training set nào được cung cấp cho widget, mặc định
là 0 và người dùng phải tự thiết lập lựa chọn), c: hằng số c0 trong hàm kernel (mặc định 0)
d: cho mức độ của hạt nhân (mặc định 3). 4.
Đặt độ lệch cho phép so với giá trị mong đợi trong Numerical Tolerance.. Đánh dấu
tick vào ô cạnh Iteration Limit để đặt số lần lặp tối đa được phép. 5. Tạo một báo cáo. 6.
Nhấp vào Apply sau khi thay đổi. Nếu bạn đánh dấu vào ô bên trái nút Apply , các
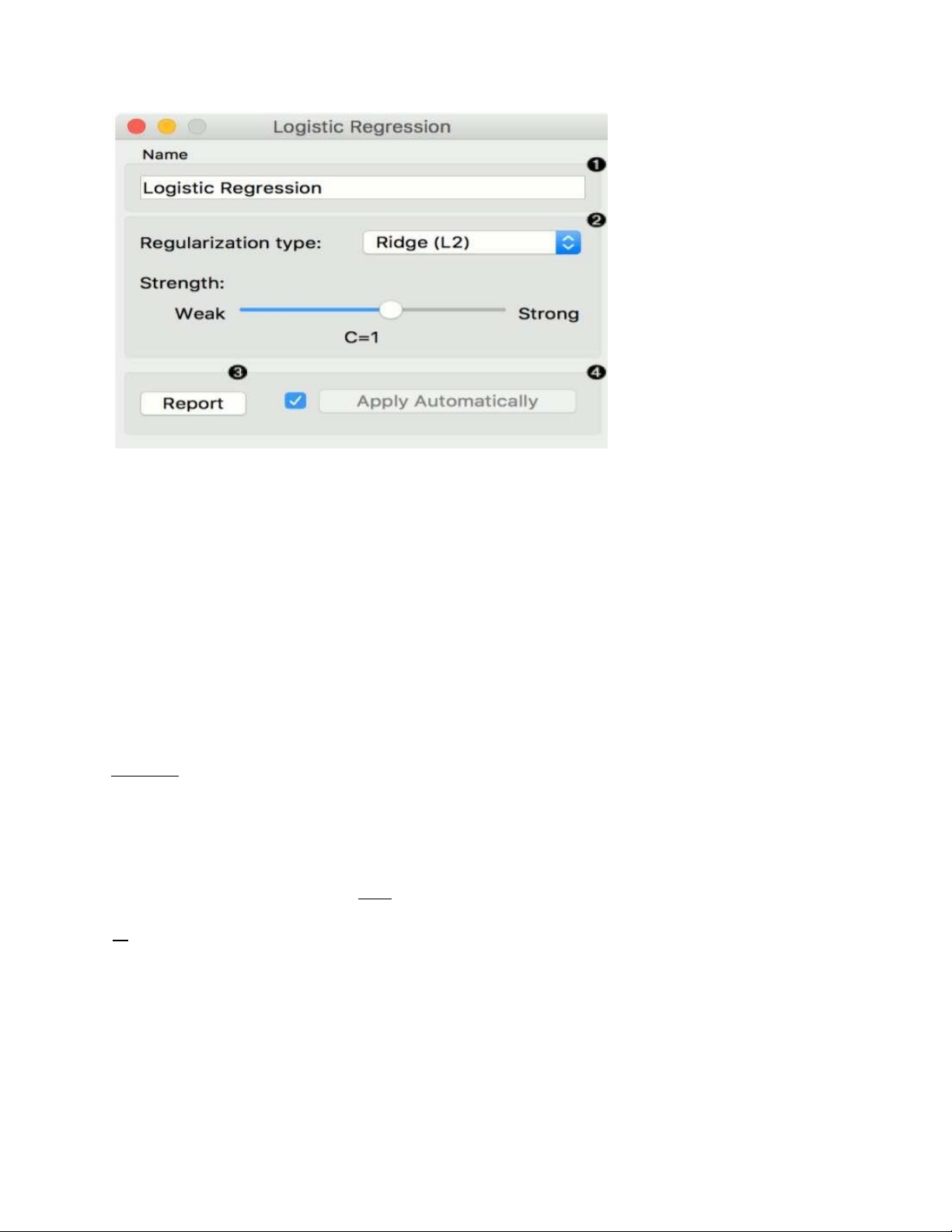
thay đổi sẽ được tự động. Hồi quy logistic
Thuật toán phân loại hồi quy logistic với chính quy hóa LASSO (L1) hoặc sườn núi (L2). Đầu vào
Dữ liệu: dữ liệu đầu vào
Tiền xử lý: phương pháp tiền xử lý Đầu ra
Học viên: thuật toán học hồi quy logistic
Mô hình: mô hình được đào tạo
Các hệ số: hệ số hồi quy logistic
Hồi quy logistic học mô hình hồi quy logistic từ dữ liệu. Nó chỉ hoạt động cho các nhiệm vụ phân loại: lOMoARcPSD| 49221369
1. Một cái tên mà theo đó người học xuất hiện trong các vật dụng khác. Tên mặc định làHồi quy Logistic Regression.
2. Quy tắc loại (hoặc L1 hoặc L2 ). Đặt cường độ chi phí (mặc định là C = 1).
3. Nhấn Áp dụng để cam kết thay đổi. Nếu Áp dụng Tự động được đánh dấu, các thay đổisẽ được.
4. Nhấp vào Apply sau khi thay đổi. Nếu bạn đánh dấu vào ô bên trái nút Apply , các
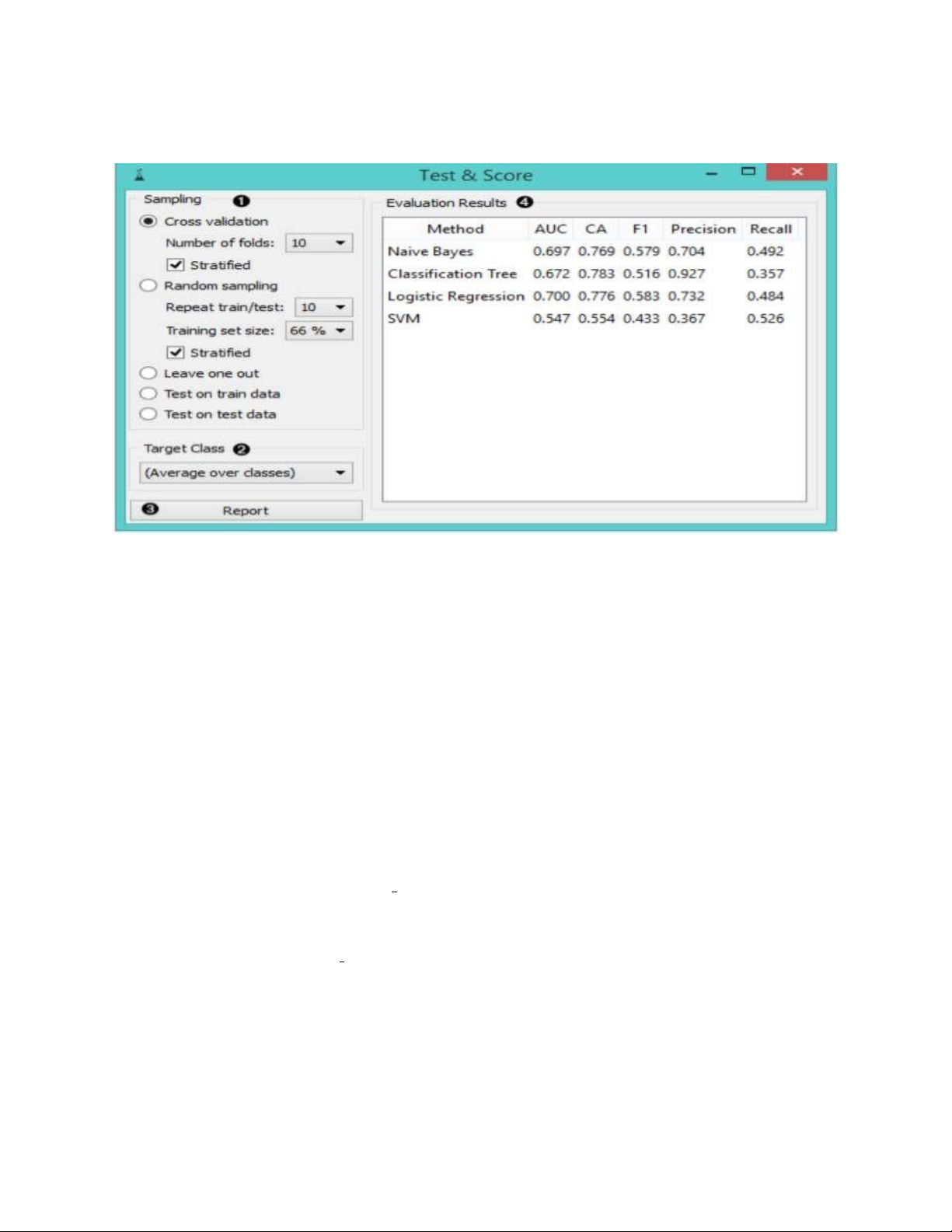
thayđổi sẽ được tự động. TEST AND SCORE Đầu vào:
Dữ liệu: dữ liệu đầu vào
Dữ liệu thử nghiệm: dữ liệu riêng biệt để thử nghiệm
Người học: thuật toán học tập Đầu ra :
Kết quả đánh giá: kết quả của các thuật toán phân loại thử nghiệm.
Các widget kiểm tra các thuật toán học tập. Đề án lấy mẫu khác nhau có sẵn, bao gồm cả
việc sử dụng dữ liệu thử nghiệm riêng biệt. Các widget làm hai điều. Đầu tiên, nó hiển thị
một bảng với các số đo hiệu suất phân loại khác nhau, chẳng hạn như độ chính xác phân
loại và diện tích dưới đường cong . Thứ hai, nó đưa ra kết quả đánh giá, có thể được sử lOMoARcPSD| 49221369
dụng bởi các vật dụng khác để phân tích hiệu suất của các trình phân loại, chẳng hạn như
Phân tích ROC hoặc Ma trận nhầm lẫn .
Các widget hỗ trợ các phương pháp lấy mẫu khác nhau.
1. Xác thực chéo chia dữ liệu thành một số lần nhất định (thường là 5 hoặc 10). Thuật toán
được kiểm tra bằng cách đưa ra các ví dụ từ một lần trong một lần; mô hình được tạo ra từ
các nếp gấp khác và các ví dụ từ nếp gấp được phân loại. Điều này được lặp lại cho tất cả các nếp gấp.
Rời khỏi một lần là tương tự, nhưng nó giữ một trường hợp tại một thời điểm, tạo ra mô
hình từ tất cả các trường hợp khác và sau đó phân loại các trường hợp được tổ chức. Phương
pháp này rõ ràng là rất ổn định, đáng tin cậy và rất chậm.
Lấy mẫu ngẫu nhiên phân chia ngẫu nhiên dữ liệu vào tập huấn luyện và kiểm tra theo tỷ
lệ nhất định (ví dụ 70:30); toàn bộ quy trình được lặp lại trong một số lần xác định.
Kiểm tra trên dữ liệu huấn luyện : sử dụng toàn bộ dữ liệu để đào tạo và sau đó để thử
nghiệm. Phương pháp này thực tế luôn cho kết quả sai.
Kiểm tra dữ liệu thử nghiệm : các phương pháp trên chỉ sử dụng dữ liệu từ tín hiệu Dữ liệu
. Để nhập dữ liệu khác với các ví dụ kiểm tra (ví dụ từ một tệp khác hoặc một số dữ liệu
được chọn trong tiện ích khác), chúng tôi chọn Tín hiệu dữ liệu thử nghiệm riêng biệt trong
kênh liên lạc và chọn kiểm tra dữ liệu thử nghiệm. lOMoARcPSD| 49221369 2.
Để phân loại, lớp Target có thể được chọn ở dưới cùng của widget. Khi lớp Target
là (Trung bình trên các lớp), các phương thức trả về điểm số được tính trung bình
theo trọng số trên tất cả các lớp. Ví dụ, trong trường hợp trình phân loại có 3 lớp,
điểm số được tính cho lớp 1 là lớp mục tiêu, lớp 2 là lớp mục tiêu và lớp 3 là lớp
mục tiêu. Các điểm số đó được tính trung bình với các trọng số dựa trên quy mô lớp
học để lấy điểm số cuối cùng. 3. Tạo một báo cáo.
Các widget sẽ tính toán một số thống kê hiệu suất: - Phân loại:
Khu vực dưới ROC là khu vực dưới đường cong vận hành máy thu.
Độ chính xác phân loại là tỷ lệ của các ví dụ được phân loại chính xác.
F-1 là một trung bình hài hòa có trọng số của độ chính xác và thu hồi (xem bên dưới).
Độ chính xác là tỷ lệ dương tính thật trong số các trường hợp được phân loại là dương tính,
ví dụ tỷ lệ Iris virginica được xác định chính xác là Iris virginica.
Nhớ lại là tỷ lệ dương tính thực sự trong số tất cả các trường hợp tích cực trong dữ liệu, ví
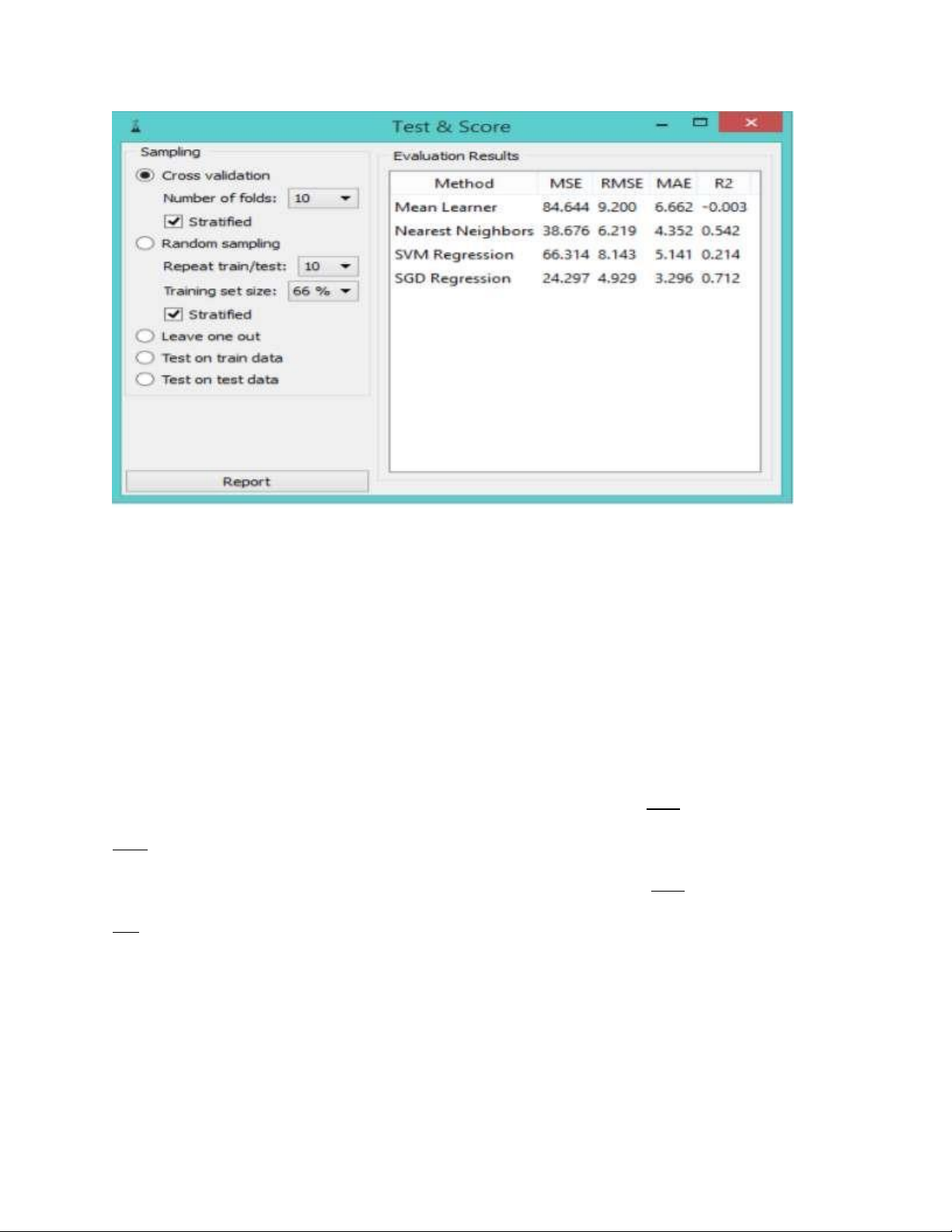
dụ như số người bị bệnh trong số tất cả được chẩn đoán là bị bệnh. - Hồi quy: lOMoARcPSD| 49221369
MSE đo trung bình bình phương của các sai số hoặc độ lệch (sự khác biệt giữa công cụ
ước tính và ước tính).
RMSE là căn bậc hai của trung bình số học của bình phương của một tập hợp số (thước đo
sự không hoàn hảo của sự phù hợp của công cụ ước tính với dữ liệu)
MAE được sử dụng để đo lường mức độ dự báo hoặc dự đoán chặt chẽ với kết quả cuối cùng.
R2 được hiểu là tỷ lệ của phương sai trong biến phụ thuộc có thể dự đoán được từ biến độc lập.
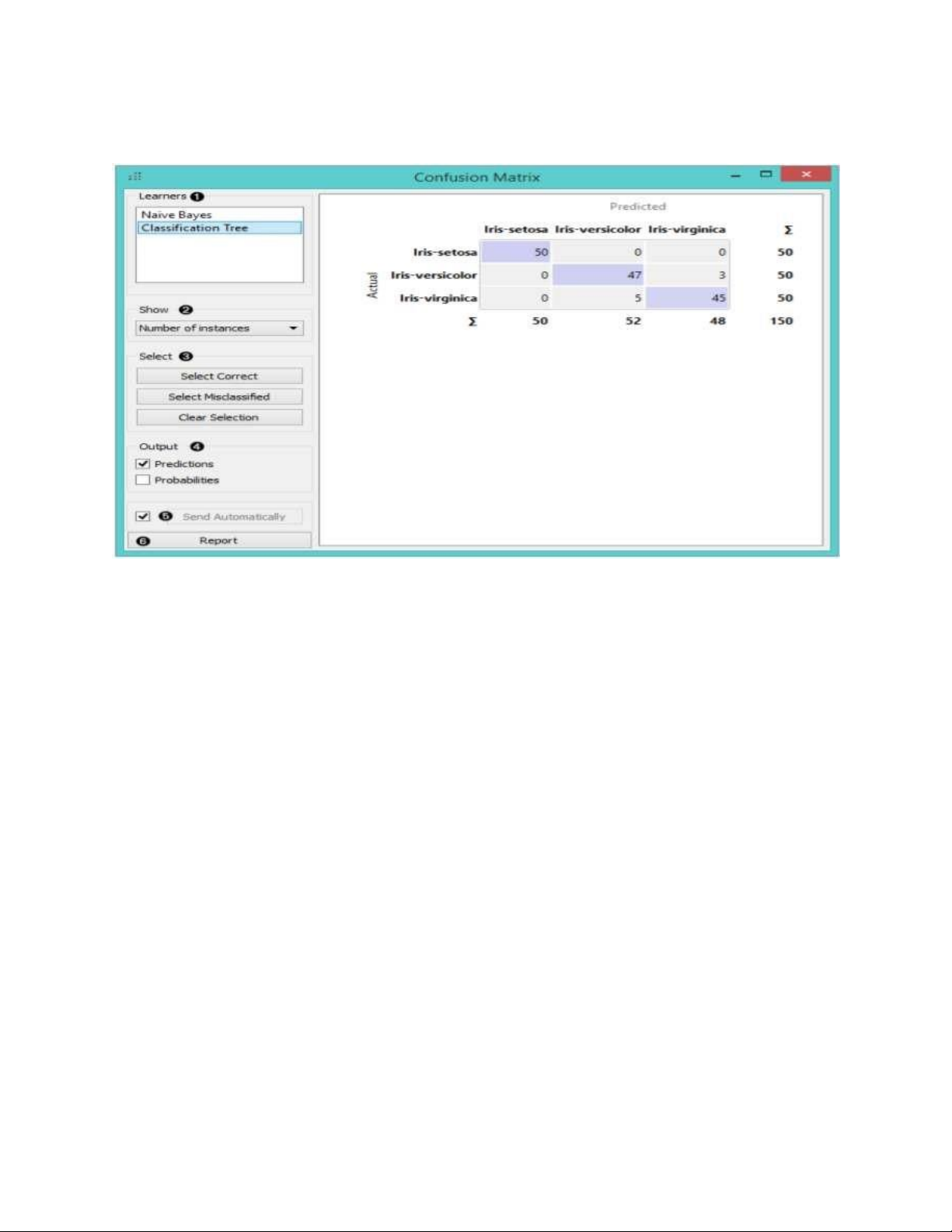
CONFUSION MATRIX (hiển thị dữ liệu giữa thực tế và dự đoán) Đầu vào:
Kết quả đánh giá: kết quả của các thuật toán phân loại thử nghiệm Đầu ra :
Dữ liệu được chọn: tập hợp dữ liệu được chọn từ ma trận nhầm lẫn
Dữ liệu: với thông tin bổ sung về việc liệu một thể hiện dữ liệu đã được chọn chưa
Các Confusion Matrix cho biết số / tỷ lệ các trường hợp giữa các lớp dự đoán và thực tế.
Việc lựa chọn các phần tử trong ma trận cung cấp các trường hợp tương ứng vào tín hiệu lOMoARcPSD| 49221369
đầu ra. Bằng cách này, người ta có thể quan sát những trường hợp cụ thể bị phân loại sai và làm thế nào.
Khi kết quả đánh giá chứa dữ liệu trên nhiều thuật toán học tập, chúng ta phải chọn một
thuật toán trong hộp Người học . Ảnh chụp nhanh cho thấy ma trận nhầm lẫn cho các mô
hình Tree và Naive Bayesian được đào tạo và thử nghiệm trên dữ liệu mống mắt . Phía bên
phải của tiện ích chứa ma trận cho mô hình Bayes ngây thơ (vì mô hình này được chọn ở
bên trái). Mỗi hàng tương ứng với một lớp chính xác, trong khi các cột biểu thị các lớp dự
đoán. Chẳng hạn, bốn trường hợp của IrisVersolor bị phân loại sai thành Iris-virginica. Cột
ngoài cùng bên phải đưa ra số lượng phiên bản từ mỗi lớp (có 50 tròng của mỗi trong ba
lớp) và hàng dưới cùng cho số lượng phiên bản được phân loại vào mỗi lớp (ví dụ: 48
trường hợp được phân loại thành virginica).
Trong Hiển thị , chúng tôi chọn dữ liệu nào chúng tôi muốn thấy trong ma trận.
Số lượng phiên bản hiển thị chính xác và không chính xác các trường hợp được phân loại số.
Tỷ lệ dự đoán cho thấy có bao nhiêu trường hợp được phân loại như, giả sử, IrisVersolor
nằm trong lớp thực sự; trong bảng chúng ta có thể đọc 0% trong số chúng thực sự là setosae,
88,5% trong số chúng được phân loại là nhiều màu là đa sắc và 7,7% là virginicae.
Tài liệu liên quan:
-

640 câu hỏi trắc nghiệm Quản trị học theo chương (Có đáp án chi tiết) môn Quản trị học | Trường Đại học Kinh tế - Đại học Đà Nẵng
47 24 -

BÁO CÁO QUẢN TRỊ HỌC NHÓM 9 VỀ CÔNG TY ĐẤT XANH EMERALD
21 11 -

Đề cương môn Quản trị học - trường đại học kinh tế Đại học đà nẵng.
123 62 -

Tài liệu ôn tập cuối kỳ - Quản trị học - Đại Học Kinh Tế - Đại học Đà Nẵng
674 337 -

Trắc nghiệm tổng hợp - Môn Quản trị học - Đại Học Kinh Tế - Đại học Đà Nẵng
598 299