Assignment 4: Decision Tree & Bayesian Classifications | Môn Data Mining - Trường Đại học Quốc tế, Đại học Quốc gia Thành phố Hồ Chí Minh
Assignment 4: Decision Tree & Bayesian Classifications Môn Data Mining. Tài liệu được sưu tầm gồm 3 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Data Mining 10 tài liệu
Trường: Trường Đại học Quốc tế, Đại học Quốc gia Thành phố Hồ Chí Minh 2 K tài liệu
Tác giả:


Preview text:
lOMoAR cPSD| 23136115 DATA MINING - ASSIGNMENT 4 ITDSIU21001 - Phan Quoc Anh July 22, 2024 Question
The following table consists of training data from an employee database.
The data have been generalized. For example, “31...35” for age represents
the age range of 31 to 35. For a given row entry, count represents the
number of data tuples having the values for department, status, age, and salary given in that row. department status age salary count sales senior 31...35 46K...50K 30 sales junior 26...30 26K...30K 40 sales junior 31...35 31K...35K 40 systems junior 21...25 46K...50K 20 systems senior 31...35 66K...70K 5 systems junior 26...30 46K...50K 3 systems senior 41...45 66K...70K 3 marketing senior 36...40 46K...50K 10 marketing junior 31...35 41K...45K 4 secretary senior 46...50 36K...40K 4 secretary junior 26...30 26K...30K 6
Let status be the class label attribute.
(a) How would you modify the basic decision tree algorithm to take
intoconsideration the count of each generalized data tuple (i.e., of each row entry)?
(b) Use your algorithm to construct a decision tree from the given data.
(c) Given a data tuple having the values “systems”, “26...30”, and
“46K...50K”for the attributes department, age, and salary, respectively,
what would a Na¨ıve Bayesian classification of the status for the tuple be? lOMoAR cPSD| 23136115 1 Answer
(a) Modifying the Decision Tree Algorithm to Consider Counts
To modify the basic decision tree algorithm to take into consideration the
count of each generalized data tuple, you can adjust the way the algorithm
calculates the impurity (such as entropy or Gini index) at each node. Here’s a step-by-step approach:
1. Weighted Impurity Calculation: Instead of treating each row as
a single data point, use the count value to weigh the impurity calculation.
For instance, if using entropy: Weighted Entropy =
where ci is the count for each row, and pi is the proportion of the class.
2. Split Decision: When deciding on the best attribute to split on,
consider the weighted impurity of the subsets created by the split.
(b) Constructing a Decision Tree
To construct a decision tree from the given data, follow these steps:
1. Calculate Initial Impurity: Calculate the initial weighted impurity
for the entire dataset. 2. Choose Attribute to Split: For each attribute
(department, age, salary), calculate the weighted impurity of the subsets
created by splitting the dataset on that attribute. 3. Select Best Split:
Choose the attribute and split point that results in the greatest reduction
in impurity. 4. Create Subsets: Split the dataset according to the best
attribute and split point. 5. Repeat Recursively: Repeat the process for
each subset until a stopping criterion is met (e.g., all instances in a subset
belong to the same class, or a maximum tree depth is reached).
(c) Na¨ıve Bayesian Classification
To perform Na¨ıve Bayesian classification for the tuple (systems, 26...30,
46K...50K), follow these steps:
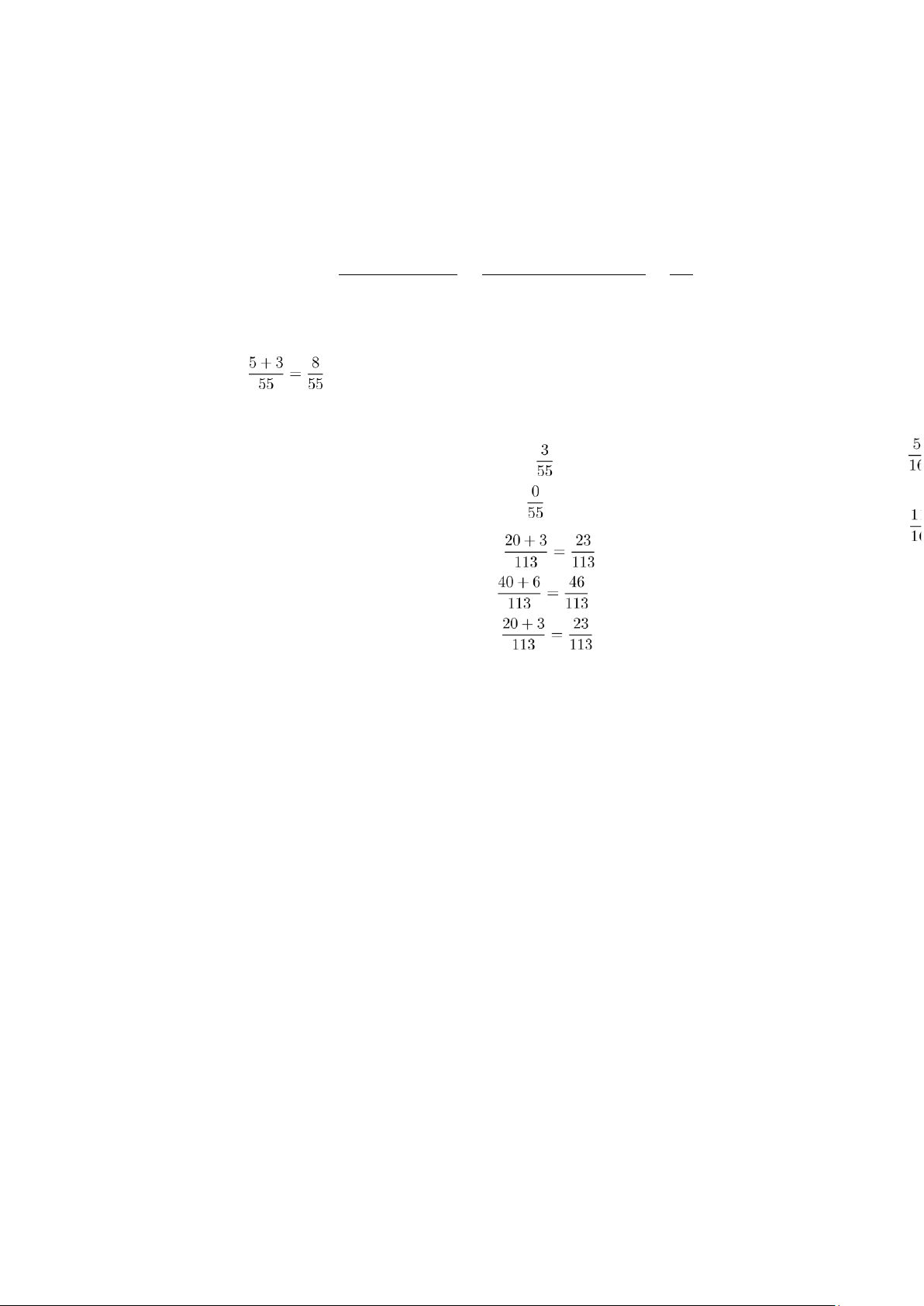
1. Calculate Prior Probabilities: Pcount of senior 30 + 5 + 3 + 3 + 10 + 4 55 P(senior) = = = lOMoAR cPSD| 23136115 Ptotal count
30 + 40 + 40 + 20 + 5 + 3 + 3 + 10 + 4 + 6 161
Pcount of junior 40 + 40 + 20 + 3 + 4 + 6 113 P(junior) = = = Ptotal count 161 161
2. Calculate Likelihoods: P(systems|senior) = 2 P(26-30|senior) = P(46-50K|senior) = = 0 P(systems|junior) = P(26-30|junior) = P(46-50K|junior) =
3. Calculate Posterior Probabilities:
P(senior|systems,26-30,46-50K) ∝
P(senior)×P(systems|senior)×P(26-30|senior)×P(46- 50K|senior) =
P(junior|systems,26-30,46-50K) ∝
P(junior)×P(systems|junior)×P(26-30|junior)×P(46- 50K|junior) =
4. Normalization: Since P(senior|systems,26-
30,46-50K) = 0, the classification is junior.
Therefore, the Na¨ıve Bayesian classification for the tuple (systems,
26...30, 46-50K) would be junior.
Tài liệu liên quan:
-

Notes: Key Concepts and Techniques | Môn Data Mining - Trường Đại học Quốc tế, Đại học Quốc gia Thành phố Hồ Chí Minh
104 52 -

Lecture 6: Decision Tree & Bayesian Classification | Môn Data Mining - Trường Đại học Quốc tế, Đại học Quốc gia Thành phố Hồ Chí Minh
123 62 -

Lab 5: Integrating Processes and Ethics | Môn Data Mining - Trường Đại học Quốc tế, Đại học Quốc gia Thành phố Hồ Chí Minh
111 56 -

Lecture 4: Knowledge Representation | Môn Data Mining - Trường Đại học Quốc tế, Đại học Quốc gia Thành phố Hồ Chí Minh
107 54 -

Lecture 3: Data Preprocessing Overview and Techniques | Môn Data Mining - Trường Đại học Quốc tế, Đại học Quốc gia Thành phố Hồ Chí Minh
115 58