BTVN và HDSD_Lab04| BT môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
BTVN và HDSD_Lab04| BT môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội. Tài liệu gồm 11 trang giúp bạn ôn tập và đạt kết quả cao trong kỳ thi sắp tới. Mời bạn đọc đón xem.
Môn: Lưu trữ và xử lý dữ liệu lớn 27 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.4 K tài liệu
Tác giả:




Preview text:
ĐẠI HỌC BÁCH KHOA HÀ NỘI
TRƯỜNG CÔNG NGHỆ THÔNG TIN VÀ TRUYỀN THÔNG BÁO CÁO
Lưu trữ và xử lý dữ liệu lớn LAB 04 Nhóm HDSD
Sinh viên thực hiện Mã sinh viên Nguyễn Trọng Hải 20183730 Võ Việt Dũng 20183723 Lê Hữu Tiến Dũng 20183719 Ngô Đình Sáng 20183819
Giảng viên: TS. Đào Thành Chung Hà Nội, 12 – 2021
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD MỤC LỤC
MỤC LỤC ................................................................................................................ 2
1. Chuẩn bị 3 máy ảo cài Hadoop và Yarn cluster ............................................... 3
2. Đẩy dữ liệu lên HDFS ......................................................................................... 4
3. Cài đặt Spark ....................................................................................................... 5
3.1 Tải Spark từ masternode .............................................................................. 5
3.2 Giải nén và di chuyển đến thư mục spark .................................................. 5
3.3 Cấu hình file /home/hadoop/.profile ............................................................. 5
3.4 Cấu hình file $SPARK_HOME/conf/spark-defaults.conf ........................... 6
3.5 Run History Server ....................................................................................... 6
3.6 Khởi động Spark bằng pyspark ................................................................... 6
4. Chạy ví dụ WordCount với dữ liệu từ DHFS ................................................... 7
4.1 Job đang ở trạng thái running ..................................................................... 7
4.2 Job đang ở trạng thái finished ..................................................................... 8
4.3 Quá trình chạy ............................................................................................... 9
4.4 Kết quả chạy ................................................................................................ 10 2 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
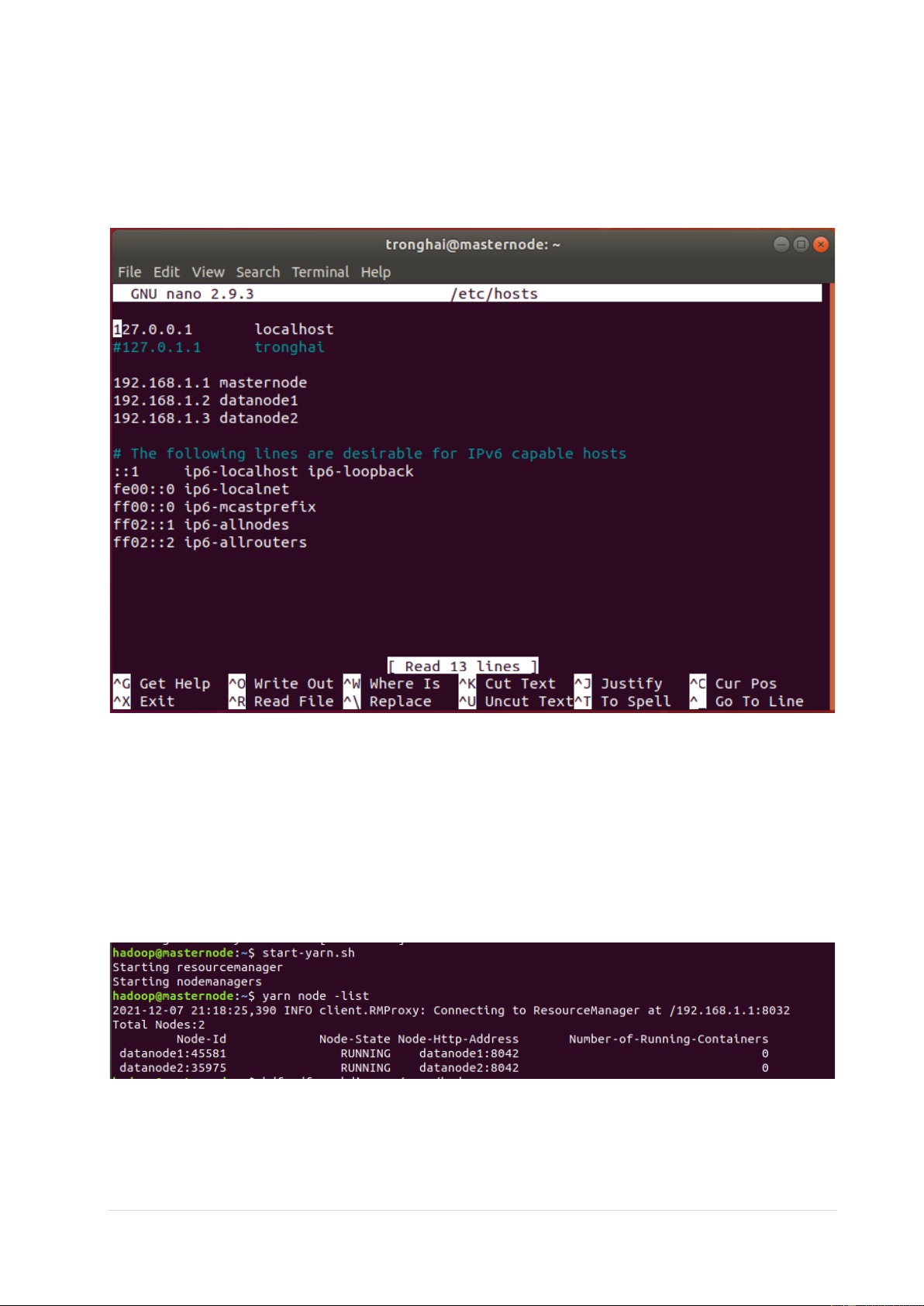
1. Chuẩn bị 3 máy ảo cài Hadoop và Yarn cluster • masternode: 192.168.1.1 • datanode1: 192.168.1.2 • datanode2: 192.168.1.3 Chú ý:
HADOOP_HOME = /home/hadoop/hadoop - Khởi động yarn
• Cụm yarn cluster gồm 2 node là datanode1 và datanode2 3 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
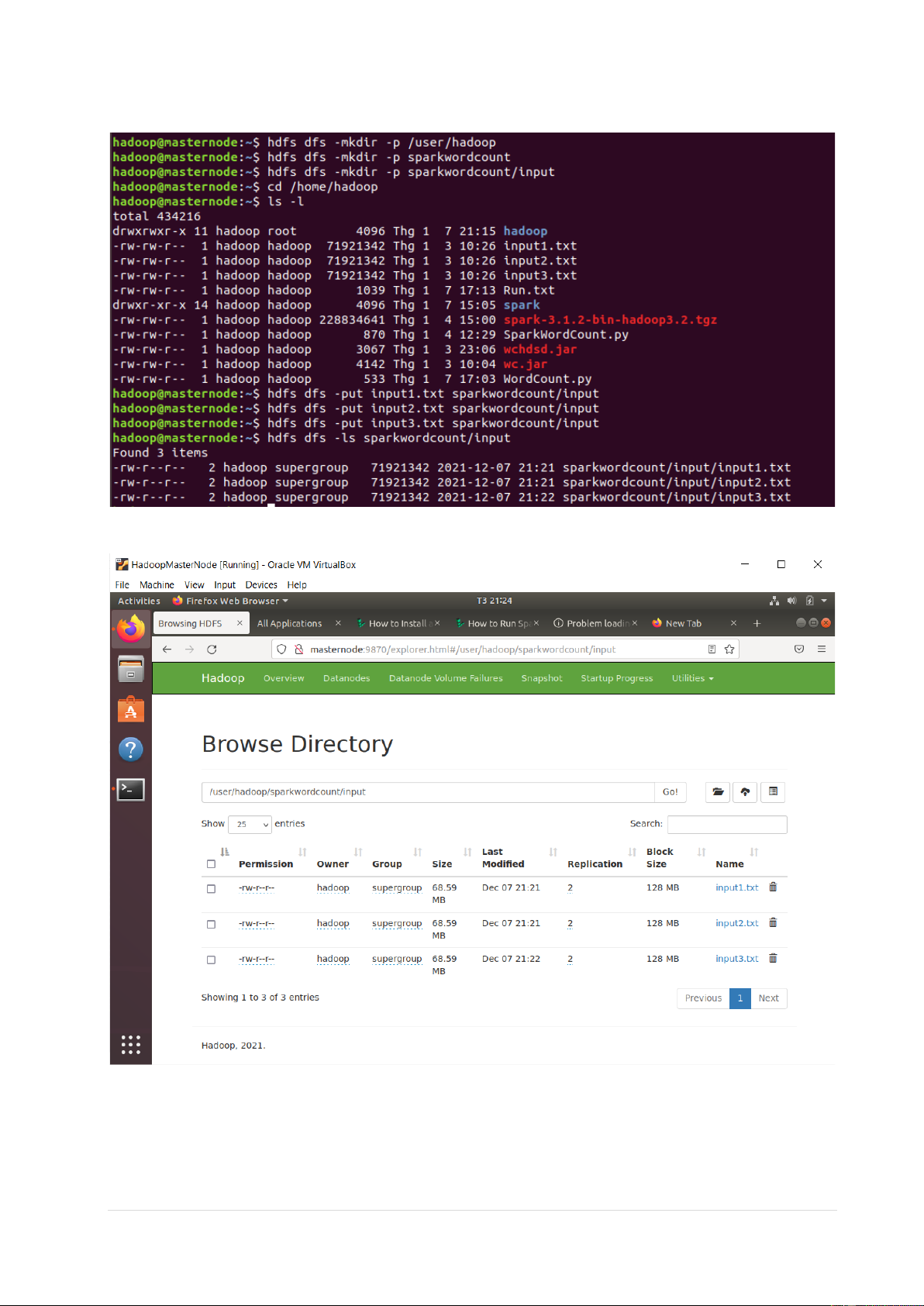
2. Đẩy dữ liệu lên HDFS
- Kết quả đẩy dữ liệu 4 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD 3. Cài đặt Spark
3.1 Tải Spark từ masternode
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
3.2 Giải nén và di chuyển đến thư mục spark
tar -xvf spark-3.1.2-bin-hadoop3.2.tgz
mv spark-3.1.2-bin-hadoop3.2 spark
3.3 Cấu hình file /home/hadoop/.profile 5 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
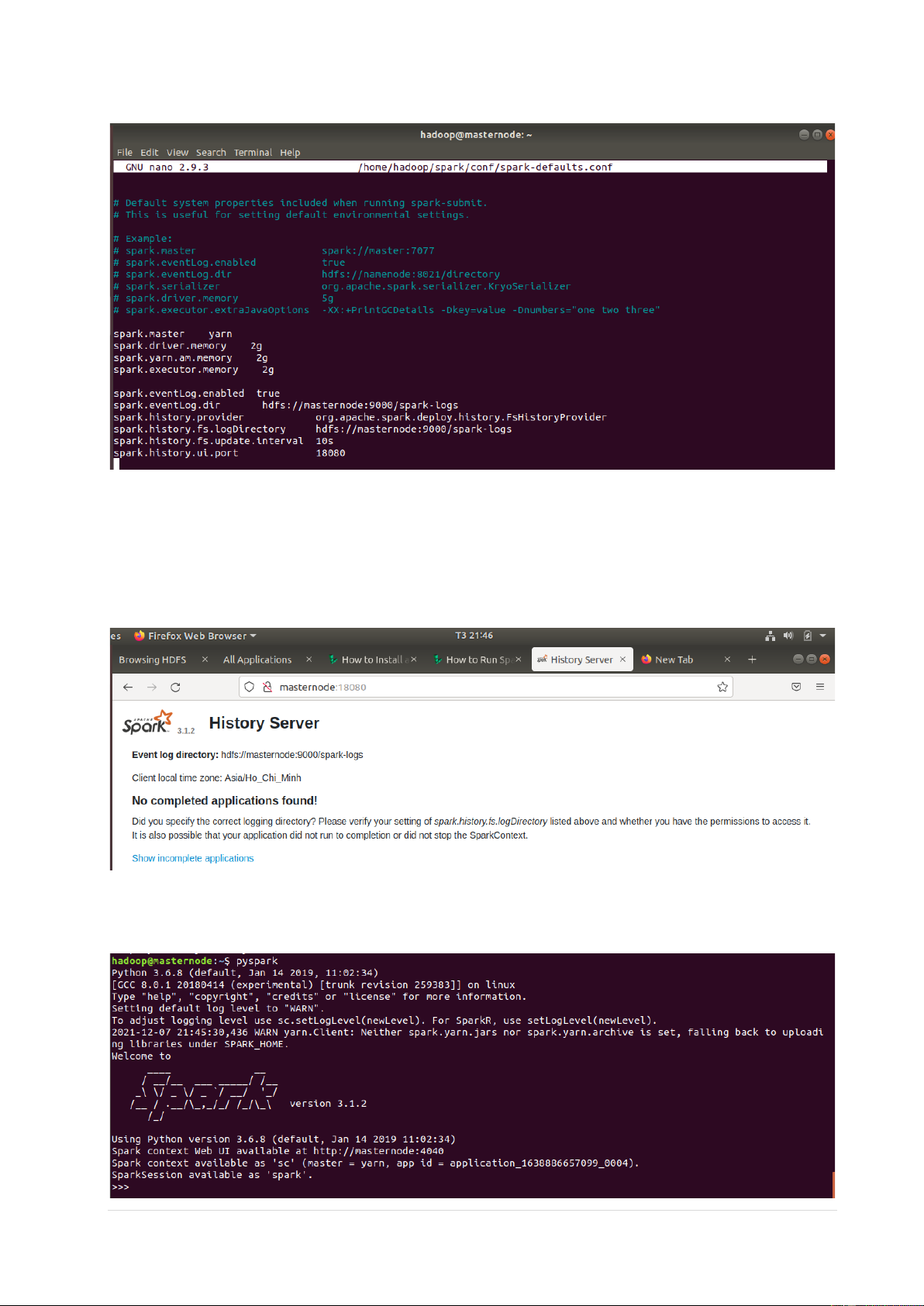
3.4 Cấu hình file $SPARK_HOME/conf/spark-defaults.conf 3.5 Run History Server
$SPARK_HOME/sbin/start-history-server.sh
• Giao điện History Server
3.6 Khởi động Spark bằng pyspark 6 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
4. Chạy ví dụ WordCount với dữ liệu từ DHFS
spark-submit --master yarn --deploy-mode client --conf
"spark.kerberos.access.hadoopFileSystems=hdfs://masternode:9000/user/hadoop/
sparkwordcount/input" WordCount.py
"hdfs://masternode:9000/user/hadoop/sparkwordcount/input/*"
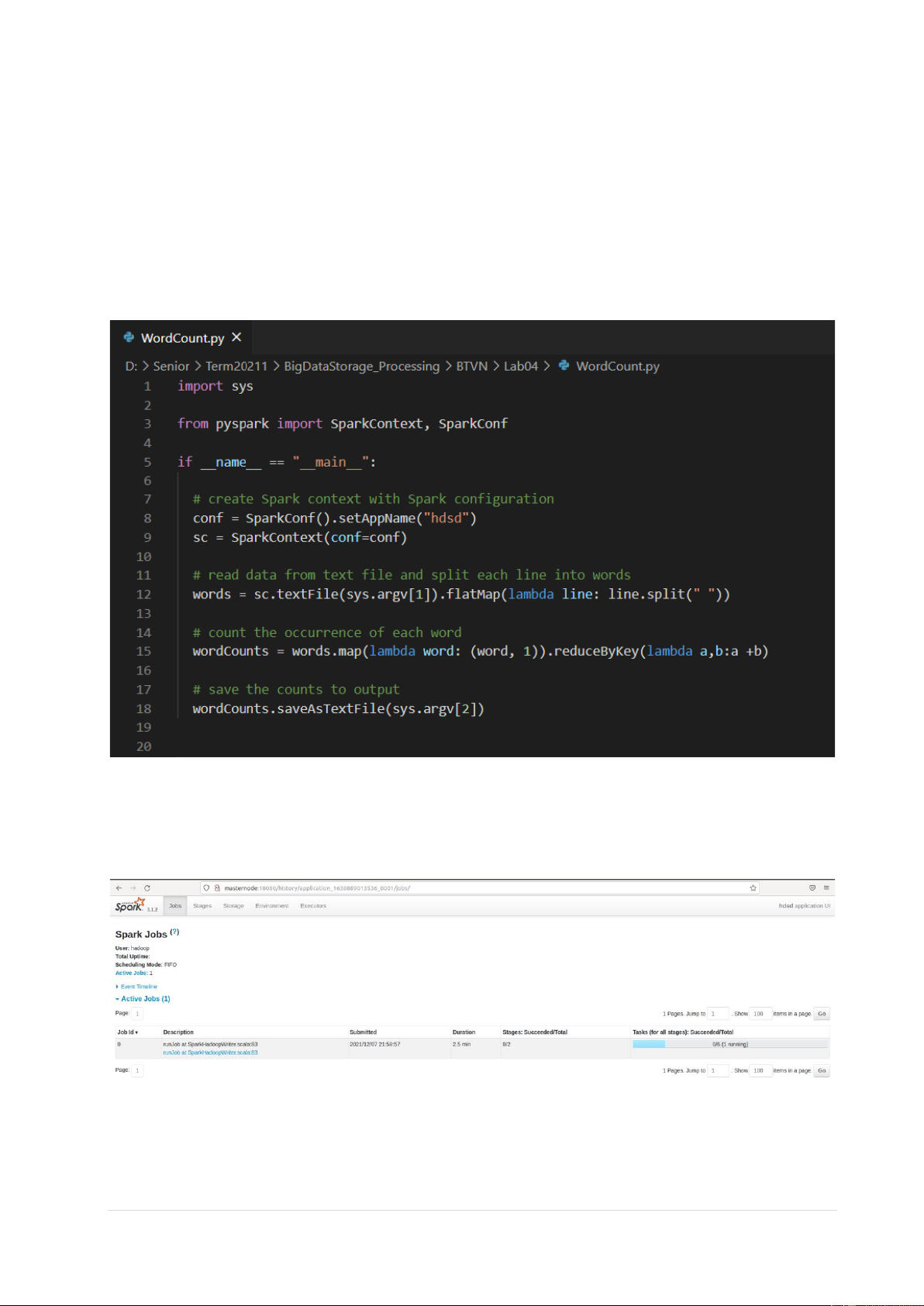
hdfs://masternode:9000/user/hadoop/sparkwordcount/output1 • Source WordCount.py
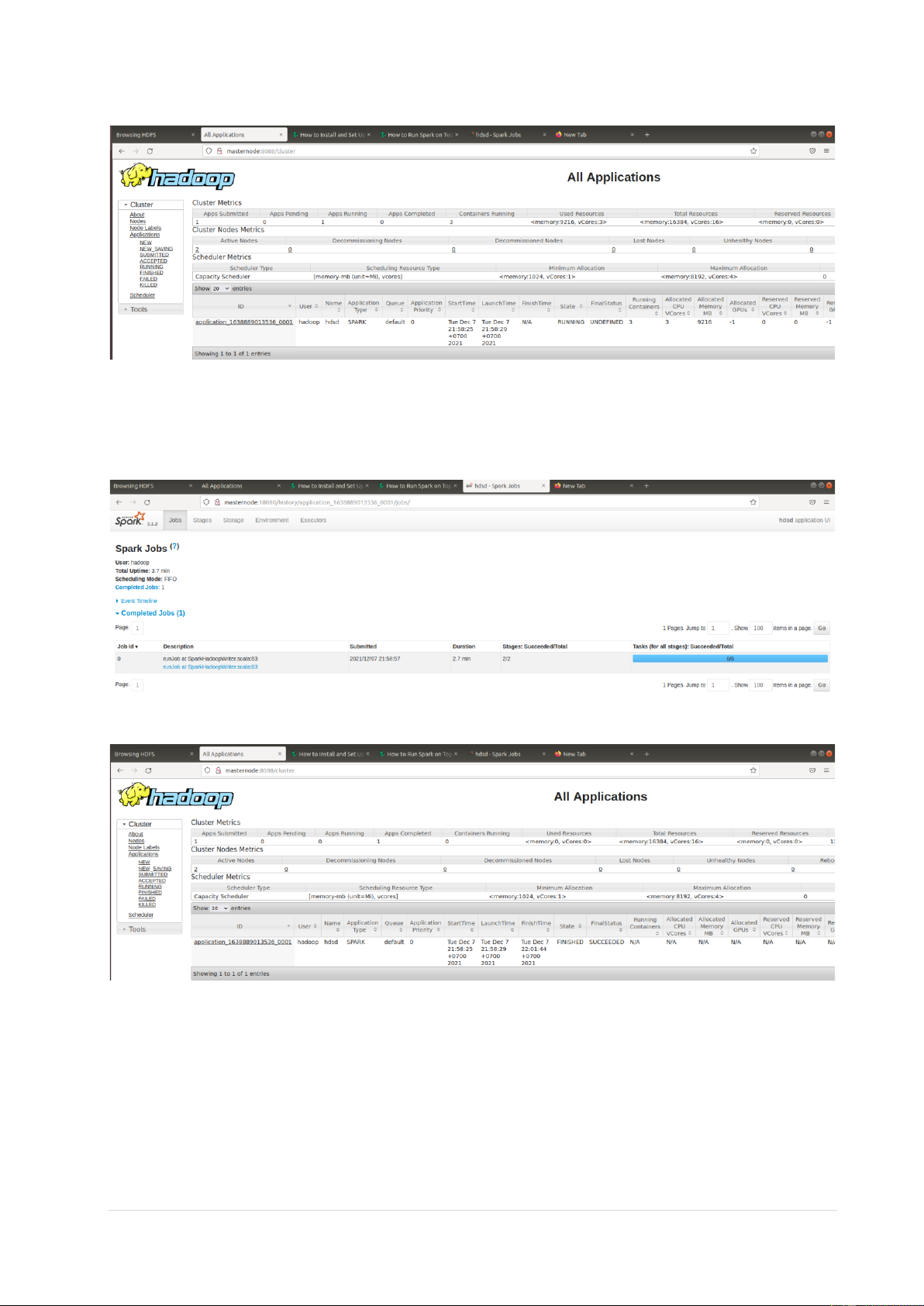
4.1 Job đang ở trạng thái running
• Giao diện Spark History Server 7 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD • Giao diện Hadoop Yarn
4.2 Job đang ở trạng thái finished
• Giao diện Spark History Server • Giao diện Hadoop Yarn 8 | P a g e
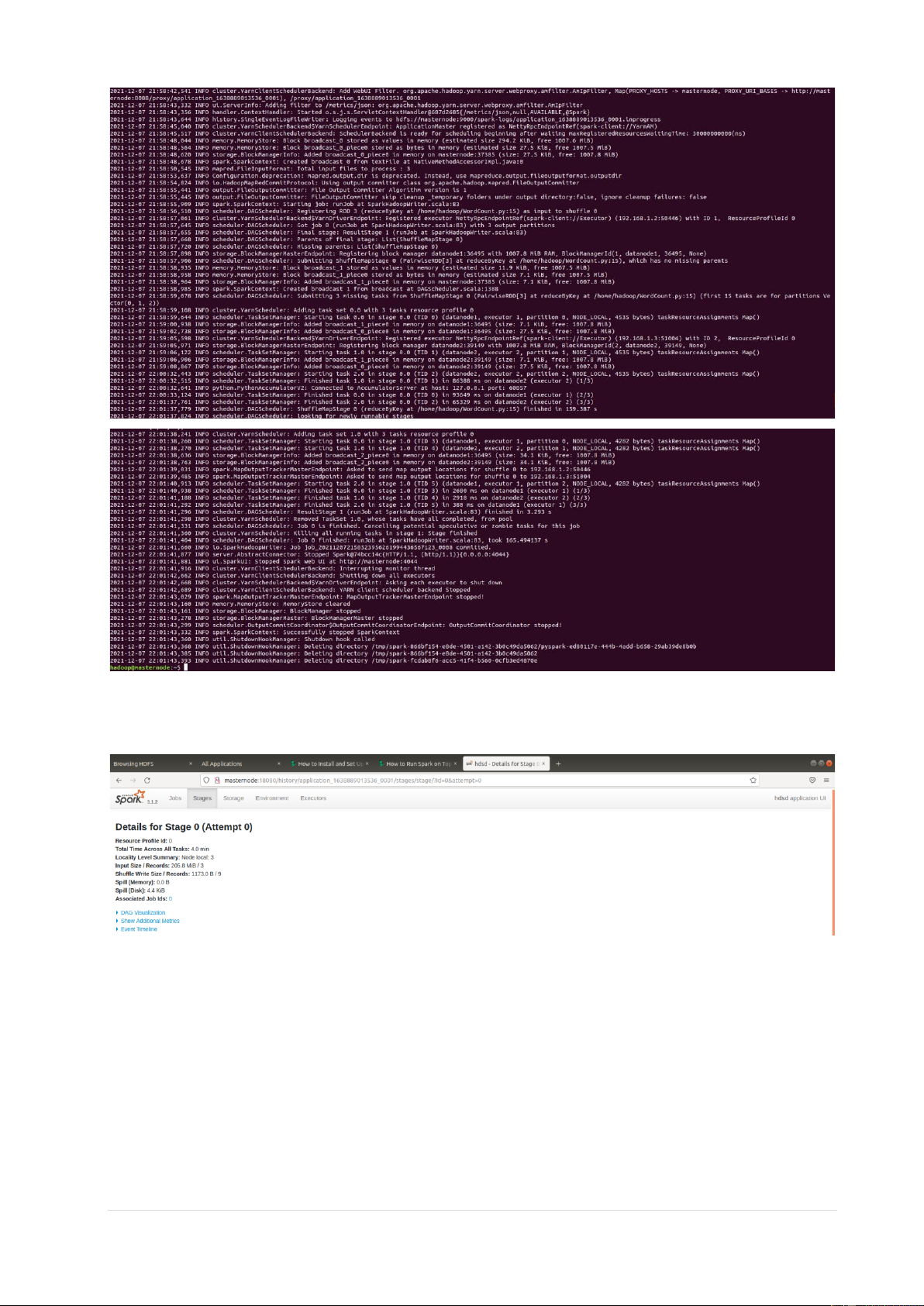
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD 4.3 Quá trình chạy 9 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD 4.4 Kết quả chạy 10 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
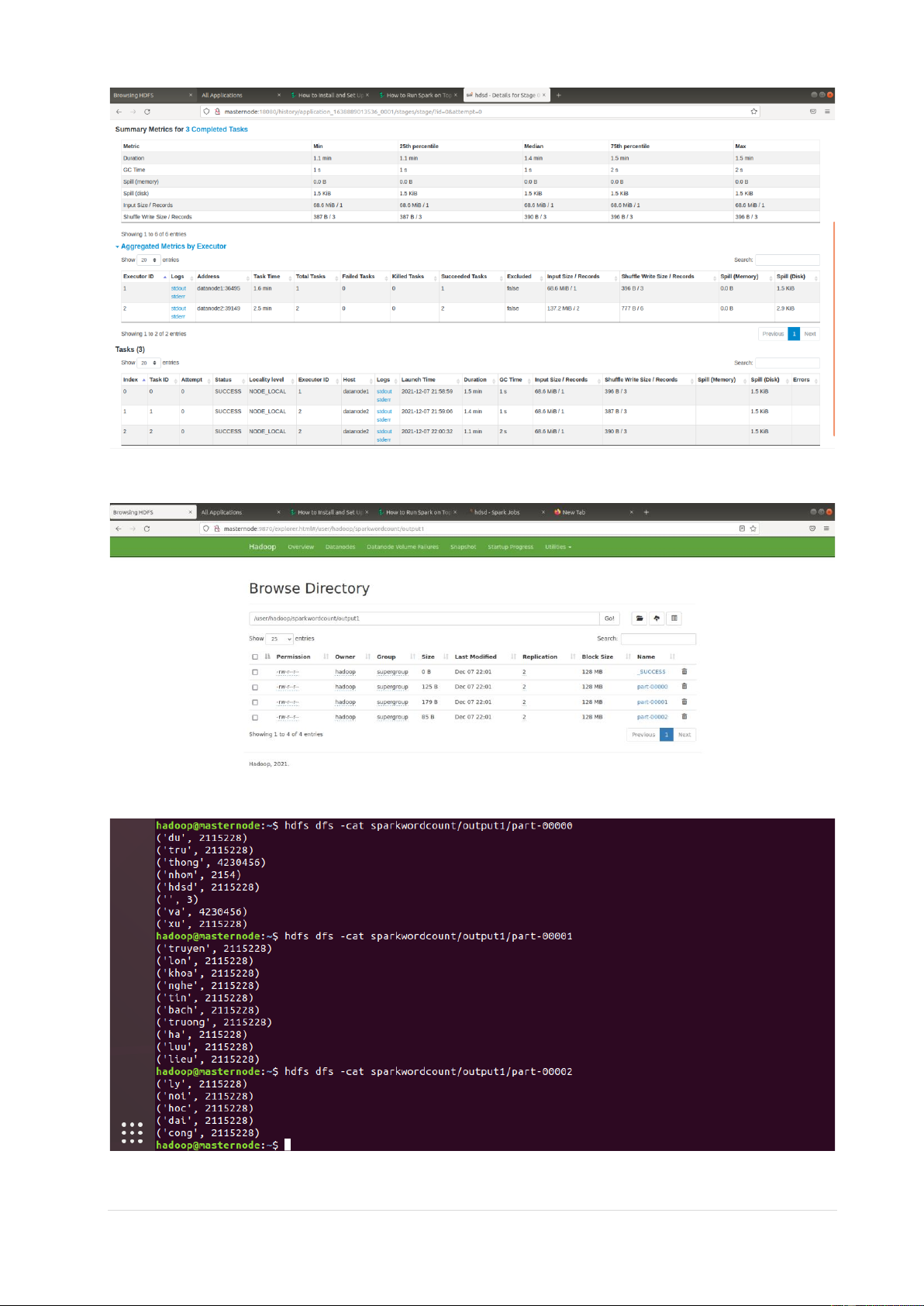
• Kết quả hiển thị trên HDFS
• Đọc file kết quả chạy 11 | P a g e
Tài liệu liên quan:
-

Báo cáo Bài Tập Lớn: Phân Tích Dữ Liệu Thời Tiết | Lưu trữ và xử lý dữ liệu | Trường Đại học Bách Khoa
10 5 -

Xây dựng luồng dữ liệu lưu trữ, xử lý và phân tích giá bất động sản tại Anh từ 1995 | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
46 23 -

TOP câu hỏi trắc nghiệm Môn Lưu trữ và xử lý dữ liệu lớn | Đại học Bách Khoa Hà Nội
55 28 -

Lưu trữ và xử lý, phân tích dữ liệu phim | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
40 20 -

Đề trắc nghiệm BigData và đáp án| Môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
519 260