BTVN và HDSD_Lab05| BT môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
BTVN và HDSD_Lab05| BT môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội. Tài liệu gồm 12 trang giúp bạn ôn tập và đạt kết quả cao trong kỳ thi sắp tới. Mời bạn đọc đón xem.
Môn: Lưu trữ và xử lý dữ liệu lớn 27 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.4 K tài liệu
Tác giả:



Preview text:
ĐẠI HỌC BÁCH KHOA HÀ NỘI
TRƯỜNG CÔNG NGHỆ THÔNG TIN VÀ TRUYỀN THÔNG BÁO CÁO
Lưu trữ và xử lý dữ liệu lớn LAB 05 Nhóm HDSD
Sinh viên thực hiện Mã sinh viên Nguyễn Trọng Hải 20183730 Võ Việt Dũng 20183723 Lê Hữu Tiến Dũng 20183719 Ngô Đình Sáng 20183819
Giảng viên: TS. Đào Thành Chung Hà Nội, 12 – 2021
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD MỤC LỤC
MỤC LỤC ................................................................................................................ 2
1. Cài đặt SPARK trên cụm 3 máy ảo Hadoop Yarn .......................................... 3
2. Chạy chương trình SocketStream ..................................................................... 3
2.1 Tạo file SocketStream.scala .......................................................................... 3
2.2 Tạo file build.sbt ............................................................................................ 4
2.3 Build SocketStream ....................................................................................... 4
2.4 Chạy ví dụ SocketStream ............................................................................. 4
2.5 Kết quả chạy .................................................................................................. 6
3. Chạy chương trình Log Analyzer ...................................................................... 7
3.1 Tạo file ApacheAcessLog.scala .................................................................... 7
3.2 Tạo file LogAnalyzerStreaming.scala ......................................................... 8
3.3 Tạo file build.sbt ............................................................................................ 8
3.3 Tạo file stream.sh .......................................................................................... 9
3.4 Build LogAnalyzerStreaming ...................................................................... 9
3.5 Chạy ví dụ LogAnalyzerStreaming ........................................................... 10
3.6 Kết quả chạy ................................................................................................ 11 2 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
1. Cài đặt SPARK trên cụm 3 máy ảo Hadoop Yarn • masternode: 192.168.1.1 • datanode1: 192.168.1.2 • datanode2: 192.168.1.3 Chú ý:
HADOOP_HOME = /home/hadoop/hadoop
SPARK_HOME = /home/hadoop/spark - Khởi động Hadoop - Khởi động Yarn
- Khởi động Spark History - Cài đặt scala
- Cài đặt sbt: https://www.scala-sbt.org/download.html
2. Chạy chương trình SocketStream
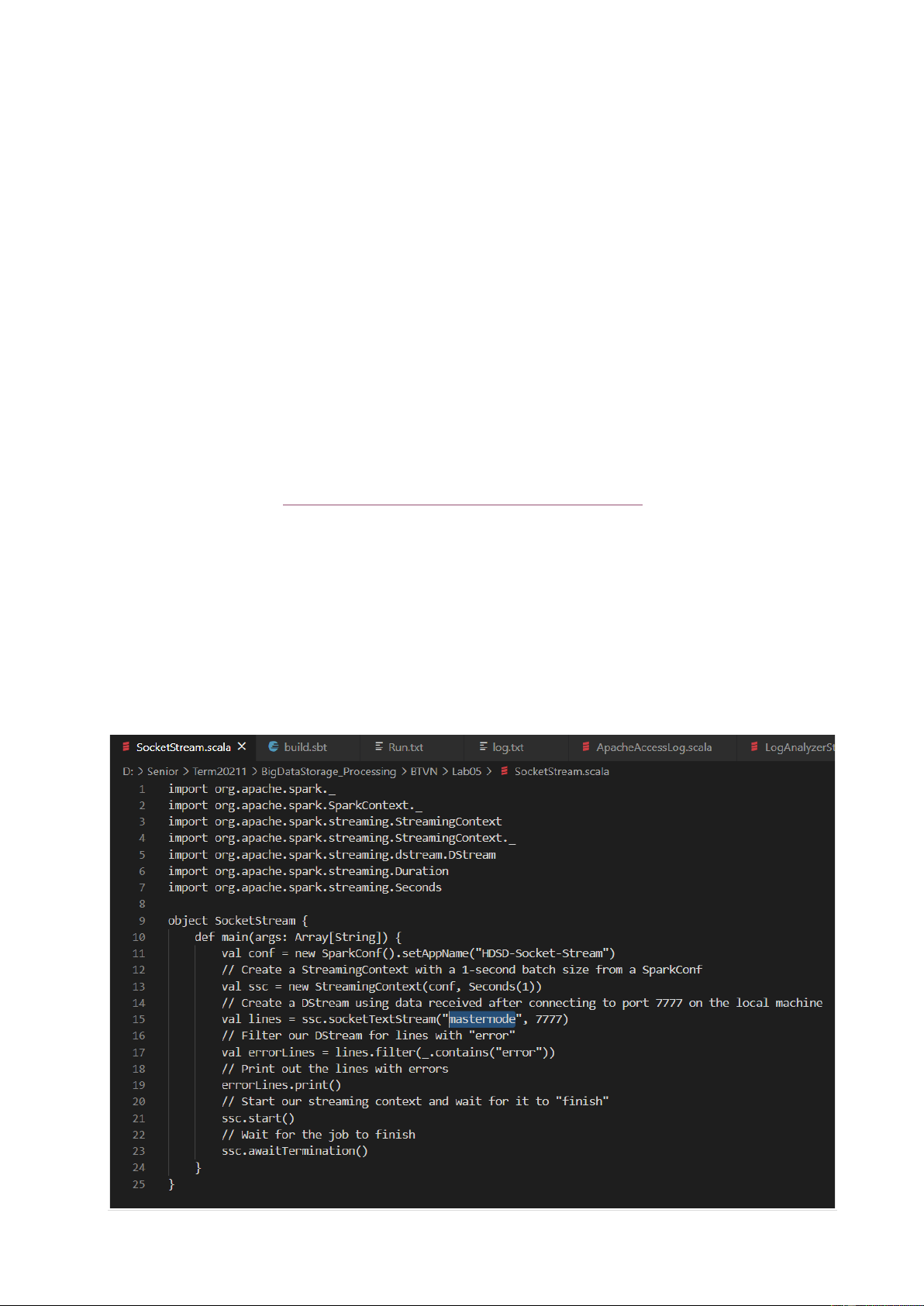
2.1 Tạo file SocketStream.scala
- Tạo file SocketStream.scala trong “$SPARK_HOME/examples/socket- stream/src/main/scala/”.
- Đặt host là “masternode”, port là “7777” trong file SocketStream.scala. 3 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
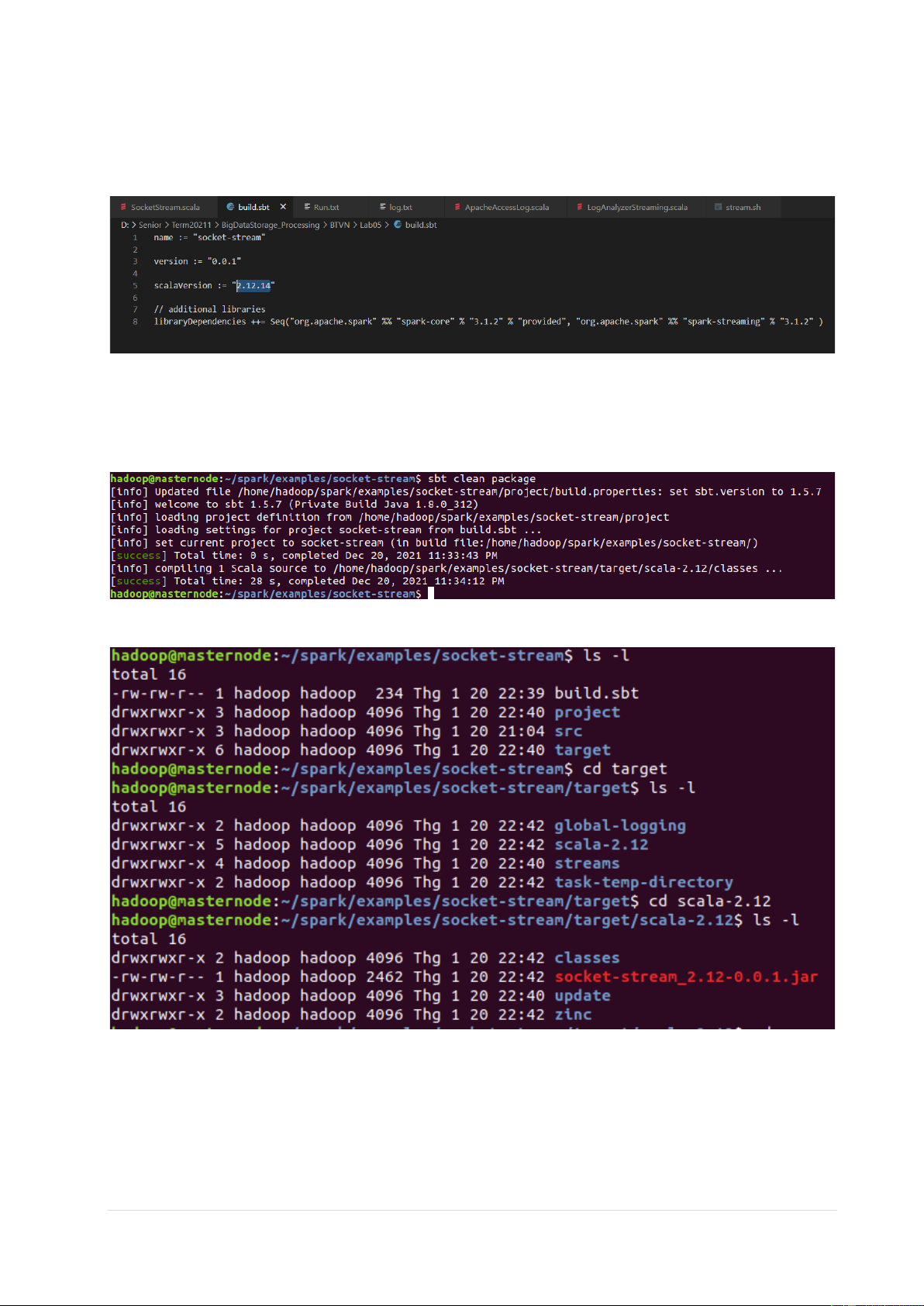
2.2 Tạo file build.sbt
- Tạo file build.sbt trong thư mục “$SPARK_HOME/examples/socket-stream/”.
- Đặt scalaVersion là “2.12.14”, spark-core là “3.1.2”, spark-streaming là “3.1.2”.
- Chạy lệnh trong thư mục “$SPARK_HOME/examples/socket-stream/”. 2.3 Build SocketStream sbt clean package
• Kết quả sau khi chạy lệnh trên
2.4 Chạy ví dụ SocketStream
- Submit và chạy Applications trong Spark
$SPARK_HOME/bin/spark-submit --master yarn --deploy-mode client --class
SocketStream target/scala-2.12/socket-stream_2.12-0.0.1.jar 4 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
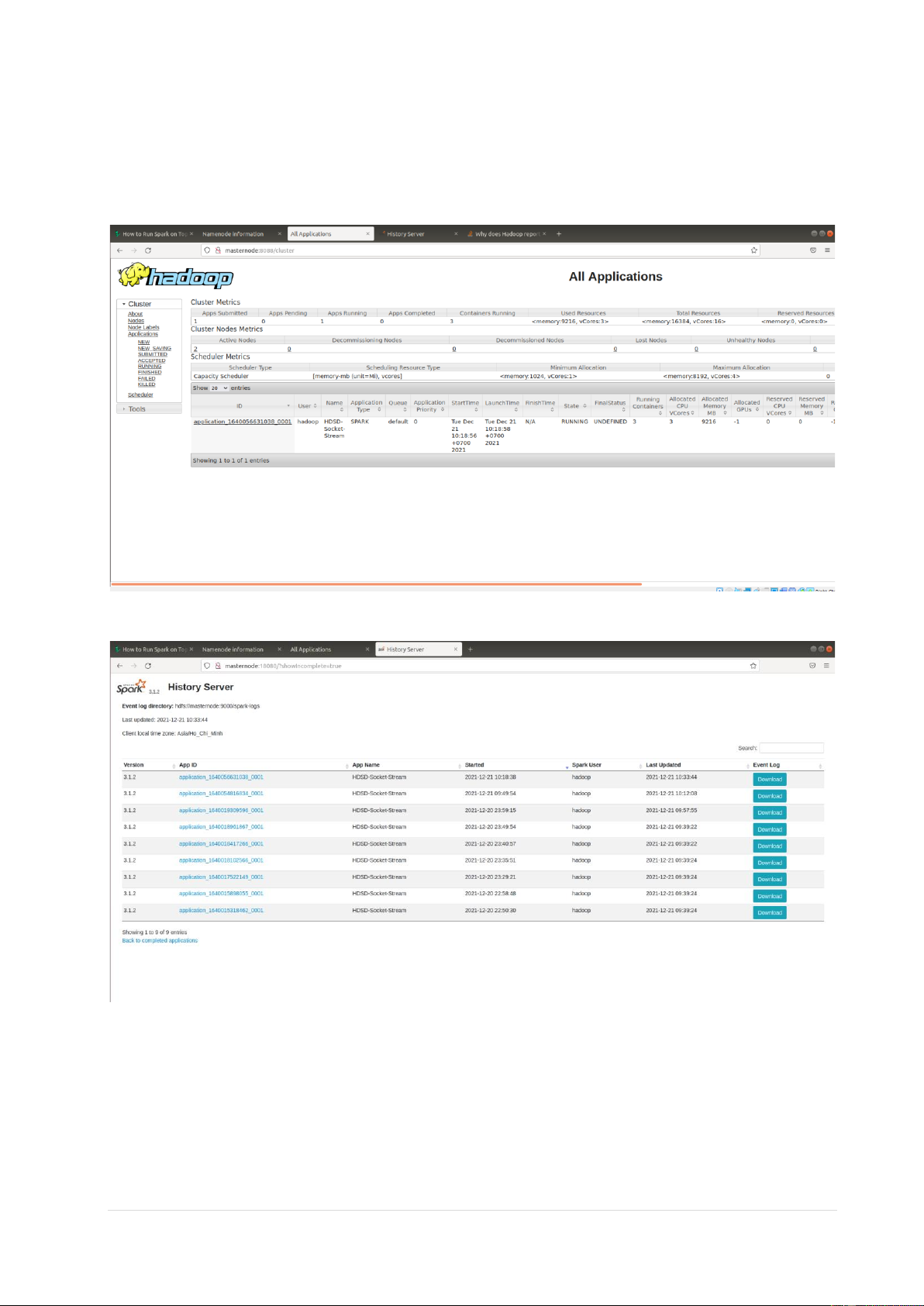
- Khi Applications vào trạng thái Running thì tạo server netcat trên một terminal khác nc -l master -p 7777
• Applications đang chạy, hiện thị trên Yarn
• Applications đang chạy, hiện thị trên Spark History 5 | P a g e
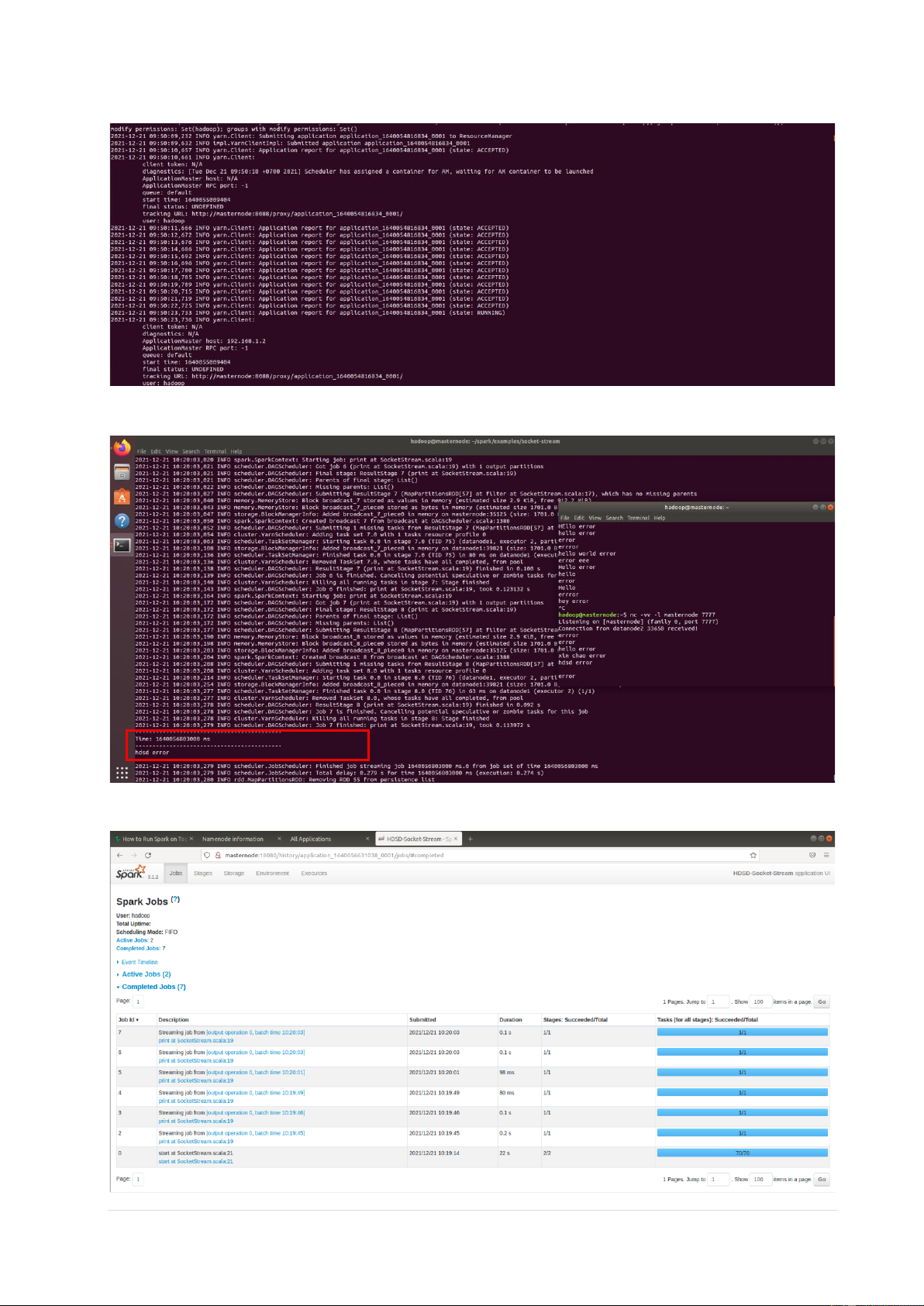
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD 2.5 Kết quả chạy
• Dòng chữ chứa từ “error” được in ra trong Terminal
• 7 jobs đã được hoàn thành (tương ứng với 7 dòng được dữ liệu từ netcat) 6 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
3. Chạy chương trình Log Analyzer
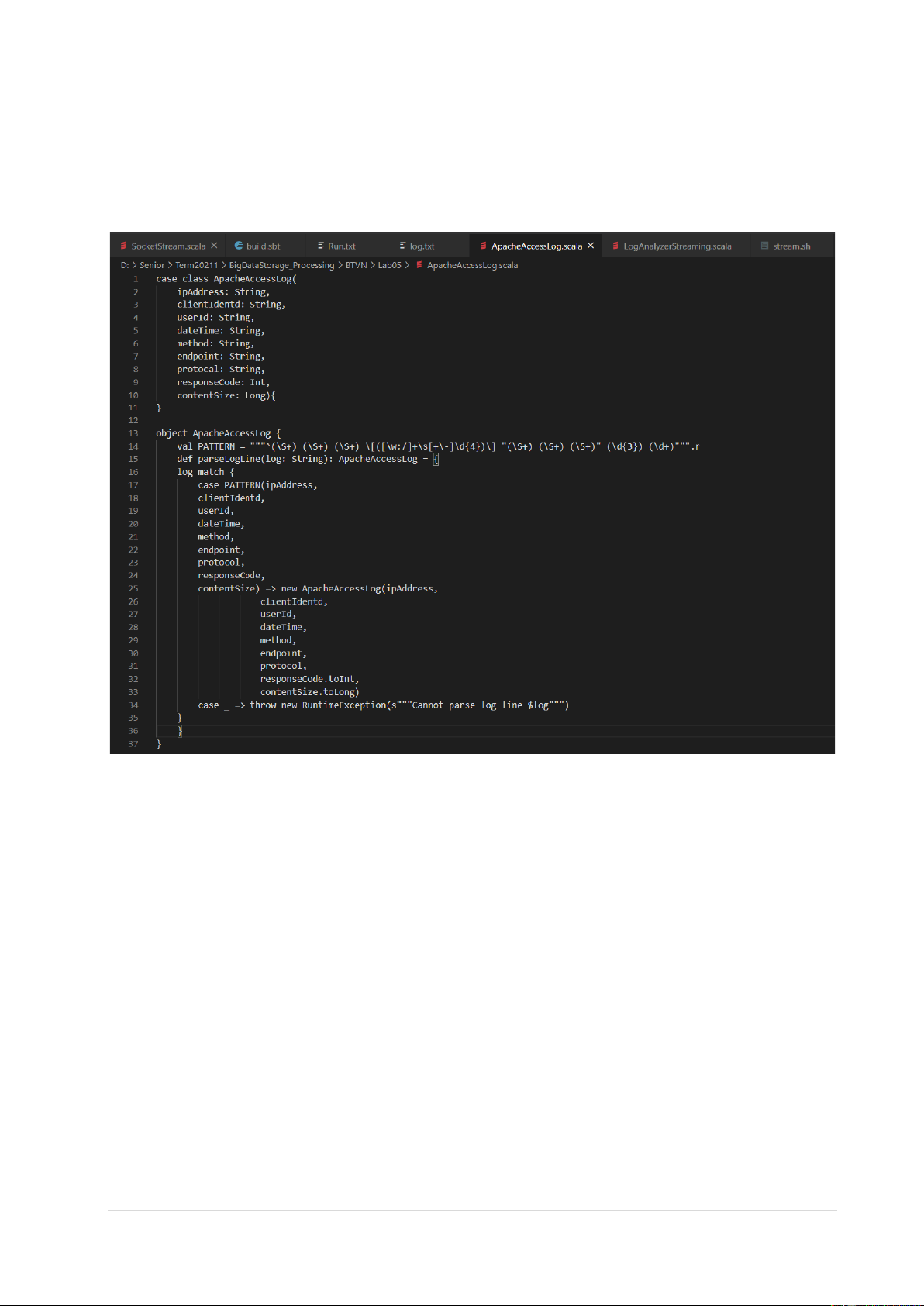
3.1 Tạo file ApacheAcessLog.scala
- Tạo file ApacheAccessLog.scala trong “$SPARK_HOME/examples/logs- analyzer/src/main/scala/”. 7 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
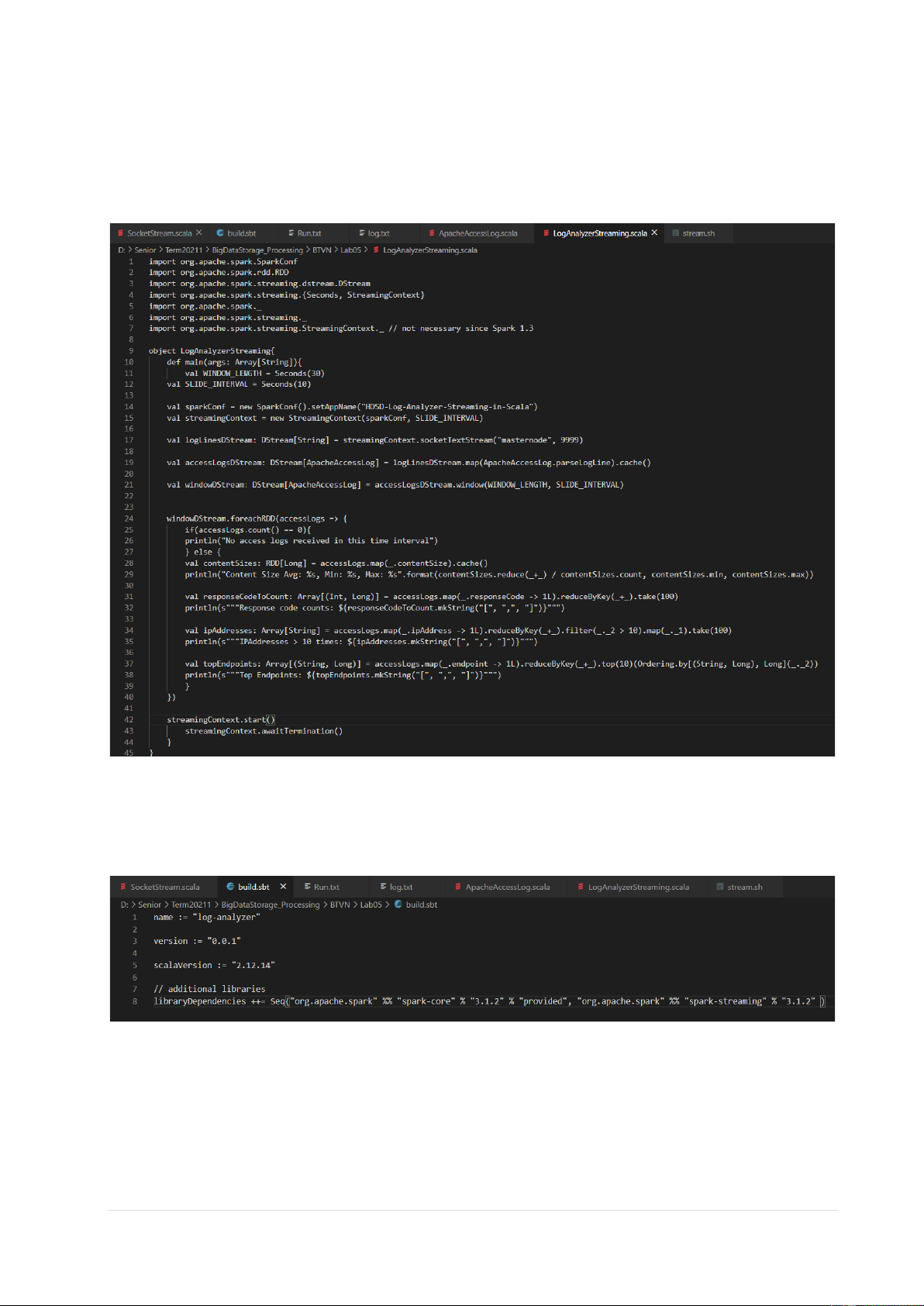
3.2 Tạo file LogAnalyzerStreaming.scala
- Tạo file LogAnalyzerStreaming.scala trong “$SPARK_HOME/examples/logs- analyzer/src/main/scala/”.
- Đặt host là “masternode”, port là “9999” trong file LogAnalyzerStreaming.scala.
3.3 Tạo file build.sbt
- Tạo file build.sbt trong “$SPARK_HOME/examples/logs-analyzer/”.
- Đặt scalaVersion là “2.12.14”, spark-core là “3.1.2”, spark-streaming là “3.1.2”. 8 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
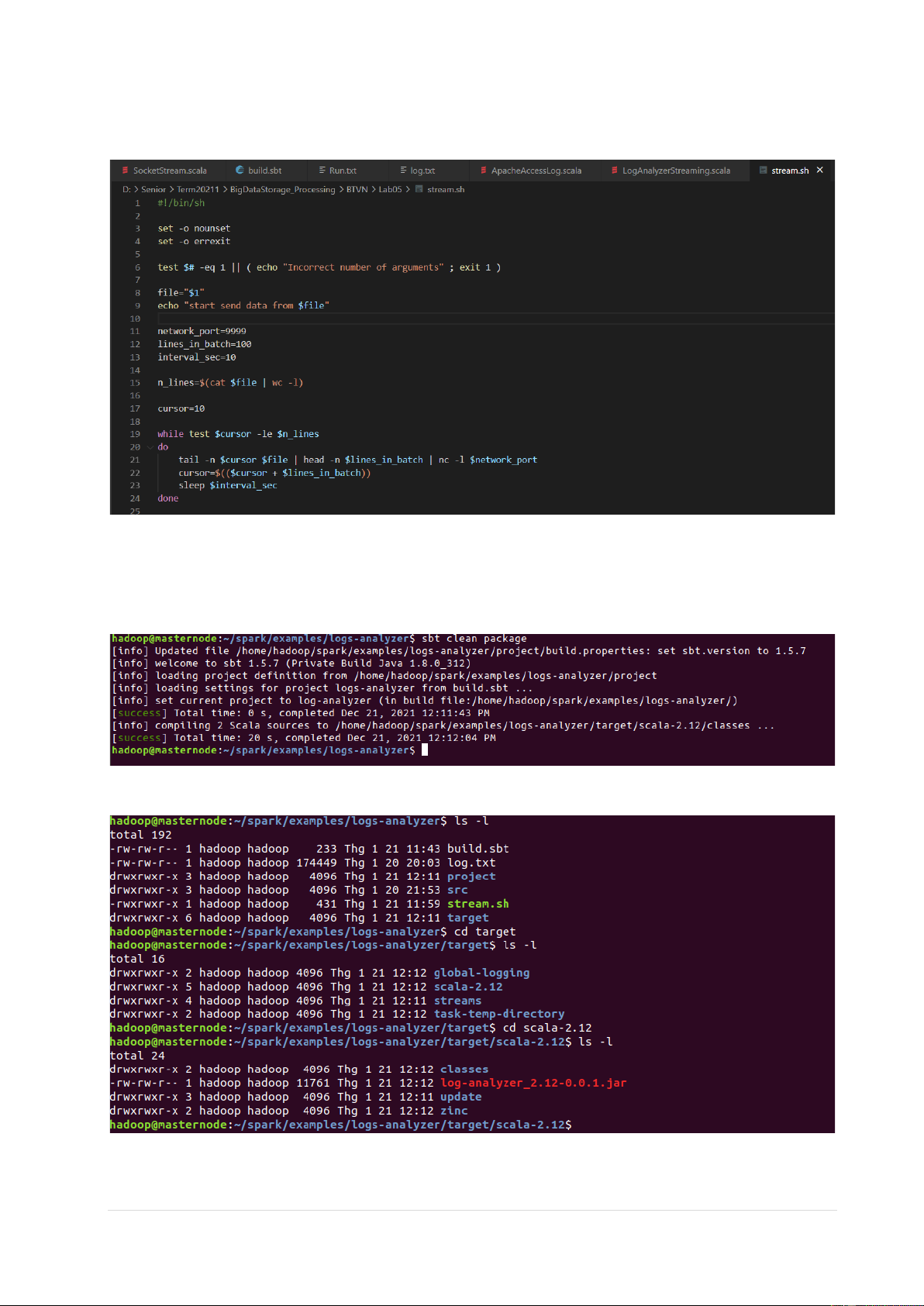
3.3 Tạo file stream.sh
- Tạo file stream.sh trong “$SPARK_HOME/examples/logs-analyzer/”.
3.4 Build LogAnalyzerStreaming
- Chạy lệnh trong thư mục “$SPARK_HOME/examples/logs-analyzer/”. sbt clean package
• Kết quả sau khi chạy lệnh trên 9 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
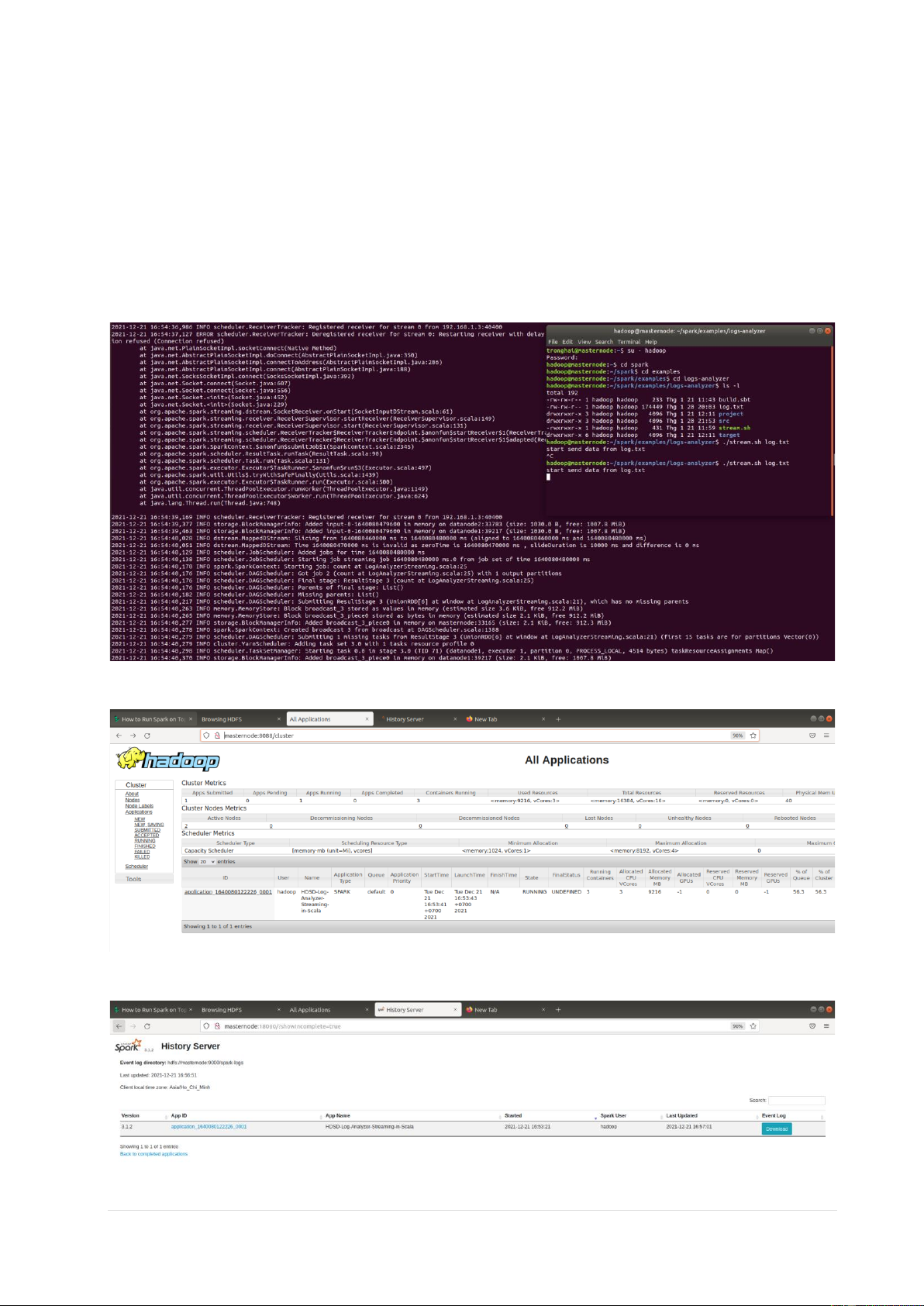
3.5 Chạy ví dụ LogAnalyzerStreaming
- Submit và chạy Applications trong Spark
$SPARK_HOME/bin/spark-submit ---master yarn --deploy-mode client --class
LogAnalyzerStreaming target/scala-2.12/log-analyzer_2.12-0.0.1.jar
- Khi Applications vào trạng thái Running thì tạo server netcat trên một terminal khác ./stream.sh log.txt
• Applications đang chạy, hiện thị trên Yarn
• Applications đang chạy, hiện thị trên Spark History 10 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD 3.6 Kết quả chạy • Content size • Response code counts • IPAddresses > 10 times • Top Endpoints
- Đoạn chương trình lặp lại 3 lần (mỗi lần 10 giây)
- Sau đó, không gửi log.txt nữa 11 | P a g e
Lưu trữ và xử lý dữ liệu lớn Nhóm HDSD
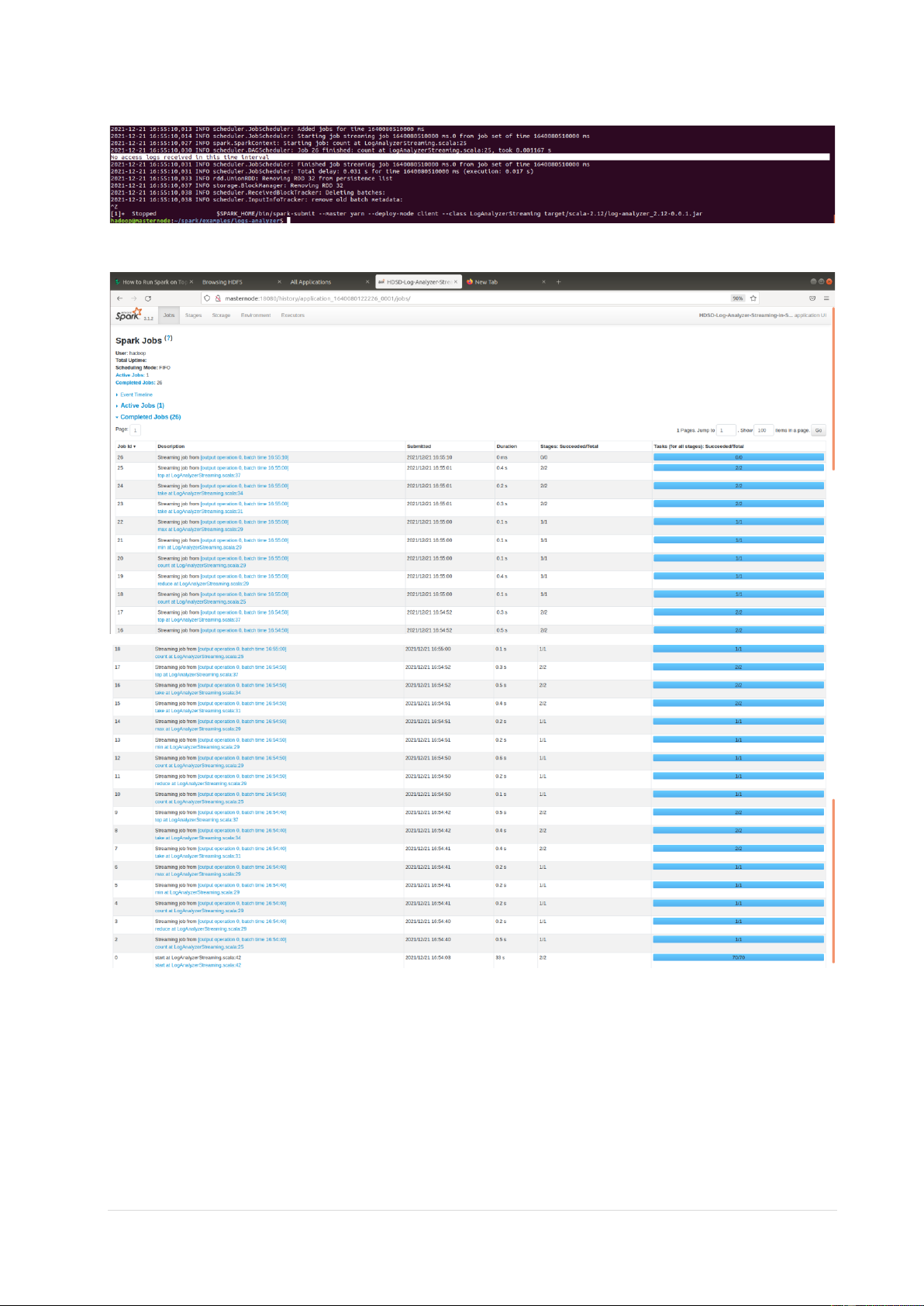
• Chương trình thông báo không nhận được log nữa
• 26 jobs đã được hoàn thành 12 | P a g e
Tài liệu liên quan:
-

Báo cáo Bài Tập Lớn: Phân Tích Dữ Liệu Thời Tiết | Lưu trữ và xử lý dữ liệu | Trường Đại học Bách Khoa
10 5 -

Xây dựng luồng dữ liệu lưu trữ, xử lý và phân tích giá bất động sản tại Anh từ 1995 | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
46 23 -

TOP câu hỏi trắc nghiệm Môn Lưu trữ và xử lý dữ liệu lớn | Đại học Bách Khoa Hà Nội
56 28 -

Lưu trữ và xử lý, phân tích dữ liệu phim | Môn Lưu trữ và xử lý dữ liệu lớn - Đại học Bách Khoa Hà Nội
40 20 -

Đề trắc nghiệm BigData và đáp án| Môn Lưu trữ và xử lý dữ liệu lớn| Trường Đại học Bách Khoa Hà Nội
520 260