Chương 3 Định danh -Tin học đại cương (IT1110) | Trường Đại học Bách khoa Hà Nội
Một hệ phân tán được tạo nên bởi rất nhiều thực thể. Thực thể ở đây có thể là bất cứ gì. Thực thể có thể là một đối tượng, một tiến trình, một máy tính hay một thiết bị, một người dùng, một mạng máy tính, v.v...
Môn: Tin học đại cương 145 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.4 K tài liệu
Tác giả:









Preview text:
lOMoAR cPSD| 27879799 3
CHƯƠNG 3 ĐỊNH DANH
Một hệ phân tán được tạo nên bởi rất nhiều thực thể. Thực thể ở đây có thể là bất cứ
gì. Thực thể có thể là một đối tượng, một tiến trình, một máy tính hay một thiết bị, một
người dùng, một mạng máy tính, v.v... Mỗi thực thể trong hệ thống đều có khả năng
cung ứng các tác vụ nhất định. Ví dụ:
¥ Máy in: tác vụ in ấn, scan, photo, v.v...
¥ CSDL: lưu trữ dữ liệu, truy xuất dữ liệu, v.v...
¥ Một chương trình/tiến trình sẽ chạy một tác vụ được xây dựng trước, như chương
trình soạn thảo văn bản, chương trình nghe nhạc, xem phim, v.v...
Vậy để khai thác được những tác vụ đó, hệ thống cần phải tìm được đến với thực thể.
Tuy nhiên, để đến được với một thực thể, hệ thống cần xác định được vị trí hay địa chỉ
của thực thể. Hệ thống tên giúp chúng ta thực hiện điều đó. Mỗi thực thể đều được gán
một Tên. Hệ thống tên sẽ lấy đầu vào là Tên của thực thể và cung cấp đầu ra là địa
chỉ/vị trí của thực thể. Quá trình đó gọi là phân giải tên.
Tên đóng một vai trò quan trọng trong tất cả các hệ thống máy tính. Chúng được sử
dụng để chia sẻ tài nguyên, nhận dạng duy nhất các thực thể, tham chiếu đến các vị trí,
v.v. Một vấn đề quan trọng khi đặt tên là tên có thể được phân giải theo thực thể mà nó
gắn tới. Do đó, việc phân giải tên cho phép một quá trình truy cập vào thực thể được
đặt tên. Để giải quyết các tên, cần phải có một hệ thống tên. Sự khác biệt giữa việc
phân giải tên trong hệ thống phân tán và hệ thống không phân tán nằm ở cách triển khai hệ thống tên.
Trong một hệ thống phân tán, việc triển khai hệ thống tên thường được phân phối trên
nhiều máy. Cách thức phân phối này đóng một vai trò quan trọng trong tính hiệu quả
và khả năng mở rộng của hệ thống tên. Trong chương này, chúng tôi tập trung vào hai
phương pháp quan trọng khác nhau mà tên được sử dụng trong các hệ thống phân tán.
Hai phương pháp này ứng với hai kiểu không gian tên như sau.
Không gian tên phẳng: Trong các hệ thống không gian tên phẳng như vậy, các thực
thể được tham chiếu bằng một mã định danh mà về nguyên tắc không mang thông tin
về vị trí của thực thể. Ngoài ra, tên phẳng không có cấu trúc, ngụ ý rằng chúng ta cần
các cơ chế đặc biệt để theo dõi vị trí của các thực thể đó. Chúng tôi thảo luận về các lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
cách tiếp cận khác nhau, từ bảng băm phân tán đến dịch vụ định danh phân cấp. Không
gian tên có cấu trúc: Trong thực tế, người dùng thích sử dụng những cái tên dễ đọc.
Những cái tên như vậy thường có cấu trúc, được biết đến thông qua cách nhắc đến các
trang Web. Tên có cấu trúc cho phép tìm kiếm máy chủ chịu trách nhiệm về thực thể
được đặt tên một cách có hệ thống cao, như được minh họa bởi Hệ thống tên miền
(Domain Name System). Chương này sẽ thảo luận về các nguyên tắc chung cũng như
các vấn đề về khả năng mở rộng.
3.1 Khái niệm tên, định danh, và địa chỉ
Như đã nhắc đến ở trên, các hệ thống phân tán được cấu thành bởi rất nhiều các thực
thể. Mỗi thực thể lại có thể cung ứng một số tác vụ nhất định. Vì vậy, để hệ thống có
thể khai thác được hết những tác vụ đó thì cần một cơ chế đến được với thực thể đó từ
tên của thực thể. Hệ thống như vậy được gọi là Hệ thống tên.
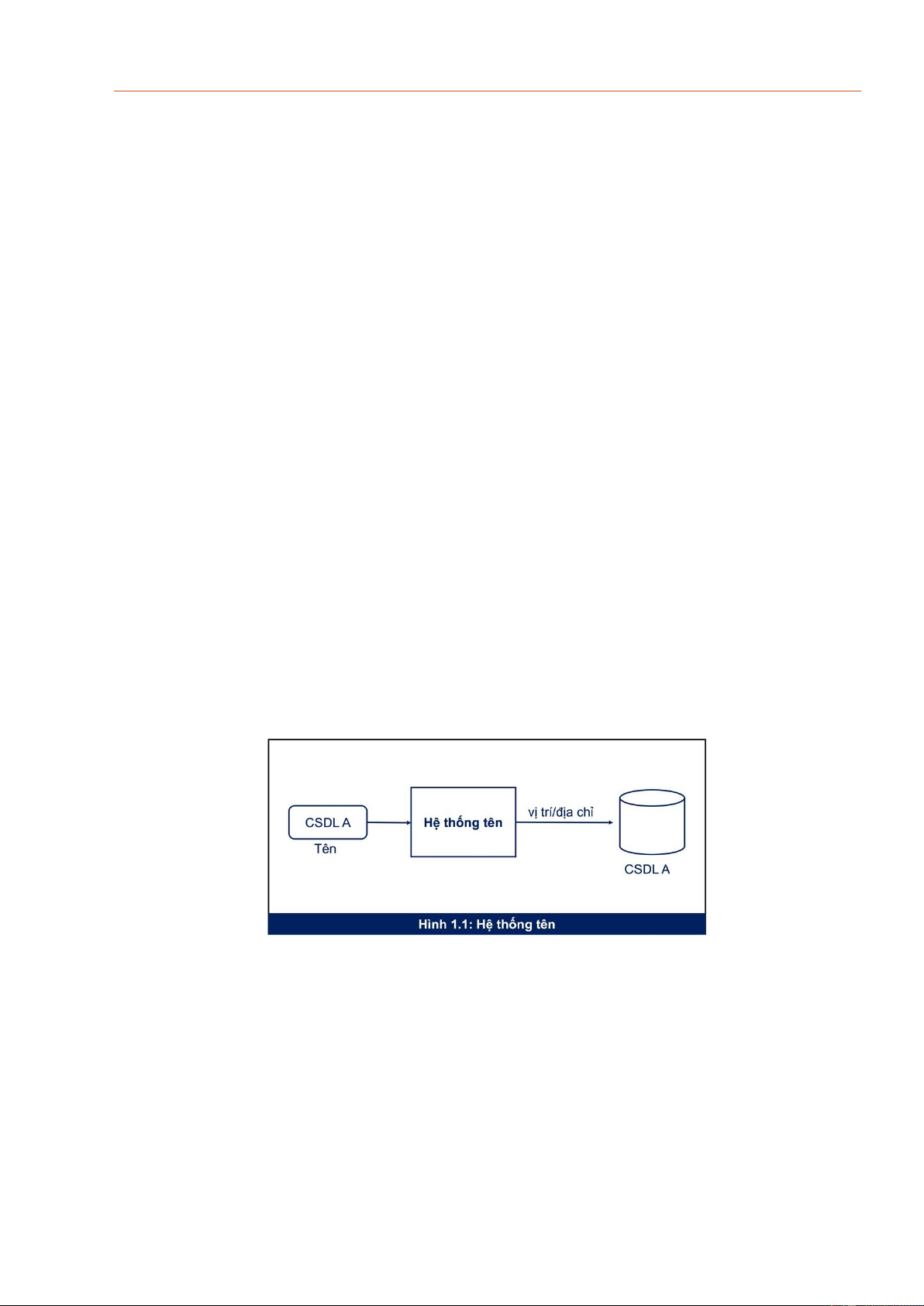
Hình 3.1 mô tả hoạt động của một Hệ thống tên. Chúng ta xét trường hợp thực thể là
một CSDL, tên của CSDL này là A. Tên A của csdl sẽ được đưa vào hệ thống tên như
một đầu vào. Hệ thống tên sẽ thực hiện tìm kiếm và đưa ra vị trí/địa chỉ của CSDL A này. Hình 3.1 Hệ thống tên
Trong các hệ thống phân tán, để có thể truy cập đến một thực thể, trước tiên hệ thống
cần truy cập đến một Điểm truy cập (Access point). Nếu như thực thể được gắn với
một tên thì Điểm truy cập được gắn với một địa chỉ. Chúng ta có thể coi Điểm truy cập
như một dạng đặc biệt của thực thể, và địa chỉ của ĐTC như một dạng đặc biệt của Tên.
Thực thể có thể là bất cứ gì, một đối tượng, một tiến trình, một máy tính hay một thiết
bị, một user, một mạng máy tính, v.v...
Tương tự vậy, nếu xét cả thực thể và điểm truy cập thì: lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Nếu coi thực thể là một đối tượng, thì điểm truy cập là tiến trình chứa đối tượng đó.
Muốn đến được với đối tượng đó thì phải truy cập qua tiến trình tương ứng.
Tương tự, nếu thực thể cần tìm kiếm là một tiến trình, thì điểm truy cập chính là máy
tính đang chứa tiến trình đó. Muốn truy cập tới tiến trình đó thì trước tiên chúng ta phải
truy cập được đến máy tính mà tiến trình đó chạy ở trong.
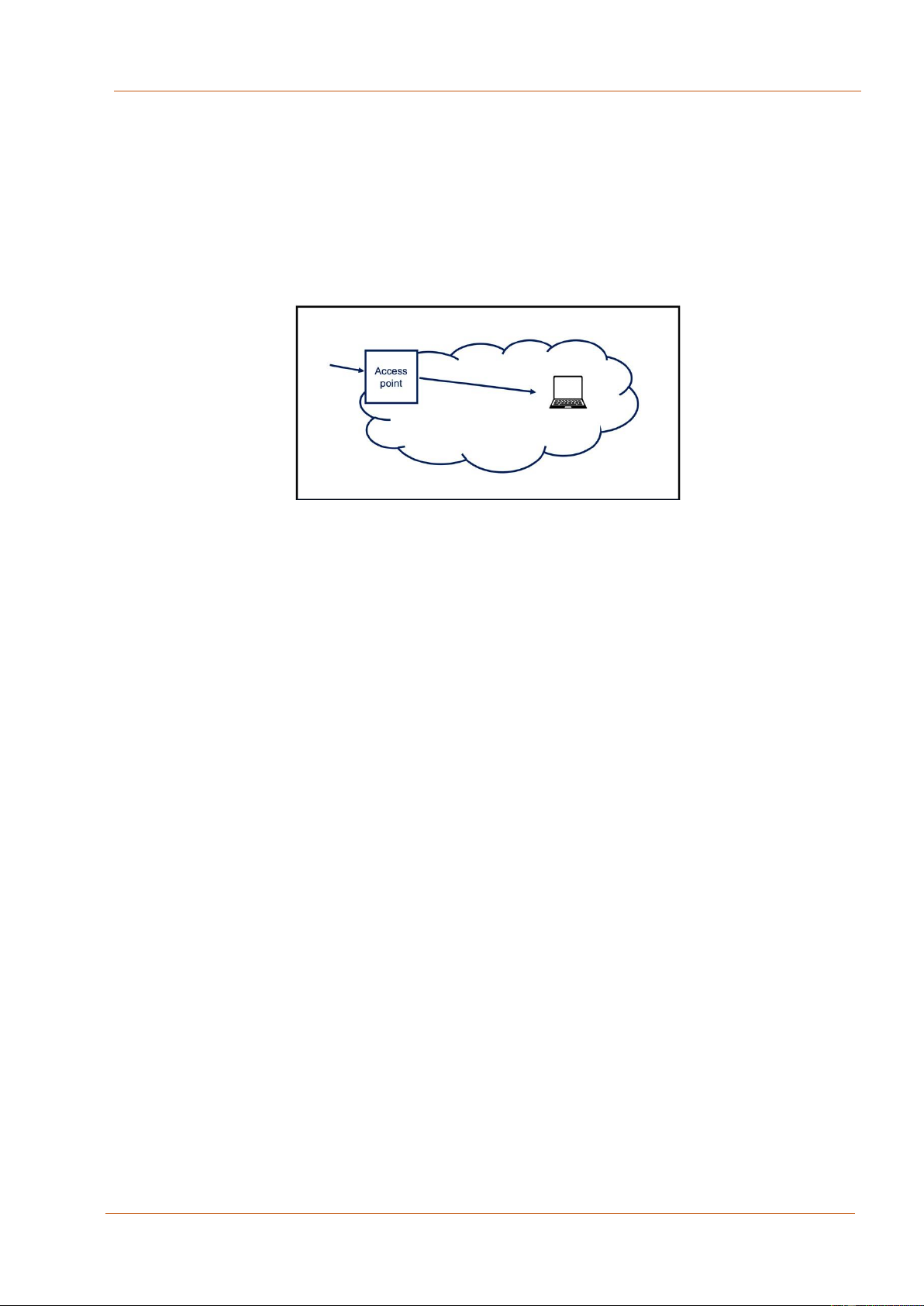
Hình 3.2: Truy cập vào mạng máy tính qua điểm truy cập
Với ví dụ trong hình 3.2, nếu chúng ta coi thực thể là một máy tính thì điểm truy cập
chính là điểm truy cập đến mạng máy tính mà máy tính đó nằm ở trong. Để đến được
với máy tính đó thì các luồng dữ liệu phải được truyền qua điểm truy cập của mạng tương ứng.
Bây giờ, chúng ta sẽ cùng nhau tìm hiểu về mối quan hệ giữa thực thể và điểm truy cập.
Thứ nhất: Thực thể có thể di chuyển qua lại giữa các Access point. Ví dụ như: Các đối
tượng có thể được di chuyển qua lại giữa các tiến trình. Hoặc, các tiến trình có thể di
chuyển qua lại giữa các máy tính (chúng ta gọi khái niệm này là di trú mã – Code
migration). Hoặc một ví dụ nữa mà chúng ta vẫn thực hiện hàng ngày: chúng ta có thể
cầm máy tính xách tay đi đến nhiều nơi như ở nhà, quán cafe, hay cơ quan làm việc,
và kết nối mạng wifi ở mỗi địa điểm đó. Thứ hai: Mỗi access point có thể gắn với nhiều
thực thể. Ví dụ: một tiến trình có thể chứa nhiều đối tượng, một máy tính có thể có
nhiều tiến trình chạy cùng lúc, hay một mạng máy tính có nhiều máy tính tham gia kết
nối. Có thể kết luận đây là quan hệ nhiều-nhiều.
Chính vì vậy, chúng ta không thể sử dụng Điểm truy cập để định danh đích xác được
thực thể. Ví dụ: chúng ta không thể dùng processID để định danh một đối tượng, không 77 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
thể dùng địa chỉ IP của một máy tính để định danh một tiến trình, cũng như không thể
dùng địa chỉ mạng để định danh một máy tính ở trong mạng đó.
Định danh được định nghĩa là một khái niệm cho phép định danh đích xác được một thực thể.
Ví dụ: trong quản lý cư dân, mỗi thẻ CCCD đều có một số định danh chỉ duy nhất cơ
dân đó có. Hay mỗi tiến trình chạy trong máy tính đều có một processID duy nhất. Việc
sử dụng định danh nhằm tránh sự nhập nhằng trong tham chiếu đến các thực thể. Ba
đặc điểm chính của một định danh bao gồm:
¥ 01 định danh trỏ đến nhiều nhất 01 thực thể
¥ Mỗi thực thể chỉ được xác định bởi 01 định danh
¥ Một định danh mãi mãi chỉ trỏ đến 01 thực thể
3 đặc điểm trên đã thể hiện mối quan hệ 1-1 giữa định danh và thực thể. Từ đó khẳng
định có thể sử dụng khái niệm định danh này để định danh đích xác một thực thể. Ví
dụ: ObjectID cho phép định danh đích xác một đối tượng. Cho biết 2 hay nhiều tiến
trình có đang tham chiếu đến cùng một đối tượng hay không.
Xét một hệ thống tên được xây dựng theo mô hình tập trung: cụ thể, chỉ có một máy
chủ tên sử dụng bảng ánh xạ tập trung với mỗi bản ghi là một cặp thông tin tên-địa chỉ.
Mỗi máy khách khi cần tìm địa chỉ thì chỉ việc gửi tên tương ứng lên máy chủ tập trung,
và máy chủ tập trung sẽ tra trong bảng và gửi trả lời địa chỉ tương ứng.
Vấn đề đặt ra với hệ thống tên theo mô hình tập trung là: khả năng mở rộng và vấn đề
thắt nút cổ chai (bottleneck). Cụ thể, nếu số lượng client quá lớn thì máy chủ tập trung
đó sẽ có nguy cơ quá tải.
Vì vậy có thể thấy răng hệ thống tên theo mô hình tập trung là không phù hợp với hệ
thống mạng cỡ lớn. Chúng ta thấy cần thiết phải triển khai các hệ thống tên theo mô hình phân tán.
Một ví dụ cụ thể là hệ thống DNS (Domain Name Service) mà chúng ta vẫn sử dụng
hàng ngày. Hệ thống bao gồm rất nhiều các máy chủ tên được phân tán khắp toàn cầu.
Đồng thời, hệ thống tên theo mô hình phân tán đã đáp ứng tốt các yêu cầu đặt ra đối với một dịch vụ tên:
¥ Qui mô: vô hạn về tên và miền tên lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
¥ Bền vững: chịu được các thay đổi
¥ Sẵn sàng, chịu lỗi, chịu rủi ro bảo mật
3.2 Không gian tên phẳng
Không gian tên phẳng, hay còn gọi là không gian tên không có cấu trúc, là ở đó các tên
của các thực thể đều là những chuỗi bít, chuỗi ký tự không cấu trúc. Những ví dụ điển
hình là: địa chỉ IP của những thiết bị kết nối vào mạng Internet, địa chỉ vật lý (địa chỉ
MAC), ID của các tiến trình đang chạy trong hệ thống, ID của các người dùng đang
truy cập vào hệ thống. Hay như các biển số xe của các phương tiện giao thông, số điện
thoại di động của các thuê bao, v.v...
Tất cả những ví dụ về tên trong không gian tên phẳng trên đều có đặc điểm chung là
chúng đều không có cấu trúc, và không đem lại cho người dùng bất kỳ thông tin nào
về vị trí hiện tại của thực thể. Nhiệm vụ lúc này của các hệ thống tên là phải xác định
được vị trí hiện tại của thực thể với thông tin đầu vào là tên của thực thể. Một số giải
pháp của hệ thống tên mà chúng ta sẽ học trong nội dung này gồm có: ¥ Các giải pháp thông thường
¥ Giải pháp dựa vào Home Agent
¥ Giải pháp dùng bảng băm phân tán (DHT – Distributed Hash Table)
¥ Cách tiếp cận phân cấp
3.2.1 Giải pháp thông thường Cơ chế quảng bá
Đầu tiên, với cơ chế quảng bá, điều kiện để có thể thực hiện được cơ chế này đó là hệ
thống phân tán có hỗ trợ cơ chế trao đổi thông tin thông qua quảng bá. Ví dụ: Mạng
LAN (mạng cục bộ hỗ trợ cơ chế quảng bá, còn mạng Internet thì không). 79 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
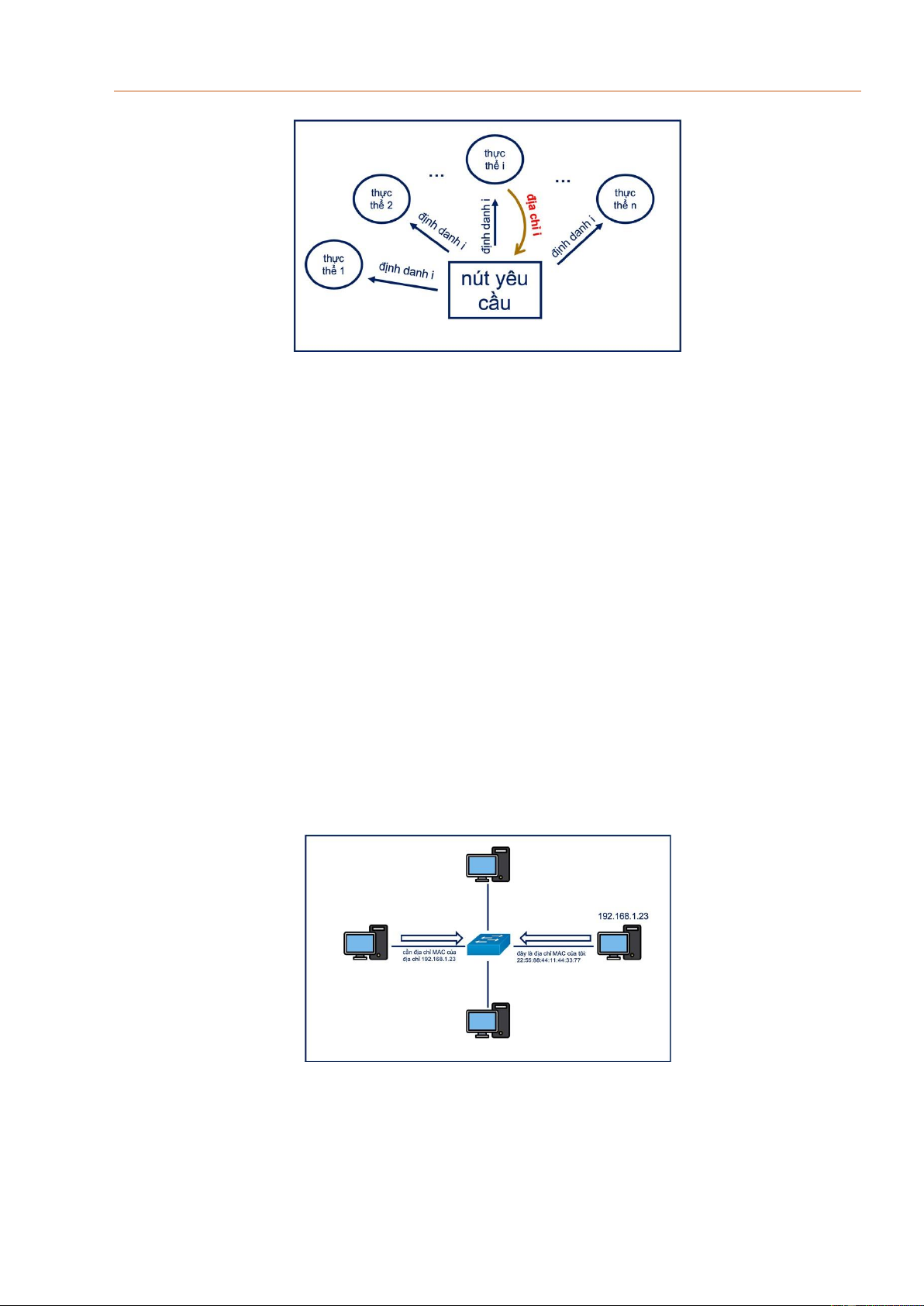
Hình 3.3. Cơ chế quảng bá
Cách thức thực hiện được mô tả trong hình 3.3 Nút yêu cầu sẽ quảng bá thông điệp tìm
kiếm đến tất cả các nút khác, kèm theo định danh của thực thể muốn tìm kiếm. Sau khi
nhận được thông điệp yêu cầu, các thực thể sẽ kiểm tra định danh mình vừa nhận được.
Chỉ thực thể nào có đúng định danh mới gửi thông điệp trả lời nút yêu cầu, trong đó có
kèm theo địa chỉ của thực thể.
Một ví dụ điển hình của cơ chế định danh bằng quảng bá đó chính là giao thức ARP
(Address Resolution Protocol). Chúng ta biết rằng trong mạng cục bộ (LAN), các thiết
bị chỉ sử dụng địa chỉ vật lý (địa chỉ MAC) để trao đổi thông tin với nhau. Vì vậy, cần
một cơ chế để chuyển đổi địa chỉ IP cục bộ sang địa chỉ MAC. Đó chính là vai trò của
giao thức ARP, giao thức này sẽ có nhiệm vụ chuyển đổi địa chỉ IP cục bộ sang địa chỉ MAC. Hình 3.4 Giao thức ARP
Ở trong ví dụ trên hình, khi máy yêu cầu cần chuyển đổi địa chỉ 192.168.1.23 sang địa
chỉ MAC, đầu tiên nó sẽ tra trong bảng ARP table xem có thông tin đó chưa, nếu chưa
có thì nó sẽ gửi thông điệp yêu cầu quảng bá vào mạng. Tất cả các máy tính khác sẽ
nhận được thông điệp yêu cầu này, và kiểm tra xem có đúng địa chỉ IP của mình không. lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Chỉ có máy có địa chỉ IP là 192.168.1.23 mới gửi thông điệp trả lời kèm theo địa chỉ MAC của máy mình.
Máy yêu cầu nhận được thông điệp trả lời thì lưu cặp thông tin địa chỉ IP-địa chỉ MAC
đó vào ARP table để có thể dùng trong các lần sau.
Đặc điểm của cơ chế quảng bá, đó là: -
Đơn giản: mỗi lần nút yêu cầu chỉ cần gửi thông điệp yêu cầu đến tất cả các nút còn lại. -
Tuy nhiên, cơ chế này kém hiệu quả đối với những hệ thống mạng có kích cỡ
lớn - Nó sẽ gây ra sự tốn kém cho tài nguyên của hệ thống như: băng thông của mạng
sẽ bị sử dụng nhiều khi quảng bá, ngoài ra, các thực thể sẽ liên tục phải xử lý các yêu
cầu tìm kiếm các thực thể khác.
– Đặc biệt, cơ chế này sẽ không áp dụng được cho những hệ thống không hỗ trợ quảng
bá, ví dụ: Mạng Internet.
Cơ chế chuyển tiếp con trỏ
Chúng ta cùng tìm hiểu cơ chế tiếp theo, vẫn nằm trong nhóm các giải pháp thông
thường: cơ chế chuyển tiếp con trỏ (Forwarding pointer)
Chúng ta biết rằng các thực thể khi tồn tại trong hệ thống thì chúng có thể dịch chuyển
đi các vị trí khác nhau. Ví dụ: một đối tượng có thể dịch chuyển từ tiến trình này sang
tiến trình khác, một tiến trình có thể dịch chuyển từ máy tính này sang máy tính khác,
hoặc một máy tính có thể dịch chuyển từ mạng này sang mạng khác.
Đứng trước thực tế đó, hệ thống cần có cơ chế để bám theo những sự chuyển động đó.
Cơ chế chuyển tiếp con trỏ là một cơ chế như vậy.
¥ Khi chuyển vị trí: thực thể để lại tham chiếu mới tại địa chỉ cũ, trỏ đến địa chỉ
mới của thực thể. Và quá trình này cứ tiếp tục như vậy.
¥ Hệ thống phải quản lý và duy trì các chuỗi con trỏ
¥ Khi có yêu cầu gửi đến tìm kiếm thực thể, yêu cầu đó sẽ được chuyển tiếp qua
chuỗi con trỏ tương ứng để đến được với vị trí hiện tại của thực thể. 81 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Vấn đề chính của cơ chế chuyển tiếp con trỏ đó là hệ thống hoạt động càng lâu, các
chuỗi con trỏ càng lớn về số lượng và quy mô độ dài, từ đó gây ra tốn kém tài nguyên
để quản lý và duy trì những chuỗi con trỏ đó.
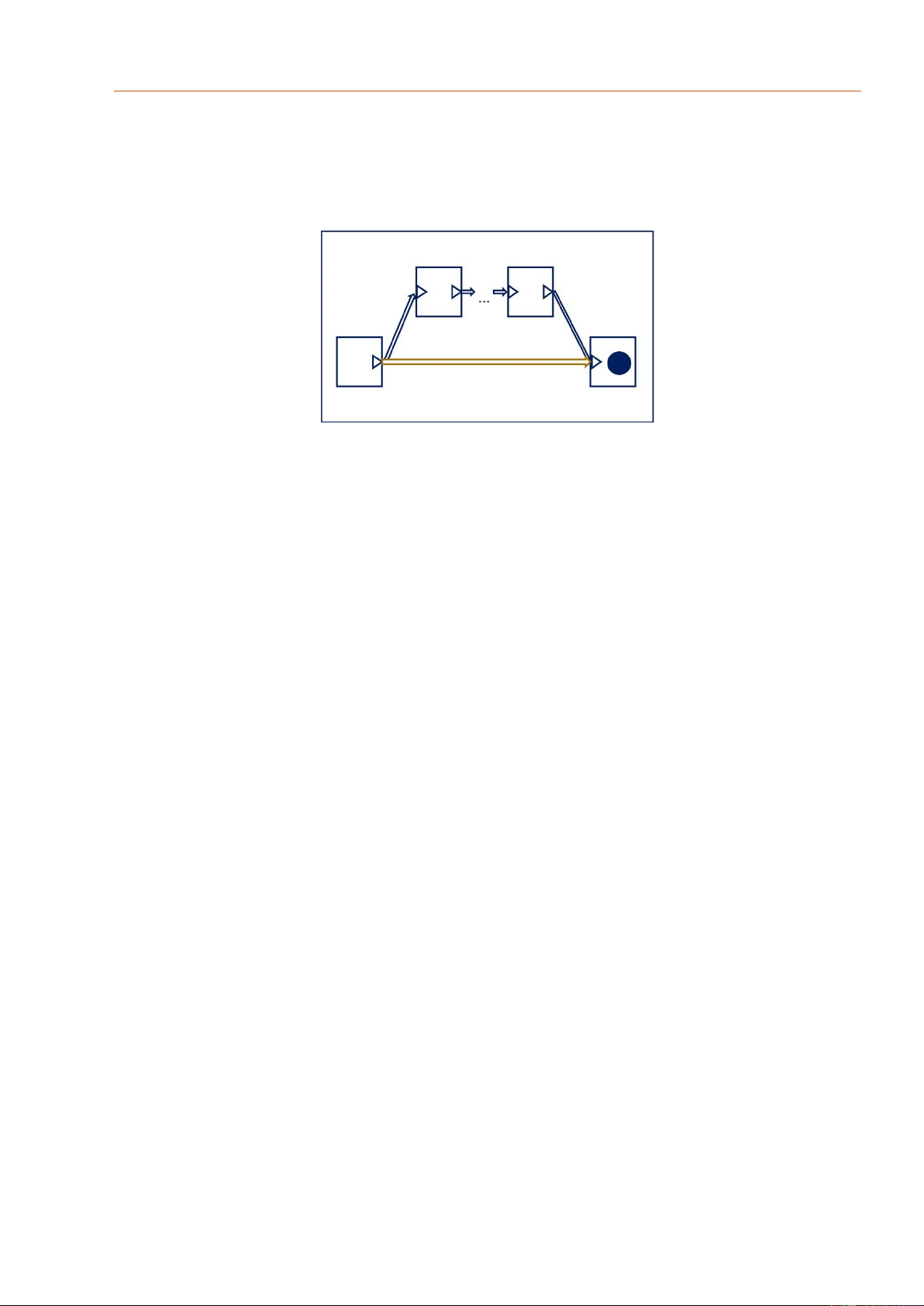
Hình 3.5 Giải pháp tái định hướng con trỏ
Giải pháp đưa ra là tái định hướng con trỏ (Hình 3.5). Cụ thể, sau khi yêu cầu tìm kiếm
đến được với vị trí hiện tại của thực thể, hệ thống sẽ tạo một tham chiếu mới trực tiếp
đến vị trí hiện tại của thực thể đó. Đồng thời, ngắt tham chiếu cũ đi. Với giải pháp này,
các chuỗi con trỏ có độ dài lớn có thể được thu nhỏ dần, giảm hao phí tài nguyên của
hệ thống để quản lý chúng.
3.2.2 Giải pháp dựa trên Home-Agent
Cơ chế hoạt động của giải pháp dựa trên Home Agent được mô tả như sau:
¥ Mỗi thực thể khi sinh ra đều sẽ được gắn với một H.A. H.A đó sẽ có trách nhiệm
lưu trữ thông tin vị trí hiện tại của thực thể đó.
¥ Mỗi lần thực thể di chuyển sẽ gửi thông báo về cho Home agent của mình để
thông báo vị trí hiện tại.
¥ Sau khi nhận được thông báo, Home agent sẽ cập nhật vị trí thực thể trong csld của mình.
¥ Các Client khi muốn tìm thực thể thì gửi yêu cầu đến Home agent. Home agent
sẽ trả lời client thông tin vị trí hiện tại của thực thể, từ đó, client có thể truy cập
đến vị trí hiện tại của thực thể.
Ví dụ điển hình của hệ thống này là hệ thống MobileIP Vấn
đề đối với giải pháp dựa trên H.A đó là: lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Khi thực thể chuyển động ra quá xa H.A, như vậy là một client khi muốn tìm vị trí của
thực thể lại phải gửi một yêu cầu đi rất xa để đến được với H.A tương ứng. Giải pháp
đặt ra là khi thực thể đã ở xa Home agent đủ lâu thì thực thể đó sẽ được gắn với một
Home agent mới gàn với thực thể hơn.
Một nhược điểm khác của phương pháp này là việc sử dụng địa điểm H.A cố định.
Trước hết, phải đảm bảo rằng vị trí H.A luôn tồn tại. Nếu không, việc liên hệ với thực
thể sẽ trở nên bất khả thi. Vấn đề trở nên trầm trọng hơn khi một thực thể tồn tại lâu
dài quyết định di chuyển vĩnh viễn đến một phần hoàn toàn khác của mạng so với nơi
đặt H.A của nó. Trong trường hợp đó, sẽ tốt hơn nếu H.A có thể chuyển đi cùng với chủ nhà.
Một giải pháp cho vấn đề này là đăng ký H.A bằng một dịch vụ đặt tên truyền thống và
để khách hàng tra cứu vị trí của H.A trước tiên. Vì vị trí nhà có thể được coi là tương
đối ổn định nên vị trí đó có thể được lưu vào bộ nhớ đệm một cách hiệu quả sau khi được tra cứu.
3.2.3 Cơ chế bảng băm phân tán
Ở giải pháp này, chúng ta sẽ cùng quay lại xem xét hệ thống Chord.
Mục đích của giải pháp sử dụng hàm băm phân tán là để tối ưu hóa cơ chế tìm kiếm
khóa của các nút trong hệ thống Chord (Hình 3.6).
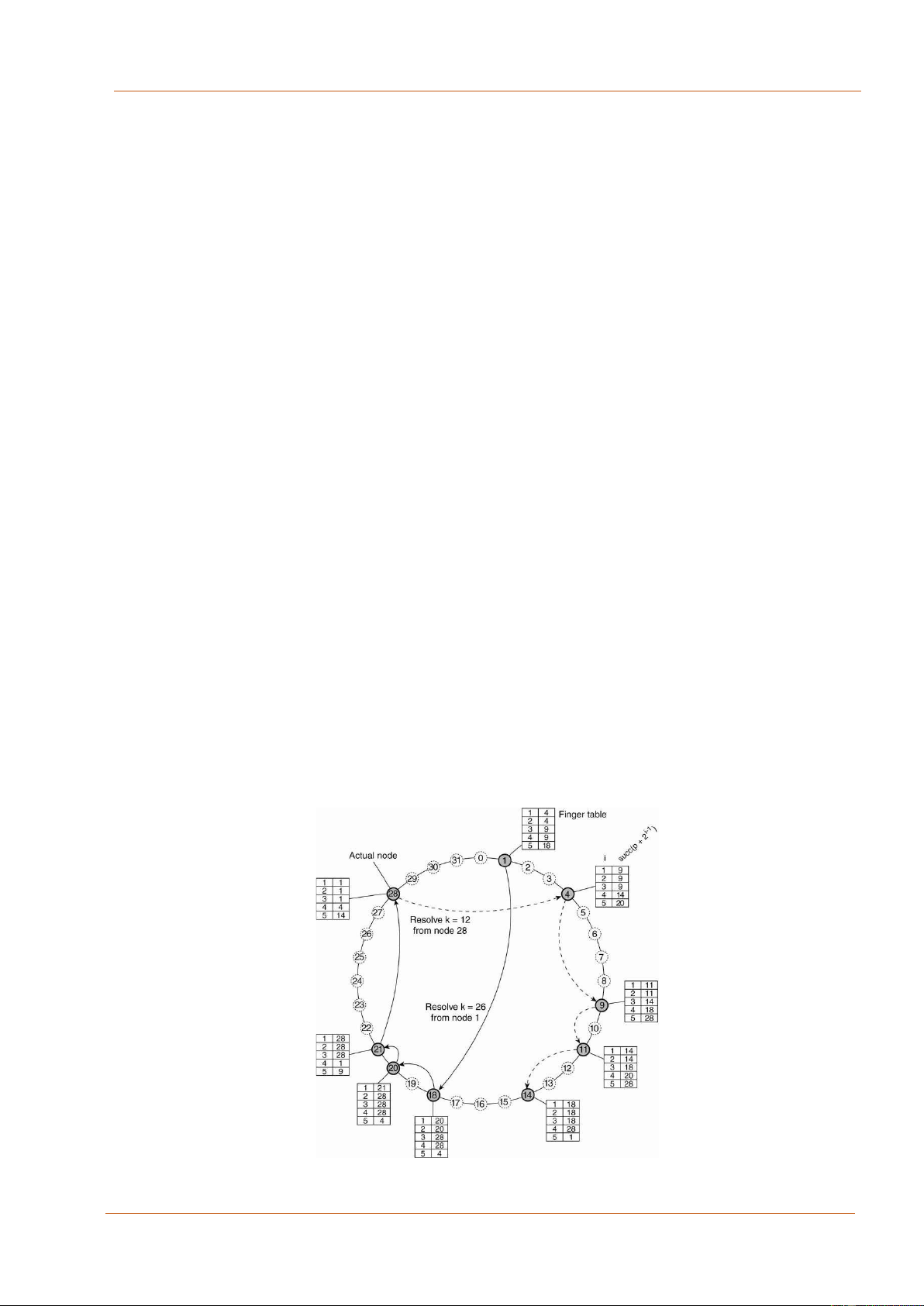
Hình 3.6 Hệ thống Chord sử dụng hàm băm phân tán 83 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Ở đây, mỗi nút màu xám trong mạng overlay sẽ quản lý một bảng Finger table.
Các giá trị trong bảng Fingertable được ghi theo công thức:
!"!#$% & ’())*+ , -"#$./
Sau khi xây dựng được bảng Finger Table, quá trình tìm kiếm sẽ được tối ưu, thay vì
tìm kiếm tuần tự thì sẽ dựa vào đó để thực hiện hiệu quả hơn.
Ví dụ: bắt đầu từ nút số 1, thay vì tuần tự tìm kiếm 1 – 4- 9 – 11 -14-18-20-21-28, thì
ở đây quá trình tìm kiếm sẽ chỉ còn là 1-18-20-21.
3.2.4 Giải pháp phân cấp
Ý tưởng của giải pháp phân cấp đó là trong một không gian không có cấu trúc, chúng
ta sẽ cấu trúc hóa chúng bằng mô hình phân cấp để dễ dàng hơn trong quản lý.
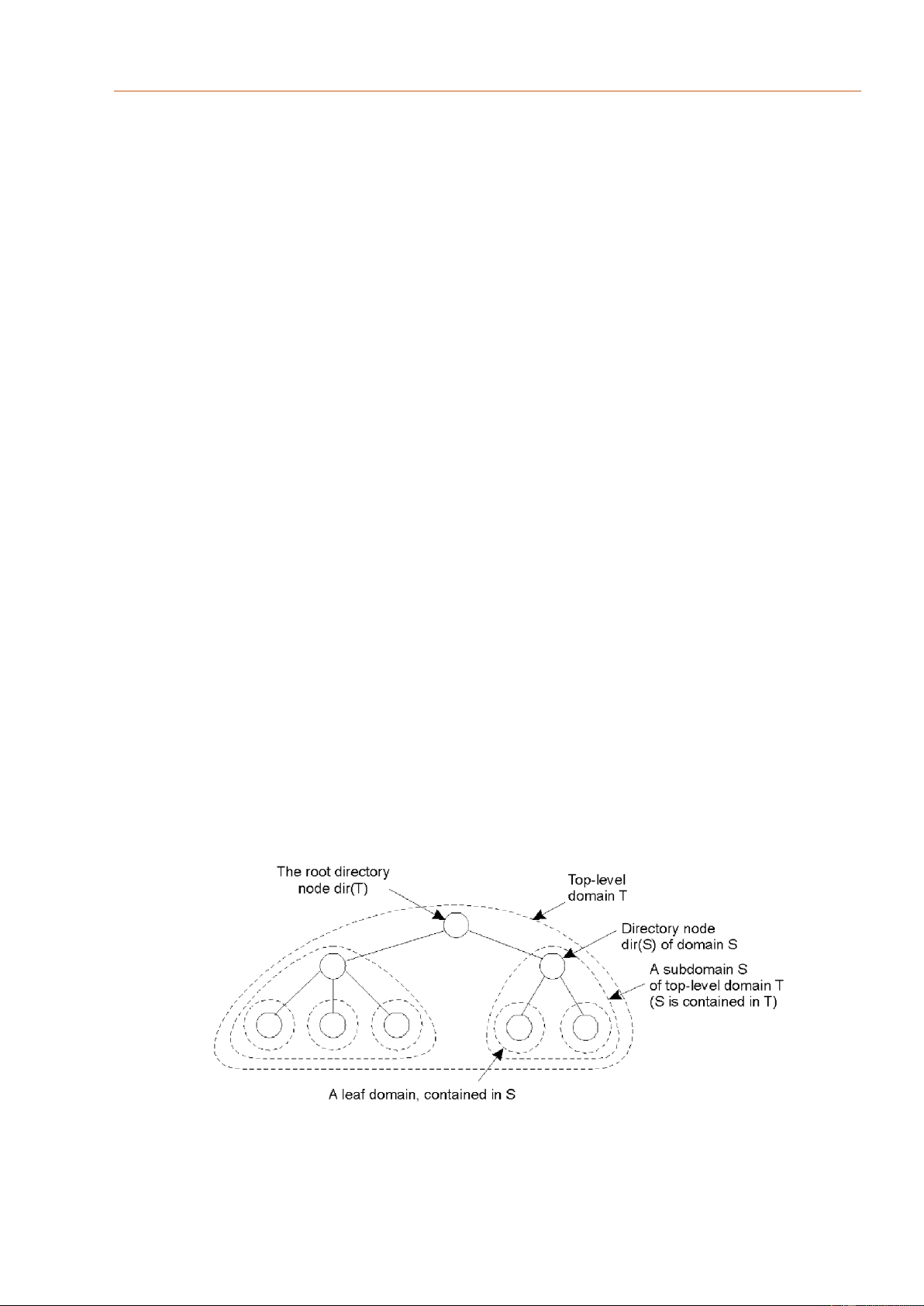
Hình thức tổ chức các domain phân cấp được thực hiện như sau: các thực thể của hệ
thống sẽ được phân vào các domain phân cấp từ cao xuống thấp (hình 3.7). Domain
mức cao nhất được gọi là Top-level domain, và domain cấp thấp nhất được gọi là
domain lá (leaf domain), đây là domain chứa thực thể. Mỗi domain sẽ được quản lý bởi
một nút thư mục (directory node). Nút thư mục mức cao nhất được gọi là nút root. Nút
này sẽ có thông tin của tất cả các thực thể đang nằm ở domain con nào trong domain của mình quản lý.
Hình 3.7 Tổ chức các domain phân cấp
Đầu tiên chúng ta tìm hiểu cơ chế tìm kiểm trong giải pháp phân cấp này.
Nút tìm kiếm sẽ gửi yêu cầu lên cho nút thư mục của ngay domain cấp trên mình. Quá
trình này lặp lại đến bao giờ nút thư mục có thông tin của thực thể cần tìm kiếm. Sau lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
đó yêu cầu được chuyển tiếp xuống domain con tương ứng. Quá trình này tiếp tục được
lặp lại cho đến bao giờ tìm thấy thực thể.
Để tối ưu hơn cho cơ chế tìm kiếm, thông tin của nút thư mục quản lý trực tiếp thực
thể sẽ được lưu lại ở nút phát động tìm kiếm. Từ đó, một lần tìm kiếm trong tương lai
thì yêu cầu sẽ được gửi trực tiếp đến cho nút thư mục kia, rút bớt rất nhiều thời gian tìm kiếm.
Đối với cơ chế cập nhật địa chỉ: Một yêu cầu tạo một địa chỉ cũng sẽ được chuyển tiếp
lên cho nút thư mục của domain cấp ngay trên domain đó. Quá trình này sẽ được lặp
lại đến bao giờ gặp một nút thư mục đã có thông tin của địa chỉ thứ nhất. Quá trình
dừng lại ở đó mà không ghi tiếp lên nữa. Quá trình xóa địa chỉ cũng được diễn ra tương
tự. Yêu cầu xóa sẽ được gửi dần lên cho các domain cấp trên. Quá trình này sẽ được
lặp lại đến bao giờ gặp một nút thư mục đã có thông tin của địa chỉ thứ nhất. Quá trình
dừng lại ở đó mà không xóa tiếp lên nữa.
3.3 Không gian tên có cấu trúc
Tên phẳng phù hợp cho máy tính nhưng nhìn chung không thuận tiện cho con người sử
dụng. Thay vào đó, các hệ thống đặt tên thường hỗ trợ các tên có cấu trúc được tạo
thành từ các tên đơn giản, dễ đọc. Không chỉ việc đặt tên tệp tin mà cả việc đặt tên máy
chủ trên Internet cũng tuân theo cách tiếp cận này. Trong phần này, chúng tôi tập trung
vào các tên có cấu trúc và cách thức phân giải tên có cấu trúc. 3.3.1 Không gian tên
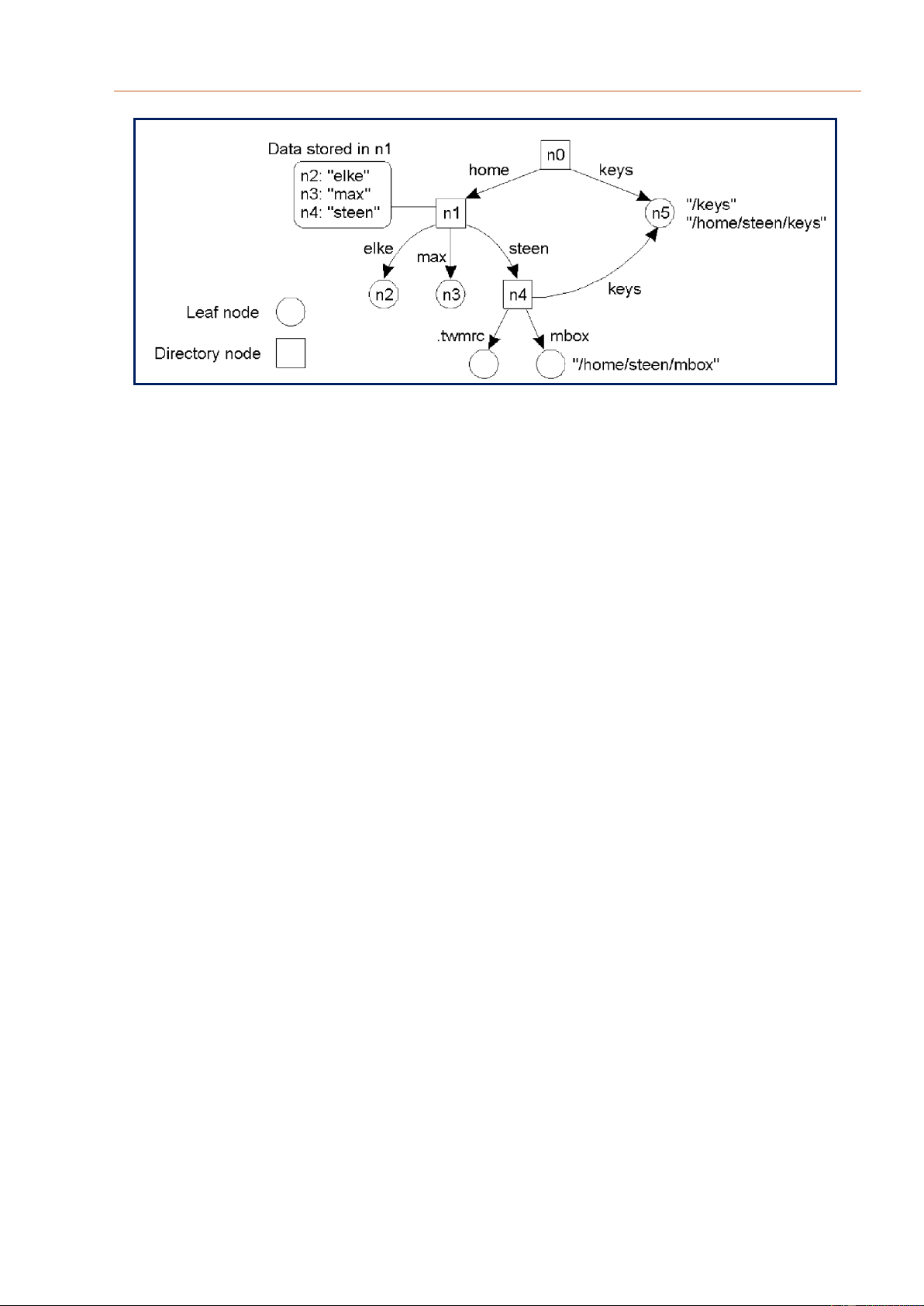
Không gian tên có cấu trúc được biểu diễn tổng quan là một đồ thị có hướng và có dán
nhãn. Có hướng: là vì các liên kết đều có chiều, biểu diễn bởi mũi tên có hướng. Dán
nhãn: là bởi vì mỗi liên kết đều được đặt tên (nhãn). Đồ thị có 2 loại nút: nút lá và nút
thư mục. Nút lá (leaf node) được biễu diễn bởi hình tròn. Nút thư mục được biểu diễn
bởi hình vuông. Nút lá là một loại nút chỉ có liên kết đi vào chứ không có liên kết đi ra. Ví dụ: n2, n3, n5, v.v... 85 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Hình 3.8 Không gian tên có cấu trúc
Ngược lại, nút thư mục là loại nút vừa có liên kết đi vào, vừa có liên kết đi ra. Ví dụ:
n1, n4. Đặc biệt, nút root trên cùng (n0) là nút thư mục chỉ có liên kết đi ra chứ không
có liên kết đi vào. Mỗi nút thư mục lưu trữ thông tin một bảng thư mục (directory table).
Trong bảng thư mục lưu trữ các cặp thông tin: tên của mỗi liên kết đi ra và nút tương
ứng mà liên kết đó trỏ đến. Ví dụ: elke-n2, max-n3, steen-n4. Nhìn chung, đây là không
gian tên tổng quan của không gian tên có cấu trúc. Bất kỳ mô hình hệ thống định danh
nào có cấu trúc cũng đều tuân theo không gian tên này. Ví dụ như: hệ thống tệp trong
Linux, hệ thống DNS.
3.3.2 Phân giải tên
Giả sử trong không gian tên có cấu trúc, chúng ta cần phải phân giải một tên là /home/steen/mbox
Các bước phân giải được mô tả lần lượt như sau:
¥ Xác định được địa chỉ thư mục gốc
¥ Đọc nội dung thư mục gốc
¥ Trong thư mục gốc đó Xác định địa chỉ của home là n1, cụ thể là liên kết home sẽ
gắn với địa chỉ của nút n1 tiếp theo. Yêu cầu được chuyển xuống cho n1.
¥ Đọc nội dung bảng thư mục của n1. Xác định địa chỉ của steen là n4. Yêu cầu
được chuyển tiếp xuống cho nút n4.
¥ Đọc nội dung bảng thư mục của n4. Xác định được được địa chỉ của mbox.
và cuối cùng đã tìm được địa chỉ của thực thể cần tìm kiếm. lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Cơ chế phân giải này là cơ chế chung và tổng quát của tất cả các cơ chế phân giải trong
các hệ thống định danh của không gian tên có cấu trúc. Cả hai ví dụ chúng ta xem xét
trong bài học này và bài học sau đề tuân theo cơ chế chung này: đó là việc phân giải
tên trong hệ thống tệp và phân giải tên trong dịch vụ DNS.
3.3.3 Ứng dụng trong hệ thống tệp Linux
Đầu tiên, chúng ta cùng nhau tìm hiểu cơ chế phân giải tê của hệ thống tệp Linux. Như
đã nói ở trên, cơ chế phân giải tên của hệ thống tệp Linux cũng tuân theo đúng cơ chế
phân giải tên tổng quan trong không gian tên có cấu trúc. Nghĩa là chúng ta sẽ thấy có
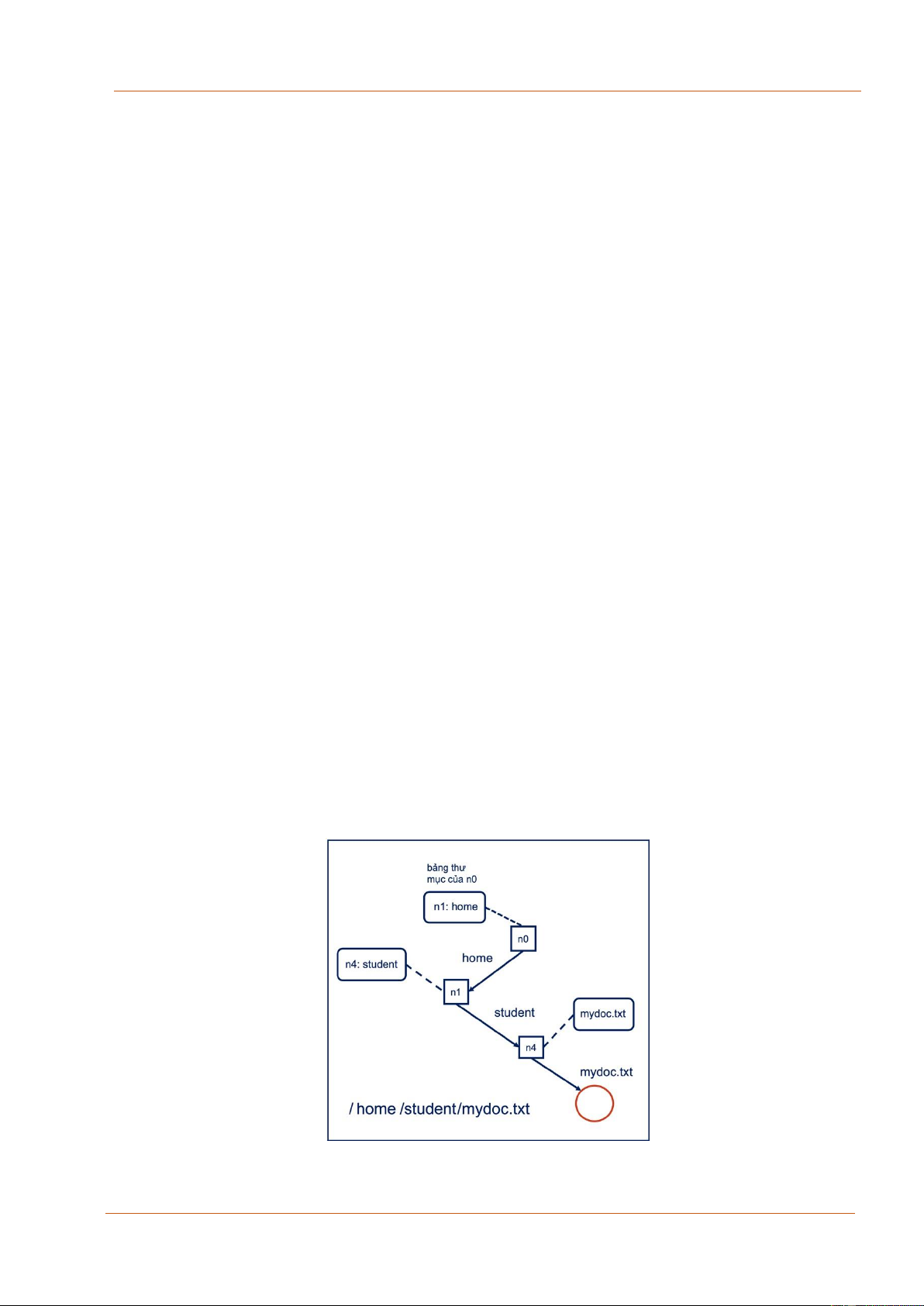
sự tương đồng. Giả sử chúng ta cần xác định tệp với đường dẫn: /home/student/mydoc.txt
¥ Xác định được địa chỉ thư mục gốc
¥ Đọc nội dung thư mục gốc
¥ Trong thư mục gốc đó Xác định địa chỉ của thư mục home là n1, cụ thể là liên kết
home sẽ gắn với địa chỉ của nút n1 tiếp theo. Yêu cầu được chuyển xuống cho n1.
¥ Đọc nội dung bảng thư mục của n1. Xác định địa chỉ của thư mục student là n4.
Yêu cầu được chuyển tiếp xuống cho nút n4.
¥ Đọc nội dung bảng thư mục của n4. Xác định được được địa chỉ của tệp mybox.txt.
Hình 3.9 Cơ chế phân giải tên trong hệ thống tệp Linux 87 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
3.3.4 Cơ chế Mounting và cơ chế Merging
Bây giờ, chúng ta sẽ cùng nhau tìm hiểu cơ chế Mounting (hình 3.10). Cơ chế này giúp
chúng ta có thể truy cập được đến một thực thể nằm trong không gian tên khác. Hình 3.10 Cơ chế Mounting
Trong ví dụ trên hình, chúng ta đã mount một thư mục /remote/vu của máy A đến với
thư mục /home/steen của máy B.
Để làm được điều này chúng ta phải đưa ra được 3 thông tin cho phép Mounting
- Giao thức sử dụng: trong ví dụ này chúng ta sử dụng giao thức NFS
- Địa chỉ của máy B: ở đây chúng ta đã dùng tên miền của máy B là flits.cs.vu.nl
- Đường dẫn cụ thể đến với nút thư mục ở máy B: /home/steen
Như vậy, cứ mỗi lần chúng ta truy cập đến nút /remote/vu là tương tự với việc chúng
ta truy cập đến nút thư mục /home/steen của máy B. Để thực hiện được cơ chế này thì
2 máy phải luôn duy trì kết nối mạng.
Cơ chế tiếp theo chúng ta tìm hiểu ở đây là cơ chế Merging (hình 3.11). Mục đích của
cơ chế này là cho phép chúng ta có thể trộn/ghép hai không gian tên lại với nhau. Giả
sử như ví dụ trên hình, chúng ta cần ghép 2 không gian tên NS1 và NS2. Để làm được
điều này, chúng ta cần tạo ra một nút root mới, sau đó tạo liên kết từ nút root mới đến
2 nút root cũ. Như vậy, chúng ta đã có một không gian tên mới là tổng hợp của hai không gian tên cũ. lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc Hình 3.11 Cơ chế Merging
Tuy nhiên, nhà quản trị hệ thống cần lưu ý khi thực hiện cơ chế trộn này, đó là lúc đó
hệ thống mới tạo ra sẽ có dung lượng lớn bằng tổng hai hệ thống cũ cộng lại, vì thế cần
chú ý tới sự phức tạp cho việc quản lý hệ thống mới.
3.3.5 Phân tán không gian tên cho DNS Một
dịch vụ tên cần đảm bảo 3 chức năng sau:
¥ Đăng ký, loại bỏ các định danh:
¥ Phân giải các định danh
¥ Tìm kiếm các định danh
Chúng ta không thể tổ chức dịch vụ tên dưới dạng tập trung. Giả sử chúng ta có một hệ
thống tên tập trung, tức là có một máy chủ lưu trữ tất cả thông tin liên quan đến cặp
tên-địa chỉ của cả hệ thống. Mỗi lần các máy client cần phân giải tên sẽ gửi yêu cầu
phân giải đến cho máy chủ đó. Máy chủ tập trung sẽ tra cứu trong csdl của mình và gửi
trả thông tin địa chỉ tương ứng. Một hệ thống tên như vậy sẽ không phù hợp cho những
hệ thống cỡ lớn vì gặp vấn đề nút cổ chai (bottle neck). Máy chủ sẽ nhanh chóng bị quá
tải với lượng client và số lượng request nhận được quá lớn.
Vì vậy, hệ thống tên cần tổ chức phân tán trên nhiều máy chủ khác nhau (gọi là máy chủ tên – Name server).
Trong hệ thống DNS, dịch vụ tên vừa phải phân tán các máy chủ tên mà các máy chủ
tên đó vừa phải được tổ chức phân cấp với 3 mức: 89 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Mức toàn thể: được hình thành bởi các nút cấp cao nhất, nghĩa là nút gốc và các nút
thư mục khác có mối liên hệ logic gần với gốc, cụ thể là các nút con của nó. Các nút
trong Mức toàn thể thường được đặc trưng bởi tính ổn định, có nghĩa là bảng thư mục
hiếm khi thay đổi. Những nút như vậy có thể đại diện cho các tổ chức hoặc nhóm các
tổ chức, trong đó các tên được lưu trữ trong không gian tên.
Mức quản trị: Mức quản trị được hình thành bởi các nút thư mục, cùng nhau được
quản lý trong một tổ chức duy nhất. Đặc điểm nổi bật của các nút thư mục trong mức
quản trị là chúng đại diện cho các nhóm thực thể thuộc cùng một tổ chức hoặc đơn vị
quản lý. Ví dụ, có thể có một nút thư mục cho mỗi bộ phận trong một tổ chức, hoặc
một nút thư mục từ đó có thể tìm thấy tất cả các máy chủ. Một nút thư mục khác có thể
được sử dụng làm điểm bắt đầu để đặt tên cho tất cả người dùng, v.v... Các nút trong
mức quản trị có tính ổn định tương đối, tuy nhiên thay đổi thường xảy ra thường xuyên
hơn so với các nút trong mức toàn thể.
Mức quản lý: Mức quản lý bao gồm các nút thường có thể thay đổi thường xuyên. Ví
dụ, các nút đại diện cho máy chủ trong mạng cục bộ thuộc tầng này. Cùng với lý do đó,
tầng này bao gồm các nút đại diện cho các tệp chia sẻ, chẳng hạn như các thư viện hoặc
tệp nhị phân. Một lớp quan trọng khác của các nút bao gồm các nút đại diện cho các
thư mục và tệp tin do người dùng tự định nghĩa. Khác với mức toàn thể và mức quản
trị, các nút trong mức quản lý được duy trì không chỉ bởi các quản trị viên hệ thống mà
còn bởi các người dùng cuối cá nhân của hệ thống phân tán.
Ở mỗi mức sẽ có yêu cầu hiệu năng khác nhau cho các máy chủ tên.
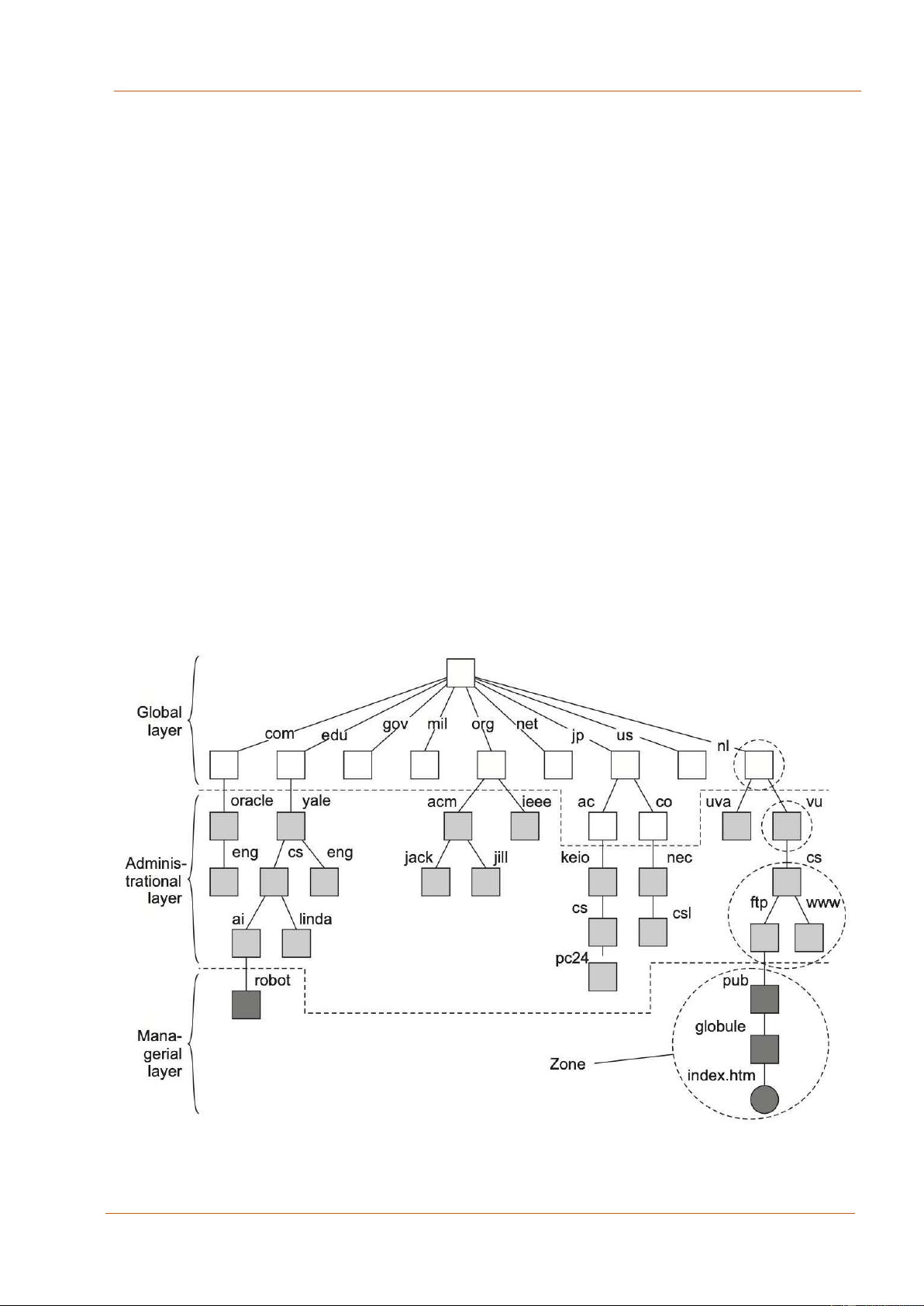
Hình trên thể hiện một ví dụ về việc phân chia một phần không gian tên DNS, bao gồm
các tên tệp tin trong một tổ chức có thể truy cập thông qua Internet, ví dụ như các trang
web và các tệp tin có thể chuyển đổi. Không gian tên được chia thành các phần không
giao lấn nhau, được gọi là vùng trong DNS. Một vùng (zone) là một phần của không
gian tên được triển khai bởi một máy chủ tên riêng biệt. Một số trong các vùng này
được minh họa trong Hình 3.12.
Nếu ta xem xét tính sẵn sàng và hiệu suất, các máy chủ tên trong mỗi mức phải đáp
ứng các yêu cầu khác nhau. Tính sẵn sàng cao cấp đặc biệt quan trọng đối với các máy
chủ tên trong mức toàn thể. Nếu một máy chủ tên gặp sự cố, một phần lớn không gian lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
tên sẽ không thể tiếp cận được vì quá trình giải quyết tên không thể tiếp tục vượt qua máy chủ gặp sự cố.
Xét về hiệu suất thì phức tạp hơn. Do tốc độ thay đổi thấp của các nút trong mức toàn
thể, kết quả của các hoạt động tra cứu thường được giữ nguyên hiệu lực trong thời gian
dài. Do đó, các kết quả đó có thể được sử dụng bộ nhớ đệm một cách hiệu quả (tức là
được lưu trữ cục bộ) bởi các máy client. Lần tiếp theo khi thực hiện cùng một hoạt
động tra cứu, kết quả có thể được truy xuất từ bộ nhớ đệm của máy client thay vì để
máy chủ tên trả về kết quả. Do đó, các máy chủ tên trong mức toàn thể không cần phải
phản hồi nhanh chóng đối với một yêu cầu tra cứu duy nhất. Tuy nhiên, lưu lượng có
thể quan trọng, đặc biệt trong các hệ thống quy mô lớn với hàng triệu người dùng.
Hình 3.12: Không gian tên DNS với 3 lớp phân cấp 91 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
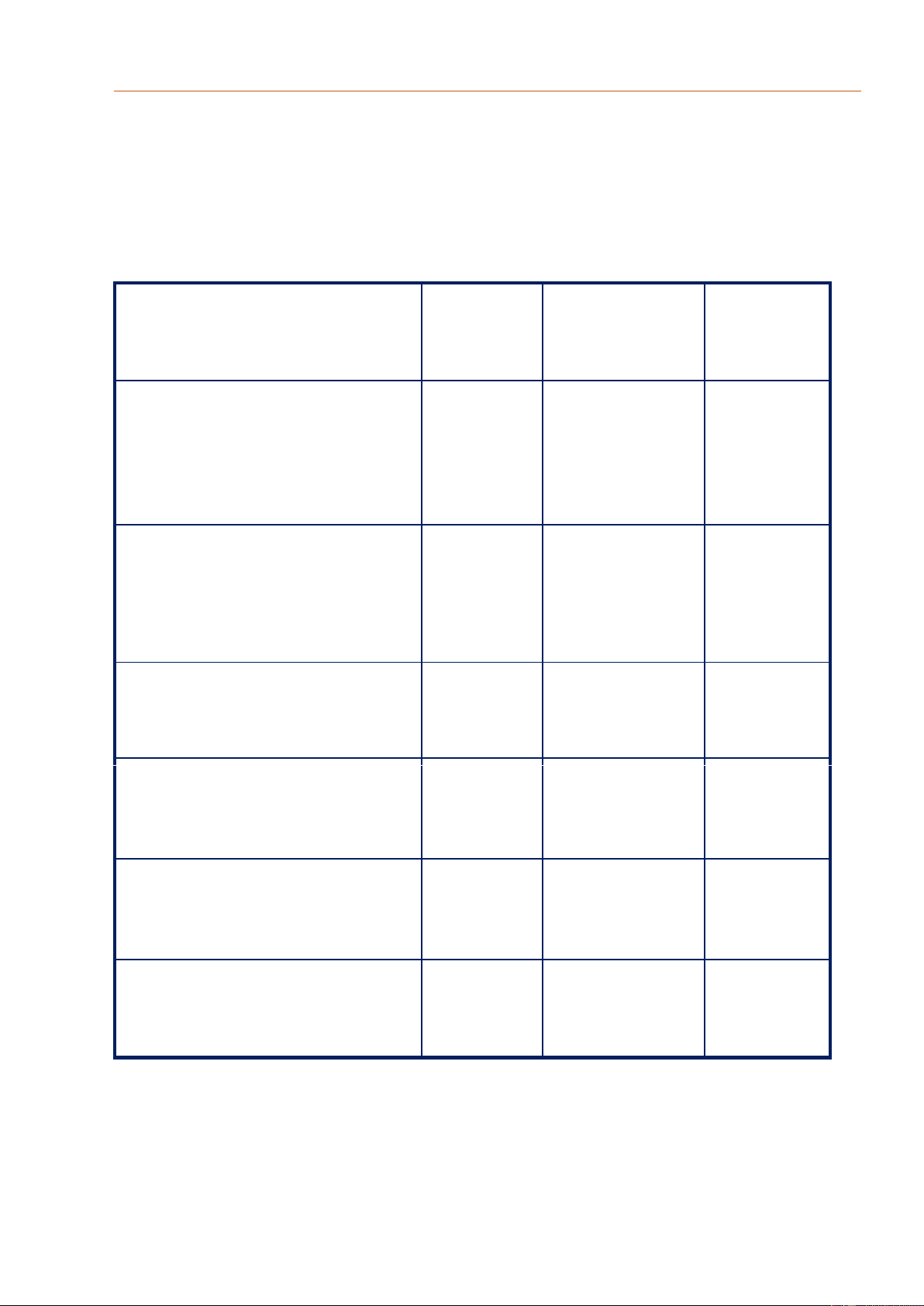
So sánh giữa các máy chủ tên ở các tầng khác nhau với các yếu tố khác nhau được thể
hiện trong bảng. Trong các hệ thống phân tán, các máy chủ tên ở mức toàn thể và quản
trị là khó thực hiện nhất. Khó khăn được gây ra bởi việc sao chép và thiết lập bộ đệm,
điều cần thiết để đảm bảo tính sẵn có và hiệu suất, nhưng cũng gây ra vấn đề về tính
nhất quán. Một số vấn đề trở nên nghiêm trọng hơn do bộ nhớ đệm và bản sao phân tán
trên mạng diện rộng, có thể gây ra độ trễ trong việc truy vấn trong quá trình tìm kiếm. Yếu tố Toàn cục Quản lý Quản trị Phạm vi địa lý Địa cầu Nước Tổ chức /tổ chức lớn nhỏ /Thành viên Số lượng nút (servers) Ít
Nhiều (số nước, Rất nhiều số tổ chức toàn cầu) Thời gian đáp ứng s ms Tức khắc Phổ biến thay đổi Chậm Ngay Ngay lập tức Số lượng bản sao Nhiều Không có hoặc Không có ít Bộ đệm trên client Có Có Có/Không
Bảng 3.1: So sánh 3 mức phân cấp của DNS
Trong hoạt động của dịch vụ DNS, về bản chất là người dùng sẽ gửi yêu cầu phân giải
tên kèm một tên miền cho hệ thống các máy chủ tên. Trả qua một quá trình phân giải
tên thì người dùng sẽ nhận được kết quả là địa chỉ IP của máy chủ có tên miền cần phân
giải. Quá trình phân giải tên này có thể diễn ra theo 2 cách: đệ quy và không đệ quy. lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
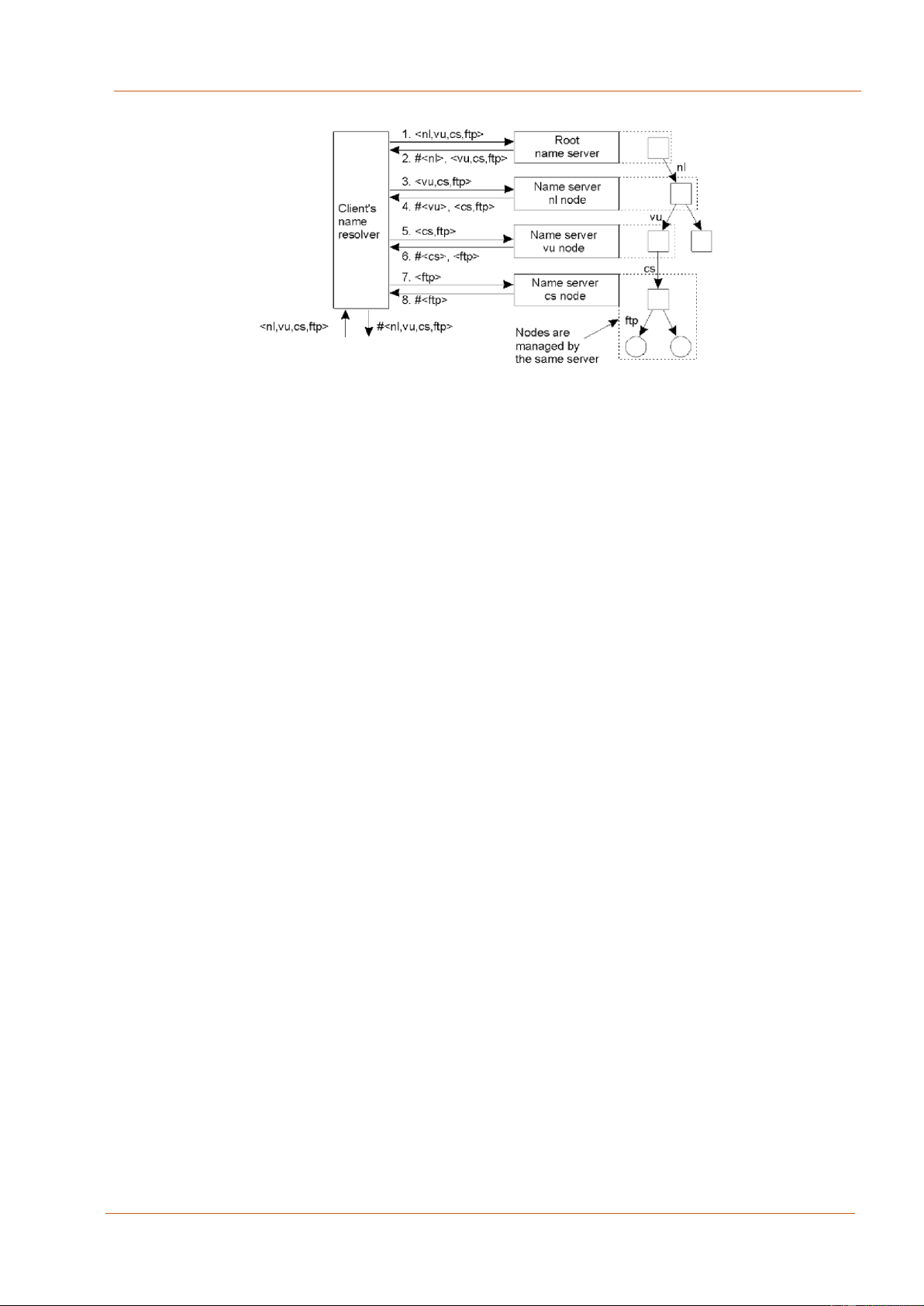
Hình 3.13. Cơ chế phân giải tên không đệ quy
Cơ chế phân giải tên không đệ quy:
Sau khi Client’s name resolver (CNR) nhận được tên miền yêu cầu từ người dùng, trong
ví dụ trong hình 3.13là ftp.cs.vu.nl, nó sẽ kiểm tra xem đã có trong bộ đệm chưa, nếu
chưa có thì nó sẽ gửi yêu cầu đến cho Root name server. Đây là máy chủ tên ở mức cao nhất.
Sau đó, máy chủ root sẽ trả về thông điệp trả lời kèm theo địa chỉ IP của máy chủ nl.
Tiếp đó, CNR sẽ gửi yêu cầu phân giải phần còn lại của tên miền cho máy chủ nl.
Tương tự, máy chủ nl lại gửi trả lời kèm theo địa chỉ IP của máy chủ ngay dưới nó là máy chủ vu.
Tương tự, sau khi nhận được yêu cầu từ CNR thì máy chủ vu sẽ gửi trả lời kèm theo
địa chỉ của máy chủ cs. Khi CRS gửi yêu cầu đến máy chủ cs, tại đây, máy chủ cs có
thông tin địa chỉ IP của máy chủ ftp và sẽ trả lời client thông tin đó. Kết thúc quá trình
phân giải tên không đệ quy, client có được địa chỉ IP.
Chúng ta có thể thấy quá trình phân giải tên không đệ quy là tập hợp nhiều các cặp yêu
cầu trả lời giữa CNR và cụm các máy chủ tên miền từ cấp cao xuống thấp. 93 lOMoAR cPSD| 27879799
Các hệ thống phân tán và Ứng dụng - Tài liệu đọc
Hình 3.14 Cơ chế phân giải tên đệ quy
Cơ chế phân giải tên đệ quy
Sau khi CNR nhận được tên miền yêu cầu từ người dùng, trong ví dụ này là ftp.cs.vu.nl
(hình 3.14), nó sẽ kiểm tra xem đã có trong bộ đệm chưa, nếu chưa có thì nó sẽ gửi yêu
cầu đến cho Root name server. Đây là máy chủ tên ở mức cao nhất.
Tài liệu liên quan:
-

zxvvxvzxvzvxzVZXvxvzZZXVvvvxvxzvxzv
3 2 -

Bài giảng Chương 1: Các khái niệm môn Tin học đại cương | Đại học Bách Khoa Hà Nội
11 6 -

mmvndjbdsiudsuvscnidivndnvdbhbfkdnwod
13 7 -
iêu đề chi tiết rõ ràng (30 ký tự) sẽ được duyệt nhanh hơn Bao gồm Trườnglớp môn học chươngb
20 10 -
báo cáo thí nghiệm linh kiện điện tử
21 11