Giới thiệu về khoa học dữ liệu và đề tài | Đại học Kinh tế Thành phố Hồ Chí Minh
Khoa học dữ liệu là lĩnh vực nghiên cứu dữ liệu nhằm khai thác những thông tin chuyên sâu có ý nghĩa đối với hoạt động kinh doanh, lập chiến lược, kế hoạch và các mục đích khác. Đây là một phương thức tiếp cận đa ngành. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem !
Môn: Kinh tế vĩ mô ( UEH) 0.9 K tài liệu
Trường: Đại học Kinh tế Thành phố Hồ Chí Minh 2.8 K tài liệu
Tác giả:
















Preview text:
lOMoAR cPSD| 46831624 LỜI MỞ ĐẦU
Lời đầu tiên, nhóm chúng em xin gửi đến thầy Nguyễn Quốc Hùng – giảng viên
Khoa Công nghệ thông tin kinh doanh lời tri ân vì đã giảng dạy và cung cấp thông tin
chuyên môn cũng như góc nhìn tổng quát về Khoa học dữ liệu. Trong xu thế phát triển
công nghệ số hiện nay, việc được trang bị kỹ năng phân tích và dự báo dữ liệu là một điểm
cộng lớn, vì thế sinh viên theo học bộ môn Khoa học dữ liệu sẽ có lợi thế lớn để phát triển
cơ hội việc làm trong xu hướng Cách mạng công nghiệp 4.0 hiện nay. Đồng thời, em muốn
gửi lời cảm ơn chân thành đến ba thành viên của nhóm vì đã san sẻ, giúp đỡ nhau trong lần làm việc lần này.
Trong quá trình học tập, dưới sự chỉ dạy tận tình, những slide bài giảng tâm huyết
của thầy thì nhóm chúng em đã được truyền tải lượng kiến thức về bộ môn Khoa học dữ
liệu. Chúng em đã dành trọn vẹn thời gian lên lớp để được quan sát học hỏi, ngoài ra còn
có những buổi tự học để làm quen với phần mềm Orange. Đây là phần mềm đồng hành
xuyên suốt quá trình học của lớp, Orange được biết đến và được đánh giá cao trong lĩnh
vực Business Intelligence Software vì tích hợp nhiều chức năng, phần mềm này có khả
năng phân tích được những dữ liệu từ đơn giản đến phức tạp, tạo ra những đồ họa bắt mắt
và hấp dẫn phù hợp cho các doanh nghiệp từ nhỏ và vừa (SMEs) tới các doanh nghiệp lớn.
Vì Orange là một công cụ hoàn toàn mới và có nhiều tính năng nên dù được tiếp cận và
làm quen với Orange qua sáu tuần học, chúng em chắc chắn vẫn chưa thể khai thác hết
được các chức năng của phần mềm này. Thế nhưng, với tinh thần học hỏi nhiệt tình, năng
nổ, nhóm đã làm việc thật sự ăn ý trong dự án cuối kỳ này với khả năng tốt nhất mà nhóm có thể thể hiện.
Nghiên cứu đề tài lần này giúp nhóm em có cái nhìn rõ nét hơn về phần mềm Orange
nói riêng và môn Khoa học dữ liệu nói chung. Thông qua đồ án, nhóm em xin được trình
bày về kiến thức và kỹ năng mà nhóm đã thu hoạch được trong suốt quá trình học tập môn
Khoa học dữ liệu. Đồ án của nhóm được trình bày rõ ràng thành từng mục, mỗi mục trình
bày một phạm vi nhỏ trong đề tài nghiên cứu để thầy có thể dễ dàng quan sát và đánh giá
bài báo cáo một cách khách quan nhất.
Lần đầu tiếp cận nghiên cứu đề tài, nhóm chúng em đã rất cố gắng nhằm đảm bảo
chất lượng báo cáo nhưng trong lúc thực hiện đồ án sẽ có những thiếu sót, hạn chế không
thể tránh khỏi. Vì vậy, chúng em mong rằng có thể nhận được những lời nhận xét từ thầy
để nhóm chúng em có thể khắc phục những nhược điểm còn đang mắc phải và góp phần
hoàn thiện đồ án kết thúc môn học một cách tốt nhất. Xin chân thành cảm ơn và trân trọng kính chào thầy. lOMoAR cPSD| 46831624
Chương 1: GIỚI THIỆU VỀ KHOA HỌC DỮ LIỆU VÀ GIỚI THIỆU ĐỀ TÀI
1.1. G iới thiệu về khoa học dữ liệu:
Khoa học dữ liệu là lĩnh vực nghiên cứu dữ liệu nhằm khai thác những thông tin chuyên
sâu có ý nghĩa đối với hoạt động kinh doanh, lập chiến lược, kế hoạch và các mục đích
khác. Đây là một phương thức tiếp cận đa ngành, kết hợp những nguyên tắc và phương
pháp thực hành của các lĩnh vực khác nhau như toán học, thống kê, trí tuệ nhân tạo và lập
trình phần mềm để phân tích khối lượng lớn dữ liệu.
Đối tượng làm việc của ngành khoa học dữ liệu là một tập hợp các dữ kiện có thể là số,
hình ảnh, chuỗi ký tự nhằm đo lường hoặc mô tả một sự vật, đối tượng cụ thể. Các hệ thống
và cổng thanh toán trực tuyến đang dần thu thập nhiều dữ liệu hơn trong những lĩnh vực
thương mại điện tử, y tế, tài chính cũng như mọi khía cạnh khác của đời sống con người.
Chúng ta có sẵn khối lượng đồ sộ dữ liệu dưới dạng văn bản, âm thanh, video và hình ảnh.
Trong"gần hai thập kỷ qua, nhờ những thành tựu đạt được trong các ngành khoa học đặc
biệt là lĩnh vực Máy học, một số bài toán ứng dụng khó trong khoa học và đời sống mà
trước đây chưa giải được nay đã được giải quyết với độ chính xác rất cao, như các vấn đề
nhận dạng tiếng nói, nhận dạng văn bản, nhận dạng ảnh, dịch tự động."
Khoa học"dữ liệu gồm ba phần chính: Tạo ra và quản trị dữ liệu, phân tích dữ liệu, và
chuyển kết quả phân tích thành giá trị của hành động. Việc phân tích và dùng dữ liệu lại
dựa vào ba nguồn tri thức: toán học (thống kê toán học), công nghệ thông tin (máy học) và
tri thức của lĩnh vực ứng dụng cụ thể."
Cũng như"các hình thức thí nghiệm khác, khoa học dữ liệu sẽ yêu cầu bạn thực hiện các
quan sát, đặt câu hỏi, hình thành các giả thuyết, tạo các bài kiểm tra, phân tích kết quả và
đưa ra một khuyến nghị thực tế. Chính vì vậy mà mục đích chính của Khoa học dữ liệu là
biến đổi một lượng lớn dữ liệu chưa qua xử lý, làm thế nào để định vị được thành mô hình
kinh doanh, từ đó giúp đỡ các tổ chức tiết giảm chi phí, gia tăng hiệu quả làm việc, nhìn
nhận cơ hội, rủi ro trên thị trường và làm gia tăng lợi thế cạnh tranh của doanh nghiệp."
Các lĩnh vực"của khoa học dữ liệu: Khai thác dữ liệu (Data mining), Thống kê (Statistic),
Học máy (Machine learning), Phân tích (Analyze) và Lập trình (Programming)."
1.2. Quy trình phân tích dữ liệu.
Bước 1: Gom dữ liệu (Gathering): Tập hợp dữ liệu là bước đầu tiên trong quá trình khai
phá dữ liệu, dữ liệu được khai thác từ một kho dữ liệu và thậm chí các dữ liệu từ các nguồn ứng dụng Web.
Bước 2: Trích lọc dữ liệu (Selection): Lựa chọn những dữ liệu phù hợp với nhiệm vụ phân tích trích rút từ CSDL. lOMoAR cPSD| 46831624
Bước 3: Làm sạch, tiền xử lý và chuẩn bị trước dữ liệu (Cleansing, Pre-processing and
Preparation): Khi tập hợp dữ liệu thường mắc phải một số lỗi như dữ liệu thiếu logic, thiếu
chặt chẽ, chưa đầy đủ, hiếm khi nào các dữ liệu thu thập được đều mang tính nhất quán.
Do đó “tiền xử lý” là một bước quan trọng sau đó giúp hạn chế những kết quả sai lệch
không mong muốn trước khi bước vào quá trình KPDL.
Bước 4: Chuyển đổi dữ liệu (Transformation): Dữ liệu được chuyển đổi hay được hợp nhất
về dạng thích hợp cho việc khai phá.
Bước 5: Khai phá dữ liệu (Data Mining): Đây là một tiến trình cốt yếu. Ở giai đoạn này
nhiều thuật toán khác nhau đã được sử dụng một cách phù hợp để trích xuất thông tin có
ích hoặc cá mẫu điển hình trong dữ liệu.
Bước 6: Đánh giá kết quả mẫu (Evaluation of Result): Ở giai đoạn này, các mẫu dữ liệu
được chiết xuất, không phải bất cứ mẫu dữ liệu nào cũng đều hữu ích, đôi khi nó bị sai
lệch. Vì vậy, cần phải ưu tiên những tiêu chuẩn đánh giá để chiết xuất ra các tri thức cần thiết.
1.3. Ứng dụng của Khoa học dữ liệu
Nếu"phân tích dữ liệu về nhu cầu thị trường ta có thể quyết định cần nuôi bao nhiêu lợn
mỗi nơi mỗi lúc. Nếu có và phân tích được dữ liệu mô phỏng các phương án xả lũ vào mùa
mưa ta có thể chọn được cách xả lũ ít thiệt hại nhất. Nếu có và phân tích được các bệnh án
điện tử của người bệnh ta có thể tìm ra được phác đồ thích hợp hơn cả cho người bệnh.
Amazon đã phân tích các lần mua hàng trước của bạn để dự đoán những món đồ bạn có
thể sẽ thích mua và gửi quảng cáo tới, v.v. Khi nghe nói về các thành tựu đột phá gần đây
của Trí tuệ nhân tạo người nghe có thể cũng chưa biết rằng phần lớn chúng đều dựa vào
các phương pháp và đột phá của"khoa học dữ liệu.
Việc"khai thác một lượng rất lớn thông tin khách hàng nhằm tăng hiệu quả kinh doanh đã
được đẩy mạnh không chỉ ở các doanh nghiệp lớn trên thế giới như Google, Facebook,
Amazon mà còn cả ở Việt Nam như FPT, Viettel, VNG hay Tiki."Và Facebook, trang mạng
xã hội lớn nhất hành tinh cho đến hiện tại, là một trong những cái tên mà hay được nhắc
tới trong giới trẻ hiện nay, là một trong những ứng dụng nổi tiếng của khoa học dữ liệu.
Khoa học dữ liệu"đóng 1 vai trò quan trọng trong hầu như tất cả các khía cạnh của cuộc
sống, đặc biệt là trong chiến lược kinh doanh. Ví dụ, nó cung cấp thông tin về khách hàng
giúp cho các công ty tạo ra chiến dịch tiếp thị mạnh mẽ và ngày càng trở nên gần gũi với
con người nhằm mục tiêu tăng doanh số sản phẩm. Ngoài ra, khoa học dữ liệu còn hỗ trợ
cho việc quản trị rủi ro tài chính, ngăn ngừa các sự cố thiết bị trong các nhà máy sản xuất
và các cơ sở công nghiệp. Nó còn giúp ngăn chặn các cuộc tấn công mạng và các mối đe
dọa khác trong lĩnh vực công nghệ thông tin trong thời đại nền kinh tế số ngày càng phát triển."
Bên cạnh đó, khoa học dữ liệu còn mang lại lợi ích cho những lĩnh vực ngoài hoạt động
kinh doanh thông thường."Người ta còn dự đoán tiềm năng rất lớn của lĩnh vực Khoa học
dữ liệu để ứng dụng vào các lĩnh vực như y học (chẩn đoán bệnh và đưa ra phác đồ điều trị lOMoAR cPSD| 46831624
nhờ phân tích một lượng lớn dữ liệu người bệnh trước đó), quản lý xã hội (quản lý giao
thông, quản lý dân cư, xác định nhu cầu giáo dục, y tế, việc làm, …) và trong mọi lĩnh vực
mà việc khai thác thông tin hiệu quả hơn sẽ đem lại lợi ích kinh tế – xã hội."Ví dụ như
trong chăm sóc sức khỏe, các ứng dụng của nó bao gồm chẩn đoán y tế, phân tích bệnh án,
lập kế hoạch điều trị, chăm sóc, nghiên cứu y tế. Nhiều tổ chức giáo dục sử dụng khoa học
dữ liệu để quản lý và theo dõi kết quả học tập và rèn luyện của người học để có những
hướng đi phù hợp trong tương lai. Các tổ chức thể thao thì lại phân tích hiệu suất, thể lực,...
của người chơi và lập chiến lược thích hợp dựa trên khoa học dữ liệu.
1.4. Giới thiệu về đề tài:
Với quá trình dần chuyển số hóa của xã hội ngày trong tất cả các ngành từ tài chính, ngân
hàng, kinh tế, giáo dục,... đã hình thành nên một khối lượng dữ liệu khổng lồ. Bởi thế,
những dữ liệu thực tế mang vai trò đặc biệt trong việc vận hành, ứng dụng và lưu trữ các
thông tin quan trọng của người tiêu dùng.
Trong thời đại chuyển đổi số như hiện nay, một khối lượng dữ liệu khổng lồ được hình
thành và tổng hợp từ tri thức của nhân loại và sự góp phần của khoa học dữ liệu từ các
ngành ngân hàng, tài chính, giáo dục, kinh tế,... và trong đó có cả y tế.
Việc ứng dụng khoa học dữ liệu vào y tế đã giảm bớt gánh nặng cho những bệnh viện để
từ đó họ có thể tập trung vào chữa trị và cứu sống bệnh nhân. Hơn thế nữa, khoa học dữ
liệu đã góp phần phân loại và thống kê các loại bệnh lý để từ đó có thể tìm ra nguyên nhân
chính gây nên các bệnh đó và đưa ra cách khắc phục.
Chính vì nhận thấy sự cấp thiết trong việc ứng dụng khoa học dữ liệu vào y tế, nhóm chúng
em đã tìm được bộ dữ liệu về những tác nhân chính gây nên bệnh tim và sẽ tiến hành xử lý
bộ dữ liệu này. Mục đích chính của chúng em là giúp tìm ra được những nguyên nhân chính
gây nên bệnh tim dựa trên phần mềm Orange và từ đó có thể tìm ra cách ngăn chặn bệnh
tim và có các giải pháp thiết yếu ngắn hạn và dài hạn để hạn chế tối đa nguy cơ mắc bệnh tim.
Chương 2: Tổng quan về chương trình sử dụng và các phương pháp sử dụng.
2.1. Tổng quan về orange:
Orange"là phần mềm dùng để khai thác dữ liệu theo phương diện mã nguồn mở. Orange
giúp cho người dùng có một giao diện lập trình sinh động và trực, dễ theo dõi chi tiết để
phân tích dữ một một cách nhân nhất, chính xác, cụ thể. Orange là gói phần mềm dựa trên
những công cụ dùng để trực quan hóa dữ liệu, khai thác và phân tích dữ liệu chính xác
thông qua ngôn ngữ lập trình. Orange cũng là một phần mềm kết hợp công cụ khai phá dữ
liệu và học máy, và cung cấp những trực quan tương tác, thẫm mỹ cho người dùng phần
mềm, nó được viết bằng Python." lOMoAR cPSD| 46831624
Orange là phần mềm hướng tới mục tiêu tự động hóa. Đây là một trong những phần mềm
khai phá dữ liệu tiện dụng, dễ dàng trong việc sử dụng nhờ giao diện nhỏ gọn, các toolbox
được sắp xếp một cách mạch lạc, hợp lý, bất kỳ ai cũng có thể sử dụng. Vì vậy, Orange là
phần mềm mà nhóm em sẽ sử dụng trong bài nghiên cứu. 2.2. Tiền xử lý dữ liệu:
Tiền xử lý dữ liệu"là một kỹ thuật khai thác dữ liệu bao gồm chuyển đổi dữ liệu thô thành
định dạng dễ hiểu. Dữ liệu trong thế giới thực thường không đầy đủ, không nhất quán hoặc
thiếu một số hành vi hoặc xu hướng nhất định và có khả năng chứa nhiều lỗi. Tiền xử lý
dữ liệu là một phương pháp đã được chứng minh để giải quyết các vấn đề đó. Tiền xử lý
dữ liệu chuẩn bị dữ liệu thô để xử lý tiếp."
Tiền xử lý dữ liệu bao gồm các bước:
Làm"sạch dữ liệu: Dữ liệu được xóa sạch thông qua các quy trình như điền vào các
giá trị bị thiếu, làm mịn dữ liệu nhiễu hoặc giải quyết sự không nhất quán trong dữ liệu."
Tích"hợp dữ liệu:s Dữ liệu với các biểu diễn khác nhau được đặt cùng nhau và xung
đột trong dữ liệu được giải quyết."
Chuyển đổi dữ liệu:”Dữ liệu được chuẩn hóa, tổng hợp và tổng quát.
Giảm dữ"liệu: Bước này nhằm mục đích trình bày giảm đại diện dữ liệu trong kho dữ liệu."
Phân biệt"dữ liệu: Liên quan đến việc giảm một số giá trị của thuộc tính liên tục
bằng cách chia phạm vi của các khoảng thuộc tính."
2.3. Tổng quan về phân lớp dữ liệu:
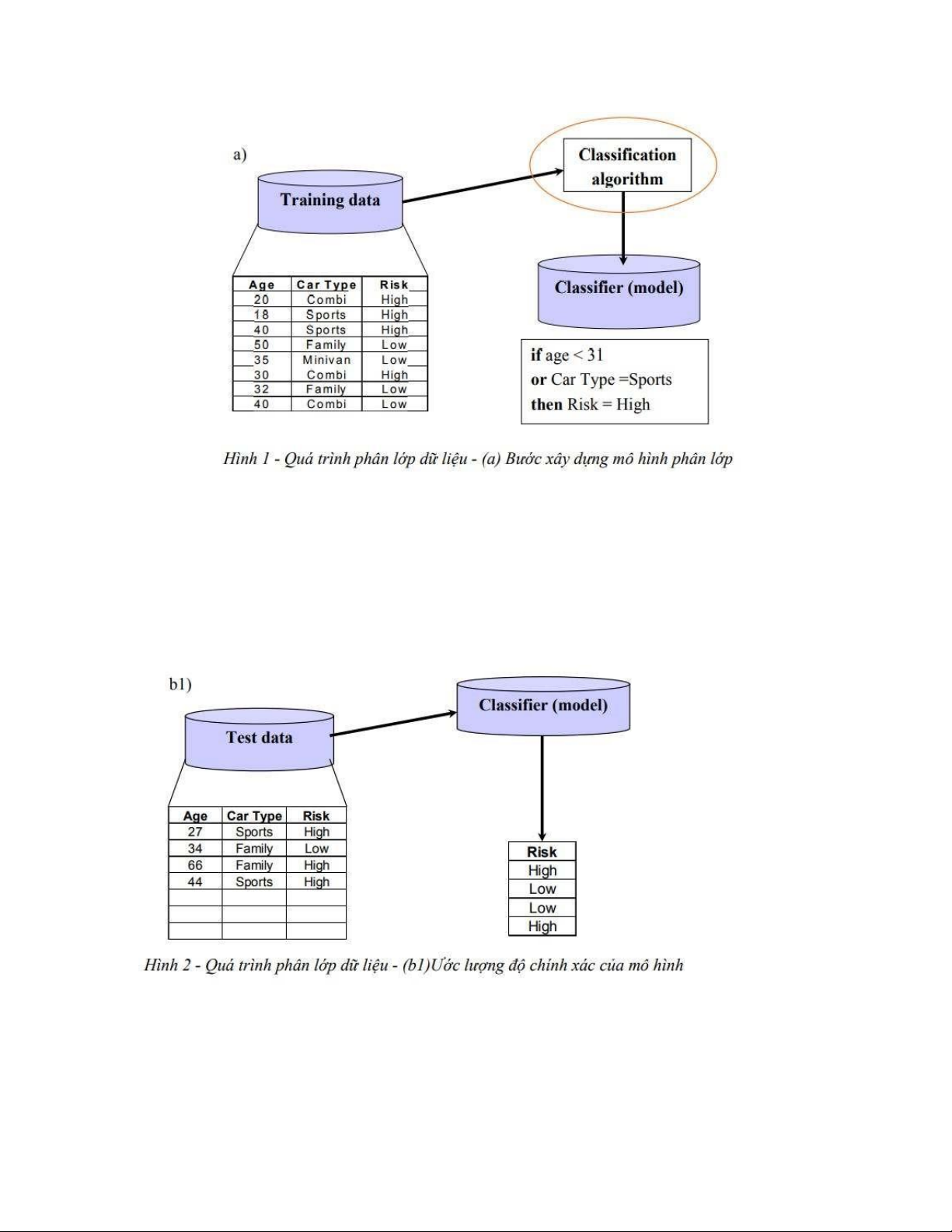
Một trong"những hướng nghiên cứu chính của khai phá dữ liệu đó là phân lớp dữ liệu
(classification). Là quá trình phân bổ một đối tượng dữ liệu vào một hay nhiều lớp (loại)
đã cho trước nhờ một mô hình phân lớp. Mô hình này được xây dựng trên một tập dữ liệu
đã được gán nhãn trước đó. Quá trình gán nhãn cho đối tượng dữ liệu chính là quá trình
phân lớp dữ liệu."Thực tế đặt ra nhu cầu là từ một cơ sở dữ liệu với nhiều thông tin ẩn con
người có thể trích rút ra các quyết định nghiệp vụ thông minh.
Phân lớp và dự đoán là hai dạng của phân tích dữ liệu nhằm trích rút ra một mô hình mô tả
các lớp dữ liệu quan trọng hay dự đoán xu hướng dữ liệu tương lai. Việc phân tích dữ liệu
bao gồm: phân lớp và dự đoán với mục đích tạo ra một mô hình mô tả lớp dữ liệu có vai
trò quan trọng hay dự đoán xu thế tương lai của dữ liệu. Phân lớp dự đoán giá trị của những
nhãn xác định (categorical label) hay những giá trị rời rạc (discrete value), có nghĩa là phân
lớp thao tác với những đối tượng dữ liệu mà có bộ giá trị là biết trước. Trong khi đó, dự
đoán lại xây dựng mô hình với các hàm nhận giá trị liên tục.
Kỹ thuật phân lớp được tiến hành bao gồm 2 bước: Xây dựng mô hình và sử dụng mô hình.
Xây dựng mô hình: là mô tả một tập những lớp được định nghĩa trước trong đó: mỗi bộ lOMoAR cPSD| 46831624
hoặc mẫu được gán thuộc về một lớp được định nghĩa trước như là được xác định bởi thuộc
tính nhãn lớp, tập hợp của những bộ được sử dụng trong việc sử dụng mô hình được gọi là tập huấn luyện.
Ví dụ mô hình"phân lớp dự báo thời tiết có thể cho biết thời tiết ngày mai là mưa, hay nắng
dựa vào những thông số về độ ẩm, sức gió, nhiệt độ,… của ngày hôm nay và các ngày
trước đó. Hay nhờ các luật về xu hướng mua hàng của khách hàng trong siêu thị, các nhân
viên kinh doanh có thể ra những quyết sách đúng đắn về lượng mặt hàng cũng như chủng
loại bày bán… Một mô hình dự đoán có thể dự đoán được lượng tiền tiêu dùng của các
khách hàng tiềm năng dựa trên những thông tin về thu nhập và nghề nghiệp của khách hàng."
Trong những năm qua,"phân lớp dữ liệu đã thu hút sự quan tâm các nhà nghiên cứu trong
nhiều lĩnh vực khác nhau như học máy (Machine Learning), hệ chuyên gia (Expert
System), thống kê (Statistics)... Công nghệ này cũng ứng dụng trong nhiều lĩnh vực khác
nhau như: thương mại, ngân hàng, marketing, nghiên cứu thị trường, bảo hiểm, y tế, giáo
dục... Phần lớn các thuật toán ra đời trước đều sử dụng cơ chế dữ liệu cư trú trong bộ nhớ
(memory resident), thường thao tác với lượng dữ liệu nhỏ. Một số thuật toán ra đời sau này
đã sử dụng kỹ thuật cư trú trên đĩa cải thiện đáng kể khả năng mở rộng của thuật toán với
những tập dữ liệu lớn lên tới hàng tỷ bản ghi."
Quá trình phân lớp dữ liệu gồm 2 bước chính:
- Bước 1: Xây dựng mô hình (hay còn gọi là giai đoạn “học” hoặc “huấn luyện”): Quá
trình học nhằm xây dựng một mô hình mô tả một tập các lớp dữ liệu hay các khái niệm định trước. •
Dữ"liệu đầu vào: là dữ liệu mẫu đã được gán nhãn và tiền xử lý. •
Các thuật toán phân lớp: cây quyết định, hàm số toán học, tập luật… •
Kết quả của bước này là mô hình phân lớp đã được huấn luyện (trình phân lớp)" lOMoAR cPSD| 46831624
- Bước 2:"Sử dụng mô hình chia thành 2 bước nhỏ:
• Bước 2.1: Đánh giá mô hình (kiểm tra tính đúng đắn của mô hình) •
Dữ liệu đầu vào: là một tập dữ liệu mẫu khác đã được gán nhãn và tiền xử lý. Tuy
nhiên lúc đưa vào mô hình phân lớp, ta “lờ” đi thuộc tính đã được gán nhãn. •
Tính đúng đắn của mô hình sẽ được xác định bằng cách so sánh thuộc tính gán nhãn
của dữ liệu đầu vào và kết quả phân lớp của mô hình."
• Bước 2.2:"Phân lớp dữ liệu mới •
Dữ liệu đầu vào: là dữ liệu “khuyết” thuộc tính cần dự đoán lớp (nhãn) •
Mô hình sẽ tự động phân lớp (gán nhãn) cho các đối tượng dữ liệu này dựa vào
những gì được huấn luyện ở bước 1" lOMoAR cPSD| 46831624
2.4. Các phương pháp phân lớp dữ liệu: 2.4.1.
Hồi quy Logistic (Logistic Regression) a. Định nghĩa:
Logistic regression là một thuật toán tuy đơn giản nhưng rất hiệu quả đối với các bài toán
phân loại. Logistic regression thường hay được sử dụng để so sánh với các thuật toán phân
loại khác nhằm tìm ra thuật toán phù hợp nhất. Đây là mô hình xác suất dự đoán được giá
trị đầu ra rời rạc từ một tập nhiều giá trị đầu vào – được biểu diễn dưới dạng vector. b. Mô tả:
Mục tiêu”của Logistic regression là ước tính xác suất của những sự kiện, trong đó bao gồm
việc xác định mối quan hệ giữa các tính năng để từ đó dự đoán xác suất của kết quả, vì vậy
nên logistic regression sẽ có:”
Input: Dữ liệu input (gồm nhãn 0 và 1)
Output : Xác suất dữ liệu input rơi vào nhãn 0 hoặc nhãn 1.
Ở hình trên,"ta gọi điểm màu xanh là nhãn 0 và điểm màu đỏ là nhãn 1. Đối với logistic
regression, ta sẽ biết được với mỗi điểm thì xác xuất để rơi vào nhãn 0 (xanh) là bao nhiêu
và xác suất rơi vào nhãn 1 (đỏ) là bao nhiêu.Ta có thể thấy rằng giữa hai vùng điểm xanh
và đỏ có một đường thẳng để phân chia rõ ràng vùng, nhưng nếu các điểm dữ liệu không
nằm sang hai bên mà trộn lẫn vào nhau thì ta sẽ phân chia bằng cách nào? Tập dữ liệu chứa
các điểm trộn lẫn như vậy gọi là tập dữ liệu nhiễu và ta phải xử lí các nhiễu đó." Đối"với phân lớp:
Tập nhãn y = {y , y ,..., yn} với n là số lớp 1 2
Một đối tượng dữ liệu lOMoAR cPSD| 46831624
X = {x , x ,..., x } với d là số thuộc tính của mỗi dòng dữ liệu và được biểu diễn dưới dạng 1 2 d vector Hàm Logistic P(y=1) =
Dự đoán đối tượng xem đối tượng x sở hữu các thuộc tính cụ thể sẽ thuộc vào lớp y nào Trong đó:
d là số lượng đặc trưng (thuộc tính) của dữ liệu w là trọng số, ban đầu sẽ được khởi tạo
ngẫu nhiên, sau đó sẽ được điều chỉnh lại cho phù hợp." c. Mục đích:
- Dự đoán một email có phải là spam hay không.
- Dự đoán một giao dịch ngân hàng là gian lận hay không.
- Dự đoán một khối u là lành hay ác tính.
- Dự đoán một khoản vay liệu có trả được không.
- Dự đoán một khoản đầu tư vào startup liệu có sinh lãi hay không.d. Ưu điểm: lOMoAR cPSD| 46831624
- Hồi quy logistic dễ triển khai, dễ diễn giải hơn và hiệu quả để đào tạo.
- Có thể dễ dàng mở rộng đến nhiều lớp (hồi quy đa thức)
- Không chỉ cung cấp thước đo về mức độ phù hợp của một yếu tố dự đoán, mà còn cả
hướng liên kết của nó
- Rất nhanh trong việc phân loạibản ghi không xác định.
- Độ chính xác tốt đối với nhiều tập dữ liệu đơn giản và nó hoạt động tốt khi tập dữ liệu có
thể phân tách tuyến tính
- Có thể giải thích các hệ số của mô hình như là các chỉ số về tầm quan trọng củatính năng.
- Ít có xu hướng phù hợp quá mức nhưng nó có thể được trang bị quá mức trongcác tập dữ
liệu có chiều cao. e. Nhược điểm:
- Nếu số lượng quan sát ít hơn số lượng tính năng, không nên sử dụng LogisticRegression
- Hạn chế chính của Logistic Regression là giả định về độ tuyến tính giữa biến phụthuộc
về các biến độc lập.
- Nó chỉ được sử dụng để dự đoán các dữ liệu rời rạc nên biến phụthuộc của Logistic
Regression bị ràng buộc với tập số rời rạc.
- Các vấn đề về phi tuyến tính không thể được giải quyết bằng Logistic Regression
- Khó có được các mối quan hệ phức tạp bằng cách sử dụng Logistic Regression.
2.4.2. SVM (Support Vector Machine) a. Định nghĩa
Support Vector Machines (Máy vector hỗ trợ) – SVM là một trong những thuật toán giám
sát, được dùng để phân loại dữ liệu và cả hồi quy (SVR). Thuật toán SVM gồm một loạt
các lý thuyết từ cơ bản đến nâng cao về đại số tuyến tính. Thuật toán này nhận dữ liệu vào
và tự hiểu dữ liệu dưới dạng các vector trong không gian. Tiếp theo, chúng sẽ được phân
vào các lớp khác nhau bằng phương pháp xây dựng một siêu phẳng trong không gian đa
chiều. Mục đích của phương pháp này là để chia dữ liệu đầu vào thành hai phần ứng với
các lớp của chúng. b. Mô tả
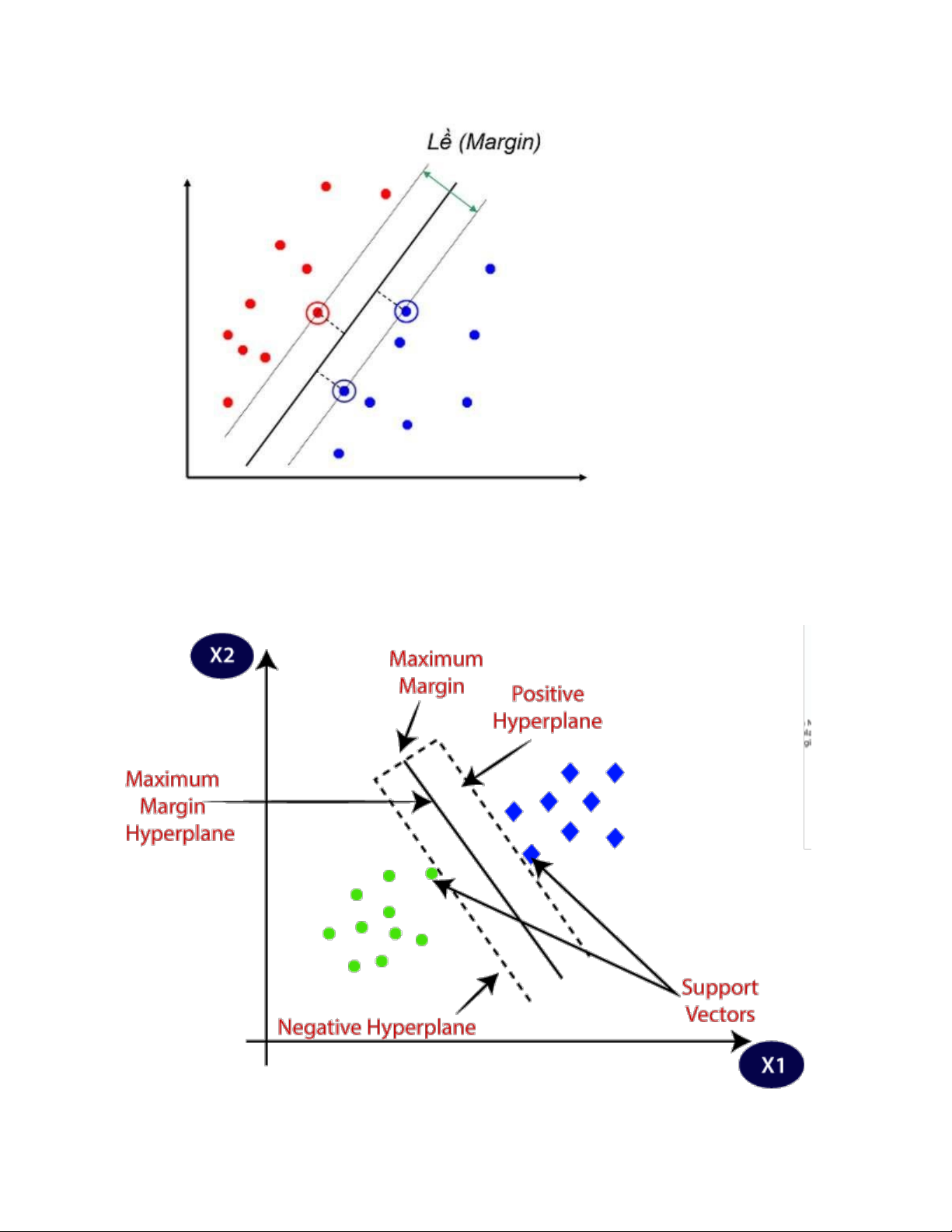
Giả sử rằng có hai lớp dữ liệu riêng biệt, hai lớp này được hình thành và phân biệt bởi các
điểm dữ liệu khác nhau. Đồng thời, xuất hiện một siêu phẳng chia chính xác hai phân lớp
đó thành hai phần bằng nhau. Hãy cùng nhìn vào hình ảnh bên dưới và đoán xem, đâu là siêu phẳng đẹp nhất? lOMoAR cPSD| 46831624
Như ta thấy, đối với các điểm dữ liệu được mô tả trong hình, có rất nhiều các mặt phân chia
chúng, vậy đâu mới là siêu phẳng cần tìm. Trên hình minh hoạ, thấy rằng có hai đường
phân chia quá gần với các điểm dữ liệu màu đỏ, điều này không đảm bảo điều kiện đồng
đều mà một siêu phẳng yêu cầu. Bên cạnh đó cũng tồn tại một mặt phân cách hơi nghiêng
về bên các điểm dữ liệu màu xanh. Tóm lại, không có một mặt phân cách nào trong ba mặt
phân cách được minh hoạ trên có thể trở thành một siêu phẳng hoàn hảo để phân lớp dữ
liệu. Để nhận được một kết quả phân lớp tối ưu thì khoảng cách đến các điểm dữ liệu
(margin) của tất cả các lớp của một siêu phẳng (hyperplane) là xa nhất có thể. Để có thể
hiểu rõ về phương pháp SVM, chúng ta cùng tìm hiểu thế nào là một điểm dữ liệu (margin)
và như thế nào là một support vector?
Margin"là khoảng cách giữa siêu phẳng (trong trường hợp không gian hai chiều là đường
thẳng) đến hai điểm dữ liệu gần nhất tương ứng với hai phân lớp.
SVM thực hiện bài toán tối ưu bằng cách tối đa hóa giá trị margin này, nhờ vậy mà tìm ra
một siêu phẳng thích hợp nhất để phân hai lớp dữ liệu."Bài toán tối ưu trong SVM là một
bài toán lồi với hàm mục tiêu là strictly convex và nghiệm của bài toán này là duy nhất.
Bằng phương pháp này, đối với các điểm dữ liệu mới được đưa vào, SVM giúp tránh được
sai lệch khi phân lớp, nói chính xác hơn là tối thiểu hoá việc phân lớp sai (còn gọi là misclassification).
Hình dưới đây mô tả lề (margin) của một siêu phẳng (hyperplane). lOMoAR cPSD| 46831624
Còn Support vectors, bài toán đưa về dạng tìm ra khoảng cách lớn nhất giữa hai đường
biên. Siêu phẳng đáp ứng yêu cầu này và khoảng cách từ siêu phẳng cần tìm đến hai đường
biên là phải bằng nhau. Trên đường biên sẽ xuất hiện các điểm nhằm hỗ trợ tìm ra được
siêu phẳng, chúng được gọi là Support vectors. c. Ưu điểm: lOMoAR cPSD| 46831624
Xử"lý trên không gian số chiều cao: SVM là một công cụ tính toán hiệu quả trong
không gian chiều cao, trong đó đặc biệt áp dụng cho các bài toán phân loại văn bản
và phân tích quan điểm nơi chiều có thể cực kỳ lớn."
Tiết kiệm bộ nhớ:"Do chỉ có một tập hợp con của các điểm được sử dụng trong quá
trình huấn luyện và ra quyết định thực tế cho các điểm dữ liệu mới nên chỉ có những
điểm cần thiết mới được lưu trữ trong bộ nhớ khi ra quyết định."
Tính"linh hoạt - phân lớp thường là phi tuyến tính. Khả năng áp dụng Kernel mới
cho phép linh động giữa các phương pháp tuyến tính và phi tuyến tính từ đó khiến
cho hiệu suất phân loại lớn hơn." d. Nhược điểm:
Bài toán"số chiều cao: Trong trường hợp số lượng thuộc tính (p) của tập dữ liệu lớn
hơn rất nhiều so với số lượng dữ liệu (n) thì SVM cho kết quả khá tồi."
Chưa"thể hiện rõ tính xác suất: Việc phân lớp của SVM chỉ là việc cố gắng tách các
đối tượng vào hai lớp được phân tách bởi siêu phẳng SVM. Điều này chưa giải thích
được xác suất xuất hiện của một thành viên trong một nhóm là như thế nào. Tuy
nhiên hiệu quả của việc phân lớp có thể được xác định dựa vào khái niệm margin từ
điểm dữ liệu mới đến siêu phẳng phân lớp mà chúng ta đã bàn luận ở trên."
2.4.3. Cây quyết định (Decision Tree) a. Định nghĩa
Cây quyết định là một hệ thống phân cấp có cấu trúc được dùng để phân lớp các đối tượng
dựa vào dãy các luật. Các thuộc tính của đối tượng có thể thuộc vào nhiều kiểu dữ liệu
khác nhau (Binary, Norminal, Ordinal, Quantitative,…) và thuộc tính phân lớp phải có kiểu
dữ liệu là Binary hoặc Ordinal. b. Mô tả
Từ dữ liệu về các đối tượng sẵn có, phương pháp cây quyết định sẽ giúp chúng ta mô tả,
phân loại, tổng quan dữ liệu cho trước này. Cụ thể hơn, cây quyết định sẽ đưa ra các dự
đoán cho từng đối tượng.
Cây"quyết định bao gồm hai loại đó là cây hồi quy và cây phân loại. Cây hồi quy có ước
tính mô hình là các giá trị số thực và cây phân loại được dùng trong các mô hình có giá trị
cuối cùng nằm mục đích chính là phần loại." c. Ưu điểm
Mô"hình sinh ra các quy tắc dễ hiểu cho người đọc, tạo ra bộ luật với mỗi nhánh lá là một luật của cây." lOMoAR cPSD| 46831624
Dữ"liệu đầu vào có thể là là dữ liệu missing, không cần chuẩn hóa hoặc tạo biến giả.
Có thể làm việc với cả dữ liệu số và dữ liệu phân loại.
Có thể xác thực mô hình bằng cách sử dụng các kiểm tra thống kê. Có khả năng
là việc với dữ liệu lớn." d. Nhược điểm:
Mô"hình cây quyết định phụ thuộc rất lớn vào dữ liệu của bạn. Thạm chí, với một
sự thay đổi nhỏ trong bộ dữ liệu, cấu trúc mô hình cây quyết định có thể thay đổi hoàn toàn."
Cây quyết định hay gặp vấn đề overfitting 2.4.4. Neural Network a. Định nghĩa:
Neural Network là"mạng nơ-ron nhân tạo, đây là một chuỗi những thuật toán được đưa ra
để tìm kiếm các mối quan hệ cơ bản trong tập hợp các dữ liệu. Thông qua việc bắt chước
cách thức hoạt động từ não bộ con người. Nói cách khác, mạng nơ-ron nhân tạo được xem
là hệ thống của các tế bào thần kinh nhân tạo. Đây thường có thể là hữu cơ hoặc nhân tạo về bản chất."
Neural Network"có khả năng thích ứng được với mọi thay đổi từ đầu vào. Do vậy, nó có
thể đưa ra được mọi kết quả một cách tốt nhất có thể mà bạn không cần phải thiết kế lại
những tiêu chí đầu ra."
Trong"lĩnh vực tài chính, mạng nơ ron nhân tạo hỗ trợ cho quá trình phát triển các quy trình
như: giao dịch thuật toán, dự báo chuỗi thời gian, phân loại chứng khoán, mô hình rủi ro
tín dụng và xây dựng chỉ báo độc quyền và công cụ phát sinh giá cả. Neural Network có
sự tương đồng chuẩn mạnh vối những phương pháp thống kê như đồ thị đường cong và phân tích hồi quy." b. Mô tả:
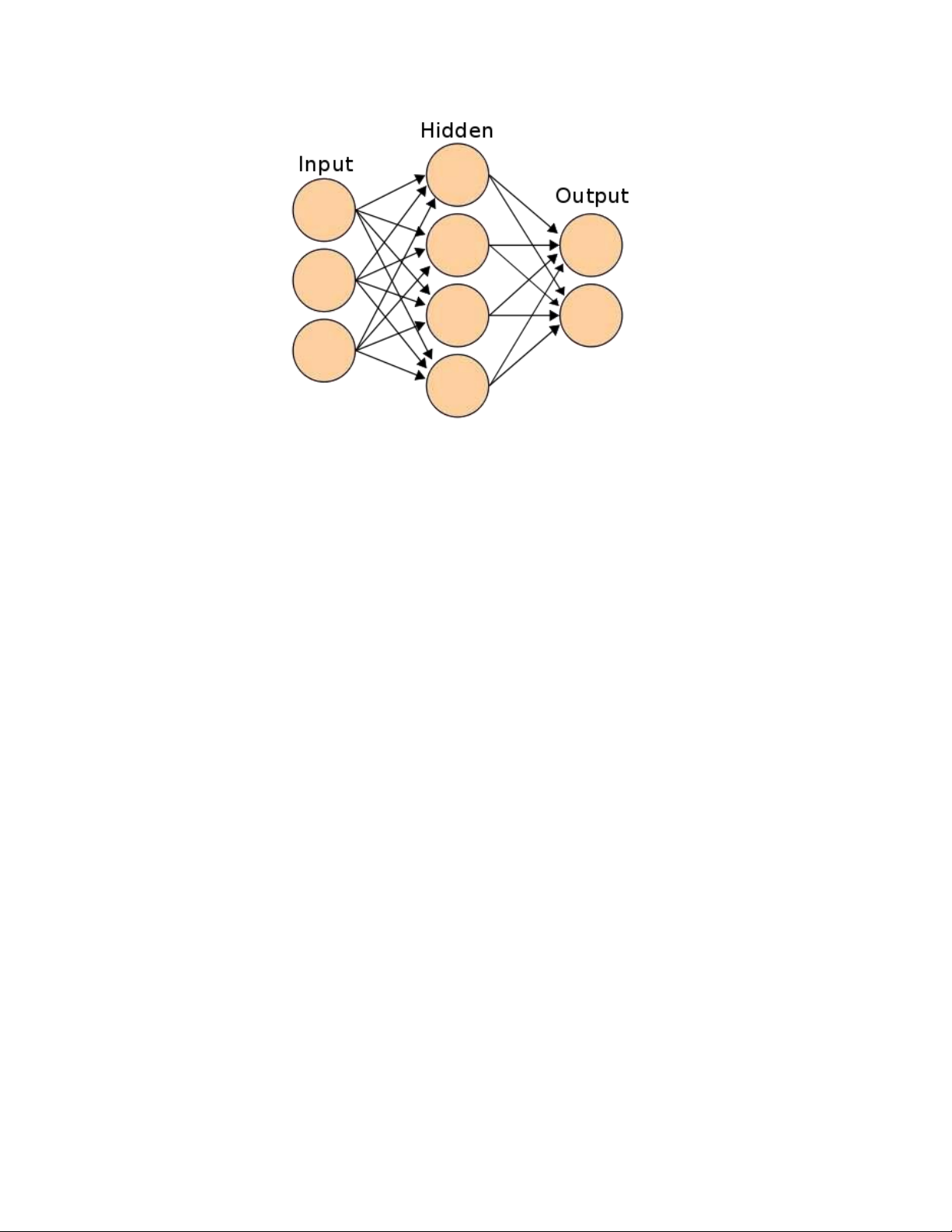
Mạng"Neural Network là sự kết hợp của những tầng perceptron hay còn gọi là perceptron
đa tầng. Và mỗi một mạng Neural Network thường bao gồm 3 kiểu tầng là:"
Tầng input layer (tầng vào): Tầng này nằm bên trái cùng của mạng, thể hiện cho các đầu vào của mạng.
Tầng output layer (tầng ra): Là tầng bên phải cùng và nó thể hiện cho những đầu ra của mạng.
Tầng hidden layer (tầng ẩn): Tầng này nằm giữa tầng vào và tầng ra nó thể hiện cho quá
trình suy luận logic của mạng. lOMoAR cPSD| 46831624
Một thuật toán perceptron (MLP) nhiều lớp với backpropagation. Đầu vào:
∘ Dữ liệu: tập dữ liệu đầu vào
∘ Tiền xử lý: (các) phương pháp tiền xử lý Kết quả:
∘ Người học: thuật toán học perceptron nhiều lớp
∘ Mô hình: mô hình được đào tạo
Như"đã thấy ở mục thành phần của Neural Network, mạng nơ-ron nhân tạo sử dụng các
lớp xử lý toán học khác nhau để hiểu thông tin mà nó được cung cấp. Thông thường, một
mạng nơ-ron nhân tạo có từ hàng chục đến hàng triệu nơ-ron nhân tạo được gọi là các đơn
vị được sắp xếp thành một loạt các lớp. Lớp đầu vào nhận các dạng thông tin khác nhau từ
thế giới bên ngoài. Đây là dữ liệu mà mạng nhắm đến để xử lý hoặc tìm hiểu. Từ lớp đầu
vào, dữ liệu đi qua một hoặc nhiều lớp ẩn khác. Công việc của các lớp ẩn là biến đầu vào
thành thứ mà lớp đầu ra có thể sử dụng."
Phần"lớn các mạng nơ-ron nhân tạo được kết nối đầy đủ từ lớp này sang lớp khác. Các kết
nối này có trọng số; Con số càng cao thì lớp này càng có ảnh hưởng lớn đến lớp khác,
tương tự như bộ não con người. Khi dữ liệu đi qua từng lớp, mạng nơ-ron nhân tạo sẽ tìm
hiểu thêm về dữ liệu. Ở phía bên kia của mạng là các lớp đầu ra, và đây là nơi đưa ra kết
quả từ các dữ liệu ban đầu." lOMoAR cPSD| 46831624
Để"mạng nơ-ron nhân tạo có thể học được, chúng cần phải có một lượng lớn thông tin được
gọi là tập hợp các cặp dữ liệu đầu vào và dữ liệu đầu ra để huấn luyện trong quá trình máy
học (training set). Khi bạn đang cố gắng dạy mạng nơ-ron nhân tạo cách phân biệt mèo với
chó, training set sẽ cung cấp hàng nghìn hình ảnh được gắn thẻ là chó để mạng nơ-ron bắt
đầu tìm hiểu. Khi nó đã được huấn luyện với lượng dữ liệu đáng kể, nó sẽ cố gắng phân
loại dữ liệu trong tương lai dựa trên những gì nó cho rằng nó đang nhìn thấy (hoặc nghe
thấy, tùy thuộc vào tập dữ liệu) trong các lớp khác nhau."
Về lý thuyết,"chúng ta có thể sử dụng mạng nơ-ron cho hầu hết mọi thứ và có thể đã sử
dụng chúng mà không nhận ra. Chúng rất phổ biến trong nhận dạng giọng nói và hình ảnh.
Ví dụ, khi hỏi Siri trạm xăng dầu gần nhất ở đâu, Iphone của bạn sẽ đưa đoạn âm thanh đó
qua mạng nơ-ron để hiểu những gì bạn đang nói, xe ô tô tự lái có thể sử dụng mạng nơ-ron
để xử lý dữ liệu hình ảnh, do đó tuân theo các quy tắc đường bộ và tránh va chạm, mạng
nơ-ron nhân tạo được sử dụng để chuyển đổi các ký tự viết tay thành các ký tự kỹ thuật số
mà máy có thể nhận ra."
Ngoài ra,"mạng nơ-ron có thể tìm hiểu thói quen của bạn để cá nhân hóa kết quả tìm kiếm
của bạn hoặc dự đoán những gì bạn sẽ tìm kiếm trong tương lai gần mà mô hình dự đoán
này rất có ích cho các nhà tiếp thị (hay bất kỳ ai khác cần dự đoán hành vi phức tạp của
con người). Khả năng nhận dạng hình ảnh, dự đoán thị trường chứng khoán, tìm đường, xử
lý dữ liệu lớn, phân tích chi phí y tế, dự báo bán hàng, trò chơi điện tử AI, … là những khả
năng gần như vô tận. Khả năng mạng nơ-ron học các mẫu, khái quát hóa và dự đoán thành
công hành vi khiến chúng có giá trị trong vô số tình huống."
d. Ưu điểm của Neural Network:
• Có thể thích ứng với nhiều loại thông số và yêu cầu dữ liệu.
• Chúng dễ sử dụng, yêu cầu số liệu thống kê tối thiểu đào tạo.
• Hơn nữa, mạng nơ-ron có khả năng học hỏi (ở một khía cạnh hạn chế), khiến chúng
trở thành mô hình gần nhất với người vận hành.
• Mạng nơ-ron đủ nâng cao để phát hiện bất kỳ mối quan hệ phức tạp nào giữa đầu
vào và đầu ra, đây là một lợi thế khác khi sử dụng mô hình này.
e. Nhược điểm của Neural Network:
• Do tính chất phức tạp và cao cấp của mô hình, chúng rất khó thiết kế.
• Do mạng nơ-ron sẽ phản ứng với những thay đổi dữ liệu dù là nhỏ nhất, nên thường
rất khó để lập mô hình phân tích.
• Việc chạy một mạng nơ-ron cũng đòi hỏi một lượng lớn tài nguyên máy tính, khiến
nó trở nên đắt đỏ và có thể không thực tế đối với một số công ty và ứng dụng.
• Hơn nữa, trong khi mạng nơ-ron rất tuyệt vời và thu thập được lượng lớn dữ liệu,
lợi thế này giảm đi so với kích thước của một mẫu dữ liệu. Ví dụ: các mẫu nhỏ sẽ
không được sử dụng hiệu quả vì mạng hoạt động tốt nhất với các mẫu lớn. lOMoAR cPSD| 46831624
• Các giải thuật của mạng đôi khi chưa đảm bảo tính hội tụ cần thiết cho quá trình sử dụng.
2.5. Các phương pháp đánh giá mô hình phân lớp:
2.5.1. Confusion matrix, Precision, Recall, F1 – score và accuracy.
Ma trận"nhầm lẫn là ma trận chỉ ra có bao nhiêu điểm dữ liệu thực sự thuộc về một lớp cụ
thể và được dự đoán rơi vào lớp nào. Ma trận nhầm lẫn có kích thước k×k với k là số lượng
của lớp dữ liệu."Ma trận nhầm lẫn bao gồm 4 loại giá trị chính như sau: •
TP (true positive) là số dự đoán chính xác của lớp i. •
FP (false positive) là số lượng các mẫu không thuộc lớp i, bị phân loại nhầm vào lớp i. •
TN (true negative) là số lượng các ví dụ không thuộc lớp i được phân loại chính xác. •
FN (false negative) là số lương các mẫu thuộc lớp i nhưng bị phân loại nhầm vào lớp khác.
Ma trận nhầm lẫn với bài toán cụ thể phân lớp với hai mẫu dữ liệu mang nhãn (+)
và mang nhãn (–). Bảng 2.1 thể hiện rõ hơn ma trận nhầm lẫn:
Bảng 2.1. Ma trận nhầm lẫn Mẫu dữ liệu
Được phân lớp bởi mô hình + – Thực tế + TP FN – FP TN
Từ bảng ma trận nhầm lẫn 2.1, ta có thể được các giá trị để đo độ chính xác của mô
hình. Độ chính xác (Precision) là tỷ lệ giữa số phân loại đúng là mẫu dương trên tổng số
các mẫu được phân loại là mẫu dương. Ta có công thức của Precision được thể hiện như sau: lOMoAR cPSD| 46831624 TP Precision= TP+FP
Độ bao phủ (Recall) được xác định số mẫu phân loại đúng là mẫu dương trên tổng
số mẫu dương thực, được thể hiện bởi công thức sau đây: TP Recall= TP+FN
Từ đó, ta có thể tính được chỉ số F1 – score và nó là tiêu chí đánh giá dựa trên sự kết
hợp của độ chính xác (Precision) và độ bao phủ (Recall). Công thức tính F1 – score như sau:
2×Precision×Recall F1−score= Precision×Recall
Ngoài ra, ta còn công thức về độ chính xác (Accuracy) như sau: Accuracy= TP+TN
TP+FP+TN+FN
Accuracy"chỉ cho chúng ta biết được tỷ lệ dữ liệu được phân loại đúng mà không
chỉ ra được cụ thể mỗi loại được phân loại như thế nào, lớp nào được phân loại đúng
nhiều nhất, và dữ liệu thuộc lớp nào thường bị phân loại nhầm vào lớp khác."
2.5.2. AUC (Area Under the Curve), ROC và Cross Validation: K-fold và Holdout.
AUC – ROC"là một phương pháp tính toán hiệu suất của một mô hình phân loại theo các
ngưỡng phân loại khác nhau. AUC là từ viết tắt của Area Under The Curve còn ROC viết
tắt của Receiver Operating Characteristics. ROC là một đường cong biểu diễn xác suất và
AUC biểu diễn mức độ phân loại của mô hình. Chỉ số AUC càng cao thì mô hình càng
chính xác trong việc phân loại các lớp. Đường cong ROC biểu diễn các cặp chỉ số (TPR,
FPR) tại mỗi ngưỡng với TPR là trục tục và FPR là trục hoành. Chỉ số AUC càng gần 1 thì
mô hình càng phân loại chính xác. AUC càng gần 0.5 thì hiệu suất phân loại càng tệ còn
nếu gần 0 thì mô hình sẽ phân loại ngược kết quả (phân loại dương tính thành âm tính và ngược lại).s Mô tả
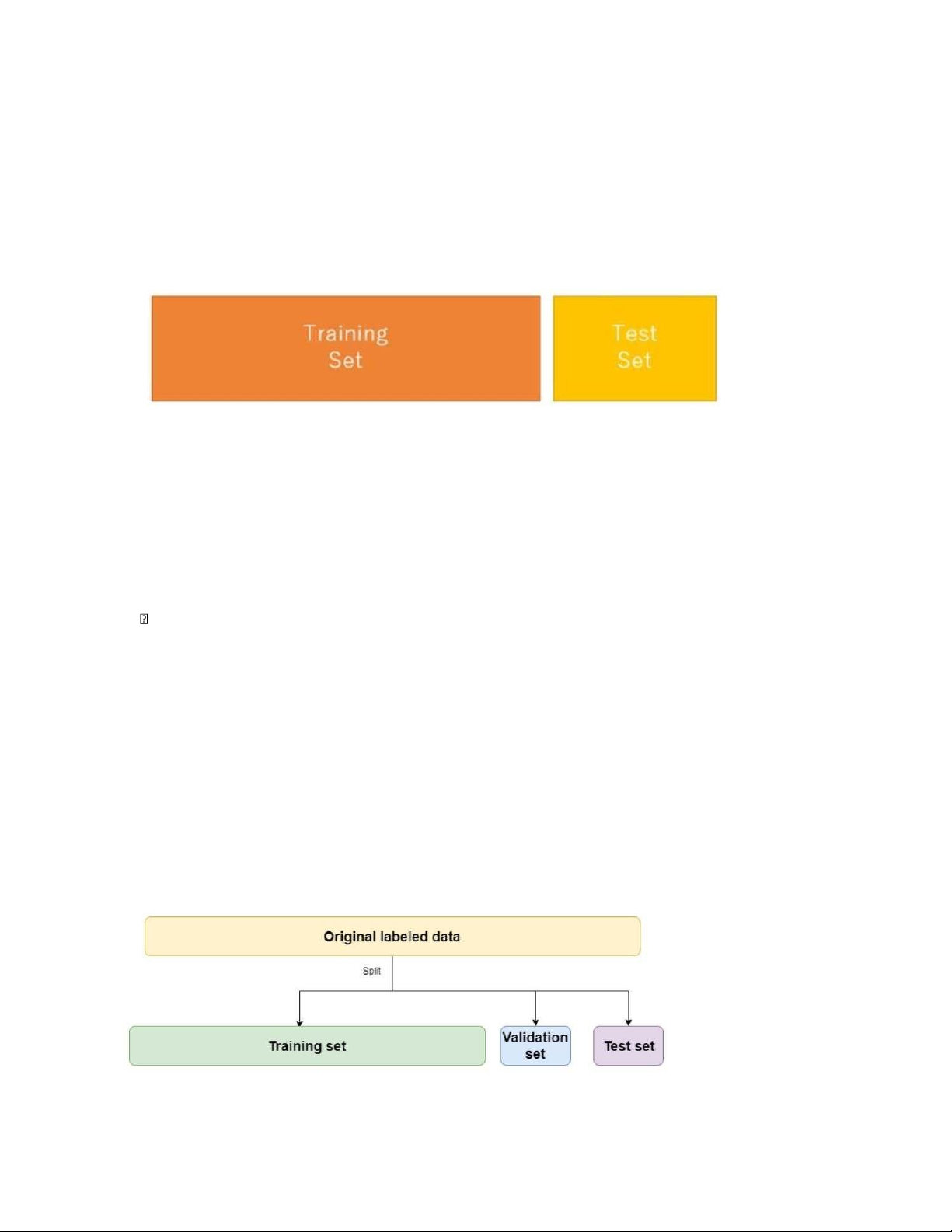
Phương"pháp Hold-out phân chia tập dữ liệu ban đầu thành 2 tập độc lập theo 1 tỷ lệ nhất
định. Ví dụ, tập huấn luyện (training set) chiếm 70%, tập thử nghiệm (testing set) chiếm
30% (tỷ lệ thông thường)." lOMoAR cPSD| 46831624
Mục đích của Hold-out là kiểm tra độ hiệu quả của mô hình khi sử dụng nhiều tập dữ liệu
khác nhau. Phương pháp này thích hợp cho các tập dữ liệu nhỏ. Tuy nhiên, các mẫu có thể
không đại diện cho toàn bộ dữ liệu
Có thể"cải tiến lỗi này bằng cách dùng phương pháp lấy mẫu sao cho mỗi lớp được phân
bố đều trong cả 2 tập dữ liệu huấn luyện và đánh giá. Hoặc lấy mẫu ngẫu nhiên : thực hiện
hold-out k lần và độ chính xác acc(M) = trung bình cộng k giá trị chính xác." Ưu điểm:
Nhanh chóng, đơn giản và linh hoạt Nhược điểm
Phương pháp hold-out có độ biến thiên cao vì do sự khác biệt khá lớn trong 2 tập dữ liệu,
vì vậy dẫn tới sự khác biệt trong việc phân loại hoặc dự báo.
Áp dụng phương pháp Hold-out cần kết hợp nhiều phương pháp để kiểm tra mức độ
khác nhau của 2 tập dữ liệu K-Fold Mô tả
Phương pháp này phân chia một dữ liệu thành k các tập con có cùng kích thước với nhau
(được gọi là các fold).
Một trong các fold này được sử dụng làm tập dữ liệu dùng để đánh giá và phần các fold
còn lại thì được sử dụng làm tập huấn luyện
Quá trình này lặp đi lặp lại cho đến khi tất cả các fold đều được dùng để làm tập dữ liệu đánh giá thì kết thúc lOMoAR cPSD| 46831624
Dưới đây là ví dụ về 5-fold cross validation (k=5) Ưu điểm
Ưu điểm của K fold là có nhiều dữ liệu hơn được sử dụng cho việc huấn luyện. Mỗi tập dữ
liệu được sử dụng để kiểm tra chỉ 1 lần nhưng trong khi đó lại được dùng trong tập huấn
luyện tận k -1 lần Nhược điểm
Nhược điểm của K fold là đòi hỏi nhiều thời gian do cần phải huấn luyện và đánh giá mô hình tận k lần
Thông thường, K fold được sử dụng với k=5 hoặc k=10 vì sẽ cho kết quả khách quan và số lần huấn luyện ít
HOLD out và K fold cross validation
Nhìn chung,"phương pháp K fold cross validation thường hay được sử dụng nhiều hơn vì
do mô hình sẽ được đánh giá và huấn luyện dựa trên nhiều phần dữ liệu khác nhau vì thế
sẽ tăng độ tin cậy cho các đánh giá của mô hình."
Còn"phương pháp Hold out thường được cho rằng là có hiệu quả tốt hơn trên các tập dữ
liệu lớn. Tuy nhiên, đối với các tập dữ liệu nhỏ hoặc vừa, hiệu quả của việc sử dụng phương
pháp hold out này phụ thuộc nhiều vào cách chia tỷ lệ dữ liệu."
Tài liệu liên quan:
-

Tiểu luận Phân Tích Giá Trái Cây 2023 | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
19 10 -

Bộ câu hỏi trắc nghiệm - Kinh tế học thị trường và cầu cung | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
19 10 -

Câu Hỏi Ôn Tập Phần Thị Trường | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
24 12 -

Kinh Tế Vi Mô: Câu Hỏi và Đáp Án Quan Trọng | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
22 11 -

Tiểu luận Món Huế và Thị Trường F&B Việt Nam | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
17 9