Thực hành phương thức kinh doanh | Đại học Kinh tế Thành phố Hồ Chí Minh
Independent Sample T-Test chúng ta sẽ áp dụng kiểm định sự khác biệt trung bình với trường hợp biến định tính có 2 giá trị. Ví dụ như biến giới tính (nam, nữ), biến thành phố (TPHCM, Hà Nội), biến vùng miền (Miền Bắc, Miền Nam). Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem !
Môn: Kinh tế vĩ mô ( UEH) 0.9 K tài liệu
Trường: Đại học Kinh tế Thành phố Hồ Chí Minh 2.8 K tài liệu
Tác giả:











Preview text:
lOMoAR cPSD| 46988474 Contents
THỐNG KÊ MÔ TẢ - KẺ BẢNG ........................................................................................................................ 1
VẼ ĐỒ THỊ ...................................................................................................................................................... 3
LINE ............................................................................................................................................................... 4
PIE CHART – thể hiện cơ cấu ......................................................................................................................... 5
Biểu đồ SCATTER PLOTS ................................................................................................................................ 5
T-TEST ............................................................................................................................................................ 6
ANOVA.........................................................................................................................................................8
CORRELATION............................................................................................................................................10
REGRESSION ANALYSIS..............................................................................................................................11
Mul 琀椀 collinearity (Đa cộng
tuyến)..............................................................................................................13 BIẾN TƯƠNG
TÁC......................................................................................................................................14
THỐNG KÊ MÔ TẢ - KẺ BẢNG
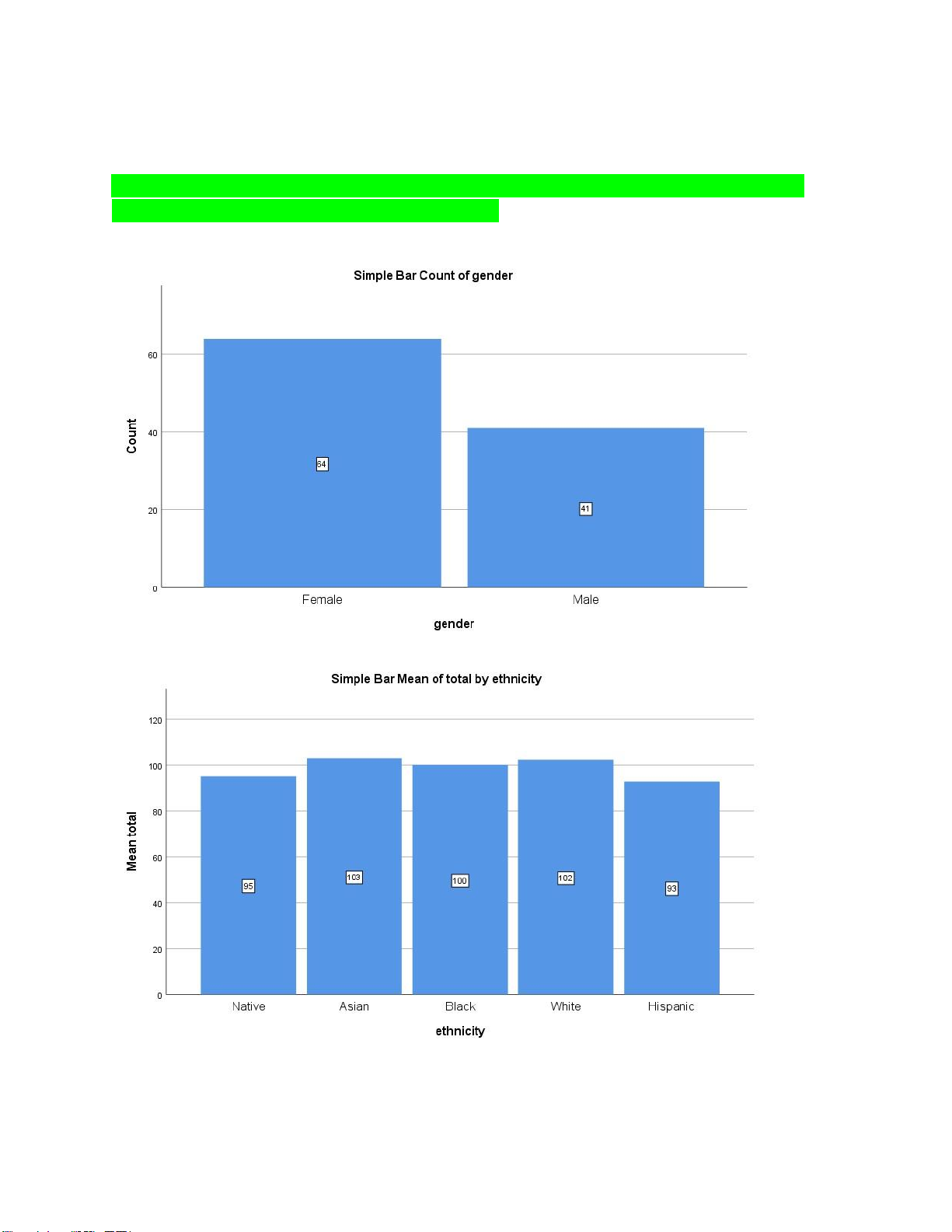
1. Frequency (bảng tần số): 01 biến phân loại. gender Frequenc Valid Cumulative y Percent Percent Percent Valid Female 64 61.0 61.0 61.0 Male 41 39.0 39.0 100.0 Total 105 100.0 100.0
2. Crosstabulation (bảng chéo): 02 biến phân loại.
gender * ethnicity Crosstabulation Count lOMoAR cPSD| 46988474 ethnicity Hispani Native Asian Black White c Total gender Female 4 13 14 26 7 64 Male 1 7 10 19 4 41 Total 5 20 24 45 11 105 Thể hiện phần trăm:
gender * ethnicity Crosstabulation ethnicity Native Asian Black White Hispanic Total gender Female Count 4 13 14 26 7 64 % within gender 6.3% 20.3% 21.9% 40.6% 10.9% 100.0% Male Count 1 7 10 19 4 41 % within gender 2.4% 17.1% 24.4% 46.3% 9.8% 100.0% Total Count 5 20 24 45 11 105 % within gender 4.8% 19.0% 22.9% 42.9% 10.5% 100.0%
gender * grade Crosstabulation grade A B C D F Total gender Female Count 15 20 23 4 2 64 % within gender 23.4% 31.3% 35.9% 6.3% 3.1% 100.0% Male Count 8 12 12 5 4 41 % within gender 19.5% 29.3% 29.3% 12.2% 9.8% 100.0% Total Count 23 32 35 9 6 105 % within gender 21.9% 30.5% 33.3% 8.6% 5.7% 100.0% Phân tích: 1. So sánh hơn
2. So sánh nhất: lớn, bé
3. Xu hướng/ Điểm nổi bật lOMoAR cPSD| 46988474 VẼ ĐỒ THỊ
GRAPHS => CHART BUILDER => CỘT DỌC THƯỜNG LÀ BIẾN PHỤ THUỘC,
CỘT NGANG THƯỜNG LÀ BIẾN ĐỘC LẬP. Bar1: 1 biến phân loại
Bar2: 1 biến phân loại + 1 biến liên tục (mean)
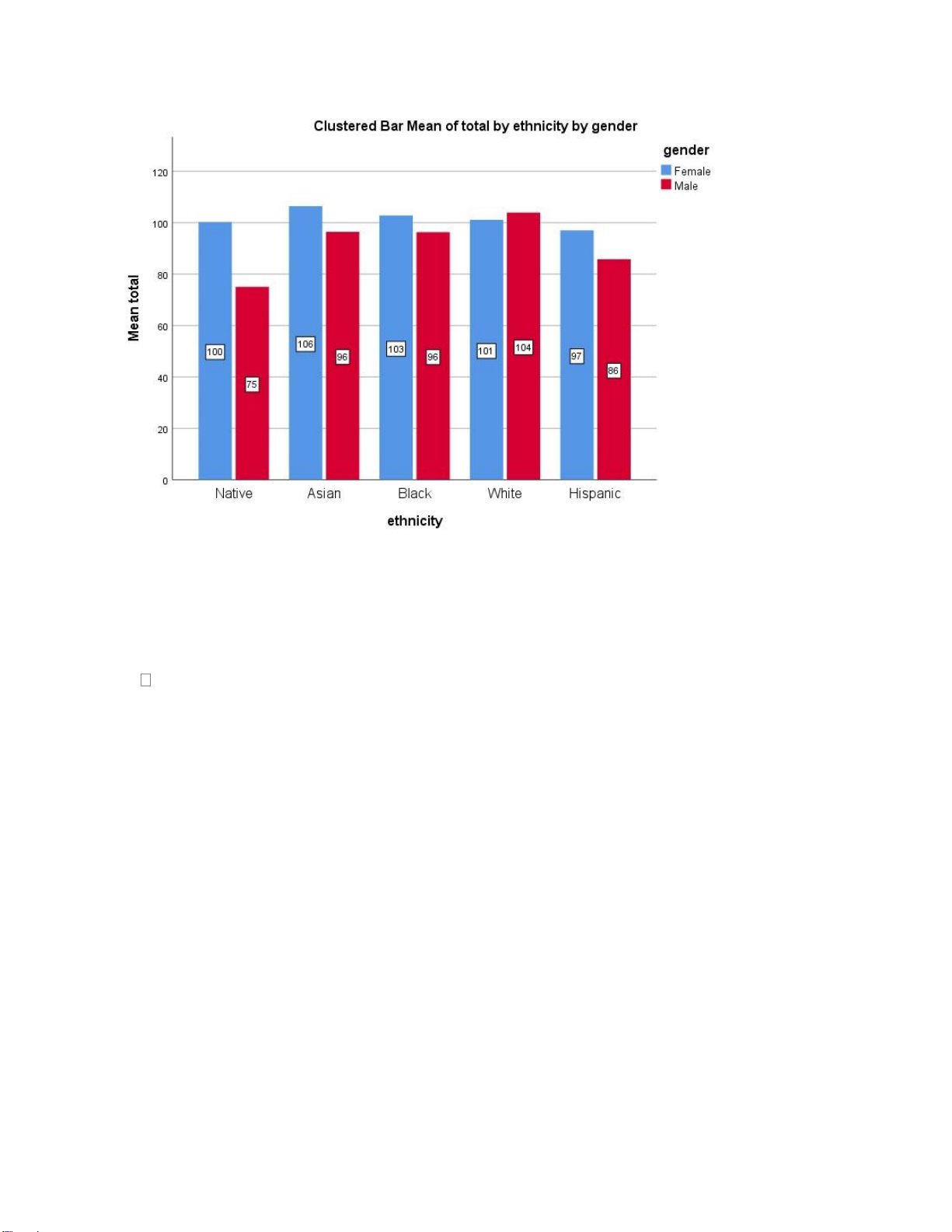
Bar3: 2 biến phân loại + 1 biến liên tục (mean). DÁN LÊN Ô TRÊN CÙNG GÓC PHẢI. lOMoAR cPSD| 46988474 Nhận xét:
Nữ thường giỏi hơn nam ở các sắc tộc. LINE
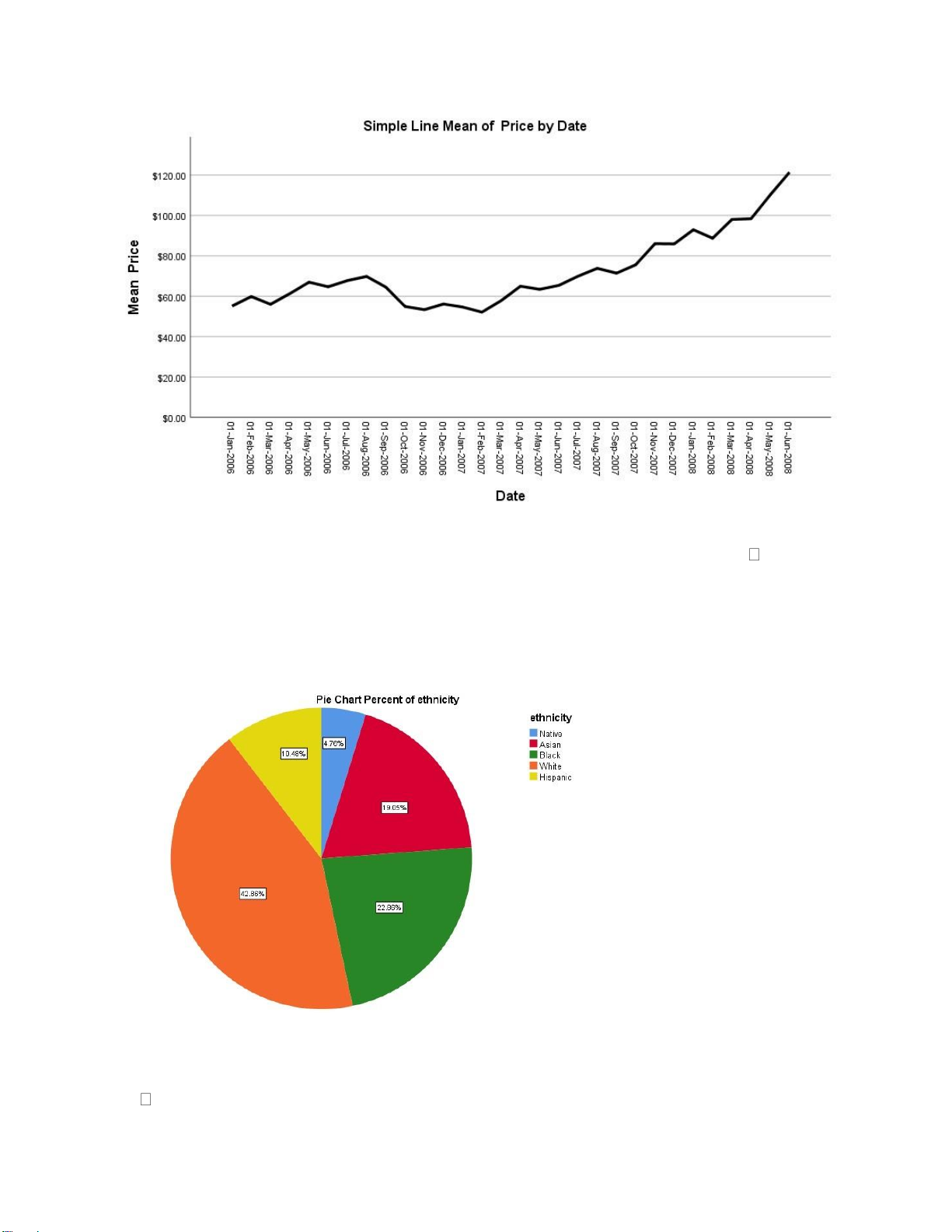
Thể hiện time series data lOMoAR cPSD| 46988474
Nhận xét: Có xu hướng tăng khá mạnh trong 2 năm qua nhưng không ổn định, từ $60 $120 (gấp 2 lần)
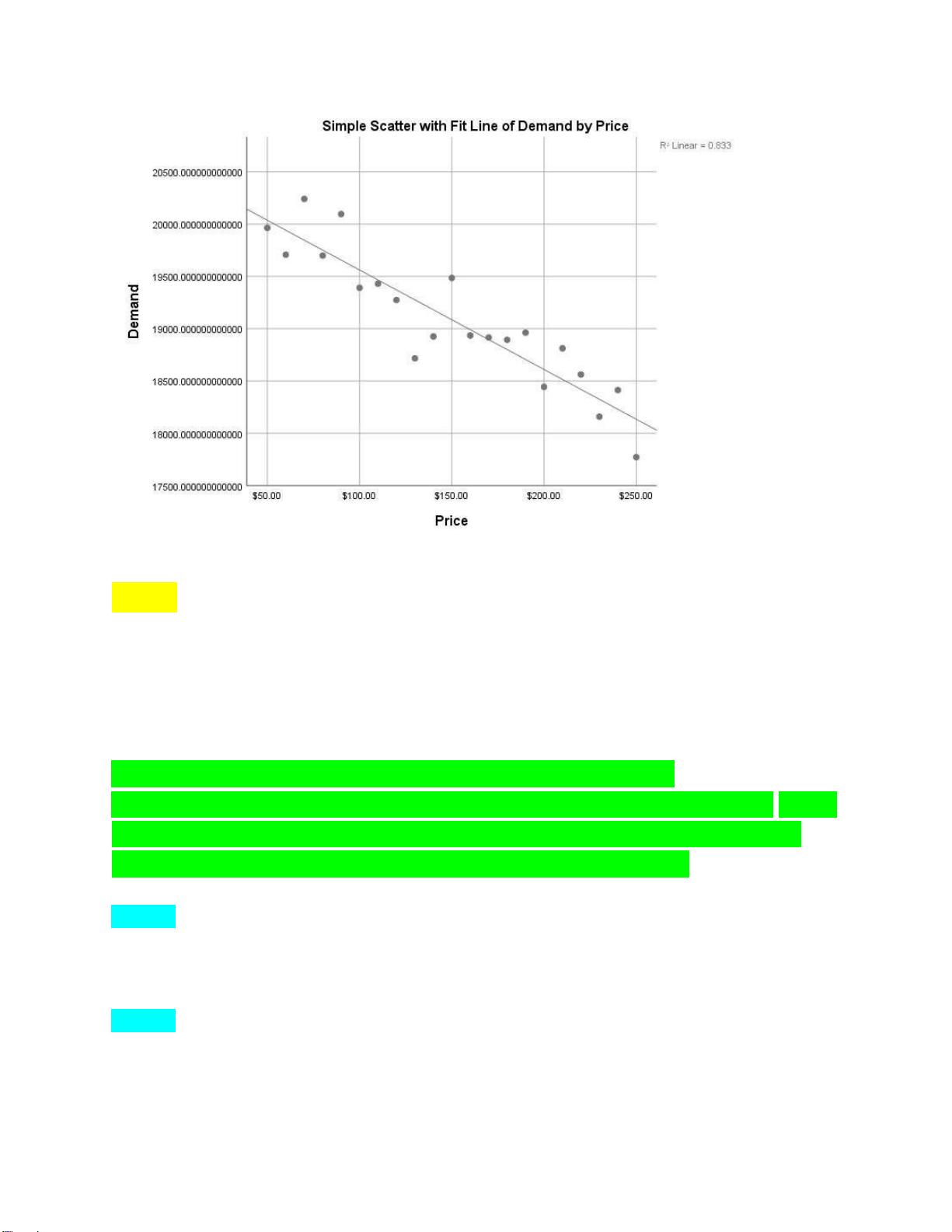
PIE CHART – thể hiện cơ cấu Biểu đồ SCATTER PLOTS
Thể hiện sự tương quan giữa 2 biến (thuận hoặc nghịch). lOMoAR cPSD| 46988474 T-TEST
BIẾN ĐỊNH LƯỢNG VÀ ĐỊNH TÍNH.
Independent Sample T-Test chúng ta sẽ áp dụng kiểm định sự khác biệt trung bình với
trường hợp biến định tính có 2 giá trị. Ví dụ như biến giới tính (nam, nữ), biến thành
phố (TPHCM, Hà Nội), biến vùng miền (Miền Bắc, Miền Nam)…
Analyze > Compare Means > Independent-Samples T Test...
CHUYỂN BIẾN ĐỊNH LƯỢNG SANG Ô TEST VARIABLES, BIẾN ĐỊNH
TÍNH (2 GIÁ TRỊ) SANG Ô GROUPING VARIABLES. => DEFINE =>
ĐIỀN 0, 1 HOẶC 1,2 TÙY VÀO MÌNH ĐÃ MÃ HÓA NTN.
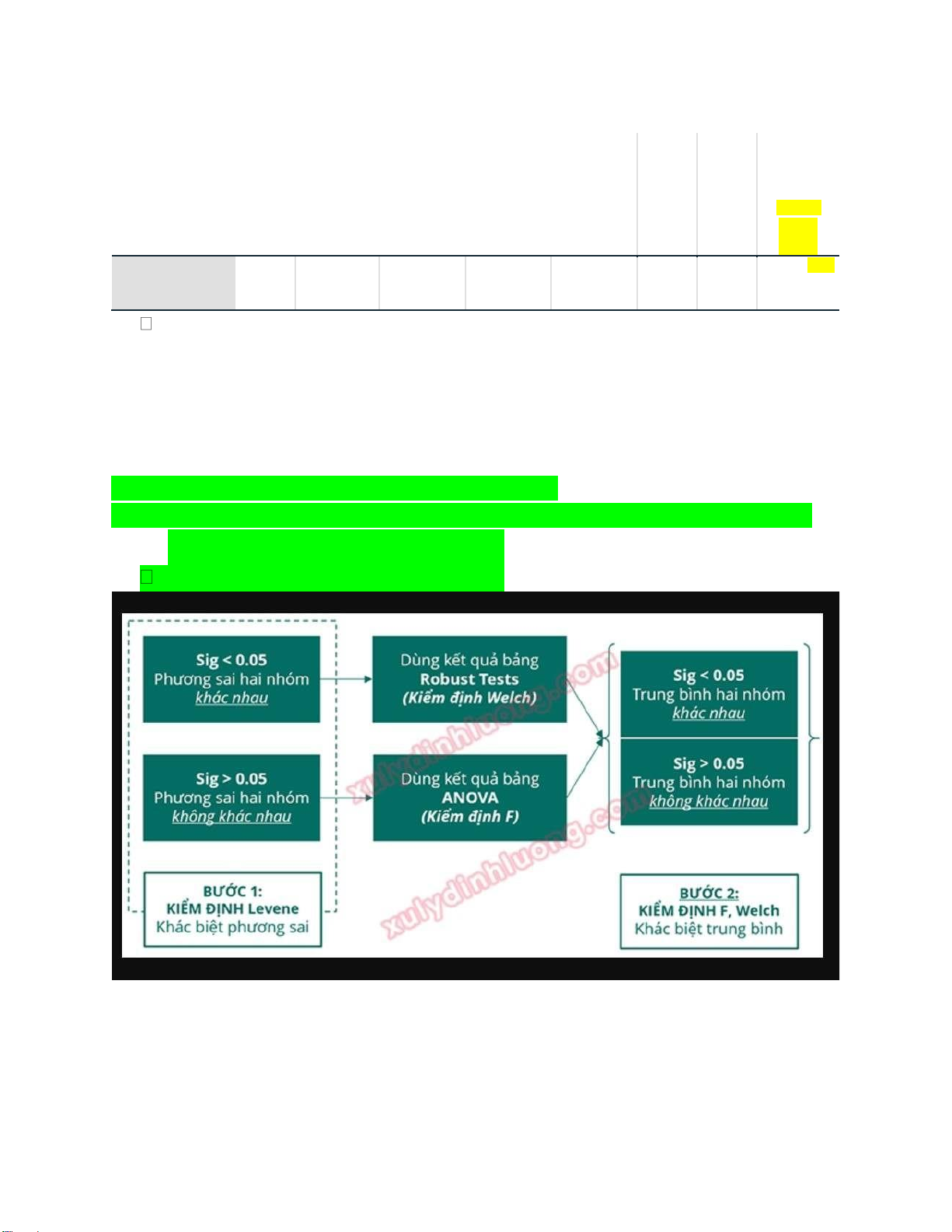
Bước 1: XEM CÓ Ý NGHĨA THỐNG KÊ KHÔNG?
- Xem sig của F. Nếu < 0.05 => Có ý nghĩa thống kê. => Xem dòng có NOT.
- Xem sig của F. Nếu > 0.05 => Không có ý nghĩa thống kê. => Xem dòng KHÔNG CÓ NOT.
Bước 2: XEM CÓ SỰ KHÁC BIỆT GIỮA HAI NHÓM KHÔNG?
- Xem sig của t (Sig 2 tailed): Nếu < 0.05 => Có sự khác biệt giữa hai nhóm. lOMoAR cPSD| 46988474
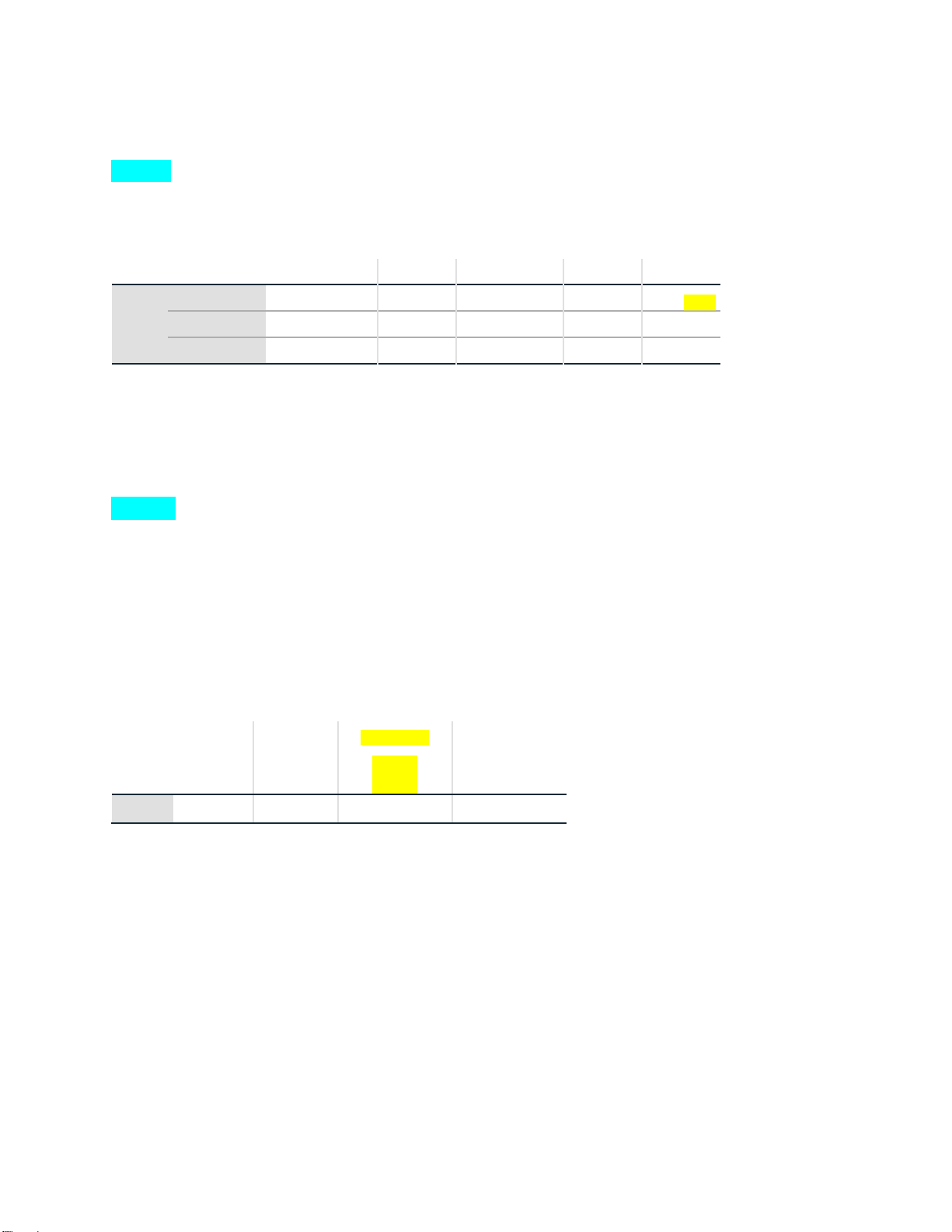
Independent-sample T Test: chỉ 2 biến Group Statistics gender N Mean
Std. Deviation Std. Error Mean total Female 64 102.03 13.896 1.737 Male 41 98.29 17.196 2.686
Independent Samples Test
Levene's Test fort-test for Equality of Means Equality of Variances % Confidence 95 Interval of the Sig. Sig. Mean Std. Error Difference F t df
(2tailed) Difference Difference Lower Upper lOMoAR cPSD| 46988474 tota 2.019 .158 1.224 103 .224 3.739 3.053 -2.317 9.794 Equal variances l assumed 1.169 72.421 .246 3.739 3.198 -2.637 10.114 Equal variances not assumed
Sig = P-value: ý nghĩa thống kê (0.05)
- Sig <0.05: Equal variance not assume
- Sig>= 0.05: Equal variance assumed
.158 >0.05, vậy dùng sigs của Equal variance assumed
- Sig <= α => có sự khác biệt về trung bình của hai biến
- Sig > α => Không có sự khác biệt giữa 2 biến
0.224 > 0.05, vậy không có sự khác biệt giữa total của Nam và nữ. Group Statistics gender N Mean
Std. Deviation Std. Error Mean gpa Female 64 2.8967 .74622 .09328 Male 41 2.5949 .76346 .11923
Independent Samples Test Levene's Test for Equality of Variances t-test for Equality of Means 95% Confidence Interval of the Difference Sig. Mean Std. Error F Sig. t df
(2tailed) Difference Difference Lower Upper .331 .566 2.004 103 .048 .30184 .15062 .00312 .60056 gpa Equal variances assumed 1.994 83.974 .049 .30184 .15138 .00080 .60288 Equal variances not assumed
Vì sig. của levene >=0.05 nên dùng Equal variance assumed.
Có sig(0.048) <α = 0.05 Có sự khác biệt, có ý nghĩa thống kê giữa GPA của 2 nhóm nam và nữ. Pair Sample Test lOMoAR cPSD| 46988474 Paired Samples Test Paired Differences 95 % Confidence Interval Sig. (2- Std. Std. Error of the Difference tailed) Mean Deviation Mean Lower Upper t df -.514 1.835 .179 -.869 -.159 -2.872 104 .005 Pair quiz1 - 1 quiz2
Sig <0.05 nên có sự khác nhau trung bình giữa 2 biến quiz 1 và quiz 2 trong nhóm 1 ANOVA
Mạnh hơn T Test, so sánh giá trị trung bình giữa 3 4 nhóm khác nhau.
Analyze > Compare Means > One-Way ANOVA....
ĐƯA BIẾN PHỤ THUỘC VÀO DEPEND, BIẾN ĐỊNH TÍNH VÀO FACTOR.
OPTIONS => CHỌN Ô 1, 3, 5 => OK lOMoAR cPSD| 46988474
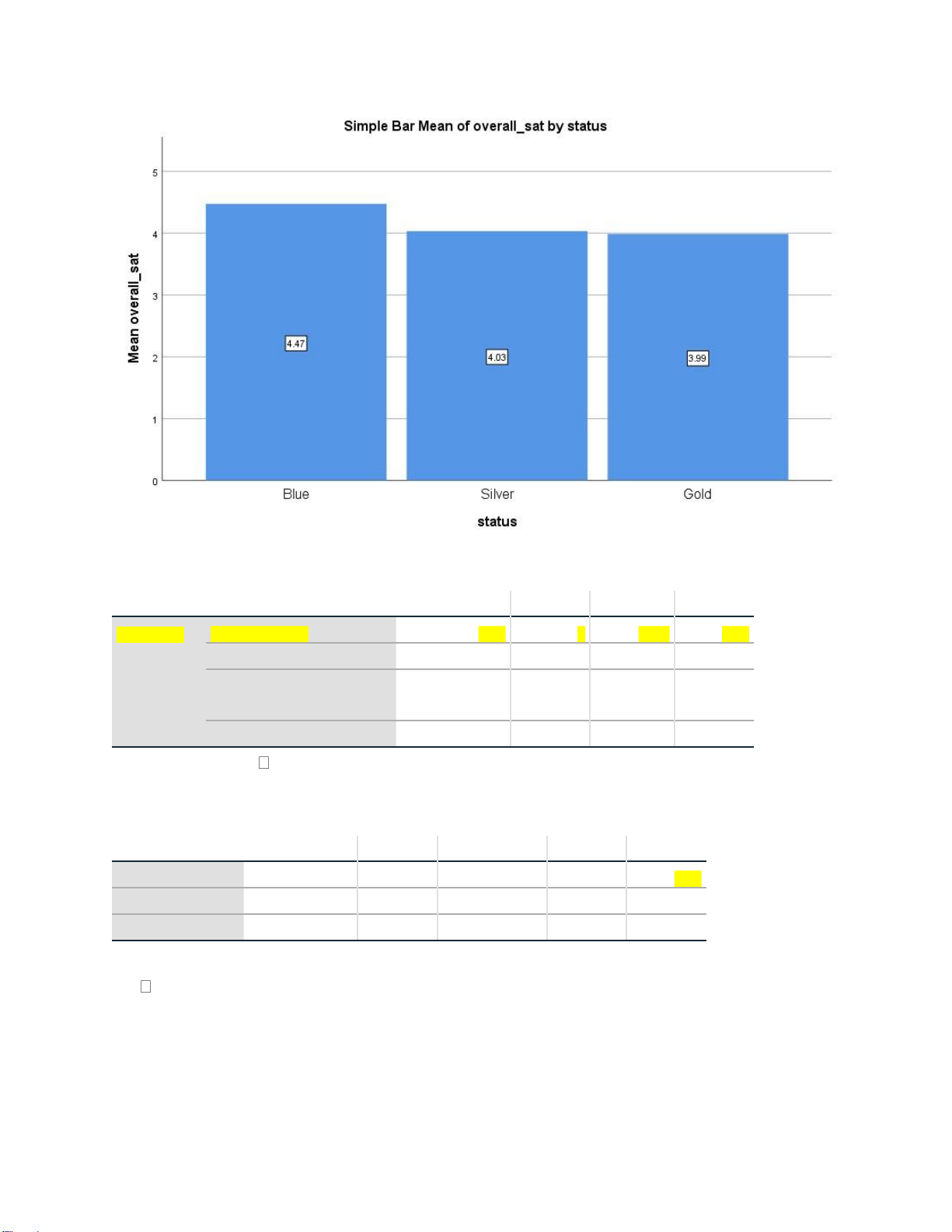
Test of Homogeneity of Variances Levene Statistic df1 df2 Sig. overall_sat Based on Mea n .907 2 1062 .40 4 Based on Median .068 2 1062 .934 Based on Median and with .068 2 1017.925 .934 adjusted df Based on trimmed mean .771 2 1062 .463
Vì sig (.404) >0.05 Dùng bảng ANOVA. ANOVA overall_sat Sum of Squares df Mean Square F Sig. Between Groups 51.755 2 25.878 9.963 .00 0 Within Groups 2758.455 1062 2.597 Total 2810.210 1064 Có sig. (0.000…)<0.05
Có sự khác biệt có ý nghĩa thống kê giữa ít nhất 2 nhóm khách hàng về giá trị trung bình
của sự hài lòng về giá. Bài tập:
Test of Homogeneity of Variances lOMoAR cPSD| 46988474 Levene Statistic df1 df2 Sig. overall_sat .046 Based on Mean 3.092 2 1062 Based on Median 2.170 2 1062 .115 2.170 2 1045.396 .115 Based on Median and with adjusted df Based on trimmed mean 3.043 2 1062 .048
Vì sig. (0,046) < 0.05 Dùng Robust
Robust Tests of Equality of Means overall_sat Statistic a df1 df2 Sig. Welch 4.820 2 37.550 .01 4
a. Asymptotically F distributed. Vì sig. (0.014) < 0.05
Có sự khác biệt có ý nghĩa thống kê giữa 3 nhóm Economy, First, Business về giá trị trung
bình của sự hài lòng về giá. CORRELATION
ANALYZE => COLLERATE =>BIVARIATE
=> Nhằm kiểm tra mối tương quan tuyến tính chặt chẽ giữa biến phụ thuộc với các
biến độc lập và sớm nhận diện vấn đề đa cộng tuyến khi các biến độc lập cũng có tương quan mạnh với nhau.
Bước 1: Xem có ý nghĩa thông kế hay không? (Dòng 2 Sig. (2-tailed))
- Xét sig kiểm định < 0.05 => Có tương quan tuyến tính với nhau.
- Xét sig kiểm định > 0.05 => Không có tương quan tuyến tính với nhau. (Kết thúc)
Bước 2: Xét độ mạnh yếu của mức tương quan. (Dòng 1 Pearson Correlation) - Trị tuyệt đối r. Xét theo bảng sau:
- Hệ số tương quan Pearson (r) (-1, 1): -1 là nghịch, 0 là không liên quan, 1 là thuậnX là trị tuyệt đối của r. lOMoAR cPSD| 46988474
X <0.1: Tương quan rất yếu X < 0.3: Tương quan yếu.
0.3 < x < 0.49: tương quan trung bình.
X > 0.49: Tương quan mạnh.
- Chuẩn hóa thì đã mất đơn vị. Correlations s1 s2 s3 s4 s1 Pearson Correlation 1 .739 ** .619 ** .717 ** Sig. (2-tailed) .000 .000 .000 N 8 103 1037 952 1033 s2 Pearson Correlation .739 ** 1 .694 ** .766 ** Sig. (2-tailed) .00 0 .000 .000 N 103 7 104 0 952 1034 s3 Pearson Correlation .619 ** .694 ** 1 .645 ** Sig. (2-tailed) .0 0 0 .00 0 .000 N 95 2 95 2 95 4 951 s4 Pearson Correlation .717 ** .766 ** .645 ** 1 Sig. (2-tailed) .000 .000 .000 N 1033 1034 951 1035
**. Correlation is significant at the 0.01 level (2-tailed).
Vì hệ số tương quan đều lớn hơn 0.49 nên chúng đều tương quan mạnh vs nhau.
NOTE: Có hai dạng là so sánh mối tương quan giữa biến độc lập với nhau hoặc so sánh tương
quan giữa biến độc lập và biến phụ thuộc.
(1). Các biến độc lập với nhau ta sẽ kỳ vọng chúng càng không tác động với nhau càng tốt => ít
có khả năng đa cộng tuyến => Kỳ vọng hai khả năng; một, sig > 0.05; hai, sig < 0.05 nhưng r
càng gần 0 càng tốt. Đặc biệt, nếu r > 0.7 là xảy ra đa cộng tuyến.
(2) Các biến độc lập và biến phụ thuộc. Ta sẽ kỳ vọng chúng tác động lên biên phụ thuộc vì vậy
sig < 0.05 và r càng lớn càng tốt. REGRESSION ANALYSIS
Analyze > Regression > Linear…
ĐƯA BIẾN PHỤ THUỘC VÀO DEPENT, ĐỌC LẬP VÀO INDEPENT
Hồi quy tuyến tính là phép hồi quy xem xét mối quan hệ tuyến tính – dạng quan
hệ đường thẳng giữa biến độc lập với biến phụ thuộc. (Phân tích tác động của
các biến độc lập lên biến phụ thuộc). Hồi quy tuyến tính đơn: 1 biến lOMoAR cPSD| 46988474
Hồi quy tuyến tính bội: >= 2 biến.
Bước 1: Xem có ý nghĩa thống kê hay không. - Xem bảng ANOVA ANOVA a Model Sum of Squares df Mean Square F Sig. 1 Regression 1423.209 4 355.802 12.627 .000 b Residual 1239.852 44 28.178 Total 2663.061 48
a. Dependent Variable: Graduation %
b. Predictors: (Constant), Top 10% HS, Median SAT, Expenditures/Student, Acceptance Rate
- Xét sig < 0.05 => Có ý nghĩa thống kê, mô hình hồi quy phù hợp.
- Xét sig > 0.05 => Không có ý nghĩa thống kê, mô hình không phù hợp. (Kết thúc).
Bước 2: Xem mô hình có phù hợp với tập dữ liệu không. - Xem bảng Summary Model Summary Adjusted R Std. Error of the Square Model R R Square Estimate 1 .731a .534 .492 5.308
a. Predictors: (Constant), Top 10% HS, Median SAT, Expenditures/Student, Acceptance Rate
- Xem số R2 hiệu chỉnh: Giá trị R bình phương hiệu chỉnh bằng 0.492 cho thấy các
biến độc lập đưa vào phân tích hồi quy ảnh hưởng 49.2% sự biến thiên của biến phụ thuộc.
NOTE: R2 hay R2 hiệu chỉnh đều có mức dao động trong đoạn từ 0 đến 1. Nếu R2 càng
tiến về 1, các biến độc lập giải thích càng nhiều cho biến phụ thuộc, nằm toàn bộ
trên đường thẳng, và ngược lại, R2 càng tiến về 0, các biến độc lập giải thích càng ít cho biến phụ thuộc. lOMoAR cPSD| 46988474
Bước 3: Xem có ý nghĩa thống kê hay không? - Xem bảng Coefficients
- Xét sig < 0.05 => Có ý nghĩa thống kê. (CÁI NÀY THẦY KÊU NÊN LẤY 0.1 THAY VÌ 0.05)
Xem hệ số B (hệ số hồi quy), nếu dương (+) => Có tác động tích cực, và ngược lại (-) là tác động tiêu cực.
- Xét sig > 0.05 / 0.1 => Không có ý nghĩa (Kết thúc).
- Sau đó lập công thức, phân tích tác động. Coefficients a Standardized Unstandardized Coefficients Coefficients Model B Std. Error Beta t Sig . 1 ( Constant ) 17.921 24.557 .730 .469 Median SAT .072 .018 .606 4.004 .0 0 0 Acceptance Rat e -.249 .083 -.446 -2.990 .0 5 0 Expenditure s/Studen t .000 .000 -.282 -2.057 .04 6 Top 10% HS -.163 .079 -.296 -2.051 .04 6
a. Dependent Variable: Graduation % Sửa: -0.249 Acceptance Rate
Nhận xét: Nếu điểm trung vị SAT (median SAT) tăng lên 1 điểm (ĐƠN VỊ), thì tỷ lệ
tốt nghiệp tăng lên 0.072%, giữ nguyên các yếu tố khác không thay đổi. lOMoAR cPSD| 46988474
Multicollinearity (Đa cộng tuyến)
Đa cộng tuyến là hiện tượng các biến độc lập có mối tương quan rất mạnh với nhau.
Mô hình hồi quy xảy ra hiện tượng đa cộng tuyến sẽ khiến nhiều chỉ số bị sai lệch, dẫn
đến kết quả của việc phân tích định lượng không còn mang lại nhiều ý nghĩa
COLLELATIONS => XEM R CÓ > 0.7 KHÔNG? NẾU CÓ THÌ KẾT LUẬN ĐA CỘNG TUYẾN. Correlations Acceptance Expenditures/ Median SAT Rate Student Top 10% HS Median SAT Pearson Correlation 1 -.602** .573** .503** Sig. (2-tailed) .000 .000 .000 N 49 49 49 49 Acceptance Rate Pearson Correlation -.602** 1 -.284* -.610** Sig. (2-tailed) .000 .048 .000 N 49 49 49 49 Expenditures/Student Pearson Correlation .573** -.284* 1 .506** Sig. (2-tailed) .000 .048 .000 N 49 49 49 49 Top 10% HS Pearson Correlation .503** -.610** .506** 1 Sig. (2-tailed) .000 .000 .000 N 49 49 49 49
**. Correlation is significant at the 0.01 level (2-tailed).
*. Correlation is significant at the 0.05 level (2-tailed). Bài tập: Coefficientsa lOMoAR cPSD| 46988474 Standardized Unstandardized Coefficients Coefficients Model B Std. Error Beta t Sig. 1 (Constant) 893.588 1824.575 .490 .628 Age 1044.146 42.141 .975 24.777 .000 MBA 14767.232 1351.802 .430 10.924 .000 a. Dependent Variable: Salary
Categorical Variables with More Than Two Levels Coefficientsa Standardized Unstandardized Coefficients Coefficients Model B Std. Error Beta t Sig. 1 (Constant) 24.494 2.473 9.904 .000 RPM .098 .010 .181 9.400 .000 Type B -13.311 .487 -.628 -27.324 .000 Type C -20.487 .487 -.966 -42.060 .000 Type D -26.037 .597 -.951 -43.621 .000
a. Dependent Variable: Surface Finish BIẾN TƯƠNG TÁC
TRANFORM => COMPUTE VARIABLE => ĐIỀN TÊN BIẾN VÀO Ô TARGET,
ĐIỀN CÔNG THỨC VÀO Ô KẾ BÊN. Câu 2:
Lập bảng tần số về Trình độ học vấn. Yêu cầu có: (i) số quan sát ứng với từng trình độ và (ii) tỷ lệ
phần trăm cụ thể cho từng trình độ. Phân tích trong mẫu nghiên cứu, trình độ học vấn nào chiếm
tỷ lệ cao nhất? trình độ học vấn nào chiếm tỷ lệ thấp nhất? lOMoAR cPSD| 46988474
Đọc kết quả mẫu nghiên cứu:
Tham số Frequency cho biết có bao nhiêu quan sát rơi vào danh mục đã cho. Cụ thể, trong 100
quan sát, có 79 người có trình độ THPT, 19 người trình độ Đại học, 1 người trình độ Thạc sĩ và 1
người trình độ Tiến sĩ.
Percent cho biết tỷ lệ phần trăm của các quan sát trong danh mục đó trong số tất cả các quan sát.
Cụ thể, trình độ học vấn THPT chiếm 79%, trình độ học vấn Đại học chứa 19%, trình độ học vấn
Thạc sĩ chiếm 1%, trình độ học vấn Tiến sĩ chiếm 1%.
Valid Percent cho ta biết tỷ lệ phần trăm trên các giá trị hợp lệ. Do không có Missing nên giá trị
cột Valid Percent bằng với giá trị cột Percent.
Cumulative Percent cho ta biết tỷ lệ phần trăm tích lũy chỉ tính trên các giá trị hợp lệ.
Phân tích trong mẫu nghiên cứu:
Từ kết quả trên, ta kết luận trình độ học vấn THPT chiếm tỷ lệ cao nhất là 79%, trình độ học vấn
Tiến sĩ và Thạc sĩ chiếm tỷ lệ thấp nhất là 1%. Câu 3:
Vẽ đồ thị hình chiếc bánh (pie chart) thể hiện tỷ lệ phần trăm của số quan sát phân theo Giới tính
(nam, nữ). Yêu cầu có tỷ lệ phần trăm cụ thể cho từng giới tính trên đồ thị. Phân tích trong mẫu
nghiên cứu, nam hay nữ chiếm tỷ lệ cao hơn.
Nhận xét: Nhìn vào biểu đồ tròn, ta thấy giới tính Nữ chiếm tỉ lệ cao hơn với 70% và giới tính
Nam chiếm tỉ lệ thấp hơn với 30% trên tổng số người tham gia khảo sát. Câu 4:
So sánh giá trị trung bình về Thu nhập của 2 nhóm Giới tính, có sự khác biệt có ý nghĩa thống kê
nào giữa 2 nhóm Giới tính về Thu nhập hay không?
Dựa vào bảng Group Statistics, ta thấy 30 người nam có thu nhập trung bình (Mean) là
7.143.333,33 VNĐ và độ lệch chuẩn (Std.Deviation) là 6.718.665,884. Tương tự, 70 người nữ có
thu nhập trung bình (Mean) là 6.645.714,29 VNĐ và độ lệch chuẩn (Std.Deviation) là
5.422.515,746. Từ đây có thể kết luận trong mẫu nghiên cứu này, người nam có thu nhập trung bình cao hơn người nữ.
Phân tích kiểm định Levene: Giá trị Sig. trong kiểm định Levene (kiểm định F) là 0.464 > 0.05
→ chấp nhận giả thuyết H0: không có sự khác nhau về phương sai của 2 tổng thể → sử dụng kết
quả ở dòng Equal variances assumed.
Phân tích Independent Samples T-test: Chỉ số Sig. (2-tailed) là 0.697 > α = 0.05 → không có sự
khác biệt có ý nghĩa về trung bình của 2 tổng thể. Kết luận: Giữa hai nhóm giới tính khác nhau thì
chưa có bằng chứng cho thấy có sự khác nhau về thu nhập. Kết luận:
Nhóm giới tính nam có thu nhập trung bình cao hơn giới tính nữ. lOMoAR cPSD| 46988474
Không có sự khác biệt có ý nghĩa về trung bình của 2 nhóm Giới tính về Thu nhập. Câu 5:
So sánh giá trị trung bình về Thu nhập của các Trình độ học vấn, có sự khác biệt có ý nghĩa thống
kê nào giữa các Trình độ học vấn về Thu nhập hay không?
Vì ở mẫu nghiên cứu của chúng tôi có số lượng tiến sĩ và thạc sĩ quá ít nên chúng ta sẽ chỉ phân
tích thu nhập của hai nhóm: nhóm người có trình độ học vấn bậc THPT và nhóm người có trình
độ học vấn bậc Đại học Cách làm:
Analyze → Compare Means → One-Way ANOVA.
Chọn biến Income vào Dependent List.
Chọn biến Education level vào Factor → Chọn Options → Chọn Descriptive, Homogeneity of variance test và Welch.
Dựa vào Bảng Descriptives, ta thấy 79 người có trình độ học vấn bậc THPT có thu nhập trung
bình (Mean) là 5.037.974,68 VNĐ và độ lệch chuẩn (Std.Deviation) là 4.341.165,618. Tương tự,
19 người có trình độ học vấn bậc Đại học có thu nhập trung bình là 12.710.526,32 VNĐ và độ
lệch chuẩn (Std.Deviation) là 5848351.595. Từ đây có thể kết luận trong mẫu nghiên cứu này,
người có trình độ học vấn bậc Đại học có thu nhập trung bình cao hơn người có trình độ học vấn bậc THPT.
Phân tích thống kê Levene: Sig của thống kê Levene = 0.002 (<0.05) nên ở độ tin cậy 95% giả
thuyết H1: “Phương sai khác nhau” được chấp nhận, và bác bỏ giả thuyết H0: “Phương sai bằng
nhau”. Do đó kết quả phân tích Bảng Robust Tests of Equality of Means có thể sử dụng.
Phân tích kết quả bảng Robust Test : Kết quả phân tích Robust test với mức ý nghĩa Sig= 0.00
< 0.05, như vậy với dữ liệu quan sát có thể khẳng định có sự khác biệt về giá trị trung bình về
thu nhập giữa các nhóm người trình độ học vấn khác nhau.
Kết luận: Có sự khác biệt trung bình về biến Thu nhập giữa các nhóm người có Trình độ học vấn khác nhau. Câu 6:
Kiểm tra có đa cộng tuyến (multicollinearity) giữa các biến Tuổi, Giới tính, Trình độ học vấn, Tình
trạng hôn nhân, Tập thể dục hay không?
Nhận xét: Dựa vào số liệu ở ma trận tương quan Pearson, ta thấy xuất hiện đa cộng tuyến giữa các
biến Age và MaritalStatus (với hệ số tương quan 0.854 > 0.7). Kết quả này cho thấy giữa biến
Tuổi (Age) và Tình trạng hôn nhân (MaritalStatus) có mối tương quan tuyến tính rất mạnh. Điều
đó là hợp lý khi xét đến thực tế, vì một người lớn tuổi sẽ có nhiều khả năng là đã kết hôn hơn so
với một người trẻ. Tuy nhiên, tương quan cao này lại vi phạm giả định của mô hình hồi quy tuyến
tính cổ điển và sẽ khiến nhiều chỉ số bị sai lệch, dẫn đến kết quả của việc phân tích định lượng
không còn mang lại nhiều ý nghĩa. lOMoAR cPSD| 46988474 Câu 7:
Sử dụng hồi quy tuyến tính bội (multiple linear regression), phân tích tác động của các biến Tuổi,
Giới tính, Trình độ học vấn, Tình trạng hôn nhân, Tập thể dục lên biến Thu nhập.
Lưu ý: Dựa vào kết quả của Câu 6, ta thấy có sự đa cộng tuyến giữa biến Age và MaritalStatus
(tương quan 0.854). Do đó, các biến độc lập có sự tương quan mạnh sẽ được đánh giá trong các
mô hình hồi quy riêng biệt. Model 1:
Phân tích kết quả:
Nhìn vào bảng Model Summary, ta thấy giá trị của hệ số R bình phương (R Square) là 0.586, có
nghĩa là 58.6% sự biến thiên của biến phụ thuộc Thu nhập (Income) được giải thích bởi các biến
độc lập bao gồm Tập thể dục (Exercise), Trình độ học vấn (EducationLevel), Giới tính (Gender)
và Tình trạng hôn nhân (MaritalStatus), còn lại 41.4% là do các biến ngoài mô hình và sai số ngẫu
nhiên. Điều này cho thấy mô hình hồi quy tuyến tính này có ý nghĩa ở mức 58.6%.
Nhìn vào bảng ANOVA, ta thấy giá trị F = 33.660 và Sig. = 0.000 < 0.05. Chứng tỏ sự kết hợp của
các biến độc lập trong mô hình có thể giải thích cho sự biến thiên của biến phụ thuộc, hay nói cách
khác là có ít nhất một biến độc lập tác động đến biến phụ thuộc. Điều này cũng đồng nghĩa với
việc mô hình hồi quy tuyến tính xây dựng được có thể suy rộng và áp dụng cho tổng thể.
Nhìn vào bảng Coefficients, ta thấy giá trị Sig. của hai biến EducationLevel và MaritalStatus nhỏ
hơn 0.05, điều này chứng tỏ hai biến này có ý nghĩa thống kê trong mô hình có tác động đến biến
phụ thuộc Income. Đồng thời, nhìn vào hệ số B ta thấy cả hai biến đều mang dấu dương, do đó cả
Trình độ học vấn và Tình trạng hôn nhân đều có tác động tích cực đến đến Thu nhập, tức Thu nhập
của một người sẽ càng cao nếu Trình độ học vấn càng cao hoặc nếu người này đã có gia đình. Cụ
thể, nếu trình độ học vấn tăng lên một bậc thì thu nhập sẽ tăng lên 3.664.103,542 đồng; một người
từ độc thân, khi có gia đình thì thu nhập sẽ tăng lên 9.072.741,319 đồng. Mặt khác, giá trị Sig. của
các biến Gender và Exercise lớn hơn 0.05, do đó nhân tố Giới tính và nhân tố Tập thể dục không
có ý nghĩa thống kê trong mô hình và không có tác động đến biến phụ thuộc. Model 2:
Phân tích kết quả:
Nhìn vào bảng Model Summary, ta thấy giá trị của hệ số R bình phương (R Square) là 0.547, có
nghĩa là 54.7% sự biến thiên của biến phụ thuộc Thu nhập (Income) được giải thích bởi các biến
độc lập bao gồm Tập thể dục (Exercise), Trình độ học vấn (EducationLevel), Giới tính (Age) và
Tuổi (Gender), còn lại 45.3% là do các biến ngoài mô hình và sai số ngẫu nhiên. Điều này cho
thấy mô hình hồi quy tuyến tính này có ý nghĩa ở mức 54.7%.
Nhìn vào bảng ANOVA, ta thấy giá trị F = 28.736 và Sig. = 0.000 < 0.05. Chứng tỏ sự kết hợp của
các biến độc lập trong mô hình có thể giải thích cho sự biến thiên của biến phụ thuộc, hay nói cách
khác là có ít nhất một biến độc lập tác động đến biến phụ thuộc. Điều này cũng đồng nghĩa với
việc mô hình hồi quy tuyến tính xây dựng được có thể suy rộng và áp dụng cho tổng thể.
Nhìn vào bảng Coefficients, ta thấy giá trị Sig. của hai biến Age và EducationLevel đều nhỏ hơn
0.05, điều này chứng tỏ hai biến này có ý nghĩa thống kê trong mô hình có tác động đến biến phụ
thuộc Income. Đồng thời, nhìn vào hệ số B ta thấy cả hai biến đều mang dấu dương, do đó cả Tuổi lOMoAR cPSD| 46988474
và Trình độ học vấn đều có tác động tích cực đến đến Thu nhập, tức là nếu Tuổi và Trình độ học
vấn càng cao thì Thu nhập sẽ càng cao. Cụ thể, nếu độ tuổi tăng lên một đơn vị thì thu nhập sẽ
tăng lên 249.532,213 đồng; nếu trình độ học vấn tăng lên một bậc thì thu nhập sẽ tăng lên
3.517.594,260 đồng. Mặt khác, giá trị Sig. của các biến Gender và Exercise lớn hơn 0.05, do đó
các nhân tố Giới tính và Tập thể dục không có ý nghĩa thống kê trong mô hình và không có tác
động đến biến phụ thuộc.
Kết luận chung: Các biến độc lập Tuổi (Age), Trình độ học vấn (EducationLevel) và Tình trạng
hôn nhân (MaritalStatus) có tác động tích cực đến biến phụ thuộc Income do giá trị Sig. nhỏ hơn
0.05 và hệ số B mang dấu dương. Mặt khác, các biến độc lập Giới tính (Gender) và Tập thể dục
(Exercise) không có tác động đến biến phụ thuộc Income do giá trị Sig. lớn hơn 0.05. Câu 8:
Tạo biến tương tác (interaction variable) giữa Tuổi và Tập thể dục. Phân tích tác động điều tiết
(moderating effect) của việc Tập thể dục lên mối quan hệ giữa Tuổi và Thu nhập. Nhận xét:
Nhìn vào bảng Coefficients, ta thấy giá trị Sig. của biến tuongtac < 0.05, điều này chứng tỏ biến
này có ý nghĩa thống kê trong mô hình có tác động đến biến phụ thuộc Income (Thu nhập). Đồng
thời, nhìn vào hệ số B mang dấu âm cho thấy Tập thể dục có tác động tiêu cực đến mối quan hệ
giữa Tuổi và Thu nhập, tức là nếu Tuổi càng cao và có Tập thể dục thì Thu nhập sẽ càng thấp.
Tài liệu liên quan:
-

Tiểu luận Phân Tích Giá Trái Cây 2023 | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
19 10 -

Bộ câu hỏi trắc nghiệm - Kinh tế học thị trường và cầu cung | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
19 10 -

Câu Hỏi Ôn Tập Phần Thị Trường | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
25 13 -

Kinh Tế Vi Mô: Câu Hỏi và Đáp Án Quan Trọng | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
22 11 -

Tiểu luận Món Huế và Thị Trường F&B Việt Nam | Kinh tế vĩ mô | Trường Đại học kinh tế Thành Phố Hồ Chí Minh
17 9