Đề tài tiểu luận: Tìm hiểu vầ kho dữ liệu và ứng dụng xây dựng kho dữ liệu Quản lý bán hàng môn Hệ quản trị cơ sở dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
Đề tài tiểu luận: Tìm hiểu vầ kho dữ liệu và ứng dụng xây dựng kho dữ liệu Quản lý bán hàng môn Hệ quản trị cơ sở dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời đọc đón xem!
Môn: Quản trị cơ sở dữ liệu kinh doanh 7 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:










Preview text:
HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG KHOA VIỄN THÔNG I
MÔN: HỆ QUẢN TRỊ CƠ SỞ DỮ LIỆU
Đề tài tiểu luận:
TÌM HIỂU VẦ KHO DỮ LIỆU VÀ ỨNG DỤNG XÂY DỰNG KHO DỮ LIỆU QUẢN LÝ BÁN HÀNG
Giảng viên hướng dẫn: PGS.TS Lê Hải Châu Nhóm tiểu luận: 07
Sinh viên thực hiện:
Vũ Hữu Thịnh - B23DCKD066
Cao Đình Thành - B23DCKD062
Lê Phi Trường - B23DCKD074
Hà Nội – 2025 MỤC LỤC
LỜI CẢM ƠN. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3
I. Phần mở đầu. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1. Lý do chọn đề tài. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2. Mục tiêu nghiên cứu. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4
II. Giới thiệu về Data Warehouse. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1. Khái niệm DW:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2. Kiến trúc Data Warehouse. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3. Mô hình dữ liệu trong Data Warehouse. . . . . . . . . . . . . . . . . . . . . . . . . . .6
III. Quy trình ETL (Extract, Transform, Load). . . . . . . . . . . . . . . . . . . . . . . . . 7
1. Extract (Trích xuất). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2. Transform (Chuyển đổi). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7
3. Load (Nạp dữ liệu). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
IV. Phân tích và thiết kế kho dữ liệu bán hàng. . . . . . . . . . . . . . . . . . . . . . . . . 8
1. Phân tích yêu cầu nghiệp vụ. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2. Phân tích dữ liệu nguồn. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .9
3. Thiết kế Mô hình Kho dữ liệu (Mô hình Sao). . . . . . . . . . . . . . . . . . . . . .9
V. Triển khai mô hình và ứng dụng. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11
1. Triển khai Kho dữ liệu (Quy trình ETL). . . . . . . . . . . . . . . . . . . . . . . . . 11
2. Xây dựng Báo cáo và Trực quan hóa (BI). . . . . . . . . . . . . . . . . . . . . . . .12
2.1. Xử lí dữ liệu và các thành phần:. . . . . . . . . . . . . . . . . . . . . 12
2.2. Mô tả báo cáo 1 số Dashboard:. . . . . . . . . . . . . . . . . . . . . . 14
VI. Kết luận :. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
VII. Hướng phát triển:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1. Mở rộng nguồn dữ liệu:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2. Tự động hóa quy trình ETL:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3. Tối ưu và mở rộng Data Warehouse:. . . . . . . . . . . . . . . . . . . . . . . . . . . .20
4. Phát triển dashboard nâng cao:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5. Tích hợp mô hình học máy (ML):. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
6. Triển khai BI ở cấp doanh nghiệp:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
VIII. Tài liệu tham khảo :. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .20
PHỤ LỤC. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212 LỜI CẢM ƠN
Đầu tiên, chúng em xin bày tỏ lòng biết ơn sâu sắc đến Học viện Công nghệ Bưu chính
Viễn thông đã đưa môn học Hệ quản trị cơ sở dữ liệu vào chương trình giảng dạy để
chúng em có cơ hội tiếp thu kiến thức quý giá.
Đặc biệt, chúng em xin gửi lời cảm ơn chân thành nhất đến thầy Lê Hải Châu. Bằng sự
tận tâm và những chia sẻ, phân tích dựa trên kinh nghiệm thực tiễn phong phú, thầy đã
giúp chúng em biến những khái niệm lý thuyết phức tạp trở nên gần gũi và dễ tiếp cận.
Những bài học của thầy không chỉ là kiến thức sách vở, mà còn là định hướng quý báu
để chúng em áp dụng các bài học đã được học vào giải quyết các bài toán thực tế.
Trong quá trình thực hiện bài tiểu luận này, dù đã hết sức cố gắng, nhưng do sự hiểu
biết và kinh nghiệm còn non nớt, bài làm của chúng em chắc chắn không tránh khỏi
những khiếm khuyết. Chúng em kính mong nhận được sự chỉ dẫn và góp ý từ thầy để hoàn thiện hơn.
Một lần nữa, chúng em xin kính chúc thầy Lê Hải Châu luôn dồi dào sức khỏe, hạnh
phúc và gặt hái thêm nhiều thành công trong sự nghiệp giảng dạy của mình. Hà Nội, tháng 11 năm 2025 3 I. Phần mở đầu
1. Lý do chọn đề tài
Trong bối cảnh chuyển đổi số diễn ra mạnh mẽ, các doanh nghiệp đặc biệt trong lĩnh
vực bán lẻ và quản lý kho đang phải đối mặt với sự bùng nổ dữ liệu chưa từng có. Mỗi
giao dịch, mỗi lần nhập – xuất kho hay mỗi tương tác của khách hàng đều tạo ra dữ
liệu liên tục, đa dạng và ngày càng phức tạp. Tuy nhiên, phần lớn dữ liệu này được lưu
trữ ở các hệ thống OLTP vốn chỉ phục vụ xử lý giao dịch, khiến việc phân tích tổng
hợp gặp nhiều khó khăn. Điều này gây trở ngại cho các nhà quản lý khi cần dự báo
doanh số, tối ưu tồn kho, đánh giá hiệu suất hay hiểu rõ hành vi khách hàng.
Trong hoàn cảnh đó, Kho dữ liệu (Data Warehouse – DW) trở thành giải pháp quan
trọng. DW đóng vai trò như trung tâm phân tích của doanh nghiệp, nơi dữ liệu được
thu thập, làm sạch, chuẩn hóa và tổ chức lại theo mô hình OLAP, giúp hỗ trợ hiệu quả
cho phân tích, báo cáo và các hệ thống Business Intelligence (BI). Nhờ có DW, doanh
nghiệp có thể theo dõi hiệu suất kinh doanh, nhận diện xu hướng tiêu dùng, tối ưu
chuỗi cung ứng và cải thiện độ chính xác của các quyết định chiến lược.
Ngoài ra, nhiều dự án thực tế hiện nay cũng mô phỏng chi tiết quá trình xây dựng một
DW cho nghiệp vụ bán hàng từ thu thập dữ liệu, xử lý ETL/ELT đến thiết kế mô hình
OLAP và trực quan hóa. Điều này giúp người học và người làm dễ dàng tiếp cận quy
trình triển khai DW, đồng thời hiểu rõ hơn cách áp dụng vào hoạt động doanh nghiệp trong thực tế.
2. Mục tiêu nghiên cứu
Mục tiêu nghiên cứu của đề tài được xây dựng theo ba hướng chính. Về mặt lý thuyết,
đề tài nhằm trình bày một cách hệ thống các khái niệm nền tảng của kho dữ liệu, bao
gồm kiến trúc tổng thể, các thành phần cấu thành cũng như những đặc điểm cơ bản
giúp DW hỗ trợ phân tích dữ liệu hiệu quả. Trên phương diện thực tiễn, nghiên cứu tập
trung áp dụng những kiến thức lý thuyết này vào việc phân tích, thiết kế và mô phỏng
một hệ thống kho dữ liệu phục vụ nghiệp vụ quản lý bán hàng, dựa trên bộ dữ liệu
“Warehouse and Retail Sales” từ Kaggle và tham khảo quy trình triển khai qua các dự
án thực tế. Cuối cùng, đề tài tiến hành đánh giá để chỉ ra những lợi ích mà kho dữ liệu
mang lại cho doanh nghiệp, đồng thời nhận diện các hạn chế và thách thức có thể phát
sinh trong quá trình triển khai và vận hành DW trong môi trường thực tế.
II. Giới thiệu về Data Warehouse 1. Khái niệm DW:
Định nghĩa Data Warehouse và vai trò trong doanh nghiệp:
Định nghĩa: Data Warehouse là một hệ thống lưu trữ dữ liệu được thiết kế đặc
biệt để phục vụ cho mục đích báo cáo và phân tích kinh doanh (Business
Intelligence - BI). Nó thu thập dữ liệu từ nhiều nguồn giao dịch (Operational
Systems) khác nhau, làm sạch, và chuyển đổi chúng để tạo thành một kho dữ
liệu tập trung, tích hợp và theo thời gian. 4
Vai trò: Cung cấp nền tảng đáng tin cậy cho việc đưa ra quyết định (decision-
making). DW giúp các nhà quản lý trả lời các câu hỏi như: "Hiệu suất bán hàng
của chúng ta trong quý trước so với năm ngoái như thế nào?", "Sản phẩm nào
mang lại lợi nhuận cao nhất?", hoặc "Xu hướng khách hàng đang thay đổi ra sao?".
So sánh giữa DataBase và Data Warehouse: Đặc điểm
DataBase (Cơ sở dữ liệu giao dịch - OLTP) Data Warehouse (Kho dữ liệu - OLAP) Mục đích
Xử lý giao dịch hàng ngày (CRUD: Tạo, Phân tích và báo cáo dữ Đọc, Cập nhật, Xóa). liệu lịch sử. Thiết kế
Tối ưu hóa cho tốc độ xử lý giao dịch
Tối ưu hóa cho tốc độ truy (chuẩn hóa cao)
vấn phân tích (giải chuẩn hóa) Dữ liệu
Hiện tại, chi tiết, hay thay đổi.
Lịch sử, tổng hợp, cố định (ít thay đổi). Truy vấn
Truy vấn đơn giản, nhanh chóng, trên từng
Truy vấn phức tạp, tổng bản ghi.
hợp khối lượng lớn dữ liệu.
Các đặc điểm chính của Data Warehouse:
Hướng chủ đề (Subject-Oriented): Dữ liệu được tổ chức xoay quanh các chủ đề
cốt lõi của doanh nghiệp (ví dụ: Khách hàng, Sản phẩm, Bán hàng), thay vì các quy trình ứng dụng.
Tích hợp (Integrated): Dữ liệu từ các nguồn khác nhau được làm sạch, biến đổi
và thống nhất về một định dạng, quy ước tên, và đơn vị đo lường chung.
Không thay đổi theo thời gian (Non-Volatile): Dữ liệu một khi đã được tải vào
DW thì không bị thay đổi hoặc xóa đi, đảm bảo tính lịch sử cho việc phân tích.
Phân tích lịch sử (Time-Variant): Mọi dữ liệu đều được gắn mốc thời gian, cho
phép theo dõi, so sánh và phân tích các xu hướng trong quá khứ.
2. Kiến trúc Data Warehouse
Kiến trúc 1 tầng, 2 tầng, 3 tầng:
1 Tầng (Single-Tier): Thường chỉ dành cho các hệ thống quy mô nhỏ, nơi máy
chủ DW và máy chủ ứng dụng BI nằm chung trên một môi trường. Rất ít được sử dụng trong thực tế.
2 Tầng (Two-Tier): Tầng nguồn dữ liệu (Source data) và tầng truy cập dữ
liệu/báo cáo (BI tools) được tách biệt. Dữ liệu được ETL trực tiếp từ nguồn vào DW.
3 Tầng (Three-Tier - Phổ biến nhất): 5
+ Tầng Nguồn dữ liệu (Bottom Tier): Các hệ thống giao dịch (OLTP) và dữ liệu ngoài.
+ Tầng Kho dữ liệu (Middle Tier): Bao gồm Data Warehouse chính và khu
vực xử lý/làm sạch dữ liệu (Staging Area).
+ Tầng Truy cập dữ liệu (Top Tier): Bao gồm các Data Mart và công cụ
phân tích/BI (OLAP tools) mà người dùng cuối sử dụng.
Các thành phần chính và vai trò:
Nguồn dữ liệu (Source Data): Các hệ thống giao dịch (OLTP) của công ty, các
file Excel, dữ liệu bên ngoài (VD: dữ liệu thị trường).
ETL (Extract, Transform, Load):
+ Extract (Trích xuất): Đọc và thu thập dữ liệu từ các nguồn khác nhau.
+ Transform (Biến đổi): Làm sạch, chuẩn hóa, tích hợp, tổng hợp, tính toán
lại dữ liệu để đáp ứng định dạng của DW. Đây là bước quan trọng nhất.
+ Load (Tải): Chuyển dữ liệu đã biến đổi vào Data Warehouse.
Kho dữ liệu trung tâm (Central Data Warehouse): Nơi lưu trữ toàn bộ dữ liệu
lịch sử, chi tiết, và tích hợp của doanh nghiệp, thường ở dạng chuẩn hóa nhẹ (ví
dụ: 3NF - Third Normal Form).
Data Mart: Là một kho dữ liệu con, tập trung vào một chủ đề hoặc bộ phận cụ
thể (ví dụ: Data Mart Bán hàng, Data Mart Tài chính). Data Mart giúp người
dùng cuối truy cập dữ liệu nhanh hơn và dễ dàng hơn mà không cần truy vấn toàn bộ DW.
3. Mô hình dữ liệu trong Data Warehouse
Các mô hình dữ liệu này thường được gọi là Mô hình chiều (Dimensional Modeling),
tối ưu hóa cho tốc độ truy vấn và sự dễ hiểu của người dùng.
Mô hình sao (Star Schema):
Cấu trúc: Gồm một Bảng sự kiện (Fact Table) trung tâm và xung quanh là các
Bảng chiều (Dimension Tables) liên kết trực tiếp với nó.
Đặc điểm: Đơn giản nhất và phổ biến nhất. Các bảng chiều không được chuẩn
hóa (denormalized), giúp giảm số lượng lần nối bảng (JOIN) khi truy vấn, từ đó tăng tốc độ báo cáo.
Mô hình bông tuyết (Snowflake Schema):
Cấu trúc: Tương tự Star Schema, nhưng các Bảng chiều được chuẩn hóa (chia
nhỏ) thêm để loại bỏ sự dư thừa dữ liệu.
Đặc điểm: Tiết kiệm không gian lưu trữ (do chuẩn hóa) nhưng yêu cầu nhiều
thao tác nối bảng (JOINs) hơn khi truy vấn, làm giảm tốc độ so với Star Schema.
Mô hình chòm sao (Fact Constellation Schema): 6
Cấu trúc: Gồm nhiều Bảng sự kiện (Fact Tables) chia sẻ một số Bảng chiều chung.
Đặc điểm: Phù hợp với các doanh nghiệp lớn, phức tạp, có nhiều quy trình kinh
doanh cần phân tích. Ví dụ: Bảng sự kiện Bán hàng và Bảng sự kiện Vận
chuyển có thể dùng chung Bảng chiều Thời gian và Sản phẩm.
Tập tin hình ảnh bạn tải lên mô tả Quy trình ETL (Extract, Transform, Load) trong
lĩnh vực Kho dữ liệu (Data Warehouse).
Dưới đây là tóm tắt và giải thích chi tiết về từng bước trong quy trình này:
III. Quy trình ETL (Extract, Transform, Load)
ETL là một quy trình ba bước cơ bản được sử dụng để di chuyển dữ liệu từ nhiều
nguồn khác nhau vào một kho dữ liệu tập trung, như Data Warehouse hoặc Data Lake. 1. Extract (Trích xuất)
Đây là bước thu thập dữ liệu từ các hệ thống nguồn.
Các nguồn dữ liệu:
+ Hệ thống bán hàng, CRM (Quản lý quan hệ khách hàng), ERP
(Hoạch định nguồn lực doanh nghiệp): Các hệ thống giao dịch hoạt động
(OLTP) chính tạo ra dữ liệu kinh doanh hàng ngày.
+ Dữ liệu bên ngoài: Dữ liệu từ bên thứ ba, mạng xã hội, hoặc các nguồn công cộng khác.
Phương pháp trích xuất dữ liệu:
+ Toàn bộ (Full): Trích xuất toàn bộ dữ liệu từ nguồn mỗi lần chạy.
Thường áp dụng cho các bảng nhỏ hoặc các lần nạp dữ liệu đầu tiên.
+ Gia tăng (Incremental): Chỉ trích xuất những dữ liệu đã thay đổi hoặc
được thêm mới kể từ lần trích xuất gần nhất. Phương pháp này hiệu quả hơn
về thời gian và tài nguyên.
2. Transform (Chuyển đổi)
Đây là bước làm sạch, chuẩn hóa và tổng hợp dữ liệu để nó phù hợp với mô hình
của Data Warehouse (thường là mô hình chiều).
Làm sạch dữ liệu (Data Cleaning): Khắc phục lỗi chính tả, định dạng không nhất
quán, và dữ liệu không hợp lệ.
Chuẩn hóa và tích hợp dữ liệu: Đảm bảo dữ liệu từ các nguồn khác nhau có cùng
định dạng, đơn vị và ý nghĩa. (Ví dụ: Chuyển đổi tất cả đơn vị tiền tệ về VNĐ).
Xử lý dữ liệu trùng lặp và thiếu sót: Loại bỏ các bản ghi trùng lặp và điền (hoặc
đánh dấu) các giá trị bị thiếu (Missing Values).
Tạo các khóa đại diện (Surrogate Key): 7
+ Là các khóa chính nhân tạo (thường là số nguyên tăng dần) được tạo ra
trong Data Warehouse để thay thế Khóa Chính ban đầu của hệ thống nguồn (Business Key).
+ Mục đích là để quản lý sự thay đổi của các Dimension (SCD - Slowly
Changing Dimensions) và tách rời Data Warehouse khỏi sự phụ thuộc vào
các khóa nguồn có thể phức tạp hoặc thay đổi. 3. Load (Nạp dữ liệu)
Đây là bước ghi dữ liệu đã được chuyển đổi vào các bảng đích trong Data
Warehouse (Fact Tables và Dimension Tables).
Chiến lược nạp dữ liệu:
+ Nạp đầy đủ (Full Load): Xóa dữ liệu cũ và nạp lại toàn bộ dữ liệu đã
được chuyển đổi. (Ít dùng trừ khi có yêu cầu đặc biệt).
+ Nạp gia tăng (Incremental Load): Chỉ chèn các bản ghi mới hoặc cập
nhật các bản ghi đã thay đổi vào các bảng. Đây là phương pháp phổ biến
nhất để duy trì Data Warehouse.
Lập lịch và tự động hóa quy trình ETL: Thiết lập lịch chạy tự động (ví dụ: hàng
đêm, hàng giờ) để đảm bảo dữ liệu trong Data Warehouse luôn được cập nhật và
sẵn sàng cho việc phân tích.
IV. Phân tích và thiết kế kho dữ liệu bán hàng
1. Phân tích yêu cầu nghiệp vụ
Phân tích file Warehouse_and_Retail_Sales.csv cho thấy dữ liệu tập trung hoàn toàn
vào Thời gian (Năm, Tháng), Sản phẩm (Mã, Tên, Loại, Nhà cung cấp), và Doanh số.
Dữ liệu này không chứa thông tin về Khách hàng hay Khu vực địa lý.
Vì vậy, các yêu cầu nghiệp vụ và câu hỏi phân tích sẽ tập trung vào hiệu suất của sản phẩm:
+ Tổng doanh số bán lẻ (RETAIL SALES) theo Tháng và Năm là bao nhiêu?
+ Sản phẩm (ITEM DESCRIPTION) nào mang lại doanh số cao nhất?
+ Nhà cung cấp (SUPPLIER) nào có tổng doanh số tốt nhất?
+ Loại mặt hàng (ITEM TYPE) nào (ví dụ: WINE, LIQUOR) là chủ lực?
Từ các câu hỏi này, chúng ta xác định rõ các yếu tố phân tích:
a) Các "con số" cần đo lường (Measures): Đây là các số liệu kinh doanh sẽ nằm trong Bảng Fact.
+ RETAIL SALES (Doanh số bán lẻ)
+ RETAIL TRANSFERS (Số lượng chuyển lẻ)
+ WAREHOUSE SALES (Doanh số kho)
b) Các "chiều" phân tích (Dimensions): Đây là các bối cảnh, trả lời cho câu hỏi "Khi nào?" và "Cái gì?".
+ Chiều Thời gian: YEAR, MONTH 8
+ Chiều Sản phẩm: ITEM CODE, ITEM DESCRIPTION, ITEM TYPE, SUPPLIER
2. Phân tích dữ liệu nguồn
Bảng 2.1: Phân tích (Data Dictionary) Tên cột (Gốc) Kiểu dữ liệu
Mô tả / Ghi chú (Mục đích trong (Gốc) DW) YEAR int64 (Số)
Năm. Dùng để tạo Dim_Date MONTH int64 (Số)
Tháng. Dùng để tạo Dim_Date. SUPPLIER object (Chữ)
Tên nhà cung cấp. Dùng để tạo Dim_Product. ITEM CODE object (Chữ)
Mã sản phẩm (Khóa nghiệp vụ).
Dùng để tạo Dim_Product. ITEM object (Chữ)
Tên/Mô tả sản phẩm. Dùng để tạo DESCRIPTION Dim_Product. ITEM TYPE object (Chữ)
Loại sản phẩm. Dùng để tạo Dim_Product. RETAILS SALES float64 (Số)
Doanh số bán lẻ. (Đây là Measure cho Bảng Fact). RETAILS float64 (Số)
(Đây là Measure cho Bảng Fact) TRANSFERS WAREHOUSE float64 (Số)
(Đây là Measure cho Bảng Fact) SALES
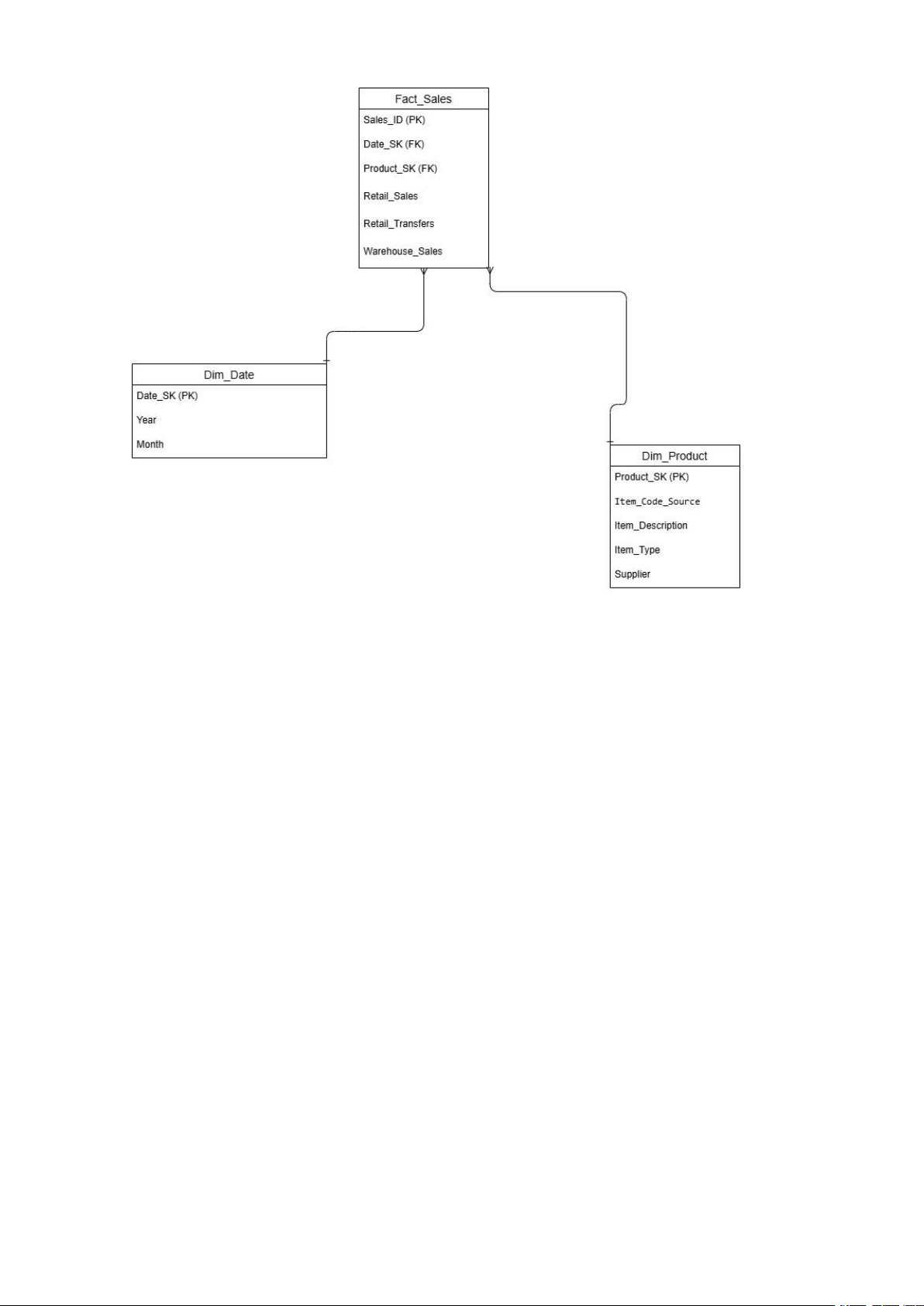
3. Thiết kế Mô hình Kho dữ liệu (Mô hình Sao)
3.1. Thiết kế Bảng Dim_Date Tên cột
Kiểu dữ liệu (PostgreSQL) Mô tả Date_SK SERIAL Khóa chính (Primary Key). Year INT Năm (Lấy từ cột YEAR). Month INT Tháng (Lấy từ cột MONTH). 9
3.2. Thiết kế Bảng Dim_Product Tên cột Kiểu dữ Mô Tả liệu( postgreSQL) Product_SK SERIAL
Khóa chính (Primary Key). Khóa thay thế tự tăng Item_Code_Source VARCHAR(50)
Mã sản phẩm gốc (Lấy từ cột ITEM CODE). Item_Description VARCHAR(255)
Tên/Mô tả sản phẩm (Lấy từ ITEM DESCRIPTION) Item_Type VARCHAR(100)
Loại sản phẩm (Lấy từ ITEM TYPE). Supplier
Tên nhà cung cấp (Lấy từ VARCHAR(255) SUPPLIER).
3.3. Thiết kế Bảng Fact_Sales Tên cột Kiểu dữ Mô Tả liệu(PostgreSQL) Sales_ID SERIAL
Khóa chính (Primary Key). Date_SK INT
Khóa ngoại (Foreign Key). Nối đến Dim_Date(Date_SK) Product_SK INT
Khóa ngoại (Foreign Key). Nối đến Dim_Product(Product_SK). Retail_Sales DECIMAL(10, 2) Measure (Lấy từ RETAIL SALES). Retail_Transfers DECIMAL(10, 2) Measure (Lấy từ RETAIL TRANSFERS). Warehouse_Sales DECIMAL(10, 2) Measure (Lấy từ WAREHOUSE SALES) 10
Hình 1: Sơ đồ mô hình sao
V. Triển khai mô hình và ứng dụng
1. Triển khai Kho dữ liệu (Quy trình ETL)
Mục tiêu của quá trình này là chuyển đổi dữ liệu thô từ một file
Warehouse_and_Retail_Sales.csv (dạng phẳng, de-normalized) thành một mô hình
Sao (Star Schema) có cấu trúc trong PostgreSQL để tối ưu hóa truy vấn và phân tích. Công cụ sử dụng: Ngôn ngữ: Python
Thư viện sử dụng : Pandas (để xử lý dữ liệu), SQLAlchemy và psycopg2 (để
kết nối và tải vào PostgreSQL).
Cơ sở dữ liệu: PostgreSQL
Quy trình ETL (Extract - Transform - Load):
a. Extract (Trích xuất)
Quy trình bắt đầu bằng việc đọc (load) file Warehouse_and_Retail_Sales.csv
vào bộ nhớ bằng lệnh pd.read_csv(). Dữ liệu này được chứa trong một
DataFrame thô tên là df_source.
b. Transform (Biến đổi) 11
Đây là bước phức tạp nhất, bao gồm việc tách dữ liệu từ 1 file thô thành 3 bảng (2
Dimension, 1 Fact) đã thiết kế ở Chương 2. Xử lý Dim_Date:
Trích xuất 2 cột YEAR và MONTH từ df_source.
Xóa các dòng trùng lặp (drop_duplicates()) để tạo ra một bảng chiều
(dimension) duy nhất về thời gian (ví dụ: chỉ có 10 dòng đại diện cho các kỳ thời gian).
Đổi tên cột (.rename()) cho khớp với CSDL (ví dụ: YEAR thành year).
Xử lý Dim_Product:
Trích xuất các cột liên quan đến sản phẩm: ITEM CODE, ITEM
DESCRIPTION, ITEM TYPE, SUPPLIER.
Xóa các dòng trùng lặp (drop_duplicates()) dựa trên ITEM CODE để
đảm bảo mỗi sản phẩm chỉ xuất hiện một lần.
Đổi tên cột cho khớp với CSDL (ví dụ: ITEM CODE thành item_code_source).
Xử lý Fact_Sales (SK Lookup):
Đây là bước "tra cứu khóa thay thế".
Đọc lại 2 bảng Dim_Date và Dim_Product (lúc này đã có khóa date_sk
và product_sk) từ CSDL vào Pandas.
Sử dụng lệnh pd.merge() (tương tự JOIN trong SQL) để kết hợp
df_source thô với 2 bảng Dim vừa đọc:
+ Merge df_source với dim_date_sk (dựa trên YEAR và MONTH).
+ Merge kết quả đó với dim_product_sk (dựa trên ITEM CODE).
Sau khi merge, bảng fact_data cuối cùng đã chứa các khóa date_sk và product_sk cần thiết.
Lọc ra các cột cuối cùng (các khóa SK và 3 cột Measures: RETAIL
SALES, RETAIL TRANSFERS, WAREHOUSE SALES). c. Load (Tải)
Quy trình tải được thực hiện theo đúng thứ tự phụ thuộc (dependency):
Chạy create_tables_new.sql: Trước khi chạy Python, file SQL được thực thi
trên pgAdmin để DROP (xóa) các bảng cũ và tạo lại cấu trúc 3 bảng rỗng
(Dim_Date, Dim_Product, Fact_Sales) với các khóa ngoại đã được định nghĩa.
Tải các bảng Dimension: Script etl.py dùng dim_date.to_sql(. .,
if_exists='append') và dim_product.to_sql(. ., if_exists='append') để tải dữ liệu vào 2 bảng Dimension.
Tải bảng Fact: Cuối cùng, script dùng fact_sales.to_sql(. ., if_exists='append')
để tải bảng Fact (đã chứa các khóa SK) vào CSDL.
Kết quả: Toàn bộ dữ liệu từ file CSV thô đã được chuyển đổi thành công sang mô
hình Sao trong CSDL sales_dw, sẵn sàng cho việc phân tích.
2. Xây dựng Báo cáo và Trực quan hóa (BI)
2.1. Xử lí dữ liệu và các thành phần: 12
a. Khắc phục lỗi kiểu dữ liệu:
Dữ liệu thô ban đầu gặp lỗi do cố gắng ép kiểu dữ liệu không tương thích, đặc biệt là
ở cột ITEM CODE (ví dụ: chứa cả chữ cái "BC" và số).
● Vấn đề: Lỗi Error xuất hiện trong cột ITEM CODE sau bước Detected Type Mismatches.
● Giải pháp: Xóa các bước gây lỗi (Kept Errors, Reordered Columns, Changed
Type) và thay đổi kiểu dữ liệu của cột ITEM CODE thành Text (Văn bản)
trong Power Query Editor. Thao tác này đã loại bỏ lỗi và cho phép dữ liệu
được tải thành công (128.355 dòng đã được tải).
b. Các cột thứ nguyên (Dimensions): Đây là các cột dùng để phân loại, nhóm, và lọc dữ liệu. Tên Cột Tên Hiển thị Kiểu Dữ
Mục đích Phân tích (Gợi ý) liệu ITEM CODE Mã Sản phẩm Text Phân tích theo ID sản phẩm. ITEM Mô tả Sản phẩm Text
Dùng để hiển thị tên sản DESCRIPTION phẩm trong báocáo. ITEM TYPE Loại Sản phẩm Text Phân tích tỷ trọng doanh thu theo loại. SUPPLIER Nhà Cung cấp Text Phân tích hiệu suất theo nhà cung cấp YEAR Năm Whole Dùng trong phân tích xu Number
hướng thời gian (trục X). MONTH Tháng Whole Dùng trong phân tích xu Number
hướng thời gian (trục X). Quarter Quý Text Dùng trong phân tích xu hướng theo quý (từ DAX).
c. Các Chỉ số (Measures) và Cột Tính toán (DAX):
- Các yếu tố này được tạo ra để thực hiện tính toán cốt lõi trong báo cáo: Tên yếu tố Loại Công thức(Mô tả) Mục đích Phân tích Quarter Calculated
Sử dụng SWITCH() để ánh xạ Phân tích xu hướng MONTH sang Q1, Q2, Q3, theo quý và tính 13 Column Q4. mùa vụ. Total Sales Measure SUM('SalesData'[RETAIL Tính Tổng Doanh SALES]) thu để hiển thị trên thẻ Card và các biểu đồ chính. Total Retail Measure SUM('SalesData'[RETAIL Tính tổng số lượng Transactions TRANSFERS]) giao dịch, dùng để phân tích tần suất mua hàng. Product Rank Measure Công thức DAX Xếp hạng Phục vụ cho việc lọc và hiển thị Top N sản phẩm.
2.2. Mô tả báo cáo 1 số Dashboard:
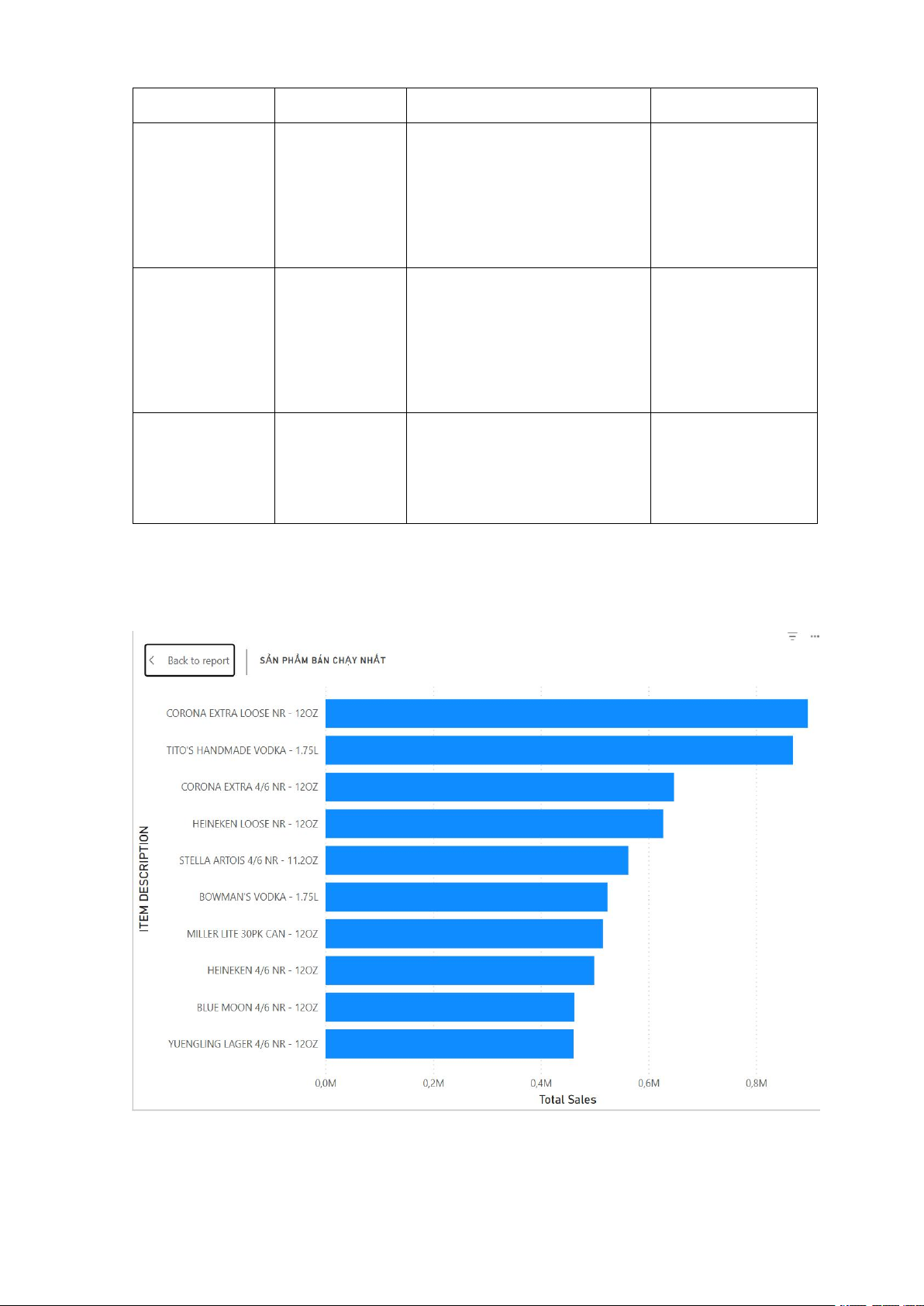
a. Phân tích sản phẩm bán chạy nhất:
- Tập trung vào sản phẩm, sử dụng tiêu chí ‘total sales’ để làm tiêu chí xếp hạng.
- Sử dụng biểu đồ thanh ngang (bar chart) 14
- Trục Y hiển thị cụ thể từng loại mặt hàng; trục X là thang đo giá trị tính bằng triệu.
- Biểu đồ này chỉ ra 10 sản phẩm đứng đầu:
+ Với sản phẩm dẫn đầu tuyệt đối thì cần đảm bảo ổn định nguồn cung cho mặt hàng này.
+ Với những sản phẩm dưới thì chứng tỏ các thương hiệu ấy vẫn rất phổ biến và cạnh tranh rất sát sao.
- Dữ liệu này là bằng chứng rõ ràng về nhu cầu thị trường, các sản phẩm trong top phải
được ưu tiên hàng đầu trong quản lý.
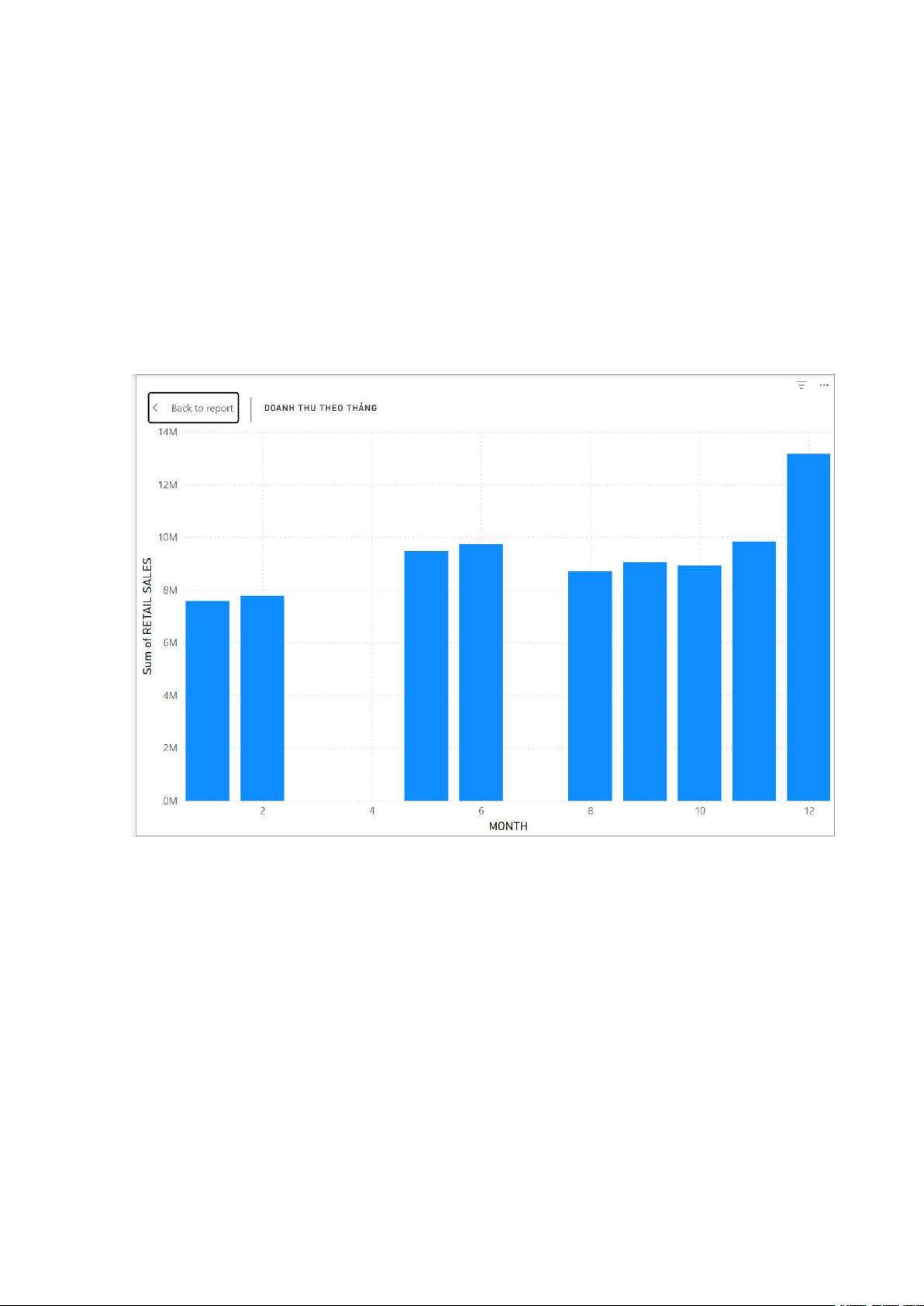
b. Phân tích doanh thu theo tháng:
- Sử dụng biểu đồ dạng cột, để hiển thị giao dịch giữa các tháng, nó giúp xác định tính
mùa vụ của doanh thu, bất kể năm nào (do nó tập hợp tất cả các năm).
- Trục X hiển thị các tháng, trục Y thể hiện tổng doanh thu bán lẻ tính bằng triệu.
- Tháng 12 là tháng có doanh thu vượt trội so với các tháng khác, có sự chênh lệch rõ ràng.
- Giai đoạn tháng 5 đến 11 là các tháng hoạt động ổn định nhất, cho thấy mô hình kinh
doanh tương đối đều đặn trong các tháng này.
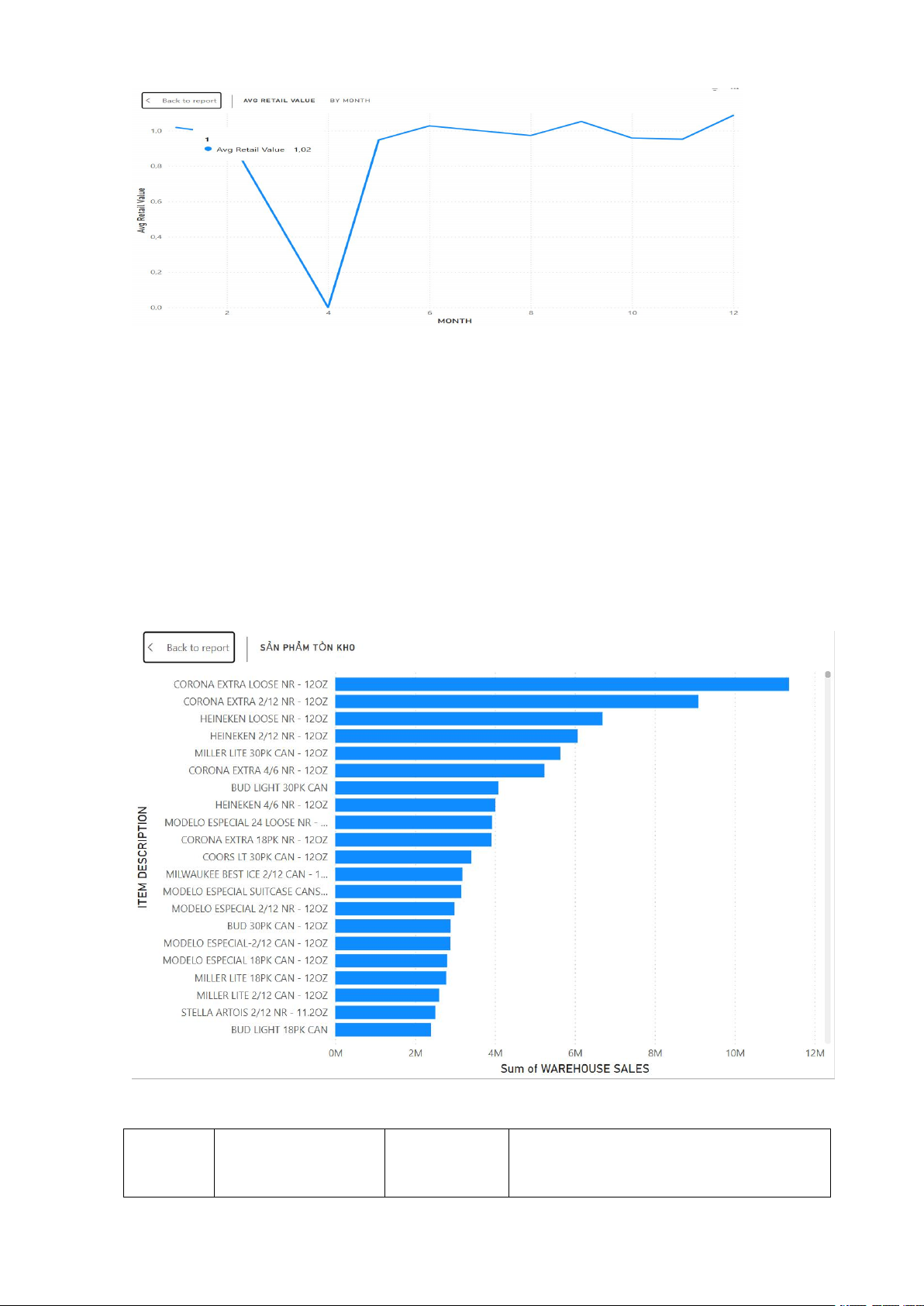
c. Phân tích giao dịch trung bình theo tháng: 15
- Biểu đồ đường với trục X hiển thị chu kì 12 tháng, trục Y là thang đo giá trị trung bình.
- Biểu đồ này giúp đánh giá chất lượng mỗi giao dịch theo thời gian. Nếu ATV tăng,
nghĩa là khách hàng đang mua nhiều mặt hàng hơn hoặc mua các mặt hàng có giá trị
cao hơn trong mỗi lần mua.
- Giá trị ổn định từ các tháng 8 đến 12. Hiệu quả của mỗi giao dịch là tốt và ổn định
nhất, tháng 12 có vẻ đạt đỉnh cao nhất.
- Tháng 4 là điểm bất thường khi ATV đột ngột giảm về 0, sau cú sốc tháng 4 thì ATV phục hồi ngay lập tức
d. Phân tích sản phẩm tồn kho, luân chuyển:
Phân tích và nghiệp vụ: Hạng Sản phẩm Giá trị Kho
Phân tích Nghiệp vụ (Ước tính) 16 #1 CORONA Khoảng
Sản phẩm Luân chuyển Lớn nhất: EXTRA LOOSE 11.5M
Mặt hàng này có giá trị luân chuyển qua
kho cao nhất, có thể do khối lượng NR - 12OZ
nhập/xuất kho lớn nhất. #2 CORONA Khoảng 9.0M
Dòng sản phẩm Chiến lược: Cả hai EXTRA 2/12 NR -
mặt hàng Corona đều chiếm vị trí dẫn
đầu, chứng tỏ nhà cung cấp Corona có 12OZ
quy mô giao dịch rất lớn. #3 HEINEKEN
Khoảng 7.0M Đối thủ Cạnh tranh Chính: Heineken LOOSE NR -
cũng là mặt hàng có giá trị luân chuyển
lớn, đòi hỏi không gian lưu trữ đáng kể 12OZ
- Biểu đồ thanh ngang với trục X là thang đo giá trị bằng triệu, trục Y mô tả sản phẩm.
- Biểu đồ này xác định những mặt hàng nào đang có tổng giá trị hàng hóa luận chuẩn qua kho lớn nhất.
- Mục đích cốt lõi của biểu đồ giúp định lượng tồn kho/luân chuyển, quản lý nguồn lực
kho và phân tích được các rủi ro.
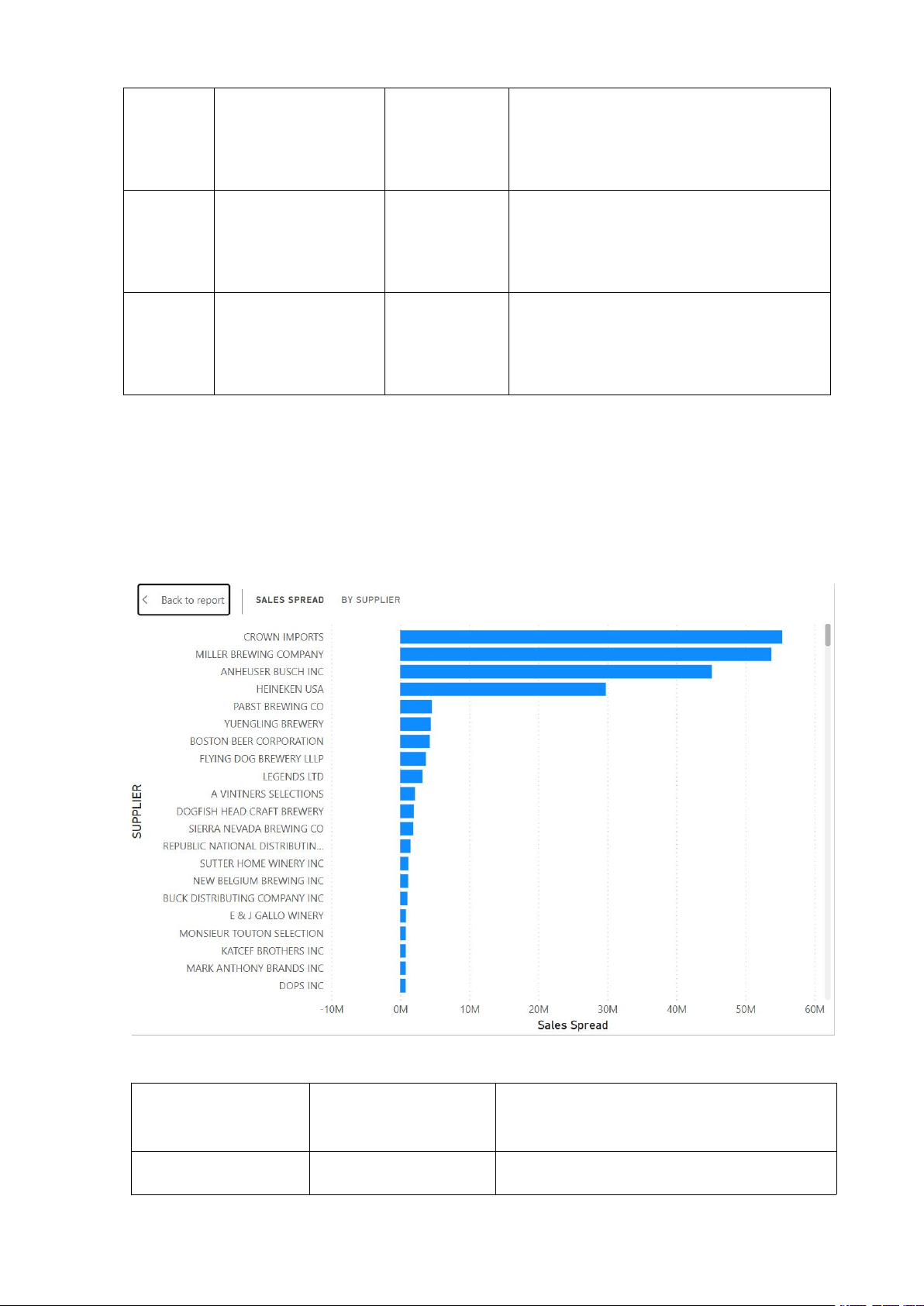
e. Phân tích rủi ro tồn kho theo nhà cung cấp:
Phân tích chuyên sâu và đề xuất: Chỉ số Sales Tình trạng
Phân tích Nghiệp vụ Spread Spread Dương Rủi ro Cao /Tồn kho
Giá trị hàng luân chuyển qua kho cao hơn
nhiều so với giá trị bán lẻ thực tế. Hàng 17 (Phần lớn biểu đồ) Thừa
đang tồn đọng, có thể là tồn kho chết, hư
hỏng, hoặc dự báo nhu cầu quá cao. Spread Âm (Phần Hiệu quả
Giá trị bán lẻ cao hơn giá trị luân chuyển dưới cùng, ngoài - Cao / Tồn kho Tối ưu
kho. Cho thấy hàng hóa luân chuyển rất 10M)
nhanh, kho hàng hoạt động hiệu quả và
đang có nhu cầu vượt trội.
- Khi spread dương lớn thì các đối tác nguy cơ bị tồn đọng vốn lớn nhất. Lúc này ta
cần thực hiện kiểm kê kho, điều chỉnh đặt hàng và lên chiến dịch xả hàng để giảm thiểu tổn thất.
- Biều đồ này là 1 công cụ cảnh báo sớm cho các nhà quản lý an tâm khi giải phóng
vốn và tối ưu hóa hàng tồn kho.
f. Phân tích cơ cấu doanh thu theo sản phẩm:
- Biểu đồ xác định cơ cấu doanh thu của toàn bộ hoạt động kinh doanh, cho thấy được nguồn thu chính.
- Với những sản phẩm có giá trị cao, chiến lược cần tập trung vào việc duy trì chất lượng thương hiệu
- Cần xem xét lại việc kinh doanh của các mặt hàng lợi nhuận không cao để tập trung
vào các mặt hàng cốt lõi
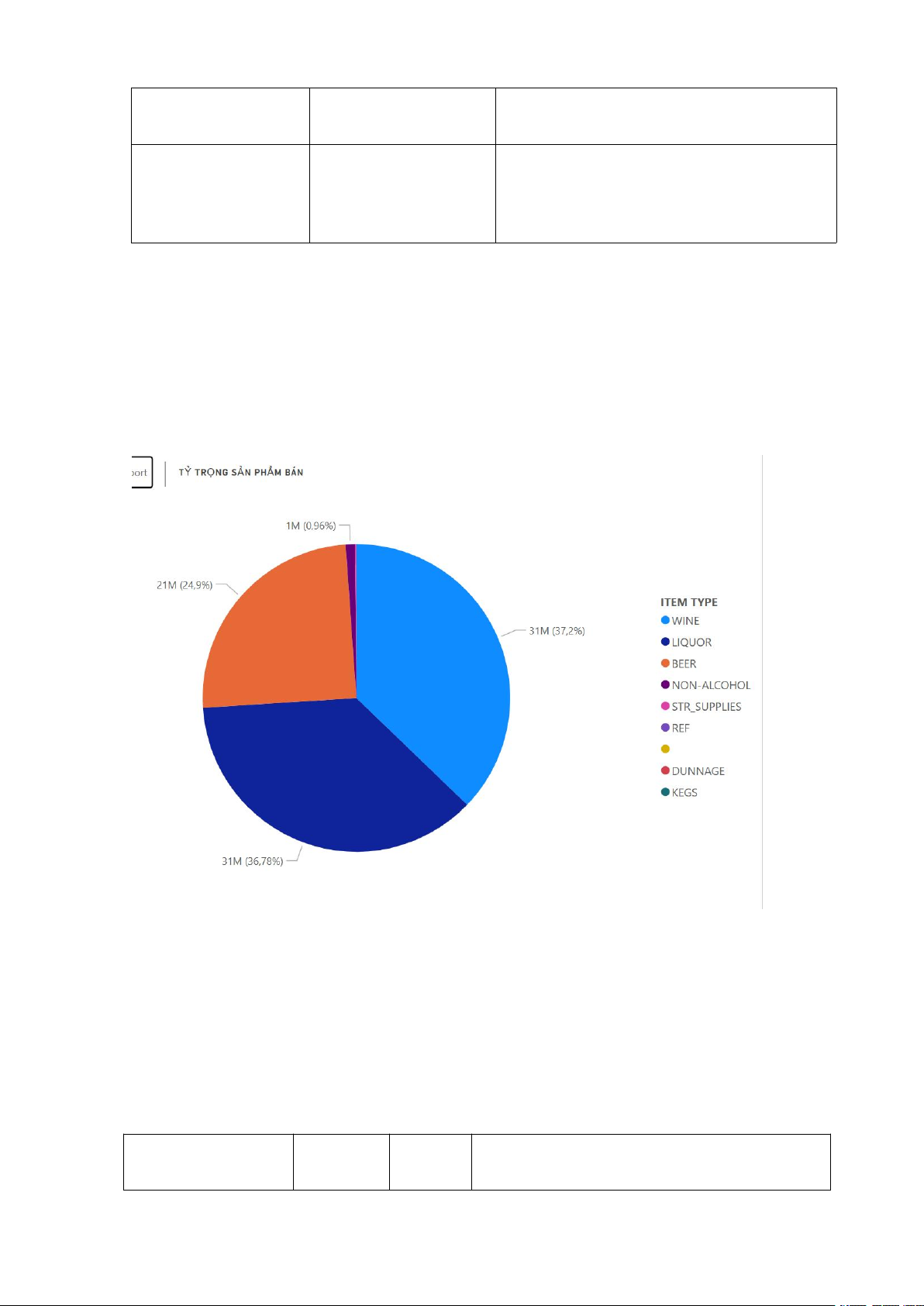
- Phân tích và phát hiện: Loại hình Sản Giá trị Tỷ
Phân tích Nghiệp vụ phẩm (ITEM 18 TYPE) (Ước trọng tính) WINE (Rượu 31M 37.2%
Sản phẩm Chủ lực #1: Chiếm tỷ trọng cao Vang)
nhất. Điều này cho thấy Rượu Vang là phân
khúc thị trường quan trọng nhất, cần được ưu
tiên về đầu tư và tìm kiếm nhà cung cấp mới. LIQUOR 31M
36.78% Sản phẩm Chủ lực #2: Gần như ngang bằng (Rượu Mạnh)
với WINE. Cùng với WINE, hai loại hình
này tạo ra khoảng 74% tổng doanh thu. BEER (Bia) 21M 24.9%
Sản phẩm Chủ lực #3: Chiếm khoảng một
phần tư doanh thu. Mặc dù là phân khúc có
số lượng bán (Quantity) lớn nhất (dựa trên
các phân tích khác), nhưng về giá trị thì thấp
hơn nhiều so với Rượu Vang và Rượu Mạnh NON-ALCO 1M 0.96%
Phân khúc Nhỏ: Các mặt hàng không cồn HOL (Không
chỉ là sản phẩm bổ sung, chiếm tỷ trọng
không đáng kể về doanh thu Cồn) VI. Kết luận :
Đề tài đã thực hiện thành công quy trình xây dựng một hệ thống Business Intelligence
(BI) cho nghiệp vụ quản lý bán hàng, bắt đầu từ dữ liệu thô dạng CSV cho đến mô
hình Kho dữ liệu (Data Warehouse) và dashboard phân tích trên Power BI.
Trước hết, báo cáo đã trình bày cơ sở lý thuyết về Kho dữ liệu, ETL và BI, làm nền
tảng cho toàn bộ quá trình triển khai. Tiếp theo, dữ liệu thô từ Kaggle được phân tích,
chuẩn hóa và tổ chức lại theo mô hình Star Schema, đảm bảo đúng các nguyên tắc của
hệ thống phân tích OLAP. Quy trình ETL được hiện thực hóa bằng Python (Pandas,
SQLAlchemy), nạp dữ liệu vào PostgreSQL để tạo ra một kho dữ liệu hoàn chỉnh, ổn
định và có khả năng truy vấn nhanh.
Cuối cùng, dữ liệu từ DW được kết nối vào Power BI để xây dựng các dashboard trực
quan, hỗ trợ trả lời những câu hỏi quan trọng như: doanh thu theo thời gian, sản phẩm
bán chạy, khu vực hoạt động hiệu quả, và xu hướng tiêu dùng của khách hàng. Kết quả
cho thấy mô hình BI mang lại góc nhìn toàn diện, giúp việc phân tích và ra quyết định
trở nên nhanh chóng, chính xác và dựa trên dữ liệu.
Nhìn chung, chúng ta có thể thấy đề tài không chỉ minh họa rõ ràng quy trình triển
khai một hệ thống BI hoàn chỉnh mà còn chứng minh vai trò quan trọng của BI trong
việc nâng cao hiệu quả hoạt động và năng lực phân tích của doanh nghiệp.
VII. Hướng phát triển:
1. Mở rộng nguồn dữ liệu:
- Kết nối thêm API bán hàng, dữ liệu CRM, dữ liệu web hoặc dữ liệu từ ERP. 19
- Thay vì chỉ dựa vào CSV, có thể thu thập dữ liệu theo thời gian thực (real-time streaming).
2. Tự động hóa quy trình ETL:
- Dùng Airflow, SSIS, hay Prefect để tự động hóa: lập lịch cập nhật dữ liệu,kiểm tra lỗi, giám sát pipeline
- Giảm thao tác thủ công, tăng tính ổn định khi vận hành.
3. Tối ưu và mở rộng Data Warehouse:
- Thêm các bảng Dimension nâng cao: Dim_Customer_Demographic, Dim_Supplier, Dim_Region.
- Áp dụng partitioning, indexing để tăng tốc truy vấn.
- Đưa DW lên Cloud Data Warehouse như BigQuery, Snowflake hoặc Redshift để mở rộng quy mô dữ liệu.
4. Phát triển dashboard nâng cao:
- Thêm các dashboard: Phân tích tồn kho Dự báo doanh số
+ Phân tích hành vi khách hàng + KPI theo từng cửa hàng
- Thiết kế dashboard theo chuẩn UI/UX của doanh nghiệp.
5. Tích hợp mô hình học máy (ML):
- Dự báo doanh thu theo mùa
- Gợi ý nhập kho tự động (inventory optimization)
- Phân loại khách hàng theo mức độ mua sắm (RFM clustering)
- Dự báo sản phẩm bán chạy theo từng thời điểm
6. Triển khai BI ở cấp doanh nghiệp:
- Chia quyền người dùng theo vai trò (Admin, Manager, Analyst)
- Tích hợp Power BI Service để chia sẻ dashboard theo thời gian thực
- Thiết lập Data Gateway cho cập nhật dữ liệu tự động
VIII. Tài liệu tham khảo :
[1] https://www.kaggle.com/datasets/divyeshardeshana/warehouse-and-retail-sales?
[2] 4 Chaudhuri S., Krishnamurthy R., Potamianos S., Shim K. “Optimizing Queries
with Materialized Views” Intl. Conference on Data Engineering, 1995
[3] “The Role of Data Warehousing in Business Intelligence Systems to support rapid
Decision-Making” R. Rea D’souza, P. Mahesh Satam, V. Rao Naidu (2023) 20
Tài liệu liên quan:
-

Bài tập lớn môn Quản trị cơ sở dữ liệu kinh doanh | Học viện Công Nghệ Bưu Chính Viễn Thông
101 51 -

Chương 2 Phân tích chu trình doanh thu môn Quản trị cơ sở dữ liệu kinh doanh | Học viện Công Nghệ Bưu Chính Viễn Thông
152 76 -

Chương 3 Phân tích chu trình sản xuất môn Quản trị cơ sở dữ liệu kinh doanh | Học viện Công Nghệ Bưu Chính Viễn Thông
91 46 -

Tổng quan về CSDL & mô hình quan hệ môn Quản trị cơ sở dữ liệu kinh doanh | Học viện Công Nghệ Bưu Chính Viễn Thông
119 60