Khóa luận tốt nghiệp thương mại điện tử đề tài "Đánh giá sự thành công của các ICO bằng Text-Mining và lập mô hình dự báo giá tiền điện tử"
Khóa luận tốt nghiệp thương mại điện tử đề tài "Đánh giá sự thành công của các ICO bằng Text-Mining và lập mô hình dự báo giá tiền điện tử" của Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: Thương mại điện tử (ECOM430984) 10 tài liệu
Trường: Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh 4.4 K tài liệu
Tác giả:



































































Preview text:
lOMoARcPSD| 37054152
TRƯỜNG ĐẠ I H ỌC SƯ PHẠ M K Ỹ THU Ậ T TP. H Ồ CHÍ MINH KHOA KINH T Ế
NGÀNH THƯƠNG MẠI ĐIỆ N T Ử
KHÓA LU Ậ N T Ố T NGHI Ệ P Đề tài
ĐÁNH GIÁ SỰ THÀNH CÔNG C Ủ A CÁC ICO
B Ằ NG TEXT-MINING VÀ L Ậ P MÔ HÌNH MÁY H Ọ
C D Ự BÁO GIÁ TI ỀN ĐIỆ N T Ử GVHD:
ThS. Tr ầ n Kim To ạ i SVTH: MSSV:
1 . Phan Th ị Minh Ph ụ ng 1812604 6 2.
Nguy ễ n Th ị Ng ọ c Trang 1812607 4 L ớ p: 181260 A Khóa: 2018 H ệ : Đạ i h ọ c chính quy
Thành ph ố H ồ Chí Minh, tháng 06 năm 2022 lOMoAR cPSD| 37054152 LỜI CẢM ƠN
Lời ầu tiên, chúng tôi xin chân thành gửi lời cảm ơn ến GVHD thầy Trần Kim
Toại ã hướng dẫn nhóm một cách tận tình cũng như có những hỗ trợ ể nhóm có thể
hoàn thành ồ án úng tiến ộ và hoàn chỉnh nhất. Trong quá trình thực hiện ồ án, thầy ã
chỉ dẫn và cung cấp nhiều kiến thức mới trong lĩnh vực Machine Learning – một lĩnh
vực mà ối với nhóm còn khá mới mẻ. Đây là nền tảng rất tốt và vô cùng quan trọng,
giúp nhóm có thể hoàn thiện ồ án và hỗ trợ nền kiến thức cho các công việc và nghiên cứu sau này.
Đồng thời, nhóm cũng gửi lời cảm ơn ến các giảng viên trường Đại học Sư Phạm
Kỹ Thuật TP.HCM. Trong thời gian học tập tại trường, các giảng viên ã hỗ trợ, cung
cấp nhiều kiến thức và kĩ năng, làm nền tảng ể các thành viên trong nhóm có nền tảng
ể hoàn thành ược ồ án tốt nghiệp này.
Lời cuối cùng, chúng tôi xin gửi ến quý Thầy, Cô trường Đại học Sư phạm Kỹ
thuật TP.HCM lời chúc sức khỏe dồi dào cũng như lời chúc tiếp tục nâng bước, hỗ
trợ cho những thế hệ sinh viên và ạt ược nhiều hơn nữa thành công trong công việc tương lai.
Nhóm xin chân thành cảm ơn! lOMoARcPSD| 37054152 MỤC LỤC
MỤC LỤC .................................................................................................................. i
DANH MỤC HÌNH ẢNH ....................................................................................... iv
DANH MỤC BẢNG BIỂU ...................................................................................... v
DANH MỤC CÁC TỪ VIẾT TẮT ....................................................................... vii
TÓM TẮT .............................................................................................................. viii
ABSTRACT ........................................................................................................... viii
CHƯƠNG 1. TỔNG QUAN ĐỀ TÀI ..................................................................... 1
1.1. GIỚI THIỆU ĐỀ TÀI ...................................................................................... 1
1.2. TÍNH CẤP THIẾT CỦA ĐỀ TÀI ................................................................... 1
1.3. CÁC CÔNG TRÌNH NGHIÊN CỨU CÓ LIÊN QUAN ................................. 3
1.4. NHỮNG ĐIỂM MỚI CỦA ĐỀ TÀI ................................................................ 6
1.5. MỤC TIÊU NGHIÊN CỨU ............................................................................ 7
1.6. ĐỐI TƯỢNG, PHẠM VI, PHƯƠNG PHÁP NGHIÊN CỨU ........................ 8
1.7. BỐ CỤC CỦA ĐỀ TÀI ................................................................................... 9
CHƯƠNG 2. CƠ SỞ LÝ THUYẾT ...................................................................... 10
2.1. ICO LÀ GÌ? .................................................................................................... 10
2.2. THUẬT TOÁN KNN (K-NEAREST NEIGHBORS) .................................. 10
2.3. THUẬT TOÁN NAIVE BAYES .................................................................. 11
2.4. CONFUSION MATRIX ................................................................................ 12
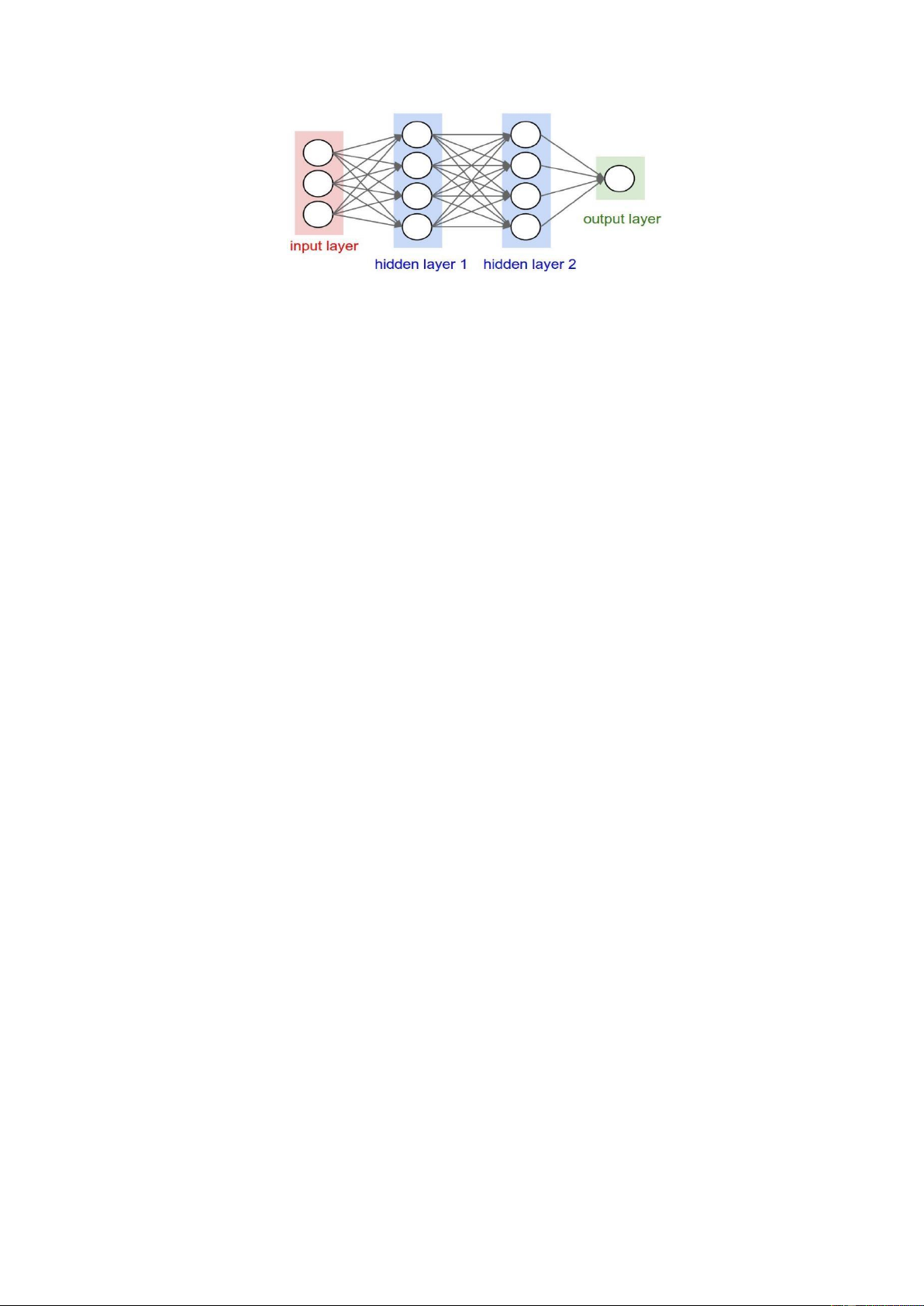
2.5. MÔ HÌNH RNN (RECURRENT NEURAL NETWORK) ........................... 13
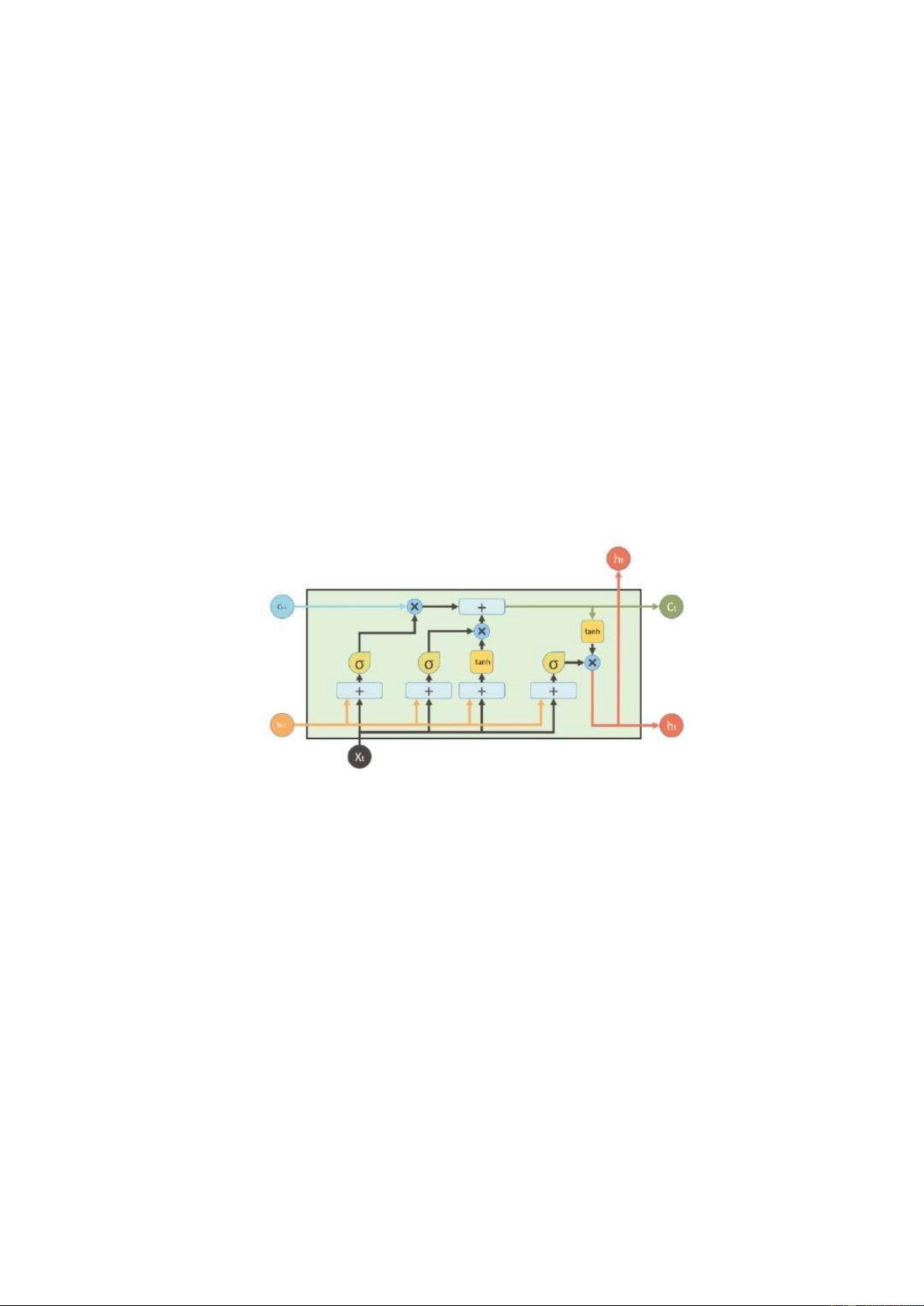
2.6. MÔ HÌNH LSTM (LONG SHORT - TERM MEMORY) ............................ 15
2.7. MÔ HÌNH CNN (CONVOLUTIONAL NEURAL NETWORK) ................ 16
CHƯƠNG 3. PHƯƠNG PHÁP THỰC HIỆN ..................................................... 18
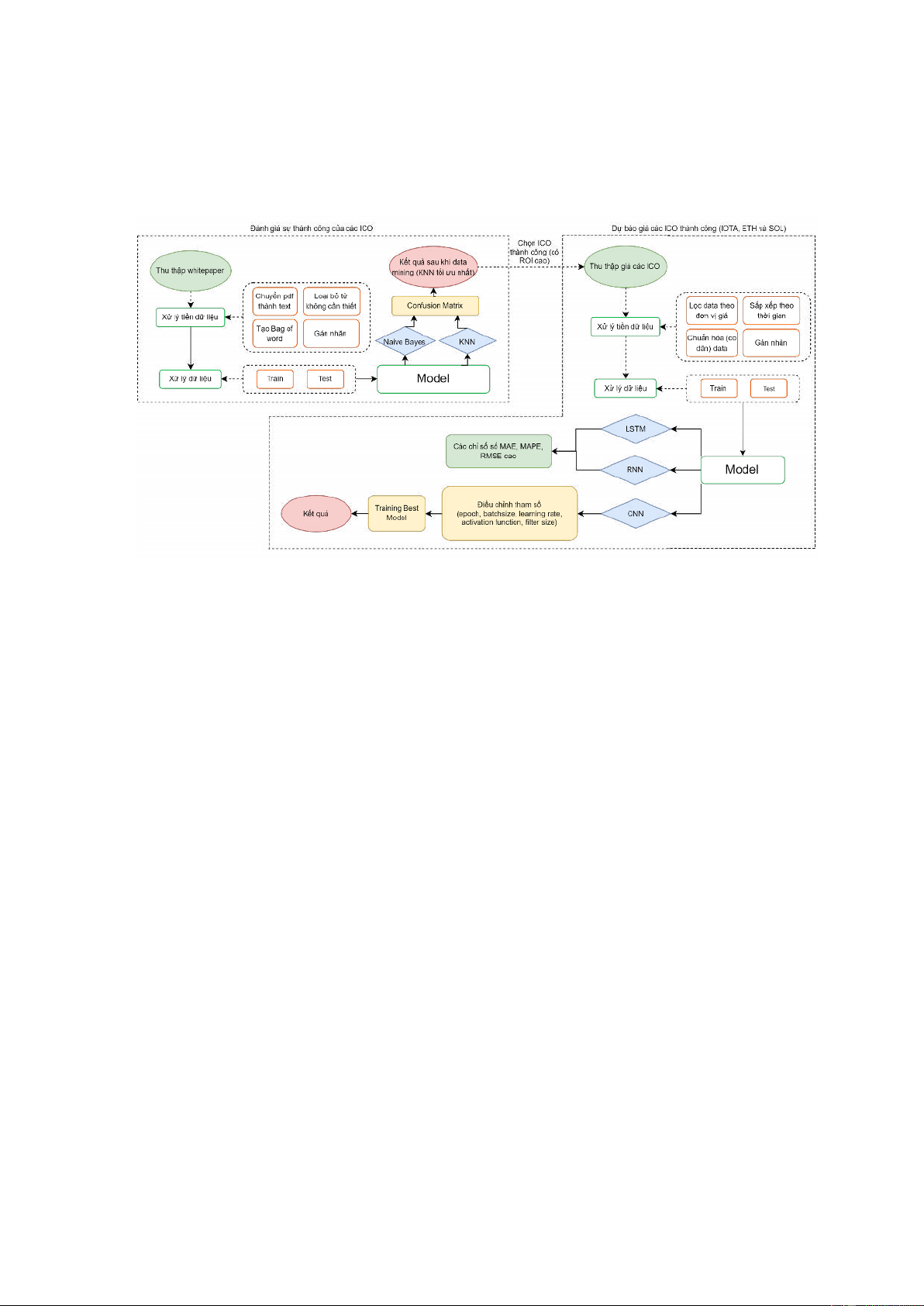
3.1. LƯU ĐỒ TỔNG QUAN QUÁ TRÌNH THỰC HIỆN ĐỀ TÀI .................... 18
3.2. PHƯƠNG PHÁP ĐÁNH GIÁ SỰ THÀNH CÔNG CỦA CÁC ICO .......... 18
3.2.1. Thu thập whitepaper của các ICO .......................................................... 18
3.2.2. Lưu ồ thực hiện text-mining ánh giá sự thành công các ICO ................ 19
3.2.3. Cấu hình phần cứng huấn luyện thuật toán ............................................ 21
3.2.4. Xây dựng thuật toán KNN ...................................................................... 22 lOMoARcPSD| 37054152
3.2.5. Xây dựng thuật toán Naive Bayes .......................................................... 26
3.3. PHƯƠNG PHÁP DỰ BÁO GIÁ TIỀN ĐIỆN TỬ ........................................ 29
3.3.1. Thu thập dữ liệu giá tiền iện tử............................................................... 29
3.3.2. Lựa chọn các ICO thành công ể dự oán giá ........................................... 32
3.3.3. Lưu ồ thực hiện xây dựng các mô hình dự oán giá ................................ 33
3.3.4. Cấu hình phần cứng huấn luyện mô hình ............................................... 34
3.3.5. Xử lý dữ liệu ........................................................................................... 35
3.3.6. Các chỉ số hiệu suất ................................................................................ 36
3.3.7. Xây dựng mô hình RNN ......................................................................... 37
3.3.8. Xây dựng mô hình LSTM ...................................................................... 38
3.3.9. Xây dựng mô hình CNN ......................................................................... 40
3.3.10. Tối ưu hóa các tham số .......................................................................... 41
CHƯƠNG 4. KẾT QUẢ THỰC HIỆN ................................................................ 43
4.1. KẾT QUẢ ĐÁNH GIÁ SỰ THÀNH CÔNG CỦA CÁC ICO ..................... 43
4.1.1. Thuật toán KNN ..................................................................................... 43
4.1.2. Thuật toán Naïve Bayes .......................................................................... 44
4.1.3. So sánh thuật toán KNN và Naïve Bayes ............................................... 45
4.2. KẾT QUẢ DỰ BÁO GIÁ TIỀN ĐIỆN TỬ .................................................. 45
4.2.1. Kết quả lựa chọn mô hình....................................................................... 45
4.2.2. Kết quả tối ưu hóa các tham số của mô hình .......................................... 46
4.2.3. Kết quả dự báo giá trong 60 phút cuối ................................................... 51
4.3. TỔNG KẾT KẾT QUẢ THỰC NGHIỆM .................................................... 56
CHƯƠNG 5. KẾT LUẬN ĐỀ TÀI - ĐỀ XUẤT HƯỚNG PHÁT TRIỂN........ 57
5.1. CÁC KẾT QUẢ ĐẠT ĐƯỢC ....................................................................... 57
5.1.1. Hoàn thành các mục tiêu ........................................................................ 57
5.1.2. Trả lời ược các câu hỏi nghiên cứu ........................................................ 58
5.2. NHỮNG HẠN CHẾ CỦA ĐỀ TÀI ............................................................... 59
5.2.1. Những hạn chế khi ánh giá sự thành công của ICO ............................... 59
5.2.2. Những hạn chế khi thực hiện dự oán giá tiền iện tử ............................... 60
5.3. ĐỀ XUẤT HƯỚNG PHÁT TRIỂN TƯƠNG LAI ....................................... 61 lOMoARcPSD| 37054152
KẾT LUẬN ............................................................................................................. 63
TÀI LIỆU THAM KHẢO ..................................................................................... 64
TIẾNG ANH ......................................................................................................... 64
TIẾNG VIỆT ......................................................................................................... 68 lOMoARcPSD| 37054152 DANH MỤC HÌNH ẢNH
Hình 2.1. Cấu trúc ma trận Confusion Matrix .......................................................... 12
Hình 2.2. Cấu trúc của mạng nơ-ron hồi quy (RNN) .............................................. 13
Hình 2.3. Hướng di chuyển luồng thông tin của RNN và feedforward neural ........ 14
Hình 2.4. Cấu trúc mạng LSTM ............................................................................... 15
Hình 2.5. Cấu trúc mạng CNN ................................................................................. 16
Hình 3.1. Lưu ồ tổng quan các bước thực hiện ề tài ........................................... 18
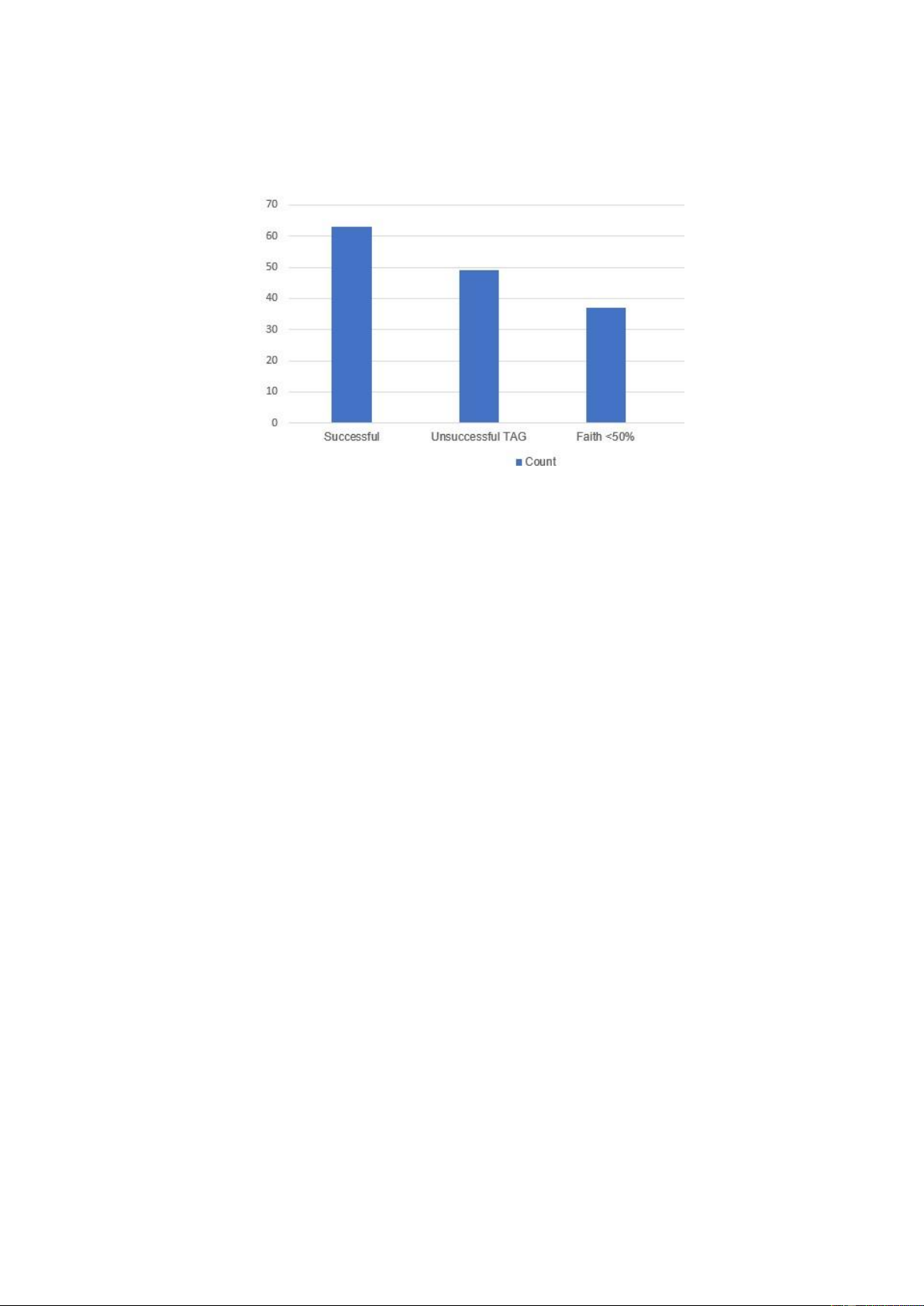
Hình 3.2. Tổng hợp số lượng ICO ã thu thập ........................................................ 19
Hình 3.3. Lưu ồ thực hiện ánh giá sự thành công của các ICO ........................... 20
Hình 3.4. Source code chuyển ổi dữ liệu sang dạng text ...................................... 22
Hình 3.5. Source code sử dụng xpdf-tools-win-4.03 ọc dữ liệu ........................... 22
Hình 3.6. Source code cài ặt tham số cho mô hình ................................................ 23
Hình 3.7. Source code xử lý tiền dữ liệu trong text-mining .................................... 23
Hình 3.8. Source code tạo ma trận Bag of words .................................................... 24
Hình 3.9. Source code thiết lập nhóm dữ liệu theo TDM ........................................ 24
Hình 3.10. Source code xếp chồng dữ liệu (Nhóm thực hiện) ................................. 25
Hình 3.11. Source code phân chia dữ liệu ............................................................... 25
Hình 3.12. Đưa dữ liệu vào thuật toán KNN ........................................................... 25
Hình 3.13. Source code chuyển dữ liệu sang text ................................................... 26
Hình 3.14. Source code xử lý tiền dữ liệu ............................................................... 27
Hình 3.15. Source code xóa các thì của từ ............................................................... 27
Hình 3.16. Source code phân chia dữ liệu ............................................................... 28
Hình 3.17. Xây dựng mô hình Naïve Bayes ............................................................ 28
Hình 3.18. Quy trình thu thập dữ liệu giá tiền iện tử bằng công cụ Coin-for-rich 29
Hình 3.19. Sơ ồ chi tiết thu dữ liệu bằng Coin-for-rich ........................................ 29
Hình 3.20. Kéo thời gian ể thu dữ liệu lịch sử từ REST APIs .............................. 30
Hình 3.21. Truy xuất dữ liệu ã thu ược ............................................................... 30
Hình 3.22. Xuất dữ liệu ã thu ược sang file csv .................................................. 31
Hình 3.23. 20 dòng dữ liệu giá SOL trên sàn binance ............................................. 32
Hình 3.24. Lưu ồ thiết kế và xây dựng mô hình dự oán giá tiền iện tử ............. 33 Hình
3.25. Sắp xếp và phân loại dữ liệu ầu vào .................................................... 35 lOMoARcPSD| 37054152
Hình 3.26. Source code thực hiện chuẩn hóa dữ liệu ............................................... 36
Hình 3.27. Source code thực hiện chuyển chiều dữ liệu ......................................... 36
Hình 3.28. Source code tính toán các chỉ số hiệu suất ............................................ 37
Hình 3.29. Cấu trúc hoạt ộng mạng RNN .............................................................. 37
Hình 3.30. Cấu trúc mạng RNN sử dụng ể dự báo giá tiền iện tử ..................... 38
Hình 3.31. Source code mô hình RNN .................................................................... 38
Hình 3.32. Cấu trúc hoạt ộng mạng LSTM ........................................................... 38
Hình 3.33. Cấu trúc mạng LSTM sử dụng ể dự báo giá tiền iện tử ................... 39
Hình 3.34. Source code mô hình LSTM .................................................................. 40
Hình 3.35. Cấu trúc mạng CNN .............................................................................. 40
Hình 3.36. Cấu trúc mạng CNN sử dụng ể dự báo giá tiền iện tử ...................... 41
Hình 3.37. Source code mô hình CNN ..................................................................... 41
Hình 4.1. Ma trận hỗn loạn thể hiện kết quả của thuật toán KNN .......................... 43
Hình 4.2. Ma trận hỗn loạn thể hiện kết quả của thuật toán Naïve Bayes .............. 44
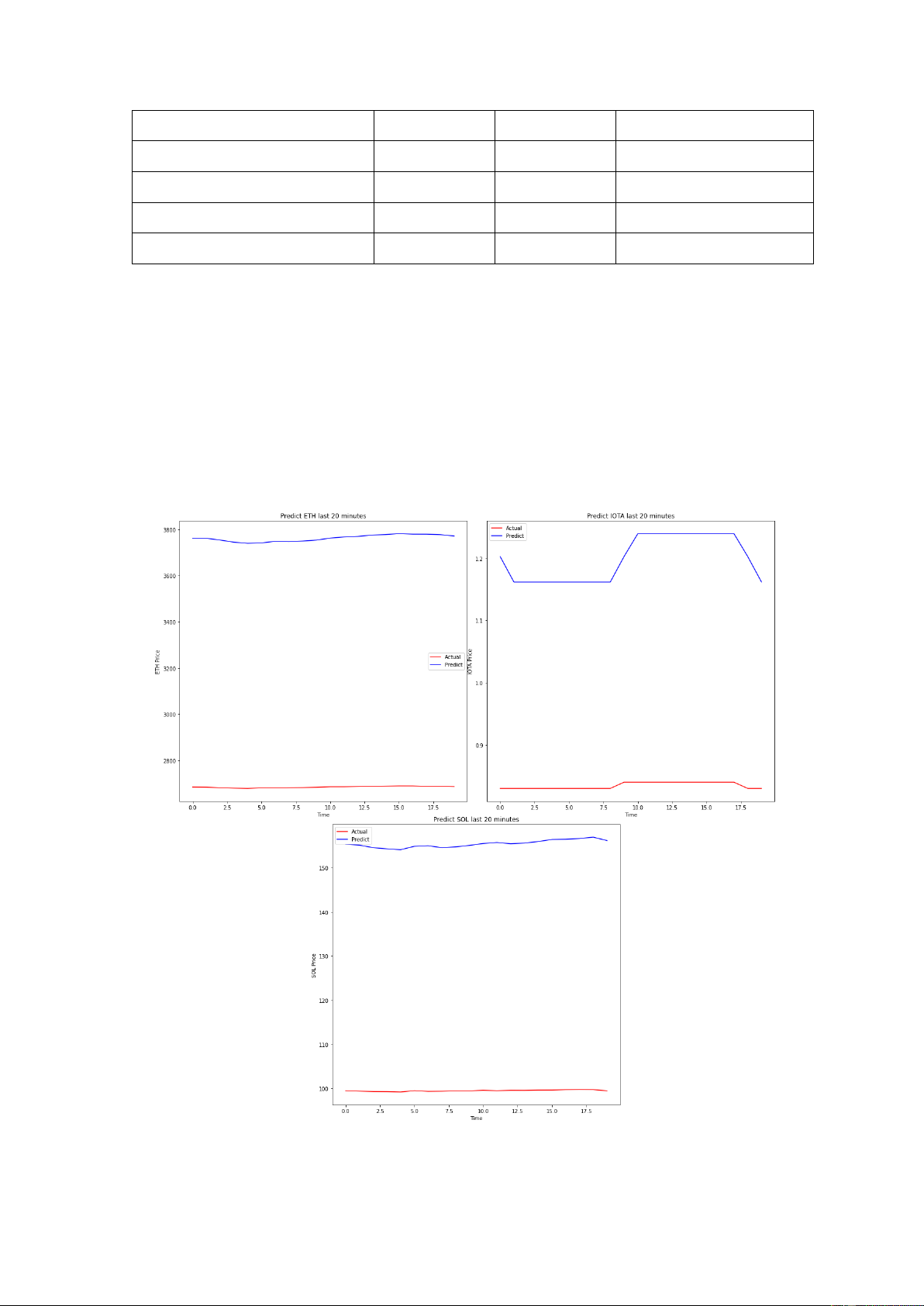
Hình 4.3. Dự oán giá 3 loại tiền iện tử trong 60 phút cuối ................................... 52
Hình 4.4. Dự oán giá 3 loại tiền iện tử trong 20 phút cuối ................................... 55
DANH MỤC BẢNG BIỂU
Bảng 4.1. Kết quả phân loại các whitepaper khi sử dụng thuật toán KNN ............. 43
Bảng 4.2. Kết quả phân loại các whitepaper khi sử dụng thuật toán Naïve Bayes . 44
Bảng 4.3. So sánh các chỉ số hiệu suất của thuật toán KNN và Naive Bayes ......... 45
Bảng 4.4. Kết quả so sánh các mô hình của 3 loại tiền iện tử ............................... 46
Bảng 4.5. Các giá trị tham số cần lựa chọn ể có ược mô hình CNN tối ưu ........ 47
Bảng 4.6. Kết quả tối ưu tham số mô hình CNN - data ETH .................................. 47
Bảng 4.7. Kết quả tối ưu tham số mô hình CNN - data IOTA ................................ 48
Bảng 4.8. Kết quả tối ưu tham số mô hình CNN – data SO ..................................... 49
Bảng 4.9. Kết quả tối ưu tham số của mô hình CNN ............................................... 50
Bảng 4.10. Kết quả các chỉ số của mô hình tối ưu .................................................. 51
Bảng 4.11. Giá gốc và giá dự báo của ETH trong 20 dòng cuối ............................. 52 lOMoAR cPSD| 37054152
Bảng 4.12. Giá gốc và giá dự báo của IOTA trong 20 dòng cuối ........................... 53
Bảng 4.13. Giá gốc và giá dự báo của SOL trong 20 dòng cuối .............................. 54 lOMoARcPSD| 37054152
DANH MỤC CÁC TỪ VIẾT TẮT ATH All Time High API
Application Programming Interface ANN Artificial Neural Network ARIMA
Autoregressive Integrated Moving Average CSV Comma Separated Values CNN Convolutional Neural Networks DNN Deep Neural Network ETH Ethereum GRU Gated Recurrent Unit ICO Initial Coin Offering IOTA
Internet Of Things Application KNN K-Nearest Neighbors LDA Latent Dirichlet Allocation LSTM Long Short-Term Memory MAE Mean Absolute Error MAPE
Mean Absolute Percentage Error MLP Multi-layer Perceptron NPL Natural Language Processing NNAR
Neural Network Auto-Regressive RNN Recurrent Neural Network ROI Return On Investment RMM Richardson Maturity Model RMSE Root-Mean-Square Error SOL Solana SVM Support Vector Machine TDM Term Document Matrix VAR Value at Risk lOMoARcPSD| 37054152 TÓM TẮT
Bài nghiên cứu xây dựng mô hình dự oán sự thành công của các ICO với các
thuật toán KNN và Naive Bayes. Sau ó tiếp tục dự oán giá các coin thành công thông
qua các mô hình RNN, LSTM và CNN. Mục ích là tìm ra ược mô hình dự oán có hiệu
suất cao, dự oán giá chuẩn xác và sai số thấp nhất.
Dữ liệu text-mining thu thập từ coinmarketcap và cryptorank. Bằng phương
pháp thủ công, thu ược 150 whitepaper. Nhóm ã xây dựng mô hình KNN và Naive
Bayes. Dữ liệu dự oán giá thu thập bằng Coin-for-rich, thu ược 3 bộ dữ liệu giá của
ETH, IOTA và SOL, mỗi bộ có 44640 dòng. Nhóm xây dựng mô hình LSTM, RNN,
CNN và sử dụng GridSearchCV ể iều chỉnh tham số phù hợp với mô hình
Kết quả text-mining cho thấy KNN là mô hình có hiệu suất cao nhất với 96,89%.
Về phần dự oán giá, CNN là mô hình phù hợp nhất, dự oán chính xác 73,684% về sự
tăng - giảm của giá ETH, 84,211% với IOTA và 63,168% với SOL.
Bài nghiên cứu chỉ phân loại sự thành công của ICO dựa vào ROI, bởi ROI ược
các nhà ầu tư quan tâm, ảnh hưởng ến quyết ịnh ầu tư. Thực tế còn nhiều yếu tố ảnh
hưởng ến vấn ề này. Về phần dự oán giá, thời gian thu thập dữ liệu còn ngắn và số
lần huấn luyện mô hình ít nên ảnh hưởng ến kết quả dự oán.
Dự oán sự thành công của ICO vẫn còn mới mẻ và chưa có nhiều nghiên cứu.
Dự oán giá tiền iện tử hiện nay nhận ược nhiều sự quan tâm. Kết quả của ề tài nghiên
cứu này sẽ là nguồn tham khảo hữu ích cho những nghiên cứu tiếp theo.
Từ khóa: sách trắng, dự oán, tiền iện tử, khai thác văn bản, máy học. ABSTRACT
This paper builds a model to predict the success of ICOs with KNN and Naive
Bayes algorithms. Then continue to predict the price of successful ICOs through
RNN, LSTM, and CNN models. The goal is to find a predictive model with high
performance, accurate price prediction, and the lowest error.
Text-mining data collected from coinmarketcap and cryptorank. By the manual
method, 150 whitepapers were obtained. The team built KNN and Naive Bayes
models. Price prediction data collected with Coin-for-rich obtained 3 sets of price lOMoAR cPSD| 37054152
data of ETH, IOTA, and SOL, each with 44640 lines. The team builds LSTM, RNN,
and CNN models and uses GridSearchCV to adjust parameters to fit the model.
Text-mining results show that KNN is the model with the highest performance
with 96.97%. As for price prediction, CNN is the most suitable model, correctly
predicting 73.684% for ETH price increase - decrease, 84.211% for IOTA, and 63.168% for SOL.
The study only classifies the success of ICOs based on ROI, because ROI is of
interest to investors, affecting investment decisions. Many factors influence this issue.
As for price prediction, the time to collect data is short and the number of times to
train model is small, which affects the prediction results.
Predicting the success of ICOs is still quite new and not much research is
available. Cryptocurrency price predictions are getting a lot of attention nowadays.
The results of this study will be a useful reference for future studies.
Keywords: whitepaper, prediction, cryptocurrency, text-mining, machine learning. lOMoARcPSD| 37054152
CHƯƠNG 1. TỔNG QUAN ĐỀ TÀI
1.1. GIỚI THIỆU ĐỀ TÀI
Theo Florysiak và Schandlbauer (2022), sách trắng ược xem là nguồn thông tin
hữu ích cung cấp cho các nhà ầu tư tiềm năng ợt phát hành coin ầu tiên (ICO) trong
các dự án trên, làm nền tảng làm cân bằng tính thực tế thông tin giữa nhà phát hành ICO và nhà ầu tư.
Feng và cộng sự (2019) ã cho biết rằng, ICO là một nguồn tài liệu vô cùng quan
trọng ối với các nhà quản lý trên khắp thế giới, chúng mang lại rất nhiều nguồn thông
tin quan trọng và ảnh hưởng ến quyết ịnh ầu tư của các nhà ầu tư bởi vì chỉ có chúng
mới mang lại những nguồn thông tin chính thống về các coin sắp ra mắt. Vậy ánh giá
ược ộ thành công của một ICO có tầm quan trọng như thế nào? Cetingok và Deola
(2018) ã thực hiện một cuộc khảo sát trong số 50 nhà ầu tư và kết quả chỉ ra rằng nội
dung của sách trắng có ảnh hưởng nhiều nhất ến quyết ịnh ầu tư. Đánh giá ược ICO
nào thành công sẽ là một bước ệm lớn trong vấn ề dự oán giá, lợi nhuận và những
biến ổi của chúng, giúp cho nhà ầu tư có những cái nhìn khách quan hơn. Ngày nay,
dự báo tiền iện tử thường ược coi là một trong những vấn ề dự oán chuỗi thời gian
thách thức nhất do số lượng lớn các yếu tố không thể oán trước liên quan và sự biến
ộng áng kể của giá tiền iện tử, dẫn ến sự phụ thuộc phức tạp theo thời gian.
Các mô hình dự báo giá ều dựa trên những kỹ thuật máy học sâu nâng cao như
các lớp bộ nhớ ngắn hạn (LSTM), phức hợp và dài hạn. Các lớp phù hợp ược sử dụng
ể lọc nhiễu trong dữ liệu chuỗi thời gian phức tạp cũng như trích xuất các tính năng
có giá trị mới trong khi các lớp LSTM ược sử dụng ể nắm bắt hiệu quả các mẫu trình
tự cũng như các phụ thuộc dài hạn và ngắn hạn.
Dựa trên các công trình trước ó, mục tiêu của nghiên cứu này gồm hai phần:
Thứ nhất, ánh giá thành công của ICO với sách trắng (phân loại theo ROI) dựa trên
thuật toán text-mining và thứ hai, dự oán giá cho các ICO thành công.
1.2. TÍNH CẤP THIẾT CỦA ĐỀ TÀI
Khai thác văn bản ã trở thành một lĩnh vực nghiên cứu thú vị vì nó giúp khám
phá thông tin có giá trị từ các văn bản phi cấu trúc. Ngoài ra, phân loại tài liệu là một
mối quan tâm trọng tâm trong các nghiên cứu khai thác văn bản, bởi vì số lượng tài lOMoAR cPSD| 37054152
liệu trong mỗi ngành ngành nghề ều ạt số lượng rất lớn và có tính liên ới với rất nhiều
ngành nghề khác, do ó việc sẽ gây ra ra rất nhiều khó khăn nếu thực hiện các quy
trình phân loại bằng tay (Ting và nnk., 2017). Việc xác ịnh các phương pháp, thuật
toán và kỹ thuật xử lý chính xác là rất quan trọng ể trích xuất thông tin bằng cách sử
dụng khai thác văn bản (Dang & Ahmad, 2014). Và trong lĩnh vực tài chính, khai thác
văn bản ã ược áp dụng trong một số hoạt ộng rộng lớn, chẳng hạn như dự oán tỷ giá
hối oái, dự oán thị trường chứng khoán, ứng dụng quản lý quan hệ khách hàng và an
ninh mạng (Kumar & Ravi, 2016). Các thuật toán rất khác nhau giữa các máy vectơ
hỗ trợ, n-gram, bản ồ tự tổ chức, LDA, v.v. Bộ dữ liệu chủ yếu tập trung vào các bài
báo, hồ sơ công ty và tweet.
Dựa trên những kết quả nghiên cứu trên thì việc áp dụng vấn ề khai thác văn bản
vào nhiều lĩnh vực sẽ có thể ưa ra ược những kết quả chính xác và tiết kiệm ược nhiều
thời gian. Chính vì vậy, việc ứng dụng việc khai thác văn bản vào việc dự oán thành
công của một ICO là một iều rất hữu ích. Do ó, sử dụng text-mining vào việc ánh giá
ICO là một lĩnh vực nghiên cứu ầy tiềm năng. Đặc biệt, sau khi dự oán ược dự án
ICO nào có khả năng thành công, việc tiến hành dự oán giá cho chúng sẽ mang lại rất
nhiều lợi ích cho những nhà ầu tư sau này.
Trong nhiều nghiên cứu trước ây về dự báo sự biến ộng của tiền iện tử bằng mô
hình hồi quy, dựa trên giá trước ó mang lại hiệu suất không cao bởi việc dự oán này
chủ yếu dựa trên sai số trung bình bình phương (RMSE) hoặc sai số phần trăm tuyệt
ối trung bình (MAPE) giữa giá trị dự oán và giá trị thực trong 1 mô hình nào ó. Những
giá trị của RMSE thấp chưa ủ nói lên việc dự oán mô hình thực sự mang lại hiệu quả.
Do ó, việc lựa chọn mô hình nghiên cứu sẽ ảnh hưởng nhiều ến tính chính xác của kết quả cuối cùng.
RNN (Elman, 1990) là mô hình máy học có khả năng xử lý ầu vào với bất kỳ ộ
dài nào, khi sử dụng mô hình này không cần lo lắng về kích cỡ mô hình sẽ tăng lên
theo kích cỡ ầu vào. Và ặc biệt, trong suốt quá trình tính toán thì trọng số sẽ ược chia
sẻ. Bên cạnh ó, mô hình RNN còn ược sử dụng nhiều ở lĩnh vực xử lý ngôn ngữ tự
nhiên. Mặc dù, mô hình RNN có khả năng ghi nhớ những thông tin trước ó, nhưng
nó không thể nhớ ược những bước ở xa do bị mất mát ạo hàm. Chính vì vậy, một mô lOMoARcPSD| 37054152
hình cải tiến ể khắc phục ược tình trạng này ra ời, có tên là LSTM (Hochreiter &
Schmidhuber, 1997). Mô hình này ược thừa hưởng toàn bộ từ mô hình RNN nhưng
nó sẽ tích hợp thêm các cổng tính toán ở lớp ẩn ể quyết ịnh giữ lại các thông tin nào.
Theo một nghiên cứu gần ây cho thấy rằng RNN và LSTM là hai mô hình hoạt
ộng tốt hơn những mô hình chuỗi thời gian dự oán tiền iện tử khác (Dutta và nnk.,
2020). Theo một nghiên cứu của Hijazi và nnk. (2015) về sử dụng CNN trong việc
nhận dạng hình ảnh, họ ã khẳng ịnh rằng CNN là thuật toán ược sử dụng rộng rãi và
mang lại nhiều lợi thế trong việc xử lý dữ liệu hình ảnh so với những thuật toán khác.
Theo như nhiều nghiên cứu trước ây cho thấy rằng CNN, LSTM và RNN là
những mô hình mang lại nhiều lợi thế trong việc dự oán tiền iện tử so với những mô
hình Machine Learning khác. (Ji và nnk., (2019); Jiang, 2020; Li & Dai, 2020). Thông
qua nhiều nghiên cứu, cũng như dựa vào những ưu iểm phù hợp cho việc dự oán tiền
ảo, chúng tôi chọn ra 3 mô hình ể thực hiện quá trình dự oán xu hướng biến ộng của
tiền iện tử là RNN, CNN và LSTM.
1.3. CÁC CÔNG TRÌNH NGHIÊN CỨU CÓ LIÊN QUAN
Hiện nay, có rất nhiều nghiên cứu về việc sử dụng text-mining cũng như dự oán
sự biến ộng giá của tiền iện tử ở rất nhiều quốc gia. Chúng tôi ã tham khảo các nghiên
cứu về dự báo tiền iện tử (cụ thể là Bitcoin) và một số nghiên cứu về mô hình khai
thác văn bản ể có thể hoàn thành ề tài một cách tốt nhất. Các báo cáo cáo trước ây gồm:
• Bijalwan và nnk. (2014) ã thực hiện nghiên cứu về việc phân loại các bài báo
dựa trên việc tìm kiếm từ khóa của người dùng bằng 3 mô hình khai thác văn bản là:
KNN, Naïve Bayes và Term Graph. Kết quả cho thấy KNN có ộ chính xác tối a so
với Naive Bayes và Term-Graph. Hạn chế ối với KNN là ộ phức tạp về thời gian của nó cao.
• Ji và nnk. (2019) ã thực hiện một nghiên cứu dự oán giá của Bitcoin dựa trên
những mô hình máy học khác nhau như DNN, LSTM, RNN và Resnets ã ưa ra kết
luận rằng khả năng dự oán của mô hình LSTM tốt hơn các mô hình dự oán khác cho
các bài toán hồi quy, còn mô hình dự trên DNN hoạt ộng tốt nhất cho các bài toán
phân loại. Họ cũng ã ã ánh giá hiệu suất dự oán về giá Bitcoin của các mô hình học lOMoAR cPSD| 37054152
sâu khác nhau như mạng LSTM, mạng nơ-ron phức hợp, mạng nơ-ron sâu, mạng dư
sâu và sự kết hợp của chúng. Kết quả cho thấy rằng mô hình dựa trên DNN thần kinh
sâu hoạt ộng tốt nhất ối với sự lên xuống của giá trong khi các mô hình LSTM hơi tốt
hơn các mô hình còn lại ể dự báo giá Bitcoin.
Li và Dai (2020) ã thực hiện một nghiên cứu về dự oán giá dựa vào các
mô hình thuật toán Machine Learning ể có thể tìm ra mô hình nào trong số những mô
hình nghiên cứu mang lại hiệu suất dự oán tốt nhất. Kết quả cho thấy mạng nơron lan
truyền ngược BP (Back Propagation Neural Network) có hiệu suất kém hơn khi em
nó i so sánh với CNN và LSTM. Trong khi CNN có nhiều lợi thế hơn về chỉ số giá
trị dự oán mà LSTM lại có các chỉ số theo hướng dự oán tốt hơn. Và khi tạo ra hỗn
hợp mạng CNN-LSTM thì ưa ra chỉ số tốt nhất cho cả hai giá trị dự oán và hướng dự oán.
Jiang (2020) ã dự oán giá của Bitcoin bằng 4 phương pháp máy học là
LSTM, GRU, MLP và RMM. Kết quả cho thấy rằng cả 4 mô hình ều có hiệu suất gần
nhau, vì vậy các mô hình khác nhau có thể ược ưu tiên trong các tình huống khác
nhau. LSTM và GRU có hiệu suất tốt nhất trên tập dữ liệu thử nghiệm gốc. Mô hình
MLP yêu cầu ít năng lực tính toán hơn trong khi nó có hiệu suất thấp hơn một chút so với mô hình RNN.
Munim và nnk. (2019) ã so sánh hai mô hình là trung bình ộng tích hợp
tự hồi quy (ARIMA) và mô hình tự ộng hồi quy mạng nơ ron (NNAR). Kết quả là
mô hình ARIMA hoạt ộng tốt hơn NNAR trong việc dự oán giá Bitcoin.
Dutta và nnk. (2020) ã dự oán giá Bitcoin bằng phương pháp tiếp cận
ơn vị ịnh kỳ thông qua mô hình RNN, GRU và LSTM. Kết quả cho thấy rằng mô
hình kết hợp giữa RNN-GRU hoạt ộng tốt hơn LSTM và GRU cũng có xu hướng
hoạt ộng tốt hơn LSTM trên dữ liệu ào tạo ít hơn.
Livieris và nkk. (2020) ã ề xuất một mô hình mạng thần kinh sâu a ầu
vào MICDL ể dự oán giá và chuyển ộng của tiền iện tử. Kết quả của nghiên cứu cho
thấy rằng mô hình ề xuất trên dự oán giá tin cậy hơn so với những mô hình máy học
truyền thống, ngoài ra mô hình này có khả năng khai thác hiệu quả dữ liệu tiền iện tử
hỗn hợp với chi phí thấp hơn. lOMoAR cPSD| 37054152
Phaladisailoed và Numnonda (2018) ã so sánh hai mô hình GRU và mô
hình hồi quy Huber về tính hiệu quả và ộ chính xác cao ể dự oán giá Bitcoin. Kết quả
cho thấy rằng GRU có ộ chính xác hơn, tuy nhiên sẽ mất nhiều thời gian hơn so với Huber.
Chuanjie và nnk. (2019) ã thực hiện một nghiên cứu về việc phân loại
các báo cáo chính thức có thể ược thực hiện thông qua mô hình hóa chủ ề với mô hình
phân bố Dirichlet tiềm ẩn (LDA). Kết quả của mô hình phân loại từ LDA ã cung cấp
rất nhiều thông tin hữu ích trong vấn ề dự oán ICO thành công.
Cetingok và Deola (2018) ã ưa ra một mô hình khai thác văn bản bằng
thuật toán KNN trên sách trắng nhằm tự ộng hóa quyết ịnh ầu tư vào dự án. Kết quả
cho thấy rằng mô hình không mắc bất kỳ sai lầm nào trong việc dự oán 10 ICO thành
công và 7 ICO không thành công.
Derbentsev và nnk. (2020) ã thực hiện một bài nghiên cứu so sánh các
ặc tính tiên lượng cho nhiệm vụ dự oán ngắn hạn về tỷ giá hối oái tiền iện tử của một
số mô hình máy học: thuật toán BART, Mạng thần kinh nhân tạo (ANN) và cây quyết
ịnh kết hợp — RF. Kết quả của nghiên cứu này cho thấy rằng các thuật toán Machine
Learning (cụ thể là ANN, C&RT và các tổ hợp của chúng) ưa ra kết quả tốt hơn so
với các thuộc tính thống kê chuỗi thời gian so với các phương pháp thống kê và kinh tế lượng cổ iển.
Một nghiên cứu so sánh giữa RNN và tự ộng hồi quy vectơ (VAR) ược
thực hiện bởi El-Abdelouarti Alouaret (2017) ể dự oán giá Bitcoin. Kết quả của họ
cho thấy rằng các mô hình RNN có hiệu suất tốt hơn so với phương pháp VAR.
Li và nnk. (2020) ã thực hiện nghiên cứu dự oán biến ộng giá Bitcoin
bằng việc sử dụng LSTM và một mạng nhúng. Kết quả cho thấy rằng mô hình kết
hợp LSTM và mạng nhúng ạt hiệu suất vượt trội so với mô hình LSTM căn bản.
Mudassir và nnk. (2020) ã thực hiện một bài nghiên cứu các dự báo giá
Bitcoin từ ngắn hạn ến trung hạn bằng cách sử dụng các mô hình máy học, bao gồm
ANN, SANN, SVM và LSTM. Kết quả cho thấy rằng các mô hình ều ạt yêu cầu và
hiệu suất tốt. Trong ó LSTM ã cho thấy hiệu suất tổng thể tốt nhất. Tuy nhiên ối với lOMoARcPSD| 37054152
những dự báo hàng ngày thì MAPE ạt hiệu suất thấp nhất là 1,44%, trong khi nó thay
ổi từ 2,88% ến 4,10% cho thời hạn từ bảy ến chín mươi ngày.
Greaves và Au (2015) ã thu thập các giao dịch Bitcoin ể dự oán giá
Bitcoin. Họ ã sử dụng bốn mô hình phân loại là: Baseline, hồi quy logistic, SVM và
mạng nơ ron. Kết quả thu ược cho thấy các mô hình có ộ chính xác gần như tương
ương nhau, cao nhất là mô hình mạng nơ-ron với 55,1%, mô hình hồi quy logistic là
54,3%, SVM là 53,7% và 53,4% ối với mô hình Baseline.
• Dai và cộng sự (2007) ã thực hiện một nghiên cứu về phân loại văn bản thông
qua mô hình Naïve Bayes và họ ã ưa ra kết luận về hiệu quả phân loại văn bản của
thuật toán Naïve Bayes ạt hiệu suất sao
• Jadhav và Channe (2014) ã thực hiện một nghiên cứu ể ánh giá hiệu suất phân
loại văn bản của các thuật toán KNN, Naive Bayes, Decision Tree và kết quả cho thầy
rằng mô hình KNN mang lại hiệu suất phán oán tốt nhất so với hai thuật toán còn lại,
Naive Bayes mang lại kết quả phán oán với thời gian huấn luyện nhanh nhất.
1.4. NHỮNG ĐIỂM MỚI CỦA ĐỀ TÀI
Thông qua những nghiên cứu trước ây có thể thấy rằng, ã có nhiều nghiên cứu
thành công nhờ áp dụng vấn ề khai thác văn bản cũng như dự oán giá tiền iện tử. Việc
chúng tôi tiếp tục sử dụng text-mining vào việc ánh giá white paper là lĩnh vực nghiên
cứu ầy tiềm năng, vừa góp phần phát triển việc ứng dụng khai thác văn bản vào việc
ánh giá các ICO. Điểm mới là chúng tôi kết hợp việc ánh giá sự thành công cộng thêm
với việc dự oán giá cho các ICO. Điều này sẽ mang lại rất nhiều lợi ích và sự tham
khảo cho những nhà ầu tư. Tuy ề tài còn hạn chế về nhiều mặt (sẽ ược trình bày cụ
thể ở chương 5), tuy nhiên cũng có thể xem là tài liệu ể các nhà nghiên cứu có chuyên
môn phát triển thêm về sau.
Theo chúng tôi tìm hiểu và nhận ịnh ở nhiều nghiên cứu trước ây, dữ liệu dự báo
giá tiền iện tử ược thu thập trên những trang web là khá hạn chế, không áp ứng ược ộ
chính xác của dự án. Tại nghiên cứu của tác giả Phạm Hoàng Anh (2021), tác giả ã
thực hiện dự báo giá của Bitcoin bằng cách thu thập dữ liệu giá Bitcoin theo từng
ngày bằng Coinmarket. Tuy kết quả thu về khá tích cực, nhưng các sai số của mô hình
tốt nhất còn khá cao. Nhận thấy iều ó, ở bài nghiên cứu này, chúng tôi ã thu thập dữ lOMoARcPSD| 37054152
liệu bằng công cụ Coin-for-rich của tác giả Trần Việt Anh và Vương Hoài Nam. Công
cụ này giúp thu thập dữ liệu thực tế ngay tại thời iểm thu cũng như thu dữ liệu lịch sử
của các loại tiền iện tử từ REST APIs trên sàn Binance, qua các biến số: giá mở cửa,
giá cao, giá thấp, giá óng cửa, số lượng giao dịch và giá trị vốn hóa thị trường. Các
biến số này ược thu về với sự biến ộng chênh lệch theo từng phút. Tất cả ều có sự tác
ộng ối với các giao dịch và hầu như ều xuất hiện trên các sàn giao dịch tiền iện tử.
Việc thu thập dữ liệu tự ộng hóa thông qua API sẽ giúp dữ liệu thu ược sạch hơn, giúp
người dùng có thể dễ dàng xây dựng ứng dụng phân tích dữ liệu của riêng mình. Với
công cụ này, người dùng có thể tùy chỉnh thời gian thu thập dữ liệu và ứng dụng theo
ý mình, chạy mô hình ngay trên database ã ược kéo. Nhờ ó, chúng tôi có thể ưa ra
những dự báo về giá thông qua các mô hình máy học một cách cụ thể và chi tiết hơn.
1.5. MỤC TIÊU NGHIÊN CỨU
Với bài nghiên cứu này, nhóm chúng tôi nhận ịnh cần phải thực hiện ược các mục tiêu cụ thể sau:
Đánh giá sự thành công của một ICO thông qua thuật toán text-mining: Để
có thể ánh giá và phân loại ược sự thành công của một ICO bất kỳ thì cần phải xác
ịnh ược yếu tố nào sẽ quyết ịnh ến khả năng thành công. Đối với các dự án kinh tế
nói chung và ICO nói riêng thì lợi nhuận sẽ là yếu tố ảnh hưởng lớn ến quyết ịnh rót
vốn của các nhà ầu tư, từ ó sẽ quyết ịnh khả năng thành công hay không của một dự
án ICO. Do ó trước khi dự oán khả năng thành công của ICO thì ta phải thu thập và
phân loại ược ROI của ICO nào thành công và không thành công qua mức ộ % của ROI.
Chọn lọc ược những ICO có khả năng thành công trong tương lai: Để có thể
chọn lọc ược ICO thành công trong tương lai thì phải dựa vào các ICO ã thành công
trong quá khứ, dựa vào trung bình %ROI của các ICO ã nổi tiếng ể có thể làm nền
tảng dự oán ược ICO thành công trong tương lai thông %ROI và chiều hướng tăng
hay giảm của các ICO này.
Phân tích và dự báo giá của những ICO thành công thông qua việc triển khai
và huấn luyện các mô hình máy học CNN, RNN và LSTM: Để có thể phân tích và
dự báo, cần phải thu thập ược bộ dữ liệu giá của các loại tiền iện từ, từ ó huấn luyện lOMoARcPSD| 37054152
chúng bằng các mô hình máy học. Sau quá trình huấn luyện, thực hiện so sánh các
chỉ số hiệu suất nhằm ể lựa chọn mô hình dự báo tốt nhất nhất, ồng thời tối ưu các
tham số của mô hình ể mô hình cuối cùng là chuẩn nhất, dự báo ược kết quả chính xác nhất.
So sánh biến ộng so với giá thực tế: Từ kết quả dự báo giá, thực hiện so sánh
thủ công ể kiểm tra ược sự biến ộng và chênh lệch so với thực tế (so sánh sự chênh
lệch của giá dự báo với sự chênh lệch của giá thực tế từ bộ dữ liệu ã thu thập từ trước).
Từ ó ưa ra ược phương án phù hợp và ề xuất hướng phát triển tốt hơn cho ề tài.
Trả lời ược các câu hỏi nghiên cứu: Cùng với các mục tiêu trên, trong bài
nghiên cứu này, chúng tôi cũng sẽ thông qua việc xây dựng các thuật toán và thực
hiện chúng mà lần lượt giải áp cho những câu hỏi dưới ây:
- Làm thế nào ể ưa ra ược ánh giá ược khả năng thành công của ICO bất kỳ
thông qua chỉ số ROI và whitepaper của các ICO?
- Trong quá trình thu thập dữ liệu thì nền tảng nào cho cho phép việc thu thập
các thông tin về ROI cũng như các whitepaper ICO?
- Việc ánh giá sự thành công của whitepaper sẽ ược thực hiện trên mô hình máy học nào?
- Việc dự oán giá dựa vào các dữ liệu thu thập bằng API sẽ mang lại kết quả
như thế nào so với các data có sẵn từ các trang web tiền iện tử uy tín như coin market?
- Mô hình thuật toán dự oán giá Machine Learning nào sẽ mang lại hiệu quả tốt
nhất, dự oán giá chính xác nhất cho các ICO ã ược ánh giá là thành công trước ó?
1.6. ĐỐI TƯỢNG, PHẠM VI, PHƯƠNG PHÁP NGHIÊN CỨU
Đối tượng, phạm vi nghiên cứu: Đồ án tập trung vào chỉ số ROI của các loại tiền
ảo trên sàn Binance với những dữ liệu về sự biến ộng giá ược thu thập bằng cách kéo
dữ liệu lịch sử từ REST APIs cùng với 150 whitepaper ược thu thập từ nền tảng coinmarket.
Phương pháp nghiên cứu: Thông qua việc thu thập dữ liệu sơ cấp và thứ cấp của
nhiều loại tiền iện tử phổ biến, kết hợp với phân tích và xử lý số liệu ể ưa ra kết quả có tính chính xác cao. lOMoARcPSD| 37054152
1.7. BỐ CỤC CỦA ĐỀ TÀI
Ngoài phần tóm tắt ề tài, kết luận, mục lục, các danh mục hình ảnh, sơ ồ và tài
liệu tham khảo, kết cấu ề tài bao gồm 5 chương:
Chương 1. Tổng quan ề tài
Chương 2. Cơ sở lý thuyết
Chương 3. Phương pháp thực hiện
Chương 4. Kết quả thực hiện
Chương 5. Kết luận ề tài - ề xuất hướng phát triển lOMoARcPSD| 37054152
CHƯƠNG 2. CƠ SỞ LÝ THUYẾT 2.1. ICO LÀ GÌ?
ICO là viết tắt của từ Initial Coin Offering ược dịch ra là phát hành tiền mã hóa
lần ầu. Đây là một cách ể giúp các nhóm dự án tiền mã hóa có thể huy ộng vốn trong
nhóm những người am hiểu và có khả năng ầu tư vào những dự án tiền mã hóa. Trong
mỗi ợt ICO, các nhóm dự án sẽ tạo ra các token trên blockchain ể bán cho những
người mua trước khi các loại tiền mã hóa này ược phát hành ể họ có thể sử dụng trước
hoặc sử dụng trong tương lai, bên cạnh ó các dự án này sẽ ược rót vốn ể phát triển tốt hơn.
ICO nổ ra phố biến vào năm 2014 và phương pháp này ược nhiều người biết ến
khi sử dụng ể huy ộng vốn cho ồng tiền Ethereum và gây ược nhiều tiếng vang ến
hiện nay. Từ ó rất nhiều dự án blockchain ã sử dụng phương pháp này ể huy ộng vốn.
2.2. THUẬT TOÁN KNN (K-NEAREST NEIGHBORS)
KNN là một kỹ thuật học có giám sát, thường ược sử dụng ể phân loại quan sát
mới thông qua việc tìm kiếm các iểm tương ồng giữa quan sát mới với những dữ liệu
sẵn có. Tuy mô hình này ơn giản nhưng ộ chính xác của nó cũng khá ổn ịnh vì nó
không có tham số như nhiều mô hình máy học khác. Mô hình sẽ không ưa ra bất cứ
giả ịnh nào trong việc phân bổ dữ liệu và mô hình này ược sử dụng trực tiếp ể phục vụ phân loại a lớp.
Zhang và nnk. (2018) cho rằng KNN là phương pháp phân loại trong khai thác
dữ liệu và thống kê các iểm gần nhất với quy trình thực hiện ơn giản và hiệu suất
phân loại áng kể. Mặc dù thuật toán KNN sẽ tốn nhiều thời gian cho các bước xử lý
tiền dữ liệu nhưng thuật toán này mang lại ộ chính xác cao hơn các thuật toán khác (Bijalwan và nnk., 2014).
Thuật toán KNN sẽ ưa ra giả ịnh rằng những thứ có tính chất giống nhau sẽ nằm
ở vị trí gần nhau. Sau ó KNN sẽ phán oán mức ộ giống nhau của 2 iểm dữ liệu dựa
vào khoảng cách giữa giữa chúng thông qua việc xây dựng công thức toán học.
Ưu iểm của mô hình này chính là quá trình huấn luyện ơn giản và không tốn nhiều
thời gian. Việc dự oán kết quả ầu ra của data cũng không phức tạp và không yêu
cầu ưa ra giả sử về vấn ề phân phối của các class. Tuy nhiên, mô hình này khi sử lOMoARcPSD| 37054152
dụng cũng có khuyết iểm là nếu tham số ịnh nghĩa K nhỏ sẽ sẽ gây ra việc nhiễu kết
quả của mô hình. Ngoài ra, KNN là thuật toán có những tính toán trong quá trình dự
oán tập trung ở khâu test dữ liệu. Do vậy, việc tính khoảng cách của từng iểm dữ
liệu của training set sẽ tốn nhiều thời gian. Tham số K càng lớn thì mức ộ phức tạp
của mô hình sẽ càng lớn. Nếu việc lưu trữ dữ liệu nằm toàn bộ trong bộ nhớ sẽ ảnh
hưởng ến hiệu suất của mô hình.
2.3. THUẬT TOÁN NAIVE BAYES
Theo Rish (2001) Naive Bayes còn ược gọi là mô hình phân lớp, có thể ơn giản
hóa việc huấn luyện mô hình một cách áng kể bằng việc giả ịnh các biến là ộc lập.
Đây là một mô hình máy học dùng ể phân loại các mẫu dựa vào các ặc tính ã ược xác
ịnh trước ó. McCallum và Nigam (1998) ã khẳng ịnh rằng mô hình Naive Bayes là
mô hình phân loại ơn giản, bởi trong quá trình phân loại ều giả ịnh rằng tất cả các
thuộc tính của các biến ộc lập với nhau trong các lớp dữ liệu. Theo Zhang và Gao
(2011), Naive Bayes ược ứng dụng nhiều trong lĩnh vực phân loại văn bản nhờ vào
ặc trưng tính ược tần số xuất hiện của một từ trong một văn bản cụ thể, dựa trên các
iều kiện xác suất của các ối tượng của thuộc tính ược chọn bằng các phương pháp lựa chọn ối tượng.
Mô hình này ược xây dựng dựa trên nguyên lý Bayes trong xác suất thống kê (Efron, 2013).:
Theo công thức trên, người ta áp dụng ịnh lý Bayes ể tính toán xác suất sự kiện
A xảy ra khi ã biết sự kiện B xảy ra, kí hiệu là P(A|B). Trong ó P(A) và P(B) lần lượt
là xác suất xảy ra của 2 sự kiện A và B.
Mô hình này có ưu iểm là khá ơn giản và dễ sử dụng, với khả năng oán nhãn của
dữ liệu test ạt ở mức cao và có ộ chính xác cao. Ngoài ra, Naive Bayes cũng ưa ra giả
ịnh các feature của dữ liệu mang tính ộc lập với nhau, nhờ ó thuật toán chạy rất nhanh
so với các thuật toán phân loại văn bản khác. Tuy nhiên, trong quá trình test, mặc dù
Naive Bayes ưa ra các dự oán chính xác, nhưng khi chạy thuật toán với dữ liệu training lOMoARcPSD| 37054152
thì ộ chính xác của nó còn khá hạn chế so với nhiều thuật toán khác. Ngoài ra thì trong
thực tế thì các biến của dữ liệu không thể hoàn toàn ộc lập với nhau. 2.4. CONFUSION MATRIX
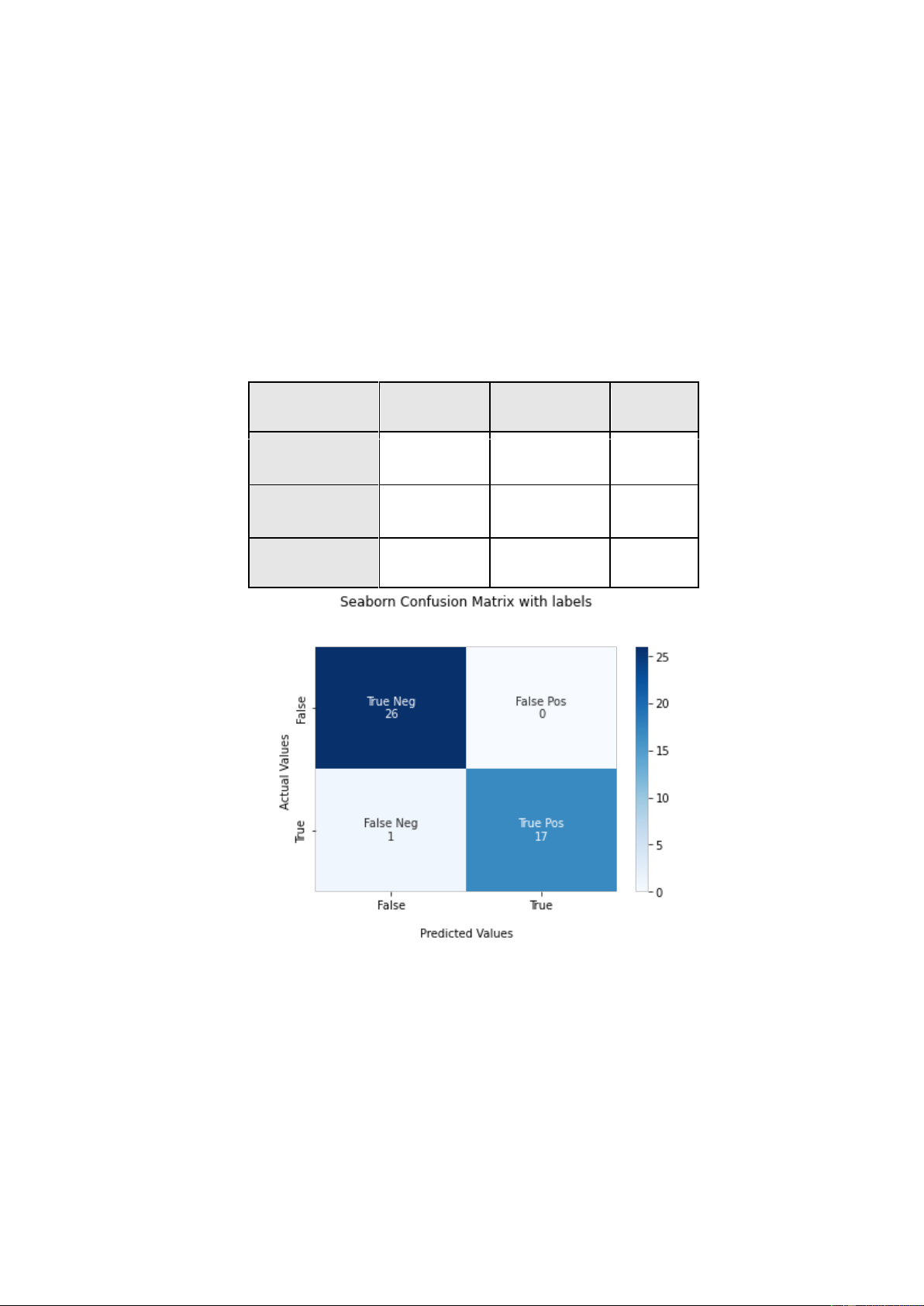
Confusion Matrix ược gọi là ma trận nhầm lẫn hay ma trận lỗi. Krstinić và nnk.
(2020) ã nhận ịnh rằng ma trận nhầm lẫn là một bản ghi chi tiết o lường hiệu suất phổ
của quá trình phân loại văn bản biến nhất và ược sử dụng phổ biến cho nhiều mô hình
máy học. Luque và nnk. (2019) ã ưa ra kết luận rằng sử dụng ma trận lỗi không chỉ ể
ánh giá hiệu suất kết cùng mà các thuật toán mang lại mà ngoài ra còn dựa vào những
chỉ số trong ma trận ể tối ưu mô hình bằng việc iều chỉnh các tham số của thuật toán.
Ma trận lỗi hiển thị ở dạng bố cục bảng ể giúp hình dung hiệu suất của một mô hình
thuật toán cụ thể và rõ ràng nhất. Cụ thể, với mỗi lớp phân loại, một confusion matrix gồm có 4 chỉ số::
Hình 2.1. Cấu trúc ma trận Confusion Matrix (Luque và nnk, 2019) Trong
ó, các chỉ số quan trọng bao gồm:
TP (True Positive): Số lượng iểm của lớp positive ược phân loại úng là positive
TN (True Negative): Số lượng iểm của lớp negative ược phân loại úng là negative
FP (False Positive): Số lượng iểm của lớp negative bị phân loại sai thành positive
FN (False Negative): Số lượng iểm của lớp positive bị phân loại sai thành negative
Từ 4 chỉ số dự oán trên, người ta sử dụng ể ánh giá ộ tin cậy của mô hình thông qua
Precision và Recall theo công thức (Krstinić và nnk, 2020): lOMoARcPSD| 37054152 Trong ó:
Precision: tỉ lệ số iểm TP trong tổng số những iểm ược phân loại là Positive
Recall: tỉ lệ số iểm TP trong tổng số những iểm thực sự là Positive.
Với 2 chỉ số này, ta có thể tính ược chỉ số ánh giá ộ chính xác cho cả mô hình theo công thức:
2.5. MÔ HÌNH RNN (RECURRENT NEURAL NETWORK)
RNN là một mô hình ngôn ngữ và tự ộng sinh văn bản, nó có thể cho biết xác
suất của một từ dựa vào khả năng nhớ các thông tin ược tính toán trước ó. RNN là
mô hình khá phổ biến và ược sử dụng nhiều trong lĩnh vực xử lý ngôn ngữ tự nhiên
hay nhận dạng giọng nói.
Hình 2.2. Cấu trúc của mạng nơ-ron hồi quy (RNN) (Peng và nnk., 2020)
RNN có cách thức hoạt ộng hoàn toàn khác so với mạng Neuron thông thường
(Feedforward Neural Network). Thông tin của mạng Neuron thông thường truyền
theo một hướng thẳng cố ịnh từ lớp ầu vào sau ó qua lớp ẩn và cuối cùng là lớp ầu ra.
Do ó luồng thông tin chỉ truyền theo một chiều và không có chiều ngược lại. Vì thế
Feedforward Neural Network không có bộ nhớ cho lớp ầu vào, nó chỉ nhớ ược những
dữ liệu trong quá khứ và không có quá trình huấn luyện. Ngược lại, RNN lại có luồng
thông tin ược di chuyển theo một vòng lặp lại, liên tục nối tiếp nhau theo thời gian.
Do ó khi RNN ưa ra dự oán của mình thì nó sẽ xem lại những dữ liệu nó ã ược nhận
trước ó dựa trên bộ nhớ. lOMoARcPSD| 37054152
Hình 2.3. Hướng di chuyển luồng thông tin của RNN và feedforward neural (Greaves và Au, 2015)
Điểm ặc biệt của RNN so với nhiều mô hình khác ó chính là nó có hai ầu vào và
dữ liệu hiện tại có sự xuất hiện của dữ liệu trong quá khứ. Điều này vô cùng hữu hiệu
vì chuỗi dữ liệu lưu trữ những thông tin xảy ra trong quá khứ sẽ giúp thuật toán ưa ra
phán oán tốt hơn. Đây là iều tạo nên sự khác biệt của RNN so với những thuật toán khác.
Ngoài ra, RNN có thể xử lý dữ liệu ầu vào với ộ dài dữ liệu là vô hạn, ồng thời
kích cỡ của mô hình không phụ thuộc vào kích cỡ của dữ liệu ầu vào. Tuy nhiên, tốc
ộ tính toán của RNN nhìn chung vẫn còn chậm so với một số mô hình khác. Việc truy
cập thông tin từ một khoản thời gian dài trước ó bị hạn chế. Nó cũng không tận dụng
ược dữ liệu ầu vào trước ó cho quá trình tính toán hiện tại.
Đối với mạng Neuron truyền thống, không có quá trình chia sẻ tham số giữa các
tầng mạng. Tuy nhiên với RNN, mạng này ã sử dụng trạng thái ẩn trước ó (ht-1) ể
tính toán trạng thái ẩn hiện tại (ht). Chính vì iều này mà kết quả ầu ra cuối cùng sẽ
phụ thuộc vào chuỗi dữ liệu thời gian. Ví dụ như ể tính ược ht, ta phải phụ thuộc vào
ht-1, mà ht-1 sẽ lại tiếp tục phụ thuộc vào ht-2…. Chính vì dữ liệu mang ý nghĩa trình
tự như thế nên nếu thay ổi trình tự dữ liệu sẽ có kết quả ầu ra khác. Ngoài ra, cũng vì
sự tuần tự này mà không tận dụng ược khả năng tính toán song song của máy tính.
Đây là một trong những hạn chế lớn của RNN.
Bên cạnh ó, RNN còn gặp phải 2 vấn ề gradient:
Vanishing gradient ( ạo hàm bị triệt tiêu): Các hàm kích hoạt là tanh và sigmoid
của RNN có kết quả ầu ra lần lượt nằm trong oạn [-1,1] và [0,1]. Chính vì thế mà ạo
hàm của 2 hàm này ều bằng 0 tại cả 2 ầu. Điều này sẽ làm nút mạng tại iểm ó bị bão
hòa, ồng nghĩa với việc các nút trước ó cũng bão hòa theo. Các giá trị nhỏ khi thực lOMoARcPSD| 37054152
hiện phép nhân ma trận ạo hàm sẽ xảy ra tình trạng ạo hàm bị triệt tiêu chỉ sau vài
bước. Khi ó làm cho mô hình không thể học ược những phụ thuộc xa và bị ảnh hưởng
ến kết quả học và dự oán.
Exploding gradient (bùng nổ ạo hàm): Vấn ề này xảy ra khi những giá trị của
ma trận lớn hơn 1. Khi xảy ra bùng nổ ạo hàm sẽ làm cho chương trình học bị dừng.
2.6. MÔ HÌNH LSTM (LONG SHORT - TERM MEMORY)
LSTM là mạng bộ nhớ ngắn hạn, ây là một dạng của RNN nhưng ã khắc phục
ược các vấn ề về Gradient mà RNN gặp phải. Mô hình này ược giới thiệu bởi
Hochreiter và Schmidhuber (1997), sau nhiều lần cải tiến ã ược sử dụng khá rộng rãi.
LSTM ược thiết kế ể khắc phục vấn ề phụ thuộc xa của mô hình RNN. Đặc trưng của
mô hình này là khả năng nhớ ược thông tin trong thời gian là ặc tính cố ịnh, không
yêu cầu người dùng huấn luyện thì LSTM vẫn nhớ ược.
Hình 2.4. Cấu trúc mạng LSTM (Peng và nnk., 2020)
LSTM hoạt ộng tương tự như mô hình RNN, tuy nhiên nó có khả năng ghi nhớ
ầu vào trong thời gian dài hơn. Bộ nhớ của mô hình LSTM có thể ọc, ghi và xóa thông
tin ra khỏi bộ nhớ của nó khá giống như bộ nhớ của một chiếc máy tính. Và bộ nhớ
của LSTM có khả năng kiểm soát dựa vào tầm quan trọng của thông tin thông qua
trọng số ược gán vào mà nó sẽ ưa ra các quyết ịnh lưu trữ hay xóa thông tin. Điều này
cho thấy rằng mô hình ược huấn luyện theo thời gian sẽ có thể tự ộng ưa ra quyết ịnh
thông tin nào quan trọng và không quan trọng.
Về cơ bản, mô hình LSTM có cấu trúc tương tự như RNN nhưng ược cải tiến,
khắc phục các vấn ề về gradient mà RNN mắc phải nhờ bộ nhớ dài hạn hơn, giúp sử
dụng những dữ liệu ầu vào trước ó ể dự oán cho những dữ liệu hiện tại và luôn giữ lOMoARcPSD| 37054152
cho các gradient ủ ộ dốc. Trong mô hình LSTM sẽ có 3 cổng là input gate, output gate
và forget gate. Ba cổng này có nhiệm vụ ưa ra quyết ịnh ưa ầu vào mới vào cổng input
gate, loại bỏ thông tin không cần thiết ở cổng forget và ưa ra ầu ra ở cổng output gate.
2.7. MÔ HÌNH CNN (CONVOLUTIONAL NEURAL NETWORK)
CNN là mạng nơ ron tích chập, ược biết ến là một trong những mô hình Deep
Learning tiên tiến nhất. Mô hình có thể cho phép người sử dụng xây dựng các hệ
thống tự ộng thông minh với ộ chính xác ạt ở mức ộ cao. Kiến trúc của CNN khá
tương tự mô hình kết nối của các nơ ron trong não người. Mô hình này thường ược
sử dụng nhiều trong phương diện nhận dạng ối tượng trong ảnh trực quan hoặc ược
xây dựng ể xử lý dữ liệu thông qua nhiều mảng.
Hình 2.5. Cấu trúc mạng CNN (Phung & Rhee, 2018)
CNN sử dụng một lớp mạng ặc biệt có tên là Convolutional layer – Conv (lớp
chập) có tác dụng làm giảm ộ phức tạp của hình ảnh ể dễ dàng hơn cho quá trình xử
lý nhưng vẫn không làm ảnh hưởng ến hiệu suất dự oán của mô hình. Ngoài
Convolutional layer ra, mô hình CNN còn có một lớp nữa ó chính là pooling layer
(lớp tổng hợp), có tác dụng làm giảm tài nguyên cho phép tính, giải quyết ược vấn ề
overfitting khi thực hiện dự oán của mô hình. Những giá trị của lớp pooling ược ưa
về một giá trị duy nhất. Việc chuyển ổi này có thể làm kích thước ầu vào cho những
lớp tiếp theo. Do ó giảm tham số học là một iều cần thiết ể tránh vấn ề mô hình bị overfitting.
Lớp cuối cùng của CNN có tên là Fully connected layer (lớp kết nối), ược dùng
ể chuyển ổi các tính năng ã ược trích xuất từ các lớp trước ể hoàn thành ược ầu ra sau
cùng. Các thông tin sau khi i qua mỗi lớp và hàm kích hoạt (ReLU) sẽ tạo ra thông lOMoARcPSD| 37054152
tin trừu tượng hơn cho những lớp tiếp sau ó. Và thông qua quá trình train model, các
lớp sẽ tự ộng học các giá trị thể hiện qua những lớp filter. lOMoARcPSD| 37054152
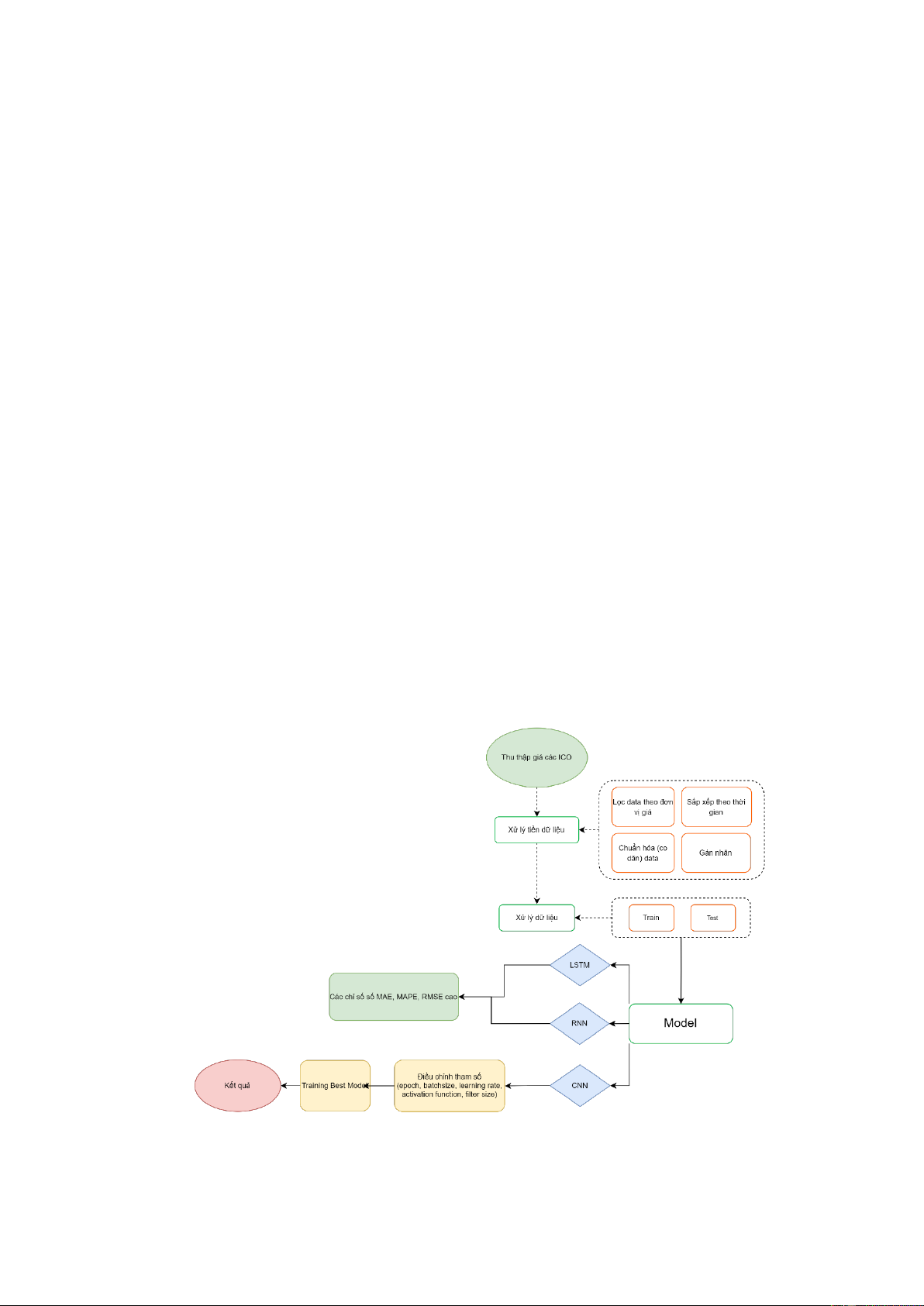
CHƯƠNG 3. PHƯƠNG PHÁP THỰC HIỆN
3.1. LƯU ĐỒ TỔNG QUAN QUÁ TRÌNH THỰC HIỆN ĐỀ TÀI
Dưới ây là lưu ồ toàn bộ quá trình thực hiện ề tài:
Hình 3.1. Lưu ồ tổng quan các bước thực hiện ề tài (Nhóm thực hiện)
Đầu tiên, chúng tôi thực hiện quá trình Xây dựng mô hình ánh giá sự thành công
của các ICO. Quá trình này ược thực hiện và coding bằng ngôn ngữ R, thao tác trên
Rstudio (trình bày cụ thể ở phần 3.2). Sau khi có ược kết quả và lựa chọn ược mô
hình phân loại ICO tốt nhất, nhóm lựa chọn ra các coin thành công, có chỉ số ROI
cao, có tiềm năng phát triển và ược nhiều nhà ầu tư quan tâm ầu tư ể tiếp tục thực
hiện quá trình dự oán giá của các coin ó. Quá trình Xây dựng mô hình dự oán giá các
loại tiền iện tử thành công và thực hiện coding bằng ngôn ngữ lập trình
Python, thao tác trực tiếp trên Google Colab (trình bày cụ thể ở phần 3.3)
3.2. PHƯƠNG PHÁP ĐÁNH GIÁ SỰ THÀNH CÔNG CỦA CÁC ICO
3.2.1. Thu thập whitepaper của các ICO
Chúng tôi thực hiện ánh giá sự thành công và không thành công của 150 ICO
dựa vào yếu tố ROI. Dữ liệu ược thu thập thủ công từ hai nguồn là coinmarketcap và
cryptorank. Trong ó cryptorank giúp thu thập thông tin về ROI của các ICO,
coinmarketcap giúp thu thập các whitepaper. Mục ích cuối cùng là tìm cách phân tích
các dự án ICO có khả năng ạt ược lợi nhuận, ược ầu tư và niêm yết sau mỗi lần bán lOMoARcPSD| 37054152
kết thúc trên các sàn giao dịch tiền iện tử uy tín một cách tự ộng. Cụ thể ở ây, chúng
tôi thực hiện tìm kiếm các ICO trên sàn giao dịch iện tử Binance.
Hình 3.2. Tổng hợp số lượng ICO ã thu thập (Nhóm thực hiện)
Để ánh giá sự thành công của các ICO, chúng tôi chọn ra 62 ICO có chỉ số ROI
ạt trên 100% từ ầu năm 2021 - 10/2021. Trong ó có những ICO ã và ang ược nhiều
nhà ầu tư quan tâm và mang lại lợi nhuận cao như Solana (SOL), Ethereum (ETH),
IOTA,... Với những ICO không thành công, chúng tôi thực hiện lựa chọn những ICO
có chỉ số ROI <30%, ã ngừng hoạt ộng hoặc ít nhất ến khoảng thời gian 10/2021
không mang lại lợi nhuận cho những nhà ầu tư. Số lượng ICO không thành công thu thập ược là 48 ICO.
Để nâng cao ược mức ộ chắc chắn cho quá trình phân tích và thực hiện
textmining, chúng tôi tạo thêm một nhóm các ICO không thành công có chỉ số ROI
<50% và chỉ số ATH ROI <100%. Trong ó, ATH là chỉ số thể hiện giá trị cao nhất
của một loại tài sản nào ó so với giá trị hiện tại của chính nó. Nếu mức lợi nhuận này
<100%, tức là ICO không thành công.
Tổng kết lại, chúng tôi ã thu thập ược whitepaper của 62 ICO thành công và 88
ICO không thành công. Dựa trên sự phân loại cơ bản này, tiếp tục thực hiện quá trình
text-mining ể ánh giá sự thành công của các ICO.
3.2.2. Lưu ồ thực hiện text-mining ánh giá sự thành công các ICO
Với mục ích là nghiên cứu ể xây dựng ược mô hình phân loại các ICO ra thành
2 loại thành công và không thành công, chúng tôi ã tham khảo nhiều nghiên cứu về
phân loại từ các bài nghiên cứu trước ây. Cuối cùng, chúng tôi phát hiện các thuật lOMoARcPSD| 37054152
toán về text-classification hay text-mining là kỹ thuật hợp lý ể có thể tiến hành phân
tích các whitepaper ã thu thập ược. Dưới ây là lưu ồ xây dựng cho mô hình text- mining:
Hình 3.3. Lưu ồ thực hiện ánh giá sự thành công của các ICO (Nhóm thực hiện)
Dựa vào các dữ liệu là các whitepaper ược phân loại theo ROI ã thu thập ược,
về cơ bản chúng ta ã biết ược các ICO nào thành công hay không thành công. Bước
tiếp theo, chúng tôi sẽ ưa những whitepaper ó vào mô hình text-mining ể thực hiện
xử lý dữ liệu phi cấu trúc và lấy ma trận số từ các whitepaper ể làm thông tin cho các thuật toán:
Bước ầu tiên của quy trình text-mining là ọc dữ liệu data và xử lý dữ liệu. Chúng
tôi tiến hành chuyển 150 file whitepaper ở dạng pdf sang dạng text ể mô hình có thể ọc hiểu ược.
Tiếp theo, chúng tôi thực hiện xử lý tiền dữ liệu. Đây là một bước quan trọng,
giúp cho dữ liệu ầu vào ược “sạch” hơn, quá trình huấn luyện mô hình cũng hiệu
quả hơn. Ở bước này chúng tôi thực hiện loại bỏ những từ không có ý nghĩa, cụ thể
là loại bỏ các mạo từ, từ kết hợp, giới từ, ại từ, URLs, chuyển hóa tất cả các từ ở
nhiều thì trở về thành từ gốc. Ví dụ các từ “singing” hay “sings” sẽ ược chuyển về
dạng từ gốc là “sing”. Bước này sẽ giúp cho quá trình huấn luyện mô hình tốt hơn,
không ảnh hưởng ến hiệu suất.
Chúng tôi thực hiện tạo mô hình bag of words (mô hình Term Document
Matrix). Khan và nnk. (2013) cho rằng bag of word là một mô hình túi từ ược sử dụng lOMoARcPSD| 37054152
trong lĩnh vực phân loại văn bản, nhằm ể biểu diễn các từ trong văn bản một cách ơn
giản phục vụ việc truy vấn thông tin khi huấn luyện các thuật toán. Cụ thể là sẽ tiến
hành tạo một cột cho mỗi từ và một hàng cho mỗi whitepaper. Bước này sẽ chuyển
ổi văn bản sang dạng ịnh lượng ể có thể phân tích từ kho dữ liệu có sẵn, loại bỏ sự
thưa thớt trong dữ liệu và tạo mô hình túi từ. Salman và Obaida (2021) ã ưa ra kết
luận rằng mô hình bag of word ược sử dụng trong vấn ề xử lý tiền dữ liệu hay mã hóa
văn bản sẽ giúp các thuật toán ưa ra kết quả sát với thực tế hơn. Cụ thể, việc tạo mô
hình này thực chất là tạo một ma trận thưa thớt, giúp lọc i những thuật ngữ ít xuất
hiện trong ma trận, từ ó giúp quá trình huấn luyện mô hình sẽ cho ra kết quả dự báo chính xác hơn.
Sau khi dữ liệu ã ược “làm sạch”, tiếp tục thực hiện dán nhãn “successful” và
“unsuccessful” cho dữ liệu (“thành công” và “không thành công”). Dữ liệu cũng ược
chia thành 2 phần, 70% là training set, tức là dữ liệu dùng ể huấn luyện mô hình, 30%
là testing set, tức là dữ liệu dùng ể kiểm tra lại quá trình huấn luyện. 70% data ó sẽ
ưa vào 2 thuật toán là KNN và Naive Bayes ể thực hiện phân loại. Mỗi thuật toán sẽ
có cách phân loại khác nhau, từ ó chọn ra thuật toán nào hoạt ộng tốt nhất.
Bước cuối cùng là ưa qua ma trận confusion (ma trận hỗn loạn) ể xem xét hiệu
suất của các thuật toán. Thông qua ma trận sẽ có thể so sánh ược kết quả của quá trình
dự oán thông qua quá trình thực nghiệm so với kết quả thực tế. Sau ó là ưa 30% testing
set vào ể kiểm tra lại và thu về kết quả cuối cùng. Ở bước này sẽ kết luận ược mô hình
nào là tốt nhất, mang lại kết quả khả quan nhất.
3.2.3. Cấu hình phần cứng huấn luyện thuật toán
Để thực hiện xây dựng và huấn luyện các mô hình Text-mining (KNN và Naive
Bayes), chúng tôi quyết ịnh lựa chọn sử dụng các thư viện của R ể triển khai các mô
hình trên. Quá trình thực nghiệm ược thực hiện với RStudio – một chương trình có
môi trường phát triển tích hợp cho R. Chúng tôi sử dụng phiên bản RStudio
2022.02.2+485 trên Laptop Intel core i3, RAM 4GB ể thực hiện xây dựng các mô hình trên. lOMoARcPSD| 37054152
3.2.4. Xây dựng thuật toán KNN
Khai báo các thư viện cần thiết
Để tiến hành xây dựng thuật toán text-mining nói chung và KNN nói riêng ta
phải cài ặt các các thư viện ể hỗ trợ trong quá trình chạy dữ liệu. Một số thư viện cần
phải cài ặt trước khi thực hiện các bước training và test dữ liệu bao gồm: class,
datasets.load, NLP, pdftools, plyr và tm.
RStudio phục vụ cho việc thực hiện các source code ngôn ngữ R không có chức
năng ọc hiểu ược dạng file pdf. Do ó các file whitepaper ở dạng pdf cần phải chuyển
sang dạng text ể có thể thực hiện các công oạn xây dựng thuật toán tiếp theo. Để có
thể thực hiện việc chuyển dữ liệu sang dạng text, cần khai báo 2 folder chứa
whitepaper của các ICO không thành công và thành công thông qua dòng code
dest_sucessful và dest_unsucessful, sau ó mới thực hiện việc chuyển ổi dạng file của dữ liệu.
Hình 3.4. Source code chuyển ổi dữ liệu sang dạng text (Nhóm thực hiện)
Mặc dù ã chuyển ổi các whitepaper sang dạng file text, nhưng ể thuật toán KNN
có thể ọc ược những dữ liệu ó thì ta cần cài ặt một công cụ hỗ trợ việc ọc hiểu các file
này ó chính là xpdf-tools-win-4.03.
Hình 3.5. Source code sử dụng xpdf-tools-win-4.03 ọc dữ liệu (Nhóm thực hiện) lOMoARcPSD| 37054152
Tiến hành cài ặt các tham số
Sau khi ã chuyển ổi các whitepaper sang dạng text, ta chỉ ịnh duới dạng các tham
số và tiến hành tạo một biến pathname ể có thể truy cập ược với các dữ liệu whitepaper
ã ược lưu trữ trong máy tính ể có thực hiện các bước xử lý tiền dữ liệu văn bản sau ó.
Hình 3.6. Source code cài ặt tham số cho mô hình (Nhóm thực hiện)
Xử lý tiền dữ liệu
Mục ích của ề tài là tạo ra một hình có thể xác ịnh mối tương quan giữa các biến
ộc lập là các thuật ngữ xuất hiện trong thuật toán và các biến phụ thuộc là các hạng
mục. Về cơ bản kết quả của mô hình sẽ là một bảng dữ liệu vô cùng lớn với các hàng
là tên các whitepaper và các cột là tất cả những từ có trong whitepaper ó. Trong ó,
mỗi ô sẽ ưa ra ược tần số xuất hiện của từ ó trong whitepaper. Nếu kết quả tạo ra một
bản kết quả lớn như vậy thì khi ưa vào các mô hình máy học sẽ gây ra việc nhiễu loạn
về hiệu suất phán oán.
Quá trình xử lý tiền dữ liệu là một bước quan trọng. Cần thực hiện làm sạch văn
bản, xóa bớt các từ không cần thiết trong quá trình chạy thuật toán, bên cạnh ó số
lượng từ trong một whitepaper là tương ối lớn. Việc “làm sạch văn bản” giúp mô hình
tối ưu việc thực hiện, kết quả dự oán nhanh hơn, chuẩn xác hơn. Trong bước tiếp theo,
chúng tôi sẽ thực hiện làm sạch những từ ngắt oạn, ngắt câu, khoảng trắng giữa các từ và dấu chấm câu.
Hình 3.7. Source code xử lý tiền dữ liệu trong text-mining (Nhóm thực hiện) lOMoARcPSD| 37054152
Xây dựng mô hình Bag of Words
Mô hình Bag of Words sẽ giúp chuyển ổi văn bản sang dạng ịnh lượng ể có
thể phân tích ược dữ liệu từ bộ dữ liệu của nhóm ã thu thập. Ngoài ra, mô hình này
còn có thể loại bỏ ược sự thưa thớt. Ma trận thưa thớt là ma trận bao gồm các ô chứa
trong các ô của nó. Để giúp cho quá trình dự oán của thuật toán ược tối ưu và chính
xác hơn, tiếp tục tiến hành loại bỏ những thuật ngữ không xuất hiện thường xuyên
trong ma trận thông qua mô hình Bag of Words với tham số của ma trận thưa thớt là 0.1.
Hình 3.8. Source code tạo ma trận Bag of words (Nhóm thực hiện)
Thiết lập các nhóm trong Term-Document-Matrix (TDM)
Đây là quá trình gắn thẻ các whitepaper là thành công hay không thành công.
Sau quá trình xử lý tiền dữ liệu, Ở bước này ta lại tiến hành chuyển ổi TDM thành ma
trận dữ liệu dạng số và tiếp tục hoán ổi các biến hàng và cột cho nhau. (TDM là ma
trận thuật ngữ tài liệu - Document-term matrix. Nó như một mô hình có dạng bảng
với các từ ngữ ể dự oán, ược hiển thị ở dạng hàng với cột là tên của các whitepaper
tương ứng). Bây giờ các whitepaper sẽ xuất hiện dưới dạng cột và các thuật ngữ sẽ
xuất hiện dưới dạng hàng. lOMoARcPSD| 37054152
Hình 3.9. Source code thiết lập nhóm dữ liệu theo TDM(Nhóm thực hiện)
Để giúp quá trình phân tích dữ liệu dễ nhìn hơn, tiếp tục thực hiện việc xếp
chồng các whitepaper của 2 nhóm thành công và không thành công lên nhau:
Hình 3.10. Source code xếp chồng dữ liệu (Nhóm thực hiện)
Phân chia dữ liệu
Ở bước tiếp theo, tiến hành chia dữ liệu ể thực hiện việc train và test model theo
tỷ lệ: 70% ể train và 30% ể test.
Hình 3.11. Source code phân chia dữ liệu (Nhóm thực hiện)
Đưa vào thuật toán KNN
Sau khi thực hiện những công oạn trên thì kết quả trả lại sẽ là một tập dataset
chứa các dữ liệu của whitepaper mà chúng tôi ã ưa vào ể thực hiện việc train model. lOMoARcPSD| 37054152
Hình 3.12. Đưa dữ liệu vào thuật toán KNN (Nhóm thực hiện)
Nhìn vào tập dataset có thể thấy chúng tôi ã lấy 148 whitepaper ể train model,
Tương ứng với các whitepaper này là 47 các biến ộc lập hay còn ược gọi là thuật ngữ
xuất hiện nhiều nhất trong mô hình, giúp mô hình có thể ưa ra dự oán chính xác nhất.
Việc xây dựng thuật toán KNN dựa trên 2 danh mục successful và unsuccessful
của tập dataset. Việc phân loại các ICO dựa trên 2 danh mục trên giúp mô hình xác
ịnh các biến tương ứng với các cột trong ma trận TDM cuối cùng sẽ có tác dụng phân
loại một nhóm dữ liệu mới. Từ ó, mô hình mới có thể dự oán ICO ó thành công hay là không thành công.
3.2.5. Xây dựng thuật toán Naive Bayes
Khai báo thư viện
Tương tự như mô hình KNN, trước khi tiến hành xây dựng thuật toán cho mô
hình Naive Bayes, ta phải khai báo các thư viện cần thiết ể ngôn ngữ R có thể ọc ược
các file whitepaper ICO. Các thư viện cần khai báo bao gồm: tm, e1071, gmodel,
pdftool, dpylr và readtext.
Tiến hành việc ọc data
Sau khi ã khai báo ầy ủ các thư viện thì ta tiến hành chuyển các file dữ liệu ở
dạng pdf sang text và thực hiện việc ọc dữ liệu.
Hình 3.13. Source code chuyển dữ liệu sang text (Nhóm thực hiện) lOMoARcPSD| 37054152
Xử lý tiền dữ liệu
Mỗi một whitepaper ICO khi ở dạng pdf thường có khoảng trung bình từ 40-70
trang nên khi chuyển dữ liệu sang dạng text thì sẽ có số lượng từ là vô cùng lớn. Trong
ó sẽ có những từ không có khả năng giúp mô hình dự oán ví dụ như: dấu chấm câu,
từ nối, khoảng trắng giữa các từ, các ại từ, mạo từ, và cũng như các từ ang ở các thì
(tương lai, quá khứ,…). Xử lý tiền dữ liệu chính là bước ể xóa các ký tự ó ra khỏi bộ
dữ liệu. Để có thể thực hiện công oạn xử lý tiền dữ liệu thì phải khai báo các thư viện
hoặc là package ể có thử xử lý ược vấn ề này.
Đầu tiên ể có thể xóa những từ dừng, dấu chấm câu, khoảng trắng, từ nối thì ta
cần xây dựng kho dữ liệu bằng cách khai báo thư viện tm và sau ó sử dụng tm_map ể
thực hiện từng nội dung cần xóa cụ thể.
Hình 3.14. Source code xử lý tiền dữ liệu (Nhóm thực hiện)
Để có thể chuyển các từ về dạng gốc của chính nó, ví dụ như “listening” về dạng
gốc là “listen” thì ta cần sử dụng thư viện SnowballC.
Hình 3.15. Source code xóa các thì của từ(Nhóm thực hiện) lOMoARcPSD| 37054152
Phân chia dữ liệu
Sau khi ã thực hiện xong quy trình xử lý tiền dữ liệu thì chúng tôi sẽ tiến hành
phân loại data ể train và test. Chúng tôi chia bộ dữ liệu theo tỷ lệ 7:3 trong ó 70%
của bộ dataset sẽ ược dùng cho việc huấn luyện mô hình và 30% còn lại sẽ ược sử
dụng ể kiểm tra mô hình sau khi ã trải qua quy trình huấn luyện.
Hình 3.16. Source code phân chia dữ liệu (Nhóm thực hiện)
Sau khi ã phân chia tỷ lệ phù hợp cho việc huấn luyện và kiểm tra kết quả của
mô hình, chúng tôi tạo tập dữ liệu huấn luyện và kiểm tra trong khoảng [1:103] và
[103:148], tiếp ến là lưu nhãn dán cho hai bộ dữ liệu ó bằng lệnh sms_dtm_train và
sms_dtm_test. Sau khi ã lưu nhãn dán, chúng tôi lại kiểm tra tỷ lệ whitepaper thành
công và không thành công của hai bộ dữ liệu. Dựa vào kết quả cho thấy rằng bộ dữ
liệu ể huấn luyện mô hình thì các ICO thành công chiếm 45,63107% và ICO không
thành công chiếm 54,26893%. Còn ối với bộ dữ liệu ể kiểm tra thì lại ưa ra kết quả là
36,95652% ICO thành công và 63,04348% ICO không thành công.
Đưa vào thuật toán Naive Bayes
Hình 3.17. Xây dựng mô hình Naïve Bayes (Nhóm thực hiện)
Đầu tiên, chúng tôi sẽ tiến hành lưu các thuật ngữ xuất hiện thường xuyên trong
bộ dataset vào một vectơ dựa vào lệnh sms_freq_words với số lần huấn luyện là 1. lOMoARcPSD| 37054152
Sau ó tạo DTM với iều kiện là các thuật ngữ thường xuyên xuất hiện trong mô hình
qua lệnh sms_dtm_freq. Chuyển ổi số ếm thành một hệ số thông qua lệnh
convert_counts. Tiếp ến sẽ tiến hành huấn luyện mô hình nhờ vào thư viện e1071 và
lệnh sms_classifier. Và cuối cùng là thực hiện ánh giá hiệu suất mô hình dựa vào lệnh
sms_test_pred <- predict(sms_classifier, sms_test) và thư viện gmodels.
3.3. PHƯƠNG PHÁP DỰ BÁO GIÁ TIỀN ĐIỆN TỬ
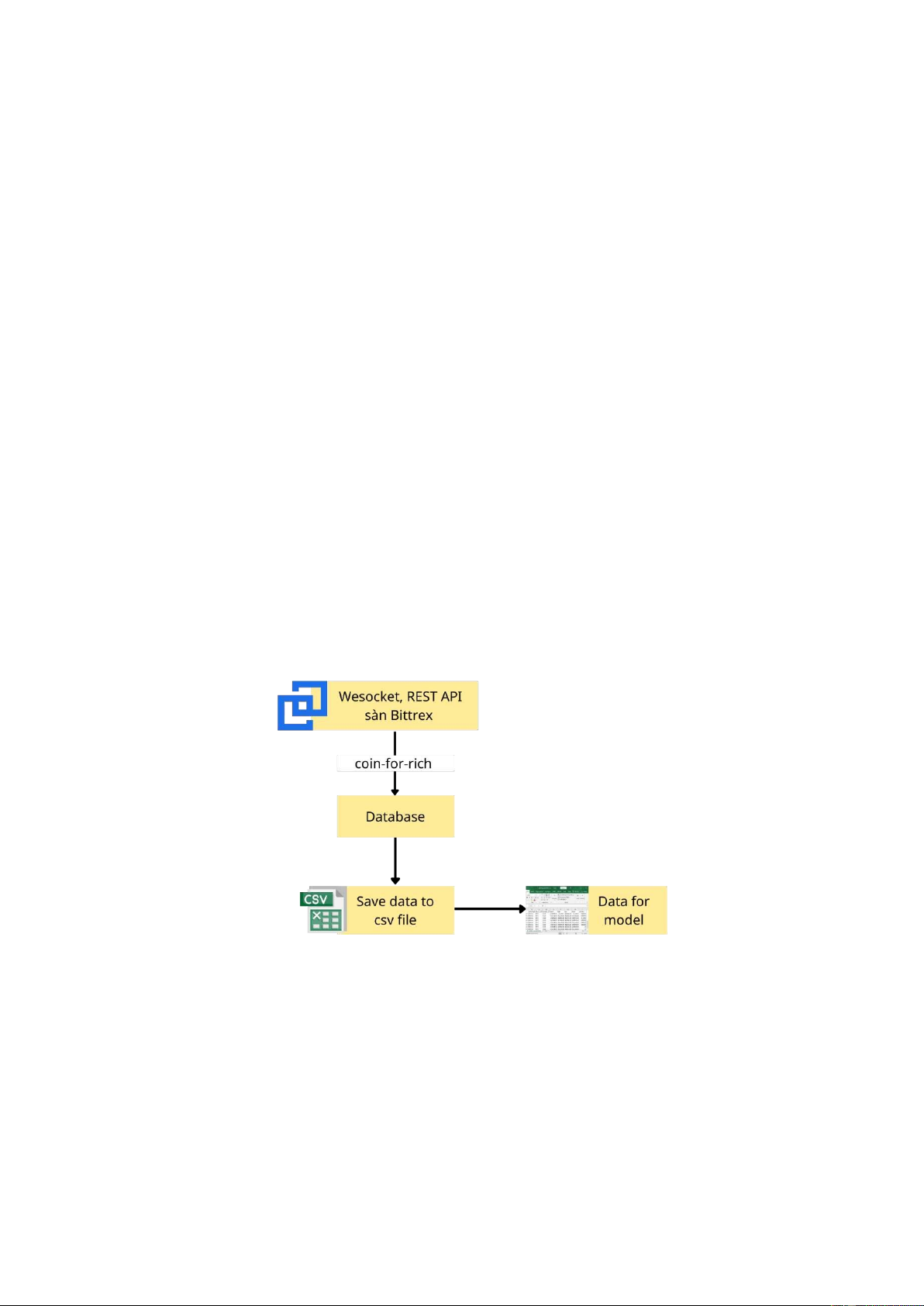
3.3.1. Thu thập dữ liệu giá tiền iện tử
Sau khi ã xem xét và phân loại sự thành công của các ICO, tiếp tục thực hiện
thu thập dữ liệu về giá của các loại tiền iện tử trên. Để thu thập dữ liệu, chúng tôi ã
sử dụng một công cụ API hoạt ộng nhờ Docker Compose có tên là Coin-for-rich, ược
xây dựng bởi 2 tác giả Trần Việt Anh và Vương Hoài Nam (2021). Công cụ này có
chức năng thu dữ liệu thực tế từ websockets và dữ liệu lịch sử từ REST APIs trên các
sàn giao dịch tiền tử, bao gồm Bittrex, Binance và Bitfinex. Dữ liệu thu ược sẽ là giá
của các loại tiền iện tử biến ộng theo từng phút. Ở bài nghiên cứu này, chúng tôi sẽ
thực hiện việc thu dữ liệu từ sàn Binance, từ ó ưa ra những dự báo về giá thông qua
các mô hình Machine Learning.
Hình 3.18. Quy trình thu thập dữ liệu giá tiền iện tử bằng công cụ Coin-for-rich (Nhóm thực hiện) lOMoARcPSD| 37054152
Hình 3.19. Sơ ồ chi tiết thu dữ liệu bằng Coin-for-rich (Nhóm thực hiện)
Giải thích từng bước trong quá trình thu dữ liệu giá tiền iện tử bằng công cụ Coin- for-rich:
Bước 1. Khởi ộng Docker Compose.
Bước 2. Clone công cụ coin-for-rich và khởi ộng công cụ.
Bước 3. Chọn thời gian cần thu dữ liệu (sử dụng lệnh: tmux a – t fetch ể trung
cập vào phiên tmux và nhập thời gian). Khi này, công cụ sẽ tự ộng tìm dữ liệu tương
ứng từ Websocket và dữ liệu lịch sử từ REST APIs sàn giao dịch Binance. Dữ liệu
sẽ ược iền vào bảng OHLCV. Chúng tôi ã thực hiện thu giá của các loại tiền iện tử
trên sàn Binance trong khoảng thời gian từ ngày 01- 31/01/2022.
Hình 3.20. Kéo thời gian ể thu dữ liệu lịch sử từ REST APIs (Nhóm thực hiện)
Bước 4. Truy vấn các dữ liệu trong bảng OHLCV (sử dụng lệnh tmux a -t psql
ể truy cập vào phiên tmux). lOMoARcPSD| 37054152
Hình 3.21. Truy xuất dữ liệu ã thu ược (Nhóm thực hiện)
Bước 5. Thực hiện xuất dữ liệu thu ược sang file CSV. Tuy nhiên, do bộ dữ liệu bao
gồm giá biến ộng theo từng phút của hầu hết tất cả các coin, do ó file CSV xuất ra sẽ
rất nặng và không thể khởi ộng ược. Trong phạm vi ề tài, chúng tôi thực hiện lựa chọn
3 coin có có chỉ số ROI cao nhất và ược ánh giá thành công trên sàn
Binance là SOL, IOTA và ETH. Do ó, khi thực hiện xuất file CSV sẽ ặt iều kiện chỉ
ể lọc ra dữ liệu giá của 3 loại tiền iện tử này. Trong trường hợp dữ liệu thu về chưa ủ,
tiếp tục thực hiện lại bước 3, chọn mốc thời gian dữ liệu còn thiếu và tiếp tục thực
hiện ến khi dữ liệu ược hoàn thiện nhất.
Hình 3.22. Xuất dữ liệu ã thu ược sang file csv (Nhóm thực hiện)
Dữ liệu giá 3 loại tiền iện tử thu ược ược xuất ra dưới dạng file CSV, bao gồm các biến:
Time (Date): Thời gian
Exchange: Tên sàn giao dịch iện tử Base_id: Loại tiền iện tử
Quote_id: Đơn vị giá
Open: Giá mở cửa của giao dịch High: Giá cao nhất
Low: Giá thấp nhất Close: Giá óng cửa
Volume: Khối lượng giao dịch trong 24h lOMoARcPSD| 37054152
Hình 3.23. 20 dòng dữ liệu giá SOL trên sàn binance (Nhóm thực hiện)
3.3.2. Lựa chọn các ICO thành công ể dự oán giá
Sau khi ã thực hiện ánh giá sự thành công của các ICO và lựa chọn ược mô hình
có khả năng phân loại tốt nhất, chúng tôi tiếp tục thực hiện dự báo giá của các ICO
thành công. Trong ề tài này, nhóm lựa chọn dự báo giá của 3 ICO là: Ethereum (ETH),
MIOTA (IOTA) và Solana (SOL). Các ICO này ược ánh giá là thành công và có chỉ
số ROI cao trong tổng số các ICO ã thu thập và thực hiện phân loại ở phần trên.
Bên cạnh ó, việc chúng tôi lựa chọn 3 ICO này ể dự oán giá không chỉ dựa vào
ROI cao mà còn là vì nhận thấy ược những tiềm năng phát triển của chúng:
- ETH là altcoin số 1 trong danh mục ầu tư của nhiều trader, ược xem như ồng
Bitcoin phiên bản 2.0. Thị trường ETH ang ngày càng lớn mạnh khi vốn hóa ạt ến
mức hơn 125 tỷ USD (tính ến 2021). Chính vì thế mà việc ầu tư vào ETH là một cơ
hội rất tiềm năng và có khả năng sinh lời cao. Cùng với ó, nó nhận ược sự quan tâm
bởi không chỉ là ồng tiền iện tử thuần mà còn tạo ra những thị trường online và những
giao dịch có thể ược lập trình.
- IOTA từ khi ra mắt năm 2016, chỉ trong thời gian ngắn ã chiếm lĩnh ược thị
trường trong tổng vốn hóa là 3%. Đồng tiền iện tử này ược nhận ịnh rằng, với tốc ộ lOMoARcPSD| 37054152
phát triển và tăng trưởng mạnh mẽ sẽ chiếm ược thị phần cao hơn trong tương lai.
Nhiều dự oán ưa ra giá IOTA coin sẽ tăng mạnh vào năm 2022, bởi nó là một ICO
tiềm năng của Internet of thing, hiện ang có quan hệ hợp tác với nhiều ối tác lớn như:
Microsoft, CISCO, Samsung, Jaguar Land Rover,… Cùng với ó là sự ra mắt bản cập
nhật Chrysalis. Điều ó khiến cho ICO này trở thành một trong những loại tiền iện tử
tiềm năng và thu hút sự ầu tư.
- SOL là ồng tiền iện tử lớn thứ 9 theo vốn hóa của thị trường (theo
CoinMarketCap). Trong năm 2021, SOL là một trong những loại tiền iện tử hoạt ộng
hàng ầu. Cụ thể vào quý 4 năm 2021, giá trị của SOL ạt mức 260USD - mức cao nhất
lịch sử của ồng tiền này. Nhiều nhà phân tích tiền iện tử cũng ã nhận thấy tiềm năng
to lớn của ICO này và nhận ịnh rằng nó có khả năng mở rộng với phí giao dịch thấp và rất dễ sử dụng.
Chính vì những lý do trên, việc lựa chọn 3 ICO này ể xây dựng mô hình ể dự
oán giá là khá phù hợp, là một tài liệu giúp các nhà ầu tư có thể tham khảo và phát
triển ể tìm ra những chiến lược phù hợp cho việc ầu tư vào các ồng tiền iện tử vô cùng tiềm năng này.
3.3.3. Lưu ồ thực hiện xây dựng các mô hình dự oán giá lOMoARcPSD| 37054152
Hình 3.24. Lưu ồ thiết kế và xây dựng mô hình dự oán giá tiền iện tử (Nhóm thực hiện)
Cụ thể các bước thực hiện như sau:
Bước 1. Sau khi thu và lọc dữ liệu bước ầu (file CSV), ưa dữ liệu vào bài và khai
báo các thư viện cần thiết (Sklearn, Keras).
Bước 2. Sắp xếp dữ liệu ưa vào theo thời gian.
Bước 3. Chia dữ liệu làm 2 phần: data_train và data_test (sử dụng train-
testsplit). Trong ó, tập data_train ược sử dụng ể huấn luyện các mô hình. Còn tập
data_test ược sử dụng ể theo dõi sự chính xác của các vòng lặp huấn luyện dựa trên
các chỉ số hiệu suất.
Bước 4. Co giãn dữ liệu trong khoảng 0 - 1 (sử dụng MinMaxScaler ể chuẩn hóa dữ liệu).
Bước 5. Sử dụng data_train ể huấn luyện từng mô hình. Ở ây, chúng tôi lựa chọn
huấn luyện 3 mô hình là LSTM, RNN và CNN.
Bước 6. Kết hợp kết quả huấn luyện mô hình với data_test ể thực hiện tính toán
các chỉ số MAE, MAPE, RMSE và R2.
Bước 7. So sánh các giá trị MAE, MAPE, RMSE và R2 của các mô hình.
Bước 8. Từ kết quả so sánh, lựa chọn ra mô hình có sai số thấp nhất.
Bước 9. Thực hiện iều chỉnh các tham số của mô hình ã lựa chọn (sử dụng GridSearchCV)
Bước 10. Huấn luyện mô hình ã ược chọn với các chỉ số ã hiệu chỉnh ể có ược mô hình tốt nhất.
Bước 11. Huấn luyện data với mô hình tốt nhất và tính toán các chỉ số của mô hình này.
Bước 12. Đưa ra kết quả dự oán giá dựa trên mô hình tốt nhất.
3.3.4. Cấu hình phần cứng huấn luyện mô hình
Thông qua nhiều nghiên cứu, cũng như những ưu iểm phù hợp cho việc dự oán
tiền ảo ã trình bày ở chương 1 và 2, chúng tôi ã ưa ra 3 mô hình ể thực hiện quá trình
dự oán xu hướng biến ộng của tiền iện tử là RNN, CNN và LSTM. Để thực hiện xây
dựng và huấn luyện các mô hình Machine Learning này, chúng tôi sử dụng Keras lOMoARcPSD| 37054152
framework chạy trên nền Tensorflow của Google API Framework. Cùng với ó, chúng
tôi quyết ịnh lựa chọn sử dụng các thư viện của Python ể triển khai các mô hình trên.
Quá trình thực nghiệm ược thực hiện trên Google Colab – một sản phẩm của
Google Reseach cho phép chạy code Python thông qua trình duyệt web. Chúng tôi
thực hiện code với Google Colab sử dụng CPU tốc ộ cao Intel Xeon Processor với
13GB RAM trên trình duyệt Chrome của Laptop Intel core i5 RAM 4GB.
3.3.5. Xử lý dữ liệu
Lọc dữ liệu theo ơn vị giá
Dữ liệu ầu vào ể thực nghiệm cho mô hình dự oán giá là giá của 3 loại tiền iện
tử thành công, có ROI cao là ETH, IOTA và SOL trong thời gian từ ngày
0131/01/2022. Dữ liệu sau khi thu về từ công cụ Coin-for-rich ược lọc lại theo ơn vị
tính giá. Chúng tôi lựa chọn ơn vị USDT ể dữ liệu ược thống nhất. Kết quả thu ược ở
mỗi loại tiền iện tử là 44640 dòng dữ liệu. Trong ó, các giá trị dữ liệu ược sử dụng ể
huấn luyện mô hình bao gồm các cột (các biến): Date, Open, High, Low và Close.
Ngoài ra, dữ liệu trước khi ưa vào huấn luyện sẽ ược sắp xếp theo thời gian tăng dần.
Sắp xếp và lựa chọn dữ liệu
Kết quả cuối cùng mà ề tài mong muốn có chính là dự oán ược giá Close của
các loại tiền iện tử và so sánh với giá trị thực tế. Do ó, các dữ liệu sẽ ược sắp xếp và phân bổ như sau:
- Các cột dữ liệu Date, Open, High ược gán cho X
- Cột Close ược gán cho Y
Dữ liệu ược chọn sẽ phân chia thành 2 nhóm: data_train và data_test. Trong ó
data_train dùng ể huấn luyện các mô hình, và data_test dùng ể kiểm tra lại và ánh
giá các sai số của thuật toán. Chúng tôi sử dụng hàm train_test_split ể chia dữ liệu
thành: X_train, X_test, y_train, y_test. Trong ó, train_size = 0.8 (tức 80%) và test_size = 0.2 (tức 20%). lOMoARcPSD| 37054152
Hình 3.25. Sắp xếp và phân loại dữ liệu ầu vào (Nhóm thực hiện)
Chuẩn hóa dữ liệu
Để các thông số ầu vào có vai trò tương tự cũng như không ảnh hưởng ến dữ
liệu ầu ra cuối cùng, chúng tôi sử dụng MinMaxScaler của thư viện Scikit-learn ể dữ
liệu ược chuẩn hóa. Sử dụng MinMaxScaler, các dữ liệu sẽ ược co giãn trong phạm
vi từ 0 - 1 ể ơn giản nhất, thực hiện theo công thức:
Hình 3.26. Source code thực hiện chuẩn hóa dữ liệu (Nhóm thực hiện) Sau khi
chuẩn hóa dữ liệu, chúng tôi thực hiện chuyển dữ liệu từ 2 chiều sang 3 chiều nhằm
hỗ trợ cho việc xây dựng các mô hình về sau.
Hình 3.27. Source code thực hiện chuyển chiều dữ liệu (Nhóm thực hiện)
3.3.6. Các chỉ số hiệu suất
Để phản ánh sự sai lệch của giá trị dự oán so với giá trị thực của từng mô hình,
ở bài nghiên cứu này, chúng tôi sử dụng 3 chỉ số hiệu suất:
MAE - Mean Absolute Error: Sai số trung bình tuyệt ối.
MAPE - Mean Absolute Percentage Error: Phần trăm sai số trung bình tuyệt ối.
RMSE - Root Mean Squared Error: Sai số toàn phương trung bình.
Những giá trị MAE, MAPE và RMSE càng nhỏ, ộ chính xác của dự oán càng
cao. Dựa vào việc so sánh các chỉ số ó, có thể lựa chọn mô hình tốt nhất ể huấn luyện
và dự báo giá tiền iện tử.
Công thức tính các chỉ số hiệu suất: lOMoARcPSD| 37054152
Hình 3.28. Source code tính toán các chỉ số hiệu suất (Nhóm thực hiện)
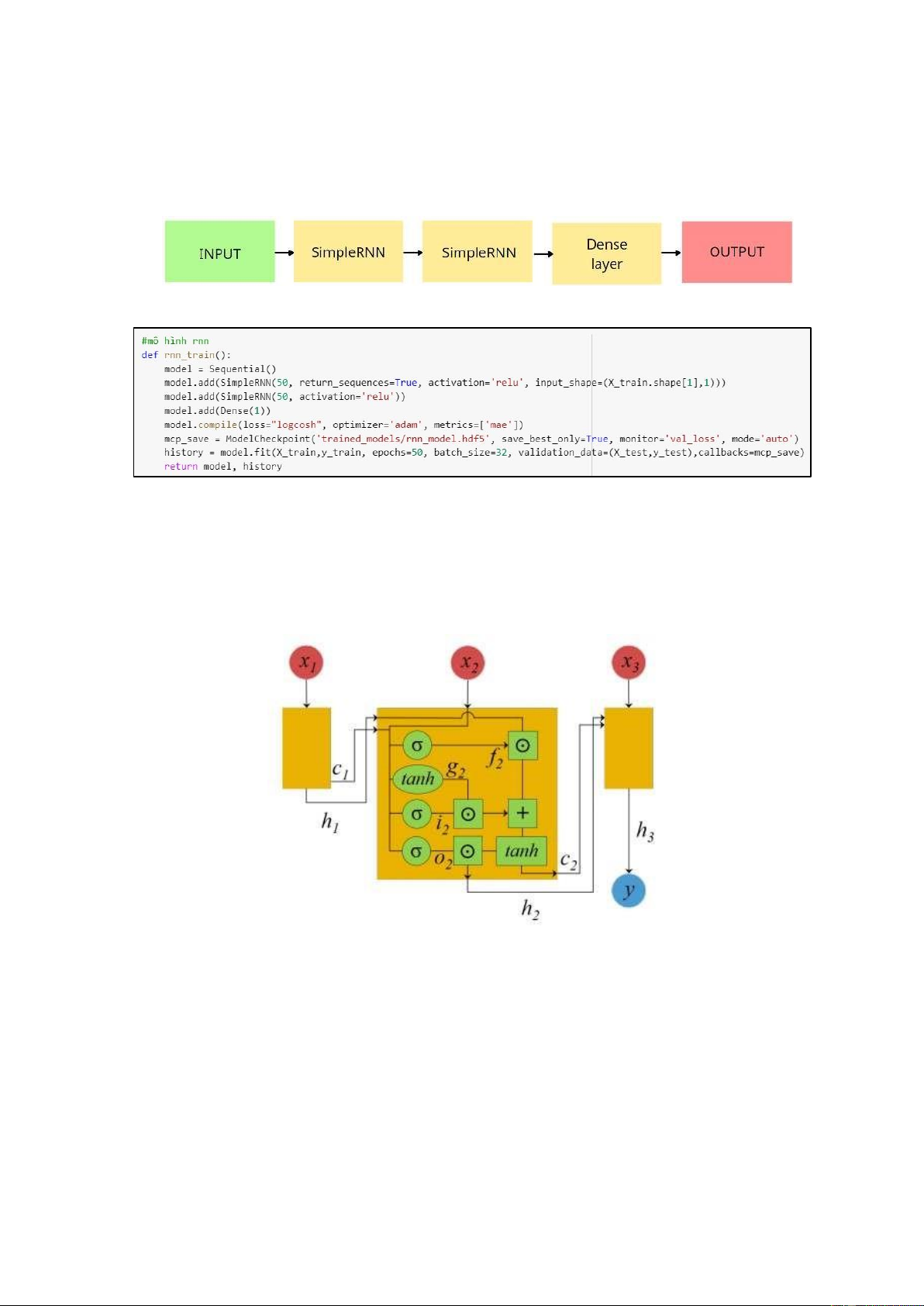
3.3.7. Xây dựng mô hình RNN
Hình 3.29. Cấu trúc hoạt ộng mạng RNN (Ji và nnk., 2019)
Mô hình RNN sẽ có các dữ liệu ầu vào x0, x1, x2, ..., xt. Các dữ liệu sẽ ược xử lý
lần lượt theo time step. Với ht là trạng thái ẩn, tương ứng với xt. yt là ầu ra của một
step tương ứng. Khi ó, ht và yt ược tính bằng công thức:
ht = g1(Whhht-1 + Whxxt + hh)
yt = g2(Wyhht + by) Trong ó:
g1 là hàm kích hoạt, thường là hàm tanh hoặc ReLU g2
là hàm kích hoạt, thường là hàm softmax
Whh , Whx và bh là các tham số cần học
Wyh , by là tham số ược học
Ở bài nghiên cứu này, chúng tôi xây dựng mô hình RNN ơn giản gồm 2 lớp
SimpleRNN với 50 node trong neuron network và 1 lớp Dense ể ịnh hình dạng ầu ra lOMoARcPSD| 37054152
cuối cùng. Ngoài ra, ể xử lý vấn ề gradient, thay vì sử dụng activation function là tanh
hay sigmoid, chúng tôi sử dụng ReLu. Bởi ạo hàm của ReLu là 0 hoặc là 1 nên phần
nào có thể kiểm soát ược vấn ề ạo hàm bị triệt tiêu.
Hình 3.30. Cấu trúc mạng RNN sử dụng ể dự báo giá tiền iện tử (Nhóm thực hiện)
Hình 3.31. Source code mô hình RNN (Nhóm thực hiện)
Bên cạnh ó, ể khắc phục vấn ề gradient của mô hình RNN, chúng tôi xây dựng
mô một hình kiến trúc có bộ nhớ dài hạn hơn, chính là LSTM.
3.3.8. Xây dựng mô hình LSTM
Hình 3.32. Cấu trúc hoạt ộng mạng LSTM (Ji và nnk., 2019)
Về cơ bản, mô hình LSTM tương tự như RNN nhưng ược cải tiến, khắc phục
các vấn ề về gradient mà RNN mắc phải nhờ bộ nhớ dài hạn hơn. LSTM có các cấu
trúc cổng vào i (input gate), cổng ra o (output gate) và cổng quên f (forget gate). Tại
thời iểm t, trạng thái ẩn ht và các vecto ầu ra của một ơn vị LSTM ược tính bằng
công thức (Ji và nnk., 2019): lOMoARcPSD| 37054152
Trong ó W, U, b là các tham số ể học, σ là hàm sigmoid và ct là vector trạng thái của ô ơn vị.
Theo hình và công thức trên có thể giải thích hoạt ộng và vai trò của các cổng như sau:
- Cổng vào i: quyết ịnh lượng thông tin ầu vào thông qua ặc iểm của hàm sigmod
( ạo hàm ầu ra là [0,1]. Khi có một vecto thông tin i qua, nếu nhân với 0, vector sẽ bị
triệt tiêu, còn nếu nhân với 1, các thông tin sẽ ược giữ lại.
- Cổng quên f: quyết ịnh bỏ i bao nhiêu thông tin của trạng thái trước.
- Cổng ra o: iều chỉnh lượng thông tin i ra ngoài và truyền tới trạng thái tiếp theo.
- Giá trị g: ược xem như một trạng thái ẩn, ược tính dựa trên xt và ht-1. Tuy nhiên
thay vì sử dụng hàm sigmoid thì sử dụng hàm tanh.
- Bộ nhớ trong ct: ct là tổng hợp của các bộ nhớ ct-1 trước ó ã ược lọc qua cổng
f, kết hợp với trạng thái ẩn g ược lọc bởi cổng i. Chính vì thế mà các thông tin sẽ ược
truyền i xa hơn, tức là bộ nhớ dài hơn. Đây chính là iểm lợi thế và cải tiến của LSTM so với RNN.
Trong bài nghiên cứu này, chúng tôi xây dựng mô hình LSTM ơn giản gồm 2
lớp LSTM với 50 node trong neuron network và 1 lớp Dense ể ịnh hình dạng ầu ra
cuối cùng. Activation function cũng lựa chọn là ReLu tương tự như ở mô hình RNN.
Hình 3.33. Cấu trúc mạng LSTM sử dụng ể dự báo giá tiền iện tử (Nhóm thực hiện) lOMoARcPSD| 37054152
Hình 3.34. Source code mô hình LSTM (Nhóm thực hiện)
Nhìn chung, LSTM khắc phục ược vấn ề gradient của RNN. Tuy nhiên việc khắc
phục chỉ giúp giảm ược một phần nào ó sự ảnh hưởng của các vấn ề gradient chứ
không thể giảm hoàn toàn. Ngoài ra, với lượng tính toán lớn thì việc vận hành mô hình LSTM khá chậm.
3.3.9. Xây dựng mô hình CNN
CNN là một thuật toán phổ biến trong Deep Learning, ược ứng dụng nhiều trong
các nghiên cứu về nhận diện hình ảnh, phân loại khuôn mặt,...
Hình 3.35. Cấu trúc mạng CNN (Lu, 2016)
So với mạng ANNs truyền thống, việc sử dụng lớp chập Conv ở mạng CNN có
nhiều ưu iểm hơn. Nếu ở mạng ANNs, các neuron lớp trước kết nối với lớp sau sẽ dễ
dẫn ến việc xuất hiện quá nhiều tham số cần học. Chính iều này làm gây ra tình trạng
overfitting và khiến quá trình huấn luyện lâu hơn. Sử dụng Conv sẽ cho phép chia sẻ
các trọng số liên kết và sử dụng các local receptive fields ể làm giảm các tham số cần học.
Ở bài nghiên cứu này, chúng tôi xây dựng một mô hình thuật toán CNN ơn giản. Mô hình gồm:
- 1 lớp Conv1D: Sử dụng ể tiếp nhận và trích xuất dữ liệu ầu vào. Việc lấy tích
chập sẽ giúp trích xuất ược những thông tin quan trọng từ dữ liệu. Trong ó, lựa chọn
giá trị kernel = 2, tức là mỗi lần dịch chuyển 2 ơn vị trên ma trận dữ liệu ầu vào. lOMoARcPSD| 37054152
Activation function lựa chọn là ReLu bởi nó tính toán ơn giản, tạo ra tính thưa
(sparsity) ở những neuron ẩn và giúp quá trình huấn luyện nhanh hơn. Và sau nhiều
lần nghiên cứu và tham khảo nhiều nghiên cứu khác, chúng tôi lựa chọn filters = 64
và sẽ thực hiện iều chỉnh tham số này về sau.
- 1 lớp pooling: Sử dụng ể làm giảm kích thước dữ liệu. Ở ây chúng tôi lựa chọn
toán tử Max Pooling. Mặc dù có nhiều toán tử khác như Sum Pooling hay L_2
Pooling, tuy nhiên Max Pooling giúp xác ịnh vị trí cho tín hiệu mạnh nhất khi áp dụng filter.
- 1 lớp flatten: sử dụng ể ịnh dạng dữ liệu.
- 1 lớp fully connected (còn gọi là Dense layer): Đặt ở tầng cuối của kiến trúc
mạng, dùng ể ịnh hình dạng ầu ra cuối cùng.
Hình 3.36. Cấu trúc mạng CNN sử dụng ể dự báo giá tiền iện tử (Nhóm thực hiện)
Hình 3.37. Source code mô hình CNN (Nhóm thực hiện)
3.3.10. Tối ưu hóa các tham số
Sau khi ã thực hiện xây dựng và huấn luyện các mô hình và lựa chọn ực mô hình
có sai số nhỏ nhất, chúng ta cần thực hiện quá trình tối ưu các tham số. Bởi trong quá
trình huấn luyện mô hình, có những tham số không thể học trực tiếp (gọi là
Hyperparameters). Những tham số này ược lựa chọn theo trực giác và dùng ể kiểm
tra thử trước khi thực hiện huấn luyện chính thức. Do ó, ể có thể lựa chọn ược giá trị
tham số sao cho tạo ra kết quả tốt nhất, sau khi chọn ược model, cần phải thực hiện
bước tối ưu các tham số của model ó và thực hiện huấn luyện lại dữ liệu với mô hình ã ược tối ưu. lOMoARcPSD| 37054152
Để thực hiện tối ưu những tham số của mô hình tốt nhất, chúng tôi sử dụng
GridSearchCV của Scikit-learning. GridSearchCV ược xem như một “từ iển”, giúp
mô tả các tham số có thể ược thử trên mô hình huấn luyện. Và các tham số mà chúng
tôi thực hiện tối ưu bao gồm:
Epochs: Số lần ưa dữ liệu vào Neural Network.
Batch Size: Số lượng mẫu dữ liệu ưa vào trong một lần huấn luyện.
Learning Rate: Tốc ộ học của mô hình.
Activation Function: Hàm kích hoạt.
Neurons: Số lượng node trong Neural Network ( ối với mô hình LSTM và CNN).
Filters size: Số lượng bộ lọc ( ối với mô hình CNN). lOMoARcPSD| 37054152
CHƯƠNG 4. KẾT QUẢ THỰC HIỆN
4.1. KẾT QUẢ ĐÁNH GIÁ SỰ THÀNH CÔNG CỦA CÁC ICO
Với 2 thuật toán KNN và RNN ã xây dựng và thực hiện huấn luyện với bộ dữ
liệu, chúng tôi thu ược kết quả như sau:
4.1.1. Thuật toán KNN
Bảng 4.1. Kết quả phân loại các whitepaper khi sử dụng thuật toán KNN (Nhóm thực hiện)
successful unsuccessful row total successful 17 0 17 unsuccessful 1 26 27 column total 18 26 44
Hình 4.1. Ma trận hỗn loạn thể hiện kết quả của thuật toán KNN (Nhóm thực hiện)
Dựa vào kết quả thu ược, chúng tôi tổng kết thông qua Bảng 4.1. Nhìn vào bảng
có thể thấy rằng chúng tôi ã sử dụng 44 whitepaper bất kỳ ể thực hiện thuật toán, trong
ó 18 whitepaper ược dán nhãn là thành công thì thuật toán dự oán có chính xác 17
whitepaper thành công và 1 whitepaper là không thành công. Đối với 26 whitepaper
ược dán nhãn là không thành công thì mô hình dự oán có chính xác 26 whitepaper ó lOMoARcPSD| 37054152
thuộc nhóm không thành công. Qua ó cho thấy phán oán của mô hình KNN có ộ chính
xác cao, ít có sự nhầm lẫn khi phán oán. Cụ thể, tính toán các chỉ số của thuật toán
KNN, cho ra kết quả: Precision = 100%; Recall = 94,44%; Chỉ số ánh giá ộ chính xác F-measure = 96,89%.
4.1.2. Thuật toán Naïve Bayes
Bảng 4.2. Kết quả phân loại các whitepaper khi sử dụng thuật toán Naïve Bayes (Nhóm thực hiện)
successful unsuccessful row total successful 10 11 21 unsuccessful 7 18 25 column total 17 29 46
Hình 4.2. Ma trận hỗn loạn thể hiện kết quả của thuật toán Naïve Bayes (Nhóm thực hiện)
Dựa vào kết quả thu ược, chúng tôi tổng kết thông qua Bảng 4.2. Theo kết quả
ở Bảng 4.2, trong 17 whitepaper ược dán nhãn là thành công thì thuật toán chỉ ánh giá
úng 10 whitepaper thuộc nhóm thành công, 7 whitepaper còn lại thuật toán ã dự oán
sai hoặc không dự oán ược. Tương tự, với nhóm whitepaper không thành công thì lOMoARcPSD| 37054152
thuật toán chỉ dự oán úng 18 trong số 29 whitepaper là thuộc nhóm không thành công,
và 11 whitepaper còn lại dự oán sai. Cụ thể, tính toán các chỉ số của thuật toán Naïve
Bayes, cho ra kết quả: Precision = 47,62%; Recall = 58,82%; Chỉ số ánh giá ộ chính xác F-measure = 52,63%.
4.1.3. So sánh thuật toán KNN và Naïve Bayes
Tổng kết lại, ở phần này, chúng tôi ã xây dựng thành công 2 mô hình KNN và
Naive Bayes ể dự oán sự thành công của các ICO. Cụ thể so sánh các chỉ số của mô
hình có thể xem xét thông qua Bảng 4.3 dưới ây:
Bảng 4.3. So sánh các chỉ số hiệu suất của thuật toán KNN và Naive Bayes (Nhóm thực hiện) Precision Recall F – measure KNN 100% 94,44% 96,89% Naive Bayes 47,62% 58,82 52,63%
Nhìn vào Bảng 4.3 có thể thấy rằng, mô hình KNN mang lại kết quả với ộ nhận
diện và phân loại tốt hơn so hơn mô hình Naive Bayes, các chỉ số Recall, Precision
và F-measure ều cao hơn áng kể với các con số lần lượt là 94,44%; 100% và 96,89%.
Mặc dù ã ược ưa qua nhiều bước xử lý tiền dữ liệu hơn KNN ể nâng cao ộ chính xác
trong quá trình dự oán nhưng thuật toán Naive Bayes vẫn mang lại kết quả phân loại
thấp hơn. Dựa vào hiệu suất dự oán thông qua ma trận nhầm lẫn của hai mô hình,
chúng tôi ưa ra kết luận rằng thuật toán KNN là thuật toán phù hợp nhất, áp ứng ược
nhu cầu phân loại ICO với ộ chính xác ạt mức cao. Ở bước tiếp theo, chúng tôi tiếp
tục thực hiện dự oán giá của các ICO thành công, có chỉ số ROI cao thông qua việc
huấn luyện dữ liệu với 3 mô hình: LSTM, RNN và CNN và kết quả cụ thể sẽ ược trình bày ở phần 4.2.
4.2. KẾT QUẢ DỰ BÁO GIÁ TIỀN ĐIỆN TỬ
4.2.1. Kết quả lựa chọn mô hình
Dữ liệu ầu vào bao gồm tập dữ liệu của 3 coin là ETH, IOTA và SOL. Chúng
tôi thực hiện huấn luyện lần lượt 3 tập dữ liệu với 3 model LSTM, RNN và CNN
với các thông số ban ầu là: epoch: 50 batch size: 32 activation: relu filters ( ối với
CNN): 64 neurons ( ối với RNN và LSTM): 50
Sau khi thực hiện huấn luyện 3 mô hình với từng tập dữ liệu ETH, IOTA và lOMoARcPSD| 37054152
SOL, chúng tôi thu ược kết quả và tổng hợp lại ở bảng dưới ây:
Bảng 4.4. Kết quả so sánh các mô hình của 3 loại tiền iện tử (Nhóm thực hiện) Mô MAE MAPE RMSE R^2 Thời gian hình
LSTM 6.278433 0.208362 6.941507 0.999777 7 phút 27 giây
ETH RNN 11.551725 0.372092 12.248563 0.999305 4 phút 04 giây
CNN 1.468522 0.0506
2.461003 0.999972 2 phút 05 giây
LSTM 0.00355 0.334072 0.004012 0.999573 6 phút 24 giây
IOTA RNN 0.002303 0.217815 0.002817 0.99979 4 phút 01 giây
CNN 0.002089 0.19466 0.002621 0.999818 2 phút 22 giây
LSTM 0.365624 0.280785 0.411638 0.999792 4 phút 43 giây
SOL RNN 0.136438 0.113845 0.193113 0.999954 3 phút 11 giây
CNN 0.101324 0.082001 0.156276 0.99997 2 phút 22 giây
Thông qua Bảng 4.1 cho thấy, ối với cả 3 loại tiền iện tử là ETH, IOTA và SOL,
khi thực hiện huấn luyện thì mô hình CNN cho ra kết quả với các sai số là thấp nhất.
Cụ thể, sai số toàn phương trung bình RMSE như sau:
Với ETH: sai số toàn phương trung bình RMSE là vào khoảng 2.461003, thấp
hơn so với RMSE của mô hình LSTM khoảng 2,8 lần và RNN là 5 lần.
Với IOTA: sai số toàn phương trung bình RMSE là khoảng 0.00226, thấp hơn
so với RMSE của mô hình LSTM khoảng 1,5 lần và RNN là 1,07 lần.
Với SOL: sai số toàn phương trung bình RMSE là khoảng 0.156276, thấp hơn
so với RMSE của mô hình LSTM và RNN khoảng 2,6 lần.
Các sai số càng nhỏ, ồng nghĩa với việc mô hình có ộ dự oán chính xác càng
cao. Dựa vào kết quả này, mô hình CNN là mô hình phù hợp nhất trong 3 mô hình
trên. Và chúng tôi sẽ tiếp tục thực hiện dự báo giá của tiền ảo dựa trên mô hình này.
4.2.2. Kết quả tối ưu hóa các tham số của mô hình
Tương ứng với mô hình CNN ã ược huấn luyện với bộ dữ liệu của từng loại tiền
iện tử, chúng tôi sẽ thực hiện tối ưu hóa bằng công cụ GridSearchCV. Đối với mỗi
tham số, chúng tôi sẽ tạo một list các giá trị ể lựa chọn ra giá trị tối ưu nhất. Tham lOMoAR cPSD| 37054152
khảo theo nghiên cứu của tác giả Phạm Hoàng Anh (2021), tác giả ã lựa chọn một
danh sách các giá trị tham số tăng dần. Ví dụ như với batch size, chúng tôi sẽ tạo một
list gồm các giá trị tăng dần [16, 32, 48, 64, 80, 96]. Khi tối ưu, mô hình sẽ lần lượt
chạy với các giá trị batch size trong list và từ kết quả sẽ ưa ra kết luận rằng tham số
nào là tối ưu nhất cho mô hình. Kết quả thu ược sẽ là tham số có trung vị cao nhất và
ộ lệch chuẩn thấp nhất trong list.
Cụ thể, các giá trị tham số cần tối ưu của thuật toán và các giá trị ược thể hiện ở bảng sau:
Bảng 4.5. Các giá trị tham số cần lựa chọn ể có ược mô hình CNN tối ưu (Nhóm thực hiện) Tham số Giá trị Epoch 100, 150, 200 Batch size 16, 32, 48, 80, 96 Learning rate 0.001, 0.01, 0.1, 0.2, 0.3 Activation function relu, tanh, sigmod, linear Filters size 16, 25, 36, 49, 64, 81
Dưới ây là kết quả của quá trình tối ưu các tham số mô hình CNN cho 3 bộ dữ
liệu ã tổng hợp ược từ kết quả thực nghiệm:
Bảng 4.6. Kết quả tối ưu tham số mô hình CNN - data ETH (Nhóm thực hiện) Tham số Trung vị Độ lệch chuẩn 100 0.999973 0.000002 Epoch 150 0.999974 0.000001 200 0.999974 0.000001 16 0.999975 0.000001 32 0.999974 0.000001 48 0.999973 0.000002 Batch size 64 0.999973 0.000001 80 0.999973 0.000001 96 0.999973 0.000001 0.001 -1.009785 76.764 Learning rate 0.01 -1.077947 149.277 0.1 -2.596059 995.948 lOMoAR cPSD| 37054152 0.2 -5.735974 3.499.093 0.3 -2.015174 703.262 relu -0.943567 0.015540 tanh -0.974810 0.035069 Activation Funcition sigmod -0.983926 0.031913 linear -0.966164 0.054442 16 -1.006.793 0.056249 25 -0.966.487 0.014434 36 -0.988.870 0.044853 Filters size 49 -0.974.180 0.018365 64 -0.951.800 0.028418 81 -0.954.069 0.025111
Thông qua kết quả từ Bảng 4.2 cho thấy, giá trị các tham số tốt nhất cho mô hình
CNN thực hiện huấn luyện với bộ dữ liệu giá ETH là: epochs = 200; batch size = 16;
learning rate = 0.001; activation function = relu; filters size = 64.
Bảng 4.7. Kết quả tối ưu tham số mô hình CNN - data IOTA (Nhóm thực hiện) Tham số Trung vị Độ lệch chuẩn 100 0.999806 0.000080 Epoch 150 0.999835 0.000008 200 0.999858 0.000009 16 0.999753 0.000061 32 0.999798 0.000048 48 0.999856 0.000021 Batch size 64 0.999872 0.000003 80 0.999839 0.000027 96 0.999844 0.000020 0.001 -0.000004 0.000001 0.01 -0.000005 0.000001 Learning rate 0.1 -0.000173 0.000109 0.2 -0.000106 0.000131 lOMoAR cPSD| 37054152 0.3 -0.020000 0.001916 relu -0.000003 0.000001 tanh -0.000003 0.000000 Activation Funcition sigmod -0.000004 0.000000 linear -0.000003 0.000000 16 -0.000003 0.000001 25 -0.000003 0.000000 36 -0.000003 0.000000 Filters size 49 -0.000003 0.000001 64 -0.000003 0.000000 81 -0.000004 0.000001
Thông qua kết quả từ Bảng 4.3 cho thấy, giá trị các tham số tốt nhất cho mô hình
CNN thực hiện huấn luyện với bộ dữ liệu giá IOTA là: epochs = 200; batch size = 64;
learning rate = 0.001; activation function = linear; filters size = 25.
Bảng 4.8. Kết quả tối ưu tham số mô hình CNN – data SOL (Nhóm thực hiện) Tham số Trung vị Độ lệch chuẩn 100 0.999972 0.000002 Epoch 150 0.999970 0.000003 200 0.999972 0.000002 16 0.999973 0.000000 32 0.999972 0.000002 48 0.999972 0.000002 Batch size 64 0.999972 0.000001 80 0.999973 0.000001 96 0.999973 0.000000 0.001 -0.010278 0.000151 0.01 -0.010254 0.000080 Learning rate 0.1 -0.030916 0.006417 0.2 -0.133268 0.073245 0.3 -0.074019 0.007399 lOMoAR cPSD| 37054152 Activation relu -0.011671 0.001105 Funcition tanh -0.009547 0.002197 sigmod -0.011536 0.000733 linear -0.008470 0.001090 16 -0.009426 1.521 25 -0.010329 0.001645 36 -0.012123 0.001527 Filters size 49 -0.015584 0.002634 64 -0.012172 0.002978 81 -0.022571 0.007831
Thông qua kết quả từ Bảng 4.4 cho thấy, giá trị các tham số tốt nhất cho mô hình
CNN thực hiện huấn luyện với bộ dữ liệu giá SOL là: epochs = 100; batch size = 96;
learning rate = 0.01; activation function = linear; filters size = 16.
Tổng kết lại, ối với từng bộ data, các giá trị tham số tốt nhất ể mô hình CNN
ược tối ưu nhất ược tổng hợp ở Bảng 4.5:
Bảng 4.9. Kết quả tối ưu tham số của mô hình CNN (Nhóm thực hiện)
Epoch Batch size Learning rate Activation function Filter size ETH 200 16 0.001 relu 64 IOTA 200 64 0.001 linear 25 SOL 100 96 0.01 linear 16
Đối với bộ dữ liệu giá ETH, các giá trị tham số ể mô hình tối ưu nhất lần lượt
là: epoch=200; batch size=16, learning rate=0.001, filter size=64 và activation
function sử dụng là relu.
Đối với bộ dữ liệu giá IOTA, các giá trị tham số ể mô hình tối ưu nhất lần lượt
là: epoch=200; batch size=64, learning rate=0.001, filter size=25 và activation
function sử dụng là linear.
Đối với bộ dữ liệu giá SOL, các giá trị tham số ể mô hình tối ưu nhất lần lượt
là: epoch=100; batch size=96, learning rate=0.01, filter size=64 và activation function sử dụng là relu. lOMoARcPSD| 37054152
Với các tham số ã ược chọn lựa tối ưu, chúng tôi tiếp tục thực hiện việc huấn
luyện mô hình CNN tốt nhất cho cả 3 file dữ liệu, cho ra kết quả ược tổng hợp như sau:
Bảng 4.10. Kết quả các chỉ số của mô hình tối ưu (Nhóm thực hiện) MAE MAPE RMSE R^2 ETH 1.381292 0.047611 2.275747 0.999976 IOTA 0.001156 0.116462 0.002132 0.999879 SOL 0.094528 0.076459 0.130821 0.999979
Từ bảng trên và kết quả ở bảng 4 cho thấy, các giá trị sai số ở mô hình tốt nhất
ã ược cải thiện hơn so với mô hình ban ầu. Cụ thể:
Với bộ data ETH: chỉ số MAE giảm 1.0632 lần, MAPE giảm 1.0628 lần và
RMSE giảm 1.0814 lần so với mô hình chưa tối ưu.
Với bộ data IOTA: chỉ số MAE giảm 1.8071 lần, MAPE giảm 1,6714 lần và
RMSE giảm 1.2294 lần so với mô hình chưa tối ưu.
Với bộ data SOL: chỉ số MAE giảm 1.0720 lần, MAPE giảm 1.0725 lần và
RMSE giảm 1.1946 lần so với mô hình chưa tối ưu.
Riêng ở bộ dữ liệu ETH, do giá biến ộng qua từng phút cao hơn so với 2 loại
tiền iện tử còn lại (không có biên ộ giới hạn) nên dẫn kết quả sai số MAE và RMSE có phần cao hơn.
4.2.3. Kết quả dự báo giá trong 60 phút cuối
Chúng tôi thực hiện dự oán giá của các loại tiền iện tử dựa trên mô hình tối ưu
nhất ã thực hiện nghiên cứu ở trên. Dưới ây là kết quả dự báo trong 60 phút cuối của các bộ dữ liệu: lOMoARcPSD| 37054152 ( a) ( b) ( c)
Hình 4.3. Dự oán giá 3 loại tiền iện tử trong 60 phút cuối
(a) ETH ; (b) IOTA ; (c) SOL (Nhóm thực hiện)
Thông qua kết quả dự oán giá trong 60 phút cuối của 3 loại tiền iện tử ETH,
IOTA và SOL cho thấy, nhìn chung thì hình dạng biến ộng giá dự oán có phần tương
tự so với giá gốc, dự oán cơ bản ược sự tăng - giảm của giá. Tuy nhiên, nhìn chung
thì phần giá dự oán có phần chênh lệch khá lớn so với giá gốc. Lý do là bởi bộ dữ liệu
ầu vào là giá chênh lệch qua từng phút, do ó mà sự chênh lệch giá giữa phút trước và
phút sau không cao. Chính vì thế làm cho quá trình học tập của máy trở nên khó khăn
hơn, và khó ưa ra ược kết quả dự báo chính xác nhất. Cụ thể dưới ây là giá gốc và giá
dự báo của ETH, IOTA và SOL tương ứng trong 20 dòng lệnh cuối cùng mà chúng
tôi ã tổng hợp ược từ kết quả thực nghiệm:
Bảng 4.11. Giá gốc và giá dự báo của ETH trong 20 dòng cuối (Nhóm thực hiện) Giá dự
Chênh lệch giá giữa Thời gian Giá Gốc oán
giá gốc/ giá dự oán 2022-01-31 23:40:00+00 2684,91 3760,72 1075,81 2022-01-31 23:41:00+00 2684,37 3760,42 1076,05 2022-01-31 23:42:00+00 2681,71 3752,67 1070,96 2022-01-31 23:43:00+00 2680,10 3743,58 1063,48 2022-01-31 23:44:00+00 2678,96 3738,79 1059,83 2022-01-31 23:45:00+00 2681,30 3740,35 1059,05 lOMoAR cPSD| 37054152 2022-01-31 23:46:00+00 2681,01 3747,62 1066,61 2022-01-31 23:47:00+00 2682,19 3746,24 1064,05 2022-01-31 23:48:00+00 2682,56 3748,56 1066,00 2022-01-31 23:49:00+00 2683,93 3752,69 1068,76 2022-01-31 23:50:00+00 2686,25 3761,37 1075,12 2022-01-31 23:51:00+00 2686,24 3766,10 1079,86 2022-01-31 23:52:00+00 2687,25 3768,46 1081,21 2022-01-31 23:53:00+00 2878,73 3774,31 895,58 2022-01-31 23:54:00+00 2688,85 3776,50 1087,65 2022-01-31 23:55:00+00 2689,73 3780,74 1091,01 2022-01-31 23:56:00+00 2689,64 3778,32 1088,68 2022-01-31 23:57:00+00 2687,91 3778,20 1090,29 2022-01-31 23:58:00+00 2688,18 3776,21 1088,03 2022-01-31 23:59:00+00 2686,94 3770,42 1083,48
Thông qua Bảng 4.7 cho thấy, mô hình cơ bản dự oán ược sự tăng – giảm về giá
của ETH. Ví dụ, ta thấy giá dự báo ở thời iểm 23h41p ngày 31/01/2022 giảm so với
giá dự báo lúc 23p40p. Tương ứng với ó, giá thực tế lúc 23h41p cũng giảm so với giá
ở 23h40p. Kết quả là trong 20 dòng lệnh với 19 sự biến ộng lên xuống về giá của
ETH, mô hình ã dự báo chính xác sự tăng – giảm của mức giá ở 14 dòng, ộ chính xác khoảng 73,684%.
Bảng 4.12. Giá gốc và giá dự báo của IOTA trong 20 dòng cuối (Nhóm thực hiện) Giá dự
Chênh lệch giá giữa Thời gian Giá Gốc oán
giá gốc/ giá dự oán 2022-01-31 23:40:00+00 0,83 1,20 0,37 2022-01-31 23:41:00+00 0,83 1,16 0,33 2022-01-31 23:42:00+00 0,83 1,16 0,33 2022-01-31 23:43:00+00 0,83 1,16 0,33 2022-01-31 23:44:00+00 0,83 1,16 0,33 2022-01-31 23:45:00+00 0,83 1,16 0,33 2022-01-31 23:46:00+00 0,83 1,16 0,33 2022-01-31 23:47:00+00 0,83 1,16 0,33 2022-01-31 23:48:00+00 0,83 1,16 0,33 2022-01-31 23:49:00+00 0,84 1,20 0,36 2022-01-31 23:50:00+00 0,84 1,24 0,40 lOMoAR cPSD| 37054152 2022-01-31 23:51:00+00 0,84 1,24 0,40 2022-01-31 23:52:00+00 0,84 1,24 0,40 2022-01-31 23:53:00+00 0,84 1,24 0,40 2022-01-31 23:54:00+00 0,84 1,24 0,40 2022-01-31 23:55:00+00 0,84 1,24 0,40 2022-01-31 23:56:00+00 0,84 1,24 0,40 2022-01-31 23:57:00+00 0,84 1,24 0,40 2022-01-31 23:58:00+00 0,83 1,20 0,37 2022-01-31 23:59:00+00 0,83 1,16 0,33
Thông qua bảng trên cho thấy, mô hình cơ bản dự oán ược sự tăng – giảm về giá
của IOTA. Ví dụ, ta thấy giá dự báo ở thời iểm 23h49p ngày 31/01/2022 tăng so với
giá dự báo lúc 23p48p. Tương ứng với ó, giá thực tế lúc 23h49p cũng tăng so với giá
ở 23h48p. Các dòng kết quả khác cũng lần lượt có sự tăng – giảm. Kết quả nhóm so
sánh, trong 20 dòng lệnh với 19 sự biến ộng lên xuống về giá của IOTA, mô hình ã
dự báo chính xác sự tăng – giảm của mức giá ở 16 dòng, ộ chính xác khoảng 84,211%.
Bảng 4.13. Giá gốc và giá dự báo của SOL trong 20 dòng cuối (Nhóm thực hiện) Giá dự
Chênh lệch giá giữa Thời gian Giá Gốc oán
giá gốc/ giá dự oán 2022-01-31 23:40:00+00 99,51 155,13 55,62 2022-01-31 23:41:00+00 99,41 154,95 55,54 2022-01-31 23:42:00+00 99,32 154,38 55,06 2022-01-31 23:43:00+00 99,30 154,08 54,78 2022-01-31 23:44:00+00 99,22 153,92 54,70 2022-01-31 23:45:00+00 99,52 154,6 55,08 2022-01-31 23:46:00+00 99,36 154,83 55,47 2022-01-31 23:47:00+00 99,39 154,33 54,94 2022-01-31 23:48:00+00 99,47 154,53 55,06 2022-01-31 23:49:00+00 99,47 154,86 55,39 2022-01-31 23:50:00+00 99,61 155,25 55,64 2022-01-31 23:51:00+00 99,51 155,54 56,03 2022-01-31 23:52:00+00 99,60 155,22 55,62 2022-01-31 23:53:00+00 99,59 155,38 55,79 2022-01-31 23:54:00+00 99,65 155,70 56,05 lOMoARcPSD| 37054152 2022-01-31 23:55:00+00 99,66 156,16 56,50 2022-01-31 23:56:00+00 99,75 156,22 56,47 2022-01-31 23:57:00+00 99,77 156,40 56,63 2022-01-31 23:58:00+00 99,76 156,70 56,94 2022-01-31 23:59:00+00 99,49 155,98 56,49
Thông qua bảng trên cho thấy, mô hình cơ bản dự oán ược sự tăng – giảm về giá
của SOL. Ví dụ, ta thấy giá dự báo ở thời iểm 23h41p ngày 31/01/2022 giảm so với
giá dự báo lúc 23p40p. Tương ứng với ó, giá thực tế lúc 23h41p cũng giảm so với giá
ở 23h40p. Các dòng kết quả khác cũng lần lượt có sự tăng – giảm. Kết quả nhóm so
sánh, trong 20 dòng lệnh với 19 sự biến ộng lên xuống về giá của SOL, mô hình ã dự
báo chính xác sự tăng – giảm của mức giá ở 12 dòng, ộ chính xác khoảng 63,168%.
Tương ứng với các bảng kết quả trên, ta có các sơ ồ như sau:
Hình 4.4. Dự oán giá 3 loại tiền iện tử trong 20 phút cuối (Nhóm thực hiện) lOMoARcPSD| 37054152
Dựa vào kết quả từ bảng và sơ ồ dự oán trên, về cơ bản ta có thể dự oán
ược sự tăng hay giảm của loại tiền iện tử tương ứng vào ngày hôm sau ể ra quyết ịnh
ặt lệnh mua hay ặt lệnh bán. Nếu giá dự oán ngày hôm sau cao hơn ngày hôm trước
thì ặt lệnh mua, và ngược lại, nếu giá dự oán thấp hơn thì ặt lệnh bán.
4.3. TỔNG KẾT KẾT QUẢ THỰC NGHIỆM
Tổng kết lại, qua bài nghiên cứu này, chúng tôi ã hoàn thành việc sử dụng
textmining ể ánh giá sự thành công của các ICO theo tiêu chí ROI với 2 mô hình là
KNN và Naive Bayes. Kết quả thu về là mô hình KNN mang lại kết quả chính xác
hơn (Chỉ số ánh giá ộ chính xác F-measure = 96,98%, cao gấp 1,84 lần so với
Fmeasure của mô hình Naive Bayes). Và trong số các ICO thành công, chúng tôi lựa
chọn ra 3 coin có chỉ số ROI cao, có tiềm năng và ang ược nhiều nhà ầu tư quan tâm
là SOL, IOTA và ETH ể tiến hành dự oán giá.
Chúng tôi ã xây dựng mô hình tối ưu nhất cho 3 loại tiền iện tử trên trong 3 mô
hình ưa ra ban ầu là LSTM, RNN và CNN. Qua quá trình thực nghiệm và ánh giá, kết
luận mô hình CNN là tốt nhất, sai số thấp nhất trong cả 3 mô hình. (Với ETH: sai số
toàn phương trung bình RMSE là vào khoảng 2.461003. Với IOTA: sai số toàn
phương trung bình RMSE là khoảng 0.00226. Với SOL: sai số toàn phương trung
bình RMSE là khoảng 0.156276.)
Và tương ứng với từng bộ dữ liệu có những chỉ số phù hợp nhất ể ưa ra kết quả
dự oán giá tiền iện tử. Thông quá quá trình tối ưu hóa, kết quả ạt ược giá trị sai số
toàn phương trung bình (RMSE) của 3 bộ dữ liệu ETH, IOTA và SOL sau khi huấn
luyện với mô hình tốt nhất lần lượt là 2.275747, 0.002132 và 0.130821. Kết quả bộ
giá dự oán có ộ chính xác về sự tăng – giảm so với giá thực tế của ETH, IOTA và
SOL lần lượt là 73,684%, 84,211% và 63,168%. lOMoARcPSD| 37054152
CHƯƠNG 5. KẾT LUẬN ĐỀ TÀI - ĐỀ XUẤT HƯỚNG PHÁT TRIỂN
5.1. CÁC KẾT QUẢ ĐẠT ĐƯỢC
5.1.1. Hoàn thành các mục tiêu
Sau quá trình nghiên cứu, thu thập dữ liệu và thực nghiệm trên các mô hình cũng
như có những phân tích và ánh giá lựa chọn, tổng kết lại ề tài của chúng tôi ạt ược
những kết quả như mục tiêu ban ầu:
- Thành công xây dựng 2 mô hình text-mining là KNN và Naive Bayes ể ánh
giá sự thành công của các ICO dựa vào tiêu chí ROI. Chúng tôi sử dụng bộ dữ liệu
150 ICO ể thực nghiệm ưa vào mô hình (bộ dữ liệu là 150 whitepaper của các ICO,
thu thủ công từ coinmarketcap và cryptorank). Kết quả cho thấy mô hình KNN là mô
hình phân loại tốt hơn với mức ộ dự oán chính xác lên ến 96,89%, trong khi mức ộ
dự oán của Naive Bayes là 52,63%, thấp hơn khoảng 1,8 lần so với KNN.
- Lựa chọn ra các ICO thành công ể tiến hành dự oán giá. Kết quả lựa chọn ược
3 ICO là: ETH, IOTA và SOL. Đây là các ICO có ROI cao, có tiềm năng phát triển
trên thị trường và ược nhiều nhà ầu tư quan tâm.
- Thu ược bộ dữ liệu giá của 3 ICO bằng công cụ Coin-for-rich, kéo từ lịch sử
từ REST APIs của sàn Binance, là bộ dữ liệu sạch và ầy ủ theo từng phút. Chúng tôi
ã xây dựng thành công 3 mô hình LSTM, RNN và CNN ể dự oán giá của 3 loại tiền
iện tử thành công. Kết quả lựa chọn ược mô hình CNN là mô hình có chỉ số sai số
thấp nhất trong 3 mô hình ã xây dựng. Sau khi tối ưu các chỉ số của mô hình bằng
công cụ GridSearchCV, tạo ra ược mô hình CNN tối ưu nhất với từng bộ tham số phù
hợp với từng bộ dữ liệu.
- Huấn luyện 3 bộ dữ liệu giá ETH, IOTA, SOL với mô hình tốt nhất, cho ra kết
quả là bộ giá dự oán có ộ chính xác về sự tăng – giảm so với giá thực tế lần lượt là
73,684%, 84,211% và 63,168%. Dựa vào kết quả dự oán giá giúp các nhà nghiên cứu,
nhà ầu tư và giới tư vấn viên có chiến lược phù hợp và an toàn khi tư vấn, ầu tư vào các ICO. lOMoARcPSD| 37054152
5.1.2. Trả lời ược các câu hỏi nghiên cứu
Làm thế nào ể ưa ra ược ánh giá ược khả năng thành công của ICO bất kỳ
thông qua chỉ số ROI và whitepaper của các ICO?
Để có thể ánh giá ược ộ thành công của các ICO, cần thu thập ROI của các ICO
ã có mặt trên thị trường hiện tại theo 3 loại lớn hơn 100%, nhỏ hơn 50% và nhỏ hơn
30%. Dựa vào việc phân loại có thể giúp ta ưa ra ược những phán oán rằng các ICO
ở nhóm ROI lớn hơn 100% là các ICO thành công và ngược lại, các ICO còn lại là
không thành công. Từ ó sẽ tiến hành thu thập các whitepaper theo 3 nhóm ROI ã phân
loại trên và tiến hành xây dựng các mô hình text-mining ể có thể phán oán và ưa ra dự oán cuối cùng.
Trong quá trình thu thập dữ liệu thì nền tảng nào cho cho phép việc thu thập
các thông tin về ROI cũng như các whitepaper ICO?
Hiện nay có rất nhiều trang web miễn phí có thể cho phép người dùng biết ược
những thông tin của các các crypto nói chung và ICO nói riêng. cryptorank.io là một
mã nguồn mở uy tín cung cấp những thông tin cần thiết về giá, lợi nhuận ầu tư, giao
dịch tiền iện tử,... Và ây là nguồn mà chúng tôi dùng ể thu thập các thông về ROI của
các ICO. Đối với việc thu thập các whitepaper ICO thì nhóm tiến hành thu thập trên
một trang web khác có tên là coinmarket.com - là một website thành lập vào năm
2013, là nơi áng tin cậy cho những nhà ầu tư có thể tìm kiếm thông tin về các loại tiền iện tử áng ầu tư.
Việc ánh giá sự thành công của whitepaper sẽ ược thực hiện trên mô hình
máy học nào ?
Các whitepaper ICO ược nhóm thu thập ều ở dạng văn bản nên ể có thể xử lý
ược dạng dữ liệu như thế này, nhóm ã sử dụng mô hình khai thác văn bản (textmining)
ể có thể khai phá triệt ể những thông tin trên cho quá trình dự oán. Tuy nhiên, lĩnh
vực khai thác văn bản là một lĩnh vực rộng và cần nhiều thời gian ể có hiểu ược vấn
ề này. Do ó, chúng tôi ã chọn ra 2 mô hình tối ưu và ược sử dụng nhiều trong lĩnh vực
khai thác văn bản ó chính là Naive Bayes và K-Nearest Neighbors (KNN) ể tiến hành
dự oán cho bộ dữ liệu mà nhóm ã thu thập. lOMoARcPSD| 37054152
Việc dự oán giá dựa vào các dữ liệu thu thập bằng API sẽ mang lại kết quả
như thế nào so với các data có sẵn từ các trang web tiền iện tử uy tín như coin market?
Data ược thu thập bằng hình thức API sẽ vô cùng sạch, các kết quả giá ược thu
thập biến ộng theo từng phút. Dữ liệu thu thập bằng hình thức API vừa có thể linh
ộng, ta có thể thu thập với ơn vị thời gian nhỏ nhất, còn ối với các data ược thu thập
từ các trang web thì lại bị hạn chế về số lượng.
Mô hình thuật toán dự oán giá Machine Learning nào sẽ mang lại hiệu quả
tốt nhất, dự oán giá chính xác nhất cho các ICO ã ược ánh giá là thành công trước ó?
Thông qua kết quả và phạm vi thực hiện bài nghiên cứu, chúng tôi nhận ịnh rằng
mô hình CNN là mô hình mang lại hiệu quả dự oán chính xác nhất cho các ICO mà
chúng tôi ã ánh giá là thành công ở giai oạn trước ó. Kết quả so sánh giữa 3 mô hình
mà chúng tôi lựa chọn, bao gồm LSTM, RNN và CNN cho thấy sau khi huấn luyện,
mô hình CNN cho ra kết quả với sai số thấp nhất, cụ thể là sai số toàn phương trung
bình (RMSE). Với 3 bộ dữ liệu giá của ETH, IOTA, SOL, sai số toàn phương trung
bình RMSE sau khi huấn luyện với CNN cho ra kết quả là lần lượt là 2.461003, 0.00226 và 0.156276.
Tuy nhiên, hiện tại thì kết quả dự oán của chúng tôi chỉ giới hạn trong phạm vi
thực hiện huấn luyện mô hình với các chỉ số ã ược ề cập ở các chương phía trên. Thực
tế, ề tài của chúng tôi vẫn còn khá nhiều hạn chế ( ã trình bày ở chương 5) cũng như
là còn có thể phát triển theo hướng khác ể có thể ánh giá kết quả lựa chọn mô hình
khách quan và chính xác hơn.
5.2. NHỮNG HẠN CHẾ CỦA ĐỀ TÀI
5.2.1. Những hạn chế khi ánh giá sự thành công của ICO
Các biến ể dự oán còn hạn chế: Để có thể dự oán một ICO thành công hay thất
bại cần phải phân tích rất nhiều yếu tố như ROI, thời gian, khối lượng phát hành, tâm
lý thị trường hay ý kiến của các chuyên gia,... (Lauren và Andrea, 2018; Huang và
cộng sự, 2021). Tuy nhiên, trong ề tài nghiên cứu này, chúng tôi hiện chỉ tập trung
vào yếu tố ROI ể phân loại ra hai nhóm ICO là thành công và không thành công. lOMoARcPSD| 37054152
Không ảm bảo kết quả phân loại là chính xác 100%: Về mặt lý thuyết, có thể
thấy ROI là yếu tố ánh giá ược mức ộ nhận vốn ầu tư từ các nhà ầu tư. Tuy nhiên,
cũng có nhiều loại tiền iện tử có ROI ạt ở mức cao, nhưng trên thực tế chúng chỉ tồn
tại trong một khoản thời gian ngắn trên thị trường và sau ó ã dừng hoạt ộng. Đề tài
nghiên cứu của chúng tôi chưa thực hiện ược việc ánh giá và phân loại các ICO theo thời gian hoạt ộng.
Chưa tự ộng hóa việc thu thập whitepaper của các ICO: Việc thu thập
whitepaper từ các trang mạng vẫn còn thực hiện thủ công. Do ó tốn rất nhiều thời gian
cho việc thu thập dữ liệu ở thời iểm chúng tôi bắt ầu dự án.
Mô hình ánh giá còn hạn chế: Text-mining có rất nhiều thuật toán ể giúp phân
loại. Tuy nhiên trong phạm vi ề tài này, chúng tôi chỉ xây dựng hai mô hình là KNN
và Naive Bayes. Đây là iểm còn có phần hạn chế, cũng như vì thế mà kết quả ánh giá
lựa chọn mô hình chưa ược khả quan nhất.
5.2.2. Những hạn chế khi thực hiện dự oán giá tiền iện tử
Thời gian thu dữ liệu còn ít: Dữ liệu giá của các loại tiền iện tử ược chúng tôi
thực hiện thu bằng công cụ Coin-for-rich là dữ liệu sạch, thể hiện giá biến ộng theo
từng phút. Tuy nhiên, thời gian thu dữ liệu chỉ gói gọn trong 1 tháng, từ 0131/01/2022.
Số lần huấn luyện mô hình ít: Lượng dữ liệu tuy chỉ gói gọn trong thời gian 1
tháng nhưng số dòng dữ liệu là khá lớn, do giá biến ộng theo từng phút. Chính vì thế
ể kết qủa dự báo ược chính xác hơn òi hỏi số lần huấn luyện phải nhiều hơn, tức là số
epoch ban ầu phải cao hơn. Tuy nhiên, số epoch cao sẽ khiến thời gian huấn luyện
tăng lên rất nhiều, và quá trình huấn luyện sẽ tốn rất nhiều RAM của máy chủ/công
cụ huấn luyện mô hình (chúng tôi sử dụng Google Colab). Do ó, trong phạm vi khả
năng, chúng tôi chỉ thực hiện huấn luyện mô hình với chỉ số epoch ban ầu là 50. Điều
này làm cho kết quả tối ưu hóa mô hình cũng như kết quả dự báo chưa ạt ược mức ộ chính xác cao.
Chưa dự báo ược giá trị của tiền iện tử trong tương lai cũng như xu hướng
ầu tư của các chủ ầu tư: Với kết quả dự oán của chúng tôi hiện tại chỉ dừng lại ở
việc dự oán ược phần nào xu hướng ầu tư theo sự tăng giảm của mức giá. Tuy nhiên,
việc dự oán giá cũng như quyết ịnh ầu tư và thực hiện giao dịch trên các sàn iện tử lOMoARcPSD| 37054152
còn phụ thuộc vào một số yếu tố như: tình hình kinh tế, xã hội hoặc sự tác ộng từ bên
ngoài của những người có sức ảnh hưởng,... Đây là iều mà ề tài chưa thực hiện dự oán và ánh giá ược.
Thông qua quá trình nghiên cứu và thực hiện ề tài, chúng tôi nhìn nhận ược ề tài
còn nhiều thiếu sót. Ở chương 6 tiếp theo, bên cạnh việc trình bày cụ thể các kết quả
của ề tài ã thực hiện, chúng tôi cũng ề xuất một số phương án phát triển và khắc phục
các iểm yếu ể các nhà nghiên cứu tương lai có thể nghiên cứu và phát triển thêm, óng
góp vào các công trình nghiên cứu về các hoạt ộng có liên quan ến việc ánh giá sự
thành công và dự báo giá các ICO.
5.3. ĐỀ XUẤT HƯỚNG PHÁT TRIỂN TƯƠNG LAI
Có thể thấy, tiền iện tử - hay còn gọi là tiền ảo ngày nay ã và ang phát triển trên
toàn cầu. Nó như một công cụ, giúp ầu tư sinh lời thụ ộng và mang lại lợi nhuận, biến
nhiều người trở thành triệu phú, tỉ phú. Giá tiền ảo ngày càng không ngừng gia tăng
giá trị và ược nhiều nhà ầu tư chú tâm và chuyển hướng sang.
Nhờ hoạt ộng trên môi trường iện tử, ứng dụng công nghệ Blockchain, việc lưu
trữ và truyền tải thông tin liên quan ến việc ầu tư vào các loại tiền iện tử ược an toàn
hơn rất nhiều. Cùng với ó là sự tiếp cận dễ dàng, có kết nối rộng khắp khiến ngày
càng có nhiều người ầu tư, nghiên cứu lĩnh vực này.
Tuy nhiên, một iều nguy hiểm và rủi ro của mà tiền iện tử gặp phải chính là các
vấn ề liên quan ến pháp lý. Bởi hiện nay tại vẫn còn rất nhiều quốc gia chưa chấp
nhận tiền iện tử như là một loại tiền tệ chính thống ể giao dịch. Điều này cũng làm
cho nhiều nhà ầu tư có phần e dè và cân nhắc trước khi ầu tư vào nó.
Từ những iểm hạn chế kể trên cũng như tiềm năng phát triển của các loại tiền
iện tử, chúng tôi nhận thấy ề tài vẫn còn nhiều khả năng khai thác và có thể phát triển
tốt hơn trong tương lai. Dưới ây là một số hướng phát triển mà chúng tôi tự ề xuất:
- Tìm kiếm hoặc nghiên cứu xây dựng công cụ ể tự ộng hóa việc thu thập các
whitepaper. Điều này sẽ giúp tiết kiệm ược thời gian rất nhiều cho quá trình thực hiện ề tài.
- Bổ sung thêm các yếu tố ể ánh giá sự thành công của các ICO, ặc biệt là yếu
tố thời gian (thời gian hoạt ộng của các ICO). Nếu kết hợp ược cả 2 yếu tố này sẽ lOMoARcPSD| 37054152
giúp mô hình dự oán tăng ộ chính xác hơn, giảm rủi ro, và các ICO ược dự oán là
thành công cũng có ộ tin cậy cao hơn.
- Bên cạnh ROI và các dữ liệu ịnh lượng như thời gian hay khối lượng phát
hành,… có thể phát triển thu thập thêm các dữ liệu ịnh tính từ những nhà ầu tư thực
tế ể ánh giá sự thành công của các loại tiền iện tử. Những dữ liệu ịnh tính này cũng
góp phần tác ộng và hỗ trợ trong quá trình dự báo giá tiền iện tử.
- Xây dựng thêm các mô hình ể ánh giá sự thành công của ICO, từ ó có thể so
sánh hiệu suất của chúng và lựa chọn ra mô hình hiệu quả nhất, mang ến kết quả tốt nhất.
- Đầu tư hệ thống cũng như thời gian ể thực hiện huấn luyện các mô hình dự
oán giá ICO với bộ dữ liệu lớn hơn, số lần huấn luyện lâu hơn. Từ ó tối ưu hóa và lựa
chọn ược một mô hình có các chỉ số tốt nhất, nhằm mang ến kết quả dự oán có ộ chính xác và ộ tin cậy cao. lOMoARcPSD| 37054152 KẾT LUẬN
Tiền iện tử là khái niệm không còn xa lại gì ối với mọi người, tuy nhiên loại tiền
này còn ẩn chứa nhiều rủi ro cao bởi chưa có nhiều chế tài pháp luật cụ thể dành riêng
cho chúng. Ngoài ra, tiền iện tử có nhiều biến ộng lớn do ảnh hưởng từ cộng ồng
những nhà ầu tư lớn cũng như những người có sự ảnh hưởng lớn ến xã hội. Có rất
nhiều yếu tố ảnh hưởng ến khả năng ầu tư vốn của các nhà ầu tư, chúng ta không thể
phán oán ược tâm lý của họ. Đề tài chúng tôi thực hiện chỉ dựa trên dữ liệu của những
ICO ã ược tung ra thị trường, còn ối với những loại ICO trong tương lai thì những
phán oán này chỉ mang tính chất tượng trưng. Do vậy, việc ánh giá sự thành công của
ICO chỉ mang tính chất tham khảo và còn vướng mắc nhiều trở ngại khi ứng dụng
những ánh giá này vào thực tế.
Bên cạnh ó, tùy vào pháp luật của mỗi quốc gia có mức ộ chấp nhận tiền iện tử
như một loại phương thức thanh toán như thế nào thì mức ộ ấy sẽ ảnh hưởng ến lượng
thông tin thu thập của những loại tiền này. Vì thế mà mỗi quốc gia khác nhau thì sẽ
có những cách ể dự oán một ICO như thế nào là thành công và dự báo giá của nó dựa
trên những yếu tố khác nhau. Do vậy, ề tài nghiên cứu của chúng tôi chỉ úng trong một phạm vi nhất ịnh.
Thời gian gần ây Machine Learning hay Deep Learning trở nên phổ biến hơn và
ược ứng dụng trong nhiều mặt của xã hội. Trong quá trình làm ề tài, chúng tôi ã học
tập, nghiên cứu ể vận dụng những kiến thức này, có ược cái nhìn tổng quan hơn về
Machine Learning, Deep Learning và Text-mining ở mức ộ cơ bản. Đây là những
nguồn kiến thức thực sự bổ ích và hỗ trợ các thành viên trong nhóm phát triển tốt hơn.
Tuy nhiên, trong thời gian triển khai thực hiện ề tài, do còn hạn hẹp về kiến thức
cũng như kinh nghiệm thực tiễn trong lĩnh vực có phần khá mới mẻ với nhóm nên
không thể tránh khỏi những sai sót. Mong rằng các giảng viên và những người có
kinh nghiệm sẽ có những góp ý ể ề tài nghiên cứu của chúng tôi có thể hoàn thiện hơn
và tương lai có thể phát triển thêm nhiều hướng mới. lOMoARcPSD| 37054152
TÀI LIỆU THAM KHẢO TIẾNG ANH 1.
Bijalwan, V., Kumar, V., Kumari, P., & Pascual, J. (2014). KNN based
Machine Learning Approach for Text and Document Mining. International Journal
of Database Theory and Application, 7 (1), 61-70. 2.
Cetingok, B., & Deola, B. S. (2018). Analysis Of Success Factors For Initial
Coin Offerings And Automatisation Of Whitepaper Analysis Using Text - Mining
Algorithms. Master’s Thesis, HEC Paris. 3.
Chuanjie, F., Andrew, K., & Paul, G. (2019). Automated theme search in
ICO whitepapers. Journal of Finance and Data Science, 1 (4), 140-158. Research
Collection School Of Computing and Information Systems. 4.
Dai, W., Xue, G. R., Yang, Q., Yu, Y. (2007). Transferring naive bayes
classifiers for text classification. Twenty-Second AAAI Conference on Artificial
Intelligence, (pp. 540-545). 5.
Dang, S., & Ahmad, P. H. (2014). Text Mining: Techniques and its
Application. International Journal of Engineering & Technology Innovations (IJETI), 1 (4), 22-25 6.
Derbentsev, V., Matviychuk, A., & Soloviev, V. N. (2020). Forecasting
of Cryptocurrency Prices Using Machine Learning. In Advanced Studies of Financial
Technologies and Cryptocurrency Markets (pp. 211-231). 7.
Dutta, A., Kumar, S., & Basu, M. (2020). A Gated Recurrent Unit
Approach to Bitcoin Price Prediction. Journal of Risk and Financial Management, 13 (2), 23. 8.
Efron, B. (2013). Bayes' Theorem in the 21st Century. Science, 340 (6137), 1177-1178. 9.
El-Abdelouarti Alouaret, Z. (2017). Comparative study of vector
autoregression and recurrent neural network applied to bitcoin forecasting. Master’s
Thesis, Technical University of Madrid. lOMoARcPSD| 37054152 10.
Elman, J. L. (1990). Finding Structure in Time. Cognitive Science, 14 (2), 179–211. 11.
Feng, C., Li, N., Wong, M. H., và Zhang, M. (2019). Initial Coin Offerings, Blockchain
Technology, and White Paper Disclosuresa. Access
from: https://ssrn.com/abstract=3256289 12.
Florysiak, D., & Schandlbauer, A. (2022). Experts or Charlatans? ICO
Analysts and White Paper Informativeness. Journal of Banking and Finance, 139, 106476. 13.
Greaves, A., & Au, B. (2015). Using the Bitcoin Transaction Graph to
Predict the Price of Bitcoin. Technical report. 14.
Hijazi, S., Kumar, R., & Rowen, C. (2015). Using Convolutional
Neural Networks for Image Recognition. Cadence 15.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory.
Neural computation, 9 (8), 1735–1780. 16.
Huang, X., Zhang, W., Tang, X., Zhang, M., Surbiryala, J., Iosifidis,
V.,… Zhang, Z. L. (2021). LSTM Based Sentiment Analysis for Cryptocurrency Prediction.
International Conference on Database Systems for Advanced Applications, 617-621. 17.
Jadhav, S. D., & Channe, H. P. (2014). Comparative study of K-NN,
naive bayes and decision tree classification techniques. International Journal of
Science and Research, 5 (1), 2319-7064. 18.
Ji, S., Kim, J., & Im, H. (2019). A Comparative Study of Bitcoin Price
Prediction Using Deep Learning. Mathematics Journal, 7(10), 898. 19.
Jiang, X. (2020). Bitcoin Price Prediction Based on Deep Learning
Methods. Journal of Mathematical Finance, 10, 132-139. 20.
Khan, M. A. H., Iwai, M., & Sezaki, K. (2013). An improved
classification strategy for filtering relevant tweets using bag-of-word classifiers. Journal of
Information Processing, 21(3), 507-516. lOMoARcPSD| 37054152 21.
Krstinić, D., Braović, M., Šerić, L., & Božić-Štulić, D. (2020). Multi
Label Classifier Performance Evaluation With Confusion Matrix. International
Conference on Soft Computing, Artificial Intelligence and Machine (pp. 01-14) 22.
Kumar, B. S., & Ravi, V. (2016). A survey of the applications of
textmining in financial domain. Knowledge-Based Systems, 114, 128-147. Access
from: https://www.sciencedirect.com/science/article/abs/pii/S0950705116303872 23.
Lauren, B., & Andrea, M. (2018). What Makes an ICO Successful? An
Investigation of the Role of ICO Characteristics, Team Quality and Market
Sentiment. SSRN Electronic Journal. 24.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-
based learning applied to document recognition. Proceedings of the IEEE, 86 (11), 2278– 2324. 25.
Li, Y., & Dai, W. (2020). Bitcoin price forecasting method based on
CNNLSTM hybrid neural network model. The 3rd Asian Conference on Artificial
Intelligence Technology (ACAIT). 26.
Li, Y., Zheng, Z., & Dai, H. N. (2020). Enhancing Bitcoin Price
Fluctuation Prediction Using Attentive LSTM and Embedding Network. Applied
Sciences Journal, 10 (14), 4872. 27.
Livieris, I. E., Kiriakidou, N., Stavroyiannis, S., & Pintelas, P. (2020).
An Advanced CNN-LSTM Model for Cryptocurrency Forecasting. Electronic Journal, 10, 287. 28.
Livieris, I. E., Pintelas, E., Stavroyiannis, S., Pintelas, P. (2020).
Ensemble Deep Learning Models for Forecasting Cryptocurrency Time-Series. Algorithms Journal, 13 (5), 121. 29.
Lu, Y. (2016). Food Image Recognition by Using Convolutional Neural
Networks (CNNs). Access from: https://arxiv.org/abs/1612.00983 30.
Luque, A., Carrasco, A., Martín, A., de las Heras, A. (2019). The impact
of class imbalance in classification performance metrics based on the binary
confusion matrix. ScienceDirect Journal, 91, 216-231. lOMoAR cPSD| 37054152 31.
McCallum, A., & Nigam, K. (1998). A Comparison of Event Models for
Naive Bayes Text Classification. Learning for Text Categorization: Papers from the
1998 AAAI Workshop (pp. 41-48). 32.
Mudassir, M., Bennbaia, S., Unal, D., & Hammoudeh, M. (2020).
Timeseries forecasting of Bitcoin prices using high-dimensional features: a machine
learning approach. Neural Computing and Applications. 33.
Munim, Z. H., Shakil, M. H., & Alon, I. (2019). Next-Day Bitcoin Price
Forecast. Journal of Risk and Financial Management, 12 (2), 1-15. 34.
Peng, K., Liu, B., Cao, X., & Guo, Y. (2020). El Niño Index Prediction
Using Deep Learning with Ensemble Empirical Mode Decomposition. Symmetry, 12 (6), 893. 35.
Phaladisailoed, T., & Numnonda, T. (2018). Machine Learning Models
Comparison for Bitcoin Price Prediction. 10th International Conference on
Information Technology and Electrical Engineering (ICITEE). 36.
Phung, V. H., Rhee, E. J. (2018). A Deep Learning Approach for
Classification of Cloud Image Patches on Small Datasets. Journal of information and
communication convergence engineering, 16(3) (2018) 173 – 178. 37.
Rish, I. (2001). An empirical study of the naive bayes classifier. IJCAI
2001 workshop on empirical methods in artificial intelligence, 3, (pp. 41-46). 38.
Salle, A., & Villavicencio, A. (2018). Restricted Recurrent Neural
Tensor Networks: Exploiting Word Frequency and Compositionality. Proceedings of the
56th Annual Meeting of the Association for Computational Linguistics, (pp. 8-13). 39.
Salman, H. A., & Obaida, T. H. (2021). BBC news data classification using
Naive Bayes based on bag of word. Journal of Hunan University, 48(9), 149-164. 40.
Sohn, S., Jeon, B. J., & Kim, H. W. (2019). A Text-mining Approach
to the Comparative Analysis of the Blockchain Issues: South Korea and the United States.
Journal of Information Technology Services, 18(1), 45-61. lOMoARcPSD| 37054152 41.
Ting, S. L., Tsang, H. C., Ip, W. H. (2017). Is Naïve Bayes a Good
Classifier for Document Classification? International Journal of Software
Engineering and Its Applications, 5 (3), 37-46. 42. Understanding LSTM Networks (27/08/2015). Access from:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/ 43.
Webb, G. I. (2017). Naïve Bayes. In Encyclopedia of Machine Learning
and Data Mining (pp. 1-2). Springer Publishing. 44.
Zaniolo, L., & Marques, O. (2020). On the use of variable stride in
convolutional neural networks. Multimedia Tools and Applications, 79 (19-20),
13581-13598. Access from: https://link.springer.com/article/10.1007/s11042-019- 08385-4 45.
Zhang, S., Li, X., Zong, M., & Wang, R. (2018). Efficient kNN
Classification With Different Numbers of Nearest Neighbors. IEEE Transactions On
Neural Networks And Learning Systems, 29 (5), 1774-1785. 46.
Zhang, W., & Gao, F. (2011). An improvement to Naive Bayes for text
classification. Procedia Engineering, 15, 2160 – 2164. 47.
Zhang, Z. (2016). Naïve Bayes classification in R. Annals of Translational Medicine, 4 (12), 5. TIẾNG VIỆT 1.
Phạm Hoàng Anh. (2021). Xây dựng mô hình dự oán giá tiền iện tử
bằng Deep Learning. Khóa luận tốt nghiệp, Đại học Sư phạm Kỹ thuật TP. Hồ Chí Minh. 2. Convolutional Neural Networks. (25/12/2016). Truy cập từ:
https://tiendv.wordpress.com/2016/12/25/convolutional- neural-networks/ 3.
Nguyễn Thanh Huyền. (24/06/2021). Recurrent Neural Network: Từ
RNN ến LSTM. Truy cập tại: https://viblo.asia/p/recurrent-neural-network-tu-rnn- denlstm-gGJ597z1ZX2 4.
ICO (Initial Coin Offering) Là Gì? (30/01/2019). Truy cập từ: lOMoARcPSD| 37054152
https://academy.binance.com/vi/articles/what-is-an-ico 5.
IOTA Coin là gì? Tiềm năng IOTA (MIOTA) ra sao, áng ầu tư không?
Truy cập từ: https://dautu.io/iota-coin-la-gi-tiem-nang-iota-ra-sao.html 6. Nguyễn Gia Luân. (15/04/2016). Naïve Bayes.
Truy cập từ: https://gialuan1991.wordpress.com/2016/04/15/2-naive- bayes/ 7.
Nguyễn Hoàng Nam. (07/2018). Giới thiệu về Naive Bayes trong
Machine Learning. Truy cập từ: https://www.noron.vn/post/gioi-thieu-ve-naive-
bayes-trongmachine-learning-40ww191xxs87 8.
Nguyễn Hoàng Nam (07/2018). Tìm hiểu về Confusion matrix trong
Machine Learning?. Truy cập từ: https://www.noron.vn/post/tim-hieu-ve-
confusionmatrix-trong-machine-learning-1fz9nhqo5ux 9.
Hà Ngọc Sang. (19/08/2021). Confusion Matrix / Ma trận nhầm lẫn /
Ma trận lỗi. Truy cập từ: https://viblo.asia/p/confusion-matrix-ma-tran-nham-lan- matran-loi-V3m5WQB7ZO7 10.
Solana là gì? Đánh giá tiềm năng token SOL. (23/05/2022). Truy cập
từ: https://www.finhay.com.vn/solana/#tiem-nang-cua-solana-la-gi 11.
Trần Đức Tân. (22/06/2019). Mô hình phân lớp Naive Bayes. Truy cập
từ: https://viblo.asia/p/mo-hinh-phan-lop-naive-bayes-vyDZO0A7lwj 12.
Tiềm năng của Ethereum? ETH và Bitcoin khác nhau như thế nào? (09/01/2021).
Truy cập từ: https://www.binance.com/vi/blog/all/tiềm-năng-
củaethereum-eth-và-bitcoin-khác-nhau-như-thế-nào-421499824684901516
Tài liệu liên quan:
-

Tìm hiểu vị trí quản lý đơn hàng tại công ty TNHH thế giới gen | Tiểu luận môn Thương mại điện tử Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
444 222 -

Công ty TNHH giáo dục master English | Báo cáo kiến tập – Nghành thương mại điện tử Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
299 150 -

Chương trình giáo dục đại học ngành thương mại điện tử | Tài liệu thương mại điện tử Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
275 138 -

Báo cáo Bảo mật Thương mại Điện tử | Môn Thương mại Điện tử Trường đại học sư phạm kỹ thuật TP. Hồ Chí Minh
351 176 -

Báo cáo cuối kỳ môn Thương mại điện tử đề tài: "Kinh doanh túi vải canvas"
457 229