Nhận diện khuôn mặt với OpenCV và CNN môn Công nghệ thông tin | Trường Đại Học Nha Trang
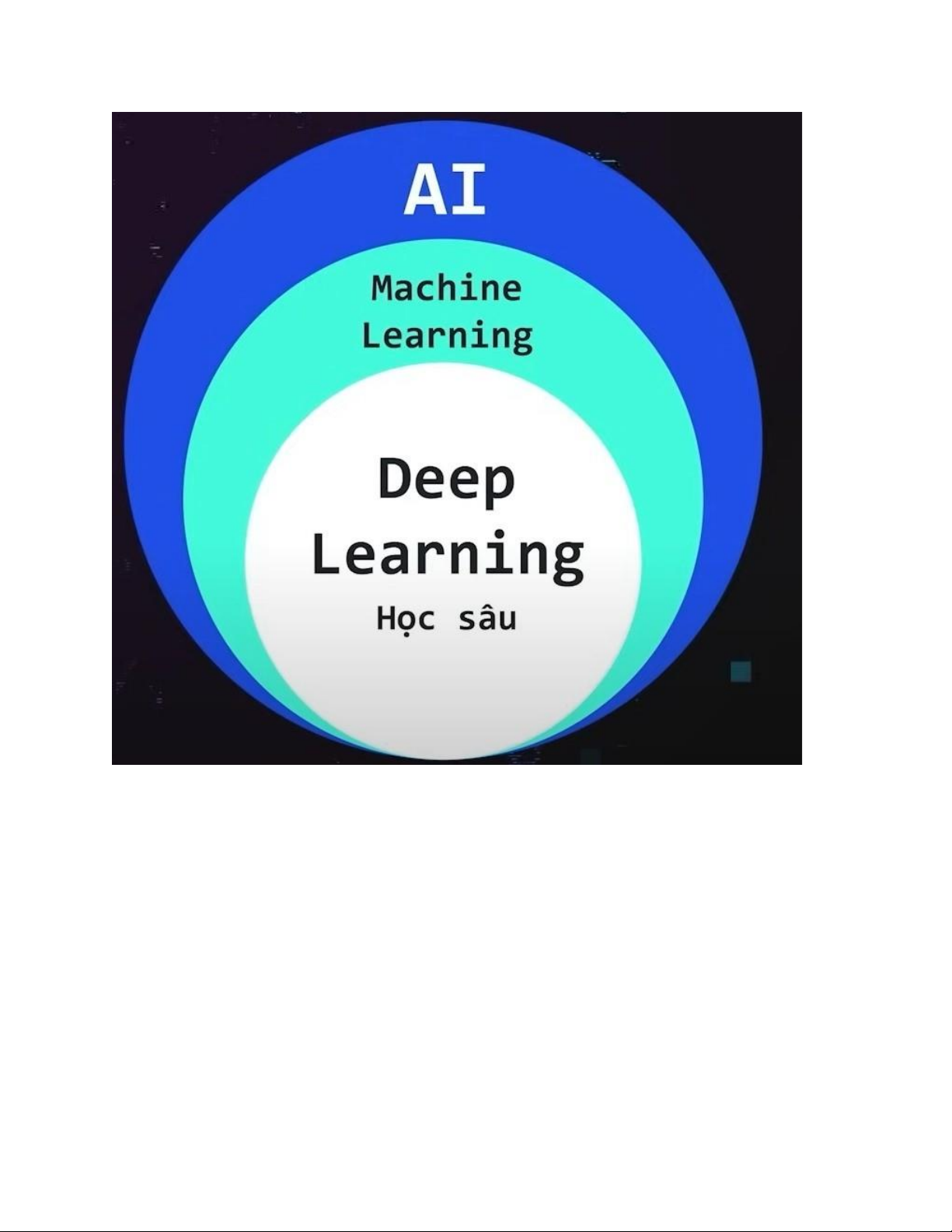
AI: Artificial Intelligence là lĩnh vực nghiên cứu và phát triển các hệ thống máy tính có khả năng thực hiện những nhiệm vụ thông minh như con người- những thuật toán có khả năng suy diễn Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem!
Môn: Công nghệ thông tin(IT6348) 30 tài liệu
Trường: Trường Đại học Nha Trang 266 tài liệu
Tác giả:














Preview text:
lOMoAR cPSD| 58490434
AI: Artificial Intelligence là lĩnh vực nghiên cứu và phát triển các
hệ thống máy tính có khả năng thực hiện những nhiệm vụ
thông minh như con người- những thuật toán có khả năng suy diễn
Machine learning : Là một lĩnh vực con của AI tập trung vào việc
giúp cho máy tính có khả năng tự học hỏi từ dữ liệu mà không
cần phải lập trình một cách “cụ thể”. lOMoAR cPSD| 58490434
Là tập hợp các thuật toán giúp mt có khả năng học hiểu dựa
trên các kinh nghiệm về hiểu biết của con người
Vd: giả sử mình lập trình cho ngân hàng phát hiện lừa đảo: cụ
thể- ko phải ML: cho nó cố định là giao dịch nước ngoài và là
1000$ trở lên mặc định là lừa đảo
Huấn luyện cho nó 1 mô hình và đưa các lịch sử giao dịch bình
thường lẫn lừa đảo để nó tự học hỏi và nhận biết đâu là thật
hay giả thì đây mới là ML Deep learning:
Là một mạng các network mà được ghép lại bằng các perception
Là lĩnh vực con của học máy có liên quan đến các thuật toán
lấy cảm ứng từ cấu trúc cũng như là chức năng của não bộ con người
Có rất nhiều ứng dụng nổi bật nhất ví dụ như chat gpt có 4
phương pháp học máy - học có giám sát:
Học có giám sát là phương pháp học máy trong đó các thuật
toán được huấn luyện trên tập dữ liệu đã gắn nhãn, nhằm tìm
ra mối quan hệ giữa đầu vào (input) và đầu ra (output), từ đó
dự đoán kết quả cho dữ liệu mới. -học không có giám sát lOMoAR cPSD| 58490434 -học bán giám sát -học tăng cường
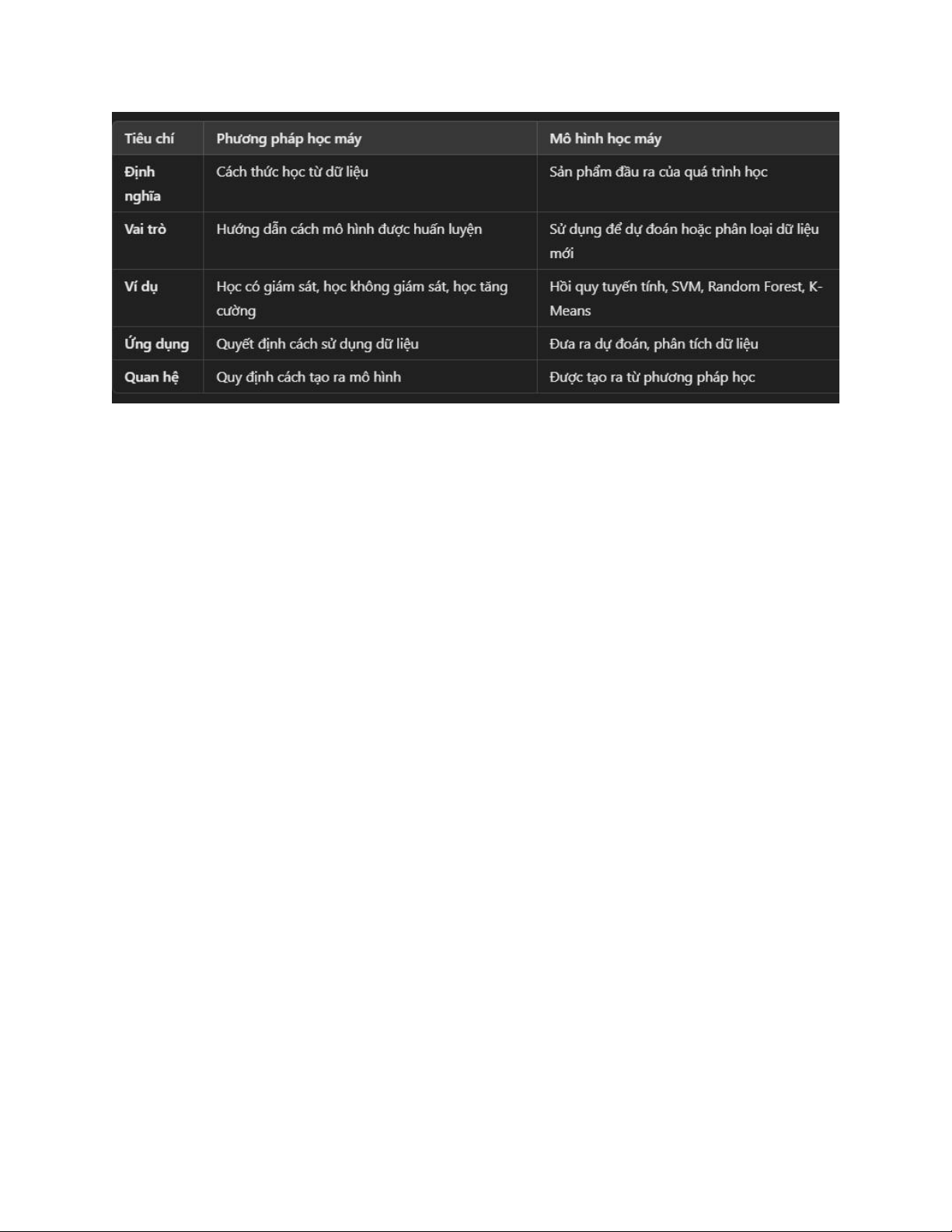
So sánh học có giám sát và học không giám sát
Học có giám sát Học không giám sát Tiêu chí (Supervised) (Unsupervised) Dữ liệu
Có nhãn (có cả đầuKhông có nhãn (chỉ có
huấn vào & đầu ra) đầu vào) luyện Học cách ánh xạ từ Mục Tìm cấu trúc ẩn trong đầu vào đến đầu tiêu dữ liệu ra Bài toán Phân cụm, Giảm số Phân loại, Hồi quy chính chiều
Học có giám sát Học không giám sát Tiêu chí lOMoAR cPSD| 58490434 (Supervised) (Unsupervised) Nhận diện khuôn Ứng Phân loại khách hàng, mặt, dự đoán giá dụng phát hiện bất thường nhà
Hồi quy và Phân lớp lOMoAR cPSD| 58490434
Data: dữ liệu – thông tin hay các giá trị được thu thập từ nhiều
nguồn khác nhau dữ liệu có thể tồn tại ở dạng thô(raw) hoặc
dạng tinh (processed data) dạng đã qua xử lí rồi
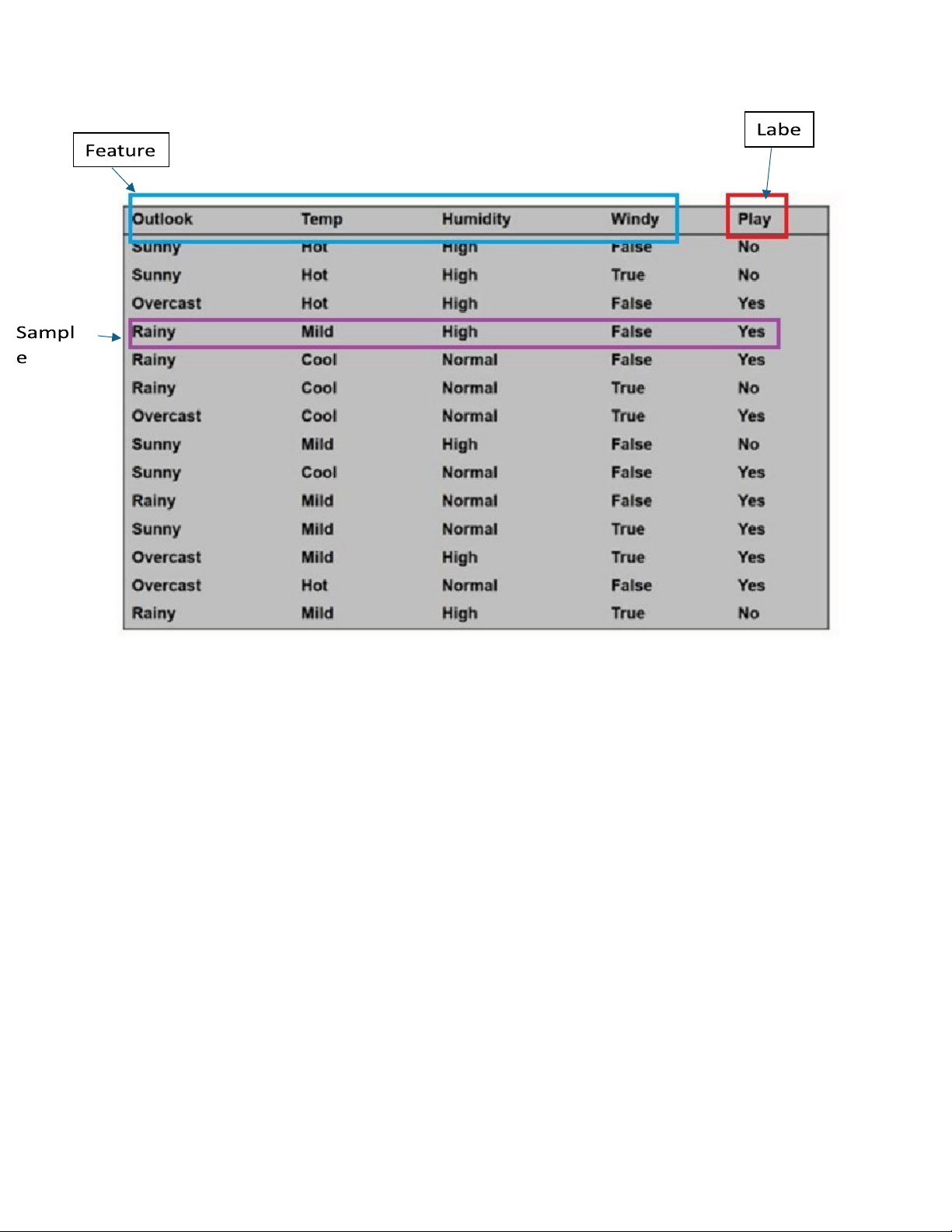
Dataset: tập dữ liệu là tập hợp các cấu trúc của mẫu dữ liệu
được tổ chức hoặc sắp xếp đc sd cho 1 mục đích nào đớ Feature : đặc trưng
Sample: đối tượng, mẫu Label: nhãn lOMoAR cPSD| 58490434
Model: mô hình là một thuật toán hay một hệ thống mà thông
qua quá trình huấn luyện sẽ học từ dữ liệu cách để đưa ra 1 dự
đoán chính xác đồng thời là sự mô phỏng của cách con người học thông qua sách vở
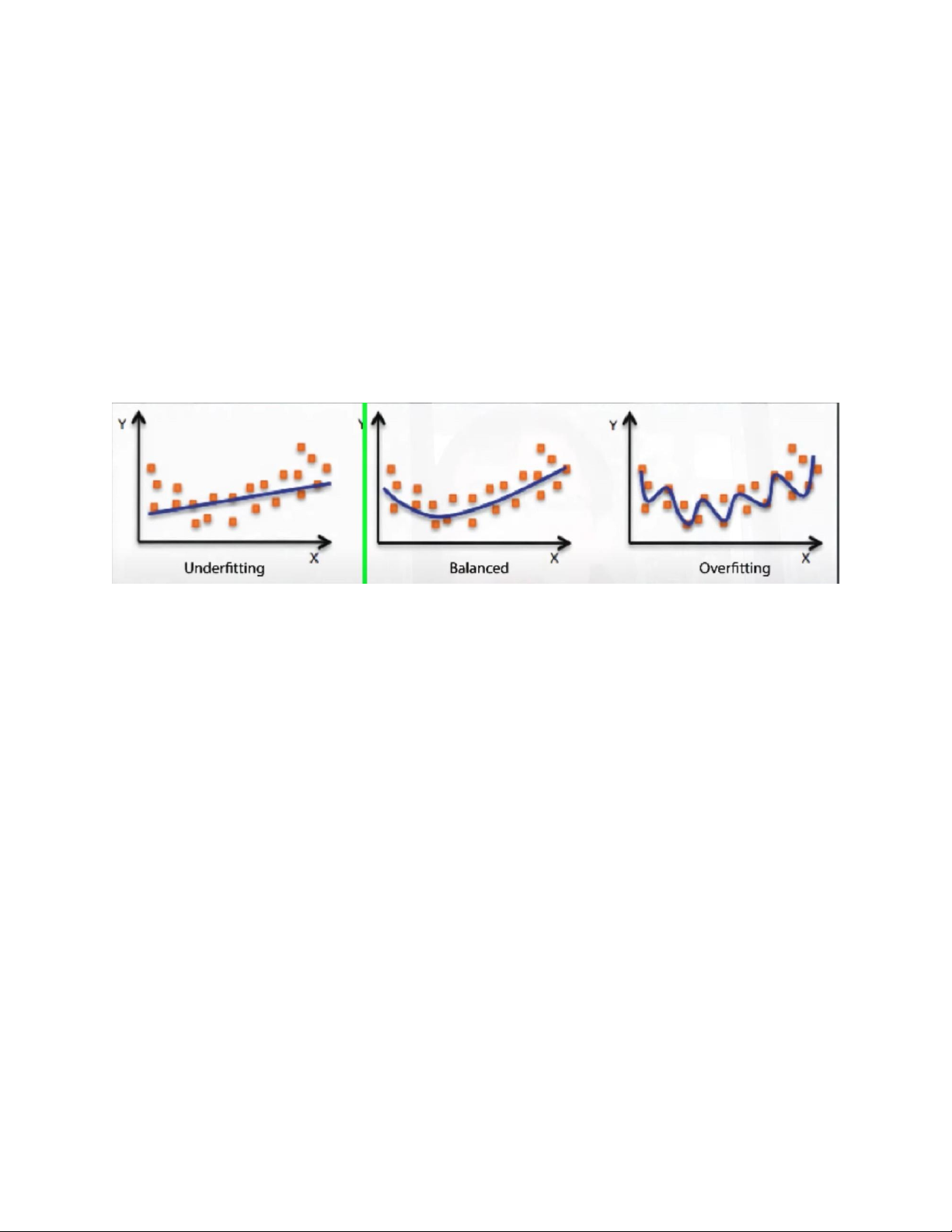
Over và Under : quá đúng và quá ẩu khiến dữ liệu không lấy
được một cách hiệu quả Balance: phân lớp tốt
- Data wrangling: làm sạch dữ liệu lOMoAR cPSD| 58490434 Feature:
+ Select: là quá trình loại bỏ các đặc trưng không quan trọng
để giảm độ phức tạp của mô hình, cải thiện hiệu suất và tránh overfitting. lOMoAR cPSD| 58490434
+ Transform: là quá trình biến đổi dữ liệu để phù hợp hơn với mô hình học máy.
+ Extract: là quá trình tạo ra đặc trưng mới từ dữ liệu gốc, giúp
mô hình học hiệu quả hơn.
Vì sao phải sử dụng các phép như chọn đặc trưng, biến đổi đặc trưng, trích đặc trưng?
Vì số lượng dặc trưng ảnh hưởng đến tốc độ xử lí, giảm độ
chính xác và khả năng hiểu của các mô hình
Training dataset: các sample được gắn (them các feature,
label) mục đích để huấn luyện mô hình hoàn thiện có độ
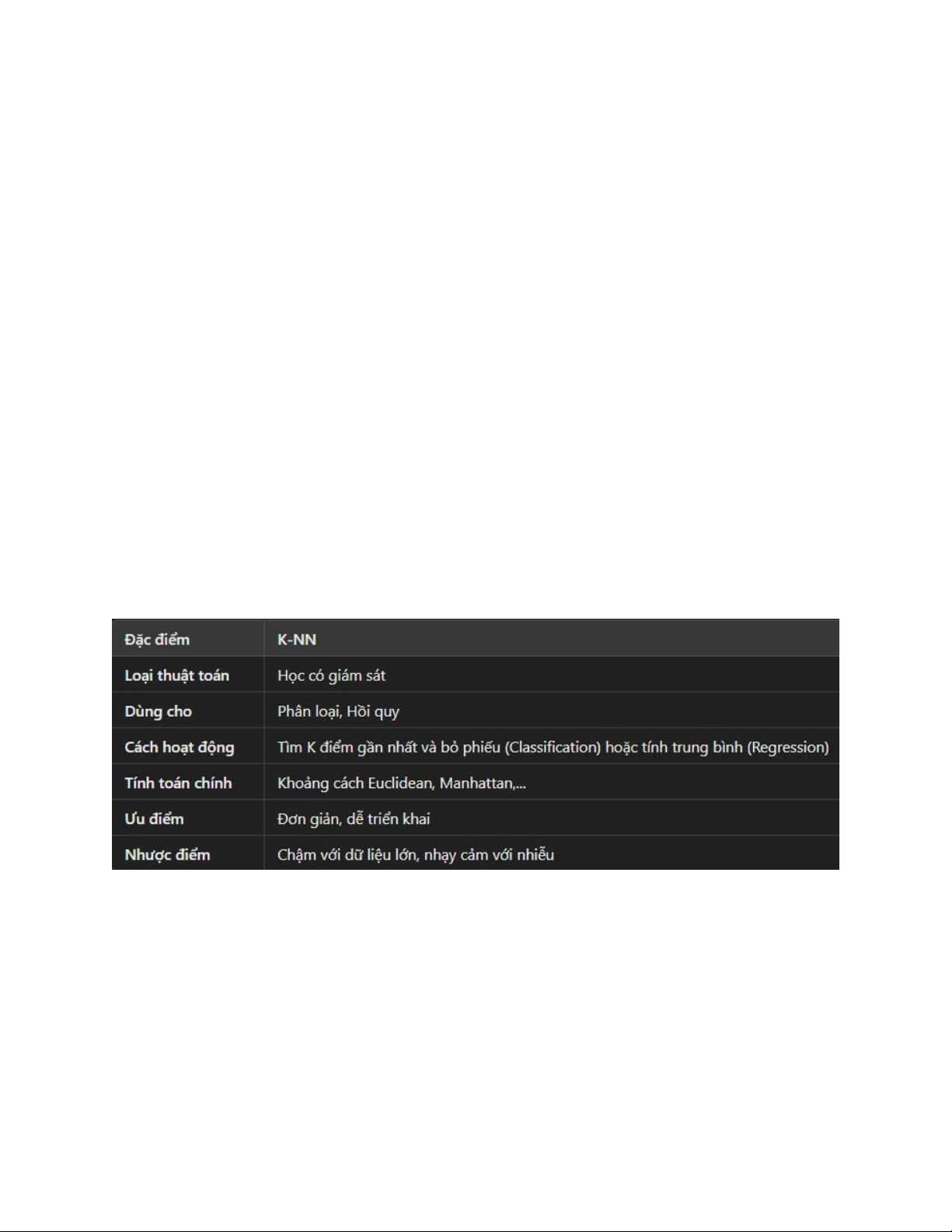
dataset cao Giải thuật K-NN: Giải thuật Decision Tree lOMoAR cPSD| 58490434
Giải thuật SVM(Support Vector Machines)
Chương 1,2,3 đều là các giải thuật học có giám sát
Entrophy vs Gini: giảm thời gian tính toán và tăng độ chính
xác phương pháp học máy và mô hình học máy là gì? phân biệt? lOMoAR cPSD| 58490434 Missing value
Tại sao học sâu lại ra đời sau học máy ? Tác dụng, lOMoAR cPSD| 58490434 1.
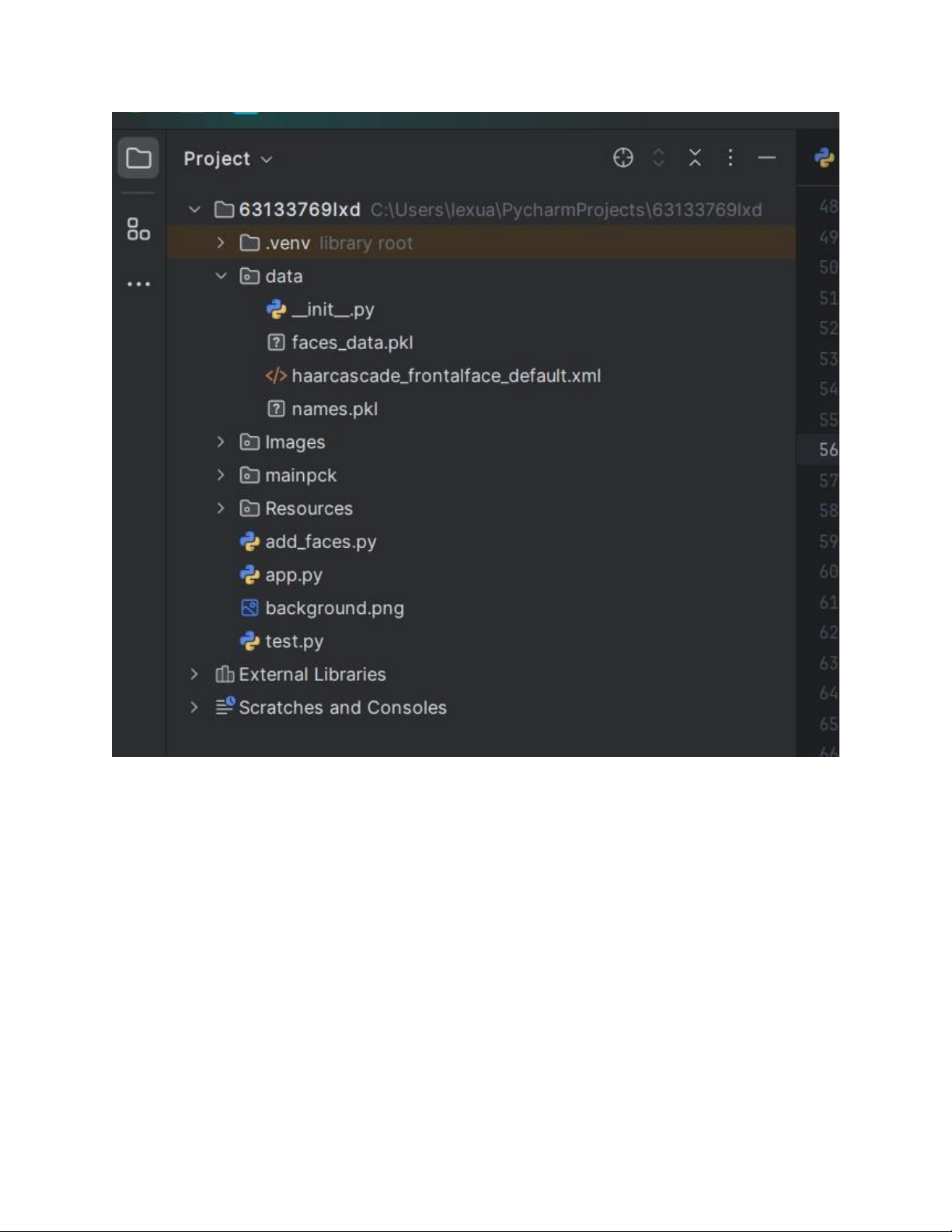
Chuẩn bị code và dữ liệu trên laptop •
Code được viết bằng Python, sử dụng thư viện OpenCV để
xử lý hình ảnh và phát hiện khuôn mặt. •
Sử dụng pickle để lưu trữ dữ liệu khuôn mặt và tên vào file
.pkl để dùng cho các bước tiếp theo. •
Code thực hiện thu thập dữ liệu khuôn mặt từ webcam,
lưu vào mảng NumPy và lưu trữ trong thư mục data/. lOMoAR cPSD| 58490434
📌 Dữ liệu của project: •
Dữ liệu đầu vào: Hình ảnh khuôn mặt được thu thập từ webcam. • Dữ liệu đầu ra:
o faces_data.pkl: Chứa dữ liệu khuôn mặt đã xử lý và
lưu dưới dạng NumPy array.
o names.pkl: Chứa danh sách tên tương ứng với dữ liệu khuôn mặt. •
Mỗi khuôn mặt thu được sẽ được resize về kích thước
50x50 để chuẩn hóa dữ liệu.
2. Lý do chọn project •
Nhận diện khuôn mặt là một ứng dụng quan trọng trong
bảo mật, điểm danh tự động, và cá nhân hóa trải nghiệm người dùng. •
Đây là một bài toán phổ biến trong lĩnh vực Computer
Vision và Machine Learning, giúp hiểu sâu hơn về cách
máy tính nhận diện hình ảnh. •
Dự án giúp rèn luyện kỹ năng xử lý ảnh bằng OpenCV, làm
việc với dữ liệu NumPy, và lưu trữ dữ liệu hiệu quả bằng pickle. lOMoAR cPSD| 58490434
3. Áp dụng lý thuyết và các phép xử lý tính toán
📌 Các lý thuyết áp dụng:
1.Xử lý ảnh với OpenCV:
o Chuyển đổi ảnh sang ảnh xám
(cv2.cvtColor) để dễ dàng phát hiện khuôn mặt.
o Sử dụng bộ phân loại Haar Cascade
(haarcascade_frontalface_default.xml) để phát hiện khuôn mặt.
o Resize khuôn mặt về kích thước 50x50 để chuẩn hóa dữ liệu.
2.Lưu trữ dữ liệu khuôn mặt:
o Dữ liệu khuôn mặt được lưu trữ dưới dạng NumPy
array để thuận tiện cho việc huấn luyện mô hình sau này.
o pickle được dùng để lưu dữ liệu vào file .pkl, giúp dễ
dàng tái sử dụng mà không cần thu thập lại dữ liệu.
3.Lặp và điều kiện dừng:
o Sử dụng vòng lặp while để liên tục thu thập dữ liệu khuôn mặt.
o Điều kiện dừng: Khi thu thập đủ 100 ảnh hoặc nhấn phím 'q'. lOMoAR cPSD| 58490434
4. Tác dụng thực tế của project
✅ Ứng dụng điểm danh tự động: Có thể mở rộng để phát
triển hệ thống điểm danh dựa trên nhận diện khuôn mặt trong lớp học
* ANN là nền tảng của Deep Learning => DL được xây dựng từ ANN
ANN sẽ hỏi về cuối kì
Neurol là danh từ - 1 nơ ron thần kinh trong con người
Neural là tính từ - tính chất là 1 cái nơ ron được tạo ra bởi con người
Perceptron là 1 cái nơ ron nhân tạo- tế bào của mạng X, w : 1 vectơ
Là 1 điểm trong không gian 1 chiều
Activation 1 là có sẵn 2 là tự tạo CNN là 1 perception lOMoAR cPSD| 58490434
DL là 1 network là nhiều perception Hồi quy tuyến tính X1 X2 X3 X4 label X1
Thu thập thông tin của những cái “nhà “ quan sát được
Vd có 1 cái nhà có giá 1 tỉ đồng mà có
Hqtt cho phép truy ra cái nhà để xác định giá
Hồi quy là 1 cái tập đoàn thể hiện giá trị đầu vào và đầu ra theo 1
Muốn sử dụng phải trực quan hóa dữ liệu và chỉ sử dụng hqtt
Trong không gian 2 chiều hay nhiều chiều bỏ vào bộ test
nếu độ chính xác thấp thì vứt bằng cách test hqtt và sử
dụng bộ dữ liệu huấn luyện của hqtt
hqtt là đường thẳng y=ax+b lOMoAR cPSD| 58490434
tách mẫu thành 2 bộ train và test 2pp K-fold: Lấy vd 10 mẫu + lấy k = 5
Lần 1: lấy bộ 1,2,3,4 đi huấn luyện mô hình lấy bộ 5 để test
Lần 2: lấy bộ 1,2,3 ------ --
Lần 5: lấy bộ 1 Hold-out: Vd: 9 mẫu
Lấy ngẫu nhiên từng sample Convolutional Mô hình sinh là chat gpt
Phân loại là tìm một nhãn hợp lí để gán vào dữ liệu mới
Phân cụm từ một đống dữ liệu lớn chúng ta tách ra thành một cụm
Bộ test: Thử từng độ đo và kiểm tra độ chính xác nếu sai số ít nhất thì chọn lOMoAR cPSD| 58490434
K-means là một thuật toán phân cụm (clustering) trong học
không giám sát (unsupervised learning), được sử dụng để chia
tập dữ liệu thành K cụm riêng biệt (với K K K là số cụm được
xác định trước). Thuật toán hoạt động bằng cách:
1.Khởi tạo ngẫu nhiên K K K tâm cụm.
2.Gán mỗi điểm dữ liệu vào cụm có tâm gần nhất (dựa trên khoảng cách Euclidean).
3.Cập nhật tâm cụm bằng cách lấy trung bình cộng của các điểm trong cụm.
4.Lặp lại các bước gán và cập nhật cho đến khi tâm cụm không
thay đổi hoặc đạt số lần lặp tối đa.
Mục tiêu của K-means là tối thiểu hóa tổng bình phương
khoảng cách từ các điểm dữ liệu đến tâm cụm gần nhất, tạo ra
các cụm có độ tương đồng cao bên trong và khác biệt lớn giữa các cụm.
Lí thuyết hỏi đến K-means là dừng
Ôn kĩ học có giám sát( chủ đề 3) nếu sợ rớt
1. Chuẩn Bị Câu Trả Lời Cho Câu Hỏi "Dự Án Em Làm Bằng
Thuật Toán Gì?" a. Câu Trả Lời Chính
Khi giáo sư hỏi "Dự án em làm bằng thuật toán gì?", bạn cần trả
lời một cách tổng quát trước, sau đó đi vào chi tiết các thành lOMoAR cPSD| 58490434
phần chính của dự án (phát hiện khuôn mặt, nhận diện khuôn
mặt, huấn luyện mô hình). Dưới đây là câu trả lời mẫu:
"Dạ, thưa thầy, dự án của em là hệ thống điểm danh bằng
nhận diện khuôn mặt, và em đã sử dụng các thuật toán sau:
1.Phát hiện khuôn mặt: Em sử dụng thuật toán Haar
Cascade Classifier của OpenCV, dựa trên phương pháp
Haar-like features và AdaBoost để phát hiện khuôn mặt
trong khung hình từ webcam.
2.Nhận diện khuôn mặt: Em xây dựng một mô hình
Convolutional Neural Network (CNN) để phân loại khuôn
mặt. Mô hình này được huấn luyện trên dữ liệu khuôn mặt
đã thu thập, sử dụng kiến trúc CNN với các tầng Conv2D,
MaxPooling2D, và Dense để trích xuất đặc trưng và dự đoán nhãn.
3.Huấn luyện mô hình: Để huấn luyện CNN, em sử dụng
thuật toán tối ưu Adam (Adaptive Moment Estimation),
với hàm mất mát là categorical cross-entropy, và áp dụng
data augmentation để tăng tính đa dạng của dữ liệu.
Ngoài ra, em cũng sử dụng một số kỹ thuật hỗ trợ như
LabelEncoder để mã hóa nhãn, và train_test_split để chia dữ
liệu thành tập huấn luyện và kiểm tra." lOMoAR cPSD| 58490434
b. Giải Thích Thêm (Nếu Giáo Sư Yêu Cầu) Haar Cascade Classifier:
o Đây là một thuật toán phát hiện đối tượng dựa trên
machine learning, được đề xuất bởi Paul Viola và Michael Jones vào năm 2001.
o Nó sử dụng các đặc trưng Haar-like (các mẫu sáng-tối)
để phát hiện khuôn mặt, sau đó dùng AdaBoost để
chọn các đặc trưng tốt nhất và tăng tốc độ phát hiện. o Em đã sử dụng file
haarcascade_frontalface_default.xml được cung cấp sẵn bởi OpenCV. •
Convolutional Neural Network (CNN):
o CNN là một loại mạng nơ-ron sâu, phù hợp cho bài
toán phân loại hình ảnh.
o Mô hình của em gồm 3 tầng Conv2D (32, 64, 128
filter), 3 tầng MaxPooling2D để giảm kích thước, và 1
tầng Dense (256 nơron) trước tầng đầu ra.
o Tầng đầu ra sử dụng hàm kích hoạt softmax để dự
đoán xác suất cho từng lớp (nhãn). • Adam Optimizer:
o Adam là một thuật toán tối ưu dựa trên gradient
descent, kết hợp ưu điểm của momentum và RMSProp. lOMoAR cPSD| 58490434
o Nó điều chỉnh learning rate tự động, giúp mô hình hội tụ nhanh hơn. • Data Augmentation:
o Em đã sử dụng ImageDataGenerator của Keras để tạo
thêm dữ liệu bằng cách xoay, dịch chuyển, lật ngang,
và thay đổi độ sáng của ảnh.
2. Dự Đoán Các Câu Hỏi Tiếp Theo Và Cách Trả Lời
Giáo sư có thể hỏi thêm các câu hỏi để kiểm tra sự hiểu biết
của bạn về thuật toán và cách bạn áp dụng chúng. Dưới đây là
một số câu hỏi phổ biến và cách trả lời:
a. Câu Hỏi: "Tại sao em chọn Haar Cascade để phát hiện
khuôn mặt? Có phương pháp nào khác tốt hơn không?" Trả Lời:
Lý do chọn Haar Cascade:
o "Dạ, em chọn Haar Cascade vì đây là một phương
pháp phổ biến, được tích hợp sẵn trong OpenCV, và
dễ triển khai. Nó cũng có tốc độ xử lý nhanh, phù hợp với ứng dụng
thời gian thực như điểm danh qua webcam." •
Hạn chế của Haar Cascade:
o "Tuy nhiên, em nhận thấy Haar Cascade có
Tài liệu liên quan:
-

Đồ án tốt nghiệp Thiết kế hệ thống điều hòa không khí môn Công nghệ kỹ thuật nhiệt lạnh | Trường Đại học Nha Trang
47 24 -

BÁO CÁO THỰC TẬP: MÔ PHỎNG THUẬT TOÁN SẮP XẾP VỚI C++ môn Công nghệ thông tin | Trường Đại Học Nha Trang
124 62 -

Báo cáo Quản lý Dự án Phần mềm: Hệ thống Cửa hàng Laptop môn Công nghệ thông tin | Trường Đại Học Nha Trang
149 75 -

Athena Lab: Hướng dẫn học CCNA môn Công nghệ thông tin | Trường Đại Học Nha Trang
139 70