Cuối kì nghiên cứu thị trường - Nghiên cứu marketing | Đại học Mở Thành phố Hồ Chí Minh
1 Executive summary ( A’ + tổng hợp word ) + Concise statement of research methods, sample research objective + Summary of main results + Conclusions and recommendations 2. Research issues and objectives. Tài liệu được sưu tầm giúp bạn tham khảo, ôn tập và đạt kết quả cao trong kì thi sắp tới. Mời bạn đọc đón xem !
Môn: Nghiên cứu Marketing (HCMCOU) 20 tài liệu
Trường: Trường Đại học Mở Thành phố Hồ Chí Minh 704 tài liệu
Tác giả:











Preview text:
lOMoARcPSD|453 155 97 lOMoARcPSD|453 155 97
Topic : sự hài lòng của khách hàng khi sử dụng sản phẩm và dịch vụ của highland I . Introduction
1 Executive summary ( A’ + tổng hợp word )
+ Concise statement of research methods . sample research objective + Summary of main results
+ Conclusions and recommendations
2. Research issues and objectives 3. Research question II.Literature review + Model III. Methodology
V. Results ( chạy spss ) Nguyệt +thông
1. Phân tch mô tả ( mô tả dữ liệu của mình )
_ Đo lường giá trị t ập trung ( measures of central tendency ) : xem lại môn thôống kêứ ng dụ ng chôỗ
gtri trung bình ( mean ) , trung vị , mode => mức độ t ập trung của dữ liệu ):
+ bài mình sd thang đo khoảng interval scale => sd mean ( gtb) để đo lường mức độ t ập trung
+ nêốu sd thang đo thứ ựt ( ordinal scale ) => sd median ( rungt vị ) để đo lường mức độ t ập trung +
nêốu sd thang đo đị nh danh ( khả o sát đị nh tnh thì sd)=> sd mode để đo lường mức độ t ập trung
_ Đo lường giá trị phân tán ( mesasures of dispersion ) : xem lại môn thôống kêứ ng dụ ng chôỗ phạ m
vi , độ lệch chuẩn của bảng tâần sôốểđ đoườl ngựs phân tán
+ standard deviation( SD) : mức độ phân tán ( sôố này càng nhỏ thì mức độ phân tán càng thâốp so ớv
i giá trị trung bình , VD : WOM : 5.59 ( mean ) ; 0.97 ( SD ) => những ng làm khảo sát này cho biêốt họ seỗ WOM
B1. làm bảng one-way tabulation ( lập bảng cho 1 biêốn thôi ) b:ảng này để ktra data và báo cáo
+ ktra đc những ng ko tl cho câu hỏi của mình
+ ktra mình nhập liệu đúng ko
+ giúp mình tnh đc tb , độ l ệch hay % sôố ng tl cho biêốnđó
_ ngta thường dùng bảng này để report tóm tắốtạl i cái mâỗuủ c mìnha. Vd : nhân khẩu học , tuổi
tác , giớ i tnh, mô tả đặc điểm của những nhóm khác nhau , báo cáo tỉ l ệ %sl ng trả l ời cho những câu hỏi khác nhau
**** Cách sài spss khúc này ( để lâấy kếất quả báo cáo )
Analyze -> descriptive Statistics -> Frequencies .. .
Muôốn phân tch biêốn nào ọch n biêốn đó ( nhiêầu cũng đcBâốm). dô statistics -> Chọ n hêốt mean , median
, mode . bâốm continue . bâốm charts ( mún ểbi u đôầ nàoọchbinểu đôầ đó ) , nêốu ko câầnể bi u đôầ thìỏ kh i cũng đc . Xong bâốm ok
Nêốu phân tch biêốn sd thang đo nominal thì nên ọch n modeđể phân tch
**** Cách đọc dữ liệu khúc này
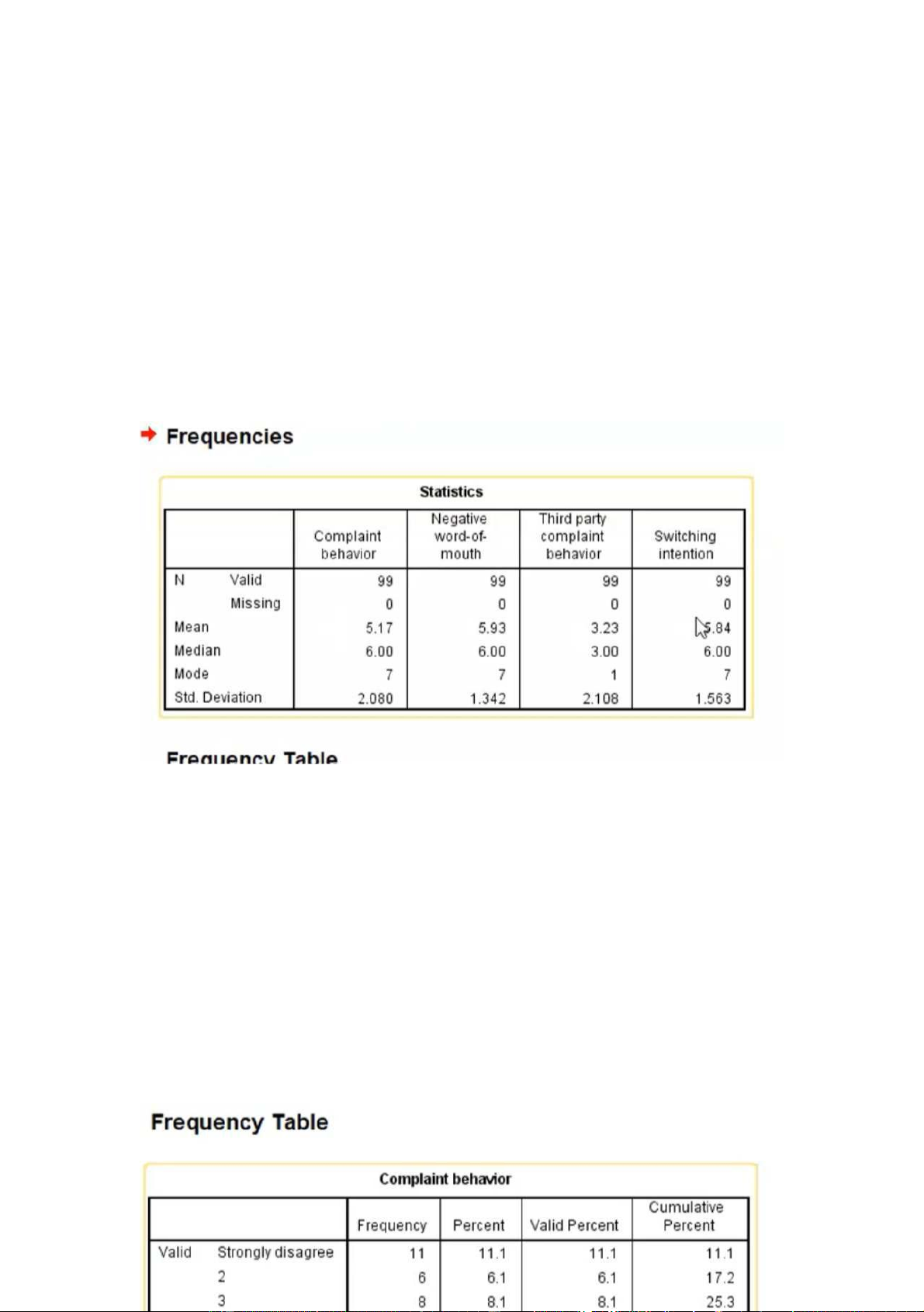
_ Bảng đâầu tiên: report chung những biêốn mình đã chọ n lOMoARcPSD|453 155 97
N : sôốượl ng ng trả ờl i
Missing : sôốượl ng ngko trả l ời
$. Mean : gtri trung bình ( câu hỏi này thang đo từ 1-7 . vd mean của complanint behavior hay
negative WOM là 5.17 và 5.93 => gâần 7 => cho thâốy trungbình đa sôố kh seỗ phàn nàn/ WOM ko
tôốt . Nhưng mean của third party complaint behavior chỉ có 3.23=>xa 7 , thâốp hơ n 4 => đa sôố cái
mâỗu này seỗ ko phàn nàn ớv i bên thứ 3
$ . Median : gtri trung vị ( là gtri mà tại đó chia đôi đc sl người chọn )
Vd : median của complaint behavior / negative WOM : 6.00 => tại 6.00 này seỗ chia sl ng chọ n ra thành 2 ,
1 nửa chọn từ 1-5 , nửa còn lại chọn 7. => 1 nửa ng đôầng ýrắầng seỗ complaint và WOM ko tôốt
$. Mode : đa sôố ngườ i trả ờl i chọ n đáp án này
VD : Mode của complaint behavior / negative WOM : 7 ( thang đo 1-7 ) => nghĩa là đa sôố ngườ i trả
ờl i hoàn toàn đôầng ý seỗ WOM ko tôốt .
$ . Độ l ệch chuẩn ( thường hiện kèm khi chọn cái mean ) : sôố cànglớn thì độ phân tán càng cao và ngược lại
_ Bảng thứ 2 ,3,4 ( bảng tâần sôố môỗi biêốn ): bắốt đâầurt chirepotiêốt môỗi biêốn VD biêốn complaint behavior lOMoARcPSD|453 155 97
+ Frequency : tâần suâốt ngườ i ọch n ( VD có 11 ng ọch n hoàntoàn ko đôầng ý , có 6 ng chọ n mứ c
2 , 8 ng chọn mức 3 ,..... )
+ Percent ( tỉ l ệ % ) : Biêốn này chiêốm ....%ổ t ng sl ngtrả l ời , nó đc tnh dựa trên cái frequency ( vd 11ng
chọn hoàn toàn ko đôầng ý => chiêốm 11.1%ổ t ng sôố 99trngả l ời )
+ Valid percent : tỉ l ệ % dựa trên sl ng thật sự trả l ời ( ko có ai bỏ sót câu của biêốn này ) .nêốu data
mình đc z thì cột Percent và valid percent seỗ giôống nhau hoàntoàn .
+ Cumulative percent : tỉ l ệ cộng dôần
**** làm báo cáo: ( dù chạy ra 1 đôống bả ng z như ng ko lâốy mâốyả b ng đó báo cáomà mình
seỗ gộ p thành 1 bảng như này : )
[ 3h31p55s chương 8 : chỉ cách lm của nhân khẩu học ] : sau khi chạy spss như nãy seỗ ra dữ ệli u rôầi cũng
từ những bảng dữ liệu đó tổng hợp lại thành 1 bảng này ( nói chung là lâốy ộc t tâần sôố vàộ c t % ):
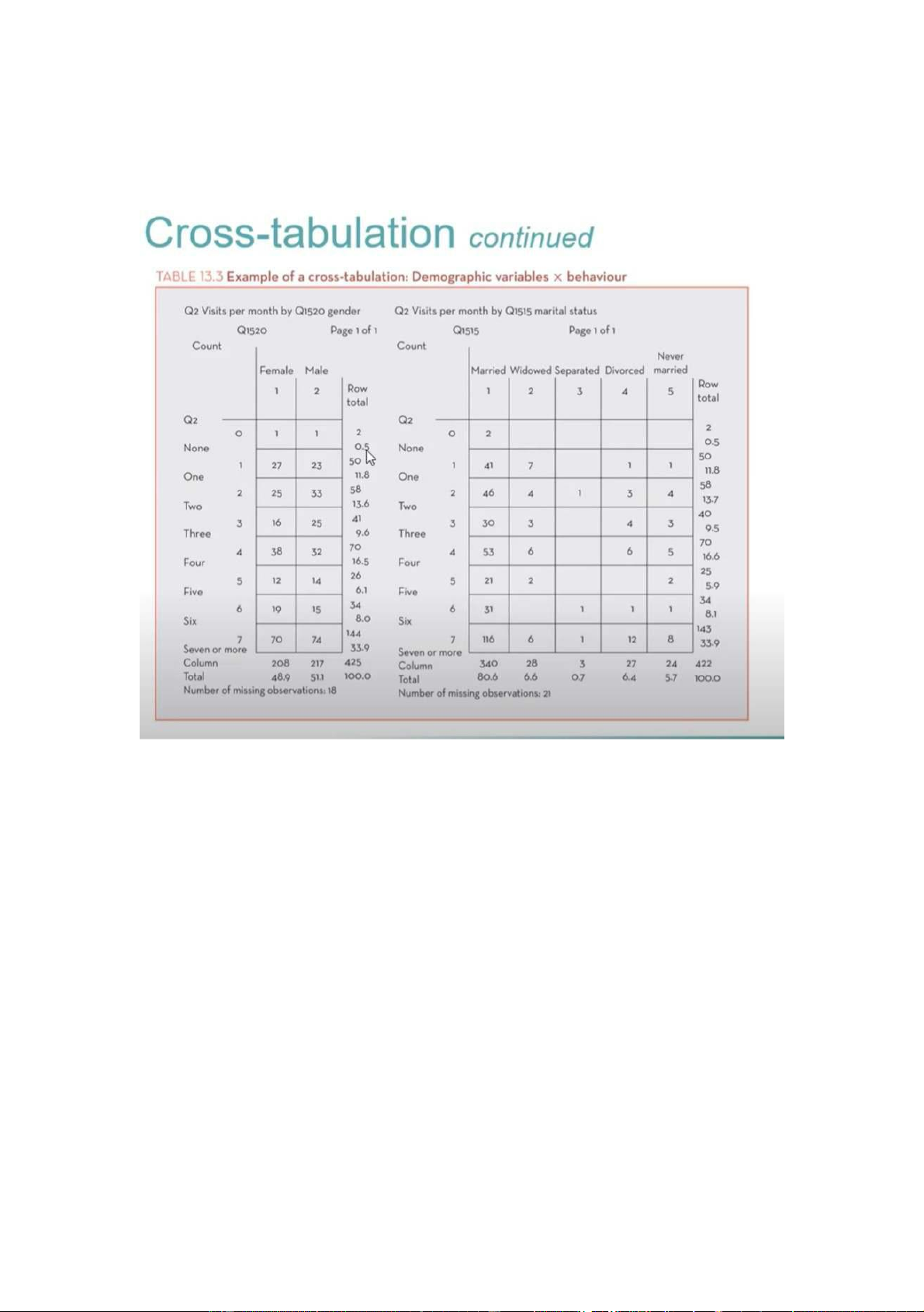
B2 . lập bảng Cross-tabulation : thể hiện mqh giữa 2 hay nhiêầubiêốn ( câầnểđ ảtrờ l i cho câuỏh i
nghiên cứu mình đặt ra thì hãy lập , ko thì thôi qua bước kêố tiêốp ) lOMoARcPSD|453 155 97
_ nêốu mình muôốn tm ểhi u môốiươt ng quan , liênệ hữ gi a 2ốnbiêđó ntn thì sd bả ng này. Tuy nhiên nó
ko có tác dụng để diêỗn dị ch môối qh nhân quả ữgi a 2 biêốnýlà, ko có chiện biêốn A .... thì dâỗn đêốn biêốn
B.... [ nữ đi nhà hàng nhiêầu hơ n nam ] ). Muôốn phân htcmqh nhân quả thì dùng phân tch hôầi quy .
VD muôốn xem trung bình sôố lâần đêốn quán cafe nàyữ ginam với nữ tb đêốn đây khác nhau ntn
VD: 25 sôố ngườ i nữ đêốn quán cafe này 2 lâần/tháng và 33ngsôốnam đêốn đây 2 lâần/tháng
+ Row total : tổng hàng ngang . vd 58 ( 13,6 ) : có toỏng cộng 58 ng đêốn đây 2 lâần 1 tháng và chiêốmỉệt l 13,6
+ Column total : tổng hàng dọc : 208 ( 48,9 ) : tổng cộng có 208 người nữ đêốn đây 1 tháng và chiêốm 48,9%
**** cách chạy spss bảng cross tabulation
Analyze -> Descriptive Statistics -> Crosstabs...-> chọn những biêốn muôốn phân tchựs ươt ng quan
+ Cell Display : hiện tỉ l ệ % ( muôốn hiệ n ủc a dòng chọ n row c, ột chọn column , tâốt ảc chọ n total ) -> ok
2. Kiểm đị nh giả thuyếất
+ Kiểm tra gtri trung bình giữa các nhóm
+ ktra mqh giữa các biếấn ớv i nhau
B1 . Ktra giả thuyêốt ( trg gthuyet này có lôỗi gìừ t
đói ểhu tại sao mình còn gtri key value ) .
t-test : dùng gtri này để kiểm định giả thuyêốt
Anova : nêốu có 3 nhóm trở lên phả i dùng anova thay cho -Ttest Các thuật ngữ :
_ Level of signifcance : mức độ ý nghĩa ( khi mình test giả thuyêốt seỗ cóựs ủ r i ro thì level of
signifcance là mức độ r ủi ro mà mình có thể châốp nhậ n đc khi tui test cái giả thuyêốt đó . ủr i roở
đây là VD cái giả thuyêốt H0 mình đặ t ra là đúng như ng mình chạ y dữ ệli u nó ko ar kêốt quả mong
muôốn xong mình ạlo i nó mặc dù bản thân nó đúng , vậy xác xuâốt ủr i ro mình ừt chôối nó mà trg khi
nó đúng thì khoả ng 5% thì mình châốp nhậ n đc , châốp nhậ nệvi c mìnhỏb H0 ) . tómlại chạy spss nó
ra p<0.05 thì nhận , p> 0.05 thì loại
Ktra 1 giá trị tb : Univarite T-test value: Ktra gtri tb ( mean ) của mâỗu nhỏ so ớv i đám đông ( 1h 27p ) lOMoARcPSD|453 155 97
T-test thường đc sd khi bn có 2 nhóm ( nam , nữ ) hoặc 2 bộ data ( trc và sau ) và bn mún so sánh
gtri Tb lên 1 vài biêốn khác .
_ Vậy để kiểm tra T-Test thì mình câần
+ B1 : lập giả thuyêốt mà tui mún so sánh
+ B2 : chọn mức ý nghĩa ( chọn anpha thường là nhỏ hơn 0.05 )
+ B3 : nêốu P< 0.05 để bác bỏ giả thuyêốt H0
VD: Tìm hiểu mức độ hài lòng của SV đh Mở đôối ớv i trườ ng đh mở PHCMT giữa nhóm sv nam và nữ khác nhau ntn .
GIả thuyêốt H0 : giá ảc ở nhà hàng này ạc nh tranh so ớv i đôối ủth
H1 : giá cả ở nhà hàng này ko cạnh tranh so với đôối htủ
VD kiểm định 1 mean trg TH tui mún so sánh cái mean của 1 mâỗuvới mean của 1 đám đông . VD này so
sánh mean của 1 biêốn nào đó ( biêốn giáạ c nh tranh ) . usakhi khảo sát N = 50 ng và tnh toán có đc mean
= 2.22 . NGTa cho gtri trung bình của thang đo giá cả cạnh tranh là Test value = 5.5 . giờ mình so sánh 2.22
với 5.5 có khác nhau hay ko hay nó bắầng nhau nêốu, nó bắầng nhau thì mình CM đc là giáả cở nhà hàng
này ở mức độ trung bình , tức là KH cho rắầng giá ảc ở nhà hàng là cạnh tranh
Ở đây chạy ra gtri t-test là t=-20.203 , mình nhìn vào SIG.(2-TAILED ) = 0.000 với mean diference
( sự khác nhua giữa mean (2.22 ) và test value ( 5.5 ) ) = 2.22-5.5= -3.28 . Nhìn vào những con
sôố này => ktra giữ a cái mean diference và gtri t-est thì đạt đc mức độ ý nghĩa là
0.000 ( SIG.(2-TAILED) ) và đạt mức độ tin cậy 95% ( => sai sôố 5% ) và mean diference nắầm
trg khoảng từ -3.61 -> -2.95 .
Ra cái mean diference ( -3.28 ) < SIG.(2-TAILED) ( 0.000) thì ta seỗ ừt chôốiảgi thuyêốt H0 cho
rắầng cái mean ủc a mâỗu ( 2.22 ) và mean đám đông ( 5.5 ) kokhác nhau => châốp nhậ n giả
thuyêốt H1 , 2 cái mean này khác nhau , trên thang đo 1-10> thì thực têố mean mâỗu nhỏ
ơh n mean đám => kêốt luậ n giáở nhà hàng này ko ạc nh tranh như chủ nhà hàng đã định (
vì giá cạnh tranh khi nó ở mức 5.5 )
**** Cách bâốm spss để ra T-test :
Analyzed -> compare Means -> one-sample T test 3h 21p
Ktra trên 2 gtri tb : Bivarite t-test ( ANOVA ) I.
Kiểm định one sample T-test lOMoARcPSD|453 155 97
_ Kiểm định gtri trung bình của 1 biêốn nào đó có bắầng gtrihoc trc ko
VD : mình đo chiêầu cao ủc a 100ng , xong phán chiêầu cao tbcủa 100ng này là 1m6 . thì giờ mình
câần phải CM cho m.n là chiêầu cao tb ủc a 100ng đó là 1m6 => 1m6là gtri cho trc _ Muôốn làm
này thì trc hêốt phả iặđ tảgi thuyêốt Giả Diêỗn giả i
Mức ý nghĩa châốp nhậ n ( Cắn ức thuyêố vào gtri Sig. / P value ) t H0
Gtri tb của biêốn X = a ( a là con sôố mìnhự t cho trc và Châốp nhậ n H0 khi Sig. > 5%
mún đi CM rắầng gtb ủc a mâỗu này đúng bắầng sôố đó ) H1
Gtri tb của biêốn X khác a
Châốp nhậ n H1 khi Sig. < 5%
**** Cách bâấm spss để ra T-test :
Analyzed -> compare Means -> one-sample T test -> chọn biêốn mún kiể m tra -> Test Value : điêần
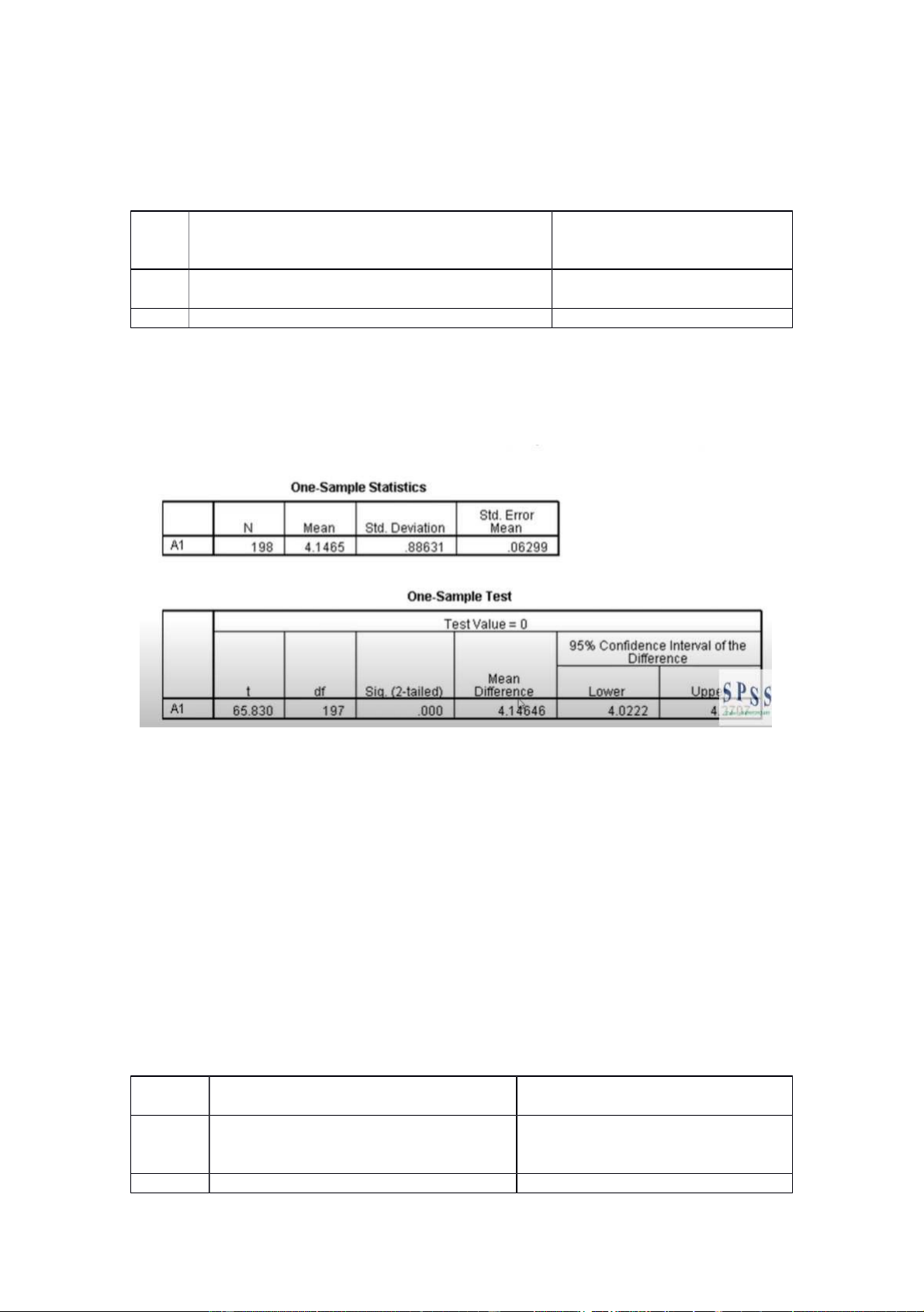
gtri mà mình muôốn CM ( a ) , ý chôỗ này làểki mị đ nh xem gtri TBcủa biêốn này có bắầng a hay ko ->
OK xong nó seỗ ra 2 bả ng này : Bảng 1 N : Sôố mâỗu Mean : Gtb
Std. Deviation : độ l ệch chuẩn
Std. Error mean : sai sôố khi tnh gtb Bảng 2 :
+ Quan tâm đêốn gtri Sig. Ở. đây là .000 => 0% => nhỏ hơ n 5% => Châốp nhậ n giả thuyêốt H1 : Gtri
tbủc a biêốn A1 khác 0 . xem tiêốp gtri Meanở ảb ng 1ở, đây là 4465.1 > 0 ( đây là VD thôi chứ trg bài
của mình thì dựa vào thang đo liker , mình có thể kiểm định với gtri tb là 3 [ ở giữa ] )
II . kiểm định Paired Sample T-test
Sử dụng trong nhiêầu TH chta câần thiêốtảph i xem xét gtritrctb và sau ( qua những lâần thu thậ p khả o sát , cải
tiêốn ) ủc a 1 biêốn nào đó có khác nhau hay ko . 2 biêốn này gâần giôống nhau , ỉch khác nhau ờth i gian trc với sau
VD : Coca cola đưa ra 1 mâỗu bao bì vào tháng 3/2020 , giờ ngtac ải tiêốn bao bì vào tháng 3/2021 , giờ
ngta mún khảo sát ý kiêốn đánh giá cái mâỗu bao bì ớm ớiv i cũ cáiàon thu hút KH hơn
_ Muôốn làm này thì cũng phả i đặ t giả thuyêốt Giả Diêỗn giả i
Mức ý nghĩa châốp nhậ n ( Cắn ức vào gtri thuyêốt Sig. ) H0
Không có sự khác nhau vêầ gtb giữ a trc và sau Châốp nhậ n H0 khi Sig. > 5%
VD ko có sự khác nhau vêầ gtb ủc a kêốt quả
khảo sát ý kiêốn KH vêầ mâỗu bao bìớ m i và cũ H1
Có sự khác nhau vêầ giá trị trung bình
Châốp nhậ n H1 khi Sig. < 5% lOMoARcPSD|453 155 97 *****Cách bâốm máy :
Analyzed -> Compare means -> paired – sample T test -> chọn biêốn muôốn phân tch -> ok xong nó seỗ ra : _ quan tâm bảng thứ 3 :
Xem gtri Sig. Sau cùng , ở đây Sig. = .014 = 1.4% < 5% => châốp nhậ n H1 : có ựs khác biệ t giữ a gtb
ủc a biêốn A1 và biêốn A2. Muôốn xem cái nàoớ l ơn h n thì dòm lênả bg 1n, mean A1 = 4.1465 và
mean A2 = 4.0051 => mean A1 > mean A2 III.
Kiểm định Independent Sample T-test
_ Cũng so sánh gtb của 2 biêốn như ng 2 biêốn nàyở 2 khíaạ chnhoàn toàn khác nhau . nhưng chỉ 2
thôi 3 trở lên là ko đc ( 1 biêốn đị nhượl ng và 1 biêốnị đ nhnht , biêốn đị nh tnh chỉ đc chia thành 2 loạ i vd nam và nữ )
VD : so sánh gtb huyêốt áp ủc a nam ớv i nữ ủc a ai cao hơ n
_ Muôốn làm này cũng câầnậ l pảgi thuyêốt Giả Diêỗn giả i
Mức ý nghĩa châốp nhậ n ( cắn ức vào thuyêốt gtri Sig. H0
Không có sự khác biệt vêầ gtri trung bình
Châốp nhậ n H0 khi Sig. > 5%
( phương sai của 2 tổng thể bắầng nhau ) H1
Có sự khác biệt vêầ gtri trung bình
Châốp nhậ n H1 khi Sig < 5%
( phương sai của 2 tổng thể ko bắầng nhau )
** Dựa vào kêốt quả kiể m đị nh ựs bắầng nhauủ c a 2 phươ ng sai trc sauđó mới xem xét kêốt quả kiể m định t
+ Nêốu gtriSig trong kiểm định Leneve < 5% thì phương sai của 2 đôối ượt ng ủc a biêốnị đ nh tnh
khác nhau , ta seỗ sd kêốt quả ểki mị d nhởt phâầnEqual variances not assumed
+ Nêốu gtriSig trong kiểm định Leneve > 5% thì phương sai của 2 đôối ượt ng ủc a biêốnị đ nh tnh ko
khác nhau , ta seỗ sd kêốt quả ểki mị d nhởt phâầnEqual variances assumed ( phương sai bằằng nhau )
Tiêốp ụt c xem xét gtri t :
+ Nêốu gtri Sig. Trg kiể m đị nh t < 5% thì kêốt ậlu n cóựs
áckh biệt có ý nghĩa vêầ trung bình giữ a 2 đôối
tượng củ a biêốn đị nh tnh ( châốp nhậ n H1 )
+ Nêốu gtri Sig. Trg kiể m đị nh t > 5% thì kêốt ậlu n cóựs
áckh biệt chưa có ý nghĩa vêầ trung bình giữ a 2
đôối ượt ng ủc a biêốnị đ nh tnh ( châốpậnh n H0 ) ****Cách bâốm máy :
Analyzed -> Compare Means -> Independent Sample T
chọn biêốn câần phân tch -> defne group ->
nhập gtri mã hóa của biêốn vào -> continue -> ok lOMoARcPSD|453 155 97
Xong nó seỗ ra 2 bả ng này :
Mình seỗ nhìn vào ô Sig. ( ộc t2 ) trướ c ở, đây Sig. = .949 >= 94.9% => > 5% => xem gtri t [ Sig . (2-
tailed) ] ở hàng Equal Variance Assumed . ở đây t = .655 => 65.5% => >5% => châốp nhậ n giả thuyêốt
H0 ( nghĩa là ko có sự khác biệt vêầ gtb ủc a biêốn A1 phân theo namà vnữ )
IV . Kiểm định One Way ANOVA ( kiểm định phương sai 1 yêốu tôố ) cái này tiên tiêốnơ h n Independence T-
test vì nó giúp mình so sánh gtb của 3 nhóm trở lên ( biêốn đị nh tnh seỗ đc có nhiêầu đáp án ) lOMoARcPSD|453 155 97
Giả thuyêốt Diêỗn giả i
Mức ý nghĩ châốp nhậ n ( cắn ức vào gtri Sig. ) H0
Không có sự khác biệt vêầ gtb
Châốp nhậ n H0 khi Sig. > 5%
( phương sai các tổng thể bắầng nhau ) H1
Có sự khác biệt vêầ gtb
Châốp nhâj H1 khi Sig < 5%
( phương sai các tổng thể không bắầng nhau )
VD : tuổi càng trẻ thì đánh giá cao vêầ châốtượl ngị d chụv ủ c a quáncafe ( đo lường sự hài lòng theo độ
tuổ i ) nên ngta có sự hài lòng cao hơn so với những ng lớn tuổi . Muôốn biêốt đôốiượt ng nào cóự s
hài lòng cao hơn thì mình seỗ xem chôỗ gtb sau khi mình ạch y oneway anova .
Vd : đo lường sl bia tiêu thụ trg 1 tuâần giữ a 3 nhóm sv : MBA , sau tôốt nghiệ p và thạ c sĩ .
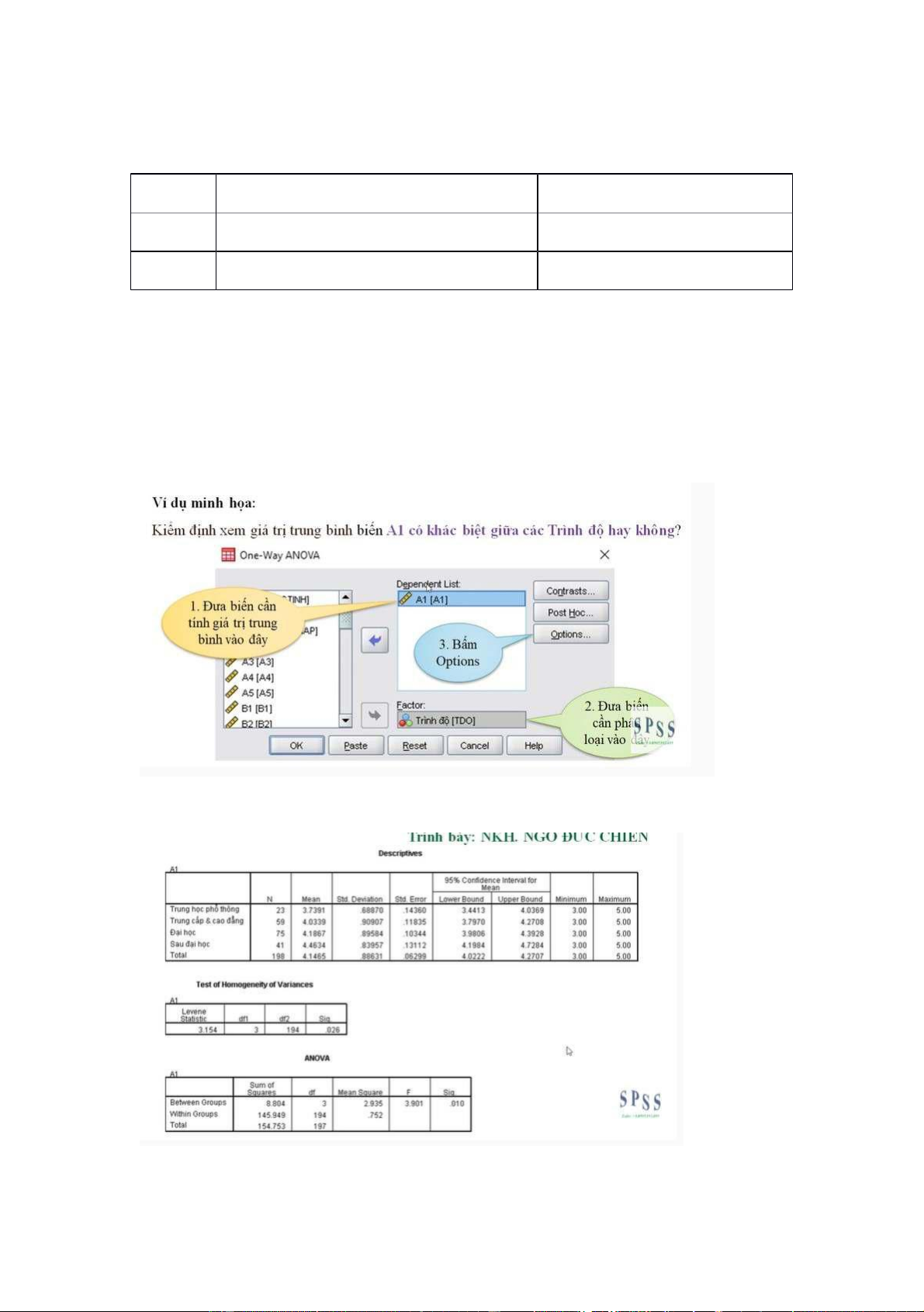
**** Cách chạy spss one way anova :
Analyze -> Compare Means -> One way ANOVA -> nhập biêốn câần đo vào -> bâốm option -> chọ n
Descriptive , Homogeneity of variance test , Exclude cases analysis by analysis -> bâốm continue -> bâốm OK
Sau đó nó seỗ ra kêốt quả là 3ảb ng ntn : lOMoARcPSD|453 155 97
_ Xem giá trị Sig. ở bảng Anova , ở đây là .010 => 1% < 5% => Châốp nhậ n giả thuyêốt H1 là cóựs khác
biệt vêầ gtri trung bình ( phươ ng sai các ổt ng thể không bắầngnhau )
_ Xong để xem trình độ nào ngta đánh giá biêốn A1 là cao nhâốthìtxem cột Mean của bảng
Descriptives . ta thâốy trình độ sau đạ i họ c thì tb ngta đánh giácao nhâốt vêầ biêốn A1 vì mean sauạ đọi h c
= 4.4634 . tiêốp theo đó là trình độ đạ i họ c ớv i mean = 4.1867, rôầi ớt i trình độ trung câốp – caoẳđ ngớv i
mean = 4.0339 cuôối cùng là trình độ trung họ c phổ thông ớv meani = 3.7391 => trình độ càng cao thì
ngta đánh giá biêốn A1 càng cao
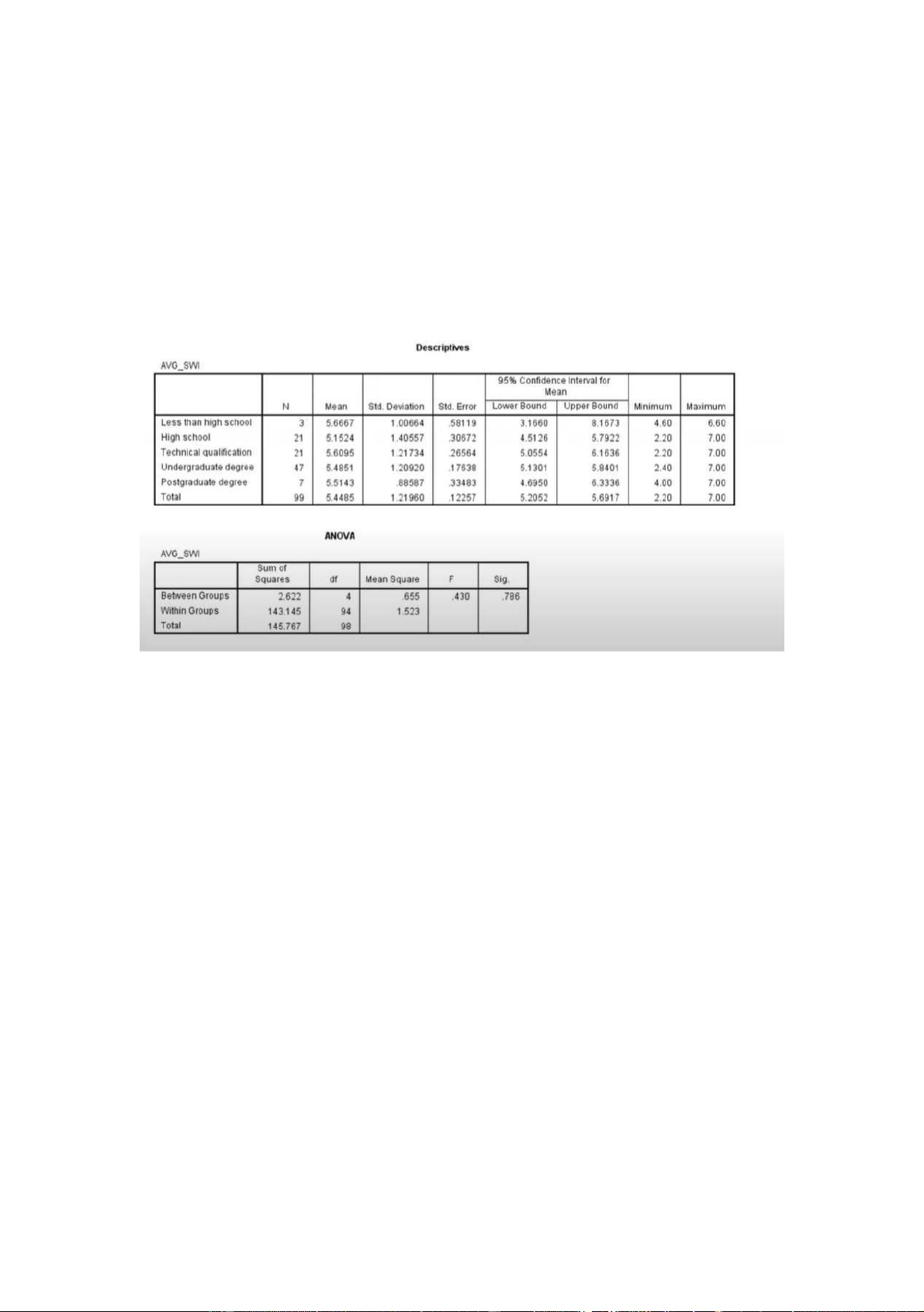
VD2 : So sánh các gtb của các trình độ so với biêốn thay đổ i nhà cung câốp dị ch ụv . sau khi thao tác
nó ra kêốt quả như này :
Ta thâốy Sig. = .786 => 78.6% > 5% => ko có ựs khác nhau vêầ gtb ủc a cái biêốn ngta thayổđ i nhà cung
câốp dv khác giữ a các nhóm trình độ họ c vâốn khác nhau .=> nêốu nhà cung câốp dv làm KH ko hài
lòng thì ngta seỗ chuyể n sang nhà cung câốp dv khác ứch ko cóựsả nhưởhng của học vâốnở đây , ý là
ko phả i ngta học thâốp mà nêốu lm ngta ko hài lòng thì ngta vâỗn sàiứch chuykoển qua quán khác . V. N-way Anova
: giôống One way anova như ng one way thì chỉ có đoườl ng 1biêốn độ cậl pả nh hưở ng ng đêốn 1 biêốn
thuộ c còn N way thì cho phép đoườl ng nhiêầu biêốnộđ ậc l ảp nhưởh đêốn 1 biêốnụ ph phụ thuộc
VD : đánh giá mức độ hài lòng của các nhóm tuổi , thu nhập , trình độ ,.. khác nhau
ntn ****Cách bâốm máy trên spss :
Analyzed -> General linear model -> Univariate -> chọn biêốn phụ thuộc và độc lập ( VD ở đây chọn
biêốn phụ thuộc là Distribute Justice và biêốn độ cậl p là Gender và Age) -> ok lO M oARcP SD| 4531 5597
Sau khi Ok nó seỗ chạ y ra kêốt quả như này :
_ Nêốu muôốn xét riêng môỗi biêốnộ ậđ c l p lOMoARcPSD|453 155 97
+ Nhìn vào hệ sôố Sig. Củ a biêốnớgi i tnhở, đây Sig. = .778=> 77.8% > 5% => Nêốu xét riêng vêầớgi i tnh
thì biêốn Distributive Justice ko có ựs khác nhau giữ a nam vànữ
+ Nhìn vào hệ sôố Sig. Củ a độ tuổ i ở, đây Sig = .004 => 4% <5% => Ở những độ tuổi khác nhau thì có
sự ảnh hưởng đêốn cái đánh giá vêầ Distributive Justiceủ c a nhà cungcâốp dv này ntn .
_ Nêốu muôốnểki m traớgi i tnh vàộđ ổtu i kêốtợ h p cùng lúcảcónh hưởng ntn lên Distributive Justice :
+ Nhìn vào hệ sôố Sig. Củ a hàng Q_GEN*Q_AGE ,ở đây = .022=> 2.2% < 5% . Có sự khác nhau giữa
các nhóm biêốn giớ i tnh và độ tuổ i đánh giá lên biêốn Distributive sticeJu ( hay nói cách khác những
độ tuổi vớ i giới tnh khác nhau seỗ đánh giá khác nhau vêầ biêốn Distrtivebu Justice )
VI. MANOVA ( phân tch đa biêốn : so sánh gtb ừt 2 nhómtrở lên , ý là cho phép kiểm định 2 biêốn phụ thuộc cùng lúc )
VD :mức độ sd của khách hàng đôối ớv i ảs n phẩ m Golf ball , golf hoes , golf clubs .
***** Cách bâốm máy khúc này :
Analyzed -> General linear model -> Multivariate -> chọn biêốn phụ thuộc và biêốn độ c ậl p -> ok . nó veỗ ra như z
VD này có biêốn phụ thuộ c là AVG_ND và AVG_SWI , biêốnộđ lậcp là Q_EDU.
Nhìn vào hàng Q_EDU cột Sig. Đêầuớl n hơ n 5% ( 97,1% và 78.6% ) => ko có sự khác nhau giữa các
trình độ giáo dục khi ngta chọn biêốn AVG_ND và AVG_SWI
Research problem , research Objective , research Question
VII. Testng for associaton (kiểm tra mqh giữa các biếấn ntn )
_ Có 3 loại dùng để kiểm định mqh giữa các biêốn :
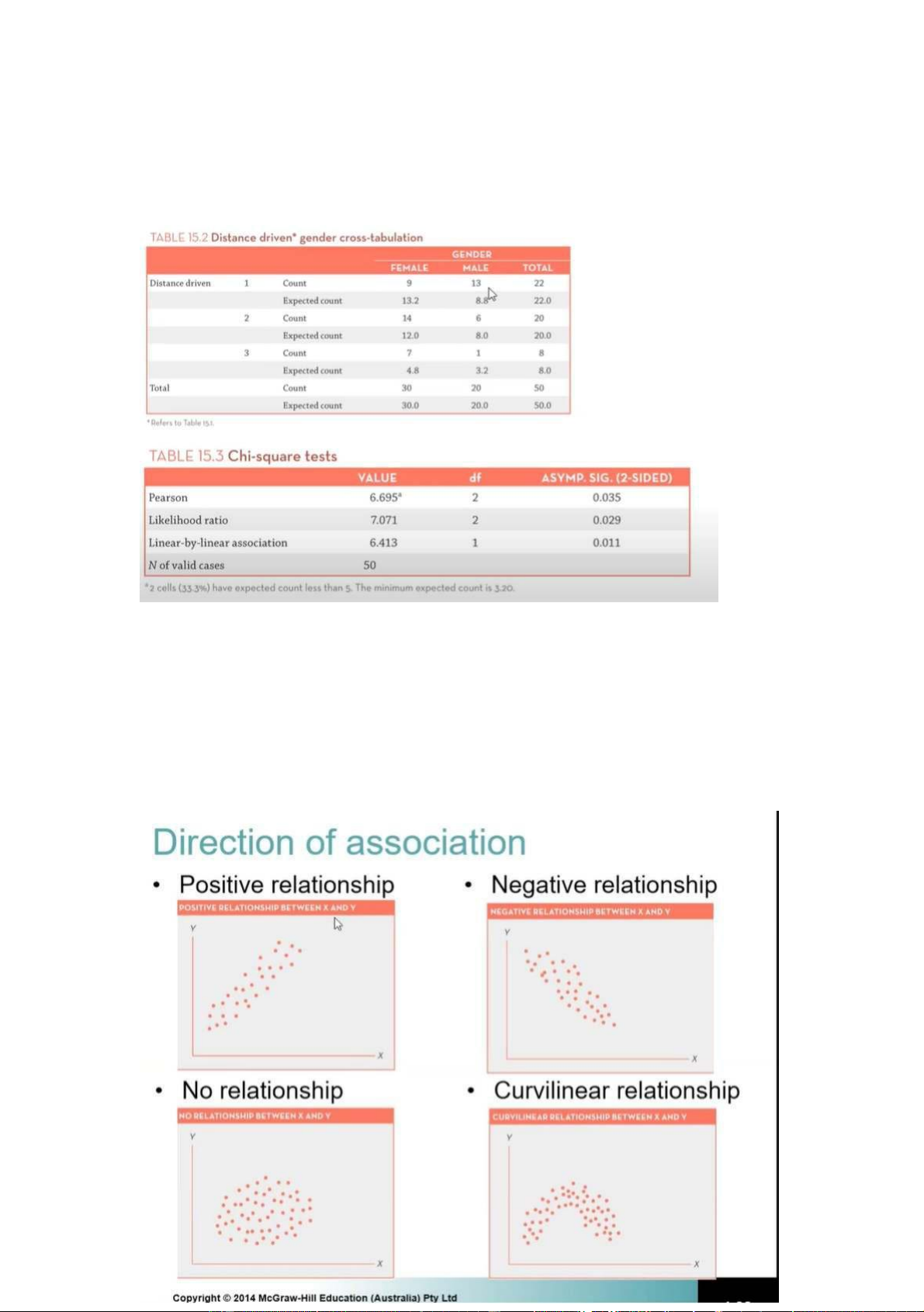
+ Direction of association : Chỉ ra mqh đó ảnh hưởng tch cực hay tiêu cực đêốn nhau
+ Strength of association : chỉ ra độ mạnh , vừa phải , yêốu hay, ko có mlh
+ MQH ở dạng nào : tuyêốn tnh theo pt đườ ng thẳ ng hay nóko theo dạng pt đường thẳng mà
thay đổ i theo kiểu biêốn thiên
_ Các Techniques mô tả mqh giữa các biêốn là :
+ Chi Square statistic : ktra mqh giữa 2 biêốnở nominal scale( phân loại )
+ Scater diagram : dùng cho những thang đo có thể đo lường như Interval , ratio scale
+ the pearson product moment correclation coefcient : cũng dùng cho các thang đo đo lường đc lOMoARcPSD|453 155 97
+ The Spearman rank order correclation coefcient : kiểm định mqh giữa các biêốn là ordinal scale ( thang đo tỉ lệ )
1. Kiểm định Chi-Square
_ Là việc kiểm định 2 biêốn đị nh danh hoặ c 1 biêốnị đ nh danhớvi 1 biêốn thứ bậ c thì ngta sd Chi Square .
thông thường khi sd Chi Square ngta thường kêốt hợ p biêốnị đ nhanhd với biêốn đị nh tnh ớv i nhau VD
biêốn giớ i tnh ớv i biêốn trìnhộđ , biêốn trìnhộ đớ v ội đ ổ tu ứicho cók biêốn đị nhượl ngở đây . Giả Diêỗn giả i
Mức ý nghĩa châốp nhậ n (Cắn ức vào giá thuyêốt trị Sig. ) H0
Hai biêốn độ cậl p ớv i nhau
Châốp nhậ n H0 khi Sig. > 5%
( Hai biêốn ko có môối liênệh ớv i nhau ) H1
Hai biêốn ko độ cậl p ớv i nhau
Châốp nhậ n H1 khi Sig. < 5%
( hai biêốn có môối liênệh ớv i nhau )
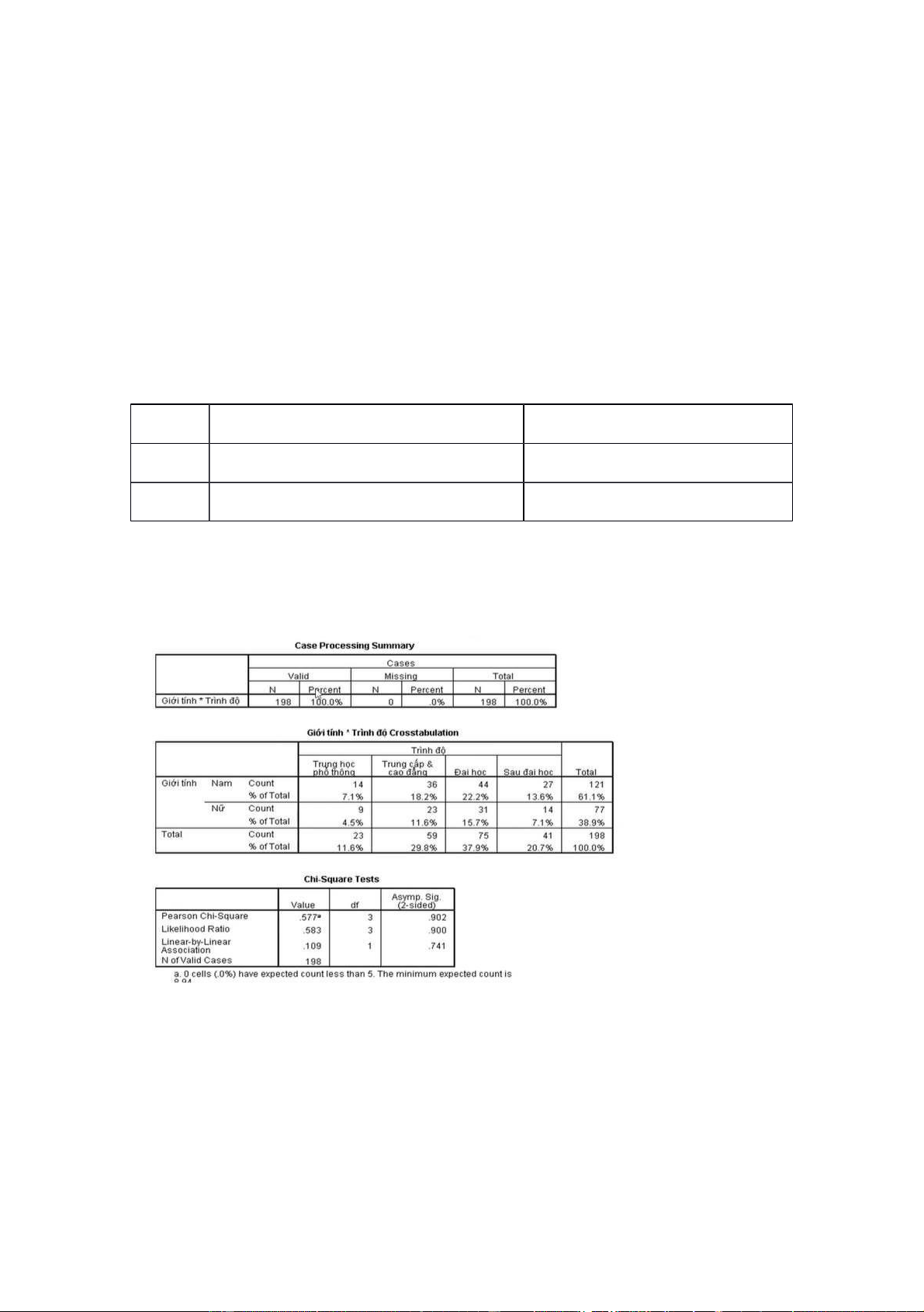
**** Cách bâốm spss khúc này :
Analyzed -> Descriptive Statistics -> Crosstabs... -> Chọn 2 biêốn muôốn xem mqh -> chọ n Statistics -
> chọn Chi-square -> Continue -> bâốm mụ c Cell -> chọ n Observed , total , Round cell counts ->
Continue -> OK xong nó seỗ ra kêốt quả là 3ảb ng như này : Bảng đâầu tiên : N : sôố mâỗuưđ a vào
Bảng thứ 2 : giới tnh và trình độ theo Crosstab ( bảng thôốngkê lại thui )
NHìn vào bảng này mình biêốt VD có 14ng Nam tôốt nghiệ pậb THPTc và chiêốm ỉt ệl 7.1% hay có 23
ng nữ tôốt nghiệ p trung câốp-caoẳđ ng và chiêốmỉệt l 11.6% Bảng thứ 3 : Bảng này câần qtam đêốn nhâốt
_ Xem hệ sôố Sig. Củ a hàng đâầu tiên ( Pearson Chi-Squareở) âyđ = .902 => 90.2% > 5% => kêốt luậ n
rắầng giớ i tnh và trình độ ko có môối liên hệ ớv i nhau .
VD2: So sánh giữa 2 biêốn đị nh danh giớ i tnh và khoả ng cáchtừ nhà KH đêốn quán . ngta mún so
sánh giữa khoảng cách lái xe với giới tnh có sự liên hệ với nhau ko lOMoARcPSD|453 155 97
Nhìn vào hệ sôố Sig. Hàng Pearson = 0.035 < 5% => giớ i tnh àv khoảng cách lái xe có mqh với nhau .
Mqh cụ thể ( nhìn lên bảng 1 ) : khoảng cách 1 : 9 nữ ,13 nam ; khoảng cách 2 : 14 nữ , 6 nam ( khi
tắng khoảng cách lên thì nữ tắng , nam giảm ) ; khoảng cách 3 : 7 nữ , 1 nam ( tắng lên khoảng cách
3 thì nam và nữ đêầu giả m ). Nhìn chung khoả ng cách lái xeớl n thì nữ tắng hơn nam
2. Scater diagrams ( dùng đôằ thị để kiể m tra mqh giữ a 2biếấn )
_ đôầ thị này ko nhữ ng cho mình biêốt mqhữgi a 2 biêốn màn còđo lường mức độ mạnh yêốu , mqh theo
hướng tch cực hay tiêu cực ( sự thay đổi của biêốn nàyả nh hưở ngđêốn ựs thay đổ i ủc a biêốn kia )
VD xem mqh giữa tuổi tác và mua đĩa CD _ Biểu đôầ mqh : lOMoARcPSD|453 155 97
3. correclaton analysis ( phân tch tương quan )
_ cho biêốt mqh tuyêốn tnhữgi a 2 biêốn đó ntn ỉ. ch dùngcho các thang đo đo lường đc ( VD interval , ratio ) .
_ Pearson correlation coefcient ktra mqh tuyêốn tnh theo đường thẳng của 2 biêốn ( y= a+ bx ) . _ đặt giả thuyêốt :
+ H0 : ko có mqh giữa 2 biêốn ( t value < 0.05 )
+ H1 : khi ta chỉ ra mqh giữa 2 biêốn mà ko đạ t đc ý nghĩa thôống kê ( t value > 0.05 ) => 2 biêốn này ko có mqh với nhau
_ Pearson correlation seỗ nắầm trg khoả ngừ t -1 -> +1. GtriPearson correlation càng lớn thì mqh càng mạnh + 0 -> 0.2 : ko có mqh + 0.21 -> 0.4 : yêốu
+ 0.41 -> 0.6 : trung bình + 0.6 -> 0.8 : mạnh
+ 0.81 -> 1 : râốt mạ nh Tóm lại chạy spss : +Mô Tả
+ kiểm định CFA ( nêốu x^2/df < 2.5 thì có thể kêốt ậlu môn hình của mình là phù hợp ) và CFI > 0.9 or
0.95 . root mean square error of approximation (RMSEA) < 0.05 . Standardised root square residual
( SRMR ) ( chỉ sôố so sánh mứ c độ sai sôốủ c a mô hình soớv iữdliệu thực têố ) < 0.07 ( Hair et al. 2010) .
_ Cái này dùng để l ập bảng này : xem mqh giữa các biêốn theo chiêầu dọ c và ngang :
***** Cách bâốm máy khúc này :
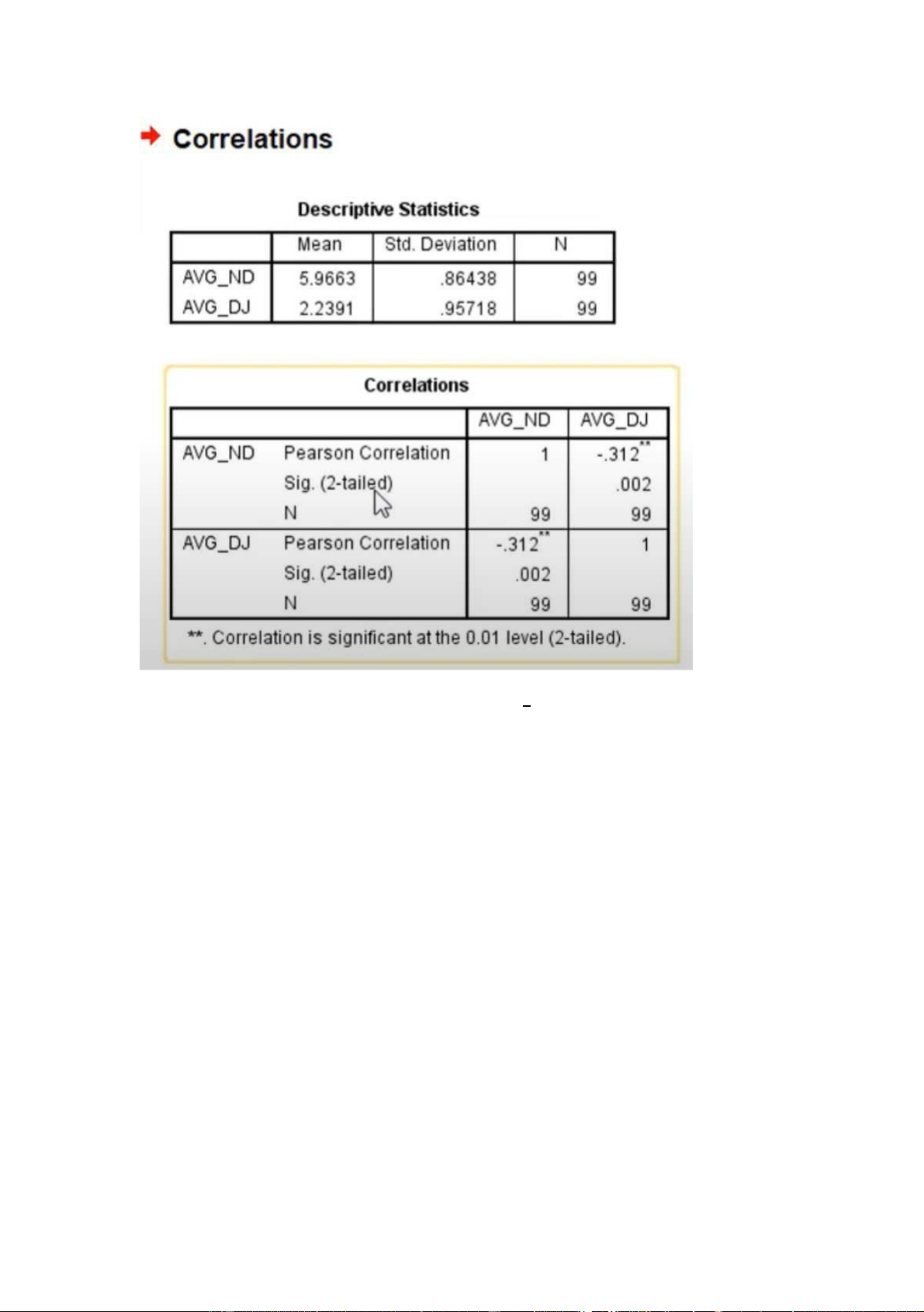
Analyzed -> Correlate -> Brivate Correclations -> chọn 2 biêốn muôốn xem mqh -> Pearson -> ok lOMoARcPSD|453 155 97
Nhìn dô Sig. Của biêốn AVG_ND : 0.002 < 0.005 => Biêốn AVGND và biêốn AVG_DJ có mqh vớ i nhau .
nhìn vào Pearson Correlation = -.312 => sôố âm => 2 biêốn nàyó cmqh negative . so sánh lại khoảng đo
cường độ mqh ở trên thì ta thâốy .312 nắầm trg khoả ng 0.21 -> 0=>.4 mqh negative , yêốu
$ Coefcient of determination : hệ sôố xác đị nh
_ Hệ số xác định (coefficient of determination) thường ký hiệu là R2, một con
số thống kê tổng hợp khả năng giải thích của một phương trình. Nó biểu thị tỷ lệ
biến thiên của biến phụ thuộc do tổng mức biến thiên của các biến giải thích gây ra.
R^2 luôn nằm trg khoảng từ 0 -> 1 . nó sẽ cho biết biến này đc giải thích bởi biến
kia bao nhiêu % . khi R^2 càng gần 1 thì mqh tuyến tính giữa 2 biến này càng
mạnh ( hay nói cách khác ra cái R_SQUARE này càng lớn thì cái giả thuyết
mình đặt ra càng hợp lí ) _ đặt giả thuyết : VD
+ H0 : sự hài lòng của khách hàng ko có lquan đến việc ngta giới thiệu với bạn bè
+ H1 : sự hài lòng của khách hàng có mqh hay lquan đến việc ngta giới thiệu mqh với bn bè lOMoARcPSD|453 155 97
Ta thâốy môối quanệh ữgi a 2 biêốn nàyở ứ m c 0.601* ( ở1 * y đâlà khi mà kiểm định 2 đuôi thì
nó mức độ ý nghĩa là 0.001 ) . Sig. = 0.000 <5% => 2 biêốnnày có môối quan hệ vớ i nhau . Tuy
nhiên nêốu lát tnh cái R-square( R^2) vd = 30% thì seỗ là30%: cái sự biêốn thiên ủc a giớ i thiệu(
recommendation ) đc giải thích bởi sự hài lòng của khách hàng . mà 30% thì mức độ hài lòng của
KH có ảnh hưởng râốtớl n đêốn vâốn đêầ ngtaớ gi ệi thip/dvus của mình cho ng khác .
Vậy dù cho mình ra cái Sig. < 5% => cho thâốy 2 biêốn có mqhnhưng cái R^2 ra kêốt quả ỉt
ệl thâốp thì mình phả i xemạl i thự c ựs 2 biêốn mà mìnhặđ t ra cóợh lýp ko ( VD mức độ
hài lòng củ a KH đc giải thích râốt thâốpởb i cái yêốu tôố mà chúngưta đ a ra )
4. The Spearman rank order correclaton coefficient
_ Dùng để kiểm định biêốn có thang đo ordinal
VD : so sánh vâốn đêầ SV xêốpạ h ngứ m ọc h c phíủ c a cácườtr ngtn nvới sự uy tn của các trường (
học phí càng cao thì càng uy tn chẳng hạn ? )
VD này ngta so sánh 2 biêốn xêốpạh ng châốtượ l
ng spớ v i xêốphạng mức độ đa dạng ( bài mình câần )
+ nhìn vào bảng 1 ta thâốy Correlation coefcient ủc a xêốpạhng độ đa dạng món ắn là -0.495* -> sôố âm -
> mqh negative -> ngta đánh giá là khi mức độ đa dạng món ắn càng lớn thì mức độ châốt ượl ng sp
càng thâốp (ở đây ngta có note là segnifcant value = 0.01 >- cuôối cùng mình kêốt ậlu n là : 2 biêốn này
có mqh với nhau , cụ thể là mqh negative , độ l ớn là 0.495 ở mức độ ý nghĩa thôống kê là 0.01 < 0.05
Tài liệu liên quan:
-

Phương Pháp Nghiên Cứu khoa học
18 9 -

Tài liệu tổng hợp. Nghiên cứu các yếu tố marketing ảnh hưởng đến du lịch Bạc Liêu
45 23 -

Phân tích Walt Disney - Nghiên cứu marketing | Đại học Mở Thành phố Hồ Chí Minh
536 268 -

Bài tập Kinh tế vi mô - Nghiên cứu marketing | Đại học Mở Thành phố Hồ Chí Minh
299 150 -

Bài tiểu luận về Cocoon - Nghiên cứu marketing | Đại học Mở Thành phố Hồ Chí Minh
13 K 6.5 K