Nhận dạng khuôn mặt bằng cách sử dụng bề mặt 3D được trích xuất | Môn quản trị chuỗi cung ứng
Giống như trong nhiều ứng dụng nhận dạng mẫu khác, cần giảm số lượng tính năng để tăng hiệu quả của công cụ nhận diện khuôn mặt. Để chọn một tập con tính năng tối ưu để đại diện cho các cá nhân cho mục đích nhận dạng khuôn mặt, tám mươi sáu tập con tính năng đã được thử nghiệm: những tập hợp con tính năng đầu tiênn các tính năng trong danh sách được sắp xếp cho tất cả n, nhu la 1- n - 86. Tập hợp các khuôn mặt đã biết của hệ thống nhận dạng khuôn mặt (tập huấn luyện) bao gồm 60 hình ảnh trực. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem !
Môn: Quản trị chuỗi cung ứng 12 tài liệu
Trường: Đại học Kinh tế Thành phố Hồ Chí Minh 2.2 K tài liệu
Tác giả:







Preview text:
lOMoAR cPSD| 49519085
Translated from English to Vietnamese - www.onlinedoctranslator.com
Nhận dạng khuôn mặt bằng cách sử dụng bề mặt 3D được trích xuất bộ mô tả
Ana Belén Moreno, Ángel Sánchez, José Fco. Vélez và Fco. Javier DíazEscuela Superior de CC.
Người thực nghiệm e Ingeniería, Đại học Rey Juan Carlos,
Campus de Móstoles, C / Tulipán s / n; Chương 28933 Tây Ban Nha
{abmoreno, an.sanchez, j. opensz, fjdiaz}@escet.urjc.es trừu tượng
Sức mạnh phân biệt của các bộ mô tả ba chiều (3D) được trích xuất từ bề mặt khuôn mặt người 3D được
phân tích. Một hệ thống nhận dạng khuôn mặt tự động sử dụng các tập con khác nhau của bộ mô tả đã được
triển khai và thử nghiệm. Chúng tôi đã sử dụng 420 mắt lưới 3D trên khuôn mặt của 60 cá nhân, bao gồm các
chế độ xem thể hiện các chuyển động xoay ánh sáng và biểu cảm khuôn mặt, cho các thí nghiệm. Một phân
đoạn HK (dựa trên các dấu hiệu của độ cong trung bình và Gaussian) để cô lập các vùng có độ cong rõ rệt đã
được thực hiện. Tám mươi sáu bộ mô tả đã được thu thập từ các vùng được phân đoạn. Ba mươi lăm phân
biệt khác trong các chế độ xem trực diện cung cấp 78% tỷ lệ nhận dạng thành công khi kết quả phù hợp nhất
được chọn và 92% thành công nhận dạng khi năm kết quả phù hợp nhất được chọn.
Từ khóa: Nhận dạng khuôn mặt, tầm nhìn 3D, bộ mô tả 3D, nhận dạng hình ảnh phạm vi. 1. Giới thiệu
Hệ thống sinh trắc học là một hệ thống nhận dạng mẫu xác định tính xác thực của một cá nhân bằng cách sử dụng một số đặc điểm thể
chất hoặc hành vi (dấu vân tay, hình ảnh khuôn mặt, chữ ký, giọng nói, v.v.) [13] [11]. Nhu cầu xã hội về kiểm soát gian lận trong nhiều
tình huống, bao gồm cả sự di chuyển theo địa lý, trong đó cần thiết lập xác thực cá nhân góp phần làm tăng nhu cầu nghiên cứu về các
hệ thống như vậy [10]. Không thực sự có thể nhận dạng hoàn hảo, nhưng việc tích hợp nhiều hơn một đặc điểm cá nhân trong hệ thống
sinh trắc học cho phép tăng tỷ lệ nhận dạng (tức là sử dụng khuôn mặt và giọng nói) và giải quyết vấn đề khi một cá nhân thiếu một đặc
điểm cụ thể. Trong số các kỹ thuật sinh trắc học khác nhau, những kỹ thuật sử dụng hình ảnh khuôn mặt, giọng nói và cách đi bộ là
những kỹ thuật ít xâm phạm hơn; nói chung, việc sử dụng hình ảnh khuôn mặt đòi hỏi ít sự cộng tác của người dùng và đây là kỹ thuật
phổ biến được con người sử dụng để xác định người [11]. Kết quả tuyệt vời đã đạt được khi hình ảnh cường độ 2D được sử dụng trong
các điều kiện thu nhận đồng nhất [12] [13]. Đó là lý do tại sao nỗ lực nghiên cứu trong lĩnh vực này thực sự hướng nhiều hơn đến tính
độc lập của các điều kiện này (tức là độ mạnh khi thay đổi ánh sáng, biến đổi hình học, nét mặt, trang điểm, tóc, v.v.).
Trong vài năm gần đây, sự quan tâm đến hệ thống nhận dạng khuôn mặt tự động dựa trên mô hình 3D đã tăng lên [6] [7] [5] [1] [15] [3].
Một kỹ thuật phổ biến về nhận dạng đối tượng 3D là dựa trên sự tương ứng giữa các điểm cảnh và điểm mô hình để
thực hiện nhận dạng và xác định tư thế và vị trí đối tượng [2]. Trong số các bộ mô tả đối tượng dạng tự do 3D để biểu
diễn các đối tượng là độ cong của bề mặt cục bộ được đánh giá tại mỗi điểm, được đặc trưng bởi các hướng mà pháp
tuyến của bề mặt thay đổi ngày càng nhanh hơn [8]. Trong Hallinan và cộng sự, một tập hợp gồm mười hai tính năng 3D
được trích xuất từ các vùng được phân đoạn bằng cách sử dụng các thuộc tính độ cong của bề mặt đã được thử
nghiệm để nhận dạng khuôn mặt bằng cách sử dụng cơ sở dữ liệu gồm 8 hình ảnh riêng lẻ và 3 hình ảnh trên mỗi cá
nhân, thu được 95,5% tỷ lệ nhận dạng cung cấp 100% trước đó khai thác tính năng chính xác [4]. Công việc của chúng tôi
tập trung vào việc tìm kiếm, phân tích sức mạnh phân biệt và lựa chọn các bộ mô tả cụ thể có thể trích xuất từ hình ảnh
phạm vi khuôn mặt. Một bộ tám mươi sáu tính năng đã được sử dụng, sử dụng cơ sở dữ liệu gồm 420 hình ảnh phạm vi
3D, 7 hình ảnh cho mỗi hình ảnh trong số 60 cá thể, 3 trong số đó thể hiện nét mặt và hai trong số đó thể hiện phép
quay ánh sáng. Những hình ảnh này có dạng lưới đa giác 3D không có thông tin về màu sắc. Thu thập cơ sở dữ liệu, phân
đoạn (sử dụng thuật toán HK dựa trên các dấu hiệu của độ cong trung vị và Gaussian), ngưỡng độ cong (để cô lập các
vùng có độ cong rõ rệt), trích xuất đặc điểm, phân tích sức mạnh phân biệt để đạt được thử nghiệm lựa chọn và nhận
dạng đối tượng là những nhiệm vụ trong việc triển khai hệ thống nhận dạng khuôn mặt của chúng tôi. Chúng tôi thu
được 78%, 84%, 86% và 92% tỷ lệ nhận biết khi một, hai,
hình ảnh được sử dụng làm tập hợp thử nghiệm (bao gồm cả những hình ảnh mà không phải tất cả các khu vực và do đó, các đối tượng địa lý đều
có thể được định vị). Để cải thiện những kết quả này, chúng tôi đã xác định một số công việc trong tương lai được đưa ra ở cuối bài báo này. Mặt
khác, tầm quan trọng của việc sử dụng cơ sở dữ liệu khuôn mặt mở rộng và phân tích khả năng phân biệt của nhiều bộ mô tả 3D được trích xuất
đảm bảo độ chính xác của kết quả thu được và việc áp dụng phương pháp nhận dạng khuôn mặt 3D được đề xuất.
Phần 2 mô tả cơ sở dữ liệu được sử dụng để thực hiện các thử nghiệm của chúng tôi. Phần 3 mô tả hệ thống nhận dạng khuôn mặt của chúng
tôi. Phần 4 mô tả các vùng và đường được phân đoạn, chỉ ra phương pháp phân đoạn được sử dụng và đưa ra kết quả thu được của giai đoạn
này. Phần 5 mô tả các đặc điểm khuôn mặt được trích xuất từ các vùng và đường được phân đoạn. Phần 6 phân tích khả năng phân biệt của các
tính năng cung cấp một tập hợp con được chọn trong số chúng có chứa các tính năng phân biệt hơn sẽ được sử dụng trong các thử nghiệm của
chúng tôi. Phần 7 mô tả các thí nghiệm nhận dạng khuôn mặt và tỷ lệ nhận dạng của chúng. Cuối cùng, phần 8 đưa ra kết luận và công việc trong tương lai. lOMoAR cPSD| 49519085
2 Mô tả cơ sở dữ liệu
Bộ 420 bề mặt 3D đã được thu thập trong các điều kiện ánh sáng thay đổi bằng cách sử dụng bộ số hóa 3D. Nền trống vì bộ số hóa
không lấy mẫu các đối tượng (tức là bức tường) được đặt xa các mặt được lấy nét. Cơ sở dữ liệu bao gồm 7 ảnh chụp chính diện khác
nhau cho mỗi một trong số 60 người thuộc chủng tộc da trắng và ở độ tuổi từ
18 đến 55. Mỗi bộ gồm 7 mẫu của một cá nhân chứa: một ảnh khuôn mặt trong đó cá nhân đang nhìn xuống (+ 35º NS xoay xấp xỉ), một
hình ảnh khuôn mặt trong đó cá nhân đang nhìn lên (-35º NS xoay khoảng), và năm hình chiếu trực diện, ba trong số chúng thể hiện nét
mặt (một cử chỉ ngẫu nhiên, cười và mỉm cười tương ứng). Nhiều khi các phần tối của khuôn mặt (như mí mắt như chúng ta có thể thấy
trong ví dụ về khuôn mặt của Hình 2) không phản chiếu ánh sáng và do đó chúng không được quét, trong những trường hợp này, các bề
mặt không hoàn thiện của khuôn mặt (thay vào đó không thực hiện đăng ký các góc nhìn khác nhau trong số đó chỉ thu được một ảnh
chụp). Cổ, tai và tóc đã được loại bỏ thủ công khi chúng có mặt. Hầu hết các cá nhân (99%) không đeo kính. Hình 1 cho thấy bảy hình
ảnh 2D của cùng một người tương ứng với các khung nhìn mà cơ sở dữ liệu chứa cho mỗi cá nhân. Hình này cũng cho thấy một lưới
tương ứng với một trong số chúng như được thu được bởi bộ số hóa 3D [9].
Các bề mặt được thể hiện bằng các mắt lưới được cung cấp bởi cảm biến laser phạm vi. Hàng nghìn điểm xấp xỉ bề mặt
của mỗi mặt được lấy mẫu và các kết nối của các điểm này tạo thành một lưới đại diện cho mặt được quét. Các tế bào của
lưới có bốn nút. Lưới cung cấp một cách dễ dàng để thiết lập hai hướng “trực giao” (ngang và dọc) mà nó có thể đi từ một nút
sang nút lân cận của nó trong lưới. Điểm trung bình cho mỗi khuôn mặt trong toàn bộ cơ sở dữ liệu là 2.186. Một giai đoạn xử
lý trước để loại bỏ nhiễu và làm mịn được thực hiện trên tất cả các lưới khuôn mặt 3D bằng cách sử dụng các bộ lọc trung
bình và Gaussian tương ứng.
Hình 1. Chế độ xem của một cá nhân có lưới bề mặt 3D tương ứng thuộc về cơ sở dữ liệu và ví dụ về lưới bề mặt 3D.
3 Mô tả hệ thống nhận dạng khuôn mặt
Hệ thống nhận dạng được đề xuất thực hiện các giai đoạn cổ điển sau: phân đoạn các vùng và đường quan tâm, trích xuất đối tượng địa lý từ các
vùng và đường được phân đoạn, phân loại bằng cách sử dụng đối sánh vectơ đặc trưng theo bộ phân loại khoảng cách Euclide tối thiểu. Khi một
lưới khuôn mặt 3D không xác định (khuôn mặt thử nghiệm) sẽ được hệ thống nhận dạng, các giai đoạn này sẽ được áp dụng cho nó. Các giai
đoạn này cũng đã được áp dụng cho các khuôn mặt đã biết tạo thành cơ sở dữ liệu hệ thống (tập huấn luyện) trong quá trình tạo hệ thống nhận
dạng. Một lựa chọn đối tượng địa lý trước đó để có được sức mạnh phân biệt tối đa đã được thực hiện là các đặc điểm kết quả, các thành phần
của vectơ đặc trưng đại diện cho các khuôn mặt trong hệ thống nhận dạng khuôn mặt của chúng tôi. Các phần sau giải thích chi tiết các giai đoạn này.
4 Giai đoạn phân đoạn
Phương pháp phân đoạn HK [14] thực hiện phân loại điểm trong ảnh phạm vi theo hình dạng cục bộ xung quanh mỗi
điểm. Điều này cho phép ghi nhãn các mảng bề mặt khác nhau trong lưới mặt 3D theo hình dạng của chúng, dựa trên
hình học vi phân. Các vùng bề mặt 3D được đặc trưng như hình elip lõm, elip lồi, hypebol, hình trụ lõm, hình trụ lồi hoặc
phẳng. Dấu hiệu của dải phân cách (NS) và Gaussian (K) các độ cong được coi là đạt được các phân loại điểm này. Bước
đầu tiên là tính cả độ cong trung vị và độ cong Gauss ở mỗi điểm, sử dụng các công thức sau: NS -(1- tôi tôi 2
NS 2 )tôi yy - 2tôi NS tôi y tôi xy - (1- tôi y ) (1) xx 2 (1- tôi 2NS - tôi 2y )3 2 2 K - tôi (2) xx tôi yy - tôi xy (1- tôi NS2 - tôi 2y )2
ở đâu tôiNS, tôiy, là đạo hàm đầu tiên của bề mặt cùng NS và y hướng tương ứng, và tôixy, tôixx, tôiyy biểu diễn các đạo
hàm thứ hai tương ứng. Dấu hiệu củaNS và K độ cong của mỗi điểm đối với một mặt ví dụ được biểu diễn trong
các Hình 2 (a) và (b), tương ứng. Những điểm sáng hơn là những điểm có giá trị độ cong tương ứng là dương và
những điểm tối hơn là những điểm có giá trị độ cong âm. Không thể đánh giá độ cong ở các điểm của đường bao
bề mặt, nơi không thể tính toán đạo hàm thứ hai. Hình 2 (c) cho thấy sự phân loại điểm kết quả dựa trên dấu hiệu
của độ cong. Ba loại điểm thu được: điểm tối nhất là điểm hypebol (K <0), mức xám trung gian là các điểm lồi hình
elip (H <0 và K> 0), và những điểm sáng nhất là những điểm lõm hình elip (H> 0 và K> 0). Điểm hình trụ (nếuK = 0
và H <0 thì điểm là hình trụ lồi; và nếuH> 0, thì nó là hình trụ lõm) và các điểm phẳng ( H = 0 và K = 0) không xuất
hiện vì sẽ khó có được giá trị độ cong chính xác bằng không. lOMoAR cPSD| 49519085 (Một) (NS) (NS) (NS)
Hình 2. Dấu hiệu của (a) đường trung bình và (b) đường cong Gaussian; (c) phân loại điểm HK và (d) phân loại HK sau khi xác định ngưỡng độ cong.
Để cô lập các vùng tránh các điểm có độ cong cao trong đó có độ cong thấp, các ngưỡng độ cong khác nhau đã được thử
nghiệm bằng thực nghiệm. Chúng tôi đã chọn các ngưỡng sau:NSNS= -0,05,KNS= -0,0005 của độ cong trung vị và độ cong Gauss,
tương ứng. Sau khi chuyển đổi độ cong thỏa mãn-0,05 cô lập ở hầu hết các mặt như thể hiện trong Hình 2 (d). Việc phân đoạn trở nên đơn giản và dễ dàng hơn vì trong hầu hết các
trường hợp, số lượng ứng viên khu vực trên mỗi khu vực đã giảm xuống còn một. Các vùng và đường được phân đoạn (từ đó sẽ
thu được các đặc điểm khuôn mặt đại diện cho các cá nhân trong hệ thống nhận dạng khuôn mặt) được thể hiện trong Hình 3.
Tiêu chí lựa chọn vùng là: chọn những vùng có độ cong rõ rệt, có hình dạng thấp sự phụ thuộc khi biểu hiện trên khuôn mặt.
Vùng 3 (R3): điểm hypebol ở sống mũi trên (từ ảnh
Vùng 4 (R4): điểm lõm hình
elip của hốc mắt trái (từ ảnh ngưỡng). Vùng 5 (R5): điểm lõm hình elip
của hốc mắt phải (từ ảnh ngưỡng).
Vùng 6 (R6): điểm elip lồi của
mắt trái (từ ảnh không ở
Vùng 7 (R7): điểm elip lồi của ngưỡng). mắt phải (từ ảnh không ngưỡng).
Dòng 1 (L1): điểm mà dấu hiệu của độ
cong trung vị (H) thay đổi ở bên trái mũi
Dòng 2 (L2): điểm trong đó dấu hiệu độ
(từ hình ảnh không ngưỡng). cong trung vị
thay đổi ở bên trái mũi
(từ hình ảnh không ngưỡng).
Vùng 1 (R1): điểm elip lồi
Vùng 2 (R2): điểm hình trụ của đầu mũi (từ ảnh
lồi của mũi (từ ảnh ngưỡng). ngưỡng).
Hình 3. Các vùng được phân đoạn trên khuôn mặt mà từ đó các đặc điểm trên khuôn mặt được trích xuất. Các vùng số 6 và 7 lấy từ hình ảnh không ngưỡng được thể hiện trong Hình 2 (c). Các
dòng 1 và 2 có thể được quan sát trong hình ảnh không ngưỡng như trong Hình 2 (a).
Phương pháp được sử dụng để phân đoạn tự động các vùng đã chọn như sau. Vùng 1 có thể dễ dàng phân biệt
vì là vùng có số lượng nút hình elip lồi nhiều nhất trong ảnh ngưỡng. Vùng 2 được tạo thành bởi các điểm hình trụ
lồi và nó là lân cận của vùng 1. Các điểm của Vùng 3 là các điểm hypebol và nằm trong vùng lân cận của Vùng 2
hướng lên từ nó. Có thể sử dụng thêm các hạn chế vị trí tương đối liên quan đến vùng mắt nếu có nhiều hơn một
vùng ứng cử viên. Vùng 4 và 5 được tạo thành bởi các điểm elip lõm. Có rất ít vùng ứng cử viên đối với họ, và việc
lựa chọn được thực hiện theo vị trí tương đối của họ đối với vùng mũi. Vùng 6 và 7 được tạo thành bởi các điểm
elip lồi trong hình ảnh không ngưỡng, loại bỏ các khu vực ứng cử viên không tuân theo các hạn chế nhất định.
Những hạn chế đó là: vị trí tương đối của chúng đối với các vùng 3, 4 và 5 (ví dụ, các điểm của chúng phải được tìm
thấy trong dải chứa ba vùng này), chiều cao (tối đa 1,7 mm) và chiều rộng của các vùng ứng viên. Các đường 1 và 2
được tìm kiếm từ đường viền bên ngoài của Vùng 2 (được nén giữa các tâm của vùng 4 và 5 và tâm của vùng 1)
theo hướng trái và phải tương ứng cho đến khi tìm thấy dấu hiệu thay đổi độ cong trung tuyến.
Một kết quả vị trí vùng hoặc đường có thể được gắn nhãn là: a) lỗi (F trong Bảng 1), b) không tồn tại (NE trong Bảng 1) và c) vị trí chính xác (C
trong Bảng 1). Không thành công có nghĩa là một khu vực hoặc đường được tìm kiếm được tìm thấy ở một vị trí không tốt và sau đó, một vùng
hoặc dòng đã tìm kiếm được tìm thấy là vùng đã chọn. Không tồn tại có nghĩa là không có bất kỳ khu vực nào dẫn đến khu vực được tìm kiếm. Vị
trí chính xác xảy ra khi khu vực được phân đoạn được tìm thấy chính xác. Kết quả phần trăm không thành công, không tồn tại và chính xác cho
các vùng và chế độ xem khác nhau trong toàn bộ cơ sở dữ liệu sau khi phân đoạn được hiển thị trong Bảng 1. Vùng 1 Vùng 2 Vùng 3 Vùng 4 Vùng 5 Vùng 6 Vùng 7 Dòng 1 Dòng 2 nhìn xuống NS 0% 0% 0% 0% 0% 8,3% 6,6% 0% 0,6% NE 0% 0% 1,2% 15% 15% 28,3% 51,6% 0% 0% NS 100% 100% 98,8% 90% 0,6% 90% 0,6% 63,4% 41,8% 100% 99,4% NS 0,6% 0,6% 1,2% 1,2% 0,6% 0,6% 0,6% tra cứu NE 0% 0% 18,3% 6,6% 8,3% 8,3% 15% 0% 1,2% lOMoAR cPSD| 49519085 NS 99,4% 99,4% 80,5% 92,8% 91,1% 90,5% 84,4% 99,4% 98,2% NS 0% 0% 0,6% 0% 0% 0,6% 0% 0% 0% nhìn trực diện NE 0% 0% 6,6% 5% 1,2% 6,6% 1,2% 0% 0% NS 100% 100% 92,8% 95% 98,8% 92,8% 98,8% 100% 0% 100% NS 0% 0% 0,6% 0% 0% 0,6% 0,6% 0% nhìn trực diện NE 0% 0% 5% 8,3% 5% 6,6% 5% 0% 0% NS 100% 100% 94,4% 91,7% 95% 0% 92,8% 94,4% 100% 0% 100% 0% NS 0% 0% 0% 0% 0,6% 0,6% ngẫu nhiên cử chỉ NE 0% 0% 8,3% 0,6% 1,2% 5% 10% 0% 0% NS 100% 100% 91,7% 99,4% 98,8% 94,4% 89,4% 100% 5% 100% NS 0% 0% 0% 0% 0% 1,2% 0,6% 1,2% cười NE 0% 0% 6,6% 0,6% 1,2% 5% 10% 0% 0% NS 100% 100% 93,4% 99,4% 98,8% 93,8% 89,4% 95% 0,6% 98,8% NS 0% 0% 0% 0% 0% 0% 0% 0% nụ cười NE 0% 0% 6,6% 0,6% 0,6% 6,6% 6,6% 0% 0% NS 100% 100% 93,4% 99,4% 99,4% 93,4% 93,4% 99,4% 100% NS 0,2% 0,2% 0,95% 0,2% 0,2% 2,85% 1,9% 1,19% 0,95% Tổng số lượt xem NE 0% 0% 9,5% 0% 0,2% NS 99,8% 99,8% 7,85% 5,71% 5,71% 87,65% 14,5% 98,81% 98,85% 91,2% 94,09% 94,09% 83,6%
Bảng 1. Tỷ lệ phần trăm không đạt (F), không tồn tại (NE) và vị trí chính xác (C) thu được trong khu vực và vị trí đường dây. Kết quả được nhóm theo các vùng và dòng được tìm kiếm
trên mỗi bộ 60 hình ảnh tương ứng với từng loại chế độ xem. Các hàng cuối cùng là tỷ lệ phần trăm trên các vùng được tìm kiếm và các dòng trên 420 hình ảnh của cơ sở dữ liệu.
Kết quả phân đoạn kém nhất thu được ở vị trí vùng mắt, đặc biệt, khi tầm nhìn của các cá thể cho thấy sự xoay
chuyển ánh sáng khi cá nhân nhìn xuống. Các vùng mắt bị che khuất đã được phần mềm của máy số hóa 3D tự
động tái tạo lại bằng cách sử dụng thuật toán nội suy. Điều này tạo ra một hiệu ứng nguy hiểm trên bề mặt, làm
nhẵn bề mặt và làm mất thông tin về độ cong thực. Hiện tượng này cũng xảy ra ở vị trí vùng 3 được đặt xung quanh
điểm nasion khi các cá nhân đang nhìn lên. Vùng điểm mũi (Vùng 1) cho kết quả tốt hơn các vùng khác, chỉ bị lỗi khi
hình ảnh có một lỗ trên bề mặt ở vị trí này. Lỗi của vị trí khu vực này tạo ra lỗi ở các vị trí còn lại trong khu vực,
nguyên nhân của các khu vực này được tìm kiếm ở các vị trí tương đối với nó.
5 Tính năng trích xuất
Sau tác vụ phân đoạn, một giai đoạn trích xuất đối tượng địa lý được thực hiện. Tám mươi sáu đối tượng địa lý không độc lập được
trích xuất từ các vùng được phân đoạn đã được tính toán. Bảng 2 mô tả và phân loại các đối tượng địa lý này thành các loại (diện tích,
khoảng cách, góc, độ cong trung bình của một vùng, v.v.). Mỗi tính năng có một số nhận dạng liên quan và một vị trí xếp hạng. Vị trí này
tương ứng với quyền lực phân biệt theo thứ tự của đối tượng địa lý theo cách mà đối tượng địa lý thể hiện sức mạnh phân biệt cao có vị trí xếp hạng nhỏ và
những người thể hiện quyền lực ít phân biệt hơn có một vị trí cấp bậc lớn. Ước tính sức mạnh phân biệt của từng đối
tượng - đã được tính toán bằng cách sử dụng hệ số Fisher [4], đại diện cho tỷ lệ giữa phương sai giữa lớp và phương sai
trong lớp, theo công thức NS ∑-NS tôi- NS- 2 (3) tôi-1 tôi -1 ix- -
là NS là số lớp học hoặc môn học, -tôi là tập hợp các giá trị tính năng cho lớp trongtôi là kích thước của -tôi, NStôi là ý nghĩa của -tôi,
và NS là giá trị trung bình chung của đối tượng trên tất cả các lớp. Có 60 lớp học tương ứng với số lượng môn học riêng biệt.
Mặc dù có bảy hình ảnh cho mỗi người, khi tính toán hệ số Fisher, chỉ những hình ảnh khuôn mặt 3D có toàn bộ các vùng và do
đó toàn bộ các tính năng được trích xuất chính xác mới được sử dụng. lOMoAR cPSD| 49519085
Khi không thể tính toán một đối tượng địa lý (luôn luôn là nguyên nhân dẫn đến sự không tồn tại của vùng / s mà từ đó nó được tạo ra), thì
đối tượng địa lý đó có giá trị bằng 0, ngoại trừ khi đối tượng địa lý tồn tại (khi đó, đối tượng địa lý không tồn tại có giá trị như tính năng đối xứng
của nó). Hơn nữa, các đối tượng địa lý dựa trên diện tích dẫn đến không có giá trị khi có ít hơn ba điểm thuộc các tứ giác tạo thành các vùng như
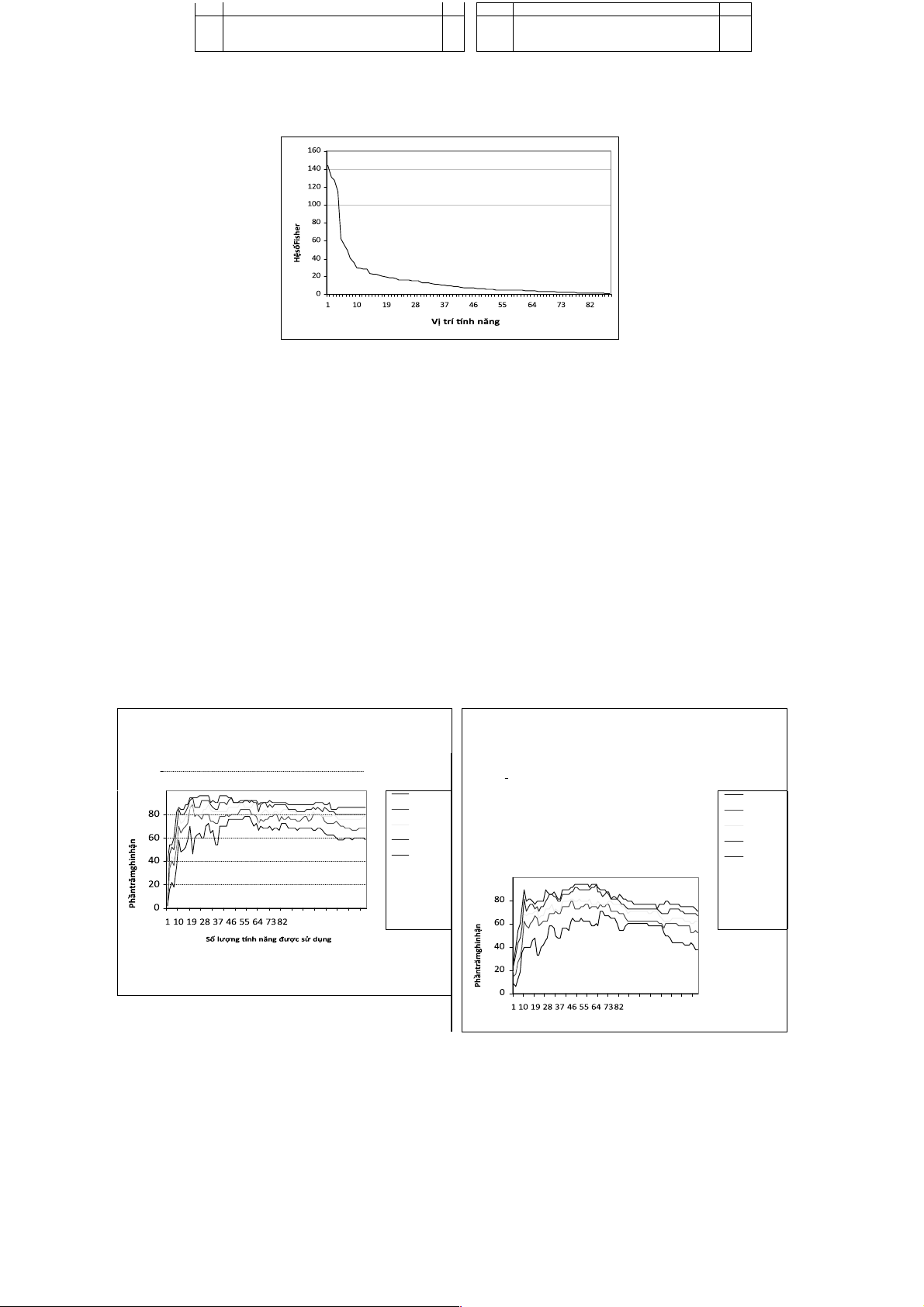
vậy. Các tính năng trích xuất đã được chuẩn hóa thành các giá trị trong thứ hạng từ 0 đến 1. Hình 4 liên hệ các hệ số Fisher tương ứng với từng vị
trí xếp hạng tính năng trong danh sách được sắp xếp theo hệ số Fisher.
Tôi. sự miêu tả yếu tố thứ hạng sự miêu tả yếu tố thứ hạng num vị trí Tôi. num pos Diện tíc h các vùng 52
Trung bình H của các điểm thuộc một vùng 0 A_R1 40 H_R1 28 1 A_R4 41 41 H_R2 24 2 A_R5 47 42 H_R3 16 3 A_R2 30 43 H_R4 17 4 A_R3 35 44 H_R5 21 5 A_R6 45 45 H_ (R4 U R5) 12 6 A_R7 50 46 H_R6 53 47 H_R7 63 Quan hệ 59 7 khu vực A_R2 / A_R1 48 H_ (R6 U R7) 48 số 8 A_R1 / A_R3 71 9 A_R1 / (A_R4 + A_R5) 70
Vùng trung bình K của các điểm thuộc một vùng 49 K_R1 33 10 A_R1 / (A_R6 + A_R7) 58 50 K_R2 37 51 K_R3 11 Trung bình củ 11 a các khu vực (A_R4 + A_R5) / 2 38 52 K_R4 20 12 (A_R6 + A_R7) / 2 42 53 K_R5 22 54 13 Khoảng cá
13 ch giữa các trung tâm khối lượng của các vùng d (C_R4, C_R5) 18 K_ (R4 U R5) 55 K_R6 55 14 d (C_R6, C_R7) 81 56 K_R7 64 15 d (C_R1, C_R3) 6 57 K_ (R6 U R7) 51 16 d (C_R4, C_R3)
số 8 Phương sai H vùng của các điểm thuộc một vùng 17 d (C_R5, C_R3) 9 58 VH_R1 74 18 d (C_R6, C_R3) 36 59 VH_R2 85 19 d (C_R7, C_R3) 34 60 VH_R3 62 20 d (C_R6, C_R1) 61 61 VH_R4 83 21 d (C_R7, C_R1) 60 62 VH_R5 72 22 d (C_R4, C_R1) 15 63 VH_ (R4 U R5) 68 23 d (C_R5, C_R1) 19 64 VH_R6 79 65 VH_R7 86 Mối quan
24 hệ giữa khoảng cách giữa các trung tâm khối lượng của các vùng d (C_R4, C_R5) / d (C_R1, C_R3) 10 66 VH_ (R6 U R7) 78 25
1/2 [d (C_R4, C_R3) + d (C_R5, C_R3)] / d (C_R3, C_R1)
32 Phương sai K vùng của các điểm thuộc một vùng 26
d (C_R6, C_R7) / d (C_R3, C_R1) 49 67 VK_R1 73 27
1/2 [d (C_R6, C_R3) + d (C_R7, C_R3)] / d (C_R3, C_R1) 40 68 VK_R2 69 69 VK_R3 82 Khoảng các 28 h trung bình
1/2 [d (C_R4, C_R3) + d (C_R5, C_R3)] 5 70 VK_R4 77 29
1/2 [d (C_R6, C_R3) + d (C_R7, C_R3)] 29 71 VK_R5 67 76
1/2 [d (C_R6, C_R1) + d (C_R7, C_R1)] 57 72 VK_ (R4 U R5) 66 77
1/2 [d (C_R4, C_R1) + d (C_R5, C_R1)] 14 73 VK_R6 75 74 VK_R7 84
Góc giữa c ác trung tâm khối lượng của các vùng ang 30 (C_R4, C_R3, C_R5) 31 1 75 VK_ (R6 U R7) 80 2 32 ang (C_R4, C_R3, C_R1) ang (C_R5, C_R3, C_R1) 4
Các tính năng dựa trên dòng 1 và 2 78
d (điểm cuối trên L1, điểm cuối trên L2) 43 33 ang (C_R4, C_R1, C_R5) 31 79
d (điểm cuối dưới L1, điểm cuối dưới L2) 65 34 ang (C_R6, C_R1, C_R7) 76 80 Chiều dài L1 44 35 ang (C_R6, C_R3, C_R7) 27 81 Chiều dài L2 46 36 ang (C_R6, C_R3, C_R1) 23 82
1/2 [Chiều dài L1 + Chiều dài L2] 39 37 ang (C_R7, C_R3, C_R1) 26 83
Diện tích của đa giác tạo bởi 4 đầu của L1, L2 54 84 56 Góc trung
38 bình1/2 [ang (C_R4, C_R3, C_R1) + ang (C_R5, C_R3, C_R1)] 3
ang (điểm dưới của L1, C_R1, điểm dưới của L2) lOMoAR cPSD| 49519085 85
ang (điểm trên của L1, C_R3, điểm trên của L2) 7 39
1/2 [ang (C_R6, C_R3, C_R1) + ang (C_R7, C_R3, C_R1)] 25
Ban 2. Trích xuất các đối tượng địa lý từ các vùng và đường được phân đoạn, và vị trí của chúng trong danh sách có thứ tự theo sức mạnh phân biệt của chúng. Các từ viết tắt được
sử dụng là:Ri = khu vực tôi; Li = hàng tôi; A_Ri = khu vực của khu vực tôi; C_Ri = trung tâm của khu vực tôi; NS(P1, P2) = Khoảng cách Euclide giữa các điểm 3D P1 và P2; ang
(P1,P2,P3) = góc được xác định bởi các điểm 3D P1,P2 và P3, hiện tại P2 đỉnh trung gian;H_Ri và K_Ri là giá trị trung bình tương ứng của độ cong trung bình và độ cong Gaussian,
được đánh giá bằng các điểm thuộc khu vực tôi; VH_Rivà VK_Ri là các phương sai tương ứng của độ cong trung bình và độ cong Gaussian được đánh giá tại các điểm thuộc khu vực tôi.
Hinh 4. Các giá trị hệ số Fisher tương ứng với từng vị trí xếp hạng tính năng trong danh sách được sắp xếp theo hệ số Fisher.
6 Lựa chọn tính năng
Giống như trong nhiều ứng dụng nhận dạng mẫu khác, cần giảm số lượng tính năng để tăng hiệu quả của công cụ nhận diện khuôn mặt.
Để chọn một tập con tính năng tối ưu để đại diện cho các cá nhân cho mục đích nhận dạng khuôn mặt, tám mươi sáu tập con tính năng
đã được thử nghiệm: những tập hợp con tính năng đầu tiênn các tính năng trong danh sách được sắp xếp cho tất cả n, nhu la 1- n - 86. Tập
hợp các khuôn mặt đã biết của hệ thống nhận dạng khuôn mặt (tập huấn luyện) bao gồm 60 hình ảnh trực diện (một hình ảnh cho mỗi cá nhân)
được chọn sao cho chúng thể hiện toàn bộ các vùng hiện có và toàn bộ các tính năng được tính toán thành công. Sáu bộ thử nghiệm được sử
dụng riêng biệt: bộ ảnh nhìn xuống xoay, bộ ảnh xoay xoay, bộ ảnh chính diện khác (khác với bộ xe lửa) không có biểu cảm khuôn mặt, bộ cử chỉ
ngẫu nhiên, bộ cử chỉ cười và bộ nụ cười. Quy trình đối sánh dựa trên bộ phân loại khoảng cách Euclid tối thiểu. Bộ thử nghiệm trình bày sự tồn
tại của toàn bộ khu vực lần lượt bao gồm 19, 41, 50, 47, 45 và 48 hình ảnh. Trong số sáu bộ thử nghiệm này, kết quả nhận dạng tốt nhất thu được
khi số đặc điểm được sử dụng để đại diện cho các cá thể được xếp hạng giữa 33 và 37 đối tượng đầu tiên (những đặc điểm ở vị trí thấp hơn
trong danh sách được sắp xếp theo hệ số Fisher). Có thể đánh giá cao trong Hình 5, nó cho thấy tỷ lệ phần trăm nhận dạng tương ứng với các số
lượng khác nhau của các đối tượng địa lý được xem xét, khi chỉ sử dụng các hình ảnh thể hiện sự tồn tại của toàn bộ các vùng. Vì lý do này, tập
hợp con đặc điểm được tạo thành bởi 35 đối tượng được xếp hạng đầu tiên đã được chọn để đại diện cho các khuôn mặt trong các thử nghiệm
hệ thống nhận dạng khuôn mặt của chúng tôi. Hình 5 (a) cho thấy tỷ lệ phần trăm nhận dạng thành công khi tập hợp thử nghiệm là tập hợp hình
ảnh chính diện và (b) khi tập hợp thử nghiệm là tập hợp nụ cười. Mỗi đường cong trong Hình 5 đại diện cho tỷ lệ phần trăm thành công công
nhận thu được khi các cá thể thử nghiệm được tìm thấy trong một, hai, ba, năm và tám hình ảnh đoàn tàu đã chọn gần nhất (tính theo khoảng
cách Euclide), tương ứng. Chỉ những hình ảnh hiển thị toàn bộ khu vực mới được thử nghiệm cho mục đích lựa chọn đối tượng địa lý.
Bộ thử nghiệm: các hình chiếu trực diện trình bày toàn bộ các tính năng
Bộ thử nghiệm: chế độ xem nụ cười trình bày toàn bộ
Tính năng, đặc điểm 100 100 1 hình ảnh 1 hình ảnh 2 hình ảnh 2 hình ảnh 3 hình ảnh 3 hình ảnh 5 hình ảnh 5 hình ảnh 8 hình ảnh 8 hình ảnh
Số lượng tính năng được sử dụng (Một) (NS)
Hình 5. Tỷ lệ nhận dạng tương ứng với từng tập hợp con tính năng với cao nhất n Hệ số Fisher (1-n-86). (a) Tập hợp thử nghiệm được hình thành bởi các khung nhìn trực diện và (b) bởi các khung nhìn
nụ cười, chứa toàn bộ các vùng và các đối tượng địa lý được trích xuất một cách chính xác.
7 thí nghiệm nhận dạng khuôn mặt
Sau khi phân tích sức mạnh phân biệt đối tượng, 35 đối tượng đầu tiên trong danh sách có thứ tự các đối tượng địa lý theo hệ số Fisher đã được sử dụng để đại diện cho
các khuôn mặt trong các thí nghiệm nhận dạng khuôn mặt của chúng tôi. Mục đích của những lOMoAR cPSD| 49519085
các thí nghiệm đang tìm kiếm vectơ đặc trưng thuộc tập huấn luyện có khoảng cách Euclide tới mỗi hình ảnh tập thử nghiệm là nhỏ nhất. Tập
hợp đào tạo các khuôn mặt đã biết được hình thành bởi 60 hình ảnh trực diện của 60 cá thể với sự tồn tại của toàn bộ các vùng và do đó là các
đặc điểm. Sáu bộ thử nghiệm được sử dụng riêng biệt, mỗi bộ trong số chúng được tạo thành bởi tập hợp các hình ảnh không được sử dụng
thuộc một trong 6 chế độ xem khác nhau có sẵn: nhìn xuống, nhìn lên, chính diện không có biểu cảm khuôn mặt và ba bộ chính diện thể hiện nét
mặt (cử chỉ ngẫu nhiên, cười lớn và cười mỉm). Hai thí nghiệm khác nhau đã được thực hiện. Đầu tiên, chúng tôi đã thử nghiệm các tập hợp
được tạo thành chỉ bởi các khuôn mặt mà tất cả các vùng đều tồn tại và do đó, tất cả các đối tượng đều có thể được tính toán. Trong thử nghiệm
thứ hai, tất cả hình ảnh của 60 cá thể có trong mỗi bộ hình ảnh thử nghiệm đã được kiểm tra, trình bày hoặc không tất cả các tính năng. Trong
thử nghiệm thứ hai, khi không thể tính được một đối tượng, nó có giá trị 0 liên quan và nó không được sử dụng trong công thức khoảng cách Euclide.
Tỷ lệ nhận dạng thành công của cả hai thử nghiệm được trình bày trong Hình 6. Kết quả tốt nhất thu được khi chỉ kiểm tra các hình ảnh chứa
tất cả các tính năng, mặc dù mức giảm tỷ lệ nhận dạng của thử nghiệm tất cả các hình ảnh là khoảng 5%. Một khía cạnh khác cần đề cập liên
quan đến thử nghiệm thứ hai là khi vectơ đối tượng dài 35 đối tượng, tất cả các hình ảnh thử nghiệm có thể được khớp vì một số trong số 35 đối
tượng này đã có mặt. Hình 7 cho thấy số lượng hình ảnh thử nghiệm có thể được khớp (nguyên nhân của sự tồn tại của đủ các đối tượng được
trích xuất để được sử dụng) trên mỗi số đối tượng được sử dụng làm thành phần vectơ đặc trưng.
Hình 6. Kết quả thử nghiệm về tỷ lệ phần trăm thành công nhận dạng khuôn mặt trên mỗi tập hợp các hình ảnh thử nghiệm bằng cách sử dụng 35 phân biệt hơn đầu tiên các tính năng đại diện cho khuôn
mặt (a) thử nghiệm hình ảnh chứa toàn bộ các tính năng và (b) thử nghiệm hình ảnh với khả năng không phải tất cả các đặc điểm đều có mặt và đã được định vị chính xác.
Hình 7. Số lượng hình ảnh thử nghiệm có một số tính năng của các tính năng đã chọn sẽ được sử dụng trong trận đấu, trong nhóm thử nghiệm thứ hai các thí nghiệm.
8 Kết luận và công việc trong tương lai
Một cơ sở dữ liệu gồm 420 hình ảnh khuôn mặt 3D với 60 cá nhân đã được thu thập để đào tạo và thử nghiệm hệ thống nhận dạng khuôn mặt. Trong số những hình ảnh này, 310
trong số chúng trình bày tất cả các vùng và đường được phân đoạn chính xác, và các đặc điểm được trích xuất tương ứng cũng chính xác; 20 hình ảnh có một hoặc nhiều hình ảnh
dương tính giả ở vị trí khu vực của chúng và những hình ảnh này bị thể hiện xấu bằng các đặc điểm không đúng; và trong 90 ảnh không phải tất cả các vùng đều tồn tại nhưng các đặc
điểm thu được từ các vùng hiện có đã được tính toán chính xác và chúng có thể đại diện cho các khuôn mặt được sử dụng trong hệ thống nhận dạng khuôn mặt (do độ dài của các
vectơ đặc trưng có thể thay đổi). Các tính năng cung cấp kết quả nhận dạng tốt hơn là các góc và khoảng cách được đo bằng cách sử dụng centroid của các vùng cũng như giá trị
trung bình của độ cong trung bình và Gaussian của các vùng. Các đối tượng địa lý dựa trên khu vực cung cấp sức mạnh phân biệt kém nhất, do sự khác biệt lớn hơn tương ứng của
chúng đối với phương sai loại của đối tượng địa lý theo tiêu chí của Fisher. Điều này có thể là do các khu vực được phân đoạn rất nhỏ, chứa số lượng điểm khan hiếm và sự khác biệt
nhỏ về số lượng điểm có thể tạo ra sự khác biệt đáng kể giữa các khu vực của một khu vực ở các cá thể trong cùng lớp. Phương sai độ cong được đánh giá cho từng vùng dẫn đến
khả năng phân biệt đối xử thấp ở các vùng được chọn. Sau và sự khác biệt nhỏ về số lượng điểm có thể tạo ra sự khác biệt đáng kể giữa các khu vực của một khu vực đối với các cá
nhân trong lớp. Phương sai độ cong được đánh giá cho từng vùng dẫn đến khả năng phân biệt đối xử thấp ở các vùng được chọn. Sau và sự khác biệt nhỏ về số lượng điểm có thể
tạo ra sự khác biệt đáng kể giữa các khu vực của một khu vực đối với các cá nhân trong lớp. Phương sai độ cong được đánh giá cho từng vùng dẫn đến khả năng phân biệt đối xử
thấp ở các vùng được chọn. Sau
phân tích sức mạnh phân biệt của 66 đặc điểm khuôn mặt 3D trong các thí nghiệm nhận dạng khuôn mặt bằng cách sử dụng các
tập hợp con các đặc điểm khác nhau, tỷ lệ nhận dạng tốt hơn thu được khi 35 đặc điểm phân biệt hơn được sử dụng để đại
diện cho khuôn mặt. Kết quả nhận dạng tốt nhất bằng cách sử dụng 35 đặc điểm phân biệt hơn đã đạt được khi kiểm tra các
góc nhìn trực diện (78%, 84%, 86%, 92%, 92% thành công khi lần lượt chọn một, hai, ba, năm và tám trận đầu tiên) . Kết quả
nhận dạng tốt thứ hai thu được khi sử dụng lượt xem có chứa biểu cảm nụ cười (62%, 77,08%, 79,17%, 89,58% và 93% thành
công khi lần lượt là một, hai, ba, năm và tám trận đấu đầu tiên là đã chọn) và các hình ảnh cử chỉ khác. Kết quả nhận dạng tồi tệ
nhất thu được khi bộ thử nghiệm bao gồm các mặt được xoay xung quanhNS trục. Các kết quả này thu được khi chỉ thử nghiệm
các hình ảnh trình bày toàn bộ các tính năng. Khi tất cả các hình ảnh thử nghiệm được sử dụng, hiển thị hoặc không hiển thị tất
cả các vùng (và có định vị chính xác hay không), tỷ lệ phần trăm nhận dạng bị suy giảm nhỏ (ví dụ: ở hình ảnh chính diện 71,67%,
80%, 83,33%, 91 , 67% và 93,3% thành công khi lần lượt chọn một, hai, ba, năm và tám trận đầu tiên). Điều này được bù đắp bởi
thực tế là có thể kiểm tra số lượng hình ảnh cao hơn bao gồm cả những hình ảnh mà không phải tất cả các vùng và do đó các
đặc điểm đều có mặt. Một kết luận khác là sẽ tốt hơn nếu bỏ quaNS-các chế độ xem xoay chuyển (những nơi mà cá nhân đang
nhìn lên và nhìn xuống) trong nhiệm vụ tính toán các hệ số Fisher, bởi vì chúng có thể đưa ra một số lỗi do khớp cắn. lOMoAR cPSD| 49519085
Khi làm việc trong tương lai, sẽ rất thuận tiện để chọn các đặc điểm khác với các đặc điểm của vùng mắt khi khuôn mặt
được xoay khi nhìn lên và nhìn xuống vì các vùng tương ứng của chúng xuất hiện theo nhiều kiểu. Ngoài ra, phát triển một quy
trình xác nhận để loại bỏ dương tính giả ở vị trí khu vực là một nhiệm vụ quan trọng để cải thiện kết quả thu được. Có thể dễ
dàng phát hiện ra lỗi trong một khu vực hoặc vị trí dòng bởi vì thông thường khu vực ứng cử viên đã chọn rất xa so với vị trí
chính xác và kích thước của ứng viên khu vực sai khác rất nhiều so với kích thước chính xác của khu vực được tìm kiếm.
Người giới thiệu
[1] Y. Aoki y S. Hashimoto (1998). Mô hình khuôn mặt vật lý dựa trên dữ liệu 3D-CT để phân tích và tổng hợp hình ảnh trên khuôn
mặt,Proc. Quốc tế thứ hai. Lời thú nhận. nhận dạng khuôn mặt và cử chỉ tự động, IEEE Comp. Society, Nara (Nhật Bản): 448- 453.
[2] RJ Campbell và PJ Flynn (2001). Khảo sát về các kỹ thuật biểu diễn và nhận dạng đối tượng dạng tự do,Thị giác Máy
tính và Hiểu biết về Hình ảnh, 81: 166-210.
[3] AM Haider và T. Kaneko (2001). Tự động đăng ký xạ ảnh 3D-2D đối với hình ảnh khuôn mặt người bằng cách sử dụng các
tính năng cạnh,Tạp chí Quốc tế về Nhận dạng Mẫu và Trí tuệ Nhân tạo, 15 (8): 1263-1276.
[4] P. Hallinan, GG Gordon, AL Yuille, P. Giblin và D. Mumford (1999). Các mẫu hai và ba chiều của khuôn mặt, Ed. AK Peters.
[5] Horace HS Ip, Lijun Yin, (1996). Tạo mô hình đầu 3D cá nhân hóa từ hai chế độ xem trực giao,Máy tính trực
quan, 12, Springer-Verlag: 254-266
[6] T. Huang và L. Tang (1995). Mã hóa video dựa trên mô hình 3D: Thị giác máy tính đáp ứng Đồ họa máy tính,Hội nghị
Khoa học Máy tính Quốc tế.
[7] TS Huang và Li-an Tang (1996). Mô hình hóa khuôn mặt 3-D và các ứng dụng của nó,Tạp chí Quốc tế về Nhận dạng
Mẫu và Trí tuệ Nhân tạo, 10, số 5.
[8] A. López de la Rica, A. de la Villa Cuenca (1997). Geometría Diferencial,Ed. CLAGSA.
[9] http://www.minolta3d.com/index.asp
[10] S. Pankanti, RM Bolle, A. Jain (2000). Sinh trắc học: Tương lai của nhận dạng,Máy tính IEEE: 4649.
[11] A.Pentland, T.Choudhury (2000). Nhận dạng khuôn mặt cho môi trường thông minh,Máy tính IEEE: 50-55.
[12] PJ Phillips, PJ, Wechsler, H., Huang JS, và Rauss, PJ (1998). Cơ sở dữ liệu FERET và Quy trình đánh giá cho các thuật
toán nhận dạng khuôn mặt,Điện toán Hình ảnh và Tầm nhìn, 16 (5): 295-306.
[13] PJ Phillips, A. Martin, CL Wilson y Mrk Przybocki (2000). Giới thiệu về Đánh giá Hệ thống Sinh trắc học, Máy tính IEEE: 56-64.
[14] E. Trucco và A. Verri (1998). Các Kỹ thuật Giới thiệu cho Thị giác Máy tính 3-D, Prentice-Hội trường.
[15] Mun Way Lee và Surendra Ranganath (2003). Nhận dạng khuôn mặt bất biến theo tư thế sử dụng mô hình 3D có thể biến dạng,Nhận dạng mẫu 36: 1835-1846.
Tài liệu liên quan:
-

Quan trị thuong hieu - Bài tập phân tích UNIQLO và đối thủ cạnh tranh
16 8 -

THỰC HÀNH HÓA SINH - Bài Tập và Kết Quả Thí Nghiệm Enzyme
67 34 -

Tài liệu về Chuỗi cung ứng của Tập đoàn cá tra Vĩnh Hoàn môn Quản trị chuỗi cung ứng | Đại học Kinh tế Thành phố Hồ Chí Minh
128 64 -

Tiểu luận về Chuỗi cung ứng của Toyota Việt Nam và các giải pháp hoàn thiện môn Quản trị chuỗi cung ứng | Đại học Kinh tế Thành phố Hồ Chí Minh
99 50 -

Chương 14: Chuỗi cung ứng tinh gọn môn Quản trị chuỗi cung ứng | Đại học Kinh tế Thành phố Hồ Chí Minh
159 80